【C++深入浅出】初识C++中篇(引用、内联函数)

目录
一. 前言
二. 引用
2.1 引用的概念
2.2 引用的使用
2.3 引用的特性
2.4 常引用
2.5 引用的使用场景
2.6 传值、传引用效率比较
2.7 引用和指针的区别
三. 内联函数
3.1 内联函数的概念
3.2 内联函数的特性
一. 前言
上期说道,C++是在C的基础之上,容纳进去了面向对象编程思想,并增加了许多有用的库,以及编程范式等。我们介绍了部分C++为了补充C语言语法上的不足而新增的内容,如命名空间,缺省参数,函数重载等等,上期传送门![]() 【C++深入浅出】初识C++(上篇)
【C++深入浅出】初识C++(上篇)![]() http://t.csdn.cn/UjbIo 本期将继续介绍C++剩下的一些有趣的功能,如引用,内联函数等等,这也是为了后面的类和对象打好基础。
http://t.csdn.cn/UjbIo 本期将继续介绍C++剩下的一些有趣的功能,如引用,内联函数等等,这也是为了后面的类和对象打好基础。![]()
话不多说,直接上菜!!!
二. 引用
2.1 引用的概念
引用并不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间。
引用就相当于我们给别人起昵称。例如你叫你女朋友小笨猪,那么对你而言,小笨猪就是你的女朋友,和叫名字是一个意思,既不是其他任何人,你也不会因此多一个女朋友![]()
2.2 引用的使用
类型& 引用变量名(对象名) = 引用实体
void Test()
{int a = 10;int& ra = a; //<====定义引用类型,此时ra就是变量a的别名,ra与a是同一块内存空间printf("a的地址为%p\n", &a);printf("ra的地址为%p\n", &ra);
}int main()
{Test();return 0;
}
我们看到变量a和引用变量ra的地址是一样的,说明它们共用同一块内存空间。

