Apache Paimon 实时数据湖 Streaming Lakehouse 的存储底座
摘要:本文整理自阿里云开源大数据表存储团队负责人,阿里巴巴高级技术专家李劲松(之信),在 Streaming Lakehouse Meetup 的分享。内容主要分为四个部分:
流计算邂逅数据湖
Paimon CDC 实时入湖
Paimon 不止 CDC 入湖
总结与生态
点击查看原文视频 & 演讲PPT
一、流计算邂逅数据湖
流计算 1.0 实时预处理
流计算 1.0 架构截止到现在也是非常主流的实时数仓中的一个实时预处理的功能,可以通过流计算把消息队列中的数据(比如:日志数据,CDC 数据等等),通过消息队列将数据读过来,通过流计算,进行数据预处理,最终把结果写到 MySQL 中。
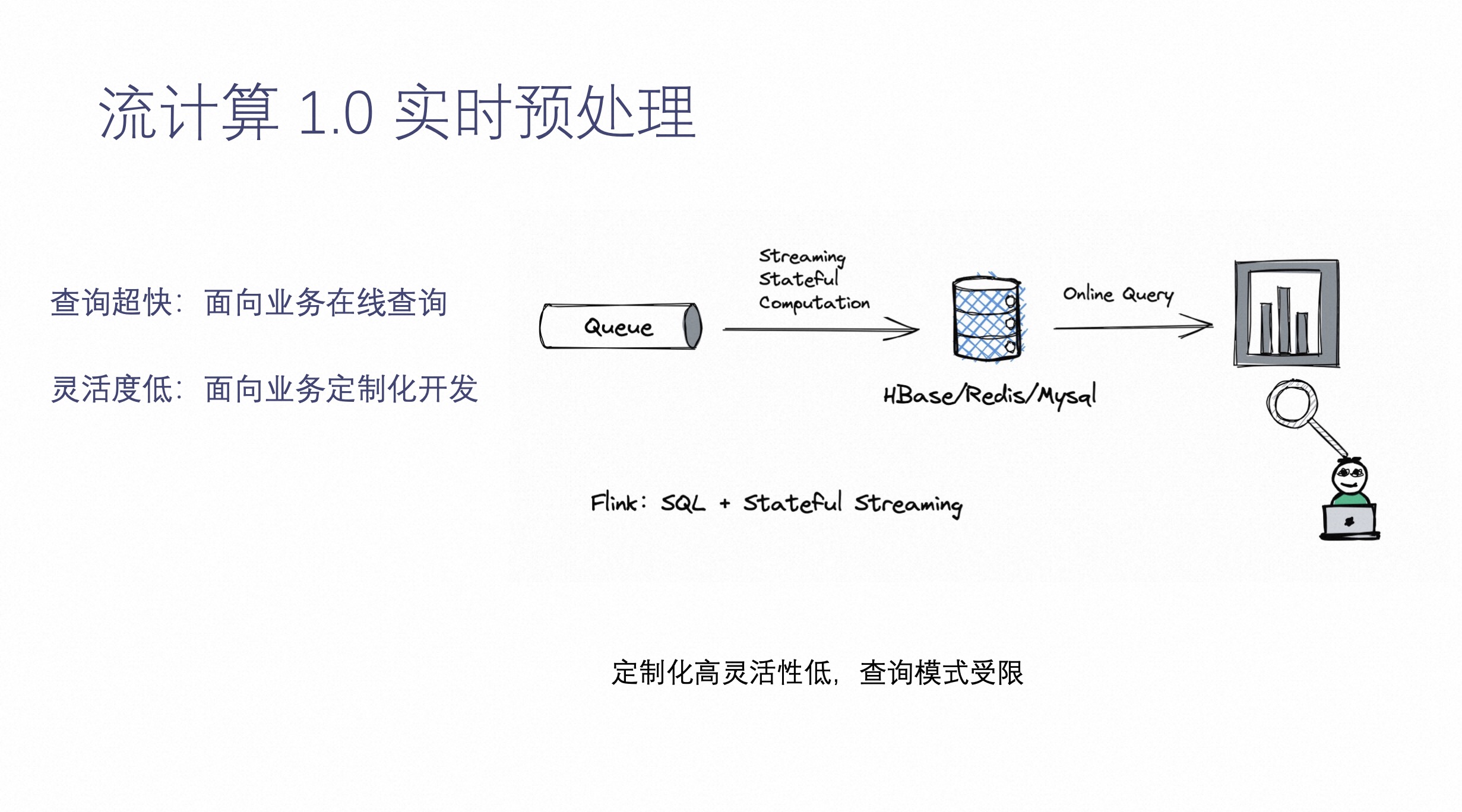
这个系统的典型特点是,它可以面向在线服务的实时查询,这就意味着用户可以把数据通过在线服务查询集成到在线业务中,然后整条链路相当于为每个业务定制的 Pipeline,满足在线业务。这个系统的缺点是,灵活性比较低,面向业务要定制化开发。
流计算 2.0 实时数仓
为了解决灵活性的问题,这就要介绍下流计算 2.0 实时数仓了。
随着计算的发展,越来越多的具有高性能的 OLAP 系统诞生出来,比如 Hologres 等等。它们最大的特点是可以把数据通过结构化的方式落到 OLAP 系统中,可以让业务根据自己灵活的需求来查询这些结构化数据。这样做的好处是,数据落进来之后,数据能够保存比较原始的或经过简单预处理的状态,能够比较灵活的提供给业务方进行实时查询。
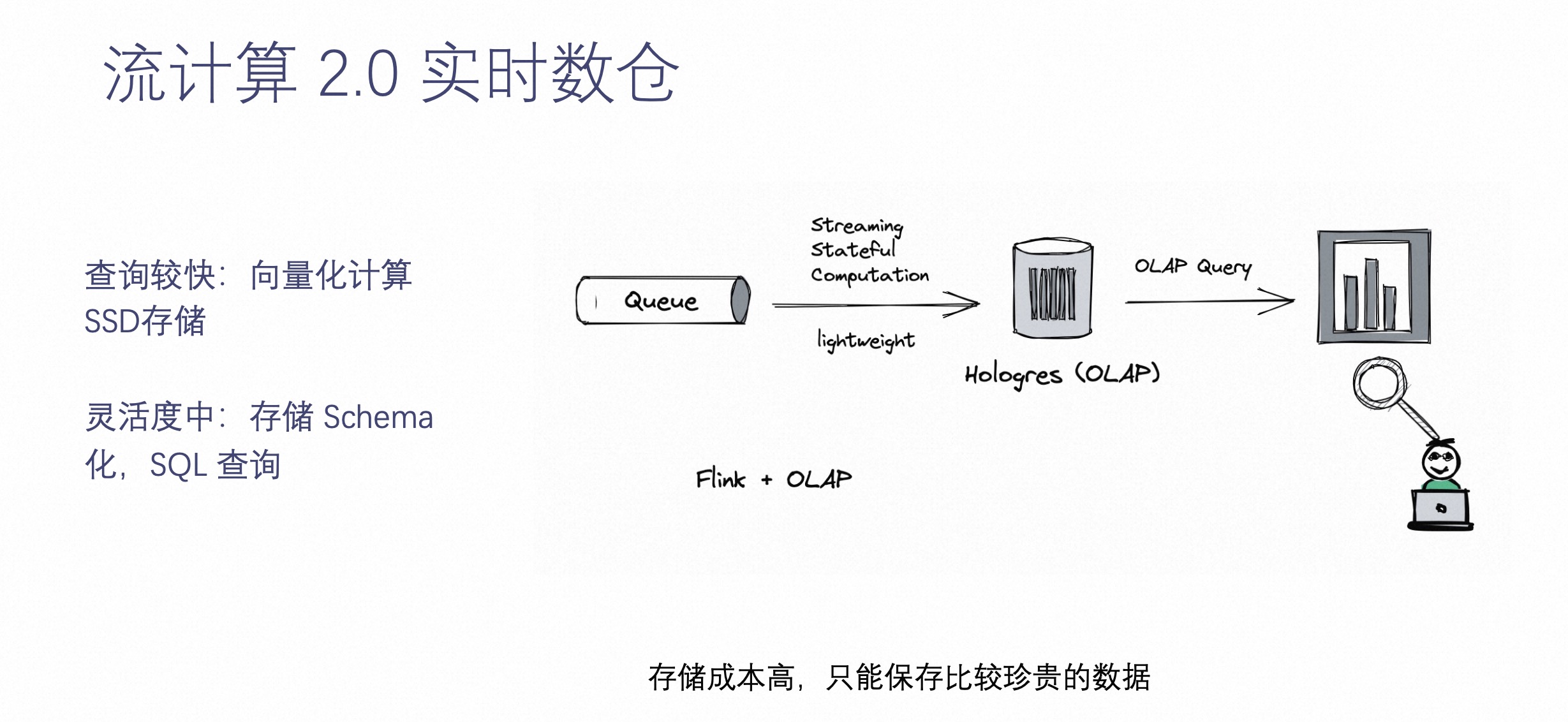
