掌握JDK21全新结构化并发编程,轻松提升开发效率!
1 概要
通过引入结构化并发编程的API,简化并发编程。结构化并发将在不同线程中运行的相关任务组视为单个工作单元,从而简化错误处理和取消操作,提高可靠性,并增强可观察性。这是一个预览版的API。
2 历史
结构化并发是由JEP 428提出的,并在JDK 19中作为孵化API发布。它在JDK 20中被JEP 437重新孵化,通过对作用域值(JEP 429)进行轻微更新。
我们在这里提议将结构化并发作为JUC包中的预览API。唯一重要变化是StructuredTaskScope::fork(...)方法返回一个[子任务],而不是一个Future,如下面所讨论的。
3 目标
推广一种并发编程风格,可以消除由于取消和关闭而产生的常见风险,如线程泄漏和取消延迟。
提高并发代码的可观察性。
4 非目标
不替换JUC包中的任何并发构造,如ExecutorService和Future。
不定义Java平台的最终结构化并发API。其他结构化并发构造可以由第三方库定义,或在未来的JDK版本中定义。
不定义在线程之间共享数据流的方法(即通道)。会在未来提出这样做。
不用新的线程取消机制替换现有的线程中断机制。会在未来提出这样做。
5 动机
开发人员通过将任务分解为多个子任务来管理复杂性。在普通的单线程代码中,子任务按顺序执行。然而,如果子任务彼此足够独立,并且存在足够的硬件资源,那么通过在不同线程中并发执行子任务,可以使整个任务运行得更快(即具有较低的延迟)。例如,将多个I/O操作的结果组合成一个任务,如果每个I/O操作都在自己的线程中并发执行,那么任务将运行得更快。虚拟线程(JEP 444)使得为每个此类I/O操作分配一个线程成为一种具有成本效益的方法,但是管理可能会产生大量线程仍然是一个挑战。
6 ExecutorService 非结构化并发
java.util.concurrent.ExecutorService API 是在 Java 5 中引入的,它帮助开发人员以并发方式执行子任务。
如下 handle() 的方法,它表示服务器应用程序中的一个任务。它通过将两个子任务提交给 ExecutorService 来处理传入的请求。
ExecutorService 立即返回每个子任务的 Future,并根据 Executor 的调度策略同时执行这些子任务。handle() 方法通过阻塞调用它们的 Future 的 get() 方法来等待子任务的结果,因此该任务被称为加入了其子任务。
Response handle() throws ExecutionException, InterruptedException {Future<String> user = esvc.submit(() -> findUser());Future<Integer> order = esvc.submit(() -> fetchOrder());String theUser = user.get(); // 加入 findUserint theOrder = order.get(); // 加入 fetchOrderreturn new Response(theUser, theOrder);
}由于子任务并发执行,每个子任务都可独立地成功或失败。在这个上下文中,"失败" 意味着抛出异常。通常,像 handle() 这样的任务应该在任何一个子任务失败时失败。当出现失败时,理解线程的生命周期会变得非常复杂:
如
findUser()抛异常,那么调用user.get()时handle()也会抛出异常,但是fetchOrder()会继续在自己的线程中运行。这是线程泄漏,最好情况下浪费资源,最坏情况下fetchOrder()的线程可能会干扰其他任务。如执行
handle()的线程被中断,这个中断不会传播到子任务。findUser()和fetchOrder()的线程都会泄漏,即使在handle()失败后仍然继续运行。如果
findUser()执行时间很长,但是在此期间fetchOrder()失败,那么handle()将不必要地等待findUser(),因为它会在user.get()上阻塞,而不是取消它。只有在findUser()完成并且user.get()返回后,order.get()才会抛出异常,导致handle()失败。
每种case下,问题在于我们的程序在逻辑上被结构化为任务-子任务关系,但这些关系只存在于开发人员的头脑中。这不仅增加错误可能性,还会使诊断和排除此类错误变得更加困难。例如,线程转储等可观察性工具会在不相关的线程调用栈中显示 handle()、findUser() 和 fetchOrder(),而没有任务-子任务关系的提示。
可尝试在错误发生时显式取消其他子任务,例如通过在失败的任务的 catch 块中使用 try-finally 包装任务,并调用其他任务的 Future 的 cancel(boolean) 方法。我们还需要在 try-with-resources 语句中使用 ExecutorService,就像
try (var executor = Executors.newVirtualThreadPerTaskExecutor()) {IntStream.range(0, 10_000).forEach(i -> {executor.submit(() -> {Thread.sleep(Duration.ofSeconds(1));return i;});});
} // executor.close() is called implicitly, and waits因为 Future 没有提供等待被取消的任务的方法。但所有这些都很难做到,并且往往会使代码的逻辑意图变得更加难以理解。跟踪任务之间的关系,并手动添加所需的任务间取消边缘,是对开发人员的一种很大要求。
无限制的并发模式
这种需要手动协调生命周期的需求是因为 ExecutorService 和 Future 允许无限制的并发模式。在涉及的所有线程中,没有限制或顺序:
- 一个线程可以创建一个
ExecutorService - 另一个线程可以向其提交工作
- 执行工作的线程与第一个或第二个线程没有任何关系
线程提交工作之后,一个完全不同的线程可以等待执行的结果。具有对 Future 的引用的任何代码都可以加入它(即通过调用 get() 等待其结果),甚至可以在与获取 Future 的线程不同的线程中执行代码。实际上,由一个任务启动的子任务不必返回到提交它的任务。它可以返回给许多任务中的任何一个,甚至可能是没有返回给任何任务。
因为 ExecutorService 和 Future 允许这种无结构的使用,它们既不强制执行也不跟踪任务和子任务之间的关系,尽管这些关系是常见且有用的。因此,即使子任务在同一个任务中被提交和加入,一个子任务的失败也不能自动导致另一个子任务的取消。在上述的 handle() 方法中,fetchOrder() 的失败不能自动导致 findUser() 的取消。fetchOrder() 的 Future 与 findUser() 的 Future 没有关系,也与最终通过其 get() 方法加入它的线程无关。与其要求开发人员手动管理这种取消,我们希望能够可靠地自动化这一过程。
任务结构应反映代码结构
