Apache Doris 入门教程32:物化视图
物化视图
物化视图是将预先计算(根据定义好的 SELECT 语句)好的数据集,存储在 Doris 中的一个特殊的表。
物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。
适用场景
- 分析需求覆盖明细数据查询以及固定维度查询两方面。
- 查询仅涉及表中的很小一部分列或行。
- 查询包含一些耗时处理操作,比如:时间很久的聚合操作等。
- 查询需要匹配不同前缀索引。
优势
- 对于那些经常重复的使用相同的子查询结果的查询性能大幅提升。
- Doris 自动维护物化视图的数据,无论是新的导入,还是删除操作都能保证 Base 表和物化视图表的数据一致性,无需任何额外的人工维护成本。
- 查询时,会自动匹配到最优物化视图,并直接从物化视图中读取数据。
自动维护物化视图的数据会造成一些维护开销,会在后面的物化视图的局限性中展开说明。
物化视图 VS Rollup
在没有物化视图功能之前,用户一般都是使用 Rollup 功能通过预聚合方式提升查询效率的。但是 Rollup 具有一定的局限性,他不能基于明细模型做预聚合。
物化视图则在覆盖了 Rollup 的功能的同时,还能支持更丰富的聚合函数。所以物化视图其实是 Rollup 的一个超集。
也就是说,之前 ALTER TABLE ADD ROLLUP 语法支持的功能现在均可以通过 CREATE MATERIALIZED VIEW 实现。
使用物化视图
Doris 系统提供了一整套对物化视图的 DDL 语法,包括创建,查看,删除。DDL 的语法和 PostgreSQL, Oracle 都是一致的。
创建物化视图
这里首先你要根据你的查询语句的特点来决定创建一个什么样的物化视图。这里并不是说你的物化视图定义和你的某个查询语句一模一样就最好。这里有两个原则:
- 从查询语句中抽象出,多个查询共有的分组和聚合方式作为物化视图的定义。
- 不需要给所有维度组合都创建物化视图。
首先第一个点,一个物化视图如果抽象出来,并且多个查询都可以匹配到这张物化视图。这种物化视图效果最好。因为物化视图的维护本身也需要消耗资源。
如果物化视图只和某个特殊的查询很贴合,而其他查询均用不到这个物化视图。则会导致这张物化视图的性价比不高,既占用了集群的存储资源,还不能为更多的查询服务。
所以用户需要结合自己的查询语句,以及数据维度信息去抽象出一些物化视图的定义。
第二点就是,在实际的分析查询中,并不会覆盖到所有的维度分析。所以给常用的维度组合创建物化视图即可,从而到达一个空间和时间上的平衡。
创建物化视图是一个异步的操作,也就是说用户成功提交创建任务后,Doris 会在后台对存量的数据进行计算,直到创建成功。
具体的语法可查看CREATE MATERIALIZED VIEW 。
SinceVersion 2.0.0
在Doris 2.0版本中我们对物化视图的做了一些增强(在本文的最佳实践4中有具体描述)。我们建议用户在正式的生产环境中使用物化视图前,先在测试环境中确认是预期中的查询能否命中想要创建的物化视图。
如果不清楚如何验证一个查询是否命中物化视图,可以阅读本文的最佳实践1。
与此同时,我们不建议用户在同一张表上建多个形态类似的物化视图,这可能会导致多个物化视图之间的冲突使得查询命中失败(在新优化器中这个问题会有所改善)。建议用户先在测试环境中验证物化视图和查询是否满足需求并能正常使用。
支持聚合函数
目前物化视图创建语句支持的聚合函数有:
- SUM, MIN, MAX (Version 0.12)
- COUNT, BITMAP_UNION, HLL_UNION (Version 0.13)
更新策略
为保证物化视图表和 Base 表的数据一致性, Doris 会将导入,删除等对 Base 表的操作都同步到物化视图表中。并且通过增量更新的方式来提升更新效率。通过事务方式来保证原子性。
比如如果用户通过 INSERT 命令插入数据到 Base 表中,则这条数据会同步插入到物化视图中。当 Base 表和物化视图表均写入成功后,INSERT 命令才会成功返回。
查询自动匹配
物化视图创建成功后,用户的查询不需要发生任何改变,也就是还是查询的 Base 表。Doris 会根据当前查询的语句去自动选择一个最优的物化视图,从物化视图中读取数据并计算。
用户可以通过 EXPLAIN 命令来检查当前查询是否使用了物化视图。
物化视图中的聚合和查询中聚合的匹配关系:
| 物化视图聚合 | 查询中聚合 |
|---|---|
| sum | sum |
| min | min |
| max | max |
| count | count |
| bitmap_union | bitmap_union, bitmap_union_count, count(distinct) |
| hll_union | hll_raw_agg, hll_union_agg, ndv, approx_count_distinct |
其中 bitmap 和 hll 的聚合函数在查询匹配到物化视图后,查询的聚合算子会根据物化视图的表结构进行改写。详细见实例2。
查询物化视图
查看当前表都有哪些物化视图,以及他们的表结构都是什么样的。通过下面命令:
MySQL [test]> desc mv_test all;
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
| IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra |
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
| mv_test | DUP_KEYS | k1 | INT | Yes | true | NULL | |
| | | k2 | BIGINT | Yes | true | NULL | |
| | | k3 | LARGEINT | Yes | true | NULL | |
| | | k4 | SMALLINT | Yes | false | NULL | NONE |
| | | | | | | | |
| mv_2 | AGG_KEYS | k2 | BIGINT | Yes | true | NULL | |
| | | k4 | SMALLINT | Yes | false | NULL | MIN |
| | | k1 | INT | Yes | false | NULL | MAX |
| | | | | | | | |
| mv_3 | AGG_KEYS | k1 | INT | Yes | true | NULL | |
| | | to_bitmap(`k2`) | BITMAP | No | false | | BITMAP_UNION |
| | | | | | | | |
| mv_1 | AGG_KEYS | k4 | SMALLINT | Yes | true | NULL | |
| | | k1 | BIGINT | Yes | false | NULL | SUM |
| | | k3 | LARGEINT | Yes | false | NULL | SUM |
| | | k2 | BIGINT | Yes | false | NULL | MIN |
+-----------+---------------+-----------------+----------+------+-------+---------+--------------+
可以看到当前 mv_test 表一共有三张物化视图:mv_1, mv_2 和 mv_3,以及他们的表结构。
删除物化视图
如果用户不再需要物化视图,则可以通过命令删除物化视图。
具体的语法可查看DROP MATERIALIZED VIEW
查看已创建的物化视图
用户可以通过命令查看已创建的物化视图的
具体的语法可查看SHOW CREATE MATERIALIZED VIEW
取消创建物化视图
CANCEL ALTER TABLE MATERIALIZED VIEW FROM db_name.table_name
最佳实践1
使用物化视图一般分为以下几个步骤:
- 创建物化视图
- 异步检查物化视图是否构建完成
- 查询并自动匹配物化视图
首先是第一步:创建物化视图
假设用户有一张销售记录明细表,存储了每个交易的交易 id,销售员,售卖门店,销售时间,以及金额。建表语句和插入数据语句为:
create table sales_records(record_id int, seller_id int, store_id int, sale_date date, sale_amt bigint) distributed by hash(record_id) properties("replication_num" = "1");
insert into sales_records values(1,1,1,"2020-02-02",1);
这张 sales_records 的表结构如下:
MySQL [test]> desc sales_records;
+-----------+--------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-----------+--------+------+-------+---------+-------+
