目标检测论文阅读:DETR算法笔记
标题:End-to-End Object Detection with Transformers
会议:ECCV2020
论文地址:https://link.springer.com/10.1007/978-3-030-58452-8_13
官方代码:https://github.com/facebookresearch/detr
作者单位:巴黎第九大学、Facebook AI
文章目录
- Abstract
- 1 Introduction
- 2 Related Work
- 2.1 Set Prediction
- 2.2 Transformers and Parallel Decoding
- 2.3 Object Detection
- 3 The DETR Model
- 3.1 Object Detection Set Prediction Loss
- 3.2 DETR Architecture
- 4 Experiments
- 4.1 Comparison with Faster R-CNN and RetinaNet
- 4.2 Ablations
- 4.3 DETR for Panoptic Segmentation
- 5 Conclusion
Abstract
我们提出了一种新的方法,将目标检测视为一个直接的集合预测问题。我们的方法简化了检测pipeline,有效地消除了许多手工设计的组件,如非极大值抑制过程或锚框生成,这些组件显式地编码了我们关于任务的先验知识。新框架,称为DEtection TRansformer或DETR,其主要成分是一个基于集合的全局损失,它通过二分图匹配强制进行唯一预测,以及一个transformer编码器-解码器结构。给定一个固定的学习到的目标query小型集合,DETR推理目标和全局图像上下文的关系,并行地直接输出最终的预测集合。与许多其它的现代探测器不同,这个新模型在概念上很简单,并且不需要专门的库。DETR在具有挑战性的COCO目标检测数据集上证明了与公认的、高度优化的Faster R-CNN基线相当的准确性和实时性能。此外,DETR可以很容易地扩展,以统一的方式产生全景分割。我们表明,它明显优于有竞争力的基线。
1 Introduction
目标检测的目标是为每个感兴趣的目标预测一组边界框和类别标签。现代检测器以间接的方式解决这个集合预测任务,通过在一个大的proposal、锚框或窗口中心集合上定义代理回归和分类问题。它们的性能在很大程度上受到后处理步骤的影响,这些步骤可以去除近似重复的预测,通过锚框集合的设计以及将目标框分配给锚框的启发式方法。为了简化这些pipeline,我们提出了一种直接的集合预测方法来绕过这些代理任务。这种端到端的思想导致了诸如机器翻译或语音识别等复杂结构化预测任务的重大进展,但在目标检测方面还没有:先前的尝试要么添加了其它形式的先验知识,要么在具有挑战性的基准测试上没有被证明和强大的基线相比具有竞争力。本文旨在弥补这一差距。
我们通过将目标检测视为直接的集合预测问题来简化训练pipeline。我们采用了基于transformers的编码器-解码器结构,这是一种流行的序列预测结构。transformers的自注意力机制显式地建模了序列中元素之间的所有成对交互,使得这些结构特别适用于集合预测的特定约束,例如删除重复预测。
我们的DEtection TRansformer(DETR,见图1)一次性预测所有目标,并使用一个集合损失函数进行端到端的训练,该损失函数在预测和真值目标之间执行二分图匹配。DETR通过删除多个手工设计的编码了先验知识的组件来简化检测pipeline,如空间锚框或非最大抑制。与大多数现有的检测方法不同,DETR不需要任何定制的层,因此可以很容易地在包含标准ResNet和Transformer类的任何框架中复现。
与以往大多数直接的集合预测工作相比,DETR的主要特点是二分图匹配损失和(非自回归)并行解码transformers的结合。相比之下,以前的工作主要集中在使用RNN的自回归解码。我们的匹配损失函数唯一地将一个预测分配给一个真值目标,并且对预测目标的排列是不变的,因此我们可以并行地输出它们。

我们在一个最流行的目标检测数据集COCO上评估了DETR,该数据集与一个非常有竞争力的Faster R-CNN基线相比。Faster R-CNN自最初发布以来,经历了多次设计迭代,性能得到了极大的提升。我们的实验表明,我们的新模型取得了相当的性能。更确切地说,DETR在大目标上表现出明显更好的性能,这可能是由于transformer的非局部计算所导致的。然而,它在小目标上的性能较低。我们期望未来的工作能够像FPN对Faster R-CNN的发展那样,在这一方面进行改进。
DETR的训练设置与标准的目标检测器有许多不同。新模型需要超长的训练时间,并且会从transformer中的辅助解码损失中获益。我们深入探究了哪些成分对演示的性能至关重要。
DETR的设计理念很容易扩展到更复杂的任务。在我们的实验中,我们展示了在预训练的DETR上训练的一个简单的分割头在全景分割上超过了具有竞争力的基线,全景分割是一个具有挑战性的像素级识别任务,最近得到了流行。
2 Related Work
我们的工作基于几个领域的先前工作:集合预测的二分图匹配损失、基于transformer的编码器-解码器结构、并行解码和目标检测方法。
2.1 Set Prediction
目前还没有典型的深度学习模型来直接预测集合。基本的集合预测任务是多标签分类,其一对多的基线方法不适用于元素之间存在潜在结构的检测等问题(即近似相同的框)。这些任务的第一个困难是避免近似重复(near-duplicates)。当前大多数检测器使用诸如非极大值抑制之类的后处理来解决此问题,但直接的集合预测是免后处理的(postprocessing-free)。它们需要全局推理方案来建模所有预测元素之间的交互,以避免冗余。对于恒定大小(constant-size)的集合预测,稠密全连接网络是足够的,但成本很高。一般的做法是使用循环神经网络等自回归序列模型。在所有情况下,损失函数都应该按照预测的排列保持不变。通常的解决方法是在匈牙利算法的基础上设计一个损失,在真值和预测之间找到一个二分图匹配。这实现了排列不变性(permutation-invariance),保证了每个目标元素具有独一无二的匹配。我们遵循二分图匹配的损失方法。然而,与大多数先前的工作不同,我们跳出自回归模型,使用具有并行解码的transformers。
2.2 Transformers and Parallel Decoding
Transformers是由Vaswani等人提出的一种新的基于注意力机制的机器翻译结构单元。注意力机制是指从整个输入序列中聚合信息的神经网络层。Transformers引入了自注意力层,类似于非局部神经网络,通过扫描序列的每个元素,并通过聚合来自整个序列的信息来更新它。基于注意力机制的模型的主要优点之一是它们的全局的计算和理想的内存,这使得它们在长序列上比RNNs更合适。在自然语言处理、语音处理和计算机视觉等诸多问题中,Transformers正在取代RNN。
Transformers最早用于自回归模型,沿用早期的序列到序列(sequence-to-sequence)模型,逐个产生输出token。然而,在音频、机器翻译、单词表示学习以及最近的语音识别领域,令人望而却步的推理代价(与输出长度成正比,且难以分批处理)导致了并行序列生成的发展。我们也结合了transformers和并行解码,以在计算成本和执行集合预测所需的全局计算能力之间进行适当的权衡。
2.3 Object Detection
大多数现代目标检测方法都是相对于一些初始猜测做出预测。两阶段检测器关于proposal的框进行预测,而单阶段方法则关于锚框或者一个可能的目标中心的网格进行预测。最近的工作证明,这些方法的最终性能在很大程度上取决于这些初始猜测的确切设置方式。在我们的模型中,我们可以移除这种手工制作的过程,并通过使用关于输入图像而不是关于锚框的绝对框预测来直接预测检测集合,从而简化检测过程。
基于集合的损失。 一些目标检测器使用了二分图匹配损失。然而,在这些早期的深度学习模型中,不同预测之间的关系仅用卷积层或全连接层建模,手工设计的NMS后处理可以提高它们的性能。最近的检测器结合NMS,使用真值和预测之间的非唯一分配(non-unique assignment)的规则。
可学习的NMS方法和关系网络通过注意力显式地建模了不同预测之间的关系。使用直接的集合损失,它们不需要任何后处理步骤。然而,这些方法使用了额外的手工制作的上下文特征,如建议框的坐标,以有效地建模检测之间的关系,而我们则寻找减少模型中编码的先验知识的解决方案。
循环检测器。 与我们的方法最接近的是用于目标检测和实例分割的端到端集合预测。与我们类似,他们使用基于CNN激活的编码器-解码器结构的二分图匹配损失直接生成一组边界框。然而,这些方法仅在小数据集上进行了评估,并没有与现代的基线相比。尤其它们是基于自回归模型(更准确地说是RNNs)的,所以它们没有利用最近的并行解码的transformers。
3 The DETR Model
在检测中,两个要素对于直接的集合预测是必不可少的:①一个集合预测损失,它迫使预测和真值框之间唯一地匹配;②一个(在单次传播内)预测一组目标并建模它们之间关系的结构。我们在图2中详细描述了我们的结构。

