ElasticSearch 7.4学习记录(DSL语法)
上文和大家一起初次了解了很多ES相关的基础知识,本文的内容将会是实际企业中所需要的吗,也是我们需要熟练应用的内容。
面对ES,我们最多使用的就是查询,当我负责这个业务时,现不需要我去考虑如何创建索引,添加文档等,只需要根据复杂业务实现查询即可,本文的重点也会在如何使用ES进行查询,并给出很多实际案例进行补充解释和演示
本次案例演示说明所需要的数据-----------student数据信息:
| 属性 | 数值 |
|---|---|
| id | 001 |
| name | zjh |
| address | 中国陕西省延安市 |
| brief | 喜欢足球的男生 |
| age | 28 |
| 属性 | 数值 |
|---|---|
| id | 002 |
| name | wxx |
| address | 中国陕西省渭南市 |
| brief | 喜欢zjh的女生 |
| age | 18 |
- 1 DSL查询语法
- 1.1 什么是DSL
- 1.2 查询所有
- 1.3 全文检索
- 1.4 精确查询
- 1.5 复合查询
- 1.6 搜索结果处理
- 1.6.1 结果排序+分页查询
- 1.6.2 结果高亮
- 2 DSL语法对应Java代码的实现
- 2.1 match_all
- 2.1' 核心代码梳理
- 2.2 match与multi_match
- 2.3 term和range
- 2.4 boolean
- 2.5 排序和分页
- 3 聚合索引
- 3.1 初体验聚合效果(buckets聚合案例)
- 3.2 优化聚合效果
- 3.3 Metrics聚合案例
- 3.4 DSL语法对应Java代码的实现
- 3.5 多条件的聚合
- 3.6 理解聚合
1 DSL查询语法
1.1 什么是DSL
就是在这个环境下查询语句,有自己的语法格式要求,需要我们熟练掌握。
或者你可以想一下,在mysql环境下的sql语法,这就是在ES环境下的DSL语法,都是为了实现查询功能。
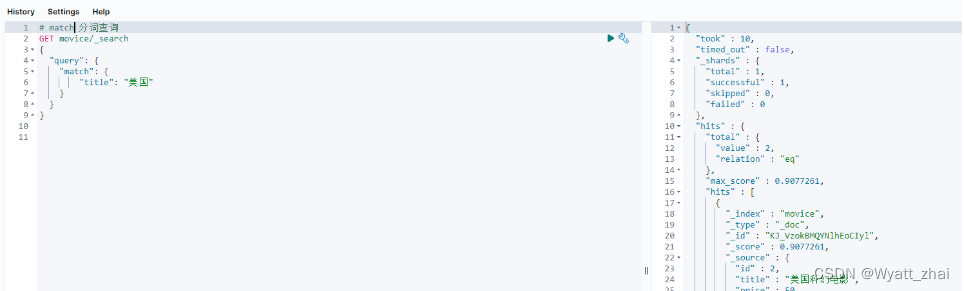
一个简化的查询模版GET /索引库名/_search
{"query":{"查询类型":{"查询条件":"条件值"}}
}
查询类型可以实现不同的查询效果,下面的案例很好的解释给了大家。
1.2 查询所有
match_all:查询全部的数据
GET /student/_search
{"query":{"match_all":{}}
}
1.3 全文检索
match查询:利用分词器进行查询,比如:传入“男生”,会将其分词取倒排索引库查询,找到含有“男”与“生”数据,即找到zjh和wxx的全部数据
这是一个模板
GET /student/_search
{"query":{"match":{"field":"text"}}
}实际案例:拆分“男生”去brief字段中查找有无”男“与”生“,最终找到zjh和wxx
GET /student/_search
{"query":{"match":{"biref":"男生"}}
}升级案例:现在不想指定一个字段去查找,想查询所有的字段中的数据是否有匹配的
GET /student/_search
{"query":{"match":{"all":"跑步工资"}}
}
这个all就表示会在所有字段id,name,address,brief的值中去匹配”跑步工资“
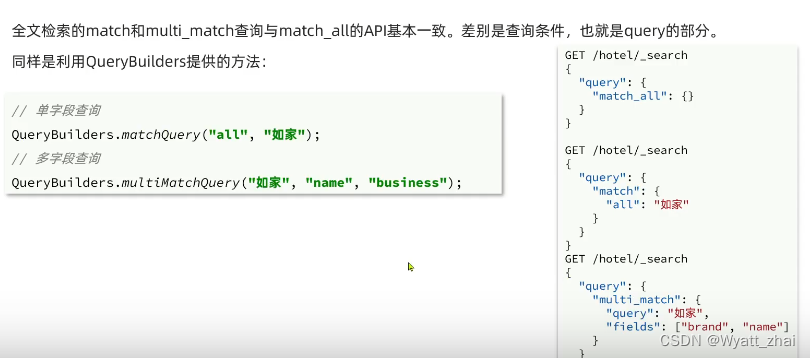
multi_match查询:允许同时查询多个字段
这是一个模板
GET /student/_search
{"query":{"multi_match":{"query":"text","fields":["field1","field2"]}}
}
实际案例:找到address含有“延安”且brief含有”喜欢“的数据,最终找到zjh和wxx
GET /student/_search
{"query":{"multi_match":{"query":"延安喜欢","fields":["address","brief"]}}
}
需要注意的是multi_match设置的字段越多,效率越慢,推荐优先使用match
1.4 精确查询
当查询条件是不可分的:keyword,数值,日期,boolean等,不会对其分词,即为精确查询
- term:根据词条精确值查询
- range:根据值范围查询
案例:
当查询内容传入:上海,就希望匹配到含有“上海”的数据,而不是含有“上”与“海”的这种数据。此乃term
当查询内容传入:100-300元,就希望匹配到在这个范围内的数据。此乃range

