Python3内置函数大全
吐血整理
Python3内置函数大全
- 1.abs()函数
- 2.all()函数
- 3.any()函数
- 4.ascii()函数
- 5.bin()函数
- 6.bool()函数
- 7.bytes()函数
- 8.challable()函数
- 9.chr()函数
- 10.classmethod()函数
- 11.complex()函数
- 12.complie()函数
- 13.delattr()函数
- 14.dict()函数
- 15.dir()函数
- 16.divmod()函数
- 17.enumerate()函数
- 18.eval()函数
- 19.exec()函数
- 20.filter()函数
- 21.float()函数
- 22.format()函数
- 23.frozenset()函数
- 24.getattr()函数
- 25.globals() 函数
- 26.hasattr()函数
- 27.hash()函数
- 28.hex() 函数
- 29id() 函数
- 30.input() 函数
- 31.int()函数
- 32isinstance() 函数
- 33.issubclass()函数
- 34.iter() 函数
- 35.lambda()函数
- 36.len()函数
- 37.list()函数
- 38.locals() 函数
- 39.map()函数
- 40.max()函数
- 41.min()函数
- 42.next()函数
- 43.oct() 函数
- 44.open() 函数
- 45.ord() 函数
- 46.pow()函数
- 47.property() 函数
- 48.range() 函数
- 49.reduece()函数
- 50.repr()函数
- 51.reversed() 函数
- 52.round()函数
- 53.setattr()函数
- 54.set() 函数
- 55.slice() 函数
- 56.sorted() 函数
- 57.staticmethod()函数
- 58.str() 函数
- 59.sum()函数
- 60.vars() 函数
- 61.zip()函数
1.abs()函数
'''
abs() 函数返回数字的绝对值。d'd'd'd
绝对值:absolutedddd
正如字面上的意思,可以返回一个绝对值
'''
import math
print('abs(45)的值:',abs(45))
print('abs(-45)的值:',abs(-45))
print('abs(45+23)的值:',abs(45+23))
print('abs(math.pi)的值:',abs(math.pi))print(help(abs))
'''
运行结果:
abs(45)的值: 45
abs(-45)的值: 45
abs(45+23)的值: 68
abs(math.pi)的值: 3.141592653589793
Help on built-in function abs in module builtins:abs(x, /)Return the absolute value of the argument.None在python2 里还可以输出 print "abs(119L) : ", abs(119L) 不过python3中abs函数只能输入int型 不然会报错
'''
2.all()函数
'''
all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False。
元素除了是 0、空、FALSE 外都算 TRUE。
语法
以下是 all() 方法的语法:
all(iterable)
参数
iterable -- 元组或列表。
返回值
如果iterable的所有元素不为0、''、False或者iterable为空,all(iterable)返回True,否则返回False;
注意:空元组、空列表返回值为True,这里要特别注意。
'''
print(all(['a','b','c',''])) #列表存在一个为空的元素,返回False
print(all(['a','b','c','d'])) #列表都有元素,返回True
print(all([0,1,2,3,4,5,6])) #列表里存在为0的元素 返回Falseprint(all(('a','b','c',''))) #元组存在一个为空的元素,返回Fasle
print(all(('a','b','c','d'))) #元组都有元素,返回True
print(all((0,1,2,3,4,5))) #元组存在一个为0的元素,返回Fasleprint(all([])) #空列表返回 True
print(all(())) #空元组返回 True
3.any()函数
'''
any() 函数用于判断给定的可迭代参数 iterable 是否全部为 False,则返回 False,如果有一个为 True,则返回 True。
元素除了是 0、空、FALSE 外都算 TRUE。
语法
以下是 any() 方法的语法:
any(iterable)
参数
iterable -- 元组或列表。
返回值
如果都为空、0、false,则返回false,如果不都为空、0、false,则返回true。
'''
print(any(['a','b','c',''])) #列表存在一个为空的元素,返回True
print(any(['a','b','c','d'])) #列表都不为空,返回True
print(any([0,'',False])) #列表里的元素全为 0,'',False 返回Falseprint(any(('a','b','c',''))) #元组存在一个为空的元素,返回True
print(any(('a','b','c','d'))) #元组都有元素,返回True
print(any((0,'',False))) #元组里的元素全为 0,'',False 返回Falseprint(any([])) #空列表返回 False
print(any(())) #空元组返回 False
4.ascii()函数
'''
ascii() 函数类似 repr() 函数, 返回一个表示对象的字符串,
但是对于字符串中的非 ASCII 字符则返回通过 repr() 函数使用 \x, \u 或 \U 编码的字符。
生成字符串类似 Python2 版本中 repr() 函数的返回值。
语法
以下是 ascii() 方法的语法:
ascii(object)参数
object -- 对象。返回值
返回字符串
'''
print(ascii('uiatfu'))#报错 SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 427-428: truncated \xXX escape
#不知道为何
5.bin()函数
'''
函数原型
bin(x)
参数解释
x
整数型,参数不可为空。
返回值
<class 'str'> 字符串类型,二进制整数。
函数说明
将一个整数转化为一个二进制整数,并以字符串的类型返回。
'''
print(bin(12)) #输出12的二进制 0b1100
print(bin(-120)) #输出-12的二进制 -0b1111000
print(type(bin(12))) #输出bin(12) 的类型 <class 'str'> 所以不能直接计算print(int(bin(10),base=2)+int(bin(20),base=2)) #输出 30#base 参数不可为空 为空默认参数为10进制 会报错 ValueError: invalid literal for int() with base 10: '0b1010'#当然了,参数不仅可以接受十进制整数,八进制、十六进制也是可以的,只要是int型数据就合法。print(bin(0b10010)) #输出0b10010
print(bin(0o1357)) #输出0b1011101111
print(bin(0x2d9)) #输出0b1011011001
6.bool()函数
'''
描述
bool() 函数用于将给定参数转换为布尔类型,如果没有参数,返回 False。
bool 是 int 的子类。
语法
以下是 bool() 方法的语法:
class bool([x])
参数
x -- 要进行转换的参数。
返回值
返回 Ture 或 False。
'''
print(bool(0)) #返回False
print(bool(1)) #返回True
print(bool(True)) #返回True
print(bool(False)) #返回False
print(bool('')) #返回False#0,False,'', 空字符串返回Fasle
7.bytes()函数
'''
描述
bytes 函数返回一个新的 bytes 对象,该对象是一个 0 <= x < 256 区间内的整数不可变序列。
它是 bytearray 的不可变版本。语法
以下是 bytes 的语法:
class bytes([source[, encoding[, errors]]])
参数
如果 source 为整数,则返回一个长度为 source 的初始化数组;
如果 source 为字符串,则按照指定的 encoding 将字符串转换为字节序列;
如果 source 为可迭代类型,则元素必须为[0 ,255] 中的整数;
如果 source 为与 buffer 接口一致的对象,则此对象也可以被用于初始化 bytearray。
如果没有输入任何参数,默认就是初始化数组为0个元素。
返回值
返回一个新的 bytes 对象。将一个字符串转换成字节类型
'''
print(bytes('python',encoding='utf-8')) #输出b'python'
print(bytes('张三',encoding='utf-8')) #输出b'\xe5\xbc\xa0\xe4\xb8\x89'print(bytes([1,2,3,4])) #输出b'\x01\x02\x03\x04'
print(bytes('hello','ascii')) #输出b'hello'
print(type(bytes([1,2,3]))) #输出<class 'bytes'>
8.challable()函数
'''
challable() 判断对象是否可以被调用,
能被调用的对象就是一个callables对象,
比如函数和带有__call__()的实例
'''print(callable(max)) #输出True
print(callable([1,2,3])) #输出Fasle
print(callable(None)) #输出Fasle
print(callable('str')) #输出Fasledef fn(x):return x*x
print(callable(fn)) #输出True 证明自定义的函数也可以
9.chr()函数
'''
查看十进制数对应的ASCII码值
描述
chr() 用一个整数作参数,返回一个对应的字符。
语法
以下是 chr() 方法的语法:
chr(i)
参数
i -- 可以是 10 进制也可以是 16 进制的形式的数字,数字范围为 0 到 1,114,111 (16 进制为0x10FFFF)。
返回值
返回值是当前整数对应的 ASCII 字符。
'''#print(chr(-1)) #报错 ValueError: chr() arg not in range(0x110000) 超出范围 不能小于0print(chr(0x30)) #输出 0
print(chr(97)) #输出 a
print(chr(8364)) #输出 €
10.classmethod()函数
'''
描述
classmethod 修饰符对应的函数不需要实例化,不需要 self 参数,
但第一个参数需要是表示自身类的 cls 参数,可以来调用类的属性,类的方法,实例化对象等。
语法
classmethod 语法:
classmethod
参数
无。
返回值
返回函数的类方法。
'''class Stud:num=1def fn1(self):print('方法一')@classmethoddef fn2(cls):print('方法二') #输出 方法二print(cls.num) #调用类的实例化对象cls().fn1() #调用类的方法Stud.fn2() #输出 方法二 不需要实例化print('===='*10)
object=Stud()
object.fn1() #输出 方法一 需要实例化
11.complex()函数
'''
描述
complex() 函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。
如果第一个参数为字符串,则不需要指定第二个参数。。
语法
complex 语法:
class complex([real[, imag]])
参数说明:
real -- int, long, float或字符串;
imag -- int, long, float;
返回值
返回一个复数。
'''print(complex(1,2)) #输出 (1+2j)
print(complex(1)) #输出 (1+0j)
print(complex('2')) #输出 (2+0j)# 注意:这个地方在"+"号两边不能有空格,也就是不能写成"1 + 2j",应该是"1+2j",否则会报错
print(complex('2+3j')) #输出 (2+3j)print(complex(1.2,3.4)) #输出 (1.2+3.4j)
12.complie()函数
'''
complie() 将字符串编译成python能识别或可以执行的代码,也可以将文字读成字符串再编译1 compile(source, filename, mode, flags=0, dont_inherit=False, optimize=-1)
2 将source编译为代码或者AST对象。代码对象能过通过exec语句来执行或者eval()进行求值。
3 参数source:字符串或者AST(abstract syntax trees)对象。
4 参数filename:代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。
5 参数model:指定编译代码的种类。可以指定'exec', 'eval', 'single'。
6 参数flag和dont_inherit:这两个参数为可选参数。
'''s="print('hello world')"
r=compile(s,'hello','exec')
print(r)#输出结果:
#<code object <module> at 0x000002EBD335CF60, file "hello", line 1>
13.delattr()函数
'''
描述:
delattr函数用于删除属性
delattr(x,'foobar)相当于del x.foobar
语法:
setattr(object,name)
参数:
object--对象
name--必须是对象的属性
返回值:
无
'''class People():sex='男'def __init__(self,name):self.name=namedef peopleinfo(self):print('欢迎%s访问'%self.name)delattr(People,'sex') #等同于 del People.sex
print(People.__dict__)#输出 {'__module__': '__main__', '__init__': <function People.__init__ at 0x000001CE3E2E52F0>, 'peopleinfo': <function People.peopleinfo at 0x000001CE3E2E5378>, '__dict__': <attribute '__dict__' of 'People' objects>, '__weakref__': <attribute '__weakref__' of 'People' objects>, '__doc__': None}class Foo:def run(self):while True:cmd=input('cmd>>: ').strip()if hasattr(self,cmd):func=getattr(self,cmd)func()def download(self):print('download....')def upload(self):print('upload...')
obj=Foo()
obj.run()
14.dict()函数
'''
描述
dict() 函数用于创建一个字典。
语法
dict 语法:
class dict(**kwarg)
class dict(mapping, **kwarg)
class dict(iterable, **kwarg)
参数说明:
**kwargs -- 关键字
mapping -- 元素的容器。
iterable -- 可迭代对象。
返回值
返回一个字典。
'''print(dict()) #创建空字典
dict1=dict(a='a', b='b', t='t') #传入关键字 构建字典
print(dict1) #输出 {'a': 'a', 'b': 'b', 't': 't'}dict2=dict(zip(['one', 'two', 'three'], [1, 2, 3])) # 映射函数方式来构造字典
print(dict2) #输出 {'one': 1, 'two': 2, 'three': 3}dict3=dict([('one', 1), ('two', 2), ('three', 3)]) # 可迭代对象方式来构造字典
print(dict3) #输出 {'one': 1, 'two': 2, 'three': 3}
15.dir()函数
'''
dir() 函数不带参数时,返回当前范围内的变量、方法和定义的类型列表;带参数时,返回参数的属性、方法列表。如果参数包含方法__dir__(),该方法将被调用。如果参数不包含__dir__(),该方法将最大限度地收集参数信息。
语法
dir 语法:
dir([object])
参数说明:
object -- 对象、变量、类型。
返回值
返回模块的属性列表。
'''print(dir()) #获得当前模块的属性列表
#输出 ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__']
print(dir([])) #获得列表的方法
#输出 ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__
print(dir(str)) #获得字符串的方法
#输出 ['__add__', '__class__', '__contains__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__getnewargs__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__rmod__', '__rmul__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'capitalize', 'casefold', 'center', 'count', 'encode', 'endswith', 'expandtabs', 'find', 'format', 'format_map', 'index', 'isalnum', 'isalpha', 'isdecimal', 'isdigit', 'isidentifier', 'islower', 'isnumeric', 'isprintable', 'isspace', 'istitle', 'isupper', 'join', 'ljust', 'lower', 'lstrip', 'maketrans', 'partition', 'replace', 'rfind', 'rindex', 'rjust', 'rpartition', 'rsplit', 'rstrip', 'split', 'splitlines', 'startswith', 'strip', 'swapcase', 'title', 'translate', 'upper', 'zfill']
