Hadoop小结(上)
最近在学大模型的分布式训练和存储,自己的分布式相关基础比较薄弱,基于深度学习的一切架构皆来源于传统,我总结了之前大数据的分布式解决方案即Hadoop:
Why Hadoop
Hadoop 的作用非常简单,就是在多计算机集群环境中营造一个统一而稳定的存储和计算环境,并能为其他分布式应用服务提供平台支持。
Hadoop 在某种程度上将多台计算机组织成了一台计算机(做同一件事),那么 HDFS 就相当于这台计算机的硬盘,而 MapReduce 就是这台计算机的 CPU 控制器。
Trouble
由于 Hadoop 是为集群设计的软件,所以我们在学习它的使用时难免会遇到在多台计算机上配置 Hadoop 的情况,这对于学习者来说会制造诸多障碍,主要有两个:
- 昂贵的计算机集群。多计算机构成的集群环境需要昂贵的硬件.
- 难以部署和维护。在众多计算机上部署相同的软件环境是一个大量的工作,而且非常不灵活,难以在环境更改后重新部署。
为了解决这些问题,我们有一个非常成熟的方式Docker。
Docker 是一个容器管理系统,它可以向虚拟机一样运行多个"虚拟机"(容器),并构成一个集群。因为虚拟机会完整的虚拟出一个计算机来,所以会消耗大量的硬件资源且效率低下,而 Docker 仅提供一个独立的、可复制的运行环境,实际上容器中所有进程依然在主机上的内核中被执行,因此它的效率几乎和主机上的进程一样(接近100%)。
Hadoop 整体设计
Hadoop 框架是用于计算机集群大数据处理的框架,所以它必须是一个可以部署在多台计算机上的软件。部署了 Hadoop 软件的主机之间通过套接字 (网络) 进行通讯。
Hadoop 主要包含 HDFS 和 MapReduce 两大组件,HDFS 负责分布储存数据,MapReduce 负责对数据进行映射、规约处理,并汇总处理结果。
Hadoop 框架最根本的原理就是利用大量的计算机同时运算来加快大量数据的处理速度。例如,一个搜索引擎公司要从上万亿条没有进行规约的数据中筛选和归纳热门词汇就需要组织大量的计算机组成集群来处理这些信息。如果使用传统数据库来处理这些信息的话,那将会花费很长的时间和很大的处理空间来处理数据,这个量级对于任何单计算机来说都变得难以实现,主要难度在于组织大量的硬件并高速地集成为一个计算机,即使成功实现也会产生昂贵的维护成本。
Hadoop 可以在多达几千台廉价的量产计算机上运行,并把它们组织为一个计算机集群。
一个 Hadoop 集群可以高效地储存数据、分配处理任务,这样会有很多好处。首先可以降低计算机的建造和维护成本,其次,一旦任何一个计算机出现了硬件故障,不会对整个计算机系统造成致命的影响,因为面向应用层开发的集群框架本身就必须假定计算机会出故障。
HDFS
Hadoop Distributed File System,Hadoop 分布式文件系统,简称 HDFS。
HDFS 用于在集群中储存文件,它所使用的核心思想是 Google 的 GFS 思想,可以存储很大的文件。
在服务器集群中,文件存储往往被要求高效而稳定,HDFS同时实现了这两个优点。
HDFS 高效的存储是通过计算机集群独立处理请求实现的。因为用户 (一半是后端程序) 在发出数据存储请求时,往往响应服务器正在处理其他请求,这是导致服务效率缓慢的主要原因。但如果响应服务器直接分配一个数据服务器给用户,然后用户直接与数据服务器交互,效率会快很多。
数据存储的稳定性往往通过"多存几份"的方式实现,HDFS 也使用了这种方式。HDFS 的存储单位是块 (Block) ,一个文件可能会被分为多个块储存在物理存储器中。因此 HDFS 往往会按照设定者的要求把数据块复制 n 份并存储在不同的数据节点 (储存数据的服务器) 上,如果一个数据节点发生故障数据也不会丢失。
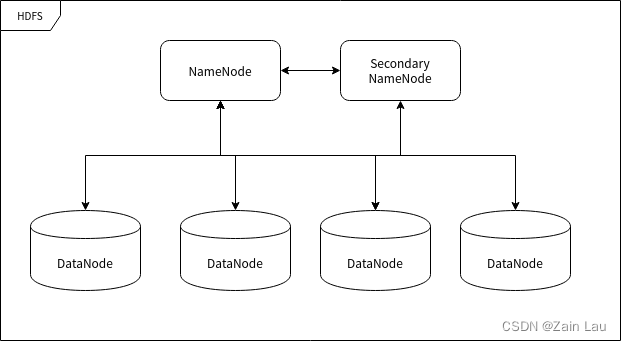
HDFS 的节点
HDFS 运行在许多不同的计算机上,有的计算机专门用于存储数据,有的计算机专门用于指挥其它计算机储存数据。这里所提到的"计算机"我们可以称之为集群中的节点。
