Java进阶篇--IO流的第二篇《多样的流》
目录
Java缓冲流
BufferedReader和BufferedWriter类
Java随机流
Java数组流
字节数组流
ByteArrayInputStream流的构造方法:
ByteArrayOutputStream流的构造方法:
字符数组流
Java数据流
Java对象流
Java序列化与对象克隆
扩展小知识:
Java使用Scanner解析文件
使用默认分隔标记解析文件
使用正则表达式作为分隔标记解析文件
Java文件对话框
Java带进度条的输入流
Java文件锁
Java缓冲流
缓冲流是Java中的一种流,它可以提供缓冲区来提高读写数据的效率。缓冲流可以将数据先暂时存储在内存中的缓冲区中,然后再一次性地写入或读取,减少了频繁的磁盘或网络操作,从而提高了读写数据的速度。
缓冲流可以起到以下作用:
- 提高读写效率:缓冲流可以减少磁盘或网络操作的次数,将数据先存储在内存中的缓冲区中,再一次性地写入或读取,从而提高了读写数据的效率。
- 提供了额外的功能:缓冲流还提供了一些额外的功能,如支持字符编码转换、支持行操作等。
在Java中,常见的缓冲流有
- BufferedInputStream:它是对InputStream的包装,提供了缓冲区来提高读取数据的效率。它可以一次读取多个字节到缓冲区中,然后逐个字节地从缓冲区中读取,减少了频繁的磁盘或网络操作。使用BufferedInputStream可以提高读取大量数据的效率。
- BufferedOutputStream:它是对OutputStream的包装,提供了缓冲区来提高写入数据的效率。它可以将数据先写入缓冲区中,然后一次性地写入到目标输出流中,减少了频繁的磁盘或网络操作。使用BufferedOutputStream可以提高写入大量数据的效率。
- BufferedReader:它是对Reader的包装,提供了缓冲区来提高读取字符数据的效率。它可以一次读取多个字符到缓冲区中,然后逐个字符地从缓冲区中读取,减少了频繁的磁盘或网络操作。使用BufferedReader可以提高读取大量字符数据的效率。
- BufferedWriter:它是对Writer的包装,提供了缓冲区来提高写入字符数据的效率。它可以将字符数据先写入缓冲区中,然后一次性地写入到目标输出流中,减少了频繁的磁盘或网络操作。使用BufferedWriter可以提高写入大量字符数据的效率。
这些缓冲流都是对字节流或字符流的包装,可以通过构造方法将字节流或字符流传入缓冲流中,然后通过缓冲流进行读写操作。
BufferedReader和BufferedWriter类
在Java中,我们把BufferedReader和BufferedWriter类创建的对象称为缓冲输入输出流,二者增强了读写文件的能力。比如,Sudent.txt是一个学生名单,每个姓名占一行。如果我们想读取名字,那么每次必须读取一行,使用FileReader流很难完成这样的任务,因为,我们不清楚一行有多少个字符,FileReader类没有提供读取一行的方法。
Java提供了更高级的流:BufferedReader流和BufferedWriter流,二者的源和目的地必须是字符输入流和字符输出流。因此,如果把文件字符输入流作为BufferedReader流的源,把文件字符输出流作为BufferedWriter流的目的地,那么,BufferedReader和BufferedWriter类创建的流将比字符输入流和字符输出流有更强的读写能力。比如,BufferedReader流就可以按行读取文件。
BufferedReader类和BufferedWriter的构造方法分别是:
BufferedReader(Reader in);
BufferedWriter(Writer out);可以把BufferedReader和BufferedWriter称为上层流,把它们指向的字符流称为底层流,Java采用缓存技术将上层流和底层流连接。底层字符输入流首先将数据读入缓存,BufferedReader流再从缓存读取数据;BufferedWriter流将数据写入缓存,底层字符输出流会不断地将缓存中的数据写入到目的地。当BufferedWriter流调用flush()刷新缓存或调用close()方法关闭时,即使缓存没有溢出,底层流也会立刻将缓存的内容写入目的地。
注意:关闭输出流时要首先关闭缓冲输出流,然后关闭缓冲输出流指向的流,即先关闭上层流再关闭底层流。在编写代码时只需关闭上层流,那么上层流的底层流将自动关闭。
例如:
由英语句子构成的文件a.txt如下,每句占一行:
hello
I like you
no yes要求按行读取a.txt,并在该行的后面加上该英语句子中含有的单词数目,然后再将该行写入到一个名字为b.txt的文件中,代码如下:
import java.io.*;
import java.util.*;
public class Main {public static void main(String args[]) {File fRead = new File("a.txt");File fWrite = new File("b.txt");try {Writer out = new FileWriter(fWrite);BufferedWriter bufferWrite = new BufferedWriter(out);Reader in = new FileReader(fRead);BufferedReader bufferRead = new BufferedReader(in);String str;while((str = bufferRead.readLine()) !=null) {StringTokenizer fenxi = new StringTokenizer(str);int count = fenxi.countTokens();str = str+"句子中单词个数:"+count;bufferWrite.write(str);bufferWrite.newLine();}bufferWrite.close();out.close();in = new FileReader(fWrite);bufferRead = new BufferedReader(in);String s = null;System.out.println(fWrite.getName()+"内容:");while((s=bufferRead.readLine()) !=null) {System.out.println(s);}bufferRead.close();in.close();}catch(IOException e) {System.out.println(e.toString());}}
}运行结果如下:
b.txt内容:
hello句子中单词个数:1
I like you句子中单词个数:3
no yes句子中单词个数:2Java随机流
RandomAccessFile类创建的流称做随机流,与前面的输入、输出流不同的是,RandomAccessFile类既不是InputStream类的子类,也不是OutputStream类的子类。但是RandomAccessFile类创建的流的指向既可以作为流的源,也可以作为流的目的地,换句话说,当准备对一个文件进行读写操作时,创建一个指向该文件的随机流即可,这样既可以从这个流中读取文件中的数据,也可以通过这个流写入数据到文件。
注意:由于RandomAccessFile是线程安全的,你可以同时打开多个RandomAccessFile对象来读取同一个文件。但是,请注意,如果你在多个线程中同时读取文件,可能会导致数据不一致或其他问题。
以下是RandomAccessFile类的两个构造方法:
- RandomAccessFile(String name,String mode):参数name用来确定一个文件名,给出创建的流的源,也是流目的地。参数mode取r(只读)或rw(可读写),决定创建的流对文件的访问权利。
- RandomAccessFile(File file,String mode):参数file是一个File对象,给出创建的流的源,也是流目的地。参数mode取r(只读)或rw(可读写),决定创建的流对文件的访问权利。
注意:RandomAccessFile流指向文件时,不刷新文件。
RandomAccessFile类中有一个方法seek(long a)用来定位RandomAccessFile流的读写位置,其中参数a确定读写位置距离文件开头的字节个数。另外流还可以调用getFilePointer()方法获取流的当前读写位置。RandomAccessFile流对文件的读写比顺序读写更为灵活。
RandomAccessFile流的常用方法如下:
| 方法 | 说明 |
| close() | 关闭文件 |
| getFilePointer() | 获取当前读写的位置 |
| length() | 获取文件的长度 |
| read() | 从文件中读取一个字节的数据 |
| readBoolean() | 从文件中读取一个布尔值,0代表false;其他值代表true |
| readByte() | 从文件中读取一个字节 |
| readChar() | 从文件中读取一个字符(2个字节) |
| readDouble() | 从文件中读取一个双精度浮点值(8 个字节) |
| readFloat() | 从文件中读取一个单精度浮点值(4个字节) |
| readFully(byte b[ ]) | 读b.length字节放入数组b,完全填满该数组 |
| readInt() | 从文件中读取一个int值(4个字节) |
| readLine() | 从文件中读取一个文本行 |
| readLong() | 从文件中读取一个长型值(8个字节) |
| readShort() | 从文件中读取一个短型值(2个字节) |
| readUnsignedByte() | 从文件中读取一个无符号字节(1个字节) |
| readUnsignedShort() | 从文件中读取一个无符号短型值(2个字节) |
| readUTF() | 从文件中读取一个UTF字符串 |
| seek(long position) | 定位读写位置 |
| setLength(long newlength) | 设置文件的长度 |
| skipBytes(int n) | 在文件中跳过给定数量的字节 |
| write(byte b[]) | 写b.length个字节到文件 |
| writeBoolean(boolean v) | 把一个布尔值作为单字节值写入文件 |
| writeByte(int v) | 向文件写入一个字节 |
| writeBytes(String s) | 向文件写入一个字符串 |
| writeChar(char c) | 向文件写入一个字符 |
| writeChars(String s) | 向文件写入一个作为字符数据的字符串 |
| writeDouble(double v) | 向文件写入一个双精度浮点值 |
| writeFloat(float v) | 向文件写入一个单精度浮点值 |
| writeInt(int v) | 向文件写入一个int值 |
| writeLong(long v) | 向文件写入一个长型int值 |
| writeShort(int v) | 向文件写入一个短型int值 |
| writeUTF(String s) | 写入一个UTF字符串 |
注意:RandomAccessFile流的readLine()方法在读取含有非ASCⅡ字符的文件时,比如含有汉字的文件,会出现“乱码”现象。因此,需要把readLine()读取的字符串用“iso-8859-1”编码重新编码存放到byte数组中,然后再用当前机器的默认编码将该数组转化为字符串,操作如下:
- 读取
String str = in.readLine(); - 用“iso-8859-1”重新编码
byte b[] = str.getBytes("iso-8859-1"); - 使用当前机器的默认编码将字节数组转化为字符串
如果机器的默认编码是“GB2312”,那么String content = new String(b);
