Spark Standalone环境搭建及测试
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇
篇一:Linux系统下配置java环境
篇二:hadoop伪分布式搭建(超详细)
篇三:hadoop完全分布式集群搭建(超详细)-大数据集群搭建
篇四:Spark Local环境搭建及测试
文章目录
- 1.Spark Standalone环境搭建介绍
- 2.搭建环境准备:
- 3.搭建步骤:
1.Spark Standalone环境搭建介绍

Apache Spark是目前最流行的大数据处理框架之一,可用于分布式数据处理和分析。在Standalone模式下搭建Spark集群是学习和开发Spark应用程序的良好起点。
2.搭建环境准备:
本次用到的环境有:
Java 1.8.0_191
Spark-2.2.0-bin-hadoop2.7
Hadoop 2.7.4
Oracle Linux 7.4
3.搭建步骤:
1.解压Spark压缩文件至/opt目录下
tar -zxvf ~/experiment/file/spark-2.2.0-bin-hadoop2.7.tgz -C /opt

2.修改解压后为文件名为spark
mv /opt/spark-2.2.0-bin-hadoop2.7 /opt/spark

3.复制spark配置文件,首先在主节点(Master)上,进入Spark安装目录下的配置文件目录{ $SPARK_HOME/conf },并复制spark-env.sh配置文件:
cd /opt/spark/conf
cp spark-env.sh.template spark-env.sh

4.Vim编辑器打开spark配置文件
vim spark-env.sh
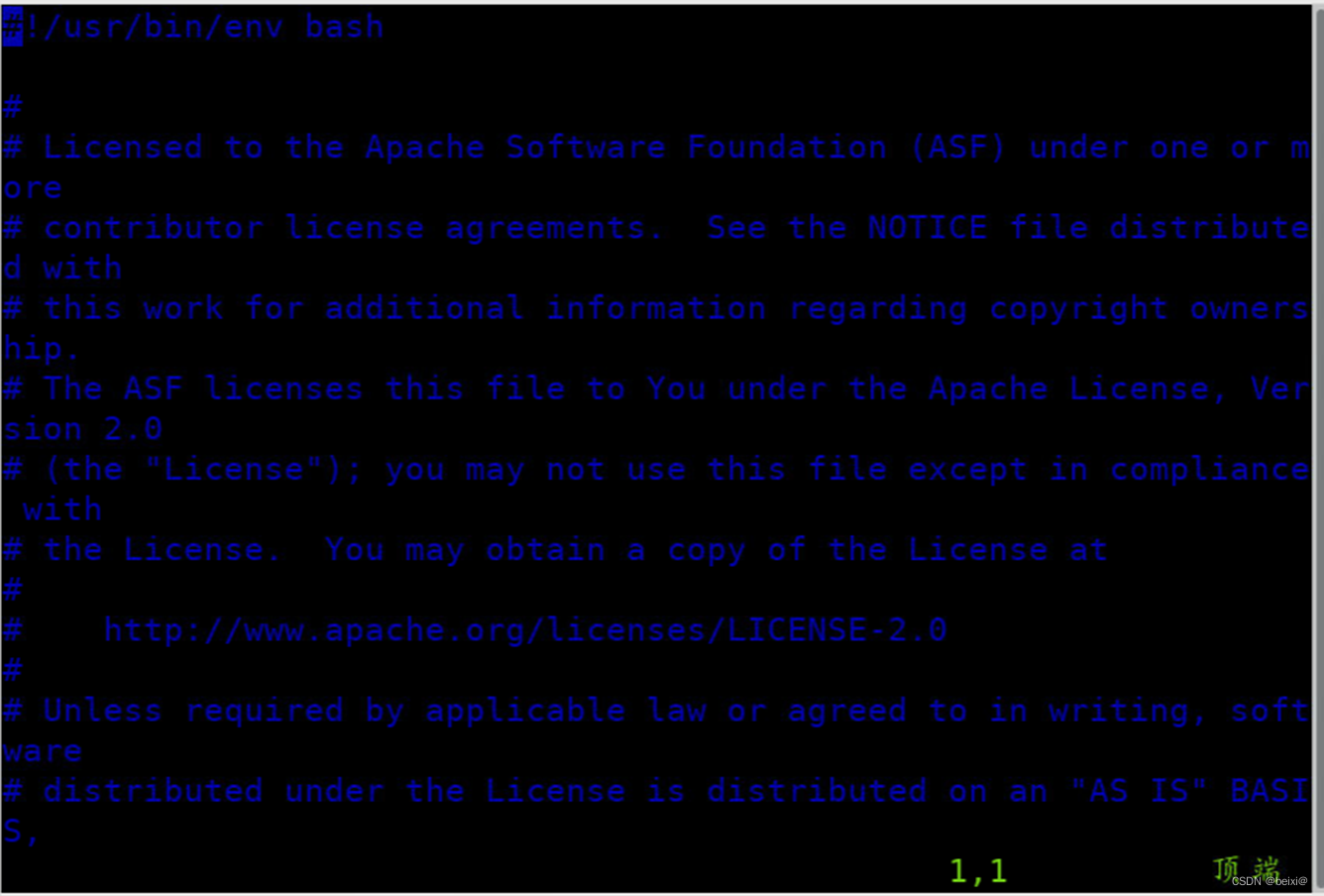
5.按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码,注意:“=”附近无空格:
export JAVA_HOME=/usr/lib/java-1.8
export SPARK_MASTER_HOST=master
export SPARK_MASTER_PORT=7077
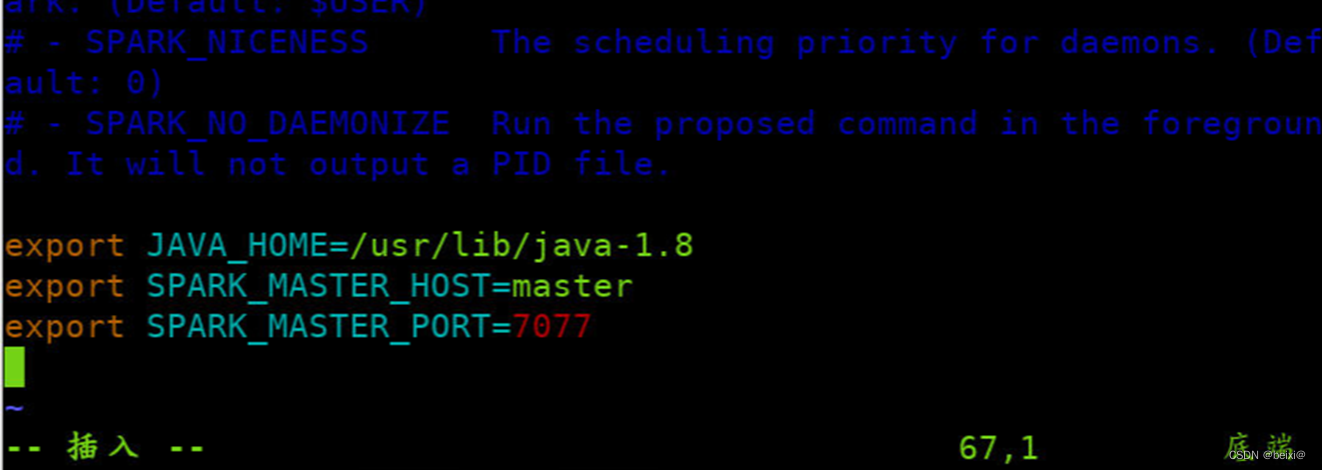
按键Esc,输入:wq保存退出
6.复制一份spark的slaves配置文件
cp slaves.template slaves

