Flask框架学习记录
Flask项目简要
项目大致结构
flaskDemo1
├─static
├─templates
└─app.py
app.py
# 从flask这个包中导入Flask类
from flask import Flask# 使用Flask类创建一个app对象
# __name__:代表当前app.py这个模块
# 1.以后出现bug,可以帮助快速定位
# 2.对于寻找模板文件,有一个相对路径
app = Flask(__name__)# 创建一个路由和视图函数的映射
@app.route('/')
def hello_world():return 'https://blog.csdn.net/m0_61465701?type=blog'if __name__ == '__main__':app.run()运行结果:
FLASK_APP = app.py
FLASK_ENV = development
FLASK_DEBUG = 0
In folder E:/PyCharmProject/flaskDemo1
E:\SoftwareFile\anaconda\python.exe -m flask run * Serving Flask app "app.py"* Environment: development* Debug mode: off* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
可以进入网站查看效果。
debug模式
开启debug模式后
- 只要修改代码后保存,就会自动重新加载,不需要手动重启项目。
- 在浏览器上就可以看到出错信息。
开启:
点击Edit Configurations… , 再勾选Configuration下的FLASK_DEBUG选项,点击OK。
社区版:修改代码
app.run(debug=True)
修改代码后,ctrl+s保存后就会自动重新加载。
* Detected change in 'E:\\PyCharmProject\\flaskDemo1\\app.py', reloading* Restarting with watchdog (windowsapi)* Debugger is active!* Debugger PIN: 296-639-520* Running on http://127.0.0.1:5000/ (Press CTRL+C to quit)
修改host
主要作用:就是让其他电脑能访问到自己电脑上的flask项目
点击Edit Configurations… , 在Configuration下的Additional options中填写即可
--host=0.0.0.0 //可以写自己电脑的ip地址
// 0.0.0.0别人可以访问你电脑上的
修改port端口号
点击Edit Configurations… , 在Configuration下的Additional options中填写
--host=0.0.0.0 --port=8000
URL与视图的映射
url: http[80]/https[443]://www.xxx.com:443/path (冒号应为英文的:)
url与视图更准确来说是path与视图,只有path部分是需要自己现在编写的。
绝大部分网站都不可能只有首页一个页面,我们在制作网站的时候,需要定义许多不同的URL来满足需求,而URL总体上来讲又分为两种,第一种是无参数的,第二种是有参数的。
定义无参URL
无参URL是在URL定义的过程中,不需要定义参数。
可以使用以下代码实现。
@app.route('/2')
def stage2():return 'stage2'@app.route('/3/abc')
def stage3():return 'stage3--abc'
注意:我们说的访问/path是不包含域名和端口号的,真正在浏览器中访问应该在前面加上域名和端口号,比如在本地开发应该为http://127.0.0.1:5000/path ,下文说的URL都是省略了域名和端口号。
定义带有参数的URL
很多时候,我们在访问某个URL的时候,需要携带一些参数过去。
比如获取博客详情,就需要把博客的id传过去,那么博客详情的URL可能为:/blog/13,其中13为博客的id。比如获取第10页的博客列表,那么博客列表的URL可能为: /blog/list/10,其中10为页码。
在Flask中,如果URL中携带了参数,那么视图函数也必须定义相应的形参来接收URL中的参数。
@app.route('/test/<int:num>')
def show(num):return "num=%s" % num
可以看到,URL中多了一对尖括号,并且尖括号中多了一个num,这个 num就是参数。然后在视图函数 show中,也相应定义了一个num的形参,当浏览器访问这个URL的时候,Flask接收到请求后,会自动解析URL中的参数 num,然后把他传给视图函数 show,在视图函数中,开发者就可以根据这个num,从数据库中查找到具体的数据,返回给浏览器。
参数类型可以不指定。
URL中的参数可以指定以下类型
| 参数类型 | 描述 |
|---|---|
| string | 字符串类型。可以接受除/以外的字符 |
| int | 整型。可以接受通过int()方法转换的字符 |
| float | 浮点类型。以接受通过float()方法转换的字符 |
| path | 路径。类似string,但是中间可以添加/。 |
| uuid | UUID类型。UUID是一组由32位数的16进制所构成。 |
| any | 备选值中的任何一个。 |
比较特殊的any举例:
@app.route('/<any(a,b,c):s>')
def show2(s):return "str=%s" % s
查询字符串的方式传参
from flask import Flask,request...@app.route('/num1')
def show3():# arguments:参数# request.args:类字典类型num = request.args.get("num",default=555,type=int)return f"num={num}"
在浏览器访问http://127.0.0.1:5000/num1 结果为
num=555
在浏览器访问http://127.0.0.1:5000/num1?num=123结果为
num=123
Jinja2模板
在Flask中,渲染HTML通常会交给模板引擎来做,而Flask中默认配套的模板引擎是Jinja2,Jinja2的作者也是Flask的作者,Jinja2可以独立于Flask使用,比如被Django使用。Jinja2是一个高效、可扩展的模板引擎。
模板渲染
在templates下新建一个html文件,index.html
<!--html 5的标签-->
<!DOCTYPE html>
<html lang="en">
<head><!--页面的字符集--><meta charset="UTF-8"><title>标题</title>
</head>
<body><h1>标题 h1</h1>
<hr><p>HTML 是一门语言,所有的网页都是有HTML这门语言编写出来的。<br>HTML 是一门语言,所有的网页都是有HTML这门语言编写出来的。
</p></body>
</html>
然后修改app.py中的代码
from flask import Flask,request,render_templateapp = Flask(__name__)@app.route('/test1')
def test1():return render_template("index.html")if __name__ == '__main__':app.run(debug=True)渲染变量
html文件:
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>博客详情</title>
</head>
<body><h1>用户名:{{ username }}</h1>
<h1>访问的博客详情是:{{ blog_id }}</h1></body>
</html>
修改app.py:
@app.route('/blog/<blog_id>')
def blog_detail(blog_id):return render_template("blog_detail.html",blog_id=blog_id,username='Xiaoming')模板访问对象属性
类
index.html:
<!--html 5的标签-->
<!DOCTYPE html>
<html lang="en">
<head><!--页面的字符集--><meta charset="UTF-8"><title>标题</title>
</head>
<body><h1>用户名/邮箱</h1><h2>{{ user.username }}/{{ user.email }}</h2></body>
</html>
app.py:
app = Flask(__name__)class User:def __init__(self,username,email):self.username = usernameself.email = email@app.route('/test2')
def test2():user = User(username="Xiaoming",email="2023@qq.com")return render_template("index.html",user=user)
字典
index.html:
<h1>用户名/邮箱</h1><div>{{ user.username }}/{{ user.email }}</div><div>{{ person['username'] }}/{{ person.email }}</div>
app.py:
app = Flask(__name__)class User:def __init__(self,username,email):self.username = usernameself.email = email@app.route('/test2')
