码农饭碗不保——ChatGPT正在取代Coder
码农饭碗不保——ChatGPT正在取代Coder
最近被OpenAI的ChatGPT刷屏了。我猜你已经读了很多关于ChatGPT的文章,不需要再介绍了。假如碰巧您还不太了解ChatGPT是什么,可以先看一下这篇文章,然后再回来继续。
与ChatGPT对话很有趣,甚至很有启发性。我们的内容创作部门已经将ChatGPT用于文案生成。那么对研发部门,ChatGPT是否有用呢?我在算法团队做了一个测试,让ChatGPT来完成算法研究中频繁要做的数据清洗和处理问题,结果让人非常满意。我甚至愿意聘请ChatGPT做算法团队的数据工程师。

文章目录
- 简单数据处理
- 任务目标
- 输出结果
- 分析
- 重构代码
- 任务目标
- 输出结果
- 分析
- 扩展代码
- 任务目标
- 输出结果
- 分析
- 总结
简单数据处理
我们首先从简单的任务入手,让ChatGPT完成数据加载和简单的清洗工作。
任务目标
- 加载数据集;
- 确保数据集中所有值均为数值类型,如果不是则尝试将其转换为数值类型;
- 检查缺失值;
- 数据集分成训练集和测试集。
上面这4个任务是算法执行前必须要做的常规工作。我们看一下ChatGPT的表现
输出结果
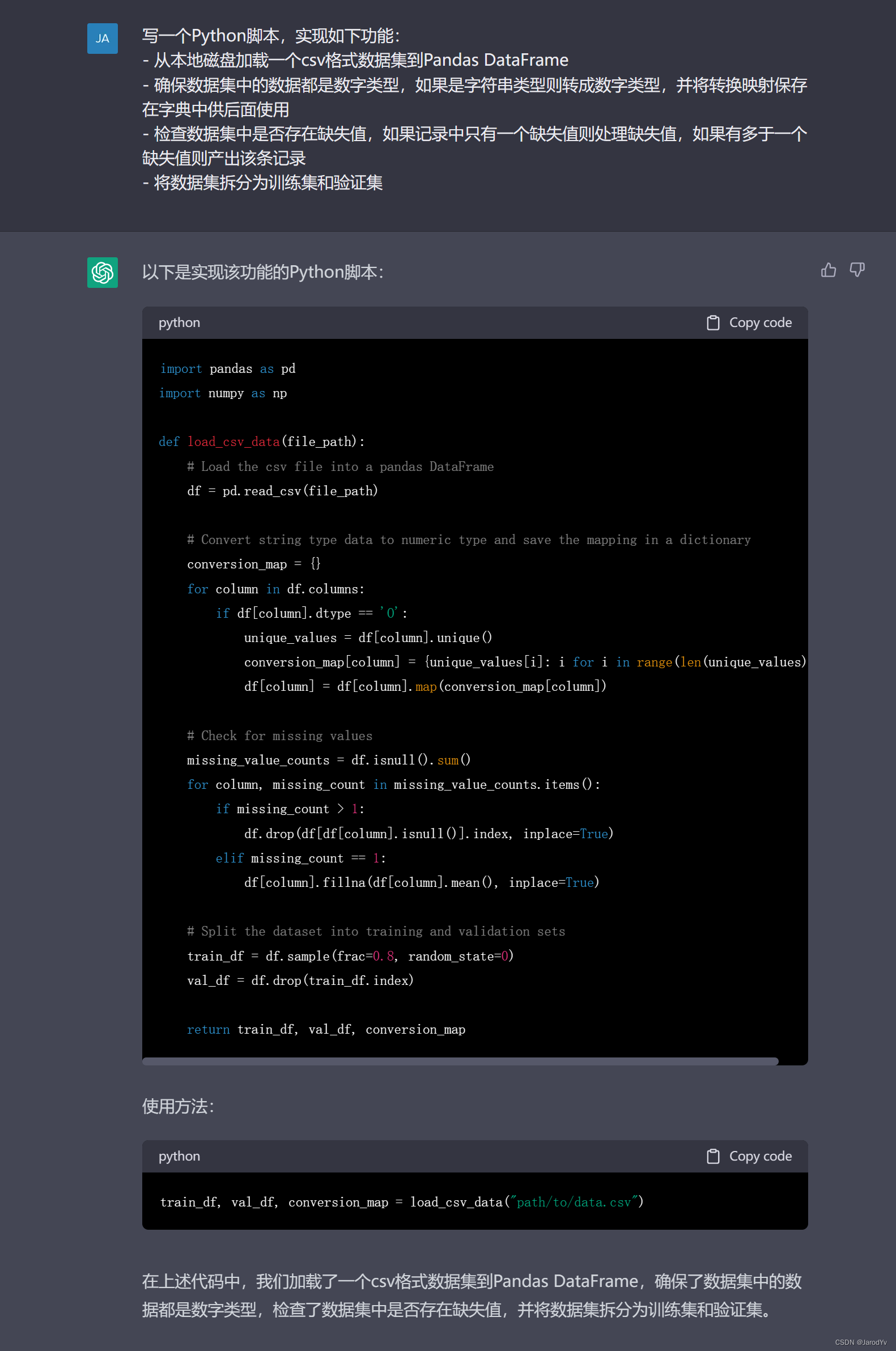
import pandas as pd
import numpy as npdef load_csv_data(file_path):# Load the csv file into a pandas DataFramedf = pd.read_csv(file_path)# Convert string type data to numeric type and save the mapping in a dictionaryconversion_map = {}for column in df.columns:if df[column].dtype == 'O':unique_values = df[column].unique()conversion_map[column] = {unique_values[i]: i for i in range(len(unique_values))}df[column] = df[column].map(conversion_map[column])# Check for missing valuesmissing_value_counts = df.isnull().sum()for column, missing_count in missing_value_counts.items():if missing_count > 1:df.drop(df[df[column].isnull()].index, inplace=True)elif missing_count == 1:df[column].fillna(df[column].mean(), inplace=True)# Split the dataset into training and validation setstrain_df = df.sample(frac=0.8, random_state=0)val_df = df.drop(train_df.index)return train_df, val_df, conversion_map分析
