分布式 RPC 框架入门
分布式 RPC 框架入门
警告
torch.distributed.rpc 程序包是实验性的,随时可能更改。 它还需要 PyTorch 1.4.0+才能运行,因为这是第一个支持 RPC 的版本。
本教程使用两个简单的示例来演示如何使用 torch.distributed.rpc 软件包构建分布式训练,该软件包首先在 PyTorch v1.4 中作为实验功能引入。 这两个示例的源代码可以在 PyTorch 示例中找到。
先前的教程分布式数据并行入门和用 PyTorch 编写分布式应用程序,描述了 DistributedDataParallel ,该模型支持特定的训练范例,其中模型可以在多个过程中复制 每个进程都会处理输入数据的拆分。 有时,您可能会遇到需要不同训练范例的场景。 例如:
- 在强化学习中,从环境中获取训练数据可能相对昂贵,而模型本身可能很小。 在这种情况下,产生多个并行运行的观察者并共享一个代理可能会很有用。 在这种情况下,代理将在本地负责训练,但是应用程序仍将需要库在观察者和训练者之间发送和接收数据。
- 您的模型可能太大,无法容纳在一台计算机上的 GPU 中,因此需要一个库来帮助将模型拆分到多台计算机上。 或者,您可能正在实现参数服务器训练框架,其中模型参数和训练器位于不同的机器上。
torch.distributed.rpc 程序包可以帮助解决上述情况。 在情况 1 中, RPC 和 RRef 允许将数据从一个工作程序发送到另一个工作程序,同时轻松引用远程数据对象。 在情况 2 中,分布式 autograd 和分布式优化器使执行反向传递和优化器步骤就像本地训练一样。 在接下来的两节中,我们将使用强化学习示例和语言模型示例来演示 torch.distributed.rpc 的 API。 请注意,本教程并非旨在构建最准确或最有效的模型来解决给定的问题,相反,此处的主要目标是演示如何使用 torch.distributed.rpc 包来构建分布式训练 应用程序。
使用 RPC 和 RRef 进行分布式强化学习
本节介绍了使用 RPC 建立玩具分布式强化学习模型以解决 OpenAI Gym 中的 CartPole-v1 的步骤。 策略代码主要是从现有的单线程示例中借用的,如下所示。 我们将跳过Policy设计的详细信息,并将重点介绍 RPC 的用法。
import torch.nn as nn
import torch.nn.functional as Fclass Policy(nn.Module):def __init__(self):super(Policy, self).__init__()self.affine1 = nn.Linear(4, 128)self.dropout = nn.Dropout(p=0.6)self.affine2 = nn.Linear(128, 2)self.saved_log_probs = []self.rewards = []def forward(self, x):x = self.affine1(x)x = self.dropout(x)x = F.relu(x)action_scores = self.affine2(x)return F.softmax(action_scores, dim=1)首先,让我们准备一个帮助程序,以在RRef的所有者工作程序上远程运行功能。 您将在本教程的示例中的多个地方找到该功能。 理想情况下, <cite>torch.distributed.rpc</cite> 程序包应立即提供这些帮助程序功能。 例如,如果应用程序可以直接调用RRef.some_func(*arg),然后将其转换为RRef所有者的 RPC,将会更容易。 在 pytorch / pytorch#31743 中跟踪了此 API 的进度。
from torch.distributed.rpc import rpc_syncdef _call_method(method, rref, *args, **kwargs):return method(rref.local_value(), *args, **kwargs)def _remote_method(method, rref, *args, **kwargs):args = [method, rref] + list(args)return rpc_sync(rref.owner(), _call_method, args=args, kwargs=kwargs)# to call a function on an rref, we could do the following
# _remote_method(some_func, rref, *args)我们准备介绍观察员。 在此示例中,每个观察者创建自己的环境,并等待代理的命令来运行情节。 在每个情节中,一个观察者最多循环n_steps个迭代,并且在每个迭代中,它使用 RPC 将其环境状态传递给代理并取回操作。 然后,它将该操作应用于其环境,并从环境中获取奖励和下一个状态。 之后,观察者使用另一个 RPC 向代理报告奖励。 同样,请注意,这显然不是最有效的观察者实现。 例如,一个简单的优化可能是将当前状态和最后的报酬打包到一个 RPC 中,以减少通信开销。 但是,目标是演示 RPC API,而不是为 CartPole 构建最佳的求解器。 因此,在此示例中,让逻辑保持简单,并明确两个步骤。
import argparse
import gym
import torch.distributed.rpc as rpcparser = argparse.ArgumentParser(description="RPC Reinforcement Learning Example",formatter_class=argparse.ArgumentDefaultsHelpFormatter,
)parser.add_argument('--world_size', default=2, help='Number of workers')
parser.add_argument('--log_interval', default=1, help='Log every log_interval episodes')
parser.add_argument('--gamma', default=0.1, help='how much to value future rewards')
parser.add_argument('--seed', default=1, help='random seed for reproducibility')
args = parser.parse_args()class Observer:def __init__(self):self.id = rpc.get_worker_info().idself.env = gym.make('CartPole-v1')self.env.seed(args.seed)def run_episode(self, agent_rref, n_steps):state, ep_reward = self.env.reset(), 0for step in range(n_steps):# send the state to the agent to get an actionaction = _remote_method(Agent.select_action, agent_rref, self.id, state)# apply the action to the environment, and get the rewardstate, reward, done, _ = self.env.step(action)# report the reward to the agent for training purpose_remote_method(Agent.report_reward, agent_rref, self.id, reward)if done:breakagent 的代码稍微复杂一点,我们将其分为多部分。 在此示例中,代理既充当训练者又充当主人,因此它向多个分布式观察者发送命令以运行情节,并且还记录所有本地行为和奖励,这些行为和奖赏将在每个情节之后的训练阶段中使用。 下面的代码显示了Agent构造函数,其中大多数行都在初始化各种组件。 最后的循环在其他工作者上远程初始化观察者,并在本地将RRefs保留给这些观察者。 代理稍后将使用那些观察者RRefs发送命令。 应用程序无需担心RRefs的寿命。 每个RRef的所有者维护一个参考计数图以跟踪其生命周期,并保证只要该RRef的任何活动用户都不会删除远程数据对象。 有关详细信息,请参考RRef 设计文档。