def test2():user = User(username="Xiaoming",email="2023@qq.com")person = {"username":"Wang Xiaoming","email":"2009@qq.com"}return render_template("index.html",user=user,person=person)过滤器的使用
在Python中,如果需要对某个变量进行处理。我们可以通过函数来实现。在模板中,我们则是通过过滤器来实现的。过滤器本质上也是函数。但是在模板中使用的方式是通过管道符号|来调用的。
例如有个字符串类型变赋 name。想要获取他的长度。则可以通过{{ name |length}}来获收。Jinja2会把name当傲第一个参数传给 length过滤器底层对应的函数。
新建filter.html文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>过滤器使用</title>
</head>
<body>{{ user.username }}-长度为:{{ user.username|length }}
<br>
{{ user.email }}-长度为:{{ user.email|length }}</body>
</html>
修改app.py
@app.route('/filter')
def filter_demo():user = User(username="Zhang",email="1999@qq.com")return render_template("filter.html",user=user)一些过滤器
-
abs(value):返回一个数值的绝对值,例如
{{ -1|abs }}。如果给的参数类型不为数字,就会报错。 -
default(value,default_value,boolean=False):如果value没有定义,则返回第二个参数default_value。如果想要让 value在被判断为False的情况下(传入
'',[],None,{}这些值的时候)使用default_value,则应该将后面的boolean参数设置为True。 -
escape(value):将一些特殊字符,比如:&,<,>,",'进行转义。因为Jinja2默认开启了全局转义,所以在大部分情况下无需手动使用这个过滤器去转义,只有在关闭转义的情况下会需要使用。
-
first(value): 返回序列的第一个元素
- 如果是一个字典,那么返回的是
key的值
- 如果是一个字典,那么返回的是
-
last(value): 返回序列的最后一个元素
-
format(value,*args,**kwargs): 格式化字符窜,和python中写法是一样的。
{{ "%s/%s"|format("username","email") }} -
join(value,d=’’): 将一个序列用d这个参数的值拼接成字符串
num=[1,2,3,4]{{ num|join('-') }}结果: 1-2-3-4
自定义过滤器
如果内置过滤器不满足需求,我们还可以自定义过滤器。
过滤器本质上是 Python的函数,他会把被过滤的值当做第一个参数传给这个函数,函数经过一些逻辑处理后,再返回新的值。在过滤器函数写好后,可以通过@app.template_ filter装饰器或者是 app.add_template_filter 函数来把函数注册成Jinja2能用的过滤器。
def add_string(value, mystr):return value+mystrapp.add_template_filter(add_string,"addstring")
其中第一个参数是需要被处理的值,然后通过app.add_template_filter,将函数注册成了过滤器,并且这个过滤器的名字,叫做addstring。那么以后在模板文件中,就可以使用了:
{{ user.username|addstring("hhhh") }}
如果app.add_template_filter没有传第二个参数,那么默认将使用函数的名称,来作为过滤器的名称。
app.add_template_filter(add_string)
{{ user.username|add_string("hhhh") }}
控制语句
if语句
Jinja2中的if语句和Python中的if语句非常的类似。可以使用>、<、>=、<=、==、!=来进行判断,也可以通过and、or、not来进行逻辑操作。
control.html
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>控制语句</title>
</head>
<body>
{% if a > 20 %}<div>a的值大于20</div>
{% elif a == 20%}<div>a的值等于20</div>
{% else %}<div>a的值小于20</div>
{% endif %}
</body>
</html>
app.py
@app.route('/control')
def control_statement():a = 22return render_template("control.html",a = a)
for循环
Jinja2中的 for循环与Python中的 for 循环也是非常类似的,只是比 Python中的 for 循环多一个endfor 代码块。
不存在break语句。
control.html
{% for person in persons %}<div>name:{{ person.name }},hobby:{{ person.hobby }}</div>
{% endfor %}
app.py
@app.route('/control')
def control_statement():a = 22persons = [{"name":"Xiaoming","hobby":"baseball"},{"name":"Xiaofang","hobby":"basketball"}]return render_template("control.html",a = a,persons = persons)
模板继承
一个网站中,大部分网页的模块是重复的,比如顶部的导航栏,底部的备案信息。如果在每个页面中都重复的去写这些代码,会让项目变得臃肿,提高后期维护成本。比较好的做法是,通过模板继承,把一些重复性的代码写在父模板中,子模板继承父模板后,再分别实现自己页面的代码。
新建一个base.html作为父模板
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>{% block title %}{% endblock %}</title>
</head>
<body>
<ul><li><a href="#">首页</a></li><li><a href="#">其他</a></li>
</ul><p>父模板的文字</p>
{% block body %}
{% endblock %}
<footer>底部标签</footer>
</body>
</html>
以上父模板中,编写好了网页的整体结构。然后针对子模板需要重写的地方,则定义成了block,比如以上定义了title、body这两个block,子模板在继承了父模板后,重写对应 block 的代码,即可完成子模板的渲染。
编写一个child1.html
{% extends "base.html" %}{% block title %}child1标题
{% endblock %}{% block body %}<p>子模版child1的部分</p>
{% endblock %}
app.py:
@app.route("/child1")
def child1():return render_template("child1.html")
加载静态文件
一个网页中,除了HTML代码以外,还需要CSS、JavaScript 和图片文件才能更加美观和实用。静态文件默认是存放到当前项目的static文件夹中,如果想要修改静态文件存放路径,可以在创建Flask对象的时候,设置static_folder 参数。
app = Flask(__name__,static_folder='C:\\Users\\Xu\\Desktop\\static')
在模板文件中,可以通过url_for加载静态文件,示例代码如下。
<link rel="stylesheet" href="{{ url_for('static',filename='style.css') }}">
第一个参数static是一个固定的,表示构建Flask 内置的static视图这个URL,第二个filename 是可以传递文件名或者文件路径,路径是相对于static或者static_folder参数自定义的路径。以上代码在被模板渲染后,会被解析成:
<link href="/static/style.css">
新建一个style.css文件
body{background: antiquewhite;
}
新建一个jstest.js文件
alert("it is js")
新建一个static.html文件
<!DOCTYPE html>
<html lang="en">
<head><meta charset="UTF-8"><title>加载静态文件</title><link rel="stylesheet" href="{{ url_for('static',filename='css/style.css') }}"></head>
<body>
<img src="{{ url_for('static',filename='images/city.png') }}" alt="">
<script src="{{ url_for('static',filename='js/jstest.js') }}">
</script>
</body>
</html>
修改app.py
@app.route("/static")
def static_demo():return render_template("static.html")
数据库
数据库是一个动态网站必备的基础功能。通过使用数据库,数据可以被动态的展示、修改、删除等,极大的提高了数据管理能力,以及数据传递的效率。
Flask想要操作数据库,必须要先安装Python操作 MySQL的驱动。在Python中,目前有以下MySQL驱动包。
-
MySQL-python:也就是 MySQLdb。是对C语言操作 MySQL数据库的一个简单封装。遵循了Python DB·API v2。但是只支持Python2。
