pytorch基础实践-数据与预处理
文章目录
- 数据集
- Fashion-MNIST 数据集
- 数据预处理
- 包的导入
- 在Pytorch中进行 ETL
- 利用torchvison包获取和处理数据集(E+T)
- 访问数据集
- 访问和查看 train_set 中的单个数据
- 利用 DataLoader 成批访问数据
数据集
Fashion-MNIST 数据集
-
MNIST
MNIST,Modified National Institute of Standards and Technology database,前面加了“modified ”是因为这个数据集已经是在原始的 NIST 数据集上修改过的版本。简单来说 MNIST 就是一个包含了 0-9 十个数字(十个类别)的手写图片数据集,都是灰度图片,每张图片 28x28 像素,每个类别 7000 张图片,一共 70000 张。并且划分了 60000 张图片作为训练集,10000 张图片作为测试集。

MNIST 在图像分类领域非常流行,主要有两个原因:一是这个数据集特别简单,适合新手上手;二是学术圈为了比较各自的算法优劣,会在相同的数据集上训练算法,就是 MNIST。MNIST 也有它的问题就是太简单了(图像分类领域的“hello world”),所以有一帮人就开发了 Fashion-MNIST 想要来取代 MNIST。
-
Fashion-MNIST
Fashion-MNIST 是一个德国的时装公司 Zalando 下面的研究院 Zalando Research 开发的,它用10类服装的图片取代了十类手写数字图片。十个类别分别是:
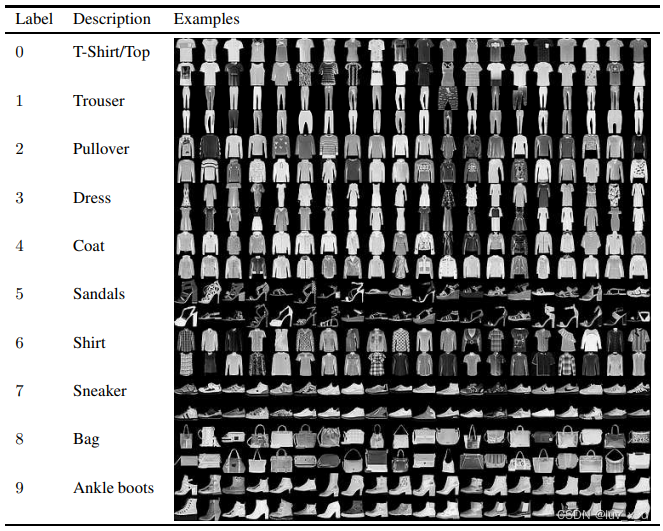
Fashion-MNIST 的设计理念就是作为 MNIST 的直接取代(direct dropin replacement),就是说以前使用 MNIST 的模型,除了数据集的链接(URL),其他什么都不用改。但替换之后的图像分类有了更高的难度。所以 Fashion-MNIST 和 MNIST 一样,都是灰度图片,28x28 像素,每类 7000 张,一共 70000 张,其中训练集 60000 张,测试集 10000 张。数据集链接
Fashion-MNIST 是直接从 Zalando 网站上的商品图片提取出来制作的,包括以下7步:① 转换为PNG;② 裁剪;③ 长边缩放为28像素;④ 锐化;⑤ 补足空白;⑥ 取负片;⑦ 取灰度。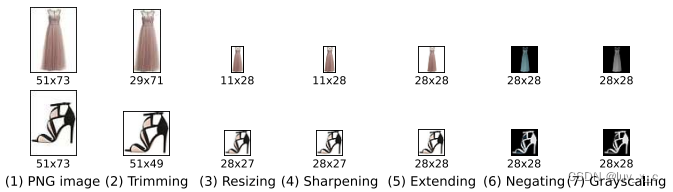
数据预处理
通过 PyTorch 的 torchvision 包获取 Fashion-MNIST 数据集。
一般而言,对一个数据集的预处理流程为 ETL,即包含 extract、transform、load 三个步骤。
1.Extract - Get the Fashion-MNIST image data from the data source.Transform - 2.Transform image data into a desirable PyTorch tensor format.
3.Load - Put data into a suitable structure to make it easily accessible.
完成 ETL 流程之后,就可以开始构建和训练深度学习模型。
包的导入
需要把所有需要的PyTorch包导入:
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as Fimport torchvision
import torchvision.transforms as transforms
对各个包的描述如下:
- torch - The top-level PyTorch package and tensor library.
- torch.nn - A subpackage that contains modules and extensible classes for building neural networks.
- torch.optim - A subpackage that contains standard optimization operations like SGD and Adam.
- torch.nn.functional - A functional interface that contains typical operations used for building neural networks like loss functions and convolutions.
- torchvision - A package that provides access to popular datasets, model architectures, and image transformations for computer vision.
- torchvision.transforms - An interface that contains common transforms for image processing.
在Pytorch中进行 ETL
对于 ETL 流程,PyTorch 提供了两个类(class):

