RabbitMQ核心内容:实战教程(java)
文章目录
- 一、安装
- 二、入门
- 1.分类
- 2.核心概念
- 3.工作原理
- 4.六大模式
- 三、模式一:"Hello World!"
- 1.依赖
- 2.生产者代码
- 3.消费者代码
- 四、模式二:Work Queues
- 1.工作原理
- 2.工具类代码:连接工厂
- 3.消费者代码
- 4.生产者代码
- 5.分发策略
- 不公平分发
- 预取值
- 五、保障消息不丢失的措施
- 1.消息应答
- 修改消费者代码
- 2.持久化
- 3.发布确认
- 单个发布确认(同步)
- 批量发布确认(同步)
- 异步发布确认
- 三种方式对比
- 六、模式三:Publish/Subscribe
- 消费者代码
- 生产者代码
- 七、模式四:Routing
- 修改消费者代码
参考:
官网
教程
本博客完整demo仓库:跳转
- 本文的几个名词解释:
消息队列=工作队列=mq=RabbitMQ
生产者=消息的发送方
消费者=工作线程=消息的消费方
exchange=交换机
binding=绑定
一、安装
建议使用docker安装,方便、快速、易上手。
# 查找镜像
docker search rabbitmq# pull最新版rabbitmq的镜像
docker pull rabbitmq# 运行 15672:15672和5673:5672 是外:内端口映射,15672是管理端口,5673是通信端口
docker run -d --hostname my-rabbit --name rabbit -p 15672:15672 -p 5673:5672 rabbitmq# 查看容器id
docker ps -a# 设置容器开机自启
docker update --restart=always 容器id# 进入容器内部 rabbit是上面--name参数值
docker exec -it rabbit bash# 开启插件管理
rabbitmq-plugins enable rabbitmq_management
访问:http://ip地址:15672
二、入门
MQ即Message Queue,消息队列,本质上是一个FIFO的队列。也是一种跨进程的通信机制,用于消息的发送方、接收方的逻辑解耦和物理解耦。
- 三大特点:
- 流量削峰:对访问进行排队,限制上限。缺点是访问的速度会稍微下降,优点是服务器不会宕机。
- 应用解耦:不使用MQ,当一个子系统异常时,请求将无法正常完成;有了MQ起了一定的延时作用,并暂时保存请求,等到子系统恢复正常就可以处理请求。
- 异步:A有一个调用B的操作,但是B处理的很慢,此时A调用完了B可以去干别的,等B执行完了会发一条消息给MQ,MQ将消息转发给A。
1.分类
1 ActiveMQ
单机吞吐量万级,时效性毫秒级,可用性高(主从架构),消息很难丢失。
缺点:太老了,官方维护很少2 Kafka
现在使用很多,大数据的杀手锏,吞吐量为百万级TPS,在数据的采集、传输、存储的过程中发挥着作用。可靠性高(数据有备份),分布式。
缺点:单机超过64个队列服务器性能会迅速降低,实时性取决于轮询间隔,消息失败不支持重试,社区更新较慢。
适用:大数据量的大型项目。3 RocketMQ
基于kafka的改进,单机吞吐量十万级,分布式架构,可靠性很高,解决了Kafka队列增多后服务器性能迅速下降的问题。
缺点:支持的客户端语言不多,仅有java和c++,其中c++不成熟,社区活跃度一般。
适用:可靠性要求高,比如金融互联网。4 RabbitMQ
吞吐量达到万级,支持多种语言,erlang语言提供了高并发性能,社区活跃度高。
缺点:商业版收费
适用:数据量没那么大的中小型项目,时效性、并发性都很好。2.核心概念
1 生产者
2 消费者
3 交换机
4 队列
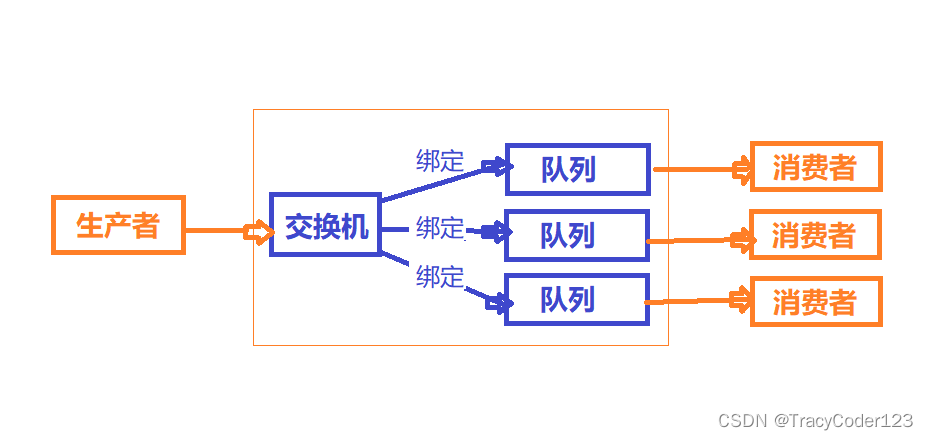
3.工作原理
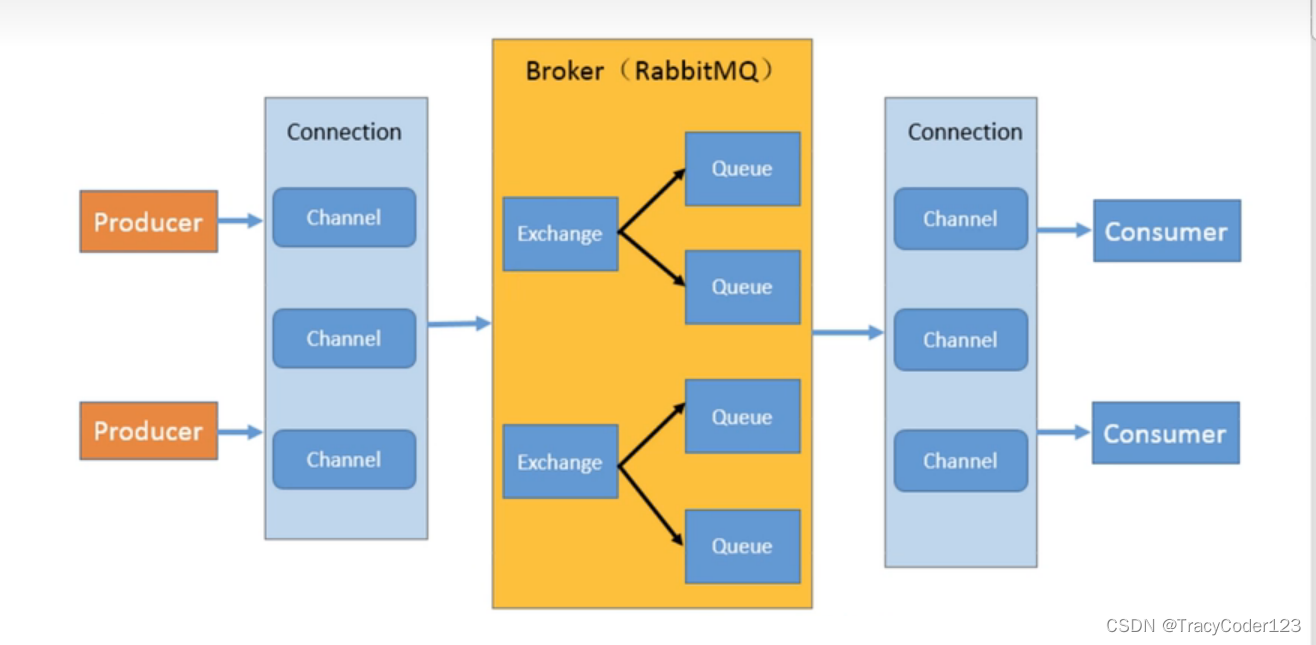
一些说明:
connection:生产者/消费者和RabbitMQ之间的TCP连接
channel:信道,创建一次connection的代价较大,因此就创建一个connection,其中有多个channel(逻辑连接,轻量级的connection),每次通信只占用一个channel。
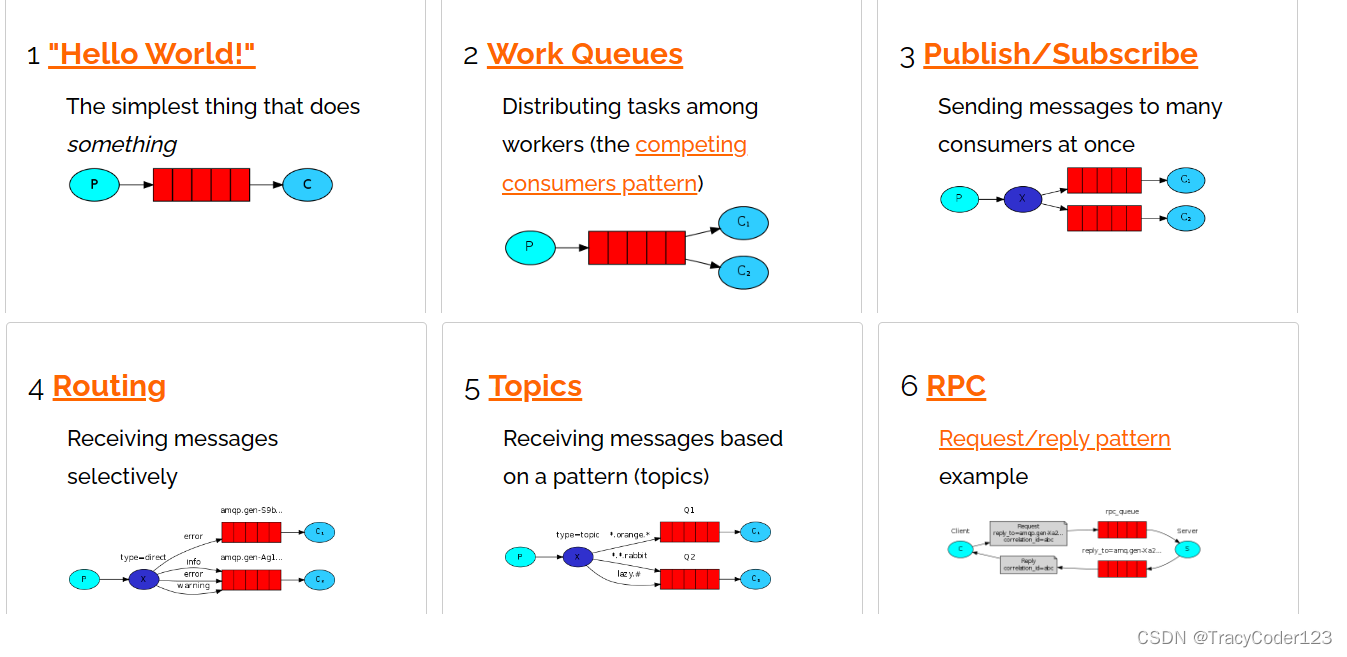
4.六大模式
第五种我不讲,说白了3、4、5的具体工作步骤都差别不大,只是绑定路由、发送消息有细微的差别而已。
第六种这篇博客也不说,下一篇再更。
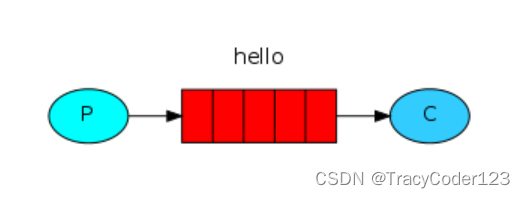
三、模式一:“Hello World!”
这是RabbitMQ中最简单的一个模式,通过它来上手消息队列是不错的。
首先确保服务器上的rabbitMQ已经跑起来了:

