自动执行探索性数据分析 (EDA),更快、更轻松地理解数据
一、说明

摄影:Charlotte Karlsen on Unsplash
二、什么是 EDA?
EDA是 exploratory data analysis (探索性数据分析 )的缩写。那么什么叫探索性数据分析?就是在进行正式分析前,将一些先验性信息探索出来。比如,数据分布属于哪个类型。
EDA是我们需要做的最重要的事情之一,作为更好地理解数据集的方法。几乎所有数据分析或数据科学专业人员在生成见解或进行数据建模之前都会执行此过程。在现实生活中,这个过程花费了很多时间,这取决于我们拥有的数据集的复杂性和完整性。当然,更多的变量会让我们在执行后续步骤之前进行更多探索,以获得所需的摘要。
这就是为什么使用R或Python(最常见的编程语言)进行数据分析的原因,一些包有助于更快,更轻松地完成该过程,但不是更好。为什么不更好?因为它只向我们展示了一个摘要,在我们专注于更深入地探索我们认为“有趣”的任何变量之前。
“80/20法则”适用:数据分析师或科学家80%的宝贵时间都花在查找、清理和组织数据上,只剩下20%用于执行分析。
三、在R语言中处理
2.1使用哪些库?
在 R 中,我们可以使用以下库:
dataMaidDataExplorerSmartEDA
在 Python 中,我们可以使用这些库:
ydata-profilingdtalesweetvizautoviz
让我们尝试上面列出的每个库,以了解它们的外观以及它们如何帮助我们进行探索性数据分析!在这篇文章中,我将使用通常用于学习如何在R或Python中编码的数据集。iris
在 R 中,可以使用以下代码加载数据集:iris
# iris is part of R's default, no need to load any packages
df = iris
# use "head()" to show the first 6 rows
head(df)
在 Python 中,您可以使用以下代码加载数据集:iris
# need to import these things first
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# use load_iris
iris = load_iris()
# convert into a pandas data frame
df = pd.DataFrame(data= np.c_[iris['data'], iris['target']], columns= iris['feature_names'] + ['species']
)
# set manually the species column as a categorical variable
df['species'] = pd.Categorical.from_codes(iris.target, iris.target_names)
# use ".head()" to show the first 5 rows
df.head()
图像 2.在 Python 中加载“鸢尾花”数据集
2.2 R:datamaid
首先,我们需要执行下面的简单代码:
# install the dataMaid library
install.packages("dataMaid")
# load the dataMaid library
library(dataMaid)
# use makeDataReport with HTML as output
makeDataReport(df, output = "html", replace = TRUE) 从第一个快照(图 3)中,我们已经获得了有关数据集的大量信息:iris
- 观测值数为 150。
- 变量数为 5。
- 根据每个变量的数据类型执行变量检查,例如识别错误编码的缺失值、具有 6 个 obs <的水平和异常值。

图像 3.使用鸢尾花数据集的“dataMaid”创建的报表的第一个快照
从第二个快照(图 4):
- 变量的汇总表包括变量类、唯一值、缺失观测值以及检测到的任何问题。我们可以看到,变量检测到了问题。
Sepal.WidthPetal.Length Sepal.Length提供了包括直方图在内的中心测量值,为我们提供了单变量分布。Sepal.Width具有列出的可能异常值。这就是摘要表显示检测到问题的原因。

图像 4.使用鸢尾花数据集的“dataMaid”创建的报表的第二个快照
从第三个快照(图 5):
Petal.Length具有列出的可能异常值。Petal.Width提供了包括直方图在内的中心测量值,为我们提供了单变量分布。Species作为目标变量检测为 a,并且每种类型的数据计数相等,即 50。factor

图像 5.使用鸢尾花数据集的“dataMaid”创建的报表的第三个快照
基于上面在 R 中创建的数据报告,我们已经通过执行一行代码获得了有关数据集的大量信息。😃dataMaidiris
2.3 R:数据资源管理器
首先,我们需要执行下面的简单代码:
# install the DataExplorer library
install.packages("DataExplorer")
# load the DataExplorer library
library(DataExplorer)
# use create_report
create_report(df)从第一个到第六个快照(图像 6、7、8、9、10、11),我们得到的信息与以前的包没有太大区别。

图像 6.使用鸢尾花数据集的“数据资源管理器”创建的报表的第一个快照

图像 7.使用鸢尾花数据集的“数据资源管理器”创建的报表的第二个快照

图像 8.使用鸢尾花数据集的“数据资源管理器”创建的报表的第三个快照

图像 9.使用鸢尾花数据集的“数据资源管理器”创建的报表的第四个快照

图像 10.使用鸢尾花数据集的“数据资源管理器”创建的报表的第五个快照

图像 11.使用鸢尾花数据集的“数据资源管理器”创建的报表的第六个快照
从第七个快照(图 12)中,我们得到了数据集中每个数值变量的 QQ 图。iris

图像 12.使用鸢尾花数据集的“数据资源管理器”创建的报表的第七个快照
从第八张快照(图 13)中,我们得到了数据集中每个变量的相关矩阵。我们可以看到一些信息,例如:iris
Petal.Width并且具有0.96的强正相关性,这意味着在数据集中,花瓣宽度越宽,花瓣长度越长。Petal.LengthirisSpecies_setosa并且具有-0.92的强负相关,这意味着在数据集中,花瓣长度越短,该物种是setosa的可能性就越高。Petal.Lengthiris- 使用上述示例,请使用此相关矩阵提供您的发现。

图像 13.使用鸢尾花数据集的“数据资源管理器”创建的报表的第八个快照
从第九个快照(图14)开始,使用主成分分析(PCA),提供了解释的方差百分比,它显示62%,越高越好。对于PCA的解释,我想我需要另一篇文章。😆

