机器学习分类,损失函数中为什么要用Log,机器学习的应用
目录
损失函数中为什么要用Log
为什么对数可以将乘法转化为加法?
机器学习(Machine Learning)
机器学习的分类
监督学习
无监督学习
强化学习
机器学习的应用
应用举例:猫狗分类
1. 现实问题抽象为数学问题
2. 数据准备
3. 选择模型
4. 模型训练及评估
5.预测结果
推荐阅读
损失函数中为什么要用Log
Loss 在使用似然函数最大化时,其形式是进行连乘,但是为了便于处理,一般会套上log,这样便可以将连乘转化为求和,求和形式更容易求偏导,应用到梯度下降中求最优解;
由于log函数是单调递增函数,因此不会改变优化结果。
极大似然估计中取对数的原因:取对数后,连乘可以转化为相加,方便求导,这是因为对数函数的求导更加简单,对数函数的导数比原函数更容易计算和优化;除此之外对数函数 ln为单调递增函数,不会改变似然函数极值点。
为什么对数可以将乘法转化为加法?
log2(x*y) = log2(y) + log2(y)
1, 2 ,3 ,4,5, 6······
和指数序列
2^(1), 2^(2) ,2^(3) ,2^(4),2^(5), 2^(6)······
,可以看出上一序列是下一序列的指数部分。那么我们如果想计算2*8 = (2^(1))*(2^(3))就可以将指数部分先加起来,即1+3=4,然后找第二个序列进行对应,就得到了2^(4)=16。这就是对数里的思想啦。
机器学习(Machine Learning)
基本思路是模仿人类学习的过程,例如人们一般通过经验归纳,总结规律,从而预测未来。
机器学习本质上就是让计算机自己在数据中学习规律,并根据所得到的规律对未来数据进行预测。
比如,不需要通过编程来识别猫或狗,机器学习可以通过使用图片来进行训练,从而归纳和识别特定的目标。
机器学习算法包括如聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning)等。
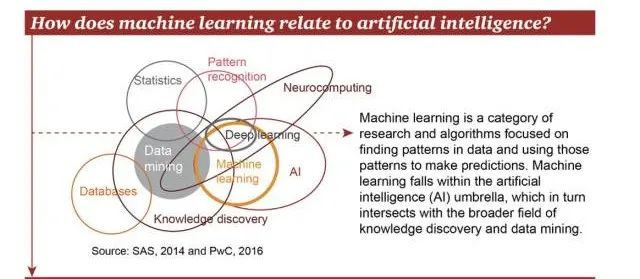
机器学习的分类
机器学习经过几十年的发展,衍生出了很多种分类方法,这里按学习模式的不同,可分为
- 监督学习
- 半监督学习
- 无监督学习
- 强化学习。
为了便于理解,用灰色圆点代表没有标签的数据,其他颜色的圆点代表不同的类别有标签数据。监督学习、无监督学习、强化学习的示意图如下所示:
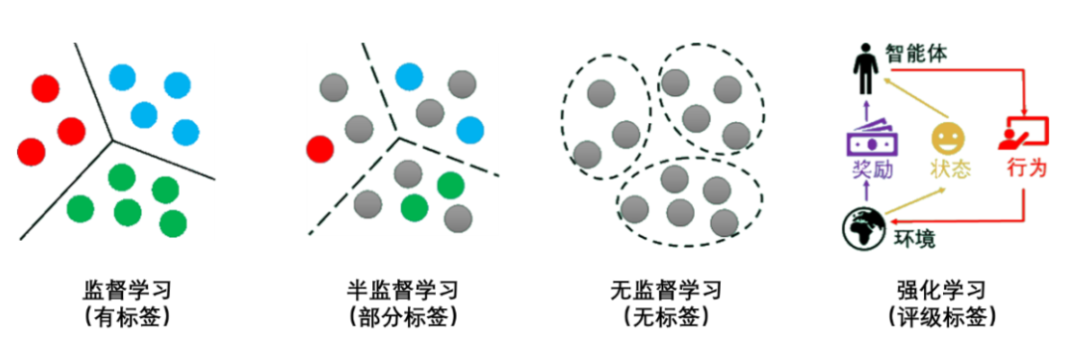
监督学习