与 ExecutorService 下的自由线程组合相反,单线程代码的执行总是强制执行任务和子任务的层次结构。方法的代码块 {...} 对应一个任务,代码块内部调用的方法对应子任务。调用的方法必须返回给调用它的方法,或者抛出异常给调用它的方法。它不能生存于调用它的方法之外,也不能返回或抛出异常给其他方法。因此,所有子任务在任务之前完成,每个子任务都是其父任务的子任务,每个子任务的生命周期相对于其他子任务和任务来说,都由代码块结构的语法规则来管理。
如单线程版本的 handle() 中,任务-子任务关系在语法结构明显:
Response handle() throws IOException {String theUser = findUser();int theOrder = fetchOrder();return new Response(theUser, theOrder);
}我们不会在 findUser() 子任务完成之前启动 fetchOrder() 子任务,无论 findUser() 是成功还是失败。如果 findUser() 失败,我们根本不会启动 fetchOrder(),而且 handle() 任务会隐式地失败。一个子任务只能返回给其父任务,这是很重要的:这意味着父任务可以将一个子任务的失败隐式地视为触发来取消其他未完成的子任务,然后自己失败。
单线程代码中,任务-子任务层次关系在运行时的调用栈中得到体现。因此,我们获得了相应的父子关系,这些关系管理着错误传播。观察单个线程时,层次关系显而易见:findUser()(及后来的 fetchOrder())似乎是在 handle() 下执行的。这使得回答问题 "handle() 正在处理什么?" 很容易。
如任务和子任务之间的父子关系在代码的语法结构中明显,并且在运行时得到了体现,那并发编程将更加容易、可靠且易于观察,就像单线程代码一样。语法结构将定义子任务的生命周期,并使得能够在运行时创建一个类似于单线程调用栈的线程层次结构的表示。这种表示将实现错误传播、取消以及对并发程序的有意义的观察。
7 结构化并发
结构化并发是一种并发编程方法,它保持了任务和子任务之间的自然关系,从而实现了更具可读性、可维护性和可靠性的并发代码。"结构化并发" 这个术语由 Martin Sústrik 提出,并由 Nathaniel J. Smith 推广。从其他编程语言中的概念,如 Erlang 中的层次监控者,可以了解到结构化并发中错误处理的设计思想。
结构化并发源于一个简单的原则:
如果一个任务分解为并发的子任务,那么所有这些子任务都会返回到同一个地方,即任务的代码块。
在结构化并发中,子任务代表任务工作。任务等待子任务的结果并监视它们的失败情况。与单线程代码中的结构化编程技术类似,结构化并发在多线程中的威力来自于两个思想:
- 为代码块中的执行流程定义明确的进入和退出点
- 在严格的操作生命周期嵌套中,以反映它们在代码中的语法嵌套方式
由于代码块的进入和退出点被明确定义,因此并发子任务的生命周期被限定在其父任务的语法块中。因为同级子任务的生命周期嵌套在其父任务的生命周期之内,因此可以将它们作为一个单元进行推理和管理。由于父任务的生命周期,依次嵌套在其父任务的生命周期之内,运行时可以将任务层次结构实现为树状结构,类似于单线程调用栈的并发对应物。这允许代码为任务子树应用策略,如截止时间,并允许可观察性工具将子任务呈现为父任务的下属。
结构化并发非常适合虚拟线程,这是由JDK实现的轻量级线程。许多虚拟线程可以共享同一个操作系统线程,从而可以支持非常大量的虚拟线程。除此外,虚拟线程足够廉价,可以表示任何涉及I/O等并发行为。这意味着服务器应用程序可以使用结构化并发来同时处理成千上万甚至百万个传入请求:它可以为处理每个请求的任务分配一个新的虚拟线程,当一个任务通过提交子任务进行并发执行时,它可以为每个子任务分配一个新的虚拟线程。在幕后,任务-子任务关系通过为每个虚拟线程提供一个对其唯一父任务的引用来实现为树状结构,类似于调用栈中的帧引用其唯一的调用者。
总之,虚拟线程提供了大量的线程。结构化并发可以正确且强大地协调它们,并使可观察性工具能够按照开发人员的理解显示线程。在JDK中拥有结构化并发的API将使构建可维护、可靠且可观察的服务器应用程序变得更加容易。
8 描述
结构化并发 API 的主要类是 java.util.concurrent 包中的 StructuredTaskScope。该类允许开发人员将一个任务结构化为一组并发的子任务,并将它们作为一个单元进行协调。子任务通过分别分叉它们并将它们作为一个单元加入,可能作为一个单元取消,来在它们自己的线程中执行。子任务的成功结果或异常由父任务汇总并处理。StructuredTaskScope 将子任务的生命周期限制在一个清晰的词法作用域内,在这个作用域中,任务与其子任务的所有交互(分叉、加入、取消、处理错误和组合结果)都发生。
前面提到的 handle() 示例,使用 StructuredTaskScope 编写:
Response handle() throws ExecutionException, InterruptedException {try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {Supplier<String> user = scope.fork(() -> findUser());Supplier<Integer> order = scope.fork(() -> fetchOrder());scope.join() // 加入两个子任务.throwIfFailed(); // ... 并传播错误// 两个子任务都成功完成,因此组合它们的结果return new Response(user.get(), order.get());}
}与原始示例相比,理解涉及的线程的生命周期在这里变得更加容易:在所有情况下,它们的生命周期都限制在一个词法作用域内,即 try-with-resources 语句的代码块内。此外,使用 StructuredTaskScope 可以确保一些有价值的属性:
- 错误处理与短路 — 如果
findUser()或fetchOrder()子任务中的任何一个失败,另一个如果尚未完成则会被取消。(这由ShutdownOnFailure实现的关闭策略来管理;还有其他策略可能)。 - 取消传播 — 如果在运行
handle()的线程在调用join()之前或之中被中断,则线程在退出作用域时会自动取消两个子任务。 - 清晰性 — 上述代码具有清晰的结构:设置子任务,等待它们完成或被取消,然后决定是成功(并处理已经完成的子任务的结果)还是失败(子任务已经完成,因此没有更多需要清理的)。
- 可观察性 — 如下所述,线程转储清楚地显示了任务层次结构,其中运行
findUser()和fetchOrder()的线程被显示为作用域的子任务。
9 突破预览版限制
StructuredTaskScope 是预览版 API,默认禁用。要使用 StructuredTaskScope API,需启用预览 API:
- 使用
javac --release 21 --enable-preview Main.java编译程序,然后使用java --enable-preview Main运行它;或 - 当使用源代码启动器时,使用
java --source 21 --enable-preview Main.java运行程序 - IDEA 运行时,勾选即可:

10 使用 StructuredTaskScope
10.1 API
public class StructuredTaskScope<T> implements AutoCloseable {public <U extends T> Subtask<U> fork(Callable<? extends U> task);public void shutdown();public StructuredTaskScope<T> join() throws InterruptedException;public StructuredTaskScope<T> joinUntil(Instant deadline)throws InterruptedException, TimeoutException;public void close();protected void handleComplete(Subtask<? extends T> handle);protected final void ensureOwnerAndJoined();}10.2 工作流程
- 创建一个作用域。创建作用域的线程是其所有者。
- 使用
fork(Callable)方法在作用域中分叉子任务。 - 在任何时间,任何子任务,或者作用域的所有者,都可以调用作用域的
shutdown()方法来取消未完成的子任务并阻止分叉新的子任务。 - 作用域的所有者将作用域(即所有子任务)作为一个单元加入。所有者可以调用作用域的
join()方法,等待所有子任务已完成(无论成功与否)或通过shutdown()被取消。或者,它可以调用作用域的joinUntil(java.time.Instant)方法,等待直到截止时间。 - 加入后,处理子任务中的任何错误并处理其结果。
- 关闭作用域,通常通过隐式使用 try-with-resources 实现。这会关闭作用域(如果尚未关闭),并等待被取消但尚未完成的任何子任务完成。
每次调用 fork(...) 都会启动一个新线程来执行一个子任务,默认情况下是虚拟线程。一个子任务可以创建它自己的嵌套的 StructuredTaskScope 来分叉它自己的子任务,从而创建一个层次结构。该层次结构反映在代码的块结构中,限制了子任务的生命周期:在作用域关闭后,所有子任务的线程都保证已终止,当块退出时不会留下任何线程。
在作用域中的任何子任务,嵌套作用域中的任何子子任务,以及作用域的所有者,都可以随时调用作用域的 shutdown() 方法,表示任务已完成,即使其他子任务仍在执行。shutdown() 方法会中断仍在执行子任务的线程,并导致 join() 或 joinUntil(Instant) 方法返回。因此,所有子任务都应该被编写为响应中断。在调用 shutdown() 后分叉的新子任务将处于 UNAVAILABLE 状态,不会被运行。实际上,shutdown() 是顺序代码中 break 语句的并发模拟。
在作用域内部调用 join() 或 joinUntil(Instant) 是强制性的。如果作用域的代码块在加入之前退出,则作用域将等待所有子任务终止,然后抛出异常。
作用域的所有者线程可能在加入之前或加入期间被中断。例如,它可能是封闭作用域的子任务。如果发生这种情况,则 join() 和 joinUntil(Instant) 将抛出异常,因为继续执行没有意义。然后,try-with-resources 语句将关闭作用域,取消所有子任务并等待它们终止。这的效果是自动将任务的取消传播到其子任务。如果 joinUntil(Instant) 方法的截止时间在子任务终止或调用 shutdown() 之前到期,则它将抛出异常,再次,try-with-resources 语句将关闭作用域。
当 join() 成功完成时,每个子任务已经成功完成、失败或因作用域被关闭而被取消。
一旦加入,作用域的所有者会处理失败的子任务并处理成功完成的子任务的结果;这通常是通过关闭策略来完成的(见下文)。成功完成的任务的结果可以使用 Subtask.get() 方法获得。get() 方法永远不会阻塞;如果错误地在加入之前或子任务尚未成功完成时调用它,则会抛出 IllegalStateException。
在作用域中分叉任务的子任务时,会继承 ScopedValue 绑定(JEP 446)。如果作用域的所有者从绑定的 ScopedValue 中读取值,则每个子任务将读取相同的值。
如果作用域的所有者本身是现有作用域的子任务,即作为分叉子任务创建的,则该作用域成为新作用域的父作用域。因此,作用域和子任务形成一个树状结构。
在运行时,StructuredTaskScope 强制执行结构和顺序并发操作。因此,它不实现 ExecutorService 或 Executor 接口,因为这些接口的实例通常以非结构化方式使用(见下文)。然而,将使用 ExecutorService 的代码迁移到使用 StructuredTaskScope 并从结构上受益是直接的。
实际上,大多数使用 StructuredTaskScope 的情况下,可能不会直接使用 StructuredTaskScope 类,而是使用下一节描述的两个实现了关闭策略的子类之一。在其他情况下,用户可能会编写自己的子类来实现自定义的关闭策略。
11 关闭策略
在处理并发子任务时,通常会使用短路模式来避免不必要的工作。有时,例如,如果其中一个子任务失败,就会取消所有子任务(即同时调用所有任务),或者在其中一个子任务成功时取消所有子任务(即同时调用任何任务)。StructuredTaskScope 的两个子类,ShutdownOnFailure 和 ShutdownOnSuccess,支持这些模式,并提供在第一个子任务失败或成功时关闭作用域的策略。
关闭策略还提供了集中处理异常以及可能的成功结果的方法。这符合结构化并发的精神,即整个作用域被视为一个单元。
11.1 案例
上面的 handle() 示例也使用了这策略,它在并发运行一组任务并在其中任何一个任务失败时失败:
<T> List<T> runAll(List<Callable<T>> tasks) throws InterruptedException, ExecutionException {try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {List<? extends Supplier<T>> suppliers = tasks.stream().map(scope::fork).toList();scope.join().throwIfFailed(); // 任何子任务失败,抛异常// 在这里,所有任务都已成功完成,因此组合结果return suppliers.stream().map(Supplier::get).toList();}
}在第一个成功的子任务返回结果后返回该结果:
<T> T race(List<Callable<T>> tasks, Instant deadline) throws InterruptedException, ExecutionException, TimeoutException {try (var scope = new StructuredTaskScope.ShutdownOnSuccess<T>()) {for (var task : tasks) {scope.fork(task);}return scope.joinUntil(deadline).result(); // 如果没有任何子任务成功完成,抛出异常}
}一旦有一个子任务成功,此作用域将自动关闭,取消未完成的子任务。如果所有子任务失败或给定的截止时间过去,任务将失败。这种模式在需要从一组冗余服务中获得任何一个服务的结果的服务器应用程序中非常有用。
虽然这俩关闭策略已内置,但开发人员可以创建自定义策略来抽象其他模式。
11.2 处理结果
在通过关闭策略(例如,通过 ShutdownOnFailure::throwIfFailed)进行集中异常处理和加入之后,作用域的所有者可以使用从调用 fork(...) 返回的 [Subtask] 对象处理子任务的结果,如果这些结果没有被策略处理(例如,通过 ShutdownOnSuccess::result())。
通常情况下,作用域所有者将只调用 get() 方法的 Subtask 方法。所有其他的 Subtask 方法通常只会在自定义关闭策略的 handleComplete(...) 方法的实现中使用。实际上,我们建议将引用由 fork(...) 返回的 Subtask 的变量类型定义为 Supplier<String> 而不是 Subtask<String>(除非当然选择使用 var)。如果关闭策略本身处理子任务结果(如在 ShutdownOnSuccess 的情况下),则应完全避免使用由 fork(...) 返回的 Subtask 对象,并将 fork(...) 方法视为返回 void。子任务应将其结果作为它们的返回结果,作为策略在处理中央异常后应处理的任何信息。
如果作用域所有者处理子任务异常以生成组合结果,而不是使用关闭策略,则异常可以作为从子任务返回的值返回。例如,下面是一个在并行运行一组任务并返回包含每个任务各自成功或异常结果的完成 Future 列表的方法:
<T> List<Future<T>> executeAll(List<Callable<T>> tasks)throws InterruptedException {try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {List<? extends Supplier<Future<T>>> futures = tasks.stream().map(task -> asFuture(task)).map(scope::fork).toList();scope.join();return futures.stream().map(Supplier::get).toList();}