print(dir(dict)) #获得字典的方法
#输出 ['__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'clear', 'copy', 'fromkeys', 'get', 'items', 'keys', 'pop', 'popitem', 'setdefault', 'update', 'values']def update_func(var):print("var 的内存地址:", id(var))var += [4]lst_1 = [1, 2, 3]print(dir()) #输出 ['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'lst_1', 'update_func']class Shape:def __dir__(self):return ['area', 'perimeter', 'location']s = Shape()
print(dir(s)) #输出 ['area', 'location', 'perimeter']16.divmod()函数
'''
python divmod() 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
在 python 2.3 版本之前不允许处理复数。
函数语法
divmod(a, b)
参数说明:
a: 数字
b: 数字
'''
print(divmod(20,4)) #返回 (5, 0)
print(divmod(7,2)) #返回 (3, 1)
print(divmod(8,2)) #返回 (4, 0)
#print(divmod(1+2j,1+0.5j))
#报错 TypeError: can't take floor or mod of complex number.
17.enumerate()函数
'''
enumerate是翻译过来是枚举的意思,看下它的方法原型:
enumerate(sequence, start=0),返回一个枚举对象。
sequence必须是序列或迭代器iterator,或者支持迭代的对象。
enumerate()返回对象的每个元素都是一个元组,
每个元组包括两个值,一个是计数,一个是sequence的值,
计数是从start开始的,start默认为0。
---------------------
'''
a=["q","w","e","r"]
c=enumerate(a)
for i in c:print(i)'''
输出如下:
(0, 'q')
(1, 'w')
(2, 'e')
(3, 'r')
'''a=["w","a","s","d"]
#这里加了个参数2,代表的是start的值
c=enumerate(a,2)
for i in c:print(i)
'''
输出如下:
(2, 'w')
(3, 'a')
(4, 's')
(5, 'd')
'''a=["q","w","e","r"]
#创建一个空字典
b=dict()
#这里i表示的是索引,item表示的是它的值
for i,item in enumerate(a):b[i]=item
print(b) #输出 {0: 'q', 1: 'w', 2: 'e', 3: 'r'}for i,j in enumerate('abc'):print(i,j)
#输出结果
# 0 a
# 1 b
# 2 c
18.eval()函数
'''
eval() 函数用来执行一个字符串表达式,并返回表达式的值。
语法
以下是 eval() 方法的语法:
eval(expression[, globals[, locals]])
参数
expression -- 表达式。
globals -- 变量作用域,全局命名空间,如果被提供,则必须是一个字典对象。
locals -- 变量作用域,局部命名空间,如果被提供,可以是任何映射对象。
返回值
返回表达式计算结果。
'''
x=7
print(eval('3*x')) #返回 21
print(eval('pow(2,2)')) #返回 4
print(eval('3+5')) #返回 8#eval函数还可以实现list、dict、tuple与str之间的转化#1.字符串转换成列表
a = "[[1,2], [3,4], [5,6], [7,8], [9,0]]"
print(type(a)) #返回 <class 'str'>
b = eval(a)
print(type(b)) #返回 <class 'list'>
print(b) #输出 [[1, 2], [3, 4], [5, 6], [7, 8], [9, 0]]#2.字符串转换成字典
a = "{1: 'a', 2: 'b'}"
print(type(a)) #返回 <class 'str'>
b = eval(a)
print(type(b)) #返回 <class 'dict'>
print(b) #输出 {1: 'a', 2: 'b'}#3.字符串转换成元组
a = "([1,2], [3,4], [5,6], [7,8], (9,0))"
print(type(a)) #返回 <class 'str'>
b=eval(a)
print(type(b)) #返回 <class 'tuple'>
print(b) #输出 ([1, 2], [3, 4], [5, 6], [7, 8], (9, 0))
19.exec()函数
'''
函数的作用:
动态执行python代码。也就是说exec可以执行复杂的python代码,而不像eval函数那样只能计算一个表达式的值。
exec(source, globals=None, locals=None, /)
source:必选参数,表示需要被指定的python代码。它必须是字符串或code对象。如果source是一个字符串,该字符串会先被解析为一组python语句,然后执行。如果source是一个code对象,那么它只是被简单的执行。
返回值:
exec函数的返回值永远为None。eval()函数和exec()函数的区别:
eval()函数只能计算单个表达式的值,而exec()函数可以动态运行代码段。
eval()函数可以有返回值,而exec()函数返回值永远为None。
'''x = 10
def func():y = 20a = exec("x+y")print("a:",a) #输出 a: Noneb = exec("x+y",{"x":1,"y":2})print("b:",b) #输出 b: Nonec = exec("x+y",{"x":1,"y":2},{"y":3,"z":4})print("c:",c) #输出 c: Noned = exec("print(x,y)")print("d:",d) #输出 d: None
func()x = 10
expr = """
z = 30
sum = x + y + z #一大包代码
print(sum)
"""
def func():y = 20exec(expr) #10+20+30 输出60exec(expr,{'x':1,'y':2}) #30+1+2 输出 33exec(expr,{'x':1,'y':2},{'y':3,'z':4}) #30+1+3,x是定义全局变量1,y是局部变量 输出34func()20.filter()函数
'''
filter() 函数是一个对于可迭代对象的过滤器,过滤掉不符合条件的元素,
返回的是一个迭代器,如果要转换为列表,可以使用 list() 来转换。
该函数接收两个参数,第一个为函数的引用或者None,第二个为可迭代对象,
可迭代对象中的每个元素作为参数传递给函数进行判,然后返回 True 或 False,最后将返回 True 的元素放到迭代器中
下面看下fiter()的用法:
'''my_list=[1,2,'',3,4,'6',' ']
new_list=list(filter(None,my_list))
print(new_list)
#None 函数 过滤掉'' 而不是过滤掉空字符串def is_oushu(x):return x%2==0
new_list=list(filter(is_oushu,list(range(1,11))))
print(new_list)
#过滤掉不是偶数的数a=[1,2,3,4,5,6,2,2,2,]
print(list(filter(lambda x:x!=2,a)))
#筛选出列表里所有的不是 2 的元素
21.float()函数
'''
描述
float() 函数用于将整数和字符串转换成浮点数。
语法
float()方法语法:
class float([x])
参数
x -- 整数或字符串
返回值
返回浮点数。
'''
print(float(1)) #输出 1.0
print(float(112.0)) #输出 112.0
print(float('123')) #输出 123.0
print(float(True)) #输出 1.0
print(float(False)) #输出 0.0#print(float('a'))
#报错 ValueError: could not convert string to float: 'a'
22.format()函数
'''
自python2.6开始,新增了一种格式化字符串的函数str.format(),此函数可以快速处理各种字符串。
语法
它通过{}和:来代替%。
请看下面的示例,基本上总结了format函数在python的中所有用法
'''
#通过位置
print ('{0},{1}'.format('chuhao',20))
#chuhao,20
print ('{},{}'.format('chuhao',20))
#chuhao,20
print ('{1},{0},{1}'.format('chuhao',20))
#20,chuhao,20
#通过关键字参数
print ('{name},{age}'.format(age=18,name='chuhao'))
#chuhao,18
class Person:def __init__(self,name,age):self.name = nameself.age = agedef __str__(self):return 'This guy is {self.name},is {self.age} old'.format(self=self)print (str(Person('chuhao',18))) #This guy is chuhao,is 18 old#通过映射 list
a_list = ['chuhao',20,'china']
print ('my name is {0[0]},from {0[2]},age is {0[1]}'.format(a_list))
#my name is chuhao,from china,age is 20#通过映射 dict
b_dict = {'name':'chuhao','age':20,'province':'shanxi'}
print ('my name is {name}, age is {age},from {province}'.format(**b_dict))
#my name is chuhao, age is 20,from shanxi#填充与对齐
print ('{:>8}'.format('189'))
# 189
print ('{:0>8}'.format('189'))
#00000189
print ('{:a>8}'.format('189'))
#aaaaa189#精度与类型f
#保留两位小数
print ('{:.2f}'.format(321.33345))
#321.33#用来做金额的千位分隔符
print ('{:,}'.format(1234567890))
#1,234,567,890#其他类型 主要就是进制了,b、d、o、x分别是二进制、十进制、八进制、十六进制。print ('{:b}'.format(18)) #二进制 10010
print ('{:d}'.format(18)) #十进制 18
print ('{:o}'.format(18)) #八进制 22
print ('{:x}'.format(18)) #十六进制1223.frozenset()函数
'''
描述
frozenset() 返回一个冻结的集合,冻结后集合不能再添加或删除任何元素。
语法
frozenset() 函数语法:
class frozenset([iterable])
参数
iterable -- 可迭代的对象,比如列表、字典、元组等等。
返回值
返回新的 frozenset 对象,如果不提供任何参数,默认会生成空集合。
'''a=frozenset(range(10))
print(a)
#输出 frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})b=frozenset('ltftyut1234')
print(b)
#输出 frozenset({'2', '4', 't', 'f', '1', '3', 'l', 'y', 'u'})# 1 frozenset([iterable])
# 2 set和frozenset最本质的区别是前者是可变的,后者是不可变的。当集合对象会被改变时(例如删除,添加元素),只能使用set,
# 3 一般来说使用fronzet的地方都可以使用set。
# 4 参数iterable:可迭代对象。
24.getattr()函数
'''
描述:
getattr()函数用于返回一个对象属性值
语法:
getattr(object,name,default)
参数:
object--对象
name--字符串,对象属性
default--默认返回值,如果不提供该参数,在没有对应属性时,将触发AttributeError。
返回值:
返回对象属性值
'''class People():sex='男'def __init__(self,name):self.name=namedef peopleinfo(self):print('欢迎%s访问'%self.name)obj=getattr(People,'sex')
print(obj) #返回值 男#obj=getattr(People,'sexage')
#print(obj)
'''
报错。。。
Traceback (most recent call last):File "G:/pythonAI/Python_funs/getattr函数详解.py", line 24, in <module>obj=getattr(People,'sexage')
AttributeError: type object 'People' has no attribute 'sexage'
'''obj=getattr(People,'sexage',None)
print(obj) #返回值 None
25.globals() 函数
'''
描述
globals() 函数会以字典类型返回当前位置的全部全局变量。
语法
globals() 函数语法:
globals()
参数
无
返回值
返回全局变量的字典
'''
a='ltftyut1234'
print(globals()) # globals 函数返回一个全局变量的字典,包括所有导入的变量。
# {'__name__': '__main__', '__doc__': '\n描述\nglobals() 函数会以字典类型返回当前位置的全部全局变量。\n语法\nglobals() 函数语法:\nglobals()\n参数\n无\n返回值\n返回全局变量的字典\n', '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x000001C5A50FB4E0>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'G:/pythonAI/Python_funs/globals函数详解.py', '__cached__': None, 'a': 'ltftyut1234'}def zero_promo():return 0def one_promo():return 1def two_promo():return 2def hello():print("Hello")if __name__ == '__main__':promos = [name for name in globals()if name.endswith("_promo")]print(promos) #输出 ['zero_promo', 'one_promo', 'two_promo']promos = [globals()[name] for name in globals() if name.endswith("_promo")]print(promos[0]()) #输出 0 调用了第一个函数26.hasattr()函数
'''
hasattr()函数用于判断是否包含对应的属性
语法:
hasattr(object,name)
参数:
object--对象
name--字符串,属性名
返回值:
如果对象有该属性返回True,否则返回False
'''class People():sex='男'def __init__(self,name):self.name=namedef peopleinfo(self):print('欢迎%s访问'%self.name)obj=People('zhangsan')
print(hasattr(People,'sex')) #输出 True
print('sex'in People.__dict__) #输出 Trueprint(hasattr(obj,'peopleinfo')) #输出 True
print(People.__dict__)
#输出 {'__module__': '__main__', 'sex': '男', '__init__': <function People.__init__ at 0x0000019931C452F0>, 'peopleinfo': <function People.peopleinfo at 0x0000019931C45378>, '__dict__': <attribute '__dict__' of 'People' objects>, '__weakref__': <attribute '__weakref__' of 'People' objects>, '__doc__': None}
27.hash()函数
'''
描述
hash() 用于获取取一个对象(字符串或者数值等)的哈希值。
语法
hash 语法:
hash(object)
参数说明:
object -- 对象;
返回值
返回对象的哈希值。
'''print(hash('test')) #输出 -2950866779904704330 会改变的
print(hash(1)) #数字 输出 1
print(hash(str([1,2,3]))) # 集合 输出 -6217131644886971364
print(hash(str(sorted({'1':1})))) # 字典 输出 -6233802074491902648'''
hash() 函数可以应用于数字、字符串和对象,不能直接应用于 list、set、dictionary。
在 hash() 对对象使用时,所得的结果不仅和对象的内容有关,还和对象的 id(),也就是内存地址有关。
'''
class Test:def __init__(self, i):self.i = i
