数学建模及数据分析 || 4. 深度学习应用案例分享
PyTorch 深度学习全连接网络分类
文章目录
- PyTorch 深度学习全连接网络分类
- 1. 非线性二分类
- 2. 泰坦尼克号数据分类
- 2.1 数据的准备工作
- 2.2 全连接网络的搭建
- 2.3 结果的可视化
1. 非线性二分类
import sklearn.datasets #数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_scoreimport torch
import numpy as np
import matplotlib.pyplot as plt
import torch.nn as nnnp.random.seed(0) #设置随机数种子
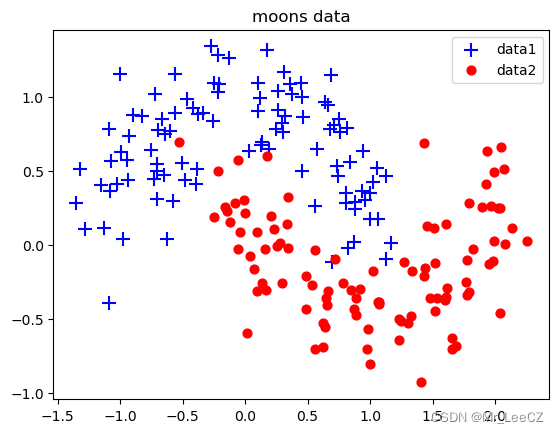
X, Y = sklearn. datasets. make_moons (200, noise=0.2) # 生成内组半圆形数据arg = np.squeeze(np.argwhere(Y==0),axis = 1) # 获取第1类数据索引
arg2 = np.squeeze(np.argwhere (Y==1), axis = 1) # 获取第2类数据索引
plt.title("moons data")
plt.scatter(X[arg,0], X[arg, 1], s=100, c='b' , marker='+' , label='data1')
plt.scatter(X[arg2,0], X[arg2, 1], s=40, c='r' ,marker='o' , label= 'data2')
plt.legend()
plt.show()
#继承nn.Module类,构建网络模型
class LogicNet(nn.Module):def __init__(self,inputdim,hiddendim,outputdim):#初始化网络结构super(LogicNet,self).__init__()self.Linear1 = nn.Linear(inputdim,hiddendim) #定义全连接层self.Linear2 = nn.Linear(hiddendim,outputdim)#定义全连接层self.criterion = nn.CrossEntropyLoss() #定义交叉熵函数def forward(self,x): #搭建用两层全连接组成的网络模型x = self.Linear1(x)#将输入数据传入第1层x = torch.tanh(x)#对第一层的结果进行非线性变换x = self.Linear2(x)#再将数据传入第2层
# print("LogicNet")return xdef predict(self,x):#实现LogicNet类的预测接口#调用自身网络模型,并对结果进行softmax处理,分别得出预测数据属于每一类的概率pred = torch.softmax(self.forward(x),dim=1)return torch.argmax(pred,dim=1) #返回每组预测概率中最大的索引def getloss(self,x,y): #实现LogicNet类的损失值计算接口y_pred = self.forward(x)loss = self.criterion(y_pred,y)#计算损失值得交叉熵return lossmodel = LogicNet(inputdim=2,hiddendim=3,outputdim=2)
optimizer = torch.optim.Adam(model.parameters(),lr=0.01)
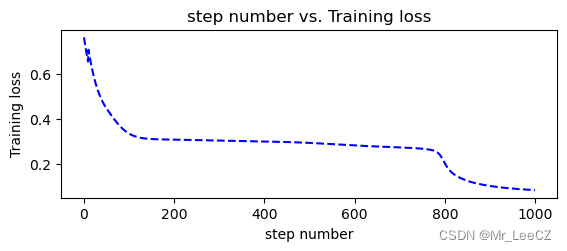
def moving_average(a, w=10):#定义函数计算移动平均损失值if len(a) < w:return a[:]return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]def plot_losses(losses):avgloss= moving_average(losses) #获得损失值的移动平均值plt.figure(1)plt.subplot(211)plt.plot(range(len(avgloss)), avgloss, 'b--')plt.xlabel('step number')plt.ylabel('Training loss')plt.title('step number vs. Training loss')plt.show()
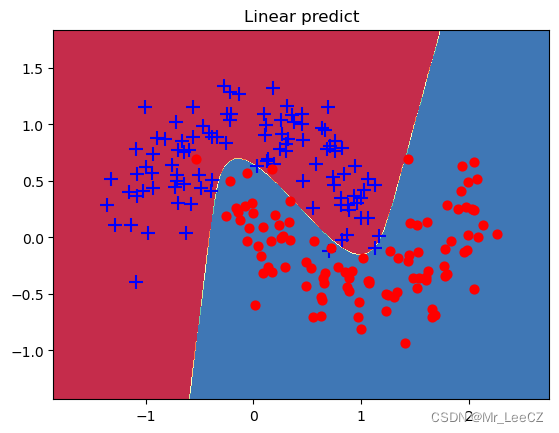
def predict(model,x): #封装支持Numpy的预测接口x = torch.from_numpy(x).type(torch.FloatTensor)ans = model.predict(x)return ans.numpy()def plot_decision_boundary(pred_func,X,Y):#在直角坐标系中可视化模型能力#计算取值范围x_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5h = 0.01#在坐标系中采用数据,生成网格矩阵,用于输入模型xx,yy=np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h))#将数据输入并进行预测Z = pred_func(np.c_[xx.ravel(), yy.ravel()])Z = Z.reshape(xx.shape)#将预测的结果可视化plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral)plt.title("Linear predict")arg = np.squeeze(np.argwhere(Y==0),axis = 1)arg2 = np.squeeze(np.argwhere(Y==1),axis = 1)plt.scatter(X[arg,0], X[arg,1], s=100,c='b',marker='+')plt.scatter(X[arg2,0], X[arg2,1],s=40, c='r',marker='o')plt.show()