等同于String content = new String(b);String content = new String(b,"GB2312");
随机流代码示例:
import java.io.*;
public class Main {public static void main(String args[]) {RandomAccessFile inAndOut = null;int data[] = {1,2,3,4,5,6,7,8,9,10};try {inAndOut = new RandomAccessFile("a.txt","rw");for(int i=0;i<data.length;i++) {inAndOut.writeInt(data[i]);}for(long i = data.length-1;i>=0;i--) {inAndOut.seek(i*4);System.out.printf("\t%d",inAndOut.readInt());/*一个int型数据占4个字节,inAndOut从文件的第36个字节读取最后面的一个整数,每隔4个字节往前读取一个整数*/}inAndOut.close();}catch(IOException e) {}}
}Java数组流
我们要知道,流的源和目的地除了可以是文件以外,还可以是计算机内存。
字节数组流
字节数组输入流ByteArrayInputStream和字节数组输出流ByteArrayOutputStream分别使用字节数组作为流的源和目的地。
ByteArrayInputStream流的构造方法:
ByteArrayInputStream(byte[] buf);
ByteArrayInputStream(byte[] buf,int offset,int length);第一个构造方法构造的字节数组流的源是参数buf指定的数组的全部字节单元。
第二个构造方法构造的字节数组流的源是buf指定的数组从offset处按顺序取的length个字节单元。
字节数组输入流调用public int read();方法可以顺序地从源中读出一个字节,该方法返回读出的字节值;调用public int read(byte[] b,int off,int len);方法可以顺序地从源中读出参数len指定的字节数,并将读出的字节存放到参数b指定的数组中,参数off指定数组b存放读出字节的起始位置,该方法返回实际读出的字节个数,如果未读出字节read方法返回-1。
ByteArrayOutputStream流的构造方法:
ByteArrayOutputStream();
ByteArrayOutputStream(int size);第一个构造方法构造的字节数组输出流指向一个默认大小为32字节的缓冲区,如果输出流向缓冲区写入的字节个数大于缓冲区时,缓冲区的容量会自动增加。
第二个构造方法构造的字节数组输出流指向的缓冲区的初始大小由参数size指定,如果输出流向缓冲区写入的字节个数大于缓冲区时,缓冲区的容量会自动增加。
字节数组输出流调用public void write(int b);方法可以顺序地向缓冲区写入一个字节;调用public void write(byte[ ] b,int off,int len);方法可以将参数b中指定的len个字节顺序地写入缓冲区,参数off指定从b中写出的字节的起始位置;调用public byte[ ] toByteArray();方法可以返回输出流写入到缓冲区的全部字节。
字符数组流
与字节数组流对应的是字符数组流CharArrayReader类和CharArrayWriter类,字符数组流分别使用字符数组作为流的源和目标。
例如,使用数组流向内存(输出流的缓冲区)写入“mid-autumn festival”和“中秋快乐”,然后再从内存读取曾写入的数据:
import java.io.*;public class Main {public static void main(String args[]) {try {// 创建一个字节数组输出流ByteArrayOutputStream outByte = new ByteArrayOutputStream();// 将字节内容 "mid-autumn festival" 写入字节数组输出流byte [] byteContent = "mid-autumn festival ".getBytes();outByte.write(byteContent);// 创建一个字节数组输入流,并将字节数组输出流的内容传递给它ByteArrayInputStream inByte = new ByteArrayInputStream(outByte.toByteArray());// 创建一个与字节数组输出流长度相同的字节数组byte backByte [] = new byte[outByte.toByteArray().length];// 从字节数组输入流中读取内容到 backByte 数组中inByte.read(backByte);// 将 backByte 数组转换为字符串并打印出来System.out.println(new String(backByte));// 创建一个字符数组输出流CharArrayWriter outChar = new CharArrayWriter();// 将字符内容 "中秋快乐" 写入字符数组输出流char [] charContent = "中秋快乐".toCharArray();outChar.write(charContent);// 创建一个字符数组输入流,并将字符数组输出流的内容传递给它CharArrayReader inChar = new CharArrayReader(outChar.toCharArray());// 创建一个与字符数组输出流长度相同的字符数组char backChar [] = new char [outChar.toCharArray().length];// 从字符数组输入流中读取内容到 backChar 数组中inChar.read(backChar);// 将 backChar 数组转换为字符串并打印出来System.out.println(new String(backChar));}catch(IOException exp) {// 处理可能发生的 IOException 异常exp.printStackTrace();}}
}Java数据流
DataInputStream和DataOutputStream类创建的对象称为数据输入流和数据输出流。这两个流是很有用的两个流,它们允许程序按着机器无关的风格读取Java原始数据。也就是说,当读取一个数值时,不必再关心这个数值应当是多少个字节。
DataInputStream和DataOutputStream的构造方法如下:
- DataInputStream(InputStream in):创建的数据输入流指向一个由参数in指定的底层输入流。
- DataOutputStream(OutputStream out):创建的数据输出流指向一个由参数out指定的底层输出流。
DataInputStream和DataOutputStream类的常用方法如下:
| 方法 | 说明 |
| close() | 关闭流 |
| readBoolean() | 读取一个布尔值 |
| readByte() | 读取一个字节 |
| readChar() | 读取一个字符 |
| readDouble() | 读取一个双精度浮点值 |
| readFloat() | 读取一个单精度浮点值 |
| readInt() | 读取一个int值 |
| readLong() | 读取一个长型值 |
| readShort() | 读取一个短型值 |
| readUnsignedByte() | 读取一个无符号字节 |
| readUnsignedShort() | 读取一个无符号短型值 |
| readUTF() | 读取一个UTF字符串 |
| skipBytes(int n) | 跳过给定数量的字节 |
| writeBoolean(boolean v) | 写入一个布尔值 |
| writeBytes(String s) | 写入一个字符串 |
| writeChars(String s) | 写入字符串 |
| writeDouble(double v) | 写入一个双精度浮点值 |
| writeFloat(float v) | 写入一个单精度浮点值 |
| writeInt(int v) | 写入一个int值 |
| writeLong(long v) | 写入一个长型int值 |
| writeShort(int v) | 写入一个短型int值 |
| writeUTF(String s) | 写入一个UTF字符串 |
例如,写几个Java类型的数据到一个文件,然后再读出来:
import java.io.*;public class Main {public static void main(String[] args) {// 写入文件try (DataOutputStream outputStream = new DataOutputStream(new FileOutputStream("a.txt"))) {int intValue = 10;double doubleValue = 3.14;String stringValue = "Hello, World!";outputStream.writeInt(intValue);outputStream.writeDouble(doubleValue);outputStream.writeUTF(stringValue);System.out.println("数据写入成功!");} catch (IOException e) {e.printStackTrace();}// 读取文件try (DataInputStream inputStream = new DataInputStream(new FileInputStream("a.txt"))) {int intValue = inputStream.readInt();double doubleValue = inputStream.readDouble();String stringValue = inputStream.readUTF();System.out.println("读取的整数值:" + intValue);System.out.println("读取的浮点数值:" + doubleValue);System.out.println("读取的字符串值:" + stringValue);} catch (IOException e) {e.printStackTrace();}}
}
Java对象流
ObjectInputStream和ObjectOutputStream类分别是InputStream和OutputStream类的子类。ObjectInputStream和ObjectOutputStream类创建的对象称为对象输入流和对象输出流。对象输出流使用writeObject(Object obj)方法将一个对象obj写入到一个文件,对象输入流使用readObject()读取一个对象到程序中。
ObjectInputStream和ObjectOutputStream类的构造方法如下:
- ObjectInputStream(InputStream in)
- ObjectOutputStream(OutputStream out)
ObjectOutputStream的指向应当是一个输出流对象,因此当准备将一个对象写入到文件时,首先用OutputStream的子类创建一个输出流。
例如,用FileOutputStream创建一个文件输出流,代码如下:
FileOutputStream fileOut = new FileOutputStream("a.txt");
ObjectOutputStream objectout = new ObjectOutputStream(fileOut);同样ObjectInputStream的指向应当是一个输入流对象,因此当准备从文件中读入一个对象到程序中时,首先用InputStream的子类创建一个输入流。
例如,用FileInputStream创建一个文件输入流,代码如下:
FileInputStream fileIn = new FileInputStream("a.txt");
ObjectInputStream objectIn = new ObjectInputStream(fileIn);当使用对象流写入或读入对象时,要保证对象是序列化的,这是为了保证能把对象写入到文件,并能再把对象正确读回到程序中。
一个类如果实现了Serializable接口(java.io包中的接口),那么这个类创建的对象就是所谓序列化的对象。Java类库提供的绝大多数对象都是所谓序列化的。需要强调的是,Serializable接口中没有方法,因此实现该接口的类不需要实现额外的方法。另外需要注意的是,使用对象流把一个对象写入到文件时不仅要保证该对象是序列化的,而且该对象的成员对象也必须是序列化的。
Serializable接口中的方法对程序是不可见的,因此实现该接口的类不需要实现额外的方法,当把一个序列化的对象写入到对象输出流时,JVM就会实现Serializable接口中的方法,将一定格式的文本(对象的序列化信息)写入到目的地。当ObjectInputStream对象流从文件读取对象时,就会从文件中读回对象的序列化信息,并根据对象的序列化信息创建一个对象。
下面是一个使用这两个类进行对象序列化和反序列化的Java代码示例:
import java.io.*;public class Main {public static void main(String[] args) {// 序列化对象并写入文件try (ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("data.obj"))) {// 创建一个自定义对象Person person = new Person("John Doe", 25);// 将对象写入文件outputStream.writeObject(person);System.out.println("对象序列化成功!");} catch (IOException e) {e.printStackTrace();}// 反序列化对象并读取文件try (ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("data.obj"))) {// 从文件中读取对象Person deserializedPerson = (Person) inputStream.readObject();System.out.println("读取的对象信息:");System.out.println("姓名:" + deserializedPerson.getName());System.out.println("年龄:" + deserializedPerson.getAge());} catch (IOException | ClassNotFoundException e) {e.printStackTrace();}}// 自定义Person类,需要实现Serializable接口才能被序列化static class Person implements Serializable {private String name;private int age;public Person(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public int getAge() {return age;}}
}
上述代码创建了一个名为Person的自定义类,并在其中定义了姓名和年龄属性。该类实现了Serializable接口,使得对象可以被序列化。首先,将一个Person对象序列化并写入到名为"data.obj"的文件中。然后,从文件中反序列化出对象,并进行相关信息的打印输出。
请注意,要想使自定义类能够被序列化,需要确保该类实现了Serializable接口。同时,反序列化过程需要进行类型转换,以恢复原始的对象类型。
Java序列化与对象克隆
Java的序列化和对象克隆都是用于处理对象的机制,但它们有不同的作用和实现方式。
-
序列化(Serialization):
- 序列化用于将对象转换为字节流的过程,以便在网络传输或持久化存储时使用。
- 通过实现
Serializable接口,类可以支持序列化。该接口没有任何方法,只是一个标记接口。 - 使用
ObjectOutputStream将对象写入输出流,使用ObjectInputStream从输入流中读取对象。 - 序列化过程会将对象的状态以及对象包含的数据保存下来,然后可以重新反序列化为原始对象。
-
对象克隆(Object Cloning):
- 对象克隆用于创建一个现有对象的副本,以便通过克隆对象进行操作,而不影响原对象。
- 在默认情况下,Java中的对象克隆是浅克隆,即只复制对象本身,而不复制引用类型的成员变量。
- 要实现对象克隆,类必须实现
Cloneable接口,并重写clone()方法。 - 使用
clone()方法可以创建一个新的与原始对象相同的副本。
虽然序列化和对象克隆都涉及对象的复制和重建,但它们的应用场景有所不同:
- 序列化主要用于对象的传输和持久化存储,例如在网络通信中发送对象、将对象保存到文件或数据库中。
- 对象克隆主要用于创建一个相同属性的对象副本,在某些场景下可以提高性能、降低开销或简化代码逻辑。
需要注意的是,虽然对象克隆可以方便地创建对象的副本,但它也有一些潜在问题,如浅克隆的风险、深克隆的复杂性等。因此,在使用对象克隆时需要谨慎,并根据具体需求选择合适的实现方式。
扩展小知识:
在编程中,克隆(Clone)和拷贝(Copy)是用于复制对象或数据的概念,但它们有一些区别:
-
克隆(Clone):
- 克隆是创建一个与原始对象具有相同状态和数据的全新对象。
- 克隆使用的是对象克隆机制,通过调用对象的
clone()方法实现。 - 克隆得到的对象是独立的,对克隆对象的修改不会影响原始对象。
- 在默认情况下,Java 的对象克隆是浅克隆,只复制对象本身,而不复制引用类型的成员变量。如果需要深度克隆,需要在
clone()方法中手动处理引用类型的成员变量。
-
拷贝(Copy):
- 拷贝是指将一个对象或数据的值复制到另一个对象或数据中。
- 拷贝可以通过多种方式进行,包括不同层级的拷贝(如深拷贝和浅拷贝)、手动逐个复制属性等。
- 拷贝的实现方式依赖于编程语言或框架提供的特定操作或函数。
区别总结:
- 克隆是创建一个全新的、与原始对象具有相同状态和数据的对象,通过对象自身的克隆机制实现。
- 拷贝是将一个对象或数据的值复制到另一个对象或数据中,可以使用不同方式实现。
- 克隆得到的对象是独立的,对克隆对象的修改不会影响原始对象;而拷贝得到的对象可能与原始对象共享引用数据。
- 在 Java 中,默认的对象克隆是浅克隆,需要手动处理引用类型的成员变量以实现深度克隆;而拷贝可以根据需求选择不同层级的拷贝方式。
下面是一个使用Java序列化和对象克隆进行对象复制的代码示例:
import java.io.*;// 实现Serializable接口以支持序列化
class Person implements Serializable, Cloneable {private String name;private int age;public Person(String name, int age) {this.name = name;this.age = age;}// 省略了Getter和Setter方法@Overridepublic String toString() {return "Person{name='" + name + "', age=" + age + "}";}// 重写clone()方法,实现对象的深拷贝@Overridepublic Object clone() throws CloneNotSupportedException {// 调用父类的clone()方法进行浅拷贝Person clonedPerson = (Person) super.clone();// 对非基本类型的字段进行拷贝clonedPerson.name = new String(this.name);return clonedPerson;}
}public class Main {public static void main(String[] args) {// 使用序列化进行对象复制Person person1 = new Person("Alice", 25);Person person2 = null;try {// 将person1序列化为字节流ByteArrayOutputStream byteOut = new ByteArrayOutputStream();ObjectOutputStream objectOut = new ObjectOutputStream(byteOut);objectOut.writeObject(person1);// 将字节流反序列化为person2对象ByteArrayInputStream byteIn = new ByteArrayInputStream(byteOut.toByteArray());ObjectInputStream objectIn = new ObjectInputStream(byteIn);person2 = (Person) objectIn.readObject();// 通过序列化实现的对象复制完成System.out.println("使用序列化进行对象复制:");System.out.println("原始对象:" + person1);System.out.println("复制后的对象:" + person2);} catch (IOException | ClassNotFoundException e) {e.printStackTrace();}// 使用对象克隆进行对象复制Person person3 = new Person("Bob", 30);Person person4 = null;try {// 调用person3的clone()方法进行对象克隆person4 = (Person) person3.clone();// 通过对象克隆实现的对象复制完成System.out.println("使用对象克隆进行对象复制:");System.out.println("原始对象:" + person3);System.out.println("复制后的对象:" + person4);} catch (CloneNotSupportedException e) {e.printStackTrace();}}
}
注意:clone()方法在java.lang.Object类中是受保护的成员,意味着它只能被同一类或子类中的方法访问。这使得对象克隆只能在类内部或继承关系中使用。在示例代码中,要想成功对Person对象进行克隆,必须在Person类中实现Cloneable接口,并覆盖clone()方法,将其访问控制修改为public。通过在Person类中实现Cloneable接口,并重写clone()方法并将其访问控制修改为public,就可以在示例代码中成功地使用对象克隆进行复制了。
Java使用Scanner解析文件
使用默认分隔标记解析文件
创建Scanner对象,并指向要解析的文件,例如:
File file = new File("a.txt");
Scanner sc = new Scanner(file);那么sc将空格作为分隔标记,调用next()方法依次返回file中的单词,如果file最后一个单词已被next()方法返回,sc调用hasNext()将返回false,否则返回true。
另外,对于数字型的单词,比如108,167.92等可以用nextInt()或nextDouble()方法来代替next()方法,即sc可以调用nextInt()或nextDouble()方法将数字型单词转化为int或double数据返回,但需要特别注意的是,如果单词不是数字型单词,调用nextInt()或nextDouble()方法将发生InputMismatchException异常,在处理异常时可以调用next()方法返回该非数字化单词。
使用正则表达式作为分隔标记解析文件
