MMKV与mmap:全方位解析
概述
MMKV 是基于 mmap 内存映射的移动端通用 key-value 组件,底层序列化/反序列化使用 protobuf 实现,性能高,稳定性强。从 2015 年中至今,在 iOS 微信上使用已有近 3 年,其性能和稳定性经过了时间的验证。近期已移植到 Android 平台。在腾讯内部开源半年之后,得到公司内部团队的广泛应用和一致好评。
MMKV 原理
内存准备:
通过 mmap 内存映射文件,提供一段可供随时写入的内存块,App 只管往里面写数据,由操作系统负责将内存回写到文件,不必担心 crash 导致数据丢失。
数据组织:
数据序列化方面我们选用 protobuf 协议,pb 在性能和空间占用上都有不错的表现。
写入优化:
考虑到主要使用场景是频繁地进行写入更新,我们需要有增量更新的能力。我们考虑将增量 kv 对象序列化后,append 到内存末尾。
空间增长:
使用 append 实现增量更新带来了一个新的问题,就是不断 append 的话,文件大小会增长得不可控。我们需要在性能和空间上做个折中。
mmap原理
内存映射:
mmap实现了一种使用内存映射到磁盘文件的方法,将本该属于磁盘文件的对象 映射到进程地址空间中,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动(默认并不实时)回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数,对文件直接通过内存映射读取从而跨过了页缓存,减少数据拷贝次数,用内存读写取代I/O读写,提高文件读取效率。
另外,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享,从而达到进程间通信和进程间共享的目的。简言之,很强大。
mmap 内存映射(memory mapping)
下面大致了解下mmap内存映射原理:
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。如下图所示:
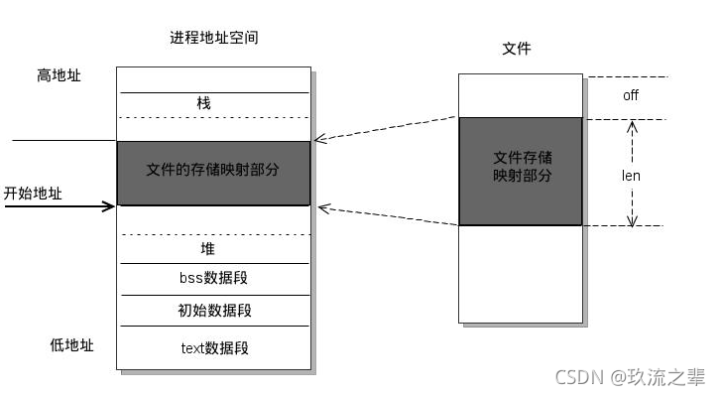
1、对文件的读取操作跨过了页缓存,减少了数据的拷贝次数,用内存读写取代I/O读写,提高了文件读取效率。
2、实现了用户空间和内核空间的高效交互方式。两空间的各自修改操作可以直接反映在映射的区域内,从而被对方空间及时捕捉。
3、提供进程间共享内存及相互通信的方式。不管是父子进程还是无亲缘关系的进程,都可以将自身用户空间映射到同一个文件或匿名映射到同一片区域。从而通过各自对映射区域的改动,达到进程间通信和进程间共享的目的。 同时,如果进程A和进程B都映射了区域C,当A第一次读取C时通过缺页从磁盘复制文件页到内存中;但当B再读C的相同页面时,虽然也会产生缺页异常,但是不再需要从磁盘中复制文件过来,而可直接使用已经保存在内存中的文件数据。
4、可用于实现高效的大规模数据传输。内存空间不足,是制约大数据操作的一个方面,解决方案往往是借助硬盘空间协助操作,补充内存的不足。但是进一步会造成大量的文件I/O操作,极大影响效率。这个问题可以通过mmap映射很好的解决。换句话说,但凡是需要用磁盘空间代替内存的时候,mmap都可以发挥其功效。
Protobuf协议
protobuf(Google Protocol Buffers)是Google提供一个具有高效的协议数据交换格式工具库(类似Json),但相比于Json,Protobuf有更高的转化效率,时间效率和空间效率都是JSON的3-5倍。 数据表示方式:每块数据由接连的若干个字节表示(小的数据用1个字节就可以表示),每个字节最高位标识本块数据是否结束(1:未结束,0:结束),低7位表示数据内容。(可以看出数据封包后体积至少增大14.2%)
例子:
数字1的表示方法为:0000 0001,这个容易理解 数字300的表示方法为:1010 1100 0000 0010 因为1表示未结束,须将标识位置移去,所以这个数字实际是0000 0010 1010 1100
1010 1100 0000 0010
→ 010 1100 000 0010//移去标识位
如下:
000 0010 010 1100
→ 000 0010 ++ 010 1100 //拼接
→ 10 0101100
→ 256 + 32 + 8 + 4 = 300//计算
实际使用的时候,protobuf最后其实会转化成一长串的二进制,二进制的形式其实就可在任何平台传输了,这里有个问题就是怎么一大串的二进制怎么隔开数据呢? 做法就是每块数据前加一个数据头,表示数据类型及协议字段序号。 msg1_head + msg1 + msg2_head + msg2 + … 数据头也是基于128bits的数值存储方式,一般1个字节就可以表示:
message Person {required int32 name = 1;//required 表示必须填入
}
如上创建了 Person 的结构并且把 name 设为 2,序列化好的二进制数据为:
0000 1000 0000 0010//以上数据转成十六进制也就是 08 02
//000 1000
//低3位表示数据类型:0,其他表示协议字段序号:1,加上最高位0, 结果就是8
简而言之,protobuf有着可跨平台的传输能力,快速转化的效率
1、序列化和反序列化效率比 xml 和 json 都高
2、字段可以乱序,欠缺,因此可以用来兼容旧的协议,或者是减少协议数据。
简单使用
相对于SP来说,mmkv的使用更为简单,只不过这里的初识化流程需要我们手动添加到Application中(保证使用前调用即可)。 下为Android java调用实例:
//初识化
MMKV.initialize(this); //这种是默认初识化,会创建默认的存储路径和日志等级打印
