Graphql中的N+1问题
开篇
原文出处
Graphql 是一种 API 查询语言和运行时环境,可以帮助开发人员快速构建可伸缩的 API。然而,尽管 Graphql 可以提供一些优秀的查询性能和数据获取的能力,但是在使用 Graphql 的过程中,开发人员也会遇到一些常见问题,其中最常见的一个问题是 N+1 问题。
什么是 GraphQL 中的 N+1 问题
在 GraphQL 中,N+1 问题指的是在一个查询语句中,某个字段需要通过 N 次额外查询来获取其关联的数据,导致查询效率低下的情况。这个问题的本质是由于 GraphQL 的数据模型本身的特性引起的。
在 GraphQL 中,查询语句可以包含多个字段,每个字段可能需要访问一个不同的数据源。当查询涉及到关联数据时,如果不做特殊处理,GraphQL 会逐个获取每个字段的数据,这可能会导致大量的额外查询,进而影响查询效率。
假设我们有一个电影网站,它有电影和演员两个实体,每部电影都有多个演员。我们可以用 GraphQL 定义如下的 schema:
type Movie {id: ID!title: String!actors: [Actor!]!
}type Actor {id: ID!name: String!age: Int!
}type Query {movies: [Movie!]!
}
现在,我们想要查询所有电影及其演员。我们可以像这样编写 GraphQL 查询:
query {movies {titleactors {name}}
}
在这个查询中,我们获取了所有电影的标题,以及每部电影的所有演员的名称。然而,如果我们没有采取任何措施来解决 N+1 问题,每个电影的演员都将需要单独查询。因此,如果我们有 100 部电影,就会产生 101 次查询(1 次获取电影,100 次获取演员),这会严重影响性能。
解决方案
Data loader
Data loader 是一个常用的解决 N+1 问题的工具,它可以将多个查询合并成一个查询,以减少查询次数。它的工作原理是在执行查询时,将多个相同类型的查询合并成一个批量查询,并将结果缓存起来,以便在需要时快速获取。Data loader 可以轻松地与 GraphQL 集成,并提供了许多可配置的选项,以便根据应用程序的需要进行优化。
下面是一个使用 data loader 的示例代码:
const DataLoader = require('dataloader')
const { actorsByMovieId } = require('./db')const actorsLoader = new DataLoader(async (movieIds) => {const actors = await actorsByMovieId(movieIds)const actorsMap = actors.reduce((acc, actor) => {acc[actor.movieId] = acc[actor.movieId] || []acc[actor.movieId].push(actor)return acc}, {})return movieIds.map((movieId) => actorsMap[movieId] || [])
})const resolvers = {Query: {movies: () => getMovies(),},Movie: {actors: (movie, args, context, info) => actorsLoader.load(movie.id),},
}
在上面的代码中,我们使用 data loader 来批量获取每个电影的演员。当 GraphQL 执行查询时,它将调用 load 函数,并将所有需要获取的电影 ID 传递给它。load 函数将所有电影 ID 作为参数,并从数据库中获取所有与这些电影相关的演员。然后,它将演员按电影 ID 分组,并将结果返回到 GraphQL 查询中。由于使用了 data loader,我们现在只需要进行一次查询来获取所有电影及其演员。
Join Monster
Join Monster 是一个解决 GraphQL N+1 问题的工具,它使用了 SQL 批量操作的思想。Join Monster 的主要思想是将多个 GraphQL 解析器的数据请求合并成一个 SQL 查询。这个 SQL 查询是经过优化的,只会查询数据库中需要的数据。同时,Join Monster 还使用了多级缓存来减少数据库的访问次数。
在代码层面,使用 Join Monster 时,我们需要先定义一个解析器,然后在 GraphQL 的 schema 中使用该解析器来查询数据。以下是一个使用 Join Monster 的示例代码:
const joinMonster = require('join-monster').default
const { GraphQLObjectType, GraphQLList } = require('graphql')
const db = require('./db')
const { UserType } = require('./userType')const CommentType = new GraphQLObjectType({name: 'Comment',fields: {id: { type: GraphQLInt },content: { type: GraphQLString },user: {type: UserType,resolve: (parent, args, context, resolveInfo) => {return joinMonster(resolveInfo, {}, (sql) => {return db.query(sql)})},},},
