精进语言模型:探索LLM Training微调与奖励模型技术的新途径
大语言模型训练(LLM Training)
LLMs Trainer 是一个旨在帮助人们从零开始训练大模型的仓库,该仓库最早参考自 Open-Llama,并在其基础上进行扩充。
有关 LLM 训练流程的更多细节可以参考 【LLM】从零开始训练大模型。
使用仓库之前,请先安装所有需要的依赖:
pip install -r requirements.txt
1. 继续预训练(Continue Pretraining)
继续预训练是指,在一个已有的模型上继续进行预训练增强,通常用于 英文模型的中文增强 或是 领域数据增强。
我们这里以英文模型 OpenLlama 在中文数据集 MNBVC 中的 少量数据 为例来演示整个流程。
1.1 数据压缩
由于预训练数据集通常比较庞大,因此先将训练数据进行压缩并流氏读取。
首先,进入到 data 目录:
cd data
找到目录下的 compress_data.py, 在该文件中修改需要压缩的数据路径:
SHARD_SIZE = 10 # 单个文件存放样本的数量, 示例中使用很小,真实训练可以酌情增大
...def batch_compress_preatrain_data():"""批量压缩预训练数据。"""source_path = 'shuffled_data/pretrain' # 源数据文件target_path = 'pretrain_data' # 压缩后存放地址files = [ # 这三个文件是示例数据'MNBVC_news','MNBVC_qa','MNBVC_wiki']...if __name__ == '__main__':batch_compress_preatrain_data()# batch_compress_sft_data()
Notes: 上述的 files 可以在 shuffled_data/pretrain/ 中找到,是我们准备的少量示例数据,真实训练中请替换为完整数据。
在 data 路径中执行 python compress_data.py, 终端将显示:
processed shuffled_data/pretrain/MNBVC_news.jsonl...
total line: 100
total files: 10
processed shuffled_data/pretrain/MNBVC_qa.jsonl...
total line: 50
total files: 5
processed shuffled_data/pretrain/MNBVC_wiki.jsonl...
total line: 100
total files: 10
随后可在 pretrain_data 中找到对应的 .jsonl.zst 压缩文件(该路径将在之后的训练中使用)。
1.2 数据源采样比例(可选)
为了更好的进行不同数据源的采样,我们提供了按照预设比例进行数据采样的功能。
我们提供了一个可视化工具用于调整不同数据源之间的分布,在 根目录 下使用以下命令启动:
streamlit run utils/sampler_viewer/web.py --server.port 8001
随后在浏览器中访问 机器IP:8001 即可打开平台。
我们查看 data/shuffled_data/pretrain 下各数据的原始文件大小:
-rw-r--r--@ 1 xx staff 253K Aug 2 16:38 MNBVC_news.jsonl
-rw-r--r--@ 1 xx staff 121K Aug 2 16:38 MNBVC_qa.jsonl
-rw-r--r--@ 1 xx staff 130K Aug 2 16:37 MNBVC_wiki.jsonl
并将文件大小按照格式贴到平台中:
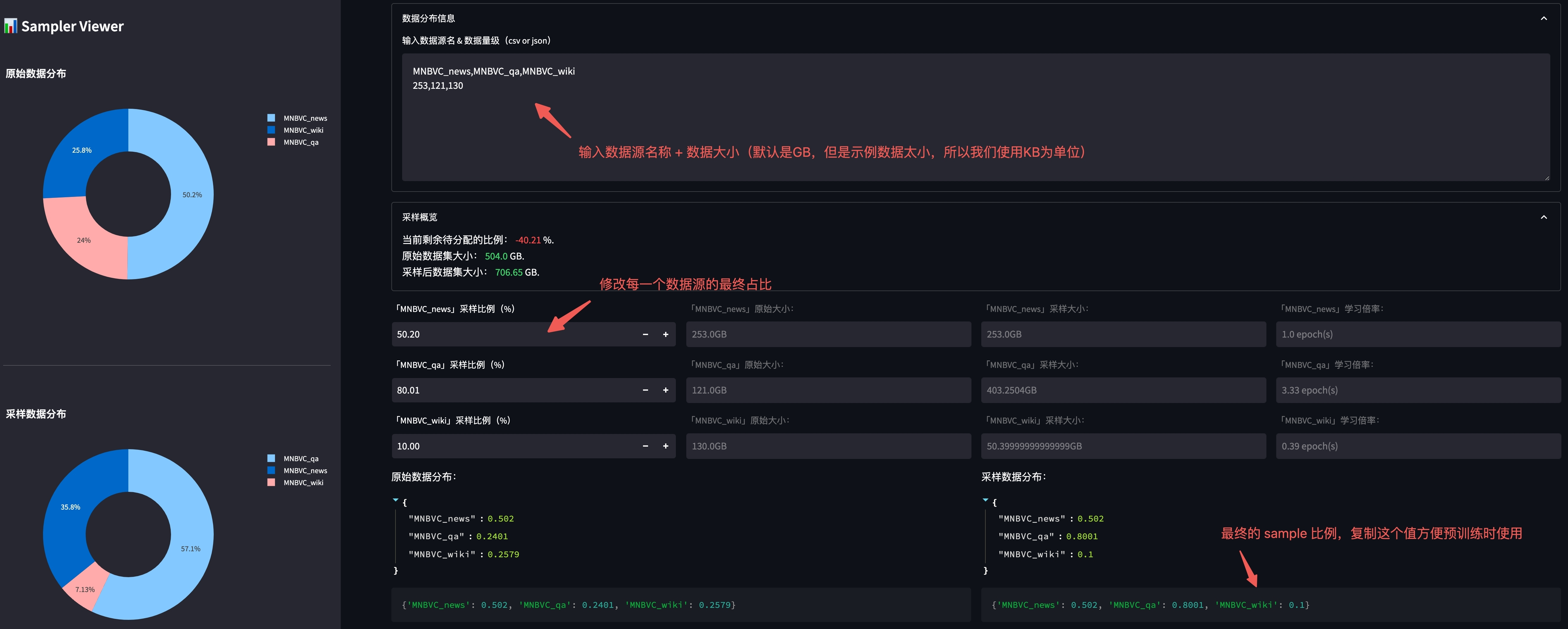
调整完毕后,复制上图右下角的最终比例,便于后续训练使用。
1.3 词表扩充(可选)
由于原始 Llama 的中文 token 很少,因此我们可以选择对原有的 tokenizer 进行词表扩充。
进入到 utils 目录:
cd utils
修改文件 train_tokenizer.py 中的训练数据(我们使用正式预训练训练数据集作为训练词表的数据集):
...
dataset = {"MNBVC_news": "../data/pretrain_data/MNBVC_news/*.jsonl.zst","MNBVC_qa": "../data/pretrain_data/MNBVC_qa/*.jsonl.zst","MNBVC_wiki": "../data/pretrain_data/MNBVC_wiki/*.jsonl.zst",
