OrienterNet: visual localization in 2D public maps with neural matching 论文阅读
论文信息
题目:OrienterNet: visual localization in 2D public maps with neural matching
作者:Paul-Edouard Sarlin, Daniel DeTone
项目地址:github.com/facebookresearch/OrienterNet
来源:CVPR
时间:2023
Abstract
人类可以使用简单的 2D 地图在 3D 环境中定位自己。不同的是,视觉定位算法主要依赖于复杂的 3D 点云,随着时间的推移,这些点云的构建、存储和维护成本高昂。
我们通过引入 OrienterNet 来弥补这一差距,这是第一个深度神经网络,可以使用与人类使用的相同的 2D 语义图以亚米级精度定位图像。 OrienterNet 通过将神经鸟瞰图与 OpenStreetMap 中开放且全局可用的地图进行匹配来估计查询图像的位置和方向,使任何人都可以在任何此类地图可用的地方进行本地化。 OrienterNet 仅受相机姿势监督,但学习以端到端的方式与各种地图元素进行语义匹配。为了实现这一目标,我们引入了一个大型众包图像数据集,其中包含从汽车、自行车和行人的不同角度拍摄的 12 个城市的图像。
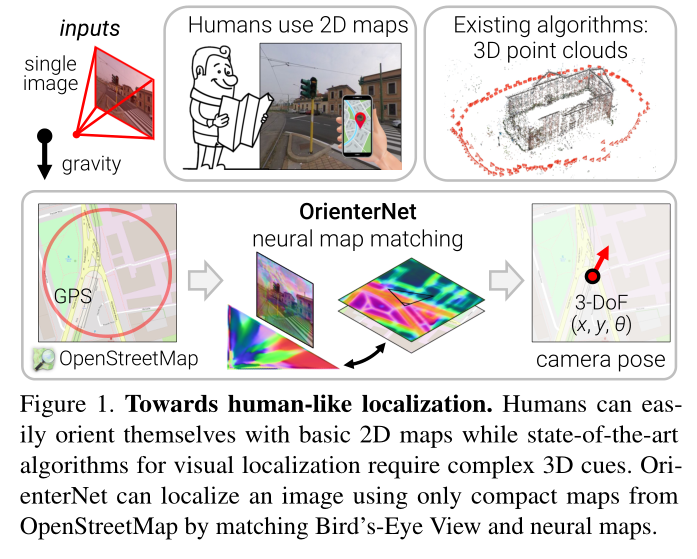
Introduction
3D 地图的存储成本也很高,因为它们比基本 2D 地图大几个数量级。这会阻碍在设备上执行本地化,并且通常需要昂贵的云基础设施。
本文介绍了第一种方法,该方法可以在人类使用的相同地图的情况下以亚米级精度定位单个图像和图像序列。这些平面地图仅编码少数重要物体的位置和粗略二维形状,而不编码它们的外观或高度。此类地图非常紧凑,尺寸比 3D 地图小 104 倍,因此可以存储在移动设备上并用于大区域内的设备上定位。我们通过 OpenStreetMap (OSM) [46] 展示了这些功能,这是一个开放访问且由社区维护的世界地图,使任何人都可以免费在任何地方进行本地化。该解决方案不需要随着时间的推移构建和维护成本高昂的 3D 地图,也不需要收集潜在敏感的地图数据。
具体来说,我们的算法估计 2D 地图中校准图像的 3-DoF 位姿,即位置和航向。该估计是概率性的,因此可以与先前不准确的 GPS 融合,或者与多摄像机装备或图像序列的多个视图融合。由此产生的解决方案比消费级 GPS 传感器更准确,并且基于特征匹配达到更接近传统管道的精度水平 [57, 60]。
我们的方法称为 OrienterNet,是一种深度神经网络,它模仿人类在查看地图时在环境中定位自己的方式,即将度量二维地图与从视觉观察中得出的心理地图进行匹配 [37,45]。 OrienterNet 学习以端到端的方式比较视觉和语义数据,仅受相机姿势的监督。通过利用 OSM 公开的高度多样性的语义类(从道路和建筑物到长凳和垃圾桶等物体),可以产生准确的姿势估计。
OrienterNet 速度快且可解释性强。我们训练了一个单一模型,该模型可以很好地推广到以前未见过的城市以及各种相机从不同角度拍摄的图像,例如汽车、自行车或头戴式、专业或消费类相机。这些功能的关键是通过 Mapillary 平台从世界各地的城市众包的图像的新的大规模训练数据集。
我们的实验表明,OrienterNet 大大优于之前在驾驶场景中的定位方面的工作,并且在应用于 Aria 眼镜记录的数据时,大大提高了其在 AR 用例中的准确性。我们相信,我们的方法是朝着 AR 和机器人技术的连续、大规模、设备上本地化迈出的重要一步。
Related work
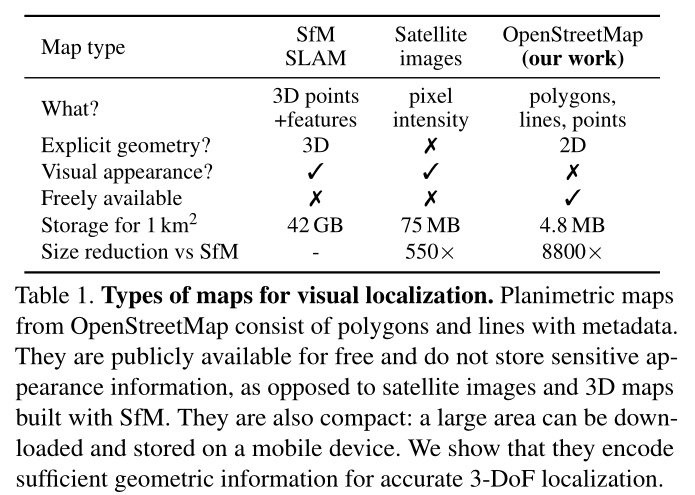
