[oneAPI] 基于BERT预训练模型的SQuAD问答任务
[oneAPI] 基于BERT预训练模型的SQuAD问答任务
- Intel® Optimization for PyTorch and Intel® DevCloud for oneAPI
- 基于BERT预训练模型的SQuAD问答任务
- 语料介绍
- 数据下载
- 构建
- 模型
- 结果
- 参考资料
比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517
Intel® DevCloud for oneAPI:https://devcloud.intel.com/oneapi/get_started/aiAnalyticsToolkitSamples/
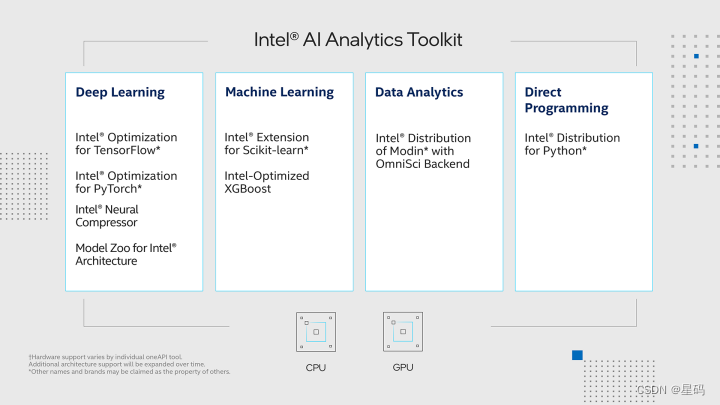
Intel® Optimization for PyTorch and Intel® DevCloud for oneAPI
我们在Intel® DevCloud for oneAPI平台上构建了实验环境,充分发挥其完全虚拟化的优势。更具影响力的是,我们充分发挥了Intel® Optimization for PyTorch的强大功能,将其无缝融入我们的PyTorch模型中。这项优化策略的成功应用,不仅进一步提升了我们实验的效果,也显著加速了模型的训练和推断过程。通过这种深度融合硬件和软件的精妙设计,我们不仅释放了硬件的潜力,还为我们的研究和实验带来了新的可能性。这一系列的努力为人工智能领域的创新开辟了更广阔的前景。
基于BERT预训练模型的SQuAD问答任务
SQuAD(Stanford Question Answering Dataset)是一个广泛使用的英文问答数据集,由斯坦福大学发布。它旨在促进机器阅读理解研究,对于理解文本内容并从中提取答案非常有价值。SQuAD数据集的主要特点是,每篇文章都有一系列问题,以及与每个问题相关的精确答案片段,这些答案是从原始文章中抽取的。
在SQuAD英文问答任务中,模型需要读取文章、理解上下文,并从中准确提取出问题的答案。该任务对于开发强大的阅读理解模型和问答系统具有重要的意义。
SQuAD英文问答任务的特点和价值:
- 真实性: SQuAD数据集的文章和问题都来自真实的文本,确保了任务的实际应用性。
- 机器阅读理解: 任务要求模型阅读文章,理解其内容,然后从中定位和提取出准确的答案,这是机器阅读理解的典型应用。
在SQuAD英文问答任务中,Bert(Bidirectional Encoder Representations from Transformers)是一种重要的模型,它通过预训练语言表示,在问答系统和信息提取领域取得了显著成就。
Bert模型的实用设计和价值影响:
- 双向上下文理解: Bert模型具备双向上下文理解能力,可以同时考虑文本的前后信息,从而更好地捕捉单词之间的关系。
- 预训练与微调: Bert在大规模语料库上进行预训练,学习了丰富的语言表示,然后通过微调在特定任务上表现出色,适应任务需求。
语料介绍
所谓问题回答指的就是同时给模型输入一个问题和一段描述,最后需要模型从给定的描述中预测出答案所在的位置(text span)。例如:
描述:苏轼是北宋著名的文学家与政治家,眉州眉山人。
问题:苏轼是哪里人?
标签:眉州眉山人
对于这样一个问题问答任务我们应该怎么来构建这个模型呢?
在做这个任务之前首先需要明白的就是:①最终问题的答案一定是在给定的描述中;②问题的答案一定是一段连续的字符。例如对于上面的描述,如果给出问题“苏轼生活在什么年代他是哪里人?”,那么模型并不会给出“北宋”和“眉州眉山人”这两个分离的答案,最好的情况下便是给出“北宋著名的文学家与政治家,眉州眉山人”这一个答案。
在有了这两个限制条件后,对于这类问答任务的本质也就变成了需要让模型预测得到答案在描述中的起始位置(start position)以及它的结束位置(end position)。所以,问题最终又变成了如何在BERT模型的基础上再构建一个分类器来对BERT最后一层输出的每个Token进行分类,判断它们是否属于start position或者是end position。
数据下载
由于没有找到类似的高质量中文数据集,所以在这里使用到的也是论文中所提到的SQuAD(The Stanford Question Answering Dataset 1.1 )数据集,即给定一个问题和描述需要模型从描述中找出答案的起止位置。
构建
对于数据预处理部分我们可以继续继承之前文本分类处理的这个类LoadSingleSentenceClassificationDataset,然后再稍微修改其中的部分方法即可。
import torch
from torch.utils.data import DataLoader
from tqdm import tqdm
import pandas as pd
import json
import logging
import os
from sklearn.model_selection import train_test_split
import collections
import sixclass Vocab:"""根据本地的vocab文件,构造一个词表vocab = Vocab()print(vocab.itos) # 得到一个列表,返回词表中的每一个词;print(vocab.itos[2]) # 通过索引返回得到词表中对应的词;print(vocab.stoi) # 得到一个字典,返回词表中每个词的索引;print(vocab.stoi['我']) # 通过单词返回得到词表中对应的索引print(len(vocab)) # 返回词表长度"""UNK = '[UNK]'def __init__(self, vocab_path):self.stoi = {}self.itos = []with open(vocab_path, 'r', encoding='utf-8') as f:for i, word in enumerate(f):w = word.strip('\n')self.stoi[w] = iself.itos.append(w)def __getitem__(self, token):return self.stoi.get(token, self.stoi.get(Vocab.UNK))def __len__(self):return len(self.itos)def build_vocab(vocab_path):"""vocab = Vocab()print(vocab.itos) # 得到一个列表,返回词表中的每一个词;print(vocab.itos[2]) # 通过索引返回得到词表中对应的词;print(vocab.stoi) # 得到一个字典,返回词表中每个词的索引;print(vocab.stoi['我']) # 通过单词返回得到词表中对应的索引"""return Vocab(vocab_path)def pad_sequence(sequences, batch_first=False, max_len=None, padding_value=0):"""对一个List中的元素进行paddingPad a list of variable length Tensors with ``padding_value``a = torch.ones(25)b = torch.ones(22)c = torch.ones(15)pad_sequence([a, b, c],max_len=None).size()torch.Size([25, 3])sequences:batch_first: 是否把batch_size放到第一个维度padding_value:max_len :当max_len = 50时,表示以某个固定长度对样本进行padding,多余的截掉;当max_len=None是,表示以当前batch中最长样本的长度对其它进行padding;Returns:"""if max_len is None:max_len = max([s.size(0) for s in sequences])out_tensors = []for tensor in sequences:if tensor.size(0) < max_len:tensor = torch.cat([tensor, torch.tensor([padding_value] * (max_len - tensor.size(0)))], dim=0)else:tensor = tensor[:max_len]out_tensors.append(tensor)out_tensors = torch.stack(out_tensors, dim=1)if batch_first:return out_tensors.transpose(0, 1)return out_tensorsdef cache(func):"""本修饰器的作用是将SQuAD数据集中data_process()方法处理后的结果进行缓存,下次使用时可直接载入!:param func::return:"""def wrapper(*args, **kwargs):filepath = kwargs['filepath']postfix = kwargs['postfix']data_path = filepath.split('.')[0] + '_' + postfix + '.pt'if not os.path.exists(data_path):logging.info(f"缓存文件 {data_path} 不存在,重新处理并缓存!")data = func(*args, **kwargs)with open(data_path, 'wb') as f:torch.save(data, f)else:logging.info(f"缓存文件 {data_path} 存在,直接载入缓存文件!")with open(data_path, 'rb') as f:data = torch.load(f)return datareturn wrapperclass LoadSingleSentenceClassificationDataset:def __init__(self,vocab_path='./vocab.txt', #tokenizer=None,batch_size=32,max_sen_len=None,split_sep='\n',max_position_embeddings=512,pad_index=0,is_sample_shuffle=True):""":param vocab_path: 本地词表vocab.txt的路径:param tokenizer::param batch_size::param max_sen_len: 在对每个batch进行处理时的配置;当max_sen_len = None时,即以每个batch中最长样本长度为标准,对其它进行padding当max_sen_len = 'same'时,以整个数据集中最长样本为标准,对其它进行padding当max_sen_len = 50, 表示以某个固定长度符样本进行padding,多余的截掉;:param split_sep: 文本和标签之前的分隔符,默认为'\t':param max_position_embeddings: 指定最大样本长度,超过这个长度的部分将本截取掉:param is_sample_shuffle: 是否打乱训练集样本(只针对训练集)在后续构造DataLoader时,验证集和测试集均指定为了固定顺序(即不进行打乱),修改程序时请勿进行打乱因为当shuffle为True时,每次通过for循环遍历data_iter时样本的顺序都不一样,这会导致在模型预测时返回的标签顺序与原始的顺序不一样,不方便处理。"""self.tokenizer = tokenizerself.vocab = build_vocab(vocab_path)self.PAD_IDX = pad_indexself.SEP_IDX = self.vocab['[SEP]']self.CLS_IDX = self.vocab['[CLS]']# self.UNK_IDX = '[UNK]'self.batch_size = batch_sizeself.split_sep = split_sepself.max_position_embeddings = max_position_embeddingsif isinstance(max_sen_len, int) and max_sen_len > max_position_embeddings:max_sen_len = max_position_embeddingsself.max_sen_len = max_sen_lenself.is_sample_shuffle = is_sample_shuffle@cachedef data_process(self, filepath, postfix='cache'):"""将每一句话中的每一个词根据字典转换成索引的形式,同时返回所有样本中最长样本的长度:param filepath: 数据集路径:return:"""raw_iter = open(filepath, encoding="utf8").readlines()data = []max_len = 0for raw in tqdm(raw_iter, ncols=80):line = raw.rstrip("\n").split(self.split_sep)s, l = line[0], line[1]tmp = [self.CLS_IDX] + [self.vocab[token] for token in self.tokenizer(s)]if len(tmp) > self.max_position_embeddings - 1:tmp = tmp[:self.max_position_embeddings - 1] # BERT预训练模型只取前512个字符tmp += [self.SEP_IDX]tensor_ = torch.tensor(tmp, dtype=torch.long)l = torch.tensor(int(l), dtype=torch.long)max_len = max(max_len, tensor_.size(0))data.append((tensor_, l))return data, max_lendef load_train_val_test_data(self, train_file_path=None,val_file_path=None,test_file_path=None,only_test=False):postfix = str(self.max_sen_len)test_data, _ = self.data_process(filepath=test_file_path, postfix=postfix)test_iter = DataLoader(test_data, batch_size=self.batch_size,shuffle=False, collate_fn=self.generate_batch)if only_test:return test_itertrain_data, max_sen_len = self.data_process(filepath=train_file_path,postfix=postfix) # 得到处理好的所有样本if self.max_sen_len == 'same':self.max_sen_len = max_sen_lenval_data, _ = self.data_process(filepath=val_file_path,postfix=postfix)train_iter = DataLoader(train_data, batch_size=self.batch_size, # 构造DataLoadershuffle=self.is_sample_shuffle, collate_fn=self.generate_batch)val_iter = DataLoader(val_data, batch_size=self.batch_size,shuffle=False, collate_fn=self.generate_batch)return train_iter, test_iter, val_iterdef generate_batch(self, data_batch):batch_sentence, batch_label = [], []for (sen, label) in data_batch: # 开始对一个batch中的每一个样本进行处理。batch_sentence.append(sen)batch_label.append(label)batch_sentence = pad_sequence(batch_sentence, # [batch_size,max_len]padding_value=self.PAD_IDX,batch_first=False,max_len=self.max_sen_len)batch_label = torch.tensor(batch_label, dtype=torch.long)return batch_sentence, batch_labelclass LoadSQuADQuestionAnsweringDataset(LoadSingleSentenceClassificationDataset):"""Args:doc_stride: When splitting up a long document into chunks, how much stride totake between chunks.当上下文过长时,按滑动窗口进行移动,doc_stride表示每次移动的距离max_query_length: The maximum number of tokens for the question. Questions longer thanthis will be truncated to this length.限定问题的最大长度,过长时截断n_best_size: 对预测出的答案近后处理时,选取的候选答案数量max_answer_length: 在对候选进行筛选时,对答案最大长度的限制"""def __init__(self, doc_stride=64,max_query_length=64,n_best_size=20,max_answer_length=30,**kwargs):super(LoadSQuADQuestionAnsweringDataset, self).__init__(**kwargs)self.doc_stride = doc_strideself.max_query_length = max_query_lengthself.n_best_size = n_best_sizeself.max_answer_length = max_answer_length@staticmethoddef get_format_text_and_word_offset(text):"""格式化原始输入的文本(去除多个空格),同时得到每个字符所属的元素(单词)的位置这样,根据原始数据集中所给出的起始index(answer_start)就能立马判定它在列表中的位置。