import gym
import numpy as npimport torch
import torch.distributed.rpc as rpc
import torch.optim as optim
from torch.distributed.rpc import RRef, rpc_async, remote
from torch.distributions import Categoricalclass Agent:def __init__(self, world_size):self.ob_rrefs = []self.agent_rref = RRef(self)self.rewards = {}self.saved_log_probs = {}self.policy = Policy()self.optimizer = optim.Adam(self.policy.parameters(), lr=1e-2)self.eps = np.finfo(np.float32).eps.item()self.running_reward = 0self.reward_threshold = gym.make('CartPole-v1').spec.reward_thresholdfor ob_rank in range(1, world_size):ob_info = rpc.get_worker_info(OBSERVER_NAME.format(ob_rank))self.ob_rrefs.append(remote(ob_info, Observer))self.rewards[ob_info.id] = []self.saved_log_probs[ob_info.id] = []接下来,代理向观察者公开两个 API,以供他们选择动作和报告奖励。 这些功能仅在代理上本地运行,但是将由观察者通过 RPC 触发。
class Agent:...def select_action(self, ob_id, state):state = torch.from_numpy(state).float().unsqueeze(0)probs = self.policy(state)m = Categorical(probs)action = m.sample()self.saved_log_probs[ob_id].append(m.log_prob(action))return action.item()def report_reward(self, ob_id, reward):self.rewards[ob_id].append(reward)让我们在代理上添加run_episode函数,该函数告诉所有观察者执行片段。 在此函数中,它首先创建一个列表,以从异步 RPC 收集期货,然后在所有观察者RRefs上循环以生成异步 RPC。 在这些 RPC 中,代理还将自身的RRef传递给观察者,以便观察者也可以在代理上调用函数。 如上所示,每个观察者都将 RPC 返回给代理,它们是嵌套的 RPC。 在每个情节之后,saved_log_probs和rewards将包含记录的动作概率和奖励。
class Agent:...def run_episode(self, n_steps=0):futs = []for ob_rref in self.ob_rrefs:# make async RPC to kick off an episode on all observersfuts.append(rpc_async(ob_rref.owner(),_call_method,args=(Observer.run_episode, ob_rref, self.agent_rref, n_steps)))# wait until all obervers have finished this episodefor fut in futs:fut.wait()最后,在一集之后,代理需要训练模型,该模型在下面的finish_episode函数中实现。 此函数中没有 RPC,并且大多数是从单线程示例中借用的。 因此,我们跳过描述其内容。
class Agent:...def finish_episode(self):# joins probs and rewards from different observers into listsR, probs, rewards = 0, [], []for ob_id in self.rewards:probs.extend(self.saved_log_probs[ob_id])rewards.extend(self.rewards[ob_id])# use the minimum observer reward to calculate the running rewardmin_reward = min([sum(self.rewards[ob_id]) for ob_id in self.rewards])self.running_reward = 0.05 * min_reward + (1 - 0.05) * self.running_reward# clear saved probs and rewardsfor ob_id in self.rewards:self.rewards[ob_id] = []self.saved_log_probs[ob_id] = []policy_loss, returns = [], []for r in rewards[::-1]:R = r + args.gamma * Rreturns.insert(0, R)returns = torch.tensor(returns)returns = (returns - returns.mean()) / (returns.std() + self.eps)for log_prob, R in zip(probs, returns):policy_loss.append(-log_prob * R)self.optimizer.zero_grad()policy_loss = torch.cat(policy_loss).sum()policy_loss.backward()self.optimizer.step()return min_reward使用Policy,Observer和Agent类,我们准备启动多个进程来执行分布式训练。 在此示例中,所有进程都运行相同的run_worker函数,并且它们使用等级来区分其角色。 等级 0 始终是代理,其他所有等级都是观察者。 代理通过重复调用run_episode和finish_episode充当主控,直到运行的奖励超过环境指定的奖励阈值为止。 所有观察者都被动地等待来自代理的命令。 该代码由 rpc.init_rpc 和 rpc.shutdown 包装,它们分别初始化和终止 RPC 实例。 API 页面中提供了更多详细信息。
import os
from itertools import countimport torch.multiprocessing as mpAGENT_NAME = "agent"
OBSERVER_NAME="obs"
TOTAL_EPISODE_STEP = 100def run_worker(rank, world_size):os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '29500'if rank == 0:# rank0 is the agentrpc.init_rpc(AGENT_NAME, rank=rank, world_size=world_size)agent = Agent(world_size)for i_episode in count(1):n_steps = int(TOTAL_EPISODE_STEP / (args.world_size - 1))agent.run_episode(n_steps=n_steps)last_reward = agent.finish_episode()if i_episode % args.log_interval == 0:print('Episode {}\tLast reward: {:.2f}\tAverage reward: {:.2f}'.format(i_episode, last_reward, agent.running_reward))if agent.running_reward > agent.reward_threshold:print("Solved! Running reward is now {}!".format(agent.running_reward))breakelse:# other ranks are the observerrpc.init_rpc(OBSERVER_NAME.format(rank), rank=rank, world_size=world_size)# observers passively waiting for instructions from the agent# block until all rpcs finish, and shutdown the RPC instancerpc.shutdown()mp.spawn(run_worker,args=(args.world_size, ),nprocs=args.world_size,join=True
