机器学习深度学习——BERT(来自transformer的双向编码器表示)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er
🌌上期文章:机器学习&&深度学习——transformer(机器翻译的再实现)
📚订阅专栏:机器学习&&深度学习
希望文章对你们有所帮助
BERT(来自transformer的双向编码器表示)
- 引入
- 从上下文无关到上下文敏感
- 从特定于任务到不可知任务
- BERT:把两个最好的结合起来
- 输入表示
- 预训练任务
- 遮蔽语言模型
- 下一句预测
- 整合代码
- 小结
引入
我们首先理解一下相关的一些概念,首先我们知道在自然语言系统中,词是意义的基本单元,那么顾名思义,词向量是用于表示单词意义的向量,并且还可以被认为是单词的特征向量或表示。将单词映射到实向量的技术称为词嵌入,也就是word2vec,词嵌入已经逐渐成为了自然语言处理的基础知识。
词嵌入word2vec的模型有多种,如跳元模型、连续词袋模型等,词嵌入还可以有全局向量的词嵌入(GloVe)。具体的相关概念不细讲了,以后如果总结的时候再讲。
词嵌入在预训练之后,输出可以被认为是一个矩阵,其中每一行都是一个预定义词表中词的向量。事实上,这些词嵌入模型都是与上下文无关的。
从上下文无关到上下文敏感
上面所说的词嵌入word2vec以及全局向量的词嵌入GloVe都将相同的预训练向量分配给同一个词,而不考虑词的上下文(如果有的话)。形式上,任何词元x的上下文无关表示是f(x),其仅仅是将x作为其输入。但是考虑到自然语言中词的多意性以及语义的复杂性,上下文无关的表示明显有局限,在不同的语境和上下文中,一个词元的意思可能是不一样的。
这推动了“上下文敏感”词表示的发展,其中词的表征取决于它们的上下文。因此,词元x的上下文敏感表示是函数f(x,c(x)),其取决于x及其上下文c(x)。流行的上下文敏感包括了ELMo(Embeddings from Language Models,来自语言模型的嵌入)。
通过将整个序列作为输入,ELMo是为输入序列中的每个单词分配一个表示的函数。添加ELMo改进了六种自然语言处理任务的技术水平:情感分析、自然语言推断、语义角色标注、共指消解、命名实体识别和问答。
从特定于任务到不可知任务
尽管ELMo显著改进了各种自然语言处理任务的解决方案,但每个解决方案仍然依赖于一个特定于任务的架构。然而,为每一个自然语言处理任务设计一个特定的架构实际上并不是一件容易的事。GPT模型为上下文的敏感表示设计了通用的任务无关模型。
然而,由于语言模型的自回归特性,GPT只能向前看(从左到右)。在“i went to the bank to deposit cash”(我去银行存现金)和“i went to the bank to sit down”(我去河岸边坐下)的上下文中,由于“bank”对其左边的上下文敏感,GPT将返回“bank”的相同表示,尽管它有不同的含义。
BERT:把两个最好的结合起来
ELMo对上下文进行双向编码,但使用特定于任务的架构;而GPT是任务无关的,但是从左到右编码上下文。BERT结合了这两个方面的优点。它对上下文进行双向编码,并且对于大多数的自然语言处理任务只需要最少的架构改变。通过使用预训练的transformer编码器,BERT能够基于其双向上下文表示任何词元。在下游任务的监督学习过程中,BERT在两个方面与GPT相似。首先,BERT表示将被输入到一个添加的输出层中,根据任务的性质对模型架构进行最小的更改,例如预测每个词元与预测整个序列。其次,对预训练Transformer编码器的所有参数进行微调,而额外的输出层将从头开始训练。
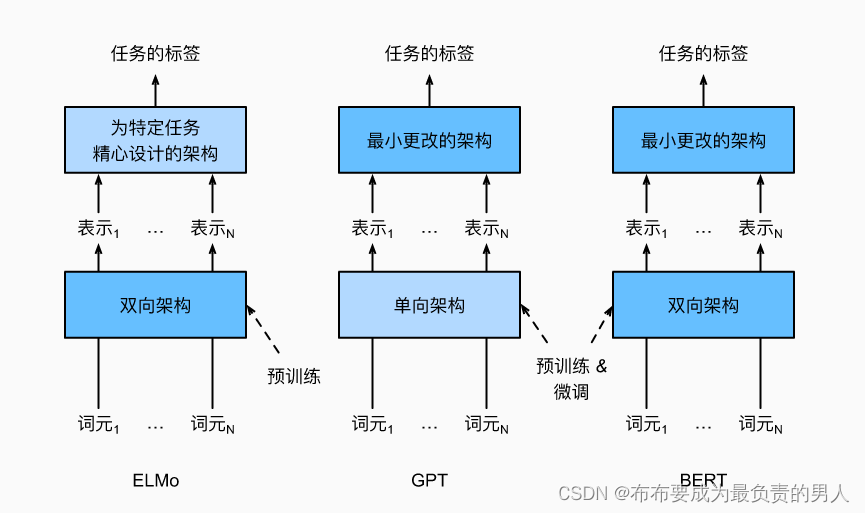
下面将深入了解BERT的训练前准备,在后续的NLP应用中,将说明针对下游任务应用的BERT微调。
import torch
from torch import nn
from d2l import torch as d2l
输入表示
在自然语言处理中,有些任务(如情感分析)以单个文本作为输入,而有些任务(如自然语言推断)以一对文本序列作为输入。BERT输入序列明确地表示单个文本和文本对。当输入为单个文本时,BERT输入序列是特殊类别词元“<cls>”、文本序列的标记、以及特殊分隔词元“<sep>”的连结。当输入为文本对时,BERT输入序列是“<cls>”、第一个文本序列的标记、“<sep>”、第二个文本序列标记、以及“<sep>”的连结。BERT输入序列可以包括一个文本序列或两个文本序列(可以与其他类型的序列区分开来,其他类型的只是一个文本序列)。
为了区分文本对,根据输入序列学到的片段嵌入
e A 和 e B e_A和e_B eA和eB
分别被添加到第一序列和第二序列的词元嵌入中。对于单文本输入,仅使用
e A e_A eA
下面的get_tokens_and_segments将一个句子或两个句子作为输入,然后返回BERT输入序列的标记及其相应的片段索引:
#@save
def get_tokens_and_segments(tokens_a, tokens_b=None):"""获取输入序列的词元及其片段索引"""tokens = ['<cls>'] + tokens_a + ['<sep>']# 0和1分别标记片段A和Bsegments = [0] * (len(tokens_a) + 2)if tokens_b is not None:tokens += tokens_b + ['<sep>']segments += [1] * (len(tokens_b) + 1)return tokens, segments
