C++ STL无序关联式容器(详解)
STL无序关联式容器
继 map、multimap、set、multiset 关联式容器之后,从本节开始,再讲解一类“特殊”的关联式容器,它们常被称为“无序容器”、“哈希容器”或者“无序关联容器”。
注意,无序容器是 C++ 11 标准才正式引入到 STL 标准库中的,这意味着如果要使用该类容器,则必须选择支持 C++ 11 标准的编译器。
和关联式容器一样,无序容器也使用键值对(pair 类型)的方式存储数据。不过,本教程将二者分开进行讲解,因为它们有本质上的不同:
- 关联式容器的底层实现采用的树存储结构,更确切的说是红黑树结构;
- 无序容器的底层实现采用的是哈希表的存储结构。
C++ STL 底层采用哈希表实现无序容器时,会将所有数据存储到一整块连续的内存空间中,并且当数据存储位置发生冲突时,解决方法选用的是“链地址法”(又称“开链法”)。有关哈希表存储结构,读者可阅读《哈希表(散列表)详解》一文做详细了解。
基于底层实现采用了不同的数据结构,因此和关联式容器相比,无序容器具有以下 2 个特点:
- 无序容器内部存储的键值对是无序的,各键值对的存储位置取决于该键值对中的键,
- 和关联式容器相比,无序容器擅长通过指定键查找对应的值(平均时间复杂度为 O(1));但对于使用迭代器遍历容器中存储的元素,无序容器的执行效率则不如关联式容器。
C++ STL无序容器种类
和关联式容器一样,无序容器只是一类容器的统称,其包含有 4 个具体容器,分别为 unordered_map、unordered_multimap、unordered_set 以及 unordered_multiset。
表 1 对这 4 种无序容器的功能做了详细的介绍。
表 1 无序容器种类
| 无序容器 | 功能 |
|---|---|
| unordered_map | 存储键值对 <key, value> 类型的元素,其中各个键值对键的值不允许重复,且该容器中存储的键值对是无序的。 |
| unordered_multimap | 和 unordered_map 唯一的区别在于,该容器允许存储多个键相同的键值对。 |
| unordered_set | 不再以键值对的形式存储数据,而是直接存储数据元素本身(当然也可以理解为,该容器存储的全部都是键 key 和值 value 相等的键值对,正因为它们相等,因此只存储 value 即可)。另外,该容器存储的元素不能重复,且容器内部存储的元素也是无序的。 |
| unordered_multiset | 和 unordered_set 唯一的区别在于,该容器允许存储值相同的元素。 |
可能读者已经发现,以上 4 种无序容器的名称,仅是在前面所学的 4 种关联式容器名称的基础上,添加了 “unordered_”。如果读者已经学完了 map、multimap、set 和 multiset 容器不难发现,以 map 和 unordered_map 为例,其实它们仅有一个区别,即 map 容器内存会对存储的键值对进行排序,而 unordered_map 不会。
也就是说,C++ 11 标准的 STL 中,在已提供有 4 种关联式容器的基础上,又新增了各自的“unordered”版本(无序版本、哈希版本),提高了查找指定元素的效率。
有读者可能会问,既然无序容器和之前所学的关联式容器类似,那么在实际使用中应该选哪种容器呢?总的来说,实际场景中如果涉及大量遍历容器的操作,建议首选关联式容器;反之,如果更多的操作是通过键获取对应的值,则应首选无序容器。
为了加深读者对无序容器的认识,这里以 unordered_map 容器为例,举个例子(不必深究该容器的具体用法):
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建并初始化一个 unordered_map 容器,其存储的 <string,string> 类型的键值对std::unordered_map<std::string, std::string> my_uMap{{"C语言教程","http://c.biancheng.net/c/"},{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"} };//查找指定键对应的值,效率比关联式容器高string str = my_uMap.at("C语言教程");cout << "str = " << str << endl;//使用迭代器遍历哈希容器,效率不如关联式容器for (auto iter = my_uMap.begin(); iter != my_uMap.end(); ++iter){//pair 类型键值对分为 2 部分cout << iter->first << " " << iter->second << endl;}return 0;
}
程序执行结果为:
str = http://c.biancheng.net/c/
C语言教程 http://c.biancheng.net/c/
Python教程 http://c.biancheng.net/python/
Java教程 http://c.biancheng.net/java/
关于 4 种无序容器各自的用法,后续章节会做详细讲解。
C++ STL unordered_map容器用法详解
C++ STL 标准库中提供有 4 种无序关联式容器,本节先讲解 unordered_map 容器。
unordered_map 容器,直译过来就是"无序 map 容器"的意思。所谓“无序”,指的是 unordered_map 容器不会像 map 容器那样对存储的数据进行排序。换句话说,unordered_map 容器和 map 容器仅有一点不同,即 map 容器中存储的数据是有序的,而 unordered_map 容器中是无序的。
对于已经学过 map 容器的读者,可以将 unordered_map 容器等价为无序的 map 容器。
具体来讲,unordered_map 容器和 map 容器一样,以键值对(pair类型)的形式存储数据,存储的各个键值对的键互不相同且不允许被修改。但由于 unordered_map 容器底层采用的是哈希表存储结构,该结构本身不具有对数据的排序功能,所以此容器内部不会自行对存储的键值对进行排序。
值得一提的是,unordered_map 容器在<unordered_map>头文件中,并位于 std 命名空间中。因此,如果想使用该容器,代码中应包含如下语句:
#include <unordered_map>
using namespace std;
注意,第二行代码不是必需的,但如果不用,则后续程序中在使用此容器时,需手动注明 std 命名空间(强烈建议初学者使用)。
unordered_map 容器模板的定义如下所示:
template < class Key, //键值对中键的类型class T, //键值对中值的类型class Hash = hash<Key>, //容器内部存储键值对所用的哈希函数class Pred = equal_to<Key>, //判断各个键值对键相同的规则class Alloc = allocator< pair<const Key,T> > // 指定分配器对象的类型> class unordered_map;
以上 5 个参数中,必须显式给前 2 个参数传值,并且除特殊情况外,最多只需要使用前 4 个参数,各自的含义和功能如表 1 所示。
表 1 unordered_map 容器模板类的常用参数
| 参数 | 含义 |
|---|---|
| <key,T> | 前 2 个参数分别用于确定键值对中键和值的类型,也就是存储键值对的类型。 |
| Hash = hash | 用于指明容器在存储各个键值对时要使用的哈希函数,默认使用 STL 标准库提供的 hash 哈希函数。注意,默认哈希函数只适用于基本数据类型(包括 string 类型),而不适用于自定义的结构体或者类。 |
| Pred = equal_to | 要知道,unordered_map 容器中存储的各个键值对的键是不能相等的,而判断是否相等的规则,就由此参数指定。默认情况下,使用 STL 标准库中提供的 equal_to 规则,该规则仅支持可直接用 == 运算符做比较的数据类型。 |
总的来说,当无序容器中存储键值对的键为自定义类型时,默认的哈希函数 hash 以及比较函数 equal_to 将不再适用,只能自己设计适用该类型的哈希函数和比较函数,并显式传递给 Hash 参数和 Pred 参数。至于如何实现自定义,后续章节会做详细讲解。
创建C++ unordered_map容器的方法
常见的创建 unordered_map 容器的方法有以下几种。
- 通过调用 unordered_map 模板类的默认构造函数,可以创建空的 unordered_map 容器。比如:
std::unordered_map<std::string, std::string> umap;
由此,就创建好了一个可存储 <string,string> 类型键值对的 unordered_map 容器。
- 当然,在创建 unordered_map 容器的同时,可以完成初始化操作。比如:
std::unordered_map<std::string, std::string> umap{{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"},{"Linux教程","http://c.biancheng.net/linux/"} };
通过此方法创建的 umap 容器中,就包含有 3 个键值对元素。
- 另外,还可以调用 unordered_map 模板中提供的复制(拷贝)构造函数,将现有 unordered_map 容器中存储的键值对,复制给新建 unordered_map 容器。
例如,在第二种方式创建好 umap 容器的基础上,再创建并初始化一个 umap2 容器:
std::unordered_map<std::string, std::string> umap2(umap);
由此,umap2 容器中就包含有 umap 容器中所有的键值对。
除此之外,C++ 11 标准中还向 unordered_map 模板类增加了移动构造函数,即以右值引用的方式将临时 unordered_map 容器中存储的所有键值对,全部复制给新建容器。例如:
//返回临时 unordered_map 容器的函数
std::unordered_map <std::string, std::string > retUmap(){std::unordered_map<std::string, std::string>tempUmap{{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"},{"Linux教程","http://c.biancheng.net/linux/"} };return tempUmap;
}
//调用移动构造函数,创建 umap2 容器
std::unordered_map<std::string, std::string> umap2(retUmap());
注意,无论是调用复制构造函数还是拷贝构造函数,必须保证 2 个容器的类型完全相同。
- 当然,如果不想全部拷贝,可以使用 unordered_map 类模板提供的迭代器,在现有 unordered_map 容器中选择部分区域内的键值对,为新建 unordered_map 容器初始化。例如:
传入 2 个迭代器,
std::unordered_map<std::string, std::string> umap2(++umap.begin(),umap.end());
通过此方式创建的 umap2 容器,其内部就包含 umap 容器中除第 1 个键值对外的所有其它键值对。
C++ unordered_map容器的成员方法
unordered_map 既可以看做是关联式容器,更属于自成一脉的无序容器。因此在该容器模板类中,既包含一些在学习关联式容器时常见的成员方法,还有一些属于无序容器特有的成员方法。
表 2 列出了 unordered_map 类模板提供的所有常用的成员方法以及各自的功能。
表 2 unordered_map类模板成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个键值对的正向迭代器。 |
| end() | 返回指向容器中最后一个键值对之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有键值对的个数。 |
| max_size() | 返回容器所能容纳键值对的最大个数,不同的操作系统,其返回值亦不相同。 |
| operator[key] | 该模板类中重载了 [] 运算符,其功能是可以向访问数组中元素那样,只要给定某个键值对的键 key,就可以获取该键对应的值。注意,如果当前容器中没有以 key 为键的键值对,则其会使用该键向当前容器中插入一个新键值对。 |
| at(key) | 返回容器中存储的键 key 对应的值,如果 key 不存在,则会抛出 out_of_range 异常。 |
| find(key) | 查找以 key 为键的键值对,如果找到,则返回一个指向该键值对的正向迭代器;反之,则返回一个指向容器中最后一个键值对之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找以 key 键的键值对的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中键为 key 的键值对所在的范围。 |
| emplace() | 向容器中添加新键值对,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新键值对,效率比 insert() 方法高。 |
| insert() | 向容器中添加新键值对。 |
| erase() | 删除指定键值对。 |
| clear() | 清空容器,即删除容器中存储的所有键值对。 |
| swap() | 交换 2 个 unordered_map 容器存储的键值对,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储键值对时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_map 容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储键值对的数量。 |
| bucket(key) | 返回以 key 为键的键值对所在桶的编号。 |
| load_factor() | 返回 unordered_map 容器中当前的负载因子。负载因子,指的是的当前容器中存储键值对的数量(size())和使用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳count个元(不超过最大负载因子)所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
注意,对于实现互换 2 个相同类型 unordered_map 容器的键值对,除了可以调用该容器模板类中提供的 swap() 成员方法外,STL 标准库还提供了同名的 swap() 非成员函数。
下面的样例演示了表 2 中部分成员方法的用法:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建空 umap 容器unordered_map<string, string> umap;//向 umap 容器添加新键值对umap.emplace("Python教程", "http://c.biancheng.net/python/");umap.emplace("Java教程", "http://c.biancheng.net/java/");umap.emplace("Linux教程", "http://c.biancheng.net/linux/");//输出 umap 存储键值对的数量cout << "umap size = " << umap.size() << endl;//使用迭代器输出 umap 容器存储的所有键值对for (auto iter = umap.begin(); iter != umap.end(); ++iter) {cout << iter->first << " " << iter->second << endl;}return 0;
}
程序执行结果为:
umap size = 3
Python教程 http://c.biancheng.net/python/
Linux教程 http://c.biancheng.net/linux/
Java教程 http://c.biancheng.net/java/
有关表 2 中其它成员方法的用法,后续章节会做详细讲解。当然,读者也可以自行查询 C++ STL标准库手册。
深度剖析C++无序容器的底层实现机制
在阅读本节内容之前,读者需了解哈希表存储结构的原理,可猛击《哈希表(散列表)详解》一节。
在了解哈希表存储结构的基础上,本节将具体分析 C++ STL 无序容器(哈希容器)底层的实现原理。
C++ STL 标准库中,不仅是 unordered_map 容器,所有无序容器的底层实现都采用的是哈希表存储结构。更准确地说,是用“链地址法”(又称“开链法”)解决数据存储位置发生冲突的哈希表,整个存储结构如图 1 所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-07p0dLwy-1692323334085)(file:///C:/Users/10789/Desktop/c%E8%AF%AD%E8%A8%80%E4%B8%AD%E6%96%87%E7%BD%91/STL/4.3%E6%B7%B1%E5%BA%A6%E5%89%96%E6%9E%90C++%E6%97%A0%E5%BA%8F%E5%AE%B9%E5%99%A8%E7%9A%84%E5%BA%95%E5%B1%82%E5%AE%9E%E7%8E%B0%E6%9C%BA%E5%88%B6_files/1-200221131A4220.gif)]
图 1 C++ STL 无序容器存储状态示意图
其中,Pi 表示存储的各个键值对。
可以看到,当使用无序容器存储键值对时,会先申请一整块连续的存储空间,但此空间并不用来直接存储键值对,而是存储各个链表的头指针,各键值对真正的存储位置是各个链表的节点。
注意,STL 标准库通常选用 vector 容器存储各个链表的头指针。
不仅如此,在 C++ STL 标准库中,将图 1 中的各个链表称为桶(bucket),每个桶都有自己的编号(从 0 开始)。当有新键值对存储到无序容器中时,整个存储过程分为如下几步:
- 将该键值对中键的值带入设计好的哈希函数,会得到一个哈希值(一个整数,用 H 表示);
- 将 H 和无序容器拥有桶的数量 n 做整除运算(即 H % n),该结果即表示应将此键值对存储到的桶的编号;
- 建立一个新节点存储此键值对,同时将该节点链接到相应编号的桶上。
另外值得一提的是,哈希表存储结构还有一个重要的属性,称为负载因子(load factor)。该属性同样适用于无序容器,用于衡量容器存储键值对的空/满程序,即负载因子越大,意味着容器越满,即各链表中挂载着越多的键值对,这无疑会降低容器查找目标键值对的效率;反之,负载因子越小,容器肯定越空,但并不一定各个链表中挂载的键值对就越少。
