16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
Flink 系列文章
1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接
13、Flink 的table api与sql的基本概念、通用api介绍及入门示例
14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性
15、Flink 的table api与sql之流式概念-详解的介绍了动态表、时间属性配置(如何处理更新结果)、时态表、流上的join、流上的确定性以及查询配置
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及FileSystem示例(1)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及Apache Kafka示例(3)
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
20、Flink SQL之SQL Client: 不用编写代码就可以尝试 Flink SQL,可以直接提交 SQL 任务到集群上
22、Flink 的table api与sql之创建表的DDL
30、Flink SQL之SQL 客户端(通过kafka和filesystem的例子介绍了配置文件使用-表、视图等)
文章目录
- Flink 系列文章
- 一、Table & SQL Connectors 示例:JDBC
- 1、maven依赖(java编码依赖)
- 2、创建 JDBC 表
- 1)、创建jdbc表,并插入、查询
- 2)、批量插入表数据
- 3)、JDBC 表在时态表关联中作为维表
- 3、连接器参数
- 4、已弃用的配置
- 5、特性
- 1)、键处理
- 2)、分区扫描
- 3)、Lookup Cache
- 4)、幂等写入
- 5、JDBC Catalog
- 1)、JDBC Catalog 的使用
- 2)、JDBC Catalog for PostgreSQL
- 3)、JDBC Catalog for MySQL
- 6、数据类型映射
本文简单的介绍了flink sql读取外部系统的jdbc示例(每个示例均是验证通过的,并且具体给出了运行环境的版本)。
本文依赖环境是hadoop、kafka、mysql环境好用,如果是ha环境则需要zookeeper的环境。
一、Table & SQL Connectors 示例:JDBC
1、maven依赖(java编码依赖)
<dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-jdbc</artifactId><version>3.1.0-1.17</version>
</dependency>在连接到具体数据库时,也需要对应的驱动依赖,目前支持的驱动如下:
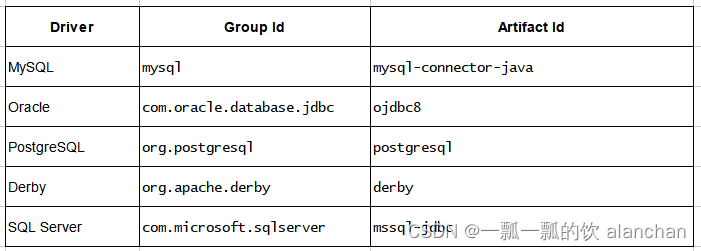
驱动jar需放在flink的安装目录lib下,且需要重启服务。
本示例jar包有
flink-connector-jdbc_2.11-1.13.6.jar
mysql-connector-java-5.1.5.jar 或
mysql-connector-java-6.0.6.jar(1.17版本中使用的mysql驱动,用上面mysql驱动有异常信息)
2、创建 JDBC 表
JDBC table 可以按如下定义,以下示例中包含创建表、批量插入以及left join的维表。
1)、创建jdbc表,并插入、查询
-- 在 Flink SQL 中注册一张 MySQL 表 'users'
CREATE TABLE MyUserTable (id BIGINT,name STRING,age INT,status BOOLEAN,PRIMARY KEY (id) NOT ENFORCED
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://localhost:3306/mydatabase','table-name' = 'users'
);-------------------具体事例----------------------------------
-- 在 Flink SQL 中注册一张 MySQL 表 'user'
CREATE TABLE Alan_JDBC_User_Table (id BIGINT,name STRING,age INT,balance DOUBLE,PRIMARY KEY (id) NOT ENFORCED
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://192.168.10.44:3306/test','table-name' = 'user'
);-- mysql中的数据
mysql> select * from user;
+----+-------------+------+---------+-----------------------+------------+
| id | name | age | balance | email | pwd |
+----+-------------+------+---------+-----------------------+------------+
| 1 | aa6 | 61 | 60000 | 6@163.com | 123456 |
| 2 | aa4 | 71 | 70000 | 7@163.com | 7123 |
| 4 | test | NULL | NULL | NULL | NULL |
| 5 | test2 | NULL | NULL | NULL | NULL |
| 7 | alanchanchn | 19 | 800 | alan.chan.chn@163.com | vx |
| 8 | alanchan | 19 | 800 | alan.chan.chn@163.com | sink mysql |
+----+-------------+------+---------+-----------------------+------------+
6 rows in set (0.00 sec)---------在flink sql中建表并查询--------
Flink SQL> CREATE TABLE Alan_JDBC_User_Table (
> id BIGINT,
> name STRING,
> age INT,
> balance DOUBLE,
> PRIMARY KEY (id) NOT ENFORCED
> ) WITH (
> 'connector' = 'jdbc',
> 'url' = 'jdbc:mysql://192.168.10.44:3306/test',
> 'table-name' = 'user'
> );
[INFO] Execute statement succeed.Flink SQL> select * from Alan_JDBC_User_Table;
+----+----------------------+--------------------------------+-------------+--------------------------------+
| op | id | name | age | balance |
+----+----------------------+--------------------------------+-------------+--------------------------------+
| +I | 1 | aa6 | 61 | 60000.0 |
| +I | 2 | aa4 | 71 | 70000.0 |
| +I | 4 | test | (NULL) | (NULL) |
| +I | 5 | test2 | (NULL) | (NULL) |
| +I | 7 | alanchanchn | 19 | 800.0 |
| +I | 8 | alanchan | 19 | 800.0 |
+----+----------------------+--------------------------------+-------------+--------------------------------+
Received a total of 6 rows
2)、批量插入表数据
-- 从另一张表 "T" 将数据写入到 JDBC 表中
INSERT INTO MyUserTable
SELECT id, name, age, status FROM T;---------创建数据表----------------------
CREATE TABLE source_table (userId INT,age INT,balance DOUBLE,userName STRING,t_insert_time AS localtimestamp,WATERMARK FOR t_insert_time AS t_insert_time
) WITH ('connector' = 'datagen','rows-per-second'='5','fields.userId.kind'='sequence','fields.userId.start'='1','fields.userId.end'='5000','fields.balance.kind'='random','fields.balance.min'='1','fields.balance.max'='100','fields.age.min'='1','fields.age.max'='1000','fields.userName.length'='10'
);-- 从另一张表 "source_table" 将数据写入到 JDBC 表中
INSERT INTO Alan_JDBC_User_Table
SELECT userId, userName, age, balance FROM source_table;-- 查看 JDBC 表中的数据
select * from Alan_JDBC_User_Table;---------------flink sql中查询----------------------------------
Flink SQL> INSERT INTO Alan_JDBC_User_Table
> SELECT userId, userName, age, balance FROM source_table;
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: e91cd3c41ac20aaf8eab79f0094f9e46Flink SQL> select * from Alan_JDBC_User_Table;
+----+----------------------+--------------------------------+-------------+--------------------------------+
| op | id | name | age | balance |
+----+----------------------+--------------------------------+-------------+--------------------------------+
| +I | 1 | ead5352794 | 513 | 4.0 |
| +I | 2 | 728297a8d9 | 410 | 35.0 |
| +I | 3 | 643c2226cd | 142 | 80.0 |
