MySQL之InnoDB引擎
MySQL之InnoDB引擎
- 简介
- 逻辑存储结构
- InnoDB架构
- 内存架构
- 缓冲池
- LRU List、Free List和Flush List
- 更改缓冲区(在5.x版本之前叫做插入缓冲区)
- 自适应hash
- 日志缓冲区
- 磁盘架构
- System Tablespace
- File Per Table Tabspace
- General Tablespce
- Undo Tablespace
- Temp Tablespace
- Doublewrite Buffer Files
- Redo Log
- 后台线程
- Master Thread
- IO Thread
- Purge Thread
- Page Cleaner Thread
- 事务原理
- 特性
- 持久性(redo log来保证)
- 原子性(undo log来保证)
- 隔离性(MVCC和锁)
- 前置概念
- 当前读
- 快照读
- MVCC
- 隐藏字段
- undo日志
- undo日志版本链
- readview
- Checkpoint技术
- 思考
简介
- InnoDB通过使用多版本并发控制(MVCC)来获得更高的并发性,并实现了SQL标准的四种隔离级别。
- 设计主要目标是面向在线事务处理(OLTP)
- 使用next-key-locking策略来避免幻读。
- 提供插入缓冲(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead)、刷新邻接页(Flush Neighbor Page)等高性能高可用的功能。
- 如果没有显式定义主键,引擎会生成一个6字节的row-id作为主键。
- InnoDB存储引擎是多线程模型,后台有多个不同的线程,负责处理不同的任务。
- 大量使用AIO来处理IO请求,这样可以极大提高数据库的性能。
- InnoDB是通过LSN(Log Seqence Number)来标记版本的。LSN是8个字节的数字。每个页、重做日志、Checkpoint都有LSN。
逻辑存储结构
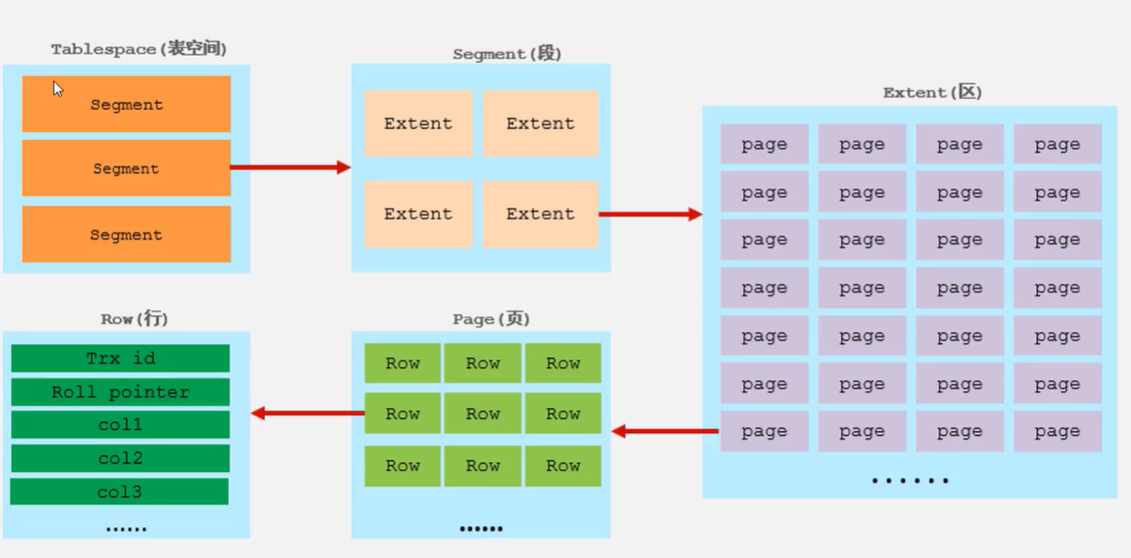
表空间(Tablespace)->段(Segment)->区(Extent)->页(Page)->(Row)行
-
表空间(ibd文件),一个mysql实例可以对应多个表空间,用于存储记录、索引等数据。
-
段,分为数据段(Leaf node segment)和索引段(Non-leaf node segment)、回滚段(Rollback segment),InnoDB是索引组织表,数据段就是B+数的叶子节点,索引段就是B+树的非叶子节点。段用来管理多个区。
-
区,表空间的单元结构,每个区的大小为1M,默认情况下,InnoDB存储引擎页大小为16KB,即一个区中共有64个连续的页。
-
页,InnoDB存储引擎磁盘管理的最小单元,每个页的大小默认为16KB。为了保证页的连续性,InnoDB存储引擎每次空磁盘申请4-5个区。
-
行,InnoDB存储引擎数据是按行进行存放的。Trx_id:每次对莫条记录进行改动时,都会把对应的事务id赋值给trx_id隐藏列。Roll_pointer:每次对某条引记录进行改动时,都会把旧的版本写入到undo日志中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
InnoDB架构
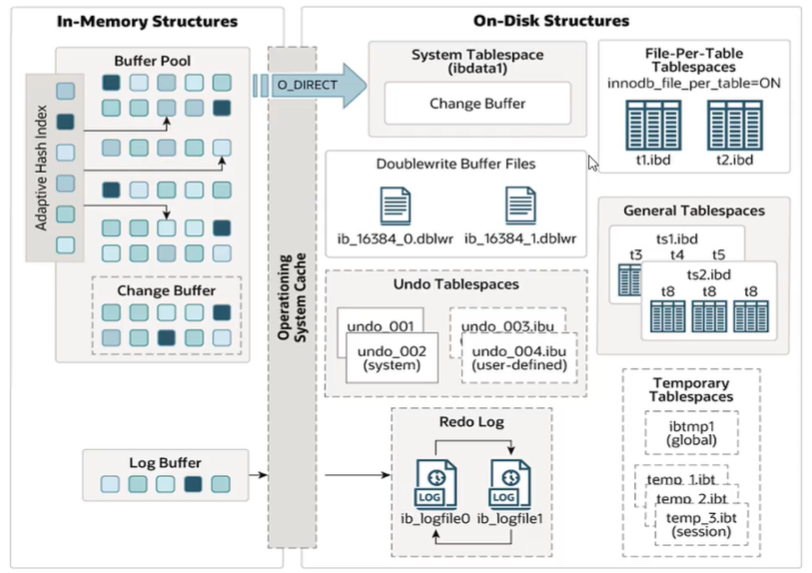
内存架构
缓冲池
- InnoDB的记录按照页的方式进行管理,底层采用链表的数据结构进行管理。缓冲池就是一块内存区域,用来弥补磁盘速度慢对数据库性能的影响。
- 数据库读页操作时,先将磁盘读到的页放入缓冲池(将页FIX到缓冲池),下次在读取就走内存,内存没有就走磁盘。
- 对于页的修改,首先在缓冲池修改,然后再以一定的频率刷新到磁盘(不是每次页更新都会发生),而是通过一种Checkpoint的机制刷新回磁盘。减少磁盘IO,加快处理速度。
- 缓冲池的数据页类型有如下几种,索引页和数据页占的最多:
- 索引页
- 数据页
- undo页
- 插入缓冲
- 自适应哈希索引
- InnoDB存储的锁信息(lock info)
- 数据字典信息(data dictionary)
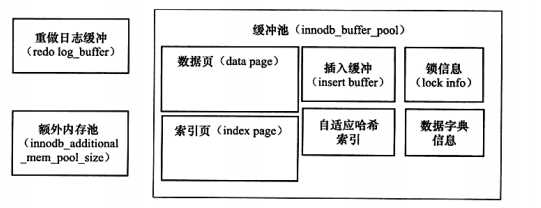
缓冲池以Page为单位,底层采用链表结构管理Page。根据状态可以将页分为三类:
- free page:空闲page,未被使用
- clean page:被使用未被修改
- dirty page:被使用且数据被修改过,数据与磁盘数据不一致
LRU List、Free List和Flush List
缓冲池是通过LRU算法进行进行管理的,页的大小默认为16KB。LRU列表用来管理已经读取的页,数据库刚启动是LRU列表是空的,这时的页都在Free列表里。
InnoDB 1.0.x之后支持压缩页的功能,将原本16KB的页压缩为1KB、2KB、4KB和8KB,非16KB的页通过unzip_LRU列表进行管理。
在LRU列表中的页被修改后,该页被称为脏页(dirty page),这个时候数据库会通过checkpoint机制刷脏,而Flush列表即为脏页列表。脏页同时存在于LRU列表和Flush列表,LRU用来管理缓冲池的可用性,Flush用来管理刷脏,二者互不影响。
更改缓冲区(在5.x版本之前叫做插入缓冲区)
针对于非唯一二级索引,在5.x版本之前叫做插入缓冲区,8版本之后叫做更改缓冲区。在执行DML语句时,如果这些数据Page没有在Buffer Pool中,不会直接修改磁盘,而是将数据变更保存在更改缓冲区里面。等待以后数据被读取时,再将数据合并到Buffer Pool中,然后再刷新到磁盘。
Change Buffer的意义:
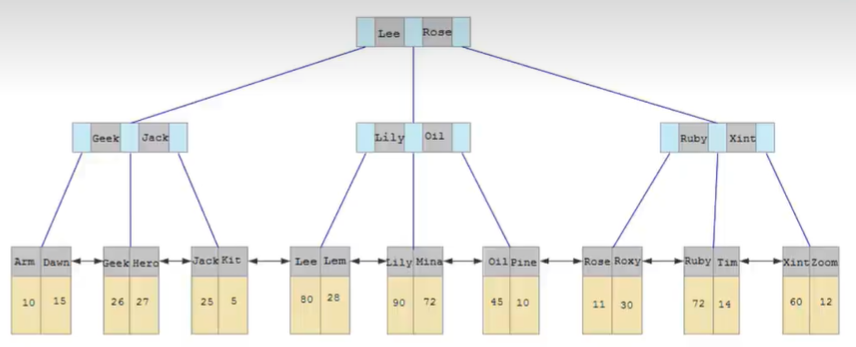
和聚簇索引不同,二级索引通常是不唯一的,并且插入和删除的顺序是随机的,可能会影响索引树中不相邻的二级索引页,要是每次都操作磁盘就会造成大量的磁盘IO。所以我们把操作合并在Change Bufer里面,减少磁盘IO。
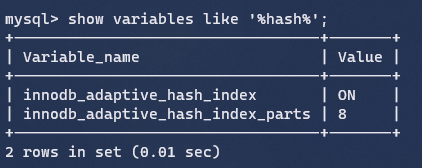
自适应hash
自适应hash索引用于单条数据的查询优化,InnoDB会监控对表上索引页的查询,如果观察到可以用hash索引提升速度,那么就会自己建立hash索引,不需要人工干预,默认是开启的。
日志缓冲区
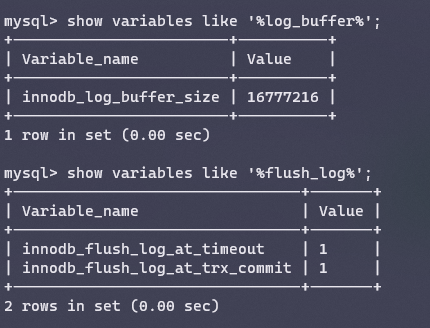
用来缓存日志(redo log、undo log),默认大小16M,日志缓冲区会定期刷新到磁盘,达到节省磁盘IO的目的。如果需要更新、插入、删除许多行的事务,可以增大该缓冲区节省磁盘IO。
innodb_log_buffer_size:缓冲区大小
innodb_flush_log_at_trx_commit:日志刷盘的时机,0表示每秒写入并刷盘,1表示每次事务提交时写入并刷盘,2表示每次事务提交后写入,并每秒刷盘。
InnoDB首先将重做日志放入这个缓冲区,然后按照一定的频率刷新到重做日志文件,该缓冲区不用设置很大,一般每一秒钟都会刷新日志文件,用户只需要保证每秒钟产生的事务量在这个大小之内即可。
下列三种情况会刷新重做日志:
- Master Thread每秒钟刷新重做日志
- 每个事务提交时
- 重做日志剩余空间小于一半时
磁盘架构
System Tablespace
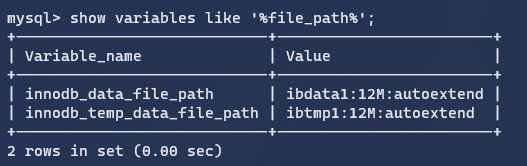
系统表空间是用来保存修改缓冲区的。如果表不是在每个独立表空间或者通用表空间中创建,它也会包含表和索引数据。(在MySQL5.x版本中还包含InnoDB数据字典、undolog等)。
参数:
innodb_data_file_path:系统表空间的存储路径
File Per Table Tabspace
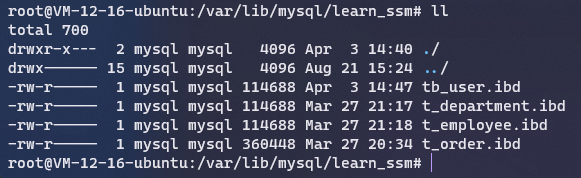
每个表的独立表空间,包含单个表的数据和索引,存储在文件系统上的单个数据文件中,默认是开启的。开启后每个数据库都会有一个独立的文件夹(如下图,是三个不同数据库的文件夹):