监督学习(Supervised Learning)是从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。如果分类标签精确度越高,则学习模型准确度越高,预测结果越精确。
监督学习主要用于回归和分类问题。
常见的监督学习的回归算法有:线性回归、回归树、K邻近、Adaboost、神经网络等。
常见的监督学习的分类算法有:朴素贝叶斯、决策树、SVM、逻辑回归、K邻近、Adaboost、神经网络等。
无监督学习
无监督学习(Unsupervised Learning)是从未标注数据中寻找隐含结构的过程。其中,
自监督学习(Self-Supervised Learning)方法在最近的学术界和工业界几年备受关注。
无监督学习主要用于关联分析、聚类和降维。
常见的无监督学习算法有:稀疏自编码(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等。
“如果人工智能是一块蛋糕,强化学习好比蛋糕上的樱桃,监督学习好比蛋糕上的糖衣,而蛋糕本身是非监督学习。—— Yann Lecun
”
LeCun 的蛋糕强调了无监督的重要性,他认为这可以突破当前 AI 技术的局限性。今天的 AI 可以轻松对图像进行分类并识别声音,但不能执行诸如推理不同对象之间的关系或预测人类运动等任务。这是无监督学习可以填补空白的地方。
强化学习
强化学习(Reinforcement Learning)类似于监督学习,但未使用样本数据进行训练,而是通过智能体(Agnet)与环境(Environment)的交互,在不断试错中进行学习的模式。
在监督学习和非监督学习中,数据是静态的、不需要与环境进行交互,比如猫狗识别,只要给出足够的差异样本,将数据输入神经网络中进行训练即可。
然而,强化学习的学习过程是动态的、不断交互的过程,所需要的数据也是通过与环境不断交互所产生的。
所以,与监督学习和非监督学习相比,强化学习涉及的对象更多,比如动作、环境、状态转移概率和回报函数等。
强化学习常用于机器人避障、棋牌类游戏(AlphaGo)、广告和推荐等应用场景中,解决的是决策问题。
机器学习的应用
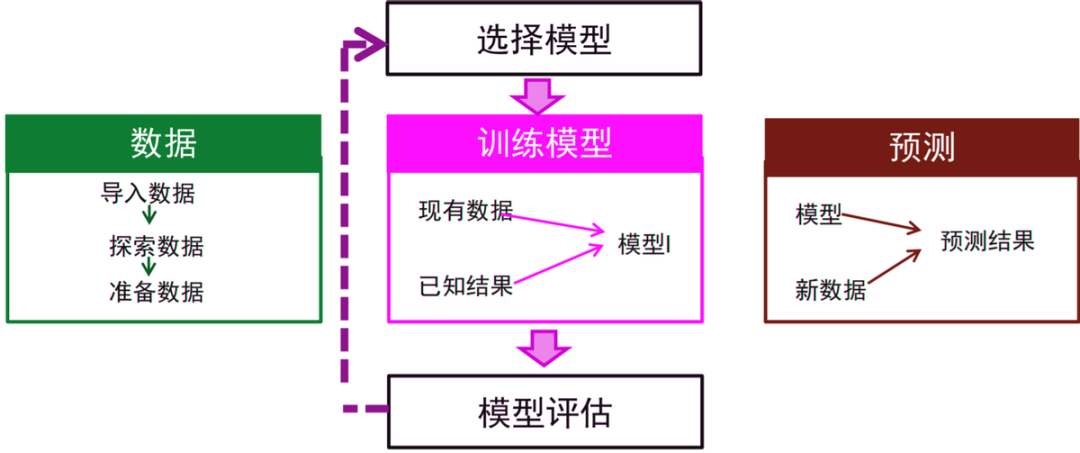
机器学习是将现实中的问题抽象为数学模型,利用历史数据对数据模型进行训练,然后基于数据模型对新数据进行求解,并将结果再转为现实问题的答案的过程。
机器学习一般的应用实现步骤如下:
-
将现实问题抽象为数学问题;
-
数据准备;
-
选择或创建模型;
-
模型训练及评估;
-
预测结果。
应用举例:猫狗分类
这里我们以Kaggle上的一个竞赛Cats vs. Dogs(猫狗大战)来举例,感兴趣的同学可亲自动手实验。