}
执行完 train_tokenizer.py 后,路径下会出现训练好的模型 test_tokenizer.model。
随后,我们将训练好的 model 和原本的 llama model 做融合:
python merge_tokenizer.py
你可以使用 这个工具 很方便的对合并好后的 tokenizer 进行可视化。
1.4 平均初始化 extend token embedding(可选)
为了减小扩展的 token embedding 随机初始化带来模型性能的影响,我们提供使用将新 token 在原 tokenizer 中的 sub-token embedding 的平均值做为初始化 embedding 的方法。
具体使用方法在 utils/extend_model_token_embeddings.py。
1.5 正式训练
当完成上述步骤后就可以开始正式进行训练,使用以下命令启动训练:
sh train_llms.sh configs/accelerate_configs/ds_stage1.yaml \configs/pretrain_configs/llama.yaml \openlm-research/open_llama_7b_v2
多机多卡则启动:
sh train_multi_node_reward_model.sh configs/accelerate_configs/ds_stage1.yaml \configs/pretrain_configs/llama.yaml \openlm-research/open_llama_7b_v2
注意,所有的训练配置都放在了第 2 个参数 configs/pretrain_configs/llama.yaml 中,我们挑几个重要的参数介绍。
-
tokenizer_path (str):tokenizer 加载路径。 -
ckpt (str):初始 model 加载路径。 -
sample_policy_file (str):数据源采样配置文件,若不包含这一项则不进行数据源采样。 -
train_and_eval (bool):该参数决定了是否在训练中执行评估函数。 -
img_log_dir (str):训练过程中的 log 图存放目录。 -
eval_methods (list):使用哪些评估函数,包括:-
single_choice_eval: 单选题正确率测试(如: C-Eval),评估数据格式参考
eval_data/knowledge/knowledge_and_reasoning.jsonl。 -
generation_eval: 生成测试,给定 prompt,测试模型生成能力,评估数据格式参考
eval_data/pretrain/generation_test.jsonl。
-
-
work_dir (str):训练模型存放路径。 -
save_total_limit (int):最多保存的模型个数(超过数目则删除旧的模型)
2. 指令微调(Instruction Tuning)
我们准备了部分 ShareGPT 的数据作为示例数据,我们仍旧使用 OpenLlama 作为训练的基座模型。
2.1 数据压缩
同预训练一样,我们先进入到 data 目录:
cd data
找到目录下的 compress_data.py, 在该文件中修改需要压缩的数据路径:
SHARD_SIZE = 10 # 单个文件存放样本的数量, 示例中使用很小,真实训练可以酌情增大
...def batch_compress_sft_data():"""批量压缩SFT数据。"""source_path = 'shuffled_data/sft'target_path = 'sft_data'files = ['sharegpt']...if __name__ == '__main__':# batch_compress_preatrain_data()batch_compress_sft_data()
Notes: 上述的 files 可以在 shuffled_data/sft/ 中找到,是我们准备的少量示例数据,真实训练中请替换为完整数据。
在 data 路径中执行 python compress_data.py, 终端将显示:
processed shuffled_data/sft/sharegpt.jsonl...
total line: 9637
total files: 964
随后可在 sft_data 中找到对应的 .jsonl.zst 压缩文件(该路径将在之后的训练中使用)。
2.2 特殊 token 扩充
受到 ChatML 的启发,我们需要在原有的 tokenizer 中添加一些 special token 用于对话系统。
