基于YOLOV8模型的课堂场景下人脸目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOV8模型的课堂场景下人脸目标检测系统可用于日常生活中检测与定位课堂场景下人脸,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检测算法训练数据集,使用Pysdie6库来搭建前端页面展示系统。另外本系统支持的功能还包括训练模型的导入、初始化;检测置信分与检测后处理IOU阈值的调节;图像的上传、检测、可视化结果展示与检测结果导出;视频的上传、检测、可视化结果展示与检测结果导出;摄像头的图像输入、检测与可视化结果展示;已检测目标个数与列表、位置信息;前向推理用时等功能。本博文提供了完整的Python代码与安装和使用教程,适合新入门的朋友参考,部分重要代码部分都有注释,完整代码资源文件请转至文末的下载链接。

需要源码的朋友在后台私信博主获取下载链接
基本介绍
近年来,机器学习和深度学习取得了较大的发展,深度学习方法在检测精度和速度方面与传统方法相比表现出更良好的性能。YOLOv8 是 Ultralytics 公司继 YOLOv5 算法之后开发的下一代算法模型,目前支持图像分类、物体检测和实例分割任务。YOLOv8 是一个 SOTA模型,它建立在之前YOLO 系列模型的成功基础上,并引入了新的功能和改进,以进一步提升性能和灵活性。具体创新包括:一个新的骨干网络、一个新的 Ancher-Free 检测头和一个新的损失函数,可以在从 CPU 到 GPU 的各种硬件平台上运行。因此本博文利用YOLOv8目标检测算法实现一种基于YOLOV8模型的课堂场景下人脸目标检测系统,再使用Pyside6库搭建出界面系统,完成目标检测页面的开发。本博主之前发布过关于YOLOv5算法的相关模型与界面,需要的朋友可从我之前发布的博客查看。另外本博主计划将YOLOv5、YOLOv6、YOLOv7和YOLOv8一起联合发布,需要的朋友可以持续关注,欢迎朋友们关注收藏。
环境搭建
(1)打开项目目录,在搜索框内输入cmd打开终端

(2)新建一个虚拟环境(conda create -n yolo8 python=3.8)

(3)激活环境,安装ultralytics库(yolov8官方库),pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple

(4)注意到这种安装方式只会安装cpu版torch,如需安装gpu版torch,需在安装包之前先安装torch:pip install torch2.0.1+cu118 torchvision0.15.2+cu118 -f https://download.pytorch.org/whl/torch_stable.html;再,pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple

(5)安装图形化界面库pyside6:pip install pyside6 -i https://pypi.tuna.tsinghua.edu.cn/simple
界面及功能展示
下面给出本博文设计的软件界面,整体界面简洁大方,大体功能包括训练模型的导入、初始化;置信分与IOU阈值的调节、图像上传、检测、可视化结果展示、结果导出与结束检测;视频的上传、检测、可视化结果展示、结果导出与结束检测;已检测目标列表、位置信息;前向推理用时。初始界面如下图:

模型选择与初始化
用户可以点击模型权重选择按钮上传训练好的模型权重,训练权重格式可为.pt、.onnx以及engine等,之后再点击模型权重初始化按钮可实现已选择模型初始化的配置。

置信分与IOU的改变
在Confidence或IOU下方的输入框中改变值即可同步改变滑动条的进度,同时改变滑动条的进度值也可同步改变输入框的值;Confidence或IOU值的改变将同步到模型里的配置,将改变检测置信度阈值与IOU阈值。
图像选择、检测与导出
用户可以点击选择图像按钮上传单张图像进行检测与识别,上传成功后系统界面会同步显示输入图像。