| record_id | INT | Yes | true | NULL | |
| seller_id | INT | Yes | true | NULL | |
| store_id | INT | Yes | true | NULL | |
| sale_date | DATE | Yes | false | NULL | NONE |
| sale_amt | BIGINT | Yes | false | NULL | NONE |
+-----------+--------+------+-------+---------+-------+
这时候如果用户经常对不同门店的销售量进行一个分析查询,则可以给这个 sales_records 表创建一张以售卖门店分组,对相同售卖门店的销售额求和的一个物化视图。创建语句如下:
MySQL [test]> create materialized view store_amt as select store_id, sum(sale_amt) from sales_records group by store_id;
后端返回下图,则说明创建物化视图任务提交成功。
Query OK, 0 rows affected (0.012 sec)
第二步:检查物化视图是否构建完成
由于创建物化视图是一个异步的操作,用户在提交完创建物化视图任务后,需要异步的通过命令检查物化视图是否构建完成。命令如下:
SHOW ALTER TABLE ROLLUP FROM db_name; (Version 0.12)
SHOW ALTER TABLE MATERIALIZED VIEW FROM db_name; (Version 0.13)
这个命令中 db_name 是一个参数, 你需要替换成自己真实的 db 名称。命令的结果是显示这个 db 的所有创建物化视图的任务。结果如下:
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+-----------+-------------------------------------------------------------------------------------------------------------------------+----------+---------+
| JobId | TableName | CreateTime | FinishedTime | BaseIndexName | RollupIndexName | RollupId | TransactionId | State | Msg | Progress | Timeout |
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+-----------+-------------------------------------------------------------------------------------------------------------------------+----------+---------+
| 22036 | sales_records | 2020-07-30 20:04:28 | 2020-07-30 20:04:57 | sales_records | store_amt | 22037 | 5008 | FINISHED | | NULL | 86400 |
+-------+---------------+---------------------+---------------------+---------------+-----------------+----------+---------------+-----------+-------------------------------------------------------------------------------------------------------------------------+----------+---------+
其中 TableName 指的是物化视图的数据来自于哪个表,RollupIndexName 指的是物化视图的名称叫什么。其中比较重要的指标是 State。
当创建物化视图任务的 State 已经变成 FINISHED 后,就说明这个物化视图已经创建成功了。这就意味着,查询的时候有可能自动匹配到这张物化视图了。
第三步:查询
当创建完成物化视图后,用户再查询不同门店的销售量时,就会直接从刚才创建的物化视图 store_amt 中读取聚合好的数据。达到提升查询效率的效果。
用户的查询依旧指定查询 sales_records 表,比如:
SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
上面查询就能自动匹配到 store_amt。用户可以通过下面命令,检验当前查询是否匹配到了合适的物化视图。
EXPLAIN SELECT store_id, sum(sale_amt) FROM sales_records GROUP BY store_id;
+----------------------------------------------------------------------------------------------+
| Explain String |
+----------------------------------------------------------------------------------------------+
| PLAN FRAGMENT 0 |
| OUTPUT EXPRS: |
| <slot 4> `default_cluster:test`.`sales_records`.`mv_store_id` |
| <slot 5> sum(`default_cluster:test`.`sales_records`.`mva_SUM__`sale_amt``) |
| PARTITION: UNPARTITIONED |
| |
| VRESULT SINK |
| |
| 4:VEXCHANGE |
| offset: 0 |
| |
| PLAN FRAGMENT 1 |
| |
| PARTITION: HASH_PARTITIONED: <slot 4> `default_cluster:test`.`sales_records`.`mv_store_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 04 |
| UNPARTITIONED |
| |
| 3:VAGGREGATE (merge finalize) |
| | output: sum(<slot 5> sum(`default_cluster:test`.`sales_records`.`mva_SUM__`sale_amt``)) |
| | group by: <slot 4> `default_cluster:test`.`sales_records`.`mv_store_id` |
| | cardinality=-1 |
| | |
| 2:VEXCHANGE |
| offset: 0 |
| |
| PLAN FRAGMENT 2 |
| |
| PARTITION: HASH_PARTITIONED: `default_cluster:test`.`sales_records`.`record_id` |
| |
| STREAM DATA SINK |
| EXCHANGE ID: 02 |
| HASH_PARTITIONED: <slot 4> `default_cluster:test`.`sales_records`.`mv_store_id` |
| |
| 1:VAGGREGATE (update serialize) |
| | STREAMING |
| | output: sum(`default_cluster:test`.`sales_records`.`mva_SUM__`sale_amt``) |
| | group by: `default_cluster:test`.`sales_records`.`mv_store_id` |
| | cardinality=-1 |
| | |
| 0:VOlapScanNode |
| TABLE: default_cluster:test.sales_records(store_amt), PREAGGREGATION: ON |
| partitions=1/1, tablets=10/10, tabletList=50028,50030,50032 ... |
| cardinality=1, avgRowSize=1520.0, numNodes=1 |
+----------------------------------------------------------------------------------------------+
从最底部的test.sales_records(store_amt)可以表明这个查询命中了store_amt这个物化视图。值得注意的是,如果表中没有数据,那么可能不会命中物化视图。