命名节点 (NameNode)
命名节点 (NameNode) 是用于指挥其它节点存储的节点。任何一个"文件系统"(File System, FS) 都需要具备根据文件路径映射到文件的功能,命名节点就是用于储存这些映射信息并提供映射服务的计算机,在整个 HDFS 系统中扮演"管理员"的角色,因此一个 HDFS 集群中只有一个命名节点。
数据节点 (DataNode)
数据节点 (DataNode) 使用来储存数据块的节点。当一个文件被命名节点承认并分块之后将会被储存到被分配的数据节点中去。数据节点具有储存数据、读写数据的功能,其中存储的数据块比较类似于硬盘中的"扇区"概念,是 HDFS 存储的基本单位。
副命名节点 (Secondary NameNode)
副命名节点 (Secondary NameNode) 别名"次命名节点",是命名节点的"秘书"。这个形容很贴切,因为它并不能代替命名节点的工作,无论命名节点是否有能力继续工作。它主要负责分摊命名节点的压力、备份命名节点的状态并执行一些管理工作,如果命名节点要求它这样做的话。如果命名节点坏掉了,它也可以提供备份数据以恢复命名节点。副命名节点可以有多个。
MapReduce
MapReduce 的含义就像它的名字一样浅显:Map 和 Reduce (映射和规约) 。
大数据处理
大量数据的处理是一个典型的"道理简单,实施复杂"的事情。之所以"实施复杂",主要是大量的数据使用传统方法处理时会导致硬件资源 (主要是内存) 不足。
现在有一段文字 (真实环境下这个字符串可能长达 1 PB 甚至更多) ,我们执行一个简单的"数字符"统计,即统计出这段文字中所有出现过的字符出现的数量:
AABABCABCDABCDE
统计之后的结果应该是:
A 5
B 4
C 3
D 2
E 1
统计的过程实际上很简单,就是每读取一个字符就要检查表中是否已经有相同的字符,如果没有就添加一条记录并将记录值设置为 1 ,如果有的话就直接将记录值增加 1。
但是如果我们将这里的统计对象由"字符"变成"词",那么样本容量就瞬间变得非常大,以至于一台计算机可能难以统计数十亿用户一年来用过的"词"。
在这种情况下我们依然有办法完成这项工作——我们先把样本分成一段段能够令单台计算机处理的规模,然后一段段地进行统计,每执行完一次统计就对映射统计结果进行规约处理,即将统计结果合并到一个更庞大的数据结果中去,最终就可以完成大规模的数据规约。
在以上的案例中,第一阶段的整理工作就是"映射",把数据进行分类和整理,到这里为止,我们可以得到一个相比于源数据小很多的结果。第二阶段的工作往往由集群来完成,整理完数据之后,我们需要将这些数据进行总体的归纳,毕竟有可能多个节点的映射结果出现重叠分类。这个过程中映射的结果将会进一步缩略成可获取的统计结果。
MapReduce 概念
示例:
假设有 5 个文件,每个文件包含两列,分别记录一个城市的名称以及该城市在不同测量日期记录的相应温度。城市名称是键 (Key) ,温度是值 (Value) 。例如:(厦门,20)。现在我们要在所有数据中找到每个城市的最高温度 (请注意,每个文件中可能出现相同的城市)。
使用 MapReduce 框架,我们可以将其分解为 5 个映射任务,其中每个任务负责处理五个文件中的一个。每个映射任务会检查文件中的每条数据并返回该文件中每个城市的最高温度。
例如,对于以下数据:
| 城市 | 温度 |
|---|---|
| 厦门 | 12 |
| 上海 | 34 |
| 厦门 | 20 |
| 上海 | 15 |
| 北京 | 14 |
| 北京 | 16 |
| 厦门 | 24 |
打个比方,你可以把 MapReduce 想象成人口普查,人口普查局会把若干个调查员派到每个城市。每个城市的每个人口普查人员都将统计该市的部分人口数量,然后将结果汇总返回首都。在首都,每个城市的统计结果将被规约到单个计数(各个城市的人口),然后就可以确定国家的总人口。这种人到城市的映射是并行的,然后合并结果(Reduce)。这比派一个人以连续的方式清点全国中的每一个人效率高得多。