然后用idea创建一个spring boot项目,我命名为了hello-world。然后配置好了项目的maven仓库。
1.依赖
<!-- rabbitMQ客户端依赖--><dependency><groupId>com.rabbitmq</groupId><artifactId>amqp-client</artifactId><version>5.8.0</version></dependency><!-- 操作文件流的一个依赖--><dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version></dependency>
2.生产者代码
package tracy.helloworld;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;import java.io.IOException;
import java.util.concurrent.TimeoutException;public class Producer {//队列名称public static final String QUEUE_NAME = "hello-world";//生产消息public static void main(String[] args) throws TimeoutException, IOException {//1 创建一个连接工厂ConnectionFactory factory=new ConnectionFactory();//2 设置工厂ip等信息 连接rabbitMQfactory.setHost("rabbitMQ的ip地址");factory.setPort(5673);//通信端口factory.setUsername("guest");//默认的用户名factory.setPassword("guest");//默认的密码//3 创建连接Connection connection=factory.newConnection();//4 获取信道Channel channel=connection.createChannel();//5 生成一个队列,参数挨个为:队列名,是否持久化,是否允许多消费者消费,其他参数channel.queueDeclare(QUEUE_NAME,false,false,false,null);//6 发消息,参数挨个为:交换机,路由的key值,其他参数,发送的消息channel.basicPublish("",QUEUE_NAME,null,"hello world111".getBytes());}
}
运行main方法之后,访问http://ip:15672/管理端即可看到生产的消息: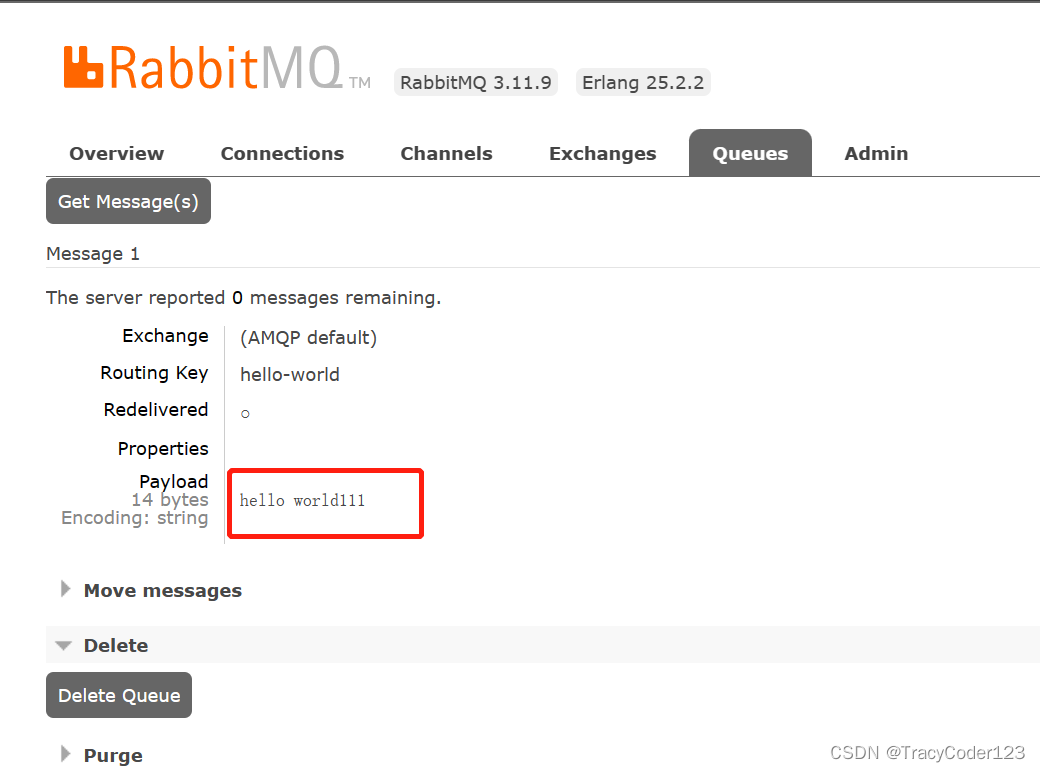
3.消费者代码
package tracy.helloworld;import com.rabbitmq.client.*;import java.io.IOException;
import java.util.concurrent.TimeoutException;public class Consumer {//队列名称public static final String QUEUE_NAME = "hello-world";//接收消息public static void main(String[] args) throws TimeoutException, IOException {//1 创建一个连接工厂ConnectionFactory factory=new ConnectionFactory();//2 设置工厂ip等信息 连接rabbitMQfactory.setHost("rabbitMQ的ip");factory.setPort(5673);//通信端口factory.setUsername("guest");//默认的用户名factory.setPassword("guest");//默认的密码//3 创建连接Connection connection=factory.newConnection();//4 获取信道Channel channel=connection.createChannel();//5 消费消息DeliverCallback deliverCallback=(consumerTag, message)->{System.out.println(new String(message.getBody()));};CancelCallback cancelCallback=consumerTag-> System.out.println("消费被中断");//参数挨个为:队列,消费成功后是否要自动应答,成功消费的回调,未成功消费的回调channel.basicConsume(QUEUE_NAME,true,deliverCallback,cancelCallback);}
}同时执行生产者、消费者的main方法:
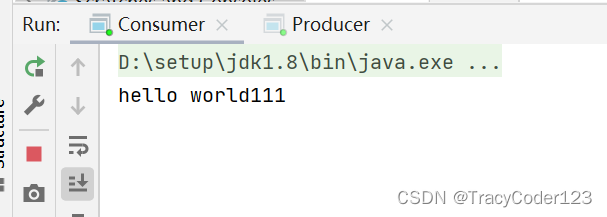
消费成功。
四、模式二:Work Queues
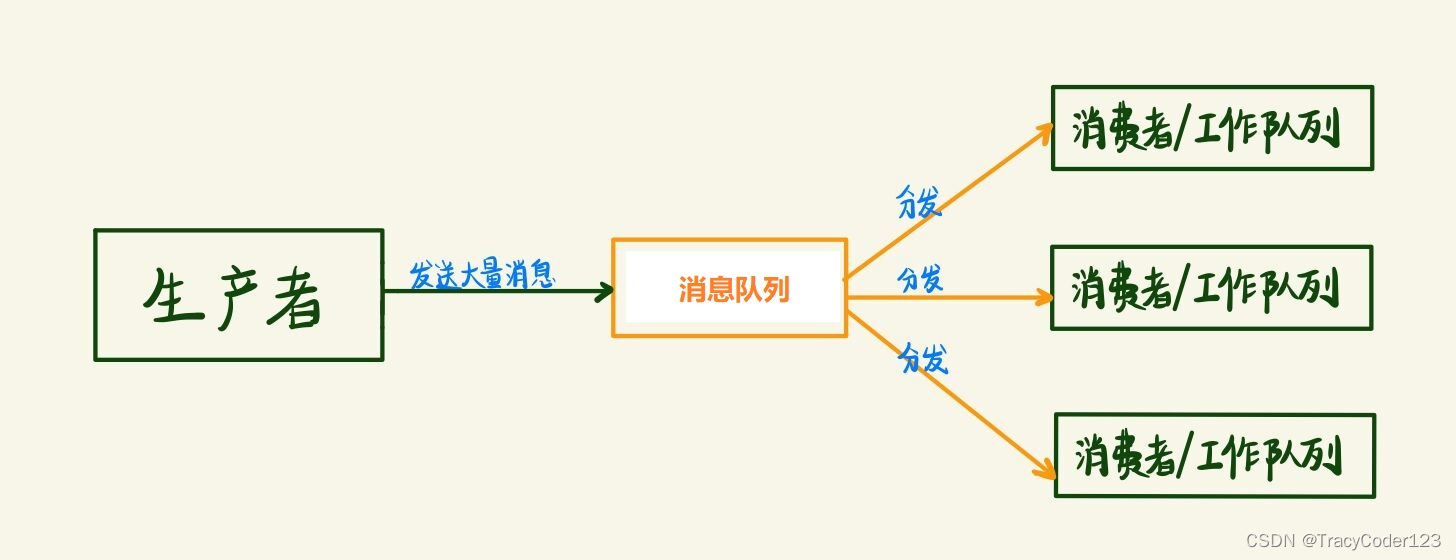
这种模式主要针对有大量资源密集型任务频繁提交的情况,创建的工作队列将会对提交的任务进行弹出和分发,让后台的一个或多个工作线程来处理这些任务,从而达到缓解高并发的目的。
下面通过实战来学习这种模式。
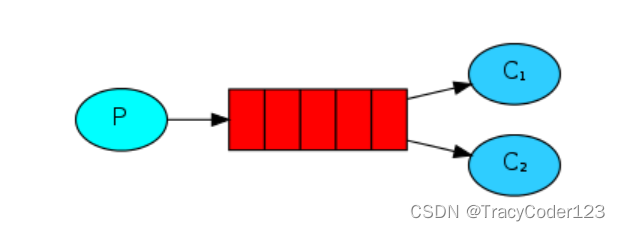
1.工作原理
- 轮询机制
由于工作队列中的消息只能被消费一次,因此消息队列会对消费者们进行轮询,为了公平挨个分配消息。
2.工具类代码:连接工厂
考虑到在模式一中生产者、消费者中有一段代码是重复的:从创建连接工厂->获取信道,为了更好地提高代码的简洁性和复用性,可以将这部分代码抽取出来。
package tracy.workqueues.utils;import com.rabbitmq.client.Connection;
import com.rabbitmq.client.ConnectionFactory;
import com.rabbitmq.client.Channel;import java.io.IOException;
import java.util.concurrent.TimeoutException;public class MQutils {//获取一个channelpublic static Channel getChannel() throws IOException, TimeoutException {//1 创建一个连接工厂ConnectionFactory factory=new ConnectionFactory();//2 设置工厂ip等信息 连接rabbitMQfactory.setHost("rabbitMQ的ip");factory.setPort(5673);//通信端口factory.setUsername("guest");//默认的用户名factory.setPassword("guest");//默认的密码//3 创建连接Connection connection=factory.newConnection();//4 获取信道return connection.createChannel();}
}3.消费者代码
基于多线程实现消费者:
package tracy.workqueues;import com.rabbitmq.client.*;
import tracy.workqueues.utils.MQutils;import java.io.IOException;
import java.util.concurrent.TimeoutException;//消费者 工作线程
public class Consumer implements Runnable{//队列名称public static final String QUEUE_NAME="queue2.0";@Overridepublic void run() {try {Channel channel = MQutils.getChannel();//消费消息DeliverCallback deliverCallback=(consumerTag, message)->{System.out.println(Thread.currentThread().getName()+":"+new String(message.getBody()));};//参数挨个为:队列,消费成功后是否要自动应答,成功消费的回调,未成功消费的回调channel.basicConsume(QUEUE_NAME,true,deliverCallback,consumerTag-> {});} catch (Exception e) {e.printStackTrace();}}//接收消息public static void main(String[] args) throws TimeoutException, IOException {//启动两个消费者/工作线程Runnable runnable= new Consumer();new Thread(runnable).start();new Thread(runnable).start();}
}4.生产者代码
通过循环的方式发送多条消息:
package tracy.workqueues;import com.rabbitmq.client.Channel;
import tracy.workqueues.utils.MQutils;import java.io.IOException;
import java.util.concurrent.TimeoutException;//生产者
public class Producer {//队列名称public static final String QUEUE_NAME="queue2.0";//生产消息public static void main(String[] args) throws TimeoutException, IOException {Channel channel=MQutils.getChannel();//生成一个队列,参数挨个为:队列名,是否持久化,是否允许多消费者消费,其他参数channel.queueDeclare(QUEUE_NAME,false,false,false,null);//发消息,参数挨个为:交换机,路由的key值,其他参数,发送的消息//发送大量消息for(int i=0;i<20;++i){String message="message"+i;channel.basicPublish("",QUEUE_NAME,null,message.getBytes());}System.out.println("生产者发送完成!");}
}- 测试:
启动生产者和消费者之后得到执行结果:
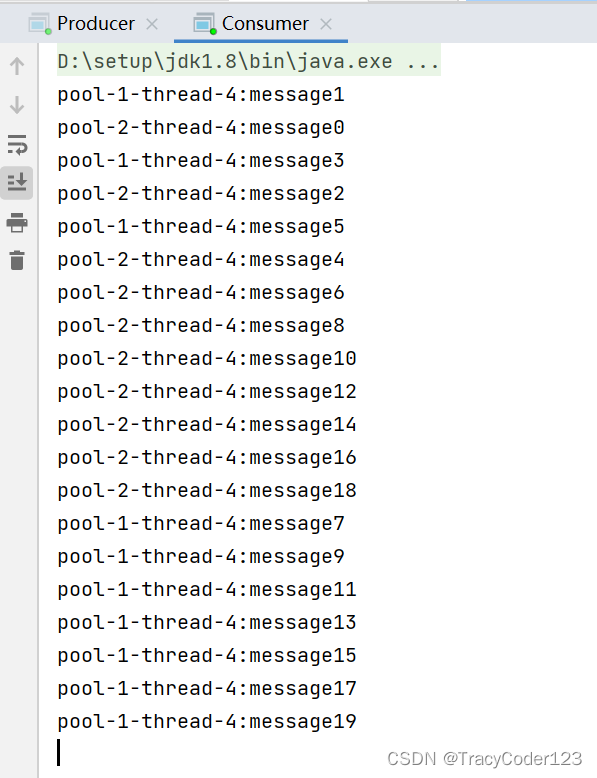
虽然消息的消费看上去是乱序的,这是由于多线程的异步导致的,但仔细看就会发现两个线程是交替消费的。
5.分发策略
不公平分发
前面的分发机制都是轮询分发,实际上这样的机制并不公平,因为不同的消费者处理消息的能力不一定是一样的,有的配置好一些,消费就会更快。因此需要引入不公平分发机制。
- 修改消费者代码:
添加channel.basicQos(1);
package tracy.workqueues;import com.rabbitmq.client.*;
import tracy.workqueues.utils.MQutils;import java.io.IOException;
import java.util.concurrent.TimeoutException;//消费者 工作线程
public class Consumer implements Runnable{//队列名称public static final String QUEUE_NAME="queue2.0";@Overridepublic void run() {try {Channel channel = MQutils.getChannel();//设置分发策略为不公平分发channel.basicQos(1);//消费消息DeliverCallback deliverCallback=(consumerTag, message)->{System.out.println(Thread.currentThread().getName()+":"+new String(message.getBody()));//接受成功后 确认应答,第二个参数表示是否批量应答,这里是false表明只确认当前消息channel.basicAck(message.getEnvelope().getDeliveryTag(),false);};//参数挨个为:队列,消费成功后是否要自动应答,成功消费的回调,未成功消费的回调channel.basicConsume(QUEUE_NAME,false,deliverCallback,consumerTag-> {});//第二个参数改成了false} catch (Exception e) {e.printStackTrace();}}//接收消息public static void main(String[] args) throws TimeoutException, IOException {//启动两个消费者/工作线程Runnable runnable= new Consumer();new Thread(runnable).start();new Thread(runnable).start();}
}在这种机制下,消费能力强的消费者会被分发更多消息。
预取值
说白了就是按比例分发的策略,比如指定10条消息分6条给消费者1,分4条给消费者2。
将消费者中 channel.basicQos(1);中的1改成大于1的数字就行了。
五、保障消息不丢失的措施
1 消息应答:消息从队列发送出去之后可能会丢失,通过开启消息应答来保障
2 持久化:将队列、消息保存到磁盘上
3 发布确认:消息发送到队列前消息可能会丢失,通过开启发布确认来保障
1.消息应答
上面的模式有一个问题:消费者在消费消息的过程中宕机了,会造成该任务消息的丢失。为了解决这种任务的丢失,引入消息应答机制。