2.3 引用的特性
使用引用时需要注意以下几点特性![]()
1、引用在定义时必须初始化
int main()
{int a = 10;int& b; //错误写法,会报错int& b=a; //正确写法return 0;
}2、一个变量可以有多个引用
int main()
{int a = 10;//下面的b,c,d均是变量a的别名int& b = a;int& c = a;int& d = c;printf("%p %p %p %p\n", &a,&b,&c,&d);return 0;
}
3、引用一旦引用一个实体,就不能引用其他实体
int main()
{int a = 10;int& b = a; //b是a的别名int c = 20; //能不能将b改成c的别名呢?b = c; //不行,这条语句是将c的值赋给引用变量b,即修改变量a的值,并不是让b引用cprintf("&a = %p &b = %p &c = %p\n", &a,&b,&c);printf("a = %d b = %d c = %d\n", a, b, c);return 0;
}
4、引用类型必须和引用实体是同种类型的
int main()
{int a = 10;double& b = a; //这种写法会报错return 0;
}
我们看到编译器报错说非常量限定,那如果我们加上const修饰呢?如下:
const double& b = a;
我们惊讶地发现通过了编译,说明上面不是因为int和double类型不一样而报错,那究竟是为什么呢?下面我们来分析分析![]()
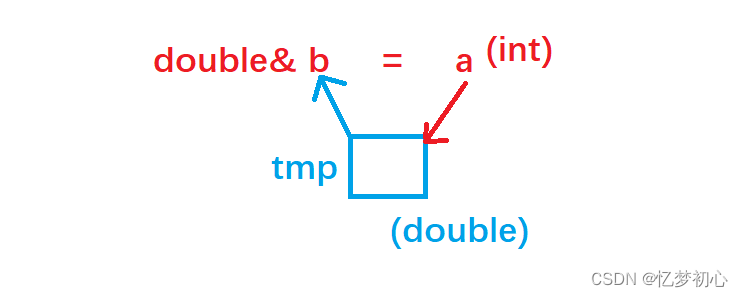
实际上,由于引用实体和引用变量的类型不同,编译器会自动进行隐式类型转换。编译器会生成一个double类型的临时变量tmp,然后将a的内容以某种形式放到临时变量tmp中,最后再让b引用临时变量tmp。
int main()
{int a = 10;const double& b = a;//类似于下面的步骤int a = 10;double tmp = a; //将a的值转换赋给tmpconst double& b = tmp; //b再引用tmpreturn 0;
}
由于临时变量具有常属性,因此tmp的类型就是const double,用double类型的引用变量引用const double类型的变量,这无疑是一种权限的放大,是不被允许的。就好比别人大门紧缩不然你进,你偏偏另辟蹊径从窗户翻入,这无疑是犯法的,私闯民宅![]() 。这就是为什么编译器会报出非常量限定的错误的原因,引用变量d需要加上const修饰,权限的平移是被允许的。
。这就是为什么编译器会报出非常量限定的错误的原因,引用变量d需要加上const修饰,权限的平移是被允许的。
最后,本来临时变量tmp在当前语句结束后就会被销毁,但此时被b所引用,其生命周期就自动被延长了。
分析了这么多,下面我们用代码来进行验证一下:
int main()
{int a = 10;const double& b = a;printf("&a = %p , &b = %p\n", &a, &b); //求a,b空间的地址printf("修改前 a = %d , b = %.2lf\n", a, b);a = 20;//b = 30; //这句代码会报错,被const修饰的变量不可修改printf("修改后 a = %d , b = %.2lf\n", a, b);return 0;
}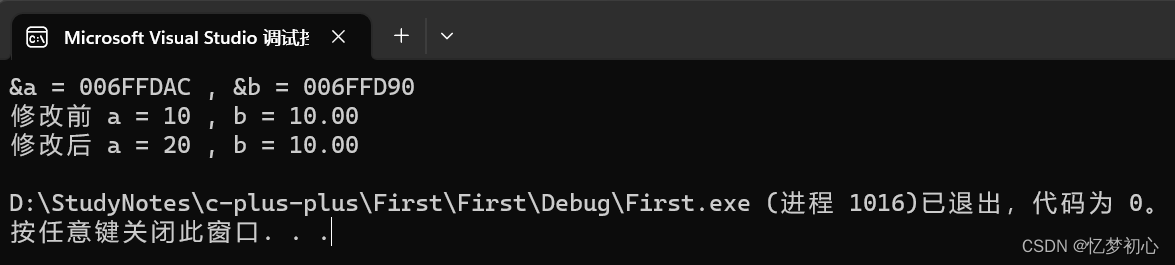
我们发现a的地址和b的地址不同,这说明了b并不是变量a的引用,而是引用了新形成的临时变量。并且,当我们对a进行修改时,b中的内容并没有发生改变,这也印证了a和b不是同一块内存空间。最后,当我们想要对b的内容进行修改时,编译器会直接报错,说明b所在的空间具有常属性。
2.4 常引用
被const关键字修饰的引用变量我们称为常引用。我们无法通过常引用来修改引用实体的值,如下:
#include<iostream>
using namespace std;
int main()
{int a = 10;const int& b = a;//b++; //会报错,b是常引用,无法修改a++; //a是普通变量,允许修改cout << "a = " << a <<' ' << "b = " << b;return 0;
}
前面我们提到了权限不能放大,也就是说:普通引用不能引用常属性变量。但是,权限允许平移或者缩小,即常引用可以引用常属性变量、常引用可以引用普通变量。如下:
#include<iostream>
using namespace std;
int main()
{int a = 10;const int& b = a; //权限的缩小,const引用引用普通变量,编译正常const int aa = 10;const int& bb = aa;//权限的缩小,const引用引用const变量,编译正常int& cc = aa;//权限的放大,普通引用引用const变量,报错return 0;
}2.5 引用的使用场景
引用的使用场景一般有两个:做函数参数、做函数返回值。
1、引用作为函数参数
在C语言中,如果我们调用函数时使用传值调用,那么形参的改变是不会影响实参的,形参是实参的临时拷贝。如果我们想在函数中对实参进行修改,那就必须使用传址调用,通过地址对实参的值进行修改。
而在C++中,新增了引用的语法,我们可以使用引用作为函数的形参,此时形参就是实参的一个别名,并不会额外开辟空间,形参和实参共同内存空间,修改形参也就是对实参进行修改。具体实现方式如下![]()
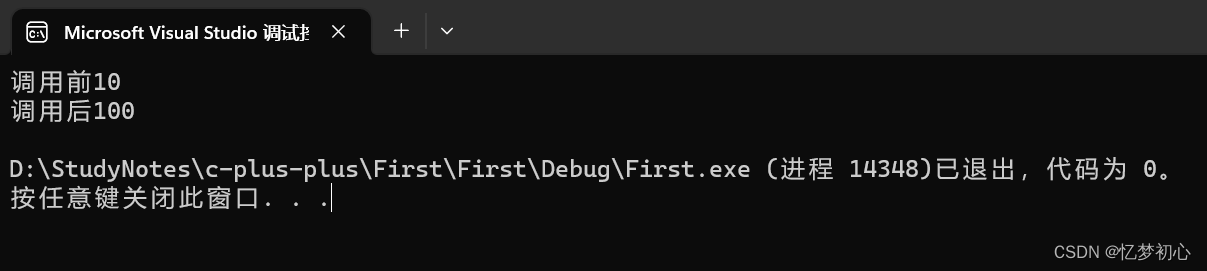
#include<iostream>
using namespace std;
void ModifyFun(int& x) //引用作为函数参数
{x = 100;
}
int main()
{int a = 10;cout << "调用前" << a << endl;ModifyFun(a);cout << "调用后" << a << endl;
}
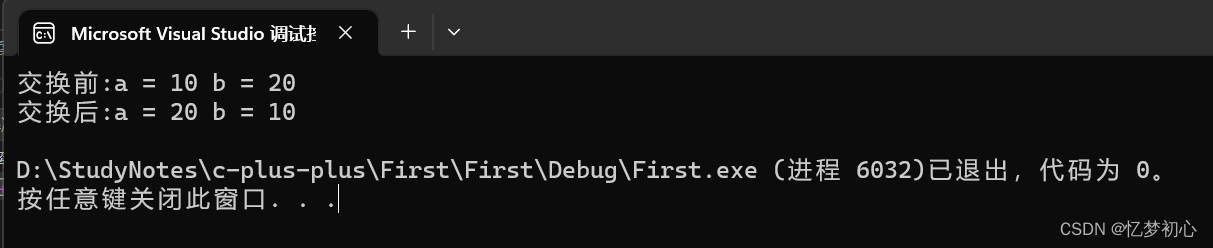
#include<iostream>
using namespace std;
void Swap(int& x , int& y) //引用作为函数参数
{int tmp = x;x = y;y = tmp;
}
int main()
{int a = 10;int b = 20;cout << "交换前:" << "a = " << a << " b = " << b << endl;Swap(a, b);cout << "交换后:" << "a = " << a << " b = " << b << endl;
}
2、引用作为函数返回值
引用也可以作为函数的返回值,如下:
#include<iostream>
using namespace std;
int& Count()
{static int n = 0; //n是一个静态变量,函数调用结束后不会销毁cout << n << endl;;return n;
}
int main()
{int& k = Count();k++;Count();return 0;
}
在Count()函数通过引用返回n,此时main函数中的引用变量k就是n的别名,当我们在main函数中修改k,就相当于对静态变量n做修改。
但是,如果以下情况使用引用返回会出现什么情况呢?
int& Add(int a, int b)
{int c = a + b; //c是局部变量,Add调用结束后被销毁return c;
}
int main()
{int& ret = Add(1, 2);Add(3, 4);cout << "Add(1, 2) is :" << ret << endl;return 0;
}
很惊讶的发现,最终ret变量的值不是3而是7,为什么呢?
这就要来谈谈上述代码出现的野引用问题了。
我们通过下图来进行分析![]()

