PyTorch 并行训练 DistributedDataParallel完整代码示例
使用大型数据集训练大型深度神经网络 (DNN) 的问题是深度学习领域的主要挑战。 随着 DNN 和数据集规模的增加,训练这些模型的计算和内存需求也会增加。 这使得在计算资源有限的单台机器上训练这些模型变得困难甚至不可能。 使用大型数据集训练大型 DNN 的一些主要挑战包括:
- 训练时间长:训练过程可能需要数周甚至数月才能完成,具体取决于模型的复杂性和数据集的大小。
- 内存限制:大型 DNN 可能需要大量内存来存储训练期间的所有模型参数、梯度和中间激活。 这可能会导致内存不足错误并限制可在单台机器上训练的模型的大小。
为了应对这些挑战,已经开发了各种技术来扩大具有大型数据集的大型 DNN 的训练,包括模型并行性、数据并行性和混合并行性,以及硬件、软件和算法的优化。
在本文中我们将演示使用 PyTorch 的数据并行性和模型并行性。
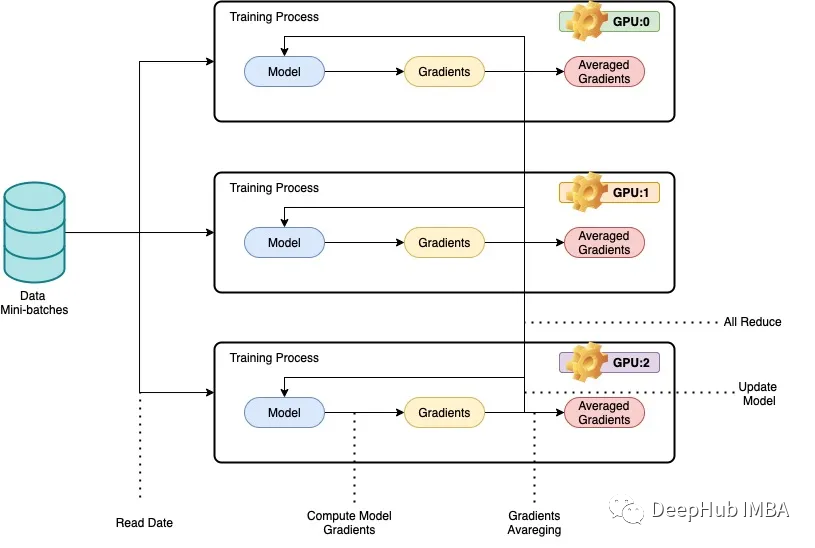
我们所说的并行性一般是指在多个gpu,或多台机器上训练深度神经网络(dnn),以实现更少的训练时间。数据并行背后的基本思想是将训练数据分成更小的块,让每个GPU或机器处理一个单独的数据块。然后将每个节点的结果组合起来,用于更新模型参数。在数据并行中,模型体系结构在每个节点上是相同的,但模型参数在节点之间进行了分区。每个节点使用分配的数据块训练自己的本地模型,在每次训练迭代结束时,模型参数在所有节点之间同步。这个过程不断重复,直到模型收敛到一个令人满意的结果。
下面我们用用ResNet50和CIFAR10数据集来进行完整的代码示例:
在数据并行中,模型架构在每个节点上保持相同,但模型参数在节点之间进行了分区,每个节点使用分配的数据块训练自己的本地模型。
PyTorch的DistributedDataParallel 库可以进行跨节点的梯度和模型参数的高效通信和同步,实现分布式训练。本文提供了如何使用ResNet50和CIFAR10数据集使用PyTorch实现数据并行的示例,其中代码在多个gpu或机器上运行,每台机器处理训练数据的一个子集。训练过程使用PyTorch的DistributedDataParallel 库进行并行化。
导入必须要的库
importosfromdatetimeimportdatetimefromtimeimporttimeimportargparseimporttorchvisionimporttorchvision.transformsastransformsimporttorchimporttorch.nnasnnimporttorch.distributedasdistfromtorch.nn.parallelimportDistributedDataParallel
接下来,我们将检查GPU
importsubprocessresult=subprocess.run(['nvidia-smi'], stdout=subprocess.PIPE)print(result.stdout.decode())
因为我们需要在多个服务器上运行,所以手动一个一个执行并不现实,所以需要有一个调度程序。这里我们使用SLURM文件来运行代码(slurm面向Linux和Unix类似内核的免费和开源工作调度程序),
defmain():# get distributed configuration from Slurm environmentparser=argparse.ArgumentParser()parser.add_argument('-b', '--batch-size', default=128, type=int,help='batch size. it will be divided in mini-batch for each worker')parser.add_argument('-e','--epochs', default=2, type=int, metavar='N',help='number of total epochs to run')parser.add_argument('-c','--checkpoint', default=None, type=str,help='path to checkpoint to load')args=parser.parse_args()rank=int(os.environ['SLURM_PROCID'])local_rank=int(os.environ['SLURM_LOCALID'])size=int(os.environ['SLURM_NTASKS'])master_addr=os.environ["SLURM_SRUN_COMM_HOST"]port="29500"node_id=os.environ['SLURM_NODEID']ddp_arg= [rank, local_rank, size, master_addr, port, node_id]train(args, ddp_arg)
然后我们使用DistributedDataParallel 库来执行分布式训练。
deftrain(args, ddp_arg):rank, local_rank, size, MASTER_ADDR, port, NODE_ID=ddp_arg# display infoifrank==0:#print(">>> Training on ", len(hostnames), " nodes and ", size, " processes, master node is ", MASTER_ADDR)print(">>> Training on ", size, " GPUs, master node is ", MASTER_ADDR)#print("- Process {} corresponds to GPU {} of node {}".format(rank, local_rank, NODE_ID))print("- Process {} corresponds to GPU {} of node {}".format(rank, local_rank, NODE_ID))# configure distribution method: define address and port of the master node and initialise communication backend (NCCL)#dist.init_process_group(backend='nccl', init_method='env://', world_size=size, rank=rank)dist.init_process_group(backend='nccl',init_method='tcp://{}:{}'.format(MASTER_ADDR, port),world_size=size,rank=rank)# distribute modeltorch.cuda.set_device(local_rank)gpu=torch.device("cuda")#model = ResNet18(classes=10).to(gpu)model=torchvision.models.resnet50(pretrained=False).to(gpu)ddp_model=DistributedDataParallel(model, device_ids=[local_rank])ifargs.checkpointisnotNone:map_location= {'cuda:%d'%0: 'cuda:%d'%local_rank}ddp_model.load_state_dict(torch.load(args.checkpoint, map_location=map_location))# distribute batch size (mini-batch)batch_size=args.batch_sizebatch_size_per_gpu=batch_size//size# define loss function (criterion) and optimizercriterion=nn.CrossEntropyLoss() optimizer=torch.optim.SGD(ddp_model.parameters(), 1e-4)transform_train=transforms.Compose([transforms.RandomCrop(32, padding=4),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),])# load data with distributed sampler#train_dataset = torchvision.datasets.CIFAR10(root='./data',# train=True,# transform=transform_train,# download=False)# load data with distributed samplertrain_dataset=torchvision.datasets.CIFAR10(root='./data',train=True,transform=transform_train,download=False)train_sampler=torch.utils.data.distributed.DistributedSampler(train_dataset,num_replicas=size,rank=rank)train_loader=torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size_per_gpu,shuffle=False,num_workers=0,pin_memory=True,sampler=train_sampler)# training (timers and display handled by process 0)ifrank==0: start=datetime.now() total_step=len(train_loader)forepochinrange(args.epochs):ifrank==0: start_dataload=time()fori, (images, labels) inenumerate(train_loader):# distribution of images and labels to all GPUsimages=images.to(gpu, non_blocking=True)labels=labels.to(gpu, non_blocking=True) ifrank==0: stop_dataload=time()ifrank==0: start_training=time()# forward passoutputs=ddp_model(images)loss=criterion(outputs, labels)# backward and optimizeoptimizer.zero_grad()loss.backward()optimizer.step()ifrank==0: stop_training=time() if (i+1) %10==0andrank==0:print('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}, Time data load: {:.3f}ms, Time training: {:.3f}ms'.format(epoch+1, args.epochs,i+1, total_step, loss.item(), (stop_dataload-start_dataload)*1000,(stop_training-start_training)*1000))ifrank==0: start_dataload=time()#Save checkpoint at every end of epochifrank==0:torch.save(ddp_model.state_dict(), './checkpoint/{}GPU_{}epoch.checkpoint'.format(size, epoch+1))ifrank==0:print(">>> Training complete in: "+str(datetime.now() -start))if__name__=='__main__':main()
代码将数据和模型分割到多个gpu上,并以分布式的方式更新模型。下面是代码的一些解释:
train(args, ddp_arg)有两个参数,args和ddp_arg,其中args是传递给脚本的命令行参数,ddp_arg包含分布式训练相关参数。
rank, local_rank, size, MASTER_ADDR, port, NODE_ID = ddp_arg:解包ddp_arg中分布式训练相关参数。
如果rank为0,则打印当前使用的gpu数量和主节点IP地址信息。
dist.init_process_group(backend=‘nccl’, init_method=‘tcp://{}:{}’.format(MASTER_ADDR, port), world_size=size, rank=rank) :使用NCCL后端初始化分布式进程组。
torch.cuda.set_device(local_rank):为这个进程选择指定的GPU。
model = torchvision.models. ResNet50 (pretrained=False).to(gpu):从torchvision模型中加载ResNet50模型,并将其移动到指定的gpu。
ddp_model = DistributedDataParallel(model, device_ids=[local_rank]):将模型包装在DistributedDataParallel模块中,也就是说这样我们就可以进行分布式训练了
加载CIFAR-10数据集并应用数据增强转换。
train_sampler=torch.utils.data.distributed.DistributedSampler(train_dataset,num_replicas=size,rank=rank):创建一个DistributedSampler对象,将数据集分割到多个gpu上。
train_loader =torch.utils.data.DataLoader(dataset=train_dataset,batch_size=batch_size_per_gpu,shuffle=False,num_workers=0,pin_memory=True,sampler=train_sampler):创建一个DataLoader对象,数据将批量加载到模型中,这与我们平常训练的步骤是一致的只不过是增加了一个分布式的数据采样DistributedSampler
为指定的epoch数训练模型,以分布式的方式使用optimizer.step()更新权重。
rank0在每个轮次结束时保存一个检查点。
rank0每10个批次显示损失和训练时间。
结束训练时打印训练模型所花费的总时间也是在rank0上。
代码测试
在使用1个节点1/2/3/4个gpu, 2个节点6/8个gpu,每个节点3/4个gpu上进行了训练Cifar10上的Resnet50的测试如下图所示,每次测试的批处理大小保持不变。完成每项测试所花费的时间以秒为单位记录。随着使用的gpu数量的增加,完成测试所需的时间会减少。当使用8个gpu时,需要320秒才能完成,这是记录中最快的时间。这是肯定的,但是我们可以看到训练的速度并没有像GPU数量增长呈现线性的增长,这可能是因为Resnet50算是一个比较小的模型了,并不需要进行并行化训练。

