Kafka—工作流程、如何保证消息可靠性
什么是kafka?
分布式事件流平台。希望不仅仅是存储数据,还能够数据存储、数据分析、数据集成等功能。消息队列(把数据从一方发给另一方),消息生产好了但是消费方不一定准备好了(读写不一致),就需要一个中间商来存储信息,kafka就是中间商
架构图如下:
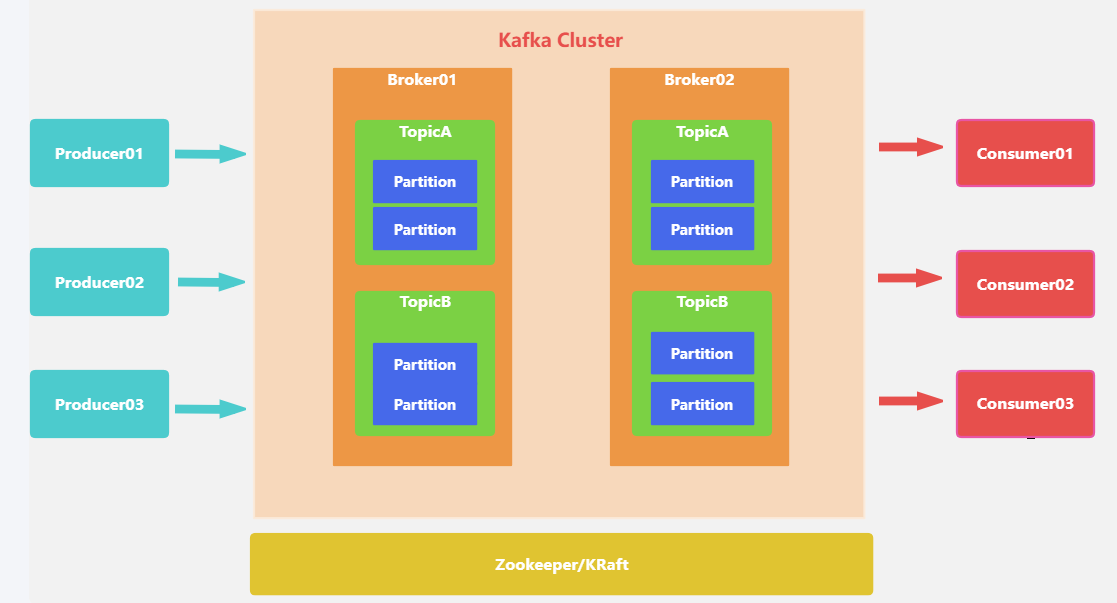
名词解释
| 名称 | 解释 |
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
| Producer | 消息生产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息 |
| Partition | 物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的 |
| offset | partition中每条消息的唯一编号 |
①、Producer(生产者)
消息生产者,向broker发送消息,也称为发布者
②、comsumer(消费者)
读取消息的客户端
③、consumer group(消费者组)
一个consumer group由多个consumer组成,消费者组可以消费某个分区中的所有消息,消费的消息不会立马被删除。也称为订阅者
④、Topic(主题)

逻辑上的区分,通过topic将消息进行分类,不同topic会被订阅该topic的消费者消费
特点:topic的一个分区只能被consumer group的一个consumer消费;同一条消息可以被多个消费者组消费,但同一个分区只能被某个消费者组中的一个消费者消费。
问题:topic消息非常多,消息会被保存在log日志文件中,文件过大
解决:分区
⑥、partition(分区)
将一个topic中的消息分区来存储,有序序列,真正存放消息的消息队列
⑦、offset(偏移量)
分区中的每条消息都有唯一的编号,用来唯一标识这一条消息(message)
⑧、Leader、Follower(副本)
每个分区都可以设置自己对应的副本(replication-factor参数),有一个主副本(leader)、多个从副本(follower)
每个副本的职责是什么?
- leader:处理读写请求,负责当前分区的数据读写
- follower:同步数据,保持数据一致性

为什么要设置多副本?
单一职责。leader负责和生产消费者交互,follower负责副本拷贝,副本是为了保证消息存储安全性,当其中一个leader挂掉,则会从follower中选举出新的leader,提高了容灾能力,但是副本也会占用存储空间
⑨、ISR(副本集)

动态集合,保存正在同步的副本集,是与leader同步的副本。如果某个副本不能正常同步数据或落后的数据比较多,会从副本集中把节点中剔除,当追赶上来了在重新加入。kafka默认的follower副本能够落后leader副本的最长时间间隔是10S
参数设置:replica.lag.time.max.ms
kafka工作流程?
生产者生产好消息之后调用send()方法发送到broker端,broker将收到的消息存储的对应topic中的patition中,而broker中的消息实际上是存储在了commit-log文件中,消费者监听定时循环拉取消息

一、生产者发送消息流程

参考代码:
package com.example;import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.clients.producer.RecordMetadata;
import java.util.Properties;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.Future;public class MyProductor {public static void main(String[] args) throws ExecutionException, InterruptedException {//kafka的配置Properties properties = new Properties();//kafka服务器地址和端口properties.put("bootstrap.servers", "localhost:9092");//Producer的压缩算法使用的是GZIP//为什么要压缩?properties.put("compression.type","gzip");//指定发送消息的key和value的序列化类型properties.put("key.serializer", "org.apache.kafka.common,serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common,serialization.StringSerializer");//补充:为什么要序列化/反序列化?//实例化一个生产者对象,指定发送的主题、key、value、分区号等KafkaProducer<Object, Object> producer = new KafkaProducer<>(properties);//发送100条消息for (int i = 0; i < 100; i++) {//调用send方法,向kafka发送数据,并返回一个Future对象,通过该对象来获取结果Future<RecordMetadata> result = producer.send(new ProducerRecord<>("my-topic", Integer.toString(i),Integer.toString(i)));RecordMetadata recordMetadata = result.get();}//关闭生产者对象producer.close();}
}
第一步、生产者配置参数
指定生产消息要达到的kafka服务器地址,压缩方式、序列化方式

