皮爷咖啡基于亚马逊云科技的数据架构,加速数据治理进程
皮爷咖啡(Peet’s Coffee)是美国精品咖啡品牌,于2017年进入中国,为中国消费者带来传统经典咖啡饮品,并特别呈现更加丰富的品质咖啡饮品体验。通过深入应用亚马逊云科技云原生数据库产品Amazon Redshift以及Amazon DMS等数据库产品,皮爷咖啡在1个月内,快速构建了敏捷的数据架构,加速数据治理进程。

皮爷咖啡采用的亚马逊云科技的产品及服务包括:Amazon Redshift、Amazon Kinesis Data Streams、Amazon Lambda、Amazon Glue、Amazon Athena、Amazon Lake formation、Amazon DMS。
机会:未经治理的数据“一口水,一口井”
皮爷咖啡是包装和连锁咖啡巨头JDE旗下的精品咖啡品牌,始终秉承着打造极致咖啡体验的理念。在中国,皮爷咖啡也在迅速发展,伴随着业务的迅速扩张,皮爷咖啡迅速意识到需要构建对应的数据治理机制,去建设大数据平台。皮爷咖啡数据架构师冯亚东强调:“2023年是皮爷咖啡的数字化里程碑的一年,我们对数据治理的要求非常明确,就是敏捷。敏捷的定义是:没什么做不了,没什么不能改,不需要从头来,不需要等太久。我们做数据,数据驱动是绕不开的话题,如果驱动不好做,十有八九是不够敏捷。”
皮爷咖啡对于数据治理的要求非常明确:打破数据孤岛,构建敏捷的数据系统,具备高效的数据整合与流动能力,实现业务部门对数据平台建设的较高参与度。在这之中,主要挑战有如下几点:
-
业务数据库繁杂、分散:由于历史原因,皮爷业务数据库有本地IDC的服务器、也包含其他云平台的服务器,数仓种类包含RDB、NoSQL等,种类繁多,场景类别多样。因此需要一个通用的、非线性方式解决数据集成问题;
-
数据治理:数据血缘元数据产品的核心能力,是大数据系统的老大难问题。数据血缘管理、数据质量监控、数据指标管理,都需要优化迭代,并适配皮爷咖啡的开源解决方案;
-
数据应用:皮爷咖啡在搭建数据中台的关键思考就是需要满足现有场景,并赋能业务人员可以省心省时省力运用和分析数据。
解决方案:1个月构建敏捷弹性的智能湖仓架构,打破数据孤岛
针对以上痛点,亚马逊云科技与皮爷咖啡进行深入讨论,最终确认了围绕“以订单系统为核心的数据主线”完成一期开发,添枝加叶,完善服务。
数据摄入:Serverless免运维架构,构建数据摄入能力
针对于皮爷咖啡多样的数据源类型,亚马逊云科技将数据源分成三种类别:面对热数据、结构化数据,也是高实时要求的数据,皮爷咖啡充分利用Amazon DMS自动化迁移功能,实现数据库和分析工作负载的快速迁移和CDC(自动数据摄取),并尽可能减少停机时间和杜绝数据丢失,并经由Amazon DMS直接进入云原生数据仓库AmazonRedshift进行分析;面对企业应用端、更加复杂的非结构化热数据,则通过Amazon Kinesis Data Streams进行实时的流数据分析,并通过Serverless架构的Amazon Lambda,对数据进行处理;而面对冷数据、存取比比较低的非结构化数据,则通过Amazon Glue存储在数据湖Amazon S3中,从而降低计算成本和存储成本,最终实现良好的冷、热、温数据分层和隔离。
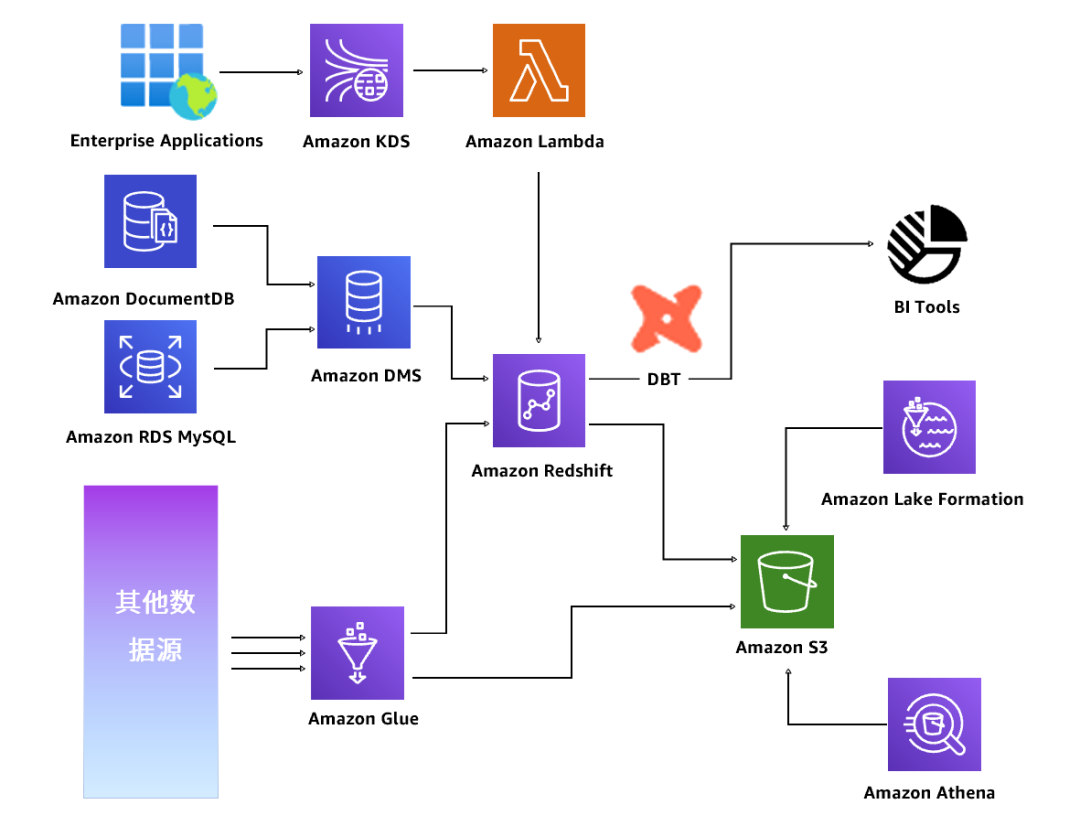
数据分析:运用冷热分离的智能湖仓架构实现降本增效