一种最简单的方式是在 tokenizer 路径中找到 special_tokens_map.json 文件,并添加以下内容:
{... # 需要添加的特殊 token"system_token": "<|system|>", # system prompt"user_token": "<|user|>", # user token"assistant_token": "<|assistant|>", # chat-bot token"chat_end_token": "<|endofchat|>" # chat end token
}
2.3 微调训练
当完成上述步骤后就可以开始正式进行训练,使用以下命令启动训练:
sh train_llms.sh configs/accelerate_configs/ds_stage1.yaml \configs/sft_configs/llama.yaml \openlm-research/open_llama_7b_v2
多机多卡则启动:
sh train_multi_node_reward_model.sh configs/accelerate_configs/ds_stage1.yaml \configs/sft_configs/llama.yaml \openlm-research/open_llama_7b_v2
注意,所有的训练配置都放在了第 2 个参数 configs/sft_configs/llama.yaml 中,我们挑几个重要的参数介绍。
-
tokenizer_path (str):tokenizer 加载路径。 -
ckpt (str):初始 model 加载路径。 -
train_and_eval (bool):该参数决定了是否在训练中执行评估函数。 -
img_log_dir (str):训练过程中的 log 图存放目录。 -
eval_methods (list):使用哪些评估函数,包括:-
generation_eval: 生成测试,给定 prompt,测试模型生成能力,评估数据格式参考
eval_data/sft/share_gpt_test.jsonl。 -
暂无。
-
-
work_dir (str):训练模型存放路径。 -
save_total_limit (int):最多保存的模型个数(超过数目则删除旧的模型)
3. 奖励模型(Reward Model)
3.1 数据集准备
我们准备 1000 条偏序对作为示例训练数据,其中 selected 为优势样本,rejected 为劣势样本:
{"prompt": "下面是一条正面的评论:","selected": "很好用,一瓶都用完了才来评价。","rejected": "找了很久大小包装都没找到生产日期。上当了。"
}
这个步骤不再需要数据压缩,因此准备好上述结构的 .jsonl 文件即可。
3.2 RM 训练
当完成上述步骤后就可以开始正式进行训练,使用以下命令启动训练:
sh train_multi_node_reward_model.sh \configs/accelerate_configs/ds_stage1.yaml \configs/reward_model_configs/llama7b.yaml
注意,所有的训练配置都放在了第 2 个参数 configs/reward_model_configs/llama.yaml 中,我们挑几个重要的参数介绍。
-
tokenizer_path (str):tokenizer 加载路径。 -
ckpt (str):初始 model 加载路径。 -
train_and_eval (bool):该参数决定了是否在训练中执行评估函数。 -
img_log_dir (str):训练过程中的 log 图存放目录。 -
test_reward_model_acc_files (list):acc 测试文件列表。 -
work_dir (str):训练模型存放路径。 -
save_total_limit (int):最多保存的模型个数(超过数目则删除旧的模型)
项目链接:https://github.com/HarderThenHarder/transformers_tasks/blob/main/LLM/LLMsTrainer/readme.md
相关文章:
精进语言模型:探索LLM Training微调与奖励模型技术的新途径
大语言模型训练(LLM Training) LLMs Trainer 是一个旨在帮助人们从零开始训练大模型的仓库,该仓库最早参考自 Open-Llama,并在其基础上进行扩充。 有关 LLM 训练流程的更多细节可以参考 【LLM】从零开始训练大模型。 使用仓库之…...