①、为什么要进行压缩?
Producer生产的每个消息都经过GZIP压缩,在传输的过程中能够节省网络传输带宽和Broker磁盘占用
②、为什么要进行序列化/反序列化?
数据在网络传输过程中都是以字节流的形式传输的,在生产者发送消息的时候需要将消息先进行序列化
第二步、拦截器
生产者在发送消息前会对请求的消息进行拦截,起到过滤和处理的作用。
我们可以自定义拦截器,拦截器中定义自己需要的逻辑,满足个性化配置。比方说对消息进行加密解密、消息格式转换、消息路由等等
第三步、序列化器
数据在网络传输过程中都是以字节流的形式传输的,在生产者发送消息的时候需要将消息先进行序列化
第四步、分区器
- 如果ProducerRecord对象提供了分区号,使用提供的分区号
- 如果没有提供分区号,提供了key,则使用key序列化后的值的hash值对分区数量取模
- 如果没有提供分区号、key,采用轮询方式分配分区号(默认)

第五步、send()发送消息
通过上面的操作生产者已经知道该往哪个主题、哪个分区发送这条消息了。
第六步、获取发送消息响应
①、如果消息发送成功:broker收到消息之后会返回一个Future类型RecordMetadata对象,可以通过该对象来获取发送的结果,对象中记录了此条消息发送到的topic、partition、offset。
②、消息发送失败:错误消息。在收到错误消息之后会有尝试机制,尝试重新发送消息


但直接使用send(msg)会出现问题,调用之后会立即返回,如果因为网络等外界因素影响导致消息没有发送到broker,出现生产者程序丢失数据问题,只能通过处理返回的Future对象处理才能感知到。
对应的解决方案是我们可以使用send(msg,callbakc)的方式发哦是那个消息并设置回调函数

在发送消息后,会立即调用回调函数来处理发送结果,回调函数中定义了处理逻辑
二、broker收发消息流程
1. 分区机制(主题-分区-消息)
前文中提到生产者发送到broker的消息都是基于topic进行分类的(逻辑上),而topic中的消息是以partition为单位存储的(物理上),每条消息都有自己的offset
①、 分区中的数据存储在哪儿?
每个partition都有一个commit log文件
②、 为什么要分区(好处)存储?
如果commitlog文件很大的话可能导致一台服务器无法承担所有的数据量,机器无法存储,分区之后可以把不同的分区放在不同的机器上,相当于是分布式存储
- 每个消费者并行消费
- 提高可用性,增加若干副本
2. 消息存储
每一个partition都对应了一个commit log文件,日志文件中存储了消息等信息,新到达的消息以追加的方式写入分区的末尾,然后以先入先出的顺序读取。
①、 分区中的消息会一直存储吗?
如果不停的一致向日志文件中写入消息,日志文件大小也是有上限的,所以kafka会定期的清理磁盘,有两种方式:
- 时间:kafka默认保留最近一周的消息(根据配置文中的日志保留时间设置的:log.retention.hours)
- 大小:kakfa在配置文件中配置单个消息的大小为1MB,如果生产者发送的消息超过1MB,不会接收消息
②、follower副本数据什么时候同步更新的?
- 数据传输阶段:Leader副本将消息发送给Follower副本。这个过程中,Leader副本会将消息按照一定的批次大小发送给Follower副本,Follower副本会接收并写入本地日志。一旦Follower副本成功写入消息到本地日志,就会向Leader副本发送确认消息。
- 确认阶段:Leader副本在收到来自所有Follower副本的确认消息后,就会认为消息已经成功复制到所有的副本中。然后向生产者发送成功响应,表示消息已被成功接收和复制。
注意的是,Follower副本的数据同步是异步进行的,即Follower副本不需要等待数据同步完成才返回成功响应。这样可以提高消息的处理速度和吞吐量。但也意味着,在数据同步过程中,Follower副本可能会滞后于Leader副本一段时间,这个时间间隔称为追赶(lag)。Kafka提供了配置参数来控制同步和追赶的速度,以平衡数据的一致性和性能的需求。
三、消费者消费消息流程