:param text::return:e.g.text = "Architecturally, the school has a Catholic character. "return:['Architecturally,', 'the', 'school', 'has', 'a', 'Catholic', 'character.'],[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 3,3, 3, 3, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6, 6]"""def is_whitespace(c):if c == " " or c == "\t" or c == "\r" or c == "\n" or ord(c) == 0x202F:return Truereturn Falsedoc_tokens = []char_to_word_offset = []prev_is_whitespace = True# 以下这个for循环的作用就是将原始context中的内容进行格式化for c in text: # 遍历paragraph中的每个字符if is_whitespace(c): # 判断当前字符是否为空格(各类空格)prev_is_whitespace = Trueelse:if prev_is_whitespace: # 如果前一个字符是空格doc_tokens.append(c)else:doc_tokens[-1] += c # 在list的最后一个元素中继续追加字符prev_is_whitespace = Falsechar_to_word_offset.append(len(doc_tokens) - 1)return doc_tokens, char_to_word_offsetdef preprocessing(self, filepath, is_training=True):"""将原始数据进行预处理,同时返回得到答案在原始context中的具体开始和结束位置(以单词为单位):param filepath::param is_training::return:返回形式为一个二维列表,内层列表中的各个元素分别为 ['问题ID','原始问题文本','答案文本','context文本','答案在context中的开始位置','答案在context中的结束位置'],并且二维列表中的一个元素称之为一个example,即一个example由六部分组成如下示例所示:[['5733be284776f41900661182', 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?','Saint Bernadette Soubirous', 'Architecturally, the school has a Catholic character......',90, 92],['5733be284776f4190066117f', ....]]"""with open(filepath, 'r') as f:raw_data = json.loads(f.read())data = raw_data['data']examples = []for i in tqdm(range(len(data)), ncols=80, desc="正在遍历每一个段落"): # 遍历每一个paragraphsparagraphs = data[i]['paragraphs'] # 取第i个paragraphsfor j in range(len(paragraphs)): # 遍历第i个paragraphs的每个contextcontext = paragraphs[j]['context'] # 取第j个contextcontext_tokens, word_offset = self.get_format_text_and_word_offset(context)qas = paragraphs[j]['qas'] # 取第j个context下的所有 问题-答案 对for k in range(len(qas)): # 遍历第j个context中的多个 问题-答案 对question_text = qas[k]['question']qas_id = qas[k]['id']if is_training:answer_offset = qas[k]['answers'][0]['answer_start']orig_answer_text = qas[k]['answers'][0]['text']answer_length = len(orig_answer_text)start_position = word_offset[answer_offset]end_position = word_offset[answer_offset + answer_length - 1]actual_text = " ".join(context_tokens[start_position:(end_position + 1)])cleaned_answer_text = " ".join(orig_answer_text.strip().split())if actual_text.find(cleaned_answer_text) == -1:logging.warning("Could not find answer: '%s' vs. '%s'",actual_text, cleaned_answer_text)continueelse:start_position = Noneend_position = Noneorig_answer_text = Noneexamples.append([qas_id, question_text, orig_answer_text," ".join(context_tokens), start_position, end_position])return examples@staticmethoddef improve_answer_span(context_tokens,answer_tokens,start_position,end_position):"""本方法的作用有两个:1. 如https://github.com/google-research/bert中run_squad.py里的_improve_answer_span()函数一样,用于提取得到更加匹配答案的起止位置;2. 根据原始起止位置,提取得到token id中答案的起止位置# The SQuAD annotations are character based. We first project them to# whitespace-tokenized words. But then after WordPiece tokenization, we can# often find a "better match". For example:## Question: What year was John Smith born?# Context: The leader was John Smith (1895-1943).# Answer: 1895## The original whitespace-tokenized answer will be "(1895-1943).". However# after tokenization, our tokens will be "( 1895 - 1943 ) .". So we can match# the exact answer, 1895.context = "The leader was John Smith (1895-1943).answer_text = "1985":param context_tokens: ['the', 'leader', 'was', 'john', 'smith', '(', '1895', '-', '1943', ')', '.']:param answer_tokens: ['1895']:param start_position: 5:param end_position: 5:return: [6,6]再例如:context = "Virgin mary reputedly appeared to Saint Bernadette Soubirous in 1858"answer_text = "Saint Bernadette Soubirous":param context_tokens: ['virgin', 'mary', 'reputed', '##ly', 'appeared', 'to', 'saint', 'bern', '##ade','##tte', 'so', '##ub', '##iro', '##us', 'in', '1858']:param answer_tokens: ['saint', 'bern', '##ade', '##tte', 'so', '##ub', '##iro', '##us':param start_position = 5:param end_position = 7return (6,13)"""new_end = Nonefor i in range(start_position, len(context_tokens)):if context_tokens[i] != answer_tokens[0]:continuefor j in range(len(answer_tokens)):if answer_tokens[j] != context_tokens[i + j]:breaknew_end = i + jif new_end - i + 1 == len(answer_tokens):return i, new_endreturn start_position, end_position@staticmethoddef get_token_to_orig_map(input_tokens, origin_context, tokenizer):"""本函数的作用是根据input_tokens和原始的上下文,返回得input_tokens中每个单词在原始单词中所对应的位置索引:param input_tokens: ['[CLS]', 'to', 'whom', 'did', 'the', 'virgin', '[SEP]', 'architectural', '##ly',',', 'the', 'school', 'has', 'a', 'catholic', 'character', '.', '[SEP']:param origin_context: "Architecturally, the Architecturally, test, Architecturally,the school has a Catholic character. Welcome moon hotel":param tokenizer::return: {7: 4, 8: 4, 9: 4, 10: 5, 11: 6, 12: 7, 13: 8, 14: 9, 15: 10, 16: 10}含义是input_tokens[7]为origin_context中的第4个单词 Architecturally,input_tokens[8]为origin_context中的第4个单词 Architecturally,...input_tokens[10]为origin_context中的第5个单词 the"""origin_context_tokens = origin_context.split()token_id = []str_origin_context = ""for i in range(len(origin_context_tokens)):tokens = tokenizer(origin_context_tokens[i])str_token = "".join(tokens)str_origin_context += "" + str_tokenfor _ in str_token:token_id.append(i)key_start = input_tokens.index('[SEP]') + 1tokenized_tokens = input_tokens[key_start:-1]str_tokenized_tokens = "".join(tokenized_tokens)index = str_origin_context.index(str_tokenized_tokens)value_start = token_id[index]token_to_orig_map = {}# 处理这样的边界情况: Building's gold 《==》 's', 'gold', 'dome'token = tokenizer(origin_context_tokens[value_start])for i in range(len(token), -1, -1):s1 = "".join(token[-i:])s2 = "".join(tokenized_tokens[:i])if s1 == s2:token = token[-i:]breakwhile True:for j in range(len(token)):token_to_orig_map[key_start] = value_startkey_start += 1if len(token_to_orig_map) == len(tokenized_tokens):return token_to_orig_mapvalue_start += 1token = tokenizer(origin_context_tokens[value_start])@cachedef data_process(self, filepath, is_training=False, postfix='cache'):""":param filepath::param is_training::return: [[example_id, feature_id, input_ids, seg, start_position,end_position, answer_text, example[0]],input_tokens,token_to_orig_map [],[],[]...]分别对应:[原始样本Id,训练特征id,input_ids,seg,开始,结束,答案文本,问题id,input_tokens,token_to_orig_map]"""logging.info(f"## 使用窗口滑动滑动,doc_stride = {self.doc_stride}")examples = self.preprocessing(filepath, is_training)all_data = []example_id, feature_id = 0, 1000000000# 由于采用了滑动窗口,所以一个example可能构造得到多个训练样本(即这里被称为feature);# 因此,需要对其分别进行编号,并且这主要是用在预测后的结果后处理当中,训练时用不到# 当然,这里只使用feature_id即可,因为每个example其实对应的就是一个问题,所以问题ID和example_id本质上是一样的for example in tqdm(examples, ncols=80, desc="正在遍历每个问题(样本)"):question_tokens = self.tokenizer(example[1])if len(question_tokens) > self.max_query_length: # 问题过长进行截取question_tokens = question_tokens[:self.max_query_length]question_ids = [self.vocab[token] for token in question_tokens]question_ids = [self.CLS_IDX] + question_ids + [self.SEP_IDX]context_tokens = self.tokenizer(example[3])context_ids = [self.vocab[token] for token in context_tokens]logging.debug(f"<<<<<<<< 进入新的example >>>>>>>>>")logging.debug(f"## 正在预处理数据 {__name__} is_training = {is_training}")logging.debug(f"## 问题 id: {example[0]}")logging.debug(f"## 原始问题 text: {example[1]}")logging.debug(f"## 原始描述 text: {example[3]}")start_position, end_position, answer_text = -1, -1, Noneif is_training:start_position, end_position = example[4], example[5]answer_text = example[2]answer_tokens = self.tokenizer(answer_text)start_position, end_position = self.improve_answer_span(context_tokens,answer_tokens,start_position,end_position)rest_len = self.max_sen_len - len(question_ids) - 1context_ids_len = len(context_ids)logging.debug(f"## 上下文长度为:{context_ids_len}, 剩余长度 rest_len 为 : {rest_len}")if context_ids_len > rest_len: # 长度超过max_sen_len,需要进行滑动窗口logging.debug(f"## 进入滑动窗口 …… ")s_idx, e_idx = 0, rest_lenwhile True:# We can have documents that are longer than the maximum sequence length.