PyTorch学习笔记(十六)——利用GPU训练
一、方式一
网络模型、损失函数、数据(包括输入、标注)
找到以上三种变量,调用它们的.cuda(),再返回即可
if torch.cuda.is_available():mynn = mynn.cuda()if torch.cuda.is_available():loss_function = loss_function.cuda()for data in train_dataloader:imgs,targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()for data in test_dataloader:imgs,targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()完整代码:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# from model import *# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../datasets",train=True,transform=torchvision.transforms.ToTensor(),download=False)
test_data = torchvision.datasets.CIFAR10(root="../datasets",train=False,transform=torchvision.transforms.ToTensor(),download=False)train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))# 利用dataloader来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)# 创建网络模型
class MyNN(nn.Module):def __init__(self):super(MyNN, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64 * 4 * 4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return x
mynn = MyNN()
if torch.cuda.is_available():mynn = mynn.cuda()# 损失函数
loss_function = nn.CrossEntropyLoss()
if torch.cuda.is_available():loss_function = loss_function.cuda()
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(mynn.parameters(), lr=learning_rate)# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练的轮数# 添加tensorboard
writer = SummaryWriter("../logs_train")start_time = time.time()
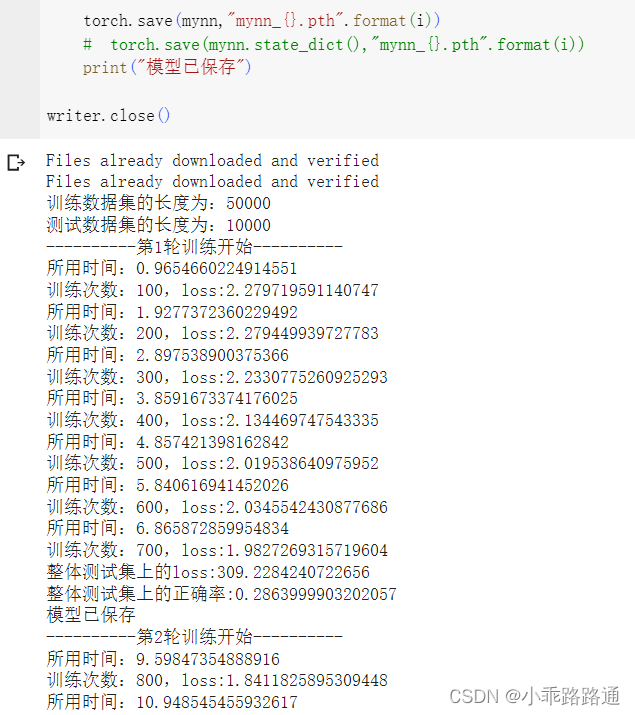
for i in range(epoch):print("----------第{}轮训练开始----------".format(i+1))# 训练步骤开始mynn.train()for data in train_dataloader:imgs,targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = mynn(imgs)loss = loss_function(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1if total_train_step % 100 == 0:end_time = time.time()print("所用时间:{}".format(end_time - start_time))print("训练次数:{},loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss",loss.item(),total_train_step)# 测试步骤开始mynn.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs,targets = dataif torch.cuda.is_available():imgs = imgs.cuda()targets = targets.cuda()outputs = mynn(imgs)loss = loss_function(outputs, targets)total_test_loss += lossaccuracy = (outputs.argmax(1) == targets).sum()total_accuracy += accuracyprint("整体测试集上的loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)total_test_step += 1torch.save(mynn,"mynn_{}.pth".format(i))# torch.save(mynn.state_dict(),"mynn_{}.pth".format(i))print("模型已保存")writer.close()比较CPU和GPU的训练时间:


查看GPU信息:
在 终端里输入nvidia-smi
使用Google Colab:Google 为我们提供了一个免费的GPU
修改 ——> 笔记本设置 ——> 硬件加速器选择GPU(每周免费使用30h)