})const Query = new GraphQLObjectType({name: 'Query',fields: {comments: {type: new GraphQLList(CommentType),resolve: (parent, args, context, resolveInfo) => {return joinMonster(resolveInfo, {}, (sql) => {return db.query(sql)})},},},
})module.exports = new GraphQLSchema({ query: Query })
在上述代码中,我们定义了一个 CommentType,它包含了一个 user 字段,该字段使用 Join Monster 进行了解析。同时,我们还定义了一个 Query,该 Query 包含了 comments 字段,使用了 joinMonster 进行解析。在 resolve 函数中,我们将 Join Monster 的解析器传入,并在其中使用了 db.query 函数执行了查询。
假设我们有如下 GraphQL 查询:
{comments {idcontentuser {idname}}
}
在使用 Join Monster 之前,该查询需要进行 N+1 次 SQL 查询,每个 comment 对应一次查询,每个 user 对应一次查询。
在使用 Join Monster 之后,我们的查询只需要进行一次 SQL 查询。Join Monster 会根据 GraphQL 查询中的字段生成相应的 SQL 查询语句,并在数据库中执行该语句。以下是 Join Monster 生成的 SQL 语句的示例:
SELECT`Comment`.`id`,`Comment`.`content`,`User`.`id` AS `user.id`,`User`.`name` AS `user.name`
FROM`Comment`
LEFT JOIN`User`
ON`Comment`.`userId` = `User`.`id`这个 SQL 查询语句会同时返回 comments 和它们对应的 users 的信息。由于只进行了一次 SQL 查询,Join Monster 大大减少了数据库访问的次数,从而提升了性能。
方案对比
| 方案 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| dataloader | 可以自动处理 N+1 查询问题;可以使用缓存机制提高性能;比较成熟稳定,社区支持度高 | 不能自动处理多层嵌套,对复杂查询支持不够好,需要手动编写基于 dataloader 嵌套查询 | 适用于中小规模的项目,需要快速上手,提高开发效率的场景 |
| join-monster | 可以自动生成高效的 SQL 查询,性能优秀; 可以自动处理多层嵌套的 N+1 查询问题 | 依赖于 SQL 数据库,不适用于非 SQL 数据库场景(需要将 Graphql 当作 ORM) | 适用于需要高性能的场景,需要处理复杂查询场景 |
Data loader 的实现
考虑到 dataloader 比较好实现,且使用广泛,我们选取它进行简单的实现,以此更加深入的理解它是如何解决 N+1 问题的。
根据DataLoader的使用例子来看,DataLoader除了构造器以外,只有一个 load 方法,所以一个简单的 DataLoader 的声明如下:
type BatchFn = <Key, Entity>(keys: Key[]): Promise<Entity[]>;class DataLoader<Key, Entity> {constructor(batchFn: BatchFn<Key, Entity>) {// todo}load(key: Key): Promise<Entity> {// todo}
}load 方法只是加入到 batch 的队列中,并不会立刻执行,执行条件是“没有地方调用 load 后“,才会执行整个 batch 队列的请求。于是有了一个小实现:
class DataLoader<Key, Entity> {readonly batchFn: BatchFn<Key, Entity>;readonly keys: Key[] = [];constructor(batchFn: BatchFn<Key, Entity>) {this.batchFn = batchFn;}async load(key: Key): Promise<void> {this.keys.push(key);if (this.keys.length === 1) {this.doBatch();//I hope it executes later}}doBatch(): Promise<Entity[]> {return this.batchFn(this.keys);}
}
代码很简单,只是遗留了一个问题,也是最重要的问题,如何让this.doBatch能够延迟行,延迟到所有的 load 同步方法调用完后。
此时就需要利用事件循环来改变它的执行顺序:
setImmediate(() => this.doBatch())
因为setImmediate会在回调阶段执行,因此会等到所有同步方法完成在执行。
一个DataLoader的最小实现就产生了:
class DataLoader<Key, Entity> {readonly batchFn: BatchFn<Key, Entity>;readonly keys: Key[] = [];constructor(batchFn: BatchFn<Key, Entity>) {this.batchFn = batchFn;}async load(key: Key): Promise<void> {this.keys.push(key);if (this.keys.length === 1) {setImmediate(() => this.doBatch());}}doBatch(): Promise<Entity[]> {return this.batchFn(this.keys);}
