一文详解4种聚类算法及可视化(Python)
在这篇文章中,基于20家公司的股票价格时间序列数据。根据股票价格之间的相关性,看一下对这些公司进行聚类的四种不同方式。
苹果(AAPL),亚马逊(AMZN),Facebook(META),特斯拉(TSLA),Alphabet(谷歌)(GOOGL),壳牌(SHEL),Suncor能源(SU),埃克森美孚公司(XOM),Lululemon(LULU),沃尔玛(WMT),Carters(CRI)、 Childrens Place (PLCE), TJX Companies (TJX), Victoria’s Secret & Co (VSCO), Macy’s (M), Wayfair (W), Dollar Tree (DLTR), CVS Caremark (CVS), Walgreen (WBA), Curaleaf Holdings Inc. (CURLF)
我们的DataFrame df_combined,包含上述公司413天的股票价格,没有遗漏数据。
目标
我们的目标是根据相关性对这些公司进行分组,并检查这些分组的有效性。例如,苹果、亚马逊、谷歌和Facebook通常被视为科技股,而Suncor和Exxon被视为石油和天然气股。我们将检查我们是否可以得到这些分类,只使用这些公司的股票价格之间的相关性。
使用相关性来对这些公司进行分类,而不是使用股票价格,如果使用股票价格,具有相似股票价格的公司将被集中在一起。但在这里,我们想根据股票价格的行为来对公司进行分类。实现这一目标的一个简单方法是使用股票价格之间的相关性。
技术交流
技术要学会分享、交流,不建议闭门造车。一个人可以走的很快、一堆人可以走的更远。
相关文件及代码都已上传,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:dkl88194,备注:来自CSDN + 加群
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
最佳集群数量
寻找集群的数量是一个自身的问题。有一些方法,如elbow方法,可以用来寻找最佳的集群数量。然而,在这项工作中,尝试将这些公司分成4个集群。理想情况下,这四个群组必须是科技股、石油和天然气股、零售股和其他股票。
首先获得我们所拥有的数据框架的相关矩阵。
correlation_mat=df_combined.corr()
定义一个效用函数来显示集群和属于该集群的公司。
# 用来打印公司名称和它们所分配的集群的实用函数
def print_clusters(df_combined,cluster_labels):cluster_dict = {}for i, label in enumerate(cluster_labels):if label not in cluster_dict:cluster_dict[label] = []cluster_dict[label].append(df_combined.columns[i])# 打印出每个群组中的公司 -- 建议关注@公众号:数据STUDIO 定时推送更多优质内容for cluster, companies in cluster_dict.items():print(f"Cluster {cluster}: {', '.join(companies)}")
方法1:K-means聚类法
K-means聚类是一种流行的无监督机器学习算法,用于根据特征的相似性将相似的数据点分组。该算法迭代地将每个数据点分配给最近的集群中心点,然后根据新分配的数据点更新中心点,直到收敛。我们可以用这个算法根据相关矩阵对我们的数据进行聚类。
from sklearn.cluster import KMeans# Perform k-means clustering with four clusters
clustering = KMeans(n_clusters=4, random_state=0).fit(correlation_mat)# Print the cluster labels
cluster_labels=clustering.labels_
print_clusters(df_combined,cluster_labels)

k-means聚类的结果
正如预期的那样,亚马逊、Facebook、特斯拉和Alphabet被聚集在一起,石油和天然气公司也被聚集在一起。此外,沃尔玛和MACYs也被聚在一起。然而,我们看到一些科技股,如苹果与沃尔玛聚集在一起。
方法2:聚和聚类法Agglomerative Clustering
聚合聚类是一种分层聚类算法,它迭代地合并类似的聚类以形成更大的聚类。该算法从每个对象的单独聚类开始,然后在每一步将两个最相似的聚类合并。
from sklearn.cluster import AgglomerativeClustering# 进行分层聚类
clustering = AgglomerativeClustering(n_clusters=n_clusters, affinity='precomputed', linkage='complete').fit(correlation_mat)# Display the cluster labels
print_clusters(df_combined,clustering.labels_)

分层聚类的结果
这些结果与我们从k-means聚类得到的结果略有不同。我们可以看到一些石油和天然气公司被放在了不同的聚类中。
方法3:亲和传播聚类法 AffinityPropagation
亲和传播聚类是一种聚类算法,不需要事先指定聚类的数量。它的工作原理是在成对的数据点之间发送消息,让数据点自动确定聚类的数量和最佳聚类分配。亲和传播聚类可以有效地识别数据中的复杂模式,但对于大型数据集来说,计算成本也很高。
from sklearn.cluster import AffinityPropagation# 用默认参数进行亲和传播聚类
clustering = AffinityPropagation(affinity='precomputed').fit(correlation_mat)# Display the cluster labels
print_clusters(df_combined,clustering.labels_)