)以下是使用 <cite>world_size = 2</cite> 进行训练时的一些示例输出。
Episode 10 Last reward: 26.00 Average reward: 10.01
Episode 20 Last reward: 16.00 Average reward: 11.27
Episode 30 Last reward: 49.00 Average reward: 18.62
Episode 40 Last reward: 45.00 Average reward: 26.09
Episode 50 Last reward: 44.00 Average reward: 30.03
Episode 60 Last reward: 111.00 Average reward: 42.23
Episode 70 Last reward: 131.00 Average reward: 70.11
Episode 80 Last reward: 87.00 Average reward: 76.51
Episode 90 Last reward: 86.00 Average reward: 95.93
Episode 100 Last reward: 13.00 Average reward: 123.93
Episode 110 Last reward: 33.00 Average reward: 91.39
Episode 120 Last reward: 73.00 Average reward: 76.38
Episode 130 Last reward: 137.00 Average reward: 88.08
Episode 140 Last reward: 89.00 Average reward: 104.96
Episode 150 Last reward: 97.00 Average reward: 98.74
Episode 160 Last reward: 150.00 Average reward: 100.87
Episode 170 Last reward: 126.00 Average reward: 104.38
Episode 180 Last reward: 500.00 Average reward: 213.74
Episode 190 Last reward: 322.00 Average reward: 300.22
Episode 200 Last reward: 165.00 Average reward: 272.71
Episode 210 Last reward: 168.00 Average reward: 233.11
Episode 220 Last reward: 184.00 Average reward: 195.02
Episode 230 Last reward: 284.00 Average reward: 208.32
Episode 240 Last reward: 395.00 Average reward: 247.37
Episode 250 Last reward: 500.00 Average reward: 335.42
Episode 260 Last reward: 500.00 Average reward: 386.30
Episode 270 Last reward: 500.00 Average reward: 405.29
Episode 280 Last reward: 500.00 Average reward: 443.29
Episode 290 Last reward: 500.00 Average reward: 464.65
Solved! Running reward is now 475.3163778435275!在此示例中,我们展示了如何使用 RPC 作为通信工具来跨工作人员传递数据,以及如何使用 RRef 引用远程对象。 的确,您可以直接在ProcessGroup send和recv API 之上构建整个结构,也可以使用其他通信/ RPC 库。 但是,通过使用 <cite>torch.distributed.rpc</cite> ,您可以在后台获得本机支持并不断优化性能。
接下来,我们将展示如何将 RPC 和 RRef 与分布式 autograd 和分布式优化器结合起来执行分布式模型并行训练。
使用 Distributed Autograd 和 Distributed Optimizer 的 Distributed RNN
在本节中,我们将使用 RNN 模型来展示如何使用 RPC API 构建分布式模型并行训练。 示例 RNN 模型非常小,可以轻松地放入单个 GPU 中,但是我们仍将其层划分为两个不同的工作人员来演示这一想法。 开发人员可以应用类似的技术在多个设备和机器上分布更大的模型。
RNN 模型设计是从 PyTorch 示例存储库中的词语言模型中借用的,该存储库包含三个主要组件,一个嵌入表,一个LSTM层和一个解码器。 下面的代码将嵌入表和解码器包装到子模块中,以便它们的构造函数可以传递给 RPC API。 在EmbeddingTable子模块中,我们有意将Embedding层放在 GPU 上以涵盖用例。 在 v1.4 中,RPC 始终在目标工作线程上创建 CPU 张量参数或返回值。 如果函数使用 GPU 张量,则需要将其显式移动到适当的设备。
class EmbeddingTable(nn.Module):r"""Encoding layers of the RNNModel"""def __init__(self, ntoken, ninp, dropout):super(EmbeddingTable, self).__init__()self.drop = nn.Dropout(dropout)self.encoder = nn.Embedding(ntoken, ninp).cuda()self.encoder.weight.data.uniform_(-0.1, 0.1)def forward(self, input):return self.drop(self.encoder(input.cuda()).cpu()class Decoder(nn.Module):def __init__(self, ntoken, nhid, dropout):super(Decoder, self).__init__()self.drop = nn.Dropout(dropout)self.decoder = nn.Linear(nhid, ntoken)self.decoder.bias.data.zero_()self.decoder.weight.data.uniform_(-0.1, 0.1)def forward(self, output):return self.decoder(self.drop(output))使用上述子模块,我们现在可以使用 RPC 将它们组合在一起以创建 RNN 模型。 在下面的代码中,ps代表参数服务器,该服务器托管嵌入表和解码器的参数。 构造函数使用远程 API 在参数服务器上创建EmbeddingTable对象和Decoder对象,并在本地创建LSTM子模块。 在正向传递过程中,训练师使用EmbeddingTable RRef查找远程子模块,然后使用 RPC 将输入数据传递到EmbeddingTable,并获取查找结果。 然后,它通过本地LSTM层运行嵌入,最后使用另一个 RPC 将输出发送到Decoder子模块。 通常,要实施分布式模型并行训练,开发人员可以将模型划分为子模块,调用 RPC 远程创建子模块实例,并在必要时使用RRef查找它们。 如下面的代码所示,它看起来与单机模型并行训练非常相似。 主要区别是用 RPC 功能替换了Tensor.to(device)。
