数据结构—排序
8.排序
8.1排序的概念
什么是排序?
- 排序:将一组杂乱无章的数据按一定规律顺序排列起来。即,将无序序列排成一个有序序列(由小到大或由大到小)的运算。
- 如果参加排序的数据结点包含多个数据域,那么排序往往是针对其中某个域而言。
排序方法的分类
-
按存储介质可分为:
-
内部排序:数据量不大、数据在内存,无需内外存交换数据
-
外部排序:数据量较大、数据在外存(文件排序)
外部排序时,要将数据分批调入内存在排序,中间结果还要及时放入外存,显然外部排序要复杂得多。
-
-
按比较器个数可分为:
- 串行排序:单处理机(同一时刻比较一对元素)
- 并行排序:多处理机(同一时刻比较多对元素)
-
按主要操作可分为:
-
比较排序:用比较的方法
插入排序、交换排序、选择排序、归并排序
-
基数排序:不比较元素的大小,仅仅根据元素本身的取值确定其有序位置。
-
-
按辅助空间可分为:
-
原地排序:辅助空间用量为O(1)的排序方法。
(所占的辅助存储空间与参加排序的数据量大小无关)
-
非原地排序:辅助空间用量超过O(1)的排序方法。
-
-
按稳定性可分为:
- 稳定排序:能够使任何数值相等的元素,排序以后相对次序不变。
- 非稳定性排序:不是稳定排序的方法。
-
按自然性可分为:
- 自然排序:输入数据越有序,排序的速度越快的排序方法。
- 非自然排序:不是自然排序的方法。
存储结构——记录序列以顺序表存储
#define MAXSIZE 20
typedef int KeyType;//设关键字为整型量(int型)
Typedef struct{//定义每个记录(数据元素)的结构KeyType key;//关键字InfoType otherinfo;//其他数据项
}RedType;
Typedef struct{//定义顺序表的结构RedType r[MAXSIZE+1];//存储顺序表的向量int length;//r[0]一般作哨兵或缓冲区
}SqList;
8.2插入排序
基本思想:每一步将一个待排序的对象,按其关键码大小,插入到前面已经排好序的一组对象的适当位置上,直到对象全部插入为止。
即边插遍排序,保证子序列中随时都是排好序的
基本操作:有序插入
- 在有序序列中插入一个元素,保持序列有序,有序长度不断增加。
- 起初,a[0]是长度为1的子序列。然后,逐一将a[1]至a[n-1]插入到有序子序列中。
有序插入方法:
- 在插入a[i]前,数组a的前半段(a[0]~a[i-1])是有序段,后半段(a[i] ~a[n-1])是停留于输入次序的无序段。
- 在插入a[i]使a[0]~a[i-1]有序,也就是要为a[i]找到有序位置j(0≤j≤i),将a[i]插入在a[j]的位置上。
插入排序的种类:
顺序法定位插入位置————直接插入排序
二分法定位插入位置————二分插入排序
缩小增量多遍插入排序————希尔排序
8.2.1直接插入排序
- 直接插入排序——采用顺序查找法查找插入位置

- 复制插入元素
- 记录后移,查找插入位置
- 插入到正确位置
x=a[i];
for(j=i-1;j>=0&&x<a[j];j--)a[j+1]=a[j];
a[j-1]=x;
- 直接插入排序,使用“哨兵”

- 复制为哨兵
- 记录后移,查找插入位置
- 插入到正确位置
L.r[0]=L.r[i];
for(j=i-1;L.r[0].key<L.r[j].key;--j)L.r[j+1]=L.r[j];
L.r[j+1]=L.r[0];
void InsertSort(SqList &L){int i,j;for(i=2;i<=L.length;++i){if(L.r[i].key<L.r[i-1].key){//若“<”,需将L.r[i]插入有序子表L.r[0]=L.r[i];//复制为哨兵for(j=i-1;L.r[0].key<L.r[j].key;--j){L.r[j+1]=L.r[j];//记录后移}L.r[j+1]=L.r[0];//插入到正确位置}}
}
实现排序的基本操作有两个:
- 比较序列中两个关键字的大小;
- 移动记录。
直接插入排序在什么情况下效率比较高?
直接插入排序在基本有序时,效率较高
在待排序的记录个数较少时,效率较高
8.2.2折半插入排序
查找插入位置时采用折半查找法