......
-------------验证mysql中的数据是否写入,此处只查总数----------------
mysql> select count(*) from user;
+----------+
| count(*) |
+----------+
| 2005 |
+----------+
1 row in set (0.00 sec)3)、JDBC 表在时态表关联中作为维表
-- 1、创建 JDBC 表在时态表关联中作为维表
CREATE TABLE Alan_JDBC_User_Table (id BIGINT,name STRING,age INT,balance DOUBLE,PRIMARY KEY (id) NOT ENFORCED
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://192.168.10.44:3306/test','table-name' = 'user'
);
-----2、查询表中的数据(实际数据是之前测试的结果) -----
Flink SQL> select * from Alan_JDBC_User_Table;
+----+----------------------+--------------------------------+-------------+--------------------------------+
| op | id | name | age | balance |
+----+----------------------+--------------------------------+-------------+--------------------------------+
| +I | 1 | ead5352794 | 513 | 4.0 |
| +I | 2 | 728297a8d9 | 410 | 35.0 |
| +I | 3 | 643c2226cd | 142 | 80.0 |
| +I | 4 | 6115f11f01 | 633 | 69.0 |
| +I | 5 | 044ba5fa2f | 74 | 71.0 |
| +I | 6 | 98a112dc87 | 729 | 54.0 |
| +I | 7 | 705326a369 | 846 | 99.0 |
| +I | 8 | 532692924f | 872 | 79.0 |
| +I | 9 | b816802948 | 475 | 67.0 |
| +I | 10 | 06906bebb2 | 109 | 57.0 |
......-----3、创建事实表,以kafka表作为代表 -----
CREATE TABLE Alan_KafkaTable_3 (user_id BIGINT, -- 用户iditem_id BIGINT, -- 商品idaction STRING, -- 用户行为ts BIGINT, -- 用户行为发生的时间戳proctime as PROCTIME(), -- 通过计算列产生一个处理时间列`event_time` TIMESTAMP(3) METADATA FROM 'timestamp',-- 事件时间WATERMARK FOR event_time as event_time - INTERVAL '5' SECOND -- 在eventTime上定义watermark
) WITH ('connector' = 'kafka','topic' = 'testtopic','properties.bootstrap.servers' = '192.168.10.41:9092,192.168.10.42:9092,192.168.10.43:9092','properties.group.id' = 'testGroup','scan.startup.mode' = 'earliest-offset','format' = 'csv'
);-----4、发送kafka消息,同时观察事实表中的数据 -----
[alanchan@server2 bin]$ kafka-console-producer.sh --broker-list server1:9092 --topic testtopic
>1,1001,"login",1692593500222
>2,1002,"p_read",1692593502242
>Flink SQL> select * from Alan_KafkaTable_3;+----+----------------------+----------------------+--------------------------------+----------------------+-------------------------+-------------------------+
| op | user_id | item_id | action | ts | proctime | event_time |
+----+----------------------+----------------------+--------------------------------+----------------------+-------------------------+-------------------------+
| +I | 1 | 1001 | login | 1692593500222 | 2023-08-22 05:33:38.830 | 2023-08-22 05:39:54.439 |
| +I | 2 | 1002 | p_read | 1692593502242 | 2023-08-22 05:33:38.833 | 2023-08-22 05:40:41.284 |
Query terminated, received a total of 2 rows-----5、以jdbc的维表进行关联查询事实表数据-----
SELECTkafkamessage.user_id, kafkamessage.item_id,kafkamessage.action, jdbc_dim_table.name,jdbc_dim_table.age,jdbc_dim_table.balance
FROM Alan_KafkaTable_3 AS kafkamessage
LEFT JOIN Alan_JDBC_User_Table FOR SYSTEM_TIME AS OF kafkamessage.proctime AS jdbc_dim_table ON kafkamessage.user_id = jdbc_dim_table.id;Flink SQL> SELECT
> kafkamessage.user_id,
> kafkamessage.item_id,
> kafkamessage.action,
> jdbc_dim_table.name,
> jdbc_dim_table.age,
> jdbc_dim_table.balance
> FROM Alan_KafkaTable_3 AS kafkamessage
> LEFT JOIN Alan_JDBC_User_Table FOR SYSTEM_TIME AS OF kafkamessage.proctime AS jdbc_dim_table ON kafkamessage.user_id = jdbc_dim_table.id;+----+----------------------+----------------------+--------------------------------+--------------------------------+-------------+--------------------------------+
| op | user_id | item_id | action | name | age | balance |
+----+----------------------+----------------------+--------------------------------+--------------------------------+-------------+--------------------------------+
| +I | 1 | 1001 | login | ead5352794 | 513 | 4.0 |
| +I | 2 | 1002 | p_read | 728297a8d9 | 410 | 35.0 |- java
该部分示例仅仅是以java实现创建表及查询,简单示例。
// 注册名为 “jdbcOutputTable” 的JDBC表String sinkDDL = "create table jdbcOutputTable (" + "id bigint not null, " + "name varchar(20) , " + "age int ,"+"balance bigint,"+"pwd varchar(20),"+"email varchar(20) , PRIMARY KEY (id) NOT ENFORCED" +") with (" + " 'connector.type' = 'jdbc', " + " 'connector.url' = 'jdbc:mysql://192.168.10.44:3306/test', " + " 'connector.table' = 'user', " + " 'connector.driver' = 'com.mysql.jdbc.Driver', " + " 'connector.username' = 'root', " + " 'connector.password' = '123456' )";tenv.executeSql(sinkDDL);String sql = "SELECT * FROM jdbcOutputTable ";String sql2 = "SELECT * FROM jdbcOutputTable where name like '%alan%'";Table table = tenv.sqlQuery(sql2);table.printSchema();DataStream<Tuple2<Boolean, Row>> result = tenv.toRetractStream(table, Row.class);result.print();env.execute();//运行结果
(`id` BIGINT NOT NULL,`name` VARCHAR(20),`age` INT,`balance` BIGINT,`pwd` VARCHAR(20),`email` VARCHAR(20)
)15> (true,+I[7, alanchanchn, 19, 800, vx, alan.chan.chn@163.com])
15> (true,+I[8, alanchan, 19, 800, sink mysql, alan.chan.chn@163.com])
3、连接器参数
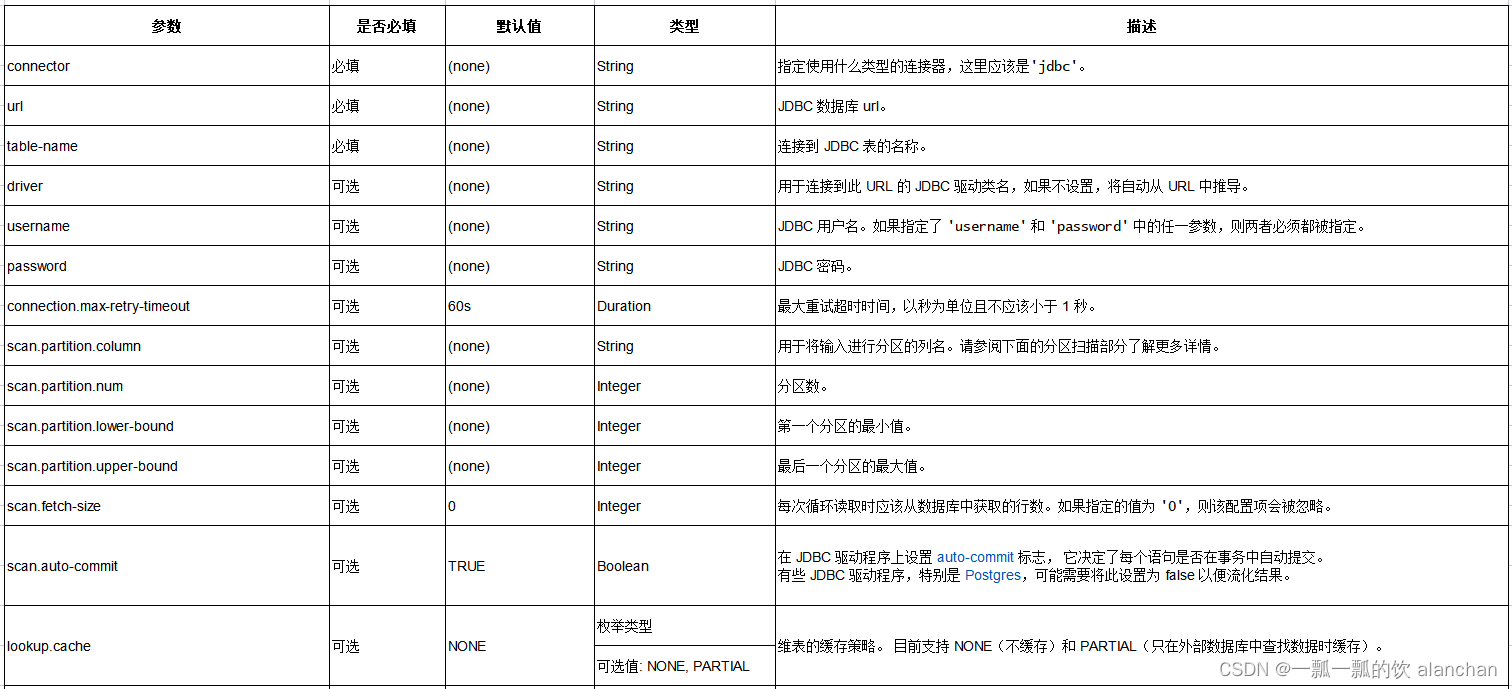
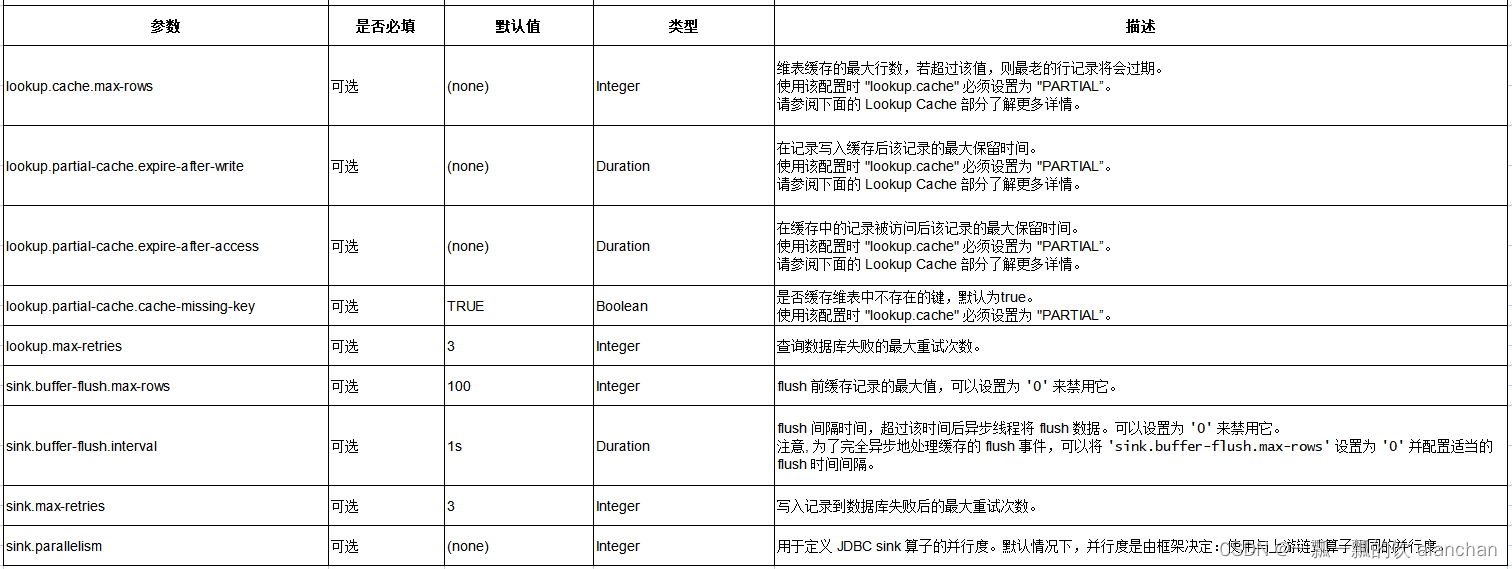
4、已弃用的配置
这些弃用配置已经被上述的新配置代替,而且最终会被弃用。请优先考虑使用新配置。
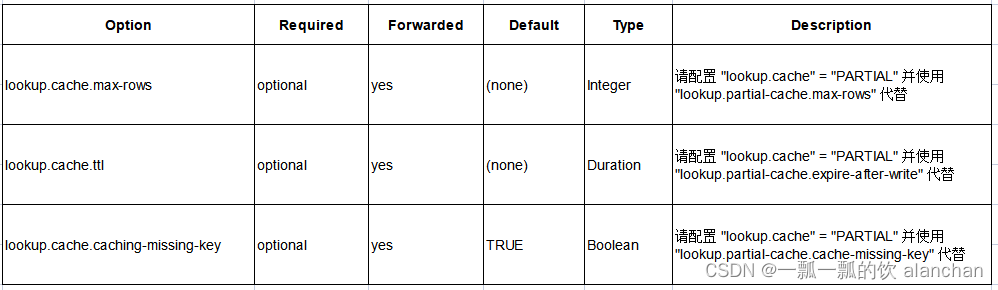
5、特性
1)、键处理
当写入数据到外部数据库时,Flink 会使用 DDL 中定义的主键。如果定义了主键,则连接器将以 upsert 模式工作,否则连接器将以 append 模式工作。