3.1 Object Detection Set Prediction Loss
DETR在通过解码器的单次传播中推理一个固定大小为NNN个预测的集合,其中NNN被设置为明显大于图像中典型的目标数。训练的主要困难之一是根据真值对预测目标(类别、位置、尺寸)进行评分。我们的损失在预测和真值目标之间产生一个最优的二分图匹配,然后优化特定目标(边界框)的损失。
用yyy表示目标的真值集合,y^={y^i}i=1N\hat{y}=\{\hat{y}_i\}_{i=1}^Ny^={y^i}i=1N表示NNN个预测的集合。假设NNN大于图像中目标的个数,我们将yyy也看作是一个大小为NNN的用∅\varnothing∅(没有目标)填充过的集合。为了在这两个集合之间找到一个二分图匹配,我们寻找一个损失最小的NNN个元素σ∈SN\sigma\in\mathfrak{S}_Nσ∈SN的排列:
σ^=argminσ∈SN∑iNLmatch(yi,y^σ(i))\hat{\sigma}=\underset{\sigma\in\mathfrak{S}_N}{\mathrm{arg~min}}\sum_i^N\mathcal{L}_{\mathrm{match}}(y_i,\hat{y}_{\sigma(i)}) σ^=σ∈SNarg mini∑NLmatch(yi,y^σ(i))其中,Lmatch(yi,y^σ(i))\mathcal{L}_{\mathrm{match}}(y_i,\hat{y}_{\sigma(i)})Lmatch(yi,y^σ(i))是真值yiy_iyi和索引为σ(i)\sigma(i)σ(i)的预测之间的成对匹配损失(pair-wise matching cost)。遵循之前的工作,这个最优分配是用匈牙利算法高效计算的。
匹配损失同时考虑了类别预测以及预测框和真值框的相似度。真值集合中的每个元素iii可以看作yi=(ci,bi)y_i=(c_i,b_i)yi=(ci,bi),其中,cic_ici是目标类别标签(可能会是∅\varnothing∅),bi∈[0,1]4b_i\in[0,1]^4bi∈[0,1]4是定义真值框中心坐标和其相对于图像尺寸高度和宽度的向量。对于索引为σ(i)\sigma(i)σ(i)的预测,我们定义类别cic_ici的概率为p^σ(i)(ci)\hat{p}_{\sigma(i)}(c_i)p^σ(i)(ci),预测框为b^σ(i)\hat{b}_{\sigma(i)}b^σ(i)。利用这些记号,我们定义Lmatch(yi,y^σ(i))\mathcal{L}_{\mathrm{match}}(y_i,\hat{y}_{\sigma(i)})Lmatch(yi,y^σ(i))为−I{ci≠∅}p^σ(i)(ci)+I{ci=∅}Lbox(bi,b^σ(i))-\mathbb{I}_{\{c_i\neq\varnothing\}}\hat{p}_{\sigma(i)}(c_i)+\mathbb{I}_{\{c_i=\varnothing\}}\mathcal{L}_{\mathrm{box}}(b_i,\hat{b}_{\sigma(i)})−I{ci=∅}p^σ(i)(ci)+I{ci=∅}Lbox(bi,b^σ(i))。
这种寻找匹配的过程与现代检测器中用于匹配proposal或anchor到真值目标的启发式分配规则具有相同的作用。主要区别在于,我们需要为没有重复、直接的集合预测找到一对一的匹配。
第二步是计算损失函数,即上一步中匹配到的所有对的匈牙利损失。我们定义的损失类似于常见目标检测器的损失,即一个类别预测的负对数似然和后面要定义的一个框损失Lbox(⋅,⋅)\mathcal{L}_{\mathrm{box}}(·,·)Lbox(⋅,⋅)的线性组合:
LHungarian(y,y^)=∑i=1N[−logp^σ^(i)(ci)+I{ci≠∅}Lbox(bi,b^σ^(i))\mathcal{L}_{\mathrm{Hungarian}}(y,\hat{y})=\sum_{i=1}^N[-\mathrm{log}~\hat{p}_{\hat{\sigma}(i)}(c_i)+\mathbb{I}_{\{c_i\neq\varnothing\}}\mathcal{L}_{\mathrm{box}}(b_i,\hat{b}_{\hat{\sigma}(i)}) LHungarian(y,y^)=i=1∑N[−log p^σ^(i)(ci)+I{ci=∅}Lbox(bi,b^σ^(i))。其中,σ^\hat{\sigma}σ^是第1步中计算的最优分配。在实际操作中,我们将ci=∅c_i=\varnothingci=∅时的对数概率项降权10倍来考虑类不平衡。这类似于Faster R-CNN在训练过程中通过二次抽样来平衡正负proposal。注意,一个目标和∅\varnothing∅之间的匹配成本并不取决于预测,这意味着在这种情况下,损失是一个常数。在匹配损失中,我们使用概率p^σ^(i)(ci)\hat{p}_{\hat{\sigma}(i)}(c_i)p^σ^(i)(ci)代替对数概率。这使得类别预测项与Lbox(⋅,⋅)\mathcal{L}_{\mathrm{box}}(·,·)Lbox(⋅,⋅)可以同单位度量,并且我们观察到了更好的实验性能。
边界框损失。 匹配成本和匈牙利损失的第二部分是Lbox(⋅,⋅)\mathcal{L}_{\mathrm{box}}(·,·)Lbox(⋅,⋅),它对边界框进行评分。不同于许多检测器关于一些初始猜测做框预测,我们直接进行框预测。这种方法在简化实现的同时,也带来了损失相对尺度的问题。最常用的ℓ1\ell_1ℓ1损失即使相对误差接近,对于小框和大框也会有不同的尺度。为了缓解这个问题,我们使用ℓ1\ell_1ℓ1损失和广义IoU损失的线性组合Liou(⋅,⋅)\mathcal{L}_{\mathrm{iou}}(·,·)Liou(⋅,⋅),它是尺度不变的。总的来说,我们的框损失Lbox(bi,b^σ(i))\mathcal{L}_{\mathrm{box}}(b_i,\hat{b}_{\sigma(i)})Lbox(bi,b^σ(i))定义为λiouLiou(bi,b^σ(i))+λL1∣∣bi−b^σ(i)∣∣1\lambda_{\mathrm{iou}}\mathcal{L}_{\mathrm{iou}}(b_i,\hat{b}_{\sigma(i)})+\lambda_{\mathrm{L1}}||b_i-\hat{b}_{\sigma(i)}||_1λiouLiou(bi,b^σ(i))+λL1∣∣bi−b^σ(i)∣∣1,其中λiou,λL1∈R\lambda_{\mathrm{iou}},\lambda_{\mathrm{L1}}\in\mathbb{R}λiou,λL1∈R是超参数。这两个损失通过batch内的目标数量进行归一化。
3.2 DETR Architecture
DETR的整体结构惊人地简单,如图2所示。它包含三个主要组成部分,我们将在下面描述:一个用于提取简练特征表示的CNN主干,一个编码器-解码器transformer,以及一个进行最终检测预测的简单前馈网络(feed forward network,FFN)。
与许多现代检测器不同,DETR可以在任何深度学习框架中实现,只要该框架提供了常见的CNN主干和transformer结构的实现,并且只需要仅仅几百行代码。在PyTorch中,DETR推理代码的实现可以少于50行。我们希望我们的方法的简洁性可以吸引新的研究人员加入检测界。
主干。 从初始图像ximg∈R3×H0×W0x_{\mathrm{img}}\in\mathbb{R}^{3×H_0×W_0}ximg∈R3×H0×W0(具有3个颜色通道。对输入图像进行批处理,使用足够的0来填充,保证它们都具有与该批里最大图像相同的维度(H0,W0)(H_0,W_0)(H0,W0))开始,一个传统的CNN主干生成一个较低分辨率的激活图f∈RC×H×Wf\in\mathbb{R}^{C×H×W}f∈RC×H×W。我们一般使用的取值为C=2048C=2048C=2048和H,W=H032,W032H,W=\frac{H_0}{32},\frac{W_0}{32}H,W=32H0,32W0。
Transformer编码器。 首先,一个1×1卷积将高层激活图fff的通道维度从CCC降低到较小的维度ddd。得到一个新的特征图z0∈Rd×H×Wz_0\in\mathbb{R}^{d×H×W}z0∈Rd×H×W。编码器期望一个序列作为输入,因此我们将z0z_0z0的空间维度压缩成一维,得到一个d×HWd×HWd×HW的特征图。每个编码器层都具有一个标准的结构,由一个多头自注意力模块和一个前馈网络(FFN)组成。由于Transformer结构是排列不变的,因此我们用固定的位置编码来补充它,这些位置编码被添加到每个注意力层的输入中。
Transformer解码器。 解码器遵循transformer的标准结构,使用多头自注意力和编码器-解码器注意力机制来转换大小为ddd的NNN个嵌入。与原始transformer不同的是,我们的模型在每个解码器层并行解码NNN个目标,而Vaswani等人使用自回归模型,一次只预测输出序列的一个元素。由于解码器也是排列不变的,所以NNN个输入嵌入必须不同才能产生不同的结果。这些输入嵌入是我们称为目标query的学习位置编码,类似于编码器,我们将它们添加到每个注意力层的输入中。解码器将这NNN个目标query转换为输出嵌入。然后通过前馈网络将它们独立地解码为框的坐标和类别标签,得到NNN个最终预测。利用这些嵌入(embeddings)的自注意力和编码器-解码器注意力,模型使用它们之间的成对关系对所有目标进行全局推理,同时能够使用整个图像作为上下文。
预测前馈网络(FFNs)。 最终的预测由一个具有ReLU激活函数和隐藏维数ddd的3层感知器和一个线性投影层计算。FFN预测关于输入图像的归一化中心坐标、框的高度和宽度,线性层使用softmax函数预测类别标签。由于我们预测了一个固定大小的NNN个边界框的集合,其中NNN通常远大于图像中感兴趣目标的实际数量,因此使用一个额外的特殊类别标签∅\varnothing∅表示在一个slot中没有检测到目标。这个类别起到了类似于标准目标检测方法中的“背景”类的作用。
辅助解码损失。 我们发现在训练过程中,解码器里使用辅助损失是有帮助的,特别是帮助模型输出正确的每个类别的目标个数。每个解码器层的输出用一个共享的layer-norm归一化,然后馈送给共享的预测头(分类和框预测)。然后我们像惯常一样应用匈牙利损失进行监督。
4 Experiments
介绍了数据集和技术细节。
4.1 Comparison with Faster R-CNN and RetinaNet