图像 14.使用鸢尾花数据集的“数据资源管理器”创建的报表的第九个快照
从第十个快照(图15)开始,仍然使用主成分分析(PCA),提供了每个变量的相对重要性,它显示具有最高百分比,几乎为0.5。Petal.Length

图像 15.使用鸢尾花数据集的“数据资源管理器”创建的报表的第十个快照
2.4 R: 智能EDA
首先,我们需要执行下面的简单代码:
# install the SmartEDA library
install.packages("SmartEDA")
# load the SmartEDA library
library(SmartEDA)
# use ExpReport
ExpReport(df, op_file = 'SmartEDA_df.html')从图 16、17、18、23 和 24 中,我们得到的信息与之前的包没有太大区别。
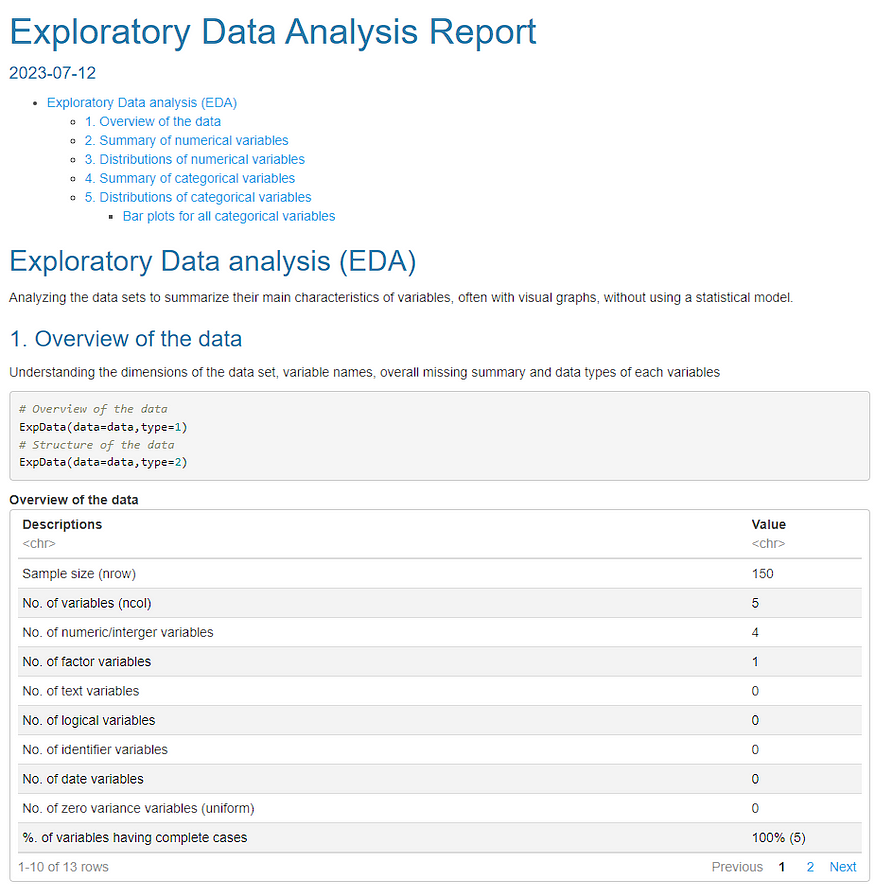
图像 16。使用鸢尾花数据集的“SmartEDA”创建的报告的第一个快照

图像 17.使用虹膜数据集的“SmartEDA”创建的报告的第二个快照

图片 18.使用虹膜数据集的“SmartEDA”创建的报告的第三个快照
从图 19 中,向我们展示了每个变量的密度图,包括偏度和峰度测量值,用于告诉我们数据是否呈正态分布。偏度和峰度的解释也需要另一篇文章,我猜 😅

图片 19.使用虹膜数据集的“SmartEDA”创建的报告的第四个快照
从图 20、21 和 22 中,向我们展示了数据集中可用的数值变量之间的散点图,直观地告诉我们相关性。它为我们提供了与数字格式的相关矩阵类似的信息。iris