数据采集:selenium 提取 Cookie 自动登陆
写在前面 工作需要,简单整理博文内容涉及 通过 selenium 实现自动登陆理解不足小伙伴帮忙指正 对每个人而言,真正的职责只有一个:找到自我。然后在心中坚守其一生,全心全意,永不停息。所有其它的路都是不完整的&#x…...

[Go版]算法通关村第十三关黄金——数字数学问题之数论问题(最大公约数、素数、埃氏筛、丑数)
目录 题目:辗转相除法(求最大公约数)思路分析:辗转相除法(也叫欧几里得算法)gcd(a,b) gcd(b,a mod b)复杂度:时间复杂度 O ( n l o g ( m a x ) ) O(nlog(max)) O(nlog(max))、空间复杂度 O (…...
Qt双击某一文件通过自己实现的程序打开,并加载文件显示
双击启动 简述方法一方法二注意 简述 在Windows系统中,双击某类扩展名的文件,通过自己实现的程序打开文件,并正确加载及显示文件。有两种方式可以到达这个目的。 对于系统不知道的扩展名的文件,第一次打开时,需要自行…...

硬件产品的量产问题------硬件工程师在产线关注什么
前言: 产品开发测试无误,但量产缺遇到很多不良甚至DOA问题。 硬件开发过程中如何确保产线的治具、生产及硬件工程师在产线需要关注一些什么。 坚信:好的产品是要可以做出来的。 1、禁忌: 禁忌热插拔;禁忌测试不防呆…...
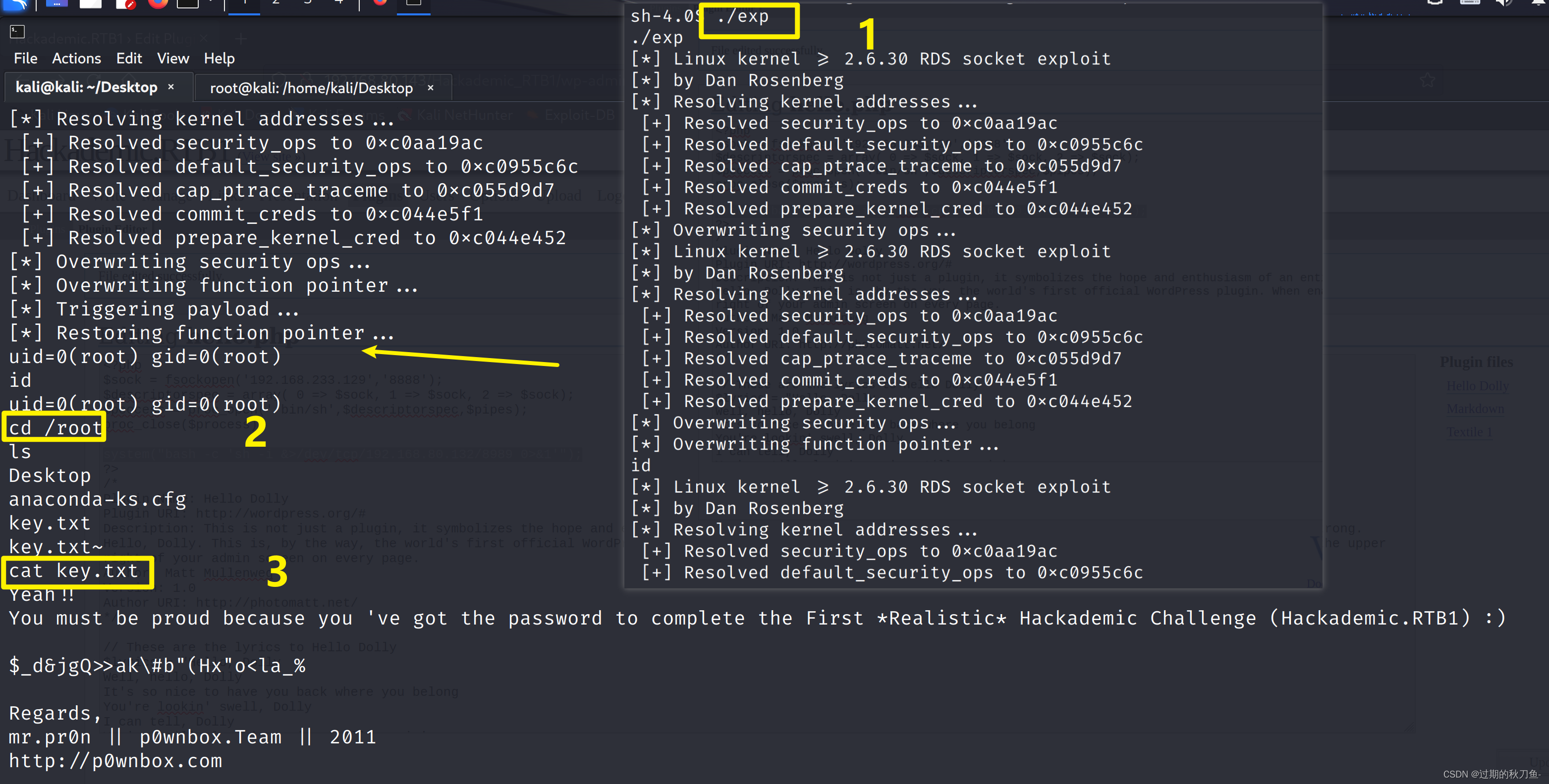
Vulnhub系列靶机--- Hackadmeic.RTB1
系列:Hackademic(此系列共2台) 难度:初级 信息收集 主机发现 netdiscover -r 192.168.80.0/24端口扫描 nmap -A -p- 192.168.80.143访问80端口 使用指纹识别插件查看是WordPress 根据首页显示的内容,点击target 点击…...
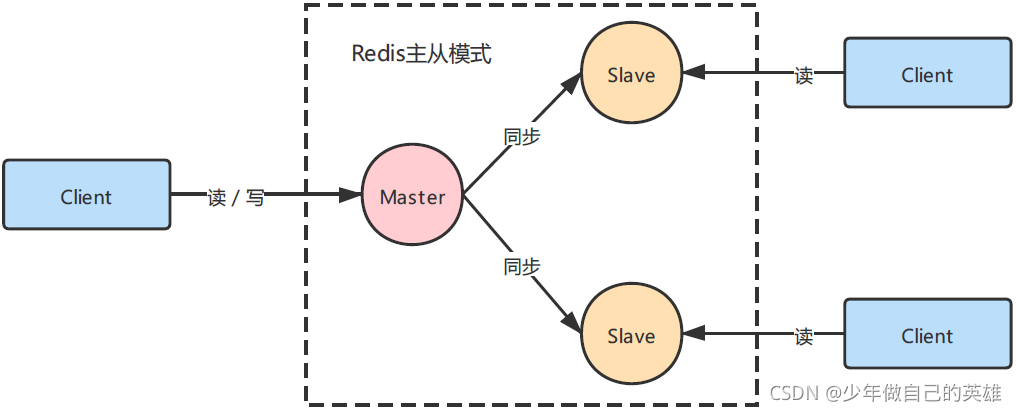
redis高级----------主从复制
redis的四种模式:单例模式;主从模式;哨兵模式,集群模式 一、主从模式 单例模式虽然操作简单,但是不具备高可用 缺点: 单点的宕机引来的服务的灾难、数据丢失单点服务器内存瓶颈,无法无限纵向扩…...