我们可以使用多种类型的地图表示来定位世界上的图像:根据地面图像构建的 3D 地图、2D 俯视卫星图像或来自 OpenStreetMap 的更简单的平面地图。表 1 总结了它们的差异
Mapping with ground-level images
使用地面图像绘制地图是迄今为止最常见的方法。通过图像检索进行地点识别可在给定一组参考图像的情况下提供粗略定位 [4,23,32,72]。为了估计厘米级精度的 6-DoF 姿势,基于特征匹配的算法需要 3D 地图 [31,39,57,60]。它们由稀疏点云组成,通常使用 Structure-fromMotion (SfM) [2,22,36,43,61,67] 从跨多个视图匹配的稀疏点构建 [9,38,53]。新查询图像的姿态由几何解算器 [10,26,33] 根据与地图的对应关系进行估计。虽然一些工作 [70, 79] 利用额外的传感器输入,例如粗略的 GPS 位置、重力方向和相机高度,但最近的定位系统非常准确且强大,这主要归功于学习的功能 [18, 19, 51, 58, 73 ]。
然而,这涉及具有大量内存占用的 3D 地图,因为它们存储具有高维视觉描述符的密集 3D 点云。个人数据泄露到地图中的风险也很高。
Localization with overhead imagery
通过假设世界大部分是平面并且重力方向通常由无处不在的机载惯性传感器给出,使用俯视图像进行定位可以将问题简化为估计 3-DoF 位姿。大量工作集中于跨视图地面到卫星定位。虽然卫星图像比 3D 地图更紧凑,但捕捉卫星图像的成本很高,通常不是免费的,而且以高分辨率存储仍然很繁重。大多数方法仅通过补丁检索来估计粗略位置[30,63,65,82]。此外,估计方向的工作并不准确[62,64,77],产生超过几米的误差。
Planimetric maps
平面地图丢弃任何外观和高度信息,仅保留地图元素的 2D 位置、形状和类型。 OSM 是此类地图的流行平台,因为它是免费的并且在全球范围内可用。给定一个查询区域,其开放 API 将地理特征列表公开为带有元数据的多边形,其中包括具有一千多种不同对象类型的细粒度语义信息。然而,过去的工作为单个或几个语义类设计检测器,缺乏鲁棒性。其中包括建筑轮廓 [5,6,15–17,74,75]、道路轮廓 [21,54] 或交叉口 [41,47,78]、车道标记 [25, 48]、街道设施 [14, 76] ,甚至文本[27]。
最近的工作通过使用端到端深度网络从地图图块计算更丰富的表示来利用更多线索[56, 80]。当他们检索具有全局图像描述符的地图图块时,他们仅估计粗略位置。在室内场景中,平面图是现有作品中常用的平面地图[28,42]。它们需要室外空间通常无法提供的高度或能见度信息。通过将射影几何的约束与端到端学习的表达能力相结合,利用 OSM 中提供的所有语义类,我们的方法在准确性和鲁棒性方面比之前的所有工作有了显着的进步。
Localizing single images in 2D maps
Problem formulation:在典型的定位场景中,我们的目标是估计图像在世界中的绝对 6-DoF 位姿。在现实的假设下,我们将这个问题简化为估计由位置 ( x , y ) ∈ R 2 (x, y) \in \mathbb{R}^2 (x,y)∈R2 和航向角 θ ∈ ( − π , π ] θ \in (−π, π] θ∈(−π,π] 组成的 3-DoF 位姿 ξ = ( x , y , θ ) \xi = (x, y, θ) ξ=(x,y,θ)。
这里我们考虑一个地心坐标系,其 x-y-z 轴对应于东西向垂直方向。
首先,我们可以很容易地假设知道重力的方向,这是人类从内耳自然拥有的信息,并且可以通过大多数设备中嵌入的惯性单元来估计。我们还观察到,我们的世界大多是平面的,室外空间中人和物体的运动大多局限于二维表面。在局部 SLAM 重建中,相机的精确高度始终可以估计为到地面的距离。