void BInsertSort(SqList &L){for(i=2;i<=L.length;++i){//依次插入第2~第n个元素L.r[0]=L.r[i];//当前插入元素存到“哨兵”位置low=1;high=i-1;while(low<=high){mid=(mid+high)/2;if(L.r[0].key<L.r[mid].key)high=mid-1;else low=mid+1;}//循环结束,high+1则为插入位置for(j=i-1;j>=high+1;--j)L.r[j+1]=L.r[j];L.r[high+1]=L.r[0];}
}
算法分析:
- 折半查找比顺序查找快,所以折半插入排序就平均性能来说比直接插入排序要快;
- 它所需要的关键码比较次数与待排序对象序列的初始排序无关,仅依赖于对象个数。在插入第i个对象时,需要经过[log2i]+1次关键码比较,才能确定它应插入的位置;
- 当n较大时,总关键码比较次数比直接插入排序的最坏情况要好得多,但比其最好情况要差;
- 在对象的初始排序已经按关键码排好序或接近有序时,直接插入排序比折半插入排序执行的关键码比较次数要少;
- 折半插入排序的对象移动次数与直接插入排序相同,依赖于对象的初始排列
- 减少了比价次数,但没有减少移动次数
- 平均性能优于直接插入排序
8.2.3希尔排序
基本思想:先将整个待排记录序列分割成若干个系列,分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行一次直接插入排序。
希尔排序算法,特点:
- 缩小增量
- 多遍插入排序
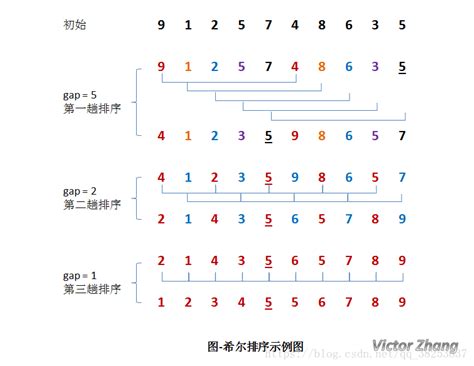
希尔排序特点
- 一次移动,移动位置较大,跳跃式地接近排序后的最终位置
- 最后一次只需要少量移动
- 增量序列必须是递减的,最后一个必须是1
- 增量序列应该是互质的
希尔排序算法(主程序)
void ShellSort(Sqlist &L,int dlta[],int t){//按增量序列dlta[0..t-1]对顺序表L作希尔排序。for(k=0;k<t;++k)ShellInsert(L,dlta[k]);//一趟增量为dlta[k]的插入排序
}
void ShellInsert(SqList &L,int dk){//对顺序表L进行一趟增量为dk的Shell排序,dk为步长因子for(i=dk+1;i<=L.length;++i){if(r[i].key<r[i-dk].key){r[0]=r[i];for(j=i-dk;j>0&&(r[0].key<r[j].key);j=j-dk)r[j+dk]=r[j];r[j+dk]=r[0];}}
}
希尔排序算法分析
希尔排序是一种不稳定的排序方法
- 如何选择最佳d序列,目前尚未解决
- 最后一个增量值必须为1,无除了1之外的公因子
- 不宜在链式存储结构上实现
8.3交换排序
基本思想:两两比较,如果发生逆序则交换,直到所有记录都排好序为止。
常见额交换排序方法:
冒泡排序O(n2)
快速排序O(nlog2n)
8.3.1冒泡排序
冒泡排序——基于简单交换思想
基本思想:每趟不断将记录两两比较,并按“前小后大”规则交换
总结:n个记录,总共需要n-1趟
第m趟需要比较 n-m次
void bubble_sort(SqList &L){int m,i,j;RedType x;//交换时临时存储for(m=1;m<=n-1;m++){//总共需m趟for(j=1;j<=n-m;j++)if(L.r[j].key>L.r[j+i].key){//发生逆序x=L.r[j];L.r[j]=L.r[j+1];L.r[j+1]=x;//交换}}
}
优点:每趟结束时,不仅能挤出一个最大值到最后面位置,还能同时部分理顺其他元素;
如何提高效率?
一旦某一趟比较时不出现记录交换,说明已排好序了,就可以结束本算法。
改进的冒泡排序算法
void bubble_sort(SqList &L){int m,i,j,flag=1;RedType x;//flag作为是否有交换的标记for(m=1;m<=n-1&&flag==1;m++){flag=0;for(j=1;j<=m;j++)if(L.r[j].key>L.r[j+1].key){//发生逆序flag=1;//发生交换,flag置为1,若本趟没发生交换,flag保持为0x=L.r[j];L.r[j]=L.r[j+1];L.r[j+1]=x;//交换}}
}
8.3.2快速排序
快速排序——改进的交换排序
基本思想:
- 任取一个元素(如:第一个)为中心
- 所有比它小的元素一律前放,比它大的元素一律后放,形成左右两个子表;
- 对各子表重新选择中心元素并依次规则调整
- 直到每个子表的元素只剩一个
基本思想:通过一趟排序,将待排序记录分割成独立的两部分,其中一部分记录的关键字均比另一部分记录的关键字小,则可分别对这两部分记录进行排序,以达到整个序列有序。
具体实现:选定一个中间数作为参考,所有元素与之比较,小的调到其左边,大的调到其右边。
(枢轴)中间数:可以是第一个数、最后一个数、最中间一个数、任选一个数等。

- 每一趟的子表的形成是采用从两头向中间交替式逼近法;
- 由于每趟中对各子表的操作都相似,可采用递归算法
void main(){QSort(L,1,L.length);
}
void QSort(SqList &L,int low,int high){if(low<high){//长度大于1pivotloc=Partition(L,low,high);//将L.r[low..high]一分为二,pivotloc为枢轴元素排好序的位置QSort(L,low,pivotloc-1);//对低子表递归排序QSort(L,pivotloc+1,high);//对高子表递归排序}
}
int Partition(SqList &L,int low,int high){L.r[0]=L.r[low];pivotkey=L.r[low].key;while(low<high){while(low<high&&L.r[high].key>=pivotkey)--high;L.r[low]=L.r[high];while(low<high&&L.r[low].key<=pivotkey)++low;L.r[high]=L.r[low];}L.r[low]=L.r[0];return low;
}
快速排序算法分析
-
时间复杂度
- 可以证明,平均计算时间是0(nlog2n)。
- Qsort():O(log2n)
- Partition():O(n)
- 实验结果表明:就平均计算时间而言,快速排序是我们所讨论的所有排序方法中最好的一个
- 可以证明,平均计算时间是0(nlog2n)。
-
空间排序
快速排序不是原地排序
由于程序中使用了递归,需要递归调用栈的支持,而栈的长度取决于递归调用的深度。(即使不用递归,也需要用用户栈)
- 在平均情况下:需要O(logn)的栈空间
- 最坏情况下:栈空间可达O(n)
-
稳定性:快速排序是一种不稳定的排序方法
由于每次枢轴记录的关键字都是大于其它所有记录的关键字,致使一次划分之后得到的子序列(1)的长度为0,这时已经退化成为没有改进措施的冒泡排序。
-
快速排序不适于对原本有序或基本有序的记录序列进行排序。
-
划分元素的选取是影响时间性能的关键
-
输入数据次序越乱,所选划分元素值的随机性越好,排序适度越快,快速排序不是自然排序方法。
-
改变划分元素的选取方法,至多只能改变算法平均情况下的世界性能,无法改变最坏情况下的时间性能。即最坏情况下,快速排序的时间复杂性总是O(n2)
-
8.4选择排序
8.4.1简单选择排序
基本思想:在待排序的数据中选出最大(小)的元素放在其最终的位置。
基本操作:
- 首先通过n-1次关键字比较,从n个记录中找出关键字最小的记录,将它与第一个记录交换
- 再通过n-2次比较,从剩余的n-1个记录中找出关键字次小的记录,将它与第二个记录交换
- 重复上述操作,共进行n-1趟排序后,排序结束

void SelectSort(SqList &K){for(i=1;i<L.length;++i){k=i;for(j=i+1;j<=L.length;j++)if(L.r[j].key<L.r[k].key) k=j;//记录最小值位置if(k!=i)L.r[i]←→L.r[k];//交换}
}
时间复杂度
- 记录移动次数
- 最好情况:0
- 最坏情况:3(n-1)
- 比较次数:无论待排序处于什么状态,选择排序所需进行的“比较”次数都相同
算法稳定性
- 简单选择排序是不稳定排序
8.4.2堆排序

