8.22笔记
8.22笔记
- 8.22笔记
- 一、Hive的HQL语法重点问题
- 1.1 DDL
- 1.1.1 Hive中数据表的分类问题
- 1.1.2 特殊的数据类型
- 1.2 DML
- 1.3 DQL
- 1.3.1 查询语法和MySQL大部分都是一致的
- 1.4 讲了三个数据库的可视化工具
- 1.4.1 navicat
- 1.4.2 dbeaver
- 1.4.3 chat2db
- 二、Hive中重点问题:Hive函数的使用
- 2.1 函数分为两种
- 2.1.1 内置函数
- 2.2 用户自定义函数
- 2.2.1 Hive自定义函数的步骤
- 2.2.2 自定义UDF函数
- 2.2.3 自定义UDTF函数
- 2.2.4 删除自定义函数
- 三、相关代码
8.22笔记
一、Hive的HQL语法重点问题
1.1 DDL
1.1.1 Hive中数据表的分类问题
Hive中数据表的分类只是用来告诉我们Hive底层在HDFS上存储的文件的规则和规范
1.1.2 特殊的数据类型
array、map、struct
Hive数据表可以指定底层的存储格式的分隔符问题row format
1.2 DML
Hive中默认不支持批量的删除和更新操作
- 增加数据
- 装载数据
- 追加和覆盖
- 删除数据(只能删除所有数据或者某个分区的数据)–truncate
- 数据导入和导出问题
1.3 DQL
1.3.1 查询语法和MySQL大部分都是一致的
-
排序问题
-
全局排序:DQL查询语法转换的MR底层只有一个reduce任务
order by -
局部排序:DQL查询语法转换的MR底层可以有多个reduce任务,每个reduce的输出有序,整体没有顺序
sort by如果要使用sort by进行局部排序,那么需要设置Hive底层的转换的MR程序的reduce任务数大于1
set mapreduce.job.reduces=num>1注意:如果我们只是使用了sort by进行排序,并且reduce的任务数大于1,那么mr程序计算的时候底层会对数据进行分区,分区数就是reduce的任务数,默认情况下,如果只使用了sort by,那么分区机制我们是无法控制
如果我们在局部排序的时候还想控制每个分区的数据,可以在sort by之前增加上一个distribute By 字段,Distribute By和sort by结合使用的,是用于负责控制分区规则的。分区规则是根据我们指定的分区字段的hash值和分区数取余数。
如果Distribute By和sort by的字段一样,我们可以使用cluster by替代上述两个操作
-
-
连接查询
Hive支持了全外连接full join
1.4 讲了三个数据库的可视化工具
1.4.1 navicat
界面特别好看的,收费的
一般只能连接RDBMS关系型数据库,连接底层不是基于JDBC
1.4.2 dbeaver
1.4.3 chat2db
增加了AI大模型
1.4.2~1.4.3:都是免费的,底层都是基于JDBC连接数据库
因此这两个软件不仅可以连接常见的RDBMS,还可以连接大数据环境:Hive、Spark等等
二、Hive中重点问题:Hive函数的使用
Hive中提供了很多的自带函数,自带函数有大部分都是为了统计分析设计的。Hive中的函数大部分都是一个Java类
2.1 函数分为两种
UDF:一对一函数
UDTF:一对多函数
UDAF:多对一函数
2.1.1 内置函数
- 如何查看系统自带的内置函数
show functions;
desc function 函数名;
desc function extended 函数名;
-
Hive中常见的一些内置函数的用法
-
数学函数:UDF
函数名 说明 abs(x) 返回x的绝对值 ceil(x) 向上取整,返回比x大的正整数中最小的那一个 floor(x) 向下取整 mod(a,b) a%b pow(a,b) a^b round(x,[n]) 四舍五入 如果不传递n 代表小数点不保留,如果n>=1 代表小数点后保留n位 sqrt(x) 根号x -
字符串函数
函数名 说明 concat 直接拼接,拼接需要传递多个参数,会把多个参数拼接起来,如果有一个参数为null值,那么结果直接为null concat_ws 可以拼接的分隔符,传递的第一个参数是一个分隔符,如果拼接了null值,null值不计算 lpad |rpad(str,x,pad) 在str左/右边以指定的pad字符填充字符串到指定的x长度 ltrim|rtrim|trim(str) 去除空格 length(x) 返回字符串的长度 replace(str,str1,replacestr) 将字符串中指定字符串替换成为另外一个字符串 everse(str) 字符串反转 split(str,x):array 字符串切割 substr|substring(str,n,[num]),截取字符串 -
日期
函数名 说明 current_date() 返回当前的日期 年月日 current_timestamp() 返回当前时间 date_format(date,“格式”) 格式化时间的 datediff(date,date1) 返回这两个时间的差值(天) -
条件判断函数
函数名 if case when then [when then] … else end -
特殊函数
-
和数组、集合操作有关的函数
函数内部需要传递一个数组,或者返回值是一个数组类型的函数
函数名 说明 split(str,spea):array collect_set(列名):array 将一列中的所有行的数据封装为一个数组 列转行 不允许重复 将一列中的所有行的数据封装为一个数组 列转行 允许重复 array(ele…):array map(key,value,key,value,key,value…):map concat_ws(spe,array(string)):String 将一个数组中的所有字符串以指定的分隔符拼接得到一个全新的字符串 explode(array,map集合) 多行多列的数据 炸裂函数 行转列的函数
如果传递的是array,那么结果是一列多行
如果传递的是map集合,那么结果就是两列多行collect_set(列名):array、collect_list(列名):array
列转行函数
将一列的多行数据转换成为一行数据
UTAF -
和字符串有关的特殊函数:(字符串必须得是URL)
-
URL的概念
URL是叫做统一资源定位符,是用来表示互联网或者主机上的唯一的一个资源的
URL整体上主要有如下几部分组成的:
协议:http/https、ftp、file、ssh
host:主机名、域名、ip地址
port:端口号
path:资源路径
queryParam:参数 ?key=value&key=value…例子:
http://192.168.35.101:9870/index.html?name=zs&age=20
https://www.baidu.com/search/a?key=valueURL
中,如果没有写端口号,那么都是有默认端口,http:80 https:443 ssh:22
-
parse_url(urlstr,"特殊字符"):string一次只能提取URL的一个成分 -
parse_url_tuple(urlstr,"特殊字符"...):每一个成分当作一列单独展示,函数可以将一个数据转换成为一行多列的数据函数多了一个特殊字符:QUERY:keyparse_url_tuple(urlstr,"特殊字符"...) as (列名...)2、3:
hive提供用来专门用来解析URL的函数:从URL中提取URL组成成分
特殊字符代表的是URL的组成成分,特殊字符有如下几种:
HOST:提取URL中的主机名、IP地址
PATH,:提取URL中资源路径
QUERY, 提取URL中的所有请求参数
PROTOCOL, 提起URL中的请求协议
AUTHORITY,
FILE,
USERINFO,
REF,
-
-
侧视图
- 侧视图Lateral View专门用来和UDTF函数结合使用,用来生成一个虚拟表格,然后这个虚拟表格一行数据会生成一个,虚拟表格是动态的,一行数据会生成一个虚拟表格,生成的虚拟表格和当前行做一个笛卡尔乘积,得到一些我们普通SQL无法实现的功能
