第八章 Flink集成Iceberg的DataStreamAPI、TableSQLAPI详解

1、概述
目前Flink支持使用DataStream API 和SQL API方式实时读取和写入I=ceberg表,建议使用SQL API方式实时读取和写入Iceberg表。
- Iceberg支持的Flink版本为1.11.x版本以上,以下为版本匹配关系:
| Flink版本 | Iceberg版本 | 备注 |
|---|---|---|
| Flink1.11.X | Iceberg0.11.1 | |
| Flink1.12.x ~ Flink1.13.x | Iceberg0.12.1 | SQL API有Bug |
| Flink1.14.x | Iceberg0.12.1 | SQL API有Bug |
本次学习以Flink和Iceberg整合使用Flink版本为1.14.5,Iceberg版本为0.12.1版本。
2、DataStream API
2.1、实时写入Iceberg表
2.1.1、导入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>flinkiceberg1</artifactId><version>1.0-SNAPSHOT</version><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target><!-- flink 1.12.x -1.13.x 版本与Iceberg 0.12.1 版本兼容 ,不能与Flink 1.14 兼容--><flink.version>1.13.5</flink.version><!--<flink.version>1.12.1</flink.version>--><!--<flink.version>1.14.2</flink.version>--><!-- flink 1.11.x 与Iceberg 0.11.1 合适--><!--<flink.version>1.11.6</flink.version>--><hadoop.version>3.1.1</hadoop.version></properties><dependencies><dependency><groupId>com.alibaba.ververica</groupId><artifactId>ververica-connector-iceberg</artifactId><version>1.13-vvr-4.0.7</version><exclusions><exclusion><groupId>com.google.guava</groupId><artifactId>guava-parent</artifactId></exclusion></exclusions></dependency><!-- Flink 操作Iceberg 需要的Iceberg依赖 --><dependency><groupId>org.apache.iceberg</groupId><artifactId>iceberg-flink-runtime</artifactId><version>0.12.1</version><!--<version>0.11.1</version>--></dependency><!-- java开发Flink所需依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-java_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-clients_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-streaming-scala_2.11</artifactId><version>${flink.version}</version></dependency><!-- Flink Kafka连接器的依赖 --><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-kafka_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-connector-base</artifactId><version>${flink.version}</version></dependency><!-- 读取hdfs文件需要jar包--><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>${hadoop.version}</version><exclusions><exclusion><artifactId>guava</artifactId><groupId>com.google.guava</groupId></exclusion></exclusions></dependency><!-- Flink SQL & Table--><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-runtime-blink_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-common</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-api-java-bridge_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>org.apache.flink</groupId><artifactId>flink-table-planner-blink_2.11</artifactId><version>${flink.version}</version></dependency><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.11</version><scope>test</scope></dependency><!-- log4j 和slf4j 包,如果在控制台不想看到日志,可以将下面的包注释掉--><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>1.7.25</version><scope>test</scope></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>1.7.25</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-nop</artifactId><version>1.7.25</version><scope>test</scope></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-simple</artifactId><version>1.7.5</version></dependency></dependencies></project>
2.1.2、创建Iceberg表
- 核心:通过Flink创建Iceberg表
-- 1、创建catalogCREATE CATALOG hadoop_catalog WITH (
> 'type'='iceberg',
> 'catalog-type'='hadoop',
> 'warehouse'='hdfs://leidi01:8020/iceberg_catalog',
> 'property-version'='1'
> );-- 2、创建databases
create database flink_iceberg;-- 3、创建Sink表
CREATE TABLE hadoop_catalog.flink_iceberg.icebergdemo1 (id STRING,data STRING
);
- 运行结果