在多个gpu上使用数据并行可以显著减少在给定数据集上训练深度神经网络(DNN)所需的时间。随着gpu数量的增加,完成训练过程所需的时间减少,这表明DNN可以更有效地并行训练。
这种方法在处理大型数据集或复杂的DNN架构时特别有用。通过利用多个gpu,可以加快训练过程,实现更快的模型迭代和实验。但是需要注意的是,通过Data Parallelism实现的性能提升可能会受到通信开销和GPU内存限制等因素的限制,需要仔细调优才能获得最佳结果。
https://avoid.overfit.cn/post/67095b9014cb40888238b84fea17e872
作者:Joseph El Kettaneh
相关文章:
PyTorch 并行训练 DistributedDataParallel完整代码示例
使用大型数据集训练大型深度神经网络 (DNN) 的问题是深度学习领域的主要挑战。 随着 DNN 和数据集规模的增加,训练这些模型的计算和内存需求也会增加。 这使得在计算资源有限的单台机器上训练这些模型变得困难甚至不可能。 使用大型数据集训练大型 DNN 的一些主要挑…...

Golang实现ttl机制保存内存数据
ttl(time-to-live) 数据存活时间,我们这里指数据在内存中保存一段时间,超过期限则不能被读取到,与Redis的ttl机制类似。本文仅实现ttl部分,不考虑序列化和反序列化。 获取当前时间 涉及时间计算,这里首先介绍如何获取…...