Hadoop 三种模式:单机模式、伪集群模式和集群模式
- 单机模式:Hadoop 仅作为库存在,可以在单计算机上执行 MapReduce 任务,仅用于开发者搭建学习和试验环境。
- 伪集群模式:此模式 Hadoop 将以守护进程的形式在单机运行,一般用于开发者搭建学习和试验环境。
- 集群模式:此模式是 Hadoop 的生产环境模式,也就是说这才是 Hadoop 真正使用的模式,用于提供生产级服务。
HDFS 配置和启动
HDFS 和数据库相似,是以守护进程的方式启动的。使用 HDFS 需要用 HDFS 客户端通过网络 (套接字) 连接到 HDFS 服务器实现文件系统的使用。
配置好 Hadoop 的基础环境,容器名为 hadoop_single,启动并进入该容器。
进入该容器后,确认一下 Hadoop 是否存在:
hadoop version
如果结果显示出 Hadoop 版本号则表示 Hadoop 存在。
接下来我们将进入正式步骤。
新建 hadoop 用户
新建用户,名为 hadoop:
adduser hadoop
安装一个小工具用于修改用户密码和权限管理:
yum install -y passwd sudo
设置 hadoop 用户密码:
passwd hadoop
接下来两次输入密码,一定要记住!
修改 hadoop 安装目录所有人为 hadoop 用户:
chown -R hadoop /usr/local/hadoop
然后用文本编辑器修改 /etc/sudoers 文件,在
root ALL=(ALL) ALL
之后添加一行
hadoop ALL=(ALL) ALL
然后退出容器。
关闭并提交容器 hadoop_single 到镜像 hadoop_proto:
docker stop hadoop_single
docker commit hadoop_single hadoop_proto
创建新容器 hdfs_single :
docker run -d --name=hdfs_single --privileged hadoop_proto /usr/sbin/init
这样新用户就被创建了。
启动 HDFS
现在进入刚建立的容器:
docker exec -it hdfs_single su hadoop
现在应该是 hadoop 用户:
whoami
应该显示 “hadoop”
生成 SSH 密钥:
ssh-keygen -t rsa
这里可以一直按回车直到生成结束。
然后将生成的密钥添加到信任列表:
ssh-copy-id hadoop@172.17.0.2
查看容器 IP 地址:
ip addr | grep 172
从而得知容器的 IP 地址是 172.17.0.2,你们的 IP 可能会与此不同。
在启动 HDFS 以前我们对其进行一些简单配置,Hadoop 配置文件全部储存在安装目录下的 etc/hadoop 子目录下,所以我们可以进入此目录:
cd $HADOOP_HOME/etc/hadoop
这里我们修改两个文件:core-site.xml 和 hdfs-site.xml
在 core-site.xml 中,我们在 标签下添加属性:
<property><name>fs.defaultFS</name><value>hdfs://<你的IP>:9000</value>
</property>
在 hdfs-site.xml 中的 标签下添加属性:
<property><name>dfs.replication</name><value>1</value>
</property>
格式化文件结构:
hdfs namenode -format
然后启动 HDFS:
start-dfs.sh
启动分三个步骤,分别启动 NameNode、DataNode 和 Secondary NameNode。
运行 jps 查看 Java 进程
到此为止,HDFS 守护进程已经建立,由于 HDFS 本身具备 HTTP 面板,我们可以通过浏览器访问http://你的容器IP:9870/来查看 HDFS 面板以及详细信息。