在 upsert 模式下,Flink 将根据主键判断插入新行或者更新已存在的行,这种方式可以确保幂等性。为了确保输出结果是符合预期的,推荐为表定义主键并且确保主键是底层数据库中表的唯一键或主键。在 append 模式下,Flink 会把所有记录解释为 INSERT 消息,如果违反了底层数据库中主键或者唯一约束,INSERT 插入可能会失败。
有关 PRIMARY KEY 语法的更多详细信息,请参见 22、Flink 的table api与sql之创建表的DDL。
2)、分区扫描
为了在并行 Source task 实例中加速读取数据,Flink 为 JDBC table 提供了分区扫描的特性。
如果下述分区扫描参数中的任一项被指定,则下述所有的分区扫描参数必须都被指定。这些参数描述了在多个 task 并行读取数据时如何对表进行分区。 scan.partition.column 必须是相关表中的数字、日期或时间戳列。
scan.partition.lower-bound 和 scan.partition.upper-bound 用于决定分区的起始位置和过滤表中的数据。如果是批处理作业,也可以在提交 flink 作业之前获取最大值和最小值。
- scan.partition.column:输入用于进行分区的列名。
- scan.partition.num:分区数。
- scan.partition.lower-bound:第一个分区的最小值。
- scan.partition.upper-bound:最后一个分区的最大值。
3)、Lookup Cache
JDBC 连接器可以用在时态表关联中作为一个可 lookup 的 source (又称为维表),当前只支持同步的查找模式。
默认情况下,lookup cache 是未启用的,你可以将 lookup.cache 设置为 PARTIAL 参数来启用。
lookup cache 的主要目的是用于提高时态表关联 JDBC 连接器的性能。
默认情况下,lookup cache 不开启,所以所有请求都会发送到外部数据库。
当 lookup cache 被启用时,每个进程(即 TaskManager)将维护一个缓存。Flink 将优先查找缓存,只有当缓存未查找到时才向外部数据库发送请求,并使用返回的数据更新缓存。 当缓存命中最大缓存行 lookup.partial-cache.max-rows 或当行超过 lookup.partial-cache.expire-after-write 或 lookup.partial-cache.expire-after-access 指定的最大存活时间时,缓存中的行将被设置为已过期。 缓存中的记录可能不是最新的,用户可以将缓存记录超时设置为一个更小的值以获得更好的刷新数据,但这可能会增加发送到数据库的请求数。
所以要做好吞吐量和正确性之间的平衡。
默认情况下,flink 会缓存主键的空查询结果,你可以通过将 lookup.partial-cache.cache-missing-key 设置为 false 来切换行为。
4)、幂等写入
如果在 DDL 中定义了主键,JDBC sink 将使用 upsert 语义而不是普通的 INSERT 语句。upsert 语义指的是如果底层数据库中存在违反唯一性约束,则原子地添加新行或更新现有行,这种方式确保了幂等性。
如果出现故障,Flink 作业会从上次成功的 checkpoint 恢复并重新处理,这可能导致在恢复过程中重复处理消息。强烈推荐使用 upsert 模式,因为如果需要重复处理记录,它有助于避免违反数据库主键约束和产生重复数据。
除了故障恢复场景外,数据源(kafka topic)也可能随着时间的推移自然地包含多个具有相同主键的记录,这使得 upsert 模式是用户期待的。
由于 upsert 没有标准的语法,因此下表描述了不同数据库的 DML 语法:
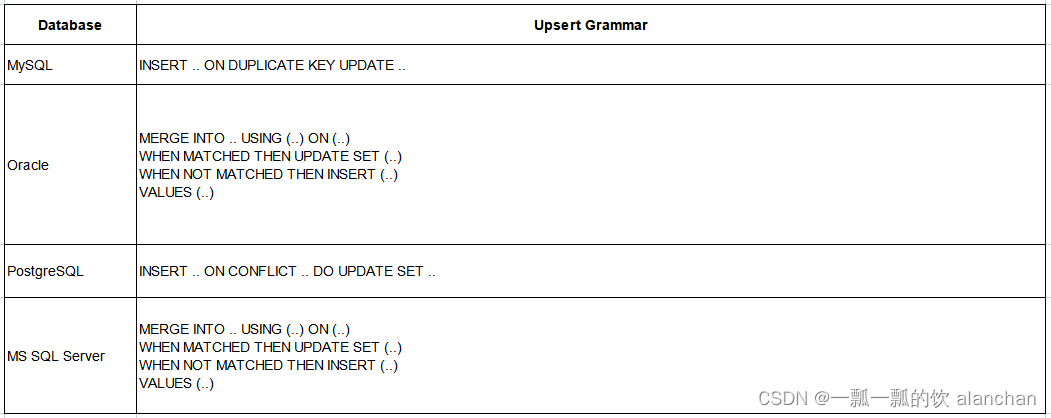
5、JDBC Catalog
JdbcCatalog 允许用户通过 JDBC 协议将 Flink 连接到关系数据库。
目前,JDBC Catalog 有两个实现,即 Postgres Catalog 和 MySQL Catalog。目前支持如下 catalog 方法。其他方法目前尚不支持。
// Postgres Catalog & MySQL Catalog 支持的方法
databaseExists(String databaseName);
listDatabases();
getDatabase(String databaseName);
listTables(String databaseName);
getTable(ObjectPath tablePath);
tableExists(ObjectPath tablePath);
其他的 Catalog 方法现在尚不支持。
1)、JDBC Catalog 的使用
本小节主要描述如果创建并使用 Postgres Catalog 或 MySQL Catalog。
本处描述的版本是flink 1.17,flink1.13版本只支持postgresql,在1.13版本中执行会出现如下异常:
[ERROR] Could not execute SQL statement. Reason:
java.lang.UnsupportedOperationException: Catalog for 'org.apache.flink.connector.jdbc.dialect.MySQLDialect@1bc49bc5' is not supported yet.JDBC catalog 支持以下参数:
-
name:必填,catalog 的名称。
-
default-database:必填,默认要连接的数据库。
-
username:必填,Postgres/MySQL 账户的用户名。
-
password:必填,账户的密码。
-
base-url:必填,(不应该包含数据库名)
对于 Postgres Catalog base-url 应为 “jdbc:postgresql://:” 的格式。
对于 MySQL Catalog base-url 应为 “jdbc:mysql://:” 的格式。 -
sql
---需要将mysql-connector-java-6.0.6.jar、flink-connector-jdbc-3.1.0-1.17.jar放在flink的lib目录,并重启flink集群
CREATE CATALOG alan_catalog WITH('type' = 'jdbc','default-database' = 'test','username' = 'root','password' = '123456','base-url' = 'jdbc:mysql://192.168.10.44:3306'
);USE CATALOG alan_catalog;
---------------------------------------------------
Flink SQL> CREATE CATALOG alan_catalog WITH(
> 'type' = 'jdbc',
> 'default-database' = 'test?useSSL=false',
> 'username' = 'root',
> 'password' = '123456',
> 'base-url' = 'jdbc:mysql://192.168.10.44:3306'
> );
[INFO] Execute statement succeed.Flink SQL> show CATALOGS;
+-----------------+
| catalog name |
+-----------------+
| alan_catalog |
| default_catalog |
+-----------------+
2 rows in setFlink SQL> use CATALOG alan_catalog;
[INFO] Execute statement succeed.- java
EnvironmentSettings settings = EnvironmentSettings.inStreamingMode();
TableEnvironment tableEnv = TableEnvironment.create(settings);String name = "my_catalog";
String defaultDatabase = "mydb";
String username = "...";
String password = "...";
String baseUrl = "..."JdbcCatalog catalog = new JdbcCatalog(name, defaultDatabase, username, password, baseUrl);
tableEnv.registerCatalog("my_catalog", catalog);// 设置 JdbcCatalog 为会话的当前 catalog
tableEnv.useCatalog("my_catalog");
- yaml
execution:...current-catalog: alan_catalog # 设置目标 JdbcCatalog 为会话的当前 catalogcurrent-database: testcatalogs:- name:alan_catalogtype: jdbcdefault-database: testusername: ...password: ...base-url: ...
2)、JDBC Catalog for PostgreSQL
- PostgreSQL 元空间映射
除了数据库之外,postgreSQL 还有一个额外的命名空间 schema。一个 Postgres 实例可以拥有多个数据库,每个数据库可以拥有多个 schema,其中一个 schema 默认名为 “public”,每个 schema 可以包含多张表。 在 Flink 中,当查询由 Postgres catalog 注册的表时,用户可以使用 schema_name.table_name 或只有 table_name,其中 schema_name 是可选的,默认值为 “public”。
因此,Flink Catalog 和 Postgres 之间的元空间映射如下:
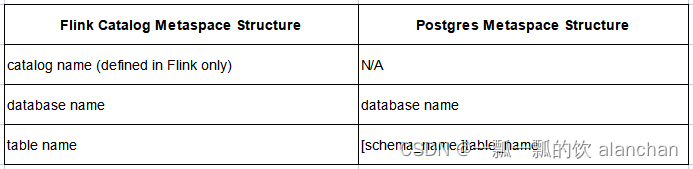
Flink 中的 Postgres 表的完整路径应该是 “..<schema.table>”。如果指定了 schema,请注意需要转义 <schema.table>。
这里提供了一些访问 Postgres 表的例子:
-- 扫描 'public' schema(即默认 schema)中的 'test_table' 表,schema 名称可以省略
SELECT * FROM mypg.mydb.test_table;
SELECT * FROM mydb.test_table;
SELECT * FROM test_table;-- 扫描 'custom_schema' schema 中的 'test_table2' 表,
-- 自定义 schema 不能省略,并且必须与表一起转义。
SELECT * FROM mypg.mydb.`custom_schema.test_table2`
SELECT * FROM mydb.`custom_schema.test_table2`;
SELECT * FROM `custom_schema.test_table2`;
3)、JDBC Catalog for MySQL
- MySQL 元空间映射
MySQL 实例中的数据库与 MySQL Catalog 注册的 catalog 下的数据库处于同一个映射层级。一个 MySQL 实例可以拥有多个数据库,每个数据库可以包含多张表。 在 Flink 中,当查询由 MySQL catalog 注册的表时,用户可以使用 database.table_name 或只使用 table_name,其中 database 是可选的,默认值为创建 MySQL Catalog 时指定的默认数据库。