js中数字运算结果与预期不一致的问题和解决方案
本文主要是和大家聊聊关于js中经常出现数字运算结果与预期结果不一致的问题,与及解决该问题的的方案。 一、问题现象 如:0.1 0.2的预期结果是0.3,但是在js中得到的计算结果却是0.30000000000000004,如下图所示 如:0…...
——基本类型)
C++ Primer Plus 学习笔记(一)——基本类型
字节与字符 计算机内存的基本单位是位(bit),字节(byte)通常指的是8位的内存单元,从这个意义上来说,字节指的就是描述计算机内存量的度量单位。 C对字节的定义则有些不同,C字节由至…...

ChatGpt与Google 谁能给出最好的回答
ChatGPT由于其先进的会话和技术功能而越来越受欢迎。你可以问聊天机器人任何你想问的问题,它会在几秒钟内输出答案。虽然它不是一个搜索引擎,你应该使用ChatGPT作为你的信息来源而不是谷歌,百度吗? 我们来根据国外的一场测试来看一下 ChatG…...

【Redis】一、CentOS64 安装 Redis
1.下载redis https://download.redis.io/releases/2.将 redis 安装包拷贝到 /opt/ 目录 最好自己创建一个文件夹 3.解压 tar -zvxf redis-6.2.1.tar.gz4. 安装gcc yum install gcc5. 进入目录 cd /opt/redis/redis-6.2.1/6. 编译 make7.执行 make install 进行安装 8. …...
Redis底层原理(持久化+分布式锁)
Redis底层原理 持久化 Redis虽然是个内存数据库,但是Redis支持RDB和AOF (Redis Database Backup file(Redis数据备份文件),也被叫做Redis数据快照。简单来说就是把内存中的所有数据都记录到磁盘中 ;Appen…...
Spring Cloud Nacos实战(八) - Nacos集群配置
Nacos集群配置 更改Nacos启动命令配置原理 我们现在知道,想要启动Naocs只需要启动startup.sh命令即可,但是如果启动3个Nacos那?所以如果我们需要启动多个Nacos,其实Nacos本身默认启动就是集群模式。 注意点:如果是l…...

什么是低代码-甲骨文对低代码的定义
什么是低代码平台?低代码阶段使用简化的界面,允许开发人员构建应用程序和软件 既用户友好又响应迅速。而不是编写几行复杂的代码和语言结构, 您可以快速轻松地利用低代码来构建具有用户界面的整体应用程序, 组合和信息。低代码可以…...

shell编程之循环语句
typora-copy-images-to: pictures typora-root-url: …\pictures 文章目录typora-copy-images-to: pictures typora-root-url: ..\..\pictures一、for循环语句1. for循环语法结构㈠ 列表循环㈡ 不带列表循环㈢ 类C风格的for循环2. 应用案例㈠ 脚本计算1-100奇数和① 思路② 落地…...

神经动力学-第一章-神经动力学基础-神经系统的元素
神经元和数学 本章的主要目的是介绍神经科学的几个基本概念,尤其是动作电位、突触后电位、触发阈值、不应期和适应性。基于这些概念,建立了神经元动力学的初步模型,这个简单的模型(漏积分-火模型)将作为本书主题——广义积分-火模型的起点和参考,在第二部分和第三部分进…...
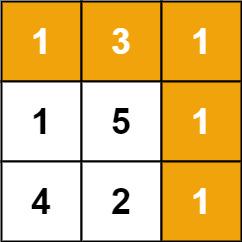
【力扣-LeetCode】64. 最小路径和 C++题解
64. 最小路径和难度中等1430收藏分享切换为英文接收动态反馈给定一个包含非负整数的 m x n 网格 grid ,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。说明:每次只能向下或者向右移动一步。示例 1:输入ÿ…...

Mysql数据库事务
数据库事务 数据库事务由一组sql语句组成。 所有sql语句执行成功则事务整体成功;任一条sql语句失败则事务整体失败,数据恢复到事务之前的状态。 Mysql 事务操作 开始事务 start transaction;- 或 begin;事务开始后,对数据的增删改操作不…...