-
mysqIclient:是 MySQL-python的另外一个分支。支持Python3并且修复了一些bug,是目前为止执行效率最高的驱动,但是安装的时候容易因为环境问题出错。
-
pymysql:纯 Python实现的一个驱动。因为是纯 Python编写的,因此执行效率不如 mysqlclient。也正因为是纯 Python写的,因此可以和Python代码无缝衔接。
-
mysql-connector-python: MySQL官方推出的纯 Python连接MySQL 的驱动,执行效率比pymysql 还慢。
这里我们用的是pymysql
通过以下命令安装。
pip install pymysql
在Flask中,我们很少会使用pymysql直接写原生SQL语句去操作数据库,更多的是通过SQLAlchemy提供的ORM技术,类似于操作普通Python对象一样实现数据库的增删改查操作,而 Flask-SQLAlchemy是对 SQLAIchemy的一个封装,使得在Flask中使用SQLAlchemy更加方便。
Flask-SQLAlchemy是需要单独安装,因为Flask-SQLAlchemy依赖SQLAlchemy,所以只要安装了Flask-SQLAlchemy,sQLAlchemy会自动安装。安装命令如下。
pip install flask-sqlalchemy
SQLAlchemy类似于Jinja2,是可以独立于Flask而被使用的,完全可以在任何Python程序被使用,SQLAlchemy的功能非常强大。
SQLAlchemy 的官方文档。
Flask连接MySQL数据库
使用 Flask-SQLAlchemy操作数据库之前,要先创建一个由 Flask-SQLAlchemy提供的SQLAlchemy类的对象。在创建这个类的时候,要传入当前的app。然后还需要在app.config中设置SQLALCHEMY_ DATABASE_URI,来配置数据库的连接。
修改app.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)# MySQL所在的主机名
HOSTNAME = "127.0.0.1"
# MySQL监听的端口号,默认3306
PORT = 3306
# 连接MySQL的用户名
USERNAME = "root"
# 连接MySQL的密码
PASSWORD = "031006"
# MySQL上创建的数据库名称
DATABASE = "xlr"app.config['SQLALCHEMY_DATABASE_URI'] = f"mysql+pymysql://{USERNAME}:{PASSWORD}@{HOSTNAME}:{PORT}/{DATABASE}?charset=utf8mb4"# 在app.config中设置好连接数据库的信息,
# 然后使用SQLAlchemy(app)创建一个db对象
# SQLAlchemy会自动读取app.config中连接数据库的信息db = SQLAlchemy(app)# 测试数据库是否连接成功
# 连接成功后结果为(1,)
with app.app_context():with db.engine.connect() as conn:rs = conn.execute("select 1")print(rs.fetchone())@app.route('/')
def hello_world(): # put application's code herereturn 'Hello World!'if __name__ == '__main__':app.run()ORM模型与表的映射
对象关系映射(Object Relationship-Mapping),简称ORM,是一种可以用Python面向对象的方式来操作关系型数据库的技术,具有可以映射到数据库表能力的 Python类我们称之为ORM模型。一个ORM模型与数据库中一个表相对应,ORM模型中的每个类属性分别对应表的每个字段,ORM模型的每个实例对象对应表中每条记录。ORM技术提供了面向对象与SQL交互的桥梁,让开发者用面向对象的方式操作数据库,使用ORM模型具有以下优势。
- 开发效率高:几乎不需要写原生SQL语句,使用纯 Python的方式操作数据库,大大的提高了开发效率。
- 安全性高:ORM模型底层代码对一些常见的安全问题,比如SQL注入做了防护,比直接使用SQL语句更加安全。
- 灵活性强:Flask-SQLAlchemy底层支持SQLite、MySQL、Oracle、PostgreSQL等关系型数据库,但针对不同的数据库,ORM模型代码几乎一模一样,只需修改少量代码,即可完成底层数据库的更换。
修改app.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemyapp = Flask(__name__)# MySQL所在的主机名
HOSTNAME = "127.0.0.1"
# MySQL监听的端口号,默认3306
PORT = 3306
# 连接MySQL的用户名
USERNAME = "root"
# 连接MySQL的密码
PASSWORD = "031006"
# MySQL上创建的数据库名称
DATABASE = "xlr"app.config['SQLALCHEMY_DATABASE_URI'] = f"mysql+pymysql://{USERNAME}:{PASSWORD}@{HOSTNAME}:{PORT}/{DATABASE}?charset=utf8mb4"# 在app.config中设置好连接数据库的信息,
# 然后使用SQLAlchemy(app)创建一个db对象
# SQLAlchemy会自动读取app.config中连接数据库的信息db = SQLAlchemy(app)# 测试数据库是否连接成功
# 连接成功后结果为(1,)
# with app.app_context():
# with db.engine.connect() as conn:
# rs = conn.execute("select 1")
# print(rs.fetchone())# User继承自db.Model
# db.Model中封装了与数据库底层交互相关的一些方法和属性
class User(db.Model):__tablename__ = 'user'id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 这样id才能成为表中的一个字段# varchar 最大长度为100 nullable=False字段不能为空username = db.Column(db.String(100), nullable=False)password = db.Column(db.String(100), nullable=False)# user = User(username="2021",password="123456")
# sql: insert user(username, password) values('2021', '123456');with app.app_context():db.create_all()@app.route('/')
def hello_world(): # put application's code herereturn 'Hello World!'if __name__ == '__main__':app.run()首先我们创建一个类名叫 User,并使得他继承自db.Model,所有ORM 模型必须是db.Model的直接或者间接子类。
然后通过_tablename_属性,指定User模型映射到数据库中表的名称。
接着我们定义了三个db.Column类型的类属性,分别是id、username、password,只有使用db.Column定义的类属性,才会被映射到数据库表中成为字段。在这个User模型中,id是 db.Integer类型,在数据库中将表现为整形,并且传递primary_key=True参数来指定id作为主键,传递autoincrement=True来设置id为自增长。接下来的username和password,我们分别指定其类型为db.String类型,在数据库中将表现为varchar类型,并且指定其最大长度为100。
ORM模型的CRUD操作
增加操作
先使用ORM模型创建一个对象,然后添加到会话中,再进行commit 操作即可。
修改app.py
class User(db.Model):__tablename__ = 'user'id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 这样id才能成为表中的一个字段# varchar 最大长度为100 nullable=False字段不能为空username = db.Column(db.String(100), nullable=False)password = db.Column(db.String(100), nullable=False)@app.route('/user/add')
def user_add():# 1. 创建ORM对象user = User(username="2021", password="123456")# 2. 将ORM对象添加到db.session中db.session.add(user)# 3. 将db.session中的改变同步到数据库中db.session.commit()return "Add success!"
查询操作
ORM模型都是继承自db.Model,db.Model内置的query属性上有许多方法,可以实现对ORM模型的查询操作。query 上的方法可以分为两大类,分别是提取方法以及过滤方法。
query常用的提取方法
| 方法名 | 描述 |
|---|---|
| query.all() | 获取查询结果集中的所有对象,是列表类型。 |
| query.first() | 获取结果集中的第一个对象。 |
| query.one() | 获取结果集中的第一个对象,如果结果集中对象数量不等于1,则会抛出异常。 |
| query.one_or_none() | 与one类似,结果不为1的时候,不是抛出异常,而是返回None。 |
| query.get(pk) | 根据主键获取当前ORM模型的第一条数据。 |