for i in range(10):t = Test(1)print(hash(t), id(t))'''
-9223371889060894604 2364702099272
147793883435 2364702134960
-9223371889060894604 2364702099272
147793883435 2364702134960
-9223371889060894604 2364702099272
147793883435 2364702134960
-9223371889060894604 2364702099272
147793883435 2364702134960
-9223371889060894604 2364702099272
147793883435 2364702134960
''''''
hash() 函数的用途
hash() 函数的对象字符不管有多长,返回的 hash 值都是固定长度的,
也用于校验程序在传输过程中是否被第三方(木马)修改,
如果程序(字符)在传输过程中被修改hash值即发生变化,
如果没有被修改,则 hash 值和原始的 hash 值吻合,
只要验证 hash 值是否匹配即可验证程序是否带木马(病毒)。
'''name1='正常程序代码'
name2='正常程序代码带病毒'
print(hash(name1)) # 2403189487915500087
print(hash(name2)) # -8751655075885266653
28.hex() 函数
'''
描述
hex() 函数将一个整数转换成十六进制字符串。
语法
hex 语法:
hex(x)
参数说明:
x -- 整数。
返回值
返回十六进制字符串。
'''
print(hex(12)) #输出12的八进制 0xc
print(hex(-120)) #输出-12的二进制 -0x78
print(type(hex(12))) #输出oct(12) 的类型 <class 'str'> 所以不能直接计算print(int(hex(10),base=16)+int(hex(15),base=16)) #输出 25#base 参数不可为空 为空默认参数为10进制 会报错 ValueError: invalid literal for int() with base 10: '0b1010'#当然了,参数不仅可以接受十进制整数,八进制、十六进制也是可以的,只要是int型数据就合法。print(hex(0b10010)) #输出0x12
print(hex(0o1357)) #输出0x2ef
print(hex(0x2d9)) #输出0x2d9
29id() 函数
'''
id() 函数用于获取对象的内存地址。
语法
id 语法:
id([object])
参数说明:
object -- 对象。
返回值
返回对象的内存地址。
'''
str='zhangsan'
print(id(str)) #输出 1556579882544 动态分配 id 每一次会改变b=1
print(id(b)) #输出 1597205568'''
id方法的返回值就是对象的内存地址。python2中会为每个出现的对象分配内存,哪怕他们的值完全相等(注意是相等不是相同)。
如执行a=2.0,b=2.0这两个语句时会先后为2.0这个Float类型对象分配内存,
然后将a与b分别指向这两个对象。所以a与b指向的不是同一对象python3中 值相等的变量 内存一样 如下图所示
'''a=10.21
b=10.21
print(id(a)) #输出2036826247912
print(id(b)) #输出2036826247912
print(a is b) #输出 True
print(a == b) #输出 True'''
id 函数 涉及到 浅拷贝和深拷贝的相关知识深copy和浅copy
深copy新建一个对象重新分配内存地址,复制对象内容。浅copy不重新分配内存地址,内容指向之前的内存地址。
浅copy如果对象中有引用其他的对象,如果对这个子对象进行修改,子对象的内容就会发生更改。
'''import copy#这里有子对象
numbers=['1','2','3',['4','5']]
#浅copy
num1=copy.copy(numbers)
#深copy
num2=copy.deepcopy(numbers)#直接对对象内容进行修改
num1.append('6')#这里可以看到内容地址发生了偏移,增加了偏移‘6’的地址
print('numbers:',numbers)
print('numbers memory address:',id(numbers))
print('numbers[3] memory address',id(numbers[3]))
print('num1:',num1)
print('num1 memory address:',id(num1))
print('num1[3] memory address',id(num1[3]))num1[3].append('6')print('numbers:',numbers)
print('num1:',num1)
print('num2',num2)
'''输出:
numbers: ['1', '2', '3', ['4', '5']]
numbers memory address: 1556526434888
numbers memory address 1556526434952
num1: ['1', '2', '3', ['4', '5'], '6']
num1 memory address: 1556526454728
num1[3] memory address 1556526434952
numbers: ['1', '2', '3', ['4', '5', '6']]
num1: ['1', '2', '3', ['4', '5', '6'], '6']
num2 ['1', '2', '3', ['4', '5']]
'''30.input() 函数
'''
Python3.x 中 input() 函数接受一个标准输入数据,返回为 string 类型。
注意:在 Python3.x 中 raw_input() 和 input() 进行了整合,
去除了 raw_input( ),仅保留了input( )函数,其接收任意任性输入,
将所有输入默认为字符串处理,并返回字符串类型。
函数语法
input([prompt])
参数说明:
prompt: 提示信息
'''a=input('请输入一个数:') #输入 10
print(a) #输出 10
print(type(a)) #输出 <class 'str'>
#b=a+10 #报错 TypeError: must be str, not int
b=int(a)+10 #转换成整型
print(b) #输出 20a=input('请输入一个字符串:') #输入 ltf1234
print(a) #输出 字符串ltf1234 可以使用字符串对应的方法
print(a.split('1')) #输出 ['ltf', '234'] split 切割字符串 直接输出列表
31.int()函数
'''
int([x[,radix]])
如果参数是字符串,那么它可能包含符号和小数点。参数radix表示转换的基数(默认是10进制)。
它可以是[2,36]范围内的值,或者0。如果是0,系统将根据字符串内容来解析。
如果提供了参数radix,但参数x并不是一个字符串,将抛出TypeError异常;
否则,参数x必须是数值(普通整数,长整数,浮点数)。通过舍去小数点来转换浮点数。
如果超出了普通整数的表示范围,一个长整数被返回。
如果没有提供参数,函数返回0。int(x, [base])
作用:
将一个数字或base类型的字符串转换成整数。
int(x=0)
int(x, base=10),base缺省值为10,也就是说不指定base的值时,函数将x按十进制处理。
注:
1. x 可以是数字或字符串,但是base被赋值后 x 只能是字符串
2. x 作为字符串时必须是 base 类型,也就是说 x 变成数字时必须能用 base 进制表示
'''#1.x是数字
print(int(2.1)) #输出 2
print(int(2e3)) #输出 2000
#print(int(1000,2)) #出错,base 被赋值后函数只接收字符串
#报错 TypeError: int() can't convert non-string with explicit base#2.x是字符串
print(int('abc12',16)) #输出 703506
#print(int('tuifyg',16)) #出错 tuifyg 超过0-9 abcdef 超出16进制
#报错 ValueError: invalid literal for int() with base 16: 'tuifyg'#3. base 可取值范围是 2~36,囊括了所有的英文字母(不区分大小写),
# 十六进制中F表示15,那么G将在二十进制中表示16,依此类推....Z在三十六进制中表示35
#print(int('FZ',16)) # 出错,FZ不能用十六进制表示
#报错 ValueError: invalid literal for int() with base 16: 'FZ'
print(int('FZ',36)) # 575#4.字符串 0x 可以出现在十六进制中,视作十六进制的符号,
# 同理 0b 可以出现在二进制中,除此之外视作数字 0 和字母 x
print(int('0x10', 16)) # 16,0x是十六进制的符号
#print(int('0x10', 17)) # 出错,'0x10'中的 x 被视作英文字母 x
print(int('0x10', 36)) # 42804,36进制包含字母 x32isinstance() 函数
'''
isinstance() 函数来判断一个对象是否是一个已知的类型,类似 type()。
isinstance() 与 type() 区别:
type() 不会认为子类是一种父类类型,不考虑继承关系。
isinstance() 会认为子类是一种父类类型,考虑继承关系。
如果要判断两个类型是否相同推荐使用 isinstance()。语法
以下是 isinstance() 方法的语法:
isinstance(object, classinfo)
参数
object -- 实例对象。
classinfo -- 可以是直接或间接类名、基本类型或者有它们组成的元组。
返回值
如果对象的类型与参数二的类型(classinfo)相同则返回 True,否则返回 False。。
'''a=2
print(isinstance(a,int)) #返回 True
print(isinstance(a,str)) #返回 Fasle
print(isinstance(a,(str,int,list))) #返回 True 是元组中的一个类型 就行class A:passclass B(A):passprint(isinstance(A(), A) ) # returns True
print(type(A()) == A ) # returns True
print(isinstance(B(), A)) # returns True
print(type(B()) == A) # returns False
33.issubclass()函数
'''
描述
issubclass() 方法用于判断参数 class 是否是类型参数 classinfo 的子类。
语法
以下是 issubclass() 方法的语法:
issubclass(class, classinfo)
参数
class -- 类。
classinfo -- 类。
返回值
如果 class 是 classinfo 的子类返回 True,否则返回 False。
'''class A:passclass B(A):passclass C(A):passprint(issubclass(B, A)) # 返回 True
print(issubclass(C, A)) # 返回 True
print(issubclass(C, B)) # 返回 False#2.class参数是classinfo的子类,并且classinfo是元组
print(issubclass(C, (A, object))) #返回 True
print(issubclass(C, (A, int, object))) #返回 True
print(issubclass(C, (int, str))) #返回 False
print(issubclass(C, (int, str, type))) #返回 False#print(issubclass(C, (1, A)))
#报错 TypeError: issubclass() arg 2 must be a class or tuple of classes34.iter() 函数
'''
描述
iter() 函数用来生成迭代器。
语法
以下是 iter() 方法的语法:
iter(object[, sentinel])
参数
object -- 支持迭代的集合对象。
sentinel -- 如果传递了第二个参数,则参数 object 必须是一个可调用的对象(如,函数),此时,iter 创建了一个迭代器对象,每次调用这个迭代器对象的__next__()方法时,都会调用 object。
打开模式
返回值
迭代器对象。1 iter(o[, sentinel])
2 返回一个iterator对象。该函数对于第一个参数的解析依赖于第二个参数。
3 如果没有提供第二个参数,参数o必须是一个集合对象,支持遍历功能(__iter__()方法)或支持序列功能(__getitem__()方法),
4 参数为整数,从零开始。如果不支持这两种功能,将处罚TypeError异常。
5 如果提供了第二个参数,参数o必须是一个可调用对象。在这种情况下创建一个iterator对象,每次调用iterator的next()方法来无
6 参数的调用o,如果返回值等于参数sentinel,触发StopIteration异常,否则将返回该值。
'''lst = [1,2,3,4,5,6,7]
for i in iter(lst):print(i) #输出1,2,3,4,5,6,7class counter:def __init__(self, _start, _end):self.start = _startself.end = _enddef get_next(self):s = self.startif(self.start < self.end):self.start += 1else:raise StopIterationreturn sc = counter(1, 5)
iterator = iter(c.get_next, 3)
print(type(iterator)) #返回 <class 'callable_iterator'>
for i in iterator:print(i) #输出 1 235.lambda()函数
'''
匿名函数lambda:是指一类无需定义标识符(函数名)的函数或子程序。
lambda 函数可以接收任意多个参数 (包括可选参数) 并且返回单个表达式的值。要点:
1,lambda 函数不能包含命令,2,包含的表达式不能超过一个。说明:一定非要使用lambda函数;任何能够使用它们的地方,都可以定义一个单独的普通函数来进行替换。
我将它们用在需要封装特殊的、非重用代码上,避免令我的代码充斥着大量单行函数。lambda匿名函数的格式:冒号前是参数,可以有多个,用逗号隔开,冒号右边的为表达式。
其实lambda返回值是一个函数的地址,也就是函数对象。
'''
def sum(x,y):return x+y
print(sum(4,6))f=lambda x,y:x+y
print(f(4,6))
#这俩个例子的效果是一样的,都是返回x+ya=lambda x:x*x
print(a(4)) #传入一个参数的lambda函数 返回x*xb=lambda x,y,z:x+y*z
print(b(1,2,3)) #返回x+y*z 即1+2*3=7#2.方法结合使用
from functools import reduce
foo=[2, 18, 9, 22, 17, 24, 8, 12, 27]
print(list(filter(lambda x:x%3==0,foo))) #筛选x%3==0 的元素
print(list(map(lambda x:x*2+10,foo))) #遍历foo 每个元素乘2+10 再输出
print(reduce(lambda x,y:x+y,foo)) #返回每个元素相加的和
36.len()函数
'''
描述
Python len() 方法返回对象(字符、列表、元组等)长度或项目个数。
语法
len()方法语法:
len( s )
参数
s -- 对象。
返回值
返回对象长度。
'''
str1='ltf1234'
print(len(str1)) #输出 7list1=[1,2,3,4,5,6,7,8]
print(len(list1)) #输出 8for i in range(len(list1)):print(i) #依次输出1-8dict = {'num':777,'name':"anne"}
print(len(dict)) #输出 237.list()函数
'''
list() 列表构造函数1 list([iterable])
2 list的构造函数。参数iterable是可选的,它可以是序列,支持编译的容器对象,或iterator对象。
3 该函数创建一个元素值,顺序与参数iterable一致的列表。如果参数iterable是一个列表,将创建
4 列表的一个拷贝并返回,就像语句iterables[:]。
'''list=[1,2,3,4,5,6,7,8,9] #构建列表
print(list) #输出 [1,2,3,4,5,6,7,8,9]list.append(10) #列表追加 10
print(list) #输出 [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]list.insert(2,18) #在列表索引为2 的位置 插入 18 其余的后移
print(list) #输出 [1, 2, 18, 3, 4, 5, 6, 7, 8, 9, 10]print(list.count(1)) #输出 列表里1 的数量list2=[-1,-2,-3]
list.extend(list2) #列表追加列表
print(list) #输出 [1, 2, 18, 3, 4, 5, 6, 7, 8, 9, 10, -1, -2, -3]list.remove(1) #删除列表里的第一个1
print(list) #输出 [2, 18, 3, 4, 5, 6, 7, 8, 9, 10, -1, -2, -3]list.sort() #列表排序
print(list) #输出 [-3, -2, -1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 18]list.reverse() #列表反转
print(list) #输出 [18, 10, 9, 8, 7, 6, 5, 4, 3, 2, -1, -2, -3]print(max(list)) #输出列表最大值 18
print(min(list)) #输出列表最小值 -3list3=[1,2,3,'q','a','s']
#print(max(list3)) #报错 >' not supported between instances of 'str' and 'int'
#print(min(list3)) #报错 >' not supported between instances of 'str' and 'int'
38.locals() 函数
'''
locals() 函数会以字典类型返回当前位置的全部局部变量。