最佳实践2 PV,UV
业务场景: 计算广告的 UV,PV。
假设用户的原始广告点击数据存储在 Doris,那么针对广告 PV, UV 查询就可以通过创建 bitmap_union 的物化视图来提升查询速度。
通过下面语句首先创建一个存储广告点击数据明细的表,包含每条点击的点击时间,点击的是什么广告,通过什么渠道点击,以及点击的用户是谁。
create table advertiser_view_record(time date, advertiser varchar(10), channel varchar(10), user_id int) distributed by hash(time) properties("replication_num" = "1");
insert into advertiser_view_record values("2020-02-02",'a','a',1);
原始的广告点击数据表结构为:
MySQL [test]> desc advertiser_view_record;
+------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+------------+-------------+------+-------+---------+-------+
| time | DATE | Yes | true | NULL | |
| advertiser | VARCHAR(10) | Yes | true | NULL | |
| channel | VARCHAR(10) | Yes | false | NULL | NONE |
| user_id | INT | Yes | false | NULL | NONE |
+------------+-------------+------+-------+---------+-------+
4 rows in set (0.001 sec)
-
创建物化视图
由于用户想要查询的是广告的 UV 值,也就是需要对相同广告的用户进行一个精确去重,则查询一般为:
SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;针对这种求 UV 的场景,我们就可以创建一个带
bitmap_union的物化视图从而达到一个预先精确去重的效果。在 Doris 中,
count(distinct)聚合的结果和bitmap_union_count聚合的结果是完全一致的。而bitmap_union_count等于bitmap_union的结果求 count, 所以如果查询中涉及到count(distinct)则通过创建带bitmap_union聚合的物化视图方可加快查询。针对这个 Case,则可以创建一个根据广告和渠道分组,对
user_id进行精确去重的物化视图。MySQL [test]> create materialized view advertiser_uv as select advertiser, channel, bitmap_union(to_bitmap(user_id)) from advertiser_view_record group by advertiser, channel; Query OK, 0 rows affected (0.012 sec)注意:因为本身 user_id 是一个 INT 类型,所以在 Doris 中需要先将字段通过函数
to_bitmap转换为 bitmap 类型然后才可以进行bitmap_union聚合。创建完成后, 广告点击明细表和物化视图表的表结构如下:
MySQL [test]> desc advertiser_view_record all; +------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+ | IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | +------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+ | advertiser_view_record | DUP_KEYS | time | DATE | Yes | true | NULL | | | | | advertiser | VARCHAR(10) | Yes | true | NULL | | | | | channel | VARCHAR(10) | Yes | false | NULL | NONE | | | | user_id | INT | Yes | false | NULL | NONE | | | | | | | | | | | advertiser_uv | AGG_KEYS | advertiser | VARCHAR(10) | Yes | true | NULL | | | | | channel | VARCHAR(10) | Yes | true | NULL | | | | | to_bitmap(`user_id`) | BITMAP | No | false | | BITMAP_UNION | +------------------------+---------------+----------------------+-------------+------+-------+---------+--------------+ -
查询自动匹配
当物化视图表创建完成后,查询广告 UV 时,Doris 就会自动从刚才创建好的物化视图
advertiser_uv中查询数据。比如原始的查询语句如下:SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel;在选中物化视图后,实际的查询会转化为:
SELECT advertiser, channel, bitmap_union_count(to_bitmap(user_id)) FROM advertiser_uv GROUP BY advertiser, channel;通过 EXPLAIN 命令可以检验到 Doris 是否匹配到了物化视图:
mysql [test]>explain SELECT advertiser, channel, count(distinct user_id) FROM advertiser_view_record GROUP BY advertiser, channel; +--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Explain String | +--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+ | PLAN FRAGMENT 0 | | OUTPUT EXPRS: | | <slot 9> `default_cluster:test`.`advertiser_view_record`.`mv_advertiser` | | <slot 10> `default_cluster:test`.`advertiser_view_record`.`mv_channel` | | <slot 11> bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mva_BITMAP_UNION__to_bitmap_with_check(`user_id`)`) | | PARTITION: UNPARTITIONED | | | | VRESULT SINK | | | | 4:VEXCHANGE | | offset: 0 | | | | PLAN FRAGMENT 1 | | | | PARTITION: HASH_PARTITIONED: <slot 6> `default_cluster:test`.`advertiser_view_record`.`mv_advertiser`, <slot 7> `default_cluster:test`.`advertiser_view_record`.`mv_channel` | | | | STREAM DATA SINK | | EXCHANGE ID: 04 | | UNPARTITIONED | | | | 3:VAGGREGATE (merge finalize) | | | output: bitmap_union_count(<slot 8> bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mva_BITMAP_UNION__to_bitmap_with_check(`user_id`)`)) | | | group by: <slot 6> `default_cluster:test`.`advertiser_view_record`.`mv_advertiser`, <slot 7> `default_cluster:test`.`advertiser_view_record`.`mv_channel` | | | cardinality=-1 | | | | | 2:VEXCHANGE | | offset: 0 | | | | PLAN FRAGMENT 2 | | | | PARTITION: HASH_PARTITIONED: `default_cluster:test`.