# To deal with this we do a sliding window approach, where we take chunks# of the up to our max length with a stride of `doc_stride`.tmp_context_ids = context_ids[s_idx:e_idx]tmp_context_tokens = [self.vocab.itos[item] for item in tmp_context_ids]logging.debug(f"## 滑动窗口范围:{s_idx, e_idx},example_id: {example_id}, feature_id: {feature_id}")# logging.debug(f"## 滑动窗口取值:{tmp_context_tokens}")input_ids = torch.tensor(question_ids + tmp_context_ids + [self.SEP_IDX])input_tokens = ['[CLS]'] + question_tokens + ['[SEP]'] + tmp_context_tokens + ['[SEP]']seg = [0] * len(question_ids) + [1] * (len(input_ids) - len(question_ids))seg = torch.tensor(seg)if is_training:new_start_position, new_end_position = 0, 0if start_position >= s_idx and end_position <= e_idx: # in trainlogging.debug(f"## 滑动窗口中存在答案 -----> ")new_start_position = start_position - s_idxnew_end_position = new_start_position + (end_position - start_position)new_start_position += len(question_ids)new_end_position += len(question_ids)logging.debug(f"## 原始答案:{answer_text} <===>处理后的答案:"f"{' '.join(input_tokens[new_start_position:(new_end_position + 1)])}")all_data.append([example_id, feature_id, input_ids, seg, new_start_position,new_end_position, answer_text, example[0], input_tokens])logging.debug(f"## start pos:{new_start_position}")logging.debug(f"## end pos:{new_end_position}")else:all_data.append([example_id, feature_id, input_ids, seg, start_position,end_position, answer_text, example[0], input_tokens])logging.debug(f"## start pos:{start_position}")logging.debug(f"## end pos:{end_position}")token_to_orig_map = self.get_token_to_orig_map(input_tokens, example[3], self.tokenizer)all_data[-1].append(token_to_orig_map)logging.debug(f"## example id: {example_id}")logging.debug(f"## feature id: {feature_id}")logging.debug(f"## input_tokens: {input_tokens}")logging.debug(f"## input_ids:{input_ids.tolist()}")logging.debug(f"## segment ids:{seg.tolist()}")logging.debug(f"## orig_map:{token_to_orig_map}")logging.debug("======================\n")feature_id += 1if e_idx >= context_ids_len:breaks_idx += self.doc_stridee_idx += self.doc_strideelse:input_ids = torch.tensor(question_ids + context_ids + [self.SEP_IDX])input_tokens = ['[CLS]'] + question_tokens + ['[SEP]'] + context_tokens + ['[SEP]']seg = [0] * len(question_ids) + [1] * (len(input_ids) - len(question_ids))seg = torch.tensor(seg)if is_training:start_position += (len(question_ids))end_position += (len(question_ids))token_to_orig_map = self.get_token_to_orig_map(input_tokens, example[3], self.tokenizer)all_data.append([example_id, feature_id, input_ids, seg, start_position,end_position, answer_text, example[0], input_tokens, token_to_orig_map])logging.debug(f"## input_tokens: {input_tokens}")logging.debug(f"## input_ids:{input_ids.tolist()}")logging.debug(f"## segment ids:{seg.tolist()}")logging.debug(f"## orig_map:{token_to_orig_map}")logging.debug("======================\n")feature_id += 1example_id += 1# all_data[0]: [原始样本Id,训练特征id,input_ids,seg,开始,结束,答案文本,问题id, input_tokens,ori_map]data = {'all_data': all_data, 'max_len': self.max_sen_len, 'examples': examples}return datadef generate_batch(self, data_batch):batch_input, batch_seg, batch_label, batch_qid = [], [], [], []batch_example_id, batch_feature_id, batch_map = [], [], []for item in data_batch:# item: [原始样本Id,训练特征id,input_ids,seg,开始,结束,答案文本,问题id,input_tokens,ori_map]batch_example_id.append(item[0]) # 原始样本Idbatch_feature_id.append(item[1]) # 训练特征idbatch_input.append(item[2]) # input_idsbatch_seg.append(item[3]) # segbatch_label.append([item[4], item[5]]) # 开始, 结束batch_qid.append(item[7]) # 问题idbatch_map.append(item[9]) # ori_mapbatch_input = pad_sequence(batch_input, # [batch_size,max_len]padding_value=self.PAD_IDX,batch_first=False,max_len=self.max_sen_len) # [max_len,batch_size]batch_seg = pad_sequence(batch_seg, # [batch_size,max_len]padding_value=self.PAD_IDX,batch_first=False,max_len=self.max_sen_len) # [max_len, batch_size]batch_label = torch.tensor(batch_label, dtype=torch.long)# [max_len,batch_size] , [max_len, batch_size] , [batch_size,2], [batch_size,], [batch_size,]return batch_input, batch_seg, batch_label, batch_qid, batch_example_id, batch_feature_id, batch_mapdef load_train_val_test_data(self, train_file_path=None,val_file_path=None,test_file_path=None,only_test=True):doc_stride = str(self.doc_stride)max_sen_len = str(self.max_sen_len)max_query_length = str(self.max_query_length)postfix = doc_stride + '_' + max_sen_len + '_' + max_query_lengthdata = self.data_process(filepath=test_file_path,is_training=False,postfix=postfix)test_data, examples = data['all_data'], data['examples']test_iter = DataLoader(test_data, batch_size=self.batch_size,shuffle=False,collate_fn=self.generate_batch)if only_test:logging.info(f"## 成功返回测试集,一共包含样本{len(test_iter.dataset)}个")return test_iter, examplesdata = self.data_process(filepath=train_file_path,is_training=True,postfix=postfix) # 得到处理好的所有样本train_data, max_sen_len = data['all_data'], data['max_len']_, val_data = train_test_split(train_data, test_size=0.3, random_state=2021)if self.max_sen_len == 'same':self.max_sen_len = max_sen_lentrain_iter = DataLoader(train_data, batch_size=self.batch_size, # 构造DataLoadershuffle=self.is_sample_shuffle, collate_fn=self.generate_batch)val_iter = DataLoader(val_data, batch_size=self.batch_size, # 构造DataLoadershuffle=False, collate_fn=self.generate_batch)logging.info(f"## 成功返回训练集样本({len(train_iter.dataset)})个、开发集样本({len(val_iter.dataset)})个"f"测试集样本({len(test_iter.dataset)})个.")return train_iter, test_iter, val_iter@staticmethoddef get_best_indexes(logits, n_best_size):"""Get the n-best logits from a list."""# logits = [0.37203778 0.48594432 0.81051651 0.07998148 0.93529721 0.0476721# 0.15275263 0.98202781 0.07813079 0.85410559]# n_best_size = 4# return [7, 4, 9, 2]index_and_score = sorted(enumerate(logits), key=lambda x: x[1], reverse=True)best_indexes = []for i in range(len(index_and_score)):if i >= n_best_size:breakbest_indexes.append(index_and_score[i][0])return best_indexesdef get_final_text(self, pred_text, orig_text):"""Project the tokenized prediction back to the original text."""# ref: https://github.com/google-research/bert/blob/master/run_squad.py# When we created the data, we kept track of the alignment between original# (whitespace tokenized) tokens and our WordPiece tokenized tokens. So# now `orig_text` contains the span of our original text corresponding to the# span that we predicted.## However, `orig_text` may contain extra characters that we don't want in# our prediction.## For example, let's say:# pred_text = steve smith# orig_text = Steve Smith's## We don't want to return `orig_text` because it contains the extra "'s".## We don't want to return `pred_text` because it's already been normalized# (the SQuAD eval script also does punctuation stripping/lower casing but# our tokenizer does additional normalization like stripping accent# characters).## What we really want to return is "Steve Smith".## Therefore, we have to apply a semi-complicated alignment heruistic between# `pred_text` and `orig_text` to get a character-to-charcter alignment. This# can fail in certain cases in which case we just return `orig_text`.def _strip_spaces(text):ns_chars = []ns_to_s_map = collections.OrderedDict()for (i, c) in enumerate(text):if c == " ":continuens_to_s_map[len(ns_chars)] = ins_chars.append(c)ns_text = "".join(ns_chars)return (ns_text, ns_to_s_map)# We first tokenize `orig_text`, strip whitespace from the result# and `pred_text`, and check if they are the same length. If they are# NOT the same length, the heuristic has failed. If they are the same# length, we assume the characters are one-to-one aligned.tok_text = " ".join(self.tokenizer(orig_text))start_position = tok_text.find(pred_text)if start_position == -1:return orig_textend_position = start_position + len(pred_text) - 1(orig_ns_text, orig_ns_to_s_map) = _strip_spaces(orig_text)(tok_ns_text, tok_ns_to_s_map) = _strip_spaces(tok_text)if len(orig_ns_text) != len(tok_ns_text):return orig_text# We then project the characters in `pred_text` back to `orig_text` using# the character-to-character alignment.tok_s_to_ns_map = {}for (i, tok_index) in six.iteritems(tok_ns_to_s_map):tok_s_to_ns_map[tok_index] = iorig_start_position = Noneif start_position in tok_s_to_ns_map:ns_start_position = tok_s_to_ns_map[start_position]if ns_start_position in orig_ns_to_s_map:orig_start_position = orig_ns_to_s_map[ns_start_position]if orig_start_position is None:return orig_textorig_end_position = Noneif end_position in tok_s_to_ns_map:ns_end_position = tok_s_to_ns_map[end_position]if ns_end_position in orig_ns_to_s_map:orig_end_position = orig_ns_to_s_map[ns_end_position]if orig_end_position is None:return orig_textoutput_text = orig_text[orig_start_position:(orig_end_position + 1)]return output_textdef write_prediction(self, test_iter, all_examples, logits_data, output_dir):"""根据预测得到的logits将预测结果写入到本地文件中:param