Flink03: 集群安装部署
Flink支持多种安装部署方式
- Standalone
- ON YARN
- Mesos、Kubernetes、AWS…
这些安装方式我们主要讲一下standalone和on yarn。
如果是一个独立环境的话,可能会用到standalone集群模式。
在生产环境下一般还是用on yarn 这种模式比较多,因为这样可以综合利用集群资源。和我们之前讲的
spark on yarn是一样的效果,这个时候我们的Hadoop集群上面既可以运行MapReduce任务,Spark任务,还可以运行Flink任务,一举三得。
一、Standalone
1. 集群规划

依赖环境
jdk1.8及以上【配置JAVA_HOME环境变量】
ssh免密码登录
在这我们使用bigdata01、02、03这三台机器,这几台机器的基础环境都是ok的,可以直接使用。
集群规划如下:
master:bigdata01
slave:bigdata02、bigdata03
2. 下载flink安装包

注意:由于目前Flink各个版本之间差异比较大,属于快速迭代阶段,所以在这我们就使用最新版本了,使用Flink1.11.1版本。
3. 安装步骤
1.安装包下载好以后上传到bigdata01的/data/soft目录中
[root@bigdata01 soft]# ll flink-1.11.1-bin-scala_2.12.tgz
-rw-r--r--. 1 root root 312224884 Aug 5 2026 flink-1.11.1-bin-scala_2.12.
tgz2. 解压
[root@bigdata01 soft]# tar -zxvf flink-1.11.1-bin-scala_2.12.tgz3.修改配置
[root@bigdata01 soft]# cd flink-1.11.1
[root@bigdata01 flink-1.11.1]# cd conf/
[root@bigdata01 conf]# vi flink-conf.yaml
......
jobmanager.rpc.address: bigdata01
......
[root@bigdata01 conf]# vi masters
bigdata01:8081
[root@bigdata01 conf]# vi workers
bigdata02
bigdata033:将修改完配置的flink目录拷贝到其它两个从节点
[root@bigdata01 soft]# scp -rq flink-1.11.1 bigdata02:/data/soft/
[root@bigdata01 soft]# scp -rq flink-1.11.1 bigdata03:/data/soft/4:启动Flink集群
[root@bigdata01 soft]# cd flink-1.11.1
[root@bigdata01 flink-1.11.1]# bin/start-cluster.sh
Starting cluster.
Starting standalonesession daemon on host bigdata01.
Starting taskexecutor daemon on host bigdata02.
Starting taskexecutor daemon on host bigdata03.5:验证一下进程
在bigdata01上执行jps
[root@bigdata01 flink-1.11.1]# jps
3986 StandaloneSessionClusterEntrypoint在bigdata02上执行jps
[root@bigdata02 ~]# jps
2149 TaskManagerRunner在bigdata03上执行jps
[root@bigdata03 ~]# jps
2150 TaskManagerRunner6:访问Flink的web界面
http://bigdata01:8081
7:停止集群,在主节点上执行停止集群脚本
[root@bigdata01 flink-1.11.1]# bin/stop-cluster.sh
Stopping taskexecutor daemon (pid: 2149) on host bigdata02.
Stopping taskexecutor daemon (pid: 2150) on host bigdata03.
Stopping standalonesession daemon (pid: 3986) on host bigdata01.4. Standalone集群核心参数
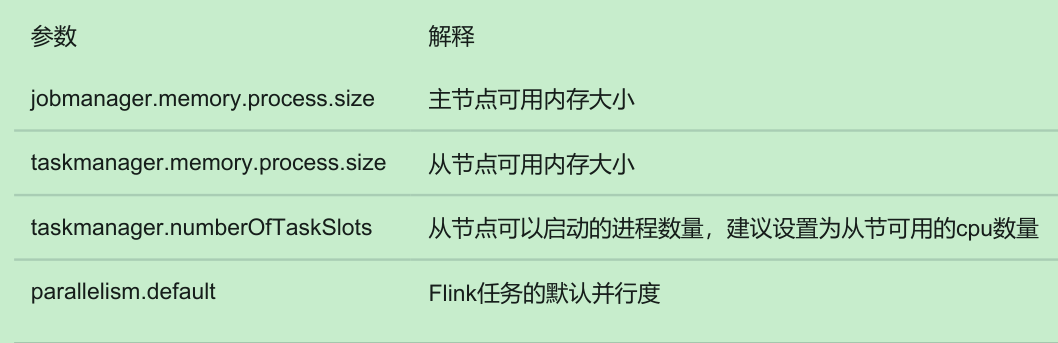
5. slot vs parallelism
1:slot是静态的概念,是指taskmanager具有的并发执行能力
2:parallelism是动态的概念,是指程序运行时实际使用的并发能力
3:设置合适的parallelism能提高程序计算效率,太多了和太少了都不好
二、Flink ON YARN
Flink ON YARN模式就是使用客户端的方式,直接向Hadoop集群提交任务即可。不需要单独启动Flink进程。
注意:
1:Flink ON YARN 模式依赖Hadoop 2.4.1及以上版本
2:Flink ON YARN支持两种使用方式