二、方式二(更常用)
定义训练设备
device = torch.device("cpu")# 对于单显卡来说,以下两种方式没有区别
device = torch.device("cuda")
device = torch.device("cuda:0")# 一种语法的简写,程序在 CPU 或 GPU/cuda 环境下都能运行
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")网络模型、损失函数、数据(包括输入、标注)
找到以上三种变量,.to(device),再返回即可
mynn = MyNN()
mynn = mynn.to(device)
# 这里可以不用再赋值给mynn,直接mynn.to(device) 也可以loss_function = nn.CrossEntropyLoss()
loss_function = loss_function.to(device)
# 这里可以不用再赋值给loss_function ,直接loss_function .to(device) 也可以for data in train_dataloader:imgs,targets = dataimgs = imgs.to(device)targets = targets.to(device)# 这里必须赋值for data in test_dataloader:imgs,targets = dataimgs = imgs.to(device)targets = imgs.to(device)# 这里必须赋值完整代码:
import torch
import torchvision
from torch import nn
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import time
# from model import *# 定义训练的设备
# device = torch.device("cpu")
# device = torch.device("cuda")
# device = torch.device("cuda:0")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 准备数据集
train_data = torchvision.datasets.CIFAR10(root="../datasets",train=True,transform=torchvision.transforms.ToTensor(),download=False)
test_data = torchvision.datasets.CIFAR10(root="../datasets",train=False,transform=torchvision.transforms.ToTensor(),download=False)train_data_size = len(train_data)
test_data_size = len(test_data)
print("训练数据集的长度为:{}".format(train_data_size))
print("测试数据集的长度为:{}".format(test_data_size))# 利用dataloader来加载数据集
train_dataloader = DataLoader(train_data,batch_size=64)
test_dataloader = DataLoader(test_data,batch_size=64)# 创建网络模型
class MyNN(nn.Module):def __init__(self):super(MyNN, self).__init__()self.model = nn.Sequential(nn.Conv2d(3, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 32, 5, 1, 2),nn.MaxPool2d(2),nn.Conv2d(32, 64, 5, 1, 2),nn.MaxPool2d(2),nn.Flatten(),nn.Linear(64 * 4 * 4, 64),nn.Linear(64, 10))def forward(self, x):x = self.model(x)return x
mynn = MyNN()
mynn.to(device)# 损失函数
loss_function = nn.CrossEntropyLoss()
loss_function.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(mynn.parameters(), lr=learning_rate)# 设置训练网络的一些参数
total_train_step = 0 # 记录训练次数
total_test_step = 0 # 记录测试次数
epoch = 10 # 训练的轮数# 添加tensorboard
writer = SummaryWriter("../logs_train")start_time = time.time()
for i in range(epoch):print("----------第{}轮训练开始----------".format(i+1))# 训练步骤开始mynn.train()for data in train_dataloader:imgs,targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = mynn(imgs)loss = loss_function(outputs, targets)# 优化器优化模型optimizer.zero_grad()loss.backward()optimizer.step()total_train_step += 1if total_train_step % 100 == 0:end_time = time.time()print("所用时间:{}".format(end_time - start_time))print("训练次数:{},loss:{}".format(total_train_step, loss.item()))writer.add_scalar("train_loss",loss.item(),total_train_step)# 测试步骤开始mynn.eval()total_test_loss = 0total_accuracy = 0with torch.no_grad():for data in test_dataloader:imgs,targets = dataimgs = imgs.to(device)targets = targets.to(device)outputs = mynn(imgs)loss = loss_function(outputs, targets)total_test_loss += lossaccuracy = (outputs.argmax(1) == targets).sum()total_accuracy += accuracyprint("整体测试集上的loss:{}".format(total_test_loss))print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))writer.add_scalar("test_loss",total_test_loss,total_test_step)writer.add_scalar("test_accuracy",total_accuracy/test_data_size,total_test_step)total_test_step += 1torch.save(mynn,"mynn_{}.pth".format(i))# torch.save(mynn.state_dict(),"mynn_{}.pth".format(i))print("模型已保存")writer.close()相关文章:
PyTorch学习笔记(十六)——利用GPU训练
一、方式一 网络模型、损失函数、数据(包括输入、标注) 找到以上三种变量,调用它们的.cuda(),再返回即可 if torch.cuda.is_available():mynn mynn.cuda() if torch.cuda.is_available():loss_function loss_function.cuda(…...
【实战】十一、看板页面及任务组页面开发(三) —— React17+React Hook+TS4 最佳实践,仿 Jira 企业级项目(二十五)
文章目录 一、项目起航:项目初始化与配置二、React 与 Hook 应用:实现项目列表三、TS 应用:JS神助攻 - 强类型四、JWT、用户认证与异步请求五、CSS 其实很简单 - 用 CSS-in-JS 添加样式六、用户体验优化 - 加载中和错误状态处理七、Hook&…...