Input:我们考虑具有已知针孔相机校准的图像 I I I。图像通过根据已知重力计算出的单应性进行校正,使其横滚和倾斜为零——然后其主轴是水平的。我们还得到了先验 ξ p r i o r \xi _{prior} ξprior 的粗略位置。这可能是一个嘈杂的 GPS 位置或之前的定位估计,并且可能偏离 20 米以上。对于城市峡谷等多路径环境中的消费级传感器来说,这是一个现实的假设。
地图数据是从 OSM 查询的,作为以 ξ p r i o r \xi _{prior} ξprior 为中心的正方形区域,其大小取决于先验的噪声程度。数据由多边形、线和点的集合组成,每个多边形、线和点都具有给定的语义类,并且其坐标在同一局部参考系中给出。
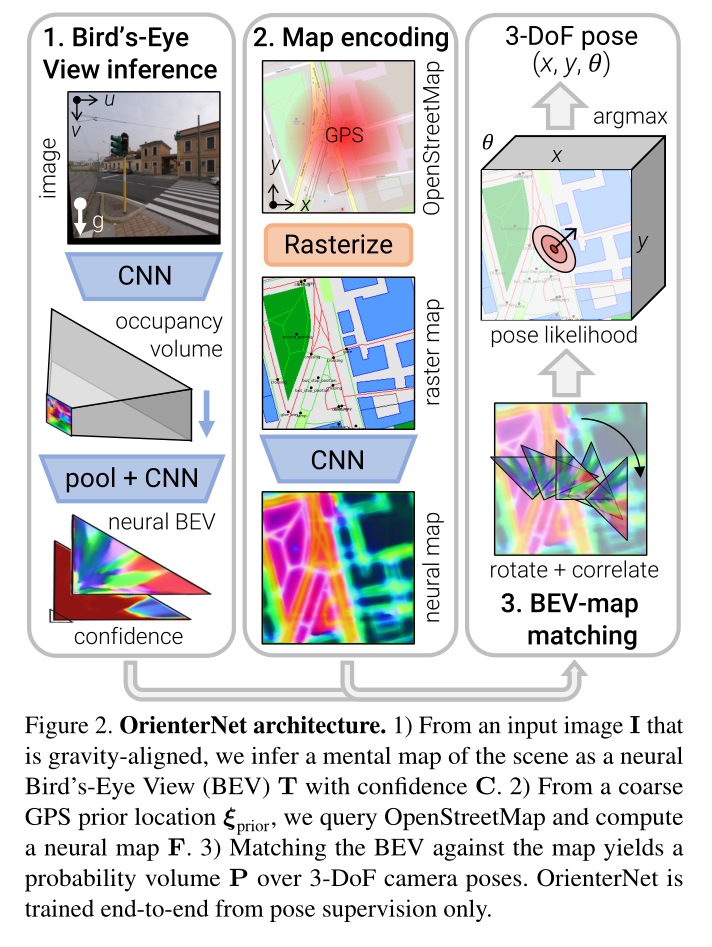
Overview-Figure 2:OrienterNet 由三个模块组成:
1)图像 CNN 从图像中提取语义特征,并通过推断场景的 3D 结构将其提升为正交鸟瞰图 (BEV) 表示 T T T。
2)OSM图由map-CNN编码为嵌入语义和几何信息的神经图 F F F。
3) 我们通过将 BEV 与地图进行详尽匹配来估计相机姿态 ξ \xi ξ 上的概率分布。
Neural Bird’s-Eye View inference
Overview:从单个图像 I I I 中,我们推断出 BEV 表示 T ∈ R L × D × N T ∈ \mathbb{R}^{L×D×N} T∈RL×D×N,分布在与相机平截头体对齐的 L × D L×D L×D 网格上,并由 N 维特征组成。网格上的每个特征都被分配一个置信度,产生一个矩阵 C ∈ [ 0 , 1 ] L × D C ∈ [0, 1]^{L×D} C∈[0,1]L×D。这种 BEV 类似于人类在俯视图中进行自我定位时从环境中推断出的心理地图 [37, 45]。
图像和地图之间的跨模态匹配需要从视觉线索中提取语义信息。事实证明,单目深度估计可以依赖于语义线索 [3],并且这两项任务具有有益的协同作用 [29, 34]。因此,我们依靠单目推理将语义特征提升到 BEV 空间。
继过去处理语义任务的工作[49,52,55]之后,我们分两步获得神经 BEV:
i)我们通过将图像列映射到极射线将图像特征转移到极坐标表示,
ii)我们对极坐标网格重新采样成笛卡尔网格(图 3)。
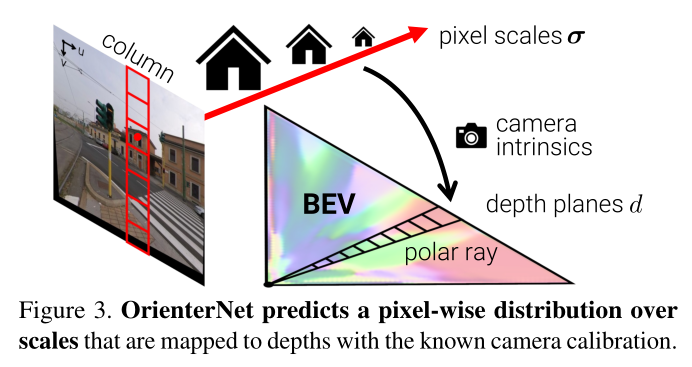
Polar representation:CNN Φ i m a g e Φ_{image} Φimage 首先从图像中提取 U × V U×V U×V 特征图 X ∈ R U × V × N X ∈ \mathbb{R}^{U×V ×N} X∈RU×V×N。我们考虑在相机前面以规则间隔 Δ 采样的 D 个深度平面,即具有值 i ⋅ Δ ∣ i ∈ 1... D {i · Δ|i ∈ {1 ... D}} i⋅Δ∣i∈1...D。由于图像是重力对齐的,因此 X 中的每个 U 列都对应于 3D 空间中的一个垂直平面。因此,我们将每一列映射到 U × D U×D U×D 极坐标表示中的一条射线 X ^ ∈ R U × D × N \hat{X} ∈ \mathbb{R}^{U×D×N} X^∈RU×D×N 。我们通过预测每个极像元 ( u , d ) (u, d) (u,d) 对应图像列中像素的概率分布 α u , d ∈ [ 0 , 1 ] V α_{u,d} ∈ [0, 1]^V αu,d∈[0,1]V 来实现此目的:
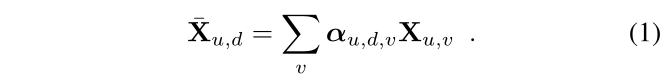
我们不是直接回归深度上的分布 α α α,而是回归独立于相机校准参数的尺度上的分布 S S S。比例尺是 3D 世界和图像 [3] 中物体大小的比率,等于焦距 f 和深度的比率。我们考虑一组 S S S 对数分布尺度