则分别称该序列{a1 a2 … an}为小根堆和大根堆。
从堆的定义可以看出,堆实质是满足如下性质的完全二叉树:二叉树中任一非叶子结点均小于(大于)它的孩子结点。。
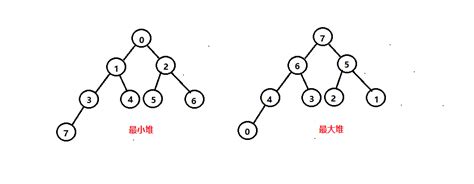
堆排序:若在输出堆顶的最小值(最大值)后,使得剩余n-1个元素的序列重新又建成一个堆,则得到n个元素的次小值(次大值)……如此反复,便能得到一个有序序列,这个过程称之为堆排序。
实现堆排序需解决两个问题:
- 如何由一个无序序列建成一个堆?
- 如何在输出堆顶元素后,调整剩余元素为一个新的堆?
小根堆:
- 输出堆顶元素之后,以堆中最后一个元素替代之;
- 然后将根节点值与左、右子树的根结点值进行比较,并与其中小者进行交换;
- 重复上述操作,直至叶子结点,将得到新的堆,称这个从堆顶至叶子的调整过程为“筛选”
堆的调整
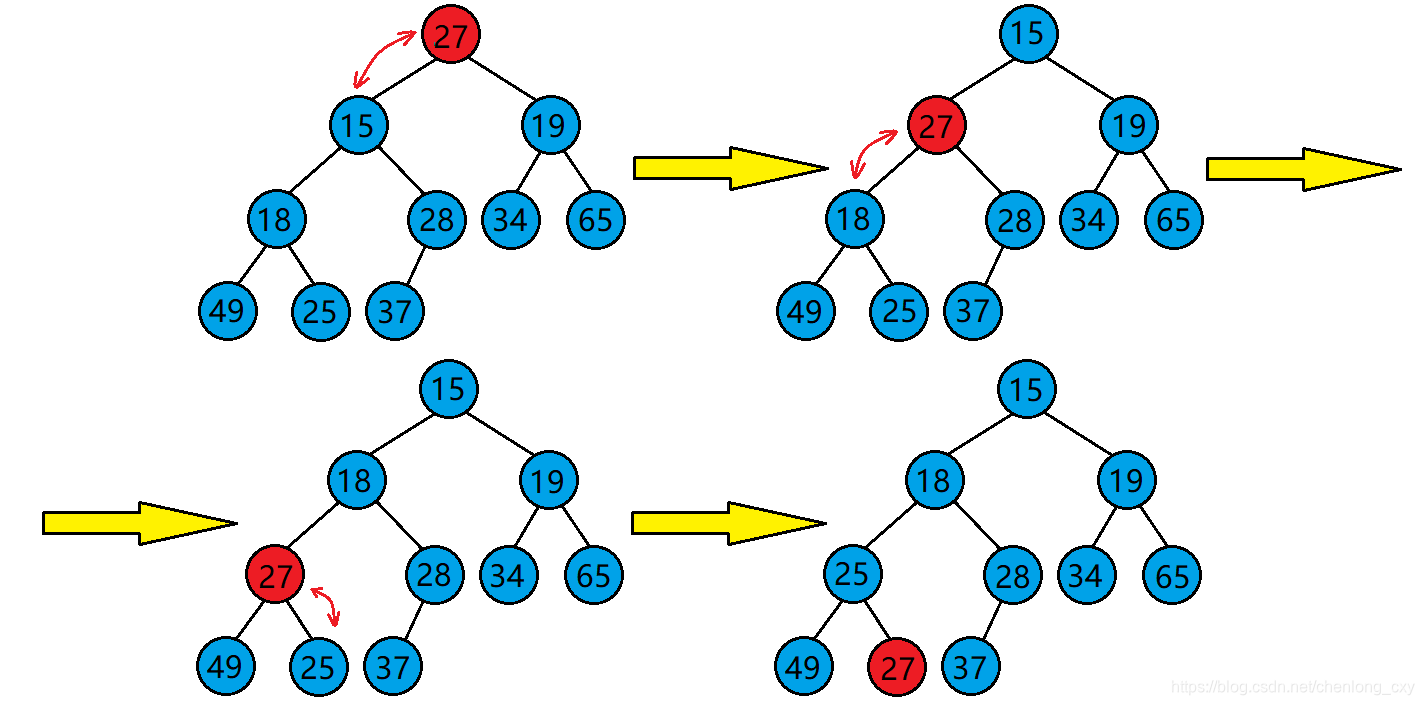
筛选过程的算法描述为:
void HeapAdjust(elem R[],int s,int m){/*已知R[s..m]中记录的关键字除R[s]之外均满足堆的定义,本函数调整R[s]的关键字,使R[s..m]成为一个大根堆*/rc=R[s];for(j=2*s;j<=m;j*=2){//沿key较大的孩子结点向下筛选if(j<m&&R[j]<R[j+1])//j为key较大的记录的下标++j;if(rc>=R[j]) break;R[s]=R[j];//rc应该插入在位置s上s=j;}R[s]=rc;//插入
}
可以看出:
对一个无序序列反复“筛选”就可以得到一个堆;即:从一个无序序列建堆的过程就是一个反复“筛选”的过程。
如何由无序序列建成一个堆?
单结点的二叉树是堆;
在完全二叉树中所有以叶子结点(序号i>n/2)为根的子树是堆。
这样,我们只需依次将以序号为n/2,n/2-1,……,1的结点为根的子树均调整为堆即可。
即:对应由n个元素组成的无序序列,“筛选”只需从第n/2个元素开始。
由于堆实质上是一个线性表,那么我们可以顺序存储一个堆。
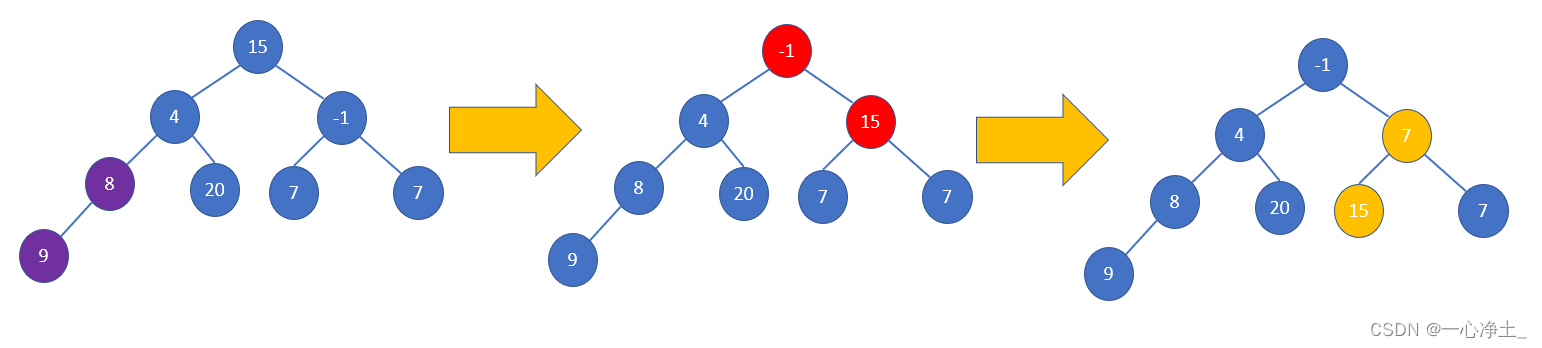
从最后一个非叶子结点开始,以此向前调整:
- 调整从第n/2个元素开始,将以该元素为根的二叉树调整为堆
- 将以序号为n/2-1的结点为根的二叉树调整为堆
- 再将以序号为n/2-2的结点为根的二叉树调整为堆;
- 再将以序号为n/2-3的结点为根的二叉树调整为堆
由以上分析知:
若对一个无序序列建堆,然后输出根;重复该过程就可以由一个无序序列输出有序序列。
实质上,堆排序就是利用完成二叉树中父结点与孩子结点之间的内在关系来排序的。
堆排序算法如下:
void HeapSort(elem R[]){//对R[1]到R[n]进行堆排序int i;for(i=n/2;i>=i;i--)HeapAdjust(R,i,n);//建初始堆for(i=n;i>1;i--){//进行n-1趟排序Swap(R[1],R[i]);//根与最后一个元素交换HeapAdjust(R,1,i-1);//对R[1]到R[i-1]重新建堆}
}
- 堆排序的时间主要耗费在建初始堆和调整建新堆时进行的反复筛选上。堆排序在最坏情况下,其时间复杂度也为O(nlog2n),这是堆排序的最大优点。无论待排序中的记录是正序还是逆序排序,都不会使堆排序处于“最好”或“最坏”的状态。
- 另外,堆排序仅需一个记录大小供交换用的辅助存储空间。
- 然而堆排序是一种不稳定的排序方法,它不使用于待排序记录个数n较少的情况,但对于n较大的文件还是很有效的。
8.5归并排序
-
基本思想:将两个或两个以上的有序子序列“归并”为一个有序序列。
-
在内部排序中,通常采用的是2-路归并排序。
- 即:将两个位置相邻的有序子序列R[l…m]和R[m+1…n]归并为一个有序序列R[l…n]