HDFS 使用
HDFS Shell
回到 hdfs_single 容器,以下命令将用于操作 HDFS:
# 显示根目录 / 下的文件和子目录,绝对路径
hadoop fs -ls /
# 新建文件夹,绝对路径
hadoop fs -mkdir /hello
# 上传文件
hadoop fs -put hello.txt /hello/
# 下载文件
hadoop fs -get /hello/hello.txt
# 输出文件内容
hadoop fs -cat /hello/hello.txt
HDFS 最基础的命令如上所述,除此之外还有许多其他传统文件系统所支持的操作。
HDFS API
HDFS 已经被很多的后端平台所支持,目前官方在发行版中包含了 C/C++ 和 Java 的编程接口。此外,node.js 和 Python 语言的包管理器也支持导入 HDFS 的客户端。
以下是包管理器的依赖项列表:
Maven:
<dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.4</version>
</dependency>
Gradle:
providedCompile group: 'org.apache.hadoop', name: 'hadoop-hdfs-client', version: '3.1.4'
NPM:
npm i webhdfs
pip:
pip install hdfs
Java 连接 HDFS 的例子(修改 IP 地址):
实例
package com.zain;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
public class Application {public static void main(String[] args) {try {// 配置连接地址Configuration conf = new Configuration();conf.set("fs.defaultFS", "hdfs://172.17.0.2:9000");FileSystem fs = FileSystem.get(conf);// 打开文件并读取输出Path hello = new Path("/hello/hello.txt");FSDataInputStream ins = fs.open(hello);int ch = ins.read();while (ch != -1) {System.out.print((char)ch);ch = ins.read();}System.out.println();} catch (IOException ioe) {ioe.printStackTrace();}}
}
相关文章:
Hadoop小结(上)
最近在学大模型的分布式训练和存储,自己的分布式相关基础比较薄弱,基于深度学习的一切架构皆来源于传统,我总结了之前大数据的分布式解决方案即Hadoop: Why Hadoop Hadoop 的作用非常简单,就是在多计算机集群环境中营…...
ORA-600 ksuloget2 恢复----惜分飞
客户在win 32位的操作系统上调至sga超过2G,数据库运行过程中报ORA-600 ksuloget2错误 Thread 1 cannot allocate new log, sequence 43586 Checkpoint not complete Current log# 1 seq# 43585 mem# 0: D:\ORACLE\ORADATA\ORCL\REDO01.LOG Fri Aug 04 14:57:02 2023 Errors i…...
NLP的tokenization
GPT3.5的tokenization流程如上图所示,以下是chatGPT对BPE算法的解释: BPE(Byte Pair Encoding)编码算法是一种基于统计的无监督分词方法,用于将文本分解为子词单元。它的原理如下: 1. 初始化:将…...