| query.exists() | 判断数据是否存在。 |
| query.count() | 获取结果集的个数。 |
query常用的过滤方法
| 方法名 | 描述 |
|---|---|
| query.filter() | 根据查询条件过滤 |
| query.filter_by() | 根据关键字参数过滤。 |
| query.slice(start,stop) | 对结果进行切片操作。 |
| query.limit(limit) | 对结果数量进行限制。 |
| query.offset(offset) | 在查询的时候跳过前面offset条数据。 |
| query.order_by() | 根据给定字段进行排序。 |
| query.group_by() | 根据给定字段进行分组。 |
@app.route('/user/query')
def user_query():# 1. get查找:根据主键查找,只查找一条数据# user = User.query.get(1)# print(f"id:{user.id},username:{user.username},password:{user.password}")# 2. filter_by查找users = User.query.filter_by(username='2021')# 是一个Query对象:类数组for user in users:print(f"id:{user.id},username:{user.username},password:{user.password}")return "Query Success"
更新操作
@app.route('/user/update')
def user_update():user = User.query.filter_by(username='2021').first()user.password = "555555"db.session.commit()return "Update success"
删除操作
@app.route('/user/delete')
def user_delete():# 1. 查找user = User.query.get(1)# 2. 从db.session中删除db.session.delete(user)# 3. 将db.session中的修改,同步到数据库中db.session.commit()return "Delete Success"
ORM模型外键与表关系
关系型数据库一个强大的功能,就是多个表之间可以建立关系。
比如文章表中,通常需要保存作者数据,但是我们不需要直接把作者数据放到文章表中,而是通过外键引用用户表。这种强大的表关系,可以存储非常复杂的数据,并且可以让查询非常迅速。在 Flask-SQLAIchemy中,同样也支持表关系的建立。
表关系建立的前提,是通过数据库层面的外键实现的。表关系总体来讲可以分为三种,分别是:一对多(多对一)、一对一、多对多。
建立关系
class Article(db.Model):__tablename__ = "article"id = db.Column(db.Integer, primary_key=True, autoincrement=True)title = db.Column(db.String(200), nullable=False)content = db.Column(db.Text, nullable=False)# 添加外键author_id = db.Column(db.Integer, db.ForeignKey("user.id"))# 通过db.relationship与User模型建立联系author = db.relationship("User")
我们添加了一个author 属性,这个属性通过db.relationship 与User模型建立了联系,以后通过Article 的实例对象访问author 的时候,比如 article.author,那么Flask-SQLAlchemy会自动根据外键author_id 从 user表中寻找数据,并形成User模型实例对象。
建立双向关系
现在的Article模型可以通过author属性访问到对应的User实例对象。但是User实例对象无法访问到和他关联的所有Article 实例对象。因此为了实现双向关系绑定,我们还需要在User模型上添加一个db.relationship类型的articles属性,并且在User模型和Article模型双方的db.relationship 上,都需要添加一个back _populates参数,用于绑定对方访问自己的属性。
class User(db.Model):__tablename__ = 'user'id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 这样id才能成为表中的一个字段# varchar 最大长度为100 nullable=False字段不能为空username = db.Column(db.String(100), nullable=False)password = db.Column(db.String(100), nullable=False)articles = db.relationship("Article", back_populates="author")class Article(db.Model):__tablename__ = "article"id = db.Column(db.Integer, primary_key=True, autoincrement=True)title = db.Column(db.String(200), nullable=False)content = db.Column(db.Text, nullable=False)# 添加外键author_id = db.Column(db.Interger, db.ForeignKey("user.id"))# 通过db.relationship与User模型建立联系author = db.relationship("User", back_populates="articles")
以上User和Article模型中,我们通过在两边的db.relationship上,传递back_populates参数来实现双向绑定,这种方式有点啰嗦,我们还可以通过只在一个模型上定义db.relationship类型属性,并且传递 backref参数,来实现双向绑定。
class User(db.Model):__tablename__ = 'user'id = db.Column(db.Integer, primary_key=True, autoincrement=True) # 这样id才能成为表中的一个字段# varchar 最大长度为100 nullable=False字段不能为空username = db.Column(db.String(100), nullable=False)password = db.Column(db.String(100), nullable=False)# articles = db.relationship("Article", back_populates="author")class Article(db.Model):__tablename__ = "article"id = db.Column(db.Integer, primary_key=True, autoincrement=True)title = db.Column(db.String(200), nullable=False)content = db.Column(db.Text, nullable=False)# 添加外键author_id = db.Column(db.Interger, db.ForeignKey("user.id"))# backref:会自动的给User模型添加一个articles的属性,用来获取文章列表author = db.relationship("User", backref="articles")
增加和查询article:
@app.route("/article/add")
def article_add():article1 = Article(title="Flask学习", content="Flaskxxxx")article1.author = User.query.get(2)article2 = Article(title="Django学习", content="Django最全学习")article2.author = User.query.get(2)# 添加到session中db.session.add_all([article1, article2])# 同步session中的数据到数据库中db.session.commit()return "Articles Add Success!"@app.route("/article/query")
def query_article():user = User.query.get(2)for article in user.articles:print(article.title)return "Article Query Success!"
flask-migrate迁移ORM模型
采用’db.create_all’在后期修改数据库表字段的时候,不会自动的映射到数据库中,必须删除表,然后重新运行’db.create_all’ 才会重新映射。
这样不符合我们的要求,因此flask-migrate就是为了解决这个问题。它可以在每次修改模型后,将修改的字段映射到数据库中。
安装
进入终端,输入
pip install flask-imgrate
使用
...
from flask_migrate import Migrate...db = SQLAlchemy(app)migrate = Migrate(app, db)...
ORM模型映射成表的三步
-
flask db init:创建迁移环境 ,迁移环境只需要创建一次。这会在你的项目根目录下创建一个migrations文件夹 。
-
flask db migrate:识别ORM模型的改变,生成迁移脚本
-
flask db upgrade:运行迁移脚本,同步到数据库中
ORM模型映射成表的三步都是在终端中输入命令。
相关文章:

Flask框架学习记录
Flask项目简要 项目大致结构 flaskDemo1 ├─static ├─templates └─app.py app.py # 从flask这个包中导入Flask类 from flask import Flask# 使用Flask类创建一个app对象 # __name__:代表当前app.py这个模块 # 1.以后出现bug,可以帮助快速定位 # 2.对于寻找…...

【Opencv 系列】 第6章 人脸检测(Haar/dlib) 关键点检测
本章内容 1.人脸检测,分别用Haar 和 dlib 目标:确定图片中人脸的位置,并画出矩形框 Haar Cascade 哈尔级联 核心原理 (1)使用Haar-like特征做检测 (2)Integral Image : 积分图加速特征计算 …...

信源分类及数学模型
本专栏包含信息论与编码的核心知识,按知识点组织,可作为教学或学习的参考。markdown版本已归档至【Github仓库:information-theory】,需要的朋友们自取。或者公众号【AIShareLab】回复 信息论 也可获取。 文章目录信源分类按照信源…...
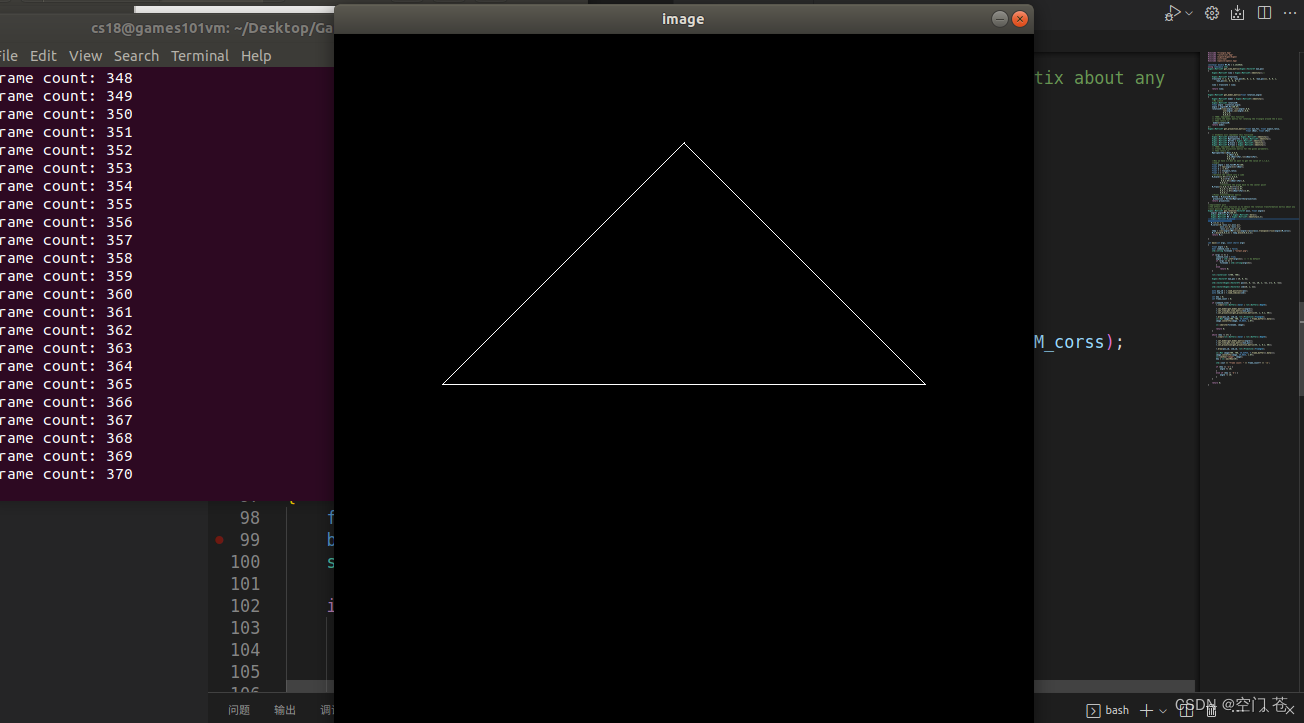
Games101-202作业1
一. 将模型从模型空间变换到世界空间下 在这个作业下,我们主要进行旋转的变换。 二.视图变换 ,将相机移动到坐标原点,同时保证物体和相机进行同样的变换(这样对形成的图像没有影响) 在这个作业下我们主要进行摄像机的平移变换&am…...
Linux系统之终端管理命令的基本使用
Linux系统之终端管理命令的基本使用一、检查本地系统环境1.检查系统版本2.检查系统内核版本二、终端介绍1.终端简介2.Linux终端简介3.终端的发展三、终端的相关术语1.终端模拟器2.tty终端3.pts终端4.pty终端5.控制台终端四、终端管理命令ps1.直接使用ps命令2.列出登录详细信息五…...