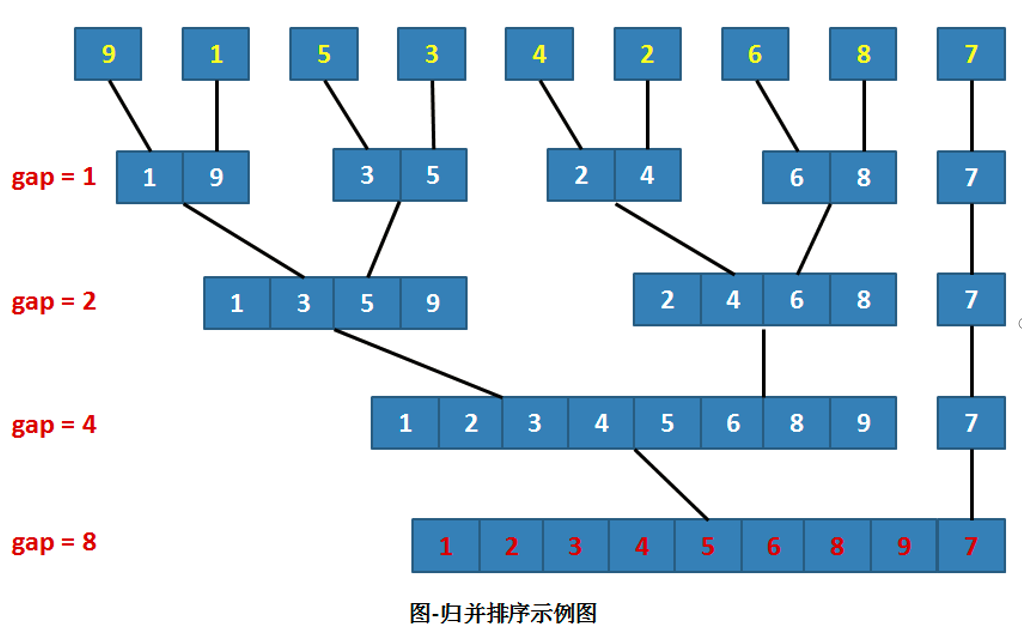
关键问题:如何将两个有序序列合成一个有序序列?
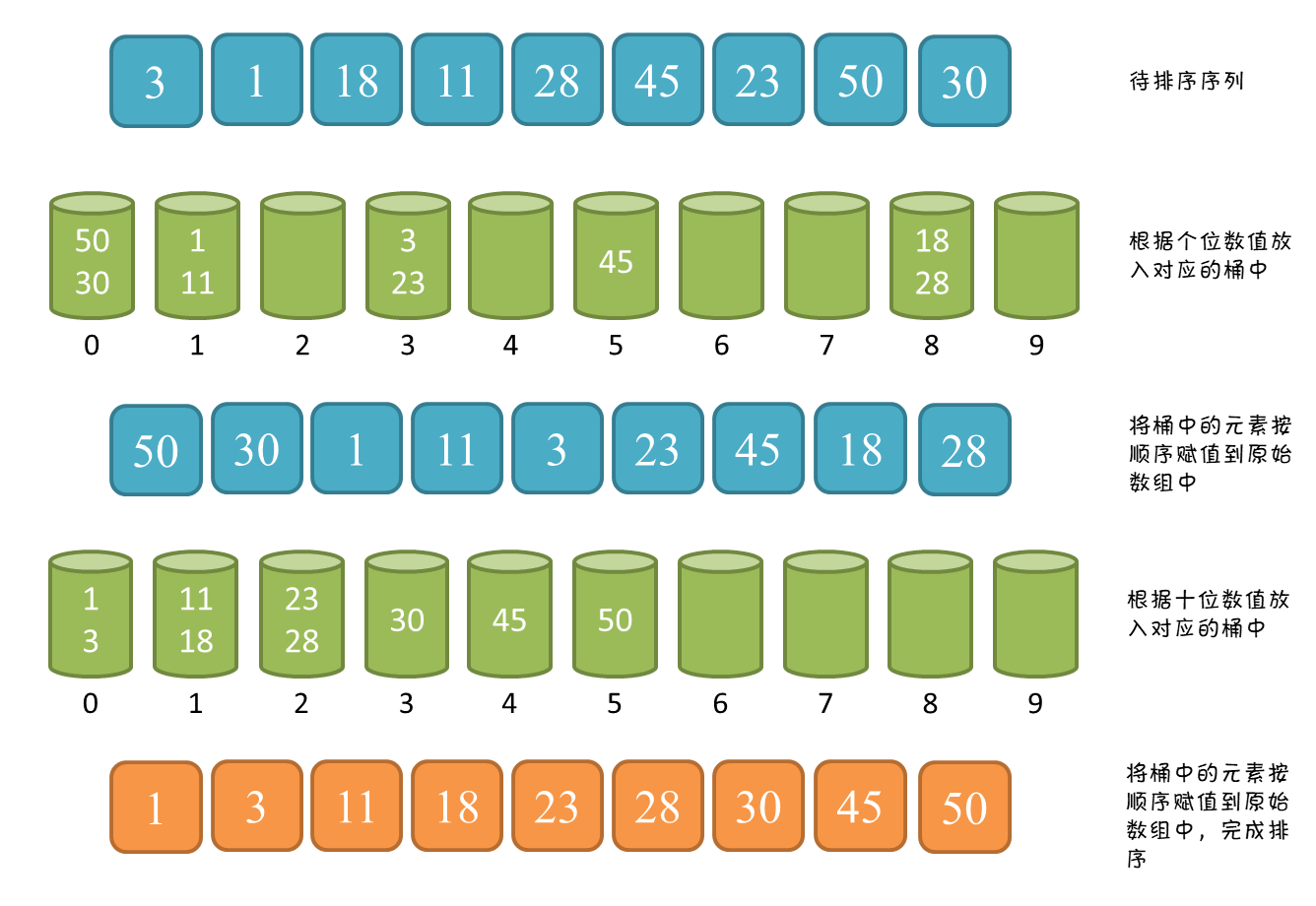
8.6基数排序
基本思想:分配+收集
也叫桶排序或箱排序:设置若干个箱子,将关键字为k的记录放入第k个箱子,然后在按序号将非空的连接。
基数排序:数字是有范围的,均由0-9这十个数字组成,则只需设置十个箱子,相继按个、十、百…进行排序。
8.7各种排序方法比较
一、时间性能
- 按平均的时间性能来分,有三类排序方法:
- 时间复杂度为O(nlogn)的方法有:、
- 快速排序、堆排序和归并排序,其中以快速排序为最好;
- 时间复杂度为O(n2)的有:
- 直接插入排序、冒泡排序和简单选择排序,其中以直接插入为最好,特别是对那些对关键字近似有序的记录序列尤为如此;
- 时间复杂度为O(n)的排序方法只有:基数排序。
- 时间复杂度为O(nlogn)的方法有:、
- 当待排记录序列按关键字顺序有序时,直接插入排序和冒泡排序能达到O(n)的时间复杂度;而对于快速排序而言,这是最不好的情况,此时的时间性能退化为O(n2),因此是应该尽量避免的情况。
- 简单选择排序、堆排序和归并排序的时间性能不随记录序列中关键字的分布而改变。
二、空间性能
指的是排序过程中所需的辅助空间大小
- 所有的简单排序方法(包括:直接插入、冒泡和简单选择)和堆排序的空间复杂度为O(1)
- 快速排序为O(logn),为栈所需的辅助空间
- 归并排序所需辅助空间最多,其空间复杂度为O(n)
- 链式基数排序需附设队列首尾指针,则空间复杂度为O(rd)
三、排序方法的稳定性能
- 稳定的排序方法指的是,对于两个关键字相等的记录,它们在序列中的相对位置,在排序之前和经过排序之后,没有改变。
- 当对多关键字的记录序列进行LSD方法排序时,必须采用稳定的排序方法。
- 对于不稳定的排序方法,只要能举出一个实例说明即可。
- 快速排序和堆排序是不稳定的排序方法。
四、关于“排序方法的时间复杂度的下限”
-
本章讨论的各种排序方法,除基数排序外,其它方法都是基于“比较关键字”进行排序的排序方法,可以证明,这类排序法可能达到的最快的时间复杂度为O(nlogn)。
(基数排序不是基于“比较关键字”的排序方法,所以它不受这个限制)
-
可以用一棵判定树来描述这类基于“比较关键字”进行排序的排序方法。
相关文章:
数据结构—排序
8.排序 8.1排序的概念 什么是排序? 排序:将一组杂乱无章的数据按一定规律顺序排列起来。即,将无序序列排成一个有序序列(由小到大或由大到小)的运算。 如果参加排序的数据结点包含多个数据域,那么排序往…...