图像 20.使用虹膜数据集的“SmartEDA”创建的报告的第五个快照

图像 21.使用虹膜数据集的“SmartEDA”创建的报告的第六个快照

图像 22.使用虹膜数据集的“SmartEDA”创建的报告的第七个快照

图像 23。使用鸢尾花数据集的“SmartEDA”创建的报告的第九个快照
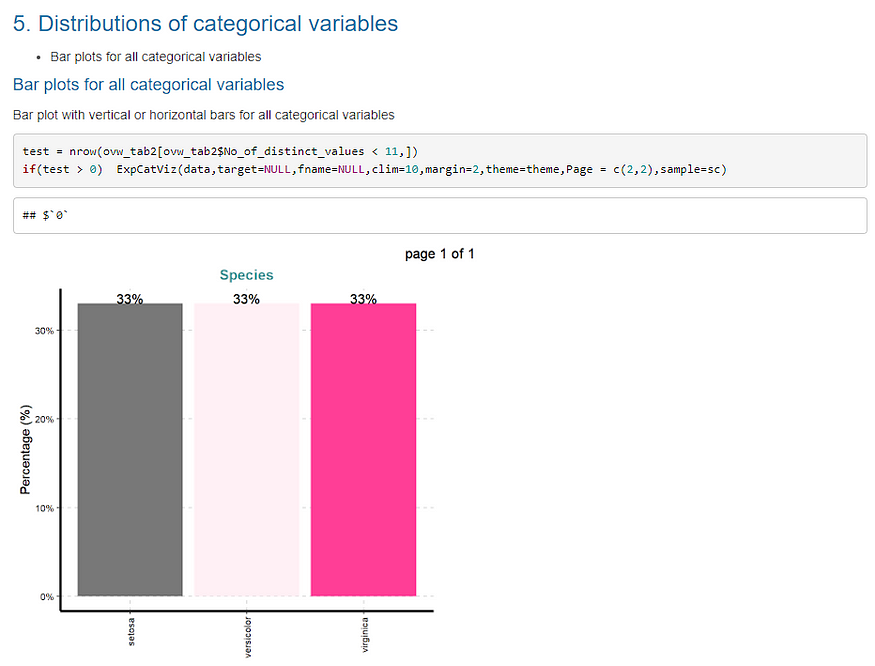
图片 24.使用虹膜数据集的“SmartEDA”创建的报告的第十个快照
2.5 R:结论
使用上面的三个包,我们获得了有关数据集的大量信息,比我们尝试手动创建数据集要快得多,但这还不够,这就是为什么我在标题中说“......更快、更容易...“,因为它只能让我们一瞥数据集,但至少它给了我们可以开始处理哪些事情,而不是寻找起点,例如:irisiris
- 没有缺失的变量/没有错误编码的变量,我们可以跳过这些步骤。
- 在某些变量中检测到异常值,我们可以通过使用任何适当的方法来开始清理数据来处理异常值,而不是手动逐个查找哪些变量具有异常值。
- 如果需要,我们可以开始处理非正态分布的变量。
- 根据相关矩阵和散点图,我们瞥见了哪些变量具有强相关性或弱相关性。
- 使用 PCA,我们知道解释的变量百分比和数据集的相对重要性。
iris
四、Python语言的处理
4.1 Python:ydata-profiling
首先,我们需要执行下面的简单代码:
# install the ydata-profiling package
pip install ydata-profiling
# load the ydata_profiling package
from ydata_profiling import ProfileReport
# use ProfileReport
pr_df = ProfileReport(df)
# show pr_df
pr_df大多数情况下,它显示类似的信息。我将尝试提及一些与以前的软件包完全不同的信息:
- 在图 26 中,我们得到了关于哪些变量具有高度相关性的句子摘要。
- 总体而言,与以前的包相比,输出更具交互性,因为我们可以单击以移动到其他选项卡,并选择要显示的特定列。
图片 25.使用鸢尾花数据集的“ydata_profiling”创建的报表的第一个快照

图像 26。使用鸢尾花数据集的“ydata_profiling”创建的报表的第二个快照

图像 27.使用鸢尾花数据集的“ydata_profiling”创建的报表的第三个快照

图像 28.使用鸢尾花数据集的“ydata_profiling”创建的报表的第四个快照

图像 29.使用鸢尾花数据集的“ydata_profiling”创建的报表的第五个快照

图像 30.使用鸢尾花数据集的“ydata_profiling”创建的报表的第六个快照
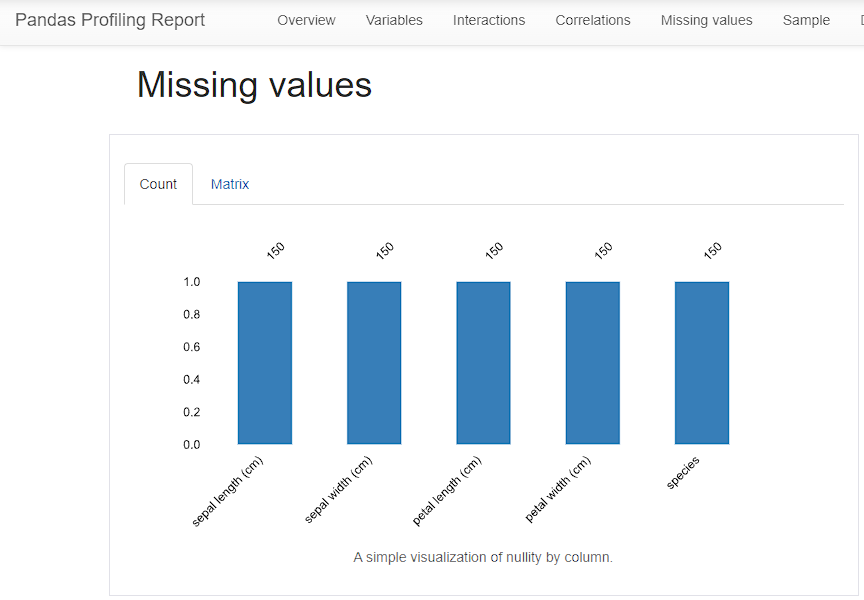
图片 31.使用鸢尾花数据集的“ydata_profiling”创建的报表的第七个快照

图像 32.使用鸢尾花数据集的“ydata_profiling”创建的报表的第八个快照

图像 33.使用鸢尾花数据集的“ydata_profiling”创建的报表的第九个快照
4.2 Python: dtale
首先,我们需要执行下面的简单代码:
# install the dtale package
pip install dtale
# load the dtale
import dtale
# use show
dtale.show(df)这个包的输出和以前的包有很大的不同,在如何使用方面,内容也差不多,但是让我们可以更好地探索。

图像 34.使用鸢尾花数据集的“dtale”创建的报表的第一个快照

图像 35。使用鸢尾花数据集的“dtale”创建的报表的第二个快照

图像 36.使用鸢尾花数据集的“dtale”创建的报表的第三个快照

图像 37.使用鸢尾花数据集的“dtale”创建的报表的第四个快照
4.3 Python: sweetviz
首先,我们需要执行下面的简单代码:
# install the sweetviz package
pip install sweetviz
# load the sweetviz
import sweetviz
# use analyze
analyze_df = sweetviz.analyze([df, "df"], target_feat = 'species')
# then show
analyze_df.show_html('analyze.html')使用这个包,UI和UX有很大的不同,请欣赏表演!