1. Flink ON YARN第一种方式
下面来看一下第一种方式
第一步:在集群中初始化一个长时间运行的Flink集群
使用yarn-session.sh脚本
第二步:使用flink run命令向Flink集群中提交任务
注意:使用flink on yarn需要确保hadoop集群已经启动成功
1. 首先在bigdata04机器上安装一个Flink客户端,其实就是把Flink的安装包上传上去解压即可,不需要启动
[root@bigdata04 soft]# tar -zxvf flink-1.11.1-bin-scala_2.12.tgz2. 接下来在执行 yarn-session.sh 脚本之前我们需要先设置 HADOOP_CLASSPATH 这个环境变量,否则,执行yarn-session.sh 是会报错的,提示找不到hadoop的一些依赖。
[root@bigdata01 flink-1.11.1]# bin/yarn-session.sh -jm 1024m -tm 1024m -d
Error: A JNI error has occurred, please check your installation and try again
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/hadoop/yarn/exceptions/YarnExceptionat java.lang.Class.getDeclaredMethods0(Native Method)at java.lang.Class.privateGetDeclaredMethods(Class.java:2701)at java.lang.Class.privateGetMethodRecursive(Class.java:3048)at java.lang.Class.getMethod0(Class.java:3018)at java.lang.Class.getMethod(Class.java:1784)at sun.launcher.LauncherHelper.validateMainClass(LauncherHelper.java:544)at sun.launcher.LauncherHelper.checkAndLoadMain(LauncherHelper.java:526)
Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.yarn.exceptions.YarnExceptionat java.net.URLClassLoader.findClass(URLClassLoader.java:382)at java.lang.ClassLoader.loadClass(ClassLoader.java:424)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:349)at java.lang.ClassLoader.loadClass(ClassLoader.java:357)... 7 more在 /etc/profile 中配置 HADOOP_CLASSPATH
[root@bigdata04 flink-1.11.1]# vi /etc/profile
export JAVA_HOME=/data/soft/jdk1.8
export HADOOP_HOME=/data/soft/hadoop-3.2.0
export HIVE_HOME=/data/soft/apache-hive-3.1.2-bin
export SPARK_HOME=/data/soft/spark-2.4.3-bin-hadoop2.7
export SQOOP_HOME=/data/soft/sqoop-1.4.7.bin__hadoop-2.6.0
export HADOOP_CLASSPATH=`${HADOOP_HOME}/bin/hadoop classpath`
export PATH=.:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HIVE_HOME/bin:$SPARK_HO
ME/bin:$SQOOP_HOME/bin:$PATH刷新配置
[root@bigdata01 flink-1.11.1]# source /etc/profile3. 接下来,使用 yarn-session.s h在YARN中创建一个长时间运行的Flink集群
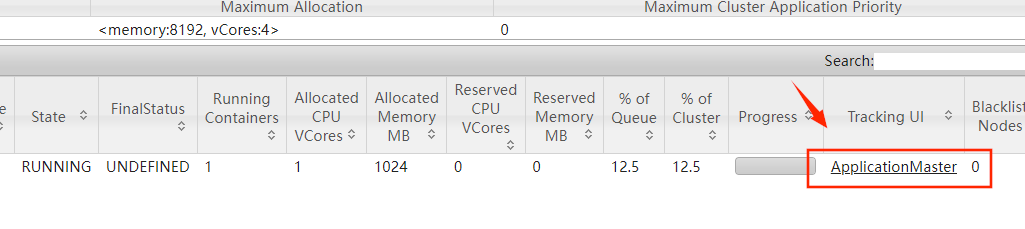
[root@bigdata04 flink-1.11.1]# bin/yarn-session.sh -jm 1024m -tm 1024m -d这个表示创建一个Flink集群, -jm 是指定主节点的内存, -tm 是指定从节点的内存, -d 是表示把这个进程放到后台去执行。启动之后,会看到类似这样的日志信息,这里面会显示flink web界面的地址,以及这个flink集群在yarn中对应的applicationid。
此时到YARN的web界面中确实可以看到这个flink集群。

可以使用屏幕中显示的flink的web地址或者yarn中这个链接都是可以进入这个flink的web界面的

4. 接下来向这个Flink集群中提交任务,此时使用Flink中的内置案例
[root@bigdata04 flink-1.11.1]# bin/flink run ./examples/batch/WordCount.jar注意:这个时候我们使用flink run的时候,它会默认找这个文件,然后根据这个文件找到刚才我们
创建的那个永久的Flink集群,这个文件里面保存的就是刚才启动的那个Flink集群在YARN中对应
的applicationid。
2023-02-19 02:11:19,306 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.
2023-02-19 02:11:19,306 INFO org.apache.flink.yarn.cli.FlinkYarnSessionCli [] - Found Yarn properties file under /tmp/.yarn-properties-root.[root@bigdata04 flink-1.11.1]# more /tmp/.yarn-properties-root
#Generated YARN properties file
#Tue Jan 20 22:50:06 CST 2026
dynamicPropertiesString=
applicationID=application_1768906309581_00055.任务提交上去执行完成之后,再来看flink的web界面,发现这里面有一个已经执行结束的任务了。
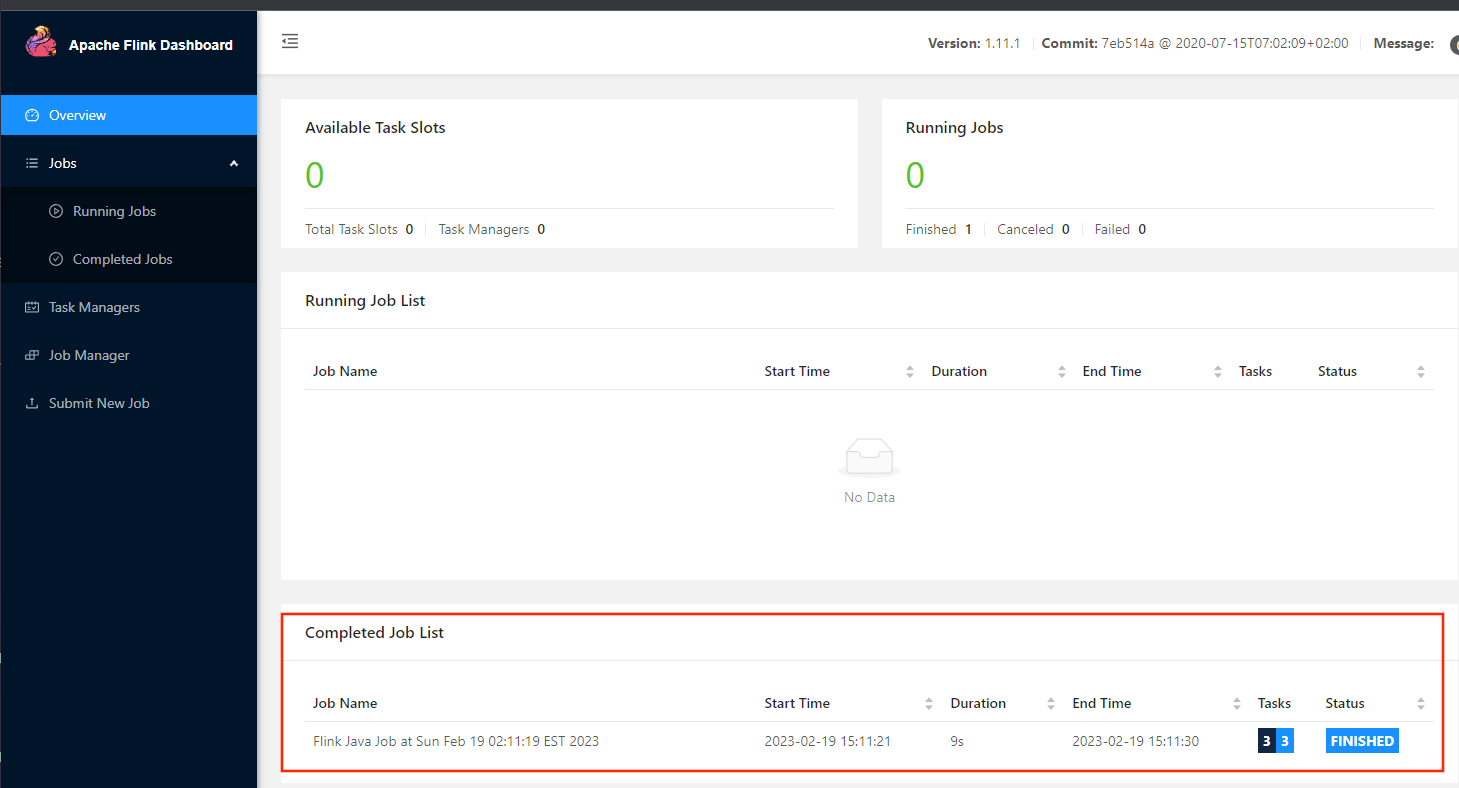
注意:这个任务在执行的时候,会动态申请一些资源执行任务,任务执行完毕之后,对应的资源会自动释放掉。
6. 最后把这个Flink集群停掉,使用yarn的kill命令
[root@bigdata04 flink-1.11.1]# yarn application -kill application_1768906309581_00057. 针对 yarn-session 命令,它后面还支持一些其它参数,可以在后面传一个 -help 参数
[root@bigdata04 flink-1.11.1]# bin/yarn-session.sh -help
Usage:
Optional
-at,--applicationType <arg> Set a custom application type for the
application on YARN
-D <property=value> use value for given property
-d,--detached If present, runs the job in detached m
ode
-h,--help Help for the Yarn session CLI.
-id,--applicationId <arg> Attach to running YARN session
-j,--jar <arg> Path to Flink jar file
-jm,--jobManagerMemory <arg> Memory for JobManager Container with o
ptional unit (default: MB)
-m,--jobmanager <arg> Address of the JobManager to which to
connect. Use this flag to connect to a different JobManager than the one sp
ecified in the configuration.
-nl,--nodeLabel <arg> Specify YARN node label for the YARN a
pplication
-nm,--name <arg> Set a custom name for the application
on YARN
-q,--query Display available YARN resources (memo
ry, cores)
-qu,--queue <arg> Specify YARN queue.
-s,--slots <arg> Number of slots per TaskManager
-t,--ship <arg> Ship files in the specified directory
(t for transfer)
-tm,--taskManagerMemory <arg> Memory per TaskManager Container with
optional unit (default: MB)
-yd,--yarndetached If present, runs the job in detached m
ode (deprecated; use non-YARN specific option instead)
-z,--zookeeperNamespace <arg> Namespace to create the Zookeeper sub-
paths for high availability mode在这我对一些常见的命令进行了整理,添加了中文注释