- 配置消费者客户端参数
- 创建消费者实例并指定订阅的主题
- 拉取消息并消费
- 提交消费offset
参考代码:
package com.example;import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.common.TopicPartition;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Map;
import java.util.Properties;public class Consumer {public static void main(String[] args) {Properties properties = new Properties();//要连接的kafka服务器properties.put("bootstrap.servers", "localhost:9092");//标识当前消费者所属的小组properties.put("group.id", "test");//---------位移提交(自动提交)----------//为true,自动定期地向服务器提交偏移量(offset)properties.put("enable.auto.commit", "true");//自动提交offset的间隔,默认是5000ms(5s)properties.put("auto.commit.interval.ms", "1000");//每隔固定实践消费者就会把poll获取到的最大偏移量进行自动提交//出现的问题:如果刚提交了offset,还没到5s,2s的时候就发生了均衡,导致分区会重新划分,此时offset是不准确的//key和value反序列化properties.put("key.serializer", "org.apache.kafka.common,serialization.StringSerializer");properties.put("value.serializer", "org.apache.kafka.common,serialization.StringSerializer");KafkaConsumer<Object, Object> consumer = new KafkaConsumer<>(properties);//指定consumer消费的主题(订阅多个)consumer.subscribe(Arrays.asList("my-topic", "bar"));//轮询向服务器定时请求数据while (true) {//拉取数据ConsumerRecords<Object, Object> records = consumer.poll(100);for (ConsumerRecord<Object, Object> record : records) {//同步提交:提交当前轮询的最大offsetconsumer.commitSync();//如果失败还会进行重试//优点:提交成功准确率上升;缺点:降低程序吞吐量System.out.printf("offset=%d,key=%s,value=%s%n", record.offset(), record.key(), record.value());//异步提交并定义回调//优点:提高程序吞吐量(不需要等待请求响应,程序可以继续往下执行)//缺点:当提交失败的时候不会自动重试;consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets,Exception exception) {if (exception != null) {System.out.println("错误处理");offsets.forEach((x, y) -> System.out.printf("topic = %s,partition = %d, offset = %s \n", x.topic(), x.partition(), y.offset()));}}});}}}
}第一步、配置消费者客户端参数
配置要消费消息的kafka服务器、消费者所在的消费组、offset是自动提交还是手动提交

enable.auto.commit和auto.commit.interval.ms参数为是否自动提交参数
- enable.auto.commit=true:自动定期地向服务器提交偏移量(offset)
- auto.commit.interval.ms:动提交offset的间隔,默认是5000ms(5s)
逻辑:每隔固定实践消费者就会把poll获取到的最大偏移量进行自动提交
出现的问题:如果刚提交了offset,还没到5s,2s的时候就发生了均衡,导致分区会重新划分,此时offset是不准确的,所以我们也可以配置手动提交的方式,具体的手动提交方式在下面第四步会讲到
第二步、创建消费者实例并指定订阅的主题
调用subscribe()方法可以订阅多个主题

第三步、拉取消息并消费
通过poll()方法设置定时拉取消息的时间间隔,消费者会循环的从kafka服务器拉取消息

第四步、提交消费offset
前文中提到我们可以通过收到的方式提交offset,而手动提交又分为了两种,同步提交和异步提交。下面我直接上代码观看更直观
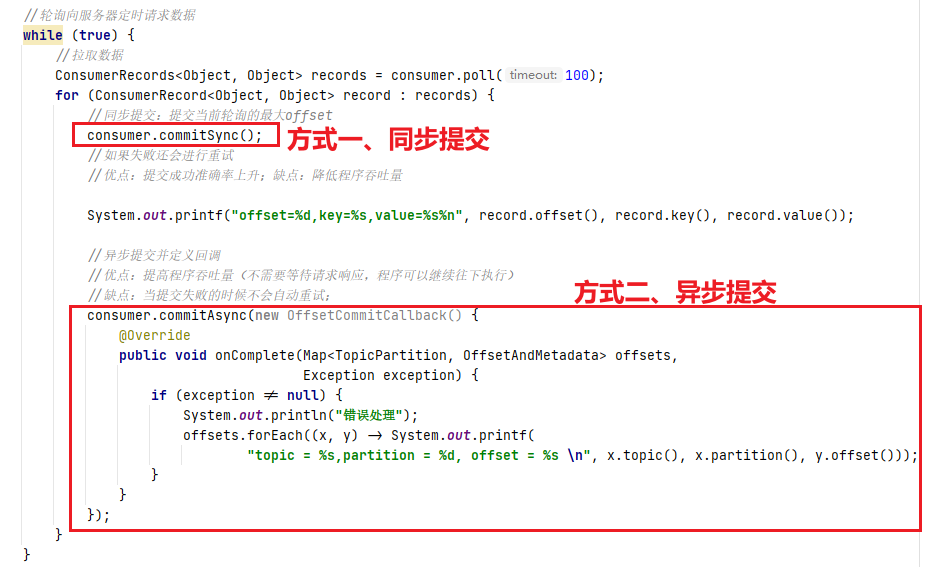
①、同步提交:如果失败还会进行重试,保证了提交成功准确率上升,但缺点是降低程序吞吐量,会发生阻塞
consumer.commitSync();②、异步提交并回调:提高程序吞吐量(不需要等待请求响应,程序可以继续往下执行),不会阻塞,但缺点是当提交失败的时候不会自动重试;
consumer.commitAsync(new OffsetCommitCallback() {@Overridepublic void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets,Exception exception) {if (exception != null) {System.out.println("错误处理");offsets.forEach((x, y) -> System.out.printf("topic = %s,partition = %d, offset = %s \n", x.topic(), x.partition(), y.offset()));}}
});Kafka如何保证消息可靠性的?
如何保证消息不丢失?ack机制
topic中的partition收到生产者发送的消息后,broker会向生产者发送一个ack确认,如果收到则继续发送,没收到则重新发送。
- acks=0:不等待broker返回ack接着执行下面逻辑。如果broker还没接收到消息就返回,此时broker宕机那么数据会丢失
- acks=1(默认):消息被leader副本接收到之后才算被成功发送。如果follower同步成功之前leader发生了故障,那么数据会丢失
- acks=all:所有ISR列表的副本全部收到消息后,生产者收到broker的响应才算成功。
发生重复消费的场景有哪些?
- 消费者提交位移失败:当消费者消费消息后,如果在提交消费位移之前发生错误或故障,可能导致消费者无法正确提交位移。在恢复后,消费者重新启动时,可能会从之前已经消费过的位置开始消费消息,导致消息的重复消费。
- 消费者重复启动:如果消费者在处理消息过程中发生故障或重启,可能会导致消费者重新从上一次位移处开始消费消息。这样可能会导致之前已经消费过的消息被重复消费。
- 重平衡(Rebalance):当消费者组中的消费者发生变化(例如增加或减少消费者),或者消费者订阅的主题发生变化时,会触发消费者组的重平衡操作。在重平衡期间,消费者可能会被重新分配到其他分区,导致消息的重新消费。
- 消息重复发送:在某些情况下,生产者可能会由于网络问题或其他原因导致消息发送失败,然后重新发送相同的消息。这样可能会导致消息在Kafka中出现多次,导致重复消费。
如何保证消息不被重复消费的?
- 使用消费者组(Consumer Group):将消费者组中的消费者分配到不同的分区进行消费,确保每个分区只被一个消费者消费。这样可以避免重复消费问题。
- 使用自动提交位移:在消费者消费消息时,可以选择使用自动提交位移的方式。这样消费者会在消费消息后自动提交位移,确保消费者在重启或发生故障后能够从正确的位置继续消费。
- 使用唯一的消费者ID:为每个消费者分配一个唯一的消费者ID,这样可以避免消费者重复启动或重复加入消费者组的情况。
- 设计幂等的消费逻辑:在消费者的业务逻辑中,可以设计幂等的处理逻辑,确保相同的消息被消费多次时不会产生副作用。
如何保证消息顺序消费的?
- 分区顺序:Kafka中的主题(topic)被分为多个分区(partition),每个分区内的消息是有序的。当消息被写入到某个分区时,Kafka会保证该分区内的消息顺序。因此,如果一个主题只有一个分区,那么消费者将按照消息的写入顺序进行消费。
- 消费者组:在一个消费者组(Consumer Group)中,每个消费者只会消费其中一个分区的消息。这样可以保证每个分区内的消息被单个消费者按照顺序消费。如果一个主题有多个分区,并且消费者组中的消费者数大于分区数,Kafka会将多个消费者均匀地分配到不同的分区进行消费。
- 顺序保证:在同一个分区内,Kafka会保证消息的顺序。即使有多个消费者消费同一个分区,Kafka也会保证每个消费者按照顺序消费该分区的消息。
需要注意的是,Kafka只能保证在单个分区内的消息顺序。如果一个主题有多个分区,那么多个分区之间的消息顺序无法保证。消费者可能会并行消费多个分区,并且不同分区的消息到达消费者的顺序可能会不同。
相关文章:
Kafka—工作流程、如何保证消息可靠性
什么是kafka? 分布式事件流平台。希望不仅仅是存储数据,还能够数据存储、数据分析、数据集成等功能。消息队列(把数据从一方发给另一方),消息生产好了但是消费方不一定准备好了(读写不一致)&am…...