再点击图像检测按钮可完成输入图像的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

再点击检测结果展示按钮可在系统左下方显示输入图像检测的结果,系统将显示识别出图片中的目标的类别、位置和置信度信息。

点击图像检测结果导出按钮即可导出检测后的图像,在保存栏里输入保存的图片名称及后缀即可实现检测结果图像的保存。

点击结束图像检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频按钮来上传图像或视频,或者点击打开摄像头按钮来开启摄像头。
视频选择、检测与导出
用户点击选择视频按钮上传视频进行检测与识别,之后系统会将视频的第一帧输入到系统界面中显示。

再点击视频检测按钮可完成输入视频的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

点击暂停视频检测按钮即可实现输入视频的暂停,此时按钮变为继续视频检测,输入视频帧与帧检测结果会保留在系统界面,可点击下拉目标框选择已检测目标的坐标位置信息,再点击继续视频检测按钮即可实现输入视频的检测。
点击视频检测结果导出按钮即可导出检测后的视频,在保存栏里输入保存的图片名称及后缀即可实现检测结果视频的保存。

点击结束视频检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频按钮来上传图像或视频,或者点击打开摄像头按钮来开启摄像头。
摄像头打开、检测与结束
用户可以点击打开摄像头按钮来打开摄像头设备进行检测与识别,之后系统会将摄像头图像输入到系统界面中显示。

再点击摄像头检测按钮可完成输入摄像头的目标检测功能,之后系统会在用时一栏输出检测用时,在目标数量一栏输出已检测到的目标数量,在下拉框可选择已检测目标,对应于目标位置(即xmin、ymin、xmax以及ymax)标签值的改变。

点击结束视频检测按钮即可完成系统界面的刷新,将所有输出信息清空,之后再点击选择图像或选择视频按钮来上传图像或视频,或者点击打开摄像头按钮来开启摄像头。
算法原理介绍
本系统采用了基于深度学习的单阶段目标检测算法YOLOv8,相较于之前的YOLO系列目标检测算法,YOLOv8目标检测算法具有如下的几点优势:(1)更友好的安装/运行方式;(2)速度更快、准确率更高;(3)新的backbone,将YOLOv5中的C3更换为C2F;(4)YOLO系列第一次尝试使用anchor-free;(5)新的损失函数。YOLOv8模型的整体结构如下图所示,原图见mmyolo的官方仓库。

YOLOv8与YOLOv5模型最明显的差异是使用C2F模块替换了原来的C3模块,两个模块的结构如下图所示,原图见mmyolo的官方仓库。

另外Head 部分变化最大,从原先的耦合头变成了解耦头,并且从 YOLOv5 的 Anchor-Based 变成了 Anchor-Free。其结构对比如下图所示。

数据集介绍
本系统使用的课堂人脸数据集手动标注了人脸这一个类别,数据集总计9072张图片。该数据集中类别都有大量的旋转和不同的光照条件,有助于训练出更加鲁棒的检测模型。本文实验的课堂人脸检测识别数据集包含训练集7203张图片,验证集1869张图片,选取部分数据部分样本数据集如下图所示。由于YOLOv5算法对输入图片大小有限制,需要将所有图片调整为相同的大小。为了在不影响检测精度的情况下尽可能减小图片的失真,我们将所有图片调整为640x640的大小,并保持原有的宽高比例。此外,为了增强模型的泛化能力和鲁棒性,我们还使用了数据增强技术,包括随机旋转、缩放、裁剪和颜色变换等,以扩充数据集并减少过拟合风险。

关键代码解析
在训练阶段,我们使用了预训练模型作为初始模型进行训练,然后通过多次迭代优化网络参数,以达到更好的检测性能。在训练过程中,我们采用了学习率衰减和数据增强等技术,以增强模型的泛化能力和鲁棒性。一个简单的单卡模型训练命令如下。

在训练时也可指定更多的参数,大部分重要的参数如下所示:

在测试阶段,我们使用了训练好的模型来对新的图片和视频进行检测。通过设置阈值,将置信度低于阈值的检测框过滤掉,最终得到检测结果。同时,我们还可以将检测结果保存为图片或视频格式,以便进行后续分析和应用。本系统基于YOLOv8算法,使用PyTorch实现。代码中用到的主要库包括PyTorch、NumPy、OpenCV、Pyside6等。