}static <T> Callable<Future<T>> asFuture(Callable<T> task) {return () -> {try {return CompletableFuture.completedFuture(task.call());} catch (Exception ex) {return CompletableFuture.failedFuture(ex);}};
}11.3 自定义关闭策略
StructuredTaskScope 可以被扩展,并且可以覆盖其受保护的 handleComplete(...) 方法,以实现除 ShutdownOnSuccess 和 ShutdownOnFailure 之外的其他策略。子类可以,例如:
- 收集成功完成的子任务的结果,并忽略失败的子任务,
- 在子任务失败时收集异常,或者
- 在出现某种条件时调用
shutdown()方法以关闭并导致join()方法唤醒。
当一个子任务完成时,即使在调用 shutdown() 之后,它也会作为一个 Subtask 报告给 handleComplete(...) 方法:
public sealed interface Subtask<T> extends Supplier<T> {enum State { SUCCESS, FAILED, UNAVAILABLE }State state();Callable<? extends T> task();T get();Throwable exception();
}当子任务在 SUCCESS 状态或 FAILED 状态下完成时,handleComplete(...) 方法将被调用。如果子任务处于 SUCCESS 状态,可以调用 get() 方法,如果子任务处于 FAILED 状态,则可以调用 exception() 方法。在其他情况下调用 get() 或 exception() 会引发 IllegalStateException 异常。UNAVAILABLE 状态表示以下情况之一:(1)子任务被 fork 但尚未完成;(2)子任务在关闭后完成,或者(3)子任务在关闭后被 fork,因此尚未启动。handleComplete(...) 方法永远不会为处于 UNAVAILABLE 状态的子任务调用。
子类通常会定义方法,以使结果、状态或其他结果在 join() 方法返回后可以被后续代码使用。收集结果并忽略失败子任务的子类可以定义一个方法,该方法返回一系列结果。实施在子任务失败时关闭的策略的子类可以定义一个方法,以获取失败的第一个子任务的异常。
扩展 StructuredTaskScope 的子类
该子类收集成功完成的子任务的结果。它定义了 results() 方法,供主任务用于检索结果。
class MyScope<T> extends StructuredTaskScope<T> {private final Queue<T> results = new ConcurrentLinkedQueue<>();MyScope() { super(null, Thread.ofVirtual().factory()); }@Overrideprotected void handleComplete(Subtask<? extends T> subtask) {if (subtask.state() == Subtask.State.SUCCESS)results.add(subtask.get());}@Overridepublic MyScope<T> join() throws InterruptedException {super.join();return this;}// 返回从成功完成的子任务获取的结果流public Stream<T> results() {super.ensureOwnerAndJoined();return results.stream();}}可以像这样使用这个自定义策略:
<T> List<T> allSuccessful(List<Callable<T>> tasks) throws InterruptedException {try (var scope = new MyScope<T>()) {for (var task : tasks) scope.fork(task);return scope.join().results().toList();}
}扇入场景
上面的示例侧重于扇出场景,这些场景管理多个并发的出站 I/O 操作。StructuredTaskScope 在扇入场景中也非常有用,这些场景管理多个并发的入站 I/O 操作。在这种情况下,我们通常会响应传入请求而动态地创建未知数量的子任务。
以下是一个服务器的示例,它在 StructuredTaskScope 中 fork 子任务以处理传入连接:
void serve(ServerSocket serverSocket) throws IOException, InterruptedException {try (var scope = new StructuredTaskScope<Void>()) {try {while (true) {var socket = serverSocket.accept();scope.fork(() -> handle(socket));}} finally {// 如果发生错误或被中断,我们停止接受连接scope.shutdown(); // 关闭所有活动连接scope.join();}}
}从并发的角度来看,这种情况与请求的方向不同,但在持续时间和任务数量方面是不同的,因为子任务是根据外部事件动态 fork 的。
所有处理连接的子任务都在作用域内创建,因此在线程转储中很容易看到它们在一个作用域的所有者的子线程。作用域的所有者也很容易被当作一个单元关闭整个服务。
可观察性
我们扩展了由 JEP 444 添加的新的 JSON 线程转储格式,以显示 StructuredTaskScope 将线程分组成层次结构:
$ jcmd <pid> Thread.dump_to_file -format=json <file>每个作用域的 JSON 对象包含一个线程数组,这些线程在作用域中被 fork,并附带它们的堆栈跟踪。作用域的所有者线程通常会在 join() 方法中被阻塞,等待子任务完成;线程转储可以通过显示由结构化并发所施加的树状层次结构,轻松地查看子任务的线程正在做什么。作用域的 JSON 对象还具有对其父级的引用,以便可以从转储中重新构建程序的结构。
com.sun.management.HotSpotDiagnosticsMXBean API 也可以用来生成这样的线程转储,可以通过平台的 MBeanServer 和本地或远程的 JMX 工具直接或间接地使用它。
为什么 fork(...) 没有返回 Future?
当 StructuredTaskScope API 处于孵化状态时,fork(...) 方法返回了 Future。这使得 fork(...) 更像是现有的 ExecutorService::submit 方法,从而提供了一种熟悉的感觉。然而,考虑到 StructuredTaskScope 的使用方式与 ExecutorService 完全不同 — 即以上文描述的结构化方式使用 — 使用 Future 带来的更多困惑远远超过了清晰性。
熟悉的 Future 的使用涉及调用其 get() 方法,它会阻塞直到结果可用。但在 StructuredTaskScope 的上下文中,以这种方式使用 Future 不仅是不鼓励的,而且是不切实际的。Structured Future 对象应该只有在 join() 返回之后查询,此时它们已知已完成或取消,而应使用的方法不是熟悉的 get(),而是新引入的 resultNow(),它永远不会阻塞。
一些开发人员想知道为什么 fork(...) 没有返回更强大的 CompletableFuture 对象。由于应该只有在已知它们已完成时才使用 fork(...) 返回的 Future,因此 CompletableFuture 不会提供任何好处,因为其高级功能只对未完成的 futures 有用。此外,CompletableFuture 是为异步编程范例设计的,而 StructuredTaskScope 鼓励阻塞范例。
总之,Future 和 CompletableFuture 的设计旨在提供在结构化并发中是有害的自由度。
结构化并发是将在不同线程中运行的多个任务视为单个工作单元,而 Future 主要在将多个任务视为单独任务时有用。因此,作用域只应该阻塞一次以等待其子任务的结果,然后集中处理异常。因此,在绝大多数情况下,从 fork(...) 返回的 Future 上唯一应该调用的方法是 resultNow()。这是与 Future 的正常用法的显著变化,而 Subtask::get() 方法的行为与在 API 孵化期间 Future::resultNow() 的行为完全相同。
替代方案
增强 ExecutorService 接口。我们对该接口进行了原型实现,该接口始终强制执行结构化并限制了哪些线程可以提交任务。然而,我们发现这在 JDK 和生态系统中的大多数使用情况下都不是结构化的。在完全不同的概念中重用相同的 API,会导致混淆。例如,将结构化 ExecutorService 实例传递给现有接受此类型的方法,几乎肯定会在大多数情况下抛出异常。
本文由博客一文多发平台 OpenWrite 发布!
相关文章:
掌握JDK21全新结构化并发编程,轻松提升开发效率!
1 概要 通过引入结构化并发编程的API,简化并发编程。结构化并发将在不同线程中运行的相关任务组视为单个工作单元,从而简化错误处理和取消操作,提高可靠性,并增强可观察性。这是一个预览版的API。 2 历史 结构化并发是由JEP 42…...