在Transformer编码器中常见是,位置嵌入被加入到输入序列的每个位置。然而,与原始的Transformer编码器不同,BERT使用可学习的位置嵌入。下图表明BERT输入序列的嵌入是词元嵌入、片段嵌入和位置嵌入的和。
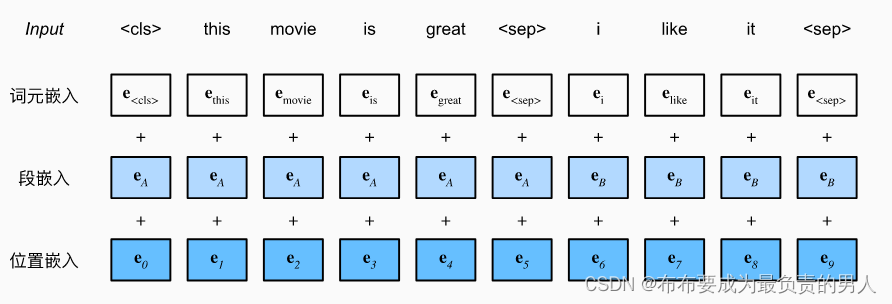
下面的BERTEncoder类似于之前的TransformerEncoder类,与其不同的是BERTEncoder使用片段嵌入和可学习的位置嵌入。
#@save
class BERTEncoder(nn.Module):"""BERT编码器"""def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,ffn_num_hiddens, num_heads, num_layers, dropout,max_len=1000, key_size=768, query_size=768, value_size=768,**kwargs):super(BERTEncoder, self).__init__(**kwargs)self.token_embedding = nn.Embedding(vocab_size, num_hiddens)self.segment_embedding = nn.Embedding(2, num_hiddens)self.blks = nn.Sequential()for i in range(num_layers):self.blks.add_module(f"{i}", d2l.EncoderBlock(key_size, query_size, value_size, num_hiddens, norm_shape,ffn_num_input, ffn_num_hiddens, num_heads, dropout, True))# 在BERT中,位置嵌入是可学习的,因此我们创建一个足够长的位置嵌入参数self.pos_embedding = nn.Parameter(torch.randn(1, max_len,num_hiddens))def forward(self, tokens, segments, valid_lens):# 在以下代码段中,X的形状保持不变:(批量大小,最大序列长度,num_hiddens)X = self.token_embedding(tokens) + self.segment_embedding(segments)X = X + self.pos_embedding.data[:, :X.shape[1], :]for blk in self.blks:X = blk(X, valid_lens)return X
假设词表大小为10000,为了演示BERTEncoder的前向推断,让我们创建一个实例并初始化它的参数。
vocab_size, num_hiddens, ffn_num_hiddens, num_heads = 10000, 768, 1024, 4
norm_shape, ffn_num_input, num_layers, dropout = [768], 768, 2, 0.2
encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape, ffn_num_input,ffn_num_hiddens, num_heads, num_layers, dropout)
我们将tokens定义为长度为8的2个输入序列,其中每个词元是词表的索引。使用输入tokens的BERTEncoder的前向推断返回编码结果,其中每个词元由向量表示,其长度由超参数num_hiddens定义。此超参数通常称为Transformer编码器的隐藏大小(隐藏单元数)。
tokens = torch.randint(0, vocab_size, (2, 8))
segments = torch.tensor([[0, 0, 0, 0, 1, 1, 1, 1], [0, 0, 0, 1, 1, 1, 1, 1]])
encoded_X = encoder(tokens, segments, None)
print(encoded_X.shape)
运行结果:
torch.Size([2, 8, 768])
预训练任务
BERTEncoder的前向推断给出了输入文本的每个词元和插入的特殊标记“<cls>”及“<seq>”的BERT表示。接下来,我们将使用这些表示来计算预训练BERT的损失函数。预训练包括以下两个任务:掩蔽语言模型和下一句预测。
遮蔽语言模型
之前所说的语言模型都是只使用左侧的上下文预测词元,右侧的会忽略不看。也就是说通过左侧的话,去预测后面的词。
为了双向编码上下文以表示每个词元,BERT随机掩蔽词元并使用来自双向上下文的词元以自监督的方式预测掩蔽词元。此任务称为掩蔽语言模型。相当于BERT从之前语言模型的预测词元变为了现在的完形填空。
在这个预训练任务中,将随机选择15%的词元作为预测的掩蔽词元。要预测一个掩蔽词元而不使用标签作弊,一个简单的方法是总是用一个特殊的“<mask>”替换输入序列中的词元。
然而,人造特殊词元“<mask>”不会出现在微调中。为了避免预训练和微调之间的这种不匹配,如果为预测而屏蔽词元(例如,在“my dog is cute”中选择掩蔽和预测“cute”),则在输入中将其替换为:
1、80%变为特殊“<mask>”词元:“my dog is <mask>”;
2、10%为随机词元:“my dog is cat”;