`advertiser_view_record`.`time` | | | | STREAM DATA SINK | | EXCHANGE ID: 02 | | HASH_PARTITIONED: <slot 6> `default_cluster:test`.`advertiser_view_record`.`mv_advertiser`, <slot 7> `default_cluster:test`.`advertiser_view_record`.`mv_channel` | | | | 1:VAGGREGATE (update serialize) | | | STREAMING | | | output: bitmap_union_count(`default_cluster:test`.`advertiser_view_record`.`mva_BITMAP_UNION__to_bitmap_with_check(`user_id`)`) | | | group by: `default_cluster:test`.`advertiser_view_record`.`mv_advertiser`, `default_cluster:test`.`advertiser_view_record`.`mv_channel` | | | cardinality=-1 | | | | | 0:VOlapScanNode | | TABLE: default_cluster:test.advertiser_view_record(advertiser_uv), PREAGGREGATION: ON | | partitions=1/1, tablets=10/10, tabletList=50075,50077,50079 ... | | cardinality=0, avgRowSize=48.0, numNodes=1 | +--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+在 EXPLAIN 的结果中,首先可以看到
VOlapScanNode命中了advertiser_uv。也就是说,查询会直接扫描物化视图的数据。说明匹配成功。其次对于
user_id字段求count(distinct)被改写为求bitmap_union_count(to_bitmap)。也就是通过 Bitmap 的方式来达到精确去重的效果。
最佳实践3
业务场景:匹配更丰富的前缀索引
用户的原始表有 (k1, k2, k3) 三列。其中 k1, k2 为前缀索引列。这时候如果用户查询条件中包含 where k1=1 and k2=2 就能通过索引加速查询。
但是有些情况下,用户的过滤条件无法匹配到前缀索引,比如 where k3=3。则无法通过索引提升查询速度。
创建以 k3 作为第一列的物化视图就可以解决这个问题。
-
创建物化视图
CREATE MATERIALIZED VIEW mv_1 as SELECT k3, k2, k1 FROM tableA ORDER BY k3;通过上面语法创建完成后,物化视图中既保留了完整的明细数据,且物化视图的前缀索引为 k3 列。表结构如下:
MySQL [test]> desc tableA all; +-----------+---------------+-------+------+------+-------+---------+-------+ | IndexName | IndexKeysType | Field | Type | Null | Key | Default | Extra | +-----------+---------------+-------+------+------+-------+---------+-------+ | tableA | DUP_KEYS | k1 | INT | Yes | true | NULL | | | | | k2 | INT | Yes | true | NULL | | | | | k3 | INT | Yes | true | NULL | | | | | | | | | | | | mv_1 | DUP_KEYS | k3 | INT | Yes | true | NULL | | | | | k2 | INT | Yes | false | NULL | NONE | | | | k1 | INT | Yes | false | NULL | NONE | +-----------+---------------+-------+------+------+-------+---------+-------+ -
查询匹配
这时候如果用户的查询存在 k3 列的过滤条件是,比如:
select k1, k2, k3 from table A where k3=3;这时候查询就会直接从刚才创建的 mv_1 物化视图中读取数据。物化视图对 k3 是存在前缀索引的,查询效率也会提升。
最佳实践4
SinceVersion 2.0.0
在Doris 2.0中,我们对物化视图所支持的表达式做了一些增强,本示例将主要体现新版本物化视图对各种表达式的支持和提前过滤。
- 创建一个 Base 表并插入一些数据。
create table d_table (k1 int null,k2 int not null,k3 bigint null,k4 date null
)
duplicate key (k1,k2,k3)
distributed BY hash(k1) buckets 3
properties("replication_num" = "1");insert into d_table select 1,1,1,'2020-02-20';
insert into d_table select 2,2,2,'2021-02-20';
insert into d_table select 3,-3,null,'2022-02-20';
- 创建一些物化视图。
create materialized view k1a2p2ap3ps as select abs(k1)+k2+1,sum(abs(k2+2)+k3+3) from d_table group by abs(k1)+k2+1;
create materialized view kymd as select year(k4),month(k4) from d_table where year(k4) = 2020; // 提前用where表达式过滤以减少物化视图中的数据量。
- 用一些查询测试是否成功命中物化视图。
select abs(k1)+k2+1,sum(abs(k2+2)+k3+3) from d_table group by abs(k1)+k2+1; // 命中k1a2p2ap3ps
select bin(abs(k1)+k2+1),sum(abs(k2+2)+k3+3) from d_table group by bin(abs(k1)+k2+1); // 命中k1a2p2ap3ps
select year(k4),month(k4) from d_table; // 无法命中物化视图,因为where条件不匹配
select year(k4)+month(k4) from d_table where year(k4) = 2020; // 命中kymd
局限性
- 如果删除语句的条件列,在物化视图中不存在,则不能进行删除操作。如果一定要删除数据,则需要先将物化视图删除,然后方可删除数据。
- 单表上过多的物化视图会影响导入的效率:导入数据时,物化视图和 Base 表数据是同步更新的,如果一张表的物化视图表超过 10 张,则有可能导致导入速度很慢。这就像单次导入需要同时导入 10 张表数据是一样的。
- 物化视图针对 Unique Key数据模型,只能改变列顺序,不能起到聚合的作用,所以在Unique Key模型上不能通过创建物化视图的方式对数据进行粗粒度聚合操作
- 目前一些优化器对sql的改写行为可能会导致物化视图无法被命中,例如k1+1-1被改写成k1,between被改写成<=和>=,day被改写成dayofmonth,遇到这种情况需要手动调整下查询和物化视图的语句。
异常错误
- DATA_QUALITY_ERROR: "The data quality does not satisfy, please check your data" 由于数据质量问题或者 Schema Change 内存使用超出限制导致物化视图创建失败。如果是内存问题,调大
memory_limitation_per_thread_for_schema_change_bytes参数即可。 注意:to_bitmap 的参数仅支持正整型, 如果原始数据中存在负数,会导致物化视图创建失败。String 类型的字段可使用 bitmap_hash 或 bitmap_hash64 计算 Hash 值,并返回 Hash 值的 bitmap。
更多帮助
关于物化视图使用的更多详细语法及最佳实践,请参阅 CREATE MATERIALIZED VIEW 和 DROP MATERIALIZED VIEW 命令手册,你也可以在 MySQL 客户端命令行下输入 HELP CREATE MATERIALIZED VIEW 和HELP DROP MATERIALIZED VIEW 获取更多帮助信息。
相关文章:

Apache Doris 入门教程32:物化视图
物化视图 物化视图是将预先计算(根据定义好的 SELECT 语句)好的数据集,存储在 Doris 中的一个特殊的表。 物化视图的出现主要是为了满足用户,既能对原始明细数据的任意维度分析,也能快速的对固定维度进行分析查询。 …...
函数详解,PHP截取字符串。)
PHP substr()函数详解,PHP截取字符串。
「作者主页」:士别三日wyx 「作者简介」:CSDN top100、阿里云博客专家、华为云享专家、网络安全领域优质创作者 「推荐专栏」:对网络安全感兴趣的小伙伴可以关注专栏《网络安全入门到精通》 substr 一、截取字符串二、截取中文字符串三、leng…...

关于flink-sql-connector-phoenix的重写逻辑
目录 重写意义 代码结构 调用链路 POM文件配置 代码解析 一、PhoenixJdbcDynamicTableFactory...
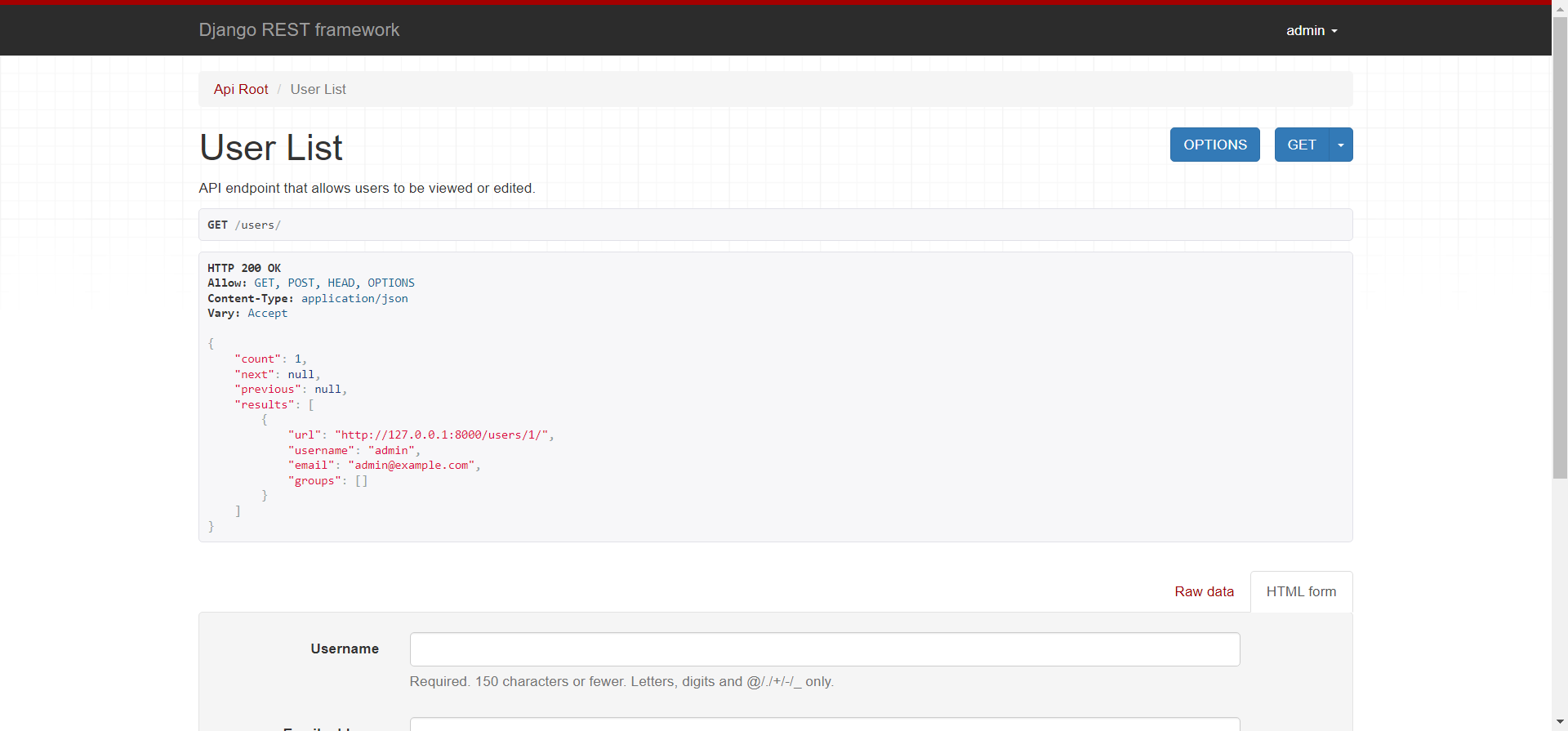
Django进阶:DRF(Django REST framework)
什么是DRF? DRF即Django REST framework的缩写,官网上说:Django REST framework是一个强大而灵活的工具包,用于构建Web API。 简单来说:通过DRF创建API后,就可以通过HTTP请求来获取、创建、更新或删除数据(…...