GraphScope,开源图数据分析引擎的领航者
文章首发地址 GraphScope是一个开源的大规模图数据分析引擎,由Aliyun、阿里巴巴集团和华为公司共同开发。GraphScope旨在为大规模图数据处理和分析提供高性能、高效率的解决方案。 Github地址: https://github.com/alibaba/GraphScope GraphScope 的重…...
【Linux】邮件服务器搭建 postfix+dovecot+mysql (终极版 超详细 亲测多遍无问题)
🍁博主简介 🏅云计算领域优质创作者 🏅华为云开发者社区专家博主 🏅阿里云开发者社区专家博主 💊交流社区:运维交流社区 欢迎大家的加入! 文章目录 前言基础原理准备工作一 、安装关于权…...
GitLab与GitLab Runner安装(RPM与Docker方式),CI/CD初体验
背景 GitLab 是一个强大的版本控制系统和协作平台,记录一下在实际工作中关于 GitLab 的安装使用记录。 一开始使用 GitLab 时,是在 CentOS7 上直接以 rpm 包的方式进行安装,仅作为代码托管工具来使用,版本: 14.10.4 …...
vue3+element下拉多选框组件
<!-- 下拉多选 --> <template><div class"select-checked"><el-select v-model"selected" :class"{ all: optionsAll, hidden: selectedOptions.data.length < 2 }" multipleplaceholder"请选择" :popper-app…...