}
可是它的功能很局限,load 方法不能返回任何的值,Graphql 的 resolve 也就解析不了了。
因此,修改如下:
export default class DataLoader<Key, Entity> {readonly batchFn: BatchFn<Key, Entity>;readonly storage: {key: Key;promise: Promise<Entity>;resolve: ((entity: Entity) => void) | null;}[] = [];constructor(batchFn: BatchFn<Key, Entity>) {this.batchFn = batchFn;}async load(key: Key): Promise<Entity> {let resolve = null;const promise = new Promise<Entity>((res) => (resolve = res));this.storage.push({key,promise,resolve,});if (this.storage.length === 1) {setImmediate(() => this.doBatch());}return promise;}doBatch(): Promise<void> {const keys = this.storage.map(({ key }) => key);return this.batchFn(keys).then((entities) =>entities.forEach((entity, index) => {const { resolve } = this.storage[index];resolve && resolve(entity);}));}
}doBatch将结果依次给到 load 当时挂载的 promise 上,这样以来 resolver 中的 promise 状态就会由 pending 转化为 fulfilled。
当然,为了考虑性能和健壮性,我们还可以继续扩展:
- 增加缓存
- 捕获异常
- 支持手动执行 batch
最终完善如下(github repo):
type BatchFn<K, E> = (keys: K[]) => Promise<E[]>;interface PromiseMeta<E> {resolve: ((entity: E) => void) | null;promise: Promise<E>;
}interface Options {immediate: boolean;
}export default class DataLoader<K, E> {readonly batchFn: BatchFn<K, E>;readonly cache = new Map<K, PromiseMeta<E>>();readonly options: Options = {immediate: true,};constructor(batchFn: BatchFn<K, E>, options?: Options) {this.batchFn = batchFn;this.options = {...this.options,...options,};}async load(key: K): Promise<E> {if (this.options.immediate) {if (this.cache.size === 0) {setImmediate(() => this.doBatch());}}let resolve = null;const promise = new Promise<E>((res) => (resolve = res));this.cache.set(key, {promise,resolve,});return promise;}doBatch(): Promise<void> {const keys = [...this.cache.keys()];return this.batchFn(keys).then((entities) =>entities.forEach((entity, index) => {const promiseMeta = this.cache.get(keys[index]);if (promiseMeta) {const { resolve } = promiseMeta;resolve && resolve(entity);}})).catch(() => this.cache.clear());}dispatch(): Promise<void> {if (!this.options.immediate) {return this.doBatch();}throw new Error("Doesn't allow to dispatch given immediate is true!");}
}最后
在本文中,我们深入探讨了 GraphQL 中的 N+1 问题。首先,我们介绍了 GraphQL 中常见的一些问题,例如查询过度嵌套和查询重复等。然后,我们详细介绍了 N+1 问题的定义及其出现的原因。接着,我们给出了具体的例子,并讨论了 N+1 问题对性能的影响。在解决 N+1 问题方面,我们列举了几种工具,包括 Batch loading、Data loader 和 Join Monster,并展示了它们在代码层面上的使用。我们还对这些工具的优缺点进行了比较和分析,并给出了最佳实践。
最后,我们介绍了一些避免 N+1 问题的最佳实践,例如避免嵌套查询、使用 GraphQL 片段和优化查询。这些实践可以帮助开发人员避免 N+1 问题并提高查询性能。
总的来说,N+1 问题是 GraphQL 中常见的性能问题之一,但是通过合适的工具和最佳实践,我们可以有效地解决它,提高查询性能,为用户提供更好的体验。
相关文章:

Graphql中的N+1问题
开篇 原文出处 Graphql 是一种 API 查询语言和运行时环境,可以帮助开发人员快速构建可伸缩的 API。然而,尽管 Graphql 可以提供一些优秀的查询性能和数据获取的能力,但是在使用 Graphql 的过程中,开发人员也会遇到一些常见问题&…...

mysql、oracle、sqlserver常见方法区分
整理了包括字符串与日期互转、字符串与数字互转、多行合并为一行、拼接字段等一些常用的函数,当然有些功能实现的方法不止一种,这里列举了部分常用的,后续会持续补充。 MySQLOracleSQL Server字符串转数字 CAST(123 as SIGNED) 或 CONVERT(12…...

AcWing 4382. 快速打字
原题链接:AcWing 4382. 快速打字 关键词:双指针、判断子序列 芭芭拉是一个速度打字员。 为了检查她的打字速度,她进行了一个速度测试。 测试内容是给定她一个字符串 I,她需要将字符串正确打出。 但是,芭芭拉作为一…...
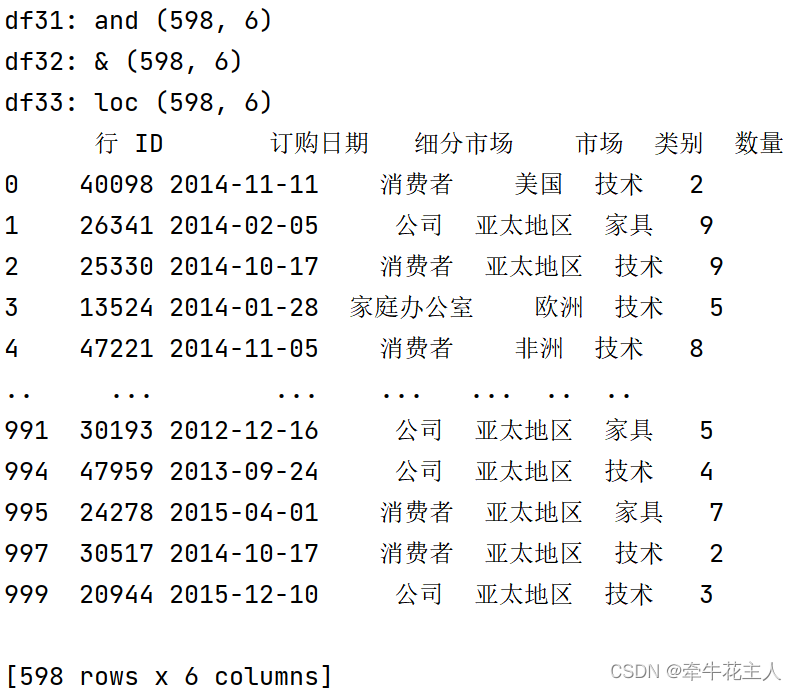
DataFrame.query()--Pandas
1. 函数功能 Pandas 中的一个函数,用于在 DataFrame 中执行查询操作。这个方法会返回一个新的 DataFrame,其中包含符合查询条件的数据行。请注意,query 方法只能用于筛选行,而不能用于筛选列。 2. 函数语法 DataFrame.query(ex…...

【C语言】美元名字和面额对应问题
题目 美元硬币从小到大分为1美分(penny)5美分(nickel)10美分(dime)25美分(quarter)和50美分(half-dollar),写一个程序实现当给出一个数字面额可以…...
)
uniapp隐藏底部导航栏(非自定义底部导航栏)
uniapp隐藏底部导航栏 看什么看,要多看uni官方文档,里面啥都有 看什么看,要多看uni官方文档,里面啥都有 uniapp官方网址:uni设置TabBar // 展示 uni.showTabBar({animation:true,success() {console.debug(隐藏成功)…...

CSS background 背景
background属性为元素添加背景效果。 它是以下属性的简写,按顺序为: background-colorbackground-imagebackground-repeatbackground-attachmentbackground-position 以下所有示例中的花花.jpg图片的大小是4848。 1 background-color background-col…...
安防监控视频平台EasyCVR视频汇聚平台和税务可视化综合管理应用方案
一、方案概述 为了确保税务执法的规范性和高效性,国家税务总局要求全面推行税务系统的行政执法公示制度、执法全过程记录制度和重大执法决定法制审核制度。为此,需要全面推行执法全过程记录制度,并推进信息化建设,实现执法全过程的…...