Flink CDC系列之:Oracle CDC 导入 Elasticsearch
Flink CDC系列之:Oracle CDC 导入 Elasticsearch 一、深入理解Flink Oracle CDC Connector二、创建docker-compose.yml文件三、启动容器四、下载Flink Oracle CDC的jar包五、启动 Flink 集群,再启动 SQL CLI六、检查 ElasticSearch 中的结果七、在 Oracl…...
Linux忘记root密码解决方法
当我们忘记root密码进不去服务器怎么办?不要担心,可以进入到linux的救援模式修改root密码。 下面直接上干货,流程如下: 1.重启电脑,按上下键滑动,保证不进入开机流程,然后按e键 2.出现此页面…...

AR/VR眼镜转接器方案,实现同时传输视频快充方案
简介 虚拟现实头戴显示器设备,简称VR头显VR眼镜,是利用仿真技术与计算机图形学人机接口技术多媒体技术传感技术网络技术等多种技术集合的产品,是借助计算机及最新传感器技术创造的一种崭新的人机交互手段。VR头显VR眼镜是一个跨时代的产品。不…...

ASP.NET Core中路由规则匹配
RESTful约束,如果在一个控制器里面有多个Get、Post...的操作 1、在一个控制器里面可以定义多个API方法 2、通过路由规则来区分 /// <summary> /// 获取用户信息 /// </summary> /// <param name"user"></param> /// <returns…...
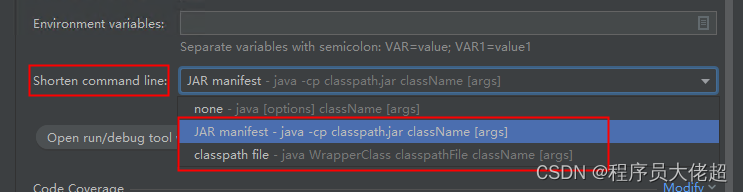
IDEA:Error running,Command line is too long. 解决方法
报错如下: Error running SendSmsUtil. Command line is too long. Shorten the command line via JAR manifest or via a classpath file and rerun.原因是启动命令过长。 解决方法: 1、打开Edit Configurations 2、点击Modify options设置&#x…...