- 侧视图使用场景:一个表格中,某一行的某一列是一个多字段组成的数据,我们想把多字段的列拆分开和当前行结合得到一个多行的结果。
-
开窗函数 overselect子语句中
-
开窗函数指的是在查询表数据时,将表按照指定的规则拆分成为多个虚拟窗口(并没有真实的拆分、类似于分组),然后可以在窗口中得到一些只有分组之后才能得到一些信息,然后将信息和原始数据结合起来,实现在同一个查询中既可以得到基础字段,还可以得到聚合字段。既需要普通字段还需要一些聚合信息的时候,开窗函数就是最完美的选择。
-
语法:
函数(参数) over(partition by 列名 order by 字段) as 别名-列名 -
可以和窗口函数结合使用的主要有三种类型的函数
-
first_value(col)|last_value(col) over(partition by 列名 order by 字段) as 别名-列名 -
聚合函数
sum/avg/count/max/min over(partition by 列名) as 列别名 -
排名函数
row_number()/rank()/dense_rank() over(partition by 列名 order by 字段) as 列别名排名函数的作用就是对数据开窗之后,查询到某一行数据之后,看一下这行数据在所属窗口的排名-位置,然后根据位置打上一个序号,序号从1开始
函数名 说明 row_number() 序号是从1开始依次递增,如果两行数据排名一致,也会依次编号 rank() 序号是从1开始依次递增,如果两行数据排名一致,两行编号一样的 跳排名 dense_rank() 序号是从1开始依次递增,如果两行数据排名一致,也会依次编号,不会跳排名 -
使用场景:求不同组中排名topN的数据信息
-
-
-
-
2.2 用户自定义函数
用户自定义函数就是我们觉得hive内置函数不满足我们的需求,我们可以自定义函数实现我们想要的功能
2.2.1 Hive自定义函数的步骤
(Hive底层也都是Java,自定义函数也是编写Java代码的)
-
创建一个Java项目
-
引入编程依赖
- 创建lib目录,自己找jar包放到lib目录下,然后lib目录add as library hive的安装目录的lib目录下
- 使用maven然后根据gav坐标引入依赖
-
编写对应的函数类:UDF、UDTF、UDAF
大部分自定义都是UDF和UDTF函数 -
将编写好的Java代码打成jar包
-
将jar包上传到HDFS上
-
通过create function …从jar包以全限定类名的方式创建函数
-
注意:自定义的函数创建的时候有两种创建方式
create [temporary] function function_name as “全限定类名” using jar “jar包在hdfs上的路径”- 临时函数:只对本次会话有效
只可以通过show functions查看,元数据库不会记录 - 永久函数:永久生效
无法通过show functions查看,但是可以通过Hive的元数据库的FUNS表中查看
- 临时函数:只对本次会话有效
2.2.2 自定义UDF函数
2.2.3 自定义UDTF函数
2.2.4 删除自定义函数
drop function 函数名
【注意】用户自定义函数有一个特别重要的问题,自定义函数和数据库绑定的。只能在创建函数的数据库使用函数。如果要在其他数据库下使用,需要在其他数据库下把函数重新创建一遍即可。
三、相关代码
-- 查看hive自带的所有函数
show functions;
-- 查看某个函数的用法
desc function abs;
-- 查看某个函数的详细用法
desc function extended parse_url;select sqrt(8);create table demo(name string
);
insert into demo values("zs"),("ls"),("ww");
select * from demo;
select concat_ws("-",collect_set(name)) from demo;select concat_ws("-",name) from demo;
select concat_ws("-","zs","ls",null);select rpad("zs",10,"-");select ltrim(" z s ");
select rtrim(" z s ");
select trim(" z s ");select replace("2022-10-11","-","/");
select reverse("zs");
select split("zs-ls-ww","-");select substring("zs is a good boy",9);select current_timestamp();
select date_format("2022-10-11 20:00:00","HH")
select datediff(current_date(),"2000-10-11");select if(1>2,"zs","ls");
select CASE 10when 10 then "zs"when 20 then "ls"else "ww"ENDselect CASE when 1>2 then "zs"when 1<2 then "ls"else "ww"ENDselect explode(array(1,2,3,4,5));
select map("name","zs","age","20","sex","man");
select explode(map("name","zs","age","20","sex","man"));select parse_url("http://www.baidu.com:80/search/a?name=zs&age=30","QUERY");
select parse_url_tuple("http://www.baidu.com:80/search/a?name=zs&age=30","QUERY","PATH","HOST","QUERY:sex")
as (query,path,host,sex);-- 侧视图的使用
create table test(name string,age int,hobby array<string>
);insert into test values("zs",20,array("play","study")),("ls",30,array("sleep","study"));
select * from test;select name,age,hobby,temp.hb from test
lateral view explode(hobby) temp as hb;-- 开窗函数的使用
create table student(student_name string,student_age int,student_sex string
);insert into student values("zs",20,"man"),("ls",20,"woman"),("ww",20,"man"),("ml",20,"woman"),("zsf",20,"man");select * from student;-- 查询不同性别的总人数
select student_sex,count(1) from student group by student_sex;
-- 查询表中所有的学生信息,并且每个学生信息后面需要跟上这个学生所属性别组的总人数
select student_name,student_age,student_sex,row_number() over(partition by student_sex order by student_name desc) as sex_count
from student;-- 排名函数的使用场景
create table employees(employees_id int,employees_name string,employees_dept int,employees_salary double