posgresql通过PL/pgSQL脚本统一修改某字段大小写
项目在做postgresql数据库适配时遇到了某些问题,需要统一将某个模式含id字段的全部表,将id字段由小写转换为大写,可以通过PL/pgSQL脚本实现。 先确保当前用户有足够的权限 DO $$ DECLARE current_table text;current_column text; BEGIN --…...

iPhone卫星通信SOS功能如何在灾难中拯救生命
iPhone上的卫星紧急求救信号功能在从毛伊岛野火中拯救一家人方面发挥了至关重要的作用。这是越来越多的事件的一部分,在这些事件中,iPhone正在帮助人们摆脱危及生命的情况。 卫星提供商国际通信卫星组织负责移动的高级副总裁Mark Rasmussen在接受Lifewir…...

NOIP真题答案 过河 数的划分
过河 题目描述 在河上有一座独木桥,一只青蛙想沿着独木桥从河的一侧跳到另一侧。在桥上有一些石子,青蛙很讨厌踩在这些石子上。由于桥的长度和青蛙一次跳过的距离都是正整数,我们可以把独木桥上青蛙可能到达的点看成数轴上的一串整点…...
图为科技-边缘计算在智慧医疗领域的作用
边缘计算在智慧医疗领域的作用 随着科技的进步,智慧医疗已成为医疗行业的重要发展趋势。边缘计算作为新兴技术,在智慧医疗领域发挥着越来越重要的作用。本文将介绍边缘计算在智慧医疗领域的应用及其优势,并探讨未来发展方向。 一、边缘计算…...
Linux配置nginx反向代理
在云服务器上部署高并发的服务,使用Nginx作为反向代理是一种常见的做法,可以实现流量分发、负载均衡,同时提升系统的可靠性和性能。 步骤概览: 安装Nginx: 确保服务器已安装Nginx。若未安装,可使用适用于你…...

随便记录记录
统一整理一下各种 pandas读csv import pandas as pd ## 默认会将第一行作为列 df pd.read_csv(path_to_your_file.csv) ## 传递 headerNone 参数来告诉 Pandas 不要将第一行 df pd.read_csv(path_to_your_file.csv, headerNone) ## 使用多种选项来处理数据,如指…...

UbuntuDDE 23.04发布,体验DeepinV23的一个新选择
UbuntuDDE 23.04发布,体验DeepinV23的一个新选择 昨晚网上搜索了一圈,无意看到邮箱一条新闻,UbuntuDDE 23.04发布了 因为前几天刚用虚拟机安装过,所以麻溜的从网站下载了ISO文件,安装上看看。本来没多想,…...
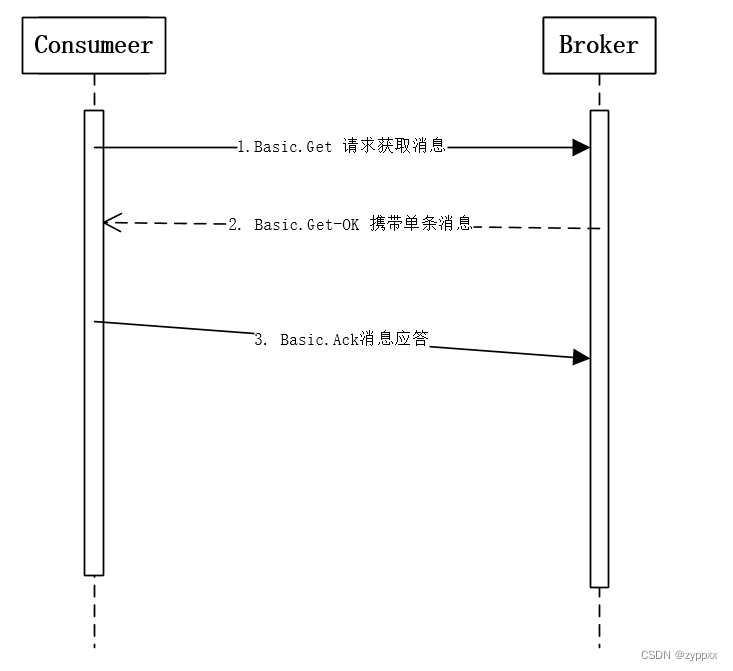
RabbitMQ 消费者
RabbitMQ的消费模式分两种:推模式和拉模式,推模式采用Basic.Consume进行消费,拉模式则是调用Basic.Get进行消费。 消费者通过订阅队列从RabbitMQ中获取消息进行消费,为避免消息丢失可采用消费确认机制 消费者 拉模式拉模式的实…...

软件测试面试真题 | 什么是PO设计模式?
面试官问:UI自动化测试中有使用过设计模式吗?了解什么是PO设计模式吗? 考察点 《page object 设计模式》:PageObject设计模式的设计思想、设计原则 《web自动化测试实战》:结合PageObject在真实项目中的实践与应用情…...