Pyside6界面设计
PySide是一个Python的图形化界面(GUI)库,由C++版的Qt开发而来,在用法上基本与C++版没有特别大的差异。相对于其他Python GUI库来说,PySide开发较快,功能更完善,而且文档支持更好。在本博文中,我们使用Pyside6库创建一个图形化界面,为用户提供简单易用的交互界面,实现用户选择图片、视频进行目标检测。
我们使用Qt Designer设计图形界面,然后使用Pyside6将设计好的UI文件转换为Python代码。图形界面中包含多个UI控件,例如:标签、按钮、文本框、多选框等。通过Pyside6中的信号槽机制,可以使得UI控件与程序逻辑代码相互连接。
实验结果与分析
在实验结果与分析部分,我们使用精度和召回率等指标来评估模型的性能,还通过损失曲线和PR曲线来分析训练过程。在训练阶段,我们使用了前面介绍的数据集进行训练,使用了YOLOv8算法对数据集训练,总计训练了100个epochs。在训练过程中,我们使用tensorboard记录了模型在训练集和验证集上的损失曲线。从下图可以看出,随着训练次数的增加,模型的训练损失和验证损失都逐渐降低,说明模型不断地学习到更加精准的特征。在训练结束后,我们使用模型在数据集的验证集上进行了评估,得到了以下结果。

下图展示了我们训练的YOLOv8模型在验证集上的PR曲线,从图中可以看出,模型取得了较高的召回率和精确率,整体表现良好。

下图展示了本博文在使用YOLOv8模型对数据集进行训练时候的Mosaic数据增强图像。

综上,本博文训练得到的YOLOv8模型在数据集上表现良好,具有较高的检测精度和鲁棒性,可以在实际场景中应用。另外本博主对整个系统进行了详细测试,最终开发出一版流畅的高精度目标检测系统界面,就是本博文演示部分的展示,完整的UI界面、测试图片视频、代码文件等均已打包上传,感兴趣的朋友可以关注我私信获取。
其他基于深度学习的目标检测系统如西红柿、猫狗、山羊、野生目标、烟头、二维码、头盔、交警、野生动物、野外烟雾、人体摔倒识别、红外行人、家禽猪、苹果、推土机、蜜蜂、打电话、鸽子、足球、奶牛、人脸口罩、安全背心、烟雾检测系统等有需要的朋友关注我,从博主其他视频中获取下载链接。
完整项目目录如下所示:

相关文章:
基于YOLOV8模型的课堂场景下人脸目标检测系统(PyTorch+Pyside6+YOLOv8模型)
摘要:基于YOLOV8模型的课堂场景下人脸目标检测系统可用于日常生活中检测与定位课堂场景下人脸,利用深度学习算法可实现图片、视频、摄像头等方式的目标检测,另外本系统还支持图片、视频等格式的结果可视化与结果导出。本系统采用YOLOv8目标检…...
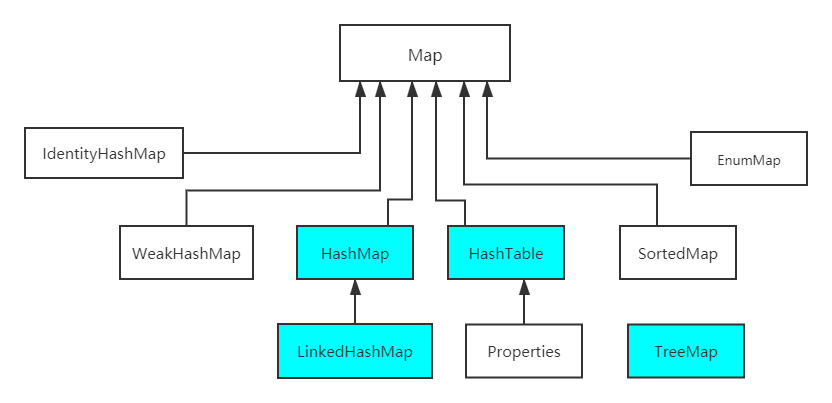
java八股文面试[数据结构]——Map有哪些子类
知识来源: 【23版面试突击】 用过哪些Map类,都有什么区别,HashMap是线程安全的吗?_哔哩哔哩_bilibili https://www.cnblogs.com/bubbleboom/p/12694013.html...