1. 现实问题抽象为数学问题
现实问题:给定一张图片,让计算机判断是猫还是狗?
数学问题:二分类问题,1表示分类结果是狗,0表示分类结果是猫。
2. 数据准备
数据下载地址:
https://www.kaggle.com/c/dogs-vs-cats。
下载 kaggle 猫狗数据集解压后分为 3 个文件 train.zip、 test.zip 和 sample_submission.csv。
训练集 train.zip,包含25000张已标记的图片文件,文件名格式为“类别.图片id.jpg”,类别为cat或dog,图片id为数字,如cat.0.jpg、dog.12247.jpg。训练集数据中标记为猫、狗的图片分别有12500张,比例1:1。
测试集 test.zip,包含12500张未标记的图片文件,文件名格式为“图片id.jpg”,图片id为数字,如1.jpg、11605.jpg。
数据集中图片尺寸大小不一,但在训练和测试时需要统一尺寸。数据中图像不一定完整包含完整猫或狗的身体,有的主体在图片中很小,图片背景复杂,图片里会出现人或其他物体,如左图1。另外,训练集中包含少量非猫或狗的图片,如右图2,这些异常数据大约占训练集的5.6 ‱,需要被清理掉。
这些异常图片文件名如下:cat.4688.jpg,cat.5418.jpg,cat.7377.jpg,cat.7564.jpg,cat.8100.jpg,cat.8456.jpg,cat.10029.jpg,cat.12272.jpg,dog.1259.jpg,dog.1895.jpg,dog.4367.jpg,dog.8736.jpg,dog.9517.jpg,dog.10190.jpg,dog.11299.jpg。