为了将不同结构、不同类型、不同来源的皮爷咖啡相关数据汇总起来并加以分析、获得见解,亚马逊云科技运用Amazon S3、Amazon Lake formation、Amazon Redshift构建起了冷热分离的湖仓一体架构,数据通过Amazon S3在亚马逊云科技体系及开源体系流转。其中,云原生数据仓库Amazon Redshift可提供强大的SQL功能,对智能湖仓存储内的超大型数据集进行快速在线分析处理(OLAP)。
此外,该数据库还提供并发扩展功能,可在几秒钟内启动更多瞬态集群,借此支持几乎无限数量的并发查询,最终在Amazon Redshift的帮助下,皮爷咖啡能够轻松实现2分钟之内完成两天增量的计算任务。冯亚东肯定道:“现阶段我们积累了皮爷咖啡从成立到现在所有时期不同的迭代版本数据的全面打通,不同数据源都落地在Amazon Redshift节点中,实现了数据的联邦查询。”
最后,冷热分离的湖仓一体架构支持分层存储,从而帮助皮爷咖啡实现成本的高度优化,数据湖与数据仓库之间的原生集成,可以允许客户从仓库存储中移出大量访问频率较低的历史数据,并降低存储成本。
数据开发:开源DBT构建数据开发流程,实现数据血缘
针对于数据开发层面,基于Amazon Redshift Data Sharing的能力,数据开发工程师可以在不同的Redshift集群之间共享数据,并在这个过程中对数据进行脱敏。
凭借该能力,皮爷咖啡的开发工程师可以基于开源工具DBT(Data Build Tool)进行数据开发,形成数据管道脚本。并在开发结束后,经过CI/CD(持续集成,持续部署)流程进行数据提交,保障提交到生产环境的数据没有质量问题,最终,将整个数据的语义层信息,包括数据目录、血缘关系、数据质量检测的结果都通过统一的途径发布给数据的消费者——也就是业务人员,让业务人员可以快速根据语义信息,业务含义搜索到数据资产,查看数据质量,并通过血缘关系找到数据的来龙去脉,从而对数据进行分析。
成果:优雅、敏捷数据架构,让咖啡师也能上手做数据分析
凭借亚马逊云科技智能湖仓架构,皮爷咖啡实现了数据资产的快速落地,从规划到整个中台系统搭建完成,皮爷咖啡只用了1个月的时间就实现了生产数据的上线,如果按照传统的方式进行建设,这个时间可能会延长30%-40%。
现如今,皮爷咖啡的业务单元正在逐步接入大数据平台中,包含HR系统、订单管理系统、ERP系统、会员中心、订单中心以及营销中心等。以DBT为例,该系统中,皮爷咖啡目前已经可以提供超过260个模型为业务部门使用,实现了数据分析的工程化、数据中台的产品化,并提供给更多的业务部门复用。正如冯亚东所预言的那样,皮爷咖啡的大数据平台正在枝繁叶茂的方向迈进。
未来,皮爷咖啡将会继续基于一条数据主线的架构,打开局面,基于Data Vault建模方法,对来自多个系统的的数据进行长期历史存储,添加更多功能,让整个技术架构向更优雅的方向演进。
相关文章:
皮爷咖啡基于亚马逊云科技的数据架构,加速数据治理进程
皮爷咖啡(Peet’s Coffee)是美国精品咖啡品牌,于2017年进入中国,为中国消费者带来传统经典咖啡饮品,并特别呈现更加丰富的品质咖啡饮品体验。通过深入应用亚马逊云科技云原生数据库产品Amazon Redshift以及Amazon DMS等…...
C++ string类详解
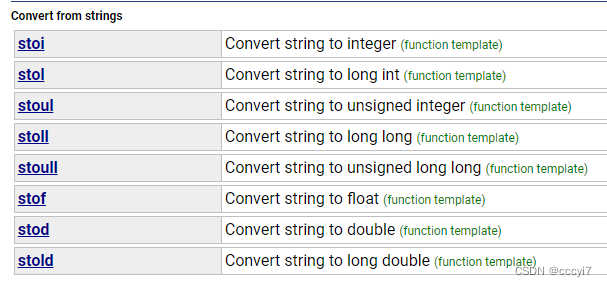
⭐️ string string 是表示字符串的字符串类,该类的接口与常规容器的接口基本一致,还有一些额外的操作 string 的常规操作,在使用 string 类时,需要使用 #include <string> 以及 using namespace std;。 ✨ 帮助文档&…...