上面代码可以完美完成目标任务,从csv文件中加载数据集,并以80/20的比例将数据集拆分为测试集和训练集,关键逻辑还加上了注释,ChatGPT甚至贴心的给出了函数使用方法。
ChatGPT生成上面代码总共用时116秒,同时我们的数据工程师编写同样功能的代码用时225秒。二者的代码差异不大,但是我们的数据工程师没写注释。
上面的任务是数据工程师几乎天天都要写的代码,他们很熟练。我又找了一个大学刚毕业还在实习期的数据助理来写,居然半个小时才完成,由于对接口不熟悉,大量时间花在了百度上[捂脸]。
第一轮比试,从各个维度上,都是ChatGPT胜。
重构代码
在上一轮的比试中,我发现我们的数据工程师有“偷鸡”行为——由于平时经常需要完成上面工作,他将很多功能封装成了独立的函数,用的时候直接引入或拷贝。使用函数按照逻辑组织代码,不仅能够促进代码复用,还有利于代码维护。所以我们接下来试着让ChatGPT重构一下自己的代码。
任务目标
将上面的代码按照功能合理地拆分成若干函数。
输出结果
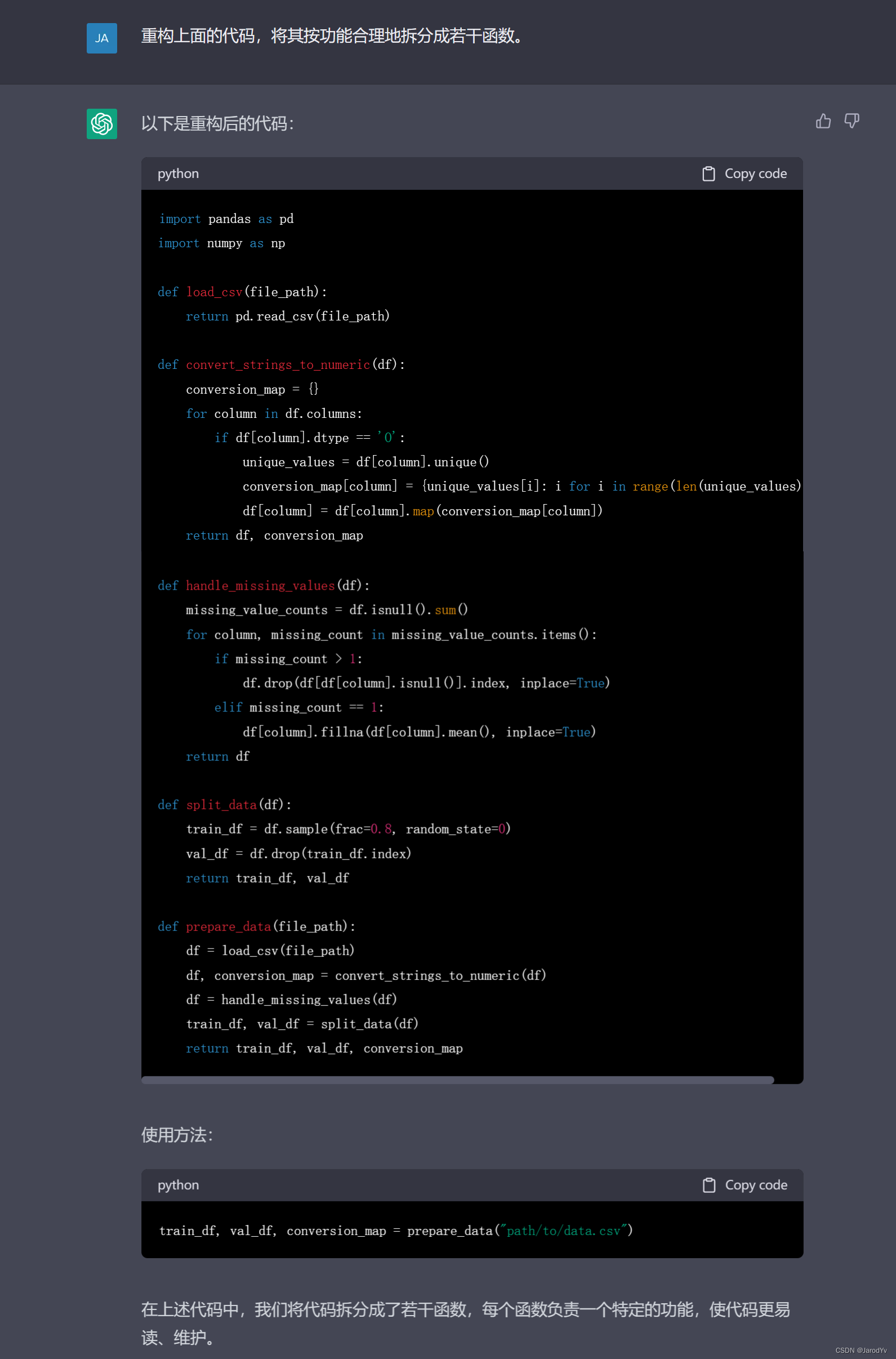
import pandas as pd
import numpy as npdef load_csv(file_path):return pd.read_csv(file_path)def convert_strings_to_numeric(df):conversion_map = {}for column in df.columns:if df[column].dtype == 'O':unique_values = df[column].unique()conversion_map[column] = {unique_values[i]: i for i in range(len(unique_values))}df[column] = df[column].map(conversion_map[column])return df, conversion_mapdef handle_missing_values(df):missing_value_counts = df.isnull().sum()for column, missing_count in missing_value_counts.items():if missing_count > 1:df.drop(df[df[column].isnull()].index, inplace=True)elif missing_count == 1:df[column].fillna(df[column].mean(), inplace=True)return dfdef split_data(df):train_df = df.sample(frac=0.8, random_state=0)val_df = df.drop(train_df.index)return train_df, val_dfdef prepare_data(file_path):df = load_csv(file_path)df, conversion_map = convert_strings_to_numeric(df)df = handle_missing_values(df)train_df, val_df = split_data(df)return train_df, val_df, conversion_map分析