这是一个term模板
GET /student/_search
{"query":{"term":{"field":{“value”:“value”}}}
}
实际案例:找到address含有“男生”的数据,找到空数据,因为必须精准为男生,才能找到zjh
GET /student/_search
{"query":{"term":{"field":{“brief”:“男生延安”}}}
}
这是一个range模板
GET /student/_search
{"query":{"range":{"field":{“gte”:“value”,“lte”:“value”}}}
}
实际案例:找到年龄在10-20之间的人,最终找到wxx
GET /student/_search
{"query":{"range":{"age":{“gte”:10,“lte”:20}}}
}
注意:gte是大于等于;gt是大于
1.5 复合查询
Boolean Query
布尔查询是一个或者多个查询字句的组合。组合方式有
- must : 必须匹配每个子查询(与)
- should:选择性匹配子查询(或)
- must_not:必须不匹配(非)不参与算分
- filter:必须匹配 不参与算分
GET /student/_search
{"query":{“bool”:{“must”:[ {"term":{“address”:“中国”} }{"term":{“name”:“zjh”} }],"should":[ {"term":{“brief”:“喜欢”} },{"term":{“brief”:“足球”} }],“must_not”:[{"range":{“age”:{"gte:20"} } },],“filter”:[{"term":{“brief”:“生”}}]}}
}
这串代码表示:
must:(address必须含有中国) 且 (name必须含有zjh)
should:(brief含有喜欢) 或者 (brief含有足球)二选一
mustnot:(年龄大于等于20)相反-----(年龄小于20)
这个案例仅仅告诉你如何理解must等,下面介绍一个贴切的案例
查询名字包含“麦当劳”,地点在北京,人均消费不高于100元,周一到周天营业的快餐店
1.6 搜索结果处理
1.6.1 结果排序+分页查询
这是一个range模板
GET /student/_search
{"query":{“查询类型”:{}},"sort":[{"fileld":”value“}]
}
实际案例:全部查询,将结果按照年龄倒序,若相等按照id升序排
GET /student/_search
{"query":{"match_all":{}},"sort":[{”age“:”desc“},{”id“:”asc“}],“from”:0,“size”:10}}
}
es查询结果默认只显示10条数据。from:0--------size:10,表示从0开始,显示10条数据
实际上,如我们会将一批数据分成10批,存在10台服务器的ES上。如果我们需要查询价格由低到高排序前100条,底层执行的逻辑是:每一台ES由低到高排序,查出前100,然后聚合10台机器的数据(10*100),从聚合结果1000中再找到前100的数据。
不过呢,当我们执行数据读取时候,一定是会扫描所有的ES节点,不需要担心查询的时候会不会只查询当前服务器上es的数据,是不会的。
1.6.2 结果高亮
浏览器搜索java,可以看到查询结果中含有java部分高亮显示,这是如何实现的?