test_iter::param all_examples::param logits_data::return:"""qid_to_example_context = {} # 根据qid取到其对应的context tokenfor example in all_examples:context = example[3]context_list = context.split()qid_to_example_context[example[0]] = context_list_PrelimPrediction = collections.namedtuple( # pylint: disable=invalid-name"PrelimPrediction",["text", "start_index", "end_index", "start_logit", "end_logit"])prelim_predictions = collections.defaultdict(list)for b_input, _, _, b_qid, _, b_feature_id, b_map in tqdm(test_iter, ncols=80, desc="正在遍历候选答案"):# 取一个问题对应所有特征样本的预测logits(因为有了滑动窗口,所以原始一个context可以构造得到多个训练样子本)all_logits = logits_data[b_qid[0]]for logits in all_logits:if logits[0] != b_feature_id[0]:continue # 非当前子样本对应的logits忽略# 遍历每个子样本对应logits的预测情况start_indexes = self.get_best_indexes(logits[1], self.n_best_size)# 得到开始位置几率最大的值对应的索引,例如可能是 [ 4,6,3,1]end_indexes = self.get_best_indexes(logits[2], self.n_best_size)# 得到结束位置几率最大的值对应的索引,例如可能是 [ 5,8,10,9]for start_index in start_indexes:for end_index in end_indexes: # 遍历所有存在的结果组合if start_index >= b_input.size(0):continue # 起始索引大于token长度,忽略if end_index >= b_input.size(0):continue # 结束索引大于token长度,忽略if start_index not in b_map[0]:continue # 用来判断索引是否位于[SEP]之后的位置,因为答案只会在[SEP]以后出现if end_index not in b_map[0]:continueif end_index < start_index:continuelength = end_index - start_index + 1if length > self.max_answer_length:continuetoken_ids = b_input.transpose(0, 1)[0]strs = [self.vocab.itos[s] for s in token_ids]tok_text = " ".join(strs[start_index:(end_index + 1)])tok_text = tok_text.replace(" ##", "").replace("##", "")tok_text = tok_text.strip()tok_text = " ".join(tok_text.split())orig_doc_start = b_map[0][start_index]orig_doc_end = b_map[0][end_index]orig_tokens = qid_to_example_context[b_qid[0]][orig_doc_start:(orig_doc_end + 1)]orig_text = " ".join(orig_tokens)final_text = self.get_final_text(tok_text, orig_text)prelim_predictions[b_qid[0]].append(_PrelimPrediction(text=final_text,start_index=int(start_index),end_index=int(end_index),start_logit=float(logits[1][start_index]),end_logit=float(logits[2][end_index])))# 此处为将每个qid对应的所有预测结果放到一起,因为一个qid对应的context应该滑动窗口# 会有构造得到多个训练样本,而每个训练样本都会对应得到一个预测的logits# 并且这里取了n_best个logits,所以组合后一个问题就会得到过个预测的答案for k, v in prelim_predictions.items():# 对每个qid对应的所有预测答案按照start_logit+end_logit的大小进行排序prelim_predictions[k] = sorted(prelim_predictions[k],key=lambda x: (x.start_logit + x.end_logit),reverse=True)best_results, all_n_best_results = {}, {}for k, v in prelim_predictions.items():best_results[k] = v[0].text # 取最好的第一个结果all_n_best_results[k] = v # 保存所有预测结果with open(os.path.join(output_dir, f"best_result.json"), 'w') as f:f.write(json.dumps(best_results, indent=4) + '\n')with open(os.path.join(output_dir, f"best_n_result.json"), 'w') as f:f.write(json.dumps(all_n_best_results, indent=4) + '\n')
模型
我们只需要在原始BERT模型的基础上取最后一层的输出结果,然后再加一个分类层即可。因此这部分代码相对来说也比较容易理解。
from Bert import BertModel
import torch.nn as nnclass BertForQuestionAnswering(nn.Module):"""用于建模类似SQuAD这样的问答数据集"""def __init__(self, config, bert_pretrained_model_dir=None):super(BertForQuestionAnswering, self).__init__()if bert_pretrained_model_dir is not None:self.bert = BertModel.from_pretrained(config, bert_pretrained_model_dir)else:self.bert = BertModel(config)self.qa_outputs = nn.Linear(config.hidden_size, 2)def forward(self, input_ids,attention_mask=None,token_type_ids=None,position_ids=None,start_positions=None,end_positions=None):""":param input_ids: [src_len,batch_size]:param attention_mask: [batch_size,src_len]:param token_type_ids: [src_len,batch_size]:param position_ids::param start_positions: [batch_size]:param end_positions: [batch_size]:return:"""_, all_encoder_outputs = self.bert(input_ids=input_ids,attention_mask=attention_mask,token_type_ids=token_type_ids,position_ids=position_ids)sequence_output = all_encoder_outputs[-1] # 取Bert最后一层的输出# sequence_output: [src_len, batch_size, hidden_size]logits = self.qa_outputs(sequence_output) # [src_len, batch_size,2]start_logits, end_logits = logits.split(1, dim=-1)# [src_len,batch_size,1] [src_len,batch_size,1]start_logits = start_logits.squeeze(-1).transpose(0, 1) # [batch_size,src_len]end_logits = end_logits.squeeze(-1).transpose(0, 1) # [batch_size,src_len]if start_positions is not None and end_positions is not None:# 由于部分情况下start/end 位置会超过输入的长度# (例如输入序列的可能大于512,并且正确的开始或者结束符就在512之后)# 那么此时就要进行特殊处理ignored_index = start_logits.size(1) # 取输入序列的长度start_positions.clamp_(0, ignored_index)# 如果正确起始位置start_positions中,存在输入样本的开始位置大于输入长度,# 那么直接取输入序列的长度作为开始位置end_positions.clamp_(0, ignored_index)loss_fct = nn.CrossEntropyLoss(ignore_index=ignored_index)# 这里指定ignored_index其实就是为了忽略掉超过输入序列长度的(起始结束)位置# 在预测时所带来的损失,因为这些位置并不能算是模型预测错误的(只能看做是没有预测),# 同时如果不加ignore_index的话,那么可能会影响模型在正常情况下的语义理解能力start_loss = loss_fct(start_logits, start_positions)end_loss = loss_fct(end_logits, end_positions)return (start_loss + end_loss) / 2, start_logits, end_logitselse:return start_logits, end_logits # [batch_size,src_len]
定义一个ModelConfig类来对分类模型中的超参数以及其它变量进行管理,代码如下所示:
class BertConfig(object):"""Configuration for `BertModel`."""def __init__(self,vocab_size=21128,hidden_size=768,num_hidden_layers=12,num_attention_heads=12,intermediate_size=3072,pad_token_id=0,hidden_act="gelu",hidden_dropout_prob=0.1,attention_probs_dropout_prob=0.1,max_position_embeddings=512,type_vocab_size=2,initializer_range=0.02):"""Constructs BertConfig.Args:vocab_size: Vocabulary size of `inputs_ids` in `BertModel`.hidden_size: Size of the encoder layers and the pooler layer.num_hidden_layers: Number of hidden layers in the Transformer encoder.num_attention_heads: Number of attention heads for each attention layer inthe Transformer encoder.intermediate_size: The size of the "intermediate" (i.e., feed-forward)layer in the Transformer encoder.hidden_act: The non-linear activation function (function or string) in theencoder and pooler.hidden_dropout_prob: The dropout probability for all fully connectedlayers in the embeddings, encoder, and pooler.attention_probs_dropout_prob: The dropout ratio for the attentionprobabilities.max_position_embeddings: The maximum sequence length that this model mightever be used with. Typically set this to something large just in case(e.g., 512 or 1024 or 2048).type_vocab_size: The vocabulary size of the `token_type_ids` passed into`BertModel`.initializer_range: The stdev of the truncated_normal_initializer forinitializing all weight matrices."""self.vocab_size = vocab_sizeself.hidden_size = hidden_sizeself.num_hidden_layers = num_hidden_layersself.num_attention_heads = num_attention_headsself.hidden_act = hidden_actself.intermediate_size = intermediate_sizeself.pad_token_id = pad_token_idself.hidden_dropout_prob = hidden_dropout_probself.attention_probs_dropout_prob = attention_probs_dropout_probself.max_position_embeddings = max_position_embeddingsself.type_vocab_size = type_vocab_sizeself.initializer_range = initializer_range@classmethoddef from_dict(cls, json_object):"""Constructs a `BertConfig` from a Python dictionary of parameters."""config = BertConfig(vocab_size=None)for (key, value) in six.iteritems(json_object):config.__dict__[key] = valuereturn config@classmethoddef from_json_file(cls, json_file):"""Constructs a `BertConfig` from a json file of parameters.""""""从json配置文件读取配置信息"""with open(json_file, 'r') as reader:text = reader.read()logging.info(f"成功导入BERT配置文件 {json_file}")return cls.from_dict(json.loads(text))def to_dict(self):"""Serializes this instance to a Python dictionary."""output = copy.deepcopy(self.__dict__)return outputdef to_json_string(self):"""Serializes this instance to a JSON string."""return json.dumps(self.to_dict(), indent=2, sort_keys=True) + "\n"
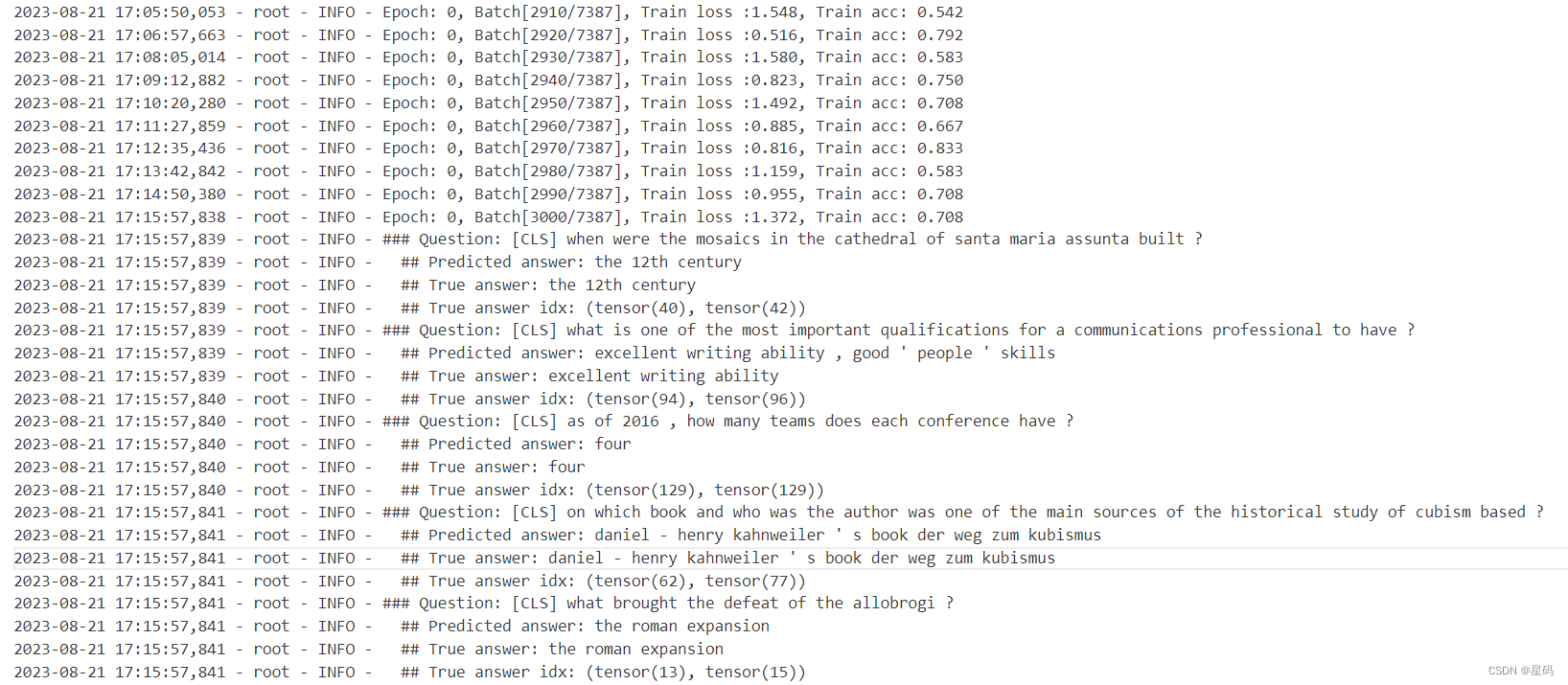
结果
参考资料
基于BERT预训练模型的SQuAD问答任务:https://www.ylkz.life/deeplearning/p10265968/
相关文章:
[oneAPI] 基于BERT预训练模型的SQuAD问答任务
[oneAPI] 基于BERT预训练模型的SQuAD问答任务 Intel Optimization for PyTorch and Intel DevCloud for oneAPI基于BERT预训练模型的SQuAD问答任务语料介绍数据下载构建 模型 结果参考资料 比赛:https://marketing.csdn.net/p/f3e44fbfe46c465f4d9d6c23e38e0517 Int…...
梯度下降法在强凸函数的收敛性分析)
机器学习笔记之优化算法(十七)梯度下降法在强凸函数的收敛性分析
机器学习笔记之优化算法——梯度下降法在强凸函数的收敛性分析 引言回顾:梯度下降法在强凸函数的收敛性二阶可微——梯度下降法在强凸函数的收敛性推论 引言 上一节介绍并证明了:梯度下降法在强凸函数上的收敛速度满足 Q \mathcal Q Q-线性收敛。 本节将…...
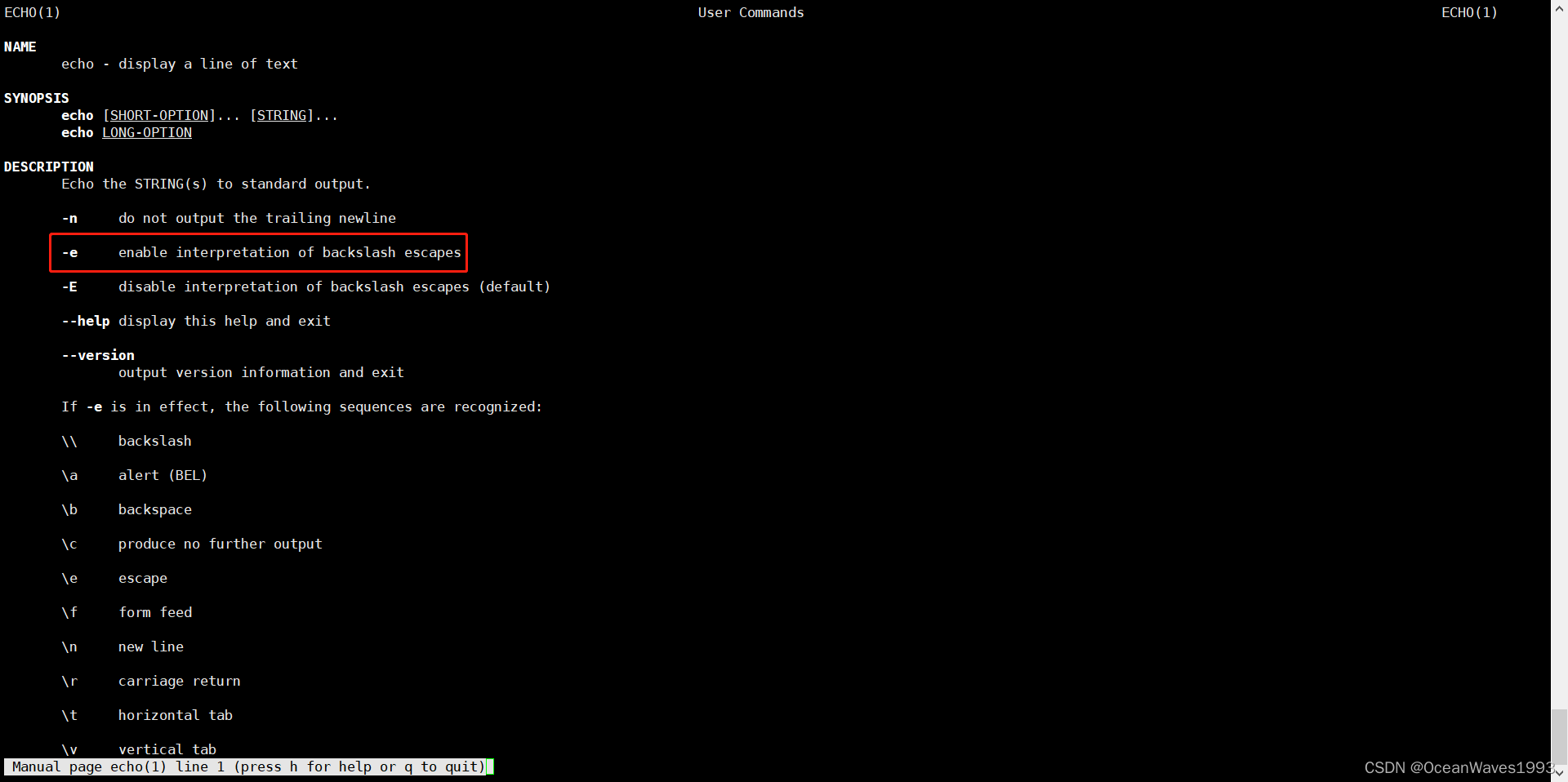
shell脚本中linux命令的特殊用法记录
shell脚本中linux命令的特殊用法记录 1、linux命令特殊参数选项1.1、sed -e1.2、echo -e 2、 shell 扩展2.1、[[ ]]支持用~进行正则匹配 3、特殊命令用法3.1、{} 变量替换 1、linux命令特殊参数选项 1.1、sed -e sed -e以严格模式执行脚本,在sed -e 后面的所有命令…...