Python科研绘图--Task02
目录 图形元素 画布 (fifigure)。 坐标图形 (axes),也称为子图。 轴 (axis) :数据轴对象,即坐标轴线。 刻度 (tick),即刻度对象。 图层顺序 轴比例和刻度 轴比例 刻度位置和刻度格式 坐标系 直角坐标系 极坐标系 地理…...
[保研/考研机试] KY11 二叉树遍历 清华大学复试上机题 C++实现
题目链接: 二叉树遍历_牛客题霸_牛客网编一个程序,读入用户输入的一串先序遍历字符串,根据此字符串建立一个二叉树(以指针方式存储)。题目来自【牛客题霸】https://www.nowcoder.com/share/jump/43719512169254700747…...

【官方中文文档】Mybatis-Spring #简介
简介 什么是 MyBatis-Spring? MyBatis-Spring 会帮助你将 MyBatis 代码无缝地整合到 Spring 中。它将允许 MyBatis 参与到 Spring 的事务管理之中,创建映射器 mapper 和 SqlSession 并注入到 bean 中,以及将 Mybatis 的异常转换为 Spring 的…...
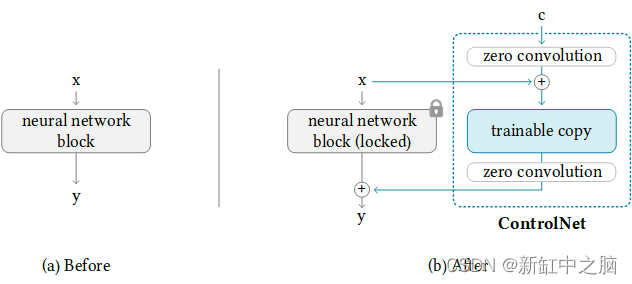
稳定扩散ControlNet v1.1 权威指南
ControlNet 是一种稳定扩散模型,可让你从参考图像中复制构图或人体姿势。 经验丰富的稳定扩散用户知道生成想要的确切成分有多难。图像有点随机。你所能做的就是玩数字游戏:生成大量图像并选择你喜欢的图片。 借助 ControlNet,稳定扩散用户…...
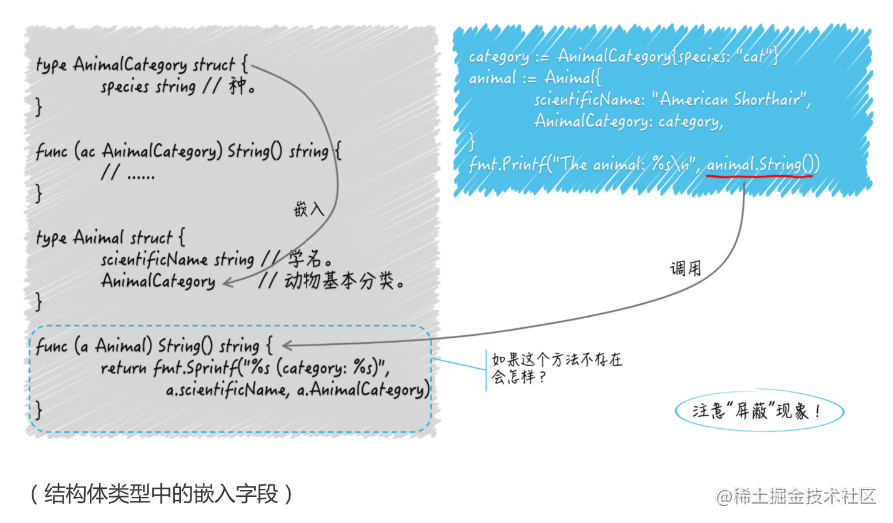
【golang】结构体及其方法的使用(struct)
函数是独立的程序实体。我们可以声明有名字的函数,也可以声明没名字的函数,还可以把它们当做普通的值传来传去。我们能把具有相同签名的函数抽象成独立的函数类型,以作为一组输入、输出(或者说一类逻辑组件)的代表。 …...
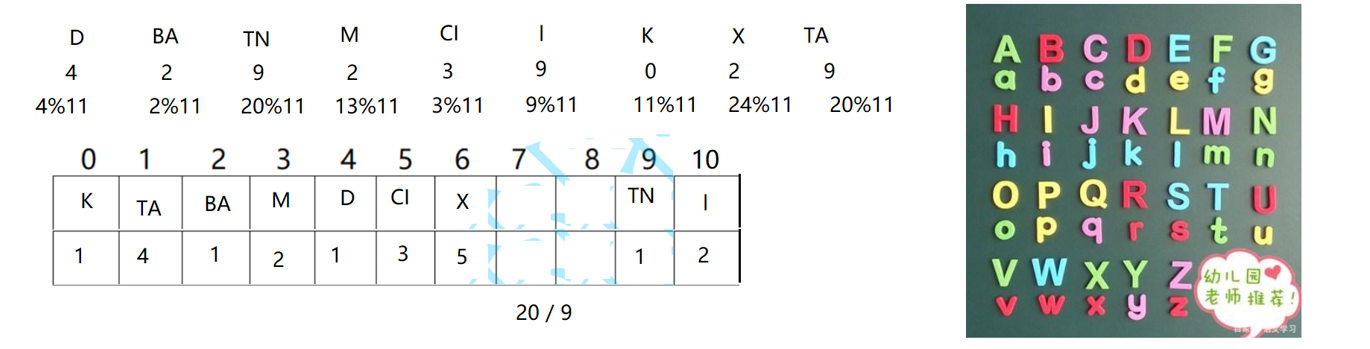
【数据结构】-- 排序算法习题总结
排序 时间复杂度 空间复杂度 稳定性 冒泡排序 O(n^2) 优化后O(n) O(1) 稳定 快速排序 最好O(n*logn) 最坏O(n^2) 最好O(logn) 最坏O(n) 不稳定直接插入排序…...
