确保Django项目的稳定运行和持续改进
确保Django项目的稳定运行和持续改进
引言
Django是一个强大的Python Web框架,用于构建高效、可靠的Web应用程序。然而,部署一个Django项目并不意味着工作已经完成。在项目上线之后,确保项目的稳定运行并不断进行改进是非常重要的。本博客将探讨一些保证Django项目稳定性和持续改进的最佳实践。
目录
- 监控和报警
- 日志记录和分析
- 自动化测试
- 定期备份和容灾
- 性能优化
- 安全加固
- 持续集成和持续部署
- 用户反馈和需求管理
监控和报警
当然,为了确保Django项目的稳定运行和持续改进,我们可以使用一些代码和工具来实现。以下是为你提供的示例代码和建议安装的工具:
监控和报警
-
安装和配置监控工具
使用工具如Prometheus、Grafana和AlertManager来监控应用程序和服务器的关键指标。你可以按照官方文档来安装这些工具,并设置合适的监控指标和警报规则。
下面是一个示例:
# 安装Prometheus $ wget https://github.com/prometheus/prometheus/releases/download/v2.33.1/prometheus-2.33.1.linux-amd64.tar.gz $ tar -xvf prometheus-2.33.1.linux-amd64.tar.gz $ cd prometheus-2.33.1.linux-amd64# 编辑配置文件 $ nano prometheus.yml# 启动Prometheus $ ./prometheus --config.file=prometheus.yml# 安装Grafana $ wget https://dl.grafana.com/oss/release/grafana-8.2.3.linux-amd64.tar.gz $ tar -xvf grafana-8.2.3.linux-amd64.tar.gz $ cd grafana-8.2.3# 启动Grafana $ ./bin/grafana-server# 配置AlertManager $ nano alertmanager.yml# 启动AlertManager $ ./alertmanager --config.file=alertmanager.yml请注意,这只是示例代码,你可能需要根据你的操作系统和需求进行相应的调整和配置。
-
在Django中集成监控指标
使用Django的
django-prometheus插件,可以方便地将Django的运行指标暴露给Prometheus进行监控。下面是一个示例:
$ pip install django-prometheus在你的Django项目的
settings.py文件中添加以下配置:INSTALLED_APPS = [# 其他应用程序'django_prometheus', ]# 在MIDDLEWARE中添加middleware MIDDLEWARE = [# 其他中间件'django_prometheus.middleware.PrometheusBeforeMiddleware','django_prometheus.middleware.PrometheusAfterMiddleware', ]# 在urls.py中添加url path from django_prometheus import exportsurlpatterns = [# 其他url patternspath('metrics/', exports.as_view(), name='metrics'), ]运行Django项目后,访问
/metrics/路径将会展示Django应用程序的监控指标。
日志记录和分析
-
配置Django日志记录
在Django项目的
settings.py文件中,可以配置Django的日志记录设置,以满足你的需求。以下是一个示例配置:LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'file': {'level': 'INFO','class': 'logging.handlers.RotatingFileHandler','filename': '/path/to/your/log/file.log','maxBytes': 1024 * 1024 * 5, # 5MB'backupCount': 5,'formatter': 'verbose',},},'loggers': {'': {'handlers': ['file'],'level': 'INFO','propagate': True,},},'formatters': {'verbose': {'format': '%(asctime)s [%(levelname)s] %(name)s: %(message)s'},}, }请将
'/path/to/your/log/file.log'替换为实际的日志文件路径。 -
使用ELK Stack进行日志分析
ELK Stack(Elasticsearch、Logstash和Kibana)是常见的日志分析工具组合。你可以使用ELK Stack来集中管理和分析Django应用程序当然,请继续看以下的代码和工具安装建议:
-
使用ELK Stack进行日志分析(续)
ELK Stack(Elasticsearch、Logstash和Kibana)是常见的日志分析工具组合。你可以使用ELK Stack来集中管理和分析Django应用程序的日志。
下面是一个示例:
-
安装和配置Elasticsearch
# 下载并安装Elasticsearch $ wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.14.0-linux-x86_64.tar.gz $ tar -xvf elasticsearch-7.14.0-linux-x86_64.tar.gz $ cd elasticsearch-7.14.0# 启动Elasticsearch $ ./bin/elasticsearch -
安装和配置Logstash
# 下载并安装Logstash $ wget https://artifacts.elastic.co/downloads/logstash/logstash-7.14.0-linux-x86_64.tar.gz $ tar -xvf logstash-7.14.0-linux-x86_64.tar.gz $ cd logstash-7.14.0# 创建一个logstash.conf配置文件 $ nano logstash.conf# 配置文件示例 input {file {path => "/path/to/your/log/file.log"start_position => "beginning"} } output {elasticsearch {hosts => ["localhost:9200"]index => "myapp-logs-%{+YYYY.MM.dd}"} }请将
/path/to/your/log/file.log替换为你的Django应用程序的日志文件路径。- 启动Logstash并运行配置文件