Nvidia H100:今年55万张够用吗?
原文标题:Nvidia H100: Are 550,000 GPUs Enough for This Year? 作者:Doug Eadline August 17, 2023 The GPU Squeeze continues to place a premium on Nvidia H100 GPUs. In a recent Financial Times article, Nvidia reports that it expects to…...
)
【Vue2.0源码学习】生命周期篇-初始化阶段(initLifecycle)
文章目录 1. 前言2. initLifecycle函数分析3. 总结 1. 前言 在上篇文章中,我们介绍了生命周期初始化阶段的整体工作流程,以及在该阶段都做了哪些事情。我们知道了,在该阶段会调用一些初始化函数,对Vue实例的属性、数据等进行初始…...
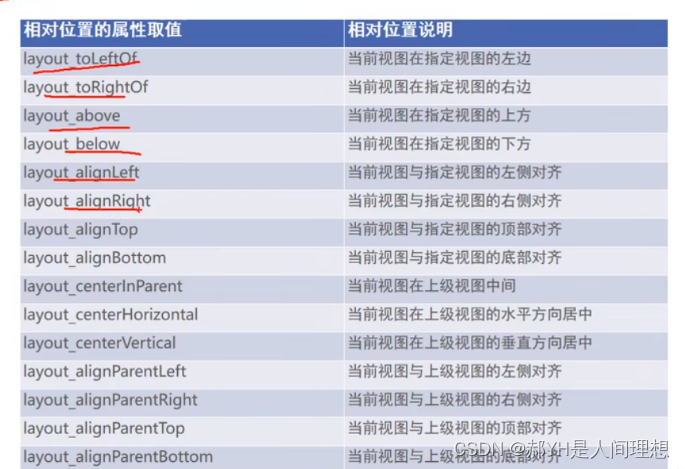
Android开发基础知识总结(三)简单控件(上)
一.文本显示 考虑到结构样式相分离的思想,我们往往在XML中设置文本 <TextViewandroid:layout_width"342dp"android:layout_height"70dp"android:text"房价计算器"android:layout_gravity"center"android:textColor"…...
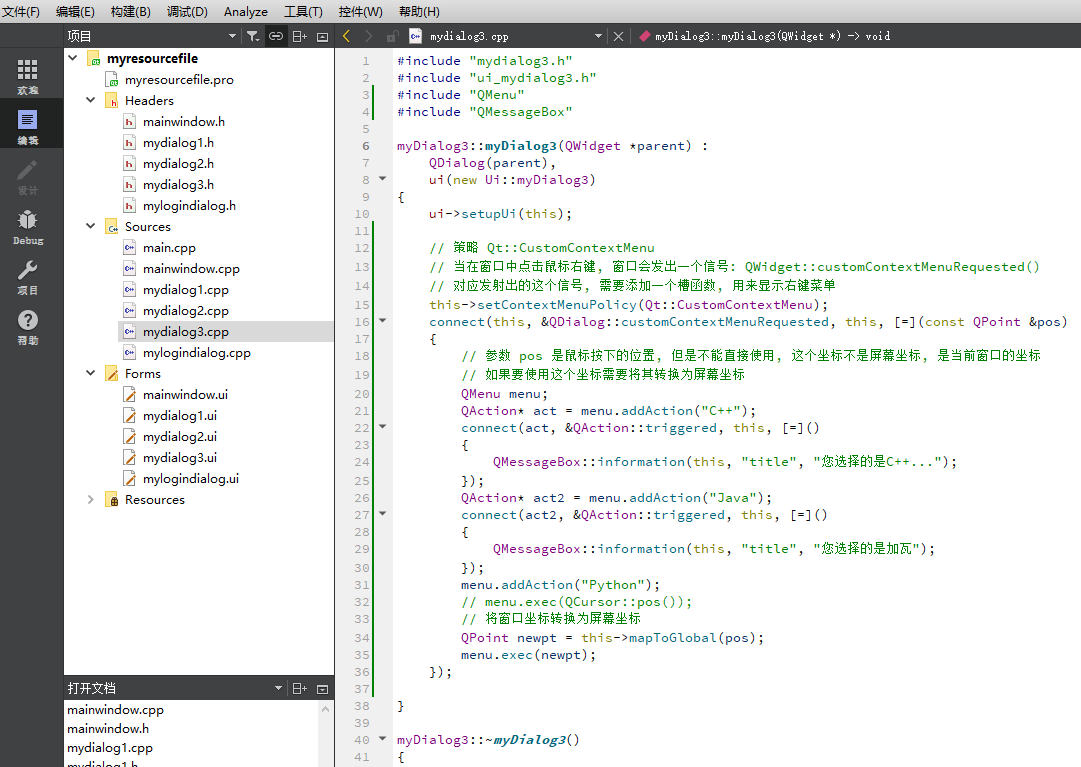
在Qt窗口中添加右键菜单
在Qt窗口中添加右键菜单 基于鼠标的事件实现流程demo 基于窗口的菜单策略实现Qt::DefaultContextMenuQt::ActionsContextMenuQt::CustomContextMenu信号API 基于鼠标的事件实现 流程 需要使用:事件处理器函数(回调函数) 在当前窗口类中重写鼠标操作相关的的事件处理器函数&a…...