【opencv源码解析0.3】调试opencv源码的两种方式
调试opencv源码的两种方式 上两篇我们分别讲了如何配置opencv环境,以及如何编译opencv源码方便我们阅读。但我们还是无法调试我们的代码,无法以我们的程序作为入口来一步一步单点调试看opencv是如何执行的。 【opencv源码解析0.1】VS如何优雅的配置ope…...
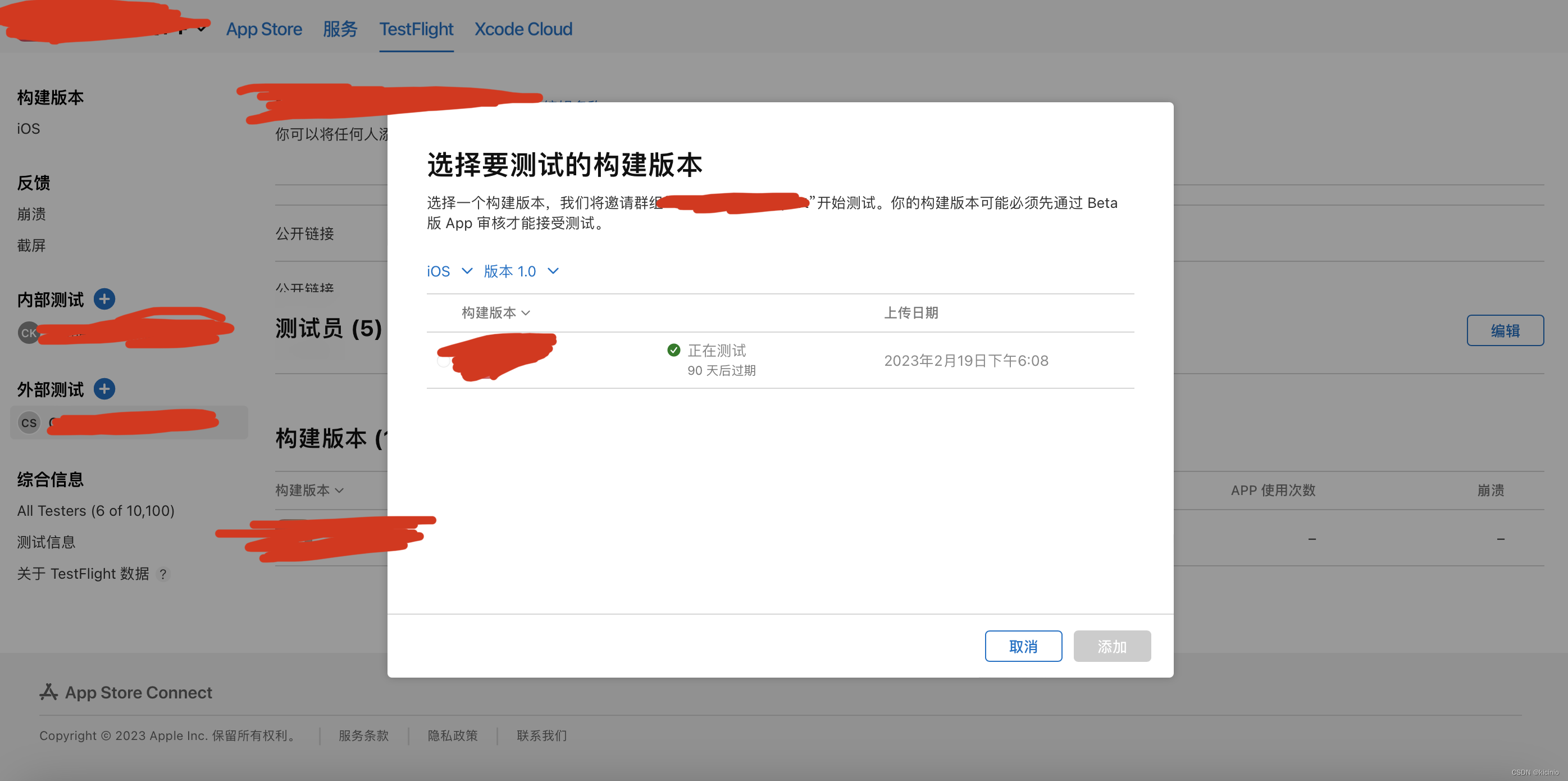
Xcode Archives打包上传 / 导出ipa 发布至TestFlight
Xcode自带的Archives工具可以傻瓜式上传到App Store Connect分发这里以分发到TestFlight为例进行操作。 环境:Xcode 14 一:Archives打包 选择Xcode菜单栏的Product,Archives选项,需要等待编译完成,进入如下界面&…...
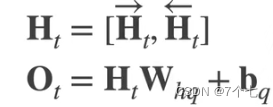
RNN GRU模型 LSTM模型图解笔记
RNN模型图解引用RNN模型GRULSTM深度RNN双向循环神经网络引用 动手学深度学习v2–李沐 LSTM长短期记忆网络3D模型–B站up梗直哥丶 RNN模型 加入了一个隐变量(状态),隐变量由上个隐变量和上一个输入而更新,这样模型就可以达到具有短期记忆的效…...