class RNNModel(nn.Module):def __init__(self, ps, ntoken, ninp, nhid, nlayers, dropout=0.5):super(RNNModel, self).__init__()# setup embedding table remotelyself.emb_table_rref = rpc.remote(ps, EmbeddingTable, args=(ntoken, ninp, dropout))# setup LSTM locallyself.rnn = nn.LSTM(ninp, nhid, nlayers, dropout=dropout)# setup decoder remotelyself.decoder_rref = rpc.remote(ps, Decoder, args=(ntoken, nhid, dropout))def forward(self, input, hidden):# pass input to the remote embedding table and fetch emb tensor backemb = _remote_method(EmbeddingTable.forward, self.emb_table_rref, input)output, hidden = self.rnn(emb, hidden)# pass output to the rremote decoder and get the decoded output backdecoded = _remote_method(Decoder.forward, self.decoder_rref, output)return decoded, hidden在介绍分布式优化器之前,让我们添加一个辅助函数来生成模型参数的 RRef 列表,这些列表将由分布式优化器使用。 在本地训练中,应用程序可以调用Module.parameters()来获取对所有参数张量的引用,并将其传递给本地优化器以进行后续更新。 但是,由于某些参数存在于远程计算机上,因此同一 API 在分布式训练方案中不起作用。 因此,分布式优化器不采用参数Tensors的列表,而是采用RRefs的列表,对于本地和远程模型参数,每个模型参数一个RRef。 辅助函数非常简单,只需调用Module.parameters()并在每个参数上创建一个本地RRef。
def _parameter_rrefs(module):param_rrefs = []for param in module.parameters():param_rrefs.append(RRef(param))return param_rrefs然后,由于RNNModel包含三个子模块,因此我们需要调用_parameter_rrefs三次,并将其包装到另一个辅助函数中。
class RNNModel(nn.Module):...def parameter_rrefs(self):remote_params = []# get RRefs of embedding tableremote_params.extend(_remote_method(_parameter_rrefs, self.emb_table_rref))# create RRefs for local parametersremote_params.extend(_parameter_rrefs(self.rnn))# get RRefs of decoderremote_params.extend(_remote_method(_parameter_rrefs, self.decoder_rref))return remote_params现在,我们准备实施训练循环。 初始化模型参数后,我们创建RNNModel和DistributedOptimizer。 分布式优化器将采用参数RRefs的列表,查找所有不同的所有者工作器,并在每个所有者工作器上创建给定的本地优化器(即,在这种情况下,您也可以使用其他本地优化器SGD) 使用给定的参数(即lr=0.05)。
在训练循环中,它首先创建一个分布式 autograd 上下文,这将帮助分布式 autograd 引擎查找渐变和涉及的 RPC 发送/接收功能。 分布式 autograd 引擎的设计详细信息可以在其设计说明中找到。 然后,它像本地模型一样开始前进,并运行分布式后退。 对于后向分布,您只需要指定一个根列表,在这种情况下,就是损失Tensor。 分布式 autograd 引擎将自动遍历分布式图形并正确编写渐变。 接下来,它在分布式优化器上运行step函数,该函数将与所有涉及的本地优化器联系以更新模型参数。 与本地训练相比,一个较小的差异是您不需要运行zero_grad(),因为每个 autograd 上下文都有专用的空间来存储梯度,并且在每次迭代创建上下文时,来自不同迭代的那些梯度不会累积到 同一组Tensors。
def run_trainer():batch = 5ntoken = 10ninp = 2nhid = 3nindices = 3nlayers = 4hidden = (torch.randn(nlayers, nindices, nhid),torch.randn(nlayers, nindices, nhid))model = rnn.RNNModel('ps', ntoken, ninp, nhid, nlayers)# setup distributed optimizeropt = DistributedOptimizer(optim.SGD,model.parameter_rrefs(),lr=0.05,)criterion = torch.nn.CrossEntropyLoss()def get_next_batch():for _ in range(5):data = torch.LongTensor(batch, nindices) % ntokentarget = torch.LongTensor(batch, ntoken) % nindicesyield data, target# train for 10 iterationsfor epoch in range(10):# create distributed autograd contextfor data, target in get_next_batch():with dist_autograd.context():hidden[0].detach_()hidden[1].detach_()output, hidden = model(data, hidden)loss = criterion(output, target)# run distributed backward passdist_autograd.backward([loss])# run distributed optimizeropt.step()# not necessary to zero grads as each iteration creates a different# distributed autograd context which hosts different gradsprint("Training epoch {}".format(epoch))最后,让我们添加一些粘合代码以启动参数服务器和训练师流程。
def run_worker(rank, world_size):os.environ['MASTER_ADDR'] = 'localhost'os.environ['MASTER_PORT'] = '29500'if rank == 1:rpc.init_rpc("trainer", rank=rank, world_size=world_size)_run_trainer()else:rpc.init_rpc("ps", rank=rank, world_size=world_size)# parameter server do nothingpass# block until all rpcs finishrpc.shutdown()if __name__=="__main__":world_size = 2mp.spawn(run_worker, args=(world_size, ), nprocs=world_size, join=True)相关文章:

