Revisiting Distributed Synchronous SGD 带有Back-up机制的分布式同步SGD方法 论文精读
论文链接:Revisiting Distributed Synchronous SGD
ABS
本文介绍了用于分布式机器学习的同步和异步SGDSGDSGD,同时指出各自的缺点:stragglersstragglersstragglers和stalenessstalenessstaleness。
同时为了解决同步SGDSGDSGD存在stragglersstragglersstragglers的问题,本文提出了一种新的算法,通过back-up来加速同步SGDSGDSGD的速度。
注:我第一次接触到stragglersstragglersstragglers是在MapReduce的论文中,MapReduce中也提出了back-up的解决办法,当然MapReduce中的back-up的方法不是由MapReduce提出的,而是引用了另一篇文章中的方法。当然本文的back-up与MapReduce中的有着一些不同的地方。
MapReduce的back-up引用的文章是:Arash Baratloo, Mehmet Karaul, Zvi Kedem, and Peter Wyckoff. Charlotte: Metacomputing on the web. In Proceedings of the 9th International Conference on Parallel and Distributed Computing Systems, 1996
1 INTRO
异步SGDSGDSGD解决分布式机器学习中的通信速率的问题的同时引入了新的问题:过期的梯度。
过期的梯度对模型的收敛速度以及收敛精度都有着不小的影响。
而如果使用同步SGDSGDSGD有存在stragglersstragglersstragglers(完成时间远远低于其他结点的节点)的问题。
本文采用同步SGDSGDSGD但是引入了back−upback-upback−up机制,能够一定程度的环节stragglersstragglersstragglers的情况,本文的主要贡献如下:
- 阐明了异步SGDSGDSGD中过期的梯度对测试精度的负面影响;
- 阐明了通过SGDSGDSGD中stragglersstragglersstragglers对训练时间的影响;
- 提出带有back−upback-upback−up机制的同步SGDSGDSGD;
- 做了实验来验证新方法的收敛速度以及收敛精确度;
- 通过实验证明新方法比异步SGDSGDSGD更加优秀(不论是收敛速度还是收敛精度)
1.1 Preliminaries and Notation
通常我们的训练需要让损失函数最小。
而我们可以通过梯度下降的方法来求出一个局部的最优解。
当将机器学习通过分布式来实现的时候,所需要做的事情是类似的,只是我们需要定期的从各个节点收集数据进行一次数据的汇总再将新的数据分发给各个节点进行新的训练。正是有了数据收集和分发的过程,才产生了两种不同算法同步SGDSGDSGD和异步SGDSGDSGD。
2 Asynchronous Stochastic Optimization
异步SGDSGDSGD的算法如下所示:

需要注意的是,虽然叫做异步算法,但是上述的过程还是存在一些同步机制,例如工作结点在从参数服务器读取参数的时候,必须要保证读取到的参数比上一轮读取到参数新(如果不这样,那么工作结点就会做多余的计算,当然这往往是必然的,因为在自己进行下一轮的读取的时候,自己本轮的参数应该会上传到服务器进行更新),也就是说在读取参数的时候不需要所有的工作结点都完成自己本轮的工作再上传参数,这也就是异步的意思。
这样做能够充分的利用资源,但是也同样存在问题,在一个工作结点进行计算的过程中Algorithm1line3−7Algorithm\ 1\ line 3 -7Algorithm 1 line3−7时,其他的工作结点可能完成了某一轮的计算,将参数上传到服务器进行更新,这也就代表正在进行工作的工作结点的参数过时了,也就是出现了stalenessstalenessstaleness。
后续的实验会说明过时梯度对最终的影响有多大。
Table1Table\ 1Table 1展示了ImageNet上使用Inception模型进行训练,工作结点个数为404040的异步SGDSGDSGD在各层出现梯度过期情况。

虽然异步SGDSGDSGD存在过期梯度的问题,但是在工作结点的个数比较少的情况下,异步SGDSGDSGD的效果还是不错的,但是当工作结点的个数增加时,异步SGDSGDSGD就变得力不从心了。
2.1 Impact of Staleness on Test Accuracy
实验的细节可以在原文的附录中找到。
Figure2Figure\ 2Figure 2展示了平均过期梯度数量与测试精度的关系。