金额千位符自定义指令
自定义指令文件 moneyFormat.js /*** v-money 金额千分位转换*/export default {inserted: inputFormatter({// 格式化函数formatter(num, util) {if(num null || num || num undefined || typeof(num) undefined){return }if(util 万元 || util 万){return formatMone…...

请不要用 JSON 作为配置文件,使用JSON做配置文件的缺点
我最近关注到有的项目使用JSON作为配置文件。我觉得这不是个好主意。 这不是JSON的设计目的,因此也不是它擅长的。JSON旨在成为一种“轻量级数据交换格式”,并声称它“易于人类读写”和“易于机器解析和生成”。 作为一种数据交换格式,JSON是…...
Hadabot:从网络浏览器操作 ROS2 远程控制器
一、说明 Hadabot Hadabot是一个学习ROS2和机器人技术的机器人套件。使用 Hadabot,您将能够以最小的挫败感和恐吓来构建和编程物理 ROS2 机器人。Hadabot套件目前正在开发中。它将仅针对ROS2功能,并强调基于Web的用户界面。 随着开发的进展&a…...

Kotlin 协程
Kotlin 协程(Coroutines)是一种轻量级的并发编程解决方案,旨在简化异步操作和多线程编程。它提供了一种顺序和非阻塞的方式来处理并发任务,使得代码可以更加简洁和易于理解。Kotlin 协程通过提供一套高级 API,使并发代…...
maven 从官网下载指定版本
1. 进入官网下载页面 Maven – Download Apache Maven 点击下图所示链接 2. 进入文件页,选择需要的版本 3. 选binaries 4. 选文件,下载即可...

数据结构---串(赋值,求子串,比较,定位)
目录 一.初始化 顺序表中串的存储 串的链式存储 二.赋值操作:将str赋值给S 链式表 顺序表 三.复制操作:将chars复制到str中 链式表 顺序表 四.判空操作 链式表 顺序表 五.清空操作 六.串联结 链式表 顺序表 七.求子串 链式表 顺序表…...
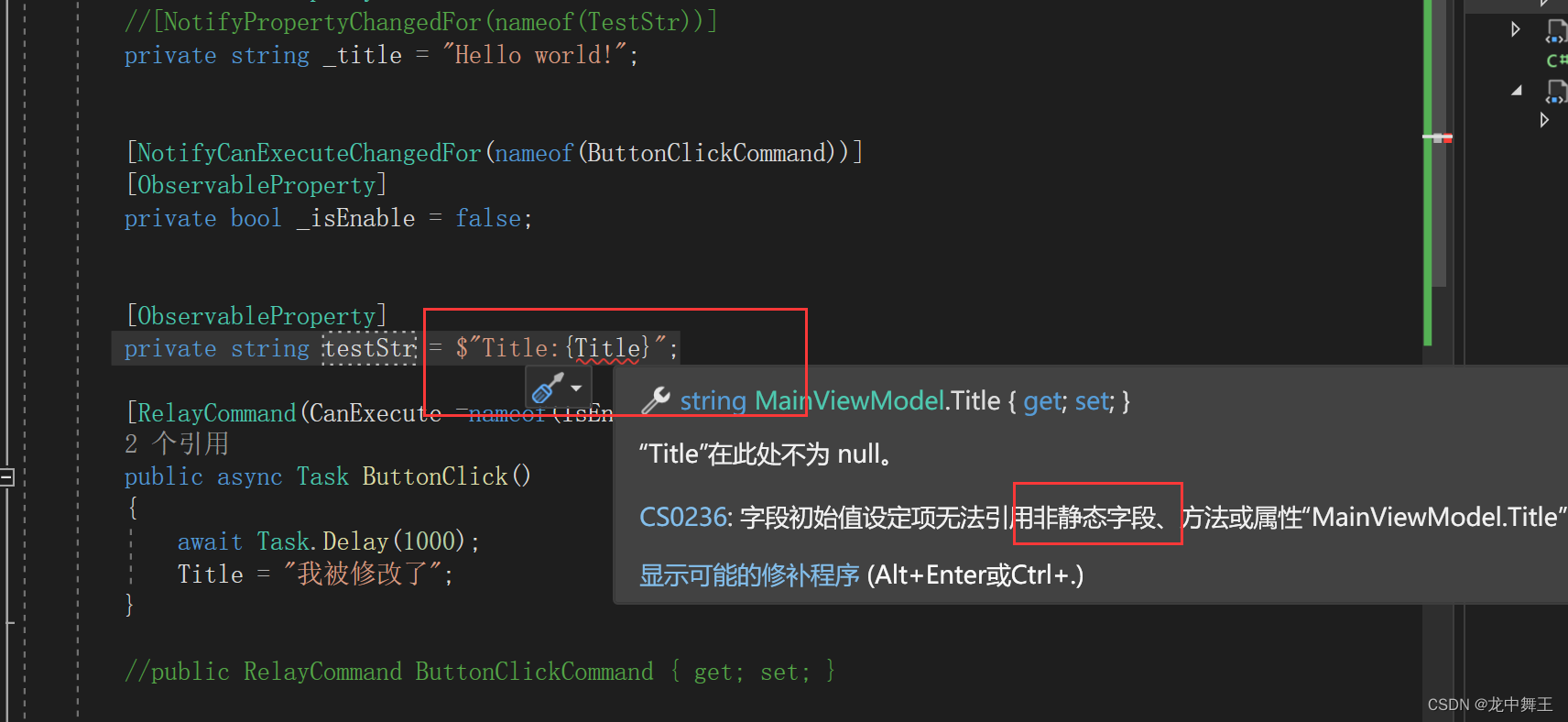
WPF CommunityToolkit.Mvvm
文章目录 前言ToolkitNuget安装简单使用SetProperty,通知更新RealyCommandCanExecute 新功能,代码生成器ObservablePropertyNotifyCanExecuteChangedForRelayCommand其他功能对应关系 NotifyPropertyChangedFor 前言 CommunityToolkit.Mvvm(…...