深入浅出Pytorch函数——torch.nn.init.ones_
分类目录:《深入浅出Pytorch函数》总目录 相关文章: 深入浅出Pytorch函数——torch.nn.init.calculate_gain 深入浅出Pytorch函数——torch.nn.init.uniform_ 深入浅出Pytorch函数——torch.nn.init.normal_ 深入浅出Pytorch函数——torch.nn.init.c…...

一、docker及mysql基本语法
文章目录 一、docker相关命令二、mysql相关命令 一、docker相关命令 (1)拉取镜像:docker pull <镜像ID/image> (2)查看当前docker中的镜像:docker images (3)删除镜像&#x…...
【计算机网络】13、ARP 包:广播自己的 mac 地址和 ip
机器启动时,会向外广播自己的 mac 地址和 ip 地址,这个即称为 arp 协议。范围是未经过路由器的部分,如下图的蓝色部分,范围内的设备都会在本地记录 mac 和 ip 的绑定信息,若有重复则覆盖更新(例如先收到 ma…...
通过微软Azure调用GPT的接口API-兼容平替OpenAI官方的注意事项
众所周知,我们是访问不通OpenAI官方服务的,但是我们可以自己通过代理或者使用第三方代理访问接口 现在新出台的规定禁止使用境外的AI大模型接口对境内客户使用,所以我们需要使用国内的大模型接口 国内的效果真的很差,现在如果想使…...

回归预测 | MATLAB实现BO-SVM贝叶斯优化支持向量机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现BO-SVM贝叶斯优化支持向量机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现BO-SVM贝叶斯优化支持向量机多输入单输出回归预测(多指标,多图)效果一览基本介绍程序设计…...