3、10%为不变的标签词元:“my dog is cute”;
在15%的时间中,有10%的时间插入了随机词元。这种偶然的噪声鼓励BERT在其双向上下文编码中不那么偏向于掩蔽词元(尤其是当标签词元保持不变时)。至于为什么是这样,15%,80%这类数据是怎么得出的,BERT的原作者只在论文中写自己是实验过且发现这样的效果很不错。
我们实现了下面的MaskLM类来预测BERT预训练的掩蔽语言模型任务中的掩蔽标记。预测使用单隐藏层的多层感知机(self.mlp)。在前向推断中,它需要两个输入:BERTEncoder的编码结果和用于预测的词元位置。输出是这些位置的预测结果。
#@save
class MaskLM(nn.Module):"""BERT的掩蔽语言模型任务"""def __init__(self, vocab_size, num_hiddens, num_inputs=768, **kwargs):super(MaskLM, self).__init__(**kwargs)self.mlp = nn.Sequential(nn.Linear(num_inputs, num_hiddens),nn.ReLU(),nn.LayerNorm(num_hiddens),nn.Linear(num_hiddens, vocab_size))def forward(self, X, pred_positions):num_pred_positions = pred_positions.shape[1]pred_positions = pred_positions.reshape(-1)batch_size = X.shape[0]batch_idx = torch.arange(0, batch_size)# 假设batch_size=2,num_pred_positions=3# 那么batch_idx是np.array([0,0,0,1,1,1])batch_idx = torch.repeat_interleave(batch_idx, num_pred_positions)masked_X = X[batch_idx, pred_positions]masked_X = masked_X.reshape((batch_size, num_pred_positions, -1))mlm_Y_hat = self.mlp(masked_X)return mlm_Y_hat
为了演示MaskLM的前向推断,我们创建了其实例mlm并对其进行了初始化。回想一下,来自BERTEncoder的正向推断encoded_X表示2个BERT输入序列。我们将mlm_positions定义为在encoded_X的任一输入序列中预测的3个指示。mlm的前向推断返回encoded_X的所有掩蔽位置mlm_positions处的预测结果mlm_Y_hat。对于每个预测,结果的大小等于词表的大小。
mlm = MaskLM(vocab_size, num_hiddens)
mlm_positions = torch.tensor([[1, 5, 2], [6, 1, 5]])
mlm_Y_hat = mlm(encoded_X, mlm_positions)
print(mlm_Y_hat.shape)
输出结果:
torch.Size([2, 3, 10000])
通过掩码下的预测词元mlm_Y的真实标签mlm_Y_hat,我们可以计算在BERT预训练中的遮蔽语言模型任务的交叉熵损失。
mlm_Y = torch.tensor([[7, 8, 9], [10, 20, 30]])
loss = nn.CrossEntropyLoss(reduction='none')
mlm_l = loss(mlm_Y_hat.reshape((-1, vocab_size)), mlm_Y.reshape(-1))
print(mlm_l.shape)
运行结果:
torch.Size([6])
下一句预测
尽管掩蔽语言建模能够编码双向上下文来表示单词,但它不能显式地建模文本对之间的逻辑关系。为了帮助理解两个文本序列之间的关系,BERT在预训练中考虑了一个二元分类任务——下一句预测。
在为预训练生成句子对时,有一半的时间它们确实是标签为“真”的连续句子;在另一半的时间里,第二个句子是从语料库中随机抽取的,标记为“假”。
下面的NextSentencePred类使用单隐藏层的多层感知机来预测第二个句子是否是BERT输入序列中第一个句子的下一个句子。由于Transformer编码器中的自注意力,特殊词元“<cls>”的BERT表示已经对输入的两个句子进行了编码。因此,多层感知机分类器的输出层(self.output)以X作为输入,其中X是多层感知机隐藏层的输出,而MLP隐藏层的输入是编码后的“<cls>”词元。
#@save
class NextSentencePred(nn.Module):"""BERT的下一句预测任务"""def __init__(self, num_inputs, **kwargs):super(NextSentencePred, self).__init__(**kwargs)self.output = nn.Linear(num_inputs, 2)def forward(self, X):# X的形状:(batchsize,num_hiddens)return self.output(X)
我们可以看到,NextSentencePred实例的前向推断返回每个BERT输入序列的二分类预测。
encoded_X = torch.flatten(encoded_X, start_dim=1)