图像 38.使用鸢尾花数据集的“甜可视化”创建的报表的第一个快照

图像 39.使用鸢尾花数据集的“甜美可视化”创建的报表的第二个快照
人类是视觉生物,这意味着人脑处理图像的速度比文本快60万倍,传输到大脑的信息中有000%是视觉的。可视化信息使协作变得更加容易,并产生影响组织绩效的新想法。这是数据分析师将最大时间花在数据可视化上的唯一原因。
4.4 Python: autoviz
首先,我们需要执行下面的简单代码:
# install the dtale package
pip install autoviz
# load the autoviz
from autoviz import AutoViz_Class
# set AutoViz_Class()
av = AutoViz_Class()
# produce AutoVize_Class of df
avt = av.AutoViz("",sep = ",",depVar = "",dfte = df,header = 0,verbose = 1,lowess = False,chart_format = "server",max_rows_analyzed = 10000,max_cols_analyzed = 10,save_plot_dir=None
)使用上面的代码,在浏览器中生成一些选项卡。我们可以使用此包看到的新内容:
- 输出在浏览器中的多个选项卡中生成,以前的包在一个选项卡中显示所有输出。
- 每个变量的小提琴图。它是箱线图和核密度图的混合版本。与以前的包相比,仍然显示类似的信息。

图像 40.使用鸢尾花数据集的“autoviz”创建的报表的第一个快照

图像 41.使用鸢尾花数据集的“autoviz”创建的报表的第二个快照

图像 41.使用鸢尾花数据集的“autoviz”创建的报表的第三个快照

图像 42.使用鸢尾花数据集的“autoviz”创建的报表的第四个快照
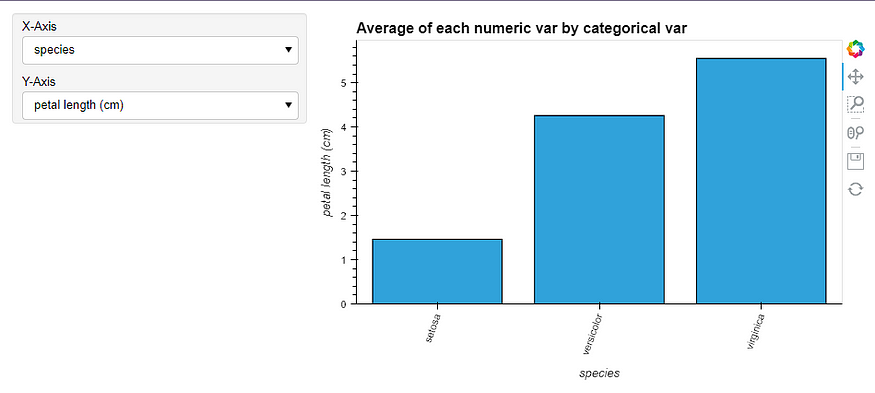
图像 43.使用鸢尾花数据集的“autoviz”创建的报表的第五个快照
4.5 Python:结论
使用上面的四个包,我们得到了很多关于数据集的信息,与R包相比没有太大的区别,但是当有更多的视角通常比拥有更少的视角更好时。一些注意事项:iris
- 与 R 包相比,Python 包的输出大多更具交互性。
- 安装软件包时,可能会出现一些错误。对于 ,常见的错误是 about 和 。您可以通过参考这篇文章来获得解决方案。
dtalejinjaescape - 在某些包中,代码不像在R包中那么简单,但我认为这不是一个大问题,只要我们不懒惰地阅读手动指令,我认为一切都很好。
五、结论
我必须使用哪一个?哪一个是最好的?哪一个与我的数据集最兼容?
这要看情况。我认为我们可以减少我们需要做EDA的时间已经是一件好事了。让我们尝试探索上面解释的每个包并明智地使用它,而不是作为主要解决方案。 以我的拙见,探索数据应该是数据分析的“有趣”部分,所以不要害怕通过手动进行EDA来“弄脏”,有时非自动化方法仍然是最好的。
相关文章:
自动执行探索性数据分析 (EDA),更快、更轻松地理解数据
一、说明 EDA是 exploratory data analysis (探索性数据分析 )的缩写。所谓EDA就是在数据分析之前需要对数据进行以此系统性研判,在这个研判后,得到基本的数据先验知识,在这个基础上进行数据分析。本文将在R语言和python语言的探索性处理。 摄…...