简单来说:消息应答就是,消费者消费完一个消息之后告诉mq它已经消费完了,mq再把队列中的该消息删除,这样就不会导致消息的丢失。
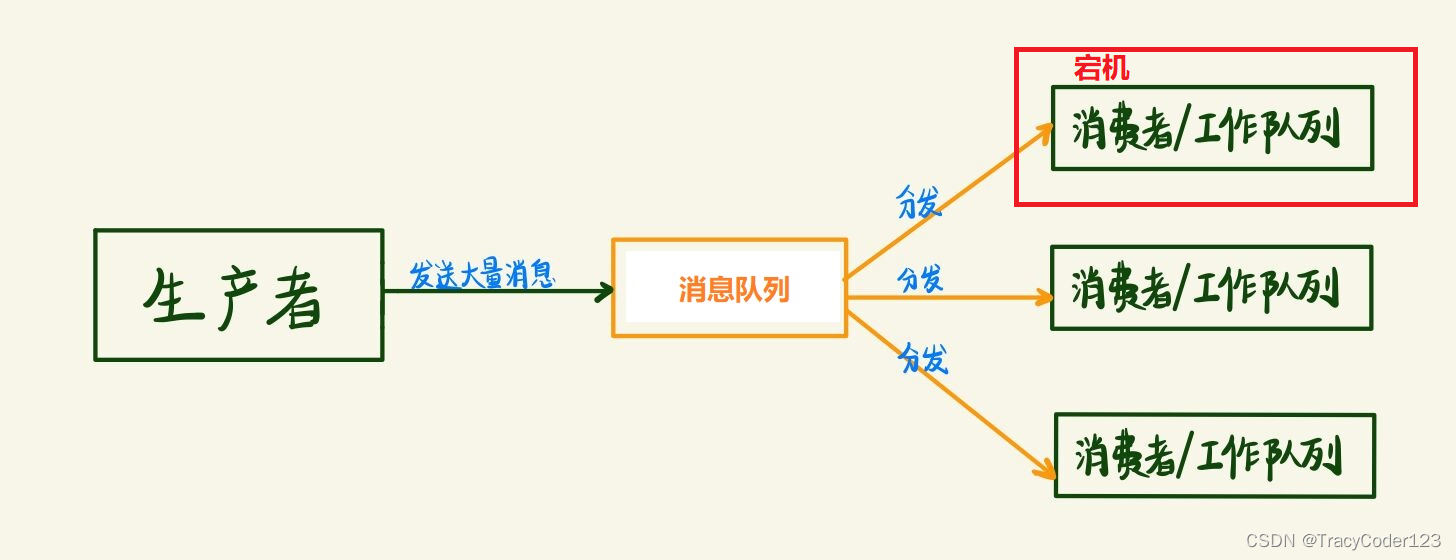
- 自动应答(默认,但是不建议):
自动应答说白了就是,只要消费者接收到了消息就进行应答,但它后面能否被成功消费完就不管了。这种方式牺牲了一定的可靠性,但能保证高吞吐量。
- 手动应答:
Channel.basicAck 肯定确认,mq会认为该消息消费成功并删除该消息,支持批量应答
Channel.basicNack 否定确认,mq会认为该消息消费不成功,支持批量应答
Channel.basicReject 否定确认,mq会认为该消息消费不成功,不支持批量应答
没有被确认应答的消息会自动重新入队,因此消息不会丢失。
修改消费者代码
package tracy.workqueues;import com.rabbitmq.client.*;
import tracy.workqueues.utils.MQutils;import java.io.IOException;
import java.util.concurrent.TimeoutException;//消费者 工作线程
public class Consumer implements Runnable{//队列名称public static final String QUEUE_NAME="queue2.0";@Overridepublic void run() {try {Channel channel = MQutils.getChannel();//消费消息DeliverCallback deliverCallback=(consumerTag, message)->{System.out.println(Thread.currentThread().getName()+":"+new String(message.getBody()));//接受成功后 确认应答,第二个参数表示是否批量应答,这里是false表明只确认当前消息channel.basicAck(message.getEnvelope().getDeliveryTag(),false);};//参数挨个为:队列,消费成功后是否要自动应答,成功消费的回调,未成功消费的回调channel.basicConsume(QUEUE_NAME,true,deliverCallback,consumerTag-> {});} catch (Exception e) {e.printStackTrace();}}//接收消息public static void main(String[] args) throws TimeoutException, IOException {//启动两个消费者/工作线程Runnable runnable= new Consumer();new Thread(runnable).start();new Thread(runnable).start();}
}2.持久化
- 队列的持久化
修改生产者中声明队列的语句:
//生成一个队列,参数挨个为:队列名,是否持久化,是否允许多消费者消费,其他参数
//第二个参数改为true表示将队列持久化
channel.queueDeclare(QUEUE_NAME,true,false,false,null);
- 消息的持久化:
修改生产者中发布消息的语句:
//第三个参数声明为MessageProperties.PERSISTENT_TEXT_PLAIN表明将消息进行保存到磁盘上
channel.basicPublish("",QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());
不过持久化不是一定成功,因为原本是保存到内存中,设置之后将保存到磁盘上,降低了丢失的可能性。
3.发布确认
单个发布确认(同步)
发一条确认一条,确认了上一条再发下一条,效率不高。
- 生产者代码:
package tracy.workqueues;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.MessageProperties;
import tracy.workqueues.utils.MQutils;import java.io.IOException;
import java.util.concurrent.TimeoutException;//生产者
public class Producer {//队列名称public static final String QUEUE_NAME="queue3.0";//生产消息public static void main(String[] args) throws TimeoutException, IOException, InterruptedException {Channel channel=MQutils.getChannel();//开启发布确认channel.confirmSelect();//声明队列时,开启队列持久化channel.queueDeclare(QUEUE_NAME,true,false,false,null);//记录发布前后耗时long start=System.currentTimeMillis();for(int i=0;i<1000;++i){String message="message"+i;//发布消息时开启消息 持久化channel.basicPublish("",QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());//单个发布确认 每发布一条 都等待确认channel.waitForConfirms();}long end=System.currentTimeMillis();System.out.println("生产者发送完成,耗时:"+(end-start)/1000.0d+"s");}
}
- 消费者代码:
package tracy.workqueues;import com.rabbitmq.client.*;
import tracy.workqueues.utils.MQutils;import java.io.IOException;
import java.util.concurrent.TimeoutException;//消费者 工作线程
public class Consumer implements Runnable{//队列名称public static final String QUEUE_NAME="queue3.0";@Overridepublic void run() {try {Channel channel = MQutils.getChannel();channel.basicQos(1);DeliverCallback deliverCallback=(consumerTag, message)->{System.out.println(Thread.currentThread().getName()+":"+new String(message.getBody()));//确认应答,只确认当前消息channel.basicAck(message.getEnvelope().getDeliveryTag(),false);};//关闭自动确认应答channel.basicConsume(QUEUE_NAME,false,deliverCallback,consumerTag-> {});} catch (Exception e) {e.printStackTrace();}}//接收消息public static void main(String[] args) throws TimeoutException, IOException {//启动两个消费者/工作线程Runnable runnable= new Consumer();new Thread(runnable).start();new Thread(runnable).start();}
}
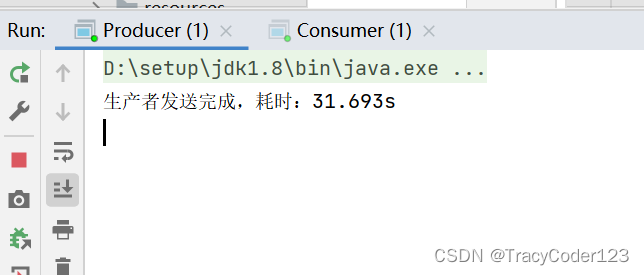
- 运行:
运行生产者、消费者之后,显示生产者发送消息用时20-30s左右。
批量发布确认(同步)
发布一批消息,然后批量确认一次。优点是比单个发布确认快,缺点是一旦这一批消息出了问题,无法得知是哪个消息出了问题,这一批消息都得重发。
- 修改生产者代码:
package tracy.workqueues;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.MessageProperties;
import tracy.workqueues.utils.MQutils;import java.io.IOException;
import java.util.concurrent.TimeoutException;//生产者
public class Producer {//队列名称public static final String QUEUE_NAME="queue3.0";//生产消息public static void main(String[] args) throws TimeoutException, IOException, InterruptedException {...int batch_size=100;//每100条确认一次for(int i=0;i<1000;++i){String message="message"+i;//发布消息时开启消息 持久化channel.basicPublish("",QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());//每100条等待确认一次if((i+1)%batch_size==0)channel.waitForConfirms();}...}
}消费者代码不改变。
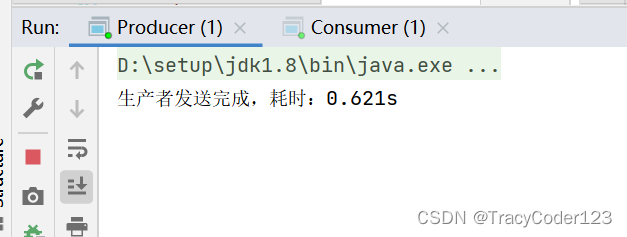
- 运行:
多次运行,时间都在1s内,性能的提升非常明显。
异步发布确认
生产者向工作队列发布了消息之后,不用等待确认就继续发布了;而工作队列收到生产者发送过来的消息之后,通过回调函数的形式告诉生产者哪些消息发布成功了,哪些发布失败了,发布失败的需要重新发布。
异步的引入对效率的提升很大。不过这种机制需要给消息进行编号,底层数据结构是基于哈希表。
- 生产者AsynProducer代码:
注意,我把队名给改了,消费者那边也要改一下队名。
package tracy.workqueues;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.ConfirmCallback;
import com.rabbitmq.client.MessageProperties;
import tracy.workqueues.utils.MQutils;import java.io.IOException;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentNavigableMap;
import java.util.concurrent.ConcurrentSkipListMap;
import java.util.concurrent.TimeoutException;//生产者 基于异步发布
public class AsynProducer {//队列名称public static final String QUEUE_NAME="queue4.0";//生产消息public static void main(String[] args) throws TimeoutException, IOException, InterruptedException {Channel channel=MQutils.getChannel();//开启发布确认channel.confirmSelect();//声明队列时,开启队列持久化channel.queueDeclare(QUEUE_NAME,true,false,false,null);//声明一个线程安全的哈希表,用来存放发送失败的消息ConcurrentSkipListMap<Long,String> failedMessage=new ConcurrentSkipListMap<>();//消息监听器,哪些成功了,哪些失败了ConfirmCallback ackCallback=(deliveryTag,multiple)->{//将发布成功的从failedMap中删除,剩下的就是发布未成功的if(multiple){//批量failedMessage.headMap(deliveryTag).clear();}else{//单个failedMessage.remove(deliveryTag);}};ConfirmCallback nackCallback=(deliveryTag,multiple)->{System.out.println("未确认的消息:"+deliveryTag);};//第一个参数为发布成功的回调,第二个为发布失败的回调,需要手动实现channel.addConfirmListener(ackCallback,nackCallback);//记录发布前后耗时long start=System.currentTimeMillis();for(int i=0;i<1000;++i){String message="message"+i;//将所有消息存储在failedMap中failedMessage.put(channel.getNextPublishSeqNo(),message);//发布消息时开启消息 持久化channel.basicPublish("",QUEUE_NAME, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());}long end=System.currentTimeMillis();System.out.println("生产者发送完成,耗时:"+(end-start)/1000.0d+"s");}
}- 运行:
快的飞起!异步yyds
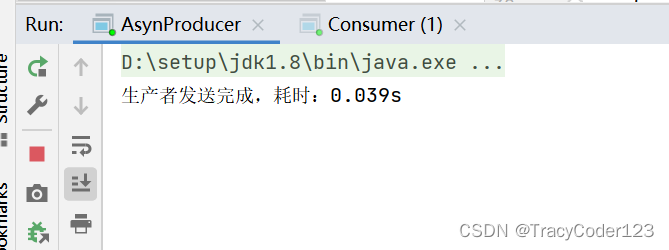
三种方式对比
第三种是最快的,性能好,能充分利用CPU资源;第一种是最慢的,性能比较差;第二种介于二者之间,但是出了问题很难定位具体出问题的消息。
