【云原生】【k8s】Kubernetes+EFK构建日志分析安装部署
目录
EFK安装部署
一、环境准备(所有主机)
1、主机初始化配置
2、配置主机名并绑定hosts,不同主机名称不同
3、主机配置初始化
4、部署docker环境
二、部署kubernetes集群
1、组件介绍
2、配置阿里云yum源
3、安装kubelet kubeadm kubectl
4、配置init-config.yaml
init-config.yaml配置
5、安装master节点
6、安装node节点
7、安装flannel
三、部署企业镜像仓库
1、部署Harbor仓库
访问测试:
2、重启harbor,导入EFK镜像
四、部署EFK业务环境
1、准备组件Yaml文件
2、部署Elasticsearch
3、部署kibana
4、部署Fluentd
5、验证容器日志收集,创建测试容器
6、配置 Kibana
EFK安装部署
一、环境准备(所有主机)
| IP地址 | 主机名 | 组件 |
| 192.168.100.131 | k8s-master | kubeadm、kubelet、kubectl、docker-ce |
| 192.168.100.132 | k8s-node01 | kubeadm、kubelet、kubectl、docker-ce、elasticsearch、fluentd |
| 192.168.100.133 | k8s-node02 | kubeadm、kubelet、kubectl、docker-ce、kibana、fluentd |
| 192.168.100.134 | harbor | docker-ce、docker-compose、harbor |
注意:所有主机配置推荐CPU:2C+ Memory:4G+、运行 Elasticsearch 的节点要有足够的内存(不低于 4GB)。若 Elasticsearch 容器退出,请检查宿主机中的/var/log/message 日志,观察是否因为系统 OOM 导致进程被杀掉。
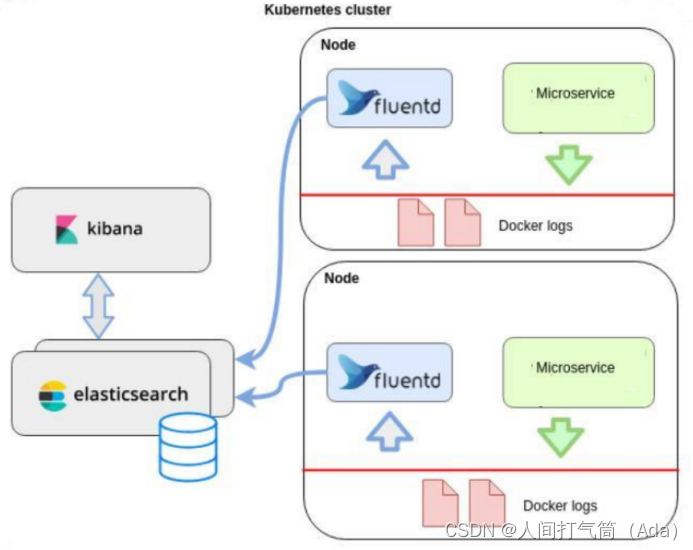
项目拓扑
1、主机初始化配置
所有主机配置禁用防火墙和selinux
[root@localhost ~]# setenforce 0[root@localhost ~]# iptables -F[root@localhost ~]# systemctl stop firewalld[root@localhost ~]# systemctl disable firewalld[root@localhost ~]# systemctl stop NetworkManager[root@localhost ~]# systemctl disable NetworkManager[root@localhost ~]# sed -i '/^SELINUX=/s/enforcing/disabled/' /etc/selinux/config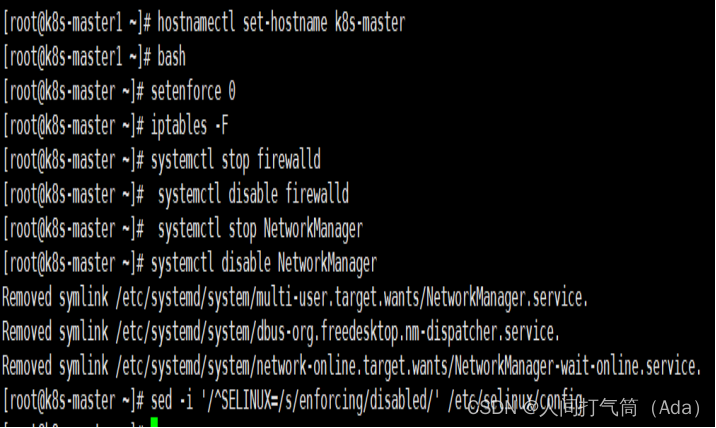
2、配置主机名并绑定hosts,不同主机名称不同
[root@localhost ~]# hostname k8s-master[root@localhost ~]# bash[root@k8s-master ~]# cat << EOF >> /etc/hosts192.168.100.131 k8s-master192.168.100.132 k8s-node01192.168.100.133 k8s-node02EOF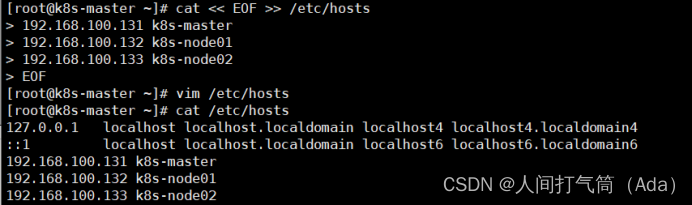
[root@localhost ~]# hostname k8s-node01
[root@k8s-node01 ~]# cat /etc/hosts

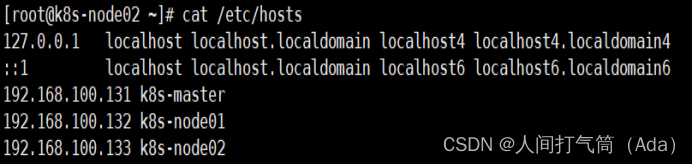
[root@localhost ~]# hostname k8s-node02
[root@k8s-node02 ~]#cat /etc/hosts
3、主机配置初始化
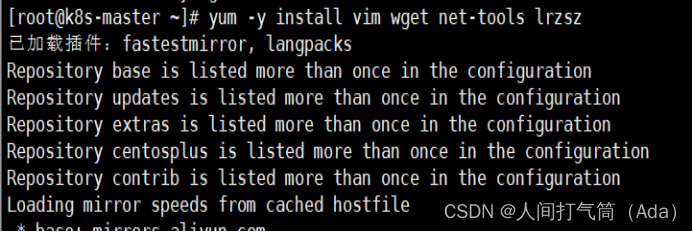
[root@k8s-master ~]# yum -y install vim wget net-tools lrzsz
[root@k8s-master ~]# swapoff -a[root@k8s-master ~]# sed -i '/swap/s/^/#/' /etc/fstab[root@k8s-master ~]# cat << EOF >> /etc/sysctl.confnet.bridge.bridge-nf-call-ip6tables = 1net.bridge.bridge-nf-call-iptables = 1EOF[root@k8s-master ~]# modprobe br_netfilter[root@k8s-master ~]# sysctl -p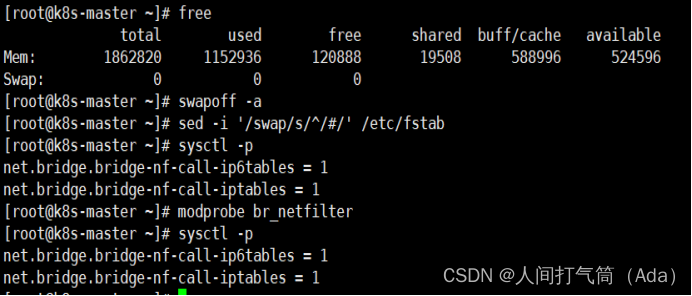
4、部署docker环境
1)三台主机上分别部署 Docker 环境,因为 Kubernetes 对容器的编排需要 Docker 的支持。
[root@k8s-master ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@k8s-master ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
2)使用 YUM 方式安装 Docker 时,推荐使用阿里的 YUM 源。
[root@k8s-master ~]# yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
3)清除缓存
[root@k8s-master ~]# yum clean all && yum makecache fast
4)启动docker
[root@k8s-master ~]# yum -y install docker-ce
[root@k8s-master ~]# systemctl start docker
[root@k8s-master ~]# systemctl enable docker