注意:这里的-j 是指定Flink任务的jar包,此参数可以省略不写也可以
2. Flink ON YARN第二种方式
flink run -m yarn-cluster (创建Flink集群+提交任务)
使用flink run直接创建一个临时的Flink集群,并且提交任务
此时这里面的参数前面加上了一个 y 参数
[root@bigdata04 flink-1.11.1]# bin/flink run -m yarn-cluster -yjm 1024
-ytm 1024 ./examples/batch/WordCount.jar提交上去之后,会先创建一个Flink集群,然后在这个Flink集群中执行任务。
针对Flink命令的一些用法汇总:

三、Flink ON YARN的好处
1:提高大数据集群机器的利用率
2:一套集群,可以执行MR任务,Spark任务,Flink任务等
四、向集群中提交Flink任务
接下来我们希望把前面我们自己开发的Flink任务提交到集群上面,在这我就使用flink on yarn的第二种方式来向集群提交一个Flink任务。
1. 在pom.xml中添加打包配置
<build><plugins><!-- 编译插件 --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.6.0</version><configuration><source>1.8</source><target>1.8</target><encoding>UTF-8</encoding></configuration></plugin><!-- scala编译插件 --><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.1.6</version><configuration><scalaCompatVersion>2.12</scalaCompatVersion><scalaVersion>2.12.11</scalaVersion><encoding>UTF-8</encoding></configuration><executions><execution><id>compile-scala</id><phase>compile</phase><goals><goal>add-source</goal><goal>compile</goal></goals></execution><execution><id>test-compile-scala</id><phase>test-compile</phase><goals><goal>add-source</goal><goal>testCompile</goal></goals></execution></executions></plugin><!-- 打jar包插件(会包含所有依赖) --><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>2.6</version><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs><archive><manifest><!-- 可以设置jar包的入口类(可选) --><mainClass></mainClass></manifest></archive></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>2. 打包代码
mvn clean package -DskipTests3. 将 db_flink-1.0-SNAPSHOT-jar-with-dependencies.jar 上传到bigdata04机器上
的 /data/soft/flink-1.11.1 目录中(上传到哪个目录都可以)
4. 提交Flink任务
注意:提交任务之前,先开启socket
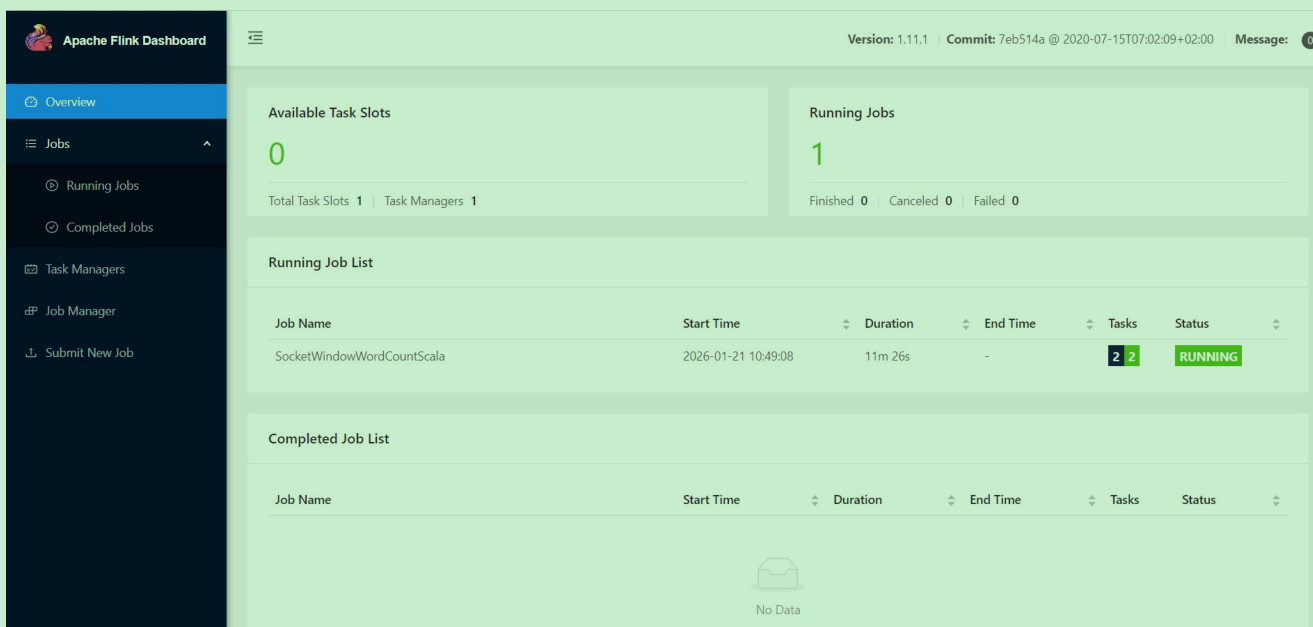
[root@bigdata04 ~]# nc -l 9001[root@bigdata04 flink-1.11.1]#bin/flink run -m yarn-cluster -c com.imooc.scala.stream.SocketWindowWordCountScala -yjm 1024 -ytm 1024 db_flink-1.0-SNAPSHOT-jar-with-dependencies.jar6. 此时到yarn上面可以看到确实新增了一个任务,点击进去可以看到flink的web界面
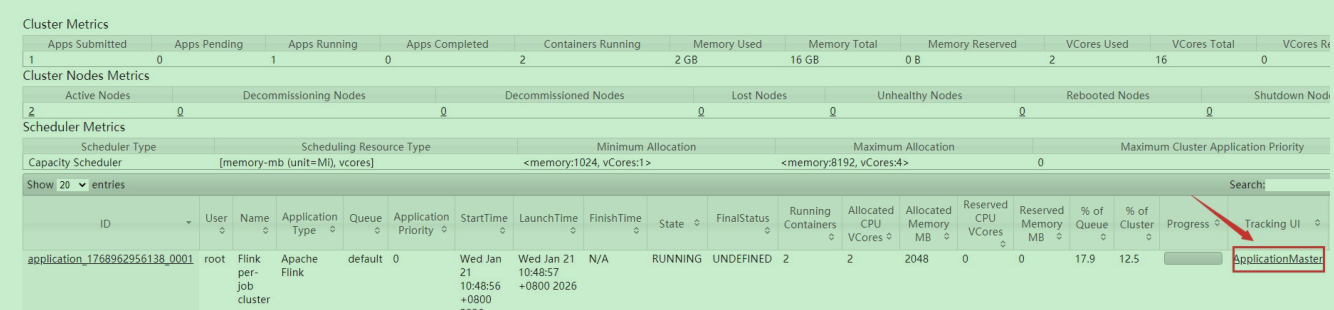
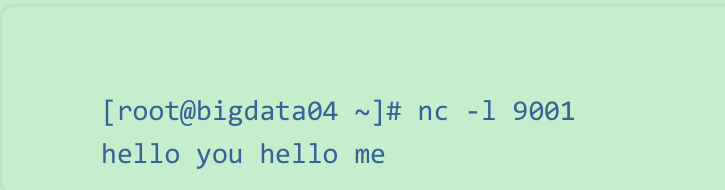
通过socket输入一串内容
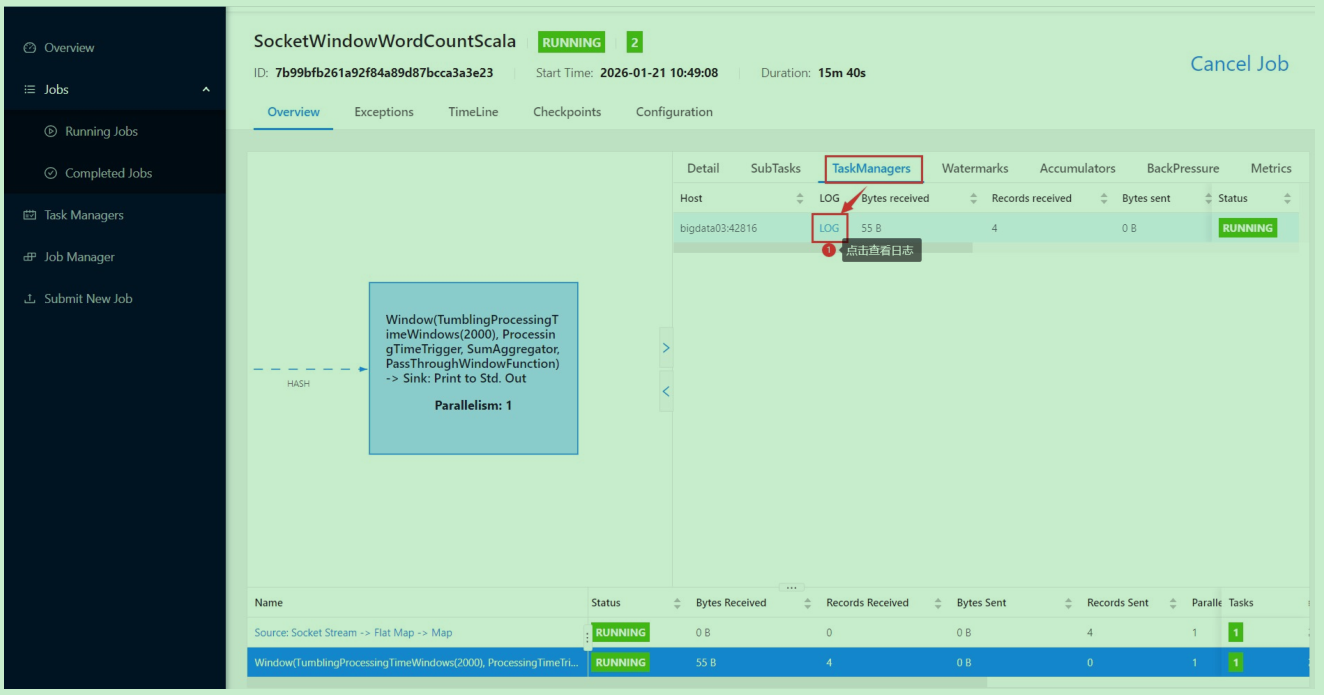
然后到flink的web界面查看日志