因此,Flink Catalog 和 MySQL catalog 之间的元空间映射如下:
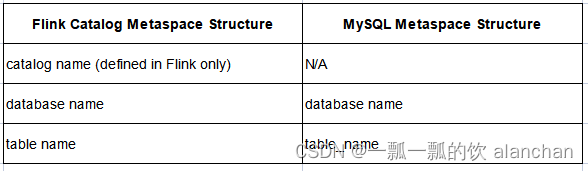
Flink 中的 MySQL 表的完整路径应该是 “<catalog>.<db>.<table>”。
这里提供了一些访问 MySQL 表的例子(在版本1.17中完成):
-- 扫描 默认数据库(test)中的 'person' 表
select * from alan_catalog.test.person;
select * from test.person;
select * from person;-- 扫描 'cdhhive' 数据库中的 'version' 表,
select * from alan_catalog.cdhhive.version;
select * from cdhhive.version;
select * from version;---------------具体操作详见下文------------------
Flink SQL> SET sql-client.execution.result-mode = tableau;
[INFO] Execute statement succeed.Flink SQL> CREATE CATALOG alan_catalog WITH(
> 'type' = 'jdbc',
> 'default-database' = 'test?useSSL=false',
> 'username' = 'root',
> 'password' = '123456',
> 'base-url' = 'jdbc:mysql://192.168.10.44:3306'
> );
[INFO] Execute statement succeed.Flink SQL> show catalogs;
+-----------------+
| catalog name |
+-----------------+
| alan_catalog |
| default_catalog |
+-----------------+
2 rows in setFlink SQL> select * from alan_catalog.test.person;+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 11 | 测试修改go语言 | 30 |
| +I | 13 | NameUpdate | 22 |
| +I | 14 | updatejson | 23 |
| +I | 189 | 再试一试 | 12 |
| +I | 191 | test-full-update | 3333 |
| +I | 889 | zhangsanswagger2 | 88 |
| +I | 892 | update | 189 |
| +I | 1001 | testupdate | 19 |
| +I | 1002 | 测试go语言 | 23 |
| +I | 1013 | slene | 0 |
| +I | 1014 | testing | 0 |
| +I | 1015 | testing | 18 |
| +I | 1016 | astaxie | 19 |
| +I | 1017 | alan | 18 |
| +I | 1018 | chan | 19 |
+----+-------------+--------------------------------+-------------+
Received a total of 15 rowsFlink SQL> use catalog alan_catalog;
[INFO] Execute statement succeed.Flink SQL> select * from test.person;+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 11 | 测试修改go语言 | 30 |
| +I | 13 | NameUpdate | 22 |
| +I | 14 | updatejson | 23 |
| +I | 189 | 再试一试 | 12 |
| +I | 191 | test-full-update | 3333 |
| +I | 889 | zhangsanswagger2 | 88 |
| +I | 892 | update | 189 |
| +I | 1001 | testupdate | 19 |
| +I | 1002 | 测试go语言 | 23 |
| +I | 1013 | slene | 0 |
| +I | 1014 | testing | 0 |
| +I | 1015 | testing | 18 |
| +I | 1016 | astaxie | 19 |
| +I | 1017 | alan | 18 |
| +I | 1018 | chan | 19 |
+----+-------------+--------------------------------+-------------+
Received a total of 15 rowsFlink SQL> use alan_catalog.test;
[INFO] Execute statement succeed.Flink SQL> select * from person;+----+-------------+--------------------------------+-------------+
| op | id | name | age |
+----+-------------+--------------------------------+-------------+
| +I | 11 | 测试修改go语言 | 30 |
| +I | 13 | NameUpdate | 22 |
| +I | 14 | updatejson | 23 |
| +I | 189 | 再试一试 | 12 |
| +I | 191 | test-full-update | 3333 |
| +I | 889 | zhangsanswagger2 | 88 |
| +I | 892 | update | 189 |
| +I | 1001 | testupdate | 19 |
| +I | 1002 | 测试go语言 | 23 |
| +I | 1013 | slene | 0 |
| +I | 1014 | testing | 0 |
| +I | 1015 | testing | 18 |
| +I | 1016 | astaxie | 19 |
| +I | 1017 | alan | 18 |
| +I | 1018 | chan | 19 |
+----+-------------+--------------------------------+-------------+
Received a total of 15 rowsFlink SQL> select * from alan_catalog.cdhhive.version;+----+----------------------+--------------------------------+--------------------------------+
| op | VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
+----+----------------------+--------------------------------+--------------------------------+
| +I | 1 | 2.1.1 | Hive release version 2.1.1 |
+----+----------------------+--------------------------------+--------------------------------+
Received a total of 1 rowFlink SQL> use catalog alan_catalog;
[INFO] Execute statement succeed.Flink SQL> select * from cdhhive.version;+----+----------------------+--------------------------------+--------------------------------+
| op | VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
+----+----------------------+--------------------------------+--------------------------------+
| +I | 1 | 2.1.1 | Hive release version 2.1.1 |
+----+----------------------+--------------------------------+--------------------------------+
Received a total of 1 rowFlink SQL> use alan_catalog.cdhhive;
[INFO] Execute statement succeed.Flink SQL> select * from version;+----+----------------------+--------------------------------+--------------------------------+
| op | VER_ID | SCHEMA_VERSION | VERSION_COMMENT |
+----+----------------------+--------------------------------+--------------------------------+
| +I | 1 | 2.1.1 | Hive release version 2.1.1 |
+----+----------------------+--------------------------------+--------------------------------+
Received a total of 1 row6、数据类型映射
Flink 支持连接到多个使用方言(dialect)的数据库,如 MySQL、Oracle、PostgreSQL、Derby 等。其中,Derby 通常是用于测试目的。下表列出了从关系数据库数据类型到 Flink SQL 数据类型的类型映射,映射表可以使得在 Flink 中定义 JDBC 表更加简单。
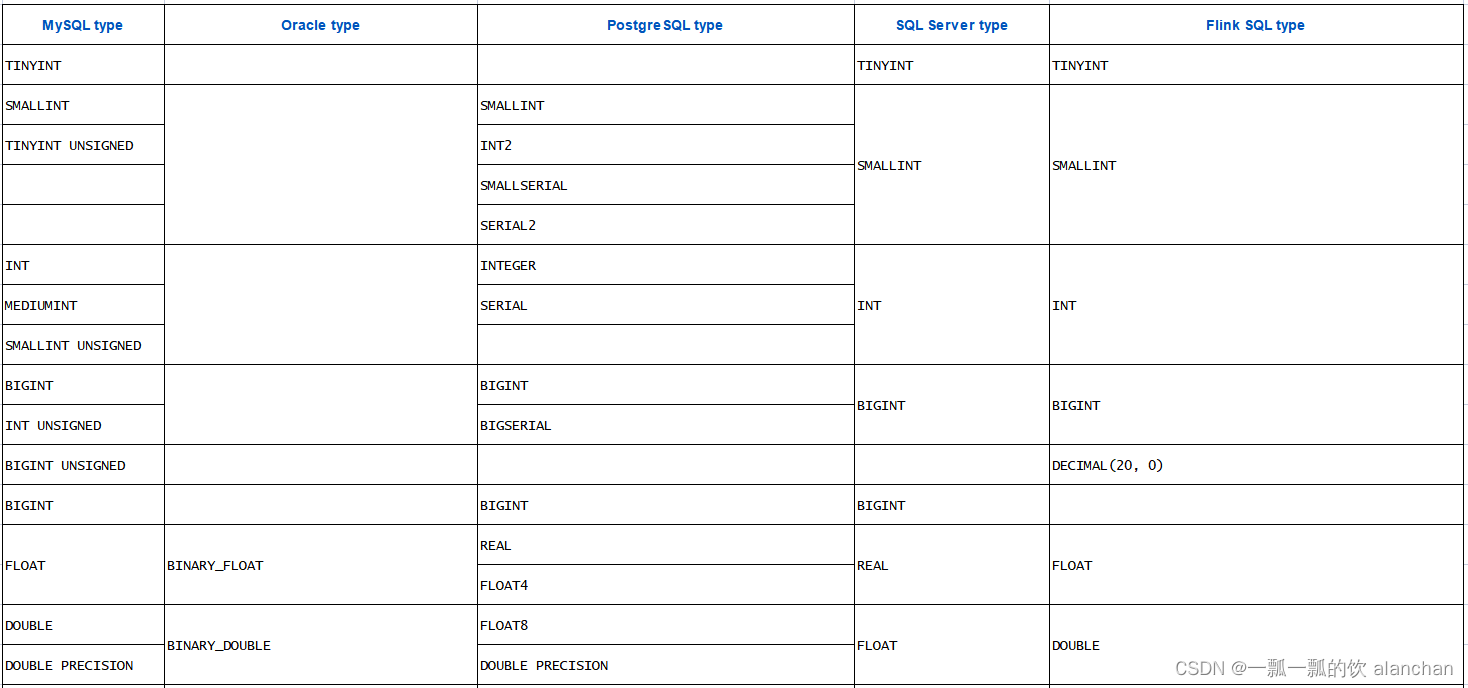
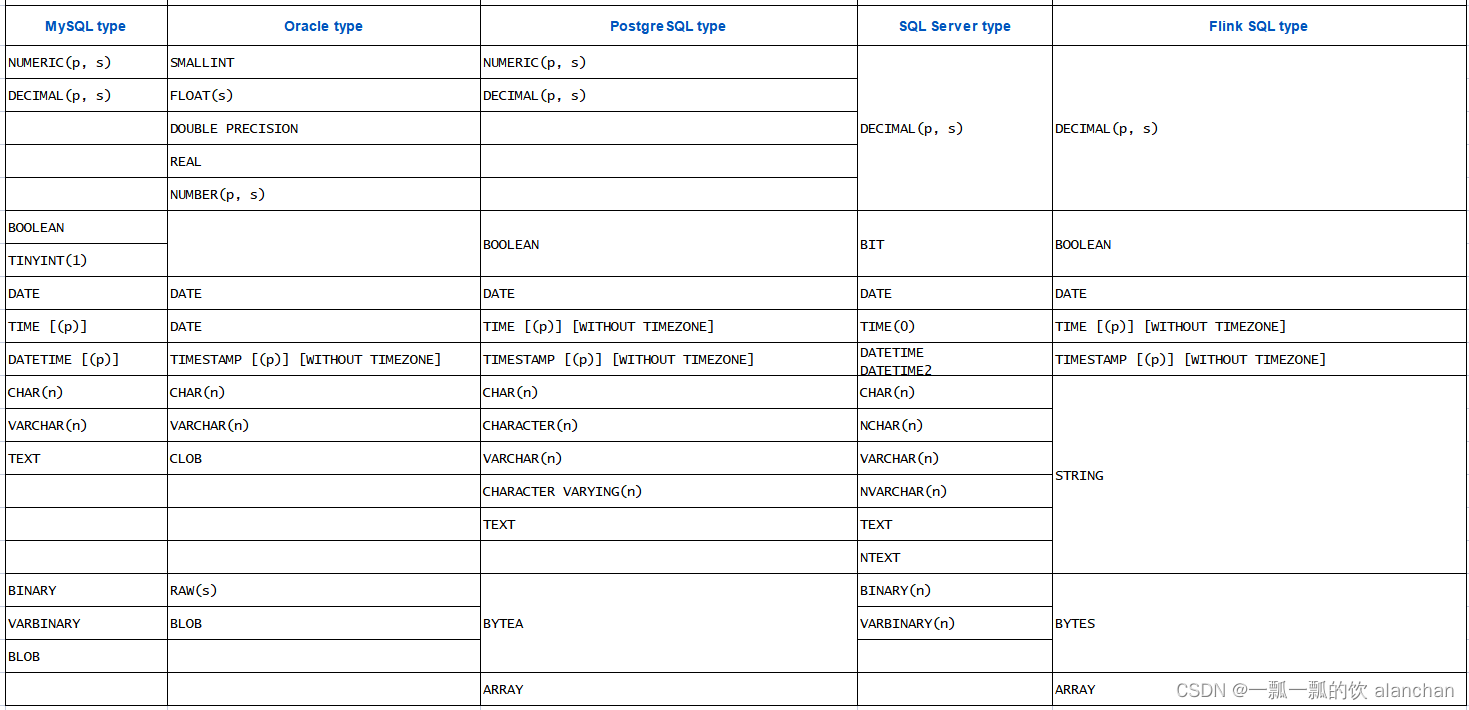
以上,简单的介绍了flink sql读取外部系统的jdbc示例。
相关文章:
16、Flink 的table api与sql之连接外部系统: 读写外部系统的连接器和格式以及JDBC示例(4)
Flink 系列文章 1、Flink 部署、概念介绍、source、transformation、sink使用示例、四大基石介绍和示例等系列综合文章链接 13、Flink 的table api与sql的基本概念、通用api介绍及入门示例 14、Flink 的table api与sql之数据类型: 内置数据类型以及它们的属性 15、Flink 的ta…...