$ ./bin/logstash -f logstash.conf -
安装和配置Kibana
# 下载并安装Kibana $ wget https://artifacts.elastic.co/downloads/kibana/kibana-7.14.0-linux-x86_64.tar.gz $ tar -xvf kibana-7.14.0-linux-x86_64.tar.gz $ cd kibana-7.14.0# 启动Kibana $ ./bin/kibana访问
http://localhost:5601即可进入Kibana的图形界面,从而对Django应用程序的日志进行查询和分析。
-
确保 Django 项目的稳定运行和持续改进一个博客
监控和报警
在一个 Django 项目中,监控和报警是非常重要的,它可以帮助我们及时发现和解决潜在的问题,保障项目的稳定运行。
使用合适的监控工具可以帮助我们实时追踪项目的关键指标,例如服务器负载、数据库连接、错误率等。同时,在出现问题时,报警系统能够及时通知开发团队,以便及时采取措施。
常用的监控和报警工具包括:
- Prometheus
- Grafana
- Sentry
- Nagios
日志记录和分析
日志记录和分析对于了解项目的运行状况、排查错误和优化性能非常重要。Django 提供了强大的日志功能,可以记录应用程序的状态和错误信息。
在 settings.py 文件中配置以下代码可以启用日志记录:
LOGGING = {'version': 1,'disable_existing_loggers': False,'handlers': {'console': {'class': 'logging.StreamHandler',},'file': {'class': 'logging.handlers.RotatingFileHandler','filename': '/path/to/logfile.log','maxBytes': 1024 * 1024 * 5, # 5 MB'backupCount': 5,},},'root': {'handlers': ['console', 'file'],'level': 'INFO',},
}
确保在生产环境中将日志级别设置为适当的水平,通过合适的配置可以将日志记录到文件,并定期进行日志文件的轮转。
分析日志可以使用 ELK Stack、Splunk 等工具,它们可以帮助我们从海量日志中挖掘有价值的信息。
自动化测试
自动化测试是确保 Django 项目质量的关键环节。编写各种类型的测试,包括单元测试、集成测试和端到端测试,可以有效减少错误和降低风险。
Django 提供了强大的测试框架,可以方便地编写和运行测试。以下是一个简单的示例测试代码:
from django.test import TestCase
from myapp.models import Blogclass BlogTestCase(TestCase):def setUp(self):Blog.objects.create(title="Test Blog", content="This is a test blog.")def test_blog_creation(self):blog = Blog.objects.get(title="Test Blog")self.assertEqual(blog.content, "This is a test blog.")
您可以在单独的 tests.py 文件中编写测试用例,并使用 python manage.py test 命令运行测试。
定期备份和容灾
为了保证数据的安全性和可用性,定期备份和容灾措施是必不可少的。
您可以通过编写一个定时任务脚本来自动执行备份,或者使用第三方工具来实现定期备份。备份的策略可以包括完全备份、增量备份或者差异备份。
另外,为了防止单点故障,您还可以将应用程序和数据库部署在多个服务器上,并设置相应的负载均衡和容灾方案,以保证项目的高可用性。
性能优化
优化 Django 项目的性能可以提升用户体验、降低服务器负载并提高应用程序的吞吐量。
以下是一些常见的性能优化技术:
-
使用缓存,例如使用 Django 的缓存框架或者使用缓存中间件。
-
优化数据库查询,例如添加索引、合理使用关联查询等。
-
压缩静态资源,例如压缩 JavaScript 和 CSS 文件。
-
使用异步任务队列
-
使用异步任务队列,例如Celery,将一些耗时的任务异步化,避免阻塞请求的处理。
-
对数据库进行优化,包括使用适当的数据库引擎和配置参数,对查询进行调优,避免过多的数据库访问等。
-
使用CDN(内容分发网络),将静态资源分发到离用户更近的服务器上,提高资源加载速度。
-
使用缓存机制,如Redis或Memcached,对经常访问的数据进行缓存,减少数据库查询次数。
-
优化前端代码,如减少HTTP请求次数、压缩JavaScript和CSS等,提升页面加载速度。
-
进行代码剖析和性能分析,通过工具如Django Debug Toolbar、Django Silk等,找出性能瓶颈并进行优化。
安全加固
确保 Django 项目的安全性对于保护用户数据、防止恶意攻击至关重要。以下是一些安全加固的建议:
- 及时更新 Django 和相关库的版本,以获取最新的安全修复。
- 设置合适的密钥和密码策略,确保密码强度。
- 防止跨站脚本攻击(XSS)和跨站请求伪造(CSRF),使用Django提供的安全中间件来预防。
- 避免SQL注入攻击,使用Django的ORM或参数化查询来防止SQL注入。
- 使用HTTPS协议加密通信,保护数据在传输过程中的安全。
- 实施访问控制和权限管理,限制敏感操作和数据的访问权限。
- 使用安全的认证和授权机制,如Django自带的认证模块或第三方库。
持续集成和持续部署
持续集成和持续部署是一种自动化的开发流程,可以减少人工操作和增加发布效率。以下是一些实现持续集成(CI)和持续部署(CD)的建议:
- 使用代码版本控制系统,如Git,确保代码的版本管理和追踪。
- 使用持续集成工具,如Jenkins、Travis CI或GitLab CI/CD,自动化构建、测试和部署的过程。
- 编写自动化测试用例,并在每次提交代码时自动运行测试。
- 使用自动化部署工具,如Fabric、Ansible或Docker,自动化部署应用程序到生产环境。
- 设置自动化的部署流程,将代码从开发、测试环境部署到生产环境。
用户反馈和需求管理
与用户保持沟通并及时获得反馈是改进和优化项目的重要方式。以下是一些建议来管理用户反馈和需求:
- 提供用户反馈的渠道,如通过联系表单、邮件或社交媒体。
- 创建一个问题跟踪系统,如Jira、GitHub Issues等,用于收集用户反馈和需求。
- 使用项目管理工具来管理需求和任务,如Trello或Asana。
- 定期与用户进行反馈和需求收集的会议或调查。
- 分析用户行为和数据,例如使用Google Analytics或用户行为分析工具,了解用户的需求和偏好。
以上是确保 Django 项目的稳定运行和持续改进博客的关键步骤和建议。使用这些技术和工具可以帮助您确保项目的质量、安全性和可用性,并不断改进和满足用户需求。
相关文章:

确保Django项目的稳定运行和持续改进
确保Django项目的稳定运行和持续改进 引言 Django是一个强大的Python Web框架,用于构建高效、可靠的Web应用程序。然而,部署一个Django项目并不意味着工作已经完成。在项目上线之后,确保项目的稳定运行并不断进行改进是非常重要的。本博客将…...

HAProxy负载均衡 代理
1.安装 yum -y install haproxy 2.配置文件 /etc/haproxy 下 global log 127.0.0.1 local2 #日志定义级别 chroot /var/lib/haproxy #当前工作目录 pidfile /var/run/haproxy.pid #进程id maxconn 4000 #最大连接…...
每天10个小知识点)
前端面试的游览器部分(8)每天10个小知识点
目录 系列文章目录前端面试的游览器部分(1)每天10个小知识点前端面试的游览器部分(2)每天10个小知识点前端面试的游览器部分(3)每天10个小知识点前端面试的游览器部分(4)每天10个小知…...
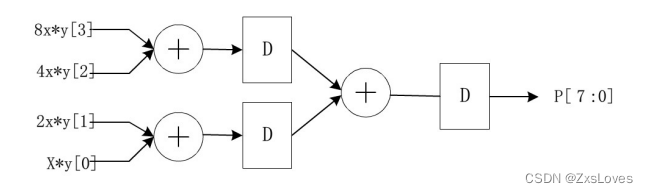
【【verilog典型电路设计之流水线结构】】