7. 接下来我们希望把这个任务停掉,因为这个任务是一个流处理的任务,提交成功之后,它会一直运行。
注意:此时如果我们使用ctrl+c关掉之前提交任务的那个进程,这里的flink任务是不会有任何影响的,可以一直运行,因为flink任务已经提交到hadoop集群里面了。
此时如果想要停止Flink任务,有两种方式:
方式一:停止yarn中任务
[root@bigdata04 flink-1.11.1]# yarn application -kill application_1768962956138_0001方式二:停止flink任务。可以在界面上点击这个按钮,或者在命令行中执行flink cancel停止都可以

或者
[root@bigdata04 flink-1.11.1]# bin/flink cancel -yid application_1768962956138_0001 7b99bfb261a92f84a89d87bcca3a3e23这个flink任务停止之后,对应的那个yarn-session(Flink集群)也就停止了。
五、开启Flink的HistoryServer
注意:此时flink任务停止之后就无法再查看flink的web界面了,如果想看查看历史任务的执行信息就看不了了,怎么办呢?
咱们之前在学习spark的时候其实也遇到过这种问题,当时是通过启动spark的historyserver进程解决的。flink也有historyserver进程,也是可以解决这个问题的。historyserver进程可以在任意一台机器上启动,在这我们选择在bigdata04机器上启动在启动historyserver进程之前,需要先修改bigdata04中的flink-conf.yaml配置文件。
[root@bigdata04 flink-1.11.1]# vi conf/flink-conf.yaml
jobmanager.archive.fs.dir: hdfs://bigdata01:9000/completed-jobs/
historyserver.web.address: 192.168.182.103
historyserver.web.port: 8082
historyserver.archive.fs.dir: hdfs://bigdata01:9000/completed-jobs/
historyserver.archive.fs.refresh-interval: 10000然后启动flink的historyserver进程
[root@bigdata04 flink-1.11.1]# bin/historyserver.sh start注意:hadoop集群中的historyserver进程也需要启动
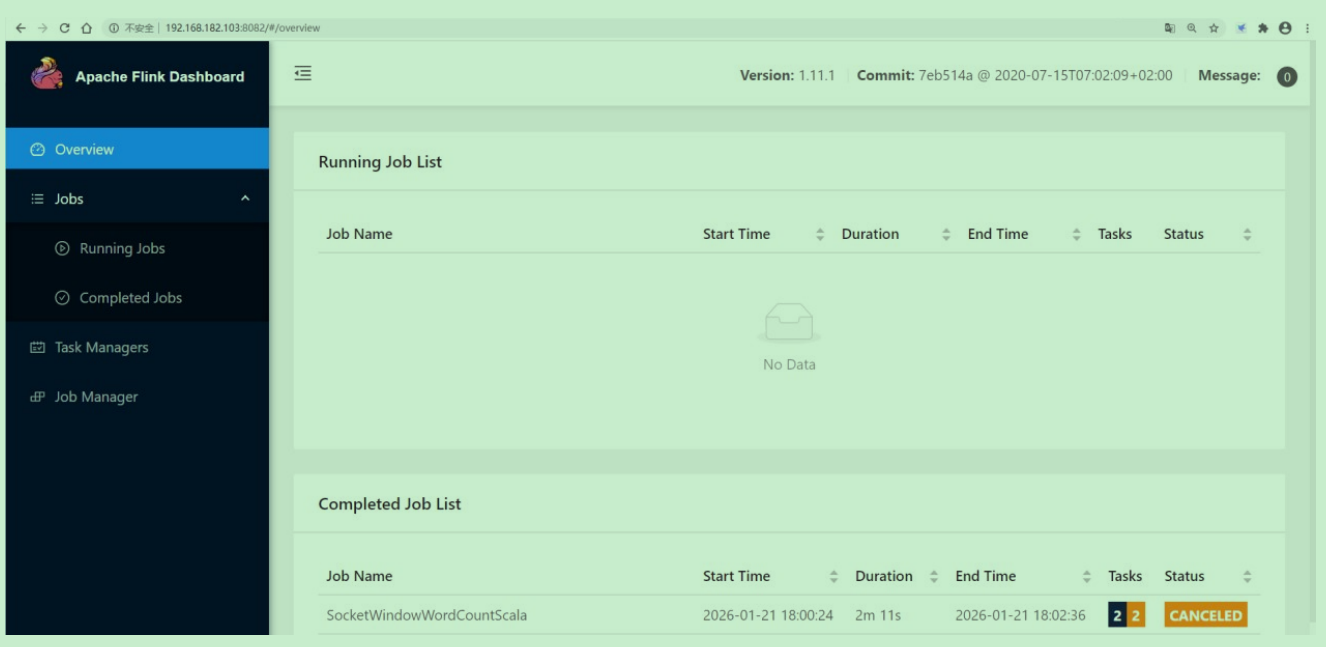
 此时Flink任务停止之后也是可以访问flink的web界面的。
此时Flink任务停止之后也是可以访问flink的web界面的。