GAN!生成对抗网络GAN全维度介绍与实战
目录 一、引言1.1 生成对抗网络简介1.2 应用领域概览1.3 GAN的重要性 二、理论基础2.1 生成对抗网络的工作原理2.1.1 生成器生成过程 2.1.2 判别器判别过程 2.1.3 训练过程训练代码示例 2.1.4 平衡与收敛 2.2 数学背景2.2.1 损失函数生成器损失判别器损失 2.2.2 优化方法优化代…...
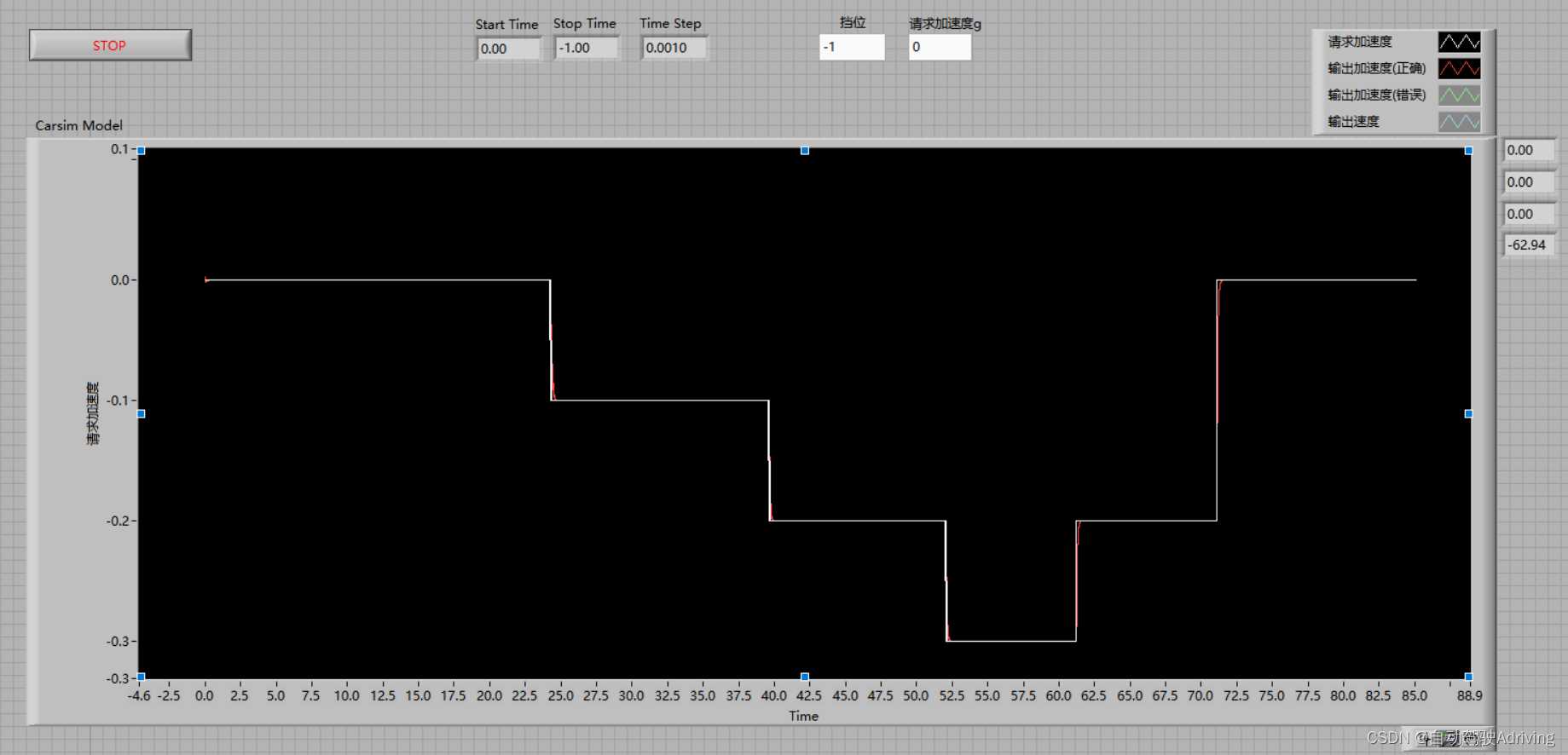
自动驾驶仿真:基于Carsim开发的加速度请求模型
文章目录 前言一、加速度输出变量问题澄清二、配置Carsim动力学模型三、配置Carsim驾驶员模型四、添加VS Command代码五、Run Control联合仿真六、加速度模型效果验证 前言 1、自动驾驶行业中,算法端对于纵向控制的功能预留接口基本都是加速度,我们需要…...