【宝藏系列】一文讲透C语言数组与指针的关系
【宝藏系列】嵌入式 C 语言代码优化技巧【超详细版】 文章目录 【宝藏系列】嵌入式 C 语言代码优化技巧【超详细版】👨🏫前言1️⃣指针1️⃣1️⃣指针的操作1️⃣2️⃣关于指针定义的争议1️⃣3️⃣对教材错误写法的小看法 2️⃣指针和数组的区别2️⃣…...

Jenkins+Jmeter集成自动化接口测试并通过邮件发送测试报告
一、Jenkins的配置 1、新增一个自由风格的项目 2、构建->选择Excute Windows batch command(因为我是在本地尝试的,因此选择的windows) 3、输入步骤: 1. 由于不能拥有相同的jtl文件,因此在每次构建前都需要删除jtl…...

clickhouse入门
clickhouse 1 课程介绍 和hadoop无关,俄罗斯,速度快3 介绍&特点 1 列式存储 在线分析处理。 使用sql进行查询。列式存储更适合查询分析的场景。新增时候有一个寻址的过程。更容易进行压缩行式存储。增删改查都需要的时候。2 DBMS功能 包括ddl,d…...

中间件: ElasticSearch的安装与部署
文档地址: https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html 单机部署 创建用户: useradd es chown -R es /opt/soft/ mkdir -p /var/log/elastic chown -R es /var/log/elastic mkdir -p /tmp/elastic chown -R es /tmp…...
LabVIEW模拟化学反应器的工作
LabVIEW模拟化学反应器的工作 近年来,化学反应器在化学和工业过程领域有许多应用。高价值产品是通过混合产品,化学反应,蒸馏和结晶等多种工业过程转换原材料制成的。化学反应器通常用于大型加工行业,例如酿酒厂公司饮料产品的发酵…...

Python基础语法入门(第二十三天)——正则表达式
正则表达式是一种文本模式,用于匹配字符串,它是由字符和特殊字符组成的模式。正则表达式可以用于验证、搜索、替换和提取字符串。其能够应用于各种编程语言和文本处理工具中,如Python、Java、JavaScript等。 正则表达式在线测试工具…...

山西电力市场日前价格预测【2023-08-20】
日前价格预测 预测明日(2023-08-20)山西电力市场全天平均日前电价为341.71元/MWh。其中,最高日前电价为367.66元/MWh,预计出现在20: 30。最低日前电价为318.47元/MWh,预计出现在04: 15。 价差方向预测 1: 实…...
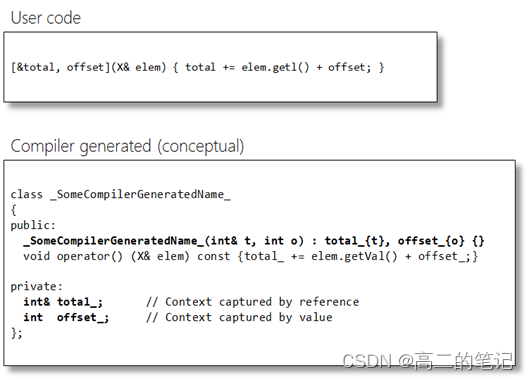
C++中function,bind,lambda
c11之前,STL中提供了bind1st以及bind2nd绑定器 首先来看一下他们如何使用: 如果我们要对vector中的元素排序,首先会想到sort,比如: void output(const vector<int> &vec) {for (auto v : vec) {cout <&l…...

跟着美团学设计模式(感处)
读了着篇文章之后发现真的是,你的思想,你的思维是真的比比你拥有什么技术要强的。 注 开闭原则 开闭原则(Open-Closed Principle)是面向对象设计中的基本原则之一,它的定义是:一个软件实体应该对扩展开放…...

2023/8/19 小红书 Java 后台开发面经
项目都做了些什么,怎么实现的用Redis实现了什么,Redis是单线程的吗,Redis是单线程的为什么快,IO多路复用模型具体实现,持久化怎么实现的为什么用Kafka,架构是什么样的,Broker、Topic、Partition…...

基于traccar快捷搭建gps轨迹应用
0. 环境 - win10 虚拟机ubuntu18 - i5 ubuntu22笔记本 - USB-GPS模块一台,比如华大北斗TAU1312-232板 - 双笔记本组网设备:路由器,使得win10笔记本ip:192.168.123.x,而i5笔记本IP是192.168.123.215。 - 安卓 手机 1.…...