复杂背景

异常数据
-
sample_submission.csv 需要将最终测试集的测试结果写入.csv 文件中。
后续的实验中,我们将数据分成3个部分:训练集(60%)、验证集(20%)、测试集(20%),用于后面的验证和评估工作。一般三者切分的比例是:6:2:2,不过验证集并不是必须的,没有也是可以的。

训练集、验证集、测试集作用这里说明一下:
-
训练集用来调试神经网络
-
验证集用来查看训练效果
-
测试集用来测试网络的实际学习能力
训练集(train)毋庸置疑,是用于模型拟合的数据样本,用来调试网络中的参数。我们容易混淆的是验证集和测试集:验证集没有参与网络参数更新的工作,按理说也能用来测试网络的实际学习能力;测试集本来也能就是用来测试效果的,按理来说也能查看训练效果。
我们换个说法或者详细一些可能就会明白了:
验证集(validation): 查看模型训练的效果是否朝着坏的方向进行。验证集的作用是体现在训练的过程。举个栗子:通过查看训练集和验证集的损失值随着epoch的变化关系可以看出模型是否过拟合,如果是可以及时停止训练,然后根据情况调整模型结构和超参数,大大节省时间。
测试集(test): 用来评估模最终模型的泛化能力。但不能作为调参、选择特征等算法相关的选择的依据。测试集的作用是体现在测试的过程。
一个形象的比喻:
-
训练集:学生的课本;学生根据课本里的内容来掌握知识。训练集直接参与了模型调参的过程,显然不能用来反映模型真实的能力(防止课本死记硬背的学生拥有最好的成绩,即防止过拟合)。
-
验证集:作业;通过作业可以知道不同学生学习情况、进步的速度快慢。验证集参与了人工调参(超参数)的过程,也不能用来最终评判一个模型(刷题库的学生不能算是学习好的学生)。
-
测试集:考试;考的题是平常都没有见过,考察学生举一反三的能力。所以要通过最终的考试(测试集)来考察一个学(模)生(型)真正的能力(期末考试)。
对原始数据进行三个数据集的划分,也是为了防止模型过拟合。当使用了所有的原始数据去训练模型,得到的结果很可能是该模型最大程度地拟合了原始训练数据。当新的样本出现,再使用该模型进行预测,效果可能还不如只使用一部分数据训练的模型。
import cv2
import os
import numpy as npimport random
import timeimport pickledata_dir = './data' # 解压后数据start_time = time.time()print("正在制作数据....")# 图片统一大小100*100
# 训练集 20000张
# 测试集 剩下的所有,测试集从训练集中进行切分,因为测试集没有标签all_data_files = os.listdir(os.path.join(data_dir, "train/"))random.shuffle(all_data_files) # 打乱文件顺序all_train_files = all_data_files[:20000] # 前20000个图片用来训练
all_test_files = all_data_files[20000:] # 后5000个图片用来测试train_images = [] # 存储图片对应的narry数组的
train_labels = [] # 存储图片对应标签
train_files = [] # 存储对应图片名test_images = []
test_labels = []
test_files = []for each in all_train_files:img = cv2.imread(os.path.join(data_dir, "train", each), 1)# print(img.shape) # 每张图片的大小不一致,需要转换成统一大小resized_img = cv2.resize(img, (100, 100))img_data = np.array(resized_img) # 统一转换成narray数组类型,因为tensorflow支持narraytrain_images.append(img_data)if 'cat' in each:train_labels.append(0) # 0表示猫elif 'dog' in each:train_labels.append(1) # 1表示狗else:raise Exception("\n%s is a wrong train file" % (each))train_files.append(each)for each in all_test_files:img = cv2.imread(os.path.join(data_dir, "train", each), 1)# print(img.shape) # 每张图片的大小不一致,需要转换成统一大小resized_img = cv2.resize(img, (100, 100))img_data = np.array(resized_img) # 统一转换成narray数组类型,因为tensorflow支持narraytest_images.append(img_data)if 'cat' in each:test_labels.append(0) # 0表示猫elif 'dog' in each:test_labels.append(1) # 1表示狗else:raise Exception("\n%s is a wrong test file" % (each))test_files.append(each)# print(len(train_images), len(test_images))train_data = {'images': train_images,'labels': train_labels,'files': train_files
}test_data = {'images': test_images,'labels': test_labels,'files': test_files