MMKV.initialize(this,"rootDir", MMKVLogLevel.LevelError);//当然,也可以修改存储路径和日志等级
//获取MMKV对象
MMKV mmkv=MMKV.defaultMMKV();//默认的mapid为mmkv.default
MMKV mmkv1=MMKV.mmkvWithID("1234");//也可修改mapid 类似getSharedPreferences("1234", Context.MODE_PRIVATE); 里的表名
//对象方法
mmkv.putInt("123",123);//存储数据
mmkv.getInt("123",1235);//获取数据
Android调用可直接依赖
dependencies {implementation 'com.tencent:mmkv-static:1.2.10'// replace "1.2.10" with any available version
}
深入源码
因为MMKV的核心代码是由C语言编译的,对于Android端引来的Jar更多的是进行JNI的调用,所以在下面代码分析的时候更多的偏向于C的调用逻辑,至于Jar包中的调用流程不再放入。 大致剖析流程如下:
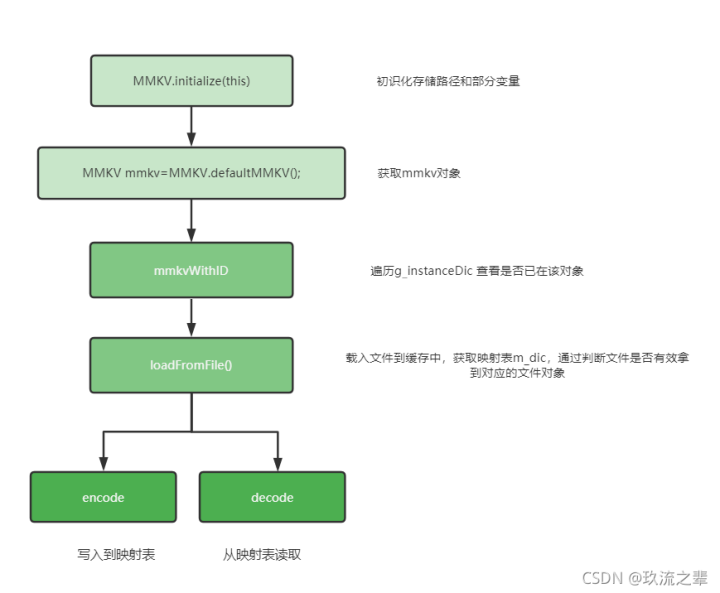
初识化 MMKV.initialize(this)
MMKV的初始化主要目的其实是对于mmkv的数据存储路径是否已经创建了,内部代码对多次初识化和多线程同时初识化进行了线程保护,这点可以学习。
void initialize() {g_instanceDic = new unordered_map<string, MMKV *>;//获取一个 unordered_mapg_instanceLock = new ThreadLock();g_instanceLock->initialize();//使用getpagesize函数获得一页内存大小//系统给我们提供真正的内存时,用页为单位提供,一次最少提供一页的真实内存空间//分配内存空间:你真实的分配了多少内存,就使用多少内存,不要越界使用//但是系统提供的真实内存空间是以页来提供的。mmkv::DEFAULT_MMAP_SIZE = mmkv::getPageSize();MMKVInfo("version %s, page size %d, arch %s", MMKV_VERSION, DEFAULT_MMAP_SIZE, MMKV_ABI);
}
void MMKV::initializeMMKV(const MMKVPath_t &rootDir, MMKVLogLevel logLevel) {g_currentLogLevel = logLevel;ThreadLock::ThreadOnce(&once_control, initialize);// 引入了ThreadLock库 最后实际 由pthread_once()指定的函数执行且仅执行一次,而once_control则表征是否执行过。//简单来说就是 pthread_once() 方法只保证这个方法只走了一次 如果多个线程同时调用,最先进入的会通过互斥锁让其他线程等待直到释放 如何其他监测到已经执行完成也会停止执行g_rootDir = rootDir;mkPath(g_rootDir);//MemoryFile.cpp 创建路径MMKVInfo("root dir: " MMKV_PATH_FORMAT, g_rootDir.c_str());//输出日志信息
}
//MemoryFile.cpp 创建路径
extern bool mkPath(const MMKVPath_t &str) {char *path = strdup(str.c_str());struct stat sb = {};bool done = false;char *slash = path;while (!done) {slash += strspn(slash, "/");slash += strcspn(slash, "/");done = (*slash == '\0');*slash = '\0';if (stat(path, &sb) != 0) {if (errno != ENOENT || mkdir(path, 0777) != 0) {MMKVWarning("%s : %s", path, strerror(errno));free(path);return false;}} else if (!S_ISDIR(sb.st_mode)) {MMKVWarning("%s: %s", path, strerror(ENOTDIR));free(path);return false;}
*slash = '/';}free(path);return true;
}
void ThreadLock::ThreadOnce(ThreadOnceToken_t *onceToken, void (*callback)()) {pthread_once(onceToken, callback);//pthread_once()都必须等待其中一个激发”已执行一次”信号,因此所有pthread_once()都会陷入永久的等待中;如果设为2,则表示该函数已执行过一次,从而所有pthread_once()都会立即返回0。
}
获取mmkv对象 MMKV mmkv=MMKV.defaultMMKV();
在获取mmkv对象的时候会先遍历一个g_instanceDic 无序map表,看看内部是否已经存在和这个mapID相关联的mmkv对象,如果已经存储了就直接取出使用,如果未存储则重新创建一个MMKV对象,同时加上了区域锁(SCOPED_LOCK(g_instanceLock)),可以规定哪部分可以被该线程访问,结束会自动释放 解决了同一文件不会产生线程冲突还能被同时多线程访问.