亲和传播聚类的结果
有趣的是,这个方法发现四个聚类是我们数据的最佳聚类数量。此外,我们可以观察到,石油和天然气公司被聚在一起,一些科技公司也被聚在一起。
方法4:DBSCAN聚类法
DBSCAN是一种基于密度的聚类算法,它将那些紧密排列在一起的点聚在一起。它不需要事先指定聚类的数量,而且可以识别任意形状的聚类。该算法对数据中的离群值和噪声具有鲁棒性,可以自动将它们标记为噪声点。
from sklearn.cluster import DBSCAN# Removing negative values in correlation matrix
correlation_mat_pro = 1 + correlation_mat# Perform DBSCAN clustering with eps=0.5 and min_samples=5
clustering = DBSCAN(eps=0.5, min_samples=5, metric='precomputed').fit(correlation_mat_pro)# Print the cluster labels
print_clusters(df_combined,clustering.labels_)

DBScan聚类的结果
在这里,与基于亲和力的聚类不同,DBScan方法将5个聚类确定为最佳数量。还可以看出,有些集群只有1或2家公司。
可视化
同时检查上述四种聚类方法的结果,以深入了解它们的性能,可能是有用的。最简单的方法是使用热图,公司在X轴上,聚类在Y轴上。
def plot_cluster_heatmaps(cluster_results, companies):# 从字典中提取key和valuemethods = list(cluster_results.keys())labels = list(cluster_results.values())# 定义每个方法的热图数据heatmaps = []for i in range(len(methods)):heatmap = np.zeros((len(np.unique(labels[i])), len(companies)))for j in range(len(companies)):heatmap[labels[i][j], j] = 1heatmaps.append(heatmap)# Plot the heatmaps in a 2x2 gridfig, axs = plt.subplots(nrows=2, ncols=2, figsize=(12, 12))for i in range(len(methods)):row = i // 2col = i % 2sns.heatmap(heatmaps[i], cmap="Blues", annot=True, fmt="g", xticklabels=companies, ax=axs[row, col])axs[row, col].set_title(methods[i])plt.tight_layout()plt.show()companies=df_combined.columns
plot_cluster_heatmaps(cluster_results, companies)
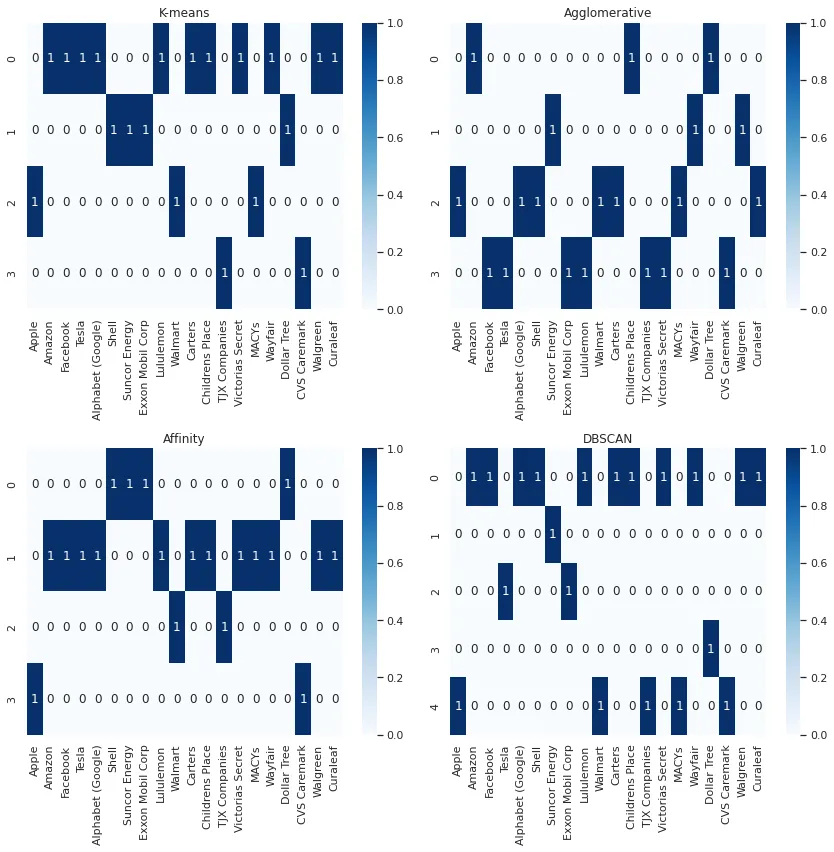
所有四种方法的聚类结果
然而,当试图比较多种聚类算法的结果时,上述的可视化并不是很有帮助。找到一个更好的方法来表示这个图将会很有帮助。
结论
在这篇文章中,我们探讨了四种不同的方法,根据20家公司的股票价格之间的相关性来进行聚类。其目的是以反映这些公司的行为而不是其股票价格的方式对其进行聚类。尝试了K-means聚类、Agglomerative聚类、Affinity Propagation聚类和DBSCAN聚类方法,每种方法都有自己的优点和缺点。结果显示,这四种方法都能以符合其行业或部门的方式对公司进行聚类,而一些方法的计算成本比其他方法更高。基于相关性的聚类方法为基于股票价格的聚类方法提供了一个有用的替代方法,可以根据公司的行为而不是股票价格来聚类。
相关文章:
一文详解4种聚类算法及可视化(Python)
在这篇文章中,基于20家公司的股票价格时间序列数据。根据股票价格之间的相关性,看一下对这些公司进行聚类的四种不同方式。 苹果(AAPL),亚马逊(AMZN),Facebook(META&…...
SpringBoot---内置Tomcat 配置和切换
😀前言 本篇博文是关于内置Tomcat 配置和切换,希望你能够喜欢 🏠个人主页:晨犀主页 🧑个人简介:大家好,我是晨犀,希望我的文章可以帮助到大家,您的满意是我的动力&#x…...