GB2312转UTF-8部分中文乱码
现象 最近写了个txt导入,客户反馈有时候导入的数据,会出现个别中文乱码的现象,但是我之前已经做过编码转换处理了,统一转成了UTF-8。 比如“鞠婧祎”,导入进来是这样: 排查思路 首先看了一下这个文本的编码格式&am…...
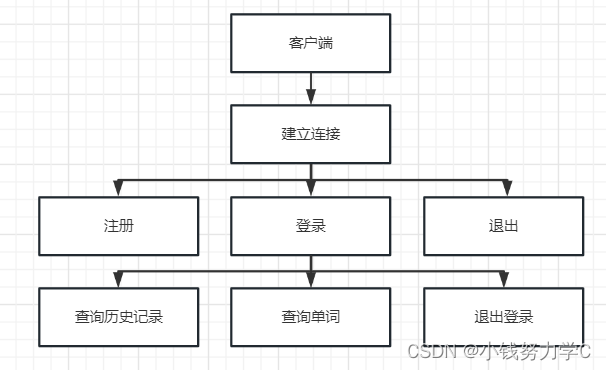
项目——电子词典(客户端、服务器交互,字典导入,单词查询)
一、项目要求 登录注册功能,不能重复登录,重复注册单词查询功能历史记录功能,存储单词,意思,以及查询时间基于TCP,支持多客户端连接采用数据库保存用户信息与历史记录将dict.txt的数据导入到数据库中保存。…...
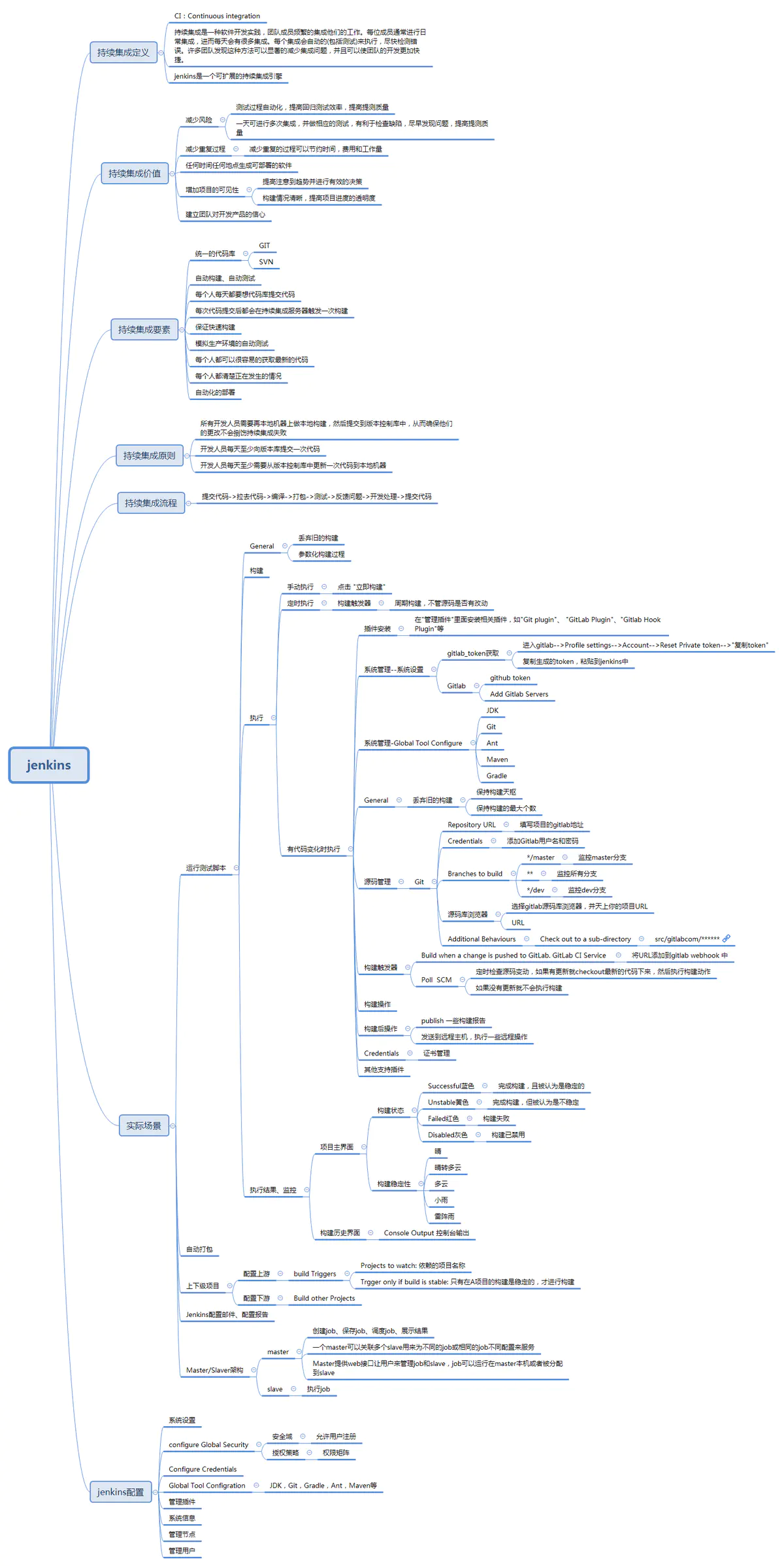
jenkins 是什么?
一、jenkins 是什么? Jenkins是一个开源的、提供友好操作界面的持续集成(CI)工具,起源于Hudson,主要用于持续、自动的构建/测试软件项目、监控外部任务的运行。Jenkins用Java语言编写,可在Tomcat等流行的servlet容器中运行&#…...