是ES帮忙做的,我们只需要告诉ES需要高亮显示的字段和内容即可
GET /student/_search
{"query":{“match”:{“all”:“中国”},“highlight”:{“fields”:{ //高亮字段“address”:{"requeire.field_match":“false”,//是否需要与查询字段匹配“pre_tags”:"<em>", //用来标记高亮字段的前置标签,“post_tags”:“</em>” //用来标记高亮字段的后置标签}}}
}2 DSL语法对应Java代码的实现
2.1 match_all
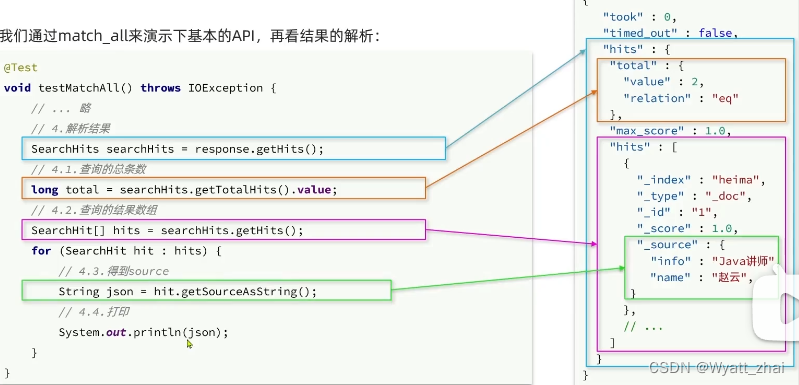
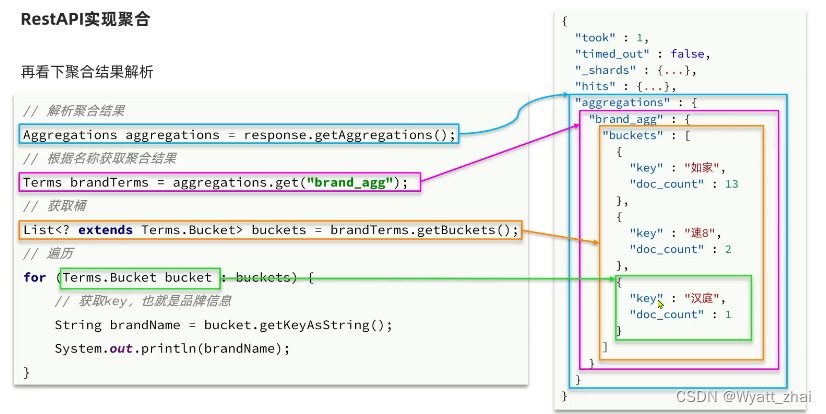
RestHighLevelClient client 注意前面我已经获取了client关于代码实现,可以理解为四个部分,不同业务需要变动代码的部分只有2,4处@Testvoid testMatchAll() throws IOException {//1.准备requestSearchRequest request = new SearchRequest("student");//2.准备DSLrequest.source().query(QueryBuilders.matchAllQuery());//3.发送请求SearchResponse response = client.search(request, RequestOptions.DEFAULT);//4.解析响应中的hitsSearchHits searchHits = response.getHits();long value = searchHits.getTotalHits().value; //获取value值(参考ES)System.out.println(value);SearchHit[] hits = searchHits.getHits(); //获取文档数据for (SearchHit hit : hits) {String json = hit.getSourceAsString();System.out.println(json);}}
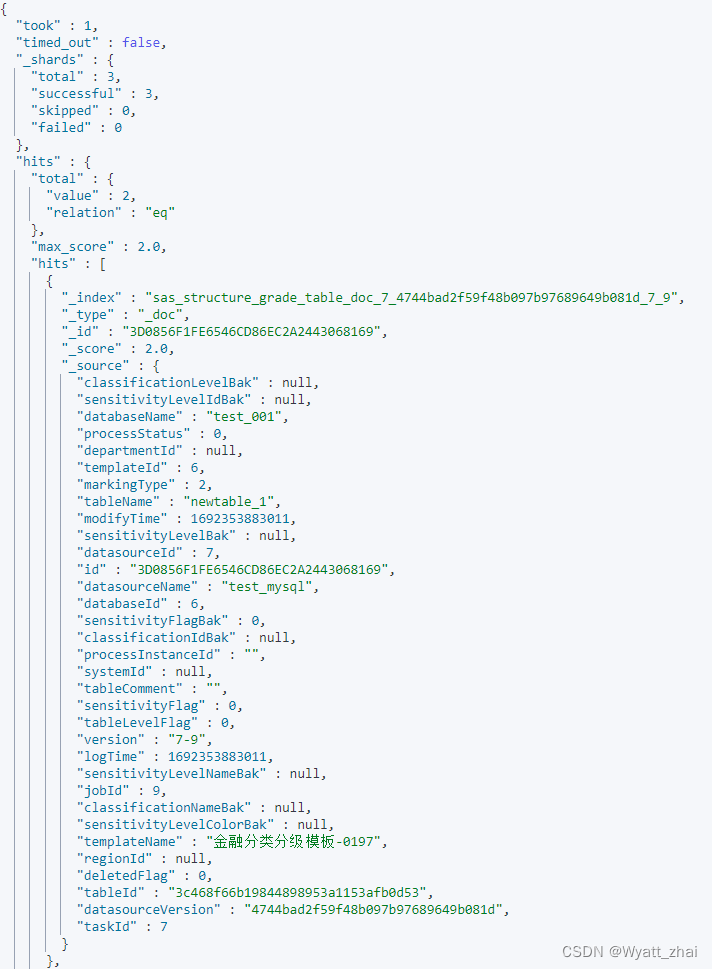
为什么解析response呢,因为其全部内容如下图,我们需要选出需要的即可
2.1’ 核心代码梳理
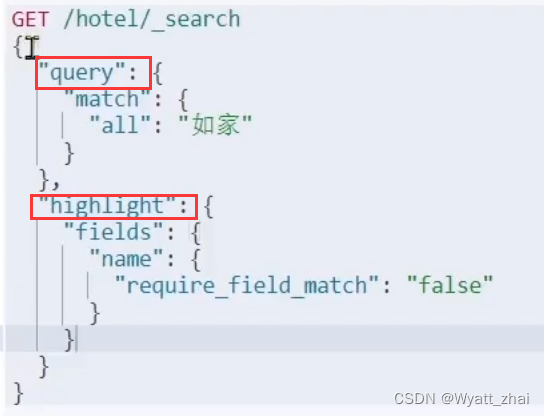
这里梳理一下上述java代码的对应关系,帮助理解
source()方法中存在操作类型,有查询query,有结果排序sort,有分页form,size等
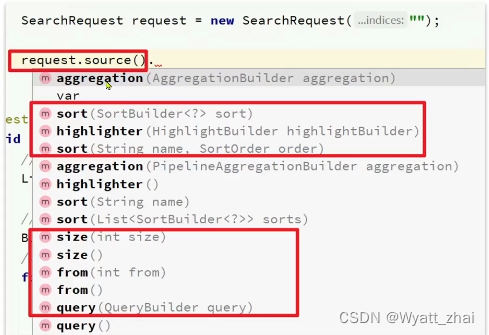
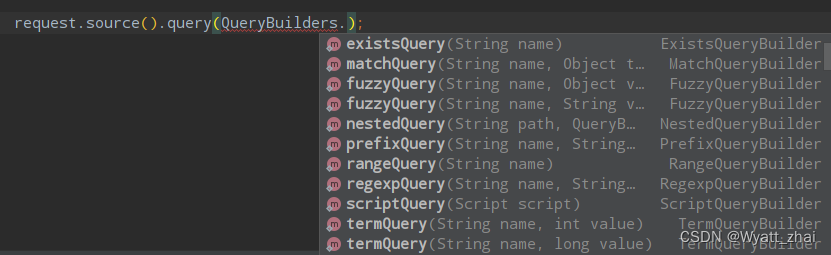
QueryBuilders()里面有查询类型,包括前面科普的精确查询term,全部查询match_all,复合查询bool等
2.2 match与multi_match
2.3 term和range