六、模式三:Publish/Subscribe
在上一种模式中,我们创建了一个工作队列。工作队列背后的假设是每个消息都是只交付给一名消费者。在这一部分中,我们将做一些事情完全不同的:向多个消费者传递消息。此模式称为发布/订阅。
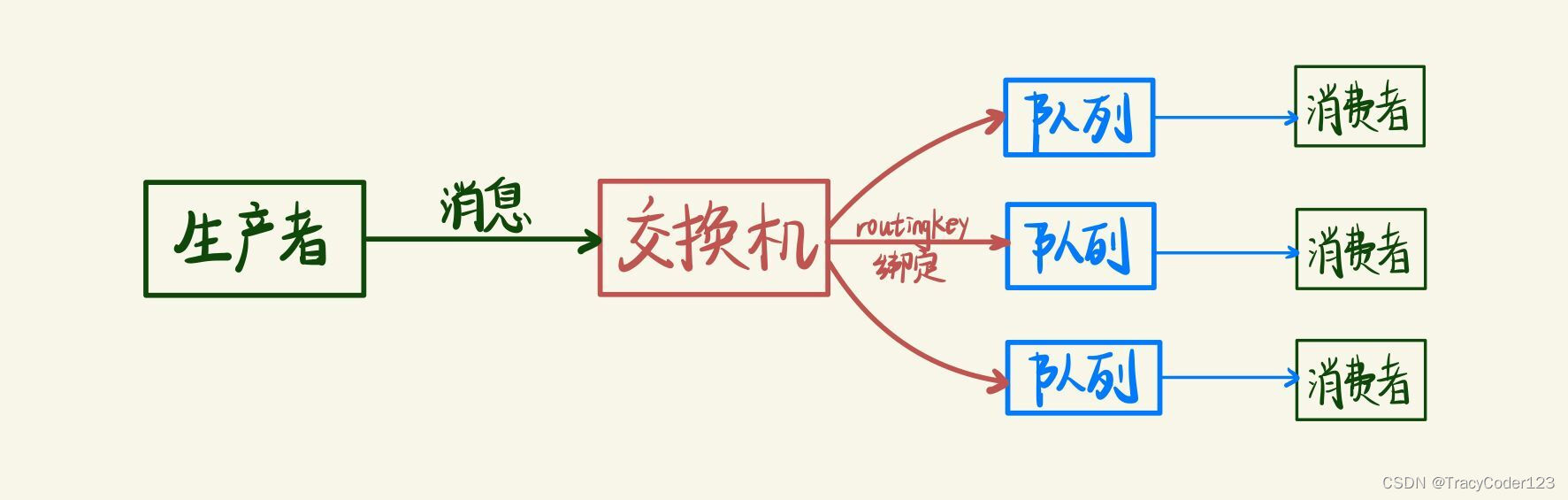
这种模式需要指定exchange的类型为fanout,exchange将把收到的消息广播到所有队列中。
消费者代码
两个消费者除了上面的三个常量有所不同,下面的代码都是一样的。但是为了模拟真实情况,我还是写了两个消费者。
package tracy.subscribe.fanout;import com.rabbitmq.client.*;
import tracy.subscribe.utils.MQutils;import java.io.IOException;
import java.util.concurrent.TimeoutException;//消费者1
public class Consumer1{public static final String QUEUE_NAME1="q1";//队列名称public static void main(String[] args) throws TimeoutException, IOException {//获取信道Channel channel=MQutils.getChannel();System.out.println("消费者1等待接收消息...");//消费消息DeliverCallback deliverCallback=(consumerTag, message)->{System.out.println(new String(message.getBody()));//消息应答channel.basicAck(message.getEnvelope().getDeliveryTag(),false);};CancelCallback cancelCallback=consumerTag-> System.out.println("消费被中断");//参数挨个为:队列,消费成功后是否要自动应答,成功消费的回调,未成功消费的回调channel.basicConsume(QUEUE_NAME1,false,deliverCallback,cancelCallback);}
}package tracy.subscribe.fanout;import com.rabbitmq.client.*;
import tracy.subscribe.utils.MQutils;import java.io.IOException;
import java.util.concurrent.TimeoutException;//消费者2
public class Consumer2{public static final String QUEUE_NAME1="q2";//队列名称public static void main(String[] args) throws TimeoutException, IOException {//获取信道Channel channel=MQutils.getChannel();System.out.println("消费者2等待接收消息...");//消费消息DeliverCallback deliverCallback=(consumerTag, message)->{System.out.println(new String(message.getBody()));//消息应答channel.basicAck(message.getEnvelope().getDeliveryTag(),false);};CancelCallback cancelCallback=consumerTag-> System.out.println("消费被中断");//参数挨个为:队列,消费成功后是否要自动应答,成功消费的回调,未成功消费的回调channel.basicConsume(QUEUE_NAME1,false,deliverCallback,cancelCallback);}
}生产者代码
package tracy.subscribe.fanout;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.ConfirmCallback;
import com.rabbitmq.client.MessageProperties;
import tracy.subscribe.utils.MQutils;import java.io.IOException;
import java.util.concurrent.ConcurrentSkipListMap;
import java.util.concurrent.TimeoutException;//生产者
public class Producer {public static final String EXCHANGE_NAME="fanout_exchange";//交换机名称public static final String QUEUE_NAME1="q1";//队列名称public static final String QUEUE_NAME2="q2";//队列名称public static void main(String[] args) throws TimeoutException, IOException, InterruptedException {//获取信道Channel channel=MQutils.getChannel();//开启发布确认channel.confirmSelect();//声明一个exchange,参数为名称和类型channel.exchangeDeclare(EXCHANGE_NAME,"fanout");//声明两个队列channel.queueDeclare(QUEUE_NAME1,true,false,false,null);channel.queueDeclare(QUEUE_NAME2,true,false,false,null);//绑定交换机与队列,参数为队列名、交换机名,routingKey,考虑到这是广播模式,不写routingKeychannel.queueBind(QUEUE_NAME1,EXCHANGE_NAME,"");channel.queueBind(QUEUE_NAME2,EXCHANGE_NAME,"");//异步发布确认ConcurrentSkipListMap<Long,String> failedMessage=new ConcurrentSkipListMap<>();ConfirmCallback ackCallback=(deliveryTag, multiple)->{if(multiple){failedMessage.headMap(deliveryTag).clear();}else{failedMessage.remove(deliveryTag);}};ConfirmCallback nackCallback=(deliveryTag,multiple)->{System.out.println("未确认的消息:"+deliveryTag);};channel.addConfirmListener(ackCallback,nackCallback);//发布消息for(int i=0;i<20;++i) {String message="message"+i;//将所有消息存储在failedMap中failedMessage.put(channel.getNextPublishSeqNo(),message);//发布消息时开启消息 持久化channel.basicPublish(EXCHANGE_NAME,"", MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());}System.out.println("生产者发送完毕");}
}
跑一下看看是否两个消费者都能消费20条消息。
七、模式四:Routing
生产者在发布消息时,通过指定routingKey来把让exchange把消息bingding给指定的队列。
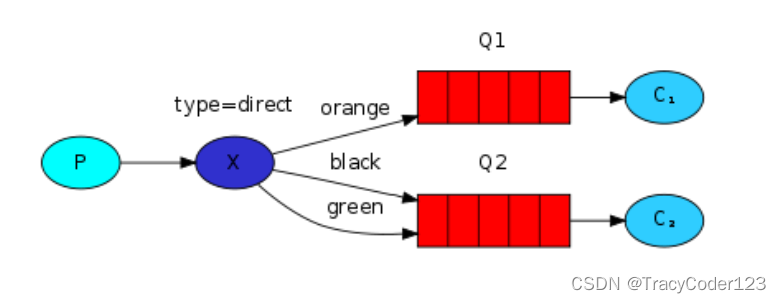
这种模式需要把exchange类型指定为direct。
修改消费者代码
其他的在上一章基础上没有发生变化,主要就是生产者binding、消息发送的过程有一些变化。
package tracy.subscribe;import com.rabbitmq.client.Channel;
import com.rabbitmq.client.ConfirmCallback;
import com.rabbitmq.client.MessageProperties;
import tracy.subscribe.utils.MQutils;import java.io.IOException;
import java.util.concurrent.ConcurrentSkipListMap;
import java.util.concurrent.TimeoutException;//生产者
public class Producer {public static final String EXCHANGE_NAME="direct_exchange";//交换机名称public static final String QUEUE_NAME1="q1";//队列名称public static final String QUEUE_NAME2="q2";//队列名称public static final String RKEY1_1="orange";//与q1绑定的routingKeypublic static final String RKEY2_1="black";//与q2绑定的routingKeypublic static final String RKEY2_2="green";//与q2绑定的routingKeypublic static void main(String[] args) throws TimeoutException, IOException, InterruptedException {//获取信道Channel channel=MQutils.getChannel();//开启发布确认channel.confirmSelect();//声明一个exchange,参数为名称和类型channel.exchangeDeclare(EXCHANGE_NAME,"direct");//声明两个队列channel.queueDeclare(QUEUE_NAME1,true,false,false,null);channel.queueDeclare(QUEUE_NAME2,true,false,false,null);//绑定交换机与队列,参数为队列名、交换机名,routingKeychannel.queueBind(QUEUE_NAME1,EXCHANGE_NAME,RKEY1_1);channel.queueBind(QUEUE_NAME2,EXCHANGE_NAME,RKEY2_1);channel.queueBind(QUEUE_NAME2,EXCHANGE_NAME,RKEY2_2);//异步发布确认ConcurrentSkipListMap<Long,String> failedMessage=new ConcurrentSkipListMap<>();ConfirmCallback ackCallback=(deliveryTag, multiple)->{if(multiple){failedMessage.headMap(deliveryTag).clear();}else{failedMessage.remove(deliveryTag);}};ConfirmCallback nackCallback=(deliveryTag,multiple)->{System.out.println("未确认的消息:"+deliveryTag);};channel.addConfirmListener(ackCallback,nackCallback);//发布消息for(int i=0;i<20;++i) {String message="message"+i;//将所有消息存储在failedMap中failedMessage.put(channel.getNextPublishSeqNo(),message);//发布消息时开启消息 持久化if((i+1)%3==0)channel.basicPublish(EXCHANGE_NAME,RKEY1_1, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());else if((i+1)%3==1)channel.basicPublish(EXCHANGE_NAME,RKEY2_1, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());else channel.basicPublish(EXCHANGE_NAME,RKEY2_2, MessageProperties.PERSISTENT_TEXT_PLAIN,message.getBytes());}System.out.println("生产者发送完毕");}
}相关文章:
RabbitMQ核心内容:实战教程(java)
文章目录一、安装二、入门1.分类2.核心概念3.工作原理4.六大模式三、模式一:"Hello World!"1.依赖2.生产者代码3.消费者代码四、模式二:Work Queues1.工作原理2.工具类代码:连接工厂3.消费者代码4.生产者代码5.分发策略不公平分发预…...
RK356x U-Boot研究所(命令篇)3.7 pci与nvme命令的用法
平台U-Boot 版本Linux SDK 版本RK356x2017.09v1.2.3文章目录 一、设备树与config配置二、pci命令的定义三、nvme命令的定义四、pci与nvme命令的用法3.1 pci总线扫描3.2 nvme设备信息3.3 nvme设备读写一、设备树与config配置 RK3568支持PCIe接口,例如ROC-RK3568-PC: 原理图如…...