Qt 显示git版本信息
项目场景: 项目需要在APP中显示当前的版本号,考虑到git共同开发,显示git版本,查找bug或恢复设置更为便捷。 使用需求: 显示的内容包括哪个分支编译的,版本号多少,编译时间,以及是否…...

Mysql的视图和管理
MySQL 视图(view) 视图是一个虚拟表,其内容由查询定义,同真实的表一样,视图包含列,其数据来自对应的真实表(基表) create view 视图名 as select语句alter view 视图名 as select语句 --更新成新的视图SHOW CREATE VIEW 视图名d…...
uniapp 顶部头部样式
<u-navbartitle"商城":safeAreaInsetTop"true"><view slot"left"><image src"/static/logo.png" mode"" class"u-w-50 u-h-50"></image></view></u-navbar>...
最新ai系统ChatGPT程序源码+详细搭建教程+mj以图生图+Dall-E2绘画+支持GPT4+AI绘画+H5端+Prompt知识库
目录 一、前言 二、系统演示 三、功能模块 3.1 GPT模型提问 3.2 应用工作台 3.3 Midjourney专业绘画 3.4 mind思维导图 四、源码系统 4.1 前台演示站点 4.2 SparkAi源码下载 4.3 SparkAi系统文档 五、详细搭建教程 5.1 基础env环境配置 5.2 env.env文件配置 六、环境…...