2.4 boolean

2.5 排序和分页

3 聚合索引
理解什么是聚合索引:类似于group by的概念,下图前两个常用。先看看聚合怎么用,文末会有个案例更清楚的解释聚合的概念

3.1 初体验聚合效果(buckets聚合案例)
比如我现在需要统计酒店的品牌数量有几种,则可以根据品牌数量进行聚合,就会得到名为“七天酒店” 34家 ;“如家” 30家 ;“速8” 20家的返回结果

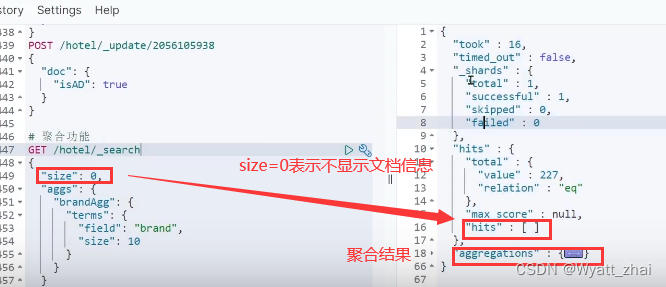
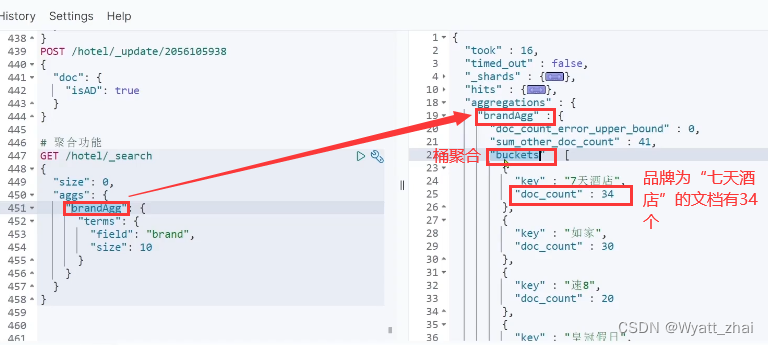
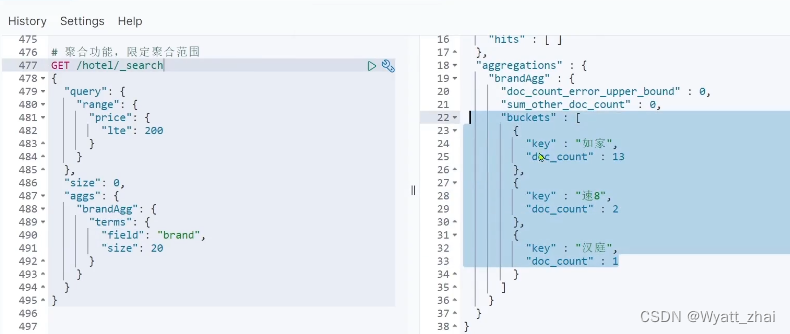
3.2 优化聚合效果
对价格在200元以内的酒店进行聚合,这个案例表示query和aggs是平级。
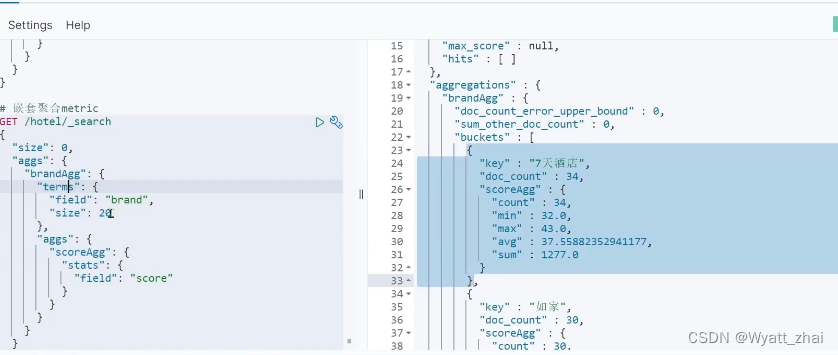
3.3 Metrics聚合案例