查询性能高,向量化计算 +SSD 存储,实现毫秒响应返回;灵活度适中,比起之前完全的预处理保留了更多的数据和更复杂结构化的模式。但是由于 OLAP 系统成本不低,不能把所有数据都保存到系统中,只将近期的或最重要的数据保存。
流计算 3.0 实时湖仓
基于以上 2.0 的情况,我们引入了流计算的第三个场景——流计算 3.0 实时湖仓。当用户不想再看到实时数据受到限制,灵活性足够大的时候,就可以把离线数仓的数据通过实时化的方式搬到这样一个支持实时化的存储上。把所有实时数据落到存储里面,所有的数据都可以被实时查询。这就是实时湖仓能够解决的问题。
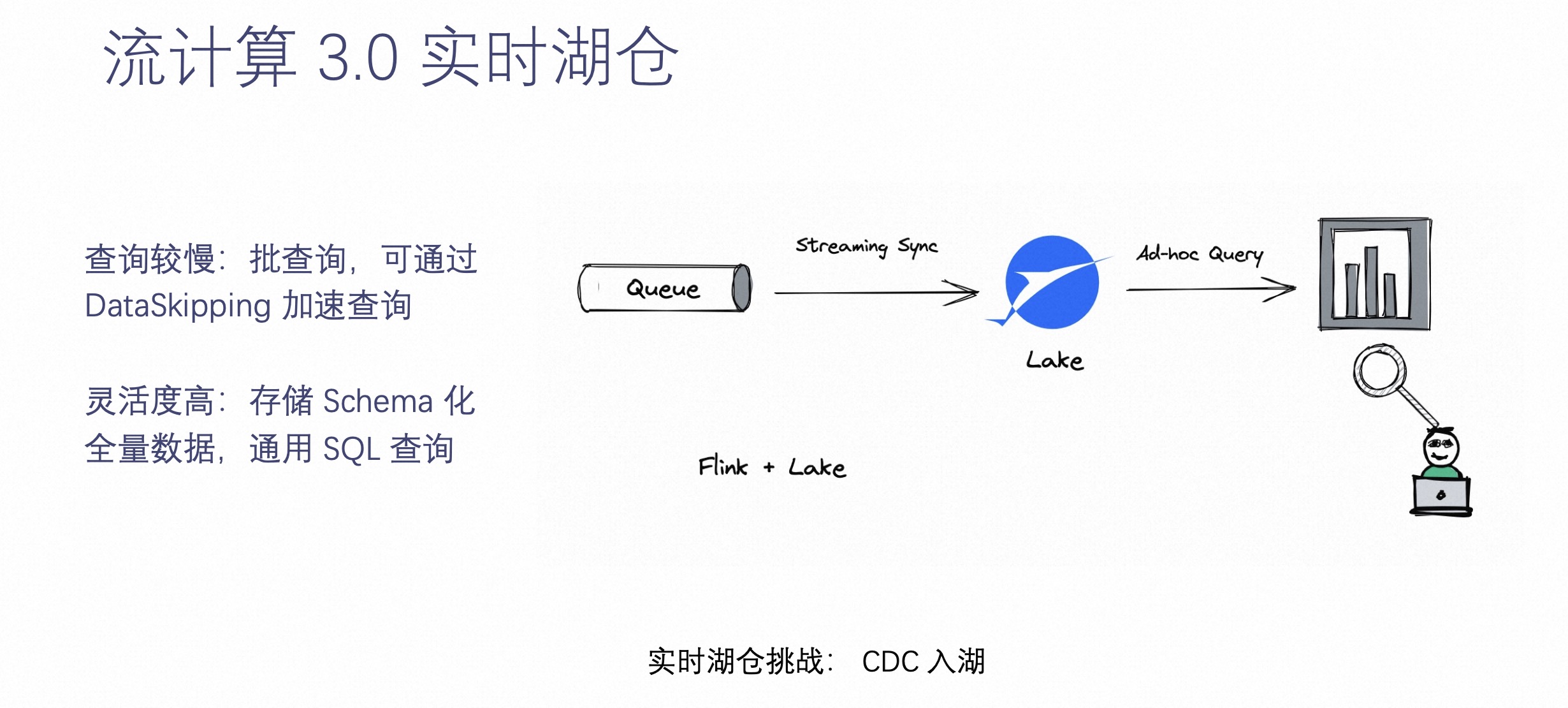
实时湖仓最大限度的解决了灵活度的问题,它可以把所有数据沉淀到湖中,通过实时手段做到业务可查询数据。但是它也带来了一些缺点,它的查询是不如 OLAP 引擎甚至不如在线服务的。所以说,实时湖仓虽然带来了灵活性,但是损失了一些查询的效率。
未来的发展方向是,实时湖仓可以通过更多的 Index 和 DataSkipping 加速查询。这也是 Apache Paimon 诞生的原因。Apache Paimon 就是一个专门为 CDC 处理、流计算而生的数据湖,希望为用户带来舒服、自动湖上流处理体验。
下面将通过一个案例介绍 Apache Paimon 在实时入湖方面做的工作。
二、Paimon CDC 实时入湖
在介绍 Paimon CDC 实时入湖之前,先来看下传统 CDC 入仓是怎么做的。
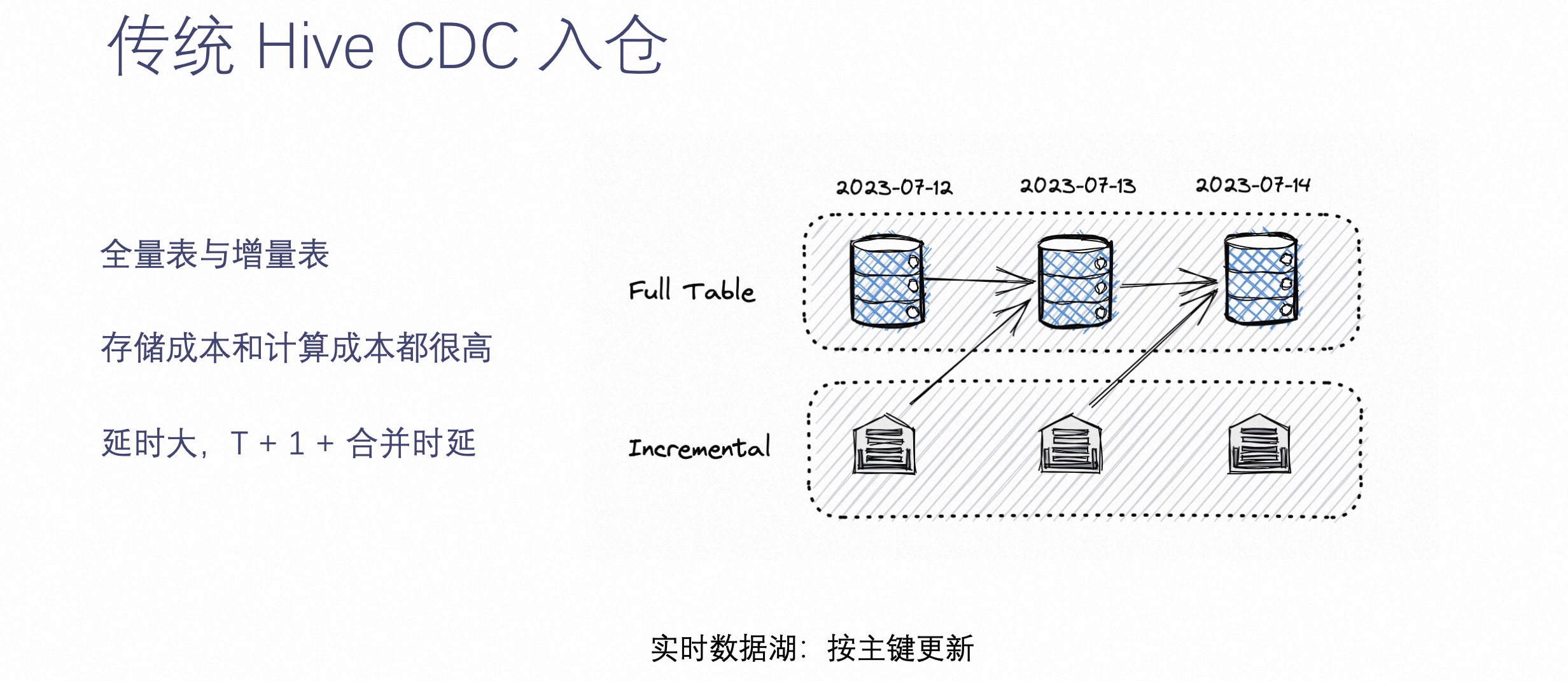
相信运维过数仓的工程师都了解传统数仓的架构。它在解决 CDC 数据的时候,往往是通过上图中全量表加增量表的方式。这种方式是指,每天的增量数据都会落到一个 Hive 增量表中,同时另外维护一个 Hive 的全量表,然后每天增量表的数据就绪后,就把增量表数据和之前的全量表数据进行一次合成,生成一个新的 Hive 全量表。