举个例子,如果设计的哈希函数不合理,使得各个键值对的键带入该函数得到的哈希值始终相同(所有键值对始终存储在同一链表上)。这种情况下,即便增加桶数是的负载因子减小,该容器的查找效率依旧很差。
无序容器中,负载因子的计算方法为:
负载因子 = 容器存储的总键值对 / 桶数
默认情况下,无序容器的最大负载因子为 1.0。如果操作无序容器过程中,使得最大复杂因子超过了默认值,则容器会自动增加桶数,并重新进行哈希,以此来减小负载因子的值。需要注意的是,此过程会导致容器迭代器失效,但指向单个键值对的引用或者指针仍然有效。
这也就解释了,为什么我们在操作无序容器过程中,键值对的存储顺序有时会“莫名”的发生变动。
C++ STL 标准库为了方便用户更好地管控无序容器底层使用的哈希表存储结构,各个无序容器的模板类中都提供表 2 所示的成员方法。
表 2 无序容器管理哈希表的成员方法
| 成员方法 | 功能 |
|---|---|
| bucket_count() | 返回当前容器底层存储键值对时,使用桶的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_map 容器底层最多可以使用多少个桶。 |
| bucket_size(n) | 返回第 n 个桶中存储键值对的数量。 |
| bucket(key) | 返回以 key 为键的键值对所在桶的编号。 |
| load_factor() | 返回 unordered_map 容器中当前的负载因子。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的最大负载因子。 |
| rehash(n) | 尝试重新调整桶的数量为等于或大于 n 的值。如果 n 大于当前容器使用的桶数,则该方法会是容器重新哈希,该容器新的桶数将等于或大于 n。反之,如果 n 的值小于当前容器使用的桶数,则调用此方法可能没有任何作用。 |
| reserve(n) | 将容器使用的桶数(bucket_count() 方法的返回值)设置为最适合存储 n 个元素的桶数。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
下面的程序以学过的 unordered_map 容器为例,演示了表 2 中部分成员方法的用法:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建空 umap 容器unordered_map<string, string> umap;cout << "umap 初始桶数: " << umap.bucket_count() << endl;cout << "umap 初始负载因子: " << umap.load_factor() << endl;cout << "umap 最大负载因子: " << umap.max_load_factor() << endl;//设置 umap 使用最适合存储 9 个键值对的桶数umap.reserve(9);cout << "*********************" << endl;cout << "umap 新桶数: " << umap.bucket_count() << endl;cout << "umap 新负载因子: " << umap.load_factor() << endl;//向 umap 容器添加 3 个键值对umap["Python教程"] = "http://c.biancheng.net/python/";umap["Java教程"] = "http://c.biancheng.net/java/";umap["Linux教程"] = "http://c.biancheng.net/linux/";//调用 bucket() 获取指定键值对位于桶的编号cout << "以\"Python教程\"为键的键值对,位于桶的编号为:" << umap.bucket("Python教程") << endl;//自行计算某键值对位于哪个桶auto fn = umap.hash_function();cout << "计算以\"Python教程\"为键的键值对,位于桶的编号为:" << fn("Python教程") % (umap.bucket_count()) << endl;return 0;
}
程序执行结果为:
umap 初始桶数: 8
umap 初始负载因子: 0
umap 最大负载因子: 1
*********************
umap 新桶数: 16
umap 新负载因子: 0
以"Python教程"为键的键值对,位于桶的编号为:9
计算以"Python教程"为键的键值对,位于桶的编号为:9
从输出结果可以看出,对于空的 umap 容器,初始状态下会分配 8 个桶,并且默认最大负载因子为 1.0,但由于其为存储任何键值对,因此负载因子值为 0。
与此同时,程序中调用 reverse() 成员方法,是 umap 容器的桶数改为了 16,其最适合存储 9 个键值对。从侧面可以看出,一旦负载因子大于 1.0(9/8 > 1.0),则容器所使用的桶数就会翻倍式(8、16、32、…)的增加。
程序最后还演示了如何手动计算出指定键值对存储的桶的编号,其计算结果和使用 bucket() 成员方法得到的结果是一致的。
关于表 2 中成员方法的具体语法和用法,都很简单,不再过多赘述,感兴趣的读者可自行翻阅 C++ STL手册。
C++ unordered_map迭代器的用法
C++ STL 标准库中,unordered_map 容器迭代器的类型为前向迭代器(又称正向迭代器)。这意味着,假设 p 是一个前向迭代器,则其只能进行 *p、p++、++p 操作,且 2 个前向迭代器之间只能用 == 和 != 运算符做比较。
在 unordered_map 容器模板中,提供了表 1 所示的成员方法,可用来获取指向指定位置的前向迭代器。
表 1 C++ unordered_map迭代器相关成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个键值对的正向迭代器。 |
| end() | 返回指向容器中最后一个键值对之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| find(key) | 查找以 key 为键的键值对,如果找到,则返回一个指向该键值对的正向迭代器;反之,则返回一个指向容器中最后一个键值对之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中键为 key 的键值对所在的范围。 |
值得一提的是,equal_range(key) 很少用于 unordered_map 容器,因为该容器中存储的都是键不相等的键值对,即便调用该成员方法,得到的 2 个迭代器所表示的范围中,最多只包含 1 个键值对。事实上,该成员方法更适用于 unordered_multimap 容器(该容器后续章节会做详细讲解)。
下面的程序演示了表 1 中部分成员方法的用法。
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap{{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"},{"Linux教程","http://c.biancheng.net/linux/"} };cout << "umap 存储的键值对包括:" << endl;//遍历输出 umap 容器中所有的键值对for (auto iter = umap.begin(); iter != umap.end(); ++iter) {cout << "<" << iter->first << ", " << iter->second << ">" << endl;}//获取指向指定键值对的前向迭代器unordered_map<string, string>::iterator iter = umap.find("Java教程");cout <<"umap.find(\"Java教程\") = " << "<" << iter->first << ", " << iter->second << ">" << endl;return 0;
}
程序执行结果为:
umap 存储的键值对包括:
<Python教程, http://c.biancheng.net/python/>
<Linux教程, http://c.biancheng.net/linux/>
<Java教程, http://c.biancheng.net/java/>
umap.find("Java教程") = <Java教程, http://c.biancheng.net/java/>
需要注意的是,在操作 unordered_map 容器过程(尤其是向容器中添加新键值对)中,一旦当前容器的负载因子超过最大负载因子(默认值为 1.0),该容器就会适当增加桶的数量(通常是翻一倍),并自动执行 rehash() 成员方法,重新调整各个键值对的存储位置(此过程又称“重哈希”),此过程很可能导致之前创建的迭代器失效。
所谓迭代器失效,针对的是那些用于表示容器内某个范围的迭代器,由于重哈希会重新调整每个键值对的存储位置,所以容器重哈希之后,之前表示特定范围的迭代器很可能无法再正确表示该范围。但是,重哈希并不会影响那些指向单个键值对元素的迭代器。
举个例子:
#include <iostream>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<int, int> umap;//向 umap 容器添加 50 个键值对for (int i = 1; i <= 50; i++) {umap.emplace(i, i);}//获取键为 49 的键值对所在的范围auto pair = umap.equal_range(49);//输出 pair 范围内的每个键值对的键的值for (auto iter = pair.first; iter != pair.second; ++iter) {cout << iter->first <<" ";}cout << endl;//手动调整最大负载因子数umap.max_load_factor(3.0);//手动调用 rehash() 函数重哈希umap.rehash(10);//重哈希之后,pair 的范围可能会发生变化for (auto iter = pair.first; iter != pair.second; ++iter) {cout << iter->first << " ";}return 0;
}
程序执行结果为:
49
49 17
观察输出结果不难发现,之前用于表示键为 49 的键值对所在范围的 2 个迭代器,重哈希之后表示的范围发生了改变。
经测试,用于遍历整个容器的 begin()/end() 和 cbegin()/cend() 迭代器对,重哈希只会影响遍历容器内键值对的顺序,整个遍历的操作仍然可以顺利完成。
C++ STL unordered_map获取元素的4种方法(超级详细)
通过前面的学习我们知道,unordered_map 容器以键值对的方式存储数据。为了方便用户快速地从该类型容器提取出目标元素(也就是某个键值对的值),unordered_map 容器类模板中提供了以下几种方法。
- unordered_map 容器类模板中,实现了对 [ ] 运算符的重载,使得我们可以像“利用下标访问普通数组中元素”那样,通过目标键值对的键获取到该键对应的值。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap{{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"},{"Linux教程","http://c.biancheng.net/linux/"} };//获取 "Java教程" 对应的值string str = umap["Java教程"];cout << str << endl;return 0;
}
程序输出结果为:
http://c.biancheng.net/java/
需要注意的是,如果当前容器中并没有存储以 [ ] 运算符内指定的元素作为键的键值对,则此时 [ ] 运算符的功能将转变为:向当前容器中添加以目标元素为键的键值对。举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建空 umap 容器unordered_map<string, string> umap;//[] 运算符在 = 右侧string str = umap["STL教程"];//[] 运算符在 = 左侧umap["C教程"] = "http://c.biancheng.net/c/";for (auto iter = umap.begin(); iter != umap.end(); ++iter) {cout << iter->first << " " << iter->second << endl;}return 0;
}
程序执行结果为:
C教程 http://c.biancheng.net/c/
STL教程
可以看到,当使用 [ ] 运算符向 unordered_map 容器中添加键值对时,分为 2 种情况:
- 当 [ ] 运算符位于赋值号(=)右侧时,则新添加键值对的键为 [ ] 运算符内的元素,其值为键值对要求的值类型的默认值(string 类型默认值为空字符串);
- 当 [ ] 运算符位于赋值号(=)左侧时,则新添加键值对的键为 [ ] 运算符内的元素,其值为赋值号右侧的元素。
- unordered_map 类模板中,还提供有 at() 成员方法,和使用 [ ] 运算符一样,at() 成员方法也需要根据指定的键,才能从容器中找到该键对应的值;不同之处在于,如果在当前容器中查找失败,该方法不会向容器中添加新的键值对,而是直接抛出
out_of_range异常。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap{{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"},{"Linux教程","http://c.biancheng.net/linux/"} };//获取指定键对应的值string str = umap.at("Python教程");cout << str << endl;//执行此语句会抛出 out_of_range 异常//cout << umap.at("GO教程");return 0;
}
程序执行结果为:
http://c.biancheng.net/python/
此程序中,第 13 行代码用于获取 umap 容器中键为“Python教程”对应的值,由于 umap 容器确实有符合条件的键值对,因此可以成功执行;而第 17 行代码,由于当前 umap 容器没有存储以“Go教程”为键的键值对,因此执行此语句会抛出 out_of_range 异常。
- 运算符和 at() 成员方法基本能满足大多数场景的需要。除此之外,还可以借助 unordered_map 模板中提供的 find() 成员方法。
和前面方法不同的是,通过 find() 方法得到的是一个正向迭代器,该迭代器的指向分以下 2 种情况:
- 当 find() 方法成功找到以指定元素作为键的键值对时,其返回的迭代器就指向该键值对;
- 当 find() 方法查找失败时,其返回的迭代器和 end() 方法返回的迭代器一样,指向容器中最后一个键值对之后的位置。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap{{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"},{"Linux教程","http://c.biancheng.net/linux/"} };//查找成功unordered_map<string, string>::iterator iter = umap.find("Python教程");cout << iter->first << " " << iter->second << endl;//查找失败unordered_map<string, string>::iterator iter2 = umap.find("GO教程");if (iter2 == umap.end()) {cout << "当前容器中没有以\"GO教程\"为键的键值对";}return 0;
}
程序执行结果为:
Python教程 http://c.biancheng.net/python/
当前容器中没有以"GO教程"为键的键值对
- 除了 find() 成员方法之外,甚至可以借助 begin()/end() 或者 cbegin()/cend(),通过遍历整个容器中的键值对来找到目标键值对。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap{{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"},{"Linux教程","http://c.biancheng.net/linux/"} };//遍历整个容器中存储的键值对for (auto iter = umap.begin(); iter != umap.end(); ++iter) {//判断当前的键值对是否就是要找的if (!iter->first.compare("Java教程")) {cout << iter->second << endl;break;}}return 0;
}
程序执行结果为:
http://c.biancheng.net/java/
C++ unordered_map insert()用法精讲
为了方便用户向已建 unordered_map 容器中添加新的键值对,该容器模板中提供了 insert() 方法,本节就对此方法的用法做详细的讲解。
unordered_map 模板类中,提供了多种语法格式的 insert() 方法,根据功能的不同,可划分为以下几种用法。
- insert() 方法可以将 pair 类型的键值对元素添加到 unordered_map 容器中,其语法格式有 2 种:
//以普通方式传递参数
pair<iterator,bool> insert ( const value_type& val );
//以右值引用的方式传递参数
template <class P>pair<iterator,bool> insert ( P&& val );
有关右值引用,可阅读《C++右值引用详解》一文,这里不再做具体解释。
以上 2 种格式中,参数 val 表示要添加到容器中的目标键值对元素;该方法的返回值为 pair类型值,内部包含一个 iterator 迭代器和 bool 变量:
- 当 insert() 将 val 成功添加到容器中时,返回的迭代器指向新添加的键值对,bool 值为 True;