【自定义系统服务】【android13】添加自定义java系统服务
背景 在平时的业务开发中,我们往往需要开发自定义的系统服务来处理自己特殊的需求,这里介绍的是添加自定义的Java系统服务,可以在系统App中直接调用 定义aidl Binder默认可以传输基本类型的数据,如果要传递类对象,则这个类需要实现序列化。我们先定义一个序列化的自定义…...
)
【Sklearn】基于随机梯度下降算法的数据分类预测(Excel可直接替换数据)
【Sklearn】基于随机梯度下降算法的数据分类预测(Excel可直接替换数据) 1.模型原理2.模型参数3.文件结构4.Excel数据5.下载地址6.完整代码7.运行结果1.模型原理 随机梯度下降(Stochastic Gradient Descent,SGD)是一种优化算法,用于训练模型的参数以最小化损失函数。在分…...
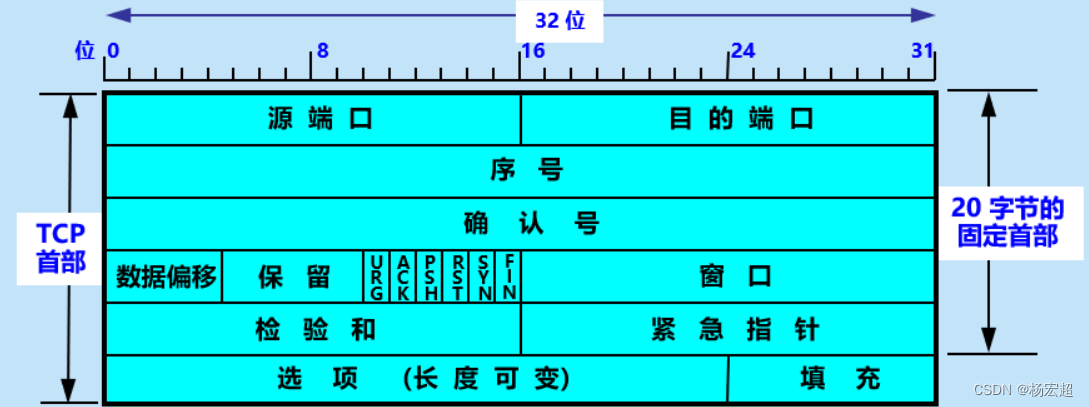
44、TCP报文(二)
接上节内容,本节我们继续TCP报文首部字段含义的学习。上节为止我们学习到“数据偏移”和“保留”字段。接下来我们学习后面的一些字段(暂不包含“检验和”的计算方法和选项字段)。 TCP首部结构(续) “数据偏移”和“保…...
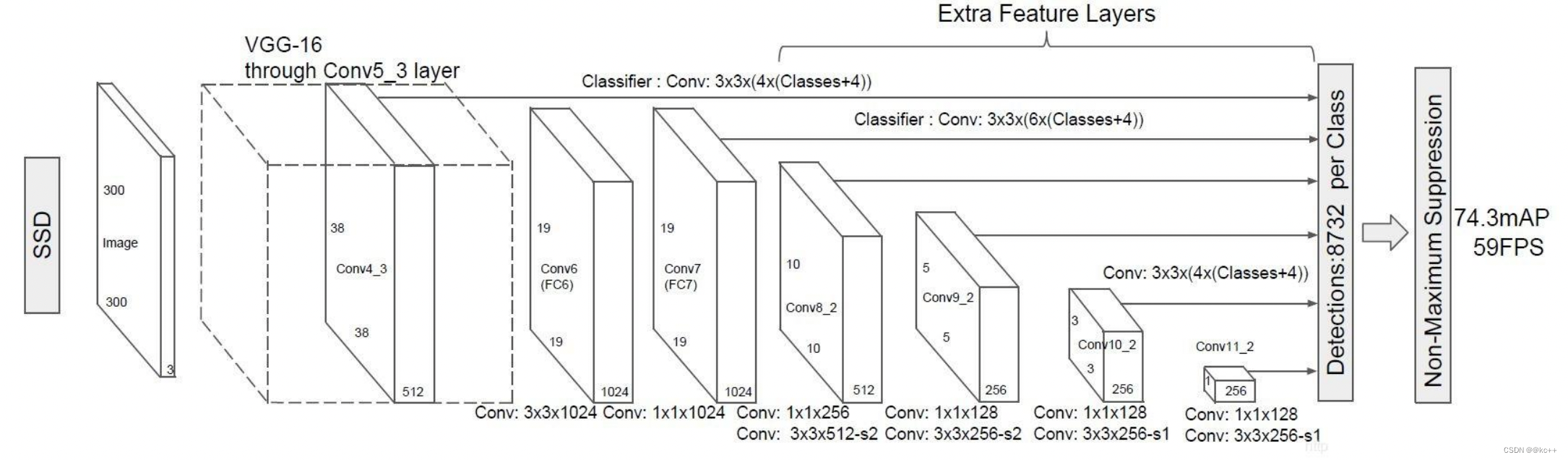
目标检测(Object Detection)
文章目录 1. 目标检测1.1 目标检测简要概述及名词解释1.2 IOU1.3 TP TN FP FN1.4 precision(精确度)和recall(召回率) 2. 边框回归Bounding-Box regression3. Faster R-CNN3.1 Faster-RCNN:conv layer3.2 Faster-RCNN&…...
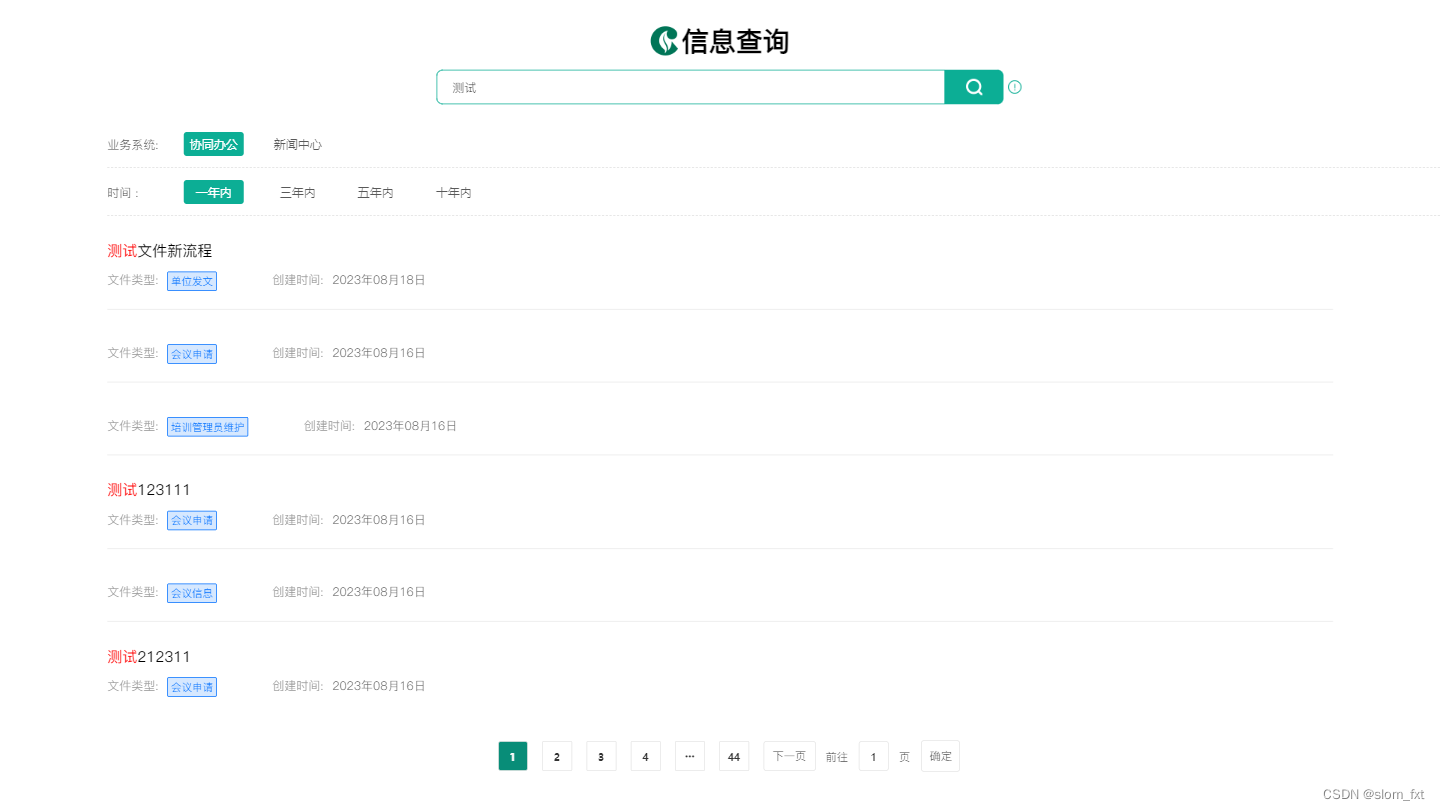
vue中实现文字检索时候将搜索内容标红
实现结果 html: <div class"searchBox"><span class"bt">标  题</span><div class"search"><div class"shuru"><!-- <span class"title">生产经营<…...