司徒理财:8.23今日黄金原油走势分析附操作策略
黄金走势分析: 黄金下跌遇阻,短线开启震荡调整走势,但跌势依旧没有改变,没有突破1906压力前,还是偏空走势,反弹继续干空。趋势行情,不要轻言翻转!即便下跌结束,…...

使用动态IP是否会影响网络
今天我们要谈论的话题是关于动态IP和网络的关系。也许有些小伙伴对这个概念还比较陌生,但别担心,我会简单明了的给你理清楚。让我们一起看看动态IP到底能否影响到网络。 首先,我们先来搞明白什么是动态IP。在互联网世界中,每一个连…...

Linux学习笔记-常用指令说明
本文目录 一、Linux指令笔记 二、"授人以鱼,不如授人以渔" 一、Linux指令笔记 0、cd 命令是 change dir 的简写,它可以把终端当前所在的路径切换至目标路径。 1、mkdir 建立文件夹。是 make directory 的简写,它可以在文件系统中创建一个新的目…...

MyBatisPlus进阶版
1.映射 1.1自动映射 【1】表名和实体类名映射 -> 表名user 实体类名User 【2】字段名和实体类属性名映射 -> 字段名name 实体类属性名name 【3】字段名下划线命名方式和实体类属性小驼峰命名方式映射 -> 字段名 user_email 实体类属性名 userEmail MybatisPlus…...
安防视频云平台EasyNVR视频汇聚平台硬件无法进入服务器的问题处理方法
EasyNVR是基于RTSP/Onvif协议的视频接入、处理及分发的安防视频云平台,可提供的视频能力包括:设备接入、实时视频直播、录像、云存储、录像回放与检索、告警、级联等,平台可支持将接入的视频流进行全平台、全终端的分发,分发的视频…...
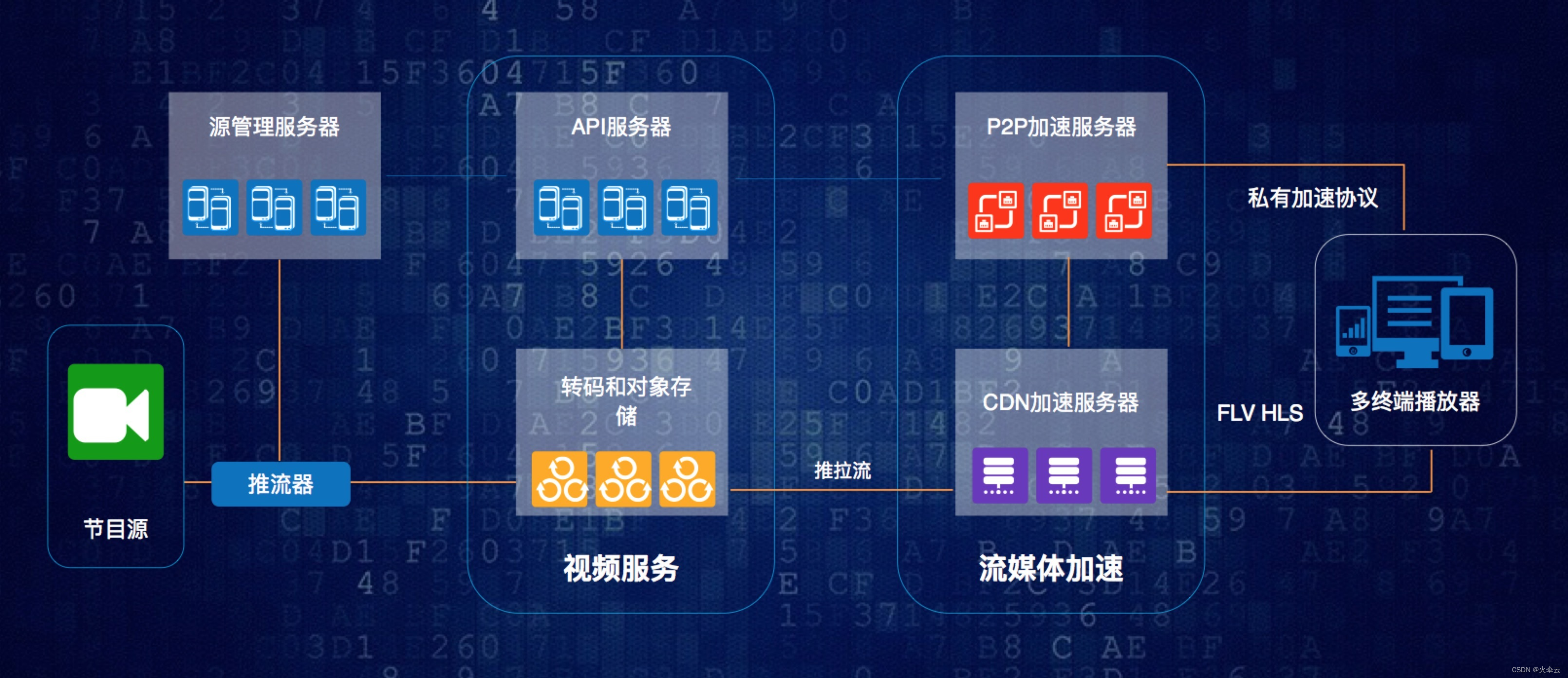
流媒体内容分发终极解决方案:当融合CDN与P2P视频交付结合
前言 随着互联网的发展,流媒体视频内容日趋增多,已经成为互联网信息的主要承载方式。相对传统的文字,图片等传统WEB应用,流媒体具有高数据量,高带宽、高访问量和高服务质量要求的特点,而现阶段互联网“尽力…...