这种方式的优点是可以实现离线数仓查询每天的全量数据,缺点是全量表每天都会保存一个全量,而增量表每天也会保存当日的增量,所以存储的成本会非常高,同时计算的成本也不低。
另外一个问题是,这种传统的 CDC 入仓方式的延迟性非常大,不但需要 T+1 才能读到昨天的数据,而且还要经过合并延迟,这就对数据湖存储来讲是个很大的挑战。
实时数据湖的基础就是按主键更新,需要有实时更新的能力。Paimon CDC 入湖是怎样的流程呢?如下图所示。
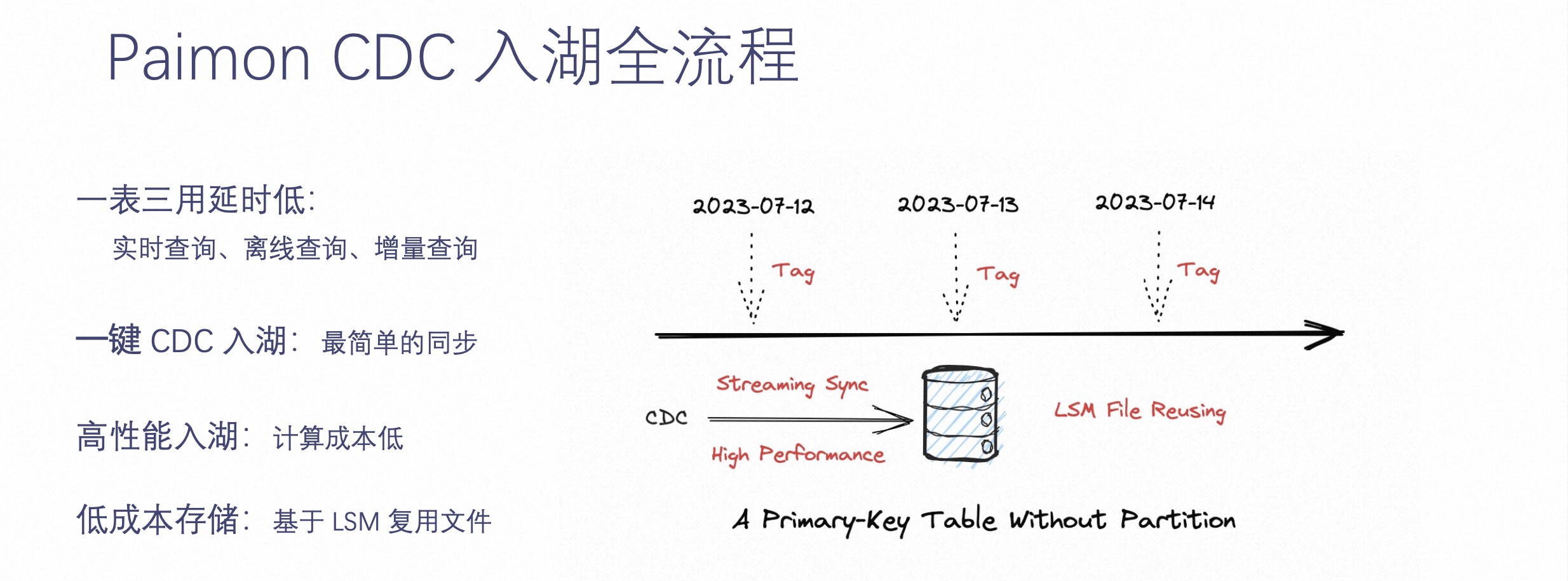
比起上文提到的 Hive 全量表+增量表的方式,Paimon 不再需要定义分区表,只需要定义一个主键表即可。这样这个主键表可以通过 Flink CDC 或是 CDC 数据实时 Streaming Sync 到表中,并且在这个基础上,可以每天晚上零点之后打一个 Tag,这个 Tag 可以维护这张表当时的状态,每个 Tag 对应离线的一个分区。
这样一整套架构带来的好处是一张表可以三用而且延迟低,它可以被实时查询、离线查询,也可以通过增量查询的方式,查询两个 Tag 之间的增量数据。
一键 CDC 入湖是 Paimon 专门为实时更新而生的,它可以实现高性能的入湖,并且通过这样的方式,相较于之前的入仓,存储成本大大降低,因为它是基于 LSM 复用文件来实现的。
接下来介绍下 Paimon CDC 简单的数据集成。
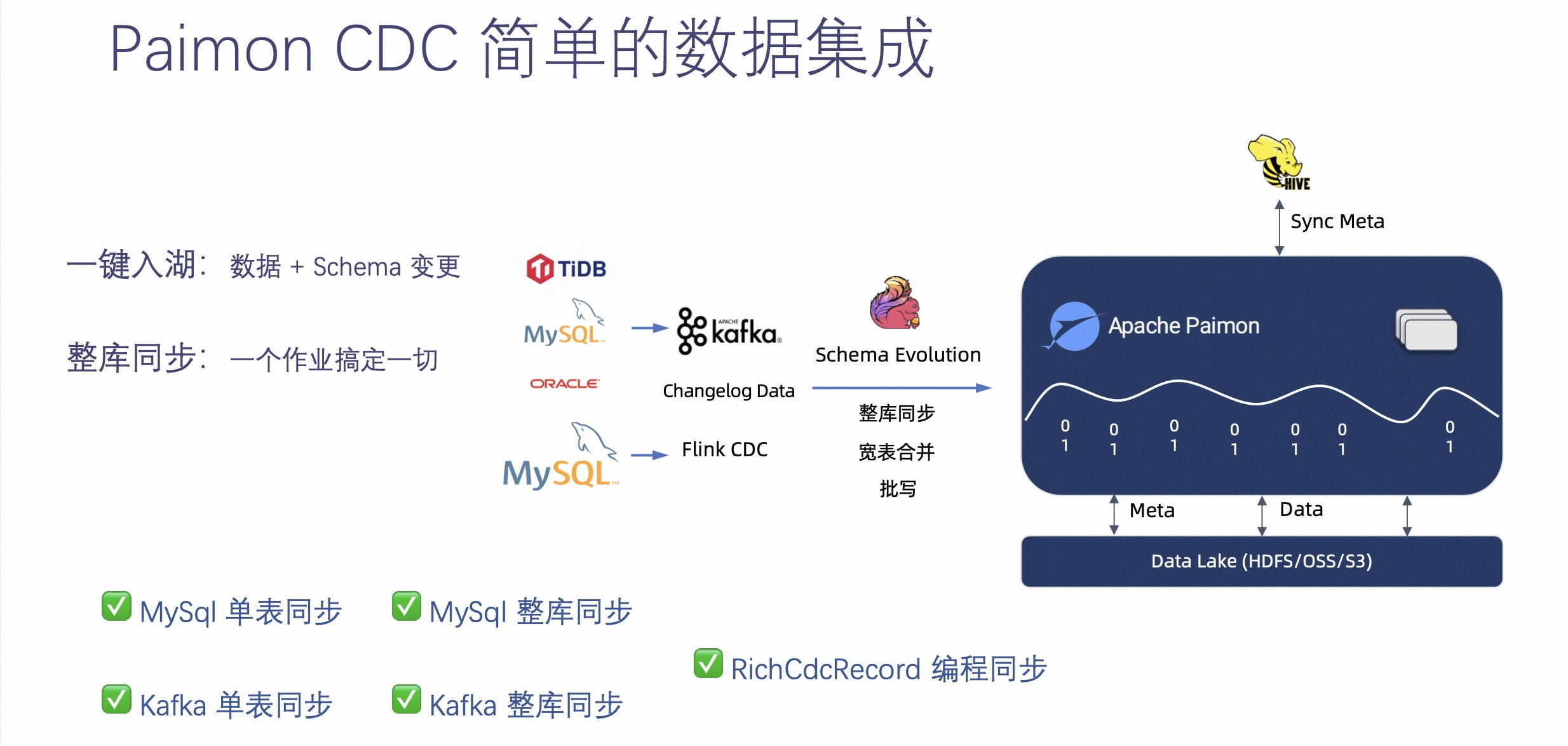