- 当 insert() 添加键值对失败时,意味着当前容器中本就存储有和要添加键值对的键相等的键值对,这种情况下,返回的迭代器将指向这个导致插入操作失败的迭代器,bool 值为 False。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建空 umap 容器unordered_map<string, string> umap;//构建要添加的键值对std::pair<string, string>mypair("STL教程", "http://c.biancheng.net/stl/");//创建接收 insert() 方法返回值的pair类型变量std::pair<unordered_map<string, string>::iterator, bool> ret;//调用 insert() 方法的第一种语法格式ret = umap.insert(mypair);cout << "bool = " << ret.second << endl;cout << "iter -> " << ret.first->first <<" " << ret.first->second << endl;//调用 insert() 方法的第二种语法格式ret = umap.insert(std::make_pair("Python教程","http://c.biancheng.net/python/"));cout << "bool = " << ret.second << endl;cout << "iter -> " << ret.first->first << " " << ret.first->second << endl;return 0;
}
程序执行结果为:
bool = 1
iter -> STL教程 http://c.biancheng.net/stl/
bool = 1
iter -> Python教程 http://c.biancheng.net/python/
从输出结果很容易看出,两次添加键值对的操作,insert() 方法返回值中的 bool 变量都为 1,表示添加成功,此时返回的迭代器指向的是添加成功的键值对。
- 除此之外,insert() 方法还可以指定新键值对要添加到容器中的位置,其语法格式如下:
//以普通方式传递 val 参数
iterator insert ( const_iterator hint, const value_type& val );
//以右值引用方法传递 val 参数
template <class P>iterator insert ( const_iterator hint, P&& val );
以上 2 种语法格式中,hint 参数为迭代器,用于指定新键值对要添加到容器中的位置;val 参数指的是要添加容器中的键值对;方法的返回值为迭代器:
- 如果 insert() 方法成功添加键值对,该迭代器指向新添加的键值对;
- 如果 insert() 方法添加键值对失败,则表示容器中本就包含有相同键的键值对,该方法返回的迭代器就指向容器中键相同的键值对;
注意,以上 2 种语法格式中,虽然通过 hint 参数指定了新键值对添加到容器中的位置,但该键值对真正存储的位置,并不是 hint 参数说了算,最终的存储位置仍取决于该键值对的键的值。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建空 umap 容器unordered_map<string, string> umap;//构建要添加的键值对std::pair<string, string>mypair("STL教程", "http://c.biancheng.net/stl/");//创建接收 insert() 方法返回值的迭代器类型变量unordered_map<string, string>::iterator iter;//调用第一种语法格式iter = umap.insert(umap.begin(), mypair);cout << "iter -> " << iter->first <<" " << iter->second << endl;//调用第二种语法格式iter = umap.insert(umap.begin(),std::make_pair("Python教程", "http://c.biancheng.net/python/"));cout << "iter -> " << iter->first << " " << iter->second << endl;return 0;
}
程序输出结果为:
iter -> STL教程 http://c.biancheng.net/stl/
iter -> Python教程 http://c.biancheng.net/python/
- insert() 方法还支持将某一个 unordered_map 容器中指定区域内的所有键值对,复制到另一个 unordered_map 容器中,其语法格式如下:
template <class InputIterator>void insert ( InputIterator first, InputIterator last );
其中 first 和 last 都为迭代器,[first, last)表示复制其它 unordered_map 容器中键值对的区域。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建并初始化 umap 容器unordered_map<string, string> umap{ {"STL教程","http://c.biancheng.net/stl/"},{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"} };//创建一个空的 unordered_map 容器unordered_map<string, string> otherumap;//指定要拷贝 umap 容器中键值对的范围unordered_map<string, string>::iterator first = ++umap.begin();unordered_map<string, string>::iterator last = umap.end();//将指定 umap 容器中 [first,last) 区域内的键值对复制给 otherumap 容器otherumap.insert(first, last);//遍历 otherumap 容器中存储的键值对for (auto iter = otherumap.begin(); iter != otherumap.end(); ++iter){cout << iter->first << " " << iter->second << endl;}return 0;
}
程序输出结果为:
Python教程 http://c.biancheng.net/python/
Java教程 http://c.biancheng.net/java/
- 除了以上 3 种方式,insert() 方法还支持一次向 unordered_map 容器添加多个键值对,其语法格式如下:
void insert ( initializer_list<value_type> il );
其中,il 参数指的是可以用初始化列表的形式指定多个键值对元素。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建空的 umap 容器unordered_map<string, string> umap;//向 umap 容器同时添加多个键值对umap.insert({ {"STL教程","http://c.biancheng.net/stl/"},{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"} });//遍历输出 umap 容器中存储的键值对for (auto iter = umap.begin(); iter != umap.end(); ++iter){cout << iter->first << " " << iter->second << endl;}return 0;
}
程序输出结果为:
STL教程 http://c.biancheng.net/stl/
Python教程 http://c.biancheng.net/python/
Java教程 http://c.biancheng.net/java/
总的来说,unordered_map 模板类提供的 insert() 方法,有以上 4 种用法,读者可以根据实际场景的需要自行选择使用哪一种。
C++ unordered_map emplace()和emplace_hint()方法
和前面学的 map、set 等容器一样,C++ 11 标准也为 unordered_map 容器新增了 emplace() 和 emplace_hint() 成员方法,本节将对它们的用法做详细的介绍。
我们知道,实现向已有 unordered_map 容器中添加新键值对,可以通过调用 insert() 方法,但其实还有更好的方法,即使用 emplace() 或者 emplace_hint() 方法,它们完成“向容器中添加新键值对”的效率,要比 insert() 方法高。
至于为什么 emplace()、emplace_hint() 执行效率会比 insert() 方法高,可阅读《为什么emplace()、emplace_hint()执行效率比insert()高》一文,虽然此文的讲解对象为 map 容器,但就这 3 个方法来说,unordered_map 容器和 map 容器是一样的。
unordered_map emplace()方法
emplace() 方法的用法很简单,其语法格式如下:
template <class... Args>pair<iterator, bool> emplace ( Args&&... args );
其中,参数 args 表示可直接向该方法传递创建新键值对所需要的 2 个元素的值,其中第一个元素将作为键值对的键,另一个作为键值对的值。也就是说,该方法无需我们手动创建键值对,其内部会自行完成此工作。
另外需要注意的是,该方法的返回值为 pair 类型值,其包含一个迭代器和一个 bool 类型值:
- 当 emplace() 成功添加新键值对时,返回的迭代器指向新添加的键值对,bool 值为 True;
- 当 emplace() 添加新键值对失败时,说明容器中本就包含一个键相等的键值对,此时返回的迭代器指向的就是容器中键相同的这个键值对,bool 值为 False。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap;//定义一个接受 emplace() 方法的 pair 类型变量pair<unordered_map<string, string>::iterator, bool> ret;//调用 emplace() 方法ret = umap.emplace("STL教程", "http://c.biancheng.net/stl/");//输出 ret 中包含的 2 个元素的值cout << "bool =" << ret.second << endl;cout << "iter ->" << ret.first->first << " " << ret.first->second << endl;return 0;
}
程序执行结果为:
bool =1
iter ->STL教程 http://c.biancheng.net/stl/
通过执行结果中 bool 变量的值为 1 可以得知,emplace() 方法成功将新键值对添加到了 umap 容器中。
unordered_map emplace_hint()方法
emplace_hint() 方法的语法格式如下:
template <class... Args>iterator emplace_hint ( const_iterator position, Args&&... args );
和 emplace() 方法相同,emplace_hint() 方法内部会自行构造新键值对,因此我们只需向其传递构建该键值对所需的 2 个元素(第一个作为键,另一个作为值)即可。不同之处在于:
- emplace_hint() 方法的返回值仅是一个迭代器,而不再是 pair 类型变量。当该方法将新键值对成功添加到容器中时,返回的迭代器指向新添加的键值对;反之,如果添加失败,该迭代器指向的是容器中和要添加键值对键相同的那个键值对。
- emplace_hint() 方法还需要传递一个迭代器作为第一个参数,该迭代器表明将新键值对添加到容器中的位置。需要注意的是,新键值对添加到容器中的位置,并不是此迭代器说了算,最终仍取决于该键值对的键的值。
可以这样理解,emplace_hint() 方法中传入的迭代器,仅是给 unordered_map 容器提供一个建议,并不一定会被容器采纳。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap;//定义一个接受 emplace_hint() 方法的迭代器unordered_map<string,string>::iterator iter;//调用 empalce_hint() 方法iter = umap.emplace_hint(umap.begin(),"STL教程", "http://c.biancheng.net/stl/");//输出 emplace_hint() 返回迭代器 iter 指向的键值对的内容cout << "iter ->" << iter->first << " " << iter->second << endl;return 0;
}
程序执行结果为:
iter ->STL教程 http://c.biancheng.net/stl/
C++ STL unordered_map删除元素:erase()和clear()
C++ STL 标准库为了方便用户可以随时删除 unordered_map 容器中存储的键值对,unordered_map 容器类模板中提供了以下 2 个成员方法:
- erase():删除 unordered_map 容器中指定的键值对;
- clear():删除 unordered_map 容器中所有的键值对,即清空容器。
本节就对以上 2 个成员方法的用法做详细的讲解。
unordered_map erase()方法
为了满足不同场景删除 unordered_map 容器中键值对的需要,此容器的类模板中提供了 3 种语法格式的 erase() 方法。
- erase() 方法可以接受一个正向迭代器,并删除该迭代器指向的键值对。该方法的语法格式如下:
iterator erase ( const_iterator position );
其中 position 为指向容器中某个键值对的迭代器,该方法会返回一个指向被删除键值对之后位置的迭代器。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap{{"STL教程", "http://c.biancheng.net/stl/"},{"Python教程", "http://c.biancheng.net/python/"},{"Java教程", "http://c.biancheng.net/java/"} };//输出 umap 容器中存储的键值对for (auto iter = umap.begin(); iter != umap.end(); ++iter) {cout << iter->first << " " << iter->second << endl;}cout << "erase:" << endl;//定义一个接收 erase() 方法的迭代器unordered_map<string,string>::iterator ret;//删除容器中第一个键值对ret = umap.erase(umap.begin());//输出 umap 容器中存储的键值对for (auto iter = umap.begin(); iter != umap.end(); ++iter) {cout << iter->first << " " << iter->second << endl;}cout << "ret = " << ret->first << " " << ret->second << endl;return 0;
}
程序执行结果为:
STL教程 http://c.biancheng.net/stl/
Python教程 http://c.biancheng.net/python/
Java教程 http://c.biancheng.net/java/
erase:
Python教程 http://c.biancheng.net/python/
Java教程 http://c.biancheng.net/java/
ret = Python教程 http://c.biancheng.net/python/
可以看到,通过给 erase() 方法传入指向容器中第一个键值对的迭代器,该方法可以将容器中第一个键值对删除,同时返回一个指向被删除键值对之后位置的迭代器。
注意,如果erase()方法删除的是容器存储的最后一个键值对,则该方法返回的迭代器,将指向容器中最后一个键值对之后的位置(等同于 end() 方法返回的迭代器)。
- 我们还可以直接将要删除键值对的键作为参数直接传给 erase() 方法,该方法会自行去 unordered_map 容器中找和给定键相同的键值对,将其删除。erase() 方法的语法格式如下:
size_type erase ( const key_type& k );
其中,k 表示目标键值对的键的值;该方法会返回一个整数,其表示成功删除的键值对的数量。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap{{"STL教程", "http://c.biancheng.net/stl/"},{"Python教程", "http://c.biancheng.net/python/"},{"Java教程", "http://c.biancheng.net/java/"} }; //输出 umap 容器中存储的键值对for (auto iter = umap.begin(); iter != umap.end(); ++iter) {cout << iter->first << " " << iter->second << endl;}int delNum = umap.erase("Python教程");cout << "delNum = " << delNum << endl;//再次输出 umap 容器中存储的键值对for (auto iter = umap.begin(); iter != umap.end(); ++iter) {cout << iter->first << " " << iter->second << endl;}return 0;
}
程序执行结果为:
STL教程 http://c.biancheng.net/stl/
Python教程 http://c.biancheng.net/python/
Java教程 http://c.biancheng.net/java/
delNum = 1
STL教程 http://c.biancheng.net/stl/
Java教程 http://c.biancheng.net/java/