MMKV *MMKV::defaultMMKV(MMKVMode mode, string *cryptKey) {
#ifndef MMKV_ANDROID //预定的宏编译return mmkvWithID(DEFAULT_MMAP_ID, mode, cryptKey);//移动端走该方法 DEFAULT_MMAP_ID "mmkv.default" MMKVPredef.h
#elsereturn mmkvWithID(DEFAULT_MMAP_ID, DEFAULT_MMAP_SIZE, mode, cryptKey);
#endif
}
unordered_map<std::string, MMKV *> *g_instanceDic;
//unordered_map内部实现了一个哈希表(也叫散列表,通过把关键码值映射到Hash表中一个位置来访问记录,查找的时间复杂度可达到O(1),其在海量数据处理中有着广泛应用)。因此,其元素的排列顺序是无序的。
//哈希表的建立比较耗费时间
//适用处,对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用unordered_map
MMKV *MMKV::mmkvWithID(const string &mmapID, MMKVMode mode, string *cryptKey, MMKVPath_t *rootPath) { //这里第四个参数其实是加密值 实际也是存储路径if (mmapID.empty()) {return nullptr;}//mmapID不能为空SCOPED_LOCK(g_instanceLock); //g_instanceLock = new ThreadLock(); 区域锁 可以规定哪部分可以被该线程访问,结束会自动释放 解决了同一文件不会产生线程冲突还能被同时多线程访问
auto mmapKey = mmapedKVKey(mmapID, rootPath);auto itr = g_instanceDic->find(mmapKey); //通过给定主键查找元素,没找到:返回unordered_map::endif (itr != g_instanceDic->end()) {//查找itr是否在map中 ?这里的写法可能有点多余 上面已经查找过了,这里又查一遍MMKV *kv = itr->second;// the mapped value (of type T)return kv;}//这个mapID其实是存在哈希表内的,如果要创建多个线程都要操作这个map表,那么这时候就需要通过mmap决定是否存在其他mapID的mmkv对象 保证同一mmapkey绑定的对象只有一个if (rootPath) {MMKVPath_t specialPath = (*rootPath) + MMKV_PATH_SLASH + SPECIAL_CHARACTER_DIRECTORY_NAME;if (!isFileExist(specialPath)) {mkPath(specialPath);}//如果这个路径为空 则创建 和初始化相同MMKVInfo("prepare to load %s (id %s) from rootPath %s", mmapID.c_str(), mmapKey.c_str(), rootPath->c_str());}//加密值不为空auto kv = new MMKV(mmapID, mode, cryptKey, rootPath);kv->m_mmapKey = mmapKey;(*g_instanceDic)[mmapKey] = kv;//将创建的kv对象放入表内return kv;
}
//返回根据mmapID的加密值 这个mapID其实是绑定线程操作表的,如果要创建多个线程都要操作这个map表,那么这时候就需要通过mmap决定是否存在其他mapID线程 保证同一mmapkey绑定的线程只有一个在运行
string mmapedKVKey(const string &mmapID, MMKVPath_t *rootPath) {if (rootPath && g_rootDir != (*rootPath)) {return md5(*rootPath + MMKV_PATH_SLASH + string2MMKVPath_t(mmapID));//MMKV_PATH_SLASH 默认分割符 返回根据mmapID创建的地址}return mmapID;
}
创建MMKV对象,通过mmapID获取文件存放目录,获取文件存储目录用于件载入,这里将载入的文件作为memoryFile对象,初识化各类线程锁,这里还有个crc文件是对数据进行校验的,区别有效数据和无效数据,具体原理这里不做展开。
MMKV::MMKV(const std::string &mmapID, MMKVMode mode, string *cryptKey, MMKVPath_t *rootPath): m_mmapID(mmapID), m_path(mappedKVPathWithID(m_mmapID, mode, rootPath))//获取文件存放的目录, m_crcPath(crcPathWithID(m_mmapID, mode, rootPath))/// 拼装 .crc 文件路径 考虑到文件系统、操作系统都有一定的不稳定性,增加了 crc 校验,对无效数据进行甄别。, m_dic(nullptr)//对照表, m_dicCrypt(nullptr), m_file(new MemoryFile(m_path))//通过路径获取内存文件对象, m_metaFile(new MemoryFile(m_crcPath))//将文件映射到内存, m_metaInfo(new MMKVMetaInfo()), m_crypter(nullptr)//加密器, m_lock(new ThreadLock())//线程锁, m_fileLock(new FileLock(m_metaFile->getFd()))//文件锁, m_sharedProcessLock(new InterProcessLock(m_fileLock, SharedLockType))//进程锁, m_exclusiveProcessLock(new InterProcessLock(m_fileLock, ExclusiveLockType))//专用进程锁, m_isInterProcess((mode & MMKV_MULTI_PROCESS) != 0) {是否多进程m_actualSize = 0;m_output = nullptr;
# ifndef MMKV_DISABLE_CRYPT根据 cryptKey 创建 AES 加解密的引擎if (cryptKey && cryptKey->length() > 0) {m_dicCrypt = new MMKVMapCrypt();m_crypter = new AESCrypt(cryptKey->data(), cryptKey->length());} else {m_dic = new MMKVMap();}
# elsem_dic = new MMKVMap();
# endif
m_needLoadFromFile = true;//是否需要加载文件 对于未使用的mmapId首次都是需要从文件加载数据到内存m_hasFullWriteback = false;//是否数据全部重新写回内存m_crcDigest = 0;m_lock->initialize();m_sharedProcessLock->m_enable = m_isInterProcess;m_exclusiveProcessLock->m_enable = m_isInterProcess;// sensitive zone{SCOPED_LOCK(m_sharedProcessLock);loadFromFile();//核心方法}
}
载入文件到缓存中,通过判断文件是否有效拿到对应的文件对象,将数据构建输入到换内存页中,这里有个dic对照表,将缓存数据放入,后续保持和dic的映射同步即可,因为后续的写入会由文件系统自动写入,即使程序出现crash,正在写入的线程也不会被影响
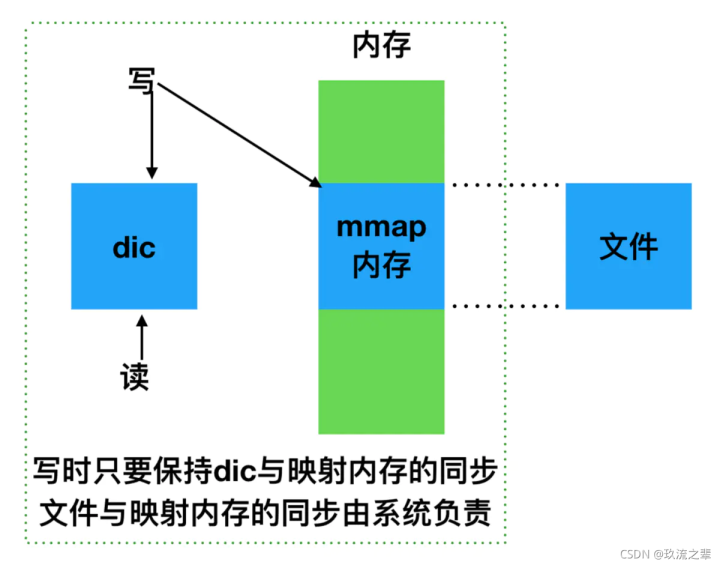
上图为该方法大致载入流程
MMKV维护了一个<String,AnyObject>的dic,在写入数据时,会在dit和mmap映射区写入相同的数据,最后由内核同步到文件。因为dic和文件数据同步,所以读取时直接去dit中的值。MMKV数据持久化的步骤:mmap 内存映射 -> 写数据 -> 读数据 -> crc校验 -> aes加密。
其中因为文件不同于内存中的对象,文件是持久存在的,而内存中的实例对象是会被回收的。 当我创建一个实例对象的时候,先要检查是否已经存在以往的映射文件, 若存在,需要先建立映射 关系,然后解析出以往的数据;若不存在,才是直接创建空文件来建立映射关系。
void MMKV::loadFromFile() {if (m_metaFile->isFileValid()) {m_metaInfo->read(m_metaFile->getMemory());//m_metaFile 文件的映射}
#ifndef MMKV_DISABLE_CRYPTif (m_crypter) {if (m_metaInfo->m_version >= MMKVVersionRandomIV) {m_crypter->resetIV(m_metaInfo->m_vector, sizeof(m_metaInfo->m_vector));}}