Paimon 集成的 Flink CDC 在开源社区提供了非常方便一键入湖,可以将 Flink CDC 数据同步到 Paimon 中,也可以通过整库同步作业把整个库成百上千的表通过一个作业同步到多个 Paimon 表中。
如上图右侧图表可见,Paimon 在开源社区做的 CDC 入湖不只是有 CDC 入湖单表同步和整库同步,也有 Kafka 单表同步和整个同步。如果这些还不能满足,用户如果有自己的消息队列和自己的格式,也可以通过 RichCdcRecord 这种编程方式达到入湖的效果。
接下来介绍下 Paimon 高性能入湖调优指南。
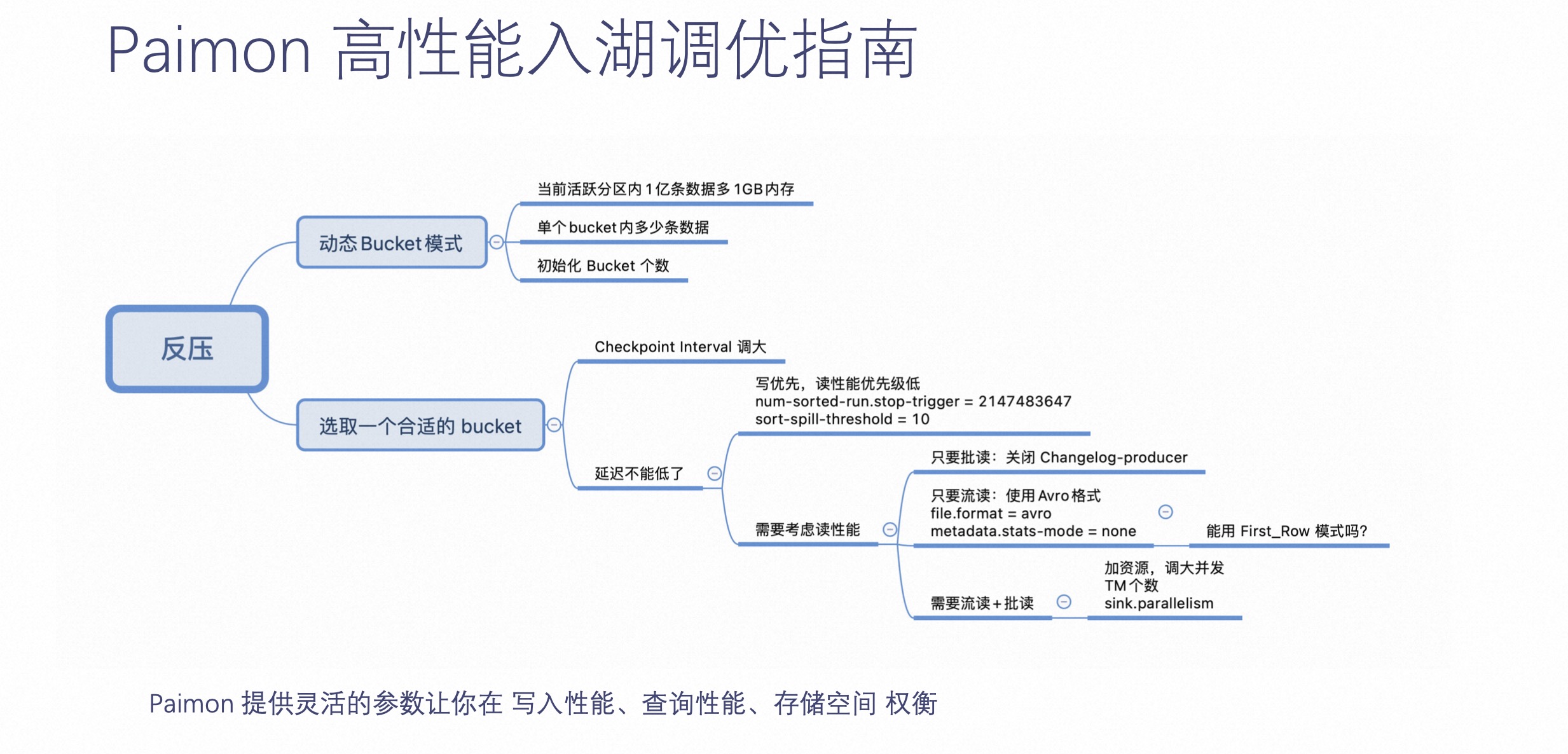
Paimon 在入湖方面,提供了灵活参数,让用户在写入性能、查询性能和存储空间中权衡。举个例子,当用户知晓作业反压了,可以选用 Paimon 的动态 Bucket 模式,也可以通过业务测出一个合适的 Bucket。如果这个时候还反压,可以调整 Checkpoint Interval,或是通过参数指定 Paimon Compaction 实现其永远不阻塞,让写入优先。
总而言之,Paimon 在这里提供了非常灵活的参数,可以让用户在流读、批读和更新场景当中做到相应的权衡。
上文提及 Paimon 是一张没有分区的表,Paimon 如何提供离线视图呢?
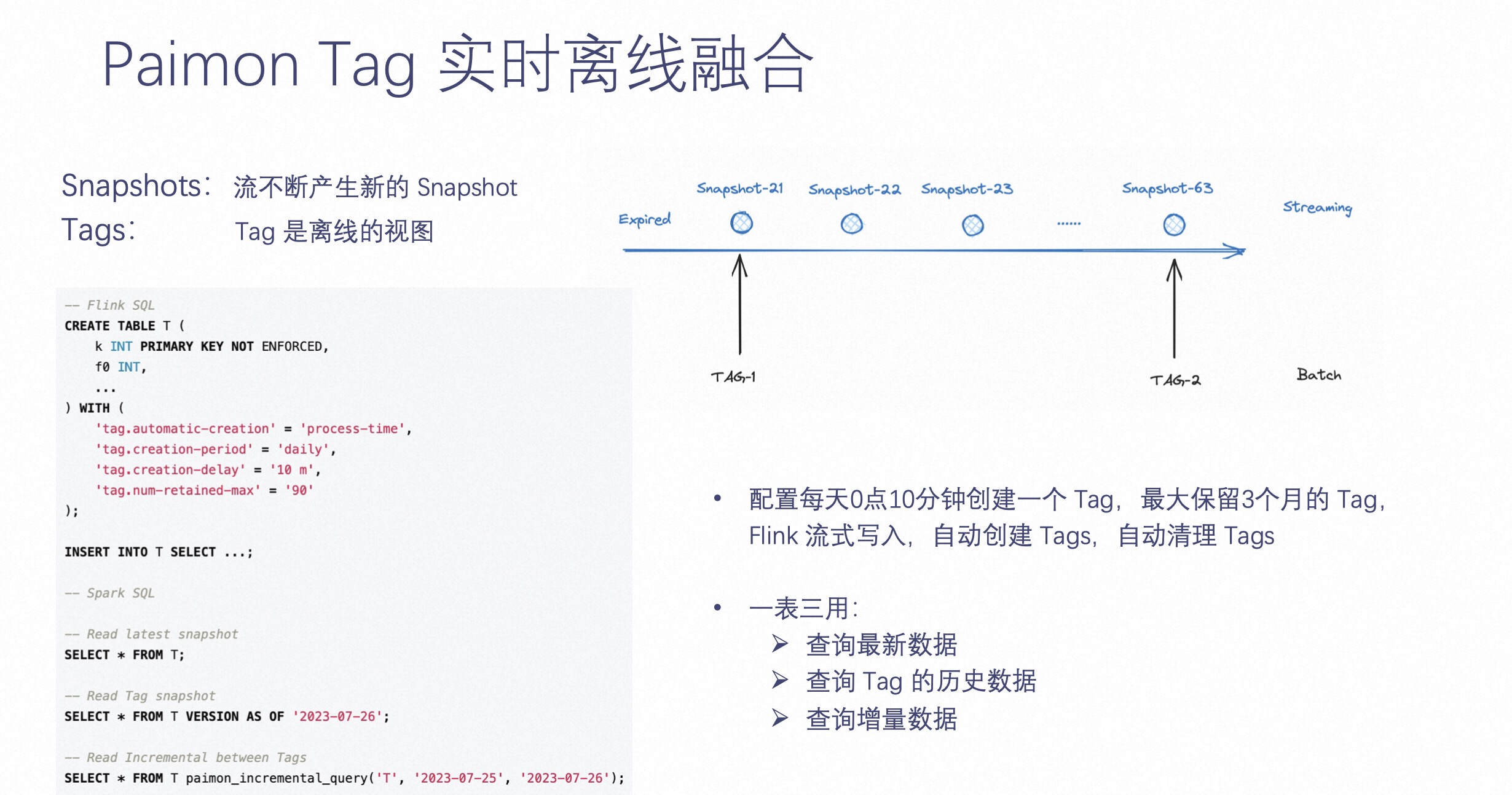
众所周知,离线数仓有个非常重要的东西,就是它需要数据有一个不可变的视图,不然两次计算出的结果就不一样了。所以 Paimon 提供了一个非常重要的功能,即 Create Tag,它可以在 Paimon 中指定一些 Tag,让这些 Tag 永不删除,永远可读。如上图左侧的示意。
第二部分最后一块内容介绍 Paimon LSM 文件存储的复用。