Vue开发中如何解决国际化语言切换问题
Vue开发中如何解决国际化语言切换问题 引言: 在如今的全球化时代,应用程序的国际化变得越来越重要。为了让不同地区的用户能够更好地使用应用程序,我们需要对内容进行本地化,以适应不同语言和文化环境。对于使用Vue进行开发的应用…...
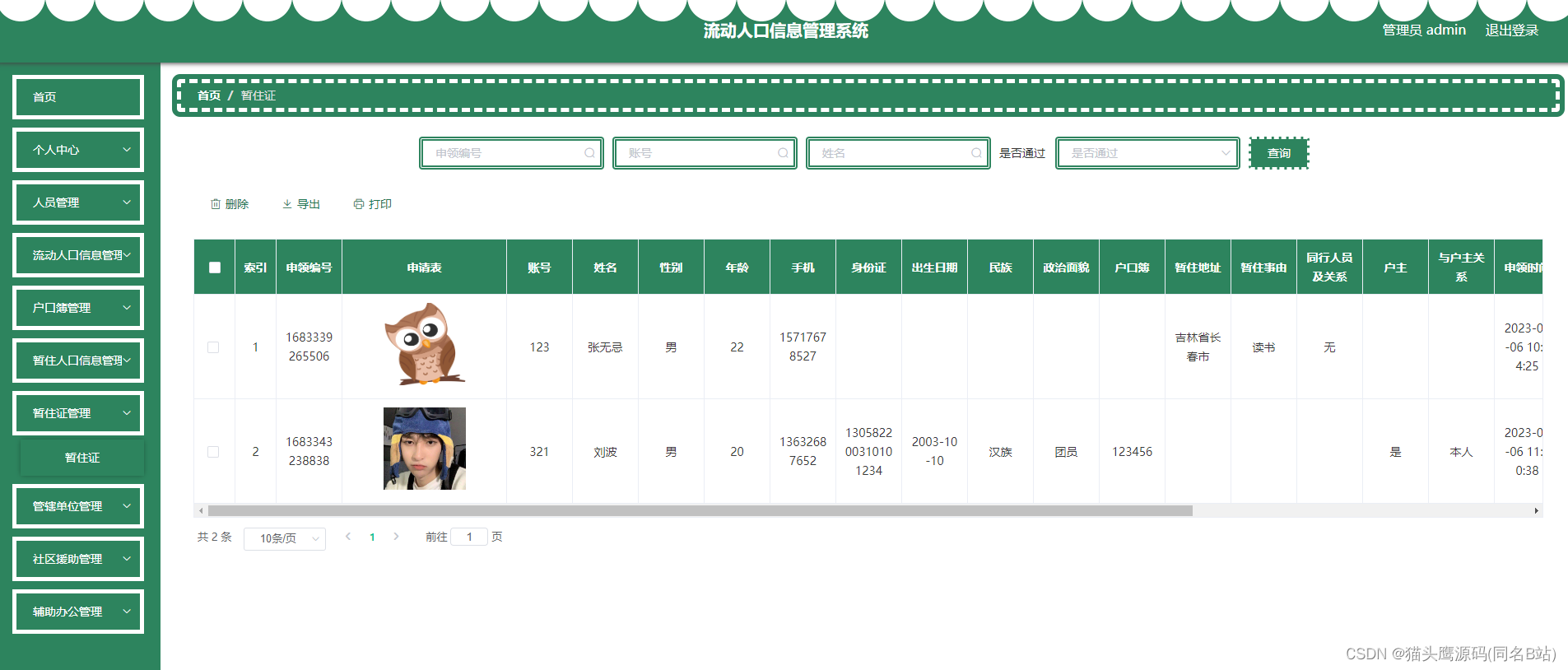
基于springboot+vue的流动人口登记系统(前后端分离)
博主主页:猫头鹰源码 博主简介:Java领域优质创作者、CSDN博客专家、公司架构师、全网粉丝5万、专注Java技术领域和毕业设计项目实战 主要内容:毕业设计(Javaweb项目|小程序等)、简历模板、学习资料、面试题库、技术咨询 文末联系获取 项目介绍…...