}with open(os.path.join(data_dir,"train-data"),'wb') as f:pickle.dump(train_data,f)with open(os.path.join(data_dir,'test-data'),'wb') as f:pickle.dump(test_data,f)end_time = time.time()print('制作结束,用时{}秒.'.format(end_time-start_time))
3. 选择模型
机器学习有很多模型,需要选择哪种模型,需要根据数据类型,样本数量,问题本身综合考虑。
如本问题主要是处理图像数据,可以考虑使用卷积神经网络(Convolutional Neural Network, CNN)模型来实现二分类,因为选择CNN的优点之一在于避免了对图像前期预处理过程(提取特征等)。
猫狗识别的卷积神经网络结构如下图所示:
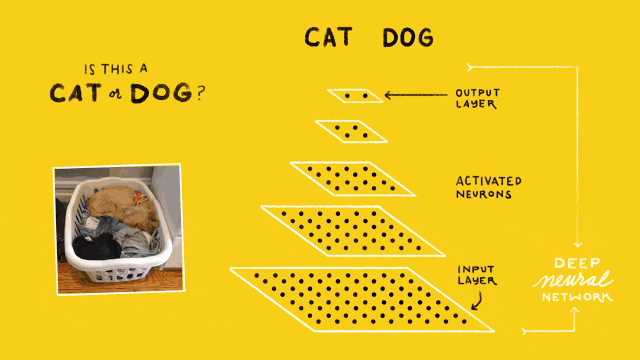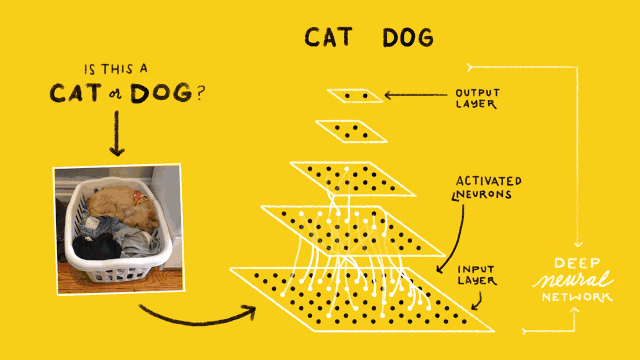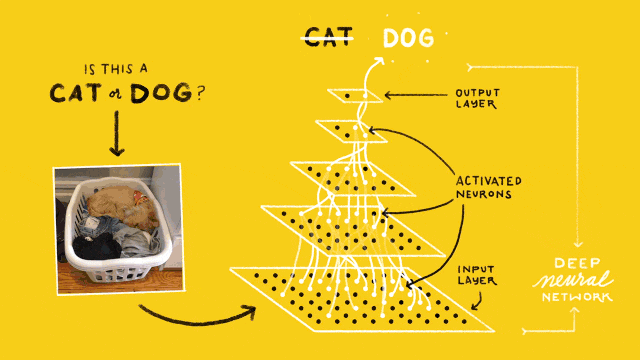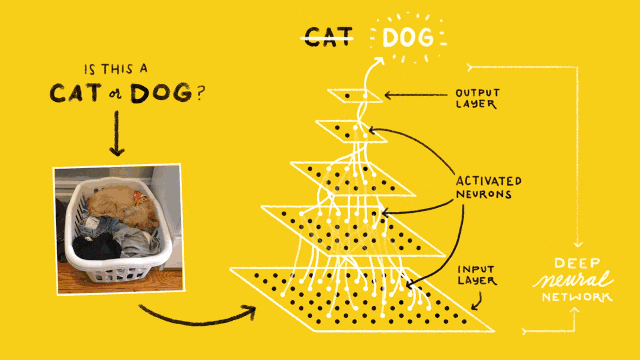
最下层是网络的输入层(Input Layer),用于读入图像作为网络的数据输入;最上层是网络的输出层(Output Layer),其作用是预测并输出读入图像的类别,由于只需要区分猫和狗,因此输出层只有2个神经计算单元;位于输入和输出层之间的,都称之为隐含层(Hidden Layer),也叫卷积层(Convolutional Layer),图示中包含3个隐含层。
4. 模型训练及评估
我们需要预先设定损失函数Loss计算得到的损失值,这里选择对数损失函数(Log Loss)作为模型评价指标。
对数损失函数(Log Loss)亦被称为逻辑回归损失(Logistic regression loss)或交叉熵损失(Cross-entropy loss),刻画的是两个概率分布之间的距离,是分类问题中使用广泛的一种损失函数。交叉熵损失越小,代表模型的性能越好。
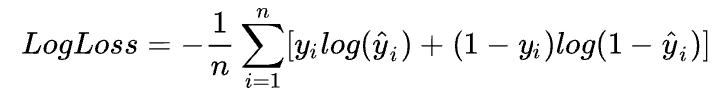
-
n是测试集中图片数量;
-
y尖 是图片预测为狗的概率;
-
如果图像是狗,则为1,如果是猫,则为0;
-
loge 是自然常数 为底的自然对数。
我们用准确率(Accuracy)来衡量算法预测结果的准确程度:
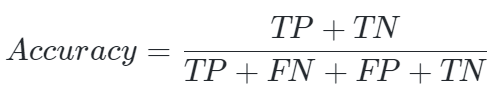
-
TP(True Positive)是将正类预测为正类的结果数目;
-
FP(False Positive)是将负类预测为正类的结果数目;
-
TN(True Negative)是将负类预测为负类的结果数目;
-
FN(False Negative)是将正类预测为负类的结果数目。
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Dropout, Convolution2D, MaxPool2D, Flatten
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.utils import to_categorical
import pickle
import numpy as npdef load_data(filename):with open(filename, 'rb') as f:data = pickle.load(f, encoding='utf-8')return np.array(data['images']), to_categorical(np.array(data['labels']), num_classes=2), np.array(data['files'])TRAIN_DIR = "data/train-data"train_images, train_labels, train_files = load_data(TRAIN_DIR)model = Sequential([Convolution2D(16, kernel_size=(3, 3), strides=(1, 1), padding="same", input_shape=(100, 100, 3), activation='relu'),# 100*100*96MaxPool2D((2, 2), strides=(2, 2), padding='same'), # 50*50*96Convolution2D(32, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'), # 50*50*192MaxPool2D((2, 2), strides=(2, 2), padding='same'), # 25*25*192Convolution2D(64, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'), # 25*25*384MaxPool2D((2, 2), strides=(2, 2), padding='same'), #Convolution2D(128, kernel_size=(3, 3), strides=(1, 1), padding='same', activation='relu'),MaxPool2D((2, 2), strides=(2, 2), padding='same'),Flatten(),Dense(512, activation='relu'),Dropout(0.3),Dense(256, activation='relu'),Dropout(0.3),Dense(2)
])
# 模型编译
model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy'])
# 模型训练
model.fit(train_images, train_labels, batch_size=200, epochs=10)
# 训练完保存模型
model.save("cat_and_dog.h5") # hdf5文件 pip intall h5py