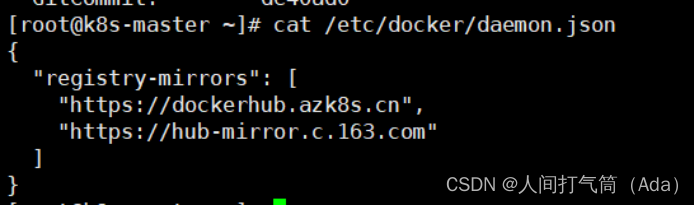
5)镜像加速器(所有主机配置)
[root@k8s-master ~]# cat << END > /etc/docker/daemon.json
{ "registry-mirrors":[ "https://nyakyfun.mirror.aliyuncs.com" ]
}
END
6)重启docker
[root@k8s-master ~]# systemctl daemon-reload
[root@k8s-master ~]# systemctl restart docker
二、部署kubernetes集群
1、组件介绍
三个节点都需要安装下面三个组件
kubeadm:安装工具,使所有的组件都会以容器的方式运行
kubectl:客户端连接K8S API工具
kubelet:运行在node节点,用来启动容器的工具
2、配置阿里云yum源
使用 YUM 方式安装 Kubernetes时,推荐使用阿里的 YUM 源。
[root@k8s-master ~]# ls /etc/yum.repos.d/
[root@k8s-master ~]# cat > /etc/yum.repos.d/kubernetes.repo

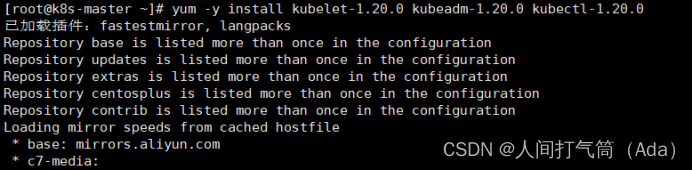
3、安装kubelet kubeadm kubectl
所有主机配置
[root@k8s-master ~]# yum install -y kubelet-1.20.0 kubeadm-1.20.0 kubectl-1.20.0
[root@k8s-master ~]# systemctl enable kubelet
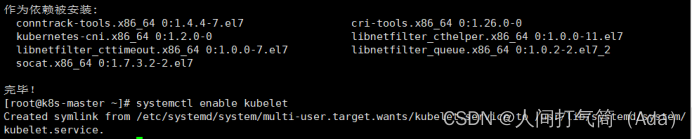
[root@k8s-master ~]# kubectl version
kubelet 刚安装完成后,通过 systemctl start kubelet 方式是无法启动的,需要加入节点或初始化为 master 后才可启动成功。
4、配置init-config.yaml
Kubeadm 提供了很多配置项,Kubeadm 配置在 Kubernetes 集群中是存储在ConfigMap 中的,也可将这些配置写入配置文件,方便管理复杂的配置项。Kubeadm 配内容是通过 kubeadm config 命令写入配置文件的。
在master节点安装,master 定于为192.168.100.131,通过如下指令创建默认的init-config.yaml文件:
[root@k8s-master ~]# kubeadm config print init-defaults > init-config.yaml

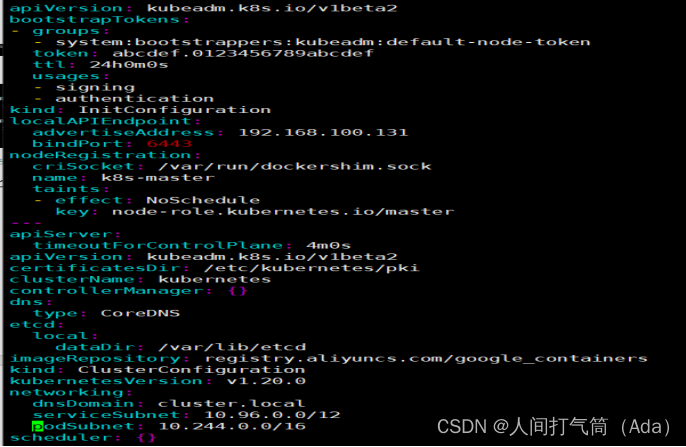
init-config.yaml配置
[root@k8s-master ~]# cat init-config.yaml
5、安装master节点
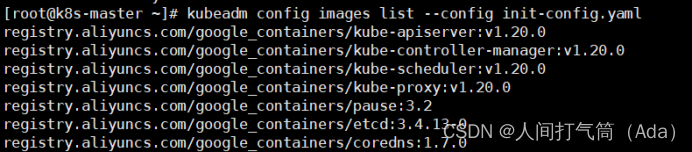
1)拉取所需镜像
[root@k8s-master ~]# kubeadm config images list --config init-config.yaml
[root@k8s-master ~]# kubeadm config images pull --config init-config.yaml
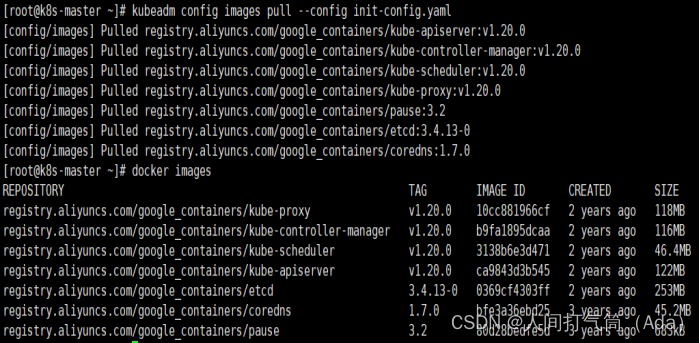
2)安装matser节点
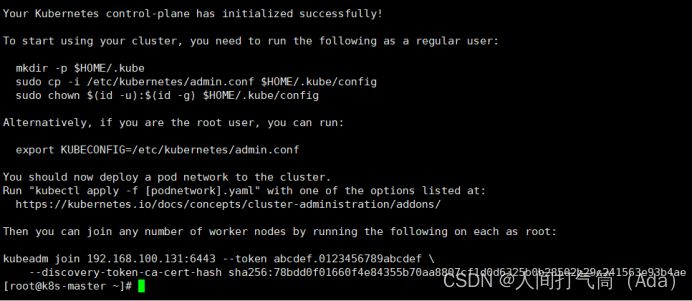
[root@k8s-master ~]# kubeadm init --config=init-config.yaml //初始化安装K8S
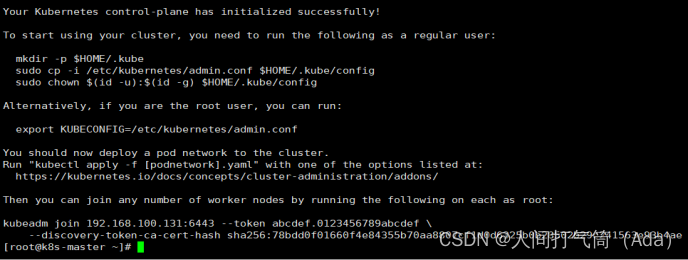
3)根据提示操作
kubectl 默认会在执行的用户家目录下面的.kube 目录下寻找config 文件。这里是将在初始化时[kubeconfig]步骤生成的admin.conf 拷贝到.kube/config
[root@k8s-master ~]# mkdir -p $HOME/.kube
[root@k8s-master ~]# cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master ~]# chown $(id -u):$(id -g) $HOME/.kube/config