【SA8295P 源码分析】00 - 系列文章链接汇总 - 持续更新中
【SA8295P 源码分析】00 - 系列文章链接汇总 - 持续更新中 一、分区、下载、GPIO等杂项相关二、开机启动流程代码分析二、OpenWFD 显示屏模块三、Touch Panel 触摸屏模块四、QUPv3 及 QNX Host透传配置五、Camera 摄像头模块(当前正在更新中...)六、网络…...
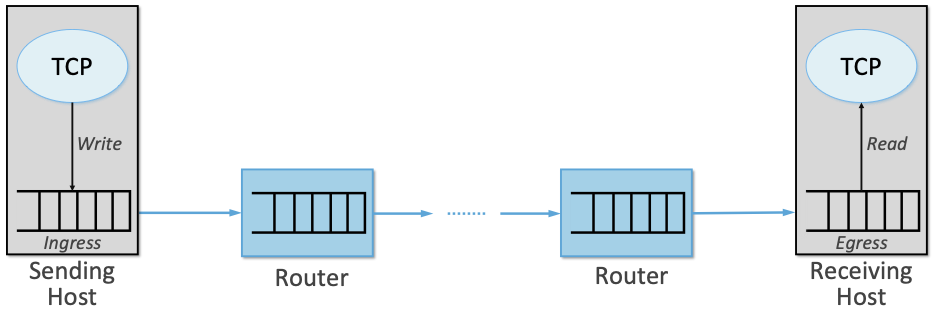
TCP拥塞控制详解 | 6. 主动队列管理
网络传输问题本质上是对网络资源的共享和复用问题,因此拥塞控制是网络工程领域的核心问题之一,并且随着互联网和数据中心流量的爆炸式增长,相关算法和机制出现了很多创新,本系列是免费电子书《TCP Congestion Control: A Systems …...