西电_数字信号处理二_学习笔记
文章目录【 第1章 离散随机信号 】【 第2章 维纳滤波 】【 第3章 卡尔曼滤波 】【 第4章 自适应滤波 】【 第5章 功率谱估计 】这是博主2022秋季所学数字信号处理二的思维导图(软件是幕布),供大家参考,如内容上有不妥之处…...
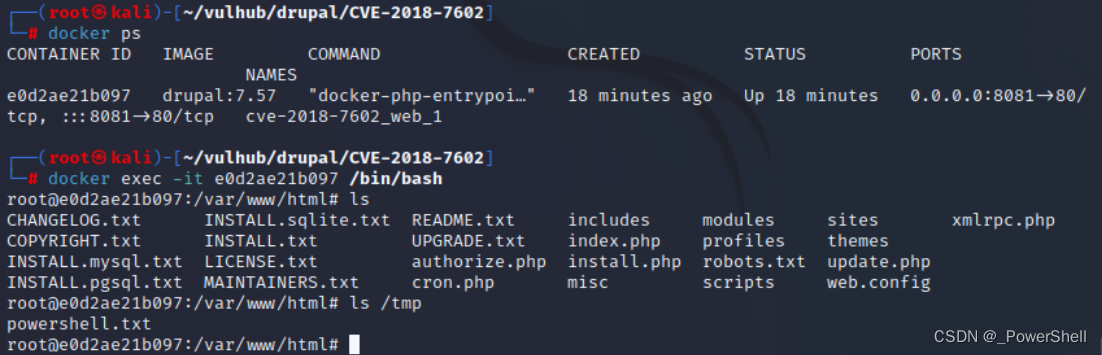
[ vulhub漏洞复现篇 ] Drupal 远程代码执行漏洞(CVE-2018-7602)
🍬 博主介绍 👨🎓 博主介绍:大家好,我是 _PowerShell ,很高兴认识大家~ ✨主攻领域:【渗透领域】【数据通信】 【通讯安全】 【web安全】【面试分析】 🎉点赞➕评论➕收藏 养成习…...
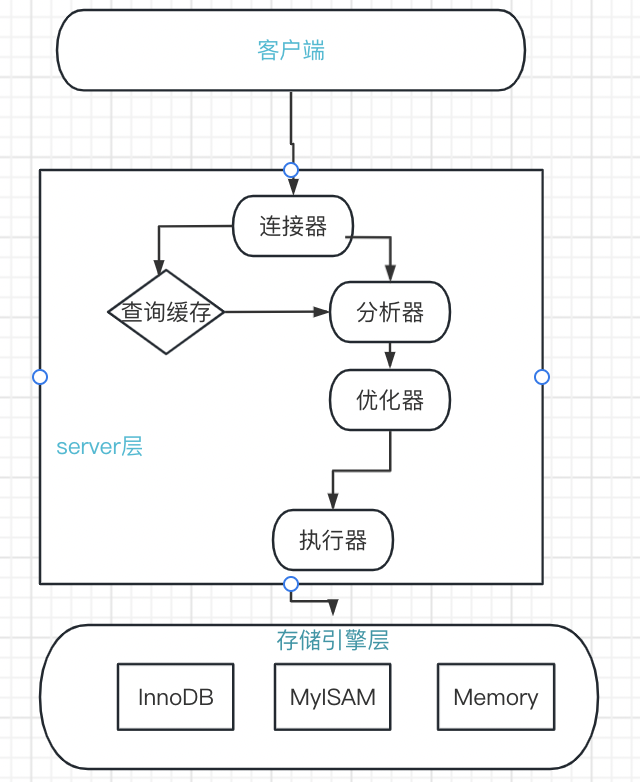
MySQL最佳实践
一、MySQL查询执行过程 1.MySQL分层结构 MySQL8.0没有查询缓存的功能了,如果频繁修改缓存,将会损耗性能查询流程就按照分层结构就可以清楚,只要了解各个组件的各自功能就行分析器主要分析语法和词法是否正确优化器主要优化SQL语句 二、MySQL更新执行过程 更新主要涉及两个重…...