【Mongoose笔记】MQTT 服务器
【Mongoose笔记】MQTT 服务器 简介 Mongoose 笔记系列用于记录学习 Mongoose 的一些内容。 Mongoose 是一个 C/C 的网络库。它为 TCP、UDP、HTTP、WebSocket、MQTT 实现了事件驱动的、非阻塞的 API。 项目地址: https://github.com/cesanta/mongoose学习 下面…...

数据结构概述
逻辑结构 顺序存储 随机访问是可以通过下标取到任意一个元素,即数组的起始位置下标 链式存储 链式存储是不连续的,比如A只保留了当前的指针,那么怎么访问到B和C呢 每个元素不仅存储自己的值还使用额外的空间存储指针指向下一个元素的地址&a…...
【前端】Vue3+Vant4项目:旅游App-项目总结与预览(已开源)
文章目录项目预览首页Home日历:日期选择开始搜索位置选择上搜索框热门精选-房屋详情1热门精选-房屋详情2其他页面项目笔记项目代码项目数据项目预览 启动项目: npm run dev在浏览器中F12: 首页Home 热门精选滑动到底部后会自动加载新数据&a…...
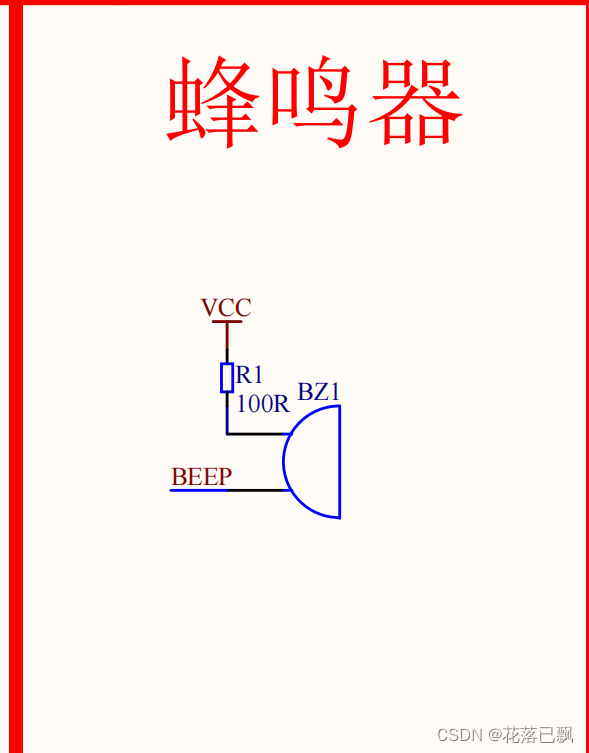
51单片机蜂鸣器的使用
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录前言一、有源蜂鸣器和无源蜂鸣器的区别二、代码编写总结前言 本文旨在介绍如何使用51单片机驱动蜂鸣器。 一、有源蜂鸣器和无源蜂鸣器的区别 有源蜂鸣器是一种电子…...