总结:函数返回时,如果出了函数作用域,返回对象还在(还没销毁还给系统),则可以使用
引用返回;如果已经还给系统了,则必须使用传值返回。
2.6 传值、传引用效率比较
在C/C++中,以值作为参数或者返回值类型,在传参和返回期间,函数并不会直接传递实参或者将变量本身直接返回,而是传递实参或者返回变量的一份临时拷贝,因此用值作为参数或者返回值类型,需要额外进行拷贝,效率是非常低下的,尤其是当参数或者返回值类型非常大时,效率就更低。
而如果以引用作为参数或者返回值类型,由于引用是作为变量的别名,并不会额外开辟空间形成拷贝。因此在传参和返回期间,就相当于直接传递实参或将变量本身直接返回,效率大大提升。下面我们通过代码来更直观地看看二者的效率差距:
值和引用作为函数参数的效率差距
#include <time.h>
struct A { int a[10000]; };
void TestFunc1(A a)
{;
}
void TestFunc2(A& a)
{;
}
void TestRefAndValue()
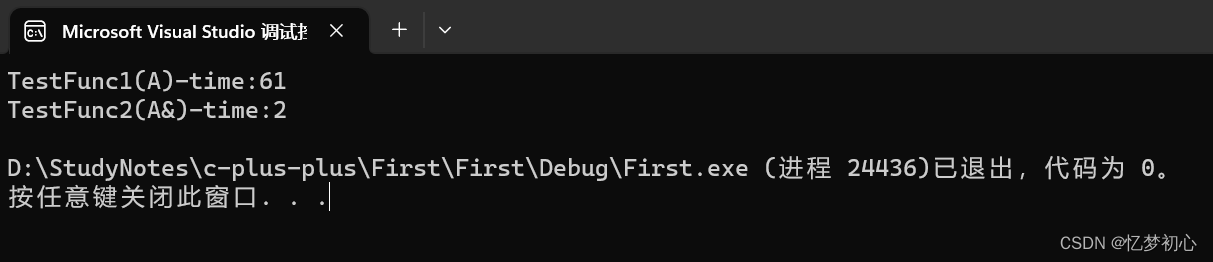
{A a;// 以值作为函数参数size_t begin1 = clock(); //clock()函数返回程序运行到调用clock()函数所耗费的时间,单位是msfor (size_t i = 0; i < 100000; ++i)TestFunc1(a);size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2(a);size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;
}
int main()
{TestRefAndValue();return 0;
}
值和引用作为返回值类型的效率差距
#include <time.h>
struct A
{int a[10000];
}a;
// 值返回
A TestFunc1()
{ return a;
}
// 引用返回
A& TestFunc2()
{ return a;
}
void TestRefAndValue()
{// 以值作为函数的返回值类型size_t begin1 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc1();size_t end1 = clock();// 以引用作为函数的返回值类型size_t begin2 = clock();for (size_t i = 0; i < 100000; ++i)TestFunc2();size_t end2 = clock();// 计算两个函数运算完成之后的时间cout << "TestFunc1 time:" << end1 - begin1 << endl;cout << "TestFunc2 time:" << end2 - begin2 << endl;
}
int main()
{TestRefAndValue();return 0;
}
通过上述代码的比较,我们发现传值和引用在作为传参以及返回值类型上效率相差很大。传引用的效率远高于传值。因此能使用引用就尽量使用引用,提高效率。
2.7 引用和指针的区别
在语法概念上引用就是一个别名,没有独立空间,和其引用实体共用同一块空间。
但在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。这点我们可以参照二者编译后生成的汇编代码证明![]()
int main()
{//引用int a = 10;int& ra = a;//指针ra = 20;int* pa = &a;*pa = 20;return 0;
}
可见,引用和指针的汇编代码是一模一样的,最后都是通过变量a的地址来修改a。
不过,引用和指针还是有不同点的,如下:
- 引用概念上定义一个变量的别名,指针存储一个变量地址。