通过输出结果可以看到,通过将 “Python教程” 传给 erase() 方法,就成功删除了 umap 容器中键为 “Python教程” 的键值对。
- 除了支持删除 unordered_map 容器中指定的某个键值对,erase() 方法还支持一次删除指定范围内的所有键值对,其语法格式如下:
iterator erase ( const_iterator first, const_iterator last );
其中 first 和 last 都是正向迭代器,[first, last) 范围内的所有键值对都会被 erase() 方法删除;同时,该方法会返回一个指向被删除的最后一个键值对之后一个位置的迭代器。
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap{{"STL教程", "http://c.biancheng.net/stl/"},{"Python教程", "http://c.biancheng.net/python/"},{"Java教程", "http://c.biancheng.net/java/"} };//first 指向第一个键值对unordered_map<string, string>::iterator first = umap.begin();//last 指向最后一个键值对unordered_map<string, string>::iterator last = umap.end();//删除[fist,last)范围内的键值对auto ret = umap.erase(first, last);//输出 umap 容器中存储的键值对for (auto iter = umap.begin(); iter != umap.end(); ++iter) {cout << iter->first << " " << iter->second << endl;}return 0;
}
执行程序会发现,没有输出任何数据,因为 erase() 方法删除了 umap 容器中 [begin(), end()) 范围内所有的元素。
unordered_map clear()方法
在个别场景中,可能需要一次性删除 unordered_map 容器中存储的所有键值对,可以使用 clear() 方法,其语法格式如下:
void clear()
举个例子:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建 umap 容器unordered_map<string, string> umap{{"STL教程", "http://c.biancheng.net/stl/"},{"Python教程", "http://c.biancheng.net/python/"},{"Java教程", "http://c.biancheng.net/java/"} };//输出 umap 容器中存储的键值对for (auto iter = umap.begin(); iter != umap.end(); ++iter) {cout << iter->first << " " << iter->second << endl;}//删除容器内所有键值对umap.clear();cout << "umap size = " << umap.size() << endl;return 0;
}
程序执行结果为:
STL教程 http://c.biancheng.net/stl/
Python教程 http://c.biancheng.net/python/
Java教程 http://c.biancheng.net/java/
umap size = 0
显然,通过调用 clear() 方法,原本包含 3 个键值对的 umap 容器,变成了空容器。
注意,虽然使用 erase() 方法的第 3 种语法格式,可能实现删除 unordered_map 容器内所有的键值对,但更推荐使用 clear() 方法。
C++ STL unordered_multimap容器精讲
C++ STL 标准库中,除了提供有 unordered_map 无序关联容器,还提供有和 unordered_map 容器非常相似的 unordered_multimap 无序关联容器。
和 unordered_map 容器一样,unordered_multimap 容器也以键值对的形式存储数据,且底层也采用哈希表结构存储各个键值对。两者唯一的不同之处在于,unordered_multimap 容器可以存储多个键相等的键值对,而 unordered_map 容器不行。
《深度剖析C++ STL无序容器底层原理》一文提到,无序容器中存储的各个键值对,都会哈希存到各个桶(本质为链表)中。而对于 unordered_multimap 容器来说,其存储的所有键值对中,键相等的键值对会被哈希到同一个桶中存储。
另外值得一提得是,STL 标准库中实现 unordered_multimap 容器的模板类并没有定义在以自己名称命名的头文件中,而是和 unordered_map 容器一样,定义在<unordered_map>头文件,且位于 std 命名空间中。因此,在使用 unordered_multimap 容器之前,程序中应包含如下 2 行代码:
#include <unordered_map>
using namespace std;
注意,第二行代码不是必需的,但如果不用,则后续程序中在使用此容器时,需手动注明 std 命名空间(强烈建议初学者使用)。
unordered_multimap 容器模板的定义如下所示:
template < class Key, //键(key)的类型class T, //值(value)的类型class Hash = hash<Key>, //底层存储键值对时采用的哈希函数class Pred = equal_to<Key>, //判断各个键值对的键相等的规则class Alloc = allocator< pair<const Key,T> > // 指定分配器对象的类型> class unordered_multimap;
以上 5 个参数中,必须显式给前 2 个参数传值,且除极个别的情况外,最多只使用前 4 个参数,它们各自的含义和功能如表 1 所示。
表 1 unordered_multimap 容器模板类的常用参数
| 参数 | 含义 |
|---|---|
| <key,T> | 前 2 个参数分别用于确定键值对中键和值的类型,也就是存储键值对的类型。 |
| Hash = hash | 用于指明容器在存储各个键值对时要使用的哈希函数,默认使用 STL 标准库提供的 hash 哈希函数。注意,默认哈希函数只适用于基本数据类型(包括 string 类型),而不适用于自定义的结构体或者类。 |
| Pred = equal_to | unordered_multimap 容器可以存储多个键相等的键值对,而判断是否相等的规则,由此参数指定。默认情况下,使用 STL 标准库中提供的 equal_to 规则,该规则仅支持可直接用 == 运算符做比较的数据类型。 |
注意,当 unordered_multimap 容器中存储键值对的键为自定义类型时,默认的哈希函数 hash 以及比较函数 equal_to 将不再适用,这种情况下,需要我们自定义适用的哈希函数和比较函数,并分别显式传递给 Hash 参数和 Pred 参数。
关于给 unordered_multimap 容器自定义哈希函数和比较函数的方法,后续章节会做详细讲解。
创建C++ unordered_multimap容器的方法
常见的创建 unordered_map 容器的方法有以下几种。
- 利用 unordered_multimap 容器类模板中的默认构造函数,可以创建空的 unordered_multimap 容器。比如:
std::unordered_multimap<std::string, std::string>myummap;
如果程序中已经默认指定了 std 命令空间,这里可以省略所有的 std::。
由此,就创建好了一个可存储 <string, string> 类型键值对的 unordered_multimap 容器,只不过当前容器是空的,即没有存储任何键值对。
- 当然,在创建空 unordered_multimap 容器的基础上,可以完成初始化操作。比如:
unordered_multimap<string, string>myummap{{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"},{"Linux教程","http://c.biancheng.net/linux/"} };
通过此方法创建的 myummap 容器中,就包含有 3 个键值对。
- 另外,unordered_multimap 模板中还提供有复制(拷贝)构造函数,可以实现在创建 unordered_multimap 容器的基础上,用另一 unordered_multimap 容器中的键值对为其初始化。
例如,在第二种方式创建好 myummap 容器的基础上,再创建并初始化一个 myummap2 容器:
unordered_multimap<string, string>myummap2(myummap);
由此,刚刚创建好的 myummap2 容器中,就包含有 myummap 容器中所有的键值对。
除此之外,C++ 11 标准中还向 unordered_multimap 模板类增加了移动构造函数,即以右值引用的方式将临时 unordered_multimap 容器中存储的所有键值对,全部复制给新建容器。例如:
//返回临时 unordered_multimap 容器的函数
std::unordered_multimap <std::string, std::string > retUmmap() {std::unordered_multimap<std::string, std::string>tempummap{{"Python教程","http://c.biancheng.net/python/"},{"Java教程","http://c.biancheng.net/java/"},{"Linux教程","http://c.biancheng.net/linux/"} };return tempummap;
}
//创建并初始化 myummap 容器
std::unordered_multimap<std::string, std::string> myummap(retummap());
注意,无论是调用复制构造函数还是拷贝构造函数,必须保证 2 个容器的类型完全相同。
- 当然,如果不想全部拷贝,可以使用 unordered_multimap 类模板提供的迭代器,在现有 unordered_multimap 容器中选择部分区域内的键值对,为新建 unordered_multimap 容器初始化。例如:
//传入 2 个迭代器,
std::unordered_multimap<std::string, std::string> myummap2(++myummap.begin(), myummap.end());
通过此方式创建的 myummap2 容器,其内部就包含 myummap 容器中除第 1 个键值对外的所有其它键值对。
C++ unordered_multimap容器的成员方法
和 unordered_map 容器相比,unordered_multimap 容器的类模板中没有重载 [ ] 运算符,也没有提供 at() 成员方法,除此之外它们完全一致。
没有提供 [ ] 运算符和 at() 成员方法,意味着 unordered_multimap 容器无法通过指定键获取该键对应的值,因为该容器允许存储多个键相等的键值对,每个指定的键可能对应多个不同的值。
unordered_multimap 类模板提供的成员方法如表 2 所示。
表 2 unordered_multimap类模板成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个键值对的正向迭代器。 |
| end() | 返回指向容器中最后一个键值对之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过在其基础上增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| cend() | 和 end() 功能相同,只不过在其基础上,增加了 const 属性,即该方法返回的迭代器不能用于修改容器内存储的键值对。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有键值对的个数。 |
| max_size() | 返回容器所能容纳键值对的最大个数,不同的操作系统,其返回值亦不相同。 |
| find(key) | 查找以 key 为键的键值对,如果找到,则返回一个指向该键值对的正向迭代器;反之,则返回一个指向容器中最后一个键值对之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找以 key 键的键值对的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中键为 key 的键值对所在的范围。 |
| emplace() | 向容器中添加新键值对,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新键值对,效率比 insert() 方法高。 |
| insert() | 向容器中添加新键值对。 |
| erase() | 删除指定键值对。 |
| clear() | 清空容器,即删除容器中存储的所有键值对。 |
| swap() | 交换 2 个 unordered_multimap 容器存储的键值对,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储键值对时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_multimap 容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储键值对的数量。 |
| bucket(key) | 返回以 key 为键的键值对所在桶的编号。 |
| load_factor() | 返回 unordered_multimap 容器中当前的负载因子。负载因子,指的是的当前容器中存储键值对的数量(size())和使用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_multimap 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳count个元(不超过最大负载因子)所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
注意,对于实现互换 2 个相同类型 unordered_multimap 容器的键值对,除了可以调用该容器模板类中提供的 swap() 成员方法外,STL 标准库还提供了同名的 swap() 非成员函数。
下面的样例演示了表 2 中部分成员方法的用法:
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main()
{//创建空容器std::unordered_multimap<std::string, std::string> myummap;//向空容器中连续添加 5 个键值对myummap.emplace("Python教程", "http://c.biancheng.net/python/");myummap.emplace("STL教程", "http://c.biancheng.net/stl/");myummap.emplace("Java教程", "http://c.biancheng.net/java/");myummap.emplace("C教程", "http://c.biancheng.net");myummap.emplace("C教程", "http://c.biancheng.net/c/");//输出 muummap 容器存储键值对的个数cout << "myummmap size = " << myummap.size() << endl;//利用迭代器输出容器中存储的所有键值对for (auto iter = myummap.begin(); iter != myummap.end(); ++iter) {cout << iter->first << " " << iter->second << endl;}return 0;
}
程序执行结果为:
myummmap size = 5
Python教程 http://c.biancheng.net/python/
C教程 http://c.biancheng.net
C教程 http://c.biancheng.net/c/
STL教程 http://c.biancheng.net/stl/
Java教程 http://c.biancheng.net/java/
值得一提的是,unordered_multimap 模板提供的所有成员方法的用法,都和 unordered_map 提供的同名成员方法的用法完全相同(仅是调用者发生了改变),由于在讲解 unordered_map 容器时,已经对大部分成员方法的用法做了详细的讲解,后续不再做重复性地赘述。
C++ STL unordered_set容器完全攻略
我们知道,C++ 11 为 STL 标准库增添了 4 种无序(哈希)容器,前面已经对 unordered_map 和 unordered_multimap 容器做了详细的介绍,本节再讲解一种无序容器,即 unordered_set 容器。
unordered_set 容器,可直译为“无序 set 容器”,即 unordered_set 容器和 set 容器很像,唯一的区别就在于 set 容器会自行对存储的数据进行排序,而 unordered_set 容器不会。
总的来说,unordered_set 容器具有以下几个特性:
- 不再以键值对的形式存储数据,而是直接存储数据的值;
- 容器内部存储的各个元素的值都互不相等,且不能被修改。
- 不会对内部存储的数据进行排序(这和该容器底层采用哈希表结构存储数据有关,可阅读《C++ STL无序容器底层实现原理》一文做详细了解);
对于 unordered_set 容器不以键值对的形式存储数据,读者也可以这样认为,即 unordered_set 存储的都是键和值相等的键值对,为了节省存储空间,该类容器在实际存储时选择只存储每个键值对的值。
另外,实现 unordered_set 容器的模板类定义在<unordered_set>头文件,并位于 std 命名空间中。这意味着,如果程序中需要使用该类型容器,则首先应该包含如下代码:
#include <unordered_set>
using namespace std;
注意,第二行代码不是必需的,但如果不用,则程序中只要用到该容器时,必须手动注明 std 命名空间(强烈建议初学者使用)。
unordered_set 容器的类模板定义如下:
template < class Key, //容器中存储元素的类型class Hash = hash<Key>, //确定元素存储位置所用的哈希函数class Pred = equal_to<Key>, //判断各个元素是否相等所用的函数class Alloc = allocator<Key> //指定分配器对象的类型> class unordered_set;
可以看到,以上 4 个参数中,只有第一个参数没有默认值,这意味着如果我们想创建一个 unordered_set 容器,至少需要手动传递 1 个参数。事实上,在 99% 的实际场景中最多只需要使用前 3 个参数(各自含义如表 1 所示),最后一个参数保持默认值即可。
表 1 unordered_set模板类定义
| 参数 | 含义 |
|---|---|
| Key | 确定容器存储元素的类型,如果读者将 unordered_set 看做是存储键和值相同的键值对的容器,则此参数则用于确定各个键值对的键和值的类型,因为它们是完全相同的,因此一定是同一数据类型的数据。 |
| Hash = hash | 指定 unordered_set 容器底层存储各个元素时,所使用的哈希函数。需要注意的是,默认哈希函数 hash 只适用于基本数据类型(包括 string 类型),而不适用于自定义的结构体或者类。 |
| Pred = equal_to | unordered_set 容器内部不能存储相等的元素,而衡量 2 个元素是否相等的标准,取决于该参数指定的函数。 默认情况下,使用 STL 标准库中提供的 equal_to 规则,该规则仅支持可直接用 == 运算符做比较的数据类型。 |
注意,如果 unordered_set 容器中存储的元素为自定义的数据类型,则默认的哈希函数 hash 以及比较函数 equal_to 将不再适用,只能自己设计适用该类型的哈希函数和比较函数,并显式传递给 Hash 参数和 Pred 参数。至于如何实现自定义,后续章节会做详细讲解。
创建C++ unordered_set容器
前面介绍了如何创建 unordered_map 和 unordered_multimap 容器,值得一提的是,创建它们的所有方式完全适用于 unordereded_set 容器。不过,考虑到一些读者可能尚未学习其它无序容器,因此这里还是讲解一下创建 unordered_set 容器的几种方法。
- 通过调用 unordered_set 模板类的默认构造函数,可以创建空的 unordered_set 容器。比如:
std::unordered_set<std::string> uset;
如果程序已经引入了 std 命名空间,这里可以省略所有的 std::。
由此,就创建好了一个可存储 string 类型值的 unordered_set 容器,该容器底层采用默认的哈希函数 hash 和比较函数 equal_to。
- 当然,在创建 unordered_set 容器的同时,可以完成初始化操作。比如:
std::unordered_set<std::string> uset{ "http://c.biancheng.net/c/","http://c.biancheng.net/java/","http://c.biancheng.net/linux/" };
通过此方法创建的 uset 容器中,就包含有 3 个 string 类型元素。
- 还可以调用 unordered_set 模板中提供的复制(拷贝)构造函数,将现有 unordered_set 容器中存储的元素全部用于为新建 unordered_set 容器初始化。
例如,在第二种方式创建好 uset 容器的基础上,再创建并初始化一个 uset2 容器:
std::unordered_set<std::string> uset2(uset);
由此,umap2 容器中就包含有 umap 容器中所有的元素。
除此之外,C++ 11 标准中还向 unordered_set 模板类增加了移动构造函数,即以右值引用的方式,利用临时 unordered_set 容器中存储的所有元素,给新建容器初始化。例如:
//返回临时 unordered_set 容器的函数
std::unordered_set <std::string> retuset() {std::unordered_set<std::string> tempuset{ "http://c.biancheng.net/c/","http://c.biancheng.net/java/","http://c.biancheng.net/linux/" };return tempuset;
}
//调用移动构造函数,创建 uset 容器
std::unordered_set<std::string> uset(retuset());
注意,无论是调用复制构造函数还是拷贝构造函数,必须保证 2 个容器的类型完全相同。
- 当然,如果不想全部拷贝,可以使用 unordered_set 类模板提供的迭代器,在现有 unordered_set 容器中选择部分区域内的元素,为新建 unordered_set 容器初始化。例如:
//传入 2 个迭代器,
std::unordered_set<std::string> uset2(++uset.begin(),uset.end());
通过此方式创建的 uset2 容器,其内部就包含 uset 容器中除第 1 个元素外的所有其它元素。
C++ unordered_set容器的成员方法
unordered_set 类模板中,提供了如表 2 所示的成员方法。
表 2 unordered_set 类模板成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的正向迭代器。 |
| end(); | 返回指向容器中最后一个元素之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| cend() | 和 end() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有元素的个数。 |
| max_size() | 返回容器所能容纳元素的最大个数,不同的操作系统,其返回值亦不相同。 |
| find(key) | 查找以值为 key 的元素,如果找到,则返回一个指向该元素的正向迭代器;反之,则返回一个指向容器中最后一个元素之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找值为 key 的元素的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中值为 key 的元素所在的范围。 |
| emplace() | 向容器中添加新元素,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新元素,效率比 insert() 方法高。 |
| insert() | 向容器中添加新元素。 |
| erase() | 删除指定元素。 |
| clear() | 清空容器,即删除容器中存储的所有元素。 |
| swap() | 交换 2 个 unordered_map 容器存储的元素,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储元素时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,unordered_map 容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储元素的数量。 |
| bucket(key) | 返回值为 key 的元素所在桶的编号。 |
| load_factor() | 返回 unordered_map 容器中当前的负载因子。负载因子,指的是的当前容器中存储元素的数量(size())和使用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳count个元(不超过最大负载因子)所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
注意,此容器模板类中没有重载 [ ] 运算符,也没有提供 at() 成员方法。不仅如此,由于 unordered_set 容器内部存储的元素值不能被修改,因此无论使用那个迭代器方法获得的迭代器,都不能用于修改容器中元素的值。
另外,对于实现互换 2 个相同类型 unordered_set 容器的所有元素,除了调用表 2 中的 swap() 成员方法外,还可以使用 STL 标准库提供的 swap() 非成员函数,它们具有相同的名称,用法也相同(都只需要传入 2 个参数即可),仅是调用方式上有差别。
下面的样例演示了表 2 中部分成员方法的用法:
#include <iostream>
#include <string>
#include <unordered_set>
using namespace std;
int main()
{//创建一个空的unordered_set容器std::unordered_set<std::string> uset;//给 uset 容器添加数据uset.emplace("http://c.biancheng.net/java/");uset.emplace("http://c.biancheng.net/c/");uset.emplace("http://c.biancheng.net/python/");//查看当前 uset 容器存储元素的个数cout << "uset size = " << uset.size() << endl;//遍历输出 uset 容器存储的所有元素for (auto iter = uset.begin(); iter != uset.end(); ++iter) {cout << *iter << endl;}return 0;
}
程序执行结果为:
uset size = 3
http://c.biancheng.net/java/
http://c.biancheng.net/c/
http://c.biancheng.net/python/
注意,表 2 中绝大多数成员方法的用法,都和 unordered_map 容器提供的同名成员方法相同,读者可翻阅前面的文章做详细了解,当然也可以到 C++
STL标准库官网查询。
C++ STL unordered_multiset容器详解
前面章节详细地介绍了 unordered_set 容器的特定和用法,在此基础上,本节再介绍一个类似的 C++ STL 无序容器,即 unordered_multiset 容器。
所谓“类似”,指的是 unordered_multiset 容器大部分的特性都和 unordered_set 容器相同,包括:
- unordered_multiset 不以键值对的形式存储数据,而是直接存储数据的值;
- 该类型容器底层采用的也是哈希表存储结构(可阅读《C++ STL无序容器底层实现原理》一文做详细了解),它不会对内部存储的数据进行排序;
- unordered_multiset 容器内部存储的元素,其值不能被修改。
和 unordered_set 容器不同的是,unordered_multiset 容器可以同时存储多个值相同的元素,且这些元素会存储到哈希表中同一个桶(本质就是链表)上。
读者可以这样认为,unordered_multiset 除了能存储相同值的元素外,它和 unordered_set 容器完全相同。
另外值得一提的是,实现 unordered_multiset 容器的模板类并没有定义在以该容器名命名的文件中,而是和 unordered_set 容器共用同一个<unordered_set>头文件,并且也位于 std 命名空间。因此,如果程序中需要使用该类型容器,应包含如下代码:
#include <unordered_set>
using namespace std;
注意,第二行代码不是必需的,但如果不用,则程序中只要用到该容器时,必须手动注明 std 命名空间(强烈建议初学者使用)。
unordered_multiset 容器类模板的定义如下:
template < class Key, //容器中存储元素的类型class Hash = hash<Key>, //确定元素存储位置所用的哈希函数class Pred = equal_to<Key>, //判断各个元素是否相等所用的函数class Alloc = allocator<Key> //指定分配器对象的类型> class unordered_multiset;
需要说明的是,在 99% 的实际场景中,最多只需要使用前 3 个参数(各自含义如表 1 所示),最后一个参数保持默认值即可。
表 1 unordered_multiset 模板类定义
| 参数 | 含义 |
|---|---|
| Key | 确定容器存储元素的类型,如果读者将 unordered_multiset 看做是存储键和值相同的键值对的容器,则此参数则用于确定各个键值对的键和值的类型,因为它们是完全相同的,因此一定是同一数据类型的数据。 |
| Hash = hash | 指定 unordered_multiset 容器底层存储各个元素时所使用的哈希函数。需要注意的是,默认哈希函数 hash 只适用于基本数据类型(包括 string 类型),而不适用于自定义的结构体或者类。 |
| Pred = equal_to | 用于指定 unordered_multiset 容器判断元素值相等的规则。默认情况下,使用 STL 标准库中提供的 equal_to 规则,该规则仅支持可直接用 == 运算符做比较的数据类型。 |
总之,如果 unordered_multiset 容器中存储的元素为自定义的数据类型,则默认的哈希函数 hash 以及比较函数 equal_to 将不再适用,只能自己设计适用该类型的哈希函数和比较函数,并显式传递给 Hash 参数和 Pred 参数。至于如何实现自定义,后续章节会做详细讲解。
创建C++ unordered_multiset容器
考虑到不同场景的需要,unordered_multiset 容器模板类共提供了以下 4 种创建 unordered_multiset 容器的方式。
- 调用 unordered_multiset 模板类的默认构造函数,可以创建空的 unordered_multiset 容器。比如:
std::unordered_multiset<std::string> umset;
如果程序已经引入了 std 命名空间,这里可以省略所有的 std::。
由此,就创建好了一个可存储 string 类型值的 unordered_multiset 容器,该容器底层采用默认的哈希函数 hash 和比较函数 equal_to。
- 当然,在创建 unordered_multiset 容器的同时,可以进行初始化操作。比如:
std::unordered_multiset<std::string> umset{ "http://c.biancheng.net/c/","http://c.biancheng.net/java/","http://c.biancheng.net/linux/" };
通过此方法创建的 umset 容器中,内部存有 3 个 string 类型元素。
- 还可以调用 unordered_multiset 模板中提供的复制(拷贝)构造函数,将现有 unordered_multiset 容器中存储的元素全部用于为新建 unordered_multiset 容器初始化。
例如,在第二种方式创建好 umset 容器的基础上,再创建并初始化一个 umset2 容器:
std::unordered_multiset<std::string> umset2(umset);
由此,umap2 容器中就包含有 umap 容器中所有的元素。
除此之外,C++ 11 标准中还向 unordered_multiset 模板类增加了移动构造函数,即以右值引用的方式,利用临时 unordered_multiset 容器中存储的所有元素,给新建容器初始化。例如:
//返回临时 unordered_multiset 容器的函数
std::unordered_multiset <std::string> retumset() {std::unordered_multiset<std::string> tempumset{ "http://c.biancheng.net/c/","http://c.biancheng.net/java/","http://c.biancheng.net/linux/" };return tempumset;
}
//调用移动构造函数,创建 umset 容器
std::unordered_multiset<std::string> umset(retumset());
注意,无论是调用复制构造函数还是拷贝构造函数,必须保证 2 个容器的类型完全相同。
- 当然,如果不想全部拷贝,可以使用 unordered_multiset 类模板提供的迭代器,在现有 unordered_multiset 容器中选择部分区域内的元素,为新建 unordered_multiset 容器初始化。例如:
//传入 2 个迭代器,
std::unordered_multiset<std::string> umset2(++umset.begin(), umset.end());
通过此方式创建的 umset2 容器,其内部就包含 umset 容器中除第 1 个元素外的所有其它元素。
C++ unordered_multimap容器的成员方法
值得一提的是,unordered_multiset 模板类中提供的成员方法,无论是种类还是数量,都和 unordered_set 类模板一样,如表 2 所示。
表 2 unordered_set 类模板成员方法
| 成员方法 | 功能 |
|---|---|
| begin() | 返回指向容器中第一个元素的正向迭代器。 |
| end(); | 返回指向容器中最后一个元素之后位置的正向迭代器。 |
| cbegin() | 和 begin() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| cend() | 和 end() 功能相同,只不过其返回的是 const 类型的正向迭代器。 |
| empty() | 若容器为空,则返回 true;否则 false。 |
| size() | 返回当前容器中存有元素的个数。 |
| max_size() | 返回容器所能容纳元素的最大个数,不同的操作系统,其返回值亦不相同。 |
| find(key) | 查找以值为 key 的元素,如果找到,则返回一个指向该元素的正向迭代器;反之,则返回一个指向容器中最后一个元素之后位置的迭代器(如果 end() 方法返回的迭代器)。 |
| count(key) | 在容器中查找值为 key 的元素的个数。 |
| equal_range(key) | 返回一个 pair 对象,其包含 2 个迭代器,用于表明当前容器中值为 key 的元素所在的范围。 |
| emplace() | 向容器中添加新元素,效率比 insert() 方法高。 |
| emplace_hint() | 向容器中添加新元素,效率比 insert() 方法高。 |
| insert() | 向容器中添加新元素。 |