ChatGPT拆分出5个函数:
load_csv(file_path)负责从csv文件中加载数据集,返回DataFrame;convert_strings_to_numeric(df)负责将DataFrame中的非数值类型数据转换为数值类型,并记录转换映射表;handle_missing_values(df)负责处理缺失值;split_data(df)负责将数据集拆分为训练集和测试集;prepare_data(file_path)将上面4给函数串起来,构成一个pipeline。
不得不说,ChatGPT有一次完美地完成了任务!并且函数名起得非常好,看函数名就能知道函数的功能,比很多中国程序员用拼音或缩写命名函数友好多了。
扩展代码
重构后的代码结构已经非常清晰了,但是还是有缺陷,那就是不够灵活,很多规则都是写死的。为了让代码更灵活、可扩展性更强,我们一般会将变量以参数的形式传入。
任务目标
重构上面的代码,以参数的形式从命令行传入以下内容:
- csv格式数据集的路径
- 拆分训练集和验证集的大小
- 阈值,缺失值大于此阈值则删除记录,小于等于此阈值则处理缺失值
输出结果
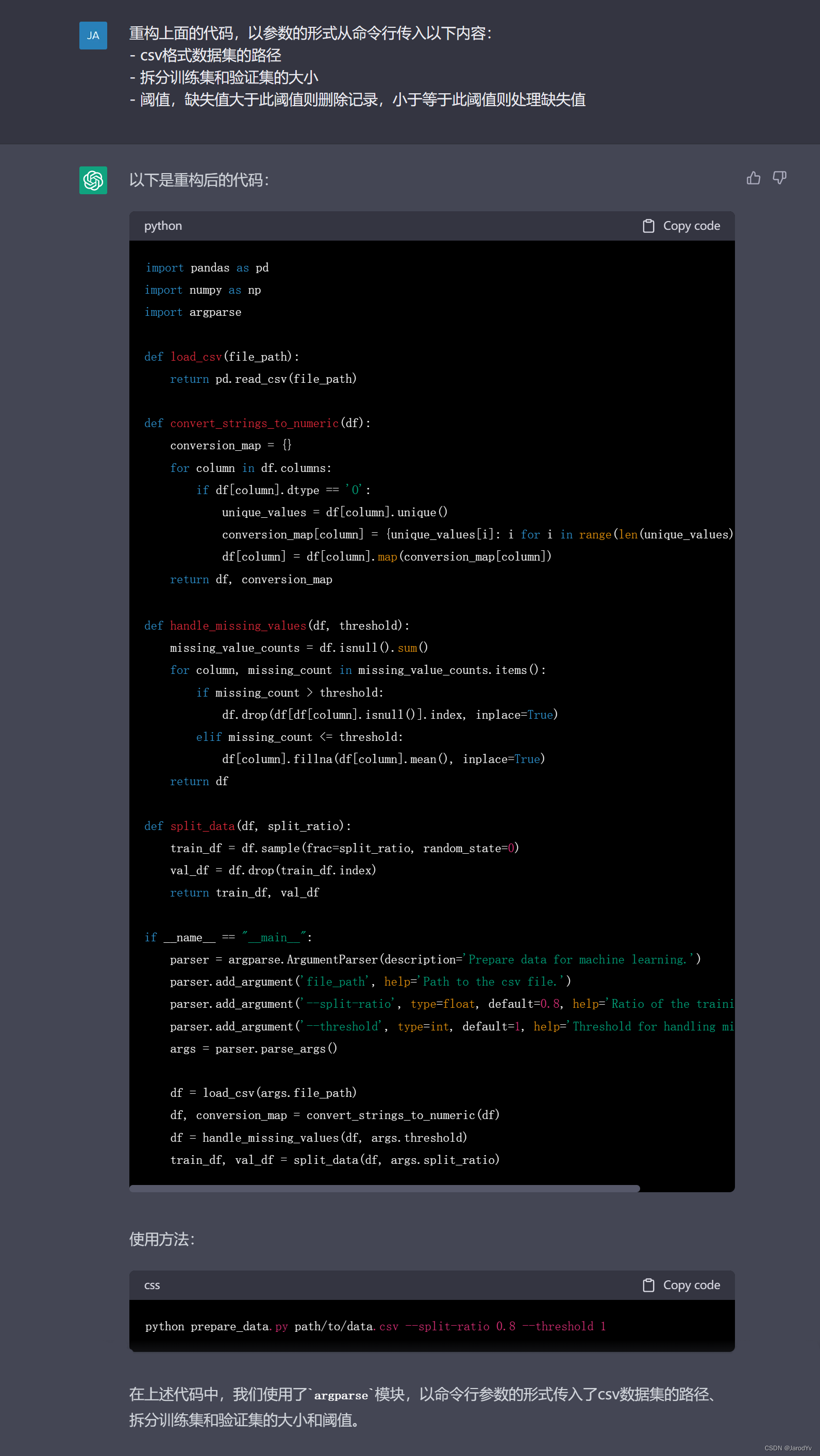
import pandas as pd
import numpy as np
import argparsedef load_csv(file_path):return pd.read_csv(file_path)def convert_strings_to_numeric(df):conversion_map = {}for column in df.columns:if df[column].dtype == 'O':unique_values = df[column].unique()conversion_map[column] = {unique_values[i]: i for i in range(len(unique_values))}df[column] = df[column].map(conversion_map[column])return df, conversion_mapdef handle_missing_values(df, threshold):missing_value_counts = df.isnull().sum()for column, missing_count in missing_value_counts.items():if missing_count > threshold:df.drop(df[df[column].isnull()].index, inplace=True)elif missing_count <= threshold:df[column].fillna(df[column].mean(), inplace=True)return dfdef split_data(df, split_ratio):train_df = df.sample(frac=split_ratio, random_state=0)val_df = df.drop(train_df.index)return train_df, val_dfif __name__ == "__main__":parser = argparse.ArgumentParser(description='Prepare data for machine learning.')parser.add_argument('file_path', help='Path to the csv file.')parser.add_argument('--split-ratio', type=float, default=0.8, help='Ratio of the training set size.')parser.add_argument('--threshold', type=int, default=1, help='Threshold for handling missing values.')args = parser.parse_args()df = load_csv(args.file_path)df, conversion_map = convert_strings_to_numeric(df)df = handle_missing_values(df, args.threshold)train_df, val_df = split_data(df, args.split_ratio)
分析
ChatGPT很好地理解了我们的意图,引入了argparse模块来管理和解析命令行参数,关键是参数名起的也非常合理,参数说明也非常准确(尽管是英文的)。参数都正确地传入了所属的函数,又一次完美的完成了任务。
总结
ChatGPT根据我们提供的规范,在创建、重构、扩展一个简单的数据预处理Python脚本方面做得非常出色,每一步的结果都符合要求。虽然这不是一个复杂任务,确实日常工作中最常见的基本工作。ChatGPT的表现确实惊艳了众人,预示着它朝着成为真正有用的编程助手迈出重要的一步。
最终我们从如下几个方面将ChatGPT和我们的数据工程师做了对比:
| ChatGPT | 人类程序员 | |
|---|---|---|
| 正确性 | ✅ | ✅ |
| 速度 | ✅ | |
| 编码规范 | ✅ | |
| 文档注释 | ✅ |
可见ChatGPT在编码速度和编码习惯上都完胜人类工程师。这让我不得不开始担心程序员未来的饭碗。是的,你没有看错!程序员这个曾经被认为是最不可能被AI取代的职业,如今将面临来自ChatGPT的巨大挑战。根据测试,ChatGPT已经通过Google L3级工程师测试,这意味着大部分基础coding的工作可以由ChatGPT完成。尽管ChatGPT在涉及业务的任务上表现不佳,但未来更可能的工作方式是架构师或设计师于ChatGPT协同完成工作,不再需要编码的码农。
相关文章:
码农饭碗不保——ChatGPT正在取代Coder
码农饭碗不保——ChatGPT正在取代Coder 最近被OpenAI的ChatGPT刷屏了。我猜你已经读了很多关于ChatGPT的文章,不需要再介绍了。假如碰巧您还不太了解ChatGPT是什么,可以先看一下这篇文章,然后再回来继续。 与ChatGPT对话很有趣,…...