# NSP的输入形状:(batchsize,num_hiddens)
nsp = NextSentencePred(encoded_X.shape[-1])
nsp_Y_hat = nsp(encoded_X)
print(nsp_Y_hat.shape)
运行结果:
torch.Size([2, 2])
也可以计算两个二元分类的交叉熵损失:
nsp_y = torch.tensor([0, 1])
nsp_l = loss(nsp_Y_hat, nsp_y)
print(nsp_l.shape)
输出结果:
torch.Size([2])
上述两个预训练任务中的所有标签都可以从预训练语料库中获得,原始BERT已经在很大的文本语料库里面训练过了。
整合代码
在预训练BERT时,最终的损失函数是掩蔽语言模型损失函数和下一句预测损失函数的线性组合。现在我们可以通过实例化三个类BERTEncoder、MaskLM和NextSentencePred来定义BERTModel类。前向推断返回编码后的BERT表示encoded_X、掩蔽语言模型预测mlm_Y_hat和下一句预测nsp_Y_hat。
#@save
class BERTModel(nn.Module):"""BERT模型"""def __init__(self, vocab_size, num_hiddens, norm_shape, ffn_num_input,ffn_num_hiddens, num_heads, num_layers, dropout,max_len=1000, key_size=768, query_size=768, value_size=768,hid_in_features=768, mlm_in_features=768,nsp_in_features=768):super(BERTModel, self).__init__()self.encoder = BERTEncoder(vocab_size, num_hiddens, norm_shape,ffn_num_input, ffn_num_hiddens, num_heads, num_layers,dropout, max_len=max_len, key_size=key_size,query_size=query_size, value_size=value_size)self.hidden = nn.Sequential(nn.Linear(hid_in_features, num_hiddens),nn.Tanh())self.mlm = MaskLM(vocab_size, num_hiddens, mlm_in_features)self.nsp = NextSentencePred(nsp_in_features)def forward(self, tokens, segments, valid_lens=None,pred_positions=None):encoded_X = self.encoder(tokens, segments, valid_lens)if pred_positions is not None:mlm_Y_hat = self.mlm(encoded_X, pred_positions)else:mlm_Y_hat = None# 用于下一句预测的多层感知机分类器的隐藏层,0是“<cls>”标记的索引nsp_Y_hat = self.nsp(self.hidden(encoded_X[:, 0, :]))return encoded_X, mlm_Y_hat, nsp_Y_hat
小结
1、word2vec和GloVe等词嵌入模型与上下文无关。它们将相同的预训练向量赋给同一个词,而不考虑词的上下文(如果有的话)。它们很难处理好自然语言中的一词多义或复杂语义。
2、对于上下文敏感的词表示,如ELMo和GPT,词的表示依赖于它们的上下文。
3、ELMo对上下文进行双向编码,但使用特定于任务的架构(然而,为每个自然语言处理任务设计一个特定的体系架构实际上并不容易);而GPT是任务无关的,但是从左到右编码上下文。
4、BERT结合了这两个方面的优点:它对上下文进行双向编码,并且需要对大量自然语言处理任务进行最小的架构更改。
5、BERT输入序列的嵌入是词元嵌入、片段嵌入和位置嵌入的和。
6、预训练包括两个任务:掩蔽语言模型和下一句预测。前者能够编码双向上下文来表示单词,而后者则显式地建模文本对之间的逻辑关系。
相关文章:
机器学习深度学习——BERT(来自transformer的双向编码器表示)
👨🎓作者简介:一位即将上大四,正专攻机器学习的保研er 🌌上期文章:机器学习&&深度学习——transformer(机器翻译的再实现) 📚订阅专栏:机器学习&am…...
Datawhale Django后端开发入门 Vscode TASK02 Admin管理员、外键的使用
一.Admin管理员的使用 1、启动django服务 使用创建管理员之前,一定要先启动django服务,虽然TASK01和TASK02是分开的,但是进行第二个流程的时候记得先启动django服务,注意此时是在你的项目文件夹下启动的,时刻注意要执…...
【ES5和ES6】数组遍历的各种方法集合
一、ES5的方法 1.for循环 let arr [1, 2, 3] for (let i 0; i < arr.length; i) {console.log(arr[i]) } // 1 // 2 // 32.forEach() 特点: 没有返回值,只是针对每个元素调用func三个参数:item, index, arr ;当前项&#…...