);insert into employees values(1,"zs",1,2000.0),(2,"ls",1,1800.0),(3,"ww",1,1700.0),(4,"ml",1,2000.0),(5,"zsf",1,1900.0),(6,"zwj",2,3000.0),(7,"qf",2,2500.0),(8,"cl",2,2500.0),(9,"jmsw",2,2000.0);select * from employees;
-- 获取每个部门薪资排名前二的员工信息
-- 部门分组 薪资降序排序 排名窗口函数 给每一行数据打上一个序号
select * from(select *,DENSE_RANK() over(partition by employees_dept order by employees_salary desc) as salary_rankfrom employees
) as b
where salary_rank <=2;
package com.sxuek.udf;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;/*** 类就是从一个字符串中找大写字符个数的函数* UDF*/
public class FindUpperCount extends GenericUDF {/*** 初始化方法,方法是用来判断函数参数的* 指定函数参数的个数以及函数参数的类型* @param objectInspectors 函数参数的类型和个数的一个数组* @return 方法的返回值代表的是函数执行完成之后的返回值类型* @throws UDFArgumentException*/@Overridepublic ObjectInspector initialize(ObjectInspector[] objectInspectors) throws UDFArgumentException {/*** 1、判断参数的类型和个数是否满足需求*///数组的长度就是函数参数的个数int length = objectInspectors.length;if (length != 1){throw new UDFArgumentException("function only need one param");}else{//ObjectInspector是一个Hive数据类型的顶尖父类 参数的类型ObjectInspector objectInspector = objectInspectors[0];//PrimitiveObjectInspectorFactory是Hive中所有基础数据类型的工厂类//返回函数的执行完成之后输出的结果类型 整数类型return PrimitiveObjectInspectorFactory.javaIntObjectInspector;}}/*** 方法就是函数实现的核心逻辑方法* @param deferredObjects 函数传递的参数* @return 返回值就是函数执行完成之后的返回结果 返回结果必须和initialize的返回值类型保持一致* @throws HiveException*/@Overridepublic Object evaluate(DeferredObject[] deferredObjects) throws HiveException {//获取函数传递的那一个参数DeferredObject deferredObject = deferredObjects[0];//get方法是获取封装的参数值Object o = deferredObject.get();String str = o.toString();int num = 0;for (char c : str.toCharArray()) {if (c >= 65 && c <= 90){num++;}}return num;}/*** HQL的解析SQL的输出----没有用处* @param strings* @return*/@Overridepublic String getDisplayString(String[] strings) {return "";}
}package com.sxuek.udtf;import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.*;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;import java.util.ArrayList;
import java.util.List;/*** 输入参数有两个:* 字符串* 分隔符* 输出结果 一列多行的结果* word* zs* ls*/
public class SplitPlus extends GenericUDTF {/*** 作用:* 1、校验输入的参数* 2、返回UDTF函数返回的列的个数、名字、类型* @param argOIs 当作一个数组来看,里面多个参数组成的* @return* @throws UDFArgumentException*/@Overridepublic StructObjectInspector initialize(StructObjectInspector argOIs) throws UDFArgumentException {List<? extends StructField> allStructFieldRefs = argOIs.getAllStructFieldRefs();if (allStructFieldRefs.size() != 2){throw new UDFArgumentException("function need two params");}else{/*** 返回一列多行 UDTF函数也可以返回多行多列*///返回的列的名字 是一个集合 集合有几项 代表UDTF函数返回几列List<String> columnNames = new ArrayList<>();columnNames.add("word");//返回的列的类型 集合的个数必须和columnNames集合的个数保持一致List<ObjectInspector> columnTypes = new ArrayList<>();columnTypes.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);//构建StandardStructObjectInspector,需要两个List集合 List<String> List<ObjectInspector>StandardStructObjectInspector standardStructObjectInspector = ObjectInspectorFactory.getStandardStructObjectInspector(columnNames,columnTypes);return standardStructObjectInspector;}}/*** UDTF函数执行的核心逻辑* 结果的输出需要借助forward方法* @param objects 函数的输入参数* @throws HiveException*/@Overridepublic void process(Object[] objects) throws HiveException {String str = objects[0].toString();String split = objects[1].toString();String[] array = str.split(split);for (String s : array) {//一行输出需要输出一次 如果输出一行数据 那么只需要调用一次forward方法即可/*** 如果一行数据有多列,可以先创建一个List集合,List<Object> 集合中把一行的多列值全部加加进来*/forward(s);}}/*** close用于关闭一些外部资源* @throws HiveException*/@Overridepublic void close() throws HiveException {}
}相关文章:

8.22笔记
8.22笔记 8.22笔记一、Hive的HQL语法重点问题1.1 DDL1.1.1 Hive中数据表的分类问题1.1.2 特殊的数据类型 1.2 DML1.3 DQL1.3.1 查询语法和MySQL大部分都是一致的 1.4 讲了三个数据库的可视化工具1.4.1 navicat1.4.2 dbeaver1.4.3 chat2db 二、Hive中重点问题:Hive函…...
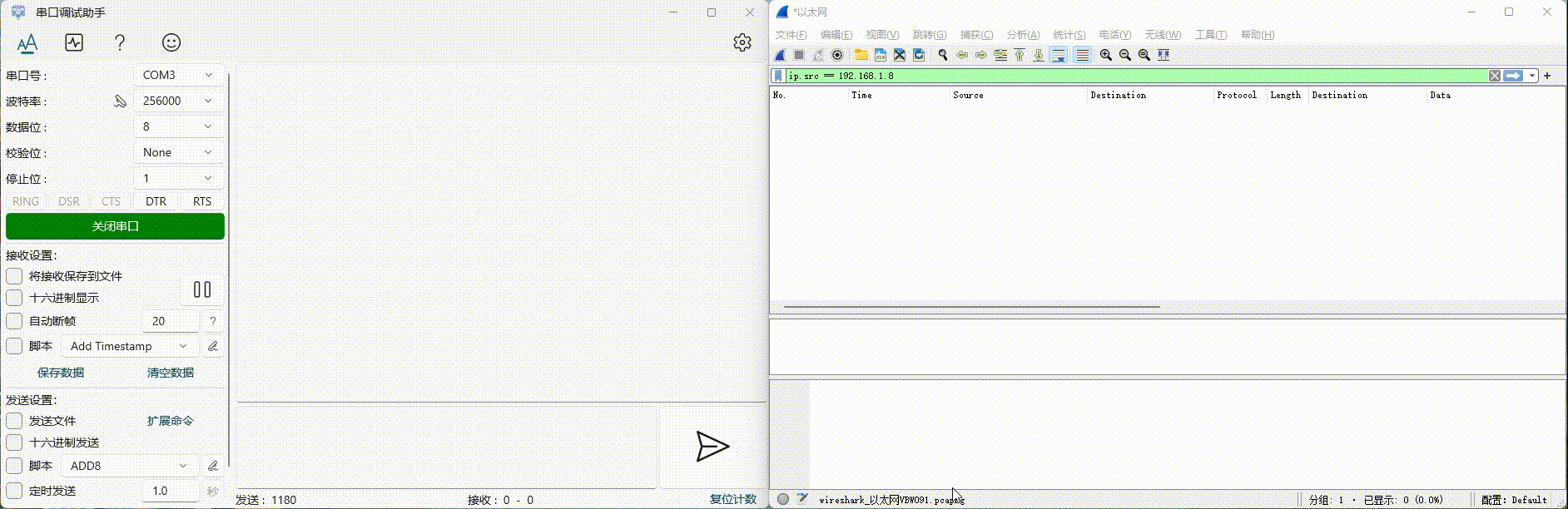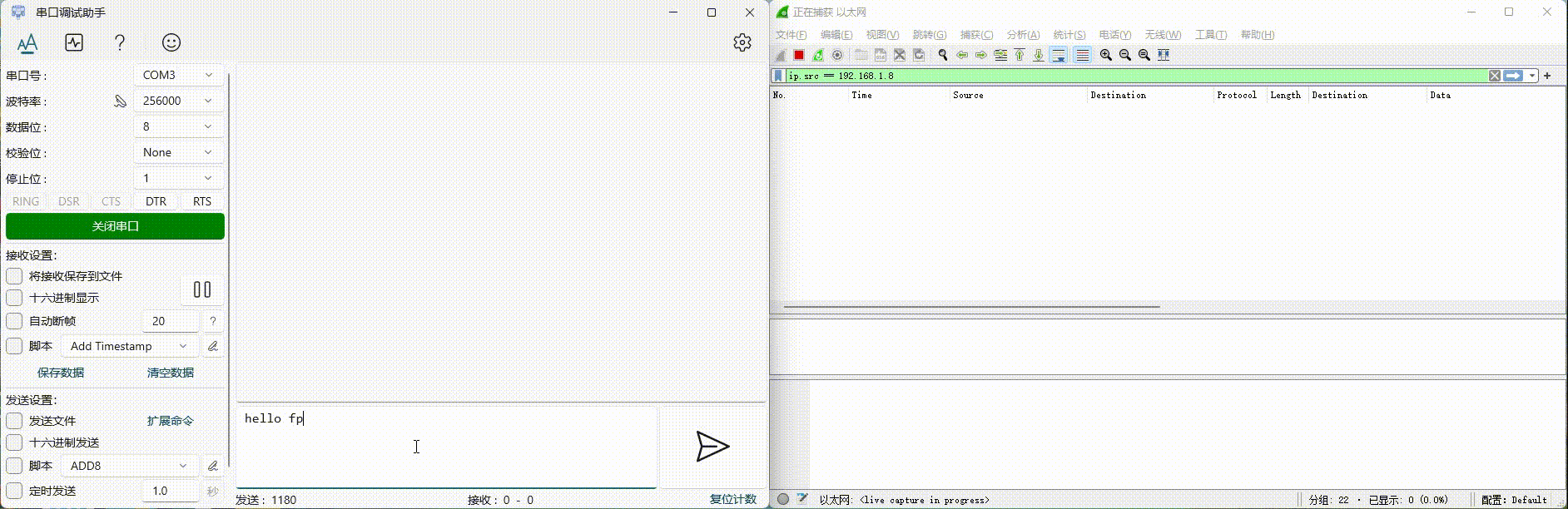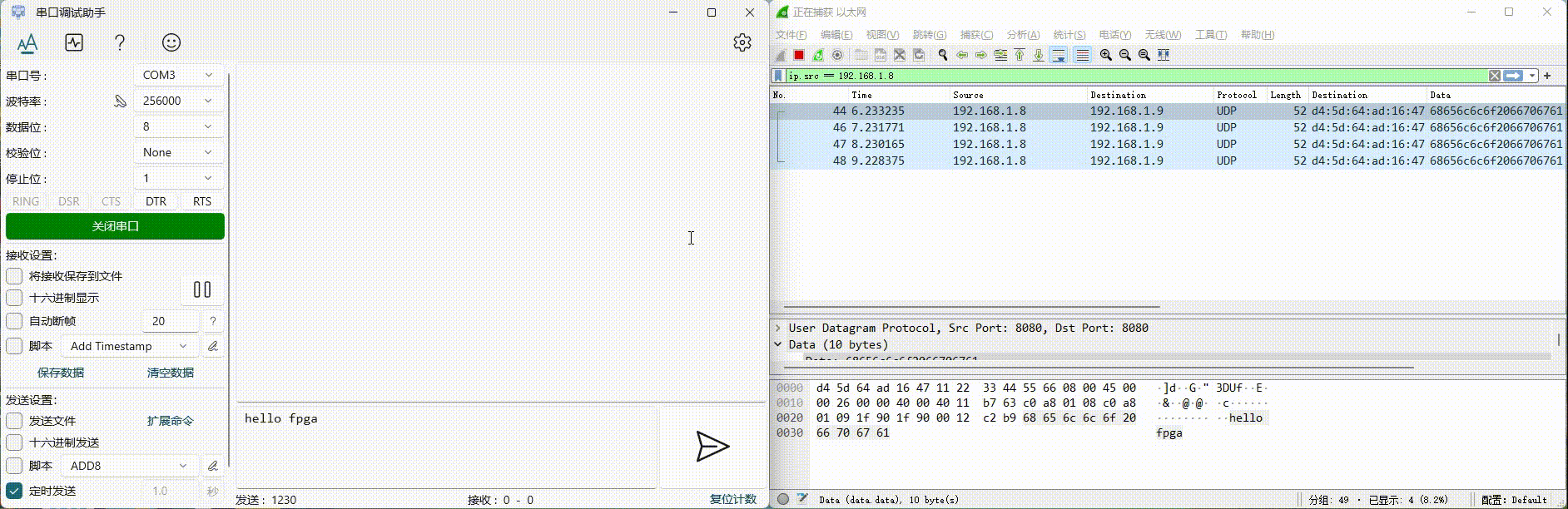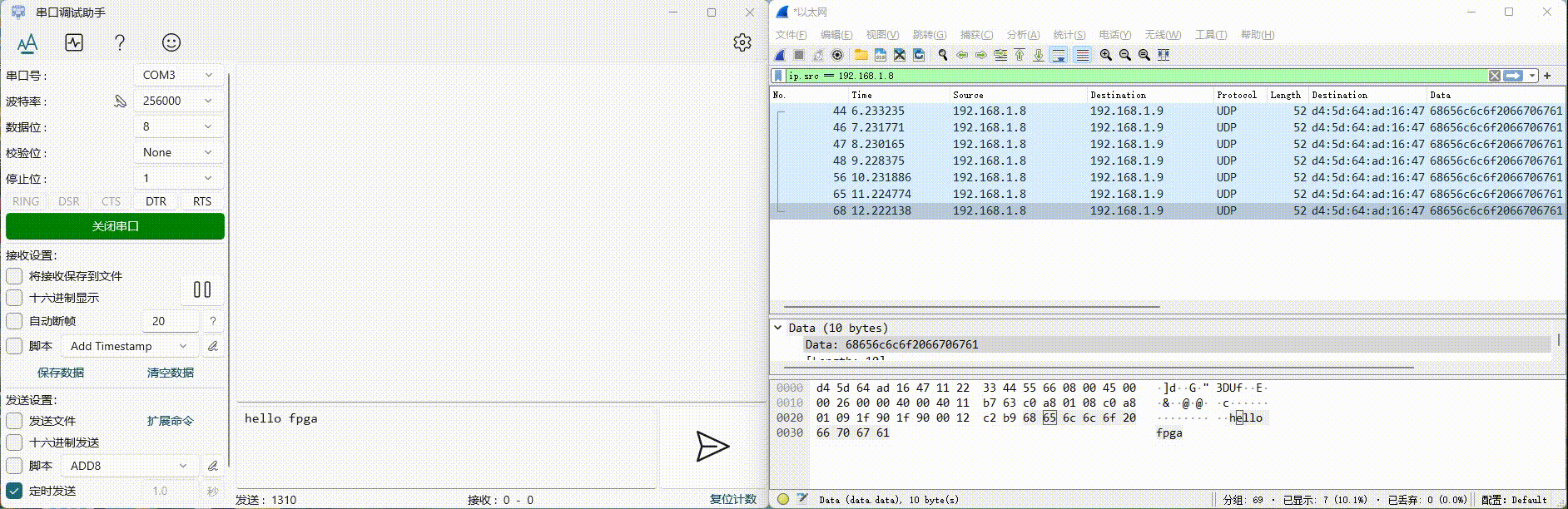
【以太网通信】RS232 串口转以太网
最近和 RK 研发同事在调试通信接口,排查与定位 RK3399 接收数据出错的问题。FPGA 与 RK3399 之间使用一路 RS232 串口进行通信,由于串口数据没有分包,不方便排查问题,想到可以开发一个 RS232 串口转以太网的工具,将串口…...
)
分享两道Java面试的算法上机题目(后续会持续补充更多)
所有题目参考答案均是小编自己想法,仅供参考,解法很多,大可不必局限,有更优解的大神无解,可评论或私聊博主指正! 题目1 找大串,给定一个字符串其中包含任意组连续字符,我们把超过3个…...