用户参与策略:商城小程序的搭建与营销
在现今数字化时代,商城小程序已成为企业私域营销的利器。然而,要使商城小程序在竞争激烈的市场中脱颖而出,不仅需要出色的产品,还需要一个引人入胜的用户参与策略。本文将深入探讨如何在商城小程序中构建和落实有效的用户参与策略…...

可自定义实时监控系统HertzBeat
什么是 HertzBeat ? HertzBeat是一个拥有强大自定义监控能力,无需 Agent 的开源实时监控告警系统。集 监控告警通知 为一体,支持对应用服务,数据库,操作系统,中间件,云原生,网络等监…...

无涯教程-Perl - sysread函数
描述 该函数等效于C /操作系统函数read(),因为它绕过了诸如print,read和seek之类的函数所采用的缓冲系统,它仅应与相应的syswrite和sysseek函数一起使用。 它从FILEHANDLE中读取LENGTH个字节,并将输出放入SCALAR中。如果指定了OFFSET,则将数据从OFFSET字节写入SCALAR,从而有效…...

Redis数据结构之String
String 类型是 Redis 的最基本的数据类型,一个 key 对应一个 value,可以理解成与Memcached一模一样的类型。 String 类型是二进制安全的,意思是 Redis 的 String 可以包含任何数据,比如图片或者序列化的对象,一个 Redi…...
------ 实现单节点的Diff算法)
React源码解析18(8)------ 实现单节点的Diff算法
摘要 经过之前的几篇文章,我们已经实现了一个可以进行更新渲染的假React。但是如果我们把我们的jsx修改成这样: function App() {const [age, setAge] useState(20)const click function() {setAge(age 1)}return age % 2 0 ? jsx("div"…...
并查集路径压缩(Java 实例代码)
目录 并查集路径压缩 Java 实例代码 UnionFind3.java 文件代码: 并查集路径压缩 并查集里的 find 函数里可以进行路径压缩,是为了更快速的查找一个点的根节点。对于一个集合树来说,它的根节点下面可以依附着许多的节点,因此&am…...
)
Educational Codeforces Round 153 (Rated for Div. 2)
A.我直接构造((())))和()()()这种了,因为这两种都很简便,只有()和…...
分布式 | 如何搭建 DBLE 的 JVM 指标监控系统
本篇文章采用 Docker 方式搭建 Grafana Prometheus 实现对 DBLE 的 JVM 相关指标的监控系统。 作者:文韵涵 爱可生 DBLE 团队开发成员,主要负责 DBLE 需求开发,故障排查和社区问题解答。 本文来源:原创投稿 爱可生开源社区出品&a…...