- 引用在定义时必须初始化,指针没有要求
- 引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体
- 引用必须初始化,故没有NULL引用,但有NULL指针
- sizeof的含义不同,sizeof(引用变量)的结果为引用实体的类型大小,而sizeof(指针)始终是地址空间所占字节个数(32位平台下占4个字节,64位平台下占8个字节)
- 引用自增即引用的实体增加1,指针自增即指针向后偏移一个类型的大小
- 有多级指针,但是没有多级引用
- 访问实体方式不同,指针需要显式解引用,引用编译器自己处理
- 从安全性的角度,引用比指针使用起来相对更安全
三. 内联函数
3.1 内联函数的概念
以inline关键字修饰的函数叫做内联函数,编译时C++编译器会在调用内联函数的地方展开,不会调用函数建立栈帧,因此内联函数提升程序运行的效率。
我们可以通过汇编代码来验证加上inline的函数是否会被调用![]()
没加inline关键字:
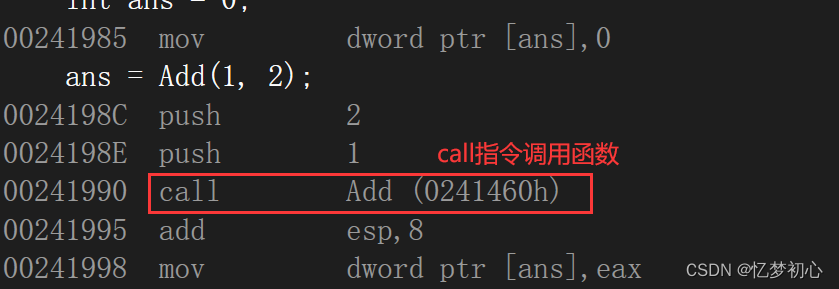
int Add(int x, int y)
{return x + y;
}
int main()
{int ans = 0;ans = Add(1, 2);return 0;
}
加上inline关键字:
inline int Add(int x, int y)
{return x + y;
}
int main()
{int ans = 0;ans = Add(1, 2);return 0;
}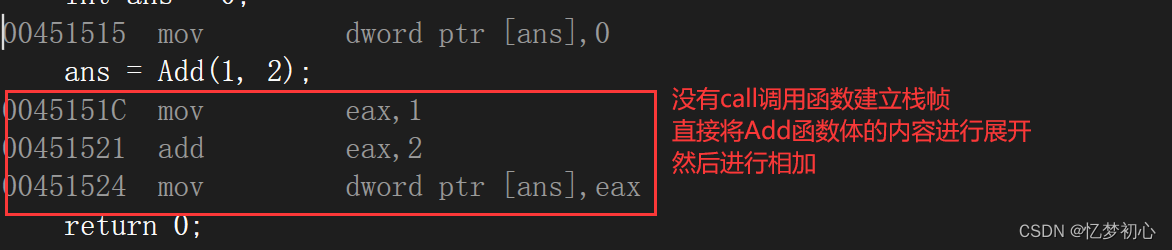
可以看到,内联函数并不会生成对应的call指令,而是直接被替换到函数调用处,减少了调用函数建立栈帧的开销。
注意事项:
内联函数的效果需要在release模式才会体现。因为在debug模式下编译器默认不会对代码进行优化,顾不会进行展开。当然我们也可以进行设置,方法如下(VS2022):
1、找到当前项目属性设置页:
2、设置调试信息格式:
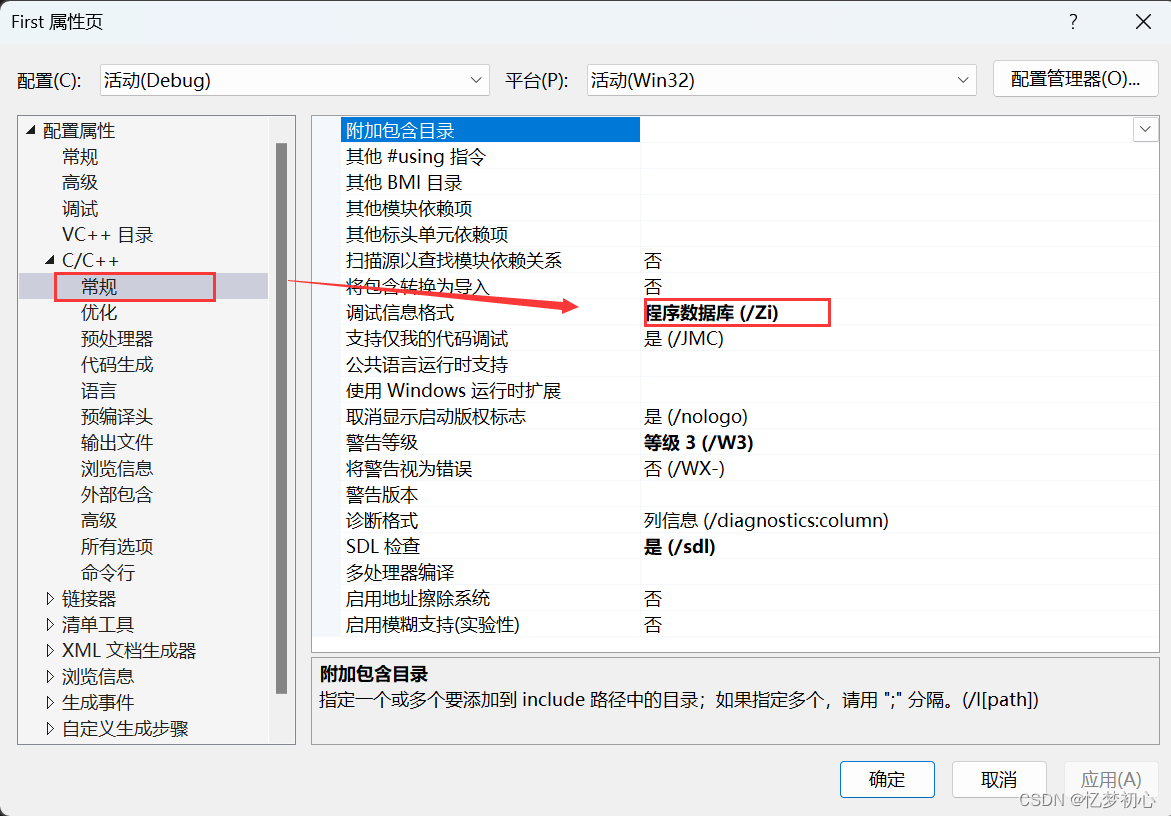
3、设置内联函数扩展:
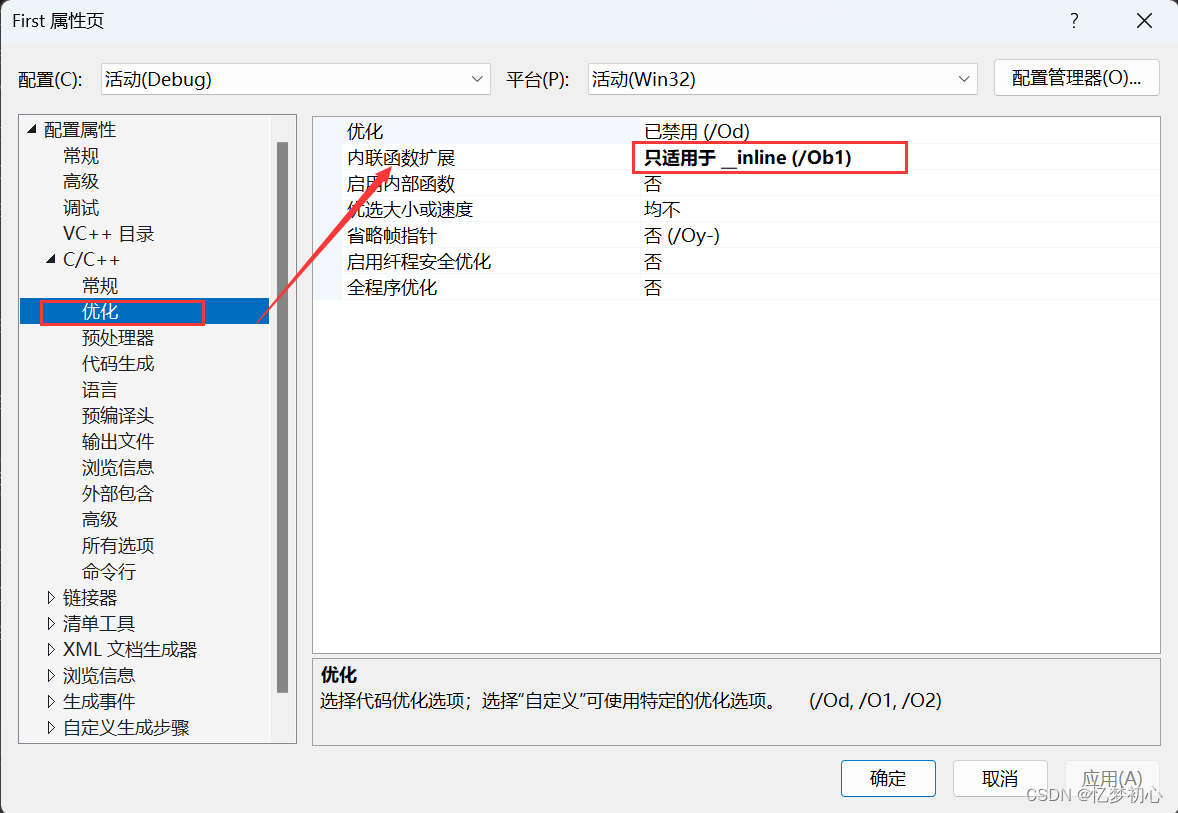
3.2 内联函数的特性
主要有如下几点特性:
- inline是一种以空间换时间的做法,如果编译器将函数当成内联函数处理,在编译阶段,会用函数体替换函数调用。缺陷:可能会使目标文件变大;优势:少了调用建立栈帧开销,提高程序运行效率。
- inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同,一般建
议:将函数规模较小(即函数不是很长,具体没有准确的说法,取决于编译器内部实现)、不是递归、且频繁调用的函数采用inline修饰,否则编译器会忽略inline特性(编译器也是很聪明的,可不要贪杯噢)。以下为《C++prime》第五版关于inline的描述:
- inline不建议声明和定义分离,分离会导致链接错误。因为inline被展开,符号表中就没有函数地址了,链接就会找不到。
// in.h #include <iostream> using namespace std; inline void f(int i);// in.cpp #include "in.h" void fun(int i) {cout << i << endl; }// main.cpp #include "in.h" int main() {fun(10);return 0; }
报错原因:由于in.h文件中只有函数的声明没有定义,顾在编译阶段main.cpp中的fun() 函数无法进行展开,只能在链接阶段进行链接。但是由于in.cpp的fun()函数被声明为内联函数,fun()函数并不会进入符号表,最后就会导致链接时找不到函数地址,报错。