【深度学习-图像识别】使用fastai对Caltech101数据集进行图像多分类(50行以内的代码就可达到很高准确率)
文章目录 前言fastai介绍数据集介绍 一、环境准备二、数据集处理1.数据目录结构2.导入依赖项2.读入数据3.模型构建3.1 寻找合适的学习率3.2 模型调优 4.模型保存与应用 总结人工智能-图像识别 系列文章目录 前言 fastai介绍 fastai 是一个深度学习库,它为从业人员…...
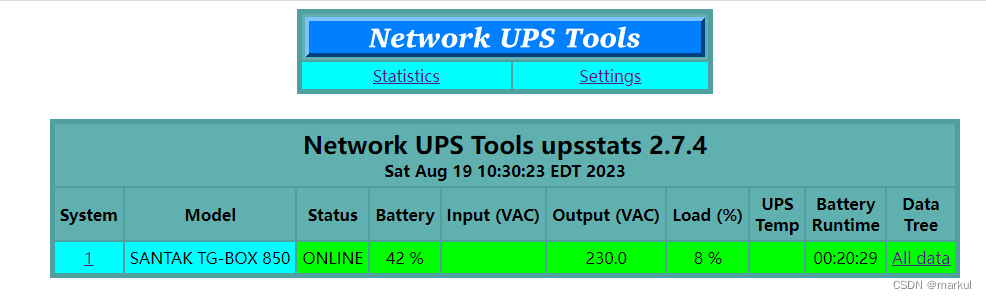
Debian10: 安装nut服务器(UPS)
UPS说明: UPS的作用就不必讲了,我选择是SANTAKTGBOX-850,规格为 850VA/510W,可以满足所需,关键是Debian10自带了驱动可以支持,免去安装驱动,将UPS通过USB线连接服务器即可,如下图所示…...