if __name__ == '__main__':xt = torch.from_numpy(X).type(torch.FloatTensor)yt = torch.from_numpy(Y).type(torch.LongTensor)epochs = 1000losses = []for i in range(epochs):loss = model.getloss(xt,yt)losses.append(loss.item())optimizer.zero_grad()loss.backward()optimizer.step()plot_losses(losses)print(accuracy_score(model.predict(xt),yt))plot_decision_boundary(lambda x: predict(model,x), xt.numpy(), yt.numpy())
0.98
2. 泰坦尼克号数据分类
2.1 数据的准备工作
计算模块和数据的准备
import os
import numpy as np
import pandas as pd
from scipy import statsimport torch
import torch.nn as nn
import torch.nn.functional as Ftitanic_data = pd.read_csv("titanic3.csv")
print(titanic_data.columns )
print('\n',titanic_data.dtypes)
Index([‘pclass’, ‘survived’, ‘name’, ‘sex’, ‘age’, ‘sibsp’, ‘parch’, ‘ticket’,
‘fare’, ‘cabin’, ‘embarked’, ‘boat’, ‘body’, ‘home.dest’],
dtype=‘object’)
------------
pclass int64
survived int64
name object
sex object
age float64
sibsp int64
parch int64
ticket object
fare float64
cabin object
embarked object
boat object
body float64
home.dest object
dtype: object
对哑变量的处理
#用哑变量将指定字段转成one-hot
titanic_data = pd.concat([titanic_data,pd.get_dummies(titanic_data['sex']),pd.get_dummies(titanic_data['embarked'],prefix="embark"),pd.get_dummies(titanic_data['pclass'],prefix="class")], axis=1)print(titanic_data.columns )
print(titanic_data['sex'])
print(titanic_data['female'])
Index([‘pclass’, ‘survived’, ‘name’, ‘sex’, ‘age’, ‘sibsp’, ‘parch’, ‘ticket’,
‘fare’, ‘cabin’, ‘embarked’, ‘boat’, ‘body’, ‘home.dest’, ‘female’,
‘male’, ‘embark_C’, ‘embark_Q’, ‘embark_S’, ‘class_1’, ‘class_2’,
‘class_3’],
dtype=‘object’)
0 female
1 male
2 female
3 male
4 female
…
1304 female
1305 female
1306 male
1307 male
1308 male
Name: sex, Length: 1309, dtype: object
0 1
1 0
2 1
3 0
4 1
…
1304 1
1305 1
1306 0
1307 0
1308 0
Name: female, Length: 1309, dtype: uint8
对缺失值的处理
#处理None值
titanic_data["age"] = titanic_data["age"].fillna(titanic_data["age"].mean())
titanic_data["fare"] = titanic_data["fare"].fillna(titanic_data["fare"].mean())#乘客票价#删去无用的列
titanic_data = titanic_data.drop(['name','ticket','cabin','boat','body','home.dest','sex','embarked','pclass'], axis=1)
print(titanic_data.columns)
Index([‘survived’, ‘age’, ‘sibsp’, ‘parch’, ‘fare’, ‘female’, ‘male’,
‘embark_C’, ‘embark_Q’, ‘embark_S’, ‘class_1’, ‘class_2’, ‘class_3’],
dtype=‘object’)
划分训练集和测试集
#分离样本和标签
labels = titanic_data["survived"].to_numpy()titanic_data = titanic_data.drop(['survived'], axis=1)
data = titanic_data.to_numpy()#样本的属性名称
feature_names = list(titanic_data.columns)#将样本分为训练和测试两部分
np.random.seed(10)#设置种子,保证每次运行所分的样本一致
train_indices = np.random.choice(len(labels), int(0.7*len(labels)), replace=False)
test_indices = list(set(range(len(labels))) - set(train_indices))
train_features = data[train_indices]
train_labels = labels[train_indices]
test_features = data[test_indices]
test_labels = labels[test_indices]
len(test_labels)#393
2.2 全连接网络的搭建
搭建全连接网络
