Pytorch-day05-可视化-checkpoint
PyTorch 可视化
- 1、模型结构可视化
- 2、训练过程可视化
- 3、模型评估可视化
#导入常用包
import os
import numpy as np
import torch
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torchvision.transforms import transforms
import torchvision
import torch.nn.functional as F
# 自定义model
class DemoModel(nn.Module):def __init__(self):super(DemoModel, self).__init__()self.conv1 = nn.Conv2d(3, 6, 5)self.pool = nn.MaxPool2d(2, 2)self.conv2 = nn.Conv2d(6, 16, 5)self.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.pool(F.relu(self.conv1(x)))x = self.pool(F.relu(self.conv2(x)))x = x.view(-1, 16 * 5 * 5)x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return x方法一 print 打印(模型结构可视化)
model = DemoModel()
#方法一:print打印(模型结构可视化)
print(model)
DemoModel((conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=400, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True)
)
方法二 torchinfo
常用来查看模型输入输出和模型参数大小
torchinfo
#pip3 install torchinfo
- trochinfo的使用也是十分简单,我们只需要使用torchinfo.summary()就行了,必需的参数分别是model,input_size[batch_size,channel,h,w]
- 提供了模块信息(每一层的类型、输出shape和参数量)、模型整体的参数量、模型大小、一次前向或者反向传播需要的内存大小等
from torchinfo import summary
model = DemoModel() # 实例化模型
#方法二:torchinfo 查看 模型结构可视化
summary(model, (1, 3, 32, 32)) # 1:batch_size 3:图片的通道数 1024: 图片的高宽
==========================================================================================
Layer (type:depth-idx) Output Shape Param #
==========================================================================================
DemoModel [1, 10] --
├─Conv2d: 1-1 [1, 6, 28, 28] 456
├─MaxPool2d: 1-2 [1, 6, 14, 14] --
├─Conv2d: 1-3 [1, 16, 10, 10] 2,416
├─MaxPool2d: 1-4 [1, 16, 5, 5] --
├─Linear: 1-5 [1, 120] 48,120
├─Linear: 1-6 [1, 84] 10,164
├─Linear: 1-7 [1, 10] 850
==========================================================================================
Total params: 62,006
Trainable params: 62,006
Non-trainable params: 0
Total mult-adds (M): 0.66
==========================================================================================
Input size (MB): 0.01
Forward/backward pass size (MB): 0.05
Params size (MB): 0.25
Estimated Total Size (MB): 0.31
==========================================================================================
方法三 Tensorboard (使用最多,可实现训练过程的可视化)
TensorBoard
- TensorBoard作为一款可视化工具能够满足 输入数据(尤其是图片)、模型结构、参数分布、debug的需求
- TensorBoard可以记录我们指定的数据,包括模型每一层的feature map,权重,以及训练loss等等
- 利用TensorBoard实现训练过程可视化
安装
pip install tensorboard
启动tensorboard
tensorboard --logdir=/path/to/logs/ --port=xxxx
- 其中“path/to/logs/“是指定的保存tensorboard记录结果的文件路径,等价于下面的“./runs”
- port是外部访问TensorBoard的端口号,可以通过访问ip:port访问tensorboard)
重点:
tensorboard --logdir=path1 与 writer = SummaryWriter(path1), 两者的目录路径要保持一致,否则tensorboard 上不能显示结果。
writer 与writer.add_graph()
# from tensorboard import SummaryWriter
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter('./runs')
print(model)
DemoModel((conv1): Conv2d(3, 6, kernel_size=(5, 5), stride=(1, 1))(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(fc1): Linear(in_features=400, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True)
)
#方法三:tensorboard查看
writer.add_graph(model,torch.rand(1, 3, 32, 32))
writer.close()
tensorboard 可视图
#超参数定义
# 批次的大小
batch_size = 16 #可选32、64、128
# 优化器的学习率
lr = 1e-4
#运行epoch
max_epochs = 2
# 方案一:指定GPU的方式
# os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 指明调用的GPU为0,1号# 方案二:使用“device”,后续对要使用GPU的变量用.to(device)即可
# device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 指明调用的GPU为1号# 数据读取
#cifar10数据集为例给出构建Dataset类的方式