Kubeadm 通过初始化安装是不包括网络插件的,也就是说初始化之后是不具备相关网络功能的,比如 k8s-master 节点上查看节点信息都是“Not Ready”状态、Pod 的 CoreDNS无法提供服务等。
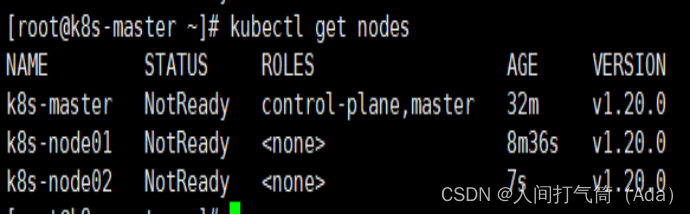
6、安装node节点
1)根据master安装时的提示信息
[root@k8s-node01 ~]# kubeadm join 192.168.100.131:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:78bdd0f01660f4e84355b70aa8807cf1d0d6325b0b28502b29c241563e93b4ae
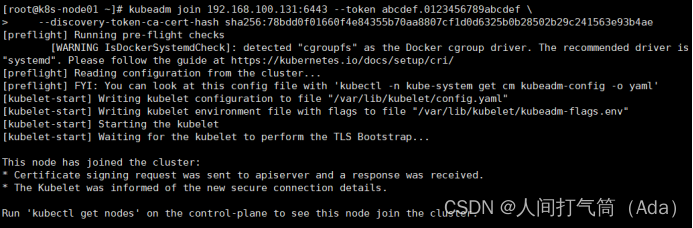
[root@k8s-master ~]# kubectl get nodes
[root@k8s-node02 ~]# kubeadm join 192.168.100.131:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:78bdd0f01660f4e84355b70aa8807cf1d0d6325b0b28502b29c241563e93b4ae
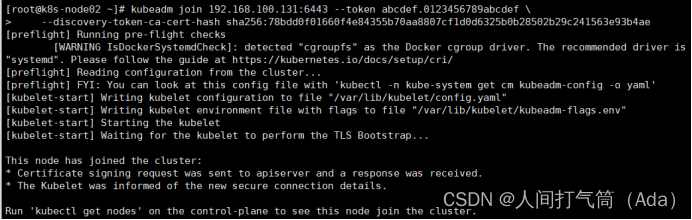
Master操作:
[root@k8s-master ~]# kubectl get nodes
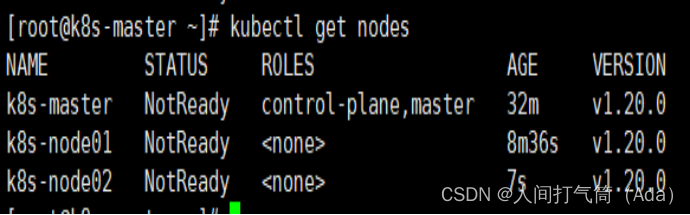
前面已经提到,在初始化 k8s-master 时并没有网络相关配置,所以无法跟 node 节点通信,因此状态都是“NotReady”。但是通过 kubeadm join 加入的 node 节点已经在k8s-master 上可以看到。
7、安装flannel
Master 节点NotReady 的原因就是因为没有使用任何的网络插件,此时Node 和Master的连接还不正常。目前最流行的Kubernetes 网络插件有Flannel、Calico、Canal、Weave 这里选择使用flannel。
所有主机:
master上传kube-flannel.yml,所有主机上传flannel_v0.12.0-amd64.tar,cni-plugins-linux-amd64-v0.8.6.tgz
[root@k8s-master ~]# docker load < flannel_v0.12.0-amd64.tar
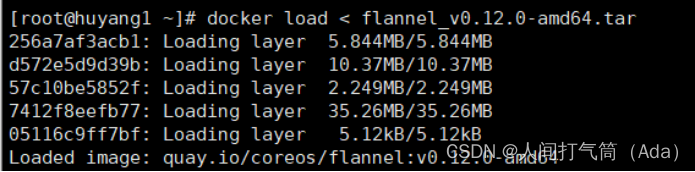
上传插件:
[root@k8s-master ~]# tar xf cni-plugins-linux-amd64-v0.8.6.tgz
[root@k8s-master ~]# cp flannel /opt/cni/bin/
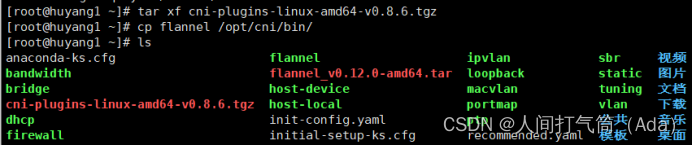
master上传kube-flannel.yml
master主机配置:
[root@k8s-master ~]# kubectl apply -f kube-flannel.yml
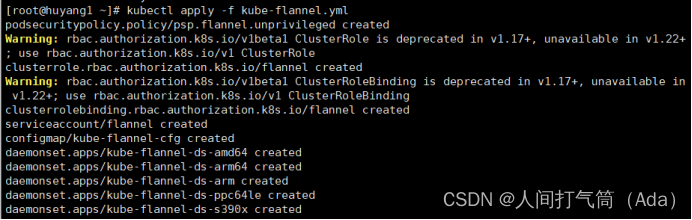
[root@k8s-master ~]# kubectl get nodes
[root@k8s-master ~]# kubectl get pods -n kube-system
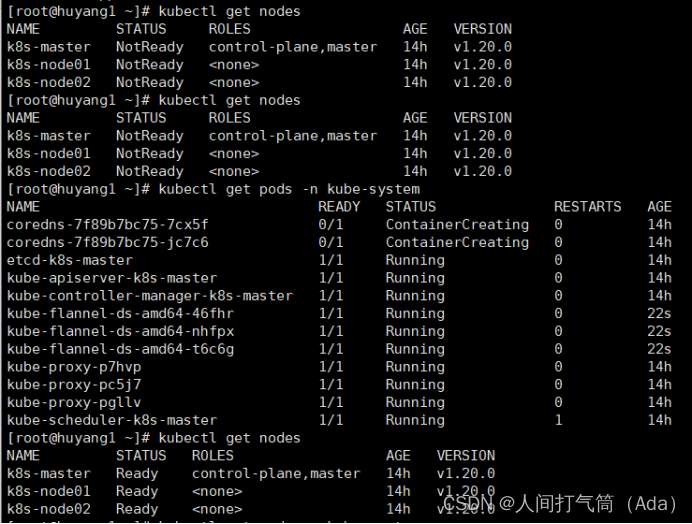
已经是ready状态
三、部署企业镜像仓库
1、部署Harbor仓库
1)所有主机配置禁用防火墙和selinux
[root@localhost ~]# setenforce 0[root@localhost ~]# iptables -F[root@localhost ~]# systemctl stop firewalld[root@localhost ~]# systemctl disable firewalld[root@localhost ~]# systemctl stop NetworkManager[root@localhost ~]# systemctl disable NetworkManager[root@localhost ~]# sed -i '/^SELINUX=/s/enforcing/disabled/' /etc/selinux/config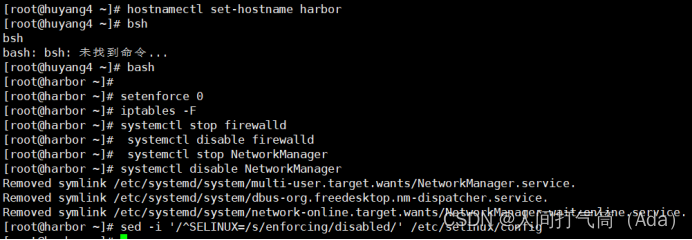
2)配置主机名
[root@localhost ~]# hostname harbor
[root@localhost ~]# bash
[root@harbor ~]#
3)部署docker环境
Harbor 仓库需要 Docker 容器支持,所以 Docker 环境是必不可少的。
[root@k8s-master ~]# wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
[root@k8s-master ~]# yum install -y yum-utils device-mapper-persistent-data lvm2
使用 YUM 方式安装 Docker 时,推荐使用阿里的 YUM 源。
[root@k8s-master ~]# yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
清除缓存
[root@k8s-master ~]# yum clean all && yum makecache fast
启动docker
[root@k8s-master ~]# yum -y install docker-ce
[root@k8s-master ~]# systemctl start docker
[root@k8s-master ~]# systemctl enable docker
镜像加速器(所有主机配置)
[root@k8s-master ~]# cat << END > /etc/docker/daemon.json
{ "registry-mirrors":[ "https://nyakyfun.mirror.aliyuncs.com" ]
}
END

重启docker
[root@k8s-master ~]# systemctl daemon-reload
[root@k8s-master ~]# systemctl restart docker
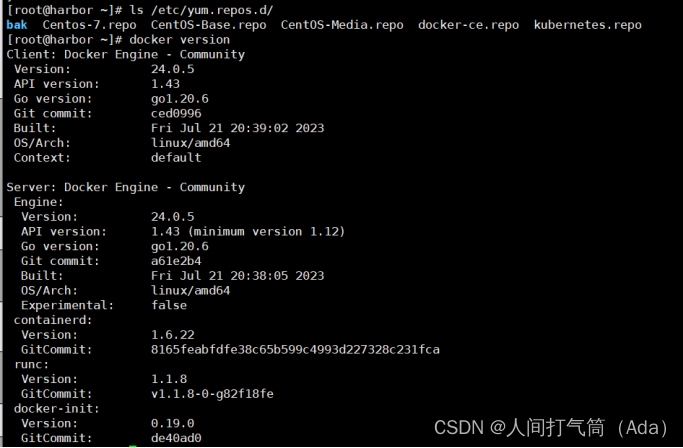
部署docker-compose
[root@harbor ~]# mv docker-compose /usr/local/bin/
[root@harbor ~]# chmod +x /usr/local/bin/docker-compose
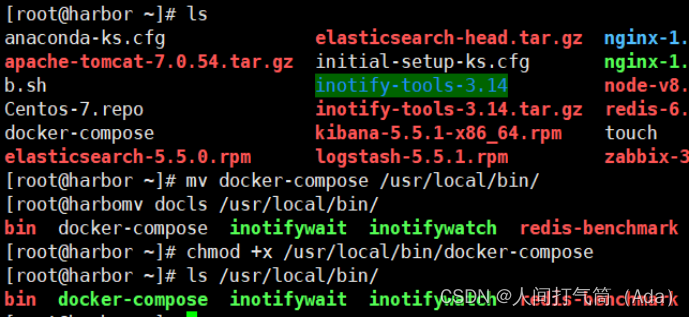
部署harbor
Harbor 私有仓库程序,采用 docker-compose 方式部署,不同的功能和应用处于不同的容器,这样带来了很好的兼容性,可在众多支持 Docker 的系统上运行 Harbor。
[root@harbor ~]# tar xf harbor-offline-installer-v1.10.6.tgz -C /usr/local/