 Practice 1004 Counting Leaves)
PAT (Advanced Level) Practice 1004 Counting Leaves
1004 Counting Leaves题目翻译代码分数 30 作者 CHEN, Yue 单位 浙江大学 A family hierarchy is usually presented by a pedigree tree. Your job is to count those family members who have no child. Input Specification: Each input file contains one test case. Eac…...

基于Redis实现的分布式锁
基于Redis实现的分布式锁什么是分布式锁分布式锁主流的实现方案Redis分布式锁Redis分布式锁的Java代码体现优化一:使用UUID防止误删除优化二:LUA保证删除原子性什么是分布式锁 单体单机部署中可以为一个操作加上锁,这样其他操作就会等待锁释…...

2023年,还找算法岗工作吗?
点击下方卡片,关注“CVer”公众号AI/CV重磅干货,第一时间送达2023年春招(补招)已经大规模启动了!距离2023年暑期实习不到2个月!距离2024届校招提前批不到4个月!距离2024届秋招正式批不到6个月&a…...

正点原子ARM裸机开发篇
裸机就是手动的操作硬件来实现驱动设备,后面会有驱动框架不需要这么麻烦 第八章 汇编 LED 灯实验 核心过程 通过汇编语言来控制硬件(驱动程序) 代码流程 1、使能 GPIO1 时钟 GPIO1 的时钟由 CCM_CCGR1 的 bit27 和 bit26 这两个位控制&…...
)
20222023华为OD机试 - 压缩报文还原(JS)
压缩报文还原 题目 为了提升数据传输的效率,会对传输的报文进行压缩处理。 输入一个压缩后的报文,请返回它解压后的原始报文。 压缩规则:n[str],表示方括号内部的 str 正好重复 n 次。 注意 n 为正整数(0 < n <= 100),str只包含小写英文字母,不考虑异常情况。 …...

SheetJS的部分操作
成文时间:2023年2月18日 使用版本:"xlsx": "^0.18.5" 碎碎念: 有错请指正。 这个库自说自话升级到0.19。旧版的文档我记得当时是直接写在github的README上。 我不太会使用github,现在我不知道去哪里可以找到…...

pytest总结
这里写目录标题一、pytest的命名规则二、界面化配置符合命名规则的方法前面会有运行标记三、pytest的用例结构三部分组成四、pytest的用例断言断言写法:五、pytest测试框架结构六、pytest参数化用例1、pytest参数化实现方式2、单参数:每一条测试数据都会…...
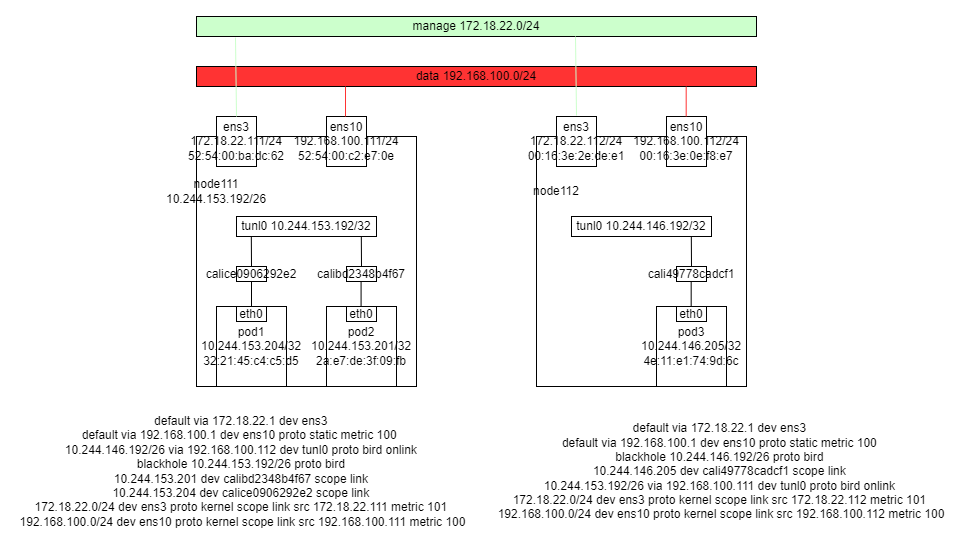
CNI 网络分析(九)Calico IPIP
文章目录环境流量分析Pod 间Node 到 PodPod 到 serviceNode 到 serviceNetworkPolicy理清和观测网络流量环境 可以看到,在宿主机上有到每个 pod IP 的路由指向 veth 设备 到对端节点网段的路由 指向 tunl0 下一跳 ens10 的 ip 有到本节点网段 第一个 ip 即 tunl0 的…...