from torchvision import datasets#“data_transform”可以对图像进行一定的变换,如翻转、裁剪、归一化等操作,可自己定义
data_transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])train_cifar_dataset = datasets.CIFAR10('cifar10',train=True, download=False,transform=data_transform)
test_cifar_dataset = datasets.CIFAR10('cifar10',train=False, download=False,transform=data_transform)#构建好Dataset后,就可以使用DataLoader来按批次读入数据了train_loader = torch.utils.data.DataLoader(train_cifar_dataset, batch_size=batch_size, num_workers=4, shuffle=True, drop_last=True)test_loader = torch.utils.data.DataLoader(test_cifar_dataset, batch_size=batch_size, num_workers=4, shuffle=False)
#训练&验证
writer = SummaryWriter('./runs')# Set fixed random number seed
torch.manual_seed(42)
# 定义损失函数和优化器
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
My_model = DemoModel()
My_model = My_model.to(device)
# 交叉熵
criterion = torch.nn.CrossEntropyLoss()
# 优化器
optimizer = torch.optim.Adam(My_model.parameters(), lr=lr)
epoch = max_epochstotal_step = len(train_loader)
train_all_loss = []
test_all_loss = []
for i in range(epoch):My_model.train()train_total_loss = 0train_total_num = 0train_total_correct = 0for iter, (images,labels) in enumerate(train_loader):images = images.to(device)labels = labels.to(device)# Write the network graph at epoch 0, batch 0if epoch == 0 and iter == 0:writer.add_graph(My_model, input_to_model=(images,labels)[0], verbose=True)# Write an image at every batch 0if iter == 0:writer.add_image("Example input", images[0], global_step=epoch)outputs = My_model(images)loss = criterion(outputs,labels)train_total_correct += (outputs.argmax(1) == labels).sum().item()#backwordoptimizer.zero_grad()loss.backward()optimizer.step()train_total_num += labels.shape[0]train_total_loss += loss.item()# Print statisticswriter.add_scalar("Loss/Minibatches", train_total_loss, train_total_num)print("Epoch [{}/{}], Iter [{}/{}], train_loss:{:4f}".format(i+1,epoch,iter+1,total_step,loss.item()/labels.shape[0]))# Write loss for epochwriter.add_scalar("Loss/Epochs", train_total_loss, epoch)My_model.eval()test_total_loss = 0test_total_correct = 0test_total_num = 0for iter,(images,labels) in enumerate(test_loader):images = images.to(device)labels = labels.to(device)outputs = My_model(images)loss = criterion(outputs,labels)test_total_correct += (outputs.argmax(1) == labels).sum().item()test_total_loss += loss.item()test_total_num += labels.shape[0]print("Epoch [{}/{}], train_loss:{:.4f}, train_acc:{:.4f}%, test_loss:{:.4f}, test_acc:{:.4f}%".format(i+1, epoch, train_total_loss / train_total_num, train_total_correct / train_total_num * 100, test_total_loss / test_total_num, test_total_correct / test_total_num * 100))train_all_loss.append(np.round(train_total_loss / train_total_num,4))test_all_loss.append(np.round(test_total_loss / test_total_num,4))Epoch [1/2], Iter [1/3125], train_loss:0.144669Epoch [1/2], Iter [710/3125], train_loss:0.119339Epoch [1/2], Iter [1254/3125], train_loss:0.121789
比较
- 方法一 print(model),打印模型块得结构
- 方法二 torchinfo , 给一个输入大小, 提供模块信息更全,包含每一层的类型、输出shape 和参数量等。 (torchsummary 也有同样功能)
https://blog.csdn.net/weixin_43183872/article/details/108329776 - 方法三 tensorboard ,TensorBoard可以记录我们指定的数据,包括模型每一层的feature map,权重,以及训练loss等等
tensorboard 使用时,
tensorboard --logdir=path1 与 writer = SummaryWriter(path1), 两者的目录路径要保持一致,否则tensorboard 上不能显示结果。
writer 与writer.add_graph()
相关文章:

Pytorch-day05-可视化-checkpoint
PyTorch 可视化 1、模型结构可视化2、训练过程可视化3、模型评估可视化 #导入常用包 import os import numpy as np import torch from torch import nn from torch.utils.data import Dataset, DataLoader from torchvision.transforms import transforms import torchvis…...

实训笔记8.23
8.23笔记 8.23笔记一、Hive中函数1.1 Hive中内置函数1.1.1 数学函数1.1.2 字符串函数1.1.3 日期函数1.1.4 条件函数1.1.5 特殊函数 1.2 Hive的自定义函数1.2.1 自定义UDF1.2.2 自定义UDTF 二、Hive的压缩机制三、数据同步工具Sqoop的安装和使用3.1 sqoop的概念3.2 sqoop的核心功…...

2023年菏泽市中职学校技能大赛“网络安全”赛项规程
2023年菏泽市中职学校技能大赛 “网络安全”赛项规程 一、赛项名称 赛项名称:网络安全 赛项所属专业大类:信息技术类 二、竞赛目的 通过竞赛,检验参赛选手对网络、服务器系统等网络空间中各个信息系统的安全防护能力,以及分析…...
Android 13 - Media框架(6)- NuPlayer
上一节我们通过 NuPlayerDriver 了解了 NuPlayer 的使用方式,这一节我们一起来学习 NuPlayer 的部分实现细节。 ps:之前用 NuPlayer 播放本地视频很多都无法播放,所以觉得它不太行,这两天重新阅读发现它的功能其实很全面ÿ…...

机器学习|DBSCAN 算法的数学原理及代码解析
机器学习|DBSCAN 算法的数学原理及代码解析 引言 聚类是机器学习领域中一项重要的任务,它可以将数据集中相似的样本归为一类。DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一种是一种经典的密度聚类…...
用NUXT.JS,轻松搞定SEO!
nuxt.js 是什么? 如果你正在准备开发一个SEO友好的新项目,而且准备用 vue 开发,那么恭喜你,用 nuxt 是一个成本和效率都比较优秀的方案。 官方文档 知识中心案例 简单介绍下背景,这是一个专门为氚云低代码平台引流…...

什么是电商RPA?电商RPA能解决什么问题?电商RPA实施难点在哪里?
RPA机器人可以应用于各个行业和领域,例如金融、保险、制造、物流、电商等。它可以减少人工错误和重复工作,提高效率和生产力。RPA还可以在处理大量数据时加快处理速度,提供更准确和可靠的结果。此外,RPA还可以为员工提供更有价值的…...

【BUG】Docker启动MySQL报错
个人主页:金鳞踏雨 个人简介:大家好,我是金鳞,一个初出茅庐的Java小白 目前状况:22届普通本科毕业生,几经波折了,现在任职于一家国内大型知名日化公司,从事Java开发工作 我的博客&am…...

Spring Boot通过企业邮箱发件被Gmail退回的解决方法
这两天给我们开发的Chrome插件:Youtube中文配音 增加了账户注册和登录功能,其中有一步是邮箱验证,所以这边会在Spring Boot后台给用户的邮箱发个验证信息。如何发邮件在之前的文章教程里就有,这里就不说了,着重说说这两…...
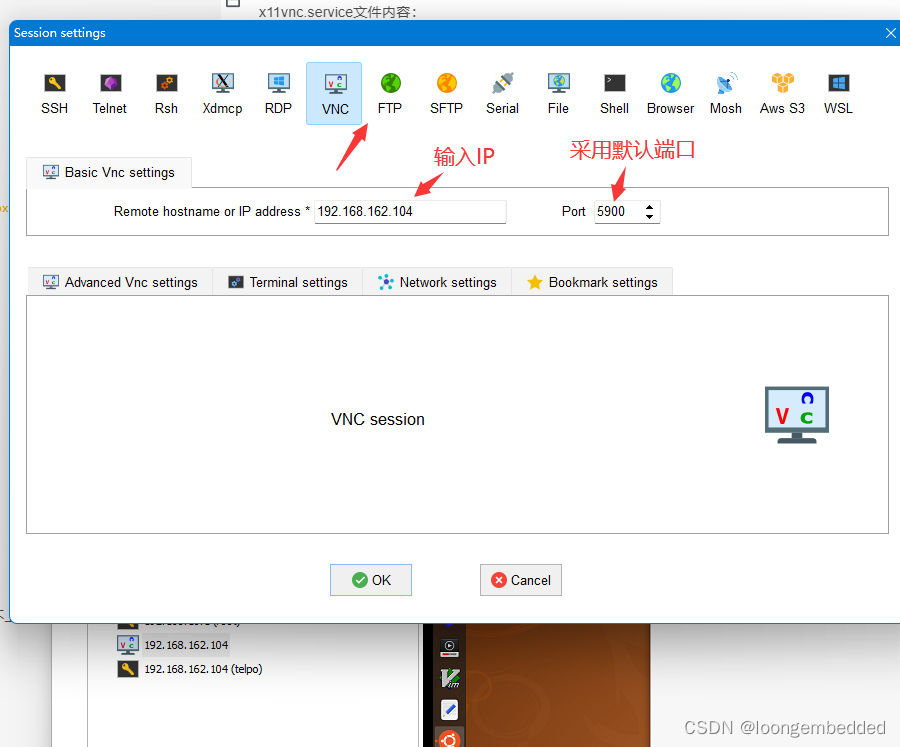
Windows使用MobaXterm远程访问ubuntu20.04桌面
参考ubuntu 2020.4 安装vnc 一、脚本文件 remote_setup.sh脚本文件内容: #! /bin/bash #参考链接:https://blog.csdn.net/hailangdeyingzi/article/details/124507304 sudo apt update sudo apt install x11vnc -y sudo x11vnc -storepasswd telpo.12…...