从Figure2Figure\ 2Figure 2可以看出当梯度过期出现的次数越多的时候,整体的错误率会有着明显上升,特别是从100100100到120120120这一段。
事实上当梯度过期的平均值达到151515的时候就已经出现错误率剧烈上升了,为了能够做更大数值的梯度过期,作者使用了一些技巧:
- 前三个epochsepochsepochs过期的数量增长较慢;
- 当梯度过期的数量过大时候,降低学习率;
- 如果上述两点依然会导致非常大的错误率,那么就多次进行实验,取最好的结果。
3 Revisiting Synchronous Stochastic Optimization
过去提出了同步SGDSGDSGD该方法解决了异步SGDSGDSGD中过期梯度的问题,但是同时又引入了新的问题,现在每一次同步的时间,取决于服务器最后收到的参数的时间(通常是完成本轮本地计算最慢的工作结点,也就是stragglersstragglersstragglers)。
stragglersstragglersstragglers的出现是很常见的,在规模越大的分布式集群中收到stragglersstragglersstragglers的影响就会越大,而出现本地计算变慢的原因也是多种多样的:例如硬件出现故障,其他进程占用资源等等。
为了解决stragglersstragglersstragglers的问题,作者提出了back-up的方法,作者将参与训练的工作结点划分为两部分:NNN个正常工作者和bbb个备用工作者。
这N+bN+bN+b个结点依然执行不同的数据上的计算,当服务器收到任意NNN个结点的参数之后,服务器就可以进行本轮的参数聚合。
注意,上述的过程中NNN和bbb仅仅只是两个参数,在算法的过程中并没有实实在在地标注那个结点属于正常工作者还是备用工作者,而是类似于自动分配的,通常(网络不出现卡顿)情况下,先完成本地计算的NNN个结点会成为正常工作者,剩下的bbb个结点此时就是备用工作者,也可以看做是bbb个stragglersstragglersstragglers,每一轮更新的备用工作者可能会发生变化。
Algorithm3,4Algorithm 3, 4Algorithm3,4分别描述了工作结点的执行步骤和参数服务器执行的步骤:

工作结点开始之前先从参数服务器读取本轮的参数(如果本轮的参数还没准备好,那么此时会阻塞),之后工作结点计算自己本地的梯度,计算完成后将梯度发送给服务器。可以看到工作结点的步骤与传统的同步SGDSGDSGD没有任何区别,而不同的地方出现在参数服务器。
参数服务器会收集本轮工作结点梯度信息(梯度信息带有时间戳,会丢弃之前的梯度,因为可能在进行新的一轮的时候,之前的stragglersstragglersstragglers才完成),当收集到NNN个梯度信息的时候就进行参数的聚合,之后就可以将参数发送给工作结点进行新的一轮计算。
上面算法中的θ‾\overline {\theta}θ是用于性能估计的。
说明:个人认为上面的算法存在一个问题。从我的理解来看,当一个工作结点在某一轮成为了stragglerstragglerstraggler之后,那么其他正常工作结点再开始下一轮计算的时候,该结点可能还没有完成本轮的计算,如果正常工作结点没有出现“卡顿”的情况,那么该工作结点在下一轮依然有很大的可能再一次成为掉队者,这样下去就会一直出现恶性循环,stragglersstragglersstragglers会更有可能成为stragglersstragglersstragglers。这就相当于这些stragglersstragglersstragglers的数据完全没有参与到更新,这等价于在一开始训练的时候我们人工的丢弃一些固定的数据,这样并不能很好的利用数据。关于这个问题,我认为至少有两种可以解决的方法:
- 根据kkk折交叉验证的想法,我想到了一个改进的想法,每一次参数服务器完成本轮更新后,应该向所有的工作结点发送信息(这条信息的数据量非常小,所以不会称为瓶颈),当收到这条信息的时候,还没有完成本轮本地计算结点应该停止本轮计算(因为参数已经进行更新了,再计算也没有意义了),然后直接开始下一轮的读取参数操作,这样当前的stragglersstragglersstragglers在下一轮的时候才有公平竞争的机会,因为这些stragglersstragglersstragglers的性能可能在下一轮的时候恢复,这个时候新的stragglersstragglersstragglers就很有可能是其他出现性能下降的结点,这样每轮丢弃的数据具有随机性,很类似于kkk折交叉验证。
- 除了上面的方法,服务器参数还可以在收到之前的梯度的时候不进行丢弃,而是将该部分的梯度也对参数进行修改,但是并不增加本轮收到的梯度个数,这样做的目的就相当于是延迟修改,这似乎比直接丢弃掉要好一些。但是延迟丢弃可能会对整体造成不好的影响,这个就需要具体进行实验分析了,或者设计更加合理的延迟更新操作。
3.1 Straggler Effects
这一部分的实验是展示stragglersstragglersstragglers的负面影响,实验的细节可以在原文的附录找到。
Figure3Figure\ 3Figure 3展示了某个模型上等待不同个数的结点完成本地计算需要的时间(一共有100100100个工作结点),Figure4Figure\ 4Figure 4代表的是等待kkk个结点完成本地计算所需要的平均数(Mean)和中位数(Median):