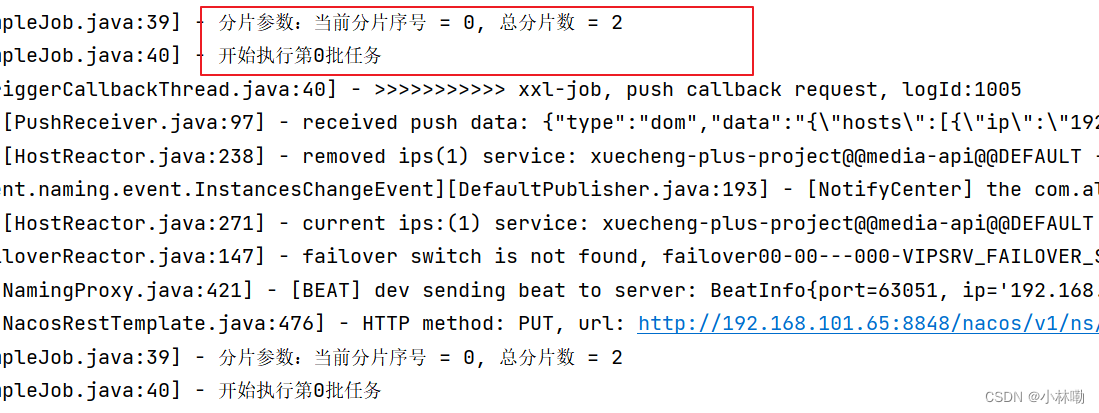
分布式任务调度(XXL-JOB)
什么是分布式任务调度? 任务调度顾名思义,就是对任务的调度,它是指系统为了完成特定业务,基于给定时间点,给定时间间隔或者给定执行次数自动执行任务。通常任务调度的程序是集成在应用中的,比如:…...
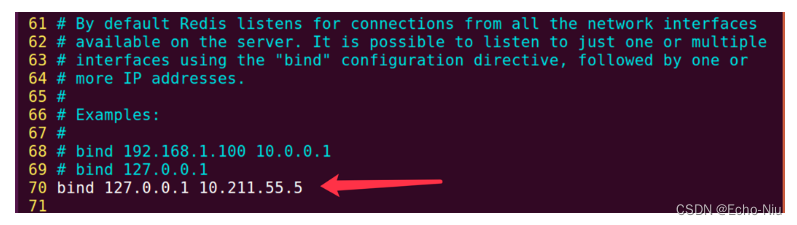
Django框架之模型视图--Session
Session 1 启用Session Django项目默认启用Session。 可以在settings.py文件中查看,如图所示 如需禁用session,将上图中的session中间件注释掉即可。 2 存储方式 在settings.py文件中,可以设置session数据的存储方式,可以保存…...
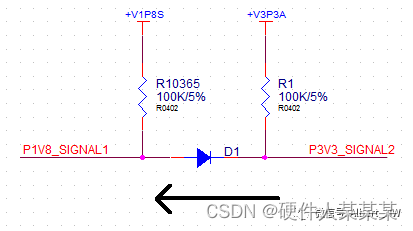
二极管的“几种”应用
不知大家平时有没有留意,二极管的应用范围是非常广的,下面我们来看看我想到几种应用,也可以加深对电路设计的认识: A,特性应用: 由于二极管的种类非常之多,这里这个大类简单罗列下:…...
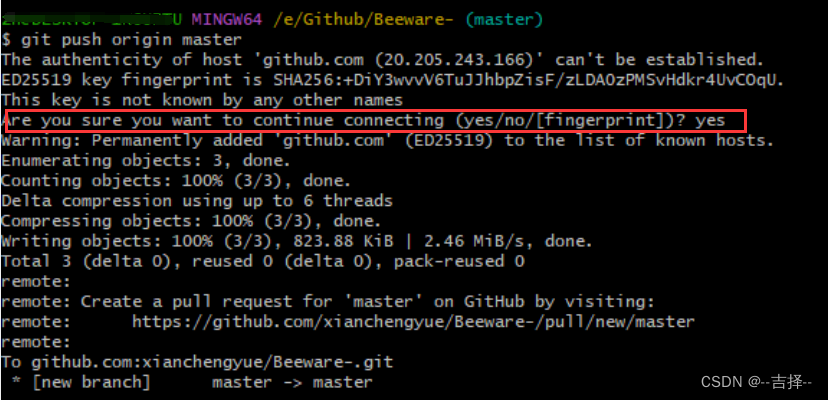
github上传本地文件详细过程
repository 也就是俗称的仓库 声明:后续操作基于win10系统 前提:有一个github账号、电脑安装了git(官方安装地址) 目的: 把图中pdf文件上传到github上的个人仓库中 效果: 温馨提示: git中复制: ctrl insert…...
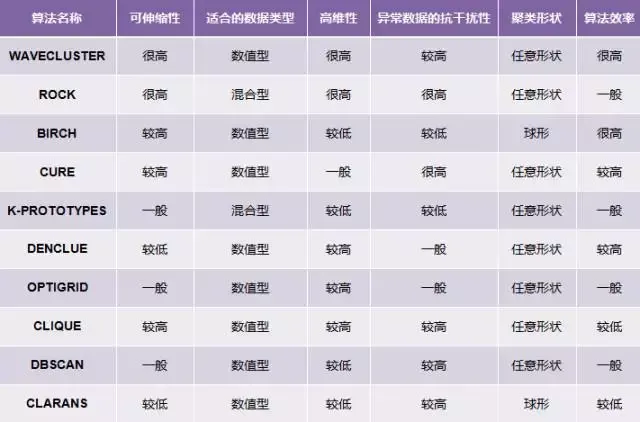
常用聚类算法分析
1. 什么是聚类 1.1. 聚类的定义 聚类(Clustering)是按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起…...