该公式相当于从极射线到图像列的注意机制,其分数从线性深度重新采样到对数尺度。当比例不明确且难以推断时,视觉特征沿着射线分布在多个深度上,但仍然为定位良好的地图点提供几何约束[35]。针对驾驶场景量身定制的作品 [49,52,55] 考虑具有相同模型的相机捕获的数据集并直接回归 α α α。因此,他们将焦距编码在网络权重中,学习从对象尺度到深度的映射。不同的是,通过假设焦距是系统的输入,我们的公式可以在测试时推广到任意相机。
BEV grid:我们通过沿横向从U极射线到以相同间隔Δ间隔的L列的线性插值,将极特征映射到尺寸为 L × D L×D L×D的笛卡尔网格。然后,生成的特征网格由小型 CNN Φ B E V Φ_{BEV} ΦBEV 处理,输出神经 BEV T T T 和置信度 C C C
Neural map encoding
我们将平面图编码为结合了几何和语义的 W × H W ×H W×H 神经图 F ∈ R W × H × N F ∈ \mathbb{R}^{W ×H×N} F∈RW×H×N。
Map data:OpenStreetMap 元素根据其语义类定义为多边形区域、多段线或单点。区域的示例包括建筑物占地面积、草地、停车场;线包括道路或人行道中心线、建筑物轮廓;点包括树木、公交车站、商店等。附录 B.1 列出了所有类别。这些元素的准确定位提供了定位所需的几何约束,而它们丰富的语义多样性有助于消除不同姿势的歧义。
Preprocessing:我们首先将区域、线和点栅格化为具有固定地面采样距离 Δ 的 3 通道图像,例如50 厘米/像素。这种表示比以前的作品 [56, 80] 中执行的人类可读 OSM 切片的简单光栅化更丰富、更准确。
Encoding:我们将每个类与学习的 N 维嵌入相关联,产生 W × H × 3 N W×H×3N W×H×3N 特征图。然后通过 CNN Φ m a p Φ_{map} Φmap 将其编码到神经图 F 中,提取对定位有用的几何特征。 F 没有被归一化,因为我们让 Φ m a p Φ_{map} Φmap 调整它的范数作为匹配中的重要性权重。图 4 中的示例表明,F 通常看起来像一个距离场,我们可以在其中清楚地识别建筑物的拐角或相邻边界等独特特征。
Φ m a p Φ_{map} Φmap 还预测地图每个单元格的一元位置先验 Ω ∈ R W × H Ω ∈ \mathbb{R}^{W ×H} Ω∈RW×H。该分数反映了在每个位置拍摄图像的可能性。我们很少期望在河流或建筑物等地方拍摄图像。
Pose estimation by template matching
Probality volume:我们估计相机姿势 ξ \xi ξ 上的离散概率分布。这是可以解释的,并充分体现了估计的不确定性。因此,在不明确的场景中,分布是多模态的。图 4 显示了各种示例。这使得将姿态估计与 GPS 等附加传感器融合起来变得很容易。计算这个体积很容易处理,因为姿势空间已减少到 3 维。它被离散化为每个地图位置和定期采样的 K 个旋转。
这会产生一个 W × H × K W ×H×K W×H×K 概率体积 P,使得 P ( ξ ∣ I , m a p , ξ p r i o r ) = P [ ξ ] P (\xi|I, map, \xi_{prior}) = P[\xi] P(ξ∣I,map,ξprior)=P[ξ]。它是图像映射匹配项 M M M 和位置先验 Ω Ω Ω 的组合:
P = s o f t m a x ( M + Ω ) P = softmax (M + Ω) P=softmax(M+Ω)
M 和 Ω 代表图像条件和图像无关的非归一化对数分数。 Ω 沿旋转维度传播,softmax 标准化概率分布。