每个表都会有一个独立的ibd文件(下图是learn_ssm数据库的表文件):
参数:innodb_file_per_table
General Tablespce
通用表空间,需要自己手动创建,后续建表可以指定使用该表空间,一般很少用。
创建表空间语法:
CREATE TABLESPACE 表空间名称 ADD DATAFILE '表文件名' ENGINE = 'innodb';
指定表空间语法:
CREATE TABLE (xxx) ENGINE=innodb TABLESPACE 表空间名称
创建测试表空间:

创建成功之后,在mysql目录下可以找到test.ibd文件:

Undo Tablespace
撤销表空间,MySQL实例在初始化时会自动创建两个默认的undo表空间(初始大小16M),用于存储undo log日志。
在MySQL目录下可以找到这两个文件:

Temp Tablespace
主要用来存储用户创建的一些临时表。
Doublewrite Buffer Files
双写缓冲区,InnoDB引擎在刷脏前,会先将页写入到双写缓冲区文件里面,便于系统异常时恢复数据。
可以在MySQL目录下找到两个双写缓冲区文件:

Redo Log
重做日志,用来实现事务的持久性,由重做日志缓冲(在内存)和重做日志文件(在磁盘)两部分组成。当事务提交之后,会把所有的修改信息都存到该日志中,用于在刷脏发生错误时,进行数据恢复。RedoLog是循环写入的,不会永久保存。
后台线程
Master Thread
这是一个非常核心的线程,主要负责调度其他线程,将缓冲池的数据异步刷新到磁盘,保证数据一致性,包括刷脏、合并插入缓冲、UNDO页的回收等。
IO Thread
该线程主要负责AIO请求的回调处理。
| 线程类型 | 默认个数 | 职责 |
|---|---|---|
| Read thread | 4 | 负责读操作 |
| Write thread | 4 | 负责写操作 |
| Log thread | 1 | 将日志刷新到磁盘 |
| Insert buffer thread | 1 | 将写缓冲区内容刷新到磁盘 |
Purge Thread
用来回收已经使用并分配的undo页,从InnoDB1.1开始,purge操作可以独立到单独的线程来减轻Master Thread的工作。用户可以在配置文件添加如下命令来启动独立的purge线程:
[mysqld]
innodb_purge_thread=1
Page Cleaner Thread
该线程是1.2.x版本引入的,单独用来做脏页刷新,减轻 Master Thread 的工作,减少阻塞。
事务原理
事务时一组操作的集合,不可分割的工作单位,事务的四大特性:ACID
特性
- 原子性(A):不可分割,要么全部成功,要么全部失败
- 一致性(C):事务完成,所有数据都保持一致
- 隔离性(I):根据隔离机制,保证事务不受外部并发操作下独立运行
- 持久性(D):一旦提交或者回滚,它对数据库的改变就是永久的
ACD是由redo log和undo log来保证的,I是由锁机制和MVCC来保证的。
持久性(redo log来保证)
持久性是有redo log来保证的。当缓冲区数据更改时,会把修改的数据保存到redo log buffer中,在事务提交的时候,会把redo log buffer刷到redo log文件里。
如果后面在刷脏的时候出错了,就可以通过redo log来恢复,因为redo log记录了当次数据的变化。
如果刷脏成功,那么redo log里的记录就没有意义了,所以每隔一段时间就会去清理redo log日志。
为什么每次事务提交都把redo log刷新到磁盘,而不是直接刷新数据?
可以直接刷新数据,但是存在严重的性能问题。因为一个事务通常会操作很多条记录,而这些记录所在的数据页都是随机的,会造成大量的随机磁盘IO。但是我们刷日志文件的话,日志文件都是顺序追加的,所以速度很快。
如果日志刷盘的时候失败了怎么办?
原子性(undo log来保证)
回滚日志,用来记录数据被修改前的信息,作用包含两个:提供回滚的MVCC,在多版本并发控制的时候,可以依据undo log来找到记录的历史版本。
redo log记录的是物理记录,即记录真实的数据,而undo log是逻辑记录,记录的是每一步的反向操作,可以认为执行delete的时候,undo log会有一条相反的insert操作,执行update操作的时候,会有一条相反的update操作。当事务回滚时,就会执行对应的反向操作,恢复成之前的数据,这样就会保证事务的原子性。
undo log销毁:一旦事务提交或者回滚,那么这份undo log也就不需要了,但是它不会立即去删除,还会去检查MVCC会不会用到该日志。
undo log存储:采用段的方式进行管理和存储,存放在rollback segment回滚段中,里面包含1024个undo log segment。
隔离性(MVCC和锁)
前置概念
当前读
读取的是记录的最新版本,读取的时候保证其他并发事务不能修改当前记录,所以会对记录进行枷锁。如:
SELECT ... LOCK IN SHARE MODE # 共享锁
SELECT ... FOR UPDATE、 INSERT、 DELETE # 排他锁
这些锁都是一种当前读。
下面演示一下当前读:
首先我们打开两个MySQL连接,选择了learn_ssm数据库,展示了tb_user表的数据
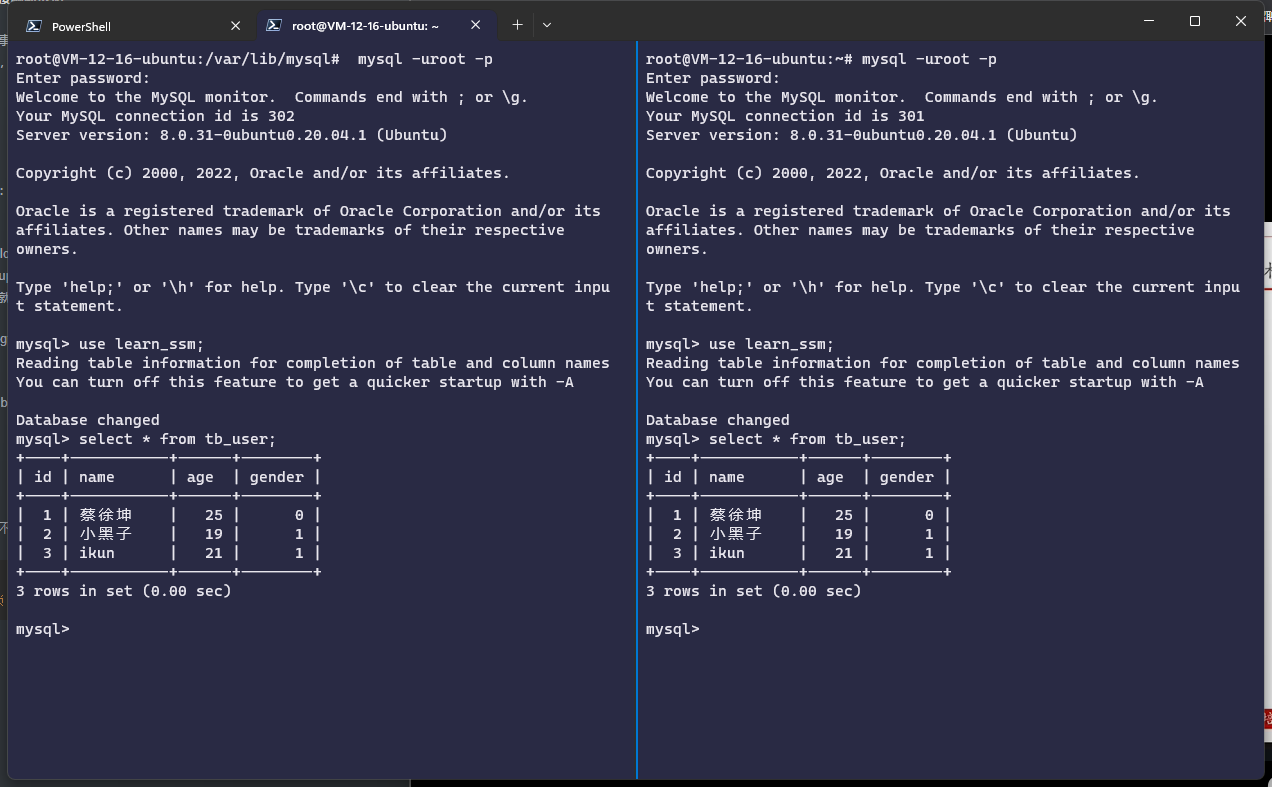
然后我们使用begin分别开启两个事务