OSG三维渲染引擎编程学习之五十八:“第五章:OSG场景渲染” 之 “5.16 简单光源”
目录 第五章 OSG场景渲染 5.16 简单光源 5.16.1 场景中使用光源 5.16.2 简单光源示例 第五章 OSG场景渲染 OSG存在场景树和渲染树,“场景数”的构建在第三章“OSG场景组...
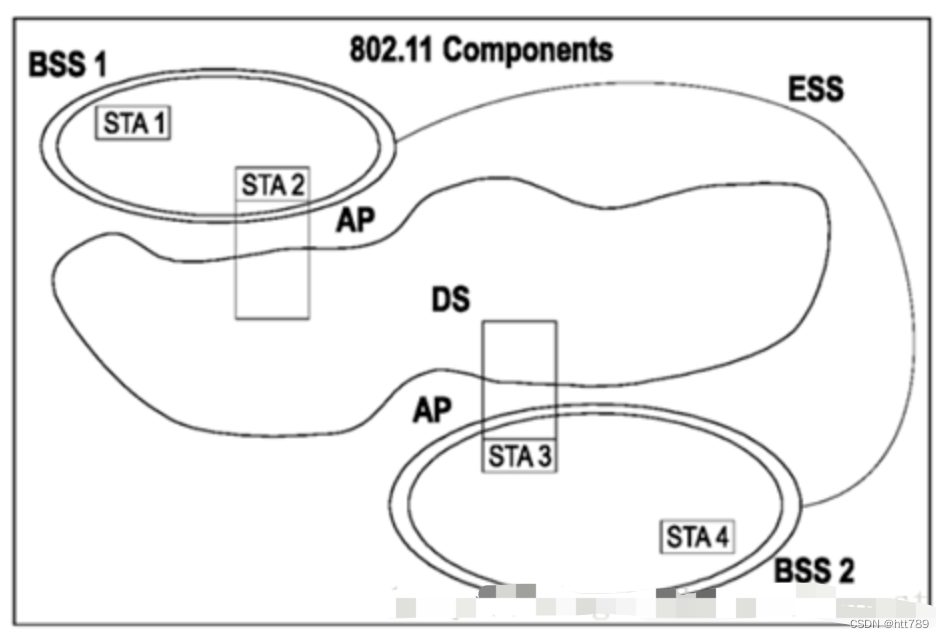
80211无线网络架构
无线网络架构物理组件BSS(Basic Service Set)基本服务集BSSID(BSS Identification)ssid(Service Set Identification)ESS(Extended Service Set)扩展服务集物理组件 无线网络包含四…...
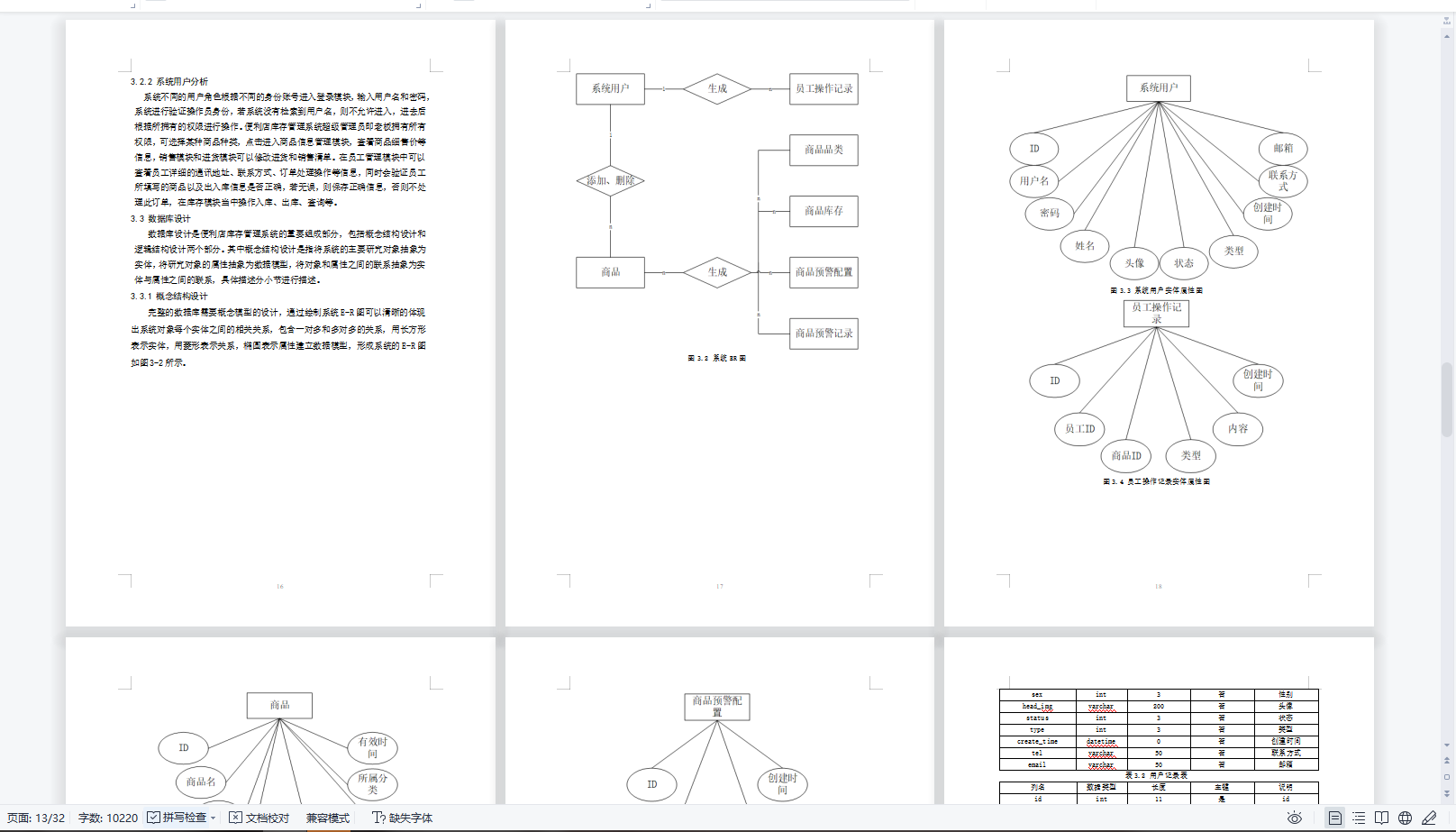
基于springboot+vue的便利店库存管理系统
基于springbootvue的便利店库存管理系统 ✌全网粉丝20W,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅文末获取项目下载方式🍅 一、项目背景…...