MySQL 自定义 split 存储过程
MySQL 没有提供 split 函数,但可以自己建立一个存储过程,将具有固定分隔符的字符串转成多行。之所以不能使用自定义函数实现此功能,是因为 MySQL 的自定义函数自能返回标量值,不能返回多行结果集。 MySQL 8: drop pr…...
专题-【十字链表】
有向图的十字链表表示法:...
)
微信小程序教学系列(2)
第二章:小程序开发基础 1. 小程序页面布局与样式 在小程序开发中,我们可以使用 WXML(WeiXin Markup Language)和 WXSS(WeiXin Style Sheet)来定义页面的布局和样式。 1.1 WXML基础 WXML 是一种类似于 H…...
社科院与美国杜兰大学金融管理硕士项目——畅游于金融世界
随着社会经济的不断发展,职场竞争愈发激烈,很多同学都打算通过报考研究生来实现深造,提升自己的综合能力和竞争优势,获得优质的证书。而对于金融专业的学生和在职人员来说,社科院与美国杜兰大学金融管理硕士项目是一个…...
功能强大、超低功耗的STM32WL55JCI7、STM32WL55CCU7、STM32WL55CCU6 32位无线远距离MCU
STM32WL55xx 32位无线远距离MCU嵌入了功能强大、超低功耗、符合LPWAN标准的无线电解决方案,可提供LoRa、(G)FSK、(G)MSK和BPSK等各种调制。STM32WL55xx无线MCU的功耗超低,基于高性能Arm Cortex-M4 32位RISC内核(工作频率高达48MHz)…...
【自适应稀疏度量方法和RQAM】疏度测量、RQAM特征、AWSPT和基于AWSPT的稀疏度测量研究(Matlab代码实现)
💥💥💞💞欢迎来到本博客❤️❤️💥💥 🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。 ⛳️座右铭&a…...