算法练习-链表(二)
算法练习-链表(二) 文章目录算法练习-链表(二)1. 奇偶链表1.1 题目1.2 题解2. K 个一组翻转链表2.1 题目2.2 题解3. 剑指 Offer 22. 链表中倒数第k个节点3.1 题目3.2 题解3.2.1 解法13.2.2 解法24. 删除链表的倒数第 N 个结点4.1 …...
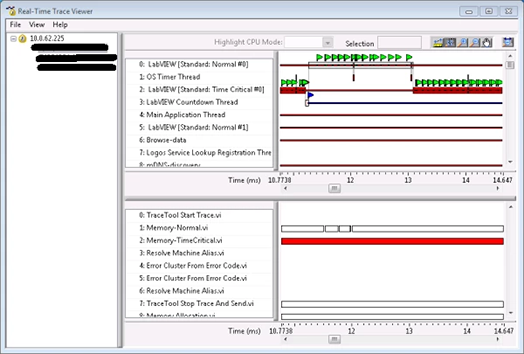
LabVIEW使用实时跟踪查看器调试多核应用程序
LabVIEW使用实时跟踪查看器调试多核应用程序随着多核CPU的推出,开发人员现在可以在LabVIEW的帮助下充分利用这项新技术的功能。并行编程在为多核CPU开发应用程序时提出了新的挑战,例如同步多个线程对共享内存的并发访问以及处理器关联。LabVIEW可自动处理…...

【go语言grpc之client端源码分析二】
go语言grpc之server端源码分析二DialContextparseTargetAndFindResolvergetResolvernewCCResolverWrapperccResolverWrapper.UpdateStatecc.maybeApplyDefaultServiceConfigccBalancerWrapper.updateClientConnState上一篇文章分析了ClientConn的主要结构体成员,然后…...

centos7安装RabbitMQ
1、查看本机基本信息 查看Linux发行版本 uname -a # Linux VM-0-8-centos 3.10.0-1160.11.1.el7.x86_64 #1 SMP Fri Dec 18 16:34:56 UTC 2020 x86_64 x86_64 x86_64 GNU/Linux cat /etc/redhat-release # CentOS Linux release 7.9.2009 (Core)2、创建创建工作目录 mkdir /…...
node基于springboot 口腔卫生防护口腔牙科诊所管理系统
目录 1 绪论 1 1.1课题背景 1 1.2课题研究现状 1 1.3初步设计方法与实施方案 2 1.4本文研究内容 2 2 系统开发环境 4 2.1 JAVA简介 4 2.2MyEclipse环境配置 4 2.3 B/S结构简介 4 2.4MySQL数据库 5 2.5 SPRINGBOOT框架 5 3 系统分析 6 3.1系统可行性分析 6 3.1.1经济可行性 6 3.…...
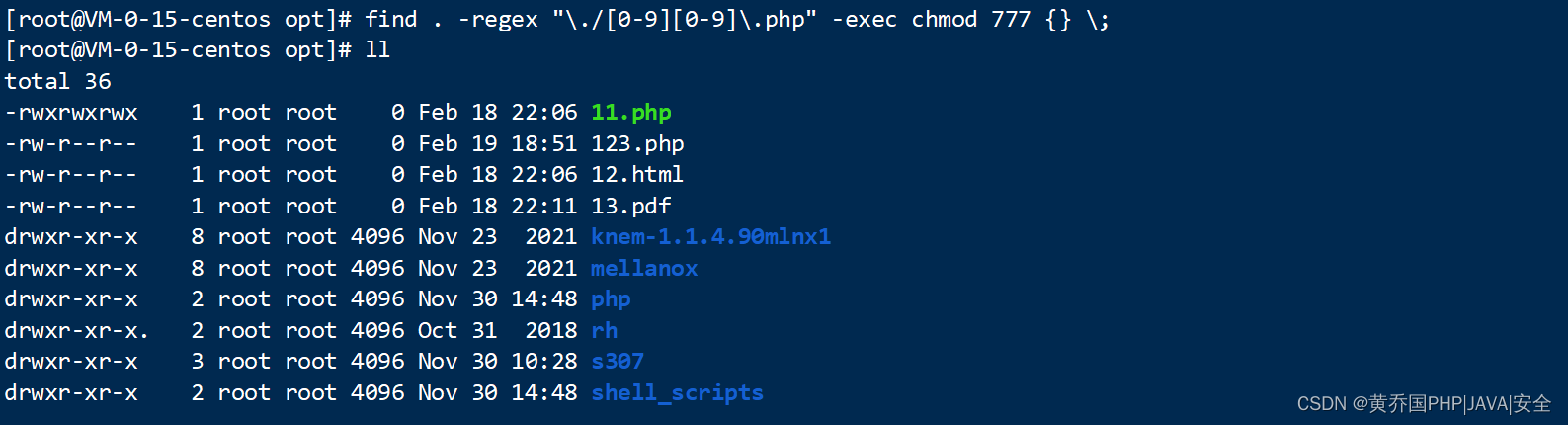
Linux常用命令之find命令详解
简介 find命令主要用于:用来在指定目录下查找文件。任何位于参数之前的字符串都将被视为欲查找的目录名。 如果使用该命令时,不设置任何参数,则find命令将在当前目录下查找子目录与文件。并且将查找到的子目录和文件全部进行显示。 是我们在…...