神经网络基础-神经网络补充概念-47-动量梯度下降法
概念 动量梯度下降法(Momentum Gradient Descent)是一种优化算法,用于加速梯度下降的收敛速度,特别是在存在高曲率、平原或局部最小值的情况下。动量法引入了一个称为“动量”(momentum)的概念,…...
 补充知识、线程池浅谈、数量谈、总结)
C++11并发与多线程笔记(13) 补充知识、线程池浅谈、数量谈、总结
C11并发与多线程笔记(13) 补充知识、线程池浅谈、数量谈、总结 1、补充一些知识点1.1 虚假唤醒:1.2 atomic 2、浅谈线程池:3、线程创建数量谈: 1、补充一些知识点 1.1 虚假唤醒: notify_one或者notify_al…...
python高级基础
文章目录 python高级基础闭包修饰器单例模式跟工厂模式工厂模式单例模式 多线程多进程创建websocket服务端手写客户端 python高级基础 闭包 简单解释一下闭包就是可以在内部访问外部函数的变量,因为如果声明全局变量,那在后面就有可能会修改 在闭包中的…...
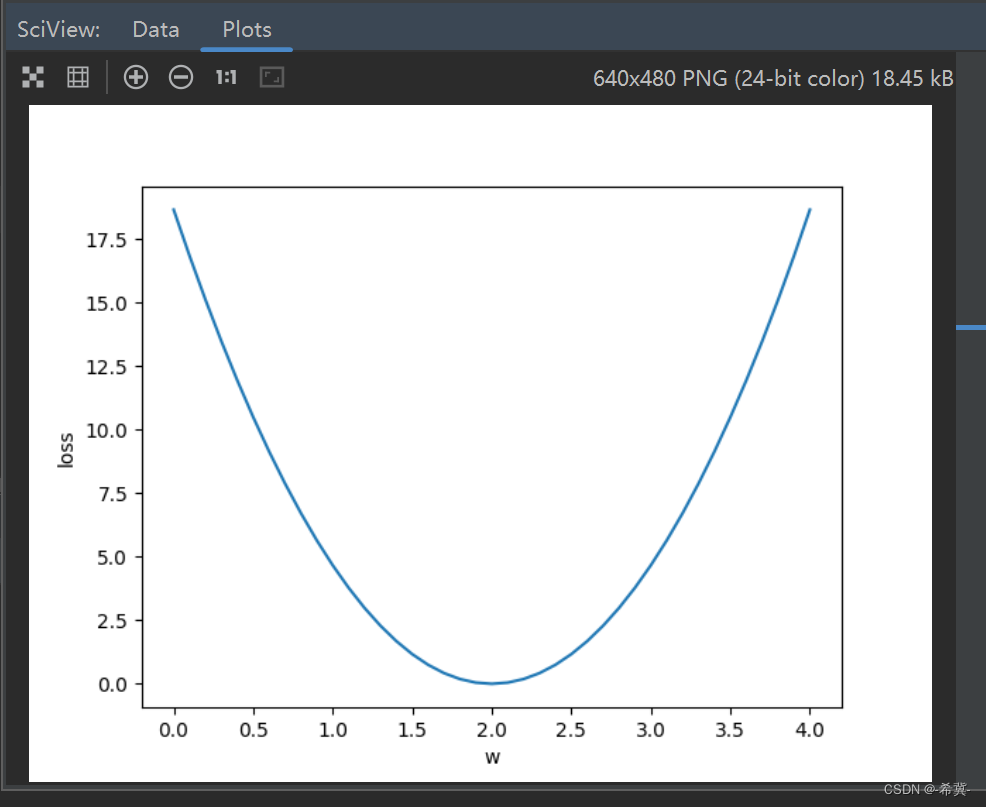
使用线性回归模型优化权重:探索数据拟合的基础
文章目录 前言一、示例代码二、示例代码解读1.线性回归模型2.MSE损失函数3.优化过程4.结果解读 总结 前言 在机器学习和数据科学中,线性回归是一种常见而重要的方法。本文将以一个简单的代码示例为基础,介绍线性回归的基本原理和应用。将使用Python和Nu…...

测试微信模版消息推送
进入“开发接口管理”--“公众平台测试账号”,无需申请公众账号、可在测试账号中体验并测试微信公众平台所有高级接口。 获取access_token: 自定义模版消息: 关注测试号:扫二维码关注测试号。 发送模版消息: import requests da…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...
:にする)
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする
日语学习-日语知识点小记-构建基础-JLPT-N4阶段(33):にする 1、前言(1)情况说明(2)工程师的信仰2、知识点(1) にする1,接续:名词+にする2,接续:疑问词+にする3,(A)は(B)にする。(2)復習:(1)复习句子(2)ために & ように(3)そう(4)にする3、…...
)
postgresql|数据库|只读用户的创建和删除(备忘)
CREATE USER read_only WITH PASSWORD 密码 -- 连接到xxx数据库 \c xxx -- 授予对xxx数据库的只读权限 GRANT CONNECT ON DATABASE xxx TO read_only; GRANT USAGE ON SCHEMA public TO read_only; GRANT SELECT ON ALL TABLES IN SCHEMA public TO read_only; GRANT EXECUTE O…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

苍穹外卖--缓存菜品
1.问题说明 用户端小程序展示的菜品数据都是通过查询数据库获得,如果用户端访问量比较大,数据库访问压力随之增大 2.实现思路 通过Redis来缓存菜品数据,减少数据库查询操作。 缓存逻辑分析: ①每个分类下的菜品保持一份缓存数据…...

OPENCV形态学基础之二腐蚀
一.腐蚀的原理 (图1) 数学表达式:dst(x,y) erode(src(x,y)) min(x,y)src(xx,yy) 腐蚀也是图像形态学的基本功能之一,腐蚀跟膨胀属于反向操作,膨胀是把图像图像变大,而腐蚀就是把图像变小。腐蚀后的图像变小变暗淡。 腐蚀…...