使用 PyTorch 创建自定义的数据集,我们通过创建子类并继承 Dataset 中的函数,来实现 Dataset 的扩展,然后就可以传递给 DataLoader 对象。
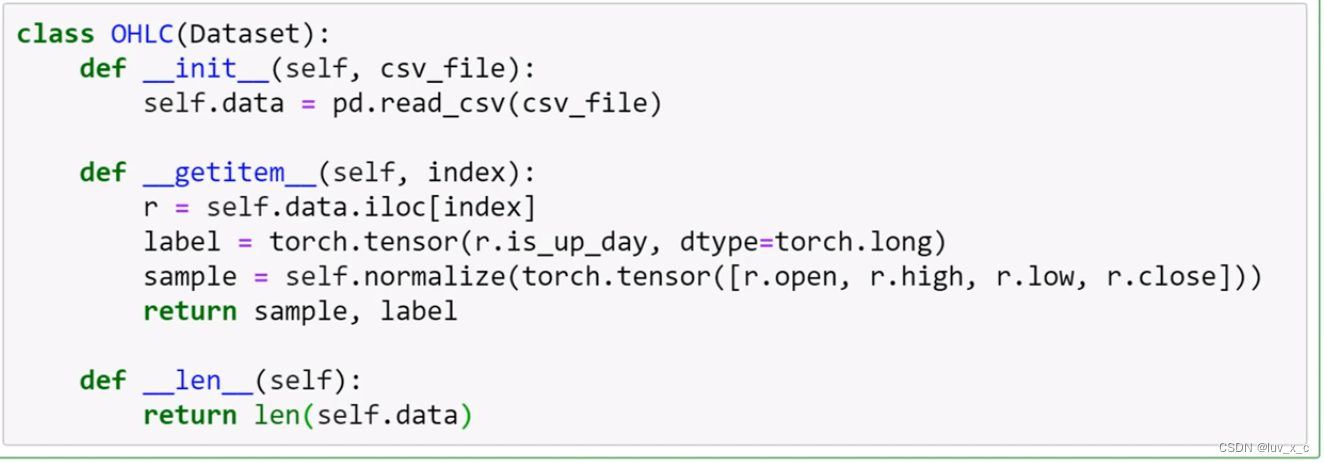
len() 和 getitm() 是其中两个必要的函数,前者的功能是计算数据集的长度,后者的功能是在数据集中按指定的索引编号将数据取出。
利用torchvison包获取和处理数据集(E+T)
利用 torchvision 获取并创建 Fashion-MNIST 数据集的一份实例(instance),这个过程中同时完成的数据集的获取(E)和转化(T),代码如下:
train_set = torchvision.datasets.FashionMNIST(root='./data',train=True,download=True,transform=transforms.Compose([transforms.ToTensor()])
)