Harbor 的配置文件是/usr/local/harbor/harbor.yml 文件,默认的 hostname 要修改为Harbor 虚拟机节点的 IP 地址。
[root@harbor ~]# vim /usr/local/harbor/harbor.yml
5 hostname: 192.168.200.114
13 #https: //https 相关配置都注释掉,包括 https、port、certificate 和 private_key
14 # https port for harbor, default is 443
15 #port: 443
16 # The path of cert and key files for nginx
17 #certificate: /your/certificate/path
18 #private_key: /your/private/key/path
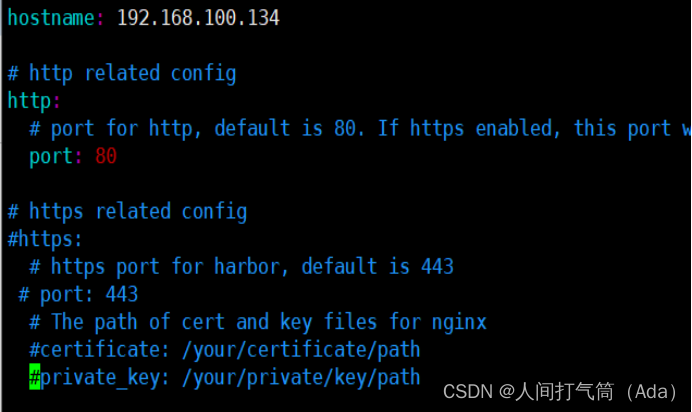
启动harbor
[root@harbor ~]# cd /usr/local/harbor/
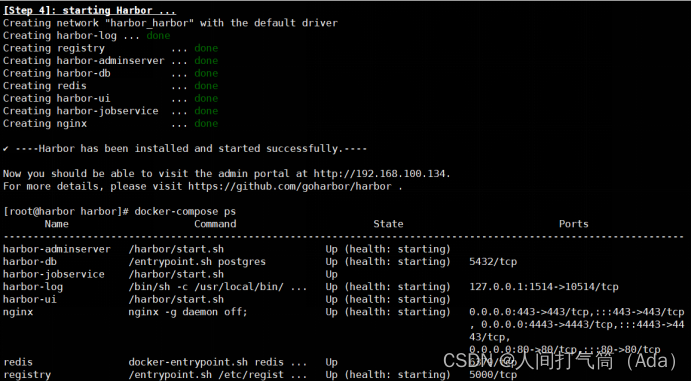
[root@harbor harbor]# sh install.sh
[root@harbor harbor]# docker-compose ps
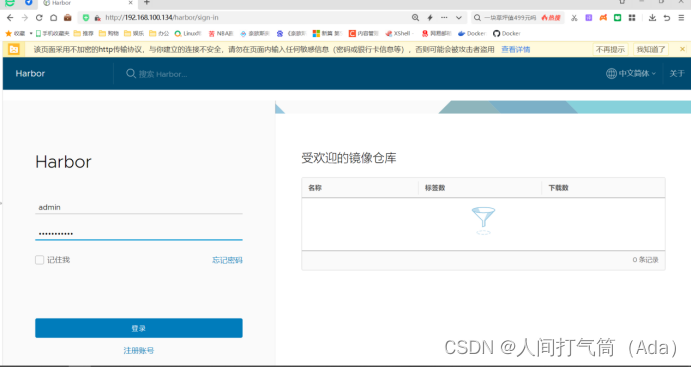
访问测试:
Harbor 启动完成后,浏览器访问 http://192.168.100.134,打开 Harbor Web 页面
修改所有主机docker启动脚本
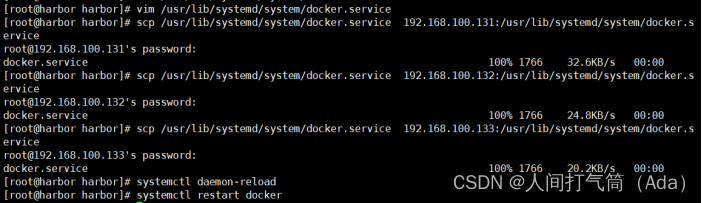
[root@harbor ~]# vim /usr/lib/systemd/system/docker.service

[root@harbor ~]# scp /usr/lib/systemd/system/docker.service 192.168.100.131:/usr/lib/systemd/system/
[root@harbor ~]# scp /usr/lib/systemd/system/docker.service 192.168.100.132:/usr/lib/systemd/system/
[root@harbor ~]# scp /usr/lib/systemd/system/docker.service 192.168.100.133:/usr/lib/systemd/system/
所有主机重启docker服务
[root@harbor ~]# systemctl daemon-reload
[root@harbor ~]# systemctl restart docker
2、重启harbor,导入EFK镜像
[root@harbor ~]# sh install.sh
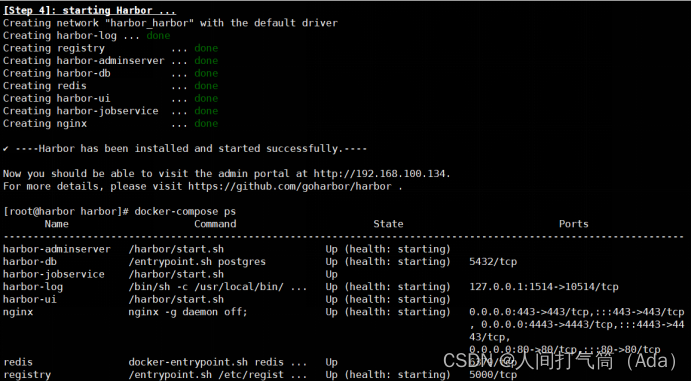
[root@harbor ~]# docker login -u admin -p Harbor12345 http://192.168.100.134

[root@harbor ~]# cd efk
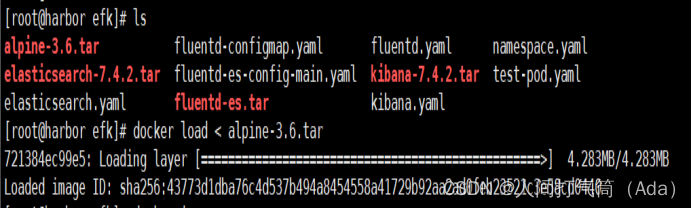
[root@harbor ~]# ls