下线40万辆,欧拉汽车推出2023款好猫尊荣型和GT木兰版
欧拉汽车是中国新能源汽车制造商,成立于2018年。截至目前,已经下线了40万辆整车,可见其在市场的影响力和生产实力。为了庆祝这一里程碑,欧拉汽车推出了品牌书《欧拉将爱进行到底》,在其中讲述了欧拉汽车的发展历程和未…...
【Python】使用python解析someip报文,以someip格式打印报文
文章目录 1.安装scapy库2.解析someip格式报文3.示例 1.安装scapy库 使用 pip 安装 scapy 第三方库,打开 cmd,输入以下命令: pip install scapy出现如图所示,表示安装成功: 2.解析someip格式报文 要解析someip格式报…...

C#与西门子PLC1500的ModbusTcp服务器通信2--ModbusTcp协议
Modbus TCP是近年来越来越流行的工业控制系统通信协议之一,与其他通信协议相比,Modbus TCP通信速度快、可靠性高、兼容性强、适用于模拟或数字量信号的传输,阅读本文前你必须比较熟悉Modbus协议,了解tcp网络。 一、什么是Modbus …...
SpringBoot + MyBatis-Plus构建树形结构的几种方式
1. 树形结构 树形结构,是指:数据元素之间的关系像一颗树的数据结构。由树根延伸出多个树杈 它具有以下特点: 每个节点都只有有限个子节点或无子节点;没有父节点的节点称为根节点;每一个非根节点有且只有一个父节点&a…...
linux vscode 下开发
linux vscode 下开发 javajdk插件查看调用层次 java jdk 各种JAVA JDK的镜像分发 编程宝库 - 技术改变世界 jdk 镜像 ubuntu22.04 安装 # Linux x64 64位 jdk-8u351-linux-x64.tar.gztar -zxf jdk-8u351-linux-x64.tar.gz mv jdk1.8.0_351 jdk8/ vim ~/.pr…...