相关文章:
Flink03: 集群安装部署
Flink支持多种安装部署方式 StandaloneON YARNMesos、Kubernetes、AWS… 这些安装方式我们主要讲一下standalone和on yarn。 如果是一个独立环境的话,可能会用到standalone集群模式。 在生产环境下一般还是用on yarn 这种模式比较多,因为这样可以综合利…...
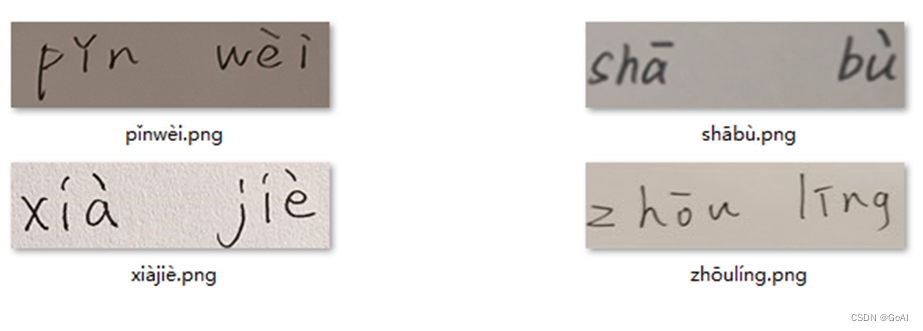
OCR项目实战(一):手写汉语拼音识别(Pytorch版)
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。 📝OCR专栏…...

【js】export default也在影响项目性能呢
这里写目录标题介绍先说结论分析解决介绍 无意间看到一个关于export与exprot default对比的话题, 于是对二者关于性能方面,有了想法,二者的区别,仅仅是在于写法吗? 于是,有了下面的测试。 先说结论 太长…...

《软件安全》 彭国军 阅读总结
对于本书,小编本意是对其讲述的内容,分点进行笔记的整理,后来学习以后,发现,这本书应该不算是一本技术提升类的书籍,更像是一本领域拓展和知识科普类书籍,所讲知识广泛,但是较少实践…...

深入讲解Kubernetes架构-节点与控制面之间的通信
本文列举控制面节点(确切说是 API 服务器)和 Kubernetes 集群之间的通信路径。 目的是为了让用户能够自定义他们的安装,以实现对网络配置的加固, 使得集群能够在不可信的网络上(或者在一个云服务商完全公开的 IP 上&am…...