.netcore grpc客户端工厂及依赖注入使用
一、客户端工厂概述 gRPC 与 HttpClientFactory 的集成提供了一种创建 gRPC 客户端的集中方式。可以通过依赖包Grpc.Net.ClientFactory中的AddGrpcClient进行gRPC客户端依赖注入AddGrpcClient函数提供了许多配置项用于处理一些其他事项;例如AOP、重试策略等 二、案…...
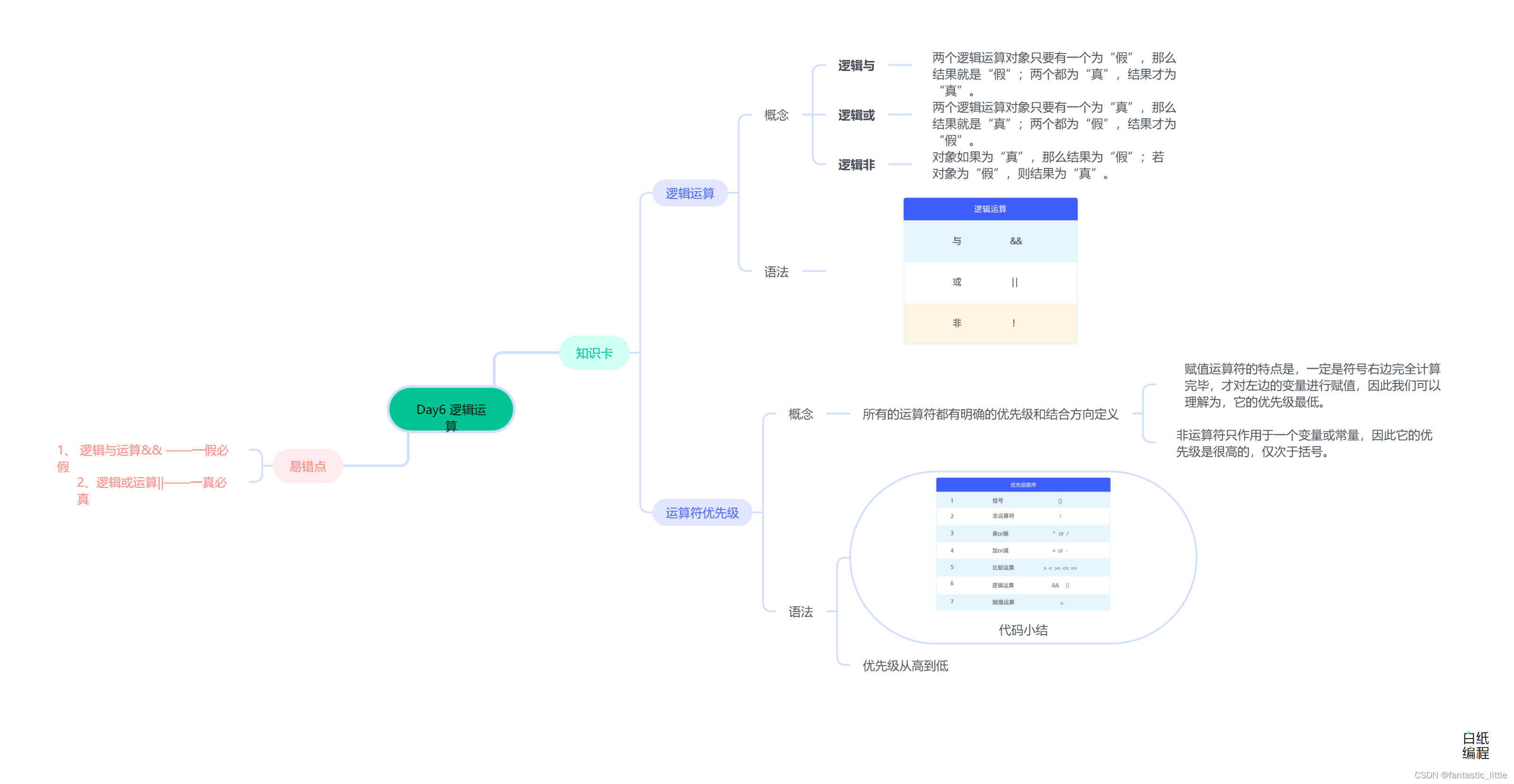
C语言入门_Day7 逻辑运算
目录: 前言 1.逻辑运算 2.优先级 3.易错点 4.思维导图 前言 算术运算用来进行数据的计算和处理;比较运算是用来比较不同的数据,进而来决定下一步怎么做;除此以外还有一种运算叫做逻辑运算,它的应用场景也是用来影…...