学科在线教育元宇宙VR虚拟仿真平台落实更高质量的交互学习
为推动教育数字化,建设全民终身学习的学习型社会、学习型大国,元宇宙企业深圳华锐视点深度融合VR虚拟现实、数字孪生、云计算和三维建模等技术,搭建教育元宇宙平台,为学生提供更加沉浸式的学习体验,提高学习效果和兴趣…...
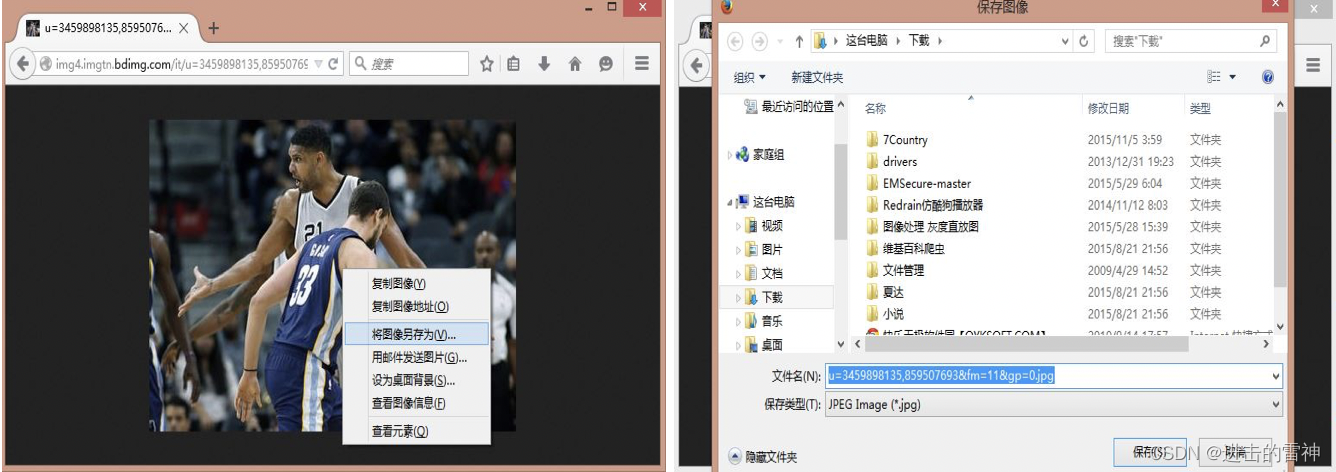
[python爬虫] 爬取图片无法打开或已损坏的简单探讨
本文主要针对python使用urlretrieve或urlopen下载百度、搜狗、googto(谷歌镜像)等图片时,出现"无法打开图片或已损坏"的问题,作者对它进行简单的探讨。同时,作者将进一步帮你巩固selenium自动化操作和urllib…...