verilog典型电路设计之流水线结构 下图是一个4位的乘法器结构,用verilog HDL 设计一个两级流水线加法器树4位乘法器 对于流水线结构 其实需要做的是在每级之间增加一个暂存的数据用来存储 我们得到的东西 我们一般来说会通过在每一级之间插入D触发器来保证数据的联…...
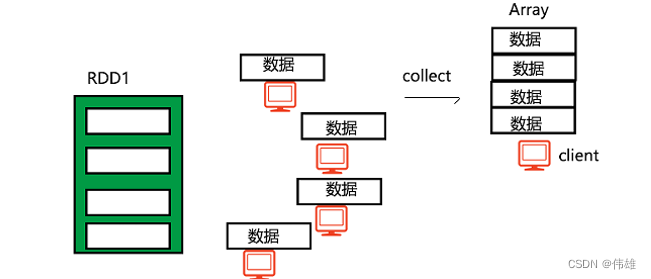
大数据课程K2——Spark的RDD弹性分布式数据集
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州 ▲ 本章节目的 ⚪ 了解Spark的RDD结构; ⚪ 掌握Spark的RDD操作方法; ⚪ 掌握Spark的RDD常用变换方法、常用执行方法; 一、Spark最核心的数据结构——RDD弹性分布式数据集 1. 概述 初学Spark时,把RDD看…...
Seaborn数据可视化(一)
目录 1.seaborn简介 2.Seaborn绘图风格设置 21.参数说明: 2.2 示例: 1.seaborn简介 Seaborn是一个用于数据可视化的Python库,它是建立在Matplotlib之上的高级绘图库。Seaborn的目标是使绘图任务变得简单,同时产生美观且具有信…...
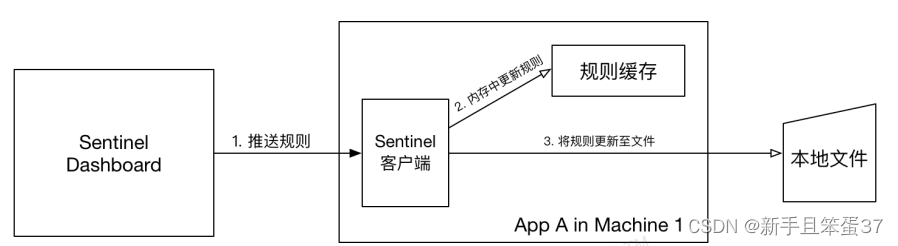
Sentinel规则持久化