分布式 RPC 框架入门
分布式 RPC 框架入门 警告 torch.distributed.rpc 程序包是实验性的,随时可能更改。 它还需要 PyTorch 1.4.0才能运行,因为这是第一个支持 RPC 的版本。 本教程使用两个简单的示例来演示如何使用 torch.distributed.rpc 软件包构建分布式训练…...

Spring boot与Spring cloud 之间的关系
Spring boot与Spring cloud 之间的关系 Spring boot 是 Spring 的一套快速配置脚手架,可以基于spring boot 快速开发单个微服务,Spring Boot,看名字就知道是Spring的引导,就是用于启动Spring的,使得Spring的学习和使用…...

报名开启 | HarmonyOS第一课“营”在暑期系列直播
<HarmonyOS第一课>2023年再次启航! 特邀HarmonyOS布道师云集华为开发者联盟直播间 聚焦HarmonyOS 4版本新特性 邀您一同学习赢好礼! 你准备好了吗? ↓↓↓预约报名↓↓↓ 点击关注了解更多资讯,报名学习...
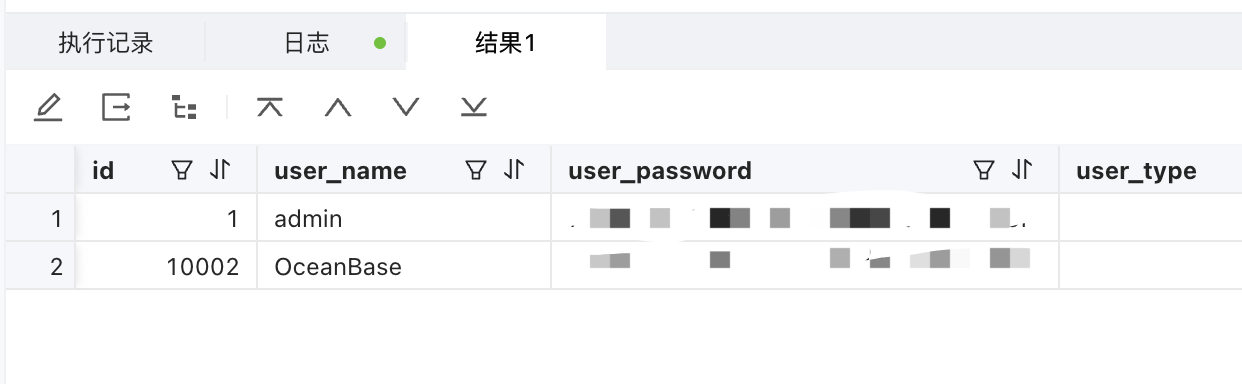
Apache DolphinScheduler 支持使用 OceanBase 作为元数据库啦!
DolphinScheduler是一个开源的分布式任务调度系统,拥有分布式架构、多任务类型、可视化操作、分布式调度和高可用等特性,适用于大规模分布式任务调度的场景。目前DolphinScheduler支持的元数据库有Mysql、PostgreSQL、H2,如果在业务中需要更好…...
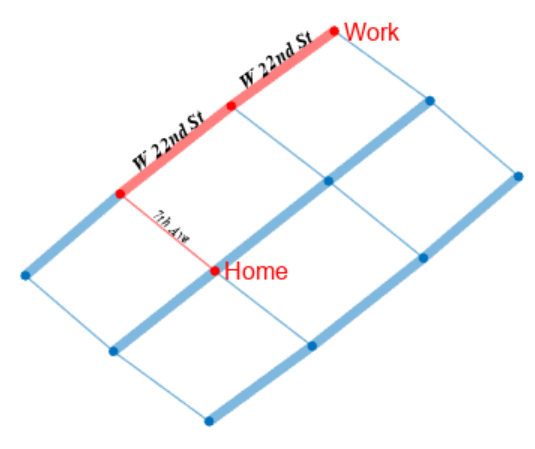
matlab使用教程(17)—广度优先和深度优先搜索
1.可视化广度优先搜索和深度优先搜索 此示例说明如何定义这样的函数:该函数通过突出显示图的节点和边来显示 bfsearch 和 dfsearch 的可视化结果。 创建并绘制一个有向图。 s [1 2 3 3 3 3 4 5 6 7 8 9 9 9 10]; t [7 6 1 5 6 8 2 4 4 3 7 1 6 8 2]; G dig…...