torch.manual_seed(0) #设置随机种子class ThreelinearModel(nn.Module):def __init__(self):super().__init__()self.linear1 = nn.Linear(12, 12)self.mish1 = Mish()self.linear2 = nn.Linear(12, 8)self.mish2 = Mish()self.linear3 = nn.Linear(8, 2)self.softmax = nn.Softmax(dim=1)self.criterion = nn.CrossEntropyLoss() #定义交叉熵函数def forward(self, x): #定义一个全连接网络lin1_out = self.linear1(x)out1 = self.mish1(lin1_out)out2 = self.mish2(self.linear2(out1))return self.softmax(self.linear3(out2))def getloss(self,x,y): #实现LogicNet类的损失值计算接口y_pred = self.forward(x)loss = self.criterion(y_pred,y)#计算损失值得交叉熵return lossclass Mish(nn.Module):#Mish激活函数def __init__(self):super().__init__()print("Mish activation loaded...")def forward(self,x):x = x * (torch.tanh(F.softplus(x)))return xnet = ThreelinearModel()
optimizer = torch.optim.Adam(net.parameters(), lr=0.04)
训练网络
num_epochs = 200input_tensor = torch.from_numpy(train_features).type(torch.FloatTensor)
label_tensor = torch.from_numpy(train_labels)losses = []#定义列表,用于接收每一步的损失值
for epoch in range(num_epochs): loss = net.getloss(input_tensor,label_tensor)losses.append(loss.item())optimizer.zero_grad()#清空之前的梯度loss.backward()#反向传播损失值optimizer.step()#更新参数if epoch % 20 == 0:print ('Epoch {}/{} => Loss: {:.2f}'.format(epoch+1, num_epochs, loss.item()))#os.makedirs('models', exist_ok=True)
#torch.save(net.state_dict(), 'models/titanic_model.pt')
Epoch 1/200 => Loss: 0.72
Epoch 21/200 => Loss: 0.55
Epoch 41/200 => Loss: 0.52
Epoch 61/200 => Loss: 0.49
Epoch 81/200 => Loss: 0.49
Epoch 101/200 => Loss: 0.48
Epoch 121/200 => Loss: 0.48
Epoch 141/200 => Loss: 0.48
Epoch 161/200 => Loss: 0.48
Epoch 181/200 => Loss: 0.48
2.3 结果的可视化
可视化函数
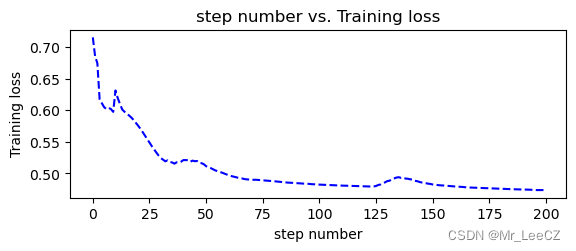
import matplotlib.pyplot as pltdef moving_average(a, w=10):#定义函数计算移动平均损失值if len(a) < w:return a[:]return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]def plot_losses(losses):avgloss= moving_average(losses) #获得损失值的移动平均值plt.figure(1)plt.subplot(211)plt.plot(range(len(avgloss)), avgloss, 'b--')plt.xlabel('step number')plt.ylabel('Training loss')plt.title('step number vs. Training loss')plt.show()
调用可视化函数作图
plot_losses(losses)#输出训练结果
out_probs = net(input_tensor).detach().numpy()
out_classes = np.argmax(out_probs, axis=1)
print("Train Accuracy:", sum(out_classes == train_labels) / len(train_labels))#测试模型
test_input_tensor = torch.from_numpy(test_features).type(torch.FloatTensor)
out_probs = net(test_input_tensor).detach().numpy()
out_classes = np.argmax(out_probs, axis=1)
print("Test Accuracy:", sum(out_classes == test_labels) / len(test_labels))
Train Accuracy: 0.8384279475982532
Test Accuracy: 0.806615776081425
相关文章:
数学建模及数据分析 || 4. 深度学习应用案例分享
PyTorch 深度学习全连接网络分类 文章目录 PyTorch 深度学习全连接网络分类1. 非线性二分类2. 泰坦尼克号数据分类2.1 数据的准备工作2.2 全连接网络的搭建2.3 结果的可视化 1. 非线性二分类 import sklearn.datasets #数据集 import numpy as np import matplotlib.pyplot as…...