7.修改spark的slaves配置文件
vim slaves

8.每一行添加工作节点(Worker)名称,按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码
slave1
slave2
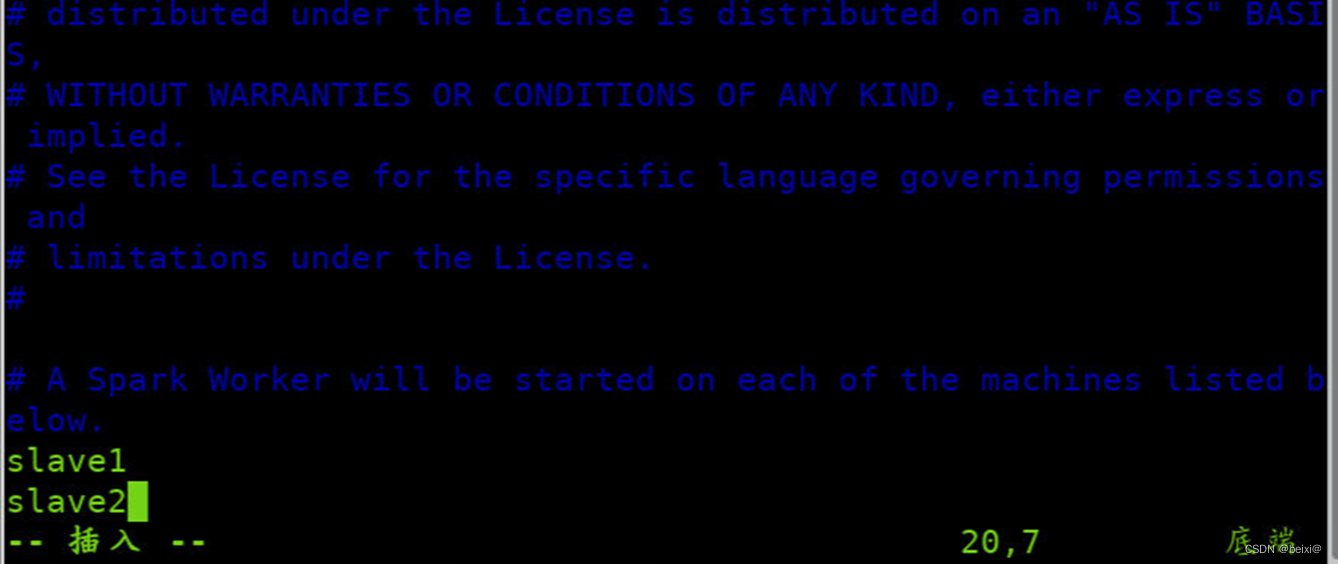
按键Esc,输入:wq保存退出
9.复制一份spark-defaults.conf
cp spark-defaults.conf.template spark-defaults.conf

10.通过远程scp指令将Master主节点的Spark安装包分发至各个从节点,即slave1和slave2节点
scp -r /opt/spark/ root@slave1:/opt/
scp -r /opt/spark/ root@slave2:/opt/