首先 Sentinel 控制台通过 API 将规则推送至客户端并更新到内存中,接着注册的写数据源会将新的规则保存到本地的文件中。 示例代码: 1.编写处理类 //规则持久化 public class FilePersistence implements InitFunc {Value("spring.application:n…...
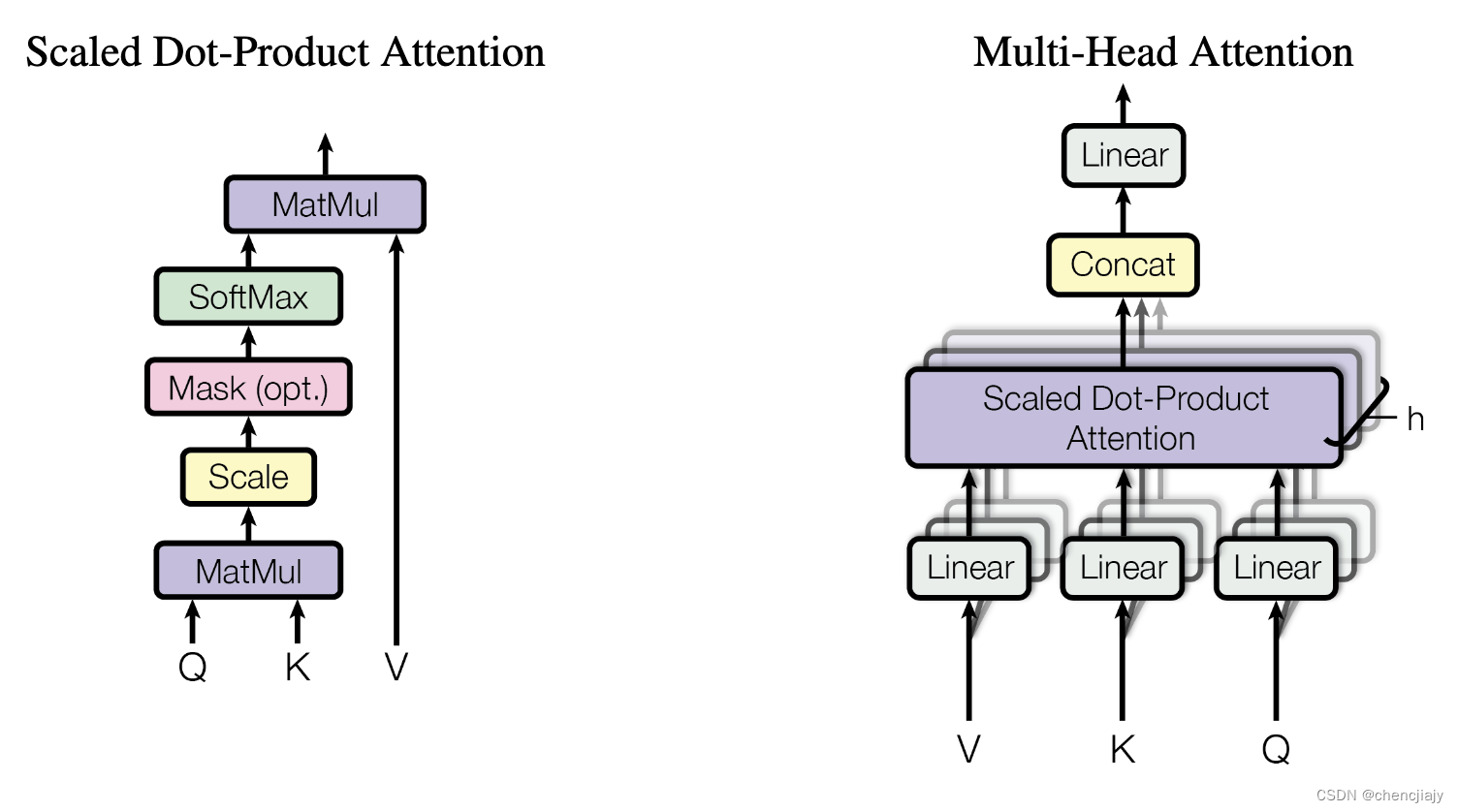
Transformer 相关模型的参数量计算
如何计算Transformer 相关模型的参数量呢? 先回忆一下Transformer模型论文《Attention is all your need》中的两个图。 设Transformer模型的层数为N,每个Transformer层主要由self-attention 和 Feed Forward组成。设self-attention模块的head个数为 …...
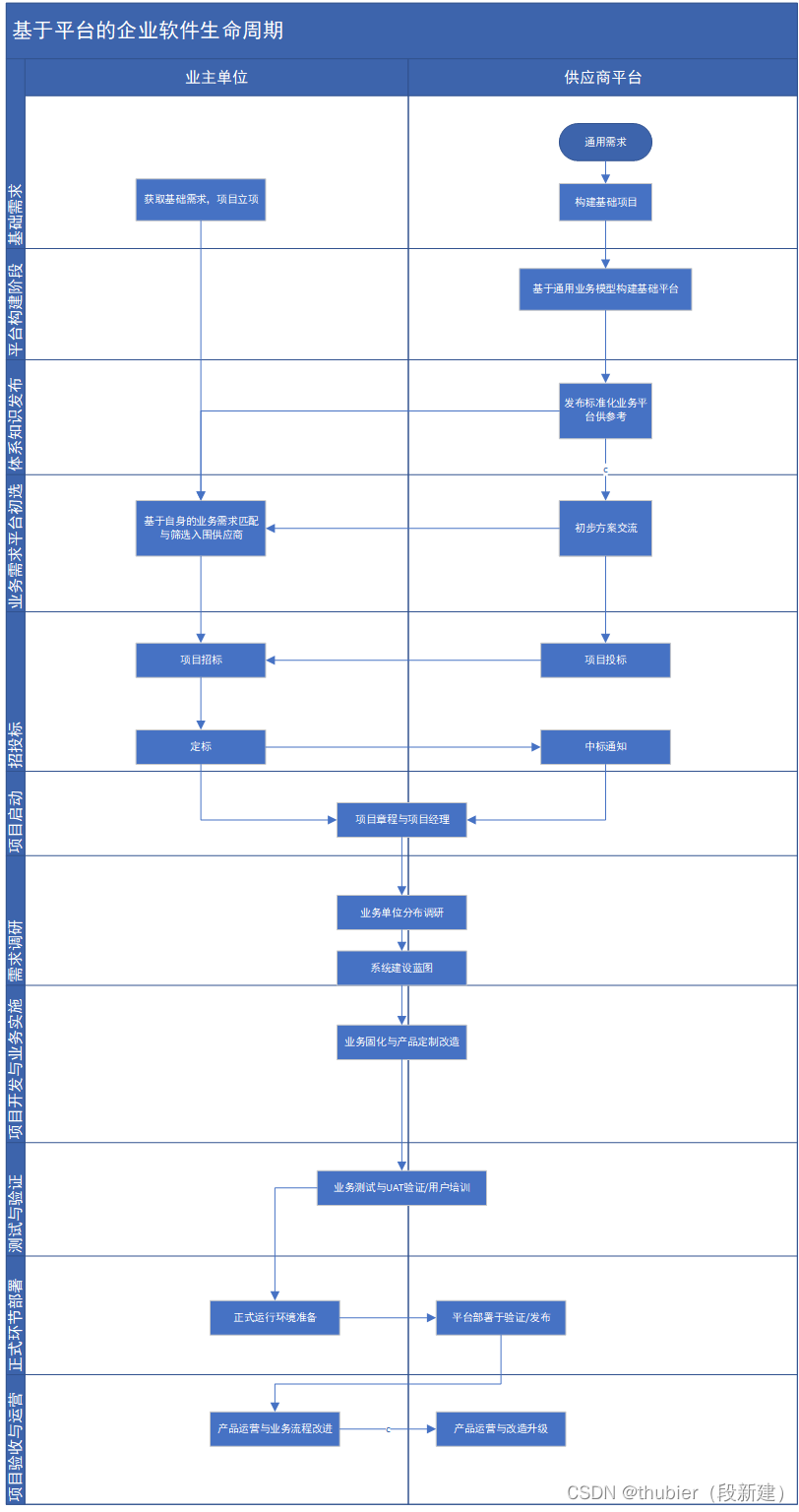
企业信息化过程----应用管理平台的构建过程
1.信息化的概念 信息化是一个过程,与工业化、现代化一样,是一个动态变化的过程。信息化已现代通信,网络、数据库技术为基础,将所有研究对象各个要素汇总至数据库,供特定人群生活、工作、学习、辅助决策等,…...