Stable Diffusion的使用以及各种资源
Stable Diffsuion资源目录 SD简述sd安装模型下载关键词,描述语句插件管理controlNet自己训练模型 SD简述 Stable Diffusion是2022年发布的深度学习文本到图像生成模型。它主要用于根据文本的描述产生详细图像,尽管它也可以应用于其他任务,如…...

Redis 分布式锁的实现方式
一般来说,在对数据进行“加锁”时,程序首先需要通过获取(acquire)锁来得到对数据排他性访问的能力,然后才能对数据执行一系列操作,最后还要将锁释放(release)给其他程序。 对于能够…...

VMware上搭建的虚拟机突然本地无法连接服务器
长时间没有使用VMware 虚拟机了,今天突然登录上去,启动虚拟服务器后发现本地等不了了, 经过排查发现是开启了:VirtualBox Host-Only Network 关闭之后就本机就可以直连服务器了...

JDBC回顾
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 JDBC回顾 前言一、JDBC1.JDBC是什么?2.如何使用?(1)注册驱动(2)获取连接(3)操作…...

mq 消息队列 mqtt emqx ActiveMQ RabbitMQ RocketMQ
省流: 十几年前,淘宝的notify,借鉴ActiveMQ。京东的ActiveMQ集群几百台,后面改成JMQ。 Linkedin的kafka,因为是scala,国内很多人不熟。淘宝的人把kafka用java写了一遍,取名metaq,后…...

沃尔玛卖家必看!解决订单被Kan、Feng号问题的终极方案!
近期有很多沃尔玛卖家和工作室联系到我提到说在沃尔玛平台上下单,买家号出现副款义常订单被k掉,是什么原因、我们该如何去解决呢? 以下是一些可能导至你的测评订单被k单的原因: 1.技术问题:有时,网站或系…...
浅谈日常使用的 Docker 底层原理-三大底座
适合的读者,对Docker有过简单了解的朋友,想要进一步了解Docker容器的朋友。 前言 回想我这两年,一直都是在使用 Docker,看过的视频、拜读过的博客,大都是在介绍 Docker 的由来、使用、优点和发展趋势,但对…...

前端面试:【DOM】编织网页的魔法
嘿,亲爱的代码魔法师!在JavaScript的奇幻世界里,有一项强大的技能,那就是DOM操作。DOM(文档对象模型)操作允许你选择、修改和创建网页元素,就像是在编织一个魔法的网页。 1. 什么是DOMÿ…...
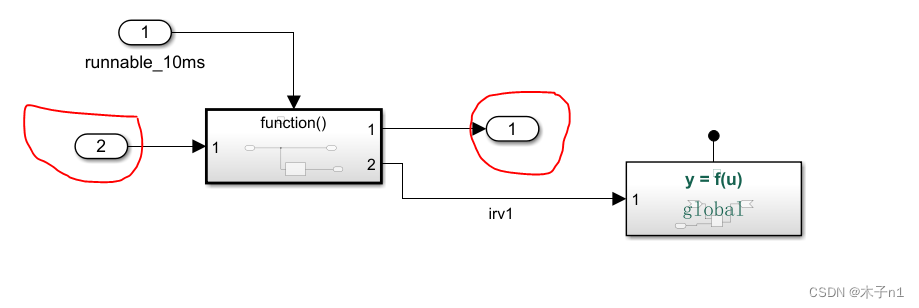
基于MATLAB开发AUTOSAR软件应用层Code mapping专题-part 2 Inport和Outports 标签页介绍
上篇我们介绍了Function页的内容,这篇我们介绍Inports和Outports页的内容,这里我们再次强调一个概念,code mapping是以simulink的角度去看的,就是先要在模型中建立simulink模块,在code mapping里映射他要对应的autosar的元素,之后生成代码时的c语言的名字是以Autosar的元…...