| erase() | 删除指定元素。 |
| clear() | 清空容器,即删除容器中存储的所有元素。 |
| swap() | 交换 2 个 unordered_multimap 容器存储的元素,前提是必须保证这 2 个容器的类型完全相等。 |
| bucket_count() | 返回当前容器底层存储元素时,使用桶(一个线性链表代表一个桶)的数量。 |
| max_bucket_count() | 返回当前系统中,容器底层最多可以使用多少桶。 |
| bucket_size(n) | 返回第 n 个桶中存储元素的数量。 |
| bucket(key) | 返回值为 key 的元素所在桶的编号。 |
| load_factor() | 返回容器当前的负载因子。所谓负载因子,指的是的当前容器中存储元素的数量(size())和使用桶数(bucket_count())的比值,即 load_factor() = size() / bucket_count()。 |
| max_load_factor() | 返回或者设置当前 unordered_map 容器的负载因子。 |
| rehash(n) | 将当前容器底层使用桶的数量设置为 n。 |
| reserve() | 将存储桶的数量(也就是 bucket_count() 方法的返回值)设置为至少容纳count个元(不超过最大负载因子)所需的数量,并重新整理容器。 |
| hash_function() | 返回当前容器使用的哈希函数对象。 |
注意,和 unordered_set 容器一样,unordered_multiset 模板类也没有重载 [ ] 运算符,没有提供 at() 成员方法。不仅如此,无论是由哪个成员方法返回的迭代器,都不能用于修改容器中元素的值。
另外,对于互换 2 个相同类型 unordered_multiset 容器存储的所有元素,除了调用表 2 中的 swap() 成员方法外,STL 标准库也提供了 swap() 非成员函数。
下面的样例演示了表 2 中部分成员方法的用法:
#include <iostream>
#include <string>
#include <unordered_set>
using namespace std;
int main()
{//创建一个空的unordered_multiset容器std::unordered_multiset<std::string> umset;//给 uset 容器添加数据umset.emplace("http://c.biancheng.net/java/");umset.emplace("http://c.biancheng.net/c/");umset.emplace("http://c.biancheng.net/python/");umset.emplace("http://c.biancheng.net/c/");//查看当前 umset 容器存储元素的个数cout << "umset size = " << umset.size() << endl;//遍历输出 umset 容器存储的所有元素for (auto iter = umset.begin(); iter != umset.end(); ++iter) {cout << *iter << endl;}return 0;
}
程序执行结果为:
umset size = 4
http://c.biancheng.net/java/
http://c.biancheng.net/c/
http://c.biancheng.net/c/
http://c.biancheng.net/python/
注意,表 2 中绝大多数成员方法的用法,都和 unordered_map 容器提供的同名成员方法相同,读者可翻阅前面的文章做详细了解,当然也可以到C++ STL标准库官网查询。
如何自定义C++ STL无序容器的哈希函数和比较规则?(超级详细)
前面在讲解 unordered_map、unordered_multimap、unordered_set 以及 unordered_multiset 这 4 种无序关联式容器(哈希容器)时,遗留过一个共性问题,即如何给无序容器自定义一个哈希函数和比较规则?
注意,虽然每种无序容器都指定了默认的 hash 哈希函数和 equal_to 比较规则,但它们仅适用于存储基本类型(比如 int、double、float、string 等)数据的无序容器。换句话说,如果无序容器存储的数据类型为自定义的结构体或类,则 STL 标准库提供的 hash 和 equal_to 将不再适用。
C++无序容器自定义哈希函数
我们知道,无序容器以键值对的方式存储数据(unordered_set 和 unordered_multiset 容器可以看做存储的是键和值相等的键值对),且底层采用哈希表结构存储各个键值对。在此存储结构中,哈希函数的功能是根据各个键值对中键的值,计算出一个哈希值(本质就是一个整数),哈希表可以根据该值判断出该键值对具体的存储位置。
简单地理解哈希函数,它可以接收一个元素,并通过内部对该元素做再加工,最终会得出一个整形值并反馈回来。需要注意的是,哈希函数只是一个称谓,其本体并不是普通的函数形式,而是一个函数对象类。因此,如果我们想自定义个哈希函数,就需要自定义一个函数对象类。
关于什么函数对象类,可阅读《C++函数对象详解》一节做详细了解,由于不是本节重点,这里不再赘述。
举个例子,假设有如下一个 Person 类:
class Person {
public:Person(string name, int age) :name(name), age(age) {};string getName() const;int getAge() const;
private:string name;int age;
};
string Person::getName() const {return this->name;
}
int Person::getAge() const {return this->age;
}
在此基础上,假设我们想创建一个可存储 Person 类对象的 unordered_set 容器,考虑到 Person 为自定义的类型,因此默认的 hash 哈希函数不再适用,这时就需要以函数对象类的方式自定义一个哈希函数。比如:
class hash_fun {
public:int operator()(const Person &A) const {return A.getAge();}
};
注意,重载 ( ) 运算符时,其参数必须为 const 类型,且该方法也必须用 const 修饰。
可以看到,我们利用 hash_fun 函数对象类的 ( ) 运算符重载方法,自定义了适用于 Person 类对象的哈希函数。该哈希函数每接收一个 Person 类对象,都会返回该对象的 age 成员变量的值。
事实上,默认的 hash 哈希函数,其底层也是以函数对象类的形式实现的。
由此,在创建存储 Person 类对象的 unordered_set 容器时,可以将 hash_fun 作为参数传递给该容器模板类中的 Pred 参数:
std::unordered_set<Person, hash_fun> myset;
但是,此时创建的 myset 容器还无法使用,因为该容器使用的是默认的 std::equal_to 比较规则,但此规则并不适用于该容器。
C++无序容器自定义比较规则
和哈希函数一样,无论创建哪种无序容器,都需要为其指定一种可比较容器中各个元素是否相等的规则。
值得一提的是,默认情况下无序容器使用的 std::equal_to 比较规则,其本质也是一个函数对象类,底层实现如下:
template<class T>
class equal_to
{
public: bool operator()(const T& _Left, const T& _Right) const{return (_Left == _Right);}
};
可以看到,该规则在底层实现过程中,直接用 == 运算符比较容器中任意 2 个元素是否相等,这意味着,如果容器中存储的元素类型,支持直接用 == 运算符比较是否相等,则该容器可以使用默认的 std::equal_to 比较规则;反之,就不可以使用。
显然,对于我们上面创建的 myset 容器,其内部存储的是 Person 类对象,不支持直接使用 == 运算符做比较。这种情况下,有以下 2 种方式可以解决此问题:
- 在 Person 类中重载 == 运算符,这会使得 std::equal_to 比较规则中使用的 == 运算符变得合法,myset 容器就可以继续使用 std::equal_to 比较规则;
- 以函数对象类的方式,自定义一个适用于 myset 容器的比较规则。
1) 重载==运算符
如果选用第一种解决方式,仍以 Python 类为例,在此类的外部添加如下语句:
bool operator==(const Person &A, const Person &B) {return (A.getAge() == B.getAge());
}
注意,这里在重载 == 运算符时,2 个参数必须用 const 修饰。
可以看到,通过此方式重载的运算符,当 std::equal_to 函数对象类中直接比较 2 个 Person 类对象时,实际上是在比较这 2 个对象的 age 成员变量是否相等。换句话说,此时的 std::equal_to 规则的含义为:只要 2 个 Person对象的 age 成员变量相等,就认为这 2 个 Person 对象是相等的。
重载 == 运算符之后,就能以如下方式创建 myset 容器:
std::unordered_set<Person, hash_fun> myset{ {"zhangsan", 40},{"zhangsan", 40},{"lisi", 40},{"lisi", 30} };
注意,虽然这里给 myset 容器初始化了 4 个 Person 对象,但由于比较规则以各个类对象的 age 值为准,myset 容器会认为前 3 个 Person 对象是相等的,因此最终 myset 容器只会存储 {“zhangsan”, 40} 和 {“lisi”, 30}。
2) 以函数对象类的方式自定义比较规则
除此之外,还可以完全舍弃 std::equal_to,以函数对象类的方式自定义一个比较规则。比如:
class mycmp {
public:bool operator()(const Person &A, const Person &B) const {return (A.getName() == B.getName()) && (A.getAge() == B.getAge());}
};
在 mycmp 规则的基础上,我们可以像如下这样创建 myset 容器:
std::unordered_set<Person, hash_fun, mycmp> myset{ {"zhangsan", 40},{"zhangsan", 40},{"lisi", 40},{"lisi", 30} };
由此创建的 myset 容器,虽然初始化了 4 个 Person 对象,但 myset 容器根据 mycmp 比较规则,可以识别出前 2 个是相等的,因此最终该容器内部存有 {“zhangsan”, 40}、{“lisi”, 40} 和 {“lisi”, 30} 这 3 个 Person 对象。
总结
总的来说,当无序容器中存储的是基本类型(int、double、float、string)数据时,自定义哈希函数和比较规则,都只能以函数对象类的方式实现。
而当无序容器中存储的是用结构体或类自定义类型的数据时,自定义哈希函数的方式仍只有一种,即使用函数对象类的形式;而自定义比较规则的方式有两种,要么也以函数对象类的方式,要么仍使用默认的 std::equal_to 规则,但前提是必须重载 == 运算符。
如下是本节的完整代码,读者可直接拷贝下来,加深对本节知识的理解:
#include <iostream>
#include <string>
#include <unordered_set>
using namespace std;
class Person {
public:Person(string name, int age) :name(name), age(age) {};string getName() const;int getAge() const;
private:string name;int age;
};
string Person::getName() const {return this->name;
}
int Person::getAge() const {return this->age;
}
//自定义哈希函数
class hash_fun {
public:int operator()(const Person &A) const {return A.getAge();}
};
//重载 == 运算符,myset 可以继续使用默认的 equal_to<key> 规则
bool operator==(const Person &A, const Person &B) {return (A.getAge() == B.getAge());
}
//完全自定义比较规则,弃用 equal_to<key>
class mycmp {
public:bool operator()(const Person &A, const Person &B) const {return (A.getName() == B.getName()) && (A.getAge() == B.getAge());}
};
int main()
{//使用自定义的 hash_fun 哈希函数,比较规则仍选择默认的 equal_to<key>,前提是必须重载 == 运算符std::unordered_set<Person, hash_fun> myset1{ {"zhangsan", 40},{"zhangsan", 40},{"lisi", 40},{"lisi", 30} };//使用自定义的 hash_fun 哈希函数,以及自定义的 mycmp 比较规则std::unordered_set<Person, hash_fun, mycmp> myset2{ {"zhangsan", 40},{"zhangsan", 40},{"lisi", 40},{"lisi", 30} };cout << "myset1:" << endl;for (auto iter = myset1.begin(); iter != myset1.end(); ++iter) {cout << iter->getName() << " " << iter->getAge() << endl;}cout << "myset2:" << endl;for (auto iter = myset2.begin(); iter != myset2.end(); ++iter) {cout << iter->getName() << " " << iter->getAge() << endl;}return 0;
}
程序执行结果为:
myset1:
zhangsan 40
lisi 30
myset2:
lisi 40
zhangsan 40
lisi 30
C++ STL容器这么多,怎样选出最适合的?
到此为止,本教程已经讲解了 C++ STL 标准库中所有容器的特性、功能以及用法,但考虑到一些读者可能在纠结“什么场景中选用哪个容器”这个问题,本节将带领大家系统回顾一下所学的这些容器,并给出一个解决此问题的思路。
值得一提的是,虽然 STL 标准库还有迭代器、算法、函数对象等,但容器仍是大多数 C++ 程序员关注的焦点。首先,和普通数组相比,容器支持动态扩容和收缩,还可以自行管理存储的元素(例如排序),同时还提供有诸多成员方法,大大提高了开发效率等等。其次,每个容器的底层实现,都采用的是精心挑选的数据结构,这意味着在使用这些容器时,不用担心它们的执行效率。
总的来说,C++ STL 标准库(以 C++ 11 为准)提供了以下几种容器供我们选择:
- 序列式容器:array、vector、deque、list 和 forward_list;
- 关联式容器:map、multimap、set 和 multiset;
- 无序关联式容器:unordered_map、unordered_multimap、unordered_set 和 unordered_multiset;
- 容器适配器:stack、queue 和 priority_queue。
注意,容器适配器本质上也属于容器,关于以上各个容器适配器,后续章节会做详细讲解。
上面是依据容器类型进行分类的。实际上,每个容器所具有的特性都和其底层选用的存储结构息息相关。根据容器底层采用的是连续的存储空间,还是分散的存储空间(以链表或者树作为存储结构),还可以将上面容器分为如下两类:
- 采用连续的存储空间:array、vector、deque;
- 采用分散的存储空间:list、forward_list 以及所有的关联式容器和哈希容器。
注意,这里将 deque 容器归为使用连续存储空间的这一类,是存在争议的。因为 deque 容器底层采用一段一段的连续空间存储元素,但是各段存储空间之间并不一定是紧挨着的。关于 deque 容器的底层存储结构(可阅读《C++ STL deque底层实现原理》一节详细了解),读者理解即可,这里不必深究。
既然 C++ STL 标准库提供了这么多种容器,在实际场景中我们应该如何选择呢?
要想选择出适用于该特定场景的最佳容器,需要综合考虑多种实际因素,例如:
- 是否需要在容器的指定位置插入新元素?如果需要,则只能选择序列式容器,而关联式容器和哈希容器是不行的;
- 是否对容器中各元素的存储位置有要求?如果没有,则可以考虑使用哈希容器,反之就要避免使用哈希容器;
- 是否需要使用指定类型的迭代器?举个例子,如果必须是随机访问迭代器,则只能选择 array、vector、deque;如果必须是双向迭代器,则可以考虑 list 序列式容器以及所有的关联式容器;如果必须是前向迭代器,则可以考虑 forward_list 序列式容器以及所有的哈希容器;
- 当发生新元素的插入或删除操作时,是否要避免移动容器中的其它元素?如果是,则要避开 array、vector、deque,选择其它容器;
- 容器中查找元素的效率是否为关键的考虑因素?如果是,则应优先考虑哈希容器。
当然,以上问题并没有涵盖所有的情形,只是起到一个抛砖引玉的作用。在实际场景中,我们需要考虑更多的因素(例如对比各个容器解决当前问题所需的时间复杂度),经过层层筛选,最终找到适合该场景的那个容器。
相关文章:
)
C++ STL无序关联式容器(详解)
STL无序关联式容器 继 map、multimap、set、multiset 关联式容器之后,从本节开始,再讲解一类“特殊”的关联式容器,它们常被称为“无序容器”、“哈希容器”或者“无序关联容器”。 注意,无序容器是 C 11 标准才正式引入到 STL 标…...
Python爬虫解析工具之xpath使用详解
文章目录 一、数据解析方式二、xpath介绍三、环境安装1. 插件安装2. 依赖库安装 四、xpath语法五、xpath语法在Python代码中的使用 一、数据解析方式 爬虫抓取到整个页面数据之后,我们需要从中提取出有价值的数据,无用的过滤掉。这个过程称为数据解析&a…...