揭秘程序员的鄙视链,你在哪一层?看完我想哭
虽然不同的编程语言都有其优缺点,而且程序员之间的技能和能力更加重要,但是有些程序员可能会因为使用不同的编程语言而产生鄙视链。 以下是一些可能存在的不同编程语言程序员之间的鄙视链: 低级语言程序员鄙视高级语言程序员:使用…...

在docker下进行mysql的主从复制
搭建步骤 1、拉取镜像 docker pull mysql:latest2、查看镜像 docker images3、创建启动容器 Master docker run -p 3306:3306 --name mysql-master -e MYSQL_ROOT_PASSWORD123456 -d mysql:latestSlave docker run -p 3307:3306 --name mysql-slave -e MYSQL_ROOT_PASSWO…...
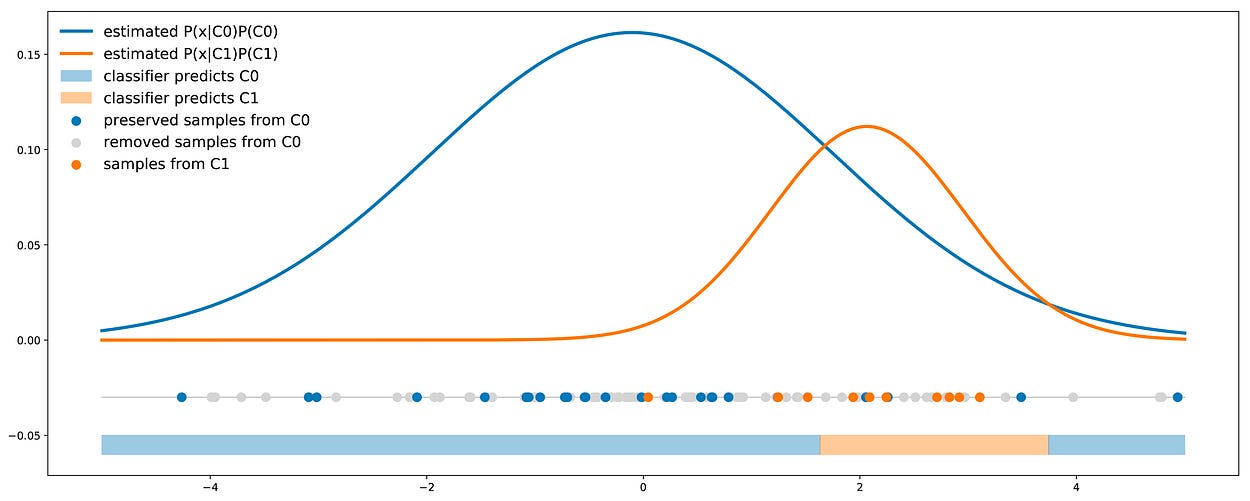
【机器学习】处理不平衡的数据集
一、介绍 假设您在一家给定的公司工作,并要求您创建一个模型,该模型根据您可以使用的各种测量来预测产品是否有缺陷。您决定使用自己喜欢的分类器,根据数据对其进行训练,瞧:您将获得96.2%的准确率! …...
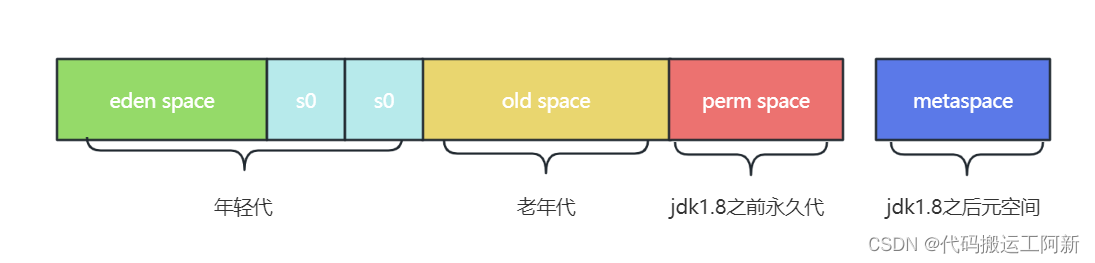
JVM前世今生之JVM内存模型
JVM内存模型所指的是JVM运行时区域,该区域分为两大块 线程共享区域 堆内存、方法区,即所有线程都能访问该区域,随着虚拟机和GC创建和销毁 线程独占区域 虚拟机栈、本地方法栈、程序计数器,即每个线程都有自己独立的区域&#…...