Figure3Figure\ 3Figure 3的纵轴代表的是整个迭代过程的占比,横轴代表所需要的时间,kkk代表等待kkk个结点完成本地计算。
从上图中我们可以看到的是,如果要等待100100100个工作结点都完成本轮的计算,需要的时间比等待的909090个结点的时候增加了很多,而且图片的说明还指出:最大的一次等待时间达到了310s310s310s。这表明stragglersstragglersstragglers的影响是非常大的,同时上面的图片也说明stragglerstragglerstraggler的占比是非常低的。
为了确定N,bN,bN,b的取值,作者做了实验Figure5Figure\ 5Figure 5是不同的NNN收敛所需要的迭代次数(N+b=100N+b=100N+b=100),可以看到N=100,b=0N=100, b = 0N=100,b=0的时候所需要的迭代次数最少。不过需要注意的时候迭代次数少时间并不一定短,如果N=100N=100N=100那么需要等待所有的工作结点完成计算,那么由上一个实验可以看到这样的时间会非常长,于是作者作者用Figure6Figure\ 6Figure 6来展示时间与NNN的关系。

可以看到N=96,b=4N=96,b=4N=96,b=4的时候收敛所花费的时间最少。
注意:并不是N=1,2,3,...,100N=1, 2, 3, ..., 100N=1,2,3,...,100的实验均做了,作者只做了部分的实验,其余的地方的是通过线性插值计算得来。
4 Experiments
更多的实验细节可以原文的附录中找到,这里只介绍一些重要的结果。
4.1 Metrics of Comparison: Faster Convergence, Better Optimum
评价的指标有两个:收敛速度和准确率。
做了关于不同学习率的实验,学习率初始化后会随着训练的进行进行指数级别的衰减。
Table 2展示了不同的初始学习率下的收敛速率以及收敛后的准确。

Figure 7的左边展示了不同学习率初始值的测试集精度随着迭代次数的变化,右边则展示了不同学习率到达某个精度所需要的迭代次数。

从上面的实验结果可以看出来,较大的学习率具有较慢的收敛速度,但是收敛速度变慢的情况下,精确度相对也有所提高。有时候较小的学习率也有可能既不能获得更高的准确度,也不能获取更快地收敛。
4.2 Inception
Inception是一个2016年提出的一个训练模型,本部分的实验数据集是ImageNet,更多该实验的细节可以在原文的附录部分找到。