对于函数, 方法, lambda 函式, 类, 以及实现了 __call__ 方法的类实例, 它都返回 True。
语法
locals() 函数语法:
locals()
参数
无
返回值
返回字典类型的局部变量1 不要修改locals()返回的字典中的内容;改变可能不会影响解析器对局部变量的使用。
2 在函数体内调用locals(),返回的是自由变量。修改自由变量不会影响解析器对变量的使用。
3 不能在类区域内返回自由变量。
'''def test_py(arg):z=1print(locals())
test_py(6) #输出 {'z': 1, 'arg': 6}def foo(arg, a):x = 100y = 'hello python!'for i in range(10):j = 1k = iprint(locals())
foo(1, 2) #输出 {'k': 9, 'j': 1, 'i': 9, 'y': 'hello python!', 'x': 100, 'a': 2, 'arg': 1}39.map()函数
'''
map()函数
map()是 Python 内置的高阶函数,它接收一个函数 f 和一个 list,
并通过把函数 f 依次作用在 list 的每个元素上,得到一个新的 list 并返回。例如,对于list [1, 2, 3, 4, 5, 6, 7, 8, 9]
如果希望把list的每个元素都作平方,就可以用map()函数:因此,我们只需要传入函数f(x)=x*x,就可以利用map()函数完成这个计算:
'''
list=[1,2,3,4,5,6,7,8,9]
def f(x):return x*x
list1=map(f,list)
print(list1)
for i in list1:print(i)'''
注意:map()函数不改变原有的 list,而是返回一个新的 list。利用map()函数,可以把一个 list 转换为另一个 list,只需要传入转换函数。由于list包含的元素可以是任何类型,因此,map() 不仅仅可以处理只包含数值的 list,
事实上它可以处理包含任意类型的 list,只要传入的函数f可以处理这种数据类型。任务
假设用户输入的英文名字不规范,没有按照首字母大写,后续字母小写的规则,
请利用map()函数,把一个list(包含若干不规范的英文名字)变成一个包含规范英文名字的
'''
def format_name(s):s1=s[0:1].upper()+s[1:].lower()return s1
names=['adam', 'LISA', 'barT']
print (map(format_name, names)) #python2 这样写可以直接输出列表
for i in map(format_name,names):print(i) #python3 得这样写才可以
40.max()函数
'''
描述
max() 方法返回给定参数的最大值,参数可以为序列。语法
以下是 max() 方法的语法:
max( x, y, z, .... )参数
x -- 数值表达式。
y -- 数值表达式。
z -- 数值表达式。返回值
返回给定参数的最大值。
'''print ("max(80, 100, 1000) : ", max(80, 100, 1000))
print ("max(-20, 100, 400) : ", max(-20, 100, 400))
print ("max(-80, -20, -10) : ", max(-80, -20, -10))
print ("max(0, 100, -400) : ", max(0, 100, -400))'''
输出结果:
max(80, 100, 1000) : 1000
max(-20, 100, 400) : 400
max(-80, -20, -10) : -10
max(0, 100, -400) : 100
'''#1.传入的多个参数的最大值
print(max(1,2,3,4)) #输出 4#2.传入可迭代对象时,取其元素最大值
s='12345'
print(max(s)) #输出 5#3.传入命名参数key,其为一个函数,用来指定取最大值的方法s = [{'name': 'sumcet', 'age': 18},{'name': 'bbu', 'age': 11}
]
a = max(s, key=lambda x: x['age'])
print(a) #输出 {'name': 'sumcet', 'age': 18}
41.min()函数
'''
描述
min() 方法返回给定参数的最小值,参数可以为序列。语法
以下是 min() 方法的语法:
min( x, y, z, .... )参数
x -- 数值表达式。
y -- 数值表达式。
z -- 数值表达式。返回值
返回给定参数的最小值。
'''print ("min(80, 100, 1000) : ", min(80, 100, 1000))
print ("min(-20, 100, 400) : ", min(-20, 100, 400))
print ("min(-80, -20, -10) : ", min(-80, -20, -10))
print ("min(0, 100, -400) : ", min(0, 100, -400))'''
输出结果
min(80, 100, 1000) : 80
min(-20, 100, 400) : -20
min(-80, -20, -10) : -80
min(0, 100, -400) : -400
'''#1.传入的多个参数的最小值
print(min(1,2,3,4)) #输出 1#2.传入可迭代对象时,取其元素最小值
s='12345'
print(min(s)) #输出 1#3.传入命名参数key,其为一个函数,用来指定取最小值的方法s = [{'name': 'sumcet', 'age': 18},{'name': 'bbu', 'age': 11}
]
a = min(s, key=lambda x: x['age'])
print(a) #输出 {'name': 'bbu', 'age': 11}
42.next()函数
'''
描述
next() 返回迭代器的下一个项目。
语法
next 语法:
next(iterator[, default])
参数说明:
iterator -- 可迭代对象
default -- 可选,用于设置在没有下一个元素时返回该默认值,如果不设置,又没有下一个元素则会触发 StopIteration 异常。
返回值
返回对象帮助信息。
'''# 首先获得Iterator对象:
it = iter([1, 2, 3, 4, 5])
# 循环:
while True:try:# 获得下一个值:x = next(it)print(x)except StopIteration:# 遇到StopIteration就退出循环breaka=iter('abcde')
print(next(a)) #输出 a
print(next(a)) #输出 b
print(next(a)) #输出 c
print(next(a)) #输出 d
print(next(a)) #输出 e
#print(next(a)) #报错 StopIteration#函数可以接收一个可选的default参数,传入default参数后,
# 如果可迭代对象还有元素没有返回,则依次返回其元素值,如果所有元素已经返回,
# 则返回default指定的默认值而不抛出StopIteration 异常。print(next(a,'e')) #这次不报错了 返回 e 即default参数43.oct() 函数
'''
描述
oct() 函数将一个整数转换成八进制字符串。
语法
oct 语法:
oct(x)
参数说明:
x -- 整数。
返回值
返回八进制字符串。
'''print(oct(12)) #输出12的八进制 0o14
print(oct(-120)) #输出-12的二进制 -0o170
print(type(oct(12))) #输出oct(12) 的类型 <class 'str'> 所以不能直接计算print(int(oct(10),base=8)+int(oct(15),base=8)) #输出 25#base 参数不可为空 为空默认参数为10进制 会报错 ValueError: invalid literal for int() with base 10: '0b1010'#当然了,参数不仅可以接受十进制整数,八进制、十六进制也是可以的,只要是int型数据就合法。print(oct(0b10010)) #输出0o22
print(oct(0o1357)) #输出0o1357
print(oct(0x2d9)) #输出0o1331
44.open() 函数
'''
python open() 函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写。
更多文件操作可参考:Python 文件I/O。
函数语法
open(name[, mode[, buffering]])
参数说明:
name : 一个包含了你要访问的文件名称的字符串值。
mode : mode 决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
不同模式打开文件的完全列表:
模式
描述
r
以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
rb
以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。
r+
打开一个文件用于读写。文件指针将会放在文件的开头。
rb+
以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。
w
打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb
以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
w+
打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
wb+
以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
a
打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
ab
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
a+
打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。
file 对象方法
file.read([size]):size 未指定则返回整个文件,如果文件大小 >2 倍内存则有问题,f.read()读到文件尾时返回""(空字串)。
file.readline():返回一行。
file.readlines([size]) :返回包含size行的列表, size 未指定则返回全部行。
for line in f: print line :通过迭代器访问。
f.write("hello\n"):如果要写入字符串以外的数据,先将他转换为字符串。
f.tell():返回一个整数,表示当前文件指针的位置(就是到文件头的比特数)。
f.seek(偏移量,[起始位置]):用来移动文件指针。
偏移量: 单位为比特,可正可负
起始位置: 0 - 文件头, 默认值; 1 - 当前位置; 2 - 文件尾
f.close() 关闭文件open(filename [, mode [, bufsize]])
打开一个文件,返回一个file对象。 如果文件无法打开,将处罚IOError异常。
应该使用open()来代替直接使用file类型的构造函数打开文件。
参数filename表示将要被打开的文件的路径字符串;
参数mode表示打开的模式,最常用的模式有:'r'表示读文本,'w'表示写文本文件,'a'表示在文件中追加。
Mode的默认值是'r'。
当操作的是二进制文件时,只要在模式值上添加'b'。这样提高了程序的可移植性。
可选参数bufsize定义了文件缓冲区的大小。0表示不缓冲;1表示行缓冲;任何其他正数表示使用该大小的缓冲区;
负数表示使用系统默认缓冲区大小,对于tty设备它往往是行缓冲,而对于其他文件往往完全缓冲。如果参数值被省却。
使用系统默认值。
'''f=open('1.txt','r',encoding='utf-8')
print(f.read())
'''
输出...
ltf
zhongguo
shanxi
yuncheng
男
20
'''
45.ord() 函数
'''
描述
ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
语法
以下是 ord() 方法的语法:
ord(c)
参数
c -- 字符。
返回值
返回值是对应的十进制整数。
'''print(ord('a')) #输出97
print(ord('b')) #输出98
print(ord('c')) #输出99print(ord(']')) #输出93
print(ord('8')) #输出56
46.pow()函数
'''
描述
pow() 方法返回 xy(x的y次方) 的值。语法
以下是 math 模块 pow() 方法的语法:
import mathmath.pow( x, y )
内置的 pow() 方法
pow(x, y[, z])
函数是计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z
注意:pow() 通过内置的方法直接调用,内置方法会把参数作为整型,而 math 模块则会把参数转换为 float。参数
x -- 数值表达式。
y -- 数值表达式。
z -- 数值表达式。返回值
返回 xy(x的y次方) 的值。
'''import math # 导入 math 模块print("math.pow(100, 2) : ", math.pow(100, 2))
# 使用内置,查看输出结果区别
print("pow(100, 2) : ", pow(100, 2))print("math.pow(100, -2) : ", math.pow(100, -2))
print("math.pow(2, 4) : ", math.pow(2, 4))
print("math.pow(3, 0) : ", math.pow(3, 0))'''
输出结果...
math.pow(100, 2) : 10000.0
pow(100, 2) : 10000
math.pow(100, -2) : 0.0001
math.pow(2, 4) : 16.0
math.pow(3, 0) : 1.0
'''
47.property() 函数
'''
描述
property() 函数的作用是在新式类中返回属性值。
语法
以下是 property() 方法的语法:
class property([fget[, fset[, fdel[, doc]]]])
参数
fget -- 获取属性值的函数
fset -- 设置属性值的函数
fdel -- 删除属性值函数
doc -- 属性描述信息
返回值
返回新式类属性
'''class C(object):def __init__(self):self._x = Nonedef getx(self):return self._xdef setx(self, value):self._x = valuedef delx(self):del self._xx = property(getx, setx, delx, "I'm the 'x' property.")class Parrot(object):def __init__(self):self._voltage = 100000#装饰器写法@propertydef voltage(self):"""Get the current voltage."""return self._voltageclass D(object):def __init__(self):self._x = None@propertydef x(self):"""I'm the 'x' property."""return self._x@x.setterdef x(self, value):self._x = value@x.deleterdef x(self):del self._x
48.range() 函数
'''
python range() 函数可创建一个整数列表,一般用在 for 循环中。
函数语法
range(start, stop[, step])
参数说明:
start: 计数从 start 开始。默认是从 0 开始。例如range(5)等价于range(0, 5);
stop: 计数到 stop 结束,但不包括 stop。例如:range(0, 5) 是[0, 1, 2, 3, 4]没有5
step:步长,默认为1。例如:range(0, 5) 等价于 range(0, 5, 1)'''for i in range(10):print(i) #输出 从0-9for i in range(0,11,2):print(i) #输出 0,2,4,6,8,10for i in range(0,-10,-3):print(i) #输出 0,-3,-6,-9list=[]
for i in range(5,-5,-1):list.append(i)
print(list) #输出 [5, 4, 3, 2, 1, 0, -1, -2, -3, -4]for i in 'ahfgohiauf':print(i) #依次输出字符49.reduece()函数
'''
在python3中如果使用reduce需要先导入from functools import reducereduce函数,reduce函数会对参数序列中元素进行累积。reduce函数的定义:
reduce(function, sequence [, initial] ) -> value
function参数是一个有两个参数的函数,reduce依次从sequence中取一个元素,
和上一次调用function的结果做参数再次调用function。
第一次调用function时,如果提供initial参数,
会以sequence中的第一个元素和initial作为参数调用function,
否则会以序列sequence中的前两个元素做参数调用function。
'''from functools import reduce
lst=[1,2,3,4,5,6]
def f(x,y):return x+y
print(reduce(f,lst))'''
过程1+2+3+4+5+6=21
'''print(reduce(lambda x,y:x*y,lst))
# 运行过程为1*2*3*4*5*6=720#来个稍微复杂的
print(reduce(lambda x,y:x*y+1,lst))'''
运算步骤:1*2+1=33*3+1=1010*4+1=4141*5+1=206206*6+1=1237
'''#再说说有初始化值的情况, 这个时候就不是取列表的前两项, 而是取初始值为第一个,
# 序列的第一个元素为第二个元素,开始进行lambda函数的应用计算.
print(reduce(lambda x,y:x+y,lst,5))'''
计算步骤:5+1=66+2=88+3=1111+4=1515+5=2020+6=26
'''
50.repr()函数
'''
描述
repr() 函数将对象转化为供解释器读取的形式。
语法
以下是 repr() 方法的语法:
repr(object)
参数
object -- 对象。
返回值
返回一个对象的 string 格式。
'''s='qwerasdf'
print(s) #输出 qwerasdf
print(repr(s)) #输出 'qwerasdf'dict={'a':1,'b':2}