根据源码,模拟实现 RabbitMQ - 内存数据管理(4)
目录 一、内存数据管理 1.1、需求分析 1.2、实现 MemoryDataCenter 类 1.2.1、ConcurrentHashMap 数据管理 1.2.2、封装交换机操作 1.2.3、封装队列操作 1.2.4、封装绑定操作 1.2.5、封装消息操作 1.2.6、封装未确认消息操作 1.2.7、封装恢复数据操作 一、内存数据管理…...

Apache Flume架构和原理
Apache Flume是一个开源的分布式、可靠的日志收集和聚合系统,旨在将大量的日志数据从不同的数据源(如应用程序、服务器、设备)收集到中心存储或数据湖中。Flume的架构设计允许用户在大规模数据流的情况下实现可靠的数据传输和处理。 Flume特性 Apache Flume是一个用于收集…...

代码随想录算法训练营day38 | LeetCode 509. 斐波那契数 70. 爬楼梯 746. 使用最小花费爬楼梯
509. 斐波那契数(题目链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台) 思路:经典的dp题。 int fib(int n){if(n 0 || n 1) return n;return fib(n-1) fib(n-2); } 70. 爬楼梯(题目…...

Linux基本指令【下】
欢迎来到Cefler的博客😁 🕌博客主页:那个传说中的man的主页 🏠个人专栏:题目解析 🌎推荐文章:题目大解析3 目录 👉🏻cat👉🏻echo(输出…...
向量检索:基于ResNet预训练模型构建以图搜图系统
1 项目背景介绍 以图搜图是一种向量检索技术,通过上传一张图像来搜索并找到与之相关的其他图像或相关信息。以图搜图技术提供了一种更直观、更高效的信息检索方式。这种技术应用场景和价值非常广泛,经常会用在商品检索及购物、动植物识别、食品识别、知…...