参数解释如下:
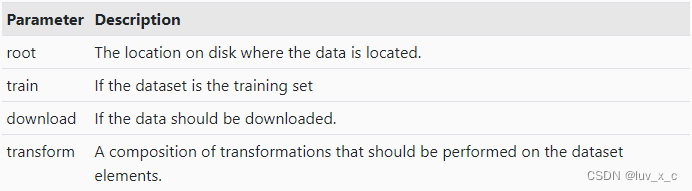
因为希望将图片数据集转换为张量,所以在 transform 中使用了 transforms.ToTensor();将此数据集命名为train_set,是因为我们希望将其作为训练数据;另外数据集仅会被下载一次,程序下载之前会检查本地有没有。
之后将获取的 train_set 打包给 DataLoader,使得数据集可以通过 DataLoader 方便的访问和加载(L):
train_loader = torch.utils.data.DataLoader(train_set)
至此已经完成了数据集的 Extract(利用url从网页下载)和 Transform(上面的transforms.ToTensor()),并且已经打包给了 DataLoader,可以通过 DataLoader 来实现 Load,比如设置 batch_size 和 shuffle:
train_loader = torch.utils.data.DataLoader(train_set,batch_size=1000,shuffle=True
)
访问数据集
首先可以查看数据集中有多少个图片,使用 Python 的 len() 函数:
>len(train_set)60000
查看所有图片的标签,只需要访问 train_set.targets 属性:
> train_set.targets
tensor([9, 0, 0, ..., 3, 0, 5])
如果希望查看数据集中每一个类别有多少个标签(即多少个图片,适用于图片全部有标记的情况),可以用 PyTorch 的 bincount() 函数:
>train_set.targets.bincount()
tensor([6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000, 6000])
Fashion-MNIST 数据集中每一类都有 6000 个图片和标签对,这种每一类的样本数量相等的数据集称作 balanced dataset,反之类别之间样本数量不一致的数据集称为 unbalanced dataset。
访问和查看 train_set 中的单个数据
一次只查看单张图片,首先将 train_set 这个对象传递给 Python 内建的 iter() 函数,它会返回一个可以在其上迭代的代表数据流(stream of data)的对象,使我们可以沿数据流访问数据。
接下来再使用 Python 的内建函数 next() 来获取数据流中的下一个数据元素,如此就可以获取数据集中的一个单独数据(因此下面命名变量都是单数形式):
> sample = next(iter(train_set))> len(sample)
2> type(sample)
tuple
获取的一个单独数据长度为 2,这是因为数据集是由图片-标签对的形式组成的,每一个 data element 中都包含两个东西,一个是存储图片数据的张量,另一个是其对应的标签。
sample 的数据类型是 tuple,tuple 是Python中的一种 sequence types,是一个可以迭代的顺序不可变的数据序列。
可以用 sequence unpacking 来将其中的图像和标签分别提取出来:
> image, label = sample
和下面这种写法是等效的:
> image = sample[0]
> label = sample[1]
查看数据类型和shape:
> type(image)
torch.Tensor> type(label)
int> image.shape
torch.Size([1, 28, 28]) > torch.tensor(label).shape
torch.Size([])
Fashion-MNIST 数据集是单通道的灰度图,所一张图片的 tensor shape 就是 1x28x28。把没有用的颜色通道 squeeze 掉:
> image.squeeze().shape
torch.Size([28, 28])
显示出图片和标签:
> plt.imshow(image.squeeze(), cmap="gray")
> torch.tensor(label)
tensor(9)
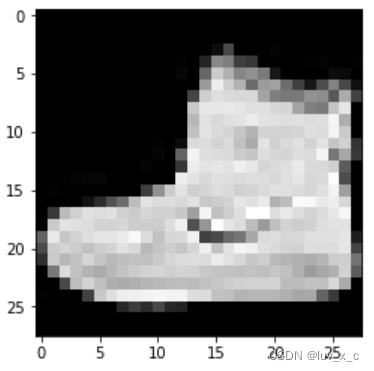
标签是“9”,代表靴子,与图片是相符的。
利用 DataLoader 成批访问数据
> batch = next(iter(train_loader))> len(batch)
2> type(batch)
list
list 也是一种 Python sequence types,与 tuple 的不同在于 list 是可变序列。
一次访问 10 张图片,则需要给 DataLoader 指定 batch_size:
> display_loader = torch.utils.data.DataLoader(train_set, batch_size=10
)
关于 DataLoader 中的“shuffle=True”:如果“shuffle=True”,则每次调用 next() 返回的 batch 都会不同,训练集中的第一组样本将在第一次调用 next() 时返回,这个功能默认是 False。
可以像上面一样对 display_loader 使用 iter() 和 next() 来每次查看 10 张图片:
> batch = next(iter(display_loader))
> print('len:', len(batch))
len: 2
进行 sequence unpacking:
> images, labels = batch> print('types:', type(images), type(labels))
> print('shapes:', images.shape, labels.shape)
types: <class 'torch.Tensor'> <class 'torch.Tensor'>
shapes: torch.Size([10, 1, 28, 28]) torch.Size([10])
此时返回的图像张量是 [10, 1, 28, 28] 的四阶张量,标签是一个长度为 10 的一阶张量。可以单独查看其中每一个图片和标签:
> images[0].shape
torch.Size([1, 28, 28])> labels[0]
tensor(9)
一次绘制一批图像,可以使用 torchvision.utils.make_grid() 函数创建一个可以按网格绘制图片的 grid:
> grid = torchvision.utils.make_grid(images, nrow=10) # nrow指定每行多少列图片> plt.figure(figsize=(15,15)) # 缩放图像显示大小?
> plt.imshow(grid.permute(1,2,0)) # 这一步让grid符合imshow的要求,不清楚细节> print('labels:', labels)
labels: tensor([9, 0, 0, 3, 0, 2, 7, 2, 5, 5])\