C++注释风格
1. 文件头注释 每个文件都应该开始于一个注释块,描述文件的目的、作者、创建日期和版权信息。 /** FileName: MyClass.cpp* Purpose: Provides functionality for XYZ operations.* Author: [Your Name]* Creation Date: YYYY-MM-DD* Last Updated: YYYY-MM-DD* C…...

Linux 编译内核模块出现--Unknown symbol mcount
文章目录 Linux suse: # cat /etc/os-release NAME"SLES" VERSION"12-SP2" VERSION_ID"12.2" PRETTY_NAME"SUSE Linux Enterprise Server 12 SP2" ID"sles" ANSI_COLOR"0;32" CPE_NAME"cpe:/o:s…...

Pywin32 Cookbook by Eric
Writing Prompt 现在你是一名专业的Python工程师,请你根据"Pywin32_Funtion"函数的功能,为其编写一个清晰的文档说明Functions win32gui.GetWindowDC(hwnd) 描述 win32gui.GetWindowDC()函数用于获取指定窗口的设备上下文(Devi…...
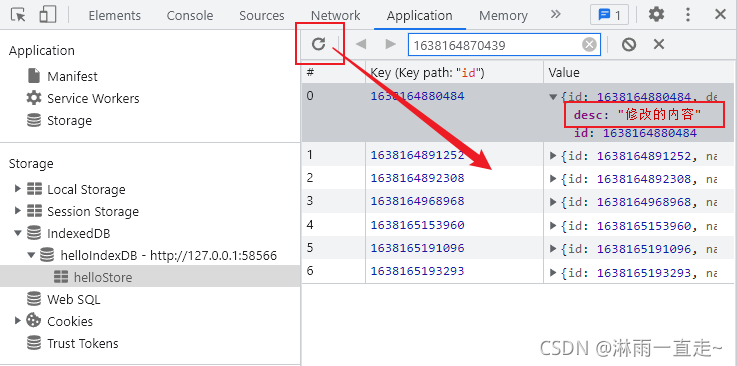
indexDB入门到精通
前言 由于开发3D可视化项目经常用到模型,而一个模型通常是几m甚至是几十m的大小对于一般的服务器来讲加载速度真的十分的慢,为了解决这个加载速度的问题,我想到了几个本地存储的。 首先是cookie,cookie肯定是不行的,因为最多以只…...