也就是在Buckets聚合上再加了一层,很好记住,(sorce字段是酒店评分)注意观察下图,发现多了count、min、max、avg,sum。什么意思呢,就是说我们对酒店评分进行聚合,得到了最大值,最小值,平均值等等。
3.4 DSL语法对应Java代码的实现

3.5 多条件的聚合
就是同时聚合多个字段:城市、星级、品牌
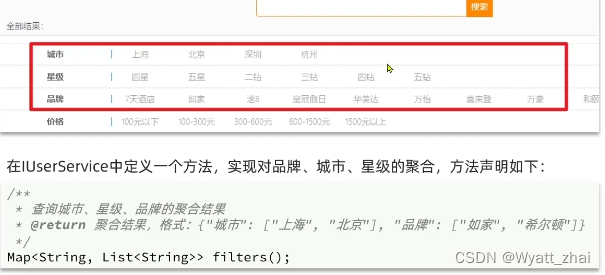
如何理解这个业务
前面提到的精确查询,根据上海就可以查出city字段中含有”上海“的所有文档,但是我们仅仅停留在粗暴的找出信息的阶段,若我需要对上海这一类文档求平均价格,计数等,term的功能就显得捉襟见肘了。所以这里需要聚合处理。理解了业务需求在看看如何实现
1.准备request
2.准备DSL2.1 多个聚合字段
3.发出请求
4.解析结果4.1 分别处理聚合名称的数据
2.1内容

4.1内容,有几个集合字段就实现几次

实际上,你只需要清楚一个字段的聚合实现流程,那么当你写多个字段的聚合时,仅仅需要重复2和4的代码,那这些代码你可以封装成函数更优雅。
3.6 理解聚合
现在我们需要搜索城市是上海的数据
直接使用精确查询:找到city字段含有”上海“的文档;(注意理解ES中文档的概念)
聚合city字段:对city字段进行聚合,得到“上海”“北京”“深圳”的聚合结果,注意,只是聚合结果,不是具体的文档数据。此外我可以对聚合结果进行求和,求平均值等操作。
相关文章:
ElasticSearch 7.4学习记录(DSL语法)
上文和大家一起初次了解了很多ES相关的基础知识,本文的内容将会是实际企业中所需要的吗,也是我们需要熟练应用的内容。 面对ES,我们最多使用的就是查询,当我负责这个业务时,现不需要我去考虑如何创建索引,添…...
全志orangepi-zero2驱动编写2,控制电平高低
使用驱动编写控制高低电平 可看我前俩篇文章: 【1】全志orangepi-zeor2驱动编写 【2】驱动函数框架详解 检索芯片手册关键信息 知道GPIO基地址 知道PC偏移地址 知道想要控制的端口的信息 知道数据位如何操作 代码实操 驱动代码 #include <linux/fs.h&…...

软考高级系统架构设计师系列之:论文典型试题写作要点和写作素材总结系列文章四
软考高级系统架构设计师系列之:论文典型试题写作要点和写作素材总结系列文章四 一、论软件的静态演化和动态演化及其应用1.论文题目2.写作要点和写作素材二、论大规模分布式系统缓存设计策略1.论文题目2.写作要点和写作素材三、论基于REST服务的Web应用系统设计1.论文题目2.写…...