深度学习实战50-构建ChatOCR项目:基于大语言模型的OCR识别问答系统实战
大家好,我是微学AI,今天给大家介绍一下深度学习实战50-构建ChatOCR项目:基于大语言模型的OCR识别问答系统实战,该项目是一个基于深度学习和大语言模型的OCR识别问答系统的实战项目。该项目旨在利用深度学习技术和先进的大语言模型,构建一个能够识别图像中文本,并能够回答与…...
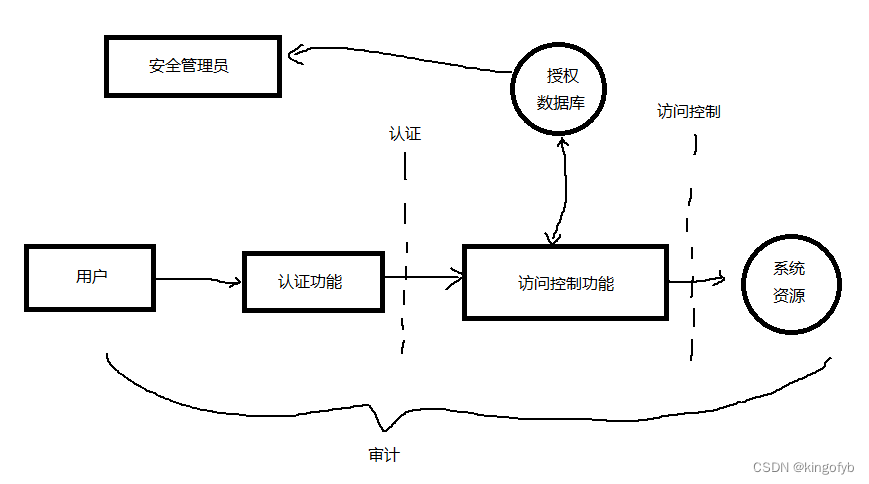
计算机安全学习笔记(I):访问控制安全原理
访问控制原理 从广义上来讲,所有的计算机安全都与访问控制有关。 RFC 4949: Internet Security Glossary, Version 2 (rfc-editor.org) RFC 4949 定义的计算机安全:用来实现和保证计算机系统的安全服务的措施,特别是保证访问控制服务的措施…...
Linux 虚拟机安装 hadoop
目录 1 hadoop下载 2 解压hadoop 3 为 hadoop 文件夹改名 4 给 hadoop 文件夹赋权 5 修改环境变量 6 刷新环境变量 7 在hadoop313目录下创建文件夹data 8 检查文件 9 编辑 ./core-site.xml文件 10 编辑./hadoop-env.sh文件 11 编辑./hdfs-site.xml文件 12 编辑./mapr…...

FxFactory 8 Pro Mac 苹果电脑版 fcpx/ae/motion视觉特效软件包
FxFactory pro for mac是应用在Mac上的fcpx/ae/pr视觉特效插件包,包含了成百上千的视觉效果,打包了很多插件,如调色插件,转场插件,视觉插件,特效插件,文字插件,音频插件,…...

解决问题:如何在 Git 中查看提交历史
可以使用以下命令查看 Git 中的提交历史: git log这将显示当前分支上的所有提交历史。每个提交的输出包括提交哈希(SHA-1 值)、作者、日期和提交注释。 您也可以添加一些选项,以获取更详细的提交历史: --oneline 显示…...
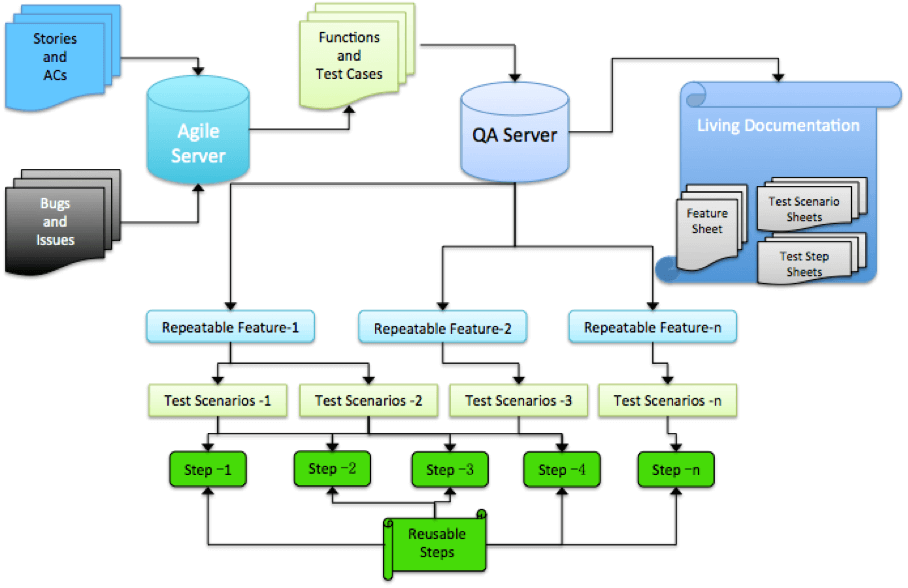
不同规模的测试团队分别适合哪些测试用例管理工具?测试用例管理工具选型指南
随着软件系统规模的持续增大,业务复杂度的持续增加,软件测试的复杂度也随之越来越大。软件测试工作的复杂性主要体现在测试用例的编写、维护、执行和管理方面。而创建易于阅读、维护和管理的测试用例能够显著减轻测试工作的复杂性。 本篇文章将较为系统的…...