FairyGUI-Unity 自定义UIShader
FairyGUI中给组件更换Shader,最简单的方式就是找到组件中的Shader字段进行赋值。需要注意的是,对于自定的shader效果需要将目标图片进行单独发布,也就是一个目标图片占用一张图集。(应该会有更好的解决办法,但目前还是…...
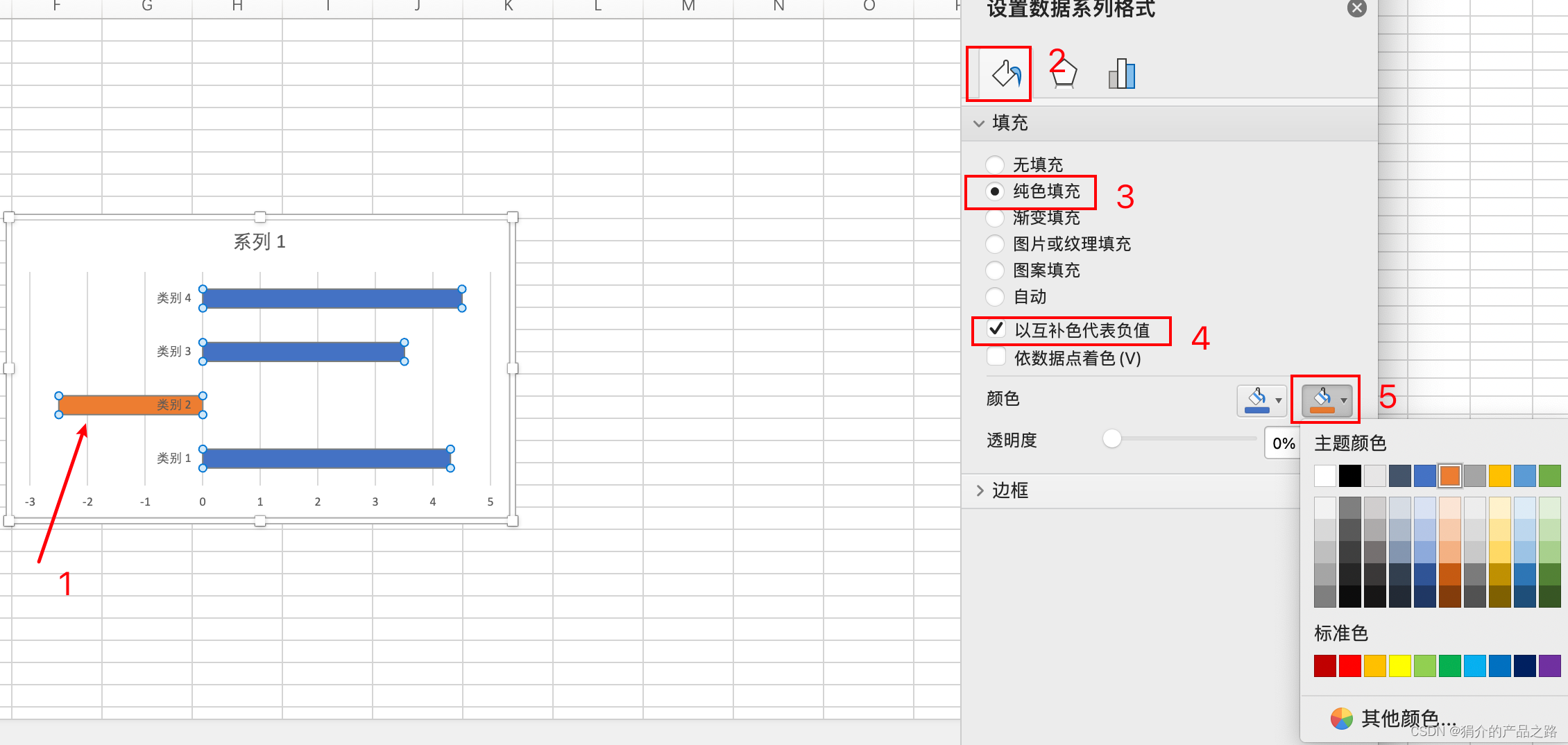
Excel/PowerPoint柱状图条形图负值设置补色
原始数据: 列1系列 1类别 14.3类别 2-2.5类别 33.5类别 44.5 默认作图 解决方案 1、选中柱子,双击,按如下顺序操作 2、这时候颜色会由一个变成两个 3、对第二个颜色进行设置,即为负值的颜色 条形图的设置方法相同...

el-date-picker 时间区域选择,type=daterange,form表单校验+数据回显问题
情景问题:新增表单有时间区域选择,选择了时间,还是提示必填的校验提示语,且修改时,通过 号赋值法,重新选择此时间范围无效。 解决方法:(重点) widthHoldTime:[]…...

LeetCode 面试题 01.02. 判定是否互为字符重排
文章目录 一、题目二、C# 题解 一、题目 给定两个由小写字母组成的字符串 s1 和 s2,请编写一个程序,确定其中一个字符串的字符重新排列后,能否变成另一个字符串,点击此处跳转。 示例 1: 输入: s1 “abc”, s2 “…...
学习maven工具
文章目录 🐒个人主页🏅JavaEE系列专栏📖前言:🏨maven工具产生的背景🦓maven简介🪀pom.xml文件(project object Model 项目对象模型) 🪂maven工具安装步骤两个前提:下载 m…...

手机直播源码开发,协议讨论篇(三):RTMP实时消息传输协议
实时消息传输协议RTMP简介 RTMP又称实时消息传输协议,是一种实时通信协议。在当今数字化时代,手机直播源码平台为全球用户进行服务,如何才能增加用户,提升用户黏性?就需要让一对一直播平台能够为用户提供优质的体验。…...