06.利用Redis实现点赞功能
学习目标: 提示:学习如何利用Redisson实现点赞功能 学习产出: 解决方案: 点赞后的用户记录在Redis的set数据类型中 1. 准备pom环境 <dependency><groupId>org.springframework.boot</groupId><artifactI…...
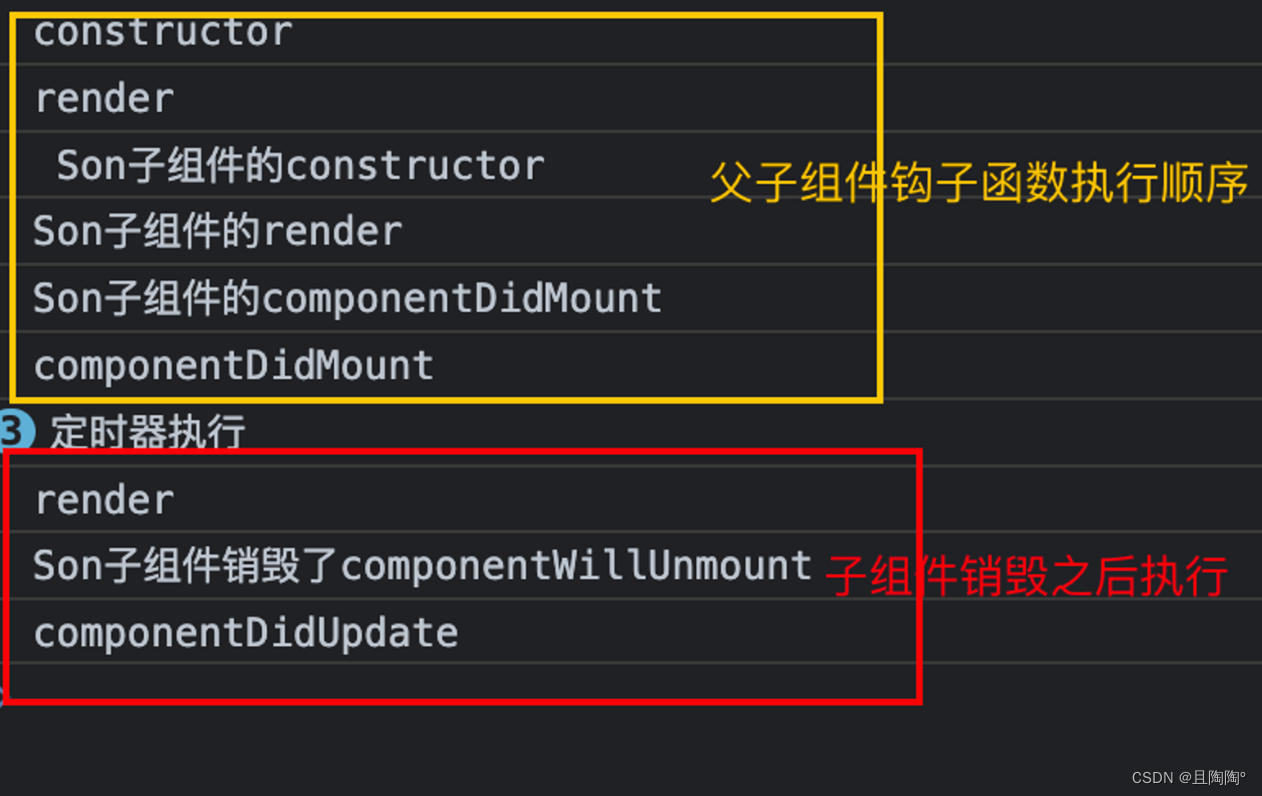
【React】生命周期和钩子函数
概念 组件从被创建到挂载到页面中运行,再到组件不用时卸载的过程。 只有类组件才有生命周期。 分为三个阶段: 挂载阶段更新阶段销毁阶段 三个阶段 挂载阶段 钩子函数 - constructor 创建阶段触发 作用:创建数据 之前定义状态是简写&…...

无涯教程-TensorFlow - 优化器
Optimizers是扩展类,其中包括用于训练特定模型的附加信息,Optimizers类使用给定的参数初始化,用于提高速度和性能,以训练特定模型。 TensorFlow的基本Optimizers是- tf.train.Optimizer 此类在tensorflow/python/training/opti…...

基于AQS+双向链表实现队列先进先出
学习AQS写的一个模拟案例 package com.tom.xiangyun.ch04_aqs;import com.tom.tuling.UnsafeFactory; import sun.misc.Unsafe;import java.util.concurrent.atomic.AtomicInteger; import java.util.concurrent.locks.ReentrantLock;/*** 使用双向链表实现队列** author 钟棋…...
无涯教程-Perl - time函数
描述 此函数返回自纪元以来的秒数(对于大多数系统,是1970年1月1日UTC,00:00:00;对于Mac OS,是1904年1月1日,00:00:00)。适用于gmtime和本地时间。 语法 以下是此函数的简单语法- time返回值 此函数返回自纪元后数秒的整数。 例 以下是显示其基本用法的示例代…...

CUDA Bug<三>当__global__函数出现里面所有输出的数组都随机赋值了
问题具体描述: eg. __global__ void Updata_HomJm(float* H,float *HJm,float* fr,float *gr,float* ur,float* urgrJm,float*wpd,float *w, float *wJm,int n) { int idx blockIdx.x*blockDim.x threadIdx.x;float t 0.0;//H*zpint idx_Ai idx*n;for (int j…...
甜椒叶病害识别(Python代码,pyTorch框架,深度卷积网络模型,很容易替换为其它模型,带有GUI识别界面)
代码运行要求:Torch>1.13.1即可 1.数据集介绍: 第一个文件夹是细菌斑叶(3460张) 第二个文件夹是 健康(4024张) 2.整个文件夹 data文件夹存放的是未被划分训练集和测试集的原始照片 picture文件夹存放的…...

Python爬虫——scrapy_日志信息以及日志级别
日志级别(由高到低) CRITICAL: 严重错误 ERROR: 一般错误 WARNING: 警告 INFO: 一般警告 DEBUG: 调试信息 默认的日志等级是DEBUG 只要出现了DEBUG或者DEBUG以上等级的日志,那么这些…...
微信小程序 echarts 画多个横向柱状图
然后是json {"usingComponents": {"ec-canvas": "../../common/ec-canvas/ec-canvas"},"navigationBarTitleText": "主题活动" } ec-canvas获取方式 在链接里下载代码 然后copy ec-canvas文件夹到自己的项目 https://gi…...

【二叉树】572. 另一棵树的子树
572. 另一棵树的子树 解题思路 遍历二叉树的思路针对每一个节点判断该节点的子树和subtree是不是相等需要编写判断两个子树是否相等的函数 /*** Definition for a binary tree node.* public class TreeNode {* int val;* TreeNode left;* TreeNode right;* …...