2.1.3、代码实现
public class FlinkIcebergDemo1 {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//1.必须设置checkpoint ,Flink向Iceberg中写入数据时当checkpoint发生后,才会commit数据。env.enableCheckpointing(5000);//2.读取Kafka 中的topic 数据KafkaSource<String> source = KafkaSource.<String>builder().setBootstrapServers("192.168.6.102:6667").setTopics("json").setGroupId("my-group-id").setStartingOffsets(OffsetsInitializer.latest()).setValueOnlyDeserializer(new SimpleStringSchema()).build();DataStreamSource<String> kafkaSource = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");//3.对数据进行处理,包装成RowData 对象,方便保存到Iceberg表中。SingleOutputStreamOperator<RowData> dataStream = kafkaSource.map(new MapFunction<String, RowData>() {@Overridepublic RowData map(String s) throws Exception {System.out.println("s = "+s);String[] split = s.split(",");GenericRowData row = new GenericRowData(4);row.setField(0, Integer.valueOf(split[0]));row.setField(1, StringData.fromString(split[1]));row.setField(2, Integer.valueOf(split[2]));row.setField(3, StringData.fromString(split[3]));return row;}});//4.创建Hadoop配置、Catalog配置和表的Schema,方便后续向路径写数据时可以找到对应的表Configuration hadoopConf = new Configuration();Catalog catalog = new HadoopCatalog(hadoopConf,"hdfs://leidi01:8020/flinkiceberg/");//配置iceberg 库名和表名TableIdentifier name =TableIdentifier.of("icebergdb", "flink_iceberg_tbl");//创建Icebeng表SchemaSchema schema = new Schema(Types.NestedField.required(1, "id", Types.IntegerType.get()),Types.NestedField.required(2, "nane", Types.StringType.get()),Types.NestedField.required(3, "age", Types.IntegerType.get()),Types.NestedField.required(4, "loc", Types.StringType.get()));//如果有分区指定对应分区,这里“loc”列为分区列,可以指定unpartitioned 方法不设置表分区
// PartitionSpec spec = PartitionSpec.unpartitioned();PartitionSpec spec = PartitionSpec.builderFor(schema).identity("loc").build();//指定Iceberg表数据格式化为Parquet存储Map<String, String> props =ImmutableMap.of(TableProperties.DEFAULT_FILE_FORMAT, FileFormat.PARQUET.name());Table table = null;// 通过catalog判断表是否存在,不存在就创建,存在就加载if (!catalog.tableExists(name)) {table = catalog.createTable(name, schema, spec, props);}else {table = catalog.loadTable(name);}TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://leidi01:8020/flinkiceberg//icebergdb/flink_iceberg_tbl", hadoopConf);//5.通过DataStream Api 向Iceberg中写入数据FlinkSink.forRowData(dataStream)//这个 .table 也可以不写,指定tableLoader 对应的路径就可以。.table(table).tableLoader(tableLoader)//默认为false,追加数据。如果设置为true 就是覆盖数据.overwrite(false).build();env.execute("DataStream Api Write Data To Iceberg");}
}
- 注意事项:
(1)需要设置Checkpoint,Flink向Iceberg中写入Commit数据时,只有Checkpoint成功之后才会Commit数据,否则后期在Hive中查询不到数据。
(2)读取Kafka数据后需要包装成RowData或者Row对象,才能向Iceberg表中写出数据。写出数据时默认是追加数据,如果指定overwrite就是全部覆盖数据。
(3)在向Iceberg表中写数据之前需要创建对应的Catalog、表Schema,否则写出时只指定对应的路径会报错找不到对应的Iceberg表。
(4)不建议使用DataStream API 向Iceberg中写数据,建议使用SQL API。
2.1.4、Kafka消费者启动
bin/kafka-console-producer.sh --topic json --broker-list leidi01:6667bin/kafka-console-consumer.sh --bootstrap-server leidi01:6667 --topic json --from-beginning
- 生产数据