redis事务对比Lua脚本区别是什么
redis官方对于lua脚本的解释:Redis使用同一个Lua解释器来执行所有命令,同时,Redis保证以一种原子性的方式来执行脚本:当lua脚本在执行的时候,不会有其他脚本和命令同时执行,这种语义类似于 MULTI/EXEC。从别…...

Java“牵手”根据店铺ID获取1688店铺所有商品数据方法,1688API实现批量店铺商品数据抓取示例
1688商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取1688整店所有商品详情页面评价内容数据,您可以通过开放平台的接口或者直接访问1688商城的网页来获取店铺所有商品详情信息的数据。以下是两…...

linux-shell脚本收集
创建同步脚本xsync mkdir -p /home/hadoop/bin && cd /home/hadoop/bin vim xsync#!/bin/bash#1. 判断参数个数 if [ $# -lt 1 ] thenecho Not Arguementexit; fi#2. 遍历集群所有机器 for host in node1 node2 node3 doecho $host #3. 遍历所有目录,挨…...

使用 MBean 和 日志查看 Tomcat 线程池核心属性数据
文章目录 CustomTomcatThreadPoolMBeanCustomTomcatThreadPool CustomTomcatThreadPoolMBean com.qww.config;public interface CustomTomcatThreadPoolMBean {String getStatus(); }CustomTomcatThreadPool package com.qww.config;import com.alibaba.fastjson.JSON; impor…...
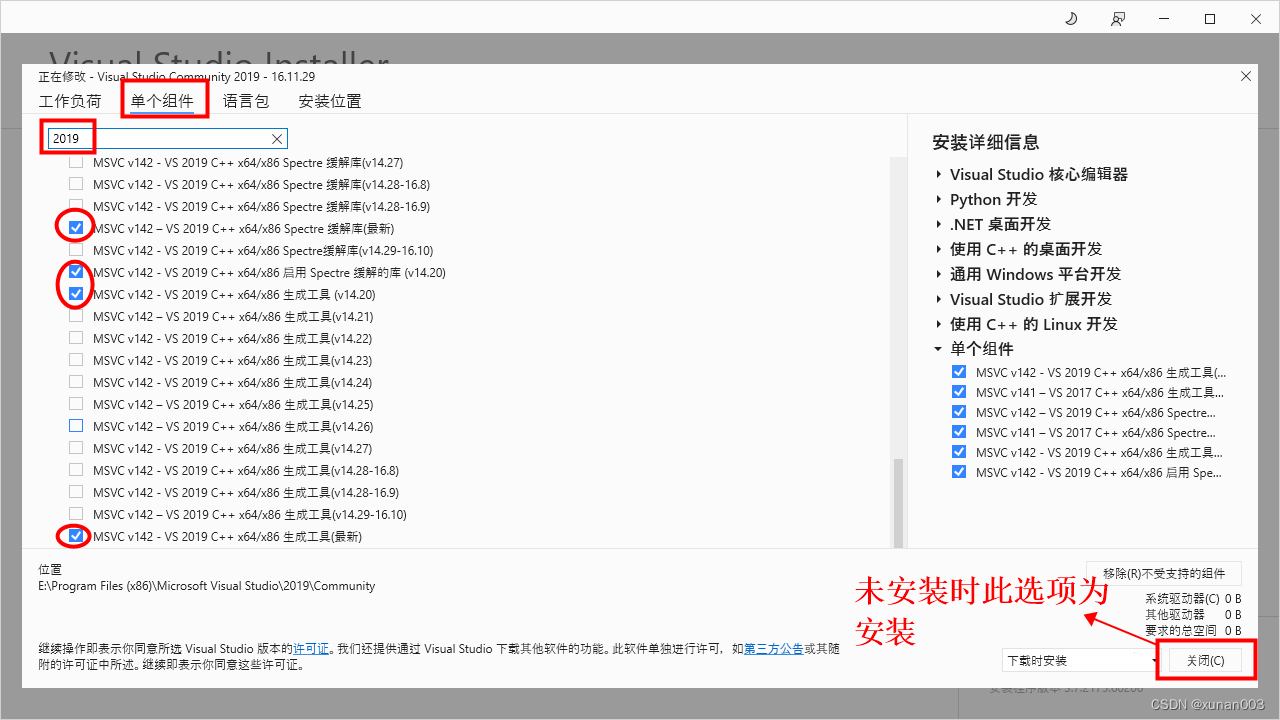
Visual Studio 2019源码编译cpu版本onnxruntime
1.下载onnxruntime源码 源码地址:gitee 》https://gitee.com/mirrors/onnx-runtime github 》https://github.com/microsoft/onnxruntime git clone --recursive https://gitee.com/mirrors/onnx-runtime 2.安装anaconda并配置python环境 安装anaconda时记得勾选默…...