CMake 入门学习4 软件包管理
CMake 入门学习4 软件包管理一、Linux下的软件包管理1. 检索已安装的软件包2. 让自己编译软件支持pkg-config搜索3. 在CMakeLists查找已安装的软件包二、适合Windows下的包管理工具1. vcpkg2. Conan(1) 安装Conan(2) 配置Conan(3) 创建工程(4) 安装依赖库(5) 使用依赖库三、CMa…...

【数据库数据乱码错误】存进去的数据乱码(???)
目录 1.当我新增一条数据的时候,成功后查看数据库中的数据时,竟然变成???乱码格式了: 2.那么问题有3处需要注意: 第一:settings配置 第二:POM文件 第三:…...
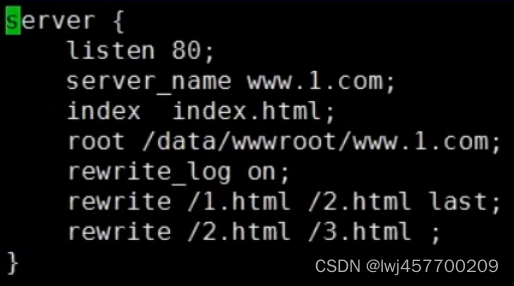
rewrite中的if、break、last
目录 rewrite 作用: 依赖: 打开重定向日志: if 判断: location {} 本身有反复匹配执行特征 在 location 中加入 break 和 last (不一样) 加了break后,立刻停止向下 且 跳出。 加了last…...

JavaSE-线程池(5)- 建议使用的方式
JavaSE-线程池(5)- 建议使用的方式 虽然JDK Executors 工具类提供了默认的创建线程池的方法,但一般建议自定义线程池参数,下面是阿里巴巴开发手册给出的理由: 另外Spring也提供了线程池的实现,比如 Thread…...

城市轨道交通供电系统研究(Matlab代码实现)
👨🎓个人主页:研学社的博客💥💥💞💞欢迎来到本博客❤️❤️💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

从零实现STL哈希容器:unordered_map/unordered_set封装详解
本篇文章是对C学习的STL哈希容器自主实现部分的学习分享 希望也能为你带来些帮助~ 那咱们废话不多说,直接开始吧! 一、源码结构分析 1. SGISTL30实现剖析 // hash_set核心结构 template <class Value, class HashFcn, ...> class hash_set {ty…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...

DBLP数据库是什么?
DBLP(Digital Bibliography & Library Project)Computer Science Bibliography是全球著名的计算机科学出版物的开放书目数据库。DBLP所收录的期刊和会议论文质量较高,数据库文献更新速度很快,很好地反映了国际计算机科学学术研…...

Modbus RTU与Modbus TCP详解指南
目录 1. Modbus协议基础 1.1 什么是Modbus? 1.2 Modbus协议历史 1.3 Modbus协议族 1.4 Modbus通信模型 🎭 主从架构 🔄 请求响应模式 2. Modbus RTU详解 2.1 RTU是什么? 2.2 RTU物理层 🔌 连接方式 ⚡ 通信参数 2.3 RTU数据帧格式 📦 帧结构详解 🔍…...

Neko虚拟浏览器远程协作方案:Docker+内网穿透技术部署实践
前言:本文将向开发者介绍一款创新性协作工具——Neko虚拟浏览器。在数字化协作场景中,跨地域的团队常需面对实时共享屏幕、协同编辑文档等需求。通过本指南,你将掌握在Ubuntu系统中使用容器化技术部署该工具的具体方案,并结合内网…...
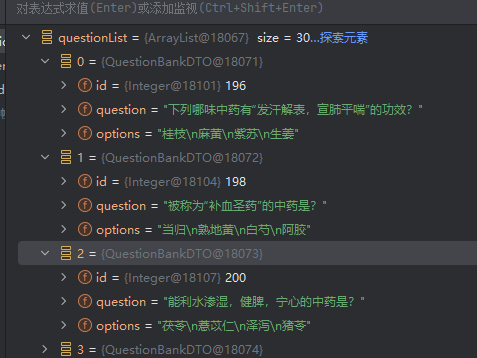
jdbc查询mysql数据库时,出现id顺序错误的情况
我在repository中的查询语句如下所示,即传入一个List<intager>的数据,返回这些id的问题列表。但是由于数据库查询时ID列表的顺序与预期不一致,会导致返回的id是从小到大排列的,但我不希望这样。 Query("SELECT NEW com…...