前端学习清单
顺序不分先后。 技术名称技术描述技术链接HTML5HTML5是下一代的HTML标准,是一种用于结构化内容的标记语言。MDN|HTMLCSS3CSS3是CSS技术的升级版本,它的最大好处就是可以让网页设计师更加方便的为网页添加各种各样的样式,而不用再局限于文字、…...

go atomic原子操作详细解读
文章目录 概要1、基本知识1.1 原子操作是什么1.2 CPU怎么实现原子操作的? 2、atomic包2.1、 Add函数2.2、CompareAndSwap函数2.3、Swap函数2.4、Load函数2.5、Store函数 3、atomic.Value值 概要 atomic包是golang通过对底层系统支持的原子操作进行封装,…...
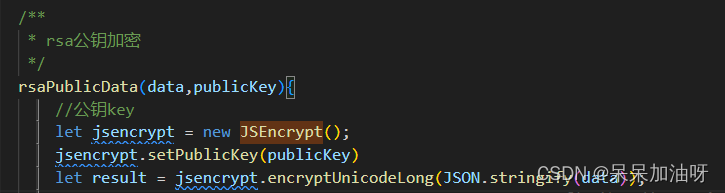
Vue用JSEncrypt对长文本json加密以及发现解密失败
哈喽 大家好啊,最近发现进行加密后 超长文本后端解密失败,经过看其他博主修改 JSEncrypt原生代码如下: // 分段加密,支持中文JSEncrypt.prototype.encryptUnicodeLong function (string) {var k this.getKey();//根据key所能编…...
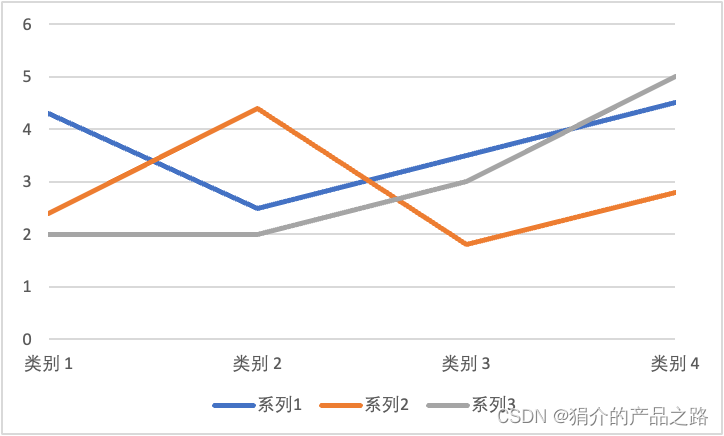
Excel/PowerPoint折线图从Y轴开始(两侧不留空隙)
默认Excel/PowerPoint折线图是这个样子的: 左右两侧都留了大块空白,很难看 解决方案 点击横坐标,双击,然后按下图顺序点击 效果...