120个IT冷知识,看完就不愁做选择题了
目录 IT冷知识 01-10 1.冰淇淋馅料 2.蠕虫起源 3.Linux和红帽子 4."间谍软件"诞生 5.游戏主机的灵魂 6.Linux之父 7.NetBSD的口号 8.安卓起源 9.不是第七代的 Win 7 10.域名金字塔 11~20 11.神奇魔盒 12. 第一个Ubuntu 正式版本 13.巾帼英雄 14.密码…...
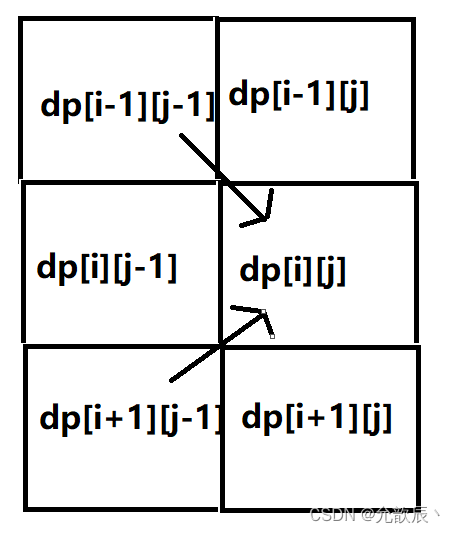
Java之动态规划之机器人移动
目录 0.动态规划问题 一.不同路径 1.题目描述 2.问题分析 3.代码实现 二.不同路径 II 1.题目描述 2.问题分析 3.代码实现 三.机器人双向走路 1.题目描述 2.问题分析 3.代码实现 0.动态规划问题 动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为小问…...
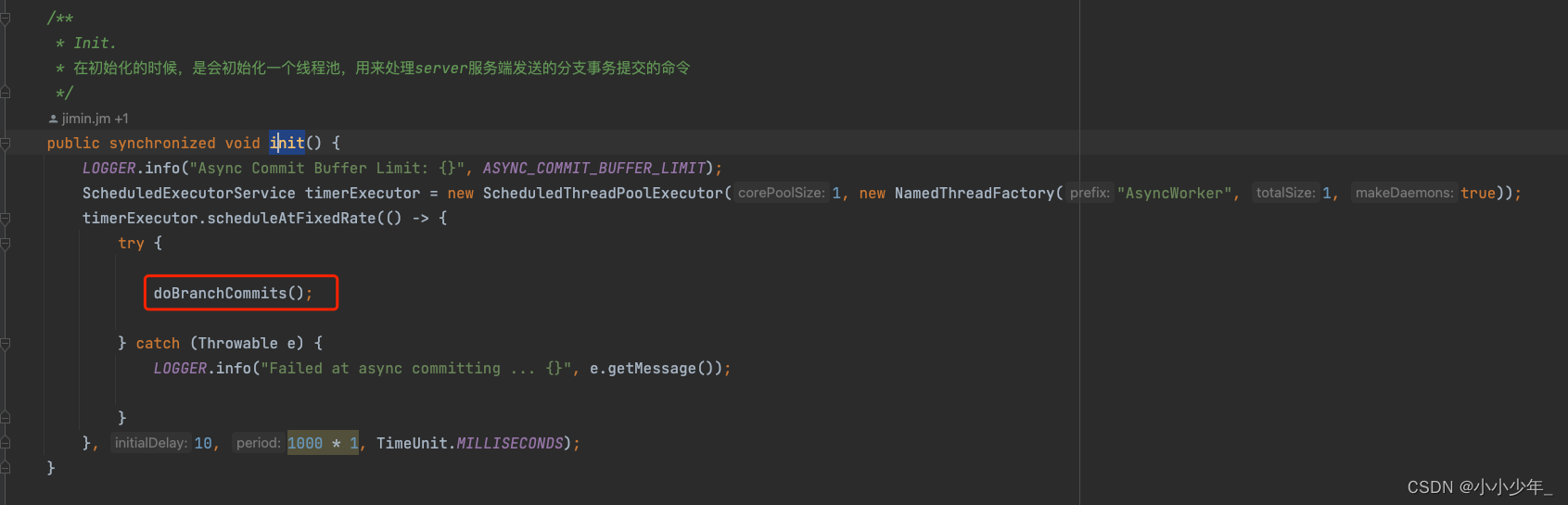
seata源码-全局事务提交 服务端源码
前面的博客中,我们介绍了,发起全局事务时,是如何进行全局事务提交的,这篇博客,主要记录,在seata分布式事务中,全局事务提交的时候,服务端是如何进行处理的 发起全局事务提交操作 事…...
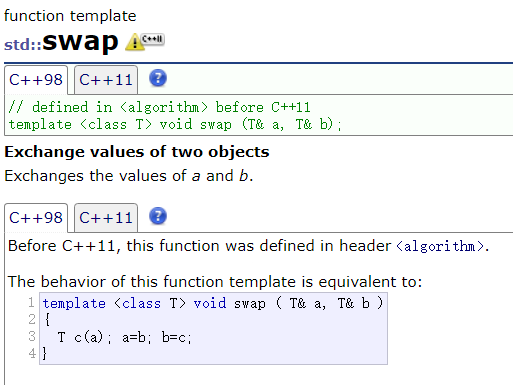
C++ 模板
文章目录一、泛型编程二、 函数模板三、类模板一、泛型编程 泛型编程:编写与类型无关的通用代码,代码复用的一种方法 在 C 中,我们可以通过函数重载实现通用的交换函数 Swap ,但是有一些缺点 重载函数只有类型不同,…...
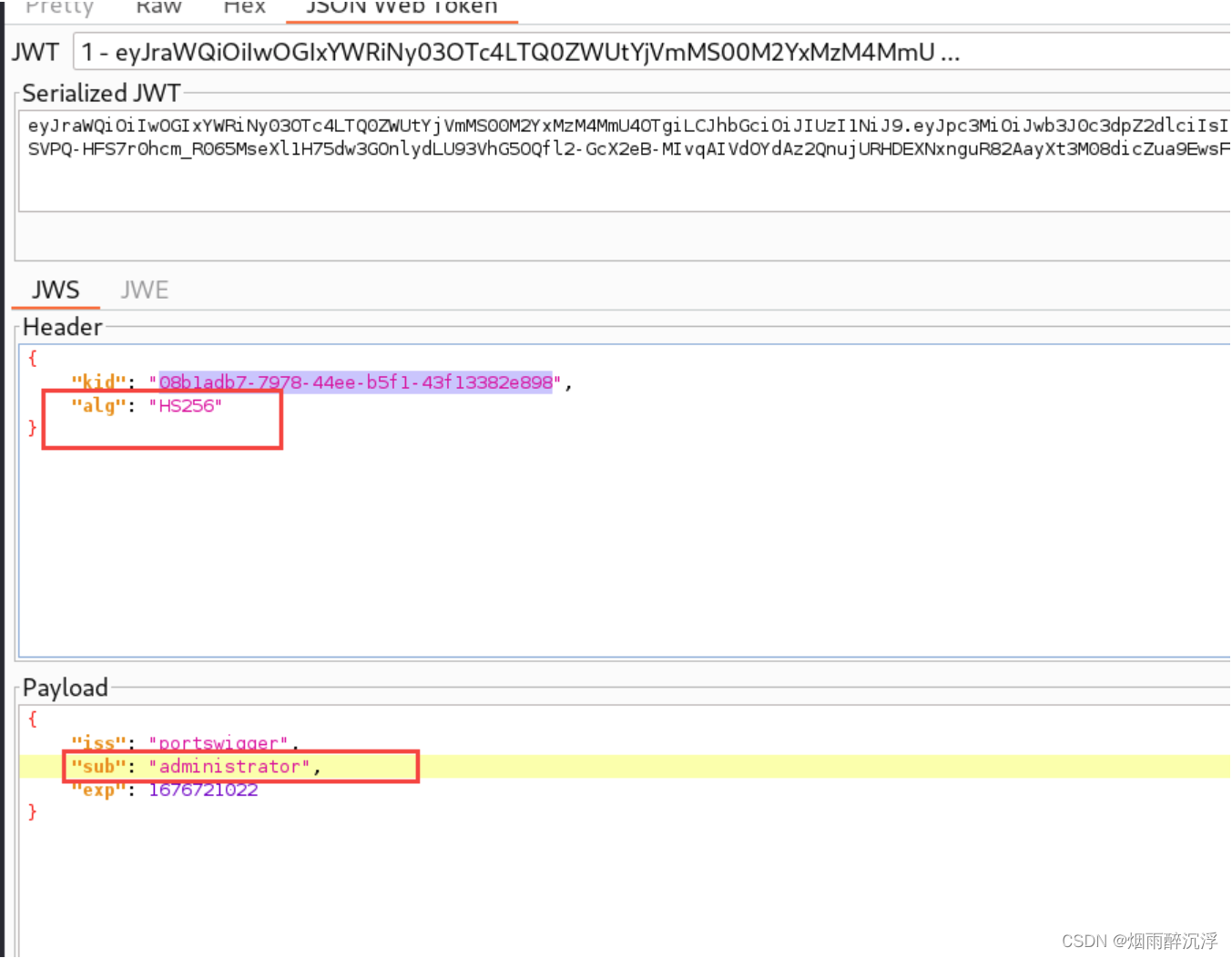
JWT安全漏洞以及常见攻击方式
前言 随着web应用的日渐复杂化,某些场景下,仅使用Cookie、Session等常见的身份鉴别方式无法满足业务的需要,JWT也就应运而生,JWT可以有效的解决分布式场景下的身份鉴别问题,并且会规避掉一些安全问题,如CO…...