[root@harbor ~]# docker load < elasticsearch-7.4.2.tar

[root@harbor ~]# docker load < fluentd-es.tar
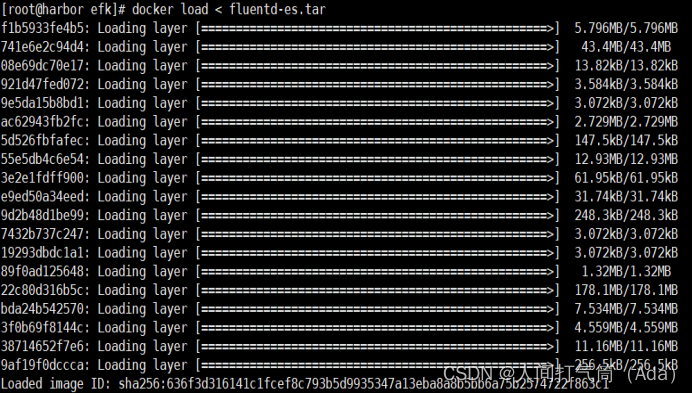
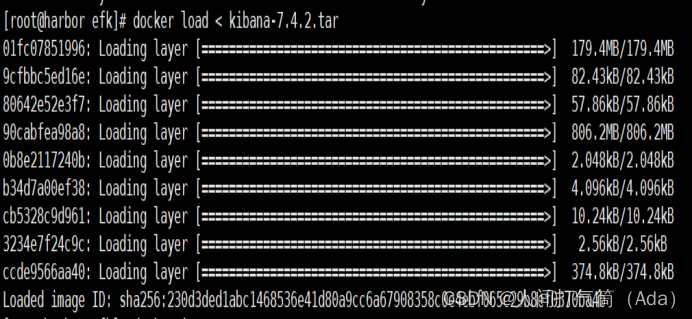
[root@harbor ~]# docker load < kibana-7.4.2.tar
[root@harbor ~]# docker load < alpine-3.6.tar
[root@harbor ~]# docker tag b1179d 192.168.100.134/efk/elasticsearch:7.4.2
[root@harbor ~]# docker tag 636f3d 192.168.100.134/efk/fluentd-es-root:v2.5.2
[root@harbor ~]# docker tag 43773d 192.168.100.134/efk/alpine:3.6
[root@harbor ~]# docker tag 230d3d 192.168.100.134/efk/kibana:7.4.2
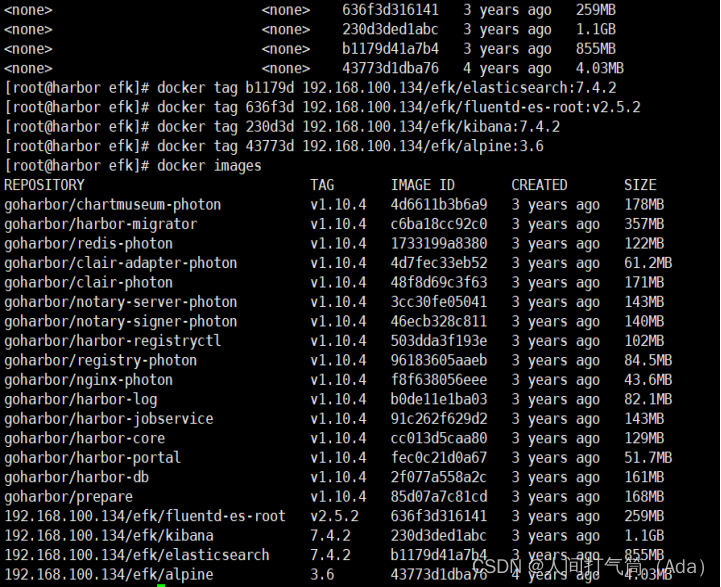
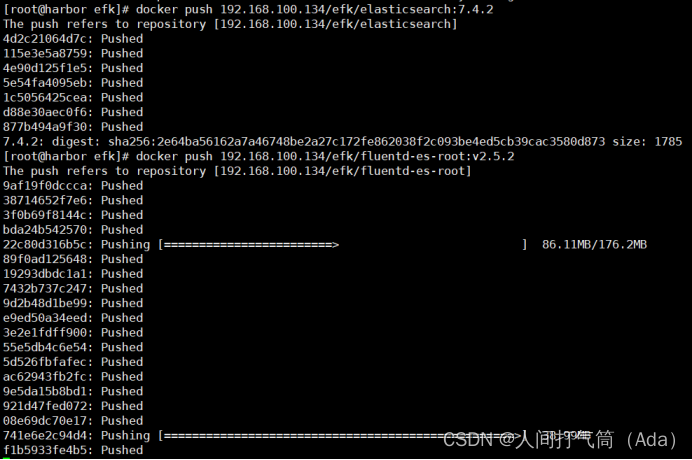
[root@harbor ~]# docker push 192.168.100.134/efk/elasticsearch:7.4.2
[root@harbor ~]# docker push 192.168.100.134/efk/fluentd-es-root:v2.5.2
[root@harbor ~]# docker push 192.168.100.134/efk/kibana:7.4.2
[root@harbor ~]# docker push 192.168.100.134/efk/alpine:3.6
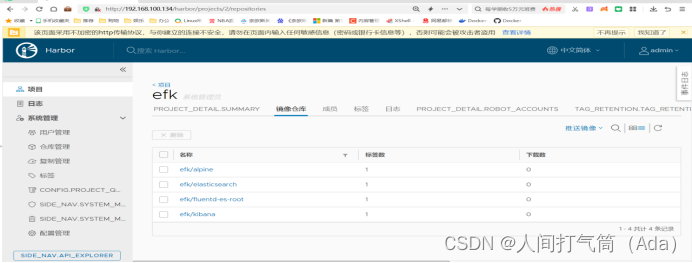
四、部署EFK业务环境
1、准备组件Yaml文件
Yaml文件中涉及到镜像地址和 nodeSelector 选择器地址需要注意修改。
[root@k8s-master ~]# mkdir efk #上传对应的yaml文件
[root@k8s-master ~]# cd efk/
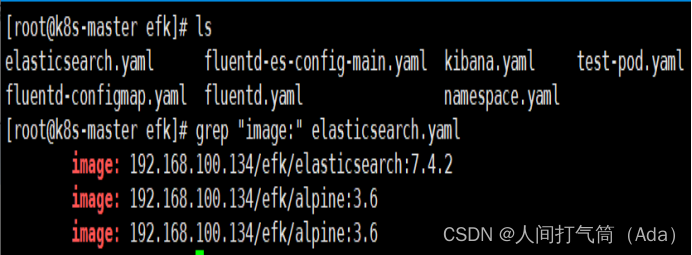
[root@k8s-master efk]# grep "image:" elasticsearch.yaml
image: 192.168.100.134/efk/elasticsearch:7.4.2
image: 192.168.100.134/efk/alpine:3.6
image: 192.168.100.134/efk/alpine:3.6
NodeSelector 节点选择器的修改,实际作用是决定将 Elasticsearch 服务部署到哪个节点。当前配置文件内是调度到 k8s-node01 节点,请根据实际负载情况进行调整。节点名称可以通过 kubectl get nodes 获取,在选择节点时务必确保节点有足够的资源。
[root@k8s-master efk]# grep -A1 "nodeSelector" elasticsearch.yaml
nodeSelector:
kubernetes.io/hostname: k8s-node01
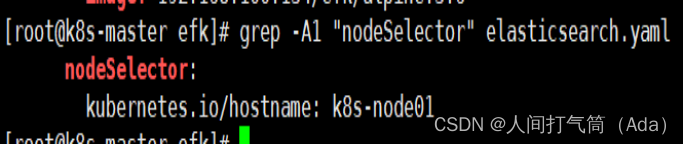
对kibana.yaml文件镜像地址和调度节点进行修改,将 Kibana 部署到 k8s-node02 节点。
[root@k8s-master efk]# grep "image:" kibana.yaml
image: 192.168.100.134/efk/kibana:7.4.2
[root@k8s-master efk]# grep -A1 "nodeSelector" kibana.yaml
nodeSelector:
kubernetes.io/hostname: k8s-node02
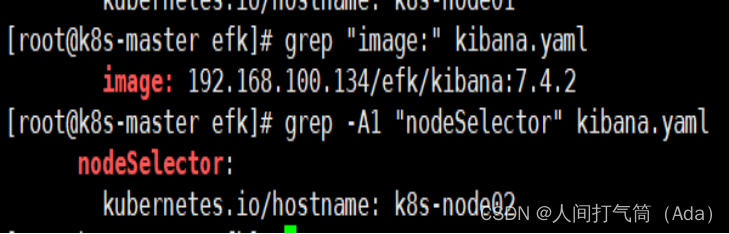
修改 fluentd.yaml的镜像地址
[root@k8s-master efk]# grep "image:" fluentd.yaml
image: 192.168.100.134/efk/fluentd-es-root:v2.5.2
修改 test-pod.yaml的镜像地址
[root@k8s-master efk]# grep "image:" test-pod.yaml
image: 192.168.100.134/efk/alpine:3.6
2、部署Elasticsearch
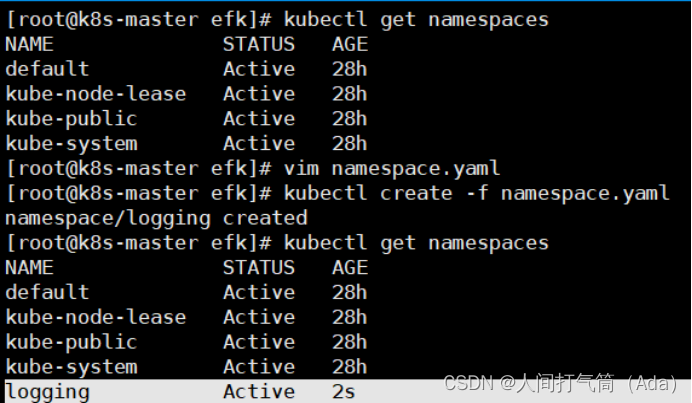
1)创建命名空间
创建名为 logging 的命名空间,用于存放 EFK 相关的服务。在 k8s-master节点的/opt/efk 目录下。
[root@k8s-master efk]# kubectl create -f namespace.yaml
[root@k8s-master efk]# kubectl get namespaces | grep logging
2)创建 es 数据存储目录
Elasticsearch 服务通常可以简写为 es。到 k8s-node01 节点创建数据目录/esdata。
[root@k8s-node01 ~]# mkdir /esdata