vue项目预览pdf功能(解决动态文字无法显示的问题)
最近,因为公司项目需要预览pdf的功能,开始的时候找了市面上的一些pdf插件,都能用,但是,后面因为pdf变成了需要根据内容进行变化的,然后,就出现了需要动态生成的文字不显示了。换了好多好多的插件…...

vue3 样式穿透:deep不生效
初学vue3,今天需要修改el-input组件的属性(去掉border和文字居右) 网上搜了一下,大致都是采用:deep 样式穿透来修改el-input的属性 <div class"input-container"><el-input placeholder"请输入111&qu…...
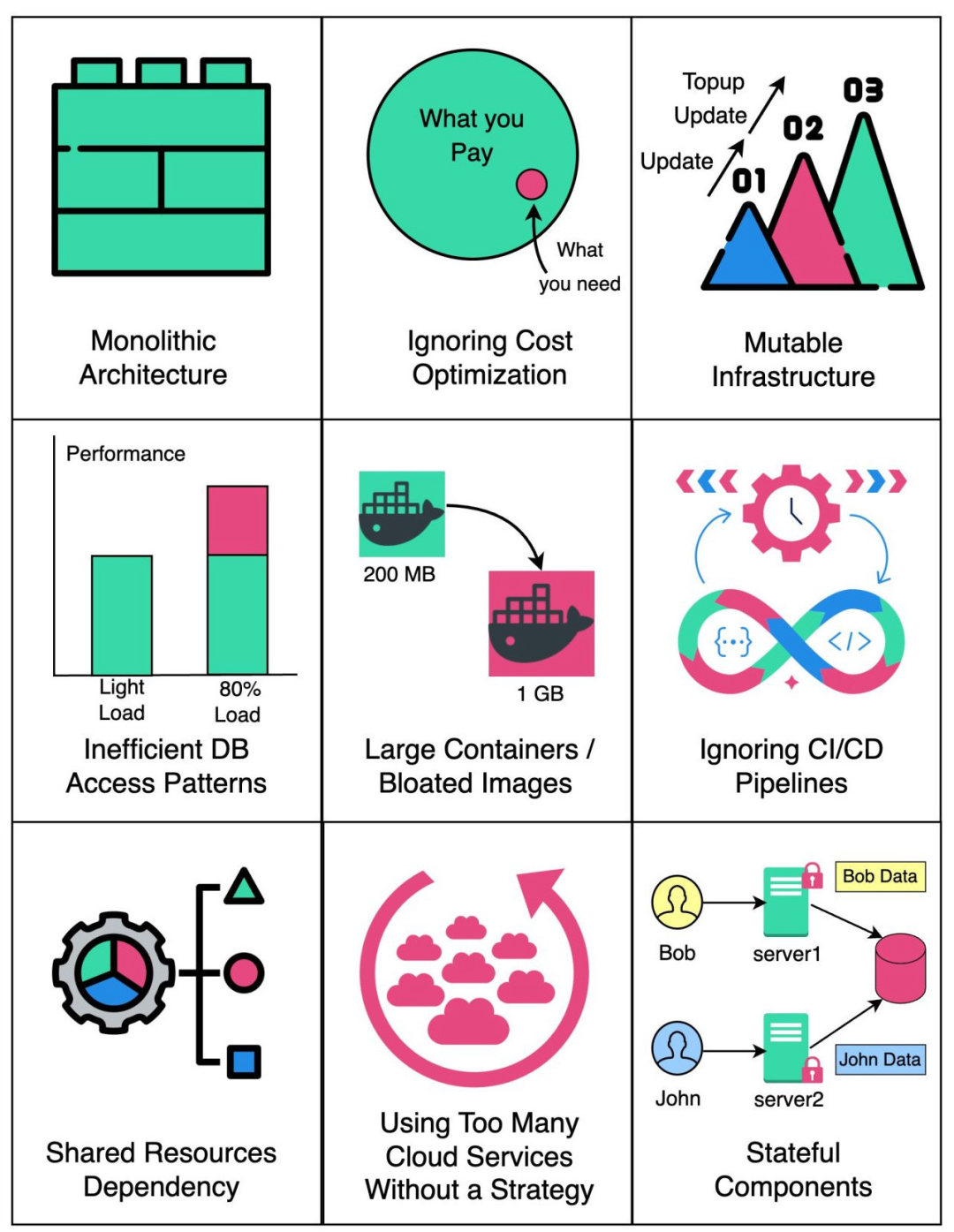
云原生反模式
通过了解这些反模式并遵循云原生最佳实践,您可以设计、构建和运营更加强大、可扩展和成本效益高的云原生应用程序。 1.单体架构:在云上运行一个大而紧密耦合的应用程序,妨碍了可扩展性和敏捷性。2.忽略成本优化:云服务可能昂贵&am…...
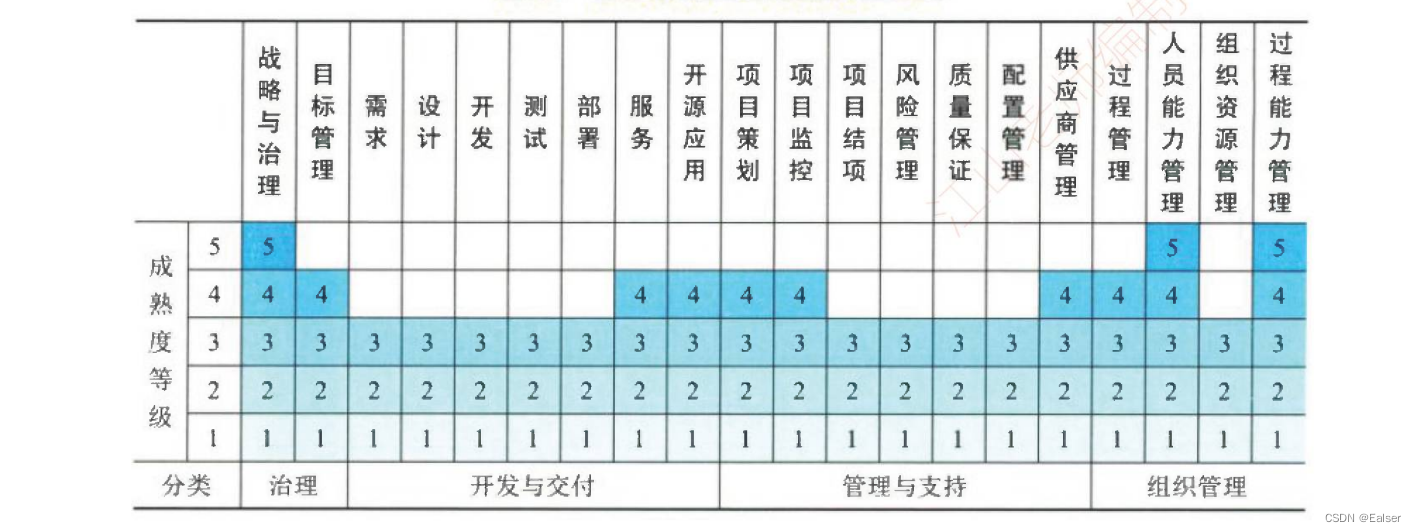
【2023年11月第四版教材】《第5章-信息系统工程(合集篇)》
《第5章-信息系统工程(合集篇)》 章节说明1 软件工程1.1 架构设计1.2 需求分析1.3 软件设计1.4 软件实现[补充第三版教材内容] 1.5 部署交付 2 数据工程2.1 数据建模2.2 数据标准化2.3 数据运维2.4 数据开发利用2.5 数据库安全 3 …...