)
华为OD机试题 - 最小施肥机能效(JavaScript)
最近更新的博客 华为OD机试题 - 任务总执行时长(JavaScript) 华为OD机试题 - 开放日活动(JavaScript) 华为OD机试 - 最近的点 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试题 - 最小步骤数(JavaScript) 华为OD机试题 - 任务混部(JavaScript) 华为OD机试题 - N 进…...
Python(1)变量的命名规则
目录 1.变量的命名原则 3.内置函数尽量不要做变量 4.删除变量和垃圾回收机制 5.结语 参考资料 1.变量的命名原则 ①由英文字母、_(下划线)、或中文开头 ②变量名称只能由英文字母、数字、下画线或中文字所组成。 ③英文字母大小写不相同 实例: 爱_aiA1 print(…...
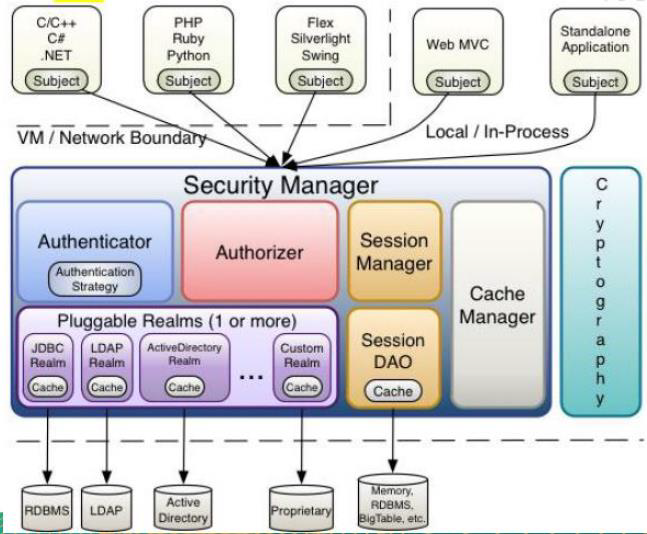
Shiro1.9学习笔记
文章目录一、Shiro概述1、Shiro简介1.1 介绍1.2 Shiro特点2、Shiro与SpringSecurity的对比3、Shiro基本功能4、Shiro原理4.1 Shiro 架构(外部)4.2 shiro架构(内部)二、Shiro基本使用1、环境准备2、登录认证2.1 登录认证概念2.2 登录认证基本流程2.3 登录认证实例2.4 身份认证源…...
2.5|iot|嵌入式Linux系统开发与应用|第4章:Linux外壳shell脚本程序编程
1.shell基础 Shell是Linux操作系统内核的外壳,它为用户提供使用操作系统的命令接口。 用户在提示符下输入的每个命令都由shell先解释然后发给Linux内核,所以Linux中的命令通称为shell命令。 通常我们使用shell来使用Linux操作系统。Linux系统的shell是…...