什么是反射机制?为什么反射慢?
目录 面试回答 知识扩展 反射常见的使用方式 反射和 Class 的关系 面试回答 反射指的是程序在运行时能够获取自身的信息。在 java 中,只要给定类的名字,那么就可以通过反射机制来获得类的所有属性和方法。 Java 的反射可以: 在运行时判断…...

list元素
列表元素 列表元素分为有序列表和无序列表 有序列表 ol – order list – 有序列表 li – list item – 列表元素 <ol type"1"><li>有序列表1</li><li>有序列表2</li><li>有序列表3</li> </ol>属性 type type属…...

OkHttp 源码浅析一
演进之路:原生Android框架不好用 ---- HttpUrlConnect 和 Apache HTTPClient 第一版 底层使用HTTPURLConnect 第二版 Square构建 从Android4.4开始 基本使用: val okhttp OkHttpClient()val request Request.Builder().url("http://www.baidu.com").buil…...

【解决问题】远程仓库GitHub/GitLab添加了SSH Key之后依然无法clone的解决办法
GitHub/GitLab添加了SSH Key之后依然无法clone的解决办法 问题现象解决办法 问题现象 在Git远程仓库添加了自己的ssh key到账户下,git clone时,依然报错clone失败,请检查是否没有权限进行clone操作。 解决办法 在git的安装目录下ÿ…...

回归预测 | MATLAB实现SA-SVM模拟退火算法优化支持向量机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现SA-SVM模拟退火算法优化支持向量机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现SA-SVM模拟退火算法优化支持向量机多输入单输出回归预测(多指标,多图)效果一览基本…...

Spring事务和事务传播机制(1)
前言🍭 ❤️❤️❤️SSM专栏更新中,各位大佬觉得写得不错,支持一下,感谢了!❤️❤️❤️ Spring Spring MVC MyBatis_冷兮雪的博客-CSDN博客 在Spring框架中,事务管理是一种用于维护数据库操作的一致性和…...