什么是Eureka?以及Eureka注册服务的搭建
导包 <?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0"xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 htt…...

Docker安装并配置镜像加速器,镜像、容器的基本操作
目录 1.安装docker服务,配置镜像加速器 (1)安装依赖的软件包 (2)设置yum源,我配置的阿里仓库 (3)选择一个版本安装 (4)启动docker服务,并设置…...

前端 -- 基础 网页、HTML、 WEB标准 扫盲详解
什么是网页 : 网页是构成网站的基本元素,它通常由 图片、链接、文字、声音、视频等元素组成。 通常我们看到的网页 ,常见以 .html 或 .htm 后缀结尾的文件, 因此俗称 HTML 文件 什么是 HTML : HTML 指的是 超文本标记语言,…...

分布式锁实现方式
分布式锁 1 分布式锁介绍 1.1 什么是分布式 一个大型的系统往往被分为几个子系统来做,一个子系统可以部署在一台机器的多个 JVM(java虚拟机) 上,也可以部署在多台机器上。但是每一个系统不是独立的,不是完全独立的。需要相互通信ÿ…...

C语言小练习(一)
🌞 “人生是用来体验的,不是用来绎示完美的,接受迟钝和平庸,允许出错,允许自己偶尔断电,带着遗憾,拼命绽放,这是与自己达成和解的唯一办法。放下焦虑,和不完美的自己和解…...