220V转5V芯片三脚芯片-AH8652
220V转5V芯片三脚芯片是一种非常常见的电源管理芯片,它通常被用于将高压交流输入转为稳定的直流5V输出。芯片型号AH8652是一款支持交流40V-265V输入范围的芯片,采用了SOT23-3三脚封装。该芯片内部集成了650V高压MOS管,能够稳定地将输入电压转…...
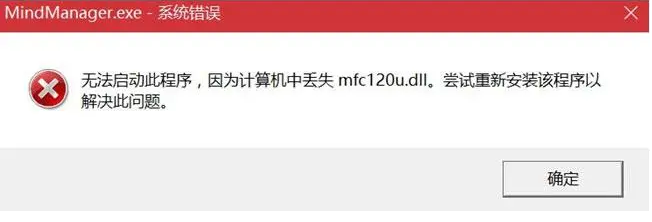
windows系统丢失mfc120u.dll的解决方法
1.mfc120u.dll是什么 mfc120u.dll是Windows操作系统中的一个动态链接库(Dynamic Link Library,简称DLL)文件。它包含了一些用于运行C程序的函数和其他资源。这个特定的DLL文件是Microsoft Foundation Classes(MFC)库的…...
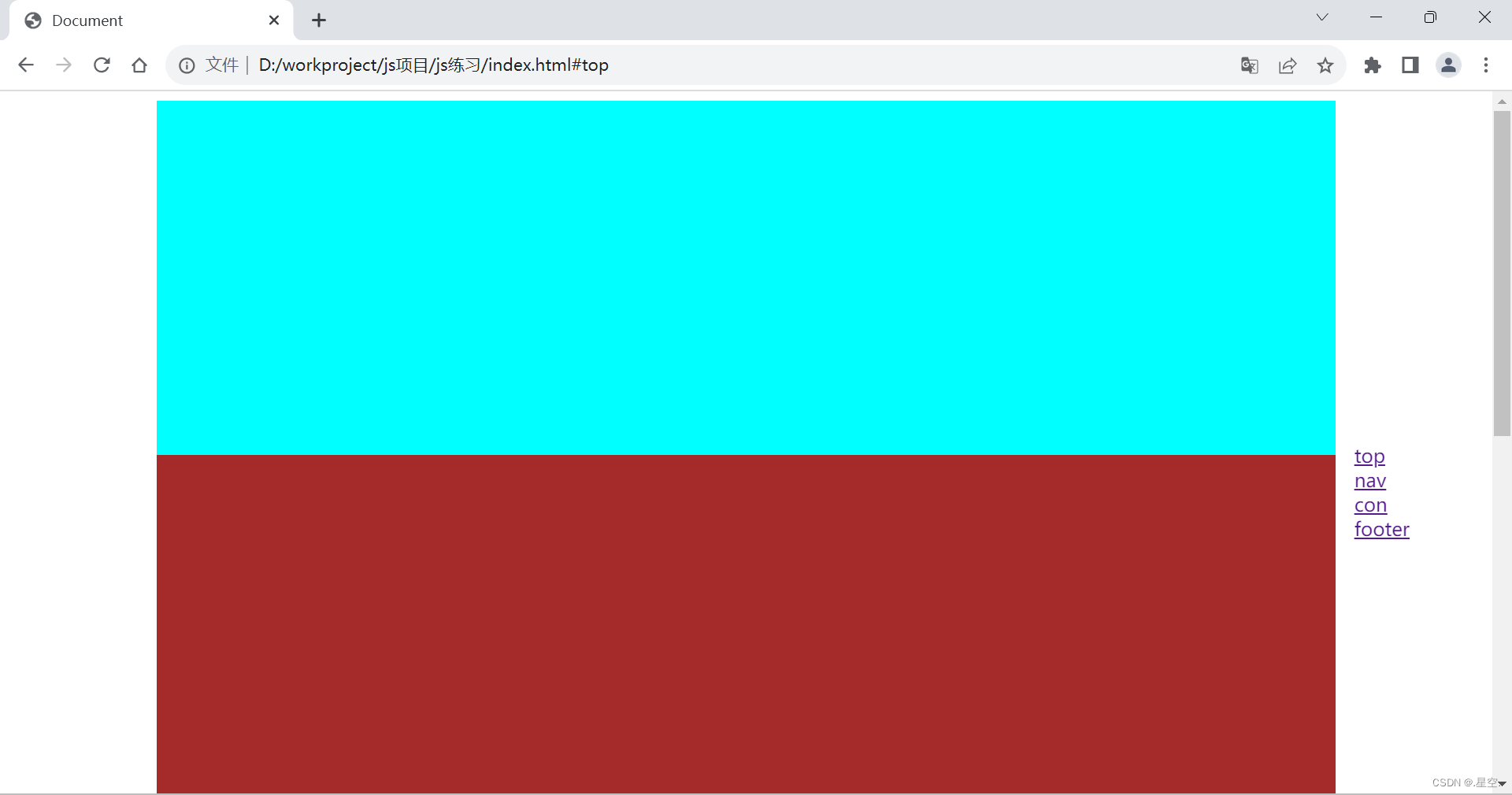
css 实现电梯导航
实现原理:利用css实现电梯导航很简单,基本原理就是通过a标签绑定跳转目标的id来实现的 html代码: <div class"body"><div class"top" id"top"></div><div class"con1" id"…...