3)部署 es 容器
进入 k8s-master节点的/efk 目录,部署 es 容器,执行如下操作。
[root@k8s-master ~]# cd efk/
[root@k8s-master efk]# kubectl create -f elasticsearch.yaml
等待片刻,即可查看到 es 的 Pod,已经部署到 k8s-node01 节点,状态变为 running。
[root@k8s-master efk]# kubectl -n logging get pods -o wide
[root@k8s-master efk]# kubectl -n logging get svc
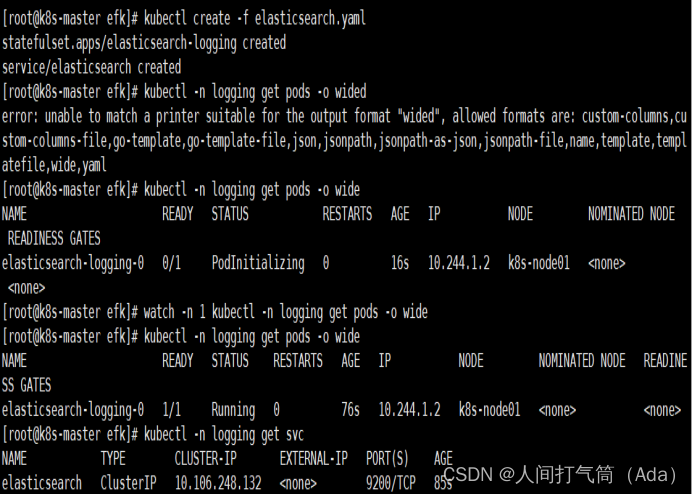
通过 curl 命令访问服务,验证 es 是否部署成功。
[root@k8s-master efk]# curl 10.98.29.202:9200
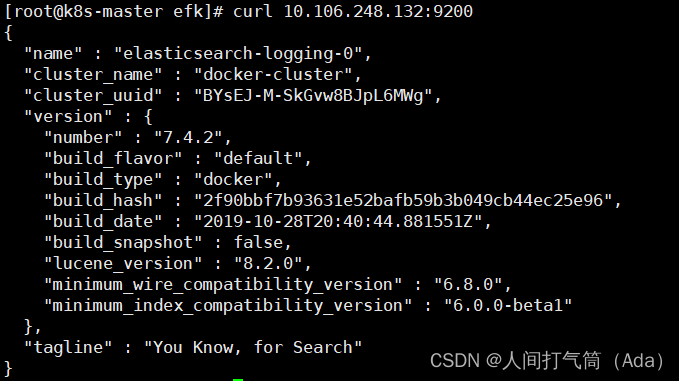
3、部署kibana
进入 k8s-master 的/opt/efk 目录,执行如下命令。
[root@k8s-master efk]# kubectl create -f kibana.yaml
service/kibana created
查看 Pod 的状态。
[root@k8s-master efk]# kubectl -n logging get pods
查看对应的 Service,得到 NodePort 值为 31732,此端口为随机端口,不同环境会不一致,请以实际结果为准。
[root@k8s-master efk]# kubectl -n logging get svc |grep
通过访问 192.168.100.131:31591 进入到 kibana 的访问界面,观察是否可以正常打开,其中 31591 端口需要替换成实际的端口号。若能正常访问,说明 Kibana 连接 es 已经正常。

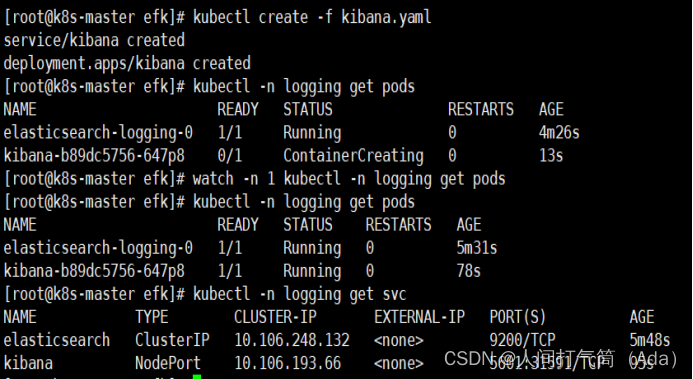
4、部署Fluentd
1)给集群节点打标签
为了自由控制需要采集集群中节点上业务容器的服务日志。因此,需要给 k8s-node01和 k8s-node02 节点打上 fluentd=true 的标签 label。
[root@k8s-master efk]# kubectl label node k8s-node01 fluentd=true
[root@k8s-master efk]# kubectl label node k8s-node02 fluentd=true