对比实验,提升主要来自大目标,小目标落后很多。具体的实验结论可以参照原文。
4.2 Ablations
编码器层数。 我们通过改变编码器层数来评估全局的图像级自注意力的重要性。在没有编码器层的情况下,整体AP下降了3.9个点,在大目标下降更明显,为6.0AP。我们猜测,通过使用全局场景推理,编码器对于分离物体是重要的。在图3中,我们可视化了训练好的模型的最后一个编码器层的注意力图,聚焦于图像中的几个点。编码器似乎已经分离了实例,这可能简化了解码器的目标提取和定位。

解码器层数。 我们在每个解码层之后施加辅助损失,因此,预测FFNs被有意地训练来预测每个解码层输出中的目标。我们通过评估在解码的每个阶段将要预测的目标来分析每个解码器层的重要性(图4)。每层后性能都有提高,第一层和最后一层之间总共有非常显著的+8.2/9.5AP提高。

DETR基于集合损失,在设计上不需要NMS。为了验证这一点,我们对每个解码器后的输出执行一个带有默认参数的标准NMS过程。NMS提高了第一个解码器的预测性能。这可以解释为transformer的单个解码层无法计算输出元素之间的任何交叉关系(cross-correlations),因此容易对同一目标进行多次预测。在第二层和后续层中,激活后的自注意力机制允许模型抑制重复预测。我们观察到NMS带来的改善随着深度的增加而减小。它在最后一层损害了AP,因为它错误地删除了真正的正预测。
与可视化编码器注意力类似,我们在图6中可视化了解码器注意力,为每个预测目标绘制不同颜色的注意力图。我们观察到解码器注意力是相当局部的,这意味着它主要关注目标的四肢,如头部或腿部。我们猜测编码器通过全局注意力分离出实例后,解码器只需要关注边缘来提取类别和目标边界。

FFN的重要性。 tranformers内部的FFN可以看作是1×1的卷积层,使得编码器类似于注意力增强卷积网络。我们尝试将其完全移除,只在transformer层留下注意力。通过将网络参数量从41.3M减少到28.7M,transformer只剩下10.8M,性能下降了2.3AP,从而得出FFN对于取得好的结果很重要。
位置编码的重要性。 在我们的模型中有两种位置编码:空间位置编码和输出位置编码(目标query)。我们用固定编码和可学习编码的各种组合进行实验,结果见附录。输出位置编码是必需的,不能被删除,所以我们在解码器输入传播一次,或者在每个解码器注意力层添加query。在第一个实验中,我们完全去除空间位置编码,并在输入传播输出位置编码,有趣的是,模型仍然达到了32AP以上,比基线损失了7.8AP。然后,在输入一次性传播固定的正弦空间位置编码和输出编码,正如原始的transformer一样,发现这比直接在注意力传播位置编码导致了1.4AP下降。传播给注意力的可学习空间编码也给出了类似的结果。令人惊讶的是,我们发现不在编码器中传播任何空间编码只会导致1.3AP的微小AP下降。当我们将编码传播给注意力时,它们是跨所有层共享的,并且输出编码(目标query)总是被学习的。
通过这些消融,我们得出结论,transformer里的组件:编码器中的全局自注意力、FFN、多个解码器层和位置编码,都对最终的目标检测性能有重要贡献。
不可见的实例数的泛化。 COCO中的一些类别在同一幅图像中的多个同类实例中没有得到很好的表示。例如,训练集中没有长颈鹿数量超过13只的图像。我们创建了一个合成图像来验证DETR(见图5)的泛化能力。我们的模型能够在明显不符合分布的图像上找到全部24只长颈鹿。本实验证实了每个目标query都不存在较强的类别专门性(class-specialization)。