数据分析15——office中的Excel基础技术汇总
0、前言: 这部分总结就是总结每个基础技术的定义,在了解基础技术名称和定义后,方便对相关技术进行检索学习。笔记不会详细到所有操作都说明,但会把基础操作的名称及作用说明,可自行检索。本文对于大部分读者有以下作用…...
C语言好题解析(四)
目录 选择题一选择题二选择题三选择题四选择题五编程题一 选择题一 已知函数的原型是: int fun(char b[10], int *a); 设定义: char c[10];int d; ,正确的调用语句是( ) A: fun(c,&d); B: fun(c,d); C: fun(&…...

英语——主谓一致
主谓一致是指句子的谓语动词与其主语在数上必须保持一致,一般遵循以下三个原则: 一、语法形式上一致,即单复数形式与谓语要一致。 二、意义上一致,即主语意义上的单复数要与谓语的单复数形式一致。 三、就近以及就远原则,即谓语动词的单复形式取决于最靠近它的词语或者离它…...

属性字符串解析
连续的KV的字符串,每个KV之间用","分隔,V中可嵌套KV的连续字符串结构,例如“ key1value1,key2value2,key3[key4value4,key5value5,key6[key7value7]],key8value8 请编写如下函数,给定字符串,输出嵌套结构的H…...
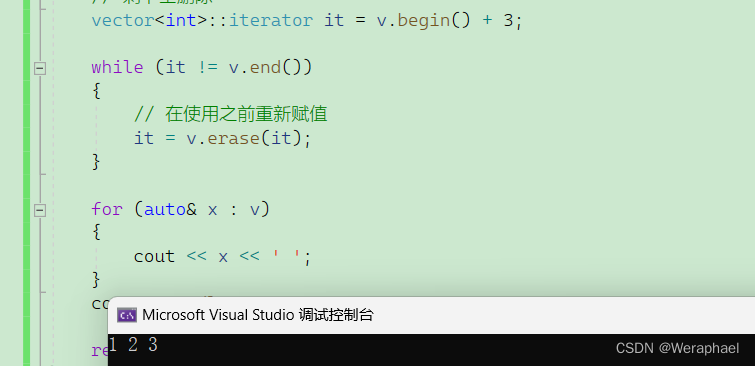
【C++初阶】vector容器
👦个人主页:Weraphael ✍🏻作者简介:目前学习C和算法 ✈️专栏:C航路 🐋 希望大家多多支持,咱一起进步!😁 如果文章对你有帮助的话 欢迎 评论💬 点赞…...