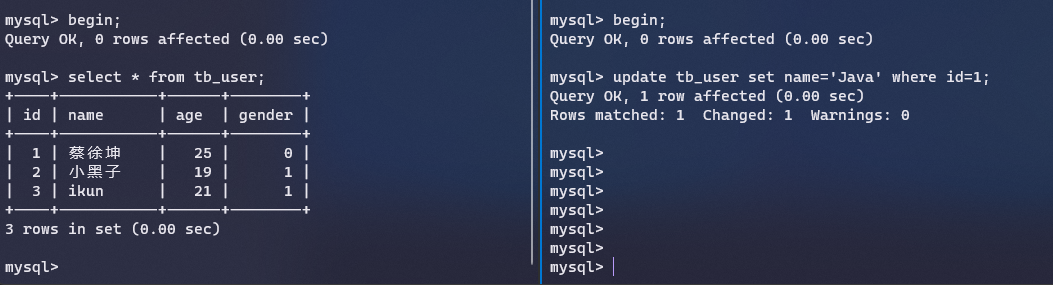
在第二个连接里面修改一条记录,这个时候事务还没有提交,我们在第一个连接里面查看,发现读取不到修改
当我们提交事务之后,发现第一个连接还是读取不到修改
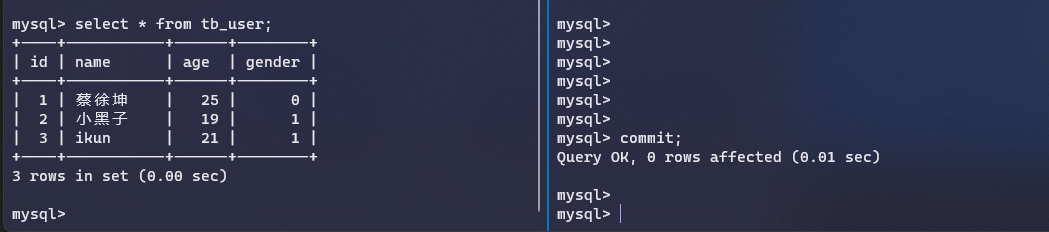
这是因为InnoDB默认的隔离级别是可重复读,所以不会感知到其他事务的修改,这个时候我们在第一个连接里面加上当前读的锁,就可以得到最新的数据
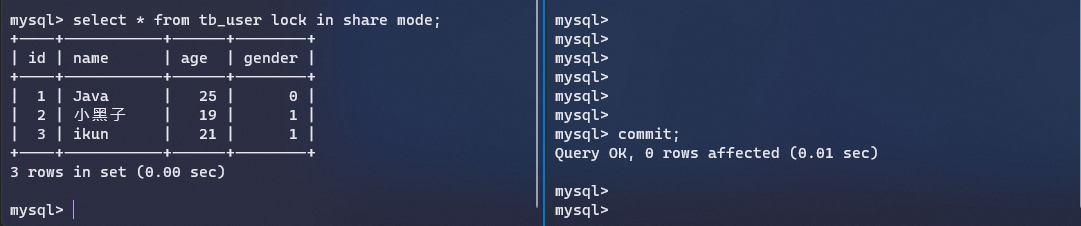
这个就是当前读的作用,用来获取记录的最新版本。
快照读
简单的不加锁的select语句就是快照读,读取的是记录数据的可见版本,有可能是历史数据,不加锁所以它是非阻塞的。
- Read Committed:每一次select都会产生一个快照读
- Repeatable Read:开启事务后第一个select语句才是快照读,后面读的都是前面产生的快照
- Serializable:快照读会退化成当前读,每一次读都会加锁
MVCC
全称 Multi-Version-Concurrency-Control,多版本并发控制。维护一个数据的多个版本,使得读写操作没有冲突,快照读给MVCC提供了非阻塞读功能。当我们在快照读的时候,就要通过MVCC来获取记录的历史版本。MVCC的实现还依赖于数据记录里的三个隐藏字段、undo日志和readView。
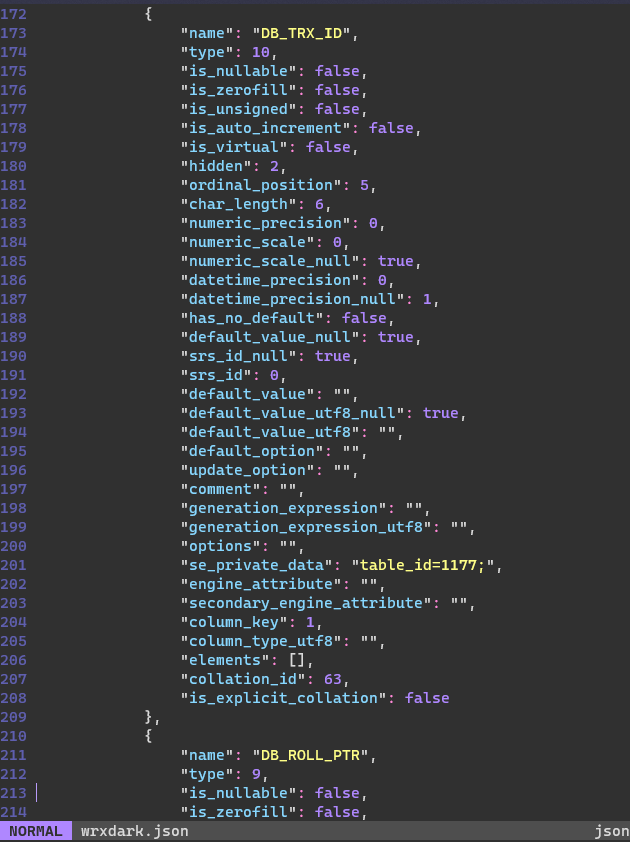
隐藏字段
| 隐藏字段 | 作用 |
|---|---|
| DB_TRX_ID | 最近一次修改或插入该记录的事务的ID |
| DB_ROLL_PTR | 回滚指针,指向这条记录的上一个版本,配合undo日志一起使用 |
| DB_ROW_ID | 隐藏主键,如果这张表没有人为设置主键,那么就会生成这个字段作为记录的主键 |
我们可以使用ibd2sdi命令查看ibd文件信息,在这里我们可以看到这些隐藏字段:
首先进入数据库目录,然后输入 ibd2sdi tb_user.ibd 查看文件信息
在columns下面我们可以找到最近事务ID和回滚指针:
undo日志
当insert的时候,产生的undo日志只在回滚时需要,所以在事务提交后,可以被立即删除。
而update、delete的时候,产生的undo日志在回滚和快照读的时候都需要,不会被立即删除。
undo日志版本链
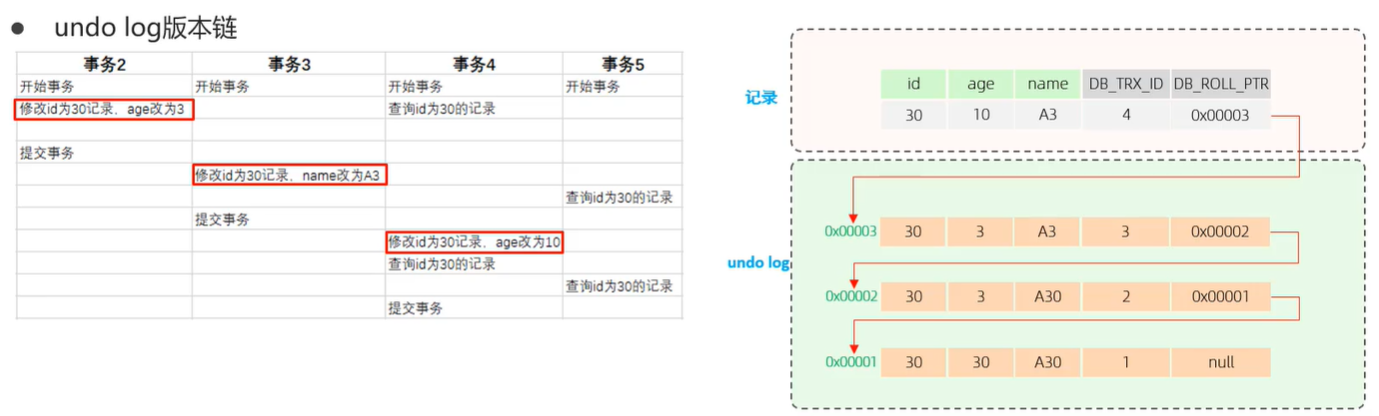
在记录未被修改之前,回滚指针指向null。当我们在事务2里面对记录进行修改,InnnoDB会在undo日志里面保存修改之前的版本,然后用在记录的新版本里面,用回滚指针指向老版本记录的地址,事务id为修改记录的事务的id。
后面的事务3和4的修改也是同样的操作,这样一来我们就得到了一条链表,链表头节点为记录的最新版本,链表尾节点为记录的最老版本,我们可以通过这样一条链表进行记录的回滚操作。
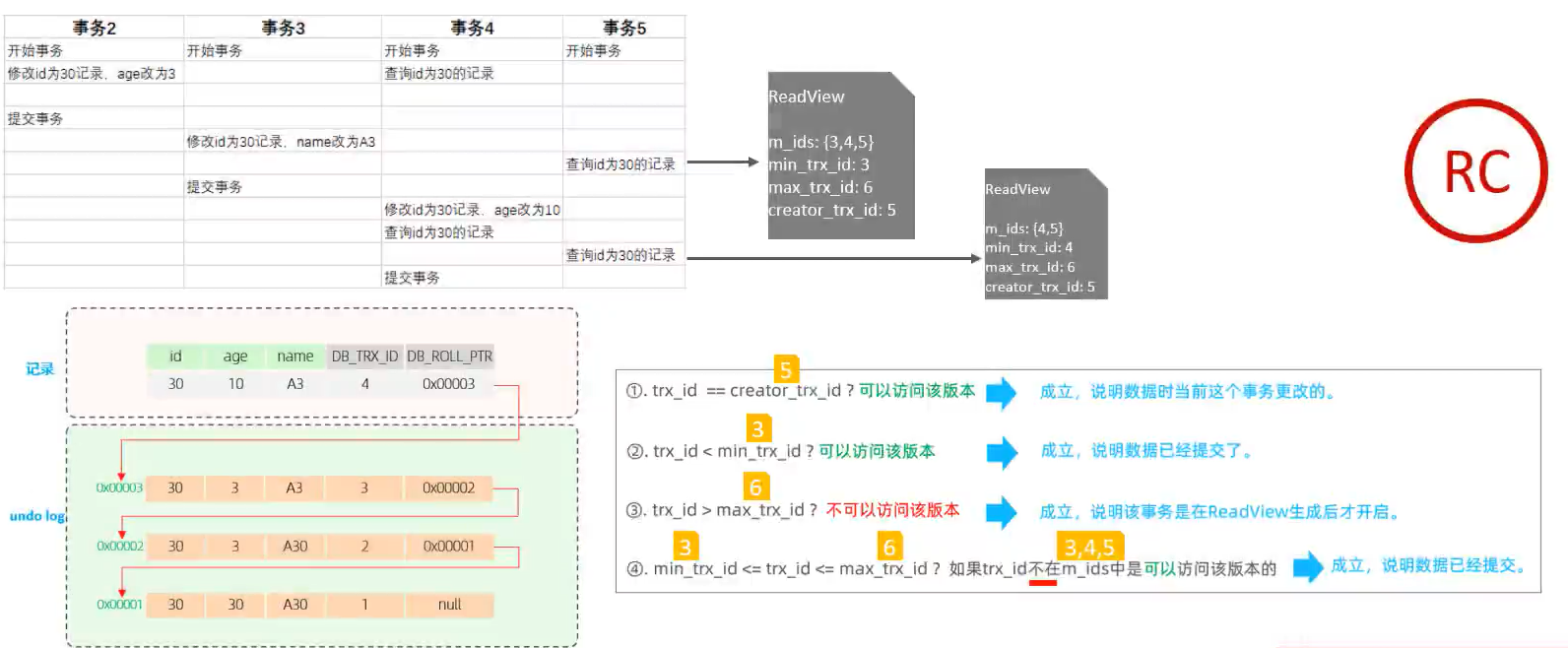
readview
读视图是快照读的时候,MVCC提取数据的依据,记录和维护当前未提交的事务id,包含如下字段:
| 字段 | 含义 |
|---|---|
| m_ids | 未提交事务id集合 |
| min_trx_id | 最小未提交事务id |
| max_trx_id | 预分配事务id,最大未提交事务id+1(因为事务id是自增的) |
| creator_trx_id | readview创建者的事务id,也就是当前查询事务的id |
快照读是使用记录的事务id字段去读取的,具体读取规则如下:
-