【qiankun】微前端在项目中的具体使用
1、安装qiankun npm install qiankun --save2、主应用中注册和配置qiankun 在主应用的入口文件main.ts中,引入qiankun的注册方法: import { registerMicroApps, start } from qiankun;创建一个数组,用于配置子应用的相关信息。每个子应用都…...

云安全与多云环境管理:讨论在云计算和多云环境下如何保护数据、应用程序和基础设施的安全
随着云计算和多云环境的广泛应用,企业正面临着数据、应用程序和基础设施安全的新挑战。在这个数字化时代,保护敏感信息和业务运作的连续性变得尤为重要。本文将深入探讨在云计算和多云环境下如何有效地保护数据、应用程序和基础设施的安全。 章节一&…...
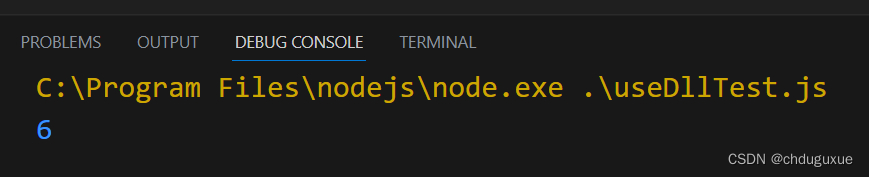
npm install ffi各种失败,换命令npm i ffi-napi成功
网上各种帖子安装ffi,基本上到了windows build tools这里会卡住。 使用命令npm install --global --production windows-build-tools 安装报错信息如下: PS E:\codes\nodejsPath\tcpTest> npm install --global --production windows-build-tools …...