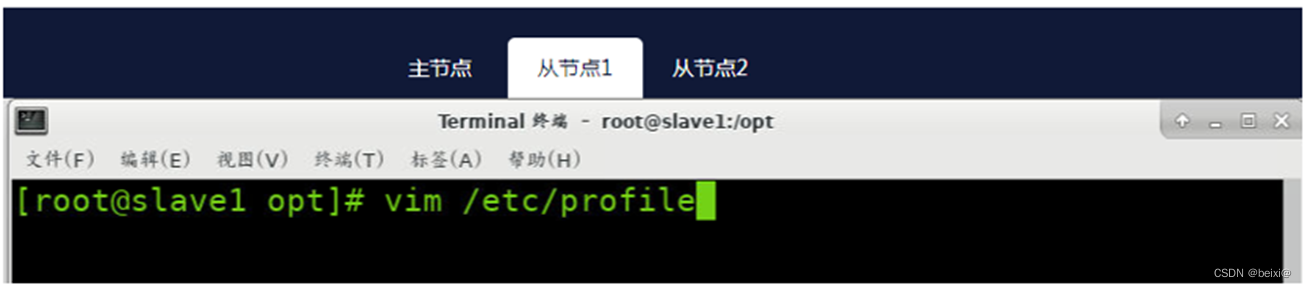
11.配置环境变量:分别在slave1和slave2节点上配置环境变量,修改【/etc/profile】,在文件尾部追加以下内容
vim /etc/profile
按键Shift+g键定位到最后一行,按键 i 切换到输入模式下,添加如下代码
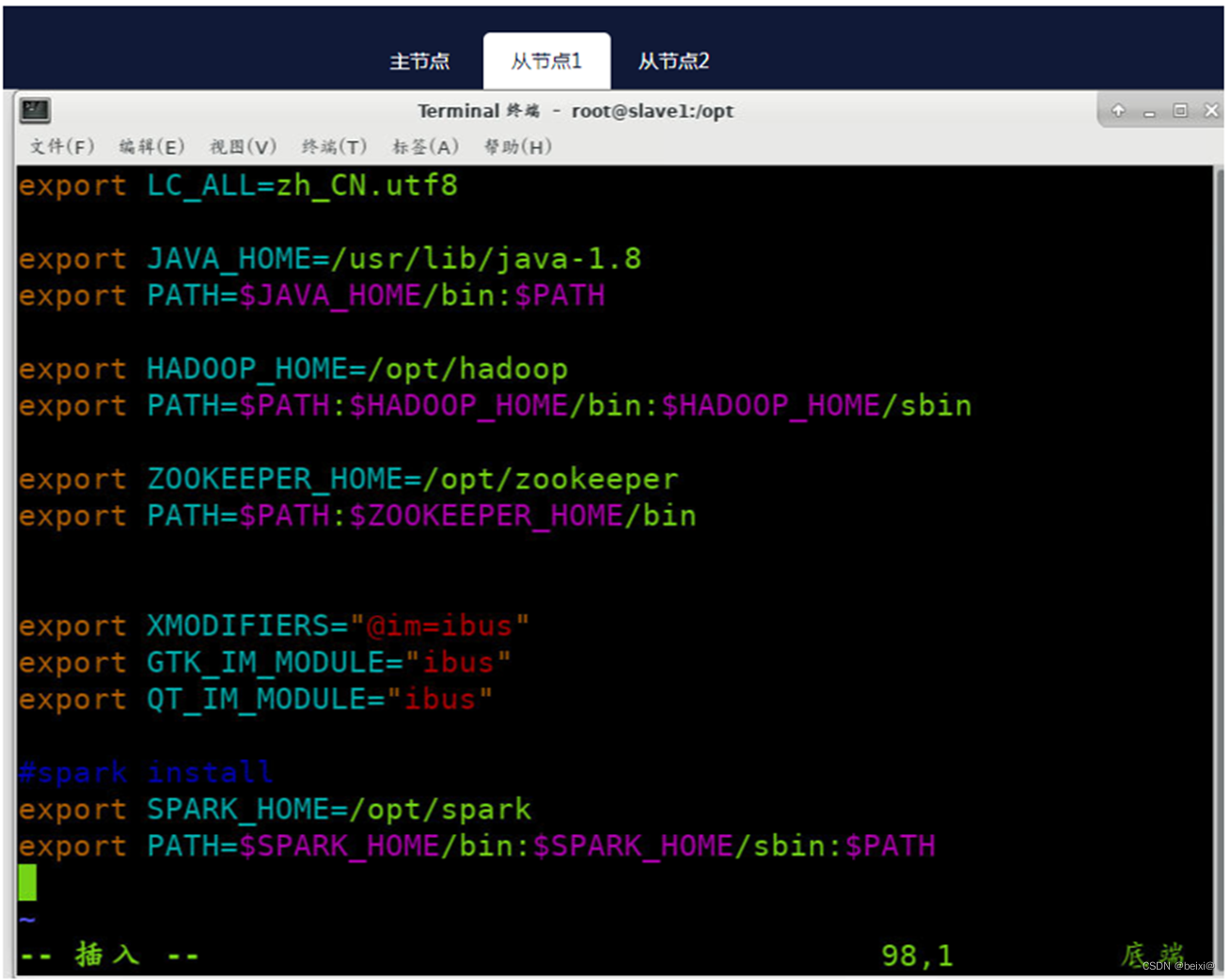
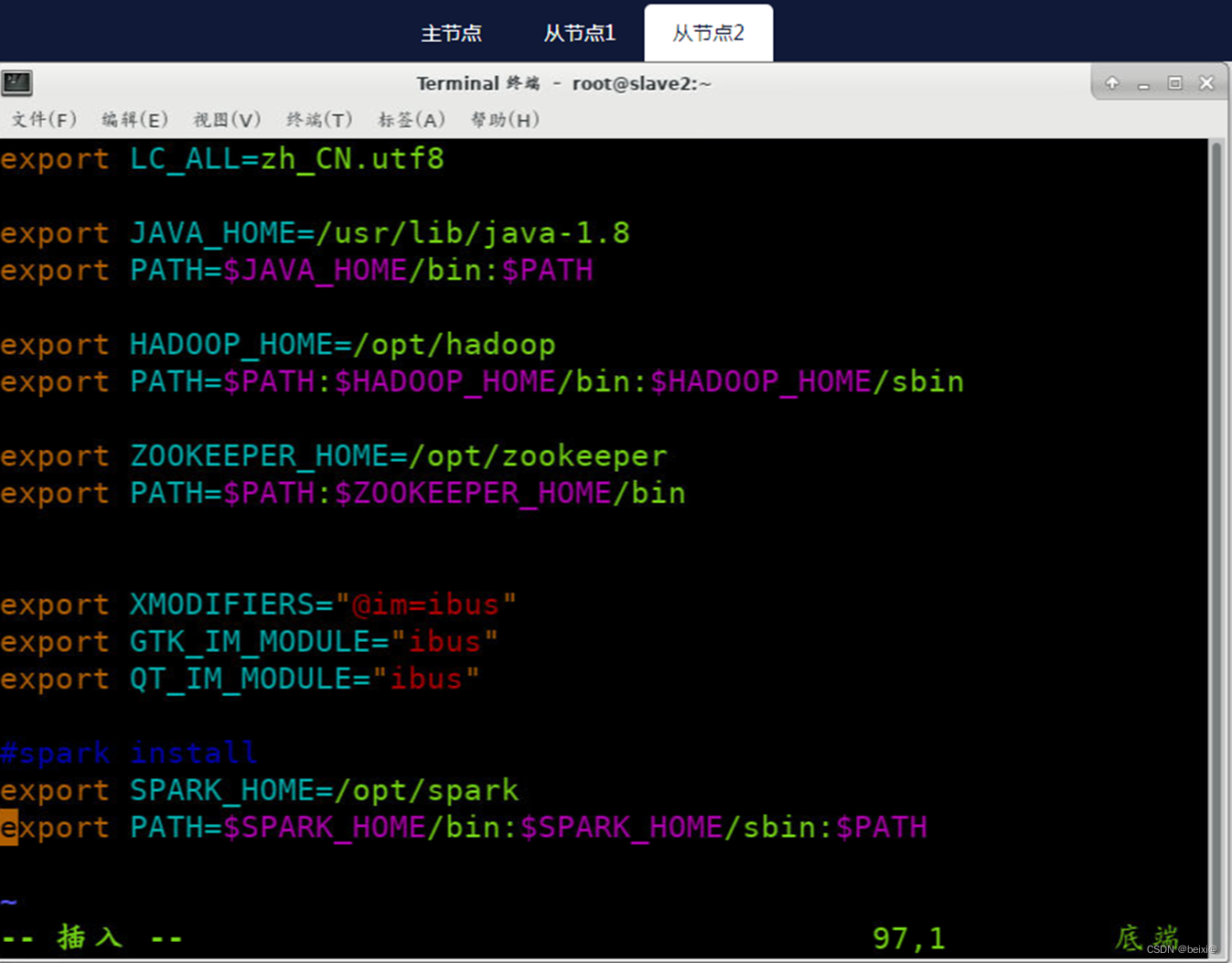
#spark install
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
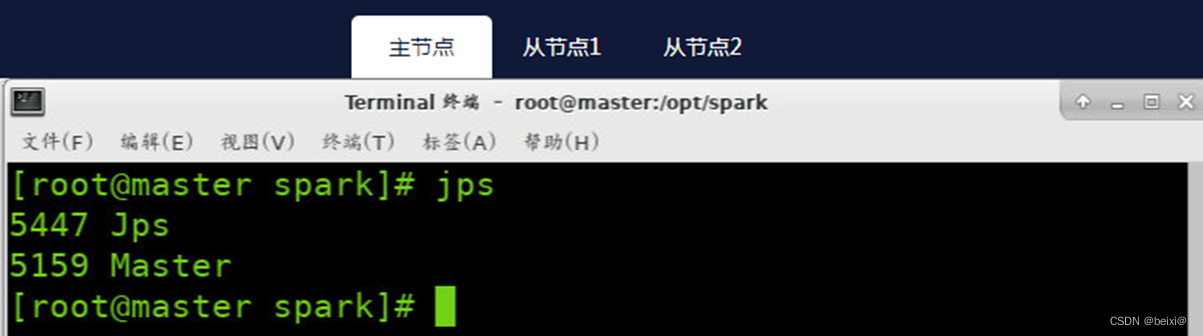
主节点(master)上执行截图,如下:

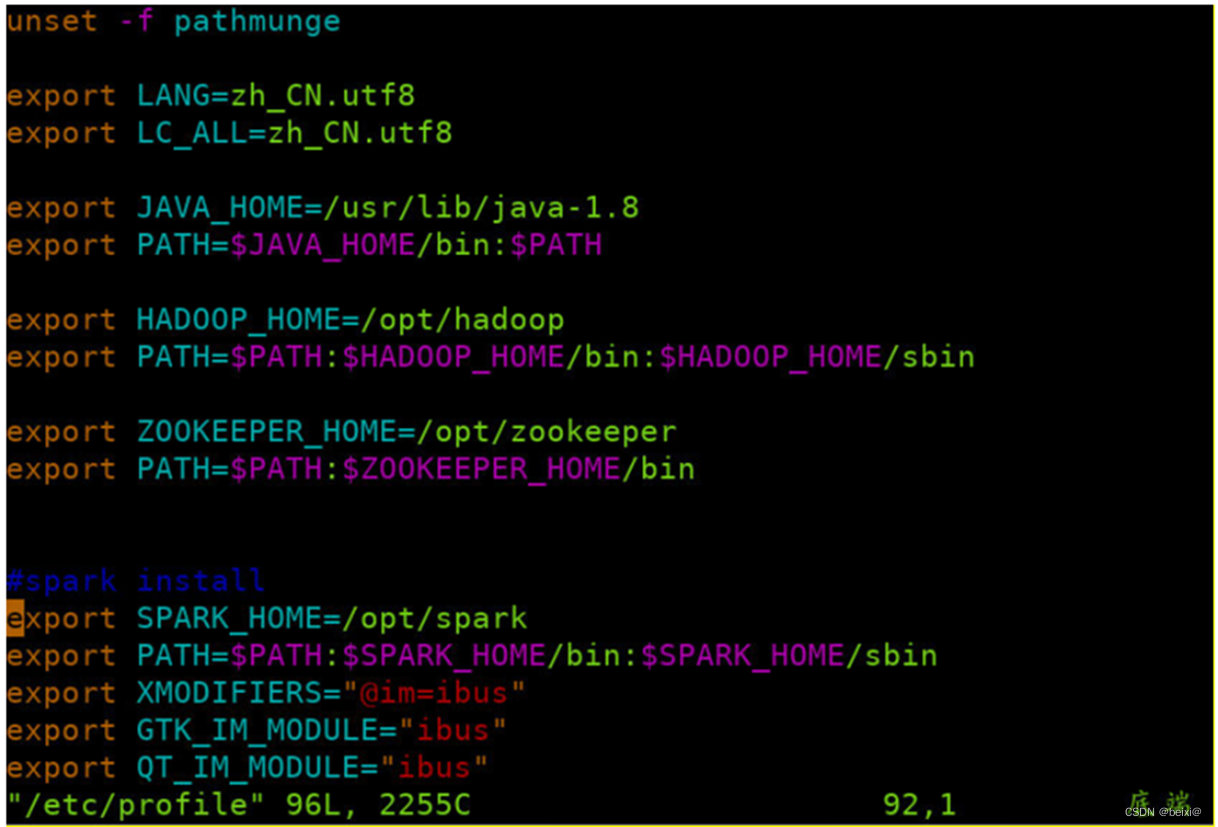
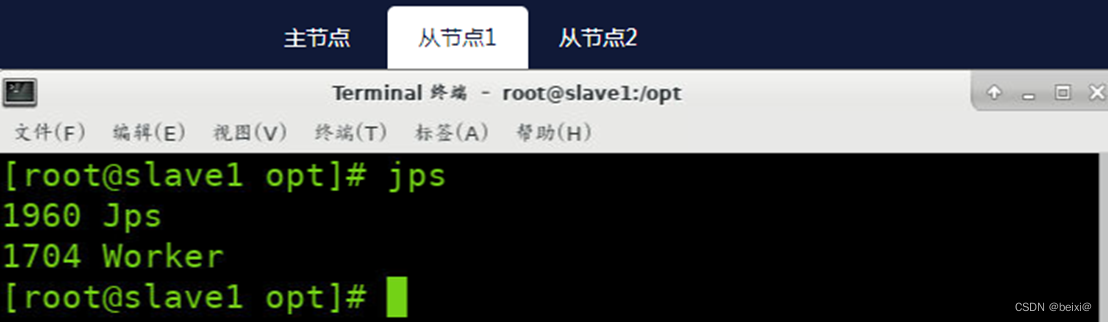
从节点1(Slave1)上执行截图,如下:
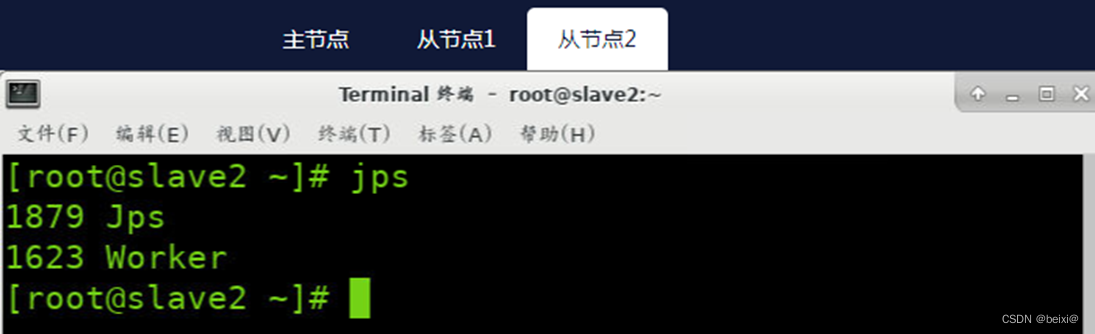
从节点2(Slave2)上执行截图,如下:

12.按键Esc,按键:wq保存退出
13.分别在Slave1和Slave2上,刷新配置文件
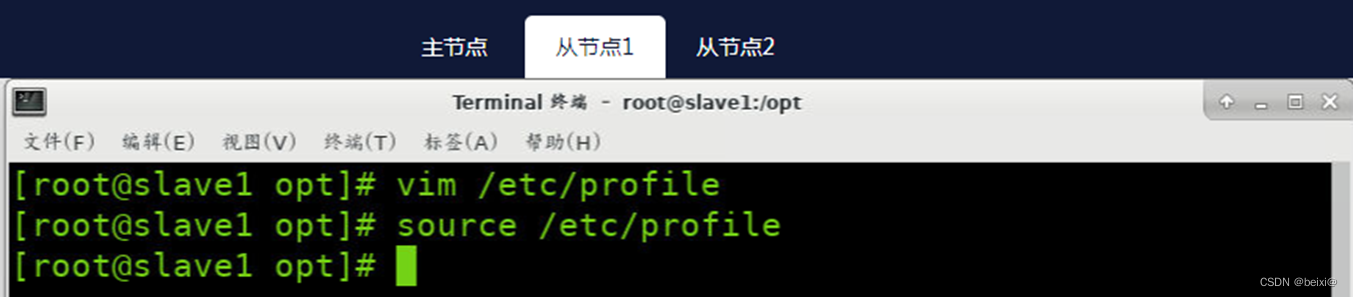