Go和Java实现模板模式
Go和Java实现模板模式 下面通过一个游戏的例子来说明模板模式的使用。 1、模板模式 在模板模式中,一个抽象类公开定义了执行它的方法的方式/模板。它的子类可以按需要重写方法实现,但调用将 以抽象类中定义的方式进行。这种类型的设计模式属于行为型…...

angular:quill align的坑
上一行设置了align为center,换行后下一个会继承上一行的格式,我想使用Quill.formatLine(newLineIndex, 0, ‘align’, left)来左对齐,发现始终不能生效。 参看quill.js源码,发现align没有left的配置 var config {scope: _parch…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

Cesium1.95中高性能加载1500个点
一、基本方式: 图标使用.png比.svg性能要好 <template><div id"cesiumContainer"></div><div class"toolbar"><button id"resetButton">重新生成点</button><span id"countDisplay&qu…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

学校招生小程序源码介绍
基于ThinkPHPFastAdminUniApp开发的学校招生小程序源码,专为学校招生场景量身打造,功能实用且操作便捷。 从技术架构来看,ThinkPHP提供稳定可靠的后台服务,FastAdmin加速开发流程,UniApp则保障小程序在多端有良好的兼…...

WordPress插件:AI多语言写作与智能配图、免费AI模型、SEO文章生成
厌倦手动写WordPress文章?AI自动生成,效率提升10倍! 支持多语言、自动配图、定时发布,让内容创作更轻松! AI内容生成 → 不想每天写文章?AI一键生成高质量内容!多语言支持 → 跨境电商必备&am…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

多种风格导航菜单 HTML 实现(附源码)
下面我将为您展示 6 种不同风格的导航菜单实现,每种都包含完整 HTML、CSS 和 JavaScript 代码。 1. 简约水平导航栏 <!DOCTYPE html> <html lang"zh-CN"> <head><meta charset"UTF-8"><meta name"viewport&qu…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

MySQL用户和授权
开放MySQL白名单 可以通过iptables-save命令确认对应客户端ip是否可以访问MySQL服务: test: # iptables-save | grep 3306 -A mp_srv_whitelist -s 172.16.14.102/32 -p tcp -m tcp --dport 3306 -j ACCEPT -A mp_srv_whitelist -s 172.16.4.16/32 -p tcp -m tcp -…...

DeepSeek 技术赋能无人农场协同作业:用 AI 重构农田管理 “神经网”
目录 一、引言二、DeepSeek 技术大揭秘2.1 核心架构解析2.2 关键技术剖析 三、智能农业无人农场协同作业现状3.1 发展现状概述3.2 协同作业模式介绍 四、DeepSeek 的 “农场奇妙游”4.1 数据处理与分析4.2 作物生长监测与预测4.3 病虫害防治4.4 农机协同作业调度 五、实际案例大…...