Image-map matching: 彻底匹配神经映射 F F F 和 BEV T T T 产生分数体积 M M M。每个元素都是通过将 F F F 与相应姿势变换后的 T T T 相关联来计算的:

Pose inference:我们通过最大似然估计单个姿势: ξ ∗ = a r g m a x ξ P ( ξ ∣ I , m a p , ξ p r i o r ) \xi^* = argmax_{\xi} P (\xi|I, map, \xi_{prior}) ξ∗=argmaxξP(ξ∣I,map,ξprior)。当分布主要是单峰时,我们可以获得不确定性的度量作为 P 围绕 ξ ∗ \xi^* ξ∗ 的协方差[7]。
Sequence and muti-camera localization
在表现出很少的独特语义元素或重复模式的位置中,单图像定位是不明确的。当已知多个视图的相对姿势时,可以通过在多个视图上积累额外的线索来消除此类挑战的歧义。这些视图可以是来自 VI SLAM 的具有姿势的图像序列,也可以是来自校准的多摄像机装置的同步视图。
图 5 显示了此类困难场景的示例,该场景通过随时间累积的预测来消除歧义。不同的框架将姿势限制在不同的方向上,例如交叉路口之前和之后。融合较长的序列可获得更高的准确度(图 6)。
让我们将 ξ i \xi_i ξi 表示为视图 i 的未知绝对位姿,将 ξ ^ i , j \hat{\xi}_{i,j} ξ^i,j 表示为从视图 j 到 i 的已知相对位姿。对于任意参考视图 i,我们将所有单视图预测的联合似然表示为