训练过中的 loss 和 accuracy,使用GPU训练速度会更快,i5 CPU也是可以跑的,增加训练轮次,准确率会更高
5.预测结果
训练好的模型,我们可以看看模型的识别效果:
from tensorflow.keras.models import load_model
from tensorflow.keras.utils import to_categorical
import pickle
import numpy as npdef load_data(filename):with open(filename, 'rb') as f:data = pickle.load(f, encoding='utf-8')return np.array(data['images']), to_categorical(np.array(data['labels']), num_classes=2), np.array(data['files'])TEST_DIR = "data/test-data" test_image, test_labels, test_files = load_data(TEST_DIR)model = load_model("cat_and_dog.h5") # 同时加载结构和参数# 模型评估loss, accuracy = model.evaluate(test_image, test_labels)
print("test loss", loss)
print("test accuracy", accuracy)

至此,我们就完成了一个简单的机器学习二分类任务。重在明白流程,细节我们都会在日后的文章中慢慢说清楚。
推荐阅读
-
一份最有效的小白学AI路线图
-
AI常用编程工具介绍与安装
-
XGBoost详解
-
通俗易懂详解注意力机制
-
关于Attention的总结
相关文章:
机器学习分类,损失函数中为什么要用Log,机器学习的应用
目录 损失函数中为什么要用Log 为什么对数可以将乘法转化为加法? 机器学习(Machine Learning) 机器学习的分类 监督学习 无监督学习 强化学习 机器学习的应用 应用举例:猫狗分类 1. 现实问题抽象为数学问题 2. 数据准备…...
PySpark安装及WordCount实现(基于Ubuntu)
先盘点一下要安装哪些东西: VMwareubuntu 14.04(64位)Java环境(JDK 1.8)Hadoop 2.7.1Spark 2.4.0(Local模式)Pycharm (一)Ubuntu VMware 和 ubuntu 14.04(…...
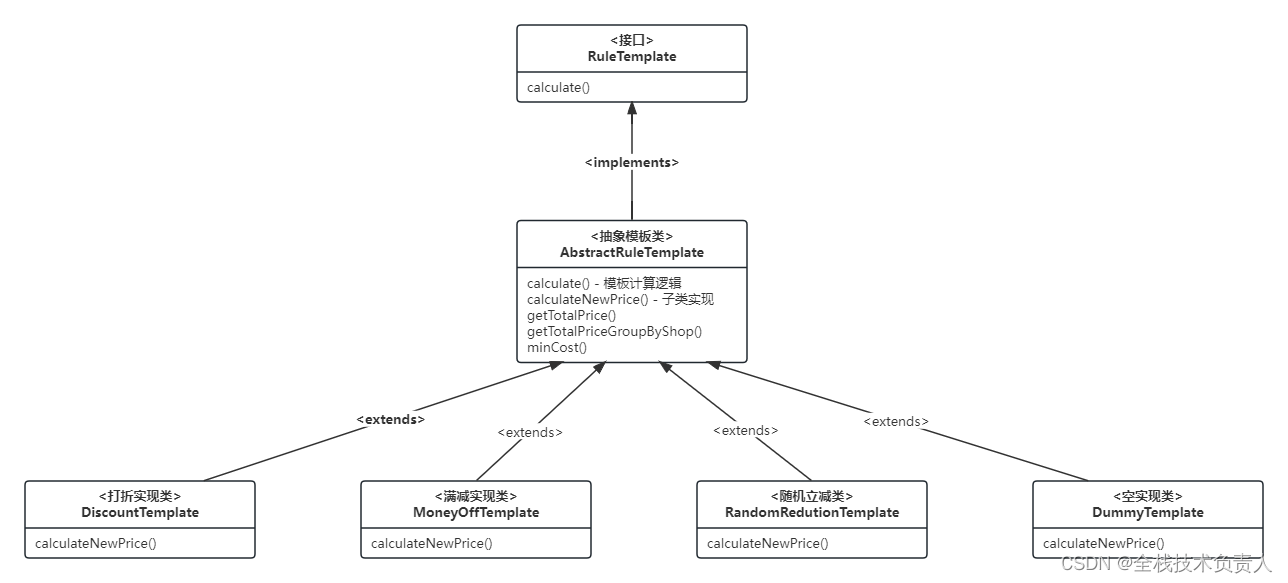
SpringBoot 模板模式实现优惠券逻辑
一、计算逻辑的类结构图 在这张图里,顶层接口 RuleTemplate 定义了 calculate 方法,抽象模板类 AbstractRuleTemplate 将通用的模板计算逻辑在 calculate 方法中实现,同时它还定义了一个抽象方法 calculateNewPrice 作为子类的扩展点。各个具…...
并查集 rank 的优化(Java 实例代码)
目录 并查集 rank 的优化 Java 实例代码 UnionFind3.java 文件代码: 并查集 rank 的优化 上一小节介绍了并查集基于 size 的优化,但是某些场景下,也会存在某些问题,如下图所示,操作 union(4,2)。 根据上一小节&…...

TDA4超级玩家浮出水面,行泊一体功能、成本刷到极致
2023年以来,智能驾驶市场进入L2普及、高阶ADAS功能(NOA)大规模量产的新周期,降本增效,打造极致性价比、提升用户体验等,成为了竞争的焦点。 其中,替换更具性价比的硬件平台、传感器复用、系统优…...

3分钟了解Android中稳定性测试
一、什么是Monkey Monkey在英文里的含义是猴子,在测试行业的学名叫“猴子测试”,指的是没有测试经验的人甚至是根本不懂计算机的人(就像一只猴子),不需要知道程序的任何用户交互方面的知识,给他一个程序&a…...
LVS-DR+keepalived实现高可用负载群集
VRRP 通信原理: VRRP就是虚拟路由冗余协议,它的出现就是为了解决静态路由的单点故障。 VRRP是通过一种竞选的一种协议机制,来将路由交给某台VRRP路由。 VRRP用IP多播的方式(多播地址224.0.0.18)来实现高可用的通信&…...

阿里云国际版注册教程
什么是阿里云国际版? 阿里云国际版是阿里云专为海外客户供给的服务器及核算资源,涵盖了云主机、弹性裸金属服务器、容器服务、数据库及安全和监控等一系列云核算解决方案。 与其他云核算服务供给商不同,阿里云国际版在安全性、稳定性、性能方…...

基于百度文心大模型创作的实践与谈论
文心概念 百度文心大模型源于产业、服务于产业,是产业级知识增强大模型。百度通过大模型与国产深度学习框架融合发展,打造了自主创新的AI底座,大幅降低了AI开发和应用的门槛,满足真实场景中的应用需求,真正发挥大模型…...
)
Java基础知识题(五)
系列文章目录 Java基础知识题(一) Java基础知识题(二) Java基础知识题(三) Java基础知识题(四) Java基础知识题(五) 文章目录 系列文章目录 前言 一 Java的数据连接——JDBC 1. 简述什么是JDBC?重点 2. JDBC PreparedStatement比Statement有什么优势&…...