微信头像昵称获取能力的变化导致了我半年没更新小程序
背景 2022年9月份,微信更改了获取头像昵称的规则,回收了原有 wx.getUserProfile 中的部分能力,为了减小对【微点记账】小程序的影响,长达半年未做任何更新,今天为了增加这个聊天机器人的功能,不得不重新查…...
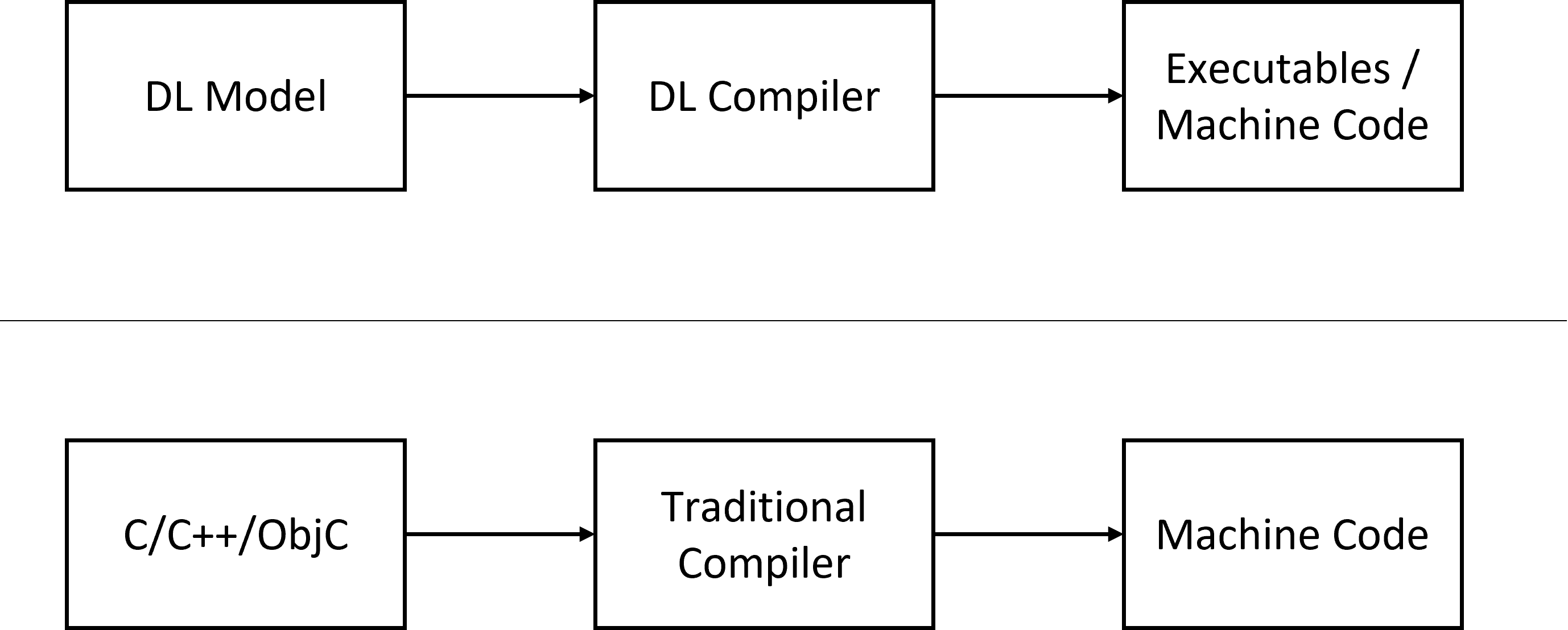
【深度学习编译器系列】1. 为什么需要深度学习编译器?
本系列是自学深度学习编译器过程中的一些笔记和总结,参考文献在文末。 1. 概述 深度学习(DL)编译器的产生有两方面的因素:深度学习模型的广泛应用,以及深度学习芯片的层出不穷。 一方面,我们现在有非常多…...
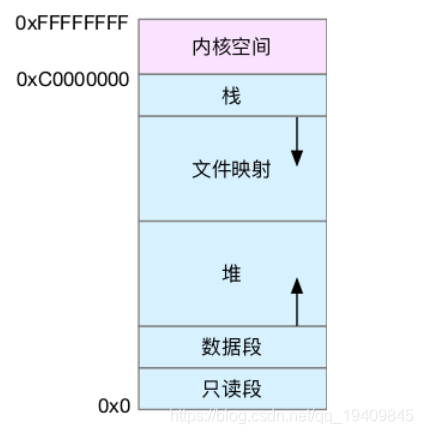
数据结构与算法总结整理(超级全的哦!)
数据结构与算法基础大O表示法时间复杂度大O表示法时间复杂度排序:最坏时间复杂度时间复杂度的几条基本计算规则内存工作原理什么是内存内存主要分为三种存储器随机存储器(RAM)只读存储器(ROM)高速缓存(Cach…...