Linux防火墙报错:Failed to start firewalld.service Unit is masked
Linux防火墙报错:Failed to start firewalld.service: Unit is masked. 1、故障现象: 启动防火墙失败,报错情况如下: systemctl start firewalld # 报错: Failed to start firewalld.service: Unit is masked.原因是…...

前端面试:【Vuex】Vue.js的状态管理利器
嗨,亲爱的Vuex探险家!在Vue.js开发的旅程中,有一个强大的状态管理库,那就是Vuex。Vuex是Vue.js的官方状态管理工具,通过State、Mutation、Action和Module等核心概念,协助你轻松管理应用的状态。 1. 什么是V…...
Kotlin协程runBlocking并发launch,Semaphore同步1个launch任务运行
Kotlin协程runBlocking并发launch,Semaphore同步1个launch任务运行 <dependency><groupId>org.jetbrains.kotlinx</groupId><artifactId>kotlinx-coroutines-core</artifactId><version>1.7.3</version><type>pom&…...

c++ Union之妙用
union的作用基本是它里面的变量都用了同一块内存,跟起了别名一样,类型不一样的别名。 基本用法: struct Union{union {float a;int b;};};Union u;u.a 2.0f;std::cout << u.a << "," << u.b << std::endl…...

JSON的处理
1、JSON JSON(JavaScript Object Notation):是一种轻量级的数据交换格式。 它是基于 ECMAScript 规范的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。 简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。易于人阅读和编写&#…...
matlab使用教程(20)—插值基础
1.网格和散点样本数据 插值是在位于一组样本数据点域中的查询位置进行函数值估算的方法。函数值是根据最接近查询点的样本数据点计算的。MATLAB 根据样本数据的结构,可以执行两种插值。样本数据可以形成网格,也可以是分散的。 网格化的样本数据使得插值…...
Python功能制作之简单的3D特效
需要导入的库: pygame: 这是一个游戏开发库,用于创建多媒体应用程序,提供了处理图形、声音和输入的功能。 from pygame.locals import *: 导入pygame库中的常量和函数,用于处理事件和输入。 OpenGL.GL: 这是OpenGL的Python绑定…...