当前记录的事务id等于creator_trx_id,也就是说这条记录是我们自己修改的,那么就可以读取。
-
否则,我们就找不超过max_rtx_id且已经提交了的事务(也就是小于min_trx_id的事务,和在min和max之间但是不在m_ids内的事务),就是我们要找的那条记录。
-
如果上述条件都不符合,那么我们就根据undo版本链表回滚记录,直到找到一个符合条件的记录。
因为是在undo日志版本链的记录是从新到旧的,所以我们找到的一定是提交的事务里,最新的那条记录。
不同隔离级别,生成readview的时机:
READ COMMITTED:每次查询都会生成,所以该隔离级别的每次查询都是快照读。
REPEATABLE READ:只在第一次查询的时候生成,后面的查询都是复用第一次,也是因为这个原因,保证了重复读。
下图是在 READ COMMITTED 隔离级别下的情况:
Checkpoint技术
如果在刷脏的时候宕机,那么数据就不能恢复了,为了避免这个问题,当前事务数据库都采用了Write Ahead Log 策略,即当事务提交时先写重做日志,再修改页,宕机之后就可以通过重做日志来恢复。
Checkpoint目的是解决以下几个问题:
- 缩短数据库恢复时间
- 缓存池不够用时,开始刷脏
- 重做日志不可用时,开始刷脏
当数据库宕机时,不需要重做所有日志,因为Checkpoint之前的页已经刷回了磁盘,只需要对Checkpoint之后的重做日志进行恢复,大大缩短了恢复时间。
当LRU算法淘汰的页是脏页时,需要强制执行Checkpoint刷脏。
重做日志的设计是循环使用的,被重用都是不需要的部分,因此可以覆盖使用,若此时重做日志还需要使用,就必须强行产生Checkpoint刷脏。
InnoDB有两种Checkpoint:
- Sharp Checkpoint:将所有脏页刷回磁盘,发生在数据库关闭时。
- Fuzzy Checkpoint:只刷新部分脏页而不是所有,发生在数据库运行时。
Fuzzy Checkpoint发生的几种情况:
- Master Thread
- FLUSH_LRU_LIST Checkpoint:保证LRU列表有100个空闲页,没有就从尾部移除,要是有脏页就进行Chekpoint。
- Async/Sync Flush Checkpoint:重做日志不可用的情况,为了保证重做日志循环使用的可用性。
- Dirty Page too much Checkpoint:脏页太多,当脏页数量占据75%时强制进行Checkpoint,刷新一部分脏页到磁盘。
思考
在可重复读的隔离级别下,分别开启两个事务A和B。在B事务里面插入一条记录的时候,A事务开启共享锁再去查询的时候,发现卡死了,直到B事务提交,A事务才继续执行,在B事务里面修改记录也一样会卡死。为什么A事务会卡死?
因为在事务修改的时候,会给对应的记录加上行锁,只有在事务提交之后才会释放锁。所以A事务去读取时,因为有锁,所以就一直卡在那了,直到事务B提交释放锁,事务A才能够上锁,进而读取数据。
在串行化隔离级别下,事务B插入一条主id=13的数据,然后事务A去查询id=13的数据,发现卡住了。然后如果这种情况发生在可重复度的隔离级别下,事务A不会卡住,会返回空记录,但是如果事务A开启共享锁去查的话,事务A也会卡住。为什么会发生这种情况?
相关文章:
MySQL之InnoDB引擎
MySQL之InnoDB引擎 简介逻辑存储结构InnoDB架构内存架构缓冲池LRU List、Free List和Flush List更改缓冲区(在5.x版本之前叫做插入缓冲区)自适应hash日志缓冲区 磁盘架构System TablespaceFile Per Table TabspaceGeneral TablespceUndo TablespaceTemp …...