sql递归查询
一、postgresql 递归sql with recursive p as(select t1.* from t_org_test t1 where t1.id2union allselect t2.*from t_org_test t2 join p on t2.parent_idp.id) select id,name,parent_id from p; sql中with xxxx as () 是对一个查询子句做别名,同时数据库会对…...

常见前端面试之VUE面试题汇总三
7. Vue 中封装的数组方法有哪些,其如何实现页面更新 在 Vue 中,对响应式处理利用的是 Object.defineProperty 对数据进 行拦截,而这个方法并不能监听到数组内部变化,数组长度变化,数 组的截取变化等,所以需…...
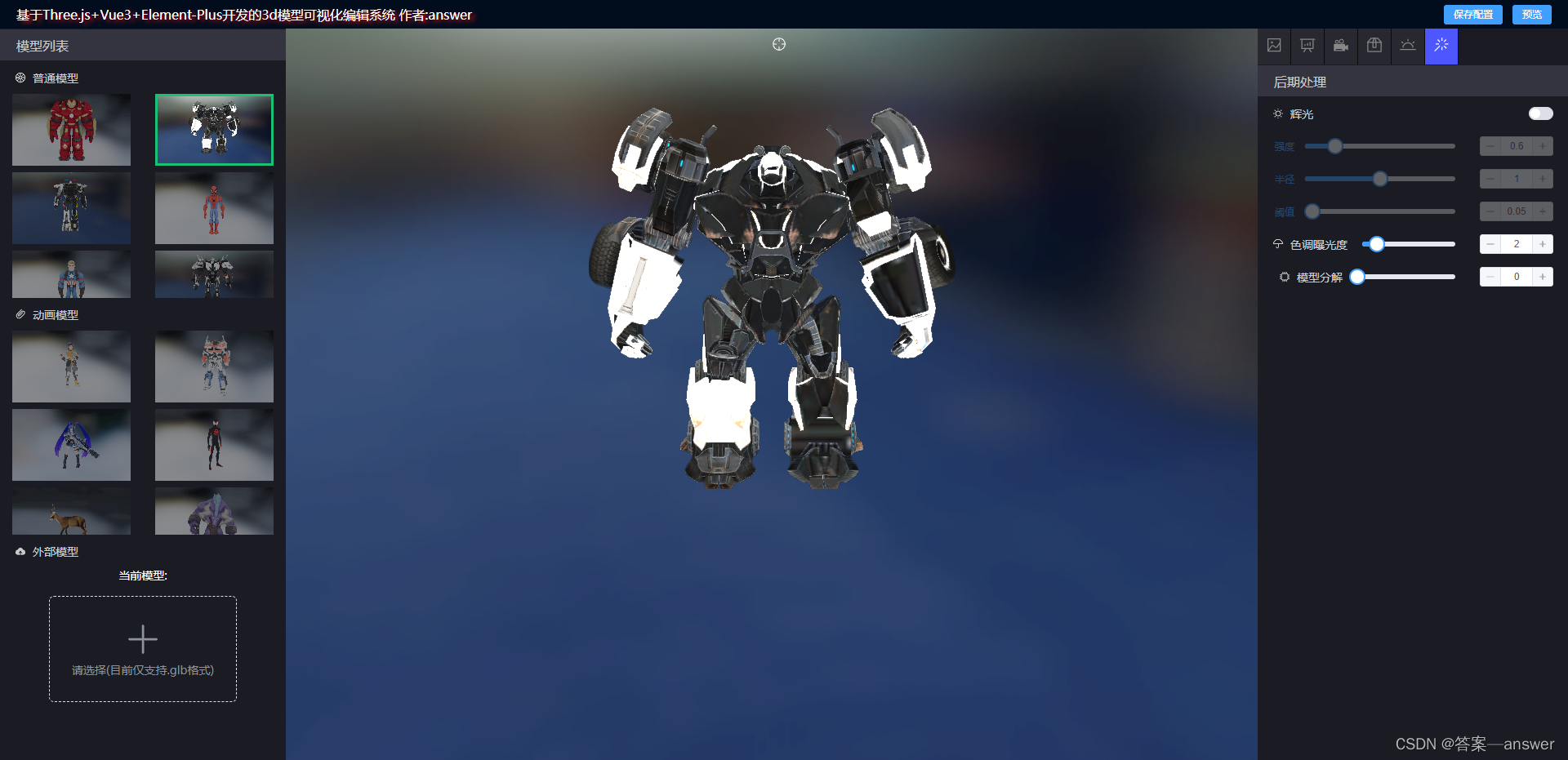
Three.js 实现模型材质分解,拆分,拆解效果
原理:通过修改模型材质的 x,y,z 轴坐标 positon.set( x,y,z) 来实现拆解,分解的效果。 注意:支持模型材质position 修改的材质类型为 type“Mesh” ,其他类型的材质修改了position 可能没有实际效果 在上一篇 Three.js加载外部glb,fbx,gltf…...