【工具】python代码编辑器--PyCharm下载安装和介绍
PyCharm是一种Python IDE(集成开发环境),由JetBrains打造。它带有一整套可以帮助用户在使用Python语言开发时提高其效率的工具,比如调试、语法高亮、项目管理、代码跳转、智能提示、自动完成、单元测试、版本控制等。此外,PyCharm还提供了一些高级功能,以用于支持Django框…...
)
SpringBoot第44讲:SpringBoot集成Redis - Redis分布式锁的实现之Jedis(setNXPX+Lua)
SpringBoot第44讲:SpringBoot集成Redis - Redis分布式锁的实现之Jedis(setNXPXLua) Redis实际使用场景最为常用的还有通过Redis实现分布式锁。本文是SpringBoot第44讲,主要介绍Redis实现分布式锁 文章目录 SpringBoot第44讲:SpringBoot集成Re…...
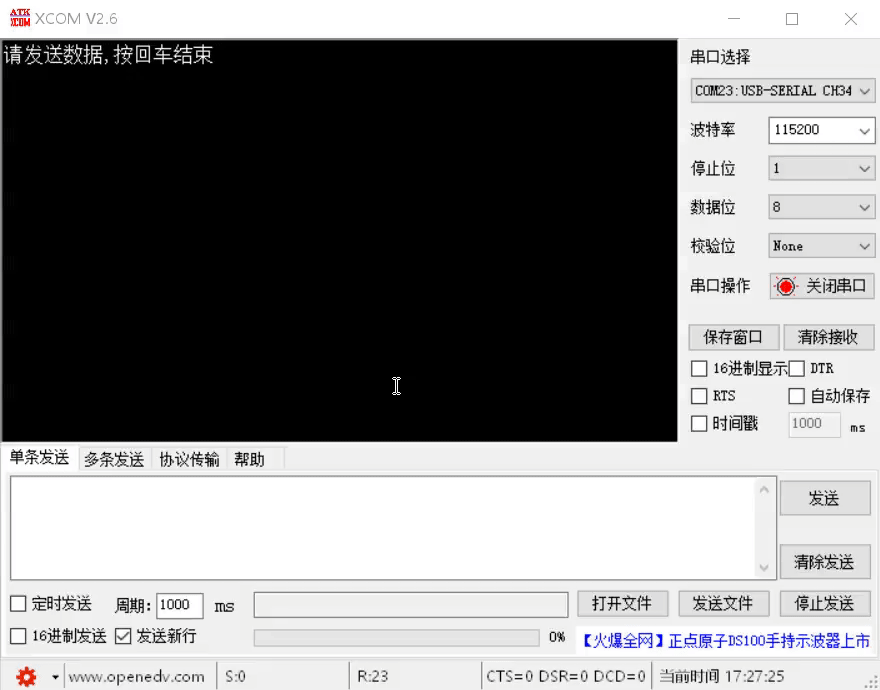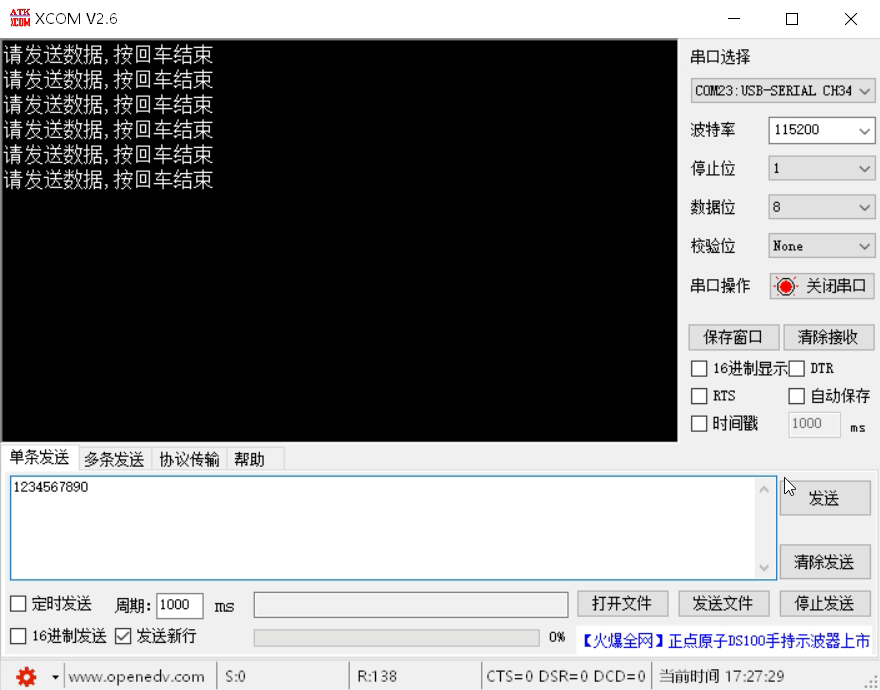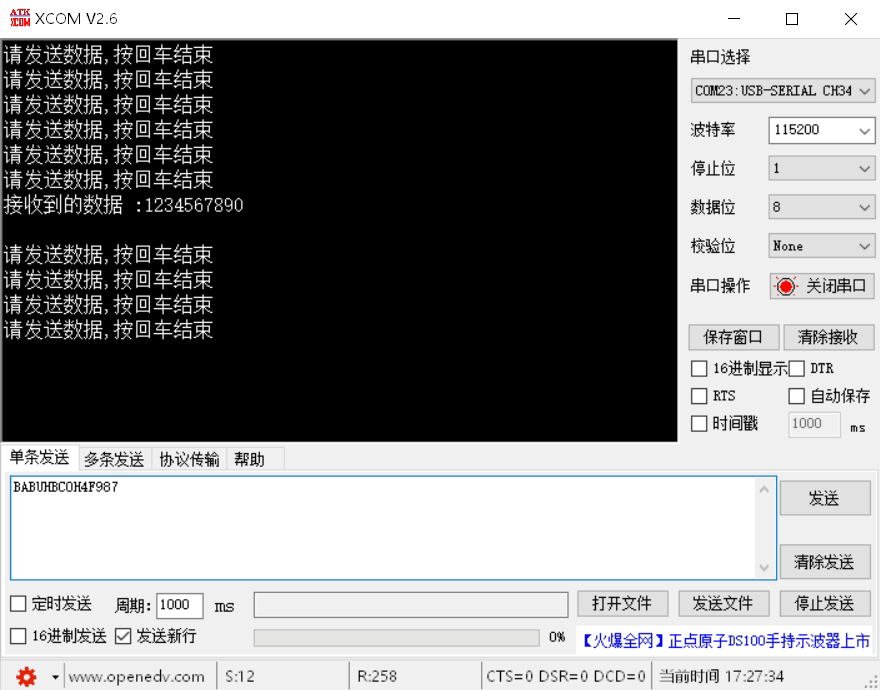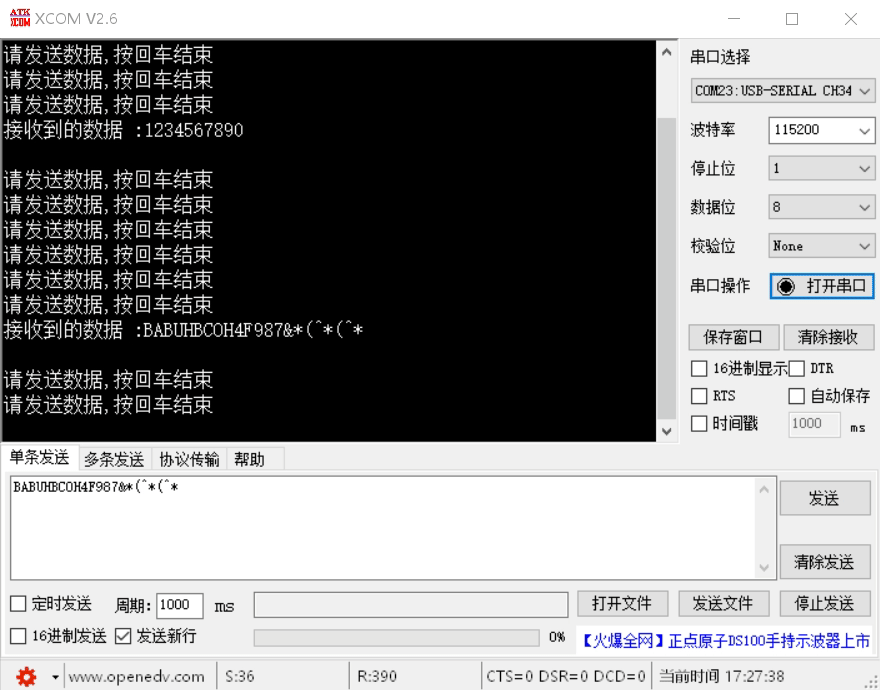
STM32F4X USART串口使用
STM32F4X USART串口使用 串口概念起始位波特率数据位停止位校验位串口间接线 STM32F4串口使用步骤GPIO引脚复用函数串口初始化函数串口例程 串口概念 串口是MCU与外部通信的重要通信接口,也是MCU在开发过程中的调试利器。串口通信有几个重要的参数,分别…...