以上,就是本期的全部内容啦🌸
制作不易,能否点个赞再走呢🙏
相关文章:

【C++深入浅出】初识C++中篇(引用、内联函数)
目录 一. 前言 二. 引用 2.1 引用的概念 2.2 引用的使用 2.3 引用的特性 2.4 常引用 2.5 引用的使用场景 2.6 传值、传引用效率比较 2.7 引用和指针的区别 三. 内联函数 3.1 内联函数的概念 3.2 内联函数的特性 一. 前言 上期说道,C是在C的基础之上&…...
前端:VUE2中的父子传值
文章目录 一、背景什么是父子传值二、业务场景子传父1、在父页面中引入子页面2、子传父:父组件标识3、子传父:子组件标识 父传子父组件调用子组件中的方法 总结: 一、背景 最近做项目中需要使用到流工作,在这里流工作需要用到父子…...
_网络编程与打包发布)
【100天精通python】Day40:GUI界面编程_PyQt 从入门到实战(完)_网络编程与打包发布
目录 8 网络编程 8.1 使用PyQt 网络模块进行网络通信 服务器端示例 客户端示例 8.2 处理网络请求和响应 9 打包和发布 9.1 创建可执行文件或安装程序 9.2 解决依赖问题 9.3 发布 PyQt 应用到不同平台 9.3.1 发布到 Windows 9.3.2 发布到 macOS 9.3.3 发布到 Linux 9…...