k8s-node01 和 k8s-node02 已经打上了 fluentd=true 的 label,那么 Fluentd 服务就会启动到这两个节点,也就意味着运行在这两个节点的 Pod 日志会被收集起来。
2)启动 Fluentd 服务
在 k8s-master节点的/opt/efk 目录,启动 Fluentd 服务
[root@k8s-master efk]# kubectl create -f fluentd-es-config-main.yaml
[root@k8s-master efk]# kubectl create -f fluentd-configmap.yaml
[root@k8s-master efk]# kubectl create -f fluentd.yaml
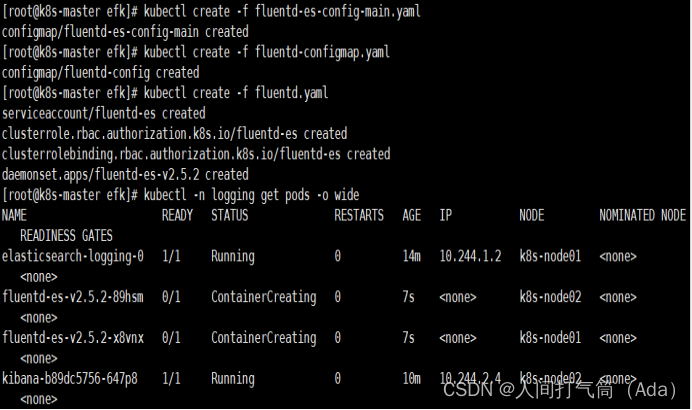
3)查看 Pod 信息
是否已经在 k8s-node01 和 k8s-node02 节点启动成功。
[root@k8s-master efk]# kubectl -n logging get pods
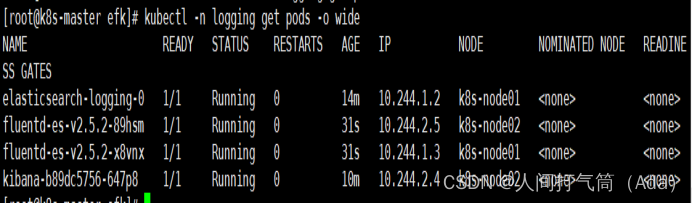
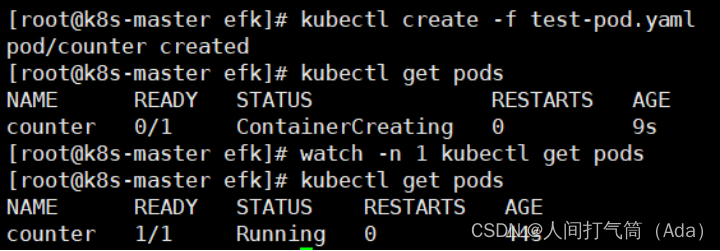
5、验证容器日志收集,创建测试容器
进入 k8s-master的/opt/efk 目录,执行如下命令。
[root@k8s-master efk]# kubectl create -f test-pod.yaml
[root@k8s-master efk]# kubectl get pods
6、配置 Kibana
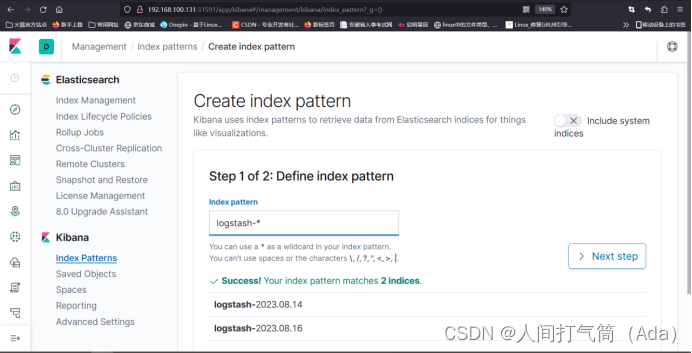
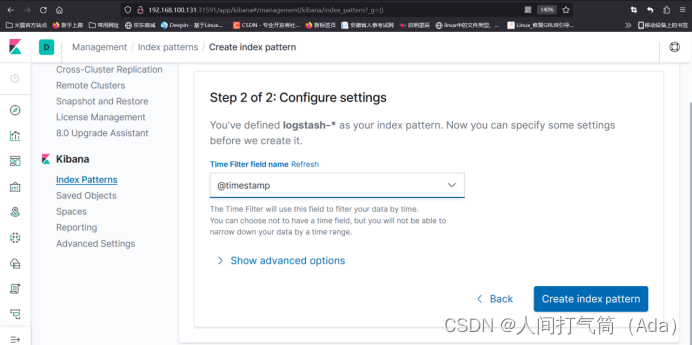
索引创建完成后,可以发现已经生成了多个索引域,稍等片刻再次点击左上角的
discover 图标,进入日志检索页面。
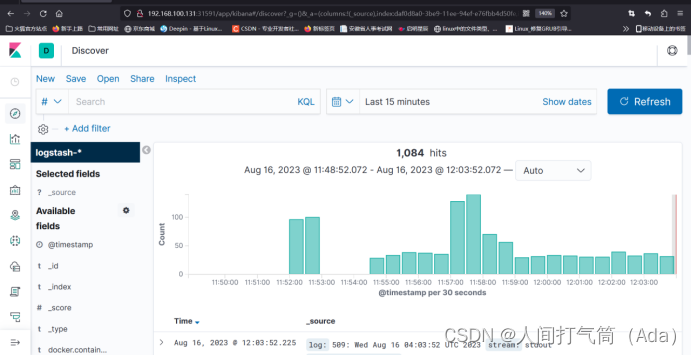
然后通过索引键去过滤,比如根据Kubernetes.host、Kubernetes.container_name、 kubernetes.container_image_id等去做过滤。
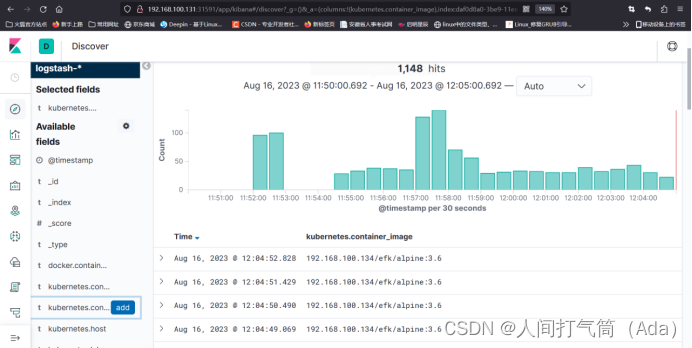
通过其他元数据也可以过滤日志数据,比如单击任何日志条目以查看其他元数据,如容器名称、Kubernetes 节点、命名空间等。
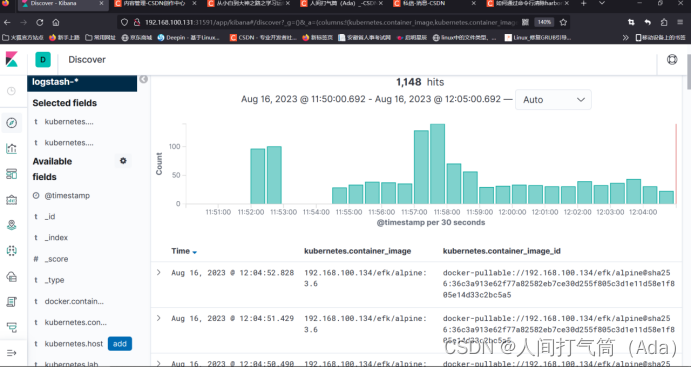
到这里,在 Kubernetes 集群上已经成功部署了 EFK。
相关文章:
【云原生】【k8s】Kubernetes+EFK构建日志分析安装部署
目录 EFK安装部署 一、环境准备(所有主机) 1、主机初始化配置 2、配置主机名并绑定hosts,不同主机名称不同 3、主机配置初始化 4、部署docker环境 二、部署kubernetes集群 1、组件介绍 2、配置阿里云yum源 3、安装kubelet kubeadm …...
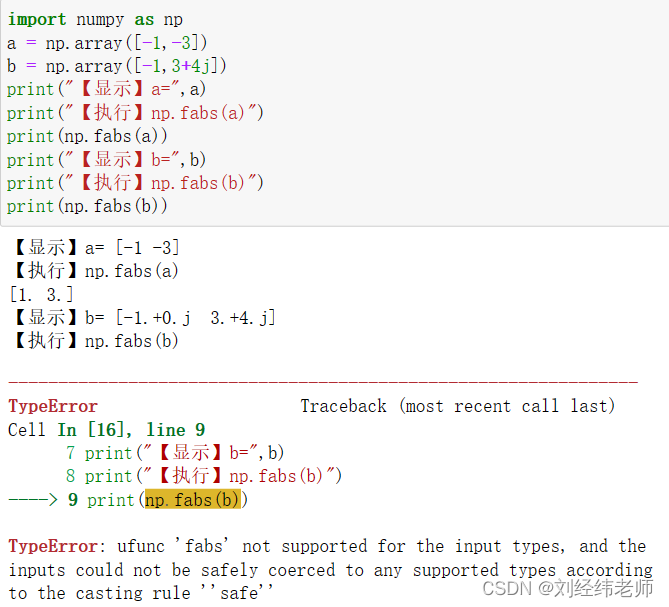
计算实数数组中所有元素的绝对值 numpy.fabs()
【小白从小学Python、C、Java】 【计算机等级考试500强双证书】 【Python-数据分析】 计算实数数组中所有元素的绝对值 numpy.fabs() [太阳]选择题 请问关于以下代码表述错误的是? iimport numpy as np a np.array([-1,-3]) b np.array([-1,34j]) print("【显…...

深入浅出Pytorch函数——torch.nn.init.orthogonal_
分类目录:《深入浅出Pytorch函数》总目录 相关文章: 深入浅出Pytorch函数——torch.nn.init.calculate_gain 深入浅出Pytorch函数——torch.nn.init.uniform_ 深入浅出Pytorch函数——torch.nn.init.normal_ 深入浅出Pytorch函数——torch.nn.init.c…...

ORACLE中UNION、UNION ALL、MINUS、INTERSECT学习
1、UNION和UNION ALL的使用与区别 如果我们需要将两个select语句的结果作为一个整体显示出来,我们就需要用到union或者union all关键字。union的作用是将多个结果合并在一起显示出来。 union和union all的区别是union会自动压缩多个结果集合中的重复结果ÿ…...
【k8s、云原生】基于metrics-server弹性伸缩
第四阶段 时 间:2023年8月18日 参加人:全班人员 内 容: 基于metrics-server弹性伸缩 目录 一、Kubernetes部署方式 (一)minikube (二)二进制包 (三)Kubeadm 二…...

回归预测 | MATLAB实现WOA-SVM鲸鱼算法优化支持向量机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现WOA-SVM鲸鱼算法优化支持向量机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现WOA-SVM鲸鱼算法优化支持向量机多输入单输出回归预测(多指标,多图)效果一览基本介绍程…...

VSCode快捷键
CtrlShiftP,F1:显示命令面板 CtrlP:快速打开 CtrlShiftN:新窗口/实例 CtrlShiftW:关闭窗口/实例 CtrlX:剪切行 CtrlC:复制行 ALT↑/↓:上下移动 ShiftAlt↓/↑:向…...

贪心算法求数组中能组成三角形的最大周长
题目:三角形的最大周长 给定由一些正数(代表长度)组成的数组arr,返回由其中三个长度组成的、面积不为零的三角形的最大周长。 如果不能形成任何面积不为零的三角形,返回0。 分析: 对数组排序,再从大到小选择三个数,再…...
VMWare Workstation 17 Pro 网络设置 桥接模式 网络地址转换(NAT)模式 仅主机模式
文章目录 网络模式配网要求CentOSDHCP虚拟网络桥接模式默认配置测试手动配置测试 网络地址转发模式 (NAT)还原配置虚拟网络配置默认配置测试手动配置测试 仅主机模式 网络模式 桥接模式: 主机与虚拟机对等, 虚拟机注册到主机所在的局域网, 会占用该网络的IP该局域网内的所有机…...

拒绝摆烂!C语言练习打卡第四天
🔥博客主页:小王又困了 📚系列专栏:每日一练 🌟人之为学,不日近则日退 ❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、选择题 📝1.第一题 📝2.第二题 Ὅ…...