DPDK — MALLOC 堆内存管理组件
目录 文章目录 目录MALLOC 堆内存管理组件rte_malloc() 接口malloc_heap 结构体malloc_elem 结构体内存初始化流程内存申请流程内存释放流程MALLOC 堆内存管理组件 MALLOC(堆内存管理组件)基于 hugetlbfs 内核文件系统来实现,能够从 HugePage 中分配一块连续的物理大页内存…...

分享113个HTML艺术时尚模板,总有一款适合您
分享113个HTML艺术时尚模板,总有一款适合您 113个HTML艺术时尚模板下载链接:https://pan.baidu.com/s/1ReoPNIRjkYov-SjsPo0vhg?pwdjk4a 提取码:jk4a Python采集代码下载链接:采集代码.zip - 蓝奏云 女性化妆用品网页模板 粉…...

2023年美赛C题Wordle预测问题一建模及Python代码详细讲解
相关链接 (1)2023年美赛C题Wordle预测问题一建模及Python代码详细讲解 (2)2023年美赛C题Wordle预测问题二建模及Python代码详细讲解 (3)2023年美赛C题Wordle预测问题三、四建模及Python代码详细讲解 &…...
小米12s ultra,索尼xperia1 iv,数码相机 拍照对比
首先说明所有的测试结果和拍摄数据我放到百度网盘了(地址在结尾) 为什么做这个测试 我一直想知道现在的手机和相机差距有多大,到底差在哪儿? 先说结论: 1.1英寸的手机cmos(2022年) 6年前(2016)的入门款相机(m43画幅) 2.手机 不能换镜头,只能在特定的拍摄距离才能发挥出全…...
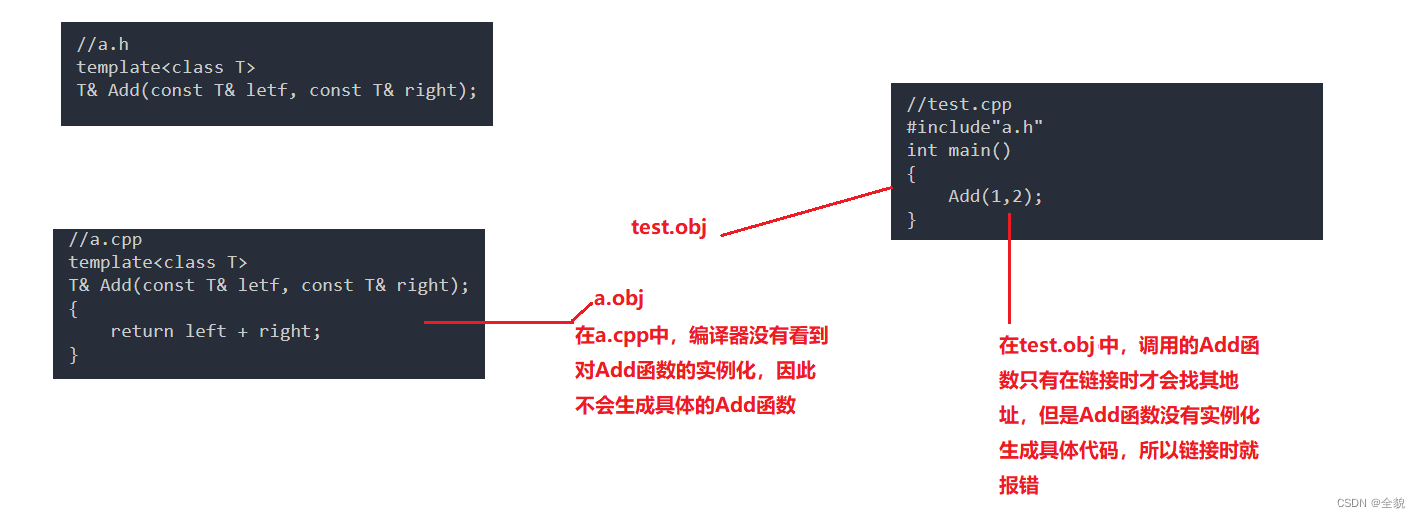
C++笔记 模板的进阶知识
目录 1. 非类型模板参数 2.模板的特化 2.1 函数模板的特化 2.2 类模板的特化 2.2.1 全特化 2.2.2 偏特化 3.模板的分离编译 3.1 什么是分离编译? 3.2 模板的分离编译 4.模板的总结 模板的初阶内容:(594条消息) C模板的原理和使用_全貌的博客-CSD…...
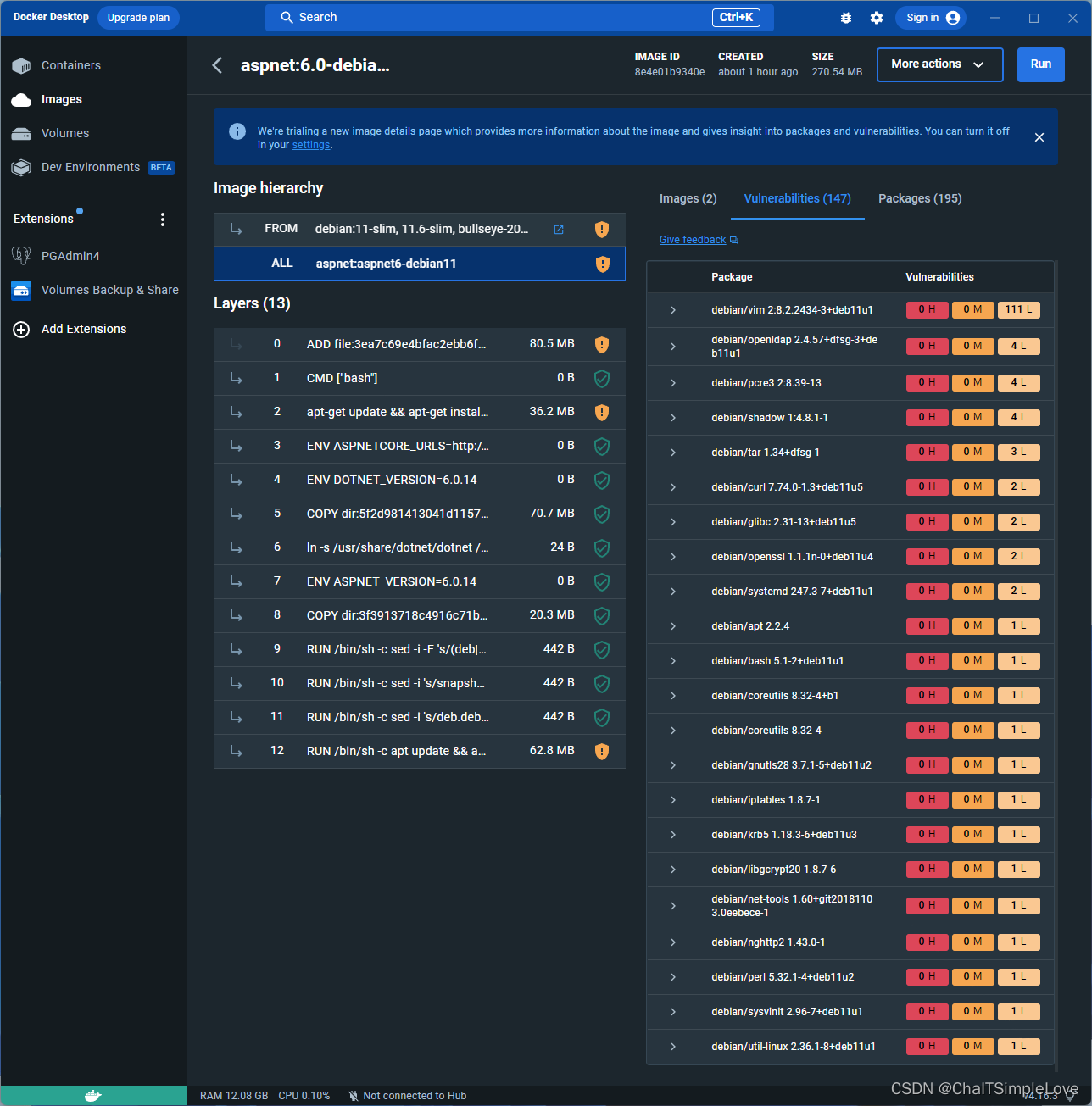
基于 Debain11 构建 asp.net core 6.x 的基础运行时镜像
基于 Debain11 构建 asp.net core 6.x 的基础运行时镜像Linux 环境说明Debian 简介Debian 发行版本关于 Debian 11Linux 常用基础工具Dockerfile 中 RUN 指令RUN 语法格式RUN 语义说明编写 Dockerfile 构建 Runtime 基础镜像ASP.NET Core Runtime 基础镜像Dockerfile 编写Windo…...
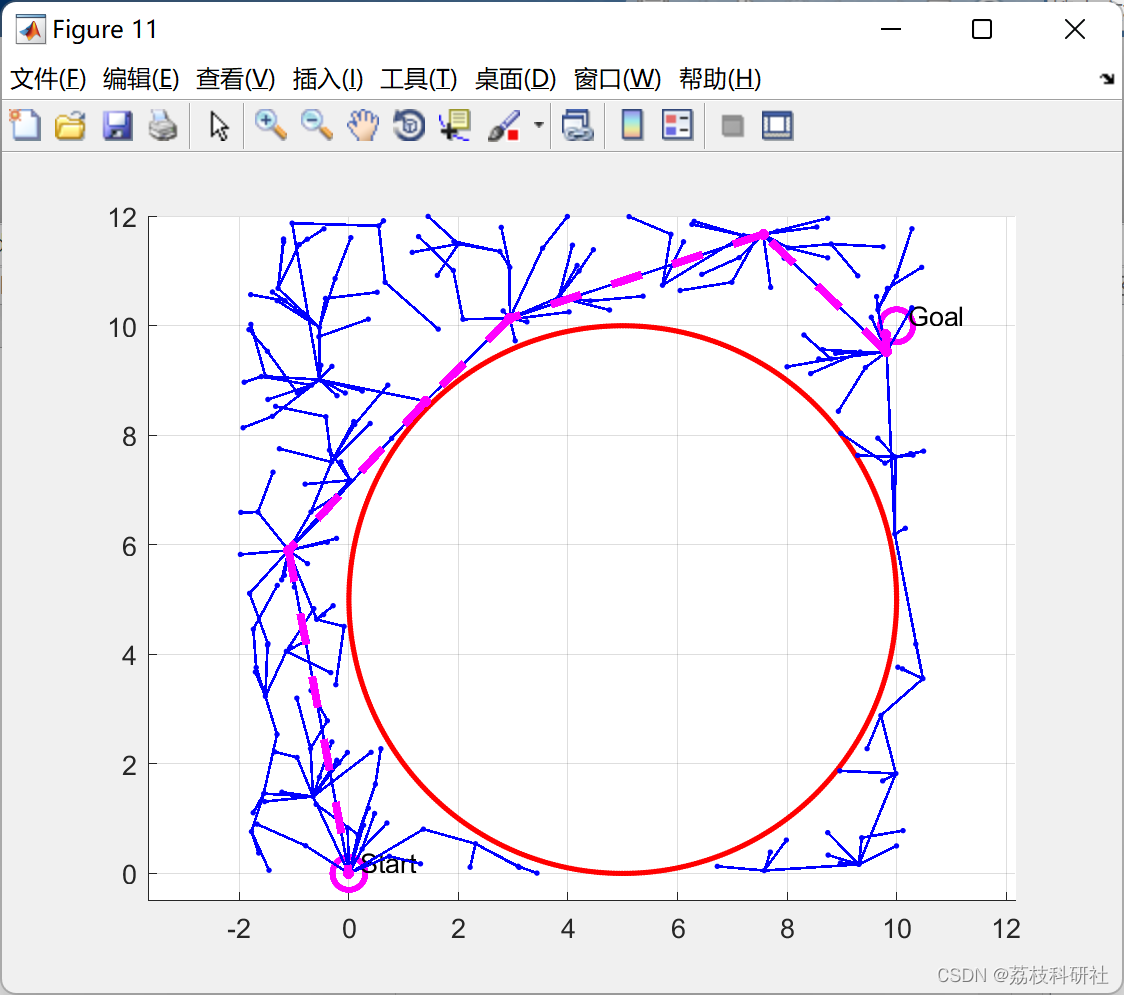
【无人机路径规划】基于IRM和RRTstar进行无人机路径规划(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...
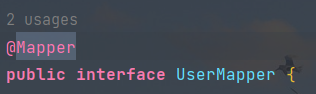
Spring Boot中使用@Autowire装配接口是怎么回事?
在学习使用Spring Boot框架时候,发现了一个特别的现象UserMapper是一个接口,在另一个类中好像直接使用Autowired装配了一个UserMapper对象???我纳闷了一会儿,接口居然可以直接实例对象吗?根据我…...
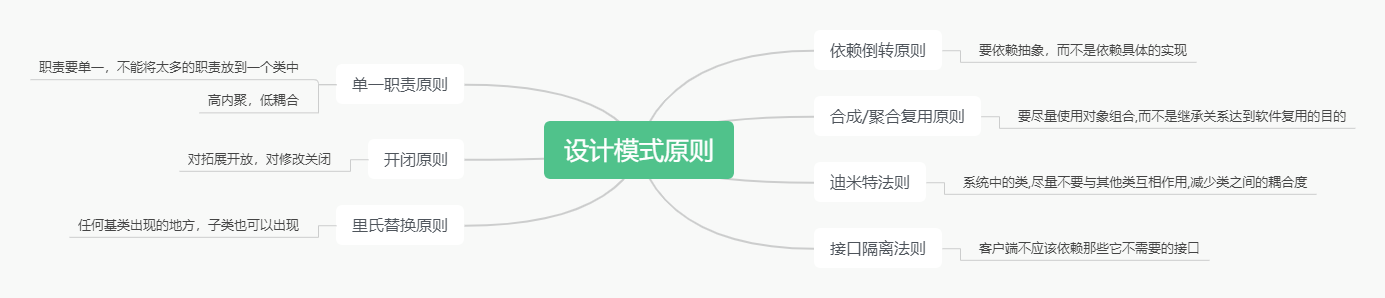
23种设计模式介绍(Python示例讲解)
文章目录一、概述二、设计模式七种原则三、设计模式示例讲解1)创建型模式1、工厂模式(Factory Method)【1】简单工厂模式(不属于GOF设计模式之一)【2】工厂方法模式2、抽象工厂模式(AbstractFactory&#x…...