前文提及 Paimon 在这种场景下较之以前的数仓,文件存储会降低数倍甚至降低数十倍或数百倍。为什么它可以达到这样的效果呢?
如上图右侧 LSM 文件示意。LSM 有个特点是,它增量数据来了,不一定需要合并到最底层的数据,也就是说最底层的这些文件,可能两个 Tag 之间完全复用这些文件。因为增量数据不足以让最底层的数据参与合并,这样能达到的效果是两个 Tag 甚至一个月的 Tag,最底层的 LSM 树都没有发生过合并,意味着最底层的文件是全复用的。所以多个 Tag 之间,文件可以完全复用,这样能达到最大的复用效果。
三、Paimon 不止 CDC 入湖
自从 Paimon 进入 Apache 孵化器后,多了非常多的贡献者,这对整个开源社区来讲都是一个飞跃的进展。
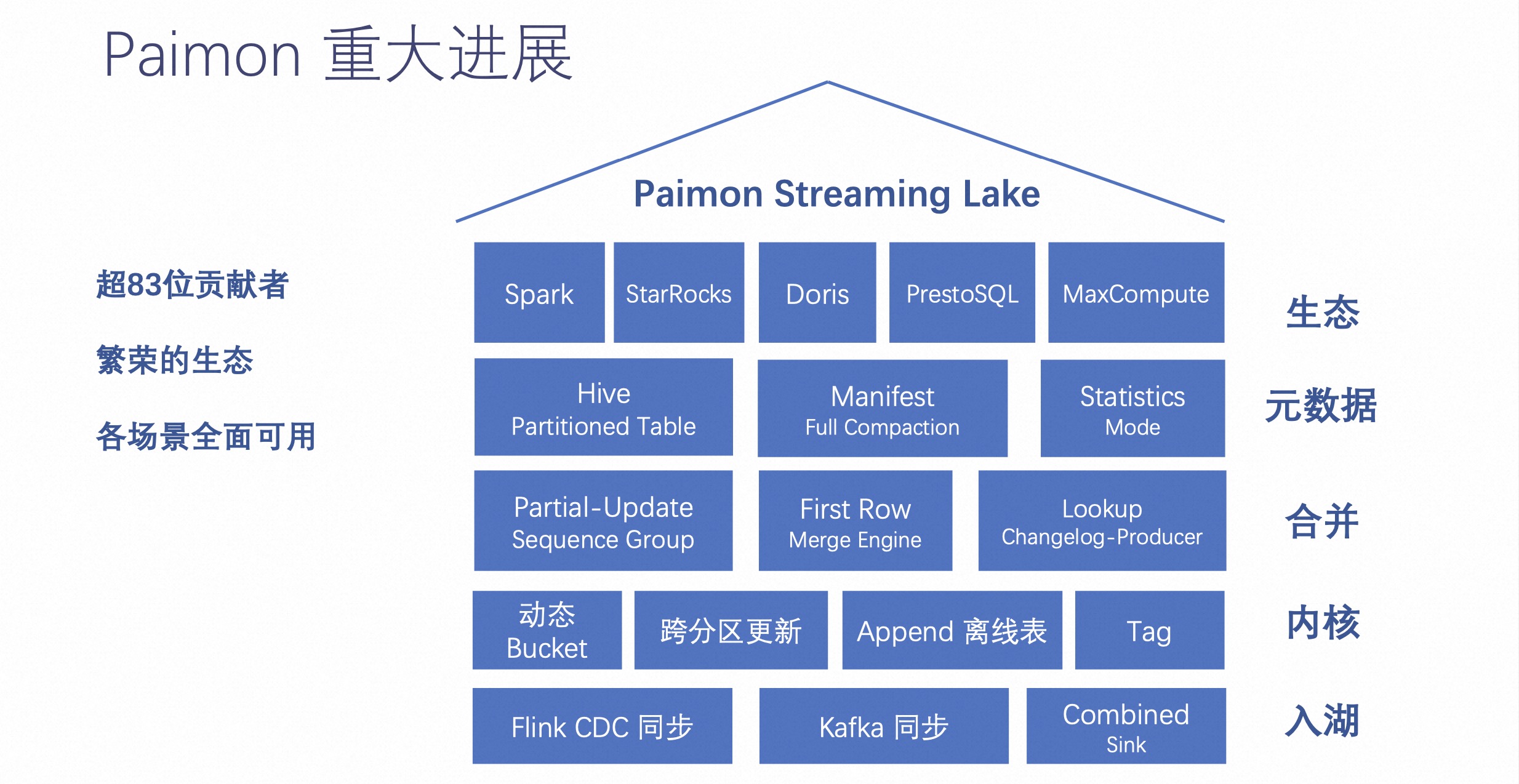
现在 Paimon 有超过 83 位贡献者,形成一个非常繁荣的生态体系,他们不只是来源于阿里巴巴,也有来自其他公司贡献者。通过这些贡献者的贡献,让 Paimon 拥有如上图右侧的全部功能。
Paimon 生态这边取得了比较大的进展。Paimon 之前主要是 Flink、Spark 等,现在还包括 StarsRocks、Doris 和 PrestoSQL 等等。这些都能在它们的计算上查询到 Paimon 的数据。
元数据包含 Hive Partitioned Table,可以通过这个把元数据保存到 HMS 上。用户也可以在 Hive 的 HMS 中查询到 Paimon 有哪些分区。
其他关于合并、内核、入湖等相关内容,可以去官网了解详情: Apache Paimon
接下来分享三个场景。
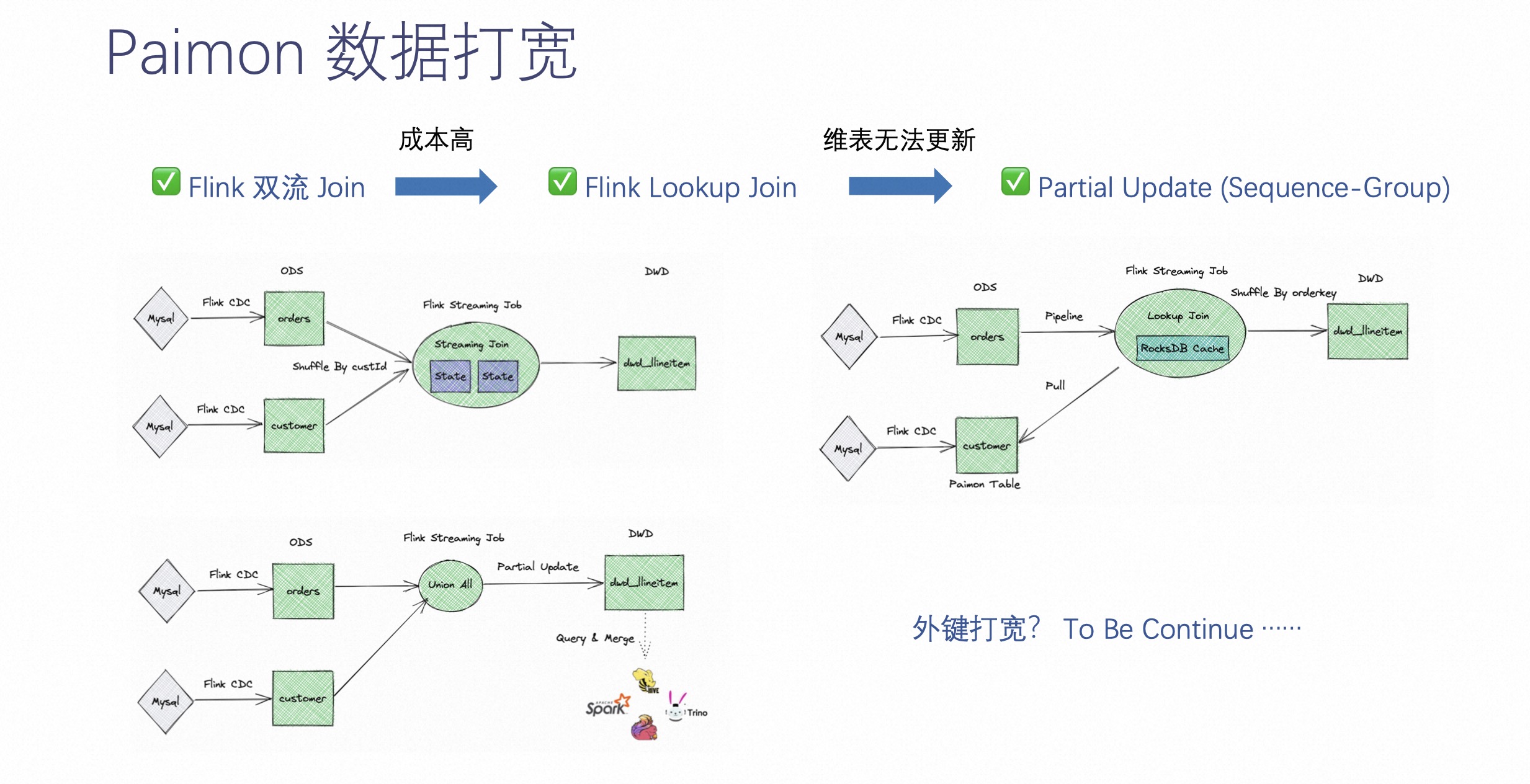
数据打宽在之前的实施中可能用 Flink 双流 join,离线中直接 join。这种方式在实施过程中有个难点就是不适用所有场景,而且成本比较高。
所以 Paimon 这边做了很多工作,包括 Paimon 可以当做 Flink lookup join 的一张表来进行 join,包括 Paimon 的 Partial Update 可以支持同组件的打宽,而且可以定义 sequence-group,让各个字段可以有不同的覆盖方式。
上图中所示意的三种方式简单介绍下。
-
第一种是 Flink 双流 join 的方式,需要维护两边比较大的 state,这也是成本比较高的原因之一。
-
第二种是通过 Flink lookup join 的方式 lookup 到 Paimon 的数据,缺点是维表的更新不能更新到已经 join 的数据上。
-
第三种是通过 Partial Update 的方式,即同组件的打宽的方式。推荐大家使用这种方式,它不仅具有高吞吐,还能带来近实时级别的延迟。
除了以上三种,未来 Paimon 还将争取在外键打宽的能力上投入精力。外键打宽是通过分钟级延时的方式来降低整体实时 join 的打宽成本。
下面介绍两个 Paimon 另外两个能力,即 Paimon 消息队列替代和 Paimon 离线表替代。
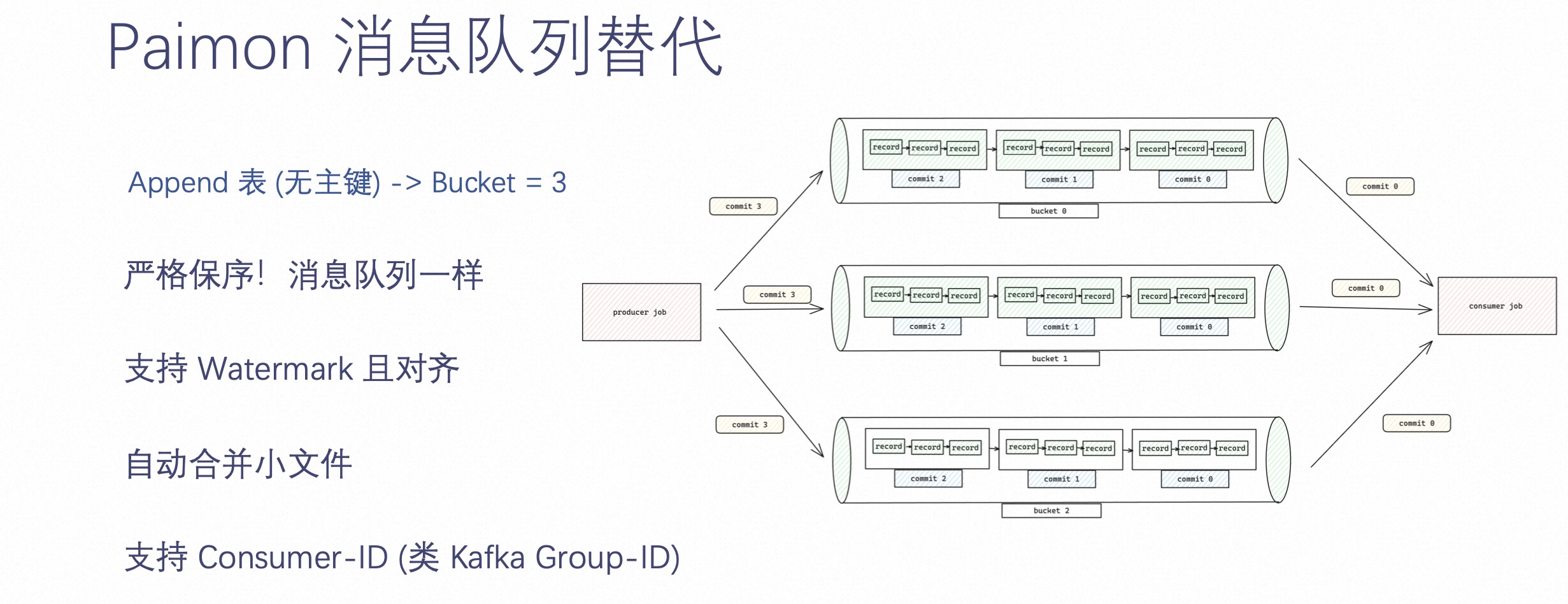
既然 Paimon 面向的是实时,不免有些人就会拿 Paimon 和 Kafka 架构进行对比。Paimon 这边做了很多工作,比如它支持 Append-only 表,即你可以不定义主键,只定义 Bucket number。当定义 Bucket number 的时候,bucket 就类似 Kafka 的 partition 概念,做到了严格保序,跟 Kafka 的消息顺序是一模一样的,而且也支持 Watermark 且对齐。在写入的过程中,能够自动合并小文件,也支持 Consumer ID 消费。
Paimon 在提供消息队列能力的同时,也沉淀了所有的历史数据,而不是像 Kafka 一样只能保存最近几天的数据。
所以通过业务图的方式可以看出,它的整体架构是想通过 Paimon 这种方式让用户在某些实时场景上替换 Kafka。Kafka 真正的能力是提供秒级延时,当业务不需要秒级延时的时候,可以考虑使用 Paimon 来替代消息队列。