Flask-flask系统运行后台轮询线程
对于有些flask系统,后台需要启动轮询线程,执行特定的任务,以下是一个简单的例子。 globals/daemon.py import threading from app.executor.ops_service import find_and_run_ops_task_todo_in_redisdef context_run_func(app, func):with …...

jsp本质-servlet
jsp本质-servlet 一、jsp文件 <% page language"java" contentType"text/html; charsetUTF-8" pageEncoding"UTF-8"%> <!DOCTYPE html> <html> <head><meta charset"UTF-8"><title>JSP Example…...
回归预测 | MATLAB实现GWO-SVM灰狼优化算法优化支持向量机多输入单输出回归预测(多指标,多图)
回归预测 | MATLAB实现GWO-SVM灰狼优化算法优化支持向量机多输入单输出回归预测(多指标,多图) 目录 回归预测 | MATLAB实现GWO-SVM灰狼优化算法优化支持向量机多输入单输出回归预测(多指标,多图)效果一览基…...

科技资讯|苹果Vision Pro新专利曝光:可调节液态透镜
苹果公司近日申请了名为“带液态镜头的电子设备”,概述了未来可能的头显设计。头显设备中的透镜采用可调节的液态透镜,每个透镜可以具有填充有液体的透镜腔,透镜室可以具有形成光学透镜表面的刚性和 / 或柔性壁。 包括苹果自家的 Vision Pr…...

Vim 调用外部命令学习笔记
Vim 外部命令集成完全指南 文章目录 Vim 外部命令集成完全指南核心概念理解命令语法解析语法对比 常用外部命令详解文本排序与去重文本筛选与搜索高级 grep 搜索技巧文本替换与编辑字符处理高级文本处理编程语言处理其他实用命令 范围操作示例指定行范围处理复合命令示例 实用技…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

Qwen3-Embedding-0.6B深度解析:多语言语义检索的轻量级利器
第一章 引言:语义表示的新时代挑战与Qwen3的破局之路 1.1 文本嵌入的核心价值与技术演进 在人工智能领域,文本嵌入技术如同连接自然语言与机器理解的“神经突触”——它将人类语言转化为计算机可计算的语义向量,支撑着搜索引擎、推荐系统、…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...

Maven 概述、安装、配置、仓库、私服详解
目录 1、Maven 概述 1.1 Maven 的定义 1.2 Maven 解决的问题 1.3 Maven 的核心特性与优势 2、Maven 安装 2.1 下载 Maven 2.2 安装配置 Maven 2.3 测试安装 2.4 修改 Maven 本地仓库的默认路径 3、Maven 配置 3.1 配置本地仓库 3.2 配置 JDK 3.3 IDEA 配置本地 Ma…...

算法:模拟
1.替换所有的问号 1576. 替换所有的问号 - 力扣(LeetCode) 遍历字符串:通过外层循环逐一检查每个字符。遇到 ? 时处理: 内层循环遍历小写字母(a 到 z)。对每个字母检查是否满足: 与…...

[免费]微信小程序问卷调查系统(SpringBoot后端+Vue管理端)【论文+源码+SQL脚本】
大家好,我是java1234_小锋老师,看到一个不错的微信小程序问卷调查系统(SpringBoot后端Vue管理端)【论文源码SQL脚本】,分享下哈。 项目视频演示 【免费】微信小程序问卷调查系统(SpringBoot后端Vue管理端) Java毕业设计_哔哩哔哩_bilibili 项…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

逻辑回归暴力训练预测金融欺诈
简述 「使用逻辑回归暴力预测金融欺诈,并不断增加特征维度持续测试」的做法,体现了一种逐步建模与迭代验证的实验思路,在金融欺诈检测中非常有价值,本文作为一篇回顾性记录了早年间公司给某行做反欺诈预测用到的技术和思路。百度…...