初识Hadoop,走进大数据世界
文章目录数据!数据!遇到的问题Hadoop的出现相较于其他系统的优势关系型数据库网格计算本文章属于Hadoop系列文章,分享Hadoop相关知识。后续文章中会继续分享Hadoop的组件、MapReduce、HDFS、Hbase、Flume、Pig、Spark、Hadoop集群管理系统以及…...
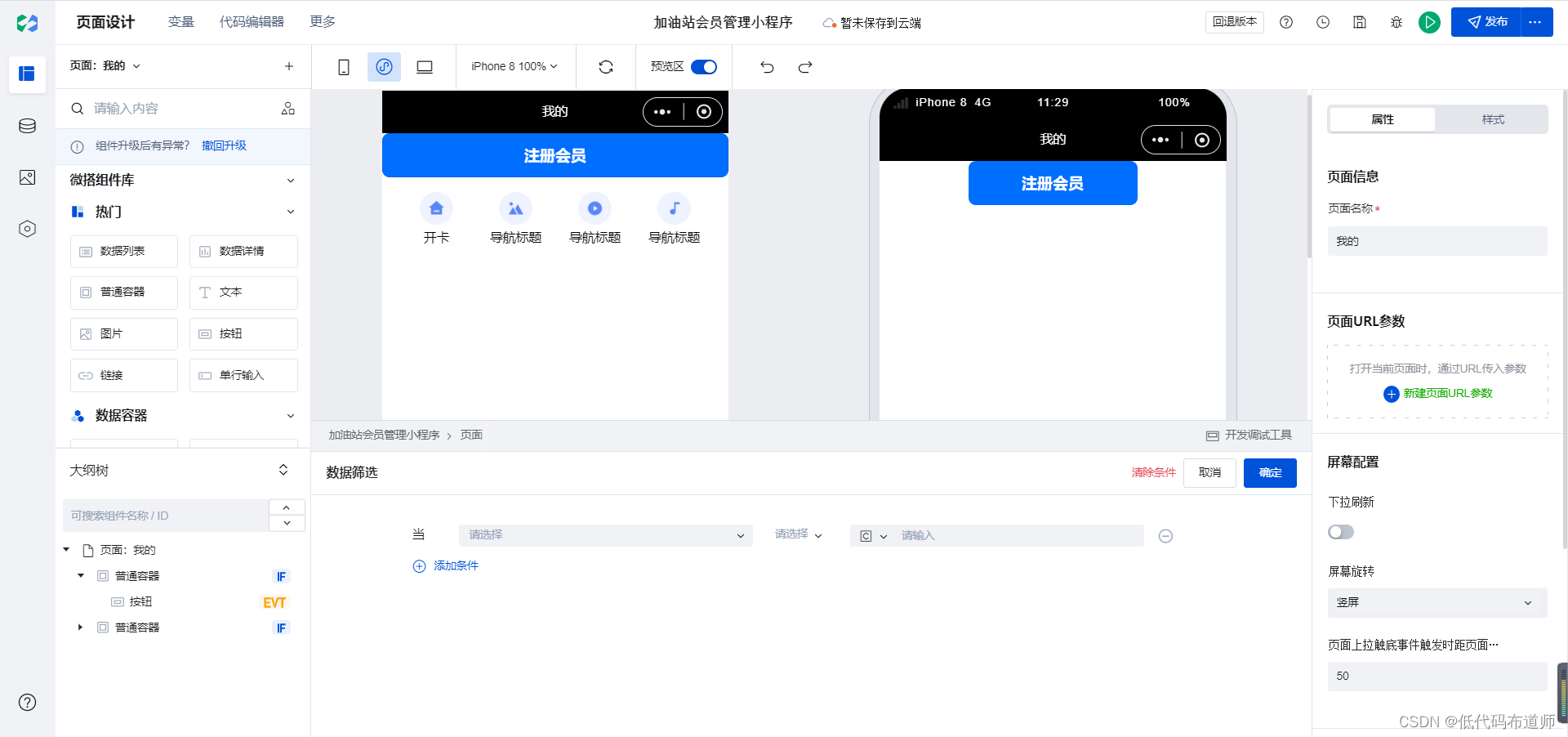
加油站会员管理小程序实战开发教程14 会员充值
我们上篇介绍了会员开卡的业务,开卡是为了创建会员卡的信息。有了会员卡信息后我们就可以给会员进行充值。当然了充值这个业务是由会员自主发起的。 按照我们的产品原型,我们在我的页面以轮播图的形式循环展示当前会员的所有卡信息。这个会员卡信息需要先用变量从数据源读取…...