ThreadLocal深度解析
简介 在并发编程中,导致并发bug的问题都会归结于对共享变量的操作不当。多个线程同时读写同一共享变量存在并发问题,我们可以利用写时复制、不变性来突破对原数据的写操作,没有写就没有并发问题,而本篇文章所介绍的技术是突破共享…...

06有监督学习——迁移学习
1.迁移学习分类 (1) 基于实例的迁移学习方法: 假设:源域中的一些数据和目标域会共享很多共同的特征方法:对源域进行instance reweighting,筛选出与目标域数据相似度高的数据,然后进行训练学习 (2&#x…...

快速连接服务器脚本 可从多个服务中选择并连接
使用 python 做一个可选择服务器登录连接的脚本 前置条件 需要有python 环境python --version 显示版本号即可检查 python 是否有 paramiko 包没有的话 python install paramiko创建一个python 文件,内容如下 # -*- coding: utf-8 -*-""" Authors: huxiaohua…...
MemSeg:一种差异和共性来检测图像表面缺陷的半监督方法
目录 1、摘要 2、Method 2.1 模拟异常样本 2.2 Memory Module 2.3 空间注意模块 2.4 多尺度特征融合模块 2.5 损失函数设置 2.6 Decoder模块 1、摘要 本文认为人为创建类内差异和保持类内共性可以帮助模型实现更好的缺陷检测能力,从而更好地区分非正常图像。如…...

迈向未来的大门:人脸识别技术的突破与应用
迈向未来的大门:人脸识别技术的突破与应用 人脸识别:人脸识别的工作流程人脸识别的作用人脸识别技术的突破与应用 在深度学习人脸识别之前我们要先知道人脸识别是什么。 人脸识别: 人脸识别是一种基于人脸图像或视频进行身份验证或识别的技术…...
Vue-9.集成(.editorconfig、.eslintrc.js、.prettierrc)
介绍 同时使用 .editorconfig、.prettierrc 和 .eslintrc.js 是很常见的做法,因为它们可以在不同层面上帮助确保代码的格式一致性和质量。这种组合可以在开发过程中提供全面的代码维护和质量保证。然而,这也可能增加一些复杂性,需要谨慎配置…...
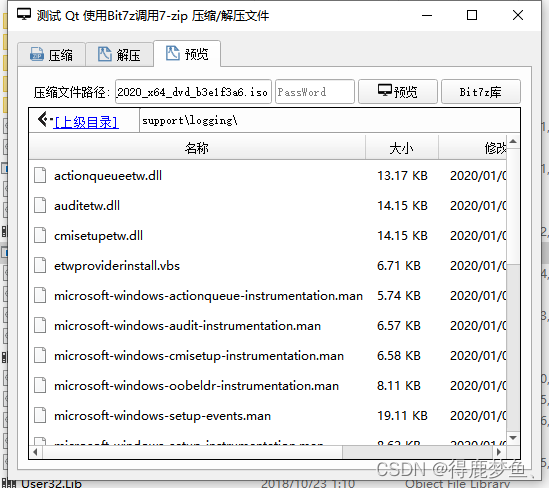
Qt 编译使用Bit7z库接口调用7z.dll、7-Zip.dll解压压缩常用Zip、ISO9660、Wim、Esd、7z等格式文件(一)
bit7z一个c静态库,为7-zip共享库提供了一个干净简单的接口 使用CMAKE重新编译github上的bit7z库,用来解压/预览iso9660,WIm,Zip,Rar等常用的压缩文件格式。z-zip库支持大多数压缩文件格式 导读 编译bit7z(C版本)使用mscv 2017编译…...

AndroidUI体系
见:GitHub - eHackyd/Android_UI: Android UI体系的学习笔记...
源码解析(1))
CBV (基于类的视图)源码解析(1)
面向对象和反射的一些补充说明 class Animal:def __init__(self, name, age, func_str):self.name nameself.age age# self 指的是类实例对象,此处指的是 Dog 的实例对象# 所以如果 Dog 中重写了 sleep 方法,那么 self.sleep() 调用的就是 Dog 中的 s…...