Experiments
Conclusion
OrienterNet 是第一个能够在人类使用的相同 2D 平面地图中以亚米级精度定位图像的深度神经网络。 OrienterNet 通过将输入地图与从视觉观察中得出的心理地图进行匹配来模仿人类在环境中定位自己的方式。与机器迄今为止所依赖的大型且昂贵的 3D 地图相比,此类 2D 地图极其紧凑,因此最终能够在大型环境中实现设备上定位。 OrienterNet 基于 OpenStreetMap 的全球免费地图,任何人都可以使用它来定位世界任何地方。
我们提供了一个大型的众包训练数据集,帮助模型在驾驶和 AR 数据集上很好地泛化。 OrienterNet 显着改进了现有的 3-DoF 定位方法,大幅提升了现有技术水平。这为部署节能机器人和 AR 设备开辟了令人兴奋的前景,这些机器人和 AR 设备无需昂贵的云基础设施即可知道自己的位置。
相关文章:
OrienterNet: visual localization in 2D public maps with neural matching 论文阅读
论文信息 题目:OrienterNet: visual localization in 2D public maps with neural matching 作者:Paul-Edouard Sarlin, Daniel DeTone 项目地址:github.com/facebookresearch/OrienterNet 来源:CVPR 时间:…...

iOS导航栏闪屏以及statusBar背景色的更改
1.如果导航栏有卡顿或者闪屏效果出现,多半是因为导航栏背景为透明色所致,可以给导航栏设置主题色,比如已白色为例 self.navigationController.navigationBar.backgroundColor [UIColor whiteColor]; 2.但是即使上述设置后,依然发…...

Centos开启防火墙和端口命令
Centos开启防火墙和端口命令 1. 开启查看关闭firewalld服务状态2. 查看端口是否开放3. 新增开放端口4. 查看开放的端口 1. 开启查看关闭firewalld服务状态 #启动/关闭firewall systemctl start/stop firewalld #查看防火墙状态 systemctl status firewalld #禁用或者启用 syst…...
基于微信小程序的宠物领养平台的设计与实现(Java+spring boot+微信小程序+MySQL)
获取源码或者论文请私信博主 演示视频: 基于微信小程序的宠物领养平台的设计与实现(Javaspring boot微信小程序MySQL) 使用技术: 前端:html css javascript jQuery ajax thymeleaf 微信小程序 后端:Java…...