如何使用CSS实现一个平滑过渡效果?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ 使用CSS实现平滑过渡效果⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅!这个专栏是为那些对Web开发感兴趣、刚…...
网络常见设备
目录 1.网络常见设备 1.交换路由设备 2.网络安全设备 3.无线网络设备 4.网络设备生产厂商 1.网络常见设备 当用户通过电子邮件给远方的朋友送去祝福时,一定不会想到这封邮件在网络中将会经历怎样复杂的行程。就好比将一封真实的信件投到邮局后,无法了解…...

数据结构与算法:通往编程高地的必修课(文末送书)
🤵♂️ 个人主页:艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞Ǵ…...

python小脚本——批量将PDF文件转换成图片
语言:python 3 用法:选择PDF文件所在的目录,点击 确定 后,自动将该目录下的所有PDF转换成单个图片,图片名称为: pdf文件名.page_序号.jpg 如运行中报错,需要自行根据报错内容按照缺失的库 例如&#x…...

cUrl的介绍和基本使用
cURL 如果你在开发接口的时候,需要调试。那么cUrl将是你必备的技能。也许你用过postman,但这个未免太重量级了。curl将会是你最佳轻量级,调试接口的工具😀 1.Curl函数的基本选项✨ 1.1 --request和 -x —request 和 -X 指定与HTTP服务器通信…...
ONLYOFFICE协作空间服务器如何一键安装自托管私有化部署
ONLYOFFICE协作空间服务器如何一键安装自托管私有化部署 如何在 Ubuntu 上部署 ONLYOFFICE 协作空间社区版?https://blog.csdn.net/m0_68274698/article/details/132069372?ops_request_misc&request_id&biz_id102&utm_termonlyoffice%20%E5%8D%8F%E4…...