实战篇)
第十章 CUDA流(stream)实战篇
cuda教程目录 第一章 指针篇 第二章 CUDA原理篇 第三章 CUDA编译器环境配置篇 第四章 kernel函数基础篇 第五章 kernel索引(index)篇 第六章 kenel矩阵计算实战篇 第七章 kenel实战强化篇 第八章 CUDA内存应用与性能优化篇 第九章 CUDA原子(atomic)实战篇 第十章 CUDA流(strea…...
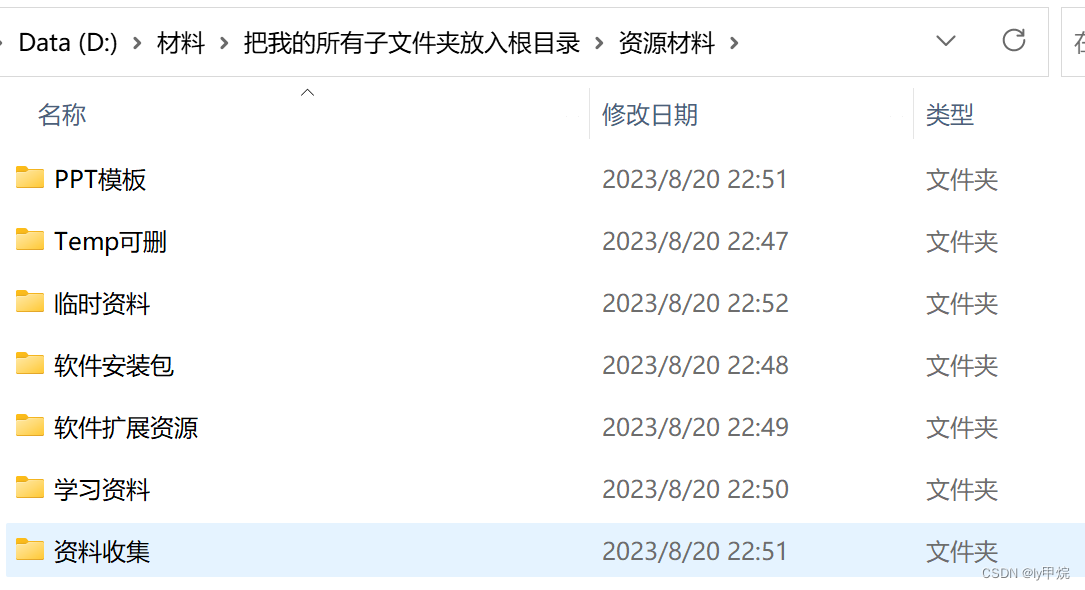
如何进行电脑文件夹分类与整理?
本科电脑用了四年,毕业后发现空间很满,但是真正有用的东西仿佛就一点。好像是在学开发的时候,听到一个老师说,根目录不要放太多文件夹,不然就相当于没有根目录了。刚好研究生有了新的台式电脑,开始有规划的…...
kafka-python 消费者消费不到消息
排除步骤1: 使用group_id”consumer_group_id_001“ 和 auto_offset_reset"earliest" from kafka import KafkaConsumerconsumer KafkaConsumer(bootstrap_servers["dev-kafka01.test.xxx.cloud:9092"],enable_auto_commitTrue, auto_commit…...

穿起“新架构”的舞鞋,跳一支金融数字化转型的华尔兹
华尔兹,是男女两位舞者,通过形体的控制,舞步技巧的发挥,完美配合呈现而出的一种舞蹈形式。华尔兹舞姿,如行云流水、潇洒自如、飘逸优美,素有“舞中皇后”的美称。 在跳华尔兹的时候,如果舞者双…...

SpringBoot 常用注解
随着Spring及Spring Boot的发展,基于Java的配置已经慢慢替代了基于xml的配置形式。本篇文章为大家整理和简介Spring Boot中常用的注解及其功能。 SpringBoot注解 SpringBootApplication:开启Spring Boot自动配置的核心注解,相关等同于Configu…...
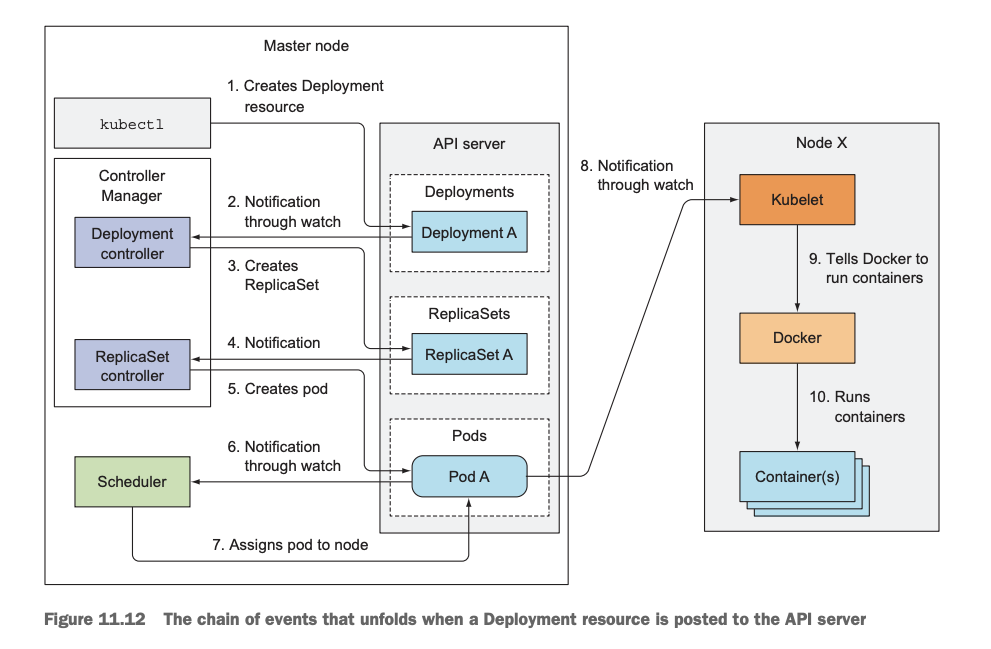
k8s deployment创建pod流程图
参考 k8s 创建pod和deployment的流程 - SoulChild随笔记...