创建Scanner对象,指向要解析的文件,并使用useDelimiter方法指定正则表达式作为分隔标记,例如:
File file = new File("a.txt");
Scanner sc = new Scanner(file);
sc.useDelimiter(正则表达式);那么sc将正则表达式作为分隔标记,调用next()方法依次返回file中的单词,如果file最后一个单词已被next()方法返回,sc调用hasNext()将返回false,否则返回true。
另外,对于数字型的单词,比如1979,0.618等可以用nextInt()或nextDouble()方法来代替next()方法,即sc可以调用nextInt()或nextDouble()方法将数字型单词转化为int或double数据返回,但需要特别注意的是,如果单词不是数字型单词,调用nextInt()或nextDouble()方法将发生InputMismatchException异常,那么在处理异常时可以调用next()方法返回该非数字化单词。
以下是使用Scanner解析文件中的数字,并计算这些数字的平均值的代码示例:
a.txt:
张三的成绩是70分,李四的成绩是80分,赵五的成绩是90分。import java.io.*;
import java.util.*;public class Main {public static void main(String[] args) {File file = new File("a.txt");Scanner sc = null;int count = 0;double sum = 0;try {double score = 0;sc = new Scanner(file);sc.useDelimiter("[^0123456789.]+"); // 使用非数字字符作为分隔符while (sc.hasNextDouble()) {score = sc.nextDouble();count++;sum = sum + score;System.out.println(score);}double average = sum / count;System.out.println("平均成绩:" + average);// 关闭Scannersc.close();} catch (Exception exp) {System.out.println(exp);}}
}
Java文件对话框
文件对话框是一个选择文件的界面。Javax.swing包中的JFileChooser类可以创建文件对话框,使用该类的构造方法JFileChooser()创建初始不可见的有模式文件对话框。然后文件对话框调用下述2个方法:
showSaveDialog(Component a);
showOpenDialog(Component a);都可以使得对话框可见,只是呈现的外观有所不同,showSaveDialog方法提供保存文件的界面,showOpenDialog方法提供打开文件的界面。上述两个方法中的参数a指定对话框可见时的位置,当a是null时,文件对话框出现在屏幕的中央;如果组件a不空,文件对话框在组件a的正前面居中显示。
用户单击文件对话框上的“确定”、“取消”或“关闭”图标,文件对话框将消失,ShowSaveDialog()或showOpenDialog()方法返回下列常量之一:
JFileChooser.APPROVE OPTION
JFileChooser.CANCEL_OPTION如果希望文件对话框的文件类型是用户需要的几种类型,比如,扩展名是.jpeg等图像类型的文件,可以使用FileNameExtensionFilter类事先创建一个对象,在JDK 1.6版本,FileNameExtensionFilter类在javax.swing.filechooser包中。
下面是一个示例代码片段,演示了如何使用JFileChooser类创建文件对话框,并设置文件类型过滤器:
import javax.swing.*;
import javax.swing.filechooser.FileNameExtensionFilter;public class Main {public static void main(String[] args) {// 创建文件对话框对象JFileChooser fileChooser = new JFileChooser();// 设置文件类型过滤器FileNameExtensionFilter filter = new FileNameExtensionFilter("图像文件", "jpg", "gif");fileChooser.setFileFilter(filter);// 显示保存文件对话框并获取用户操作的结果int result = fileChooser.showSaveDialog(null);// 处理用户的操作结果if (result == JFileChooser.APPROVE_OPTION) {// 用户点击了"确定"按钮String selectedFilePath = fileChooser.getSelectedFile().getPath();System.out.println("用户选择的文件路径:" + selectedFilePath);} else if (result == JFileChooser.CANCEL_OPTION) {// 用户点击了"取消"按钮System.out.println("用户取消了操作");}}
}
在上述示例中,我们创建了一个JFileChooser对象,并通过setFileFilter()方法设置文件类型过滤器为指定的图像文件类型(.jpg和.gif)。然后,我们调用showSaveDialog(null)来显示保存文件的文件对话框。根据用户的操作结果,我们可以处理用户选中的文件路径或取消操作的情况。
Java带进度条的输入流
ProgressMonitorInputStream是一个可以显示读取进度条的输入流类。它可以在文件读取过程中弹出一个进度条窗口来显示读取速度和进度。其构造方法是:
ProgressMonitor InputStream(Conmponent c,String s,InputStream);- 组件c指定了进度条窗口将显示在哪个组件的前面。可以传入一个具体的组件对象,如JFrame或JPanel,进度条会显示在该组件的正前方。如果你传入null,则进度条将显示在屏幕的正前方。
- 字符串s是进度条窗口的标题,用于描述正在进行的操作。可以根据需要给进度条窗口设置一个有意义的标题。
- 输入流InputStream是要读取的文件的输入流。通过将文件输入流传给ProgressMonitorInputStream,你可以在读取文件时实时显示进度条并监控读取的进度。
需要注意的是,ProgressMonitorInputStream属于javax.swing包,所以在使用之前需要确保已经导入该包。另外,为了使进度条能够正常显示,需要在图形界面线程中执行文件的读取操作。
import javax.swing.*;
import java.io.*;public class Main {public static void main(String args[]) {byte b[] = new byte[1024]; // 增加缓冲区的大小,以便更好地读取文件内容try {FileInputStream input = new FileInputStream("a.txt");// 创建进度条窗口的父组件(例如:JFrame)JFrame frame = new JFrame();ProgressMonitorInputStream in = new ProgressMonitorInputStream(frame, "读取txt", input);ProgressMonitor p = in.getProgressMonitor(); // 获得进度条int bytesRead; // 用来记录每次读取到的字节数while ((bytesRead = in.read(b)) != -1) {String s = new String(b, 0, bytesRead); // 仅使用读取到的字节构建字符串System.out.print(s);Thread.sleep(1000); // 为了看清进度条,延迟了一定时间}in.close();// 关闭进度条窗口frame.dispose();} catch (Exception e) {e.printStackTrace();}}
}
Java文件锁
通过使用文件锁,可以确保多个程序对同一个文件进行处理时不会发生混乱。Java在JDK 1.4版本后提供了文件锁功能,可以通过FileLock和FileChannel类来实现。
下面是使用文件锁的基本步骤:
- 使用RandomAccessFile流建立指向文件的流对象,并设置读写属性为"rw"。
RandomAccessFile input = new RandomAccessFile("a.txt","rw"); - input流调用方法getChannel()获得一个连接到底层文件的FileChannel对象(信道)。
FileChannel channel = input.getChannel(); - 信道调用tryLock()或lock()方法获得一个FileLock(文件锁)对象,这一过程也称做对文件加锁。
FileLock lock = channel.tryLock();
文件锁对象产生后,将禁止任何程序对文件进行操作或再进行加锁。对一个文件加锁之后,如果想读、写文件必须让FileLock对象调用release()释放文件锁。
lock.release();以下是一个代码示例,演示如何使用文件锁进行文件读写:
import java.io.RandomAccessFile;
import java.nio.channels.FileChannel;
import java.nio.channels.FileLock;public class Main {public static void main(String[] args) {RandomAccessFile file = null;FileChannel channel = null;FileLock lock = null;try {// 1. 创建RandomAccessFile流对象并设置读写属性为"rw"file = new RandomAccessFile("a.txt", "rw");// 2. 获取FileChannel对象channel = file.getChannel();while (true) {try {// 3. 尝试加锁lock = channel.tryLock();if (lock != null) {// 文件已被锁定System.out.println("文件已被锁定");// 进行文件读取操作String line = file.readLine();System.out.println("读取的文本: " + line);// 释放文件锁lock.release();System.out.println("释放文件锁");// 继续下一轮循环continue;}} catch (Exception e) {// 加锁失败e.printStackTrace();}// 等待一段时间后再尝试加锁Thread.sleep(1000);}} catch (Exception e) {e.printStackTrace();} finally {try {if (file != null)file.close();if (channel != null)channel.close();} catch (Exception e) {e.printStackTrace();}}}
}
该示例中,首先创建一个RandomAccessFile对象并设置读写属性为"rw"。然后通过调用getChannel()方法获取与文件连接的FileChannel对象。进入循环后,程序会尝试对文件进行加锁,并检查是否成功获取到FileLock对象。如果成功获取到锁,则进行文件读取操作,读取完毕后释放文件锁。如果未能获取到锁,则等待一段时间后再次尝试。
相关文章:

Java进阶篇--IO流的第二篇《多样的流》
目录 Java缓冲流 BufferedReader和BufferedWriter类 Java随机流 Java数组流 字节数组流 ByteArrayInputStream流的构造方法: ByteArrayOutputStream流的构造方法: 字符数组流 Java数据流 Java对象流 Java序列化与对象克隆 扩展小知识&#x…...
iPhone 14 Pro 动态岛的功能和使用方法详解
当iPhone 14 Pro机型发布时,苹果公司将软件功能与屏幕顶部的药丸状切口创新集成,称之为“灵动岛”,这让许多人感到惊讶。这篇文章解释了它的功能、工作原理,以及你如何与它互动以执行动作。 一、什么是灵动岛?它是如何工作的 在谣言周期的早期iPhone 14 Pro 在宣布时…...

掌握这20条你将超过90%的测试员
1、不断学习 不管是“软技能”,比如公开演讲, 或者编程语言,亦或新的测试技术,成功的软件测试工程师总是会从繁忙中抽出时间来坚持学习。 2、管理你的时间 我们的时间很容易被大块的工作和不断的会议所占据,导致我们…...

LightDB create table时列约束支持enable/disable关键字
功能介绍 为了方便用户从Oracle数据库迁移到LightDB数据库,LightDB从23.3版本开始支持 create table时列约束支持enable/disable关键字。这个功能仅是语法糖。 使用说明 执行create table时,列约束后面可以选择性添加enable/disable关键字。 create …...