4.3 DETR for Panoptic Segmentation
全景分割最近引起了计算机视觉界的广泛关注。类似于Faster R-CNN到Mask R-CNN的扩展,DETR可以通过在解码器输出上方添加一个掩码头进行自然地扩展。在本节中,我们证明了这样一个头部可以用来产生全景分割,以统一的方式处理stuff和thing类别。我们在COCO数据集的全景标注上进行了实验,该数据集除了80个thing类别外,还有53个stuff类别。
我们使用相同的配方,在COCO上训练DETR来预测stuff和thing类别周围的框。为了使训练成为可能,需要预测框,因为匈牙利匹配是使用框之间的距离计算的。我们还添加了一个掩码头,为每个预测框预测一个二进制掩码,如图7所示。它将每个目标的ransformer解码器的输出作为输入,并在编码器的输出上计算该嵌入的多头(有MMM个头)注意力分数,以小分辨率生成每个目标的MMM个注意力热图。为了进行最终的预测并提高分辨率,采用了类似FPN的结构。更多细节参见附录。掩码的最终分辨率为stride4,每个掩码使用DICE/F-1损失和Focal Loss独立监督。
掩码头可以联合训练,也可以分两步训练,即DETR只训练框,然后冻结所有权重,只训练25个epoch的掩码头。实验上,这两种方法给出了类似的结果,我们报告了使用后一种方法的结果,因为它的计算量较小。
为了预测最终的全景分割,我们只需在每个像素的掩码得分上使用一个argmax,并将相应的类别分配给结果掩码。这个过程保证了最终的掩码没有重叠,因此DETR不需要启发式步骤来对齐不同的掩码。


具体的训练细节和实验结论可以参照原文。
5 Conclusion
我们提出了DETR,一种新的基于transformers和二分图匹配损失的直接集合预测目标检测系统设计。该方法在具有挑战性的COCO数据集上取得了与最优的Faster R-CNN基线相当的结果。DETR实现简单,具有灵活的结构,易于扩展到全景分割,具有竞争性的结果。此外,它在大目标上取得了显著更好的性能,这可能是由于自注意力对全局信息的处理。
这种新的检测器设计也带来了新的挑战,特别是在小目标的训练、优化和性能方面。目前的检测器需要几年的改进来应对类似的问题,我们期望未来的工作能够成功地解决这些问题。
相关文章:
目标检测论文阅读:DETR算法笔记
标题:End-to-End Object Detection with Transformers 会议:ECCV2020 论文地址:https://link.springer.com/10.1007/978-3-030-58452-8_13 官方代码:https://github.com/facebookresearch/detr 作者单位:巴黎第九大学、…...

Golang sync.Once 源码浅析
本文分析了Golang sync.Once 源码,并由此引申,简单讨论了单例模式的实现、 atomic 包的作用和 Java volatile 的使用。 sync.Once 使用例子 sync.Once 用于保证一个函数只被调用一次。它可以用于实现单例模式。 有如下类型: type instanc…...
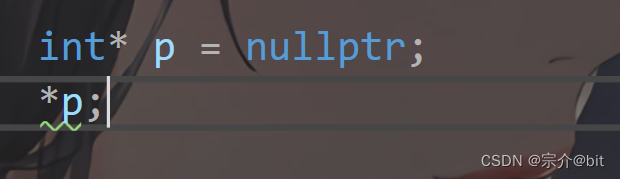
C++面向对象(上)
文章目录前言1.面向过程和面向对象初步认识2.引入类的概念1.概念与用法2.类的访问限定符及封装3.类的作用域和实例化4.类的大小计算5.this指针3.总结前言 本文将对C面向对象进行初步介绍,引入类和对象的概念。围绕类和对象介绍一些基础知识,为以后深入学…...

经常用但是不知道什么是BFC?
BFC学习 block formatting context 块级格式上下文 简单理解: 一个独立容器,内部布局不会受到外面的影响 形成条件: 1.浮动元素:float除none之外的值 2.绝对定位:position:absolute,fixed 3.display:inline-blo…...

GO的临时对象池sync.Pool
GO的临时对象池sync.Pool 文章目录GO的临时对象池sync.Pool一、临时对象池:sync.Pool1.1 临时对象的特点1.2 临时对象池的用途1.3 sync.Pool 的用法二、临时对象池中的值会被及时清理掉2.1 池清理函数2.2 池汇总列表2.3 临时对象池存储值所用的数据结构2.4 临时对象…...
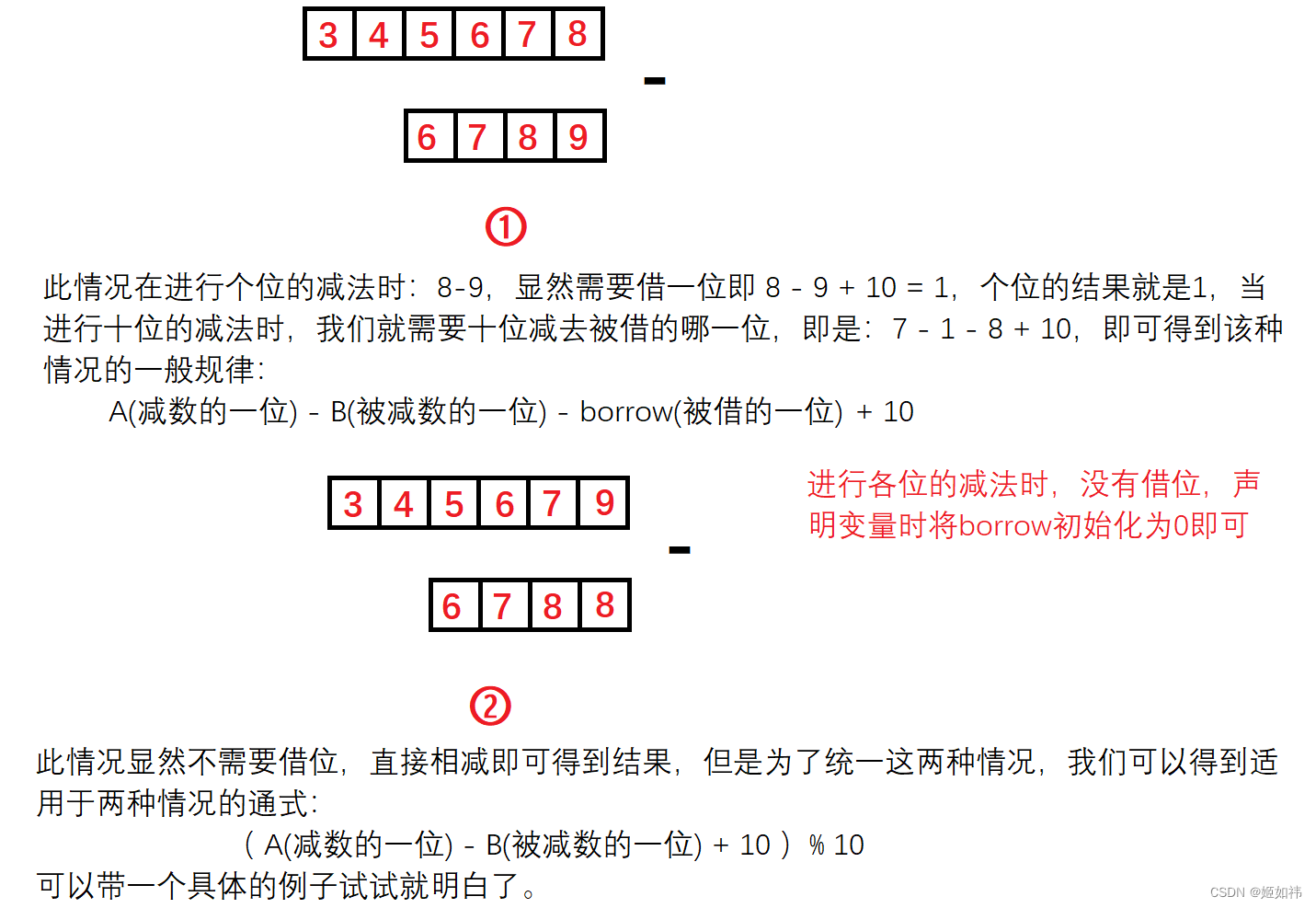
高精度算法一
目录 1. 基础知识 2. 大整数 大整数 3. 大整数 - 大整数 1. 基础知识 利用计算机进行数值计算,有时会遇到这样的问题:有些计算要求精度高,希望计算的数的位数可达几十位甚至几百位,虽然计算机的计算精度也算较高了,…...