Redis——set类型详解
概要 Set(集合),将一些有关联的数据放到一起,集合中的元素是无序的,并且集合中的元素是不能重复的 之前介绍的list就是有序的,对于列表来说[1, 2, 3] 和 [2, 1, 3]是两个不同的列表,而对于集合…...

redis---》高级用法之慢查询/pipline与事务/发布订阅/bitmap位图/HyperLogLog/GEO地理位置信息/持久化
高级用法之慢查询 # 配置一个时间,如果查询时间超过了我们设置的时间,我们就认为这是一个慢查询 # 配置的慢查询,只在命令执行阶段# 慢查询演示-设置慢查询---》只要超过某个时间的命令---》都会保存起来# 设置记录所有命令CONFIG SET slowl…...

Find My资讯|苹果Vision Pro开发者需将设备配对 AirTag
最近苹果Vision Pro获开发者申请,苹果要求获批的申请者使用 Measure and Fit 应用确认合适的佩戴尺寸,并会根据申请者提交的信息,定制不同的 Vision Pro 开发者套件,以便于契合申请者的面部特征,提供更好的佩戴体验。 …...

Go 语言中排序的 3 种方法
原文链接: Go 语言中排序的 3 种方法 在写代码过程中,排序是经常会遇到的需求,本文会介绍三种常用的方法。 废话不多说,下面正文开始。 使用标准库 根据场景直接使用标准库中的方法,比如: sort.Intsso…...

12----Emoji表情
本节我们主要讲解markdown的Emoji 在 Markdown 里使用 Emoji 表情有两种方法:一种是直接输入 Emoji 表情,另一种是使用 Emoji 表情短码(emoji shartcodes)。 一、打印方式: 直接输入 Emoji 表情:在 Markdown 中,可以直接输入 Em…...

C++四种强制类型转换
一、C强制转换与C强制转换 c语言强制类型转换主要用于基础的数据类型间的转换,语法为: (type-id)expression//转换格式1 type-id(expression)//转换格式2c除了能使用c语言的强制类型转换外,还新增了四种强制类型转换:static_cas…...

git仓库新建上传记录
新建git仓会出现版本分支问题,解决过程: 其他的前期绑定之类的传送:https://blog.csdn.net/qq_37194189/article/details/130767397 大概思路:新建一个分支,上传,合并,删除分支 git branch …...

flutter调用so
lutter是一种基于Dart语言的跨平台开发框架,通常用于开发Android和iOS应用程序。如果您想要在Flutter应用程序中调用一个SO库,您可以按照以下步骤进行操作: 首先,将您的SO库文件复制到Flutter项目的“lib”目录下。 接下来&…...

c#依赖注入
依赖注入(Dependency Injection,简称 DI)是一种设计模式,用于将对象的创建和管理责任从使用它的类中分离出来,从而实现松耦合和易于测试的代码。在 C# 中,依赖注入通常通过以下方式实现: 构造函数注入(Constructor Injection): 这是最常见的依赖注入方式,通过类的构…...

Django框架使用定时器-APScheduler实现定时任务:django实现简单的定时任务
一、系统环境依赖 系统:windows10 python: python3.9.0 djnago3.2.0 APScheduler3.10.1 二、django项目配置 1、创建utils包,在包里面创建schedulers包 utils/schedulers/task.py #1、设置 Django 环境,就可以导入项目的模型类这些了 …...

Go学习笔记之数据类型
文章目录 GO数据类型数组array切片slice集合map结构体make和new GO数据类型 在go语言中,定义的全局数据结构不使用不会报错,定义的局部数据结构必须使用,否则报错;建议定义的数据类型就要使用,要么不定义。 数组array …...

Spring Cloud 微服务
前言 Spring Cloud 中的所有子项目都依赖Spring Boot框架,所以Spring Boot 框架的版本号和Spring CLoud的版本号之间也存在以来及兼容关系。 Spring Cloud生态下的服务治理的解决方案主要有两个: Spring Cloud Netfix 和 Spring Cloud Alibaba。这两个…...