使用BeeWare实现iOS调用Python
1、准备工作 1.1、安装Python 1.2、设置虚拟环境 我们现在将创建一个虚拟环境——一个“沙盒”,如果我们将软件包安装到虚拟环境中,我们计算机上的任何其他Python项目将不会受到影响。如果我们把虚拟环境搞得一团糟,我们将能够简单地删除它…...

无公网IP内网穿透使用vscode配置SSH远程ubuntu随时随地开发写代码
文章目录 前言1、安装OpenSSH2、vscode配置ssh3. 局域网测试连接远程服务器4. 公网远程连接4.1 ubuntu安装cpolar内网穿透4.2 创建隧道映射4.3 测试公网远程连接 5. 配置固定TCP端口地址5.1 保留一个固定TCP端口地址5.2 配置固定TCP端口地址5.3 测试固定公网地址远程 前言 远程…...
二叉树、红黑树、B树、B+树
二叉树 一棵二叉树是结点的一个有限集合,该集合或者为空,或者是由一个根节点加上两棵别称为左子树和右子树的二叉树组成。 二叉树的特点: 每个结点最多有两棵子树,即二叉树不存在度大于2的结点。二叉树的子树有左右之分…...

12,【设计模式】工厂
设计模式工厂 通过工程来构建任意参数对象&&std::forwardstd::move 在C中,“工厂”(Factory)是一种设计模式,它提供了一种创建对象的方式,将对象的创建和使用代码分离开来,提高了代码的可扩展性和可…...
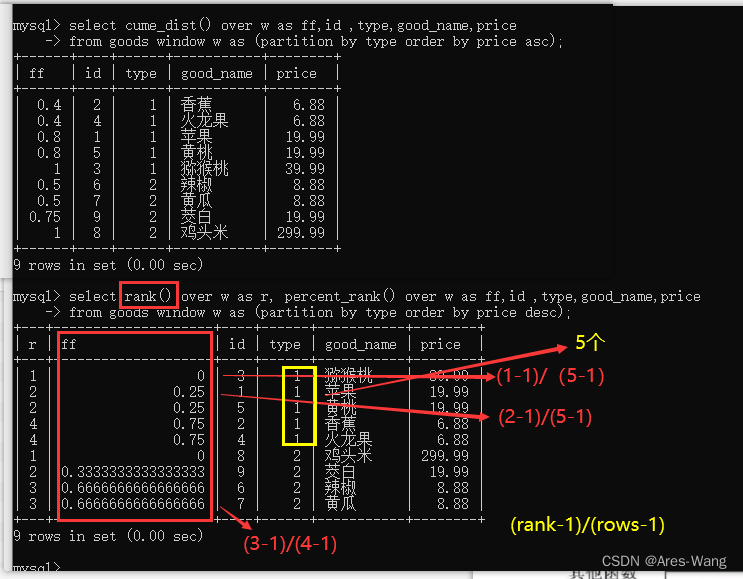
mysql 8.0 窗口函数 之 分布函数 与 sql server (2017以后支持) 分布函数 一样
mysql 分布函数 percent_rank() :等级值 百分比cume_dist() :累积分布值 percent_rank() 计算方式 (rank-1)/(rows-1), 其中 rank 的值为使用RANK()函数产生的序号,rows 的值为当前…...