2023年全国最新食品安全管理员精选真题及答案1
百分百题库提供食品安全管理员考试试题、食品安全员考试预测题、食品安全管理员考试真题、食品安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.预包装食品的标签内容应使用规范的汉字,但可以同时使用&a…...
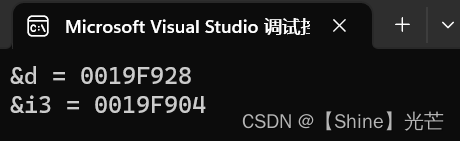
C++入门:引用
目录 一. 什么是引用 1.1 引用的概念 1.2 引用的定义 二. 引用的性质和用途 2.1 引用的三大主要性质 2.2 引用的主要应用 三. 引用的效率测试 3.1 传值调用和传引用调用的效率对比 3.2 值返回和引用返回的效率对比 四. 常引用 4.1 权限放大和权限缩小问题 4.2 跨…...
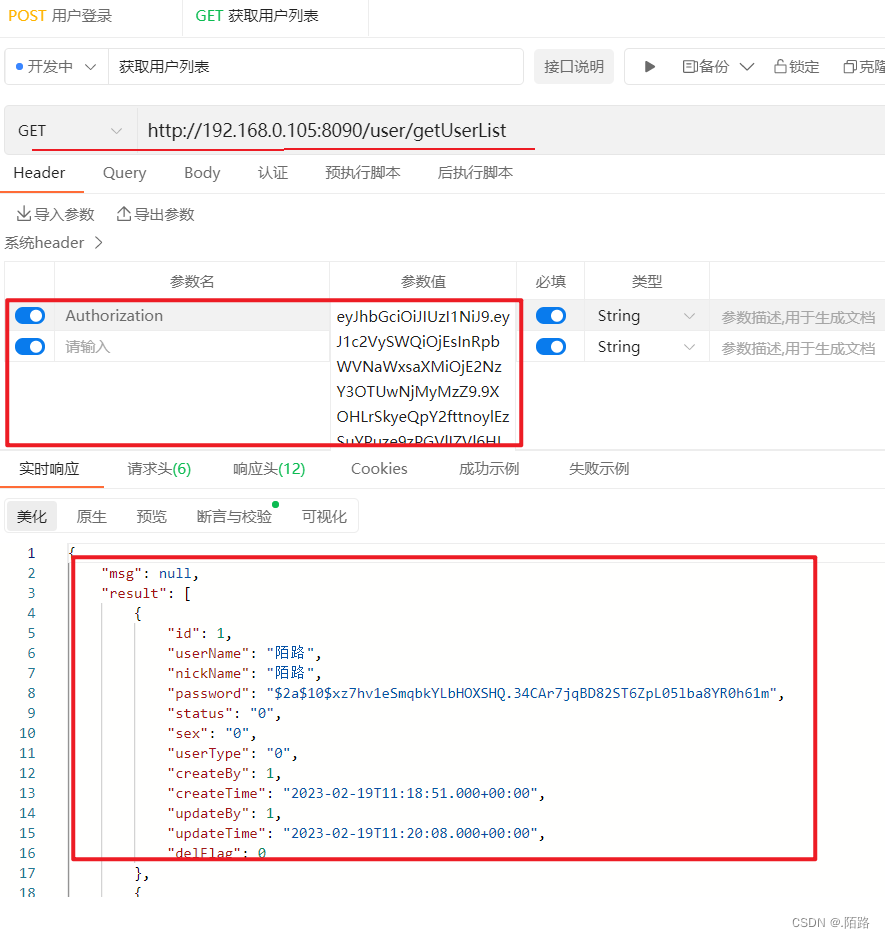
SpringSecurity的权限校验详解说明(附完整代码)
说明 SpringSecurity的权限校是基于SpringSecurity的安全认证的详解说明(附完整代码) (https://blog.csdn.net/qq_51076413/article/details/129102660)的讲解,如果不了解SpringSecurity是怎么认证,请先看下【SpringSecurity的安…...
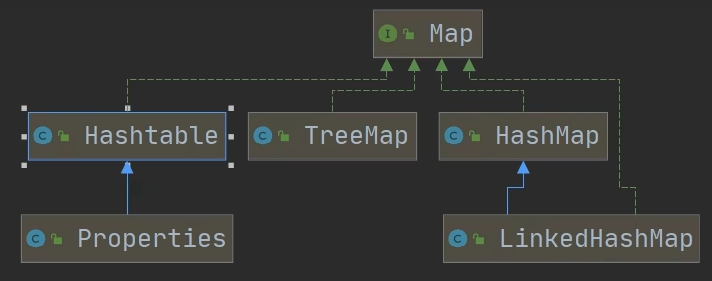
Java-集合(5)
Map接口 JDK8 Map接口实现子类的特点 Map和Collection是并列关系,Map用于保存具有映射关系的数据:Key-ValueMap中的key和value可以是任何引用类型的数据,会封装到HashMap$Node对象中Map中的key不允许重复,原因和HashSet一样Map…...
设计定型阶段)
研制过程评审活动(四)设计定型阶段
1、设计定型阶段主要任务 设计定型的主要任务是对武器装备性能和使用要求进行全面考核,以确认产品是否达到《研制任务书》和《研制合同》的要求。 设计定型阶段应最终确定《产品规范》、《工艺规范》和《材料规范》的正式版本,并形成正式的全套生产图样、有关技术文件及目…...
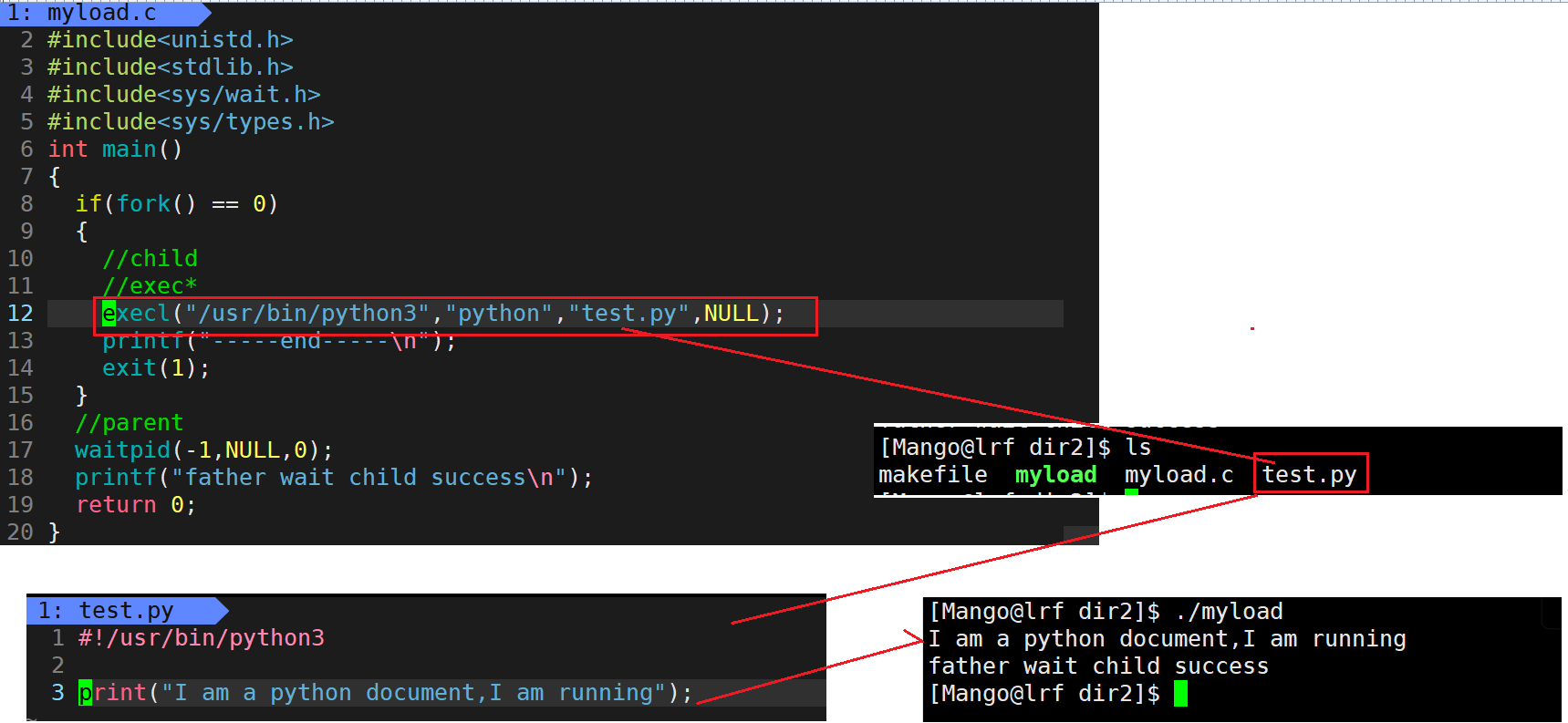
【Linux】进程替换
文章目录进程程序替换替换原理替换函数函数返回值函数命名理解在makefile文件中一次生成两个可执行文件总结:程序替换时运行其它语言程序进程程序替换 程序要运行要先加载到内存当中 , 如何做到? 加载器加载进来,然后程序替换 为什么? ->冯诺依曼 因为CPU读取数据的时候只…...