SpringBoot 响应头添加版本号、打包项目后缀添加版本号和时间
文章目录 响应头添加版本号获取版本号添加响应处理器请求结果 打包项目后缀添加版本号和时间实现打包结果 响应头添加版本号 获取版本号 在 pom.xml 中,在 project.version 下定义版本号 在 application.yml 获取 pom.xml 中 project.version 中的信息 添加响应处…...

优化指南:带宽限制的可行策略
大家好!作为一名专业的爬虫程序员,我们经常面临的一个挑战就是带宽限制。尤其是在需要快速采集大量数据时,带宽限制成为了我们提升爬虫速度的一大阻碍。今天,我将和大家分享一些解决带宽限制的可行策略,希望能帮助大家…...

计算机提示mfc120u.dll缺失(找不到)怎么解决
在计算机领域,mfc120u.dll是一个重要的动态链接库文件。它包含了Microsoft Foundation Class (MFC) 库的特定版本,用于支持Windows操作系统中的应用程序开发。修复mfc120u.dll可能涉及到解决与该库相关的问题或错误。这可能包括程序崩溃、运行时错误或其…...
Java基于SpringBoot+Vue实现酒店客房管理系统(2.0 版本)
文章目录 一、前言介绍二、系统结构三、系统详细实现3.1用户信息管理3.2会员信息管理3.3客房信息管理3.4收藏客房管理3.5用户入住管理3.6客房清扫管理 四、部分核心代码 博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝30W,Csdn博客专家、掘金/华为云/阿里云…...
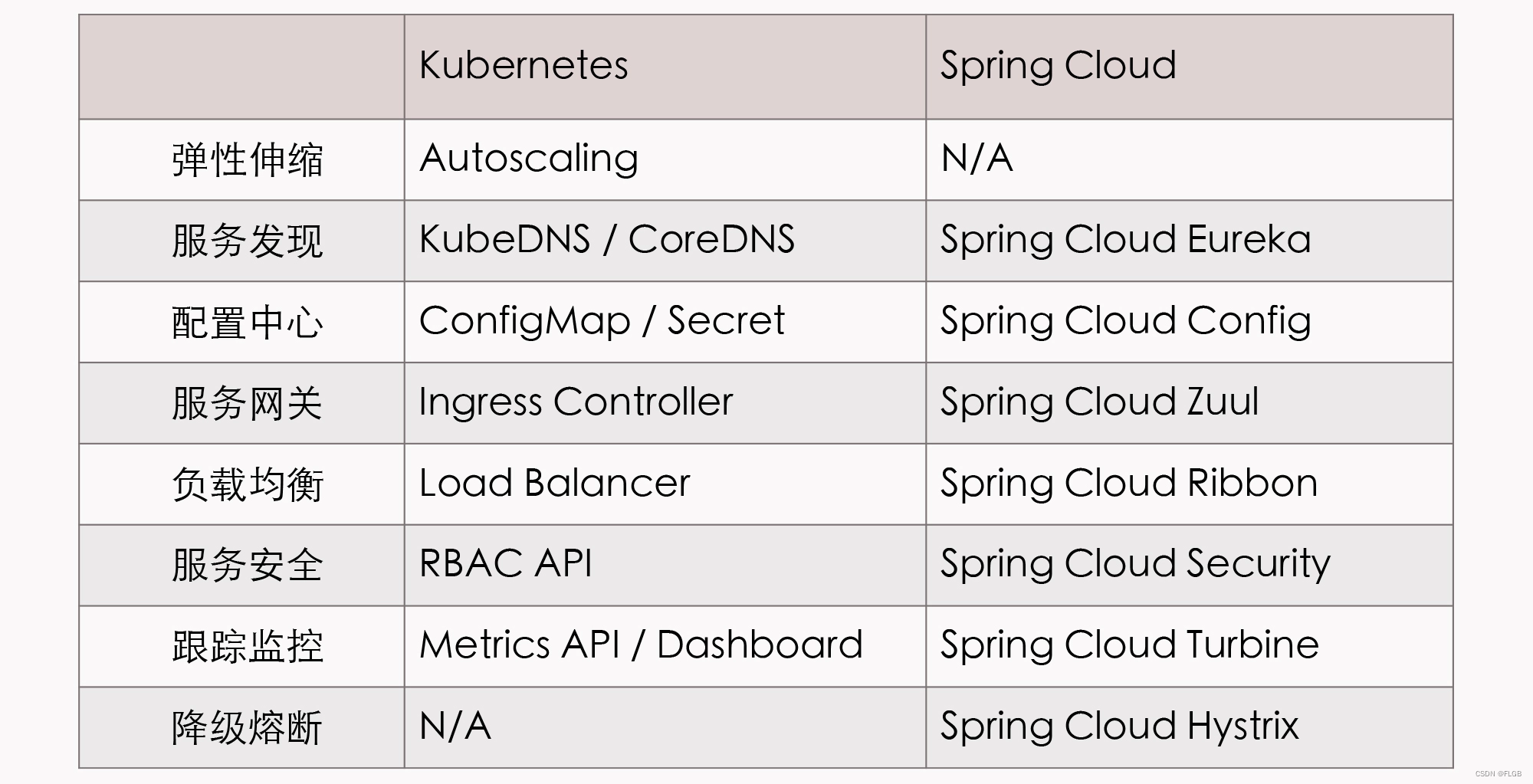
微服务架构2.0--云原生时代
云原生 云原生(Cloud Native)是一种关注于在云环境中构建、部署和管理应用程序的方法和理念。云原生应用能够最大程度地利用云计算基础设施的优势,如弹性、自动化、可伸缩性和高可用性。这个概念涵盖了许多方面,包括架构、开发、…...
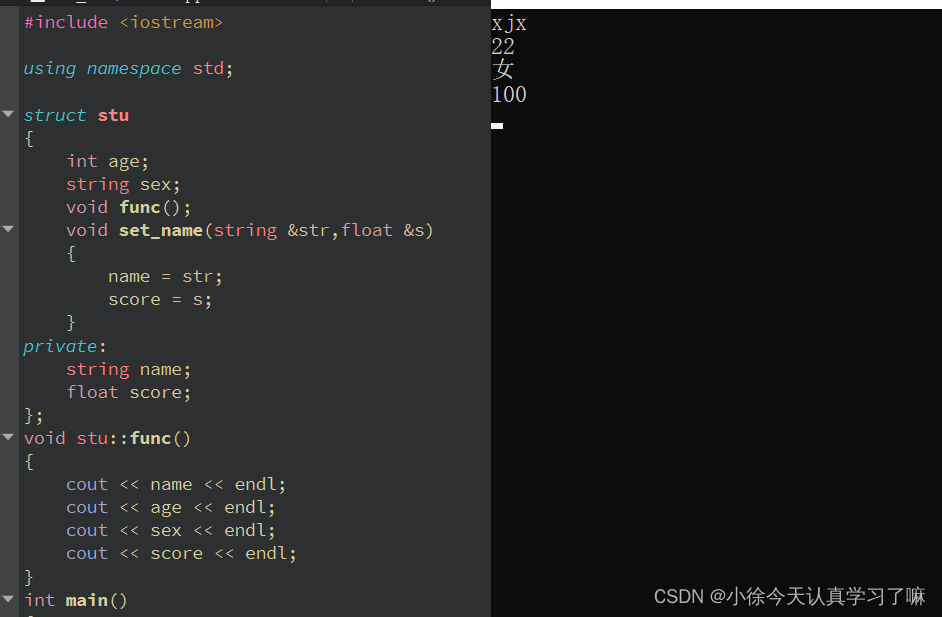
C++day2作业(2023.8.22)
1.定义一个学生的结构体,包含学生的姓名,年龄,成绩,性别,学生的成绩,姓名,定义为私有权限;定义一个学生类型的结构体变量,设置公有函数用于给学生的成绩和名字进行赋值&a…...