PCL protocol composition logic
PCL 协议组合逻辑 一 主体(principal)和线程(thread)的区分 1.主体:指 **协议的参与者,用X^来表示。**每个主体可以扮演一个或多个角色,如 InitCR和RespCR ; 2.线程:主…...
聊聊看React和Vue的区别
Vue 更适合小项目,React 更适合大公司大项目; Vue 的学习成本较低,很容易上手,但项目质量不能保证...... 真的是这样吗?借助本篇文章,我们来从一些方面的比较来客观的去看这个问题。 论文档的丰富性 从两个…...
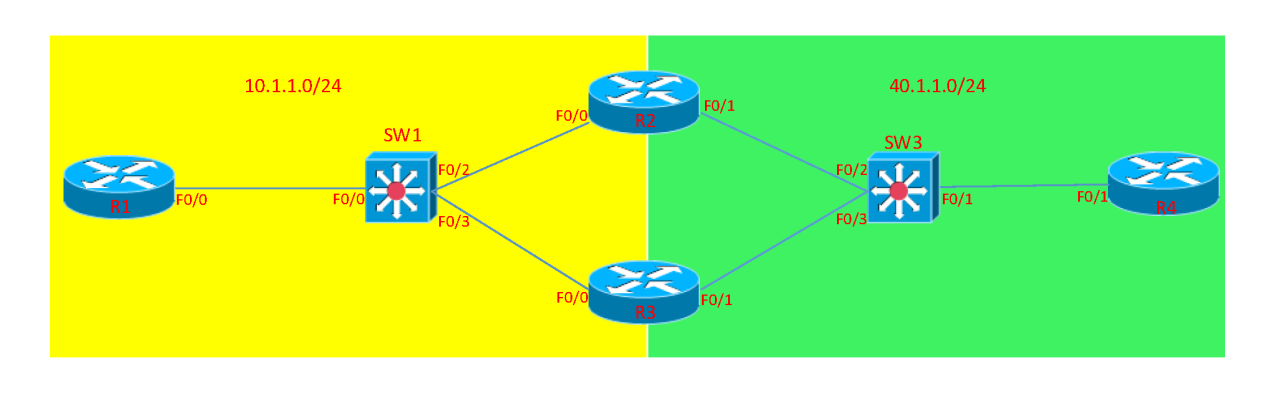
OSPF在广播类型的网络拓扑中DR和BDR的选举
指定路由器(DR): 一个网段上的其他路由器都和指定路由器(DR)构成邻接关系,而不是它们互相之间构成邻接关系。 备份指定路由器(BDR): 当DR出现问题,由BDR接…...
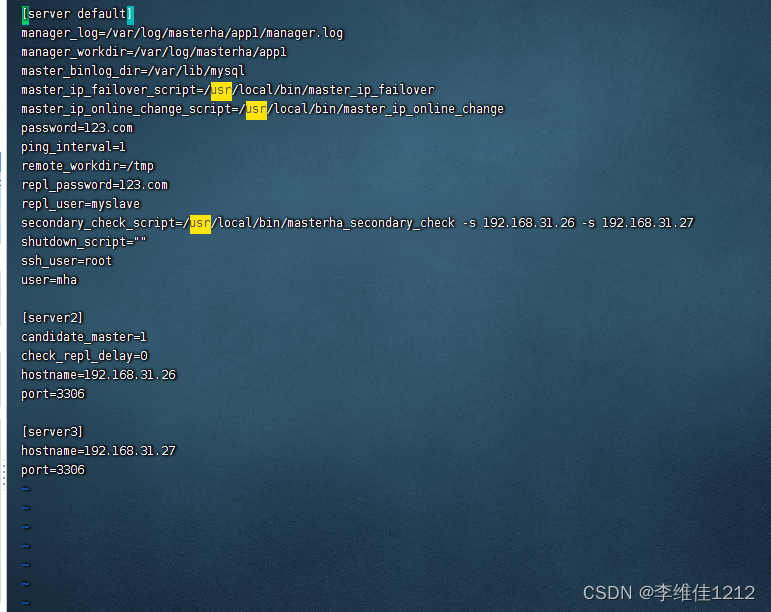
系统学习Linux-Mariadb高可用MHA
概念 MHA(MasterHigh Availability)是一套优秀的MySQL高可用环境下故障切换和主从复制的软件。 MHA 的出现就是解决MySQL 单点的问题。 MySQL故障切换过程中,MHA能做到0-30秒内自动完成故障切换操作。 MHA能在故障切换的过程中最大程度上…...