leetcode-5-最长回文串
题目描述 给你一个字符串 s,找到 s 中最长的回文子串。 如果字符串的反序与原始字符串相同,则该字符串称为回文字符串。 示例 1: 输入:s “babad” 输出:“bab” 解释:“aba” 同样是符合题意的答案。 示…...

二、Oracle 数据库安装集
一、CentOS 安装 OCI下载地址 1. 启动 # 1. 登录服务器,切换到oracle用户,或者以oracle用户登录 su - oracle# 2. 打开监听服务 lsnrctl start# 3. 查看Oracle监听器运行状况 lsnrctl status# 4. 以sys用户身份登录 sqlplus /nolog# 5. 切换用户conn 用…...

【Python】Python中的常用函数及用法
目录 输入输出类型转换引用哈希字符串常用操作判断类型查找替换大小写转换文本对齐去除空白字符拆分和连接 列表常用操作增删改查增删改统计排序 元组常用操作 字典常用操作 范围随机数学比较常用函数三角函数数学常量 输入 input():从键盘等待用户的输入࿰…...
基于JavaEE的ssm公司员工信息管理系统的设计与实现
基于JavaEE的ssm公司员工信息管理系统的设计与实现043 开发工具:idea 数据库mysql5.7 数据库链接工具:navcat,小海豚等 技术:ssm 摘 要 现代经济快节奏发展以及不断完善升级的信息化技术,让传统数据信息的管理升级为软件存…...
)
cornerstoneJS加载图片(base、矩阵)
cornerstoneJS默认加载dicom影像数据,将识别到的dicom数据转换成imageData数据,在界面上展示。故,cornerstoneJS也可直接加载imageData。 imageData数据的data是一个数组,每四个元素代表一个点,四个元素分别表示R、G、…...
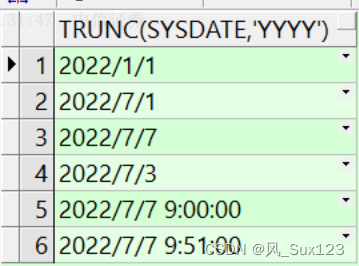
3.Trunc截断函数用法
TRUNC函数用于对值进行截断 用法有两种:TRUNC(NUMBER)表示截断数字,TRUNC(date)表示截断日期 (1)截断数字 格式:TRUNC(n1,n2),n1表示被截断的数字…...

腾讯云 CODING 荣获 TiD 质量竞争力大会 2023 软件研发优秀案例
点击链接了解详情 8 月 13-16 日,由中关村智联软件服务业质量创新联盟主办的第十届 TiD 2023 质量竞争力大会在北京国家会议中心召开。本次大会以“聚焦数字化转型 探索智能软件研发”为主题,聚焦智能化测试工程、数据要素、元宇宙、数字化转型、产融合作…...

VSCode如何为远程安装预设(固定)扩展
背景 在使用VSCode进行远程开发时(python开发之远程开发工具选择_CodingInCV的博客-CSDN博客),特别是远程的机器经常变化时(如机器来源于动态分配),每次连接新的远程时,都不得不手动安装一些开…...

一文解析HTTP与HTTPS,它们的区别和联系
一文解析HTTP与HTTPS,它们的区别和联系 HTTP和HTTPS之间不同点 尽管HTTP和HTTPS在安全性方面存在差异,但它们仍然共享许多相同的基本特征和功能。这些相同点使得HTTP成为广泛应用的标准协议,并且HTTPS作为更安全的替代方案被广泛采用。HTTP…...
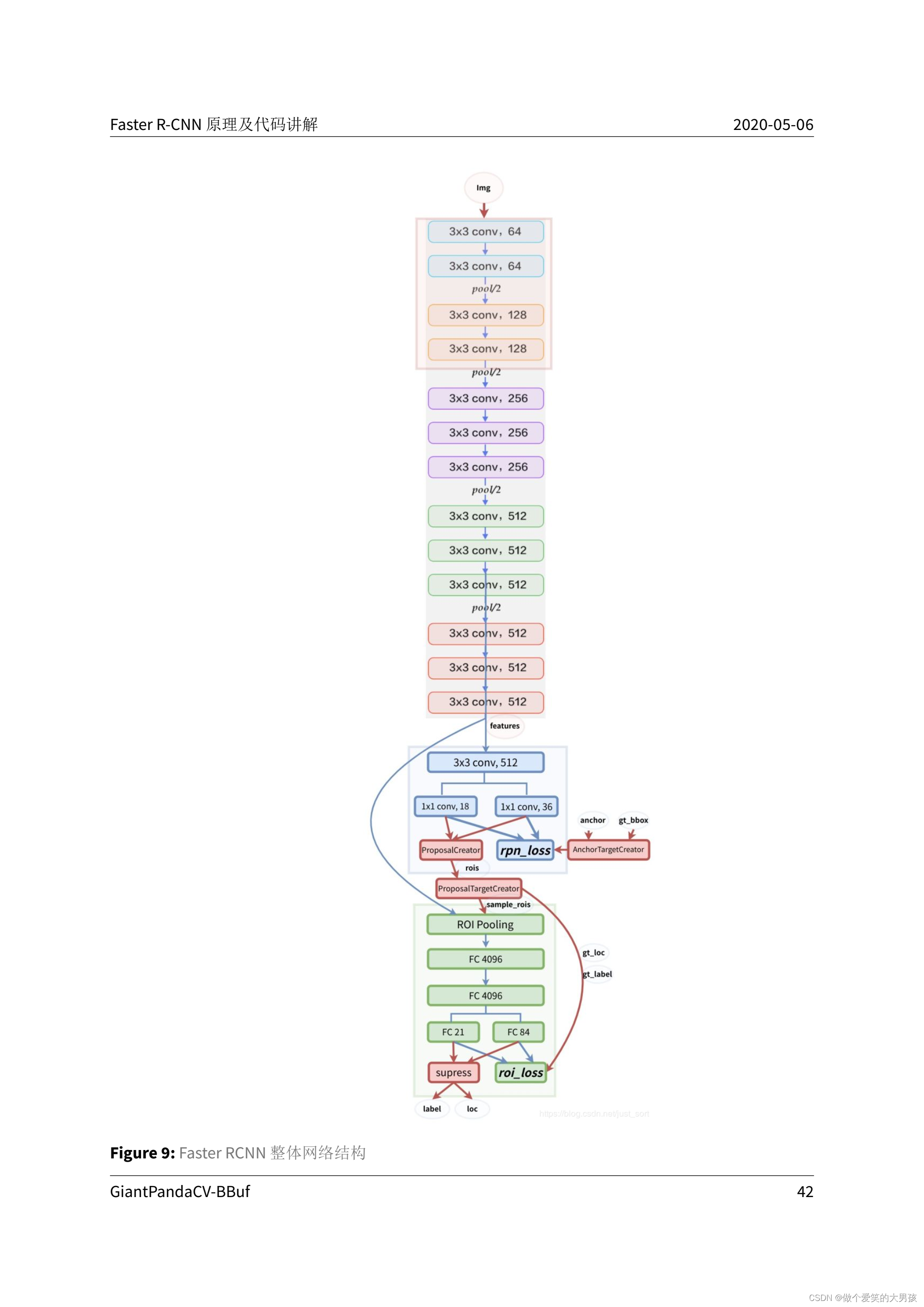
Faster RCNN网络数据流总结
前言 在学习Faster RCNN时,看了许多别人写的博客。看了以后,对Faster RCNN整理有了一个大概的了解,但是对训练时网络内部的数据流还不是很清楚,所以在结合这个版本的faster rcnn代码情况下,对网络数据流进行总结。以便…...

拒绝摆烂!C语言练习打卡第五天
🔥博客主页:小王又困了 📚系列专栏:每日一练 🌟人之为学,不日近则日退 ❤️感谢大家点赞👍收藏⭐评论✍️ 目录 一、选择题 📝1.第一题 📝2.第二题 Ὅ…...

ai辅助开发:让快马生成智能助手,链接notepad下载与个性化代码推荐
今天想和大家分享一个有趣的实践:如何用AI辅助开发的方式,让Notepad这个老牌文本编辑器焕发新生。我们平时下载Notepad可能只是简单获取软件,但如果结合AI能力,就能把"下载-使用"的流程升级成"智能助手"体验。…...

实战LangGraph构建智能客服系统:在快马平台实现工单自动分类与处理全流程
今天想和大家分享一个用LangGraph构建智能客服系统的实战经验。这个项目主要解决工单自动分类和处理的问题,整个过程在InsCode(快马)平台上完成,从开发到部署一气呵成。 项目背景与需求分析 传统客服系统需要人工处理大量工单,效率低下且容易…...

OpenClaw自动化周报生成:Qwen3-32B私有镜像精准提取Git提交记录
OpenClaw自动化周报生成:Qwen3-32B私有镜像精准提取Git提交记录 1. 为什么需要自动化周报生成 每周五下午,我都会面临同样的困扰:需要从零散的Git提交记录中手动整理本周工作内容,再拼凑成一份结构化的周报。这个过程不仅耗时&a…...
)
告别C盘爆炸!手把手教你将Dify+Docker数据盘迁移到D盘(附.ENV配置详解)
告别C盘爆炸!手把手教你将DifyDocker数据盘迁移到D盘(附.ENV配置详解) Windows系统盘空间告急是许多开发者的共同烦恼,尤其是当你开始使用Docker部署AI开发环境时。C盘空间像被黑洞吞噬一样迅速消失,系统运行速度也随之…...
和fmod()解决C语言浮点数计算中的常见坑)
手把手教你用modf()和fmod()解决C语言浮点数计算中的常见坑
深入解析C语言浮点数计算:modf()与fmod()的实战应用 浮点数计算在C语言开发中无处不在,从游戏物理引擎到嵌入式传感器数据处理,精确的浮点运算直接关系到程序行为的正确性。然而,许多开发者第一次遭遇浮点数计算误差时,…...

多模态扩展实验:OpenClaw+Qwen3-32B处理图片描述生成
多模态扩展实验:OpenClawQwen3-32B处理图片描述生成 1. 实验背景与动机 最近在探索如何将OpenClaw的自动化能力扩展到视觉领域。作为一个长期依赖文本交互的框架,OpenClaw能否结合多模态大模型处理图像任务?这引发了我的兴趣。恰好手头有台…...

【Mojo跨语言互操作权威配置白皮书】:实测TensorFlow/NumPy/Pandas三方库零报错接入方案
第一章:Mojo跨语言互操作的核心原理与架构定位Mojo并非传统意义上的独立运行时语言,而是以“Python超集”为设计原点、深度嵌入LLVM生态的系统级编程语言。其跨语言互操作能力不依赖FFI桥接层或胶水代码,而是通过统一的中间表示(M…...

GitHub下载加速终极指南:告别龟速,3分钟让下载速度飙升300%
GitHub下载加速终极指南:告别龟速,3分钟让下载速度飙升300% 【免费下载链接】Fast-GitHub 国内Github下载很慢,用上了这个插件后,下载速度嗖嗖嗖的~! 项目地址: https://gitcode.com/gh_mirrors/fa/Fast-GitHub …...

LaTeX排版踩坑记:用了soul包高亮,为什么一加\cite就报错?
LaTeX排版进阶:soul包高亮冲突的底层原理与系统化解决方案 当你正在用LaTeX优雅地排版论文,突然在引用文献时遭遇神秘的报错——这种体验就像穿着正装踩到香蕉皮。soul包作为文本装饰的瑞士军刀,其高亮和删除线功能深受喜爱,但一旦…...

OneAPI 百度文心一言ERNIE-Bot接入:千帆平台Key对接指南
OneAPI 百度文心一言ERNIE-Bot接入:千帆平台Key对接指南 安全提示:使用 root 用户初次登录系统后,务必修改默认密码 123456! 1. 引言:为什么需要统一的API管理平台 在当今AI技术快速发展的时代,企业和开发…...