Python 之 Matplotlib 散点图、箱线图和词云图
文章目录一、散点图1. scatter() 函数2. 设置图标大小3. 自定义点的颜色和透明度4. 可以选择不同的颜色条,配合 cmap 参数5. cmap 的分类5.1 Sequential colormaps:连续化色图5.2 Diverging colormaps:两端发散的色图 .5.3 Qualitative color…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

uniapp 字符包含的相关方法
在uniapp中,如果你想检查一个字符串是否包含另一个子字符串,你可以使用JavaScript中的includes()方法或者indexOf()方法。这两种方法都可以达到目的,但它们在处理方式和返回值上有所不同。 使用includes()方法 includes()方法用于判断一个字…...
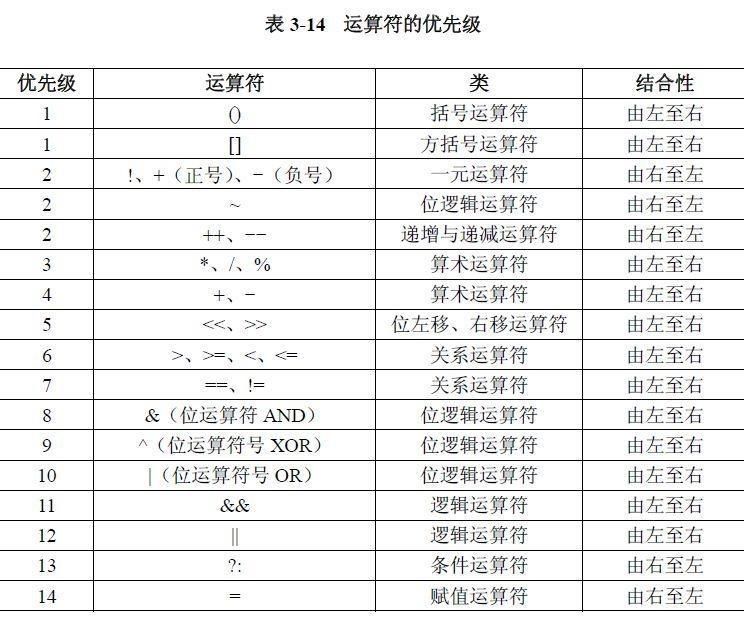
02.运算符
目录 什么是运算符 算术运算符 1.基本四则运算符 2.增量运算符 3.自增/自减运算符 关系运算符 逻辑运算符 &&:逻辑与 ||:逻辑或 !:逻辑非 短路求值 位运算符 按位与&: 按位或 | 按位取反~ …...
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡
何谓AI编程【02】AI编程官网以优雅草星云智控为例建设实践-完善顶部-建立各项子页-调整排版-优雅草卓伊凡 背景 我们以建设星云智控官网来做AI编程实践,很多人以为AI已经强大到不需要程序员了,其实不是,AI更加需要程序员,普通人…...
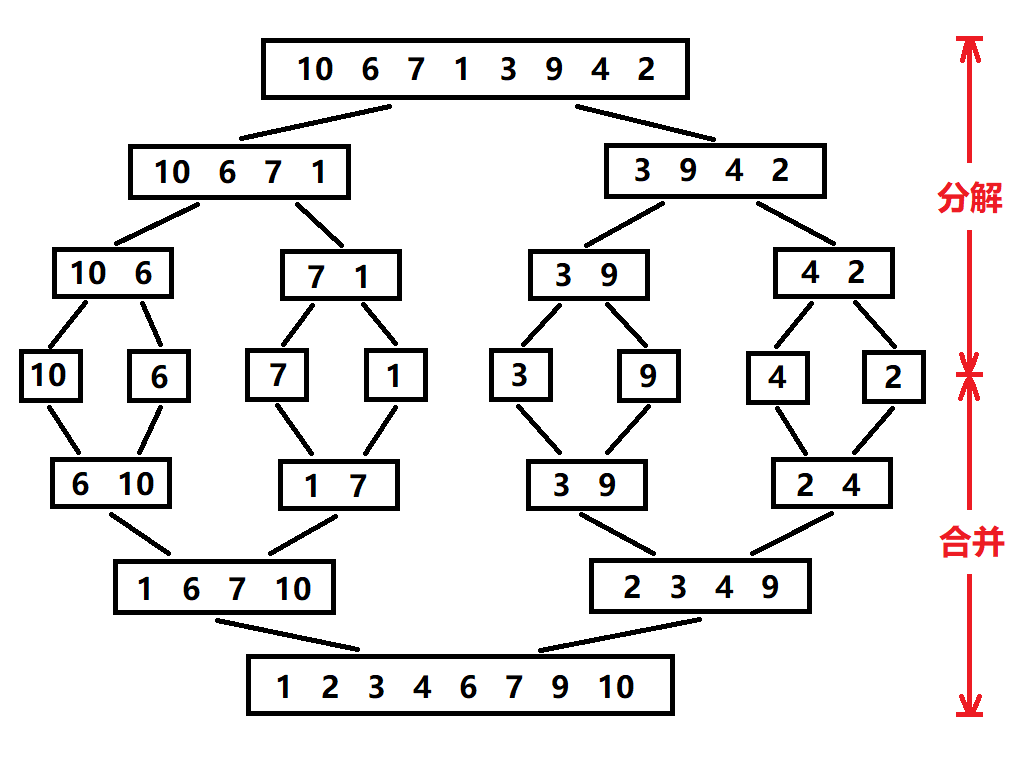
归并排序:分治思想的高效排序
目录 基本原理 流程图解 实现方法 递归实现 非递归实现 演示过程 时间复杂度 基本原理 归并排序(Merge Sort)是一种基于分治思想的排序算法,由约翰冯诺伊曼在1945年提出。其核心思想包括: 分割(Divide):将待排序数组递归地分成两个子…...
VSCode 使用CMake 构建 Qt 5 窗口程序
首先,目录结构如下图: 运行效果: cmake -B build cmake --build build 运行: windeployqt.exe F:\testQt5\build\Debug\app.exe main.cpp #include "mainwindow.h"#include <QAppli...