Mongodb基础操作
一、简介 MongoDB是一个NoSQL型的数据库,基于分布式文档型储存数据库,由C语言编写,它的特点是开源、高性能、高可用、高扩展、易部署。支持 Golang、RUBY、PYTHON、JAVA、C、PHP等多种开发语言。 二、应用场景 MongoDB适用于高并发读写、数据…...

数据结构与算法:计算机科学的基石
文章目录 数据结构:构建数据的框架算法:问题的解决方案编程语言:实现数据结构的工具结论 🎉欢迎来到数据结构学习专栏~数据结构与算法:计算机科学的基石 ☆* o(≧▽≦)o *☆嗨~我是IT陈寒🍹✨博客主页&…...

曲线救国 | 双非渣硕的秋招路
作者 | 带带大兄弟 面试锦囊之面经分享系列,持续更新中 欢迎后台回复"面试"加入讨论组交流噢 一篇旧文,可以参考~ 写在前面 双非渣硕,0实习,3篇水文,三个给老板当打工仔的nlp横向项目,八月份开…...
气传导耳机怎么样?四款值得入手的气传导耳机推荐
随着科技的进步,蓝牙耳机越来越受欢迎。类型也越来越多,其中气传导耳机因其不入耳设计,佩戴更舒适,音质更自然,能够提供更为清晰、自然的音质。面对还不知如何挑选气传导耳机的用户,在这里,我…...

HTML <svg> 标签
实例 画一个圆: <svg width="100" height="100"><circle cx="50" cy="50" r="40" stroke="green" stroke-width="4" fill="yellow" /> </svg>页面下方有更多 TIY 实例。…...

Python随机密码生成。编写程序,在26个字母大小写和10个数字随机生成10个8位密码。
题目:随机密码生成。编写程序,在26个字母大小写和10个数字随机生成10个8位密码。 样例:类似AB12cdHi的十组8位密码。 代码: import random def passwords():a, b, c ord(a), ord(A), ord(1)r list(range(a , a 26)) list(ra…...
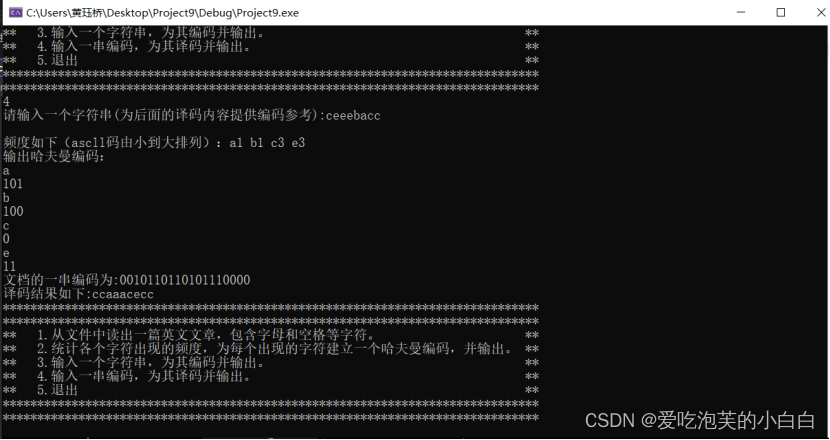
数据结构作业——哈夫曼树
/*【基本要求】 (1) 从文件中读出一篇英文文章,包含字母和空格等字符。 (2) 统计各个字符出现的频度。 (3) 根据出现的频度,为每个出现的字符建立一个哈夫曼编码,并输出。…...

Python XML处理中级篇:深入探索lxml库
lxml库是Python中处理XML和HTML文档的强大库,提供了丰富的API以进行各种操作。在初级篇中,我们介绍了如何使用lxml库解析、访问和修改XML文档。在这篇中级篇中,我们将更深入地探讨如何使用lxml库,包括如何创建XML文档,…...

岩棉革新——洛科威推出NGF新一代岩棉产品
作为全球领先的岩棉制品生产商,洛科威公司基于在岩棉性能革新领域八十多年的深入研究和生产工艺的不断优化,在中国市场正式推出NGF新一代岩棉制品,并在上海国际绿色建筑建材博览会和2023国际绿色低碳技术展上正式发布。 洛科威NGF产品作为革…...