攻防世界-fileinclude
原题 解题思路 题目已经告诉了,flag在flag.php中,先查看网页源代码(快捷键CTRLU)。 通过抓包修改,可以把lan变量赋值flag。在cookie处修改。新打开的网页没有cookie,直接添加“Cookie: languagephp://filte…...
流媒体服务器SRS的搭建及QT下RTMP推流客户端的编写
一、前言 目前市面上有很多开源的流媒体服务器解决方案,常见的有SRS、EasyDarwin、ZLMediaKit和Monibuca。这几种的对比如下: (本图来源:https://www.ngui.cc/zz/1781086.html?actiononClick) 二、SRS的介绍 SRS&am…...
)
Effective C++条款11——在operator=中处理“自我赋值”(构造/析构/赋值运算)
“自我赋值”发生在对象被赋值给自己时: class Widget {}; Widget w; // ... w w; // 赋值给自己 这看起来有点愚蠢,但它合法,所以不要认定客户绝不会那么做。此外赋值动作并不总是那么可被一眼辨识出来,例如: a[i] a[j]; …...
-气泡图(一))
可视化绘图技巧100篇基础篇(八)-气泡图(一)
目录 前言 适用场景 图例 绘图工具及代码实现 EXCEL 1、单轴气泡图...

Elasticsearch查询之Disjunction Max Query
前言 Disjunction Max Query 又称最佳 best_fields 匹配策略,用来优化当查询关键词出现在多个字段中,以单个字段的最大评分作为文档的最终评分,从而使得匹配结果更加合理 写入数据 如下的两条例子数据: docId: 1 title: java …...
Lock wait timeout exceeded; try restarting transaction的错误
文章目录 一、异常发现二、异常定位1、锁表语句确认2、实际场景排查三、解决思路1、本次解决方式2、其他场景解决思路扩展1、【治标方法】innodb_lock_wait_timeout 锁定等待时间改大2、【治标方法】事务信息查询3、【治标方法】如果杀掉线程依然不能解决,可以查找执行线程耗时…...

ShardingSphere01-docker环境安装
使用docker安装数据库是一个非常好的选择,后续的读写分离、数据分片等功能的数据库都是由docker创建。 一、安装准备 1、前提条件 Docker可以运行在Windows、Mac、CentOS、Ubuntu等操作系统上 Docker支持以下的CentOS版本: CentOS 7 (64-bit)CentOS …...
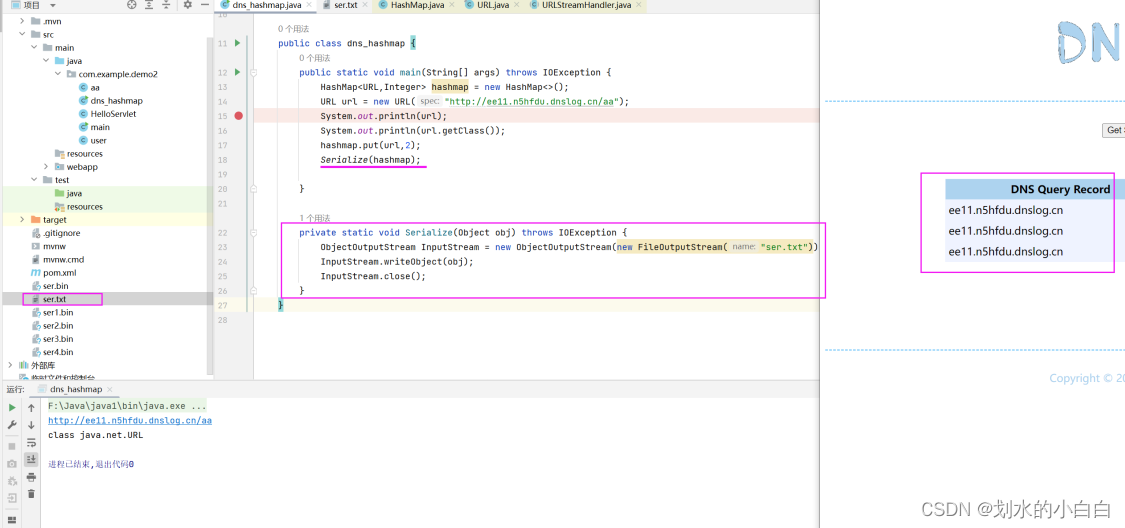
Java代码审计13之URLDNS链
文章目录 1、简介urldns链2、hashmap与url类的分析2.1、Hashmap类readObject方法的跟进2.2、URL类hashcode方法的跟进2.3、InetAddress类的getByName方法 3、整个链路的分析3.1、整理上述的思路3.2、一些疑问的测试3.3、hashmap的put方法分析3.4、反射3.5、整个代码 4、补充说明…...