KubeSphere 社区双周报 | Java functions framework 支持 SkyWalking | 2023.8.4-8.17
KubeSphere 社区双周报主要整理展示新增的贡献者名单和证书、新增的讲师证书以及两周内提交过 commit 的贡献者,并对近期重要的 PR 进行解析,同时还包含了线上/线下活动和布道推广等一系列社区动态。 本次双周报涵盖时间为:2023.08.04-2023.…...
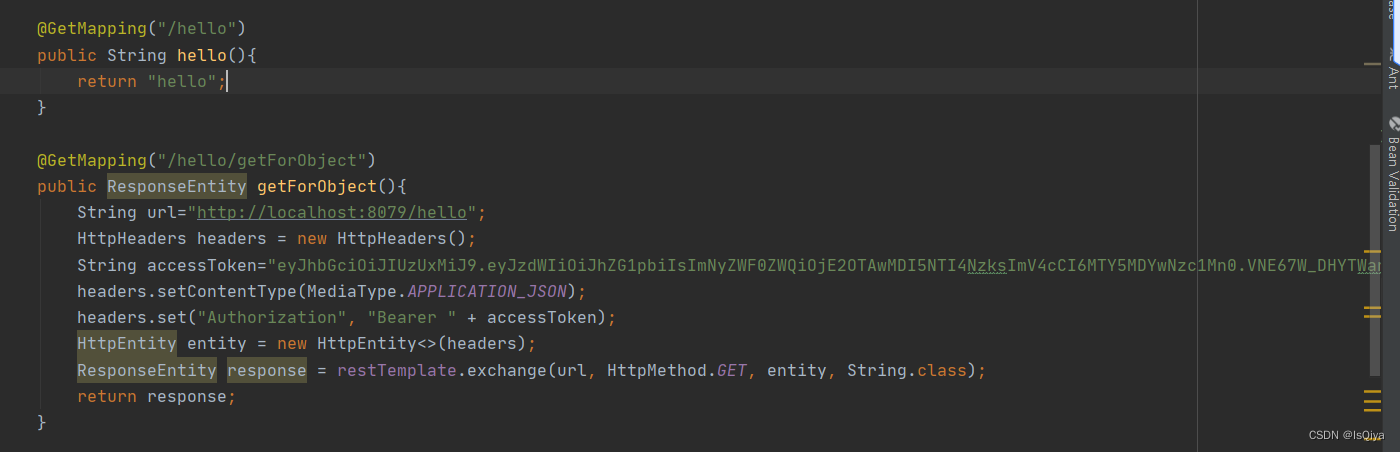
【学习笔记之java】使用RestTemplate调用第三方接口
1.首先需要导入依赖 <!-- RestTemplate使用导入的依赖--><dependency><groupId>org.apache.httpcomponents</groupId><artifactId>httpclient</artifactId><version>4.5.13</version></dependency>2.跟启动类同级创建…...
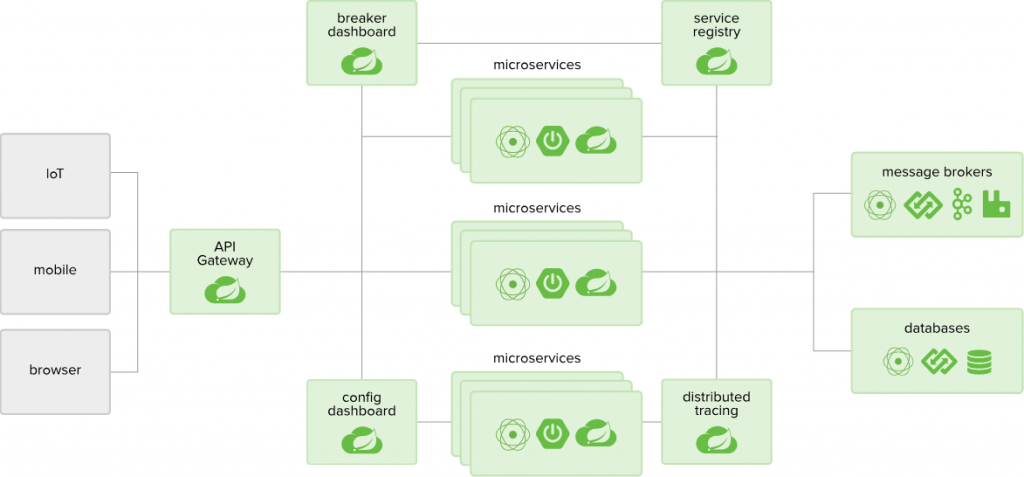
数据集成革新:去中心化微服务集群的无限潜能
在当今数据密集型的业务环境下,传统的集中式架构已经难以满足高可用性和高并发性的要求。而去中心化微服务集群则通过分散式的架构,将系统划分为多个小型的、独立部署的微服务单元,每个微服务负责特定的业务功能,实现了系统的高度…...

后端返回可下载的xlsx文件,但是前端接收下载后为乱码
我的接收数据进行处理的代码为: download_signal_list() {return new Promise((resolve, reject) > {get_download_signal({project_id: this.projectId,version_id: this.versionId}).then(response > {const url window.URL.createObjectURL(new Blob([res…...

提升资源管理效率必备工具推荐
一、数据传输 1、Textify(PC) 作为一名技术人员,需要经常研究各种技术,因此,复制粘贴的操作十分常见。 Textify可以快速复制各种控件中的文本,包括浏览器中当前页面的标题、聊天窗口中各个部分的文字、桌…...

HJ23 删除字符串中出现次数最少的字符
描述 实现删除字符串中出现次数最少的字符,若出现次数最少的字符有多个,则把出现次数最少的字符都删除。输出删除这些单词后的字符串,字符串中其它字符保持原来的顺序。 数据范围:输入的字符串长度满足 1≤n≤20 1≤n≤20 &…...

文心一言 VS 讯飞星火 VS chatgpt (76)-- 算法导论7.3 1题
一、如果用go语言,为什么我们分析随机化算法的期望运行时间,而不是其最坏运行时间呢? 文心一言: 在分析算法的性能时,期望运行时间是一个重要的指标,它描述了算法在平均情况下的表现。期望运行时间考虑了所有可能的…...

Leetcode - 滑动窗口
文章目录 1. 滑动窗口2. 举例2.1 无重复字符的最长子串2.2 长度最小的子数组2.3 滑动窗口最大值2.4 最小覆盖子串2.5 删除有序数组中的重复项 1. 滑动窗口 滑动窗口的大概思想如下: 可以通过两个指针来标识窗口的边界。窗口的长度是可以固定的,也可以是…...

如何保证数据传输的安全?
要确保数据传输的安全,您可以采取以下措施: 使用加密协议:使用安全的传输协议,如HTTPS(HTTP over SSL/TLS)或其他安全协议,以保护数据在传输过程中的安全性。加密协议可以有效防止数据被窃听或篡改。 强化身份验证&…...
政务、商务数据资源有效共享:让数据上“链”,记录每一个存储过程!
数据上链是目前“区块链”最常见的场景。因为链上所有参与方都分享了统一的事实来源,所有人都可以即时获得最新的信息,数据可用不可见。因此,不同参与方之间的协作效率得以大幅提高。同时,因为区块链上的数据难以篡改,…...

利用最小二乘法找圆心和半径
#include <iostream> #include <vector> #include <cmath> #include <Eigen/Dense> // 需安装Eigen库用于矩阵运算 // 定义点结构 struct Point { double x, y; Point(double x_, double y_) : x(x_), y(y_) {} }; // 最小二乘法求圆心和半径 …...

React 第五十五节 Router 中 useAsyncError的使用详解
前言 useAsyncError 是 React Router v6.4 引入的一个钩子,用于处理异步操作(如数据加载)中的错误。下面我将详细解释其用途并提供代码示例。 一、useAsyncError 用途 处理异步错误:捕获在 loader 或 action 中发生的异步错误替…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

线程同步:确保多线程程序的安全与高效!
全文目录: 开篇语前序前言第一部分:线程同步的概念与问题1.1 线程同步的概念1.2 线程同步的问题1.3 线程同步的解决方案 第二部分:synchronized关键字的使用2.1 使用 synchronized修饰方法2.2 使用 synchronized修饰代码块 第三部分ÿ…...

工程地质软件市场:发展现状、趋势与策略建议
一、引言 在工程建设领域,准确把握地质条件是确保项目顺利推进和安全运营的关键。工程地质软件作为处理、分析、模拟和展示工程地质数据的重要工具,正发挥着日益重要的作用。它凭借强大的数据处理能力、三维建模功能、空间分析工具和可视化展示手段&…...

srs linux
下载编译运行 git clone https:///ossrs/srs.git ./configure --h265on make 编译完成后即可启动SRS # 启动 ./objs/srs -c conf/srs.conf # 查看日志 tail -n 30 -f ./objs/srs.log 开放端口 默认RTMP接收推流端口是1935,SRS管理页面端口是8080,可…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

Linux --进程控制
本文从以下五个方面来初步认识进程控制: 目录 进程创建 进程终止 进程等待 进程替换 模拟实现一个微型shell 进程创建 在Linux系统中我们可以在一个进程使用系统调用fork()来创建子进程,创建出来的进程就是子进程,原来的进程为父进程。…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

莫兰迪高级灰总结计划简约商务通用PPT模版
莫兰迪高级灰总结计划简约商务通用PPT模版,莫兰迪调色板清新简约工作汇报PPT模版,莫兰迪时尚风极简设计PPT模版,大学生毕业论文答辩PPT模版,莫兰迪配色总结计划简约商务通用PPT模版,莫兰迪商务汇报PPT模版,…...