Figure 8展示了这一部分的实验结果:
- (a)图展示了不同工作结点个数下各算法的测试准确度与迭代次数的变换关系。
- (b)图展示了不同工作结点个数下各算法最终收敛的测试精度。
- ©图展示了不同工作结点个数下各算法收敛所需要的迭代次数。
- (d)图展示了不同工作结点个数下各算法收敛所需要的时间。
- (e)图展示了不同工作结点个数下各算法每一次迭代的平均时间。
从上面的结果可以看出本文提出的算法收敛的更快,准确度更加高。
4.3 Pixel CNN Experiments
Pixel CNN是2016年提出的一个模型,数据集是CIFAR-10。
实验结果如Figure 9所示:
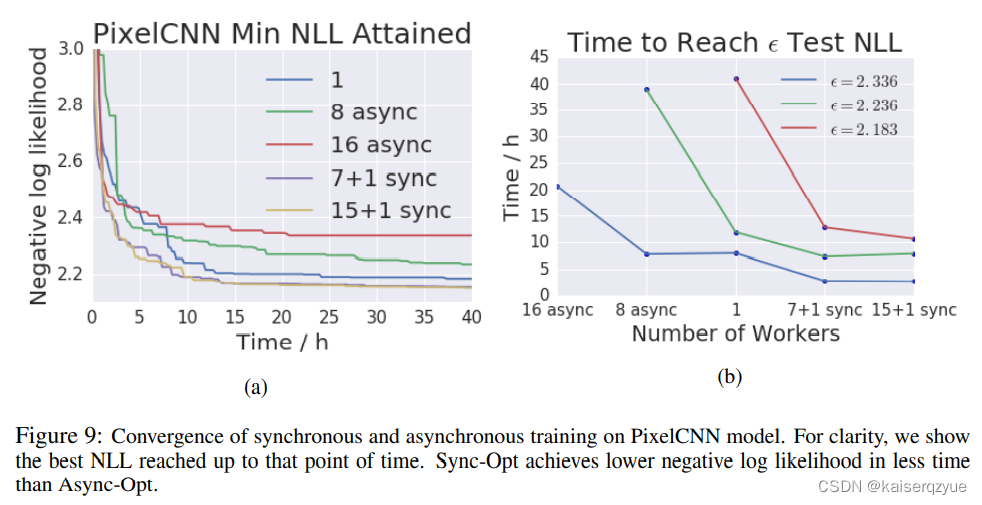
左图展示的是NLL和训练时间的变化(NLL越小效果越好),右图则是达到某个NLL值所需要的时间。
值得指出的异步的SGDSGDSGD的效果不如串行的RMSProRMSProRMSPro,这也表明过期的梯度对训练结果有着较大的影响。
5 Related Work
这一部分介绍了一些相关工作,个人认为其中有两篇很有参考意义,后续会做这两篇论文的精读:
软同步:Staleness-Aware Async-SGD for distributed deep learning,在进行异步SGDSGDSGD先进行一部分的本地聚合。
不需要参数服务器进行分布式机器学习:Ako: Decentralised deep learning with partial gradient exchange使用轮转的方式来实现参数的聚合。
6 Conclusion and Future Work
随着数据集的以及模型的增大,分布式机器学习会变得越来越重要。
本文介绍了同步SGDSGDSGD和异步SGDSGDSGD各自的缺点,并且提出了一定程度上解决同步SGDSGDSGD缺点的新方法。
未来可以将能够共享的工作结点先进行本地的聚合,再在服务器进行参数聚合。亦或是可以将back-up机制更改为超时机制,这也意味着每轮参与参数聚合的结点个数将不再固定。
相关文章:
Revisiting Distributed Synchronous SGD 带有Back-up机制的分布式同步SGD方法 论文精读
论文链接:Revisiting Distributed Synchronous SGD ABS 本文介绍了用于分布式机器学习的同步和异步SGDSGDSGD,同时指出各自的缺点:stragglersstragglersstragglers和stalenessstalenessstaleness。 同时为了解决同步SGDSGDSGD存在straggle…...
shiro CVE-2020-13933
0x00 前言 同CVE-2020-1957,补充一下笔记,在CVE-2020-1957的基础上进行了绕过。 影响版本:Apache Shiro < 1.6.0 环境搭建参考:shiro CVE-2020-1957 0x01 漏洞复现 CVE-2020-13933中使用%3b绕过了shiro /*的检测方式&…...

斐波那契数列(递归+迭代)
目录什么是斐波那契数列递归写法使用递归写法的缺点迭代写法(效率高)什么是斐波那契数列 斐波那契数列(Fibonacci sequence),又称黄金分割数列,因数学家莱昂纳多斐波那契(Leonardo Fibonacci)以兔子繁殖为例…...
2022黑马Redis跟学笔记.实战篇(六)
2022黑马Redis跟学笔记.实战篇 六4.7.达人探店功能4.7.1.分享探店图文1. 达人探店-发布探店笔记2. 达人探店-查看探店笔记4.7.2.点赞功能4.7.3.基于List实现点赞用户列表TOP104.7.4.基于SortedSet实现点赞排行榜4.8.关注列表4.8.1.关注列表实现原理4.8.2.添加关注1. 好友关注-关…...
Linux-VMware常用设置(时间+网络)及网络连接激活失败解决方法-基础篇②
目录一、设置时间二、网络设置1. 激活网卡方法一:直接启动网卡(仅限当此)方法二:修改配置文件(永久)2. 将NAT模式改为桥接模式什么是是NAT模式?如何改为桥接模式?三、虚拟机网络连接…...