C++的类成员对齐
这是个小语法点,之前我们的对齐方式都是使用#pragma pack,这个方式实际是依赖编译器,且粒度粗(如果#pragma pack(1)之后没有#pragma pack(),那就作用整个进程了)。在C11之后引入关键字alignas,以此来实现对齐更加便利,…...

敏感挂载userhelper容器逃逸复现
目录 前言 分析 实验 前言 分析 实验 # Creates a payload cat "#!/bin/sh" > /evil-helper cat "ps > /output" >> /evil-helper chmod x /evil-helper # Finds path of OverlayFS mount for container # Unless the configuration ex…...

深度解读Promise.prototype.finally
由一个问题引发的血案: 手写源码实现Promise.prototype.finally。 我们知道,对于promise来讲,当状态敲定,无论状态兑现或拒绝时都需要调用的函数,可以使用Promise.prototype.finally的回调来实现。那么如何手写实现Pro…...

如何实现24/7客户服务自动化?建设智能客服知识库
客户自助服务是指用户通过企业或者第三方建立的网络平台或者终端,实现相关的自定义处理。实现客户服务自动化,对提高客户满意度、维持客户关系至关重要。客户服务自动化可以帮助企业以更快的速度和更高的效率来满足客户的售后服务要求,以进一…...

和鲸 ModelWhale 与中科可控多款服务器完成适配认证,赋能中国云生态
当前世界正处于新一轮技术革命及传统产业数字化转型的关键期,云计算作为重要的技术底座,其产业发展与产业规模对我国数字经济的高质量运行有着不可取代的推动作用。而随着我国数字上云、企业上云加快进入常规化阶段,云计算承载的业务应用越来…...
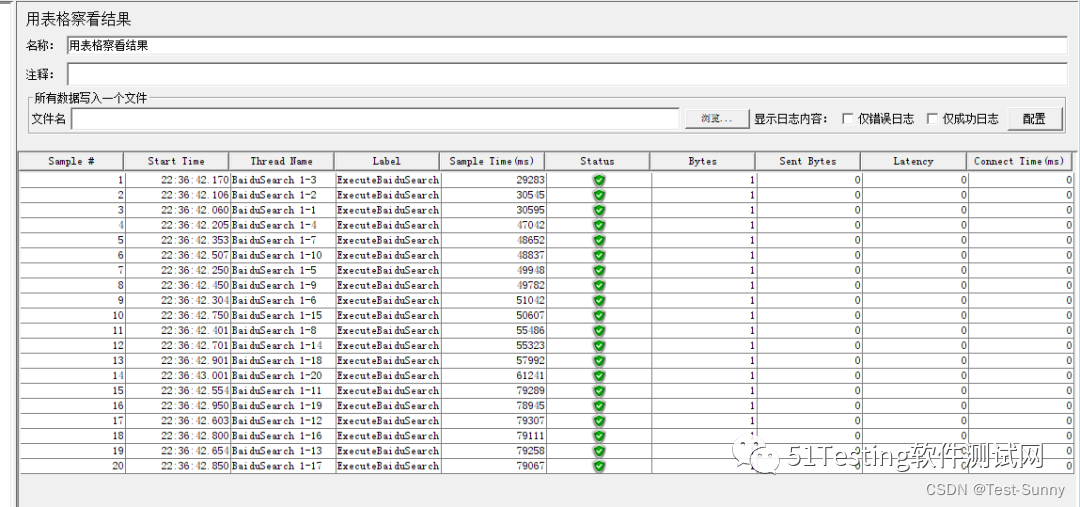
selenium +Jmeter 的性能测试
通过Jmeter快速将已有的Selenium 代码以性能测试的方式组织起来,并使用JMeter 丰富的报表展示测试结果 from selenium import webdriver from selenium.webdriver.common.action_chains import ActionChains from selenium.webdriver.common.by import By driver …...

探索高效的HTTP异步接口测试方法:从轮询等待到自动化方案
本文将深入探讨HTTP异步接口测试的多个方面,包括轮询等待、性能测试以及自动化方案。通过详细的解释和实际案例,帮助您了解如何有效地测试异步接口,确保系统的稳定性和性能。 在现代软件开发中,HTTP异步接口扮演着至关重要的角色&…...

Android资深工程书之LiveData核心组件原理剖析
LiveData是Android架构组件库中的一个类,用于在应用程序组件之间共享数据。它是一种可观察的数据持有者,可以感知应用程序组件的生命周期,并在数据发生变化时通知观察者。 使用LiveData 在Android应用程序中使用LiveData,你可以…...

Vue的五种方法实现加减乘除运算
五种方法的详细说明: 计算属性(Computed Properties): 计算属性是Vue.js提供的一种便捷的属性,它根据依赖的数据动态计算出一个新的值。计算属性的值会被缓存,只有当依赖的数据发生变化时,才会…...
Linux基础知识)
C++(1)Linux基础知识
经济下行,计算机就业形势严峻,为了勉励自己继续进步,继续学习代码提高核心竞争力。 安装QT Creator 首先,安装QT开发工具QT Creator 参考:2021最新Qt6开发环境(Qt Creator)安装以及卸载记录_q…...

接口自动化yaml文件读取与写入
前言 在走进yaml文件之前大家应该都很想知道他是用来干嘛的? 是的是的,他是用来做接口自动化测试的。 我们一起来学习他吧!——(一定要收藏带走哦❤) 1、yaml文件有什么作用呢? ①可作为配置文件使用—…...

Java Map、JSONObject、实体类互转
文章目录 前言Map、JSONObject、实体类互转 前言 使用库 com.alibaba.fastjson2,可完成大部分JSON转换操作。 详情参考文章: Java FASTJSON2 一个性能极致并且简单易用的JSON库 Map、JSONObject、实体类互转 import com.alibaba.fastjson2.JSON; import com.alib…...

在Hive/Spark上执行TPC-DS基准测试 (PARQUET格式)
在上一篇文章:《在Hive/Spark上运行执行TPC-DS基准测试 (ORC和TEXT格式)》中,我们介绍了如何使用 hive-testbench 在Hive/Spark上执行TPC-DS基准测试,同时也指出了该项目不支持parquet格式。 如果我们想要生成parquet格式的测试数据,就需要使用其他工具了。本文选择使用另…...

iOS 26 携众系统重磅更新,但“苹果智能”仍与国行无缘
美国西海岸的夏天,再次被苹果点燃。一年一度的全球开发者大会 WWDC25 如期而至,这不仅是开发者的盛宴,更是全球数亿苹果用户翘首以盼的科技春晚。今年,苹果依旧为我们带来了全家桶式的系统更新,包括 iOS 26、iPadOS 26…...

ElasticSearch搜索引擎之倒排索引及其底层算法
文章目录 一、搜索引擎1、什么是搜索引擎?2、搜索引擎的分类3、常用的搜索引擎4、搜索引擎的特点二、倒排索引1、简介2、为什么倒排索引不用B+树1.创建时间长,文件大。2.其次,树深,IO次数可怕。3.索引可能会失效。4.精准度差。三. 倒排索引四、算法1、Term Index的算法2、 …...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...