慢SQL的原因
如何排查慢SQL问题 识别慢SQL:使用数据库性能监控工具,如慢SQL日志,识别耗时较长的查询。执行计划分析:使用数据库提供的分析工具,例如EXPLAIN来查看查询的执行计划,判断是否存在全表扫描,索引…...

php正则替换文章的图片
要使用正则表达式替换文章中的图片链接,可以按照以下步骤进行操作: 1. 获取文章内容:首先,你需要获取包含图片链接的文章内容。你可以从文件中读取文章,或者从数据库中检索文章内容。 2. 使用正则表达式匹配图片链接…...

57 | TAPTAP客户端分析
TAPTAP客户端分析 一、用户群分析 首先,TapTap用户群可分为三大类: 游戏爱好者游戏发烧者游戏开发者(次要用户,有开发者后台,可以显示数据,不重点分析)注:爱好者与发烧者区别在于,前者是用空余时间来玩游戏,时间不如后者充足,且后者更执着于游戏,游戏种类更多。 …...
开源了一套基于springboot+vue+uniapp的商城,包含分类、sku、商户管理、分销、会员、适合企业或个人二次开发
RuoYi-Mall-JAVA商城-电商系统简介 开源了一套基于若依框架,SringBoot2MybatisPlusSpringSecurityjwtredisVueUniapp的前后端分离的商城系统, 包含分类、sku、商户管理、分销、会员、适合企业或个人二次开发。 前端采用Vue、Element UI(ant…...
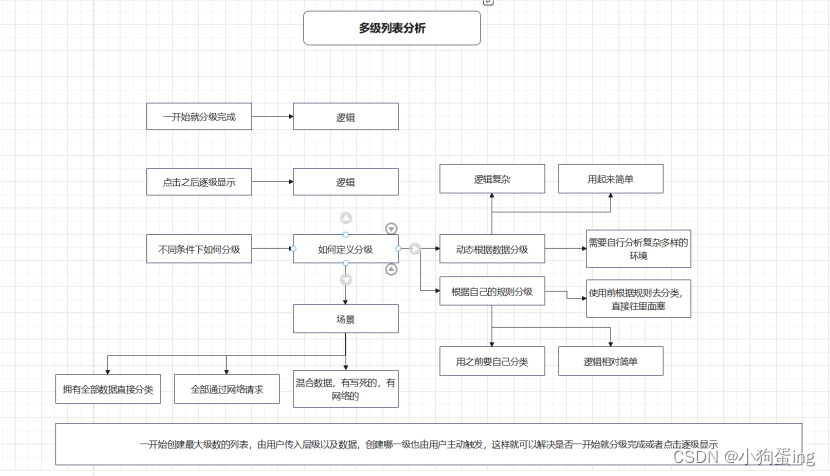
Android进阶之多级列表
遇到一个需求需要显示多级列表,因为界面是在平板上的,所以层级是从左向右往下排的,类似于 我当时的写法是在xml布局里一个个RecyclerView往下排的 当然前提是已经规定好最大的层级我才敢如此去写界面,如果已经明确规定只有两级或…...