《JVM修仙之路》初入JVM世界
《JVM修仙之路》初入JVM世界 博主目前正在学习JVM的相关知识,想以一种不同的方式记录下,娱乐一下 清晨,你睁开双眼,看到刺眼的阳光,你第一反应就是完了完了,又要迟到了。刚准备起床穿衣的你突然意识到不对&…...
苍穹外卖 day1 搭建成功环境
引入 idea找不到打包生成的文件目录怎么办,首先点击这个小齿轮 show ecluded files然后就能找到隐藏的文件 这个jar包内含tomcat,可以直接丢在linux上用 开发环境:开发人员在开发阶段使用的环境,一般外部用户无法访问 测试环…...

智能主体按照功能划分
(1) 构件接口主体 构件接口主体提供构件与用户之间的接口。当一个用户通过代理主体向 元组空间提出申请,并找到相匹配的构件主体时,此构件主体会将其所在构件主体 组中的构件接口主体通过申请用户的代理主体传送到用户的界面。 (2) 构件主体 通过构…...
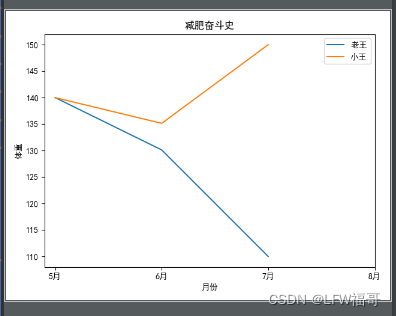
python中的matplotlib画折线图(数据分析与可视化)
先导包(必须安装了numpy 、pandas 和matplotlib才能导包): import numpy as np import pandas as pd import matplotlib.pyplot as plt核心代码: import numpy as np import pandas as pd import matplotlib.pyplot as pltpd.se…...
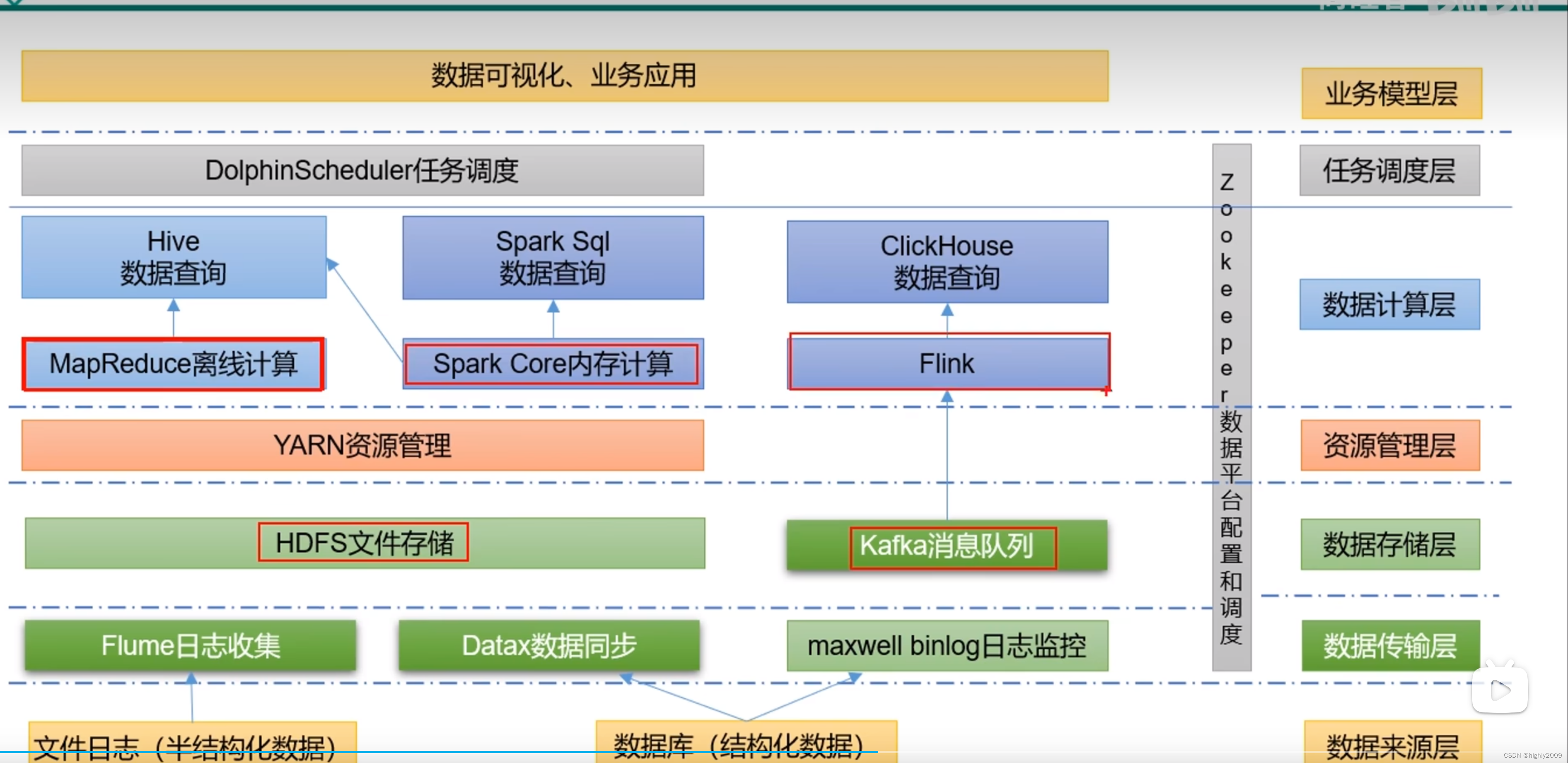
大数据数据仓库
一.在线教育 1.数据采集 1.数仓概念 数据仓库是为企业制定决策,提供数据支持的。数据采集和存储、对数据进行计算和分析 2.项目架构 2.数据分类 业务数据 用户行为数据 爬虫数据 2.离线数仓 3.实时数仓...