API自动化管理: 从繁琐到轻松
在数字化时代,API(应用程序编程接口)在软件开发中扮演着至关重要的角色。然而,API管理可能会变得十分繁琐,耗费大量时间和资源。那么,如何实现API自动化管理,从而节省时间、提高效率,…...
Databend 开源周报第 107 期
Databend 是一款现代云数仓。专为弹性和高效设计,为您的大规模分析需求保驾护航。自由且开源。即刻体验云服务:https://app.databend.cn 。 Whats On In Databend 探索 Databend 本周新进展,遇到更贴近你心意的 Databend 。 理解连接参数 …...

计算机网络参考模型
目录 编辑 简介 1.分层模型 1.1 分层的思想 1.2 OSI参考模型与TCP/IP协议簇 1.OSI 参考模型 2.TCP/IP 参考模型 简介 本章大家将学习网络参考模型的概念,对干参考模型的讲解将会贯穿网络课程的始终,因为它是理解网络这个全新世界的关键所在&…...
【React基础全篇】
文章目录 一、关于 React二、脚手架2.1 create-react-app 脚手架的使用2.2 项目目录解析2.3 抽离配置文件2.4 webpack 二次封装2.4.1 集成 css 预处理器2.4.2 配置解析别名 2.5 setupProxy 代理 三、JSX3.1 jsx 语法详解3.2 React.createElement 四、组件定义4.1 类组件4.2 函数…...