【JavaEE基础学习打卡05】JDBC之基本入门就可以了
目录 前言一、JDBC学习前说明1.Java SE中JDBC2.JDBC版本 二、JDBC基本概念1.JDBC原理2.JDBC组件 三、JDBC基本编程步骤1.JDBC操作的数据库准备2.JDBC操作数据库表步骤 四、代码优化1.简单优化2.with-resources探讨 总结 前言 📜 本系列教程适用于JavaWeb初学者、爱好…...
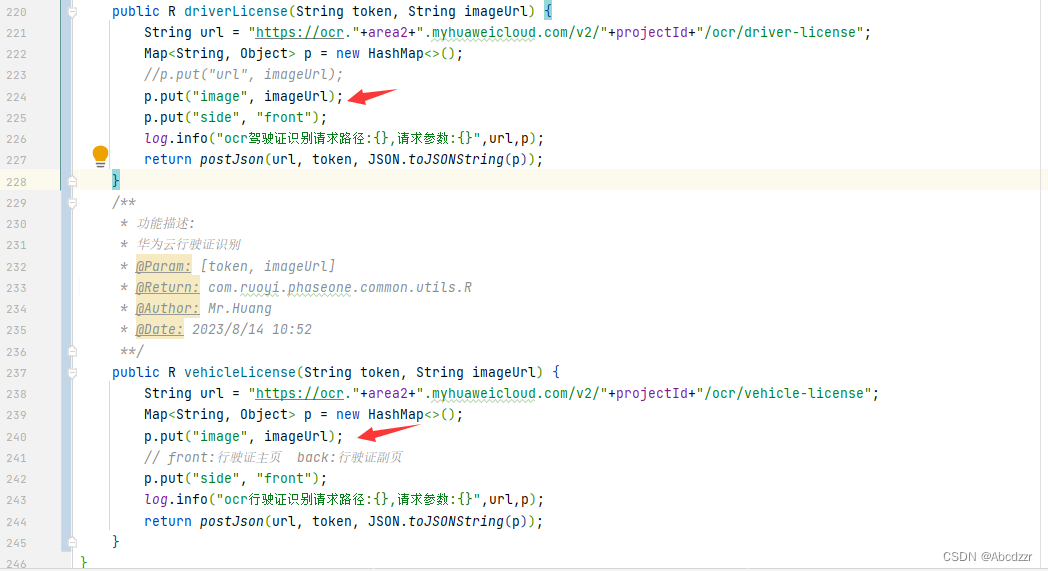
2023/8/16 华为云OCR识别驾驶证、行驶证
目录 一、 注册华为云账号开通识别驾驶证、行驶证服务 二、编写配置文件 2.1、配置秘钥 2.2、 编写配置工具类 三、接口测试 3.1、测试接口 3.2、结果 四、实际工作中遇到的问题 4.1、前端传值问题 4.2、后端获取数据问题 4.3、使用openfeign调用接口报错 4.3、前端显示问题…...

【Java开发】 Mybatis-Plus 07:创建时间、更新时间自动添加
Mybatis-Plus 可以通过配置实体类的注解来自动添加创建时间和更新时间,这可以减轻一定的开发量。 1 在实体类中添加注解 public class User {TableId(type IdType.AUTO)private Long id;private String username;private String password;TableField(fill FieldF…...

解决vue2项目在IE11浏览器中无画面的兼容问题
解决vue2项目在IE11浏览器中无画面的兼容问题 背景介绍当前网上能找打的教程 背景介绍 当前项目面临其他浏览器都可以运行,但是在IE11浏览器中出现白屏的现象,F12后台也没有报错,项目月底也要交付了。当前项目的vue版本为2.6.11,…...

信号
信号也是IPC中的一种,是和管道,消息队列,共享内存并列的概念。 本文参考: Linux中的信号_linux中信号_wolf鬼刀的博客-CSDN博客 Linux系统编程(信号处理 sigacation函数和sigqueue函数 )_花落已飘的博客-CSDN博客 Linu…...

产品经理的真实薪资有多少?今天带你看看
作为产品经理,除了需要拥有扎实的技术背景和出色的产品设计能力,还需具备出色的领导力和商业敏感度。因此,产品经理的薪资也越来越成为人们关注的话题。那么,一般来说,产品经理的薪资水平如何呢? 薪资多少…...
《一个操作系统的实现》windows用vm安装CentOS——从bochs环境搭建到第一个demo跑通
vm安装CentOS虚拟机带有桌面的版本。su输入密码123456。更新yum -y update 。一般已经安装好后面这2个工具:yum install -y net-tools wget。看下ip地址ifconfig,然后本地终端连接ssh root192.168.249.132输入密码即可,主要是为了复制网址方便…...