vue3学习总结1
一.vue3与vue2相比带来哪些变化?a.性能的提升(包括打包大小减少,初次渲染的速度加快,更新渲染速度加快,内存减少)b.源码的升级(响应式的原理发生了变化,由原来的defineProperty变成了…...
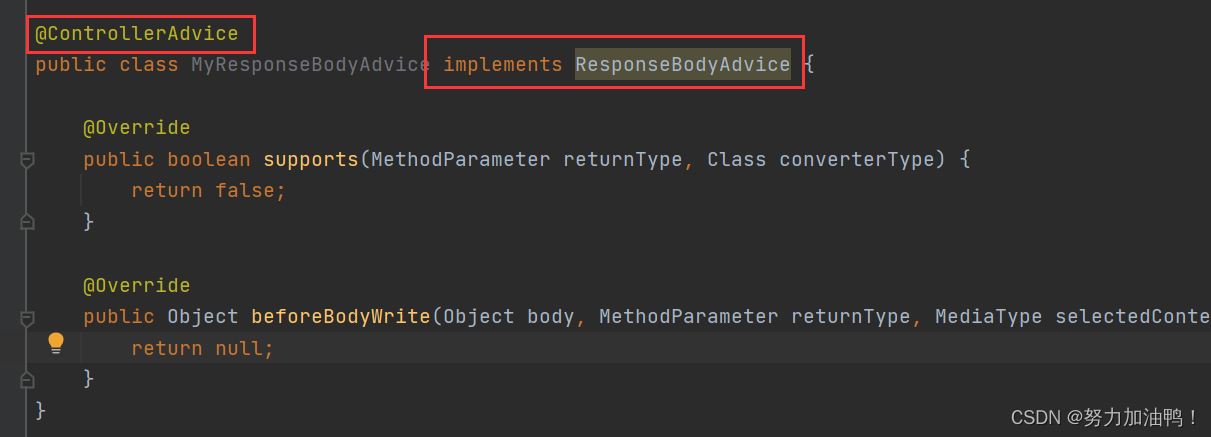
SpringBoot统一功能处理
一、统一用户登录权限验证 1.1Spring拦截器 实现拦截器需要以下两步: 1.创建自定义拦截器,实现 HandlerInterceptor 接⼝的 preHandle(执行具体方法之前的预处理)方法。 2.将⾃定义拦截器加⼊ WebMvcConfigurer 的 addIntercept…...
答案解析)
2022年3月电子学会Python等级考试试卷(五级)答案解析
目录 一、单选题(共25题,共50分) 二、判断题(共10题,共20分) 三、编程题(共3题,共30分) 青少年软件编程(Python)等级考试试卷(五级&#...