#endifif (!m_file->isFileValid()) {m_file->reloadFromFile();//如果文件不是有效的(文件大小等待),则重新进行加载 m_file:m_file(new MemoryFile(m_path))这里获取的对象}if (!m_file->isFileValid()) {MMKVError("file [%s] not valid", m_path.c_str());//重新加载后仍然无效则报错} else {// error checkingbool loadFromFile = false, needFullWriteback = false;checkDataValid(loadFromFile, needFullWriteback);//尝试从上次确认的位置自动恢复MMKVInfo("loading [%s] with %zu actual size, file size %zu, InterProcess %d, meta info ""version:%u",m_mmapID.c_str(), m_actualSize, m_file->getFileSize(), m_isInterProcess, m_metaInfo->m_version);auto ptr = (uint8_t *) m_file->getMemory();// loading 需要从文件获取数据if (loadFromFile && m_actualSize > 0) {MMKVInfo("loading [%s] with crc %u sequence %u version %u", m_mmapID.c_str(), m_metaInfo->m_crcDigest,m_metaInfo->m_sequence, m_metaInfo->m_version);// 构建输入缓存MMBuffer inputBuffer(ptr + Fixed32Size, m_actualSize, MMBufferNoCopy);//先清空 后写入if (m_crypter) {clearDictionary(m_dicCrypt);} else {clearDictionary(m_dic);}// 进行写入 Protobufif (needFullWriteback) {
#ifndef MMKV_DISABLE_CRYPTif (m_crypter) {MiniPBCoder::greedyDecodeMap(*m_dicCrypt, inputBuffer, m_crypter);} else
#endif{MiniPBCoder::greedyDecodeMap(*m_dic, inputBuffer); }} else {
#ifndef MMKV_DISABLE_CRYPTif (m_crypter) {MiniPBCoder::decodeMap(*m_dicCrypt, inputBuffer, m_crypter);} else
#endif{MiniPBCoder::decodeMap(*m_dic, inputBuffer);}}// 构建输出数据m_output = new CodedOutputData(ptr + Fixed32Size, m_file->getFileSize() - Fixed32Size);m_output->seek(m_actualSize);// 进行重整回写, 剔除重复的数据if (needFullWriteback) {fullWriteback();}} else {//说明文件中没有数据, 或者校验失败了// file not valid or empty, discard everythingSCOPED_LOCK(m_exclusiveProcessLock);
m_output = new CodedOutputData(ptr + Fixed32Size, m_file->getFileSize() - Fixed32Size);//清空文件中的数据if (m_actualSize > 0) {writeActualSize(0, 0, nullptr, IncreaseSequence);sync(MMKV_SYNC);} else {writeActualSize(0, 0, nullptr, KeepSequence);}}auto count = m_crypter ? m_dicCrypt->size() : m_dic->size();MMKVInfo("loaded [%s] with %zu key-values", m_mmapID.c_str(), count);}m_needLoadFromFile = false;
}
数据写入 mmkv.put
put方法实际执行的是encodeInt方法,也就是MMKV.cpp里面的set方法,在申请映射内存时是按页来计算的,默认一页是1024字节,每次将数据写入前会先判断映射内存是否有足够的空间进行写入,如果空间不够就会进行扩容,每次扩容都是原理扩容的两倍,也就是前面提到的空间增长。动态的申请内存空间,用官方的话来说就是在性能和空间上做个折中。
// 写入32位整型
bool MMKV::set(int32_t value, MMKVKey_t key) {if (isKeyEmpty(key)) {return false;}//传入key值不可为空字符串size_t size = pbInt32Size(value);MMBuffer data(size);CodedOutputData output(data.getPtr(), size);output.writeInt32(value);
return setDataForKey(move(data), key);
}
bool MMKV::setDataForKey(MMBuffer &&data, MMKVKey_t key, bool isDataHolder) {if ((!isDataHolder && data.length() == 0) || isKeyEmpty(key)) {return false;}SCOPED_LOCK(m_lock);SCOPED_LOCK(m_exclusiveProcessLock);checkLoadData();
#ifndef MMKV_DISABLE_CRYPTif (m_crypter) {if (isDataHolder) {auto sizeNeededForData = pbRawVarint32Size((uint32_t) data.length()) + data.length();if (!KeyValueHolderCrypt::isValueStoredAsOffset(sizeNeededForData)) {data = MiniPBCoder::encodeDataWithObject(data);//将value构造出一个Protobuf数据对象isDataHolder = false;}}auto itr = m_dicCrypt->find(key);if (itr != m_dicCrypt->end()) {
# ifdef MMKV_APPLEauto ret = appendDataWithKey(data, key, itr->second, isDataHolder);
# else//存数据逻辑auto ret = appendDataWithKey(data, key, isDataHolder);
# endifif (!ret.first) {return false;}if (KeyValueHolderCrypt::isValueStoredAsOffset(ret.second.valueSize)) {KeyValueHolderCrypt kvHolder(ret.second.keySize, ret.second.valueSize, ret.second.offset);memcpy(&kvHolder.cryptStatus, &t_status, sizeof(t_status));itr->second = move(kvHolder);} else {itr->second = KeyValueHolderCrypt(move(data));}} else {auto ret = appendDataWithKey(data, key, isDataHolder);if (!ret.first) {return false;}if (KeyValueHolderCrypt::isValueStoredAsOffset(ret.second.valueSize)) {auto r = m_dicCrypt->emplace(key, KeyValueHolderCrypt(ret.second.keySize, ret.second.valueSize, ret.second.offset));if (r.second) {memcpy(&(r.first->second.cryptStatus), &t_status, sizeof(t_status));}} else {m_dicCrypt->emplace(key, KeyValueHolderCrypt(move(data)));}}} else
#endif // MMKV_DISABLE_CRYPT{//在这里判断m_dic是否已经存在该Key,有就替换,没就添加auto itr = m_dic->find(key);if (itr != m_dic->end()) {auto ret = appendDataWithKey(data, itr->second, isDataHolder);if (!ret.first) {return false;}itr->second = std::move(ret.second);} else {auto ret = appendDataWithKey(data, key, isDataHolder);if (!ret.first) {return false;}m_dic->emplace(key, std::move(ret.second));//和insert类似 只不过emplace 最大的作用是避免产生不必要的临时变量}}m_hasFullWriteback = false;