线程Thread
文章目录 一、概念1、进程2、线程3、CPU与线程的关系4、并行、并发5、线程的生命周期 二、创建1、继承Thread2、实现Runnable接口3、实现Callable接口 三、API1、获取运行使用的线程2、唯一标识3、线程名4、优先级5、是否处于活动状态6、守护线程7、join1、API2、有无join对比 …...

OpenClaw移动办公:Phi-3-mini-128k-instruct通过钉钉审批电子合同
OpenClaw移动办公:Phi-3-mini-128k-instruct通过钉钉审批电子合同 1. 为什么需要移动审批电子合同? 上周三我在高铁上收到法务同事的紧急消息:"有个供应商合同今天必须签完,但关键条款需要你确认"。当时手边既没电脑也…...

LTR308环境光传感器驱动开发与嵌入式集成指南
1. LTR308环境光传感器库技术解析与工程实践指南Lite-On LTR-308 是一款高精度、低功耗的环境光传感器(Ambient Light Sensor, ALS),专为智能手机、平板电脑、可穿戴设备及工业人机界面等对光照感知精度和能效比要求严苛的应用场景设计。其核…...

OpenClaw自动化测试:千问3.5-27B驱动UI全流程验证
OpenClaw自动化测试:千问3.5-27B驱动UI全流程验证 1. 为什么选择OpenClaw做自动化测试? 去年接手一个前端重构项目时,我遇到了一个典型困境:每次代码改动后,都需要手动执行47个关键页面的功能测试。这套测试流程完整…...

2026 codex 大模型 api 配置指南:auth.json、config.toml 与 401/超时排查
当 codex --version 已经能正常输出,很多人会以为接下来只剩下提问和改代码。但真正决定 Codex 能不能顺利进入项目的,往往是 codex 大模型 api 有没有按要求接好:只要 auth.json、config.toml 或网关地址有一点偏差,就可能马上碰…...

嵌入式软件缺陷预防与设计规范实战指南
1. 嵌入式软件缺陷预防与设计规范作为一名在嵌入式领域摸爬滚打多年的工程师,我见过太多因为软件缺陷导致的灾难性后果。从航天器失联到医疗设备故障,这些事故背后往往都隐藏着本可以在设计阶段就规避的代码问题。今天我想分享的是:为什么一个…...

Ubuntu 20.04安装搜狗输入法全攻略:从配置到常见错误解决
Ubuntu 20.04 中文输入终极方案:搜狗输入法深度配置指南 在Linux桌面环境中实现流畅的中文输入一直是许多用户的痛点。作为国内最受欢迎的中文输入法之一,搜狗输入法凭借其强大的词库和智能预测功能,成为Ubuntu用户的首选。本文将带你从零开始…...

日结零工市场的权益保障困境与系统性治理路径
一、现象审视:弱势单元的权益真空日结零工作为弹性用工体系中最灵活、最底层的用工形态,其劳动者长期处于权益保障的真空地带。本文基于对B市线上日结零工市场的田野研究发现,日结零工劳动者面临三重结构性弱势:第一,法…...

深圳市场调研公司_广东第三方调研机构_珠三角市场调查落地服务-知行市场调研
深圳市场调研公司_广东第三方调研机构_珠三角市场调查落地服务-知行市场调研知行市场调研(欢迎直接访问我们业务站) 在粤港澳大湾区经济蓬勃发展的浪潮中,深圳作为核心引擎,辐射带动珠三角产业升级与市场迭代。企业无论是新品研发…...

【DCTDECODE JPG】
import timeimport PyPDF2 import pdfplumber from PIL import Imagedef extract_image(page):try:# 提取第2页图片(从0开始计数)page_image pdf_image_reader.getPage(pageNumber1)extract_image(page_image)if /XObject in page[/Resources]:xObject …...

深圳地铁大数据客流分析系统:如何用开源技术栈破解千万级乘客的交通治理难题
深圳地铁大数据客流分析系统:如何用开源技术栈破解千万级乘客的交通治理难题 【免费下载链接】SZT-bigdata 深圳地铁大数据客流分析系统🚇🚄🌟 项目地址: https://gitcode.com/gh_mirrors/sz/SZT-bigdata 深圳地铁作为中国…...