LeetCode171-Excel表列序号(进制转换问题)
LeetCode171-Excel表列序号1、问题描述2、解题思路:进制转换3、代码实现1、问题描述 给你一个字符串columnTitle,表示Excel表格中得列名称。返回该列名称对应得列序号。 例如: A -> 1 B -> 2 C -> 3 ... Z -> 26 AA -> 27 AB -> 28 …...
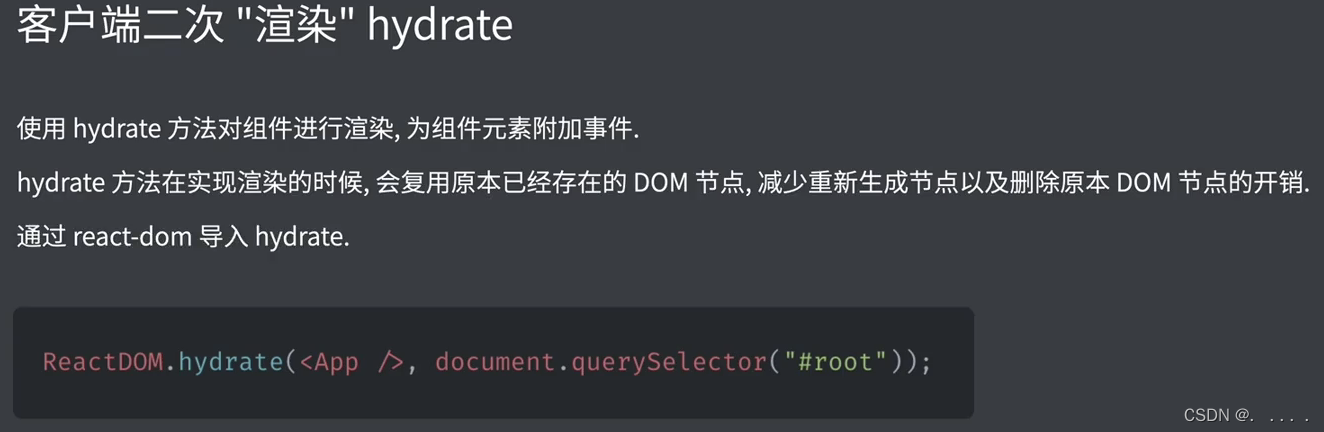
React SSR
ReactDOMServer 参考链接:https://zh-hans.reactjs.org/docs/react-dom-server.html ReactDOMServer 对象允许你将组件渲染成静态标记。通常,它被使用在 Node 服务端上 // ES modules import * as ReactDOMServer from react-dom/server; // CommonJS v…...