【C++】智能指针
目录 一、先来看一下什么是智能指针 二、 auto_ptr 1、C98版本 2、C11的auto_ptr 三、boost 库中的智能指针 1. scoped_ptr 2、shared_ptr(最好的智能指针) 四、C11中新提供的智能指针 unique_ptr shared_ptr std::shared_ptr的循环引用问题…...
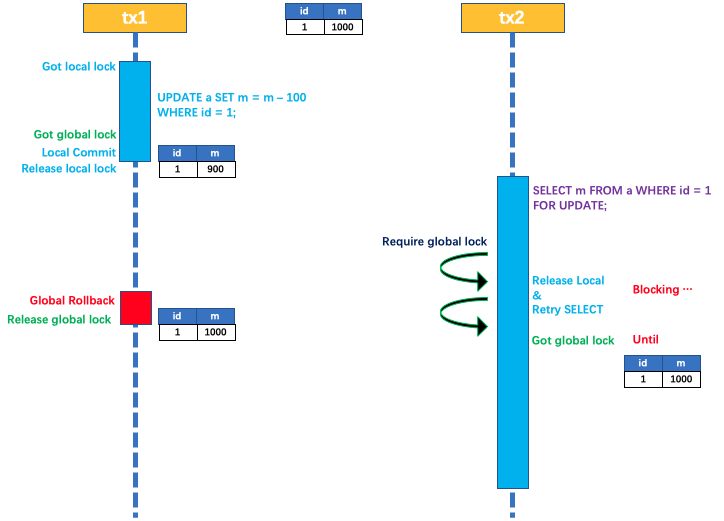
Seata架构篇 - AT模式
AT 模式 概述 Seata AT 模式是一种非侵入式的分布式事务解决方案,Seata 在内部做了对数据库操作的代理层,我们使用 Seata AT 模式时,实际上用的是 Seata 自带的数据源代理 DataSourceProxy,Seata 在这层代理中加入了很多逻辑&am…...
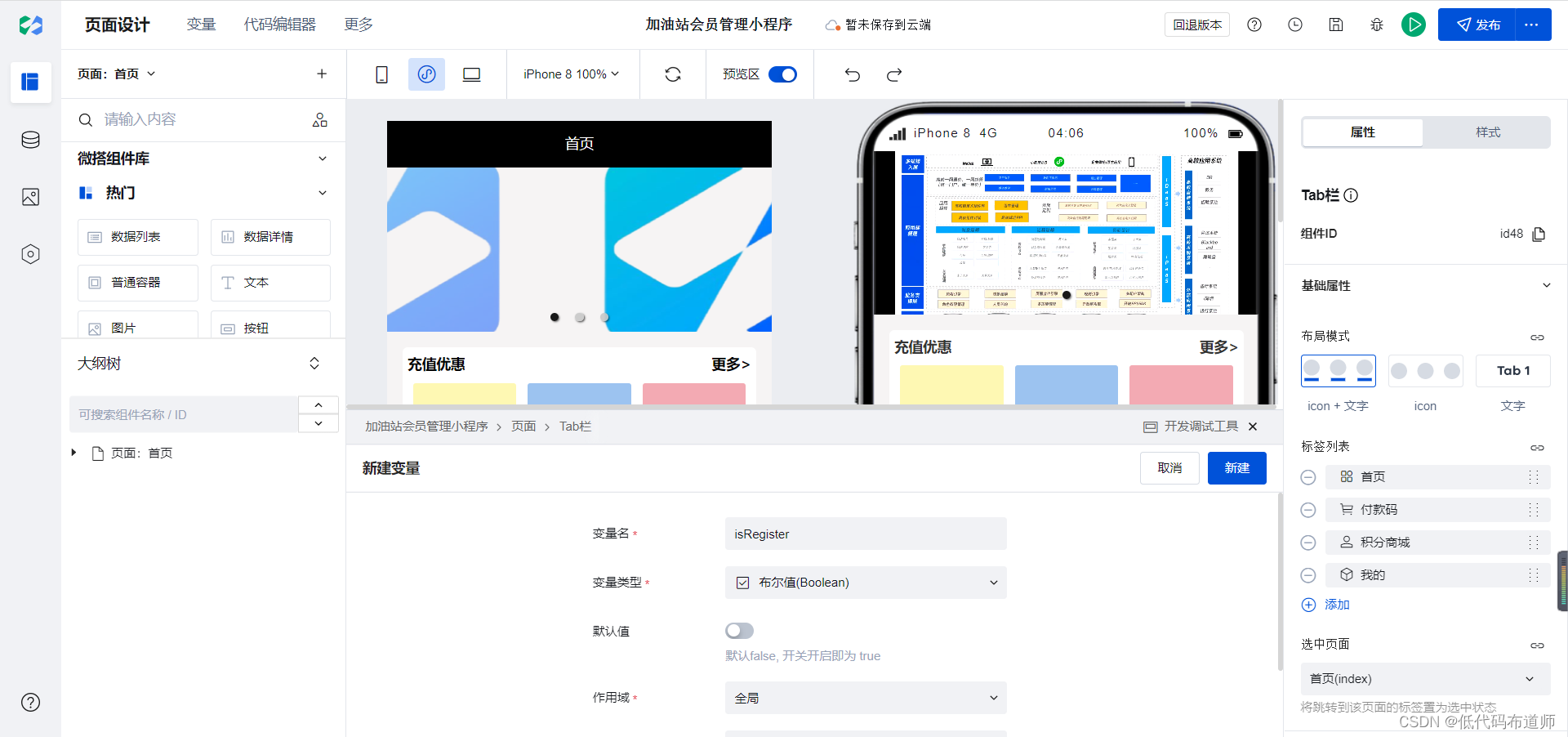
加油站会员管理小程序实战开发教程12
我们上一篇介绍了会员数据源的开发,本节我们介绍一下会员注册功能。 首先呢梳理一下会员注册的业务逻辑,如果用户是首次登录,那他肯定还没有给我们的小程序提交任何的信息。那么我们就在我的页面给他显示一个注册的按钮,如果他已经注册过了,那么就正常显示会员的信息,他…...
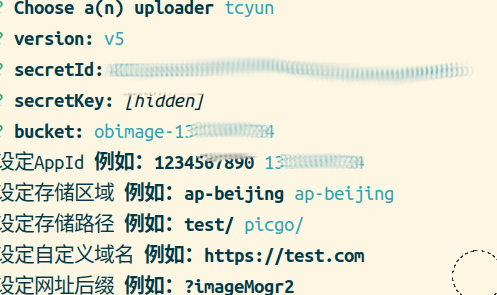
用腾讯云同步Obsidian笔记
介绍 之前用gitee同步OB笔记,同时做图床。但由于git系产品设置起来相对复杂,且后续可能有外链过审等问题。周五被同事小姐姐安利了用腾讯云COS,试了一下,果然不错。其主要优点如下: 设置简单,学习成本低&…...
浅析C++指针与引用,栈传递的关系
目录 前言 C 堆指针 栈指针 常量指针 指针常量 引用 常量引用 总结 前言 目前做了很多项目,接触到各种语言,基本上用什么学什么,语言的边际就会很模糊,实际上语言的设计大同小异,只是语言具备各自的特性区别。…...