Paimon 是一个数据湖,数据湖最常见的应用是离线表。Paimon 也拥有这样的能力。
在 Append 表定义的时候,把 Bucket 表定义为-1,那么 Paimon 就会认为这张表是一张离线表。Paimon 作为一张离线表可以替代原有的 Hive 数仓,比如 Paimon 支持批读批写,支持 INSERT OVERWRITE,也支持流读流写。而且 Paimon 可以自动合并小文件,也支持湖存储特性 ACID、Time Travel、Z-Order 排序加速查询和 Delete、Update 等等。
综上所述,Paimon 基本上能做到大部分离线表的能力。
四、总结与生态

通过前三部分的整体介绍,结论是:Paimon 基本成熟,是 Streaming Lake 的优选。
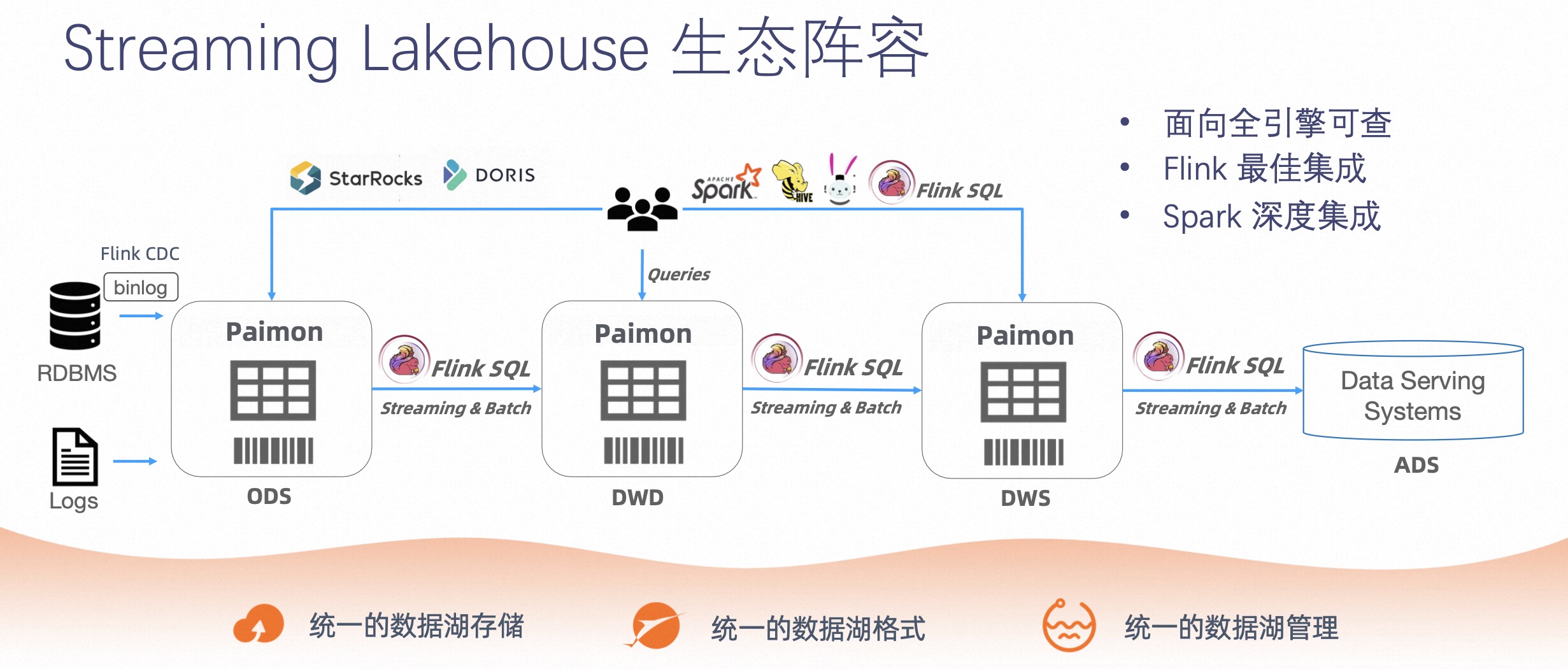
下面介绍下 Streaming Lakehouse 的生态阵容。Streaming Lakehouse 具有以下几个特点:
-
第一,Streaming Lakehouse 具有统一的数据湖存储能力;
-
第二,Streaming Lakehouse 具有统一的数据湖格式;
-
第三,Streaming Lakehouse 具有统一的数据湖管理。
今天 Streaming Lakehouse 拥有非常丰富的生态,它可以通过 Flink CDC,包括数据落到湖中,可以通过 Flink SQL ETL 以 Streaming 的方式,把数据流动起来,也能做到实时数据订正。
在此基础上,Paimon 已经拥有了一个非常好的生态,欢迎大家使用。
最后介绍下阿里云在 Paimon 上的实践。
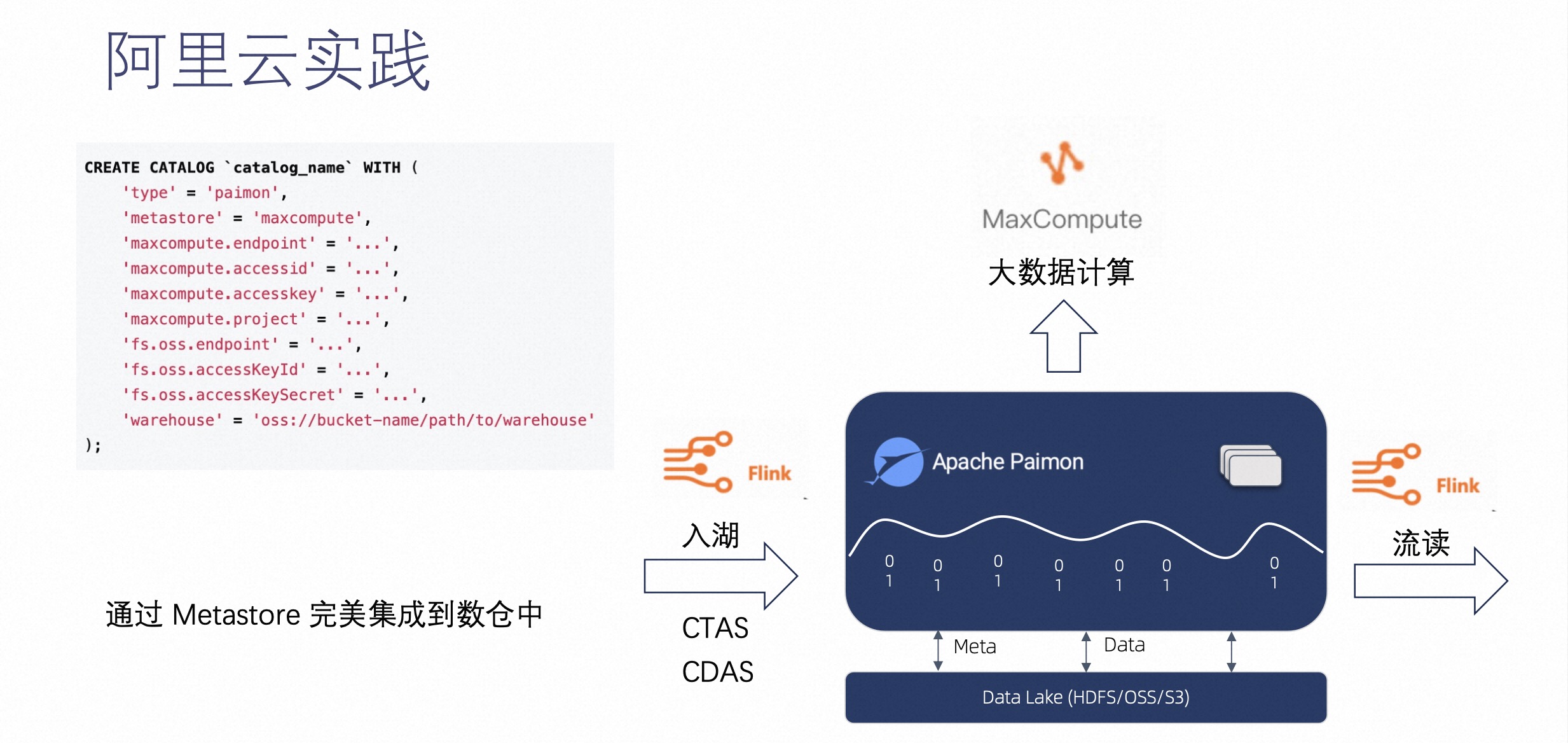
我们将 Paimon 和阿里云的 MaxCompute 产品做了深度集成,如上图右侧可见,这是一个简单的 Flink 的 Create Catalog,用户可以通过 Metastore 完美集成到 MaxCompute 数仓中。
这样指定后,再在 Flink 上创建表,它的元数据就会被同步到 MaxCompute 的元数据中,然后在 MaxCompute 那边就可以直接对这些表进行查询了。这样就可以达到一个 Flink 入湖 MaxCompute 分析这样一个流程。
通过阿里云的实践,我们可以看到 Paimon 的设计是非常灵活且开放的,它可以通过 Metastore 完美集成到阿里云或是其他企业原有的数仓中,集成之后能达到非常好的完整链路的写入和分析的效果。
Q&A
Q:请问 Paimon 是否有 Hudi 的实时旅行一样的功能么?
A:Paimon 本身就支持实时旅行,但是因为 Snapshot 每三分钟就会有一个,一天产生的量很大,也就是说数据的冗余会很大,对于存储成本不友好。所以 Paimon 就提供了 Create Tag 的方式以解决这个问题,Snapshot 可以很快被删掉,你可以创建 Tag 保证 Time Travel 的有效性。
Q:Paimon 一定程度上提供了 Kafka 的能力,提供了很多数据的接入方式,那么如果是文件,有没有特别好的接入方式呢?
A:你的意思是文件不留在 Queue 中,直接流到 Paimon 中。如果是这样的话,目前可以通过 Flink 或是 Spark 的这种批计算调度方式,来把文件同步到 Paimon 中。
Q:Paimon 可以被像 StarRocks 这样的产品查询,那像我们使用阿里云的 ADB,是不是它也可以跟 ADB 有这样的连接,在 ADB 里进行查询?
A:非常好的问题,我认为这是可以的,按时目前还没有和 ADB 集成,后面是可以推进的。
请关注 Paimon
流式数据湖的发展需要你的支持:
- 关注微信公众号:Apache Paimon,了解行业实践与最新动态
- 进入 Paimon 交流钉钉群:搜索 10880001919,讨论技术并得到实时的支持
- Github GitHub - apache/incubator-paimon: Apache Paimon(incubating) is a streaming data lake platform that supports high-speed data ingestion, change data tracking and efficient real-time analytics. 点赞支持
点击查看原文视频 & 演讲PPT
相关文章:
Apache Paimon 实时数据湖 Streaming Lakehouse 的存储底座
摘要:本文整理自阿里云开源大数据表存储团队负责人,阿里巴巴高级技术专家李劲松(之信),在 Streaming Lakehouse Meetup 的分享。内容主要分为四个部分: 流计算邂逅数据湖 Paimon CDC 实时入湖 Paimon 不止…...
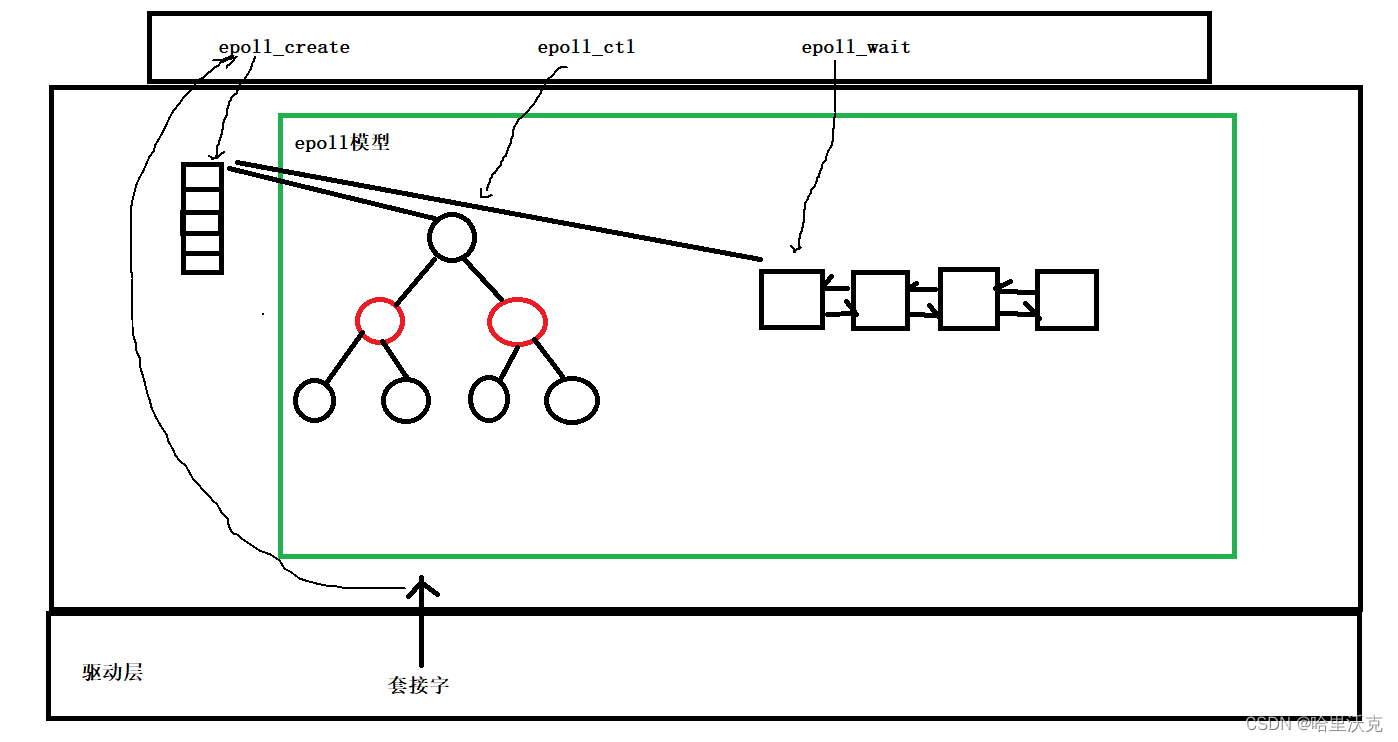
计算机网络(10) --- 高级IO
计算机网络(9) --- 数据链路层与MAC帧_哈里沃克的博客-CSDN博客数据链路层与MAC帧https://blog.csdn.net/m0_63488627/article/details/132178583?spm1001.2014.3001.5501 1.IO介绍 1.IO本质 1.如果数据没有出现,那么读取文件其实会被阻塞住…...