如何系统地优化页面性能
页面优化,其实就是要让页面更快地显示和响应。由于一个页面在它不同的阶段,所侧重的关注点是不一样的,所以如果要讨论页面优化,就要分析一个页面生存周期的不同阶段。 通常一个页面有三个阶段:加载阶段、交互阶段和关…...
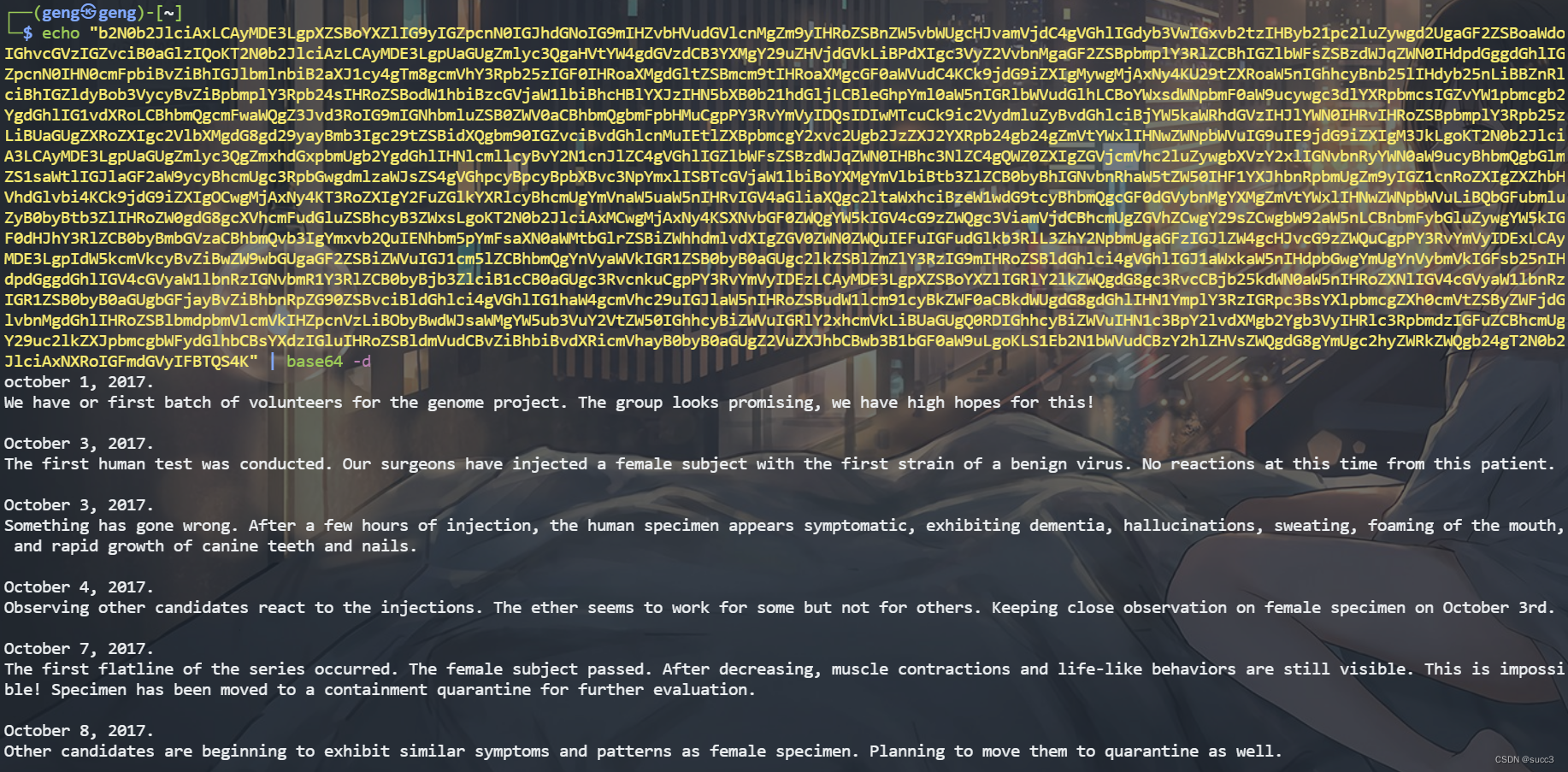
Vulnhub 渗透练习(八)—— THE ETHER: EVILSCIENCE
环境搭建 环境下载 靶机和攻击机网络适配都选 NAT 即可。 信息收集 主机扫描 两个端口,22 和 80,且 apache httpd 2.4.0~2.4.29 存在换行解析漏洞。 Apache HTTPD是一款HTTP服务器,它可以通过mod_php来运行PHP网页。其2.4.0~2.4.29版本中…...
| 代码+思路+重要知识点)
华为OD机试题 - 水仙花数 2(JavaScript)| 代码+思路+重要知识点
最近更新的博客 华为OD机试题 - 字符串加密(JavaScript) 华为OD机试题 - 字母消消乐(JavaScript) 华为OD机试题 - 字母计数(JavaScript) 华为OD机试题 - 整数分解(JavaScript) 华为OD机试题 - 单词反转(JavaScript) 使用说明 参加华为od机试,一定要注意不要完全背…...
字符设备驱动基础(二)
目录 一、五种IO模型------读写外设数据的方式 二、阻塞与非阻塞 三、多路复用 3.1 应用层:三套接口select、poll、epoll 3.2 驱动层:实现poll函数 四、信号驱动 4.1 应用层:信号注册fcntl 4.2 驱动层:实现fasync函数 一、…...
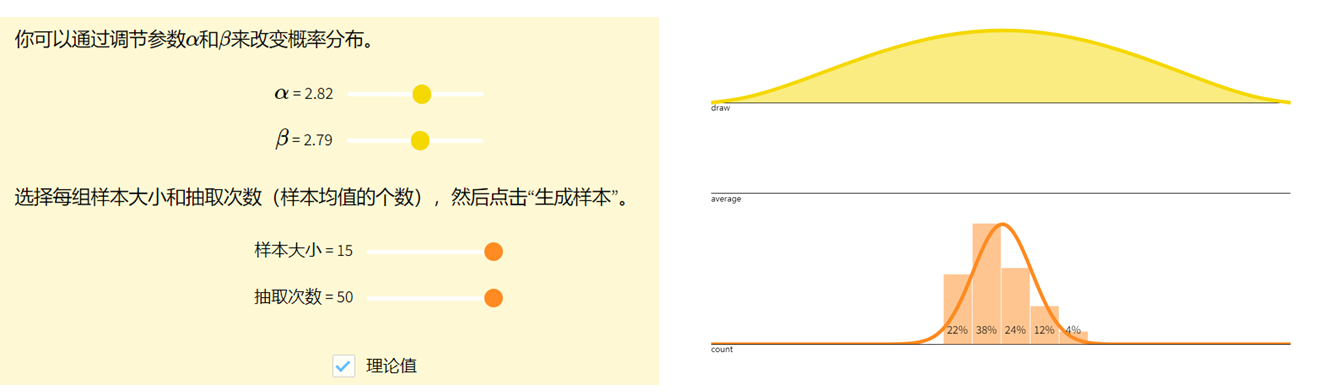
看见统计——第三章 概率分布
看见统计——第三章 概率分布 参考 https://github.com/seeingtheory/Seeing-Theory中心极限定理 概率分布描述了随机变量取值的规律。 随机变量Random Variables 🔥 定义:将样本空间中的结果映射到实数的函数 XXX 称为随机变量(random variable)&a…...
【基于众包标注的语文教材句子难易度评估研究 论文精读】
基于众包标注的语文教材句子难易度评估研究 论文精读信息摘 要0 引言1 相关研究2 众包标注方法3 语料库构建3.1 数据收集3.1 基于五点量表的专家标注3.3 基于成对比较的众包标注4 特征及模型4.1 特征抽取4.2 模型与实验设计4.2.1 任务一:单句绝对难度评估4.2.2 任务二:句对相对…...