0.flink学习资料
论文: (1)google dataflow model 下载链接:p1792-Akidau.pdf (vldb.org) Akidau T, Bradshaw R, Chambers C, et al. The dataflow model: a practical approach to balancing correctness, latency, and cost in massive-scal…...

C语言:字符函数和字符串函数
往期文章 C语言:初识C语言C语言:分支语句和循环语句C语言:函数C语言:数组C语言:操作符详解C语言:指针详解C语言:结构体C语言:数据的存储 目录 往期文章前言1. 函数介绍1.1 strlen1.…...
基于.Net Core开发的医疗信息LIS系统源码
SaaS模式.Net Core版云LIS系统源码 医疗信息LIS系统是专为医院检验科设计的一套实验室信息管理系统,能将实验仪器与计算机组成网络,使病人样品登录、实验数据存取、报告审核、打印分发,实验数据统计分析等繁杂的操作过程实现了智能化、自动化…...

部署工业物联网可以选择哪些通信方案?
部署工业物联网有诸多意义,诸如提升生产效率,降低管理成本,保障生产品质稳定,应对长期从业劳动力变化趋势等。针对不同行业、场景,工业物联网需要选择不同的通信方案,以达到成本和效益的最佳平衡。本篇就简…...

flutter-移动端适配
不同屏幕之间的尺寸适配 使用插件 flutter_screenutil flutter_screenutil flutter 屏幕适配方案,用于调整屏幕和字体大小的flutter插件,让你的UI在不同尺寸的屏幕上都能显示合理的布局! 安装 # add flutter_screenutil flutter_screenutil: ^5.8.4 o…...

MySQL 常用函数
一、数学函数 1、ABS(x) 返回绝对值。 mysql> select abs(-4); --------- | abs(-4) | --------- | 4 | --------- 1 row in set (0.00 sec) 2、PI() 返回圆周率,并四舍五入保留五位小数。 mysql> select pi(); ----------…...

动态路由的实现—正则表达式
文章目录 前言一、什么是正则表达式?二、正则表达式在动态路由中的作用三、实现一个简单的路由调度器总结 前言 动态路由有很多种实现方式,支持的规则、性能等有很大的差异。例如开源的路由实现gorouter支持在路由规则中嵌入正则表达式,例如…...

Android实现超出固定行数折叠文字“查看全文“、“收起全文“
先上效果图 分析问题 网上有很多关于这个的代码,实现都过于复杂了,github上甚至还看到一篇文章600多行代码,结果一跑起来全是bug。还是自己写吧!!! 如果我们需要换行的"查看全文"、"收起全…...

LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器的上位机配置操作说明
LBE-LEX系列工业语音播放器|预警播报器|喇叭蜂鸣器专为工业环境精心打造,完美适配AGV和无人叉车。同时,集成以太网与语音合成技术,为各类高级系统(如MES、调度系统、库位管理、立库等)提供高效便捷的语音交互体验。 L…...

谷歌浏览器插件
项目中有时候会用到插件 sync-cookie-extension1.0.0:开发环境同步测试 cookie 至 localhost,便于本地请求服务携带 cookie 参考地址:https://juejin.cn/post/7139354571712757767 里面有源码下载下来,加在到扩展即可使用FeHelp…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

今日科技热点速览
🔥 今日科技热点速览 🎮 任天堂Switch 2 正式发售 任天堂新一代游戏主机 Switch 2 今日正式上线发售,主打更强图形性能与沉浸式体验,支持多模态交互,受到全球玩家热捧 。 🤖 人工智能持续突破 DeepSeek-R1&…...

让AI看见世界:MCP协议与服务器的工作原理
让AI看见世界:MCP协议与服务器的工作原理 MCP(Model Context Protocol)是一种创新的通信协议,旨在让大型语言模型能够安全、高效地与外部资源进行交互。在AI技术快速发展的今天,MCP正成为连接AI与现实世界的重要桥梁。…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

Caliper 配置文件解析:config.yaml
Caliper 是一个区块链性能基准测试工具,用于评估不同区块链平台的性能。下面我将详细解释你提供的 fisco-bcos.json 文件结构,并说明它与 config.yaml 文件的关系。 fisco-bcos.json 文件解析 这个文件是针对 FISCO-BCOS 区块链网络的 Caliper 配置文件,主要包含以下几个部…...