学习中ChatGPT的17种用法
ChatGPT本质上是一个聊天工具,旧金山的人工智能企业OpenAI于2022年11月正式推出ChatGPT。那么,ChatGPT与其他人工智能产品相比有什么特殊呢? 它除了可以回答结构性的问题,例如语法修正、翻译和查找答案之外。最关键的是它能够去解…...
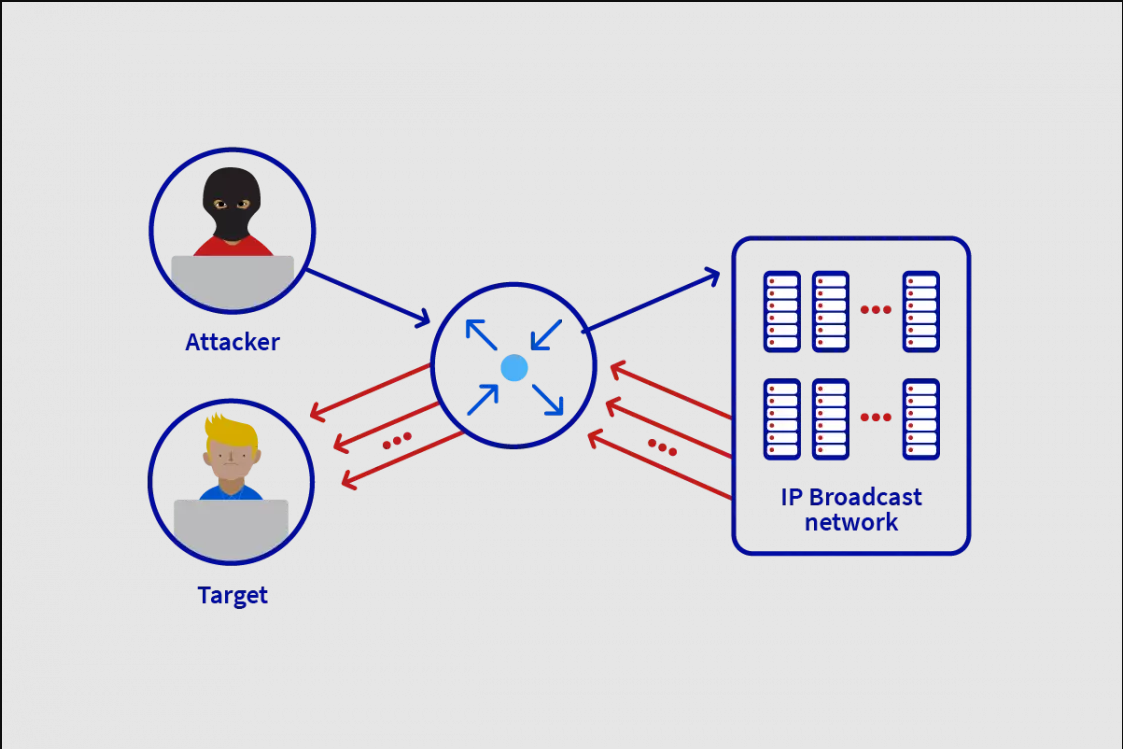
融合CDN 如何有效的抵抗DDoS攻击
绝大部分对外网站所有者都离不开CDN的支持,据统计,全球高达70%的互联网流量都是通过CDN来进行缓存和加速的,不论是国外知名的CDN厂商:如Cloudflare、AWS、Akamai等,还是国内主流的CDN厂商阿里云华为云腾讯云等…...
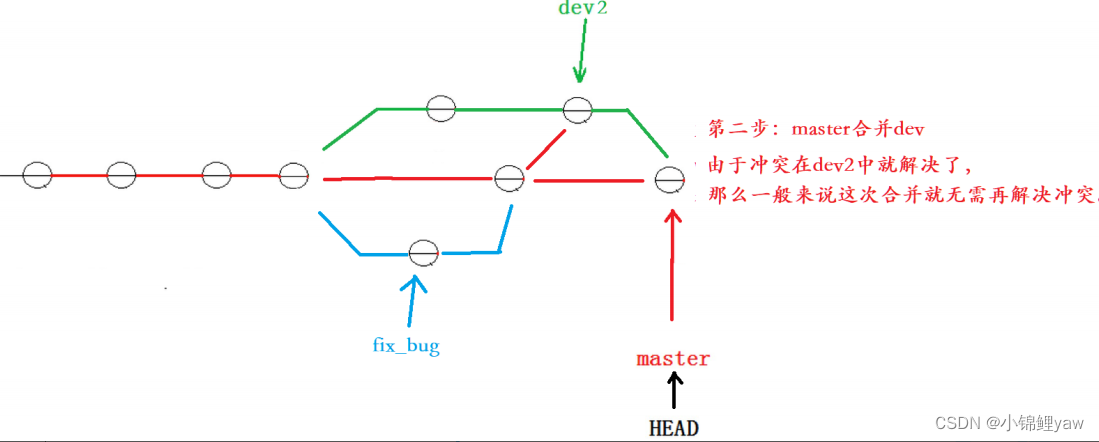
Git 原理与使用
1.版本控制器 所谓的版本控制器,就是能让你了解到⼀个⽂件的历史,以及它的发展过程的系统。通俗的讲就是⼀个可以记录⼯程的每⼀次改动和版本迭代的⼀个管理系统,同时也⽅便多⼈协同作业。 ⽬前最主流的版本控制器就是 Git 。Git 可以控制电脑…...