Day8 智慧商城
项目演示 项目收获 创建项目 调整初始化目录 1.删components里的所有文件 2.删views里的所有文件 3.router/index.js 删路由 删规则 import Vue from vue import VueRouter from vue-routerVue.use(VueRouter)const router new VueRouter({routes: [] })export default route…...

LeetCode:Hot100python版本之回溯
回溯算法其实是纯暴力搜索。for循环嵌套是写不出的 组合:没有顺序 排列:有顺序 回溯法可以抽象为树形结构。只有在回溯算法中递归才会有返回值。 46. 全排列 排列是有顺序的。 组合类问题用startindex,排序类问题用used,来标…...
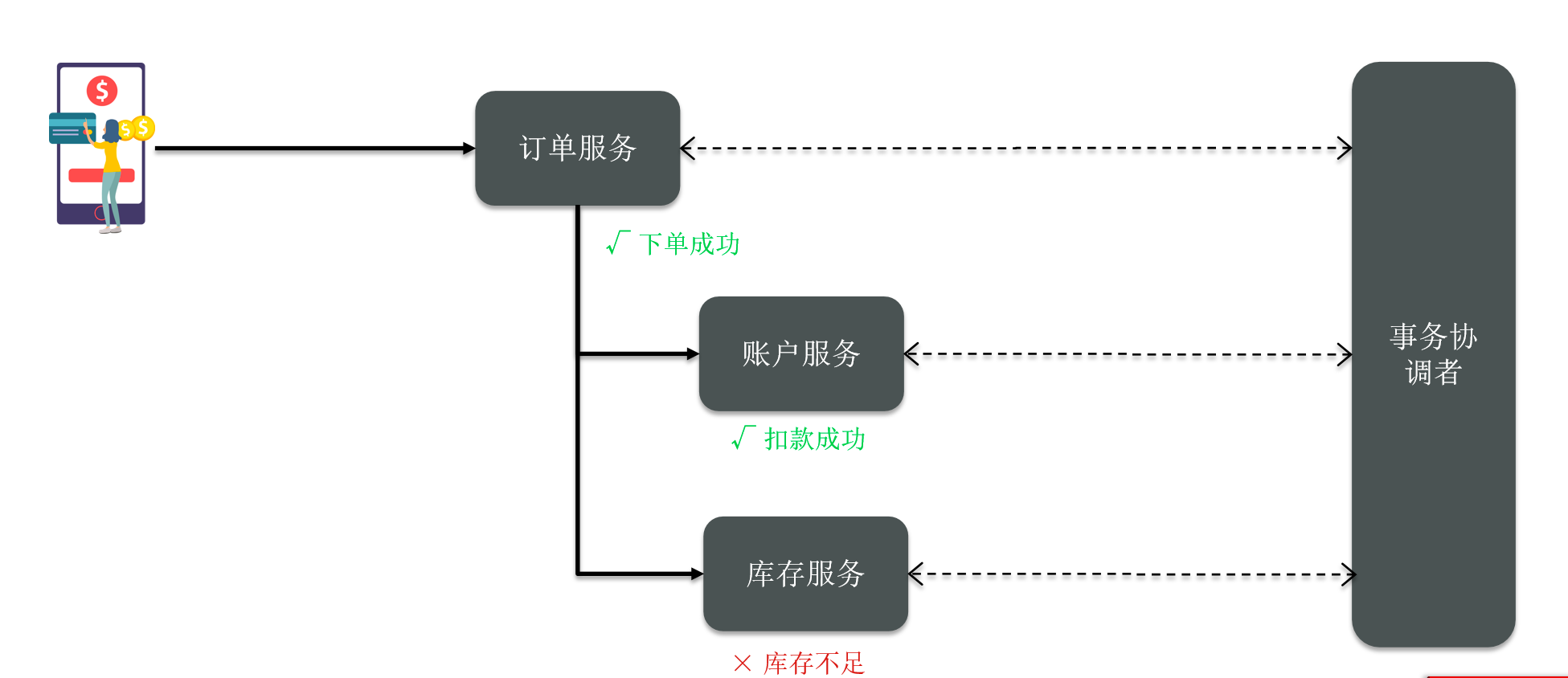
分布式事务理论基础
今天啊,本片博客我们一起来学习一下微服务中的一个重点和难点知识:分布式事务。 我们会基于Seata 这个框架来学习。 1、分布式事务问题 事务,我们应该比较了解,我们知道所有的事务,都必须要满足ACID的原则。也就是 …...