SpringBoot属性配置
SpringBoot提供了多种属性配置方式 application.properties server.port80 application.yml server:port: 81application.yaml server:port: 82SpringBoot配置文件加载顺序 application.properties > application.yml > application.yaml常用配置文件种类 application.…...
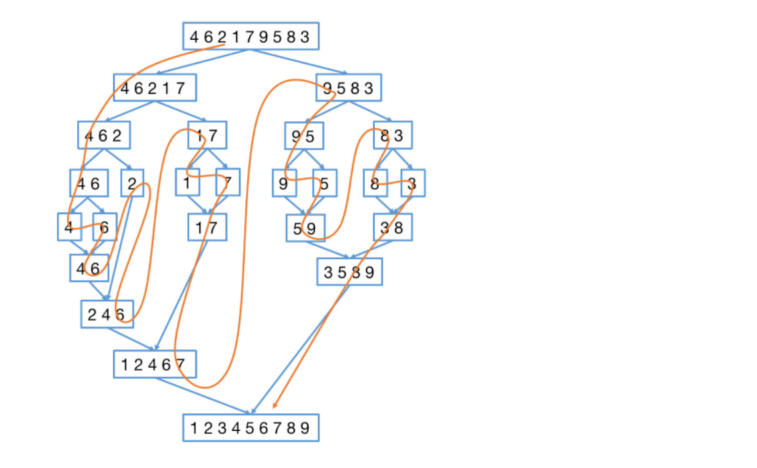
算法通关村第十关 | 归并排序
1. 归并排序原理 归并排序(MERARE-SORT)简单来说就是将大的序列先视为若干个比较小的数组,分成比较小的结构,然后是利用归并的思想实现的排序方法,该算法采用经典的分治策略(分就是将问题分成一些小的问题分…...
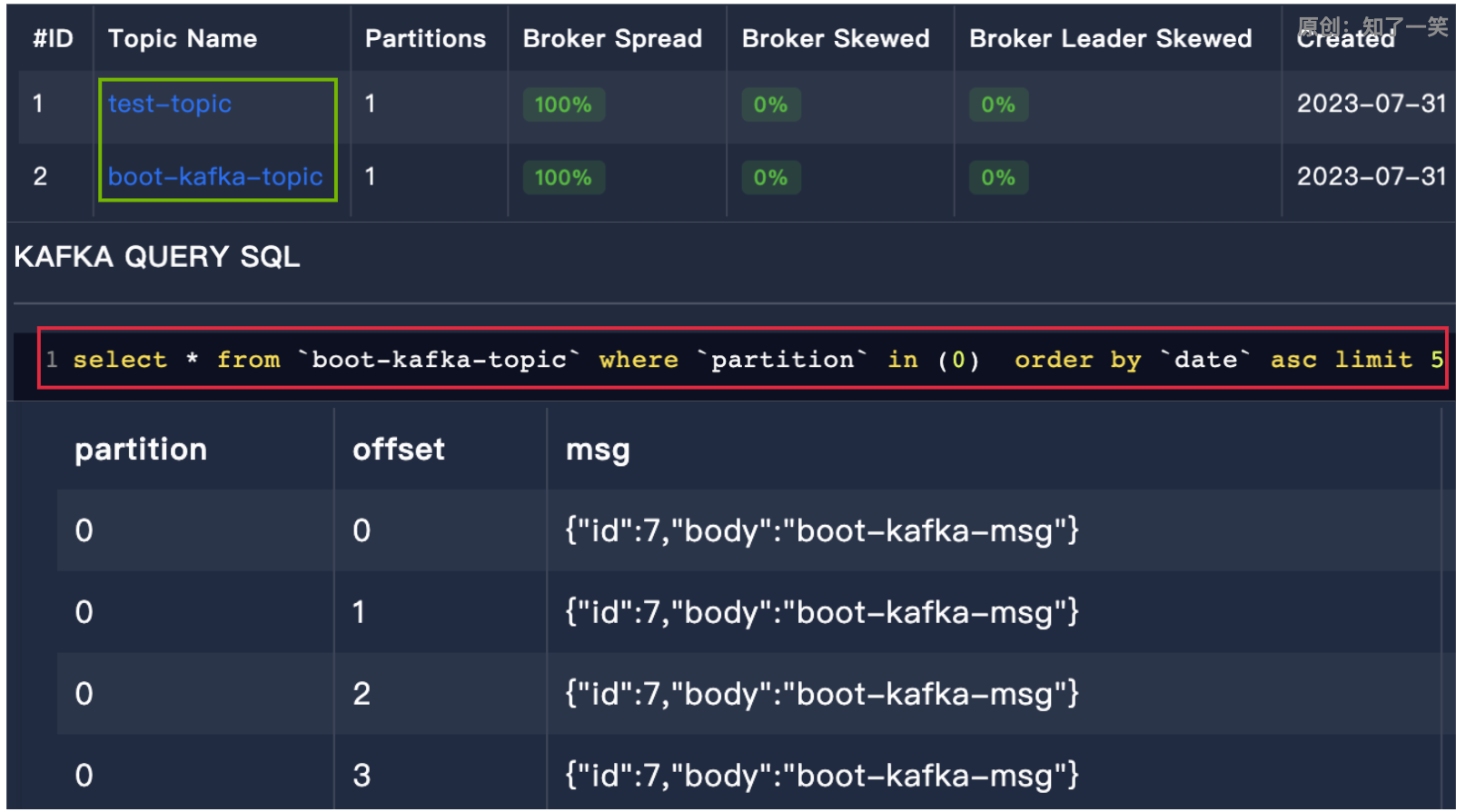
SpringBoot3集成Kafka
标签:Kafka3.Kafka-eagle3; 一、简介 Kafka是一个开源的分布式事件流平台,常被用于高性能数据管道、流分析、数据集成和关键任务应用,基于Zookeeper协调的处理平台,也是一种消息系统,具有更好的吞吐量、内…...

css学习1
1、样式定义如何显示元素。 2、样式通常保存至外部的css文件中。 3、样式可以使内容与表现分离。 4、css主要有两部分组成:选择器与一条或多条声明。 选择器通常为要改变的html元素,每条声明由一个属性和一个值组成。每个属性有一个值,属性…...
——切片传参和解引用赋值)
rust踩雷笔记(1)——切片传参和解引用赋值
最近学习rust,网上资料还是很有限,做题遇到的问题,有时需要自己试验。把自己做题过程遇到的问题,和试验的结论,做一些简单记录。 阅读下列文字和代码 用切片(的引用)做参数要非常小心ÿ…...

<6>-MySQL表的增删查改
目录 一,create(创建表) 二,retrieve(查询表) 1,select列 2,where条件 三,update(更新表) 四,delete(删除表…...

基于距离变化能量开销动态调整的WSN低功耗拓扑控制开销算法matlab仿真
目录 1.程序功能描述 2.测试软件版本以及运行结果展示 3.核心程序 4.算法仿真参数 5.算法理论概述 6.参考文献 7.完整程序 1.程序功能描述 通过动态调整节点通信的能量开销,平衡网络负载,延长WSN生命周期。具体通过建立基于距离的能量消耗模型&am…...