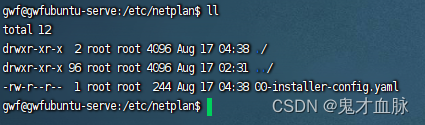
Ubuntu 20.04配置静态ip
ip配置文件 cd /etc/netplan配置 根据需求增加 # Let NetworkManager manage all devices on this system network:version: 2renderer: NetworkManager # 管理 不是必须ethernets:enp4s0: #网卡名dhcp4: no #关闭ipv4动态分配ip地址dhcp6: no #关闭ipv6动态分配…...
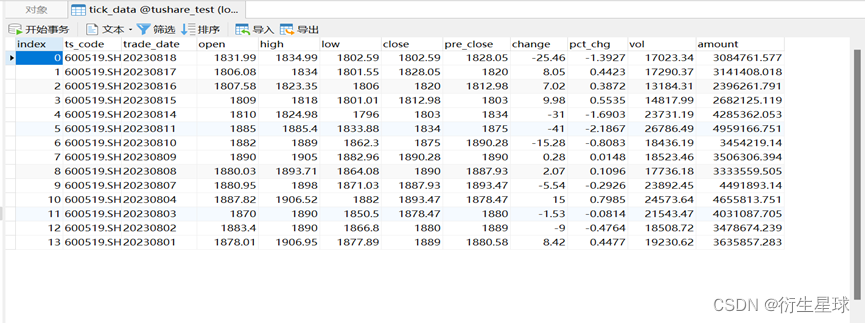
Tushare入门小册
Tushare入门小册 一、Tushare平台介绍 Pro版数据更稳定质量更好了,我们提供的不再是直接从互联网抓取,而是通过社区的采集和整理存入数据库经过质量控制后再提供给用户。但Pro依然是个开放的,免费的平台,不带任何商业性质和目的…...
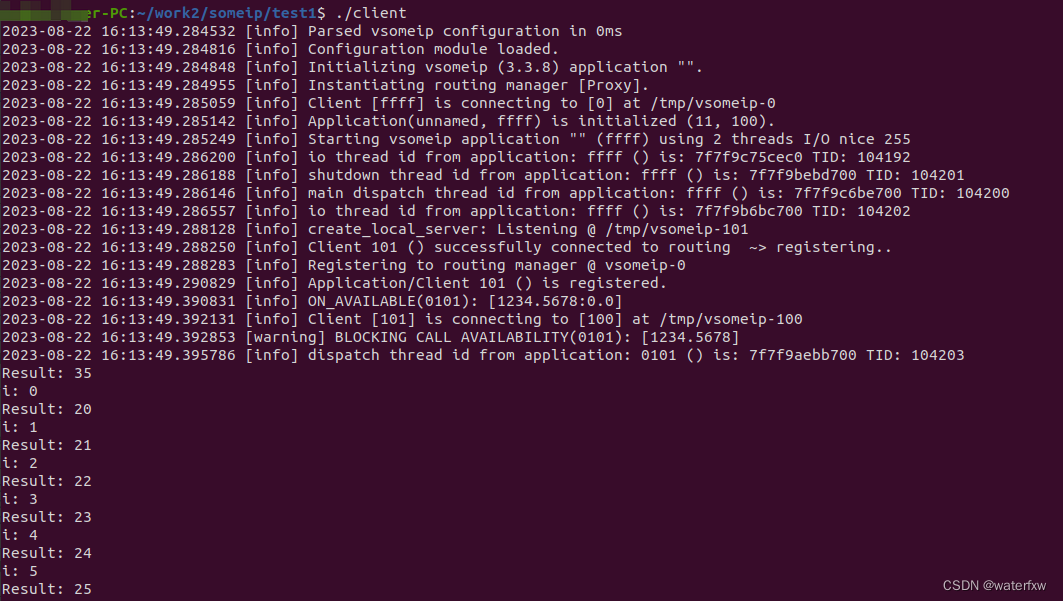
<c++开发>通信工具 -之-SOME/IP移植部署 第一篇文章
<c开发>通信工具 -之-SOME/IP移植ubuntu部署 第一篇文章 一 前言 SOME/IP (Scalable service-Oriented MiddlewarE over IP) 是一种通信协议,主要用于嵌入式系统和车载网络中的服务导向通信。SOME/IP是AUTOSAR(AUTomotive Open …...

权威的软件测试服务供应商分享,怎么获得软件安全检测报告?
我们深知在如今的数字化时代,软件安全对于企业和个人来说具有极其重要的意义。然而,许多用户对于软件安全测试报告的概念还不够清晰,也不知道如何获得这样的报告。在本文中,小编将为您简析什么是安全测试报告以及如何获取这样的报…...