source /etc/profile
14.开启standalone集群守护进程,分别开启Standalone集群的守护进程:Master和Worker。注意:需要在主节点执行该操作!
start-master.sh
start-slaves.sh
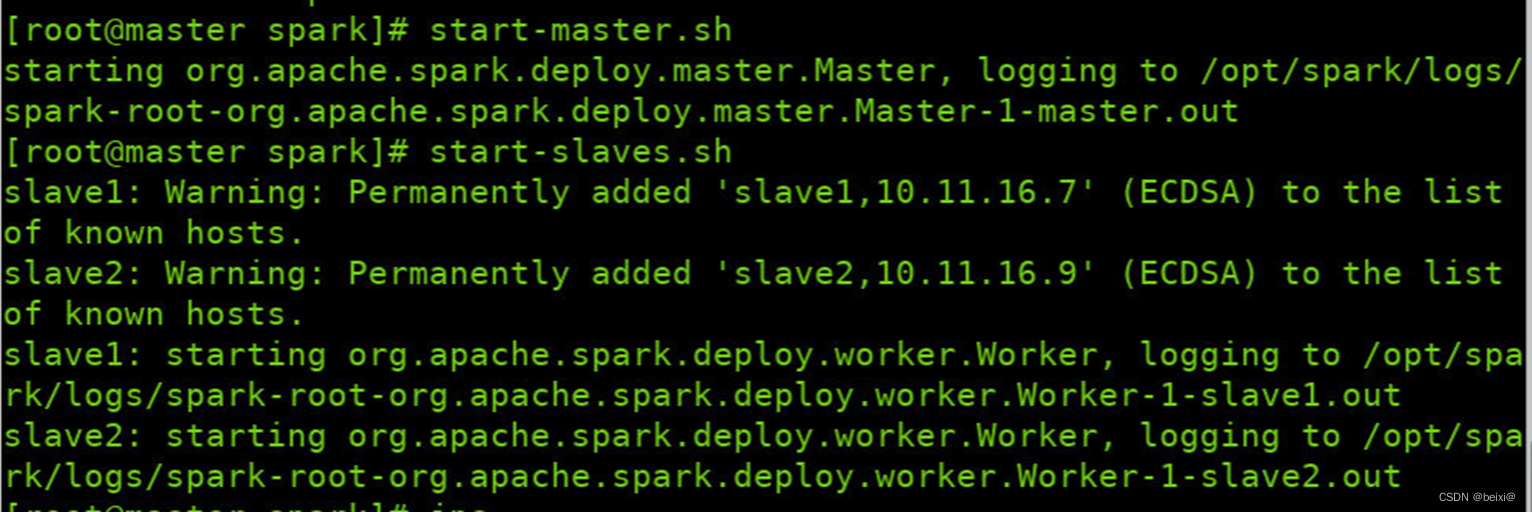
15.Spark独立集群搭建成功后,查看后台守护线程,如图所示,即Standalone模式搭建成功!!
jps
16.查看WebUI监控,独立集群管理器开启后,可以通过WebUI监控界面查看集群管理器的相关信息,地址为:http://master:8080 如图所示
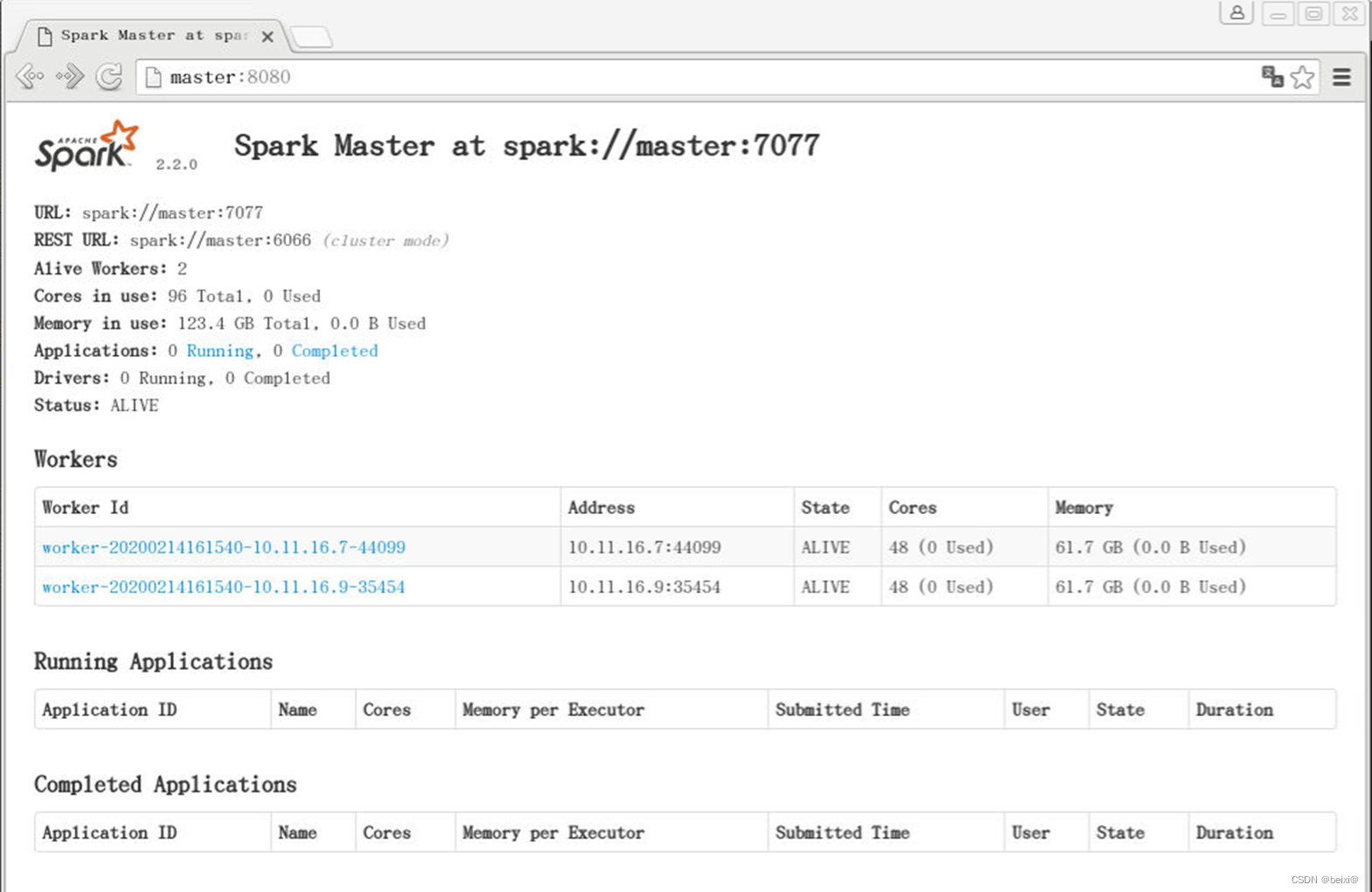
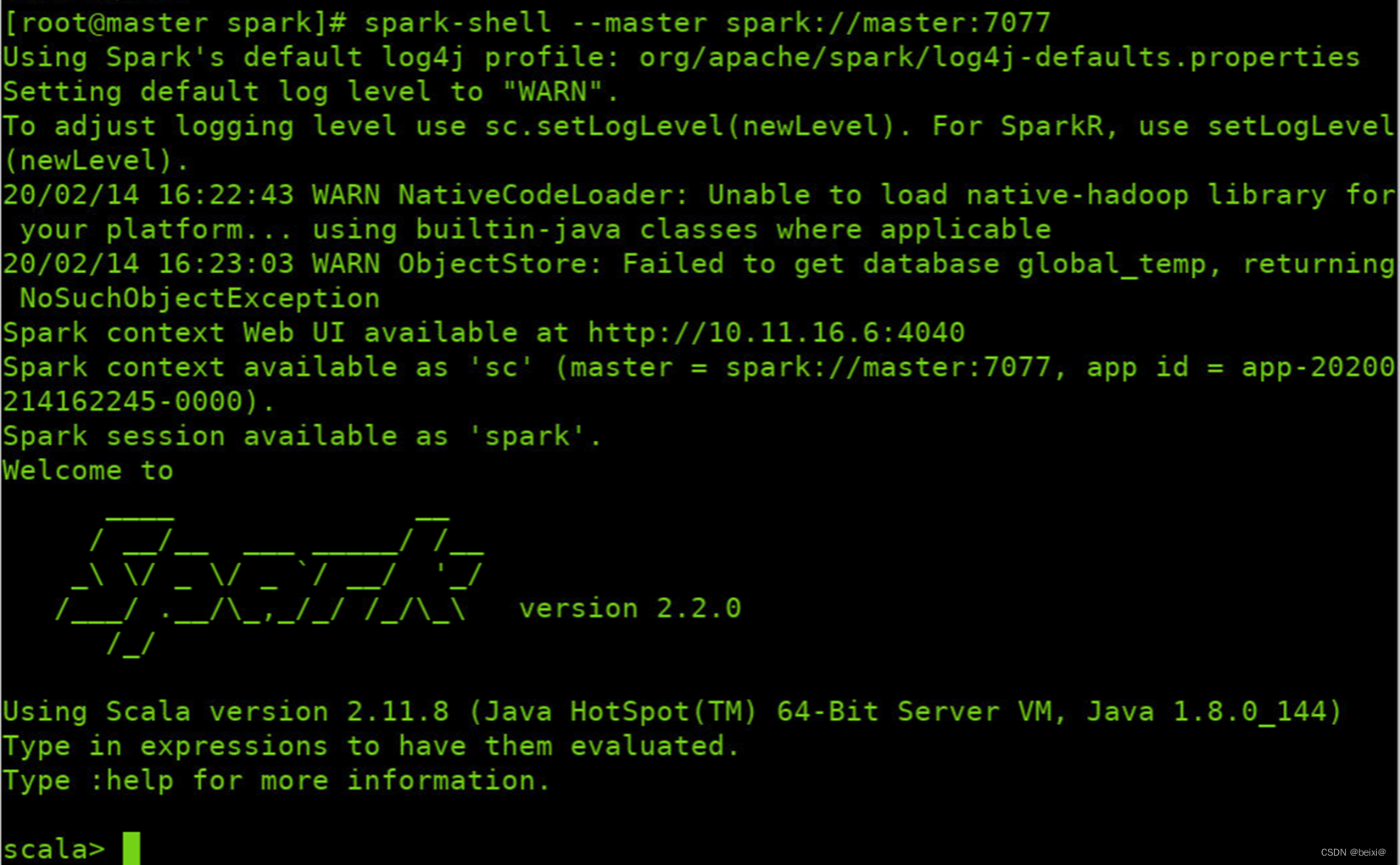
17.开启spark-shell会话,向独立集群管理器提交应用,需要把spark://masternode:7070作为主节点参数传–master。指令如下
spark-shell --master spark://master:7077
所有配置完成,如果本篇文章对你有帮助,记得点赞关注+收藏哦~
相关文章:
Spark Standalone环境搭建及测试
🥇🥇【大数据学习记录篇】-持续更新中~🥇🥇 篇一:Linux系统下配置java环境 篇二:hadoop伪分布式搭建(超详细) 篇三:hadoop完全分布式集群搭建(超详细…...