关于 docker 基础题目
1.安装docker服务,配置镜像加速器 http://t.csdn.cn/E3zQ8 2.下载系统镜像(Ubuntu、 centos) 执行该命令后,Docker会自动从Docker Hub镜像库中下载Ubuntu镜像,并将其保存到本地计算机上: [rootmaster ~]# docker pull …...

Skywalking全链路追踪【学习笔记】
Skywalking全链路追踪的服务搭建,使用docker进行安装。 搭建服务 搭建【ES】 # 拉取 docker pull docker.elastic.co/elasticsearch/elasticsearch:7.17.10 # 启动 docker run -p 127.0.0.1:9200:9200 -p 127.0.0.1:9300:9300 -e "discovery.typesingle-nod…...
Sphinx——Python生成API文档
1、简介 Sphinx是Python文档生成器,它基于reStructuredText标记语言,可自动根据项目生成HTML,PDF等格式的文档,无数著名项目的文档均用Sphinx生成,如机器学习库scikit-learn、交互式神器Jupyter Notebook sphinx是一…...

倒计时动效
1. 效果 2. html <div class"count"><span>3</span><span>2</span><span>1</span> </div>3. css body {width: 100vw;height: 100vh;overflow: hidden;display: flex;justify-content: center;align-items: cente…...
安卓主板定制_电磁屏/电容屏安卓平板基于MTK联发科方案定制
定制化行业平板 在各行各业中的地位越来越重要,甚至在行业转型和发展中发挥着不可替代的作用。随着工业化社会的快速发展,工业生产对智控设备要求越来越高,运用的范畴也越来越普遍广泛,工业级平板就是其中一种应用广泛的设备。 新…...

Unity 之 ScreenPointToRay() (将点转换成射线的方法)
文章目录 ScreenPointToRay() ScreenPointToRay() ScreenPointToRay() 是Unity中Camera类的一个方法,用于将屏幕上的一个点转换为一条射线。这条射线的起点是摄像机在屏幕上对应的点,方向是从摄像机出发指向那个点。这在进行射线命中检测时非常有用&…...

C++ 线程池
目录 一、线程池实现原理 二、定义线程池的结构 三、创建线程池实例 四、添加工作的线程的任务函数 五、管理者线程的任务函数 六、往线程池中添加任务 七、获取线程池工作的线程数量与活着的线程数量 八、线程池的销毁 一、线程池实现原理 线程池的组成主要分为3个部…...

地震勘探——干扰波识别、井中地震时距曲线特点
目录 干扰波识别反射波地震勘探的干扰波 井中地震时距曲线特点 干扰波识别 有效波:可以用来解决所提出的地质任务的波;干扰波:所有妨碍辨认、追踪有效波的其他波。 地震勘探中,有效波和干扰波是相对的。例如,在反射波…...

【杂谈】-递归进化:人工智能的自我改进与监管挑战
递归进化:人工智能的自我改进与监管挑战 文章目录 递归进化:人工智能的自我改进与监管挑战1、自我改进型人工智能的崛起2、人工智能如何挑战人类监管?3、确保人工智能受控的策略4、人类在人工智能发展中的角色5、平衡自主性与控制力6、总结与…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

转转集团旗下首家二手多品类循环仓店“超级转转”开业
6月9日,国内领先的循环经济企业转转集团旗下首家二手多品类循环仓店“超级转转”正式开业。 转转集团创始人兼CEO黄炜、转转循环时尚发起人朱珠、转转集团COO兼红布林CEO胡伟琨、王府井集团副总裁祝捷等出席了开业剪彩仪式。 据「TMT星球」了解,“超级…...

linux arm系统烧录
1、打开瑞芯微程序 2、按住linux arm 的 recover按键 插入电源 3、当瑞芯微检测到有设备 4、松开recover按键 5、选择升级固件 6、点击固件选择本地刷机的linux arm 镜像 7、点击升级 (忘了有没有这步了 估计有) 刷机程序 和 镜像 就不提供了。要刷的时…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...