2023-08-17 Untiy进阶 C#知识补充7——C#8主要功能与语法
文章目录 一、Using 声明二、静态本地函数三、Null 合并赋值四、解构函数 Deconstruct五、模式匹配增强功能 注意:在此仅提及 Unity 开发中会用到的一些功能和特性,对于不适合在 Unity 中使用的内容会忽略。 C# 8 对应 Unity 版本: Un…...
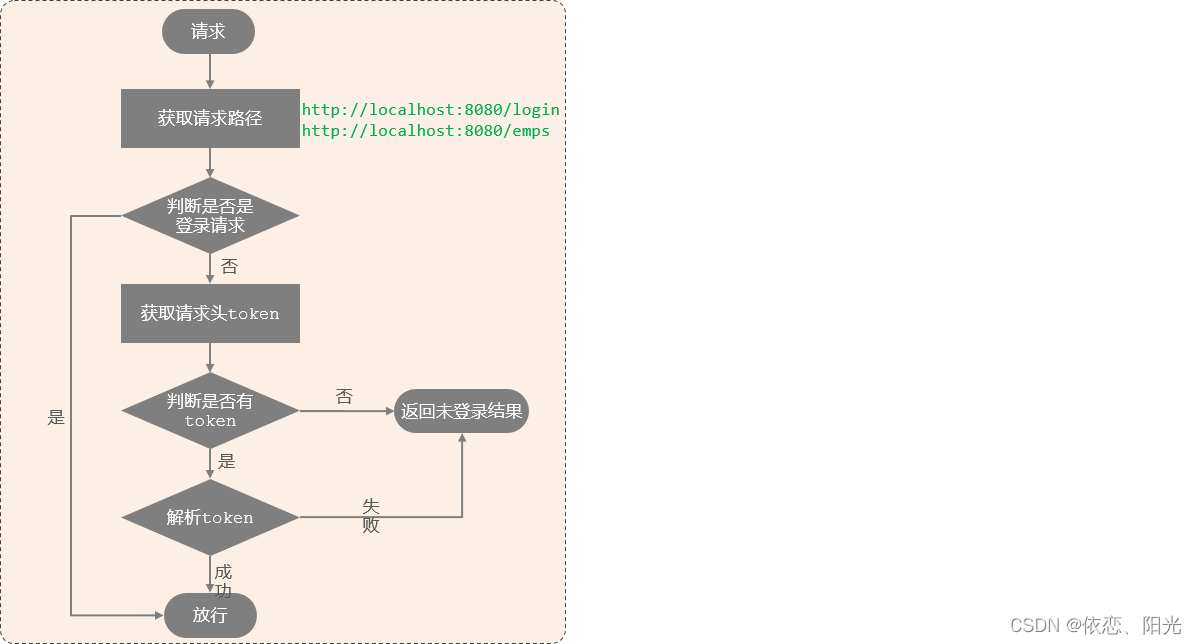
登陆接口的的Filter过滤
目录 一、概述 二、基本操作 三、登陆检查接口 一、概述 什么是Filter? Filter表示过滤器,是 JavaWeb三大组件(Servlet、Filter、Listener)之一。 过滤器可以把对资源的请求拦截下来,从而实现一些特殊的功能 使用了过滤器之后࿰…...

【Python原创设计】基于Python Flask的全国气象数据采集及可视化系统-附下载方式以及项目参考论文,原创项目其他均为抄袭
基于Python Flask的全国气象数据采集及可视化系统 一、项目简介二、项目技术三、项目功能四、运行截图五、分类说明六、实现代码七、数据库结构八、源码下载 一、项目简介 本项目是一个基于Web技术的实时气象数据可视化系统。通过爬取中国天气网的各个城市气象数据,…...

【力扣】42. 接雨水 <模拟、双指针、单调栈>
【力扣】42. 接雨水 给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 目录 【力扣】42. 接雨水题解暴力双指针单调栈 示例 1: 输入:height [0,1,0,2,1,0,1,3,2,1,2,1] 输出&…...

【leetcode 力扣刷题】链表基础知识 基础操作
链表基础知识 基础操作 链表基础操作链表基础知识插入节点删除节点查找节点 707. 设计链表实现:单向链表:实现:双向链表 链表基础操作 链表基础知识 在数据结构的学习过程中,我们知道线性表【一种数据组织、在内存中存储的形式】…...