Docker、Wsl 打包迁移环境
电脑需要开启wsl2 可以使用wsl -v 查看当前的版本 wsl -v WSL 版本: 2.2.4.0 内核版本: 5.15.153.1-2 WSLg 版本: 1.0.61 MSRDC 版本: 1.2.5326 Direct3D 版本: 1.611.1-81528511 DXCore 版本: 10.0.2609…...

STM32 低功耗设计全攻略:PWR 模块原理 + 睡眠 / 停止 / 待机模式实战(串口 + 红外 + RTC 应用全解析)
文章目录 PWRPWR(电源控制模块)核心功能 电源框图上电复位和掉电复位可编程电压监测器低功耗模式模式选择睡眠模式停止模式待机模式 修改主频一、准备工作二、修改主频的核心步骤:宏定义配置三、程序流程:时钟配置函数解析四、注意…...

Unity基础-Mathf相关
Unity基础-Mathf相关 一、Mathf数学工具 概述 Mathf是Unity中封装好用于数学计算的工具结构体,提供了丰富的数学计算方法,特别适用于游戏开发场景。它是Unity开发中最常用的数学工具之一,能够帮助我们处理各种数学计算和插值运算。 Mathf…...

ubuuntu24.04 编译安装 PostgreSQL15.6+postgis 3.4.2 + pgrouting 3.6.0 +lz4
文章目录 下载基础包下载源码包编译 PG编译 postgis编译安装 pgrouting下载源码包配置编译参数编译安装 初始化数据库建表并检查列是否使用了 lz4 压缩算法检查 postgis 与 pgrouting 是否可以成功创建 下载基础包 sudo apt update && sudo apt upgrade -y sudo apt i…...