- 运行结果:
data中有两个分区

2.1.5、查询表结果
- 说明:
在Flink SQL中创建Hadoop Catalog。
-- 1、创建Hadoop Catalog
CREATE CATALOG flinkiceberg WITH ('type'='iceberg','catalog-type'='hadoop','warehouse'='hdfs://leidi01:8020/flinkiceberg/','property-version'='1'
);-- 2、查询表中数据
use catalog flinkiceberg;
use icebergdb;
select * from flink_iceberg_tbl;
- 运行结果

2.2、批量/实时读取Iceberg表
- 核心:DataStream API 读取Iceberg表又分为批量读取和实时读取,通过方法“streaming(true/false)”来控制。
2.2.1、批量读取
- 说明:设置方法“streaming(false)”
- 代码实现
public class FlinkIcebergRead {public static void main(String[] args) throws Exception {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();//1.配置TableLoaderConfiguration hadoopConf = new Configuration();TableLoader tableLoader = TableLoader.fromHadoopTable("hdfs://leidi01:8020/flinkiceberg//icebergdb/flink_iceberg_tbl", hadoopConf);//2.从Iceberg中读取全量/增量读取数据DataStream<RowData> batchData = FlinkSource.forRowData().env(env).tableLoader(tableLoader)//默认为false,整批次读取,设置为true 为流式读取.streaming(false).build();batchData.map(new MapFunction<RowData, String>() {@Overridepublic String map(RowData rowData) throws Exception {int id = rowData.getInt(0);String name = rowData.getString(1).toString();int age = rowData.getInt(2);String loc = rowData.getString(3).toString();return id+","+name+","+age+","+loc;}}).print();env.execute("DataStream Api Read Data From Iceberg");}
}
- 运行结果
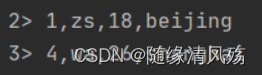
2.2.2、实时读取
-
说明:设置方法“streaming(true)”
-
代码实现
DataStream<RowData> batchData = FlinkSource.forRowData().env(env).tableLoader(tableLoader)//默认为false,整批次读取,设置为true 为流式读取.streaming(true).build();
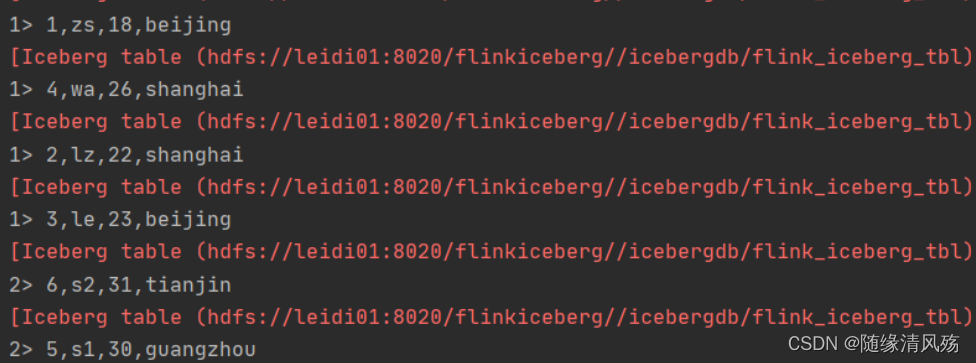
- Flink SQL插入数据
insert into flink_iceberg_tbl values (5,'s1',30,'guangzhou'),(6,'s2',31,'tianjin');
- 运行结果
2.2.3、指定基于快照实时增量读取数据
- 核心:设置方法StartSnapshotId(快照编号)
(1)查看快照编号
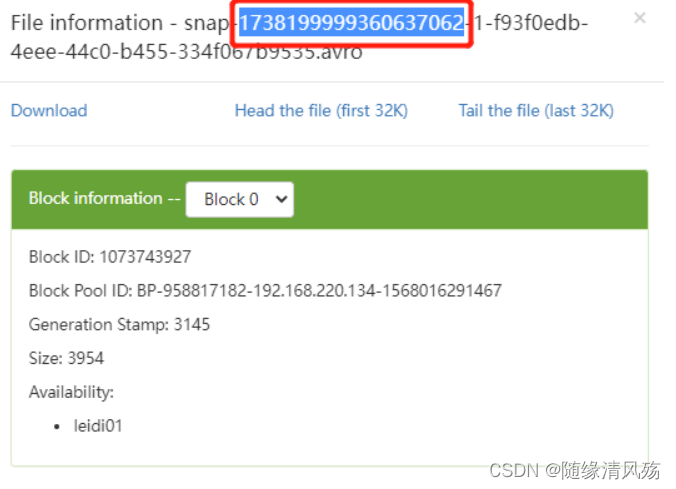
(2)代码实现
//2.从Iceberg中读取全量/增量读取数据
DataStream<RowData> batchData = FlinkSource.forRowData().env(env).tableLoader(tableLoader)//基于某个快照实时增量读取数据,快照需要从元数据中获取.startSnapshotId(1738199999360637062L)//默认为false,整批次读取; 设置为true为流式读取.streaming(true).build();
(3)运行结果
- 说明:*只读取到指定快照往后的数据*