相关文章:
pytorch基础实践-数据与预处理
文章目录 数据集Fashion-MNIST 数据集 数据预处理包的导入在Pytorch中进行 ETL利用torchvison包获取和处理数据集(ET) 访问数据集访问和查看 train_set 中的单个数据利用 DataLoader 成批访问数据 数据集 Fashion-MNIST 数据集 MNIST MNIST,…...

Java智慧工地系统源码(微服务+Java+Springcloud+Vue+MySQL)
智慧工地系统是依托物联网、互联网、AI、可视化建立的大数据管理平台,是一种全新的管理模式,能够实现劳务管理、安全施工、绿色施工的智能化和互联网化。围绕施工现场管理的人、机、料、法、环五大维度,以及施工过程管理的进度、质量、安全三…...

PV3D: A 3D GENERATIVE MODEL FOR PORTRAITVIDEO GENERATION 【2023 ICLR】
ICLR:International Conference on Learning Representations CCF-A 国际表征学习大会:深度学习的顶级会议 生成对抗网络(GANs)的最新进展已经证明了生成令人惊叹的逼真肖像图像的能力。虽然之前的一些工作已经将这种图像gan应用于无条件的2D人像视频生…...

Apache BeanUtils工具介绍
beanutils,顾名思义,是java bean的一个工具类,可以帮助我们方便的读取(get)和设置(set)bean属性值、动态定义和访问bean属性;细心的话,会发现其实JDK已经提供了一个java.beans包,同样可以实现以上功能&…...

java 原子操作 笔记
目录 java 变量原子操作 java byte[] 原子操作 java 变量原子操作 public class Counter {private int count 0;public synchronized void increment() {count;}public synchronized int getCount() {return count;} } java byte[] 原子操作 public class SharedArray {pr…...