【PHP】流程控制-ifswitchforwhiledo-whilecontinuebreak
文章目录 流程控制顺序结构分支结构if分支switch分支 循环结构for循环while循环do-while循环continue和break 流程控制 顺序结构:代码从上往下,顺序执行。(代码执行的最基本结构) 分支结构:给定一个条件,…...

Pytorch-day04-模型构建-checkpoint
PyTorch 模型构建 1、GPU配置2、数据预处理3、划分训练集、验证集、测试集4、选择模型5、设定损失函数&优化方法6、模型效果评估 #导入常用包 import os import numpy as np import torch from torch.utils.data import Dataset, DataLoader from torchvision.transfor…...
使用Xshell7控制多台服务同时安装ZK最新版集群服务
一: 环境准备: 主机名称 主机IP 节点 (集群内通讯端口|选举leader|cline端提供服务)端口 docker0 192.168.1.100 node-0 2888 | 3888 | 2181 docker1 192.168.1.101 node-1 2888 | 388…...

python numpy array dtype和astype类型转换的区别
Python3 本身对整数的支持做了提升,可以支持无限长度的整数:比如: b 0xffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffffPython的模块numpy array定义的数组在windows和MACOS上默认长度是…...

浮动属性样式
🍓浮动属性 属性名称中文注释备注float设置盒子浮动left左浮动,right右浮动,none不浮动clear清除浮动left清除左浮动,right清除右浮动,both左右浮动都清除(注意:clear清除浮动一般只有作用在块…...

keepalived双机热备 (四十五)
一、概述 Keepalived 是一个基于 VRRP 协议来实现的 LVS 服务高可用方案,可以解决静态路由出现的单点故障问题。 原理 在一个 LVS 服务集群中通常有主服务器(MASTER)和备份服务器(BACKUP)两种角色的服务器…...
SpringBoot整合阿里云OSS,实现图片上传
在项目中,将图片等文件资源上传到阿里云的OSS,减少服务器压力。 项目中导入阿里云的SDK <dependency><groupId>com.aliyun.oss</groupId><artifactId>aliyun-sdk-oss</artifactId><version>3.10.2</version>…...

Dynaminc Programming相关
目录 3.1 最长回文子串(中等):标志位 3.2 最大子数组和(中等):动态规划 3.3 爬楼梯(简单):动态规划 3.4 买卖股票的最佳时机(简单)࿱…...
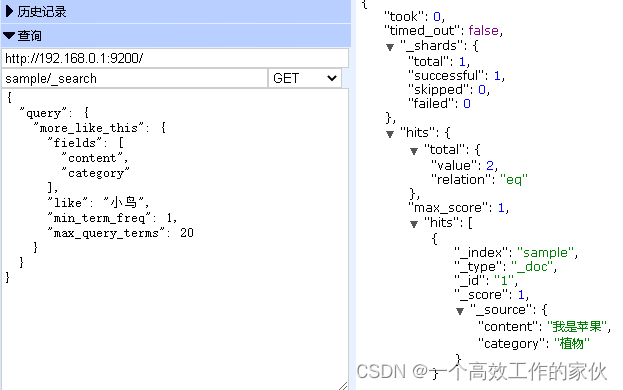
使用 Elasticsearch 轻松进行中文文本分类
本文记录下使用 Elasticsearch 进行文本分类,当我第一次偶然发现 Elasticsearch 时,就被它的易用性、速度和配置选项所吸引。每次使用 Elasticsearch,我都能找到一种更为简单的方法来解决我一贯通过传统的自然语言处理 (NLP) 工具和技术来解决…...

MNN学习笔记(八):使用MNN推理Mediapipe模型
1.项目说明 最近需要用到一些mediapipe中的模型功能,于是尝试对mediapipe中的一些模型进行转换,并使用MNN进行推理;主要模型包括:图像分类、人脸检测及人脸关键点mesh、手掌检测及手势关键点、人体检测及人体关键点、图像嵌入特征…...

主力吸筹指标及其分析和使用说明
文章目录 主力吸筹指标指标代码分析使用说明使用配图主力吸筹指标 VAR1:=REF(LOW,1); VAR2:=SMA(MAX(LOW-VAR1,0),3,1)/SMA(ABS(LOW-VAR1),3,1)*100; VAR3:=EMA(VAR2,3); VAR4:=LLV(LOW,34); VAR5:=HHV(VAR3,34); VAR7:=EMA(IF(LOW<=VAR4,(VAR3+VAR5*2)/2,0),3); /*底线:0,…...
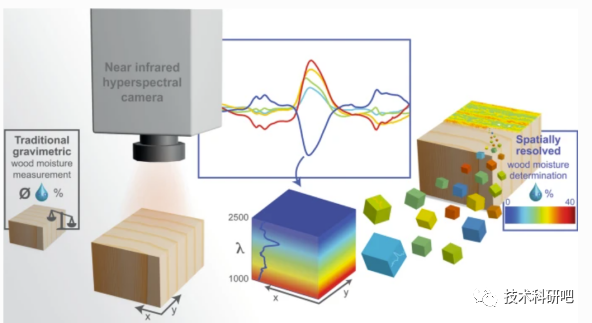
Python高光谱遥感数据处理与高光谱遥感机器学习方法教程
详情点击链接:Python高光谱遥感数据处理与高光谱遥感机器学习方法教程 第一:高光谱基础 一:高光谱遥感基本 01)高光谱遥感 02)光的波长 03)光谱分辨率 04)高光谱遥感的历史和发展 二:高光谱传感器与数据获取 01)高光谱遥感…...
【洛谷】P1678 烦恼的高考志愿
原题链接:https://www.luogu.com.cn/problem/P1678 目录 1. 题目描述 2. 思路分析 3. 代码实现 1. 题目描述 2. 思路分析 将每个学校的分数线用sort()升序排序,再二分查找每个学校的分数线,通过二分找到每个同学估分附近的分数线。 最后…...