2.2.4、合并Data Flies
- 说明:Iceberg提供Api通过定期提交任务将小文件合并成大文件,可以通过Flink 批任务来执行。
(1)未处理文件
- 说明:Iceberg每提交一次数据都会产生一个Data File。
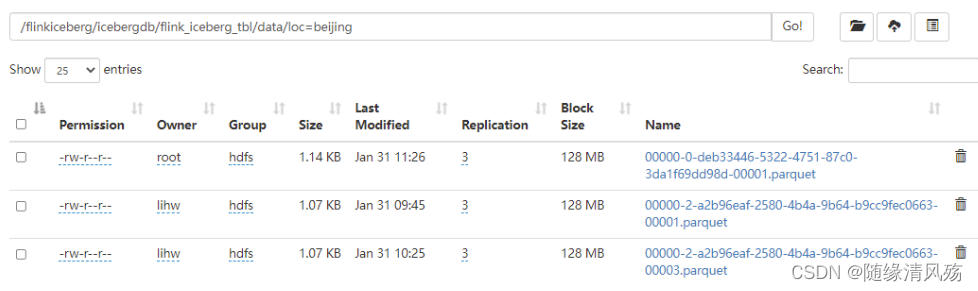
(2)代码实现
public class RewrietDataFiles {public static void main(String[] args) {ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();// 1、配置TableLoaderConfiguration hadoopConf = new Configuration();//2.创建Hadoop配置、Catalog配置和表的Schema,方便后续向路径写数据时可以找到对应的表Catalog catalog = new HadoopCatalog(hadoopConf,"hdfs://leidi01:8020/flinkiceberg/");//3.配置iceberg 库名和表名并加载表TableIdentifier name = TableIdentifier.of("icebergdb", "flink_iceberg_tbl");Table table = catalog.loadTable(name);//4..合并 data files 小文件RewriteDataFilesActionResult result = Actions.forTable(table).rewriteDataFiles()//默认 512M ,可以手动通过以下指定合并文件大小,与Spark中一样。.targetSizeInBytes(536870912L).execute();}
}
(3)运行结果
3、SQL API
3.1、创建表并插入数据
(1)代码实现
public class SQLAPIWriteIceberg {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tblEnv = StreamTableEnvironment.create(env);env.enableCheckpointing(1000);//1.创建CatalogtblEnv.executeSql("CREATE CATALOG hadoop_iceberg WITH (" +"'type'='iceberg'," +"'catalog-type'='hadoop'," +"'warehouse'='hdfs://leidi01:8020/flinkiceberg')");//2.使用当前CatalogtblEnv.useCatalog("hadoop_iceberg");//3.创建数据库tblEnv.executeSql("create database iceberg_db");//4.使用数据库tblEnv.useDatabase("iceberg_db");//5.创建iceberg表 flink_iceberg_tbltblEnv.executeSql("create table hadoop_iceberg.iceberg_db.flink_iceberg_tbl2(id int,name string,age int,loc string) partitioned by (loc)");//6.写入数据到表 flink_iceberg_tbltblEnv.executeSql("insert into hadoop_iceberg.iceberg_db.flink_iceberg_tbl2 values (1,'zs',18,'beijing'),(2,'ls',19,'shanghai'),(3,'ww',20,'guangzhou')");}
}
(2)运行结果
- 说明:通过HDFS查看文件是否生成。
(3)查看数据
- 说明:通过FlinkSQL查看表中数据
-- 1、创建CatalogCREATE CATALOG flinkiceberg WITH (
> 'type'='iceberg',
> 'catalog-type'='hadoop',
> 'warehouse'='hdfs://leidi01:8020/flinkiceberg/',
> 'property-version'='1'
> );-- 2、查询数据
use catalog flinkiceberg
use iceberg_db;
select * from flink_iceberg_tbl2;
- 查看结果