九龙证券|连续七周获加仓,四大行业成“香饽饽”!
本周17个申万职业北上资金持股量环比增加。 北上资金抢筹铝业龙头 本周A股商场全体冲高回落,沪指收跌1.12%,深成指跌2.18%,创业板指跌3.76%。北上资金周内小幅净流入。在大盘体现较差的周四周五,北上资金别离逆市回流67.94亿元、…...
210天从外包踏进华为跳动那一刻,我泪目了
前言 没有绝对的天才,只有持续不断的付出。对于我们每一个平凡人来说,改变命运只能依靠努力幸运,但如果你不够幸运,那就只能拉高努力的占比。 2021年4月,我有幸成为了华为的一名高级测试工程师,正如标题所…...

CMake 引入第三方库
CMake 引入第三方库 在 CMake 中,如何引入第三方库是一个常见的问题。在本文中,我们将介绍 CMake 中引入第三方库的不同方法,以及它们的优缺点。 1. 使用 find_package 命令 在 CMake 中,使用 find_package 命令是最简单和最常…...

软考中级-面向对象
面向对象基础(1)类类分为三种:实体类(世间万物)、接口类(又称边界类,提供用户与系统交互的方式)、控制类(前两类之间的媒介)。对象:由对象名数据&…...

Linux 系统构成:bootloader、kernel、rootfs
写在前面: 本文章旨在总结备份、方便以后查询,由于是个人总结,如有不对,欢迎指正;另外,内容大部分来自网络、书籍、和各类手册,如若侵权请告知,马上删帖致歉。 目录前言bootloaderk…...
SpringCloud - Eureka注册发现
目录 提供者与消费者 Eureka原理分析 搭建Eureka服务 服务注册 服务发现 提供者与消费者 服务提供者: 一次业务中,被其它微服务调用的服务(提供接口给其它微服务)服务消费者: 一次业务中,调用其它微服务的服务(调用其它微服务…...

Docker 运行 Kafka 带 SASL 认证教程
Docker 运行 Kafka 带 SASL 认证教程 Docker 运行 Kafka 带 SASL 认证教程一、说明二、环境准备三、编写 Docker Compose 和 jaas文件docker-compose.yml代码说明:server_jaas.conf 四、启动服务五、验证服务六、连接kafka服务七、总结 Docker 运行 Kafka 带 SASL 认…...

高危文件识别的常用算法:原理、应用与企业场景
高危文件识别的常用算法:原理、应用与企业场景 高危文件识别旨在检测可能导致安全威胁的文件,如包含恶意代码、敏感数据或欺诈内容的文档,在企业协同办公环境中(如Teams、Google Workspace)尤为重要。结合大模型技术&…...

Module Federation 和 Native Federation 的比较
前言 Module Federation 是 Webpack 5 引入的微前端架构方案,允许不同独立构建的应用在运行时动态共享模块。 Native Federation 是 Angular 官方基于 Module Federation 理念实现的专为 Angular 优化的微前端方案。 概念解析 Module Federation (模块联邦) Modul…...

C# 类和继承(抽象类)
抽象类 抽象类是指设计为被继承的类。抽象类只能被用作其他类的基类。 不能创建抽象类的实例。抽象类使用abstract修饰符声明。 抽象类可以包含抽象成员或普通的非抽象成员。抽象类的成员可以是抽象成员和普通带 实现的成员的任意组合。抽象类自己可以派生自另一个抽象类。例…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

华硕a豆14 Air香氛版,美学与科技的馨香融合
在快节奏的现代生活中,我们渴望一个能激发创想、愉悦感官的工作与生活伙伴,它不仅是冰冷的科技工具,更能触动我们内心深处的细腻情感。正是在这样的期许下,华硕a豆14 Air香氛版翩然而至,它以一种前所未有的方式&#x…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...

vulnyx Blogger writeup
信息收集 arp-scan nmap 获取userFlag 上web看看 一个默认的页面,gobuster扫一下目录 可以看到扫出的目录中得到了一个有价值的目录/wordpress,说明目标所使用的cms是wordpress,访问http://192.168.43.213/wordpress/然后查看源码能看到 这…...