管理类联考——逻辑——真题篇——按知识分类——汇总篇——二、论证逻辑——假设——第二节——搭桥假设
文章目录 第二节 假设-分类1-搭桥假设-当题干推理存在明显断点,常见形式比如:“因为A→B,C→D,所以A→D”,则正确选项为“B→C”真题(2014-39)-假设-分类1-题干推理存在明显断点-搭桥假设-建模搭桥-“因为A→B,所以A→C”,搭桥假设为“B→C”真题(2019-44)-假设-分…...

百度云BOS云存储的图片如何在访问时,同时进行格式转换、缩放等处理
前言 之前做了一个图片格式转换和压缩的服务,结果太占内存。后来查到在访问图片链接时,支持进行图片压缩和格式转换,本来想着先格式转换、压缩图片再上传到BOS,现在变成了上传后,访问时进行压缩和格式转换。想了想&am…...

自制BLE112串口编程器:基于Bootloader的免调试器烧录方案
1. 项目概述:为BLE112模块打造一款免调试器的RS232编程器在嵌入式开发,特别是早期的蓝牙低功耗(BLE)模块应用中,我们常常会遇到一个棘手的问题:官方开发工具链的依赖和限制。以Silicon Labs(当时…...
)
大佬推荐的网络安全学习路线(从基础到高级,超级详细)
大佬推荐的网络安全学习路线(从基础到高级,超级详细) 说起网络安全,你可能会担心它是一个过时的行业。有人说,网络安全快卷死了,你既要攻又要防,并且随着技术的发展,你还要不断地学…...

氘可来昔替尼常见副作用为鼻咽炎头痛及腹泻,如何应对?
任何口服药物的临床价值,都必须在疗效与安全性的天平上找到精准的平衡点。氘可来昔替尼以PASI 75应答率的全面胜出证明了自己在银屑病治疗中的卓越地位,而其不良反应谱同样经过了严苛的临床验证。鼻咽炎、头痛和腹泻构成了这款药物最需关注的三大安全信号…...

DeepSeek模型微调全链路解析:从数据准备、LoRA配置到推理部署的7大关键步骤
更多请点击: https://intelliparadigm.com 第一章:DeepSeek模型微调全链路概览 DeepSeek系列大语言模型(如DeepSeek-V2、DeepSeek-Coder)凭借其开源特性、高性能推理能力与丰富的领域适配性,已成为工业界与学术界微调…...

XZ1018,100V,40A,NMOS 封装:TO252
封装:TO252类型:NVDS:100V VGS: 20V ID:40ARDS(ON):10V <14mΩRDS(ON):4.5V <19mΩ型号: XZ1018 封装:TO252类型…...
 指针的常见操作)
C语言(12) 指针的常见操作
指针的常见操作指针变量,有两方面的意思:一个指针指向的内容(数据值,一级)指针变量本身存储的数据 (地址值)#include <stdio.h>int main() {int a 10;int b 0 ;int c 50;int *p NULL;int *q NULL;p &a; // 对指针变量本身进行修改// 对指…...

基于晶体管逻辑的水箱自动控制器设计与实现
1. 项目概述:一个基于晶体管逻辑的自动水箱/湿度灌溉控制器 如果你也像我一样,曾经为家里的花园、阳台植物或者农村老家的储水塔手动开关水泵而烦恼,那么这个项目就是为你准备的。我设计并制作了一个完全自动化的水箱水位控制器,它…...

观察Token消耗明细,Taotoken用量看板如何帮助控制预算
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 观察Token消耗明细,Taotoken用量看板如何帮助控制预算 对于个人开发者或项目管理者而言,在使用大模型API时…...

8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由
8款网盘直链下载助手:彻底告别限速烦恼,实现高速下载自由 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移…...

Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态
Windows 11 LTSC安装微软商店的终极解决方案:3步恢复完整应用生态 【免费下载链接】LTSC-Add-MicrosoftStore Add Windows Store to Windows 11 24H2 LTSC 项目地址: https://gitcode.com/gh_mirrors/ltscad/LTSC-Add-MicrosoftStore LTSC-Add-MicrosoftStor…...