5分钟搞定!Universal Pokemon Randomizer ZX:让宝可梦游戏焕发新生
5分钟搞定!Universal Pokemon Randomizer ZX:让宝可梦游戏焕发新生 【免费下载链接】universal-pokemon-randomizer-zx Public repository of source code for the Universal Pokemon Randomizer ZX 项目地址: https://gitcode.com/gh_mirrors/un/univ…...

传统永磁同步电机的FOC离散化simulink模型,效果较好 附赠传递函数离散化推导的文档
传统永磁同步电机的FOC离散化simulink模型,效果较好 附赠传递函数离散化推导的文档,初学者可以入手直接上干货。今天咱们聊聊永磁同步电机FOC控制在Simulink里的离散化实现,重点说说怎么让仿真模型更贴近实际DSP的运行环境。别被那些花里胡哨…...

短视频 SEO 与文章 SEO 有什么不同_如何制作高质量的短视频提升 SEO
短视频 SEO 与文章 SEO 有什么不同_如何制作高质量的短视频提升 SEO 在数字化时代,短视频和文章作为两种主要的内容形式,各有其独特的魅力和推广方式。而在搜索引擎优化(SEO)中,它们的策略也有许多不同之处。本文将详…...

开源可二次开发的物联网云平台,支持工业设备远程控制与数据采集
物联网云平台工业设备对接远程控制数据采集视频接入开源可二次开发 该物联网云平台使用 Java 语言、主流技术组合开发,支持多数据源,支持代码一键生成,方便快速开发。 1、内含物联网云平台全套源码(源码全部开放,无任何…...
原理、读写流程、Compaction适配与生产调优全指南)
15. Doris 系列第15篇:Unique Key 深度精讲|Merge-on-Write(MOW)原理、读写流程、Compaction适配与生产调优全指南
适用人群:数仓开发、Doris运维、实时画像/订单状态更新业务落地、2.0版本升级改造 核心价值:纯干货落地版,含底层结构、全流程拆解、多场景优化、监控告警、常见坑解决方案,直接照搬上线一、Merge-on-Write(MOW)核心概念ÿ…...

Mirage Flow智能代码补全:提升VS Code开发效率300%
Mirage Flow智能代码补全:提升VS Code开发效率300% 作为一名在代码世界里摸爬滚打了十多年的老程序员,我经历过从记事本写代码到现代IDE的完整进化史。这些年,我试用过无数号称能“提升效率”的工具,但真正让我感到惊艳、甚至改变…...

薄膜型声学超材料在汽车NVH中的应用:COMSOL仿真全流程解析
薄膜型声学超材料在汽车NVH优化中的COMSOL仿真实践 汽车NVH(噪声、振动与声振粗糙度)性能直接影响驾乘体验,而传统吸隔声材料在低频段往往表现不佳。薄膜型声学超材料通过局域共振机制打破了质量定律限制,为200-1000Hz频段的噪声…...

如何高效安全使用免Root框架:LSPatch Android模块注入完全指南
如何高效安全使用免Root框架:LSPatch Android模块注入完全指南 【免费下载链接】LSPatch LSPatch: A non-root Xposed framework extending from LSPosed 项目地址: https://gitcode.com/gh_mirrors/ls/LSPatch 在Android定制领域,免Root框架一直…...

突破限制的暗黑2单机革新工具:PlugY生存套件全面解析
突破限制的暗黑2单机革新工具:PlugY生存套件全面解析 【免费下载链接】PlugY PlugY, The Survival Kit - Plug-in for Diablo II Lord of Destruction 项目地址: https://gitcode.com/gh_mirrors/pl/PlugY 痛点场景:单机暗黑2玩家的四大困境 你的…...

胡桃工具箱:一站式原神桌面助手完整指南
胡桃工具箱:一站式原神桌面助手完整指南 【免费下载链接】Snap.Hutao 实用的开源多功能原神工具箱 🧰 / Multifunctional Open-Source Genshin Impact Toolkit 🧰 项目地址: https://gitcode.com/GitHub_Trending/sn/Snap.Hutao 还在为…...