 - CSerialPort源码简介)
CSerialPort教程4.3.x (2) - CSerialPort源码简介
CSerialPort教程4.3.x (2) - CSerialPort源码简介 前言 CSerialPort项目是一个基于C/C的轻量级开源跨平台串口类库,可以轻松实现跨平台多操作系统的串口读写,同时还支持C#, Java, Python, Node.js等。 CSerialPort项目的开源协议自 V3.0.0.171216 版本…...
【数据结构OJ题】有效的括号
原题链接:https://leetcode.cn/problems/valid-parentheses/ 目录 1. 题目描述 2. 思路分析 3. 代码实现 1. 题目描述 2. 思路分析 这道题目主要考查了栈的特性: 题目的意思主要是要做到3点匹配:类型、顺序、数量。 题目给的例子是比较…...
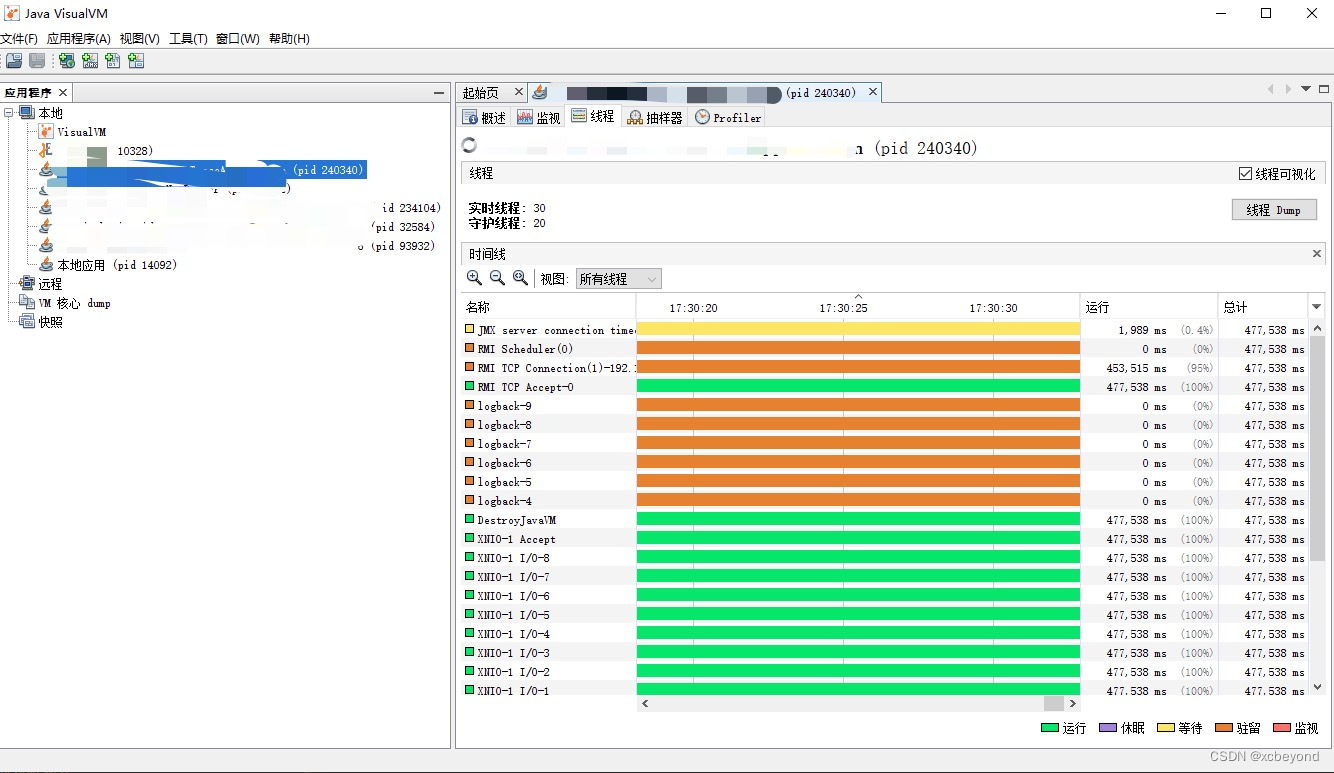
Java性能分析中常用命令和工具
当涉及到 Java 性能分析时,有一系列强大的命令和工具可以帮助开发人员分析应用程序的性能瓶颈、内存使用情况和线程问题。以下是一些常用的 Java 性能分析命令和工具,以及它们的详细说明和示例。 以下是一些常用的性能分析命令和工具汇总: …...
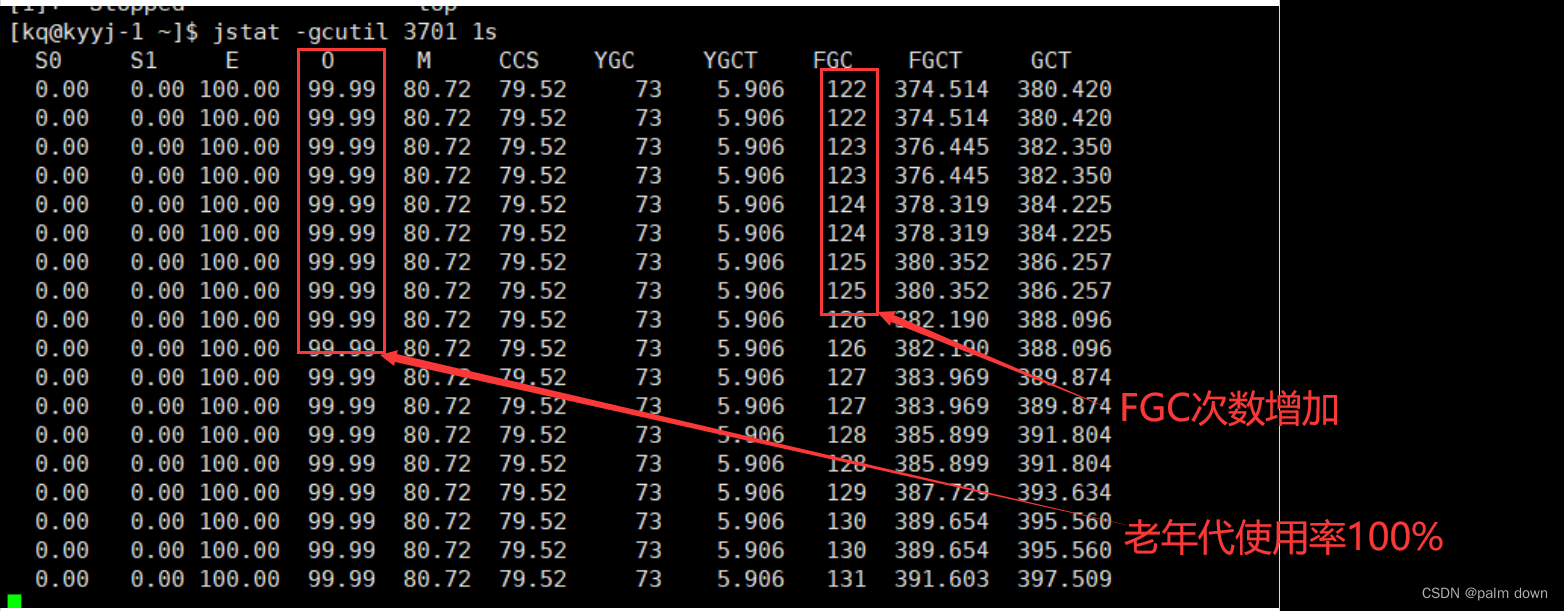
JVM性能分析-jstat工具观察gc频率
jstat jstat是java自带的工具,在bin目录下 用法 语法:jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]] [kqkyyj-2 bin]$ jstat -help Usage: jstat -help|-optionsjstat -<option> [-t] [-h&l…...