3|物联网控制|计算机控制-刘川来胡乃平版|第1章:绪论|青岛科技大学课堂笔记|U1 ppt
目录绪论(2学时)常用仪表设备(3学时)计算机总线技术(4学时)过程通道与人机接口(6学时)数据处理与控制策略(6学时)网络与通讯技术(3学时࿰…...
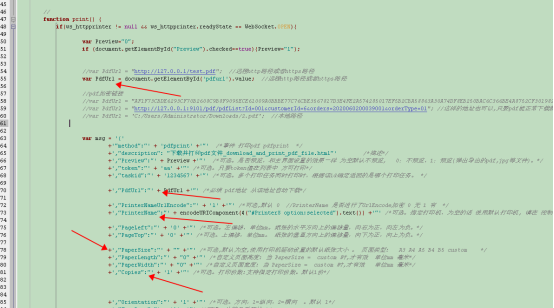
js打印本地pdf(使用HttpPrinter打印插件)
js打印本地pdf(使用HttpPrinter打印插件)第一步:启动HttpPrinter打印插件第二步:用浏览器打开示例文件\调用示例\websocket协议示例\html\打印pdf.html输入pdf地址 点击 “下载并打印pdf文件”按钮,就可以静默打印了。…...
 | 机试题算法思路 【2023】)
华为OD机试 - 双十一(Python) | 机试题算法思路 【2023】
最近更新的博客 【新解法】华为OD机试 - 关联子串 | 备考思路,刷题要点,答疑,od Base 提供【新解法】华为OD机试 - 停车场最大距离 | 备考思路,刷题要点,答疑,od Base 提供【新解法】华为OD机试 - 任务调度 | 备考思路,刷题要点,答疑,od Base 提供【新解法】华为OD机试…...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

线程与协程
1. 线程与协程 1.1. “函数调用级别”的切换、上下文切换 1. 函数调用级别的切换 “函数调用级别的切换”是指:像函数调用/返回一样轻量地完成任务切换。 举例说明: 当你在程序中写一个函数调用: funcA() 然后 funcA 执行完后返回&…...

华为云Flexus+DeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建
华为云FlexusDeepSeek征文|DeepSeek-V3/R1 商用服务开通全流程与本地部署搭建 前言 如今大模型其性能出色,华为云 ModelArts Studio_MaaS大模型即服务平台华为云内置了大模型,能助力我们轻松驾驭 DeepSeek-V3/R1,本文中将分享如何…...

【数据分析】R版IntelliGenes用于生物标志物发现的可解释机器学习
禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者! 文章目录 介绍流程步骤1. 输入数据2. 特征选择3. 模型训练4. I-Genes 评分计算5. 输出结果 IntelliGenesR 安装包1. 特征选择2. 模型训练和评估3. I-Genes 评分计…...

Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析
Java求职者面试指南:Spring、Spring Boot、MyBatis框架与计算机基础问题解析 一、第一轮提问(基础概念问题) 1. 请解释Spring框架的核心容器是什么?它在Spring中起到什么作用? Spring框架的核心容器是IoC容器&#…...

AGain DB和倍数增益的关系
我在设置一款索尼CMOS芯片时,Again增益0db变化为6DB,画面的变化只有2倍DN的增益,比如10变为20。 这与dB和线性增益的关系以及传感器处理流程有关。以下是具体原因分析: 1. dB与线性增益的换算关系 6dB对应的理论线性增益应为&…...

LangChain知识库管理后端接口:数据库操作详解—— 构建本地知识库系统的基础《二》
这段 Python 代码是一个完整的 知识库数据库操作模块,用于对本地知识库系统中的知识库进行增删改查(CRUD)操作。它基于 SQLAlchemy ORM 框架 和一个自定义的装饰器 with_session 实现数据库会话管理。 📘 一、整体功能概述 该模块…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...