线性代数强化第三章
目录 一,关于A伴随,A逆与初等矩阵 二,分块矩阵 三,矩阵方程 一,关于A伴随,A逆与初等矩阵 如何证明行列式的值不能是0; 此秩为1. 法一: 法二: 不用看是列变换还是行变…...
---之配置)
搭建自己的私有 开源LoRaWAN 网络服务器(The ThingsStack)---之配置
介绍 这是使用 Docker 在您自己的硬件上安装 Things Stack Enterprise 或开源代码以运行您自己的私有 LoRaWAN 网络服务器的指南。 运行 The Things Stack 的方法有多种。 Things Stack 开源和企业发行版旨在在您自己的硬件上运行,本指南也对此进行了介绍。 对于具有高吞吐量的…...
多维时序 | MATLAB实现SCNGO-CNN-Attention多变量时间序列预测
多维时序 | MATLAB实现SCNGO-CNN-Attention多变量时间序列预测 目录 多维时序 | MATLAB实现SCNGO-CNN-Attention多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.SCNGO-CNN-Attention超前24步多变量回归预测算法。 程序平台:无Attention适…...

clickhouse的删除和更新
clickhouse不擅长更新和删除操作,更新操作很重,更新是重新创建一个分区,更新完后,太混之前的 ClickHouse提供了DELETE和UPDATE的能力,这类操作被称为Mutation查询,它可以看作ALTER语句的变种。虽然Mutation…...
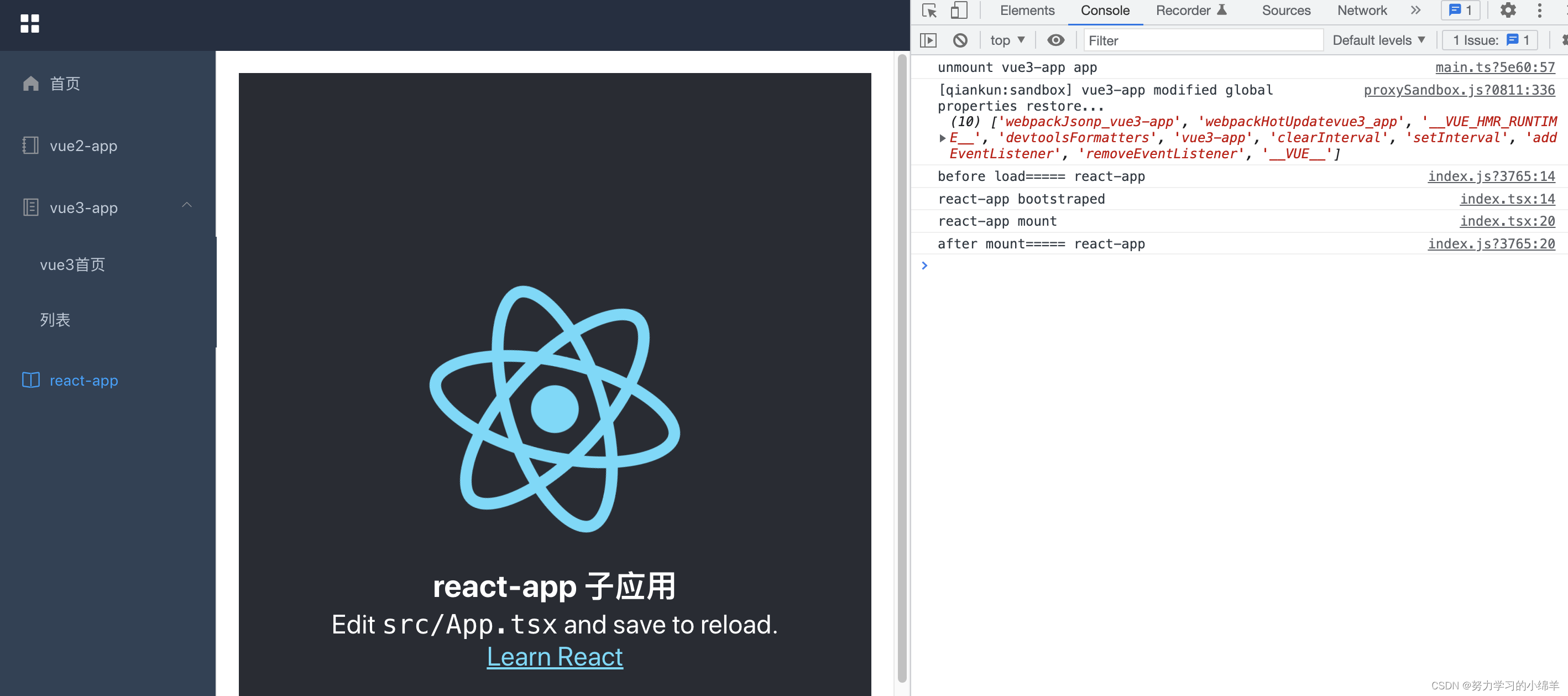
微前端 - qiankun
qiankun 是一个基于 single-spa 的微前端实现库,旨在帮助大家能更简单、无痛的构建一个生产可用微前端架构系统。 本文主要记录下如何接入 qiankun 微前端。主应用使用 vue2,子应用使用 vue3、react。 一、主应用 主应用不限技术栈,只需要提…...