大型活动交通拥堵治理的视觉算法应用
大型活动下智慧交通的视觉分析应用 一、背景与挑战 大型活动(如演唱会、马拉松赛事、高考中考等)期间,城市交通面临瞬时人流车流激增、传统摄像头模糊、交通拥堵识别滞后等问题。以演唱会为例,暖城商圈曾因观众集中离场导致周边…...

在rocky linux 9.5上在线安装 docker
前面是指南,后面是日志 sudo dnf config-manager --add-repo https://download.docker.com/linux/centos/docker-ce.repo sudo dnf install docker-ce docker-ce-cli containerd.io -y docker version sudo systemctl start docker sudo systemctl status docker …...

什么是Ansible Jinja2
理解 Ansible Jinja2 模板 Ansible 是一款功能强大的开源自动化工具,可让您无缝地管理和配置系统。Ansible 的一大亮点是它使用 Jinja2 模板,允许您根据变量数据动态生成文件、配置设置和脚本。本文将向您介绍 Ansible 中的 Jinja2 模板,并通…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现企业微信功能
1. 开发环境准备 安装DevEco Studio 3.1: 从华为开发者官网下载最新版DevEco Studio安装HarmonyOS 5.0 SDK 项目配置: // module.json5 {"module": {"requestPermissions": [{"name": "ohos.permis…...
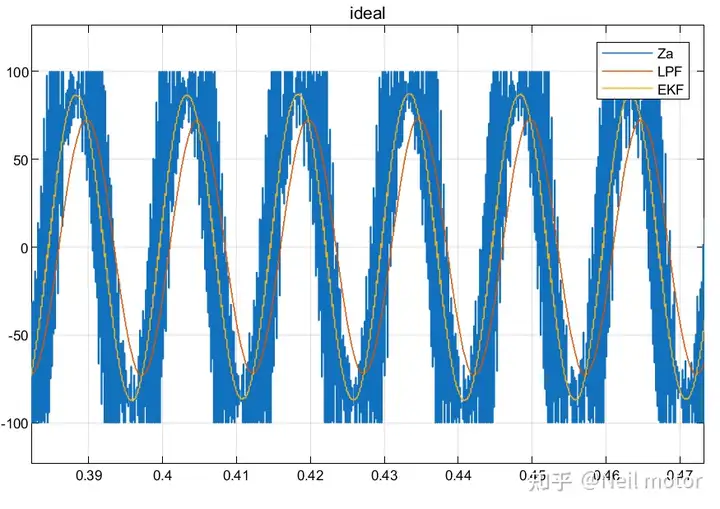
永磁同步电机无速度算法--基于卡尔曼滤波器的滑模观测器
一、原理介绍 传统滑模观测器采用如下结构: 传统SMO中LPF会带来相位延迟和幅值衰减,并且需要额外的相位补偿。 采用扩展卡尔曼滤波器代替常用低通滤波器(LPF),可以去除高次谐波,并且不用相位补偿就可以获得一个误差较小的转子位…...
【LeetCode】算法详解#6 ---除自身以外数组的乘积
1.题目介绍 给定一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积 。 题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。 请 不要使用除法,且在 O…...
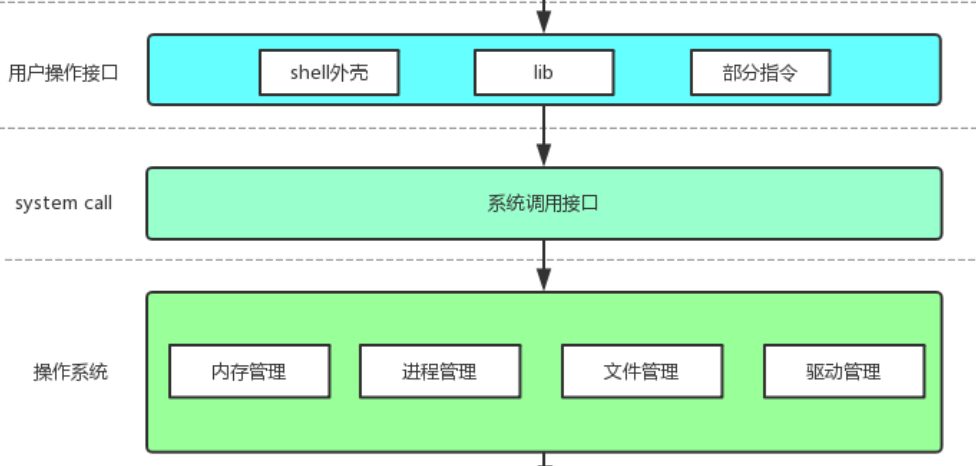
【Linux手册】探秘系统世界:从用户交互到硬件底层的全链路工作之旅
目录 前言 操作系统与驱动程序 是什么,为什么 怎么做 system call 用户操作接口 总结 前言 日常生活中,我们在使用电子设备时,我们所输入执行的每一条指令最终大多都会作用到硬件上,比如下载一款软件最终会下载到硬盘上&am…...

在golang中如何将已安装的依赖降级处理,比如:将 go-ansible/v2@v2.2.0 更换为 go-ansible/@v1.1.7
在 Go 项目中降级 go-ansible 从 v2.2.0 到 v1.1.7 具体步骤: 第一步: 修改 go.mod 文件 // 原 v2 版本声明 require github.com/apenella/go-ansible/v2 v2.2.0 替换为: // 改为 v…...