图解LeetCode——剑指 Offer 10- II. 青蛙跳台阶问题
一、题目 一只青蛙一次可以跳上1级台阶,也可以跳上2级台阶。求该青蛙跳上一个 n 级的台阶总共有多少种跳法。 答案需要取模 1e97(1000000007),如计算初始结果为:1000000008,请返回 1。 二、示例 2.1>…...

【Linux】用户分类+权限管理+umask+粘滞位说明
目录 1.用户分类 su指令 2.认识Linux权限 2.1 文件访问者的分类 2.2 文件类型和访问权限 a. 文件类型 file指令 b. 访问权限 2.3 文件权值的表示方法 a. 字母表示法 b. 八进制表示法 3.如何修改文件访问者的权限及相关指令 1. chmod指令 2. chown指令 3. chgrp指…...
【干货】如何打造HR无法拒绝的简历?测试开发大牛带手把手你写简历!
通过率90%,优秀的软件测试简历长什么样? 也许口才好的人会觉得简历不重要,能说就行了,那是因为你没有体会过石沉大海的感觉! 很多人觉得疑惑,为什么我投了那么多简历,都没有接到面试通知&…...
nodejs学习-4:nodejs连接mongodb和相关操作
1. express生成器生成express模板 前提需要首先下载好:express-generator,命令如下(全局安装) npm install -g express-generator生成模板命令如下: express 项目名称 --viewejs // --view 参数表示前端界面使用的引擎,这里使用…...

【博客629】Linux DNS解析原理与配置
Linux DNS解析原理与配置 1、DNS缓存 作用: 程序客户端、下游的 DNS 服务器每次查询 DNS 成功之后,通常会将该 DNS 记录缓存一段时间,避免频繁发出查询请求的耗时。 Linux下的DNS缓存: Linux 系统默认不会在本地建立 DNS 缓存…...