服务器遭受攻击,CPU升高,流量升高,你一般如何处理
服务器遭受攻击,CPU升高,流量升高,你一般如何处理? 在什么情况下服务器遭受攻击,会导致CPU升高,流量升高 1.DDoS(分布式拒绝服务攻击):这是一种常见的网络攻击方式&…...

GPT生产实践之定制化翻译
GPT生产实践之定制化翻译 GPT除了能用来聊天以外,其实功能非常强大,但是我们如何把它运用到生产实践中去,为公司带来价值呢?下面一个使用案例–使用gpt做专业领域定制化翻译 思路: 定制化:有些公司词条的…...

SpringMVC入门笔记
一、SpringMVC简介 1. 什么是MVC MVC是一种软件架构的思想,将软件按照模型、视图、控制器来划分 M:Model,模型层,指工程中的JavaBean,作用是处理数据 JavaBean分为两类: 一类称为实体类Bean࿱…...

如何构建多域名HTTPS代理服务器转发
在当今互联网时代,安全可靠的网络访问是至关重要的。本文将介绍如何使用SNI Routing技术来构建多域名HTTPS代理服务器转发,轻松实现多域名的安全访问和数据传输。 SNI代表"Server Name Indication",是TLS协议的扩展,用于…...

【Java 高阶】一文精通 Spring MVC - 数据验证(七)
👉博主介绍: 博主从事应用安全和大数据领域,有8年研发经验,5年面试官经验,Java技术专家,WEB架构师,阿里云专家博主,华为云云享专家,51CTO 专家博主 ⛪️ 个人社区&#x…...

木叶飞舞之【机器人ROS2】篇章_第一节、ROS2 humble及cartorgrapher安装
ROS2的humble安装 1、系统配置ubuntu 22.04 假如长期使用ros2,建议是ubuntu系统或者双系统下安装操作,不要在虚拟机中进行。ubuntu系统能用最新的大系统就用最新的,比如22.04。等明年24.04出来可以用24.04 2、humble安装 ros版本选择humb…...

K8S认证|CKS题库+答案| 11. AppArmor
目录 11. AppArmor 免费获取并激活 CKA_v1.31_模拟系统 题目 开始操作: 1)、切换集群 2)、切换节点 3)、切换到 apparmor 的目录 4)、执行 apparmor 策略模块 5)、修改 pod 文件 6)、…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

PL0语法,分析器实现!
简介 PL/0 是一种简单的编程语言,通常用于教学编译原理。它的语法结构清晰,功能包括常量定义、变量声明、过程(子程序)定义以及基本的控制结构(如条件语句和循环语句)。 PL/0 语法规范 PL/0 是一种教学用的小型编程语言,由 Niklaus Wirth 设计,用于展示编译原理的核…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...