什么是线程安全性问题?Java中有哪些常用的同步机制来解决线程安全性问题?
线程安全性问题是指在多线程环境下,多个线程同时访问和修改共享数据时可能引发的数据不一致、竞态条件和并发访问异常等问题。线程安全性问题的主要原因是多个线程之间的并发执行,导致数据的访问和修改顺序不确定,从而产生不一致的结果。 为…...
Gitlab 安装全流程
Version:gitlab-ce:16.2.4-ce.0 简介 Gitlab 是一个开源的 Git 代码仓库系统,可以实现自托管的 Github 项目,即用于构建私有的代码托管平台和项目管理系统。系统基于 Ruby on Rails 开发,速度快、安全稳定。它拥有与 Github 类似…...
pdf转word最简单方法~
pdf转word最简单方法!pdf转word最简单方法我们都知道,PDF文件是一种只读文件格式,无法按照需求对PDF文件进行更改与编辑,从而影响到了PDF文件的使用。所以,我们需要将PDF文件转换为word文档,以此来保证文件…...

Android 9.0 WiFi 扫描结果上报和获取流程
本文是对wifi扫描结果上报和获取过程的java层代码流程梳理总结。 我们先分析扫描成功的上报和获取过程。 一、WiFi扫描成功的上报和获取过程 WiFi扫描成功的上报和获取大致是由三条不连贯流程组成的,分别是通知framework和WifiTracker获取扫描结果以及应用主动获取…...

Java 项目日志实例:Log4j2
点击下方关注我,然后右上角点击...“设为星标”,就能第一时间收到更新推送啦~~~ Apache Log4j 2 是对 Log4j 的升级,与其前身 Log4j 1.x 相比有了显着的改进,并提供了许多 Logback 可用的改进,同时支持 JCL 以及 SLF4J…...
)
Effective C++条款14——在资源管理类中小心coping行为(资源管理)
条款13导入这样的观念:“资源取得时机便是初始化时机”(Resource Acquisitionls Initialization; RAII),并以此作为“资源管理类”的脊柱,也描述了auto_ ptr和tr1::shared ptr如何将这个观念表现在 heap-based资源上。然而并非所有资源都是heap-based&am…...
【网络教程】如何创建/添加钉钉机器人以及如何获取机器人的Token/Secret
文章目录 创建钉钉机器人添加钉钉机器人获取机器人的Token/Secret相关网站创建钉钉机器人 这里以PC端的操作为例,按照如下操作进行 访问 钉钉开放平台选择机器人选项卡,点击右上角的创建应用,这里会有一个弹窗,我这里选择的是继续使用旧版,如图按照要求填写相关信息创建自…...
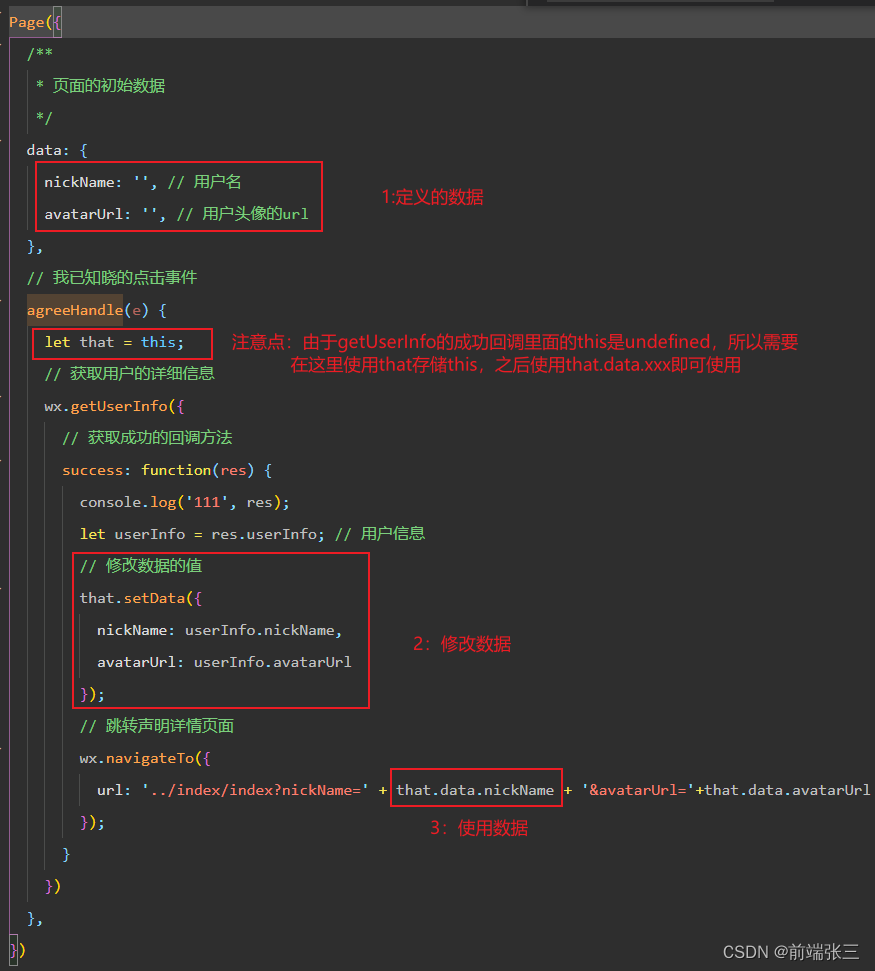
wx原生微信小程序入门常用总结
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、定义值和修改值1、定义值2、修改值(1)代码(2)代码说明(3)注意点 二、点击事件三、微…...
制作一个专属于安防监控业的小程序商城
随着科技的发展和人们生活水平的提高,安防监控设备在我们的日常生活中起到了越来越重要的作用。因此,建立一个安防监控设备商城小程序就变得尤为重要。下面将介绍如何建立这样一个小程序。 第一步,登录乔拓云平台后台,进入商城管理…...