如何快速在vscode中实现不同python文件的对比查看
总体而言:两种方式。一种是直接点击vscode右上角的图标(见下图)。 另一种方式就是使用快捷键啦“**Ctrl**”,用的时候选中想要对比的python文件,然后快捷键就可以达到下图效果了: 建议大家直接使用第二种…...
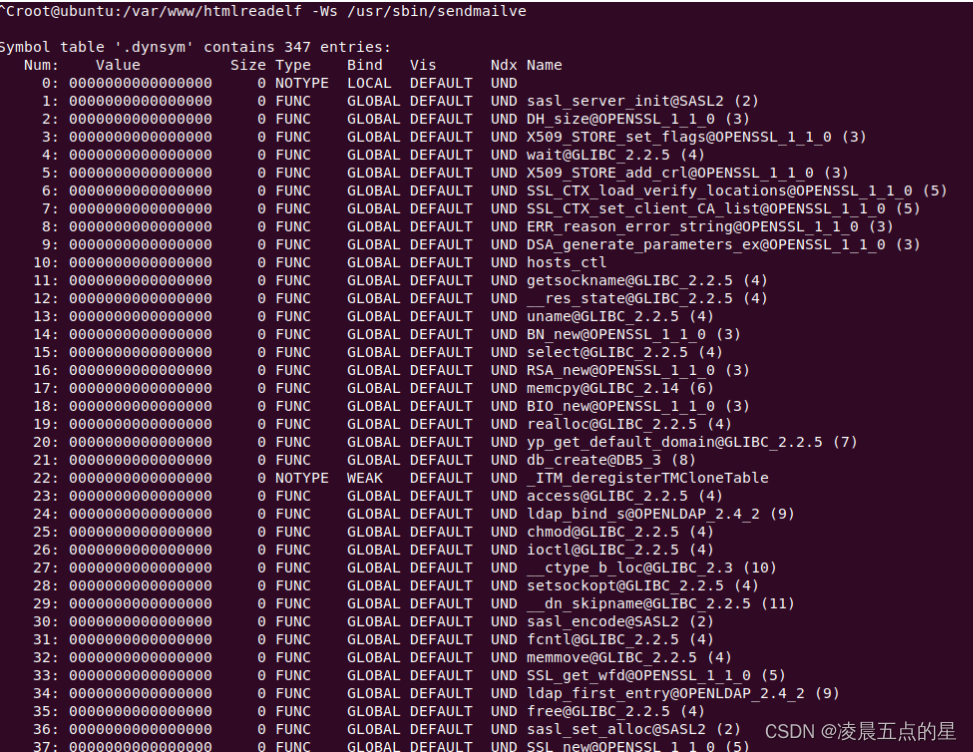
网络安全---Ring3下动态链接库.so函数劫持
一、动态链接库劫持原理 1.1、原理 Unix操作系统中,程序运行时会按照一定的规则顺序去查找依赖的动态链接库,当查找到指定的so文件时,动态链接器(/lib/ld-linux.so.X)会将程序所依赖的共享对象进行装载和初始化,而为什么可以使用…...
leetcode283. 移动零
难度:简单题 题目 给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。 请注意 ,必须在不复制数组的情况下原地对数组进行操作。 思路: 一开始想,从前往后遍历&am…...
GuLi商城-前端基础Vue-生命周期和钩子函数
下图展示了实例的生命周期。你不需要立马弄明白所有的东西,不过随着你的不断学习和使用,它 的参考价值会越来越高。 VUE 的生命周期指的是组件在创建、运行和销毁过程中所经历的一系列事件,通过这些事件可以 让开发者在不同阶段进行相应的…...
输入输出+暴力模拟入门:魔法之树、染色の树、矩阵、字母加密、玫瑰鸭
秋招实习刷题网站推荐:codefun2000.com,还有题解博客:blog.codefun2000.com/。以下内容都是来自塔子哥的~ 输入输出 2023.04.15-春招-第三题-魔法之树 //#include<bits/stdc.h> #include<vector> #include<iostream>usin…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

stm32G473的flash模式是单bank还是双bank?
今天突然有人stm32G473的flash模式是单bank还是双bank?由于时间太久,我真忘记了。搜搜发现,还真有人和我一样。见下面的链接:https://shequ.stmicroelectronics.cn/forum.php?modviewthread&tid644563 根据STM32G4系列参考手…...
)
React Native 导航系统实战(React Navigation)
导航系统实战(React Navigation) React Navigation 是 React Native 应用中最常用的导航库之一,它提供了多种导航模式,如堆栈导航(Stack Navigator)、标签导航(Tab Navigator)和抽屉…...
)
React Native 开发环境搭建(全平台详解)
React Native 开发环境搭建(全平台详解) 在开始使用 React Native 开发移动应用之前,正确设置开发环境是至关重要的一步。本文将为你提供一份全面的指南,涵盖 macOS 和 Windows 平台的配置步骤,如何在 Android 和 iOS…...

Oracle查询表空间大小
1 查询数据库中所有的表空间以及表空间所占空间的大小 SELECTtablespace_name,sum( bytes ) / 1024 / 1024 FROMdba_data_files GROUP BYtablespace_name; 2 Oracle查询表空间大小及每个表所占空间的大小 SELECTtablespace_name,file_id,file_name,round( bytes / ( 1024 …...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

el-switch文字内置
el-switch文字内置 效果 vue <div style"color:#ffffff;font-size:14px;float:left;margin-bottom:5px;margin-right:5px;">自动加载</div> <el-switch v-model"value" active-color"#3E99FB" inactive-color"#DCDFE6"…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

IoT/HCIP实验-3/LiteOS操作系统内核实验(任务、内存、信号量、CMSIS..)
文章目录 概述HelloWorld 工程C/C配置编译器主配置Makefile脚本烧录器主配置运行结果程序调用栈 任务管理实验实验结果osal 系统适配层osal_task_create 其他实验实验源码内存管理实验互斥锁实验信号量实验 CMISIS接口实验还是得JlINKCMSIS 简介LiteOS->CMSIS任务间消息交互…...

如何理解 IP 数据报中的 TTL?
目录 前言理解 前言 面试灵魂一问:说说对 IP 数据报中 TTL 的理解?我们都知道,IP 数据报由首部和数据两部分组成,首部又分为两部分:固定部分和可变部分,共占 20 字节,而即将讨论的 TTL 就位于首…...