【CSP】202212-2 训练计划
题目 问题背景 西西艾弗岛荒野求生大赛还有 天开幕! 问题描述 为了在大赛中取得好成绩,顿顿准备在 天时间内完成“短跑”、“高中物理”以及“核裂变技术”等总共 项科目的加强训练。其中第 项( )科目编号为 ,也可简…...
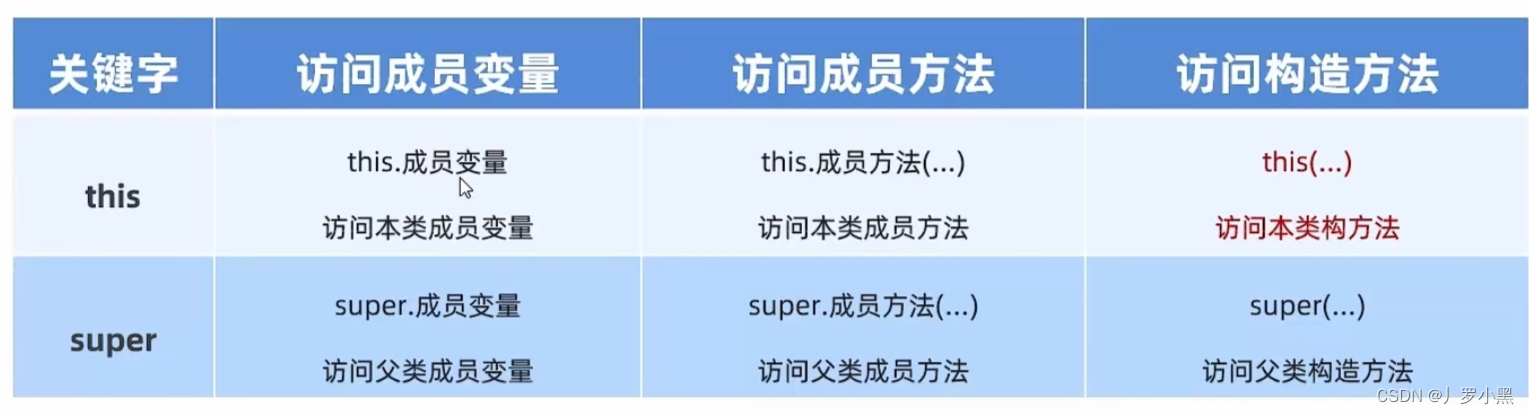
java基础学习 day42(继承中构造方法的访问特点,this、super的使用总结)
继承中,构造方法的访问特点 父类的构造方法不会被子类继承,但可以通过super()调用父类的构造方法,且只能在子类调用,在测试类中是不能手动单写构造方法的。子类中所有的构造方法默认先调用父类的无参构造,再执行自己构…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

【第二十一章 SDIO接口(SDIO)】
第二十一章 SDIO接口 目录 第二十一章 SDIO接口(SDIO) 1 SDIO 主要功能 2 SDIO 总线拓扑 3 SDIO 功能描述 3.1 SDIO 适配器 3.2 SDIOAHB 接口 4 卡功能描述 4.1 卡识别模式 4.2 卡复位 4.3 操作电压范围确认 4.4 卡识别过程 4.5 写数据块 4.6 读数据块 4.7 数据流…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

Java + Spring Boot + Mybatis 实现批量插入
在 Java 中使用 Spring Boot 和 MyBatis 实现批量插入可以通过以下步骤完成。这里提供两种常用方法:使用 MyBatis 的 <foreach> 标签和批处理模式(ExecutorType.BATCH)。 方法一:使用 XML 的 <foreach> 标签ÿ…...

GruntJS-前端自动化任务运行器从入门到实战
Grunt 完全指南:从入门到实战 一、Grunt 是什么? Grunt是一个基于 Node.js 的前端自动化任务运行器,主要用于自动化执行项目开发中重复性高的任务,例如文件压缩、代码编译、语法检查、单元测试、文件合并等。通过配置简洁的任务…...

Rust 开发环境搭建
环境搭建 1、开发工具RustRover 或者vs code 2、Cygwin64 安装 https://cygwin.com/install.html 在工具终端执行: rustup toolchain install stable-x86_64-pc-windows-gnu rustup default stable-x86_64-pc-windows-gnu 2、Hello World fn main() { println…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...
QT开发技术【ffmpeg + QAudioOutput】音乐播放器
一、 介绍 使用ffmpeg 4.2.2 在数字化浪潮席卷全球的当下,音视频内容犹如璀璨繁星,点亮了人们的生活与工作。从短视频平台上令人捧腹的搞笑视频,到在线课堂中知识渊博的专家授课,再到影视平台上扣人心弦的高清大片,音…...