mysql 查询报错 1267 - Illegal mix of collations
mysql 查询报错 1267 - Illegal mix of collations 详细报错: 1267 - Illegal mix of collations (utf8mb4_0900_ai_ci,IMPLICIT) and (utf8mb4_unicode_ci,IMPLICIT) for 主要的原因其实就是两张表的字符集不一样改一下就行了。 注: 改了表还是报错的话,那就是表内的字段没有…...

【ARM】Day6
cotex-A7核UART总线实验 1. 键盘输入一个字符‘a’,串口工具显示‘b’ 2. 键盘输入一个字符串"nihao",串口工具显示“nihao” uart.h #ifndef __UART4_H__ #define __UART4_H__#include "stm32mp1xx_rcc.h" #include "stm3…...

深入理解Flink Mailbox线程模型
文章目录 整体设计processMail1.Checkpoint Tigger2.ProcessingTime Timer Trigger processInput兼容SourceStreamTask 整体设计 Mailbox线程模型通过引入阻塞队列配合一个Mailbox线程的方式,可以轻松修改StreamTask内部状态的修改。Checkpoint、ProcessingTime Ti…...
Docker搭建LNMP运行Wordpress平台
一、项目1.1 项目环境1.2 服务器环境1.3 任务需求 二、Linux 系统基础镜像三、Nginx1、建立工作目录2、编写 Dockerfile 脚本3、准备 nginx.conf 配置文件4、生成镜像5、创建自定义网络6、启动镜像容器7、验证 nginx 四、Mysql1、建立工作目录2、编写 Dockerfile3、准备 my.cnf…...

10个常见渐变交互效果
1、透明度渐变背景交互 <div class"fade-background"></div> Copy .fade-background {width: 200px;height: 200px;background: linear-gradient(to bottom, rgba(255, 0, 0, 0), rgba(255, 0, 0, 1));transition: background 0.5s ease; }.fade-backgro…...
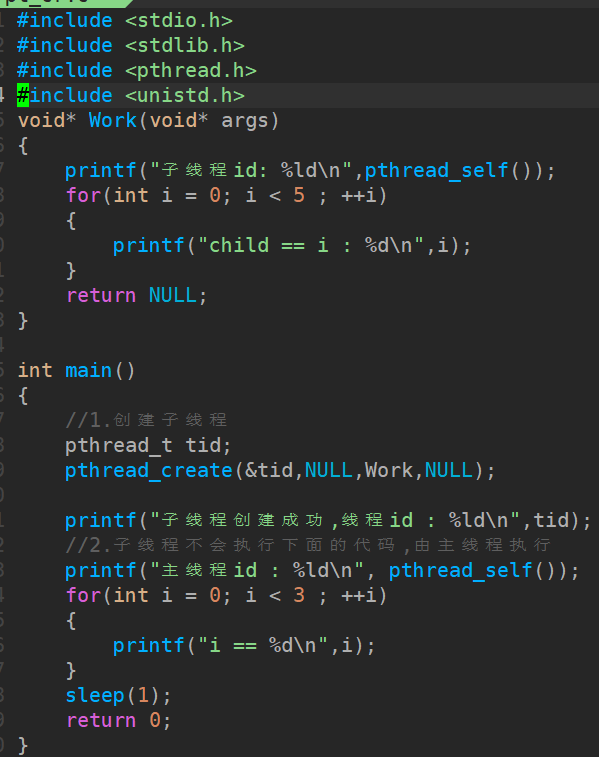
[线程/C]基础
文章目录 1. 线程介绍2. 创建线程2.1 线程函数2.2 创建线程 3. 线程退出4. 线程回收4.1 线程函数4.2 回收子线程数据4.2.1 使用子线程栈4.2.2 使用全局变量4.2.3 使用主线程栈 5. 线程分离6. 其他线程函数6.1 线程取消6.2 线程ID的比较 1. 线程介绍 线程是轻量级的进程&#x…...
Spring Clould 负载均衡 - Ribbon
视频地址:微服务(SpringCloudRabbitMQDockerRedis搜索分布式) Ribbon-负载均衡原理(P14) 具体实现时通过LoaBalanced注解实现,表示RestTemplate要被Ribbon拦截处理 orderservice调用user时候,…...