基于java羽毛球馆管理系统设计与实现
摘 要 时代的变化速度实在超出人类的所料,21世纪,计算机已经发展到各行各业,各个地区,它的载体媒介-计算机,大众称之为的电脑,是一种特高速的科学仪器,比人类的脑袋要灵光无数倍,什么…...

安装elasticsearch8.9.0及修改配置
安装es流程 打开文件,添加以下行 vim /etc/sysctl.conf vm.max_map_count=262144重启生效 sysctl -p创建用户 useradd es passwd es修改es目录所属用户 chown -R es:es /opt/elasticsearch-8.9.0如果内存不足,可以修改es的初始化内存和Max内存,修改文件/opt/elasticsearch-8…...
如何构建高效的接口自动化测试框架?看完你就会了...
在选择接口测试自动化框架时,需要根据团队的技术栈和项目需求来综合考虑。对于测试团队来说,使用Python相关的测试框架更为便捷。无论选择哪种框架,重要的是确保 框架功能完备,易于维护和扩展,提高测试效率和准确性。今…...

53 | 金融行业股票销售指标分析
金融行业股票销售指标分析 引言: 金融行业中的股票销售指标分析是评估股票市场表现、投资者行为以及交易平台效果的重要手段。通过深入分析关键的销售指标,投资者、金融机构和交易平台可以更好地了解市场趋势,作出明智的投资决策,优化交易策略。本文将探讨金融行业股票销售…...