Python Opencv实践 - 图像直方图自适应均衡化
import cv2 as cv import numpy as np import matplotlib.pyplot as pltimg cv.imread("../SampleImages/cat.jpg", cv.IMREAD_GRAYSCALE) print(img.shape)#整幅图像做普通的直方图均衡化 img_hist_equalized cv.equalizeHist(img)#图像直方图自适应均衡化 #1. 创…...

Linux编程:在程序中异步的调用其他程序
Linux编程:execv在程序中同步调用其他程序_风静如云的博客-CSDN博客 介绍了同步的调用其他程序的方法。 有的时候我们需要异步的调用其他程序,也就是不用等待其他程序的执行结果,尤其是如果其他程序是作为守护进程运行的,也无法等待其运行的结果。 //ssss程序 #include …...

04有监督算法——支持向量机
1.支持向量机 1.1 定义 支持向量机( Support Vector Machine )要解决的问题 什么样的法策边界才是最好的呢? 特征数据本身如果就很难分,怎么办呢? 计算复杂度怎么样?能实际应用吗? 支持向量机( Support Vector Machine , SVM)是一类按监督学习( s…...
)
macos 使用vscode 开发python 爬虫(安装一)
使用VS Code进行Python爬虫开发是一种常见的选择,下面是一些步骤和建议: 安装VS Code:首先,确保你已经在你的macOS上安装了VS Code。你可以从官方网站(https://code.visualstudio.com/)下载并安装最新版本…...

专有网络VPC私网/公网类产品选择
私网类产品选择 VPC互连:云企业网,对等连接 VPC与本地IDC互连:VPN网关,高速通道,云企业网,智能接入网关 VPC与多站点连接:VPN网关,智能接入网关,VPN网关高速通道 远程接…...
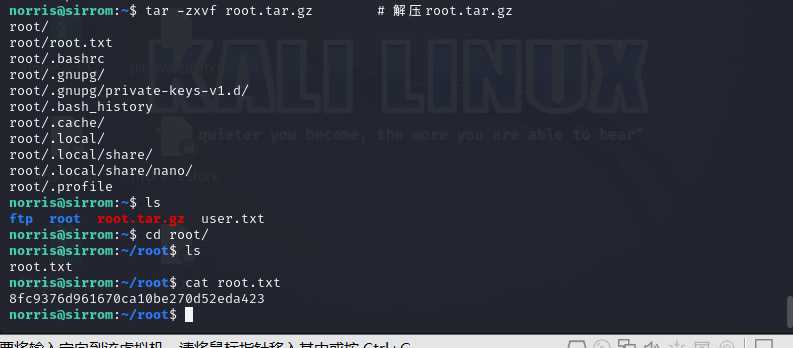
Connect-The-Dots靶场
靶场下载 https://www.vulnhub.com/entry/connect-the-dots-1,384/ 一、信息收集 探测存活主机 netdiscover -r 192.168.16.161/24nmap -sP 192.168.16.161/24端口操作系统扫描 nmap -sV -sC -A -p 1-65535 192.168.16.159扫描发现开放端口有 21 ftp 80 http 20…...