#ifdef MMKV_APPLE[key retain];
#endifreturn true;
}
//将该对象添加到内存里
//pair是将2个数据组合成一个数据,当需要这样的需求时就可以使用pair,
//如stl中的map就是将key和value放在一起来保存。另一个应用是,当一个函数需要返回2个数据的时候,可以选择pair。
//pair的实现是一个结构体,主要的两个成员变量是first second 因为是使用struct不是class,所以可以直接使用pair的成员变量。
KVHolderRet_t MMKV::appendDataWithKey(const MMBuffer &data, const KeyValueHolder &kvHolder, bool isDataHolder) {SCOPED_LOCK(m_exclusiveProcessLock);
uint32_t keyLength = kvHolder.keySize;// size needed to encode the keysize_t rawKeySize = keyLength + pbRawVarint32Size(keyLength);// ensureMemorySize() might change kvHolder.offset, so have to do it early{auto valueLength = static_cast<uint32_t>(data.length());if (isDataHolder) {valueLength += pbRawVarint32Size(valueLength);}auto size = rawKeySize + valueLength + pbRawVarint32Size(valueLength);//计算存储的数据内存大小bool hasEnoughSize = ensureMemorySize(size);//目前内存页是否足够存储if (!hasEnoughSize) {return make_pair(false, KeyValueHolder());}}auto basePtr = (uint8_t *) m_file->getMemory() + Fixed32Size;MMBuffer keyData(basePtr + kvHolder.offset, rawKeySize, MMBufferNoCopy);return doAppendDataWithKey(data, keyData, isDataHolder, keyLength);//添加到内存里
}
//扩容
bool MMKV::ensureMemorySize(size_t newSize) {if (!isFileValid()) {MMKVWarning("[%s] file not valid", m_mmapID.c_str());return false;}
if (newSize >= m_output->spaceLeft() || (m_crypter ? m_dicCrypt->empty() : m_dic->empty())) {// try a full rewrite to make spaceauto fileSize = m_file->getFileSize();auto preparedData = m_crypter ? prepareEncode(*m_dicCrypt) : prepareEncode(*m_dic);auto sizeOfDic = preparedData.second;size_t lenNeeded = sizeOfDic + Fixed32Size + newSize;size_t dicCount = m_crypter ? m_dicCrypt->size() : m_dic->size();size_t avgItemSize = lenNeeded / std::max<size_t>(1, dicCount);size_t futureUsage = avgItemSize * std::max<size_t>(8, (dicCount + 1) / 2);// 1. no space for a full rewrite, double it// 2. or space is not large enough for future usage, double it to avoid frequently full rewrite//如果文件空间小于需要的空间长度会进行扩容,每次空间的扩容为原来的两倍if (lenNeeded >= fileSize || (lenNeeded + futureUsage) >= fileSize) {size_t oldSize = fileSize;do {//进行扩容fileSize *= 2;} while (lenNeeded + futureUsage >= fileSize);MMKVInfo("extending [%s] file size from %zu to %zu, incoming size:%zu, future usage:%zu", m_mmapID.c_str(),oldSize, fileSize, newSize, futureUsage);// if we can't extend size, rollback to old state//无法扩容判断 if (!m_file->truncate(fileSize)) {return false;}// check if we fail to make more space//扩容失败if (!isFileValid()) {MMKVWarning("[%s] file not valid", m_mmapID.c_str());return false;}}return doFullWriteBack(move(preparedData), nullptr);}return true;
}
数据读取 mmkv.get
读取相对写入就跟简单了,直接从映射内存页里将数据查找取出即可。
int32_t MMKV::getInt32(MMKVKey_t key, int32_t defaultValue) {if (isKeyEmpty(key)) {return defaultValue;}SCOPED_LOCK(m_lock);auto data = getDataForKey(key);if (data.length() > 0) {try {CodedInputData input(data.getPtr(), data.length());return input.readInt32();} catch (std::exception &exception) {MMKVError("%s", exception.what());}}return defaultValue;
}
MMBuffer MMKV::getDataForKey(MMKVKey_t key) {checkLoadData();
#ifndef MMKV_DISABLE_CRYPTif (m_crypter) {auto itr = m_dicCrypt->find(key);if (itr != m_dicCrypt->end()) {auto basePtr = (uint8_t *) (m_file->getMemory()) + Fixed32Size;return itr->second.toMMBuffer(basePtr, m_crypter);//从映射表内拿出}} else
#endif{auto itr = m_dic->find(key);if (itr != m_dic->end()) {auto basePtr = (uint8_t *) (m_file->getMemory()) + Fixed32Size;return itr->second.toMMBuffer(basePtr);}}MMBuffer nan;return nan;
}
以上为MMKV与mmap的解析;有关更多Android的技术进阶;各位可以参考《Android核心技术手册》这个文档。点击查看
mmkv产生的SP存在的问题
通过对原理啊的了解,我们会发现这样做有很多问题。总一下,主要有如下几个问题:
- 1.最终写入XML文件实用的是IO操作,IO操作需要两次拷贝,效率是比较低的。(原因自行百度,这里就不再赘述了)
- 2.实用XML格式进行存储,并且全部以字符串的形式进行保存,浪费存储空间。比如value=“469068865”。需要占用17个字节,utf-8一个英文字符占用1个字节,则存储该值需要17个字节。
- 3.每次编辑时,都需要对文件进行全量的写入操作。因为每次都是对完整的数据Map进行写入操作,哪怕只修改了一个值。这样做无疑是极大的浪费。
- 4.SP虽然支持多进程访问,但是多进程的读取是相当不安全的,因为进程间内存不能共享,而SP的多进程是每个进程一个对象进行操作。所以我们安全的使用方式仍然是使用一个进程去读取,并提供ContentProvider的方式供其它进程访问或者增加文件锁的方式,这样做无疑增加了我们使用复杂度。
- 5.线程阻塞问题。上面我们看到,只有全部加载完xml中的内容后,getString的函数才能继续往下执行。所以线程会被阻塞。
解决办法:
- 实现高效的文件操作
- 实现更精简的数据格式
- 实现更优的数据更新方式
- 解决多进程一致性
- 线程阻塞问题
相关文章:
MMKV与mmap:全方位解析
概述 MMKV 是基于 mmap 内存映射的移动端通用 key-value 组件,底层序列化/反序列化使用 protobuf 实现,性能高,稳定性强。从 2015 年中至今,在 iOS 微信上使用已有近 3 年,其性能和稳定性经过了时间的验证。近期已移植…...