print(dict) #输出 {'a': 1, 'b': 2}
print(repr(dict)) #输出 {'a': 1, 'b': 2} 没改变么print(repr([0,1,2,3,4])) #输出 [0, 1, 2, 3, 4]
print(repr('hello')) #输出 'hello'print(str(1.0/7.0)) #输出 0.14285714285714285
print(repr(1.0/7.0)) #输出 0.14285714285714285
51.reversed() 函数
'''
描述
reversed 函数返回一个反转的迭代器。语法
以下是 reversed 的语法:
reversed(seq)
参数
seq -- 要转换的序列,可以是 tuple, string, list 或 range。
返回值
返回一个反转的迭代器。1 reversed(seq)
2 返回一个逆序的iterator对象。参数seq必须是一个包含__reversed__()方法的对象或支持序列操作(__len__()和__getitem__())
3 该函数是2.4中新增的
'''str='wasdqwer'
print(list(reversed(str))) #输出 ['r', 'e', 'w', 'q', 'd', 's', 'a', 'w']tuple=('r', 'e', 'w', 'q', 'd', 's', 'a', 'w')
print(list(reversed(tuple))) #输出 ['w', 'a', 's', 'd', 'q', 'w', 'e', 'r']seqRange = range(5, 9)
print(list(reversed(seqRange))) #输出 [8, 7, 6, 5]seqList = [1, 2, 4, 3, 5]
print(list(reversed(seqList))) #输出 [5, 3, 4, 2, 1]a=[1,2,3,4,5,6]
b=reversed(a)
print(b) #输出 <list_reverseiterator object at 0x0000023E2A448748> 显示为一个迭代器
print(list(b)) #输出 [6, 5, 4, 3, 2, 1]
print(list(b)) #输出 []#由此可知:reversed()返回的是一个迭代器对象,只能进行一次循环遍历。显示一次所包含的值!
52.round()函数
'''
描述
round() 方法返回浮点数x的四舍五入值。语法
以下是 round() 方法的语法:
round( x [, n] )参数
x -- 数字表达式。
n -- 表示从小数点位数,其中 x 需要四舍五入,默认值为 0。返回值
返回浮点数x的四舍五入值。
'''print ("round(70.23456) : ", round(70.23456))
print ("round(56.659,1) : ", round(56.659,1))
print ("round(80.264, 2) : ", round(80.264, 2))
print ("round(100.000056, 3) : ", round(100.000056, 3))
print ("round(-100.000056, 3) : ", round(-100.000056, 3))'''
输出结果...
round(70.23456) : 70
round(56.659,1) : 56.7
round(80.264, 2) : 80.26
round(100.000056, 3) : 100.0
round(-100.000056, 3) : -100.0
'''
53.setattr()函数
'''
描述:
setattr函数,用于设置属性值,该属性必须存在
语法:
setattr(object,name,value)
参数:
object--对象
name--字符串,对象属性
value--属性值
返回值:
无
'''class People():sex='男'def __init__(self,name):self.name=namedef peopleinfo(self):print('欢迎%s访问'%self.name)obj=People('zhangsan')
setattr(People,'x',123)
print(People.x) #等同于 Peopel.x=123setattr(obj,'age',18)
print(obj.__dict__) #输出 {'name': 'zhangsan', 'age': 18}print(People.__dict__)
#输出
#{'__module__': '__main__', 'sex': '男', '__init__': <function People.__init__ at 0x00000259A92752F0>, 'peopleinfo': <function People.peopleinfo at 0x00000259A9275378>, '__dict__': <attribute '__dict__' of 'People' objects>, '__weakref__': <attribute '__weakref__' of 'People' objects>, '__doc__': None, 'x': 123}
54.set() 函数
'''
描述
set() 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。
语法
set 语法:
class set([iterable])
参数说明:
iterable -- 可迭代对象对象;
返回值
返回新的集合对象。
'''a=set('www.baidu.com')
b=set('www.gogle.com') #重复的元素被删除 元素唯一 可以用来去重
print(a) #输出 {'u', '.', 'm', 'c', 'w', 'd', 'i', 'a', 'o', 'b'}
print(b) #输出 {'.', 'm', 'e', 'c', 'w', 'o', 'l', 'g'}print(a&b) #交集 {'m', 'c', 'w', '.', 'o'}
print(a|b) #并集 {'m', 'c', 'i', 'w', 'b', 'd', 'u', 'g', 'e', 'a', '.', 'o', 'l'}
print(a-b) #差集 {'i', 'b', 'd', 'u', 'a'}#1.比较
se = {11, 22, 33}
be = {22, 55}
temp1 = se.difference(be) #找到se中存在,be中不存在的集合,返回新值
print(temp1) #{33, 11}
print(se) #{33, 11, 22}temp2 = se.difference_update(be) #找到se中存在,be中不存在的集合,覆盖掉se
print(temp2) #None
print(se) #{33, 11},#2.删除
se = {11, 22, 33}
se.discard(11)
se.discard(44) # 移除不存的元素不会报错
print(se)se = {11, 22, 33}
se.remove(11)
#se.remove(44) # 移除不存的元素会报错
print(se)se = {11, 22, 33} # 移除末尾元素并把移除的元素赋给新值
temp = se.pop()
print(temp) # 33
print(se) # {11, 22}#3.取交集
se = {11, 22, 33}
be = {22, 55}temp1 = se.intersection(be) #取交集,赋给新值
print(temp1) # 22
print(se) # {11, 22, 33}temp2 = se.intersection_update(be) #取交集并更新自己
print(temp2) # None
print(se) # 22#4.判断
se = {11, 22, 33}
be = {22}print(se.isdisjoint(be)) #False,判断是否不存在交集(有交集False,无交集True)
print(se.issubset(be)) #False,判断se是否是be的子集合
print(se.issuperset(be)) #True,判断se是否是be的父集合#5.合并
se = {11, 22, 33}
be = {22}temp1 = se.symmetric_difference(be) # 合并不同项,并赋新值
print(temp1) #{33, 11}
print(se) #{33, 11, 22}temp2 = se.symmetric_difference_update(be) # 合并不同项,并更新自己
print(temp2) #None
print(se) #{33, 11}#6.取并集se = {11, 22, 33}
be = {22,44,55}temp=se.union(be) #取并集,并赋新值
print(se) #{33, 11, 22}
print(temp) #{33, 22, 55, 11, 44}#7.更新
se = {11, 22, 33}
be = {22,44,55}se.update(be) # 把se和be合并,得出的值覆盖se
print(se)
se.update([66, 77]) # 可增加迭代项
print(se)#8.集合的转换
se = set(range(4))
li = list(se)
tu = tuple(se)
st = str(se)
print(li,type(li)) #输出 [0, 1, 2, 3] <class 'list'>
print(tu,type(tu)) #输出 [0, 1, 2, 3] <class 'tuple'>
print(st,type(st)) #输出 [0, 1, 2, 3] <class 'str'>55.slice() 函数
'''
描述
slice() 函数实现切片对象,主要用在切片操作函数里的参数传递。
语法
slice 语法:
class slice(stop)
class slice(start, stop[, step])
参数说明:
start -- 起始位置
stop -- 结束位置
step -- 间距
返回值
返回一个切片对象。
实例
'''myslice=slice(5) #设置一个 截取五个元素的切片
print(myslice) #输出 slice(None, 5, None)arr=list(range(10))
print(arr) #输出 [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
print(arr[myslice]) #输出 [0, 1, 2, 3, 4]print(arr[3:6]) #输出 [3, 4, 5]
56.sorted() 函数
'''
描述
sorted() 函数对所有可迭代的对象进行排序操作。
sort 与 sorted 区别:
sort 是应用在 list 上的方法,sorted 可以对所有可迭代的对象进行排序操作。
list 的 sort 方法返回的是对已经存在的列表进行操作,而内建函数 sorted 方法返回的是一个新的 list,而不是在原来的基础上进行的操作。
语法
sorted 语法:
sorted(iterable, key=None, reverse=False)
参数说明:
iterable -- 可迭代对象。
key -- 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse -- 排序规则,reverse = True 降序 , reverse = False 升序(默认)。
返回值
返回重新排序的列表。
'''print(sorted([2,3,4,1,5,6])) #输出 [1, 2, 3, 4, 5, 6]#另一个区别在于list.sort() 方法只为 list 定义。而 sorted() 函数可以接收任何的 iterable。
print(sorted({1: 'D', 2: 'B', 3: 'B', 4: 'E', 5: 'A'})) #输出 [1, 2, 3, 4, 5]#利用key进行倒序排序
example_list = [5, 0, 6, 1, 2, 7, 3, 4]
result_list = sorted(example_list, key=lambda x: x*-1)
print(result_list) #输出 [7, 6, 5, 4, 3, 2, 1, 0]#要进行反向排序,也通过传入第三个参数 reverse=True:
example_list = [5, 0, 6, 1, 2, 7, 3, 4]
result_list=sorted(example_list, reverse=True)
print(result_list) #输出 [7, 6, 5, 4, 3, 2, 1, 0]#sorted 的应用,也可以通过 key 的值来进行数组/字典的排序,比如
array = [{"age":20,"name":"a"},{"age":25,"name":"b"},{"age":10,"name":"c"}]
array = sorted(array,key=lambda x:x["age"])
print(array) #输出 [{'age': 10, 'name': 'c'}, {'age': 20, 'name': 'a'}, {'age': 25, 'name': 'b'}]
57.staticmethod()函数
'''
python staticmethod 返回函数的静态方法。
该方法不强制要求传递参数,如下声明一个静态方法:
class C(object):@staticmethoddef f(arg1, arg2, ...):...
以上实例声明了静态方法 f,类可以不用实例化就可以调用该方法 C.f(),当然也可以实例化后调用 C().f()。
函数语法
staticmethod(function)
参数说明:
无
'''class C(object):@staticmethoddef f():print('hello world')
C.f() # 静态方法无需实例化
cobj = C()
cobj.f() # 也可以实例化后调用class A(object):def foo(self, x):print("executing foo(%s,%s)" % (self, x))print('self:', self)@classmethoddef class_foo(cls, x):print("executing class_foo(%s,%s)" % (cls, x))print('cls:', cls)@staticmethoddef static_foo(x):print("executing static_foo(%s)" % x)
a = A()
print(a.foo) #输出 <bound method A.foo of <__main__.A object at 0x000001B5B2A51D30>>
print(a.class_foo) #输出 <bound method A.class_foo of <class '__main__.A'>>
print(a.static_foo) #输出 <function A.static_foo at 0x000001B5B2A55598>58.str() 函数
'''
描述
str() 函数将对象转化为适于人阅读的形式。
语法
以下是 str() 方法的语法:
class str(object='')
参数
object -- 对象。
返回值
返回一个对象的string格式。
'''print(str(1)) #输出 字符串1
print(type(str(1))) #输出 <class 'str'>
print(str(b'\xe5\xbc\xa0\xe4\xb8\x89',encoding='utf-8')) #输出张三dict={'zhangsan':'zhang1234','lisi':'li1234'}
print(type(dict)) #输出 <class 'dict'>
a=str(dict)
print(str(dict)) #输出 字符串 {'zhangsan': 'zhang1234', 'lisi': 'li1234'}
print(type(a)) #输出 <class 'str'>
59.sum()函数
'''
描述
sum() 方法对系列进行求和计算。
语法
以下是 sum() 方法的语法:
sum(iterable[, start])
参数
iterable -- 可迭代对象,如:列表、元组、集合。
start -- 指定相加的参数,如果没有设置这个值,默认为0。
返回值
返回计算结果
'''print(sum([0,1,2])) # 列表总和 3
print(sum((2,3,4),1)) # 元组计算总和后再加 1
print(sum([2,3,4,5,6],8)) # 列表计算总和后再加 2a = list(range(1,11))
b = list(range(1,10))
c = sum([item for item in a if item in b])
print(c) #输出 45
60.vars() 函数
'''
描述
vars() 函数返回对象object的属性和属性值的字典对象。
语法
vars() 函数语法:
vars([object])
参数
object -- 对象
返回值
返回对象object的属性和属性值的字典对象,如果没有参数,就打印当前调用位置的属性和属性值 类似 locals()。
'''print(vars())
#输出 {'__name__': '__main__', '__doc__': '\n描述\nvars() 函数返回对象object的属性和属性值的字典对象。\n语法\nvars() 函数语法:\nvars([object])\n参数\nobclass A:a=1__dict__ = 'ltf'
print(vars(A))
#输出 {'__module__': '__main__', 'a': 1, '__dict__': <attribute '__dict__' of 'A' objects>, '__weakref__': <attribute '__weakref__' of 'A' objects>, '__doc__': None}a=A()
print(vars(a))
#输出 ltfprint(a.__dict__)
#输出 ltf
61.zip()函数
#zip函数接受任意多个可迭代对象作为参数,将对象中对应的元素打包成一个tuple,然后返回一个可迭代的zip对象.
#这个可迭代对象可以使用循环的方式列出其元素
#若多个可迭代对象的长度不一致,则所返回的列表与长度最短的可迭代对象相同.#1.用列表生成zip对象
x=[1,2,3]
y=[4,5,6]
z=[7,8,9]
h=['a','b','c','d']
zip1=zip(x,y,z)
print(zip1)
for i in zip1:print(i)zip2=zip(x,y,h)
for i in zip2:print(i)zip3=zip(h)
for i in zip3:print(i)zip4=zip(*h*3)
for i in zip4:print(i) #这是干啥哟。。print('==*=='*10)
#2.二维矩阵变换
l1=[[1,2,3],[4,5,6],[7,8,9]]
print(l1)
print([[j[i] for j in l1] for i in range(len(l1[0])) ])
zip5=zip(*l1)
for i in zip5:print(i)
相关文章:

Python3内置函数大全
吐血整理 Python3内置函数大全 1.abs()函数2.all()函数3.any()函数4.ascii()函数5.bin()函数6.bool()函数7.bytes()函数8.challable()函数9.chr()函数10.classmethod()函数11.complex()函数12.complie()函数13.delattr()函数14.dict()函数15.dir()函数16.divmod()函数17.enumer…...

什么是“新型基础设施”?建设重点是什么?
一是信息基础设施。主要是指基于新一代信息技术演化生成的基础设施,比如,以5G、物联网、工业互联网、卫星互联网为代表的通信网络基础设施,以人工智能、云计算、区块链等为代表的新技术基础设施,以数据中心、智能计算中心为代表的…...
混杂接口模式---vlan
策略在两个地方可以用--1、重发布 2、bgp邻居 2、二层可以干的,三层也可以干 3、未知单播:交换机的MAC地址表的记录保留时间是5分钟,电脑的ARP表的记录保留时间是2小时 4、route recursive-lookup tunnel 华为默认对于bgp学习来的路由不开启标…...

Greenplum多级分区表添加分区报错ERROR: no partitions specified at depth 2
一般来说,我们二级分区表都会使用模版,如果没有使用模版特性,那么就会报ERROR: no partitions specified at depth 2类似的错误。因为没有模版,必须要显式指定分区。 当然我们在建表的时候,如果没有指定,那…...