如何使用 Vue.js 侦听嵌套数据?
new Vue({el: "#app",data: {target: {list: [],},},watch: {"target.list": {handler(newVal, oldVal) {},deep: true,},} }); 给target的list属性增加侦听器,需要在watch中使用字符串的写法 "target.list" 来标记侦听的内容 han…...

Spring AOP详解
Spring AOP是Spring框架中的一个模块,它允许开发人员使用面向切面编程(AOP)的思想来解耦系统的不同层次。 Spring AOP的核心概念是切面(aspect)、连接点(join point)、通知(advice)、切点(pointcut)和引入(introduction)。 切面(aspect):切面是一个类, 它…...
linux iptables安全技术与防火墙
linux iptables安全技术与防火墙 1、iptables防火墙基本介绍1.1netfilter/iptables关系1.2iptables防火墙默认规则表、链结构 2、iptables的四表五链2.1四表2.2五链2.3四表五链总结2.3.1 规则链之间的匹配顺序2.3.2 规则链内的匹配顺序 3、iptables的配置3.1iptables的安装3.2i…...
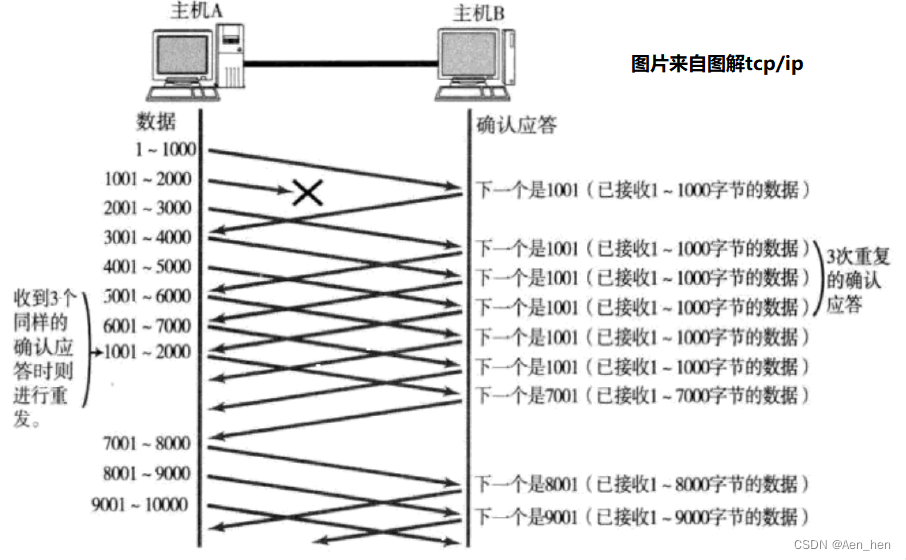
TCP性能机制
延迟应答 为什么有延迟应答 发送方如果长时间没有收到ACK应答,则会触发超时重传机制,重新发送数据包。但如果接收数据的主机立刻返回ACK应答, 这时候返回的窗口可能比较小,发送方一次只能发少量数据,效率较低。 举个例子理解一…...

qt信号槽同步问题
目录 信号槽: 注意事项: 具体例子: 线程安全问题的例子: 信号槽: 在Qt编程中,信号(Signal)和槽(Slot)是一种用于在对象之间进行通信的机制。信号用于发出…...
七夕特惠-8折抢购,从速
在七夕这个特殊的日子,我们推出了8折优惠活动,具体如下: 不管是充值会员,还是购买套路文章,一律享受8折优惠,活动截止时间为2023年8月24日12时。 甚至还有免费抽奖活动 兑奖方式,复制兑奖码…...
[NLP]LLM--transformer模型的参数量
1. 前言 最近,OpenAI推出的ChatGPT展现出了卓越的性能,引发了大规模语言模型(Large Language Model, LLM)的研究热潮。大规模语言模型的“大”体现在两个方面:模型参数规模大,训练数据规模大。以GPT3为例,GPT3的参数量…...

5 Python的面向对象编程
概述 在上一节,我们介绍了Python的函数,包括:函数的定义、函数的调用、参数的传递、lambda函数等内容。在本节中,我们将介绍Python的面向对象编程。面向对象编程(Object-Oriented Programming, 即OOP)是一种…...

卷积神经网络——上篇【深度学习】【PyTorch】【d2l】
文章目录 5、卷积神经网络5.1、卷积5.1.1、理论部分5.1.2、代码实现5.1.3、边缘检测 5.2、填充和步幅5.2.1、理论部分5.2.2、代码实现 5.3、多输入多输出通道5.3.1、理论部分5.3.2、代码实现 5.4、池化层 | 汇聚层5.4.1、理论部分5.4.2、代码实现 5、卷积神经网络 5.1、卷积 …...

【从零学习python 】54. 内存中写入数据
文章目录 内存中写入数据StringIOBytesIO进阶案例 内存中写入数据 除了将数据写入到一个文件以外,我们还可以使用代码,将数据暂时写入到内存里,可以理解为数据缓冲区。Python中提供了StringIO和BytesIO这两个类将字符串数据和二进制数据写入…...
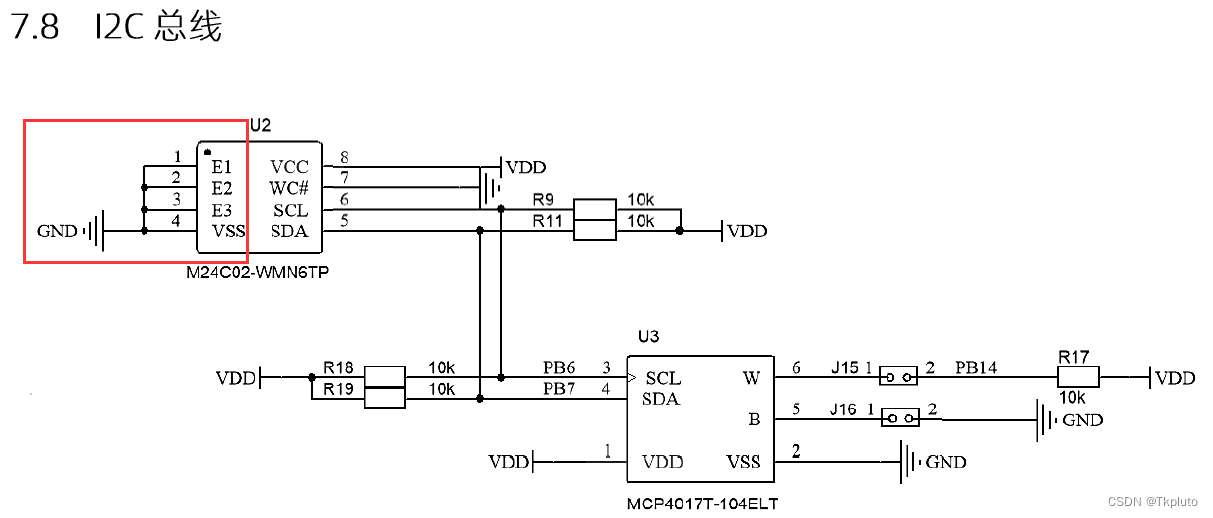
速通蓝桥杯嵌入式省一教程:(九)AT24C02芯片(E2PROM存储器)读写操作与I2C协议
AT24C02芯片(又叫E2PROM存储器、EEPROM存储器),是一种通过I2C(IIC)协议通信的掉电保存存储器芯片,其内部含有256个8位字节。在介绍这款芯片之前,我们先来粗略了解一下I2C协议。 I2C总线是一种双向二线制的同步串行总线…...