Linux解决RocketMQ中NameServer启动问题
启动步骤可以查看官网,https://github.com/apache/rocketmq 一下说明遇到的问题。 1:ROCKETMQ_HOME问题 根据官网提示进入mq/bin目录下,可以使用./mqnamesrv进行NameServer启动,但是会遇到第一个问题,首次下载Rocket…...
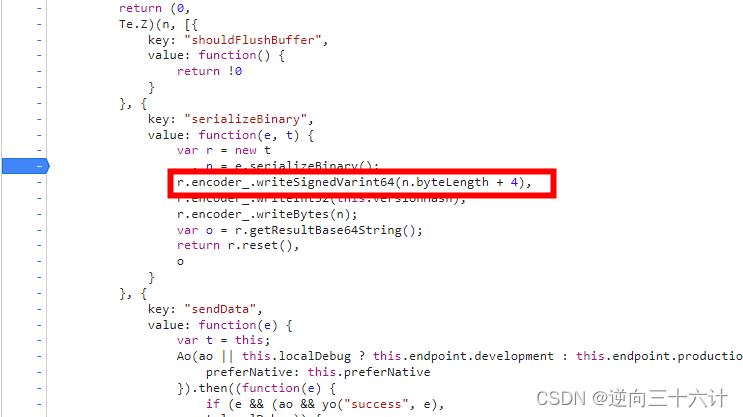
js逆向实战之某书protobuf反序列化
什么是Protobuf? \qquad Protobuf(Protocol Buffer)是 Google 开发的一套数据存储传输协议,作用就是将数据进行序列化后再传输,Protobuf 编码是二进制的,它不是可读的,也不容易手动修改…...
cpolar+JuiceSSH实现手机端远程连接Linux服务器
文章目录 1. Linux安装cpolar2. 创建公网SSH连接地址3. JuiceSSH公网远程连接4. 固定连接SSH公网地址5. SSH固定地址连接测试 处于内网的虚拟机如何被外网访问呢?如何手机就能访问虚拟机呢? cpolarJuiceSSH 实现手机端远程连接Linux虚拟机(内网穿透,手机端连接Linux虚拟机) …...
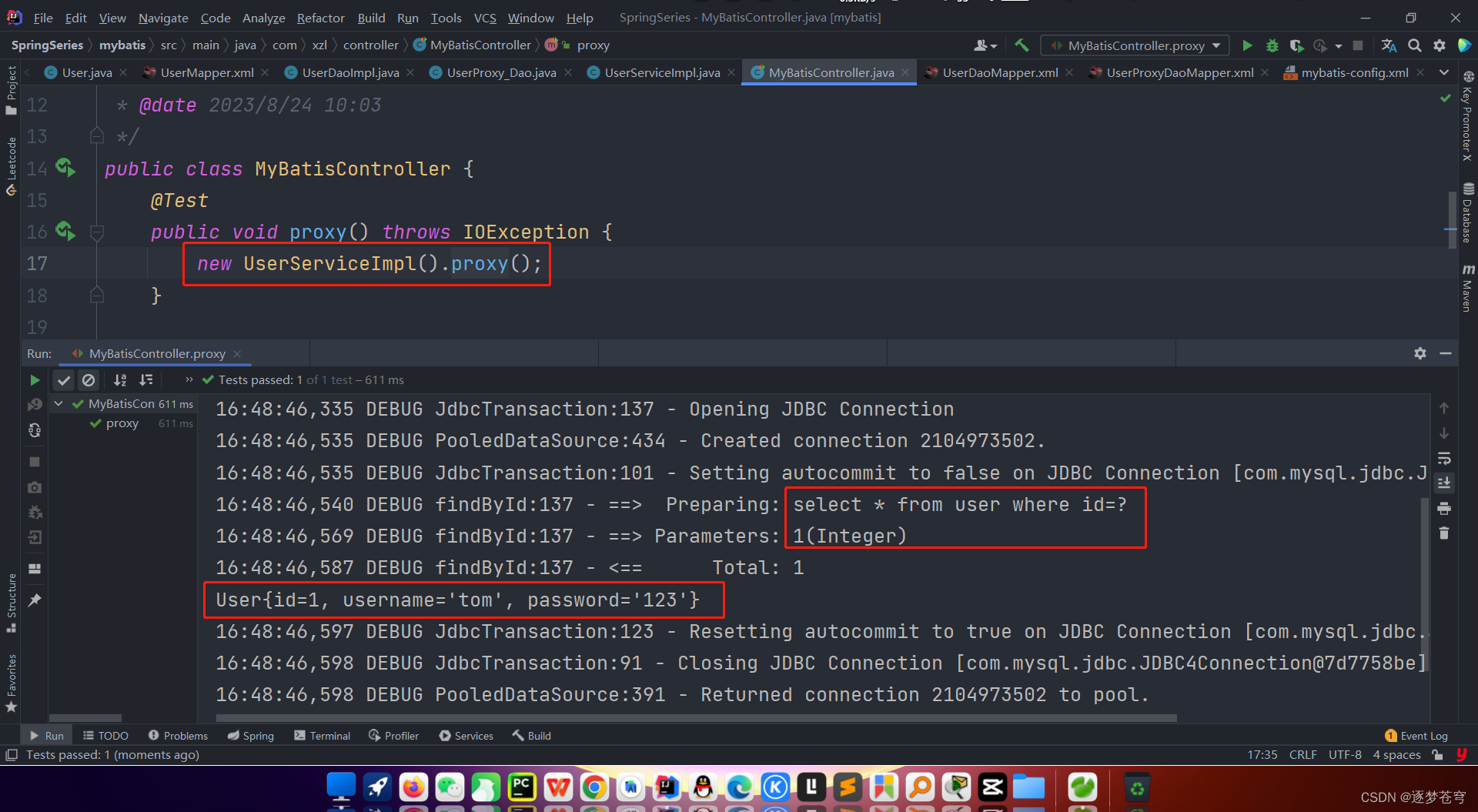
[MyBatis系列②]Dao层开发的两种方式
目录 1、传统开发 1.1、代码 1.2、存在的问题 2、代理开发 2.1、开发规范 2.2、代码 ⭐mybatis系列①:增删改查 1、传统开发 传统的mybatis开发中,是在数据访问层实现相应的接口,在实现类中用"命名空间.id"的形式找到对应的映…...

言语理解-中心理解之主题词及行文脉络
例题 例题 例题 例题 例题 例题...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...

关于iview组件中使用 table , 绑定序号分页后序号从1开始的解决方案
问题描述:iview使用table 中type: "index",分页之后 ,索引还是从1开始,试过绑定后台返回数据的id, 这种方法可行,就是后台返回数据的每个页面id都不完全是按照从1开始的升序,因此百度了下,找到了…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

学习STC51单片机31(芯片为STC89C52RCRC)OLED显示屏1
每日一言 生活的美好,总是藏在那些你咬牙坚持的日子里。 硬件:OLED 以后要用到OLED的时候找到这个文件 OLED的设备地址 SSD1306"SSD" 是品牌缩写,"1306" 是产品编号。 驱动 OLED 屏幕的 IIC 总线数据传输格式 示意图 …...
)
【HarmonyOS 5 开发速记】如何获取用户信息(头像/昵称/手机号)
1.获取 authorizationCode: 2.利用 authorizationCode 获取 accessToken:文档中心 3.获取手机:文档中心 4.获取昵称头像:文档中心 首先创建 request 若要获取手机号,scope必填 phone,permissions 必填 …...

python报错No module named ‘tensorflow.keras‘
是由于不同版本的tensorflow下的keras所在的路径不同,结合所安装的tensorflow的目录结构修改from语句即可。 原语句: from tensorflow.keras.layers import Conv1D, MaxPooling1D, LSTM, Dense 修改后: from tensorflow.python.keras.lay…...

C/C++ 中附加包含目录、附加库目录与附加依赖项详解
在 C/C 编程的编译和链接过程中,附加包含目录、附加库目录和附加依赖项是三个至关重要的设置,它们相互配合,确保程序能够正确引用外部资源并顺利构建。虽然在学习过程中,这些概念容易让人混淆,但深入理解它们的作用和联…...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...

mac 安装homebrew (nvm 及git)
mac 安装nvm 及git 万恶之源 mac 安装这些东西离不开Xcode。及homebrew 一、先说安装git步骤 通用: 方法一:使用 Homebrew 安装 Git(推荐) 步骤如下:打开终端(Terminal.app) 1.安装 Homebrew…...

【MATLAB代码】基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),附源代码|订阅专栏后可直接查看
文章所述的代码实现了基于最大相关熵准则(MCC)的三维鲁棒卡尔曼滤波算法(MCC-KF),针对传感器观测数据中存在的脉冲型异常噪声问题,通过非线性加权机制提升滤波器的抗干扰能力。代码通过对比传统KF与MCC-KF在含异常值场景下的表现,验证了后者在状态估计鲁棒性方面的显著优…...