EV PV AC SPI CPI TCPI
SPI EV / PV CPI EV / ACCPI 1.25 SPI 0.8 PV 10 000 BAC 100 000EV PV * SPI 10 000 * 0.8 8000 AC EV / CPI 8000 / 1.25 6400TCPI (BAC - EV) / (BAC -AC) (100 000 - 8 000) / (100 000 - 6 400) 92 000 / 93 600 0.98290598...

【电商领域】Axure在线购物商城小程序原型图,品牌自营垂直电商APP原型
作品概况 页面数量:共 60 页 兼容软件:Axure RP 9/10,不支持低版本 应用领域:网上商城、品牌自营商城、商城模块插件 作品申明:页面内容仅用于功能演示,无实际功能 作品特色 本作品为品牌自营网上商城…...
Cpp基础Ⅰ之编译、链接
1 C是如何工作的 工具:Visual Studio 1.1 预处理语句 在.cpp源文件中,所有#字符开头的语句为预处理语句 例如在下面的 Hello World 程序中 #include<iostream>int main() {std::cout <"Hello World!"<std::endl;std::cin.get…...
用户新增预测(Datawhale机器学习AI夏令营第三期)
文章目录 简介任务1:跑通Baseline实操并回答下面问题:如果将submit.csv提交到讯飞比赛页面,会有多少的分数?代码中如何对udmp进行了人工的onehot? 任务2.1:数据分析与可视化编写代码回答下面的问题…...
RGOS日常管理操作
RGOS日常管理操作 一、前言二、RGOS平台概述2.1、锐捷设备的常用登陆方式2.2、使用Console登入2.3、Telnet远程管理2.4、SSH远程管理2.5、登陆软件:SecureCRT 三、CLI命令行操作3.1、CLI命令行基础3.2、CLI模式3.3、CLI模式互换3.4、命令行特性3.4.1、分屏显示3.4.2…...
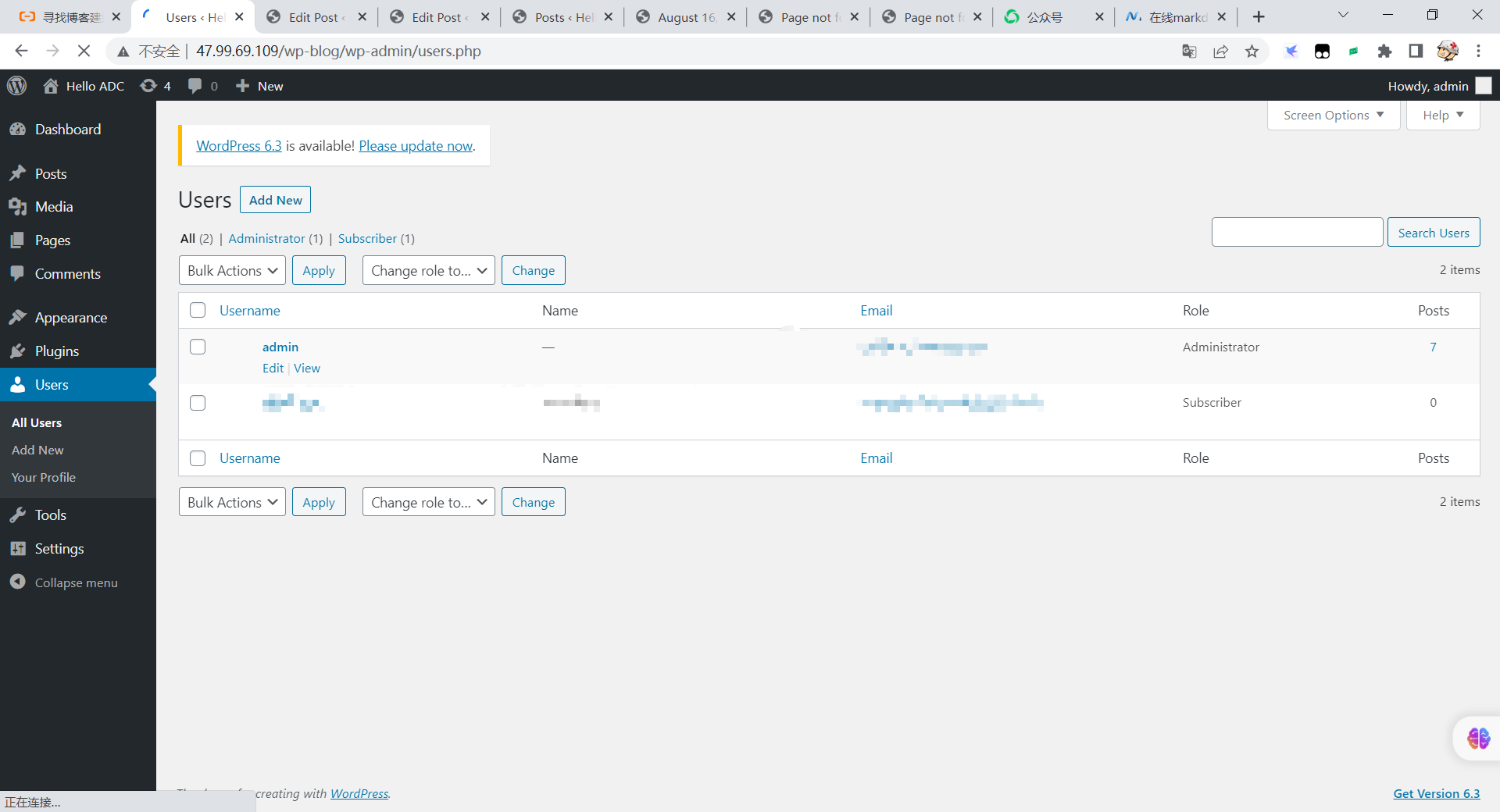
阿里云使用WordPress搭建个人博客
手把手教你使用阿里云服务器搭建个人博客 一、免费创建服务器实例 1.1 点击试用 点击试用会需要你创建服务器实例,直接选择默认的操作系统即可,点击下一步 1.2 修改服务器账号密码 二、创建云数据库实例 2.1 免费获取云数据库使用 2.2 实例列表页 在…...