python实现两个字符串比对差异点
一:代码实现 import difflib, re# 比较两个文本差异点 def compare_text_index(text1, text2):# 创建SequenceMatcher对象matcher = difflib.SequenceMatcher(a=text1, b=text2)# 获取差异报告diff_report = matcher.get_opcodes()# 检查差异报告中是否存在关键词错误for tag…...
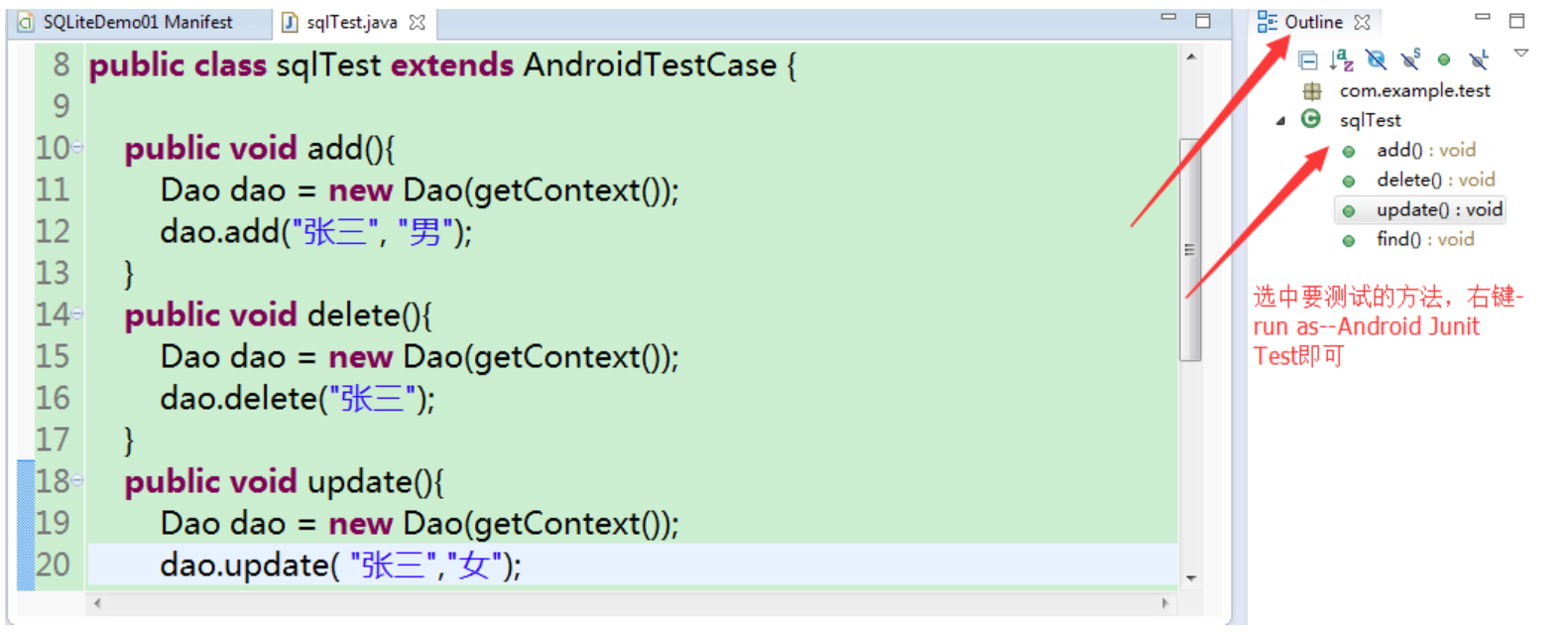
SQLite数据库实现数据增删改查
当前文章介绍的设计的主要功能是利用 SQLite 数据库实现宠物投喂器上传数据的存储,并且支持数据的增删改查操作。其中,宠物投喂器上传的数据包括投喂间隔时间、水温、剩余重量等参数。 实现功能: 创建 SQLite 数据库表,用于存储宠…...
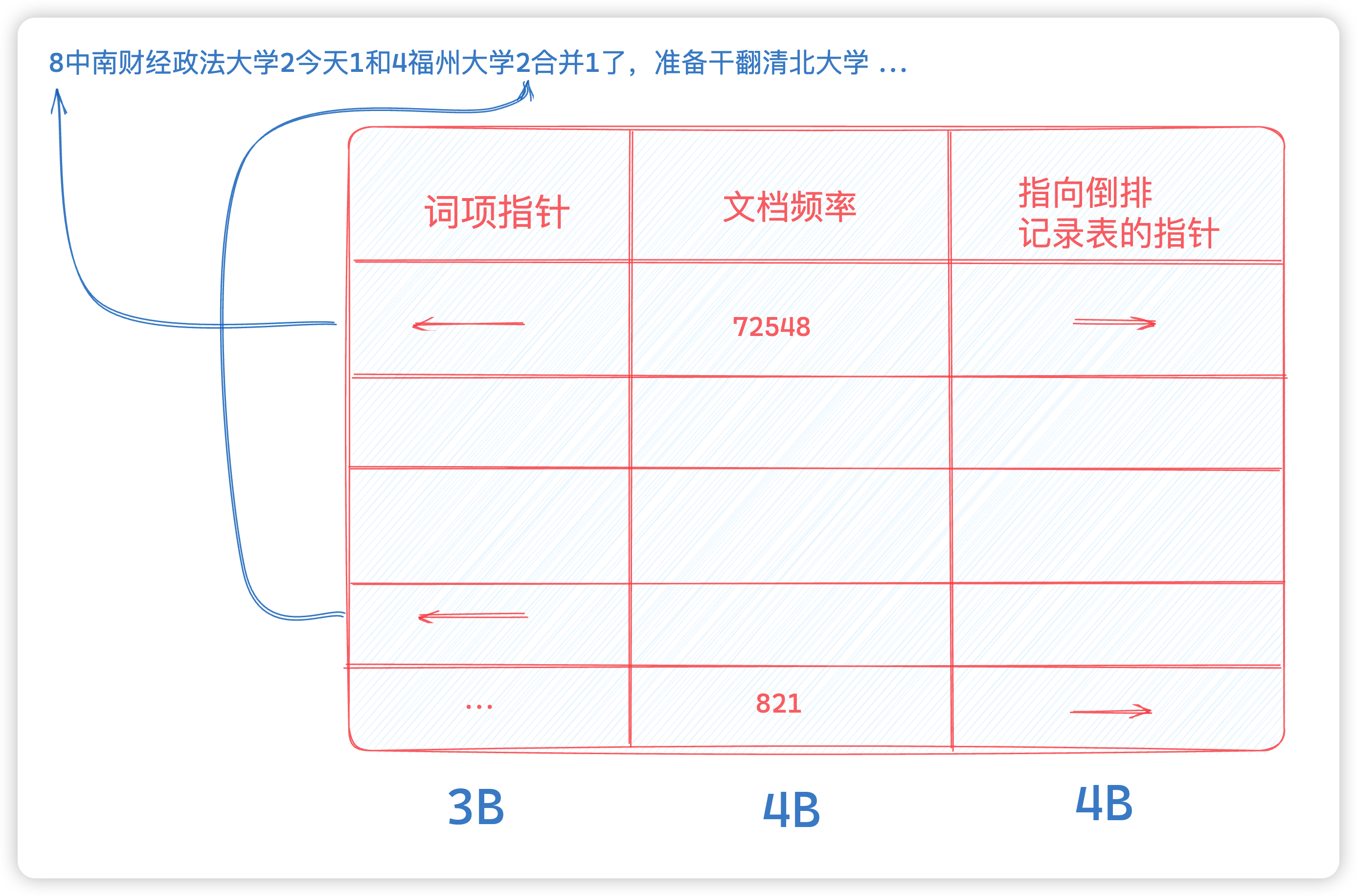
【Golang系统开发】搜索引擎(2) 压缩词典
写在前面 这篇文章我们就给出一系列的数据结构,使得词典能达到越来越高的压缩比。当然,和倒排索引记录表的大小相比,词典只占据了非常小的空间。那么为什么要对词典进行压缩呢? 这是因为决定信息检索系统的查询响应时间的一个重…...