【Spring Boot】Spring Retry减少1000 行代码讲解
文章目录 前言问题介绍解决方案Let’s start hacking!1. 设置 Spring 重试2. 重构代码 总结 前言 本文翻译自国外论坛 medium,原文地址:levelup.gitconnected.com/how-i-delet…,原文作者:Hari Ohm Prasath 使用 Spring Retry 重…...
【数据结构OJ题】相交链表
原题链接:https://leetcode.cn/problems/intersection-of-two-linked-lists/description/ 目录 1. 题目描述 2. 思路分析 3. 代码实现 1. 题目描述 2. 思路分析 看到这道题,很容易想到的方法就是暴力求解,就是将一个链表的每个结点的地址…...

【华为OD机试】最小传输时延I【2023 B卷|200分】
【华为OD机试】-真题 !!点这里!! 【华为OD机试】真题考点分类 !!点这里 !! 题目描述 某通信网络中有N个网络结点,用1到N进行标识。网络通过一个有向无环图表示, 其中图的边的值表示结点之间的消息传递时延。 现给定相连节点之间的时延列表times[i]={u,v,w},其中u表示…...

Android13 网络 Adb 默认开启
Android 13 网络 Adb 默认开启 文章目录 Android 13 网络 Adb 默认开启一、前言二、默认adb 代码实现1、修改的目录:2、具体修改:(1)在XXX_device.mk 添加属性(2)设置固定端口号(3)去…...

用时光本重构工作时间管理:从个人规划到团队协同的全流程方案
矩阵日历 智能分析 团队协同,让时间管理更简单 管理大师杜拉克曾说:“不能管理时间,便什么也不能管理”,这句话道尽了时间管理对于工作的核心意义 —— 时间是世界上最短缺的资源,除非严加管理,否则就会…...

算法设计与分析里面的渐进符号难以理解
算法设计中的渐进符号(Asymptotic Notation)之所以让人觉得抽象,是因为它跳出了具体代码的细节,转而去研究“当数据量变得无穷大时,算法耗时的增长趋势”。为了让你彻底理解这个概念,我们可以把它想象成一套…...

ccmusic-database部署案例:高校数字人文实验室构建中国民乐流派迁移分类子系统
ccmusic-database部署案例:高校数字人文实验室构建中国民乐流派迁移分类子系统 1. 项目背景与价值 音乐流派分类是数字人文研究中的重要课题,特别是在中国传统民乐的保护与研究中,自动化的流派识别技术能够大幅提升研究效率。ccmusic-datab…...

春联生成模型-中文-base实战:Java后端集成与SpringBoot服务开发
春联生成模型-中文-base实战:Java后端集成与SpringBoot服务开发 春节临近,电商平台想给用户送祝福,企业年会要给员工发福利,社区活动需要准备大量装饰……这时候,如果需要一个能批量、快速生成个性化春联的工具&#…...

Ostrakon-VL-8B赋能Java应用:SpringBoot集成多模态AI服务实战
Ostrakon-VL-8B赋能Java应用:SpringBoot集成多模态AI服务实战 最近在做一个电商后台项目,产品经理提了个需求,说能不能让系统自动识别用户上传的商品图片,然后生成一段描述文案。比如用户传个水杯的照片,系统就能知道…...

TikTok风控核心:X-Gorgon协议算法逆向与变种RC4的魔改细节揭秘
TikTok风控体系深度解析:X-Gorgon协议与魔改RC4算法实战 在移动互联网安全攻防领域,应用层协议逆向工程始终是技术对抗的前沿阵地。本文将深入剖析TikTok风控体系中的核心组件X-Gorgon协议,重点解密其基于RC4算法的深度定制化改造方案。不同于…...
)
Python实战:用NumPy实现拉格朗日插值法(附完整代码与可视化)
Python实战:用NumPy实现拉格朗日插值法(附完整代码与可视化) 在数据分析和科学计算领域,插值技术是处理离散数据的重要工具。当我们只有有限个数据点却需要估计未知点的值时,拉格朗日插值法提供了一种优雅的数学解决方…...
)
Docker 27沙箱增强技术白皮书核心节选(仅限首批订阅者开放的内核级加固参数表)
第一章:Docker 27沙箱增强技术演进与安全范式跃迁Docker 27标志着容器运行时安全模型的根本性重构,其核心在于将传统基于命名空间和cgroups的隔离机制,升级为融合eBPF驱动的细粒度策略执行、不可变镜像签名验证与硬件辅助虚拟化(如…...

山东大学项目实训-医患沟通系统
(这是初版策划案,待答辩后与导师沟通后修改) 项目背景 医患沟通是临床诊疗的核心环节,良好的沟通能显著提升患者满意度、减少医疗纠纷。然而,传统医患沟通培训多依赖标准化病人(SP)或角色扮演&…...

DeepSeek App登顶应用商店,背后是产品力的降维打击
在2025年初,全球应用商店的下载榜单迎来了一位“黑马”——DeepSeek App。这款由中国杭州深度求索人工智能基础技术研究有限公司开发的AI应用,不仅在中国区苹果App Store免费榜登顶,更在美国地区超越了ChatGPT、Meta旗下社交媒体平台Threads、…...