供应链安全和第三方风险管理:讨论如何应对供应链中的安全风险,以及评估和管理第三方合作伙伴可能带来的威胁
第一章:引言 在当今数字化时代,供应链的安全性越来越受到重视。企业的成功不仅仅依赖于产品和服务的质量,还取决于供应链中的安全性。然而,随着供应链越来越复杂,第三方合作伙伴的参与也带来了一系列安全风险。本文将…...

《Java极简设计模式》第04章:建造者模式(Builder)
作者:冰河 星球:http://m6z.cn/6aeFbs 博客:https://binghe.gitcode.host 文章汇总:https://binghe.gitcode.host/md/all/all.html 源码地址:https://github.com/binghe001/java-simple-design-patterns/tree/master/j…...
Go download
https://go.dev/dl/https://golang.google.cn/dl/...
)
2023年Java核心技术面试第四篇(篇篇万字精讲)
目录 八. 对比Vector,ArrayList, LinkedList有何区别? 8.1 典型回答 8.1.1 Vector: 8.1.2 ArrayList : 8.1.3 LinkedList 8.2 考察点分析: 8.2.1 不同容器类型适合的场景 八. 对比Vector,ArrayList, Linke…...

数字化时代,数据仓库和商业智能BI系统演进的五个阶段
数字化在逐渐成熟的同时,社会上也对数字化的性质有了进一步认识。当下,数字化除了前边提到的将复杂的信息、知识转化为可以度量的数字、数据,在将其转化为二进制代码,引入计算机内部,建立数据模型,统一进行…...
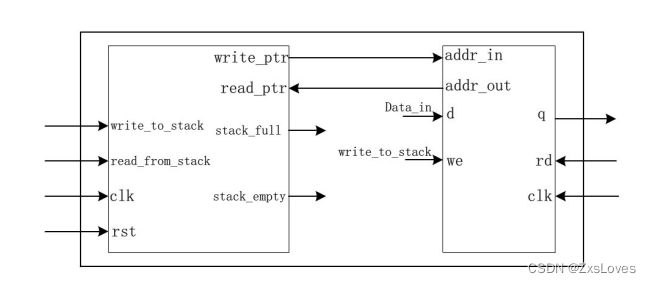
【【Verilog典型电路设计之FIFO设计】】
典型电路设计之FIFO设计 FIFO (First In First Out)是一种先进先出的数据缓存器,通常用于接口电路的数据缓存。与普通存储器的区别是没有外部读写地址线,可以使用两个时钟分别进行写和读操作。FIFO只能顺序写入数据和顺序读出数据࿰…...
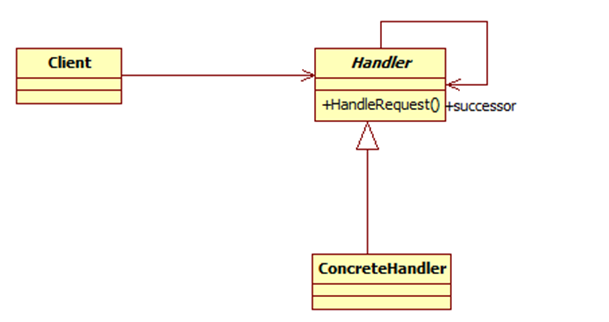
JAVA设计模式总结之23种设计模式
一、什么是设计模式 设计模式(Design pattern)是一套被反复使用、多数人知晓的、经过分类编目的、代码设计…...
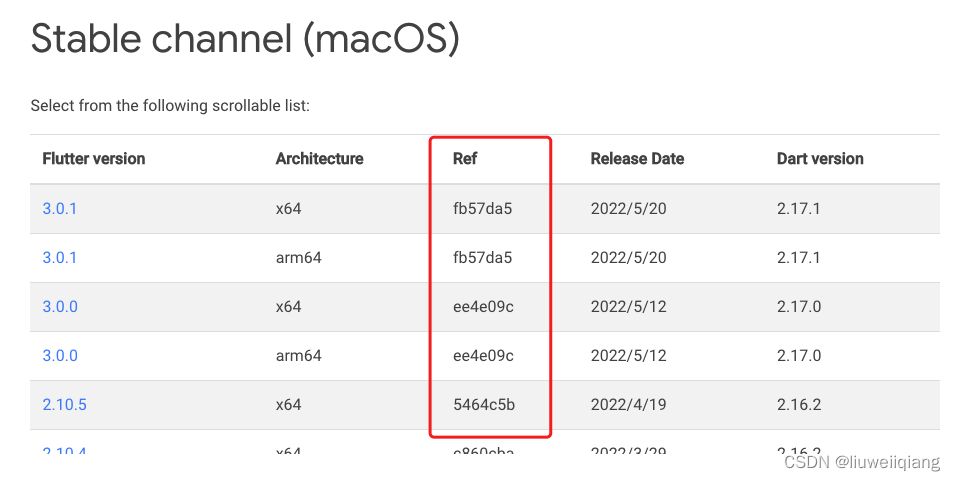
Flutter 测试小结
Flutter 项目结构 pubspec.yaml 类似于 RN 的 package.json,该文件分别在最外层及 example 中有,更新该文件后,需要执行的 Pub get lib 目录下的 dart 文件为 Flutter 插件封装后的接口源码,方便在其他 dart 文件中调用 example 目…...

docker build -t 和 docker build -f 区别
docker build 是用于构建Docker镜像的命令,它允许你基于一个Dockerfile来创建一个镜像。在 docker build 命令中,有两个常用的选项 -t 和 -f,它们有不同的作用。 -t’选项: -t’选项用于指定构建出来的镜像的名称和标签。格式为 &…...

Java 项目日志实例基础:Log4j
点击下方关注我,然后右上角点击...“设为星标”,就能第一时间收到更新推送啦~~~ 介绍几个日志使用方面的基础知识。 1 Log4j 1、Log4j 介绍 Log4j(log for java)是 Apache 的一个开源项目,通过使用 Log4j,我…...

【Python】 -- 趣味代码 - 小恐龙游戏
文章目录 文章目录 00 小恐龙游戏程序设计框架代码结构和功能游戏流程总结01 小恐龙游戏程序设计02 百度网盘地址00 小恐龙游戏程序设计框架 这段代码是一个基于 Pygame 的简易跑酷游戏的完整实现,玩家控制一个角色(龙)躲避障碍物(仙人掌和乌鸦)。以下是代码的详细介绍:…...

智慧医疗能源事业线深度画像分析(上)
引言 医疗行业作为现代社会的关键基础设施,其能源消耗与环境影响正日益受到关注。随着全球"双碳"目标的推进和可持续发展理念的深入,智慧医疗能源事业线应运而生,致力于通过创新技术与管理方案,重构医疗领域的能源使用模式。这一事业线融合了能源管理、可持续发…...

Unity3D中Gfx.WaitForPresent优化方案
前言 在Unity中,Gfx.WaitForPresent占用CPU过高通常表示主线程在等待GPU完成渲染(即CPU被阻塞),这表明存在GPU瓶颈或垂直同步/帧率设置问题。以下是系统的优化方案: 对惹,这里有一个游戏开发交流小组&…...

C++八股 —— 单例模式
文章目录 1. 基本概念2. 设计要点3. 实现方式4. 详解懒汉模式 1. 基本概念 线程安全(Thread Safety) 线程安全是指在多线程环境下,某个函数、类或代码片段能够被多个线程同时调用时,仍能保证数据的一致性和逻辑的正确性…...

python执行测试用例,allure报乱码且未成功生成报告
allure执行测试用例时显示乱码:‘allure’ �����ڲ����ⲿ���Ҳ���ǿ�&am…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...
集成 Mybatis-Plus 和 Mybatis-Plus-Join)
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join
纯 Java 项目(非 SpringBoot)集成 Mybatis-Plus 和 Mybatis-Plus-Join 1、依赖1.1、依赖版本1.2、pom.xml 2、代码2.1、SqlSession 构造器2.2、MybatisPlus代码生成器2.3、获取 config.yml 配置2.3.1、config.yml2.3.2、项目配置类 2.4、ftl 模板2.4.1、…...

Golang——6、指针和结构体
指针和结构体 1、指针1.1、指针地址和指针类型1.2、指针取值1.3、new和make 2、结构体2.1、type关键字的使用2.2、结构体的定义和初始化2.3、结构体方法和接收者2.4、给任意类型添加方法2.5、结构体的匿名字段2.6、嵌套结构体2.7、嵌套匿名结构体2.8、结构体的继承 3、结构体与…...

解决:Android studio 编译后报错\app\src\main\cpp\CMakeLists.txt‘ to exist
现象: android studio报错: [CXX1409] D:\GitLab\xxxxx\app.cxx\Debug\3f3w4y1i\arm64-v8a\android_gradle_build.json : expected buildFiles file ‘D:\GitLab\xxxxx\app\src\main\cpp\CMakeLists.txt’ to exist 解决: 不要动CMakeLists.…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...