)
【信息系统项目管理师】项目管理十大知识领域记忆敲出(整体范围进度)
【信息系统项目管理师】项目管理十大知识领域记忆敲出(整体范围进度) 【信息系统项目管理师】项目管理十大知识领域记忆敲出(整体范围进度)【信息系统项目管理师】项目管理十大知识领域记忆敲出(整体范围进度ÿ…...

一起学 pixijs(3):Sprite
大家好,我是前端西瓜哥。今天来学习 pixijs 的 Sprite。 Sprite pixijs 的 Sprite 类用于将一些纹理(Texture)渲染到屏幕上。 Sprite 直译为 “精灵”,是游戏开发中常见的术语,就是将一个角色的多个动作放到一个图片…...

深入讲解Kubernetes架构-垃圾收集
垃圾收集(Garbage Collection)是 Kubernetes 用于清理集群资源的各种机制的统称。 垃圾收集允许系统清理如下资源:终止的 Pod已完成的 Job不再存在属主引用的对象未使用的容器和容器镜像动态制备的、StorageClass 回收策略为 Delete 的 PV 卷…...
Flink03: 集群安装部署
Flink支持多种安装部署方式 StandaloneON YARNMesos、Kubernetes、AWS… 这些安装方式我们主要讲一下standalone和on yarn。 如果是一个独立环境的话,可能会用到standalone集群模式。 在生产环境下一般还是用on yarn 这种模式比较多,因为这样可以综合利…...
OCR项目实战(一):手写汉语拼音识别(Pytorch版)
✨写在前面:强烈推荐给大家一个优秀的人工智能学习网站,内容包括人工智能基础、机器学习、深度学习神经网络等,详细介绍各部分概念及实战教程,非常适合人工智能领域初学者及研究者学习。➡️点击跳转到网站。 📝OCR专栏…...

【js】export default也在影响项目性能呢
这里写目录标题介绍先说结论分析解决介绍 无意间看到一个关于export与exprot default对比的话题, 于是对二者关于性能方面,有了想法,二者的区别,仅仅是在于写法吗? 于是,有了下面的测试。 先说结论 太长…...

《软件安全》 彭国军 阅读总结
对于本书,小编本意是对其讲述的内容,分点进行笔记的整理,后来学习以后,发现,这本书应该不算是一本技术提升类的书籍,更像是一本领域拓展和知识科普类书籍,所讲知识广泛,但是较少实践…...

深入讲解Kubernetes架构-节点与控制面之间的通信
本文列举控制面节点(确切说是 API 服务器)和 Kubernetes 集群之间的通信路径。 目的是为了让用户能够自定义他们的安装,以实现对网络配置的加固, 使得集群能够在不可信的网络上(或者在一个云服务商完全公开的 IP 上&am…...

120个IT冷知识,看完就不愁做选择题了
目录 IT冷知识 01-10 1.冰淇淋馅料 2.蠕虫起源 3.Linux和红帽子 4."间谍软件"诞生 5.游戏主机的灵魂 6.Linux之父 7.NetBSD的口号 8.安卓起源 9.不是第七代的 Win 7 10.域名金字塔 11~20 11.神奇魔盒 12. 第一个Ubuntu 正式版本 13.巾帼英雄 14.密码…...
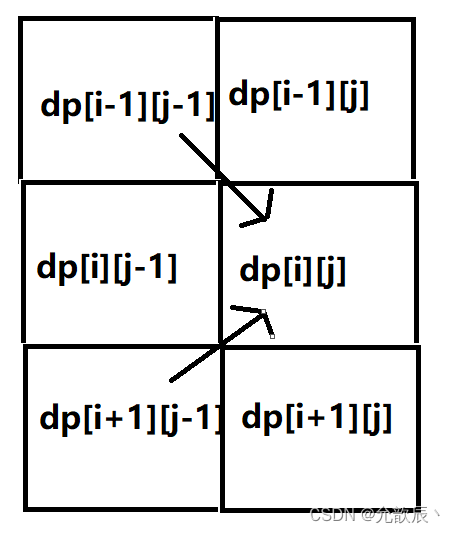
Java之动态规划之机器人移动
目录 0.动态规划问题 一.不同路径 1.题目描述 2.问题分析 3.代码实现 二.不同路径 II 1.题目描述 2.问题分析 3.代码实现 三.机器人双向走路 1.题目描述 2.问题分析 3.代码实现 0.动态规划问题 动态规划(Dynamic Programming)算法的核心思想是:将大问题划分为小问…...