java分析公司名称:AI智能工具助力提取地名、品牌名、行业名
java分析公司名称:AI智能工具助力提取地名、品牌名、行业名 一、java智能提取地名 /*** 通过“武汉”补全省市区* throws Exception*/public void getPlace4() throws Exception{String r1 "武汉";String fileName2 "D:\\Personal\\Desktop\\txt…...

php 二维数组排序
要对二维数组进行排序,可以使用 PHP 的函数 array_multisort()。该函数可以按照指定的键值对对数组进行排序。 下面是一个示例代码,展示如何对二维数组按照某个键进行排序: // 定义一个二维数组 $students array(array(name > John, ag…...

postgresql 性能调优
性能调优是为了提高 PostgreSQL 数据库的性能和响应速度。下面是一些常见的 PostgreSQL 性能调优技巧: 1 确保合适的硬件资源:确保数据库服务器具有足够的内存、处理器和磁盘空间,以满足数据库负载的需求。2 优化查询语句:检查并优…...

派森 #P128. csv存json格式
描述 编写一个 Python 程序,读取movie.in(csv格式,utf-8编码) 的数据,将数据转成保存到movie.out(接送格式,utf-8编码)文件中。 格式 输入 movie.in文件,测试格式,utf-8编码。 …...
iPhone开启“轻点唤醒”功能但点击屏幕无反应怎么解决?
iPhone的“轻点唤醒”功能启用时,用户只需手指轻触或点击手机屏幕即可快速唤醒设备,无需按压任何按钮。然而,有些用户在使用“轻点唤醒”功能唤醒屏幕时,遇到该功能失灵,无法正常唤醒屏幕的情况,这是怎么回…...