开机自启CPU设置定频
sudo apt-get install expect sudo apt-get install cpufrequtils具体步骤如下: 安装 cpufrequtils 工具 ⚫ sudo apt-get install cpufrequtils ⚫ 需要联网下载修改配置文件 ⚫ sudo vi /etc/init.d/cpufrequtils ⚫ 将 GOVERNOR“ondemand” 改为: &g…...
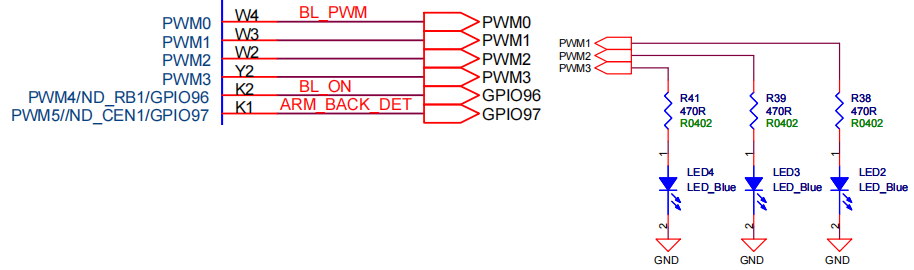
嵌入式Linux开发实操(十二):PWM接口开发
# 前言 使用pwm实现LED点灯,可以说是嵌入式系统的一个基本案例。那么嵌入式linux系统下又如何实现pwm点led灯呢? # PWM在嵌入式linux下的操作指令 实际使用效果如下,可以通过shell指令将开发板对应的LED灯点亮。 点亮3个LED,则分别使用pwm1、pwm2和pwm3。 # PWM引脚的硬…...

消息中间件介绍
消息队列已经逐渐成为企业IT系统内部通信的核心手段。它具有低耦合、可靠投递、广播、流量控制、最终一致性等一系列功能,成为异步RPC的主要手段之一。当今市面上有很多主流的消息中间件,如ActiveMQ、RabbitMQ,Kafka,还有阿里巴巴…...

[Unity] 基础的编程思想, 组件式开发
熟悉 C# 开发的朋友, 在刚进入 Unity 开发时, 不可避免的会有一些迷惑, 例如不清楚 Unity 自己的思想, 如何设计与架构一个应用程序之类的. 本篇文章简要的介绍一下 Unity 的基础编程思想. 独立 Unity 很少使用 C# 的标准库, 例如 C# 的网络, 事件驱动, 对象模型, 这些概念在 …...
SVN 项目管理笔记
SVN 项目管理笔记 主要是介绍 SVN 管理项目的常用操作,方便以后查阅!!! 一、本地项目提交到SVN流程 在SVN仓库下创建和项目名同样的文件夹目录;选中本地项目文件,选择SVN->checkout,第一个是远程仓库项…...

Android获取手机已安装应用列表JAVA实现
最终效果: 设计 实现java代码: //获取包列表private List<String> getPkgList() {List<String> packages new ArrayList<String>();try {//使用命令行方式获取包列表Process p Runtime.getRuntime().exec("pm list packages");//取得命令行输出…...

从零开始打造 OpenSTLinux 6.6 Yocto 系统(基于STM32CubeMX)(九)
设备树移植 和uboot设备树修改的内容同步到kernel将设备树stm32mp157d-stm32mp157daa1-mx.dts复制到内核源码目录下 源码修改及编译 修改arch/arm/boot/dts/st/Makefile,新增设备树编译 stm32mp157f-ev1-m4-examples.dtb \stm32mp157d-stm32mp157daa1-mx.dtb修改…...

Springcloud:Eureka 高可用集群搭建实战(服务注册与发现的底层原理与避坑指南)
引言:为什么 Eureka 依然是存量系统的核心? 尽管 Nacos 等新注册中心崛起,但金融、电力等保守行业仍有大量系统运行在 Eureka 上。理解其高可用设计与自我保护机制,是保障分布式系统稳定的必修课。本文将手把手带你搭建生产级 Eur…...

Java面试专项一-准备篇
一、企业简历筛选规则 一般企业的简历筛选流程:首先由HR先筛选一部分简历后,在将简历给到对应的项目负责人后再进行下一步的操作。 HR如何筛选简历 例如:Boss直聘(招聘方平台) 直接按照条件进行筛选 例如:…...

redis和redission的区别
Redis 和 Redisson 是两个密切相关但又本质不同的技术,它们扮演着完全不同的角色: Redis: 内存数据库/数据结构存储 本质: 它是一个开源的、高性能的、基于内存的 键值存储数据库。它也可以将数据持久化到磁盘。 核心功能: 提供丰…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...

[USACO23FEB] Bakery S
题目描述 Bessie 开了一家面包店! 在她的面包店里,Bessie 有一个烤箱,可以在 t C t_C tC 的时间内生产一块饼干或在 t M t_M tM 单位时间内生产一块松糕。 ( 1 ≤ t C , t M ≤ 10 9 ) (1 \le t_C,t_M \le 10^9) (1≤tC,tM≤109)。由于空间…...

2025年低延迟业务DDoS防护全攻略:高可用架构与实战方案
一、延迟敏感行业面临的DDoS攻击新挑战 2025年,金融交易、实时竞技游戏、工业物联网等低延迟业务成为DDoS攻击的首要目标。攻击呈现三大特征: AI驱动的自适应攻击:攻击流量模拟真实用户行为,差异率低至0.5%,传统规则引…...

boost::filesystem::path文件路径使用详解和示例
boost::filesystem::path 是 Boost 库中用于跨平台操作文件路径的类,封装了路径的拼接、分割、提取、判断等常用功能。下面是对它的使用详解,包括常用接口与完整示例。 1. 引入头文件与命名空间 #include <boost/filesystem.hpp> namespace fs b…...
goreplay
1.github地址 https://github.com/buger/goreplay 2.简单介绍 GoReplay 是一个开源的网络监控工具,可以记录用户的实时流量并将其用于镜像、负载测试、监控和详细分析。 3.出现背景 随着应用程序的增长,测试它所需的工作量也会呈指数级增长。GoRepl…...

Java毕业设计:办公自动化系统的设计与实现
JAVA办公自动化系统 一、系统概述 本办公自动化系统基于Java EE平台开发,实现了企业日常办公的数字化管理。系统包含文档管理、流程审批、会议管理、日程安排、通讯录等核心功能模块,采用B/S架构设计,支持多用户协同工作。系统使用Spring B…...