leetcode 1792. 最大平均通过率
一所学校里有一些班级,每个班级里有一些学生,现在每个班都会进行一场期末考试。给你一个二维数组 classes ,其中 classes[i] [passi, totali] ,表示你提前知道了第 i 个班级总共有 totali 个学生,其中只有 passi 个学…...

15-基础加强-2-xml(约束)枚举注解
文章目录1.xml1.1概述【理解】(不用看)1.2标签的规则【应用】1.3语法规则【应用】1.4xml解析【应用】1.5DTD约束【理解】1.5.1 引入DTD约束的三种方法1.5.2 DTD语法(会阅读,然后根据约束来写)1.6 schema约束【理解】1.6.1 编写schema约束1.6.…...
)
13:高级篇 - CTK 事件管理机制(signal/slot)
作者: 一去、二三里 个人微信号: iwaleon 微信公众号: 高效程序员 在《12:高级篇 - CTK 事件管理机制(sendEvent/postEvent)》一文中,我们介绍了如何进行插件间通信 - sendEvent()/postEvent() + ctkEventHandler。然而,除了这种方式之外,EventAdmin 还提供了另一种方…...
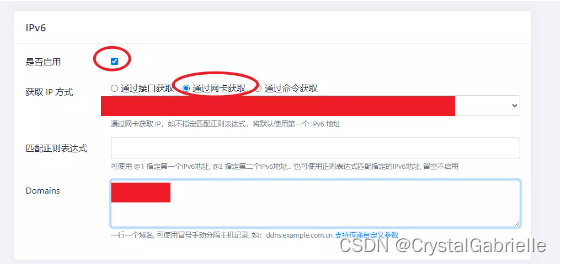
群晖-第1章-IPV6的DDNS
群晖-第1章-IPV6的DDNS 方案:腾讯云群晖DS920 本文参考群晖ipv6 DDNS-go教程-牧野狂歌,感谢原作者的分享。 这篇文章只记录了我需要的部分,其他的可以查看原文,原文还记录了更多的内容,可能帮到你。 一、购买域名 …...

利用ngx_stream_return_module构建简易 TCP/UDP 响应网关
一、模块概述 ngx_stream_return_module 提供了一个极简的指令: return <value>;在收到客户端连接后,立即将 <value> 写回并关闭连接。<value> 支持内嵌文本和内置变量(如 $time_iso8601、$remote_addr 等)&a…...

突破不可导策略的训练难题:零阶优化与强化学习的深度嵌合
强化学习(Reinforcement Learning, RL)是工业领域智能控制的重要方法。它的基本原理是将最优控制问题建模为马尔可夫决策过程,然后使用强化学习的Actor-Critic机制(中文译作“知行互动”机制),逐步迭代求解…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

cf2117E
原题链接:https://codeforces.com/contest/2117/problem/E 题目背景: 给定两个数组a,b,可以执行多次以下操作:选择 i (1 < i < n - 1),并设置 或,也可以在执行上述操作前执行一次删除任意 和 。求…...

linux 下常用变更-8
1、删除普通用户 查询用户初始UID和GIDls -l /home/ ###家目录中查看UID cat /etc/group ###此文件查看GID删除用户1.编辑文件 /etc/passwd 找到对应的行,YW343:x:0:0::/home/YW343:/bin/bash 2.将标红的位置修改为用户对应初始UID和GID: YW3…...
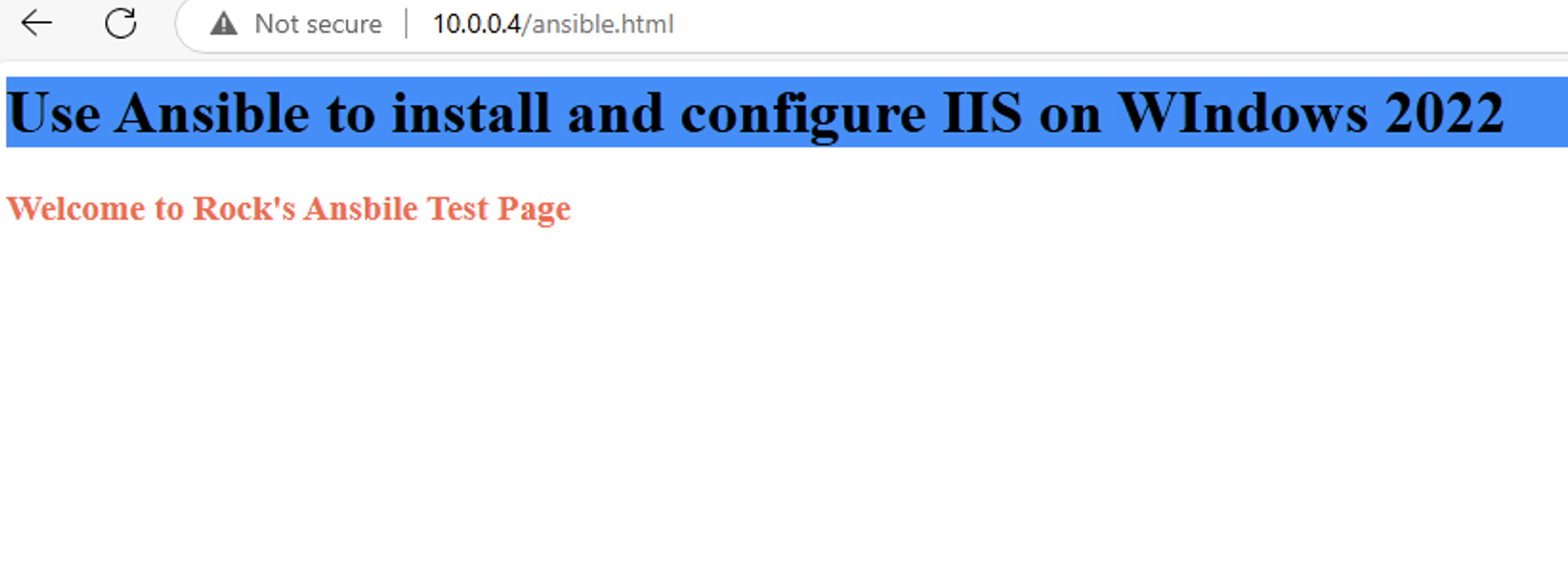
通过 Ansible 在 Windows 2022 上安装 IIS Web 服务器
拓扑结构 这是一个用于通过 Ansible 部署 IIS Web 服务器的实验室拓扑。 前提条件: 在被管理的节点上安装WinRm 准备一张自签名的证书 开放防火墙入站tcp 5985 5986端口 准备自签名证书 PS C:\Users\azureuser> $cert New-SelfSignedCertificate -DnsName &…...

【深度学习新浪潮】什么是credit assignment problem?
Credit Assignment Problem(信用分配问题) 是机器学习,尤其是强化学习(RL)中的核心挑战之一,指的是如何将最终的奖励或惩罚准确地分配给导致该结果的各个中间动作或决策。在序列决策任务中,智能体执行一系列动作后获得一个最终奖励,但每个动作对最终结果的贡献程度往往…...

【Linux】Linux安装并配置RabbitMQ
目录 1. 安装 Erlang 2. 安装 RabbitMQ 2.1.添加 RabbitMQ 仓库 2.2.安装 RabbitMQ 3.配置 3.1.启动和管理服务 4. 访问管理界面 5.安装问题 6.修改密码 7.修改端口 7.1.找到文件 7.2.修改文件 1. 安装 Erlang 由于 RabbitMQ 是用 Erlang 编写的,需要先安…...

Windows 下端口占用排查与释放全攻略
Windows 下端口占用排查与释放全攻略 在开发和运维过程中,经常会遇到端口被占用的问题(如 8080、3306 等常用端口)。本文将详细介绍如何通过命令行和图形化界面快速定位并释放被占用的端口,帮助你高效解决此类问题。 一、准…...

「Java基本语法」变量的使用
变量定义 变量是程序中存储数据的容器,用于保存可变的数据值。在Java中,变量必须先声明后使用,声明时需指定变量的数据类型和变量名。 语法 数据类型 变量名 [ 初始值]; 示例:声明与初始化 public class VariableDemo {publi…...