Flask RESTful 示例
目录 1. 环境准备2. 安装依赖3. 修改main.py4. 运行应用5. API使用示例获取所有任务获取单个任务创建新任务更新任务删除任务 中文乱码问题: 下面创建一个简单的Flask RESTful API示例。首先,我们需要创建环境,安装必要的依赖,然后…...
:OpenBCI_GUI:从环境搭建到数据可视化(下))
脑机新手指南(八):OpenBCI_GUI:从环境搭建到数据可视化(下)
一、数据处理与分析实战 (一)实时滤波与参数调整 基础滤波操作 60Hz 工频滤波:勾选界面右侧 “60Hz” 复选框,可有效抑制电网干扰(适用于北美地区,欧洲用户可调整为 50Hz)。 平滑处理&…...

【Java学习笔记】Arrays类
Arrays 类 1. 导入包:import java.util.Arrays 2. 常用方法一览表 方法描述Arrays.toString()返回数组的字符串形式Arrays.sort()排序(自然排序和定制排序)Arrays.binarySearch()通过二分搜索法进行查找(前提:数组是…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

Unit 1 深度强化学习简介
Deep RL Course ——Unit 1 Introduction 从理论和实践层面深入学习深度强化学习。学会使用知名的深度强化学习库,例如 Stable Baselines3、RL Baselines3 Zoo、Sample Factory 和 CleanRL。在独特的环境中训练智能体,比如 SnowballFight、Huggy the Do…...

成都鼎讯硬核科技!雷达目标与干扰模拟器,以卓越性能制胜电磁频谱战
在现代战争中,电磁频谱已成为继陆、海、空、天之后的 “第五维战场”,雷达作为电磁频谱领域的关键装备,其干扰与抗干扰能力的较量,直接影响着战争的胜负走向。由成都鼎讯科技匠心打造的雷达目标与干扰模拟器,凭借数字射…...

(转)什么是DockerCompose?它有什么作用?
一、什么是DockerCompose? DockerCompose可以基于Compose文件帮我们快速的部署分布式应用,而无需手动一个个创建和运行容器。 Compose文件是一个文本文件,通过指令定义集群中的每个容器如何运行。 DockerCompose就是把DockerFile转换成指令去运行。 …...

在WSL2的Ubuntu镜像中安装Docker
Docker官网链接: https://docs.docker.com/engine/install/ubuntu/ 1、运行以下命令卸载所有冲突的软件包: for pkg in docker.io docker-doc docker-compose docker-compose-v2 podman-docker containerd runc; do sudo apt-get remove $pkg; done2、设置Docker…...

Redis数据倾斜问题解决
Redis 数据倾斜问题解析与解决方案 什么是 Redis 数据倾斜 Redis 数据倾斜指的是在 Redis 集群中,部分节点存储的数据量或访问量远高于其他节点,导致这些节点负载过高,影响整体性能。 数据倾斜的主要表现 部分节点内存使用率远高于其他节…...