论AI与大数据之间的关系
前言 在21世纪,"AI"和"大数据"已经成为科技领域的热门词汇。它们不仅是创新的代名词,更是现代技术发展的双翼。然而,很多人对于AI与大数据之间的关系仍然停留在表面的理解。本文旨在深入探讨这两者之间的深厚关系&#…...

6.ES基础概念及术语详细解读
一、Elasticsearch概述: ES是基于Lucene的搜索服务器,它提供了一个分布式多用户能力的全问搜索引擎,且ES支持RestFulweb风格的url访问。ES是基于Java开发的开源搜索引擎,设计用于云计算,能够达到实时搜索,…...
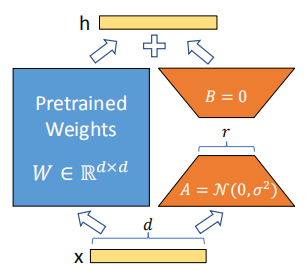
大语言模型微调实践——LoRA 微调细节
1. 引言 近年来人工智能领域不断进步,大语言模型的崛起引领了自然语言处理的革命。这些参数量巨大的预训练模型,凭借其在大规模数据上学习到的丰富语言表示,为我们带来了前所未有的文本理解和生成能力。然而,要使这些通用模型在特…...
国内ChatGPT对比与最佳方案
很久没写内容了,主要还是工作占据了太多时间。简单分享下我这段时间的研究吧,由于时间仓促,有很多内容没有具体写,请自行到我分享的网站体验查看。 前言 ChatGPT 的出现确实在很大程度上改变了世界。许多人已经亲身体验到了ChatGPT作为一个…...

绝美的古诗词AI作画,惊艳到我了!
前言 时光荏苒,科技的飞速发展催生出了许多令人惊叹的创新成果。近年来,人工智能技术在艺术领域的应用日益引人注目,其中最为引人瞩目的莫过于AI作画。这项技术将传统的古诗词与现代的人工智能相结合,创造出一幅幅令人叹为观止的…...
数据结构—排序
8.排序 8.1排序的概念 什么是排序? 排序:将一组杂乱无章的数据按一定规律顺序排列起来。即,将无序序列排成一个有序序列(由小到大或由大到小)的运算。 如果参加排序的数据结点包含多个数据域,那么排序往…...

3.3.1_1 检错编码(奇偶校验码)
从这节课开始,我们会探讨数据链路层的差错控制功能,差错控制功能的主要目标是要发现并且解决一个帧内部的位错误,我们需要使用特殊的编码技术去发现帧内部的位错误,当我们发现位错误之后,通常来说有两种解决方案。第一…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

分布式增量爬虫实现方案
之前我们在讨论的是分布式爬虫如何实现增量爬取。增量爬虫的目标是只爬取新产生或发生变化的页面,避免重复抓取,以节省资源和时间。 在分布式环境下,增量爬虫的实现需要考虑多个爬虫节点之间的协调和去重。 另一种思路:将增量判…...

GC1808高性能24位立体声音频ADC芯片解析
1. 芯片概述 GC1808是一款24位立体声音频模数转换器(ADC),支持8kHz~96kHz采样率,集成Δ-Σ调制器、数字抗混叠滤波器和高通滤波器,适用于高保真音频采集场景。 2. 核心特性 高精度:24位分辨率,…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...
iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

Git常用命令完全指南:从入门到精通
Git常用命令完全指南:从入门到精通 一、基础配置命令 1. 用户信息配置 # 设置全局用户名 git config --global user.name "你的名字"# 设置全局邮箱 git config --global user.email "你的邮箱example.com"# 查看所有配置 git config --list…...

STM32---外部32.768K晶振(LSE)无法起振问题
晶振是否起振主要就检查两个1、晶振与MCU是否兼容;2、晶振的负载电容是否匹配 目录 一、判断晶振与MCU是否兼容 二、判断负载电容是否匹配 1. 晶振负载电容(CL)与匹配电容(CL1、CL2)的关系 2. 如何选择 CL1 和 CL…...

「全栈技术解析」推客小程序系统开发:从架构设计到裂变增长的完整解决方案
在移动互联网营销竞争白热化的当下,推客小程序系统凭借其裂变传播、精准营销等特性,成为企业抢占市场的利器。本文将深度解析推客小程序系统开发的核心技术与实现路径,助力开发者打造具有市场竞争力的营销工具。 一、系统核心功能架构&…...