Stochastic: Distribution-Expectation-Inequalities
见:https://www.math.hkust.edu.hk/~makchen/MATH5411/Chap1Sec2.pdf...
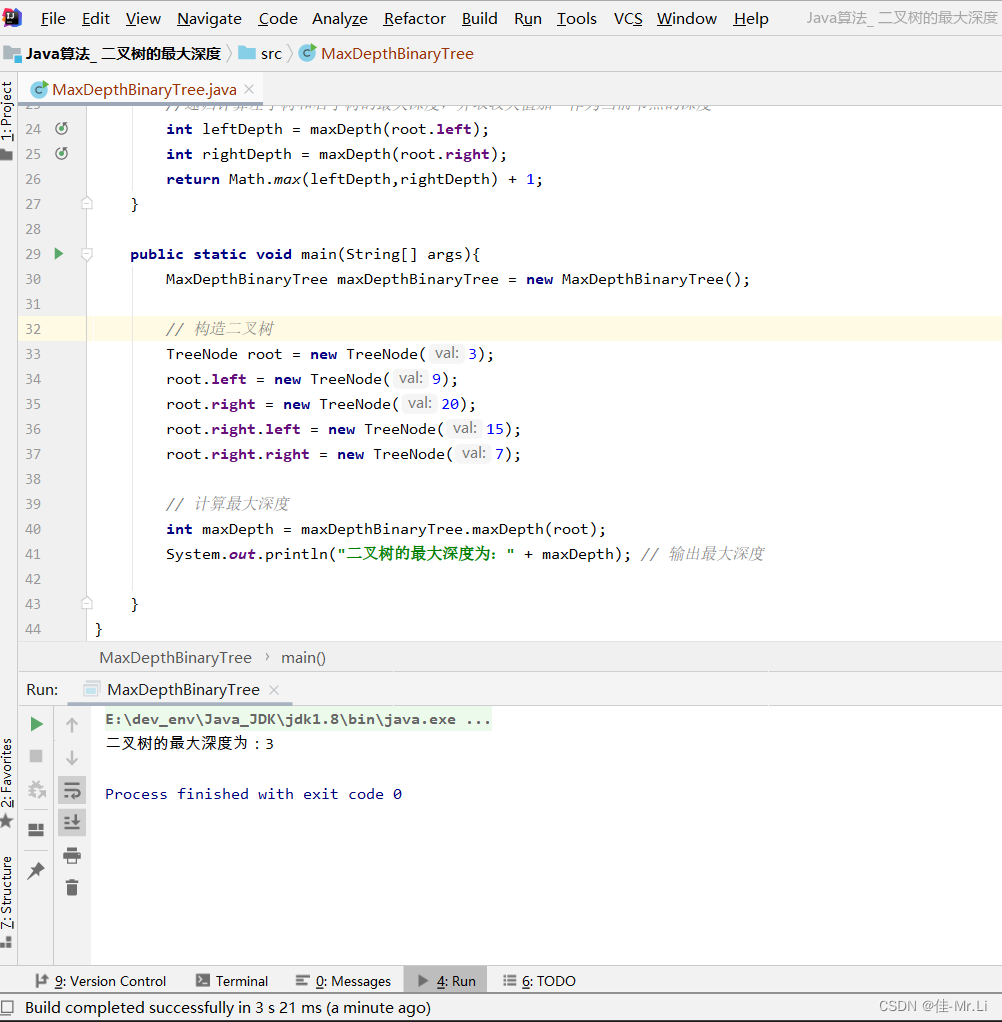
Java算法_ 二叉树的最大深度(LeetCode_Hot100)
题目描述:给定一个二叉树 ,返回其最大深度。root 二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。 获得更多?算法思路:代码文档,算法解析的私得。 运行效果 完整代码 /*** 2 * Author: LJJ* 3 * Date: 2023/…...
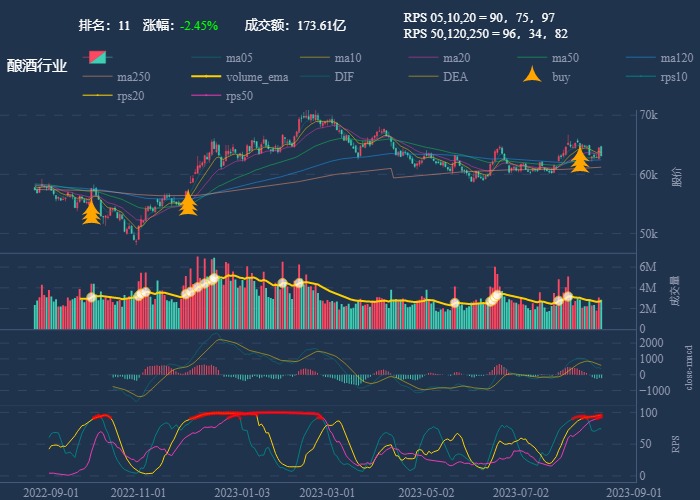
行业追踪,2023-08-18
自动复盘 2023-08-18 凡所有相,皆是虚妄。若见诸相非相,即见如来。 k 线图是最好的老师,每天持续发布板块的rps排名,追踪板块,板块来开仓,板块去清仓,丢弃自以为是的想法,板块去留让…...

js将项目中的图片上传到服务器
项目上有时候会有奇怪的需求,比如前端有一些示例,想点击按钮就能上传图片,而这个图片是在前端的项目中的,如果不上传吧,又获取不到一些业务数据的id,但后端又不想为这块功能做特殊的处理,这时想通过前端直接上传到后端,需要file对象才可以。 这个时候我们需要将img转换…...
【C语言】指针的进阶
目录 一、字符指针 二、指针数组 三、数组指针 1.数组指针的定义 2.&数组名和数组名区别 3.数组指针的使用 四、数组参数与指针参数 1.一维数组传参 2.二维数组传参 3.一级指针传参 4.二级指针传参 五、函数指针 六、函数指针数组 七、指向函数指针数组的指针…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

多云管理“拦路虎”:深入解析网络互联、身份同步与成本可视化的技术复杂度
一、引言:多云环境的技术复杂性本质 企业采用多云策略已从技术选型升维至生存刚需。当业务系统分散部署在多个云平台时,基础设施的技术债呈现指数级积累。网络连接、身份认证、成本管理这三大核心挑战相互嵌套:跨云网络构建数据…...

k8s从入门到放弃之Ingress七层负载
k8s从入门到放弃之Ingress七层负载 在Kubernetes(简称K8s)中,Ingress是一个API对象,它允许你定义如何从集群外部访问集群内部的服务。Ingress可以提供负载均衡、SSL终结和基于名称的虚拟主机等功能。通过Ingress,你可…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...
)
相机Camera日志分析之三十一:高通Camx HAL十种流程基础分析关键字汇总(后续持续更新中)
【关注我,后续持续新增专题博文,谢谢!!!】 上一篇我们讲了:有对最普通的场景进行各个日志注释讲解,但相机场景太多,日志差异也巨大。后面将展示各种场景下的日志。 通过notepad++打开场景下的日志,通过下列分类关键字搜索,即可清晰的分析不同场景的相机运行流程差异…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

JVM 内存结构 详解
内存结构 运行时数据区: Java虚拟机在运行Java程序过程中管理的内存区域。 程序计数器: 线程私有,程序控制流的指示器,分支、循环、跳转、异常处理、线程恢复等基础功能都依赖这个计数器完成。 每个线程都有一个程序计数…...