剑指offer20_链表中环的入口节点
链表中环的入口节点 给定一个链表,若其中包含环,则输出环的入口节点。 若其中不包含环,则输出null。 数据范围 节点 val 值取值范围 [ 1 , 1000 ] [1,1000] [1,1000]。 节点 val 值各不相同。 链表长度 [ 0 , 500 ] [0,500] [0,500]。 …...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个生活电费的缴纳和查询小程序
一、项目初始化与配置 1. 创建项目 ohpm init harmony/utility-payment-app 2. 配置权限 // module.json5 {"requestPermissions": [{"name": "ohos.permission.INTERNET"},{"name": "ohos.permission.GET_NETWORK_INFO"…...

【C语言练习】080. 使用C语言实现简单的数据库操作
080. 使用C语言实现简单的数据库操作 080. 使用C语言实现简单的数据库操作使用原生APIODBC接口第三方库ORM框架文件模拟1. 安装SQLite2. 示例代码:使用SQLite创建数据库、表和插入数据3. 编译和运行4. 示例运行输出:5. 注意事项6. 总结080. 使用C语言实现简单的数据库操作 在…...

NXP S32K146 T-Box 携手 SD NAND(贴片式TF卡):驱动汽车智能革新的黄金组合
在汽车智能化的汹涌浪潮中,车辆不再仅仅是传统的交通工具,而是逐步演变为高度智能的移动终端。这一转变的核心支撑,来自于车内关键技术的深度融合与协同创新。车载远程信息处理盒(T-Box)方案:NXP S32K146 与…...

20个超级好用的 CSS 动画库
分享 20 个最佳 CSS 动画库。 它们中的大多数将生成纯 CSS 代码,而不需要任何外部库。 1.Animate.css 一个开箱即用型的跨浏览器动画库,可供你在项目中使用。 2.Magic Animations CSS3 一组简单的动画,可以包含在你的网页或应用项目中。 3.An…...

pycharm 设置环境出错
pycharm 设置环境出错 pycharm 新建项目,设置虚拟环境,出错 pycharm 出错 Cannot open Local Failed to start [powershell.exe, -NoExit, -ExecutionPolicy, Bypass, -File, C:\Program Files\JetBrains\PyCharm 2024.1.3\plugins\terminal\shell-int…...

Python网页自动化Selenium中文文档
1. 安装 1.1. 安装 Selenium Python bindings 提供了一个简单的API,让你使用Selenium WebDriver来编写功能/校验测试。 通过Selenium Python的API,你可以非常直观的使用Selenium WebDriver的所有功能。 Selenium Python bindings 使用非常简洁方便的A…...

Sklearn 机器学习 缺失值处理 获取填充失值的统计值
💖亲爱的技术爱好者们,热烈欢迎来到 Kant2048 的博客!我是 Thomas Kant,很开心能在CSDN上与你们相遇~💖 本博客的精华专栏: 【自动化测试】 【测试经验】 【人工智能】 【Python】 使用 Scikit-learn 处理缺失值并提取填充统计信息的完整指南 在机器学习项目中,数据清…...
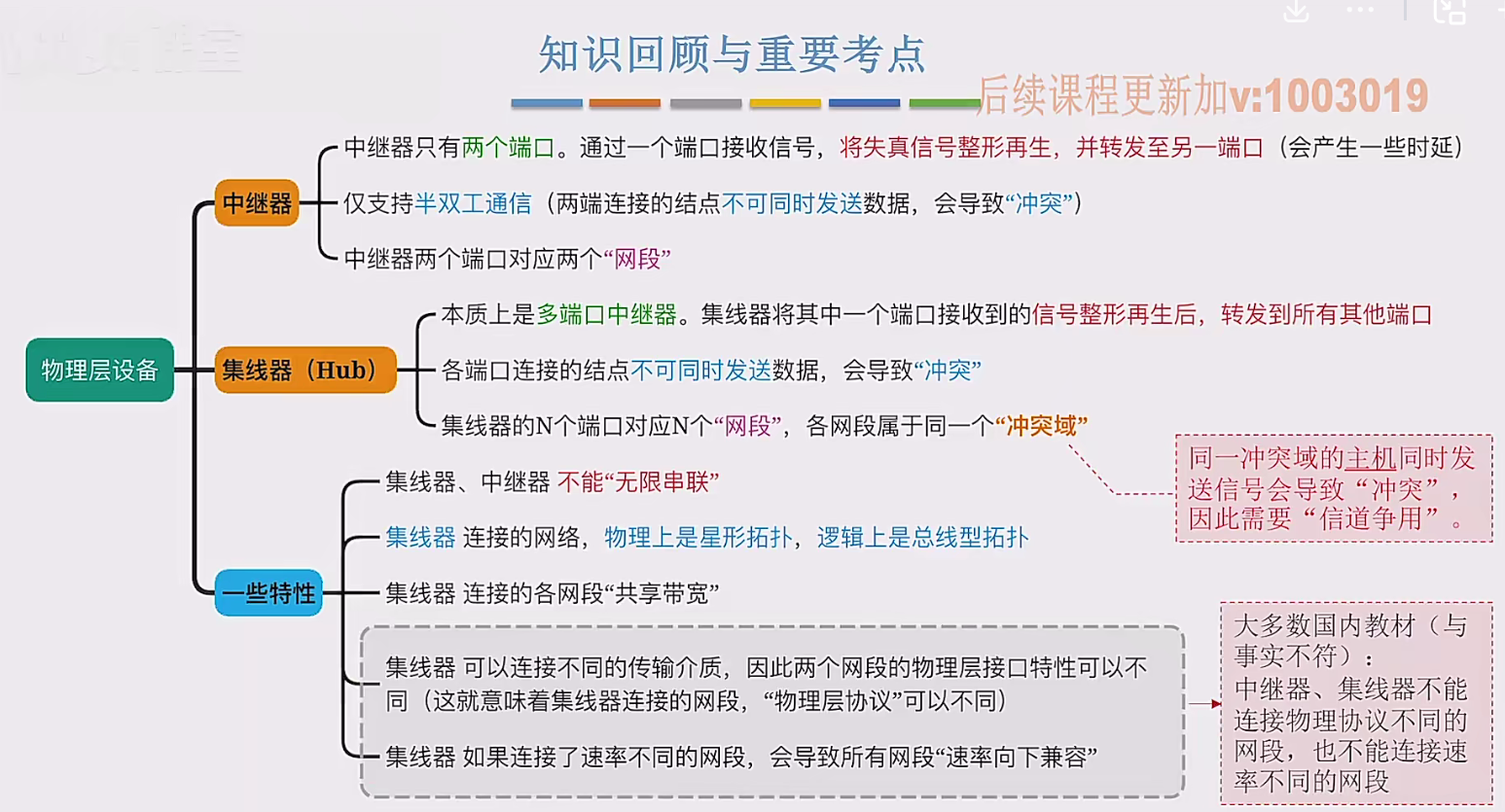
2.3 物理层设备
在这个视频中,我们要学习工作在物理层的两种网络设备,分别是中继器和集线器。首先来看中继器。在计算机网络中两个节点之间,需要通过物理传输媒体或者说物理传输介质进行连接。像同轴电缆、双绞线就是典型的传输介质,假设A节点要给…...
CSS3相关知识点
CSS3相关知识点 CSS3私有前缀私有前缀私有前缀存在的意义常见浏览器的私有前缀 CSS3基本语法CSS3 新增长度单位CSS3 新增颜色设置方式CSS3 新增选择器CSS3 新增盒模型相关属性box-sizing 怪异盒模型resize调整盒子大小box-shadow 盒子阴影opacity 不透明度 CSS3 新增背景属性ba…...