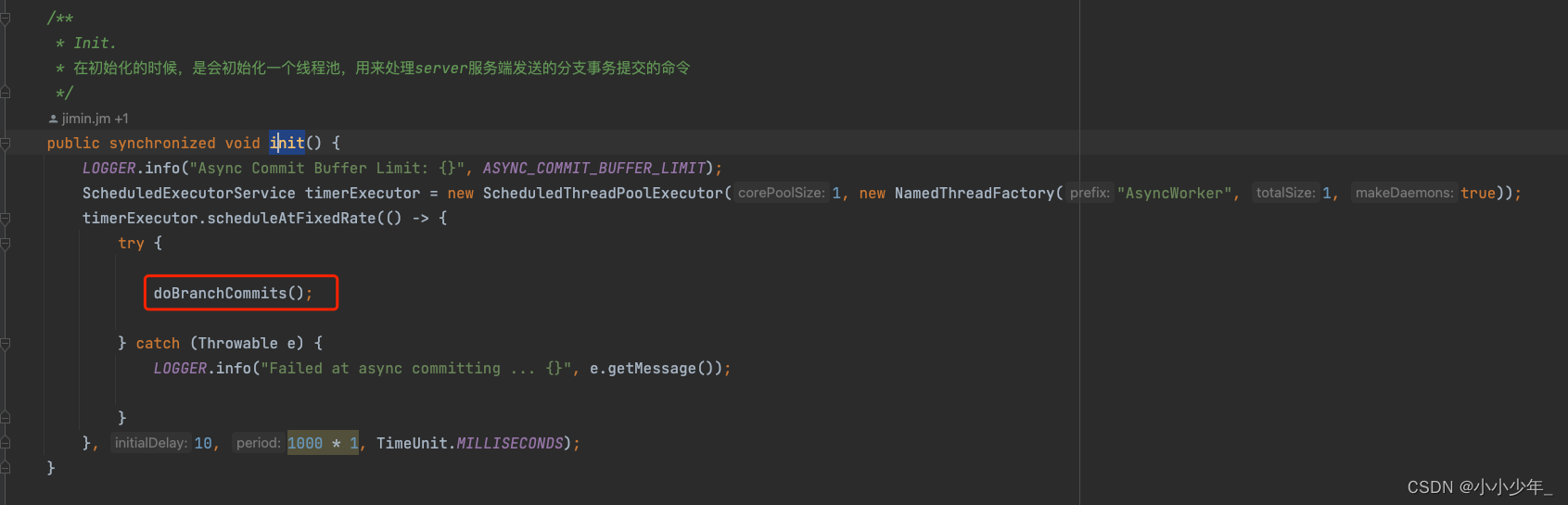
seata源码-全局事务提交 服务端源码
前面的博客中,我们介绍了,发起全局事务时,是如何进行全局事务提交的,这篇博客,主要记录,在seata分布式事务中,全局事务提交的时候,服务端是如何进行处理的 发起全局事务提交操作 事…...
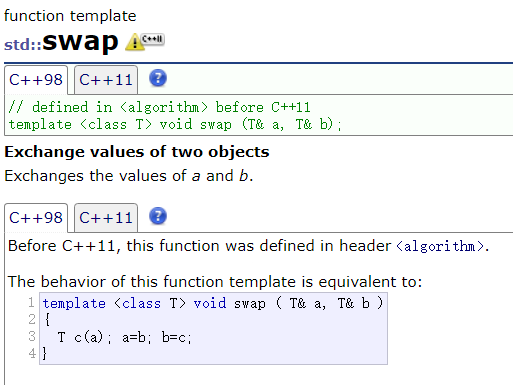
C++ 模板
文章目录一、泛型编程二、 函数模板三、类模板一、泛型编程 泛型编程:编写与类型无关的通用代码,代码复用的一种方法 在 C 中,我们可以通过函数重载实现通用的交换函数 Swap ,但是有一些缺点 重载函数只有类型不同,…...
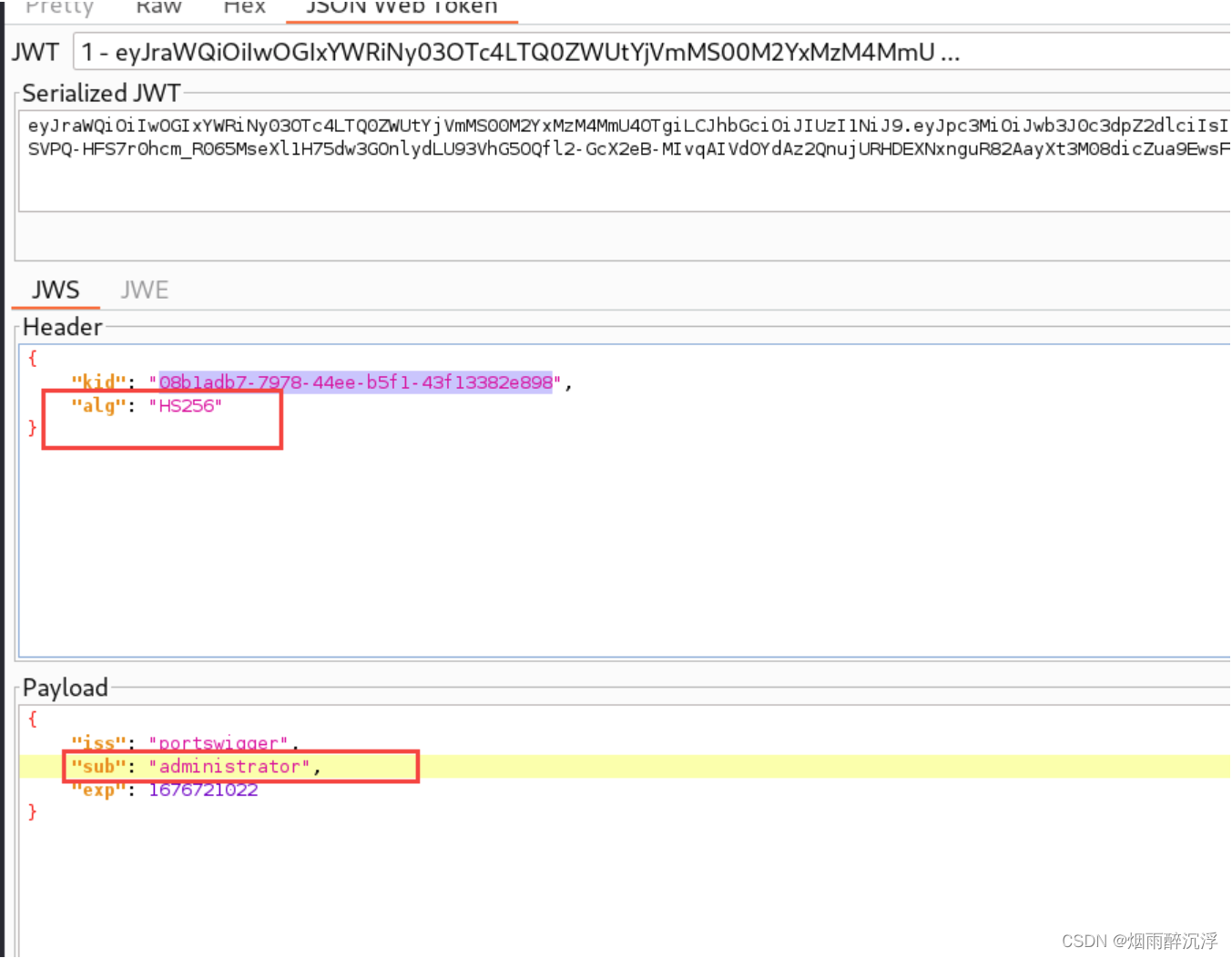
JWT安全漏洞以及常见攻击方式
前言 随着web应用的日渐复杂化,某些场景下,仅使用Cookie、Session等常见的身份鉴别方式无法满足业务的需要,JWT也就应运而生,JWT可以有效的解决分布式场景下的身份鉴别问题,并且会规避掉一些安全问题,如CO…...