无涯教程-PHP - sql_regcase()函数
sql_regcase() - 语法 string sql_regcase (string string) 可以将sql_regcase()函数视为实用程序函数,它将输入参数字符串中的每个字符转换为包含两个字符的带括号的表达式。 sql_regcase() - 返回值 返回带括号的表达式字符串以及转换后的字符。 sql_regcase…...

在流式响应中,OpenClaw 如何控制生成速率和输出平滑度?是否使用了异步令牌生成?
在讨论流式响应中的生成速率和平滑度控制时,一个常见的误区是认为这仅仅是一个技术参数调整的问题。实际上,它更像是在平衡一场对话中的节奏感——说得太快,对方可能跟不上;说得太慢,又会显得拖沓。OpenClaw 在这方面的…...

26 Python 分类:一棵树不够稳,那就很多棵树一起判断?一文入门随机森林
Python 数据分析入门:一棵树不够稳,那就很多棵树一起判断?一文入门随机森林适合人群:Python 初学者 / 数据分析入门 / 机器学习入门 / 教学案例分享前一篇文章里,我们已经认识了组合分类,知道了一个很重要的…...

新手必看!前端如何玩转Blob对象:从URL生成到文件下载全流程解析
前端开发者必备:Blob对象实战指南——从URL生成到文件下载全流程 在Web开发中,处理二进制数据是每个前端工程师迟早要面对的挑战。Blob(Binary Large Object)作为浏览器提供的原生对象,能够高效地处理文件流、图像数据…...
)
FT8430-LRT非隔离5V100MA电源芯片:小家电、智能照明与MCU供电的高效解决方案(附典型电路图)
1. FT8430-LRT芯片:小功率设备的"能量心脏" 当你拆开一个智能灯泡或者电动牙刷,总会发现一块小小的电路板,上面密密麻麻的元件中藏着一个不起眼但至关重要的部件——电源管理芯片。FT8430-LRT就是这样一款专为小功率设备设计的非隔…...

从路径遍历到RCE:深度剖析Ollama CVE-2024-37032漏洞原理与利用链
1. Ollama与CVE-2024-37032漏洞背景 Ollama作为本地运行大型语言模型的工具链,近年来在开发者社区中迅速走红。它简化了从模型下载、配置到交互的全流程,甚至能让不懂机器学习原理的用户快速体验AI能力。但正是这种"开箱即用"的特性ÿ…...

OpenStack物理机与虚拟机外部网络连接:网卡配置实战指南
1. OpenStack网络连接基础概念 第一次接触OpenStack网络配置时,我也被各种网桥和虚拟设备搞得晕头转向。简单来说,OpenStack的网络连接就像是在物理机和虚拟机之间搭建一座桥梁。物理网卡(eth0、ens33这类)是真实的硬件设备&#…...

保姆级教程:用六叶树UTC2202适配器在Ubuntu 20.04上搞定大陆ARS408毫米波雷达的RVIZ点云显示
从零搭建ARS408毫米波雷达的Ubuntu 20.04开发环境:硬件连接与数据可视化全流程指南 当你第一次拿到大陆ARS408毫米波雷达和六叶树UTC2202适配器时,可能会被一堆线缆和陌生的术语搞得手足无措。别担心,这篇文章将带你一步步完成从硬件连接到RV…...
)
DiskGenius实战:误删分区后如何用‘搜索丢失分区‘功能救回数据(附详细步骤)
DiskGenius数据恢复实战:误删分区后的完整救援指南 当你发现硬盘上的某个分区突然消失,或者系统提示"未格式化"时,那种心跳加速的感觉我深有体会。去年帮一位摄影师客户恢复婚礼照片时,亲眼见证了他从绝望到欣喜的全过程…...

学霸同款 8个降AIGC平台测评:本科生降AI率必看攻略
在当前学术写作中,AI生成内容的普及让论文查重和AIGC率问题变得愈发突出。对于本科生而言,如何在保持原文逻辑与语义的前提下,有效降低AI痕迹和重复率,成为毕业论文撰写过程中的一大挑战。而AI降重工具的出现,为学生提…...

最新!2026年3月全球大模型全景:国产登顶、百万上下文、智能体爆发,AI进入实用新纪元
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...