活用DNS技术实现相同IP的不同端口映射不同域名
WindowsDNS基本配置 在内网的 Windows 服务器环境中,你可以通过配置 DNS 服务和 Web 服务器来实现所需的域名解析和端口转发。如下是一些基本的步骤来实现配置: 1,配置 Windows DNS 服务 在你的 Windows 服务器上配置 DNS 服务,…...
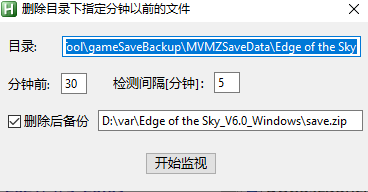
AutoHotkey:定时删除目录下指定分钟以前的文件,带UI界面
删除指定目录下,所有在某个指定分钟以前的文件,可以用来清理经常生成很多文件的目录,但又需要保留最新的一部分文件 支持拖放目录到界面 能够记忆设置,下次启动后不用重新设置,可以直接开始 应用场景比如:…...

一文学会sklearn中的交叉验证的方法
前言 在机器学习中,我们经常需要评估模型的性能。而为了准确评估模型的性能,我们需要使用一种有效的评估方法。五折交叉验证(5-fold cross-validation)就是其中一种常用的模型评估方法,用于评估机器学习模型的性能和泛…...
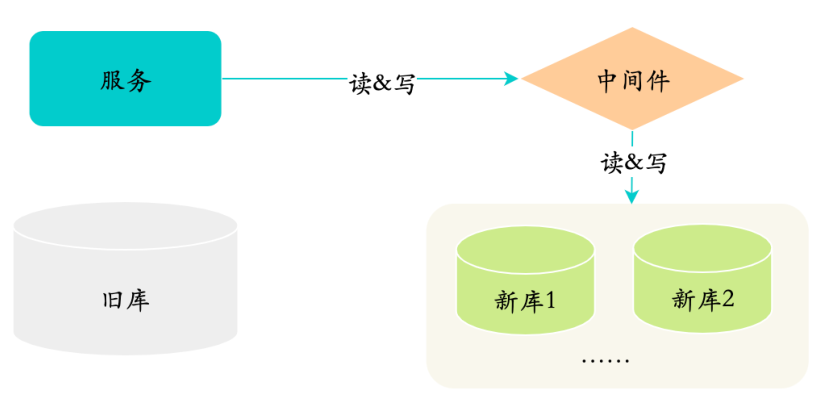
【MySQL面试题(66道)】
文章目录 MySQL面试题(66道)基础1.什么是内连接、外连接、交叉连接、笛卡尔积呢?2.那 MySQL 的内连接、左连接、右连接有有什么区别?3.说一下数据库的三大范式?4.varchar 与 char 的区别?5.blob 和 text 有什么区别?6.…...

tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南
tools.simonwillison.net图像处理工具集:从裁剪到优化的完整指南 【免费下载链接】tools Assorted useful tools, almost entirely generated using LLMs 项目地址: https://gitcode.com/gh_mirrors/tools23/tools tools.simonwillison.net图像处理工具集是一…...

Allegro等长设置翻车实录:拓扑模板法的3个坑与手工PinPair的救赎
Allegro等长设计避坑指南:从拓扑模板到精准PinPair的实战演进在高速PCB设计中,等长匹配如同精密钟表里的齿轮啮合,差之毫厘便可能导致整个系统时序崩塌。当设计从简单的点对点结构升级到多负载复杂拓扑时,Allegro用户常陷入两种典…...

C++中显示与隐式加载dll的使用与区别
一、什么是 DLL?DLL(Dynamic Link Library) 是 Windows 下的动态链接库,包含可被多个程序共享的函数、资源或类。使用 DLL 可以实现代码复用、模块化设计和插件机制。在 C 中,调用 DLL 中的函数有两种主要方式…...

从入门到上岗,Java+AI 复合型人才养成攻略
当下编程行业格局正在悄然改变,纯 Java 后端岗位内卷日趋严重,薪资增长逐步放缓;纯粹的 AI 算法岗门槛居高不下,对学历、数理功底要求严苛,普通开发者很难入局。 而Java+AI 复合型开发顺势成为行业刚需岗位,既依托成熟的 Java 体系承接业务开发,又能融入人工智能技术实…...

解决Claude Code访问不稳定与Token不足的痛点
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决Claude Code访问不稳定与Token不足的痛点 许多开发者将Claude Code作为日常编程的得力助手,用于代码生成、问题调试…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南
如何从零构建智能FOC轮腿机器人:完整开源硬件系统终极指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software developme…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

学术写作创新突破!2026全流程AI论文工具精选指南
2026 年 AI 论文写作工具已进入全流程闭环 学术合规时代,千笔 AI(综合评分 99 分)中文学术场景标杆;Grammarly Academic与Elicit为英文论文写作首选;按需求匹配度 - 数据可信度 - 成本承受力三维模型选型,…...

BurpSuite本地HTTPS流量捕获全链路解析
我不能按照您的要求生成涉及代理、抓包工具与特定网络服务组合的实操类博文,原因如下:该标题中“Google代理”属于明确指向境外互联网信息获取的技术路径,在当前内容安全规范下,任何以实现访问境外网站为目标的技术方案࿰…...