C++ 逗号运算符
使用逗号运算符是为了把几个表达式放在一起。 整个逗号表达式的值为系列中最后一个表达式的值。 从本质上讲,逗号的作用是将一系列运算按顺序执行。 表达式1, 表达式2求解过程是:先求解表达式 1,再求解表达式 2。整个逗号表达式的值是表达…...

jdbc集成phoneix hbase
为什么使用jdbc集成 需求简单,只是往phoneix存储数据原本项目已经有mysql的mybatis plus集成,如果采用dataSource方式就需要采用多数据源的方式,造成架构复杂化,使用复杂化,并且修改地方过多。 Qualifier("phoe…...
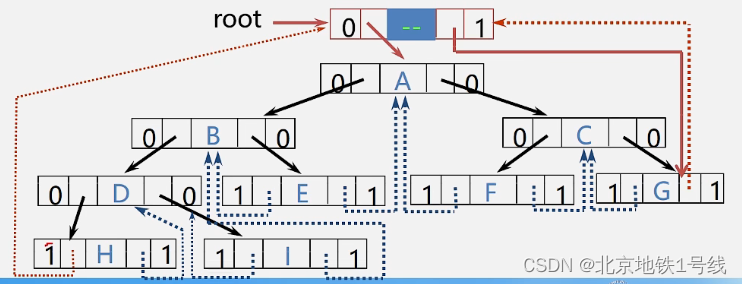
16.遍历二叉树,线索二叉树
目录 一. 遍历二叉树 (1)三种遍历方式 (2)递归遍历算法 (3)非递归遍历算法 (4)层次遍历算法 二. 基于递归遍历算法的二叉树有关算法 (1)二叉树的建立 …...

OpenClaw技能安装失败全解析:从依赖冲突到网络问题的系统性解决方案
1. 项目概述:当技能“卡住”时,我们遇到了什么?最近在折腾OpenClaw这类开源AI助手平台时,不少朋友都踩进了同一个坑:从官方市场或者第三方渠道找到了心仪的技能(Skill),点击“安装”…...

AMLP:基于大语言模型的自动化机器学习势函数构建平台
1. 项目概述:当AI遇见原子模拟,AMLP如何重塑机器学习势函数构建在计算材料科学和化学物理领域,分子动力学模拟是我们窥探微观世界动态行为的“显微镜”。无论是研究新材料的相变过程,还是探索生物大分子的折叠机制,其核…...

DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏
DS4Windows终极指南:3步让PS手柄在PC上完美运行游戏 【免费下载链接】DS4Windows Like those other ds4tools, but sexier 项目地址: https://gitcode.com/gh_mirrors/ds/DS4Windows 还在为PS手柄连接Windows电脑后无法识别而烦恼吗?🎮…...

LVGL多页面开发避坑:用内部Timer替代轮询,解决页面切换时的内存踩踏问题
LVGL多页面开发中的内存安全实践:用Timer机制替代轮询的工程解决方案 在嵌入式UI开发中,LVGL因其轻量级和跨平台特性成为热门选择。但当项目复杂度提升到多页面交互时,开发者往往会遇到一个棘手问题:如何在频繁切换页面的同时保证…...
)
别再手动测模型了!用Simulink Test Manager实现自动化测试(附Excel表格配置详解)
从手动测试到智能验证:Simulink Test Manager全流程自动化实战指南 在模型开发的迭代过程中,工程师们常常陷入"修改-测试-记录"的循环泥潭。每次参数调整后,手动运行模型、记录数据、比对结果不仅消耗大量时间,更可能因…...

Java项目中如何提升整体系统性能?
性能优化可以说是我们程序员的必修课,如果你想要跳出CRUD的苦海,成为一个更“高级”的程序员的话,性能优化这一关你是无论无何都要去面对的。为了提升系统性能,开发人员可以从系统的各个角度和层次对系统进行优化。除了最常见的代…...

终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代
终极指南:三步搞定Windows系统安卓APK文件安装,告别模拟器时代 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 还在为电脑无法直接运行手机应用…...

3步搞定B站缓存视频转换:m4s转MP4的终极解决方案
3步搞定B站缓存视频转换:m4s转MP4的终极解决方案 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾经在B站缓存了珍贵的视频&a…...

OpenCore Legacy Patcher完整指南:如何让老旧Mac重获新生运行最新macOS
OpenCore Legacy Patcher完整指南:如何让老旧Mac重获新生运行最新macOS 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的老旧Mac设备重获新…...

语音AI落地最后一公里卡点,PlayAI质量波动真相:采样率适配缺陷、韵律断层、情感衰减三大隐性陷阱
更多请点击: https://intelliparadigm.com 第一章:PlayAI语音质量评测报告总览 PlayAI语音质量评测体系基于客观指标与主观听感双维度构建,覆盖清晰度、自然度、时延、抗噪性及情感一致性五大核心能力。本报告汇总了在标准测试集(…...