【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的“no matching...“系列算法协商失败问题
【SSH疑难排查】轻松解决新版OpenSSH连接旧服务器的"no matching..."系列算法协商失败问题 摘要: 近期,在使用较新版本的OpenSSH客户端连接老旧SSH服务器时,会遇到 "no matching key exchange method found", "n…...

Vite中定义@软链接
在webpack中可以直接通过符号表示src路径,但是vite中默认不可以。 如何实现: vite中提供了resolve.alias:通过别名在指向一个具体的路径 在vite.config.js中 import { join } from pathexport default defineConfig({plugins: [vue()],//…...

基于江科大stm32屏幕驱动,实现OLED多级菜单(动画效果),结构体链表实现(独创源码)
引言 在嵌入式系统中,用户界面的设计往往直接影响到用户体验。本文将以STM32微控制器和OLED显示屏为例,介绍如何实现一个多级菜单系统。该系统支持用户通过按键导航菜单,执行相应操作,并提供平滑的滚动动画效果。 本文设计了一个…...

2025年- H71-Lc179--39.组合总和(回溯,组合)--Java版
1.题目描述 2.思路 当前的元素可以重复使用。 (1)确定回溯算法函数的参数和返回值(一般是void类型) (2)因为是用递归实现的,所以我们要确定终止条件 (3)单层搜索逻辑 二…...
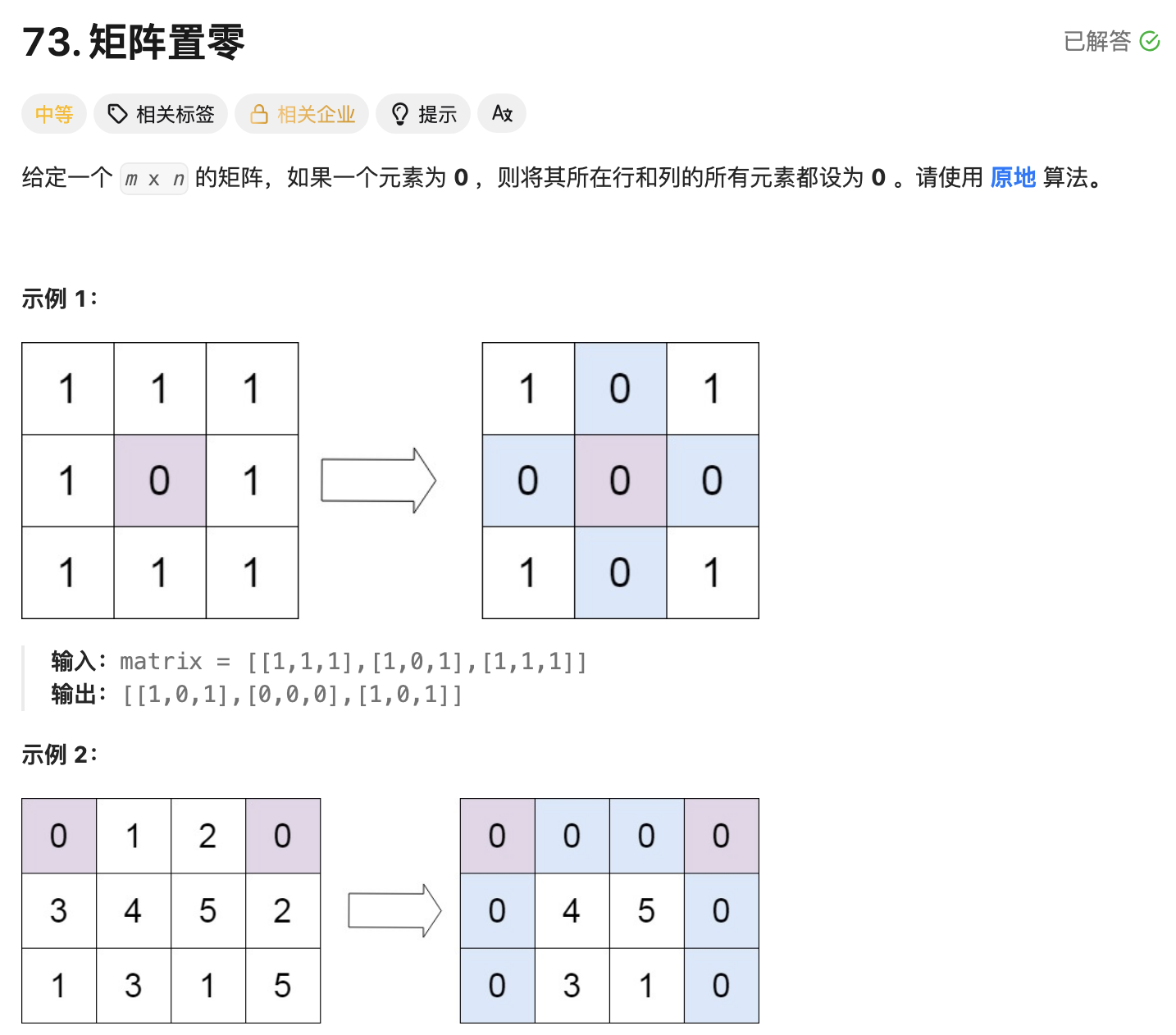
leetcode73-矩阵置零
leetcode 73 思路 记录 0 元素的位置:遍历整个矩阵,找出所有值为 0 的元素,并将它们的坐标记录在数组zeroPosition中置零操作:遍历记录的所有 0 元素位置,将每个位置对应的行和列的所有元素置为 0 具体步骤 初始化…...