音视频——I2S 协议详解
I2S 协议详解 I2S (Inter-IC Sound) 协议是一种串行总线协议,专门用于在数字音频设备之间传输数字音频数据。它由飞利浦(Philips)公司开发,以其简单、高效和广泛的兼容性而闻名。 1. 信号线 I2S 协议通常使用三根或四根信号线&a…...
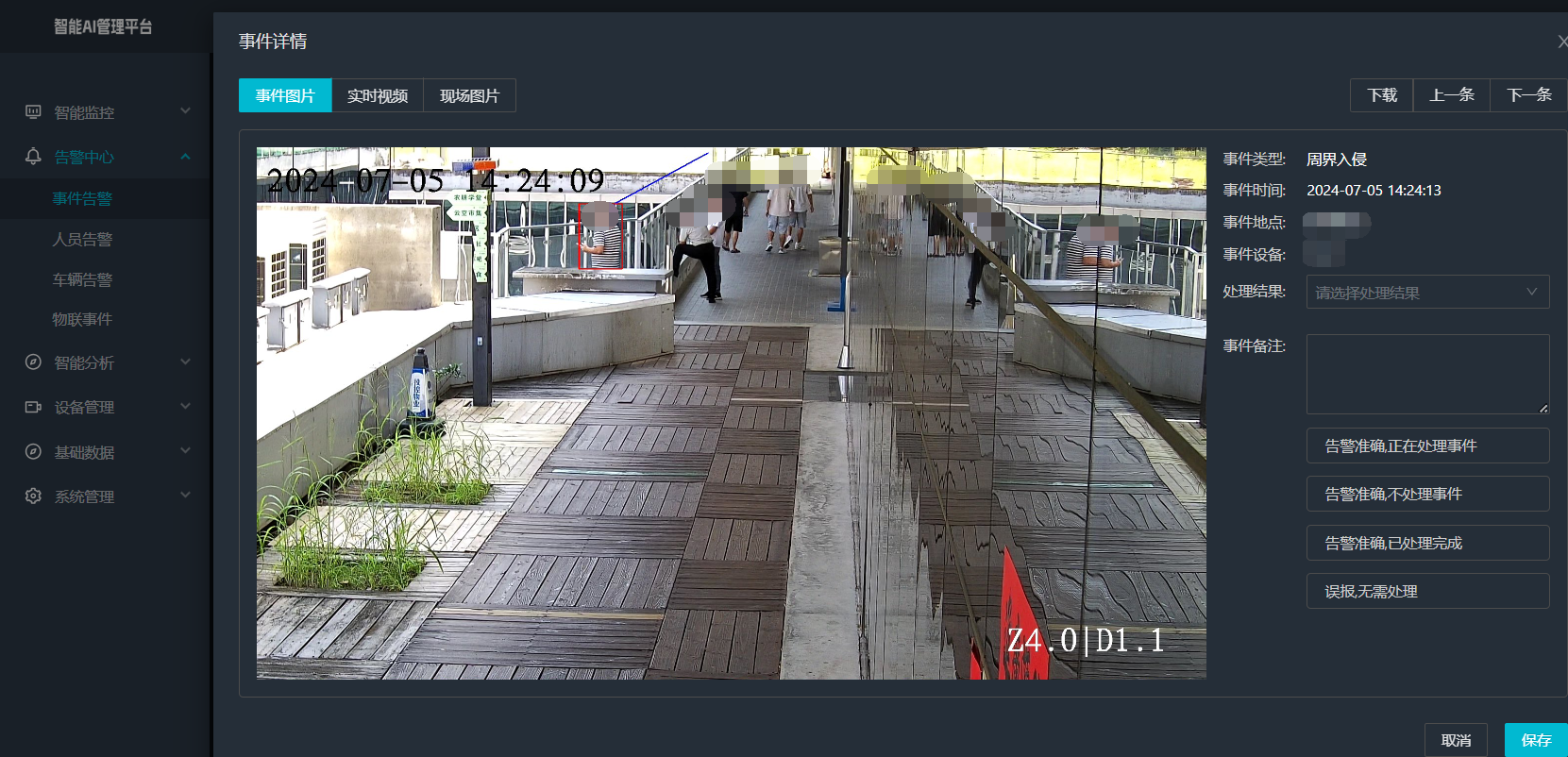
打手机检测算法AI智能分析网关V4守护公共/工业/医疗等多场景安全应用
一、方案背景 在现代生产与生活场景中,如工厂高危作业区、医院手术室、公共场景等,人员违规打手机的行为潜藏着巨大风险。传统依靠人工巡查的监管方式,存在效率低、覆盖面不足、判断主观性强等问题,难以满足对人员打手机行为精…...

基于Java+VUE+MariaDB实现(Web)仿小米商城
仿小米商城 环境安装 nodejs maven JDK11 运行 mvn clean install -DskipTestscd adminmvn spring-boot:runcd ../webmvn spring-boot:runcd ../xiaomi-store-admin-vuenpm installnpm run servecd ../xiaomi-store-vuenpm installnpm run serve 注意:运行前…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...
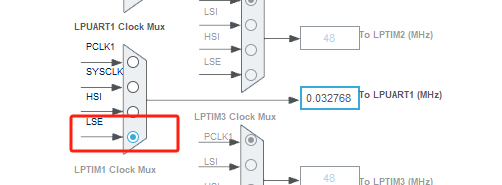
stm32wle5 lpuart DMA数据不接收
配置波特率9600时,需要使用外部低速晶振...

API网关Kong的鉴权与限流:高并发场景下的核心实践
🔥「炎码工坊」技术弹药已装填! 点击关注 → 解锁工业级干货【工具实测|项目避坑|源码燃烧指南】 引言 在微服务架构中,API网关承担着流量调度、安全防护和协议转换的核心职责。作为云原生时代的代表性网关,Kong凭借其插件化架构…...