负载均衡:优化性能与可靠性的关键
在现代互联网时代,数以万计的用户访问着各种在线服务,从即时通讯、社交媒体到电子商务和媒体流媒体,无不需要应对海量的请求和数据传输。在这个高并发的环境下,负载均衡成为了关键的技术,它旨在分散工作负载࿰…...

T113-S3-TCA6424-gpio扩展芯片调试
目录 前言 一、TCA6424介绍 二、原理图连接 三、设备树配置 四、内核配置 五、gpio操作 总结 前言 TCA6424是一款常用的GPIO(通用输入输出)扩展芯片,可以扩展微控制器的IO口数量。在T113-S3平台上,使用TCA6424作为GPIO扩展芯…...

奥威BI数据可视化工具:个性化定制,打造独特大屏
每个人都有自己独特的审美,因此即使是做可视化大屏,也有很多人希望做出不一样的报表,用以缓解审美疲劳的同时提高报表浏览效率。因此这也催生出了数据可视化工具的个性化可视化大屏制作需求。 奥威BI数据可视化工具:个性化定制&a…...

13 秒插入 30 万条数据,批量插入!
数据库表 CREATE TABLE t_user (id int(11) NOT NULL AUTO_INCREMENT COMMENT 用户id,username varchar(64) DEFAULT NULL COMMENT 用户名称,age int(4) DEFAULT NULL COMMENT 年龄,PRIMARY KEY (id) ) ENGINEInnoDB DEFAULT CHARSETutf8 COMMENT用户信息表; User实体 /*** …...

YOLOv8改进:引入ECA高效通道注意力机制,轻量级涨点神器!
摘要 在目标检测领域,注意力机制已成为提升模型性能的关键技术之一。然而,传统的通道注意力机制(如SENet)虽然有效,但引入了大量的额外参数和计算量,导致模型复杂度增加。本文详细介绍了一种轻量高效的通道注意力机制——ECA(Efficient Channel Attention),并手把手教…...

膨胀处理相当于给障碍物穿羽绒服
基于改进混合a星算法的自动泊车路径规划,其中包括环境地图建模,路径规划及优化。。深夜两点,调试完最后一段路径优化代码,显示屏上的虚拟小车终于丝滑地倒进狭小车位。这个瞬间让我想起驾校教练常说的"打死方向盘,…...

GM1602lib:面向CO传感器的轻量级模拟驱动设计
1. GM1602lib 库概述:面向 Honeywell GM1602-CO 气体传感器的嵌入式驱动设计GM1602lib 是一个专为 Honeywell GM1602-CO 一氧化碳(CO)气体传感器设计的 Arduino 兼容驱动库。该库并非基于数字通信协议(如 IC 或 SPI)&a…...

使用STM32G431芯片编写的可移植性强的基于PLL锁相环的程序和MATLAB仿真文件,包含...
PLL锁相环程序MATLAB仿真文件。 (SOGIDQ)程序用stm32G431芯片写的(hall库),可移植性强。锁相环这玩意儿在电力电子里算是基本功了,最近在STM32G431上折腾了个基于SOGIDQ结构的数字锁相方案。核心算法总共就两个.c文件,配合MATLAB仿真验证过电…...

高通平台Android Display调试指南:常见问题与解决方案汇总
高通平台Android Display调试实战:从硬件兼容到框架优化的全链路解决方案 在移动设备开发领域,Display模块的稳定性直接影响用户体验,而高通平台作为Android生态的核心硬件基础,其显示系统的调试复杂度往往令开发者望而生畏。本文…...
)
Linux系统管理员必看:logrotate权限问题终极解决方案(附su指令详解)
Linux系统管理员必看:logrotate权限问题终极解决方案(附su指令详解) 在Linux系统运维的日常工作中,日志管理是每个管理员都无法回避的重要任务。而logrotate作为系统自带的日志轮转工具,其稳定性和可靠性直接关系到系统…...

哈工大机器学习实战解析:从SVM到核方法
1. 从线性可分到最大间隔:SVM的核心思想 第一次听说支持向量机(SVM)时,我完全被那些数学符号吓退了。直到在哈工大实验室里亲手用Python实现了一个分类器,才真正理解它的精妙之处。想象你在玩一个拼图游戏,…...

避坑指南:银河麒麟系统安装PostgreSQL时readline-devel报错解决方案
银河麒麟系统PostgreSQL安装全攻略:从依赖报错到高效运维 在国产操作系统生态快速发展的今天,银河麒麟作为主流国产操作系统之一,其稳定性和安全性得到了广泛认可。然而,当我们在银河麒麟系统上部署PostgreSQL这类开源数据库时&am…...

Vue3实战:高德地图离线化部署全攻略——从瓦片下载到内网集成
1. 为什么需要高德地图离线化部署? 最近在做一个政府单位的内部GIS系统项目时,遇到了一个棘手的问题:他们的办公环境是完全隔离的内网,但业务又必须使用地图功能。这让我不得不深入研究高德地图的离线化部署方案,今天就…...

CityJSON 城市数据解析与应用实战指南
1. CityJSON入门:3D城市模型的JSON编码 CityJSON是一种基于JSON的3D城市模型编码格式,专门用于存储数字孪生城市数据。我第一次接触这个格式是在处理阿姆斯特丹城市模型项目时,当时我们需要一个既能保留丰富语义信息又便于开发者使用的数据格…...