从Java转行大模型应用,Advanced-RAG 学习
一、RAG 进阶概述(Advanced-RAG)基础RAG(检索增强生成)核心是“检索生成”的两阶段流程,解决大模型“幻觉”和知识时效性问题,但在复杂场景(长文档、模糊查询、高精准需求)中存在检索…...
)
告别手动维护!用DataX-Web搞定MySQL到ClickHouse的增量同步(含时间戳配置)
高效构建MySQL到ClickHouse的增量同步管道:DataX-Web实战指南 在数据驱动的商业环境中,企业每天都会产生海量的业务数据。这些数据通常存储在OLTP系统如MySQL中,但为了进行分析和报表生成,我们需要将这些数据同步到OLTP系统如Clic…...

南北阁Nanbeige 4.1-3B Git版本控制实战:从入门到团队协作
南北阁Nanbeige 4.1-3B Git版本控制实战:从入门到团队协作 本文面向刚接触版本控制的开发者,手把手教你用南北阁Nanbeige 4.1-3B掌握Git核心技能,从基础命令到团队协作全流程。 1. 为什么你需要Git版本控制? 刚开始写代码时&…...

毕业季论文救星:深度解析百考通AI如何智能攻克文献综述与开题报告
又到一年毕业季,无数莘莘学子在为自己学术生涯的“终极答卷”——毕业论文而挑灯夜战。其中,文献综述的浩如烟海与开题报告的千头万绪,无疑是横亘在大多数同学面前的两座大山。你是否也曾面对海量文献不知如何筛选梳理?是否为构建…...

一键获取B站完整评论区数据:告别数据采集烦恼的终极方案
一键获取B站完整评论区数据:告别数据采集烦恼的终极方案 【免费下载链接】BilibiliCommentScraper 项目地址: https://gitcode.com/gh_mirrors/bi/BilibiliCommentScraper 还在为B站评论数据采集不完整而烦恼吗?想要批量获取视频评论区信息却无从…...
)
Drone流水线进阶玩法:用.drone.yml实现多阶段构建+钉钉通知(2023最新版)
Drone流水线进阶实战:多阶段构建与智能通知全链路设计 当你的团队从单体架构转向微服务时,CI/CD流水线会突然变得复杂起来。上周我接手的一个电商项目就遇到了典型问题:每次代码提交后需要同时处理Java后端的Maven构建、前端Node.js打包、Doc…...

bert-base-chinese详细步骤:如何将test.py改造成支持流式文本处理的微服务
bert-base-chinese详细步骤:如何将test.py改造成支持流式文本处理的微服务 1. 项目背景与价值 在实际的工业场景中,我们经常需要处理大量的文本数据流。传统的批处理方式虽然简单,但无法满足实时性要求高的应用场景。比如智能客服系统需要实…...

Qwen3-0.6B-FP8模型服务化:使用Git进行版本管理与CI/CD集成
Qwen3-0.6B-FP8模型服务化:使用Git进行版本管理与CI/CD集成 1. 引言 咱们做AI模型部署的,是不是经常遇到这种烦心事:好不容易把模型服务调通了,过两天想加点新功能,结果发现原来的配置参数、客户端代码、甚至API封装…...

从基础到卓越:Mac Mouse Fix的技术演进与用户价值提升之路
从基础到卓越:Mac Mouse Fix的技术演进与用户价值提升之路 【免费下载链接】mac-mouse-fix Mac Mouse Fix - A simple way to make your mouse better. 项目地址: https://gitcode.com/GitHub_Trending/ma/mac-mouse-fix 解决鼠标体验痛点:从功能…...
)
图解CV中的交叉注意力:用QKV三兄弟搞定图像特征增强(附PyTorch代码示例)
图解CV中的交叉注意力:用QKV三兄弟搞定图像特征增强(附PyTorch代码示例) 在计算机视觉领域,注意力机制正逐渐成为提升模型性能的关键技术。不同于传统卷积操作的固定感受野,注意力机制赋予模型动态聚焦重要区域的能力。…...