前端编辑页面修改后和原始数据比较差异
在软件研发过程中,会遇到很多编辑页面,有时编辑页面和新增页面长的基本上一样,甚至就是一套页面供新增和编辑共用。编辑页面的场景比较多,例如: 场景一、字段比较多,但实际只修改了几个字段,如…...

docker第一次作业
docker第一次作业 1.安装docker服务,配置镜像加速器 yum install -y yum-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo sed -i sdownload.docker.commirrors.aliy…...

Springboot3.0.0+集成SpringDoc并配置knife4j的UI
环境:JDK17,Springboot3,springdoc2,knife4j 4 Springdoc本身也是集成了Swagger3,而knife4j美化了Swagger3的UI Knife4j官网: 快速开始 | Knife4j Springdoc官网 OpenAPI 3 Library for spring-boot 1.pom配置 由于此knife4j内依赖了S…...
电脑运行缓慢?4个方法,加速电脑运行!
“我电脑才用了没多久哎!怎么突然就变得运行很缓慢了呢?有什么方法可以加速电脑运行速度吗?真的很需要,看看我吧!” 电脑的运行速度快会让用户在使用电脑时感觉愉悦,而电脑运行缓慢可能会影响我们的工作效率…...

3.Docker 搭建 MySQL8.0
1、docker仓库搜索mysql docker search mysql2、docker仓库拉取mysql8.0 docker pull mysql:8.0 备注: docker pull mysql //默认拉取最新版本3、查看本地仓库镜像是否下载成功 docker images mysql:8.04、安装运行mysql8.0容器 docker run -p 3306:3306 --name…...

Qwen3-0.6B-FP8企业落地实践:中小企业低成本AI对话助手部署方案
Qwen3-0.6B-FP8企业落地实践:中小企业低成本AI对话助手部署方案 1. 引言:为什么中小企业需要自己的AI助手? 想象一下,你的客服团队每天要处理上百条重复的咨询,你的内容团队为了一篇产品介绍绞尽脑汁,你的…...
)
Flutter项目实战:如何用ZXingLite打造高定制化二维码扫描功能(附完整代码)
Flutter项目实战:如何用ZXingLite打造高定制化二维码扫描功能(附完整代码) 在移动应用开发中,二维码扫描功能已经成为许多应用的标配需求。然而,市面上大多数现成的Flutter二维码插件往往存在扩展性不足的问题…...

解决AI绘画痛点:造相-Z-Image针对RTX 4090的BF16优化与防爆技巧
解决AI绘画痛点:造相-Z-Image针对RTX 4090的BF16优化与防爆技巧 1. RTX 4090上的AI绘画挑战与解决方案 1.1 高端显卡的隐藏痛点 RTX 4090作为消费级显卡的旗舰产品,拥有24GB显存和强大的计算能力,理论上应该能轻松应对各种AI绘画任务。但在…...

java微信小程序高校学生兼职系统的设计与实现
目录需求分析技术选型数据库设计后端开发前端开发测试与部署运维与迭代项目技术支持可定制开发之功能创新亮点源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作需求分析 明确高校学生兼职系统的核心功能需求,包括学生端、企业端和…...

Qwen3-32B镜像免配置实战:RTX4090D单卡10分钟完成大模型推理服务上线
Qwen3-32B镜像免配置实战:RTX4090D单卡10分钟完成大模型推理服务上线 1. 开箱即用的私有部署方案 你是否遇到过这样的困扰:想部署一个大语言模型服务,却被复杂的依赖安装、环境配置、模型加载等问题搞得焦头烂额?特别是像Qwen3-…...

GLM-TTS新手避坑指南:参考音频选择和参数设置技巧
GLM-TTS新手避坑指南:参考音频选择和参数设置技巧 1. 前言:为什么需要这份指南 语音合成技术已经变得越来越普及,但很多新手在使用GLM-TTS这类高级语音克隆工具时,常常会遇到各种"坑"——生成的语音不像、效果不自然、…...

别再只pip install了!PySerial模块在Windows/Linux/macOS上的完整安装与验证指南
别再只pip install了!PySerial模块在Windows/Linux/macOS上的完整安装与验证指南 当你第一次尝试用Python控制Arduino或树莓派的串口时,pip install pyserial这个看似简单的命令可能会让你陷入长达数小时的调试噩梦。不同操作系统、Python版本和环境配置…...

SPX截图神器隐藏玩法:除了撕边效果,还能批量给图片加动态水印?
SPX截图神器进阶指南:从动态水印到高效办公的全能玩法 在数字办公时代,截图工具早已不再是简单的屏幕捕捉软件。SPX Instant Screen Capture作为一款轻量级却功能强大的截图工具,其隐藏的高级功能可以显著提升工作效率。本文将深入探索SPX的进…...
Pixel Mind Decoder 在游戏NPC中的应用:实时生成富有情感的对话
Pixel Mind Decoder 在游戏NPC中的应用:实时生成富有情感的对话 1. 技术亮点与核心价值 Pixel Mind Decoder为游戏开发带来了一项突破性能力——让NPC对话不再机械重复。传统游戏中的NPC对话往往基于预设脚本,玩家很快就能摸清套路。而这项技术通过实时…...

Dify + Celery + Webhook深度集成:构建高可靠异步管道的6大关键配置点
第一章:Dify自定义节点异步处理的核心架构演进Dify 自 v0.6.10 起将自定义节点(Custom Node)的执行模型从同步阻塞式全面转向基于事件驱动的异步处理架构,其核心目标是解耦节点执行与工作流调度,提升高并发场景下的资源…...