qiuzhiji1
前言:记录一下毕业后的求职历程 背景:18级 湖北理工学院计算机学院(黄石) 网络工程 本文初次撰写于2023年8月17日,正处于离职找工作的空档期,部分经历可能记不清了。所有内容尽量保证了客观,主要是分享一下自己的经历,顺带锻炼文字能力。 文章会不定期更新,较新的日期会…...
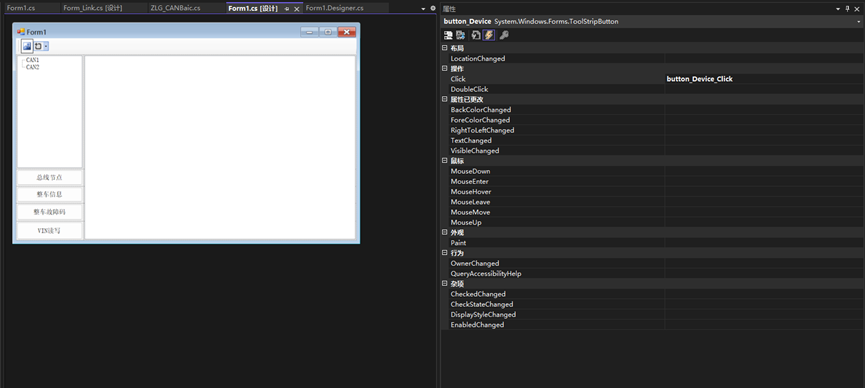
使用VisualStudio制作上位机(二)
文章目录 使用VisualStudio制作上位机(二)第三部分:GUI内部函数设计使用VisualStudio制作上位机(二) Author:YAL 第三部分:GUI内部函数设计 事件添加 给窗体或窗体按钮相关的操作添加事件有两种方式,事件的名字直白的表面了这是什么事件。 直接双击界面,自动生成窗…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

安宝特方案丨XRSOP人员作业标准化管理平台:AR智慧点检验收套件
在选煤厂、化工厂、钢铁厂等过程生产型企业,其生产设备的运行效率和非计划停机对工业制造效益有较大影响。 随着企业自动化和智能化建设的推进,需提前预防假检、错检、漏检,推动智慧生产运维系统数据的流动和现场赋能应用。同时,…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

Matlab | matlab常用命令总结
常用命令 一、 基础操作与环境二、 矩阵与数组操作(核心)三、 绘图与可视化四、 编程与控制流五、 符号计算 (Symbolic Math Toolbox)六、 文件与数据 I/O七、 常用函数类别重要提示这是一份 MATLAB 常用命令和功能的总结,涵盖了基础操作、矩阵运算、绘图、编程和文件处理等…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...

Python 包管理器 uv 介绍
Python 包管理器 uv 全面介绍 uv 是由 Astral(热门工具 Ruff 的开发者)推出的下一代高性能 Python 包管理器和构建工具,用 Rust 编写。它旨在解决传统工具(如 pip、virtualenv、pip-tools)的性能瓶颈,同时…...

C#中的CLR属性、依赖属性与附加属性
CLR属性的主要特征 封装性: 隐藏字段的实现细节 提供对字段的受控访问 访问控制: 可单独设置get/set访问器的可见性 可创建只读或只写属性 计算属性: 可以在getter中执行计算逻辑 不需要直接对应一个字段 验证逻辑: 可以…...
的使用)
Go 并发编程基础:通道(Channel)的使用
在 Go 中,Channel 是 Goroutine 之间通信的核心机制。它提供了一个线程安全的通信方式,用于在多个 Goroutine 之间传递数据,从而实现高效的并发编程。 本章将介绍 Channel 的基本概念、用法、缓冲、关闭机制以及 select 的使用。 一、Channel…...

计算机基础知识解析:从应用到架构的全面拆解
目录 前言 1、 计算机的应用领域:无处不在的数字助手 2、 计算机的进化史:从算盘到量子计算 3、计算机的分类:不止 “台式机和笔记本” 4、计算机的组件:硬件与软件的协同 4.1 硬件:五大核心部件 4.2 软件&#…...

比较数据迁移后MySQL数据库和OceanBase数据仓库中的表
设计一个MySQL数据库和OceanBase数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...