在 Spring Boot 中使用 OpenAI ChatGPT API
1、开始咯 我们来看看如何在 Spring Boot 中调用 OpenAI ChatGPT API。 我们将创建一个 Spring Boot 应用程序,该应用程序将通过调用 OpenAI ChatGPT API 生成对提示的响应。 2、OpenAI ChatGPT API 在开始具体讲解之前,让我们先探讨一下我们将在本教…...

告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点
告别命令行!用Python脚本批量管理Docker容器,效率提升不止一点点每次在终端敲入docker ps、docker stop、docker rm时,你是否想过——当容器数量超过两位数,这种重复劳动是否在消耗你的生命?去年我们团队在迁移微服务架…...

UE4动画蓝图实战:用双骨骼IK节点搞定手部穿模,附完整蓝图节点截图
UE4动画蓝图实战:双骨骼IK节点解决手部穿模的完整指南在角色动画开发中,手部穿模问题堪称"视觉杀手"。想象一下精心设计的角色挥拳时,拳头直接穿过墙壁或敌人身体——这种违和感足以毁掉整个场景的沉浸感。本文将彻底解决这个痛点&…...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

ShrinkBox后门攻击:如何让自动驾驶模型“看错”距离,威胁ML-ADAS安全
1. 项目概述在自动驾驶和高级驾驶辅助系统(ADAS)领域,基于机器学习的目标检测模型,如YOLO系列,已成为感知环境、实现碰撞预警的核心组件。这些模型通过实时识别和定位道路上的车辆、行人等目标,为后续的距离…...

别再只用递归了!用C语言栈实现非递归快速排序,内存效率提升实战
从递归到迭代:C语言栈实现非递归快速排序的工程实践 在嵌入式开发和大规模数据处理场景中,递归实现的快速排序常常面临栈溢出风险。当排序10万个元素的数组时,递归深度可能达到log₂100000≈17层,在仅有2KB栈空间的STM32F103上极易…...

原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析
原神私服新纪元:KCN-GenshinServer图形化服务端全功能解析 【免费下载链接】KCN-GenshinServer 基于GC制作的原神一键GUI多功能服务端。 项目地址: https://gitcode.com/gh_mirrors/kc/KCN-GenshinServer 你是否曾想过拥有一个完全由自己掌控的提瓦特大陆&am…...

深度解析:JetBrains IDE试用期重置机制的技术实现
深度解析:JetBrains IDE试用期重置机制的技术实现 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 在软件开发工作流中,JetBrains IDE试用期管理是一个常见的技术挑战,尤其是在多…...

3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南
3个实用场景教你轻松解锁网易云音乐NCM加密文件:ncmdumpGUI完整指南 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的…...

Xia Sql插件:可调试的SQL注入决策引擎
1. 这不是又一个“自动扫SQL”的插件,而是把渗透工程师的判断逻辑塞进了Burp里你有没有过这种经历:在Burp Proxy里看着一堆GET参数、POST JSON、Cookie字段,心里清楚“这里大概率能注入”,但手动拼payload试了七八轮,还…...

收藏|2026年AI大模型就业爆发!岗位暴涨12倍、月薪6W+,小白零基础入门指南
2026年,AI已从“科技热点”彻底变为职场“刚需赛道”!脉脉高聘人才智库最新发布的《2026年1-2月中高端人才求职招聘洞察》,用硬核数据揭示行业真相:AI人才成招聘市场顶流,岗位量、薪资双双爆发式增长。尤其对零基础小白…...