Java“牵手“速卖通商品详情页面数据获取方法,速卖通API实现批量商品数据抓取示例
速卖通商城是一个网上购物平台,售卖各类商品,包括服装、鞋类、家居用品、美妆产品、电子产品等。要获取速卖通商品详情数据,您可以通过开放平台的接口或者直接访问速卖通商城的网页来获取商品详情信息。以下是两种常用方法的介绍:…...
【Git】代码误推送还原(真实项目环境,非纸上谈兵)
背景 RT, 我今天眼睛花了,不小心把工作分支【合并】到了一个不相干的功能分支上,并且代码已经推送到远程仓库了。于是,只能尝试还原到上一次提交中。 【合并】分支有一个点我们是不可避免的,文字很难描述,…...

CPU 飙升?这3大场景助你精准定位
1 常用的 Load 分析方法 CPU高、Load高 通过 top 命令查找占用CPU最高的进程PID; 通过top -Hp PID查找占用CPU最高的线程TID; 对于java程序,使用jstack打印线程堆栈信息; 通过printf %x tid打印出最消耗CPU线程的十六进制; …...
6、Spring_Junit与JdbcTemplate整合
Spring 整合 1.Spring 整合 Junit 1.1新建项目结构 1.2导入依赖 导入 junit 与 Spring 依赖 <!-- 添加 spring 依赖--> <dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version…...
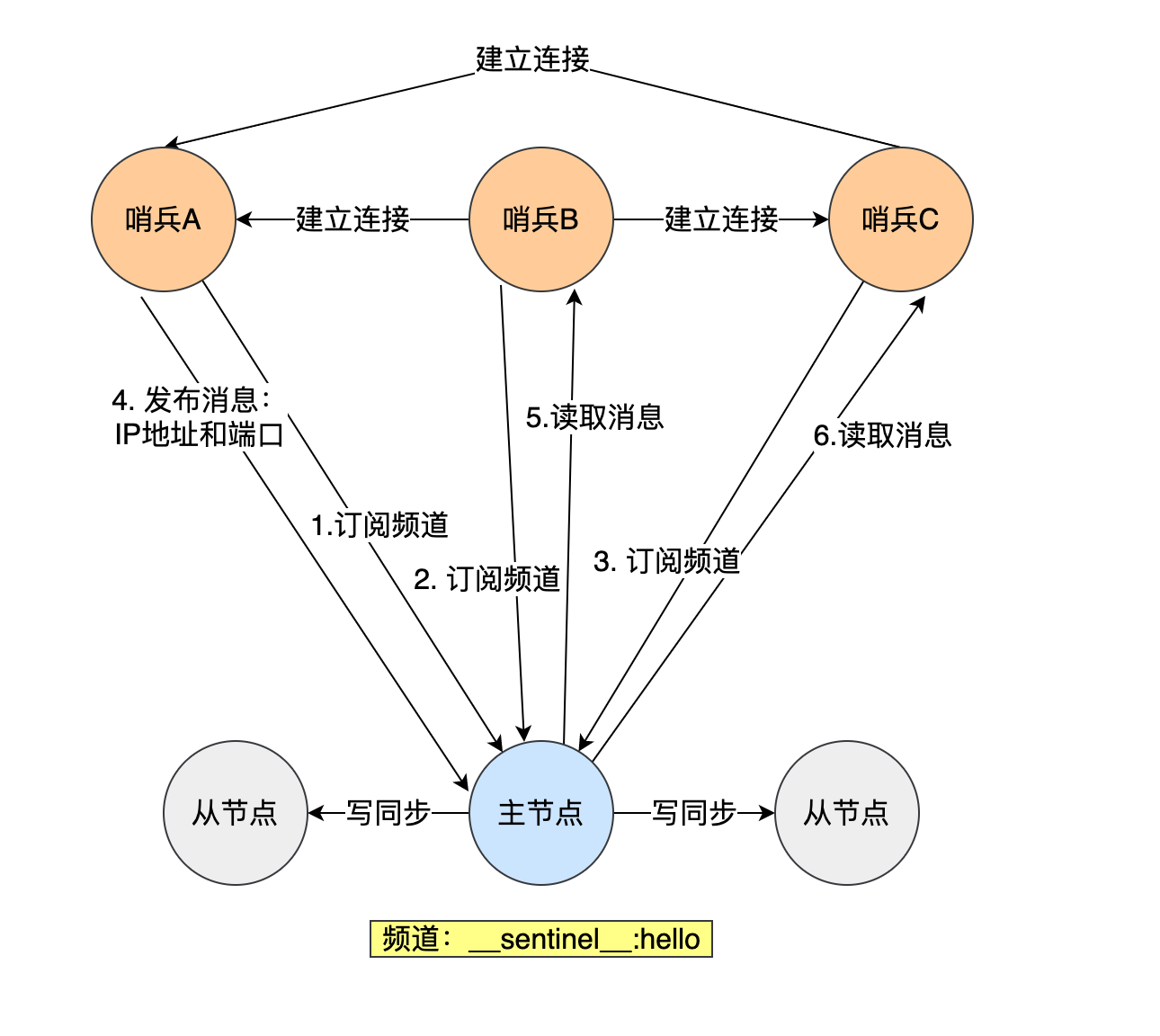
Redis是如何保证高可用的?
Redis这种基于内存的关系型数据库我们在选用的时候就是考虑到它的快。而且可以很方便的实现诸如分布式锁、消息队列等功能。 笔者在前一段秋招面试的时候就被提问,“Redis是怎么保证高可用的?” 后续的子问题包含,集群模式是怎么实现的&…...

Ubuntu环境下离线部署Docker生态全攻略:从安装到镜像迁移
1. 为什么需要离线部署Docker?从企业内网说起 大家好,我是老张,在运维和开发这个行当里摸爬滚打了十几年,经手过不少企业级项目。今天想和大家聊聊一个非常实际,但又常常让新手头疼的场景:在完全没有外网的…...

拒绝黑盒!一文看懂大模型底层原理与产品区别,小白程序员必收藏
在当今数字化时代,AI 大模型早已不是陌生词汇 —— 从日常聊天的 ChatGPT,到帮我们处理工作的智能助手,它正悄悄改变着我们的生活与工作节奏。但对大多数人来说,AI 大模型就像个 “黑盒子”:知道它好用,却搞…...

Flutter 三方库 ipsum 的鸿蒙化适配指南 - 让 UI 占位更具灵性、在鸿蒙端实现高效设计打样与排版验证实战
欢迎加入开源鸿蒙跨平台社区:https://openharmonycrossplatform.csdn.net Flutter 三方库 ipsum 的鸿蒙化适配指南 - 让 UI 占位更具灵性、在鸿蒙端实现高效设计打样与排版验证实战 前言 在进行 Flutter for OpenHarmony 的 UI 开发初期,我们经常会遇…...
)
CodeQL实战:如何用5分钟快速搭建你的第一个代码安全查询(附常见错误排查)
CodeQL实战:如何用5分钟快速搭建你的第一个代码安全查询(附常见错误排查) 最近和几个刚接触代码安全审计的朋友聊天,发现大家普遍对CodeQL有种“敬畏感”——功能强大,但总觉得配置复杂、学习曲线陡峭,还没…...

Qwen3-TTS-12Hz-1.7B-Base效果实测:葡萄牙语巴西俚语语音生成能力
Qwen3-TTS-12Hz-1.7B-Base效果实测:葡萄牙语巴西俚语语音生成能力 你有没有试过让AI说出“Cara, t de brincadeira?!”——那种带着夸张语气、拖着尾音、还带点街头感的巴西葡语?不是教科书里的标准发音,而是里约热内卢小摊主招呼熟客时的真…...

ofa_image-caption实战落地:为AI绘画工作流增加‘图像反向理解’能力模块
ofa_image-caption实战落地:为AI绘画工作流增加‘图像反向理解’能力模块 你有没有遇到过这种情况?用AI生成了一张特别满意的图片,想分享出去,却不知道该怎么描述它。或者,在整理自己的AI绘画作品集时,面对…...
)
Linux下HYM8563 RTC驱动加载失败的5种排查姿势(附i2cdetect实战)
Linux下RTC驱动加载失败:从硬件到内核的深度排查实战指南 最近在调试一块嵌入式板卡时,遇到了一个典型的RTC驱动加载问题:系统启动时HYM8563 RTC芯片驱动加载失败,但重启后却能正常工作。这种“开机失败、重启正常”的现象在嵌入式…...

AMD Ryzen处理器深度优化:SMUDebugTool技术突破与系统级调试指南
AMD Ryzen处理器深度优化:SMUDebugTool技术突破与系统级调试指南 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: …...

消息队列RabbitMQ的配置操作及使用
一、RabbitMQ的体系结构 RabbitMQ是一个基于AMQP(Advanced Message Queuing Protocol,高级消息队列协议)实现的开源消息中间件,主要用于在分布式系统中存储和转发消息。它由Erlang语言编写,以高性能、高可用性以及高扩…...

工作流整理
现在加了uk环境 1 jira分任务 2 按jira ticket name起branch进行开发,开发完成后写ut 3 本地测试过后,准备AT test case,升version,推到dev env 4 跑AT,测试通过后提pr 5 pr merge到main后上sit,hk上完上uk…...