如何批量加密PDF文件并设置不同密码 - 批量PDF加密工具使用教程
如果你正在寻找一种方法来批量加密和保护你的PDF文件,批量PDF加密工具是一个不错的选择。 它是一个体积小巧但功能强大的Windows工具软件,能够批量给多个PDF文件加密和限制,包括设置打印限制、禁止文字复制,并增加独立的打开密码。…...

【Unity 工程化】unity一些资源路径用途
Resources Resources 目录用于存放可以通过 Unity 的 Resources.Load 函数进行加载的资源。这些资源会在构建时被打包为一个单独的资源包,因此它们必须满足一些 Unity 所要求的命名和文件夹结构规则。由于这些资源被打包在一起,因此在构建后的游戏中可以…...

使用Docker进行模型部署
一、常见的模型部署场景 实时的、小数据量的预测应用 部署方式:采用python-httpserve应用部署(如flask, fastApi, django),缺点是可能需要跨环境,从Java跨到Python环境实时的、大数据量的预测应用 部署方式࿱…...

第59步 深度学习图像识别:误判病例分析(TensorFlow)
基于WIN10的64位系统演示 一、写在前面 本期内容对等于机器学习二分类系列的误判病例分析(传送门)。既然前面的数据可以这么分析,那么图形识别自然也可以。 本期以mobilenet_v2模型为例,因为它建模速度快。 同样,基…...
【Vue框架】基本的login登录
前言 最近事情比较多,只能抽时间看了,放几天就把之前弄的都忘了,现在只挑着核心的部分看。现在铺垫了这么久,终于可以看前端最基本的登录了😂。 1、views\login\index.vue 由于代码比较长,这里将vue和js…...
)
Python21天打卡Day16-内置方法map()
在 Python 中,map() 方法是一个内置的函数,用于将函数应用于可迭代对象(如列表、元组等)中的每个元素,返回一个包含结果的迭代器。 map() 方法的语法如下: map(function, iterable)function:表…...
伦敦银和伦敦金的区别
伦敦银河伦敦金并称贵金属交易市场的双璧,一般投资贵金属的投资者其实不是交易伦敦金就是交易伦敦银。相信经过一段时间的学习和投资,不少投资者都能分辨二者的区别。下面我们就来谈谈伦敦银和伦敦金有什么异同,他们在投资上是否有差别。 交易…...

【从零学习python 】92.使用Python的requests库发送HTTP请求和处理响应
文章目录 URL参数传递方式一:使用字典传递参数URL参数传递方式二:直接在URL中拼接参数获取响应头信息获取响应体数据a. 获取二进制数据b. 获取字符数据c. 获取JSON数据 进阶案例 URL参数传递方式一:使用字典传递参数 url https://www.apiop…...

Python requests实现图片上传接口自动化测试
最近帮别人写个小需求,需要本地自动化截图,然后图片自动化上传到又拍云,实现自动截图非常简单,在这里就不详细介绍了,主要和大家写下,如何通过Pythonrequests实现上传本地图片到又拍云服务器。 话不多说&a…...

【LeetCode-面试经典150题-day13】
目录 141.环形链表 2.两数相加 21.合并两个有序链表 138.复制带随机指针的链表 92.反转链表Ⅱ 141.环形链表 题意: 给你一个链表的头节点 head ,判断链表中是否有环。 如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,…...

taro.js和nutui实现商品选择页面
1. 首先安装 Taro.js 和 NutUI: npm install -g tarojs/cli npm install taro-ui 2. 创建 Taro 项目并进入项目目录: taro init myapp cd myapp 3. 选用 Taro 模板一并安装依赖: npm install 4. 在页面目录中创建商品选择页: taro cre…...

数据结构--算法的时间复杂度和空间复杂度
文章目录 算法效率时间复杂度时间复杂度的概念大O的渐进表示法计算实例 时间复杂度实例 常见复杂度对比例题 算法效率 算法效率是指算法在计算机上运行时所消耗的时间和资源。这是衡量算法执行速度和资源利用情况的重要指标。 例子: long long Fib(int N) {if(N …...
Vue中使用element-plus中的el-dialog定义弹窗-内部样式修改-v-model实现-demo
效果图 实现代码 <template><el-dialog class"no-code-dialog" v-model"isShow" title"没有收到验证码?"><div class"nocode-body"><div class"tips">请尝试一下操作</div><d…...
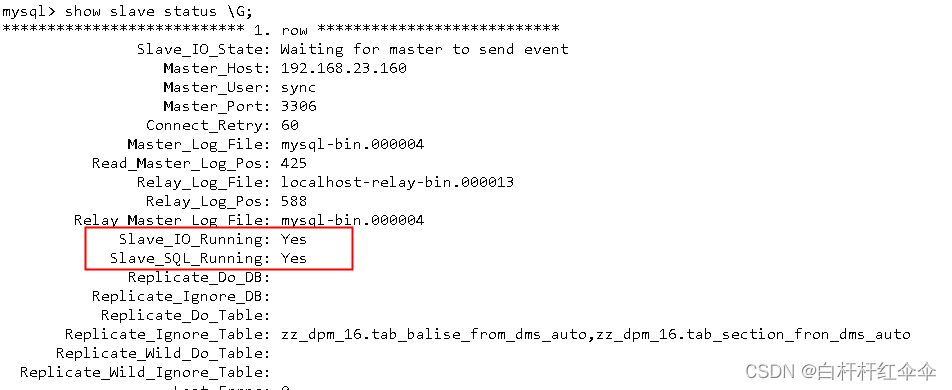
MySQL 主从配置
环境 centos6.7 虚拟机两台 主:192.168.23.160 从:192.168.23.163 准备 在两台机器上分别安装mysql5.6.23,安装完成后利用临时密码登录mysql数据修改root的密码;将my.cnf配置文件放至/etc/my.cnf,重启mysql服务进…...

上海亚商投顾:创业板指反弹大涨1.26% 核污染概念股午后全线走强
上海亚商投顾前言:无惧大盘涨跌,解密龙虎榜资金,跟踪一线游资和机构资金动向,识别短期热点和强势个股。 市场情绪 三大指数今日集体反弹,沪指午后冲高回落,创业板指盘中涨超2%,尾盘涨幅也有所收…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...
)
【位运算】消失的两个数字(hard)
消失的两个数字(hard) 题⽬描述:解法(位运算):Java 算法代码:更简便代码 题⽬链接:⾯试题 17.19. 消失的两个数字 题⽬描述: 给定⼀个数组,包含从 1 到 N 所有…...

蓝牙 BLE 扫描面试题大全(2):进阶面试题与实战演练
前文覆盖了 BLE 扫描的基础概念与经典问题蓝牙 BLE 扫描面试题大全(1):从基础到实战的深度解析-CSDN博客,但实际面试中,企业更关注候选人对复杂场景的应对能力(如多设备并发扫描、低功耗与高发现率的平衡)和前沿技术的…...

Python实现prophet 理论及参数优化
文章目录 Prophet理论及模型参数介绍Python代码完整实现prophet 添加外部数据进行模型优化 之前初步学习prophet的时候,写过一篇简单实现,后期随着对该模型的深入研究,本次记录涉及到prophet 的公式以及参数调优,从公式可以更直观…...

Frozen-Flask :将 Flask 应用“冻结”为静态文件
Frozen-Flask 是一个用于将 Flask 应用“冻结”为静态文件的 Python 扩展。它的核心用途是:将一个 Flask Web 应用生成成纯静态 HTML 文件,从而可以部署到静态网站托管服务上,如 GitHub Pages、Netlify 或任何支持静态文件的网站服务器。 &am…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

2025 后端自学UNIAPP【项目实战:旅游项目】6、我的收藏页面
代码框架视图 1、先添加一个获取收藏景点的列表请求 【在文件my_api.js文件中添加】 // 引入公共的请求封装 import http from ./my_http.js// 登录接口(适配服务端返回 Token) export const login async (code, avatar) > {const res await http…...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...