)
华为OD机试题 - 最小施肥机能效(JavaScript)
最近更新的博客 华为OD机试题 - 任务总执行时长(JavaScript) 华为OD机试题 - 开放日活动(JavaScript) 华为OD机试 - 最近的点 | 备考思路,刷题要点,答疑 【新解法】 华为OD机试题 - 最小步骤数(JavaScript) 华为OD机试题 - 任务混部(JavaScript) 华为OD机试题 - N 进…...
Python(1)变量的命名规则
目录 1.变量的命名原则 3.内置函数尽量不要做变量 4.删除变量和垃圾回收机制 5.结语 参考资料 1.变量的命名原则 ①由英文字母、_(下划线)、或中文开头 ②变量名称只能由英文字母、数字、下画线或中文字所组成。 ③英文字母大小写不相同 实例: 爱_aiA1 print(…...
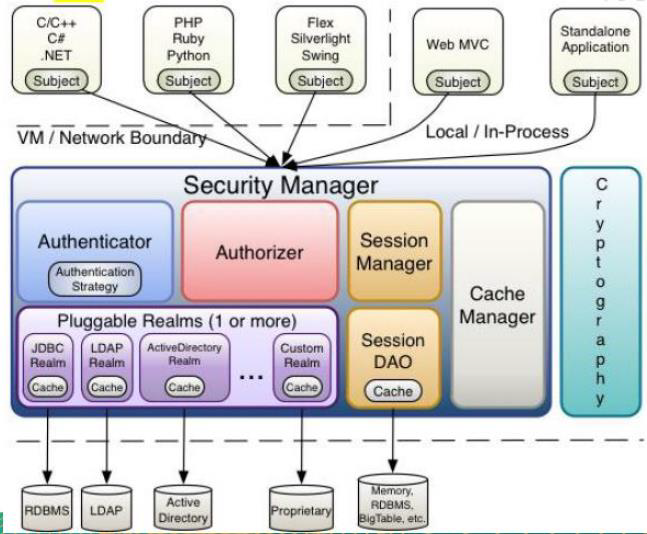
Shiro1.9学习笔记
文章目录一、Shiro概述1、Shiro简介1.1 介绍1.2 Shiro特点2、Shiro与SpringSecurity的对比3、Shiro基本功能4、Shiro原理4.1 Shiro 架构(外部)4.2 shiro架构(内部)二、Shiro基本使用1、环境准备2、登录认证2.1 登录认证概念2.2 登录认证基本流程2.3 登录认证实例2.4 身份认证源…...
2.5|iot|嵌入式Linux系统开发与应用|第4章:Linux外壳shell脚本程序编程
1.shell基础 Shell是Linux操作系统内核的外壳,它为用户提供使用操作系统的命令接口。 用户在提示符下输入的每个命令都由shell先解释然后发给Linux内核,所以Linux中的命令通称为shell命令。 通常我们使用shell来使用Linux操作系统。Linux系统的shell是…...

九龙证券|连续七周获加仓,四大行业成“香饽饽”!
本周17个申万职业北上资金持股量环比增加。 北上资金抢筹铝业龙头 本周A股商场全体冲高回落,沪指收跌1.12%,深成指跌2.18%,创业板指跌3.76%。北上资金周内小幅净流入。在大盘体现较差的周四周五,北上资金别离逆市回流67.94亿元、…...
210天从外包踏进华为跳动那一刻,我泪目了
前言 没有绝对的天才,只有持续不断的付出。对于我们每一个平凡人来说,改变命运只能依靠努力幸运,但如果你不够幸运,那就只能拉高努力的占比。 2021年4月,我有幸成为了华为的一名高级测试工程师,正如标题所…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

.Net框架,除了EF还有很多很多......
文章目录 1. 引言2. Dapper2.1 概述与设计原理2.2 核心功能与代码示例基本查询多映射查询存储过程调用 2.3 性能优化原理2.4 适用场景 3. NHibernate3.1 概述与架构设计3.2 映射配置示例Fluent映射XML映射 3.3 查询示例HQL查询Criteria APILINQ提供程序 3.4 高级特性3.5 适用场…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

23-Oracle 23 ai 区块链表(Blockchain Table)
小伙伴有没有在金融强合规的领域中遇见,必须要保持数据不可变,管理员都无法修改和留痕的要求。比如医疗的电子病历中,影像检查检验结果不可篡改行的,药品追溯过程中数据只可插入无法删除的特性需求;登录日志、修改日志…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

镜像里切换为普通用户
如果你登录远程虚拟机默认就是 root 用户,但你不希望用 root 权限运行 ns-3(这是对的,ns3 工具会拒绝 root),你可以按以下方法创建一个 非 root 用户账号 并切换到它运行 ns-3。 一次性解决方案:创建非 roo…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

云原生安全实战:API网关Kong的鉴权与限流详解
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 一、基础概念 1. API网关(API Gateway) API网关是微服务架构中的核心组件,负责统一管理所有API的流量入口。它像一座…...

从面试角度回答Android中ContentProvider启动原理
Android中ContentProvider原理的面试角度解析,分为已启动和未启动两种场景: 一、ContentProvider已启动的情况 1. 核心流程 触发条件:当其他组件(如Activity、Service)通过ContentR…...

tomcat指定使用的jdk版本
说明 有时候需要对tomcat配置指定的jdk版本号,此时,我们可以通过以下方式进行配置 设置方式 找到tomcat的bin目录中的setclasspath.bat。如果是linux系统则是setclasspath.sh set JAVA_HOMEC:\Program Files\Java\jdk8 set JRE_HOMEC:\Program Files…...