区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测
区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测 目录 区间预测 | MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列区间预测效果一览基本介绍模型描述程序设计参考资料 效果一览 基本介绍 MATLAB实现QRBiGRU双向门控循环单元分位数回归时间序列…...

Python面向对象植物大战僵尸
先来一波效果图 来看看如何设计游戏架构 import sysimport pygameclass BaseSprite(pygame.sprite.Sprite):def __init__(self, name):super().__init__()self.image pygame.image.load(name)self.rect self.image.get_rect()class AnimateSprite(BaseSprite):def __init__(…...
)
Windows 11下Zotero 7与百度网盘的无缝同步配置(含软链接避坑技巧)
Windows 11下Zotero 7与百度网盘的高效同步方案 作为一名长期使用Zotero管理学术文献的研究者,我深刻理解文献同步的重要性。当Zotero 7发布后,许多用户发现原有的ZotFile插件不再兼容,这给依赖云同步的研究者带来了不小困扰。本文将分享我在…...

除了连电脑,你的联想小新蓝牙鼠标还能这么玩:一键切换Win10/iPad/手机
联想小新蓝牙鼠标的跨设备生产力革命:解锁Win10/iPad/手机的协同操控 当你的办公桌上同时摆放着Windows笔记本、iPad和安卓手机时,频繁切换键鼠设备会成为效率杀手。而联想小新蓝牙鼠标内置的多设备切换功能,正是为这种场景量身定制的解决方…...

基于电流模型与磁链估算的异步电动机高速矢量控制系统设计
基于电流模型转子磁链估算的异步电动机有速度传感器矢量控制系统异步电机矢量控制玩得溜不溜,关键就看磁链估算准不准。今天咱们来唠唠基于电流模型的转子磁链估算方案,这可是带速度传感器的经典玩法。别被专业名词吓到,说白了就是既要电流模…...

保姆级教程:用Fish-Speech-1.5为视频配音,支持中英日等13种语言
保姆级教程:用Fish-Speech-1.5为视频配音,支持中英日等13种语言 1. 为什么选择Fish-Speech-1.5为视频配音? 在视频制作过程中,配音往往是最耗时耗力的环节之一。传统配音需要专业录音设备、配音演员和后期处理,成本高…...

java进阶知识思维导图
...

【DiT视频生成技术】第一章:DiT基础架构与视频化扩展
第一章:DiT基础架构与视频化扩展 目录 第一章:DiT基础架构与视频化扩展 视频扩散模型的架构演进 位置编码机制 脚本实现 视频扩散模型的架构演进 在视频扩散模型的架构演进中,时空维度的联合建模构成了从图像生成向视频生成迁移的核心技术挑战。不同于图像数据的静态二…...

AntDesign栅格系统进阶:从Row/Col到Flex布局的实战迁移
1. 为什么需要从Row/Col迁移到Flex布局? AntDesign的24栏栅格系统(Row/Col)确实帮我们解决了很多布局问题,但最近在重构一个后台管理系统时,我遇到了几个头疼的场景:需要实现动态伸缩的侧边栏、不规则卡片瀑…...
用C++实现信奥题 P6093 [JSOI2015] 套娃)
打卡信奥刷题(2989)用C++实现信奥题 P6093 [JSOI2015] 套娃
P6093 [JSOI2015] 套娃 题目背景 刚从俄罗斯旅游回来的 JYY 买了很多很多好看的套娃作为纪念品!JYY 由于太过激动,把所有的套娃全部都打开了。而由于很多套娃长得过于相像,JYY 现在不知道该如何把它们装回去了(他实在搞不清&…...
)
时域信道估计和时域信道均衡以及matlab代码手搓(注意是时域,后续讲ofdm相关的频域信道估计和均衡)
时域信道估计与信号均衡笔记**约定**:共轭转置统一记为 \((\cdot)^{H}\),\(L\) 为信道多径个数(即信道冲激响应 \(h\) 的长度),\(N\) 为输入发送信号 \(x\) 的长度。原卷积输入输出模型: \[ y h \otimes x…...

【无人售货柜・RK+YOLO】篇 4:效果拉满!针对无人售货柜场景的 YOLO 模型优化技巧,解决 90% 的识别问题
目录 一、先搞懂:你的模型效果差,到底是哪里出了问题? 二、痛点一:相似商品误识别,90% 的商用项目都栽在这 1. 最高优先级:难例挖掘,让模型专门学容易认错的商品 2. 第二优先级:…...