3.2、批量查询表数据
- 说明:SQL API批量查询表中数据,直接查询显示即可
(1)代码逻辑

(2)代码实现
public class SQLAPIReadIceberg {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tblEnv = StreamTableEnvironment.create(env);env.enableCheckpointing(1000);//1.创建CatalogtblEnv.executeSql("CREATE CATALOG hadoop_iceberg WITH (" +"'type'='iceberg'," +"'catalog-type'='hadoop'," +"'warehouse'='hdfs://leidi01:8020/flinkiceberg')");
//2.批量读取表数据TableResult tableResult = tblEnv.executeSql("select * from hadoop_iceberg.iceberg_db.flink_iceberg_tbl2 ");tableResult.print();}
}
- 运行结果

3.3、实时查询表数据
- 说明:link SQL API 实时查询Iceberg表数据时需要设置参数**“table.dynamic-table-options.enabled”为true**,以支持SQL语法中的“OPTIONS”选项
(1)代码逻辑

(2)代码实现
public class SQLStreamReadIceberg {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tblEnv = StreamTableEnvironment.create(env);env.enableCheckpointing(1000);Configuration configuration = tblEnv.getConfig().getConfiguration();// 支持SQL语法中的 OPTIONS 选项configuration.setBoolean("table.dynamic-table-options.enabled", true);//1.创建CatalogtblEnv.executeSql("CREATE CATALOG hadoop_iceberg WITH (" +"'type'='iceberg'," +"'catalog-type'='hadoop'," +"'warehouse'='hdfs://leidi01:8020/flinkiceberg')");//2.从Iceberg表当前快照读取所有数据,并继续增量读取数据// streaming指定为true支持实时读取数据,monitor_interval 监控数据的间隔,默认1sTableResult tableResult = tblEnv.executeSql("select * from hadoop_iceberg.iceberg_db.flink_iceberg_tbl2 /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s')*/");tableResult.print();}
}
- 运行结果:

(3)测试验证
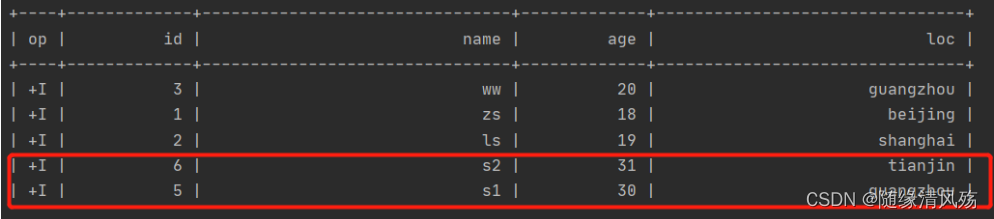
- FlinkSQL插入数据
insert into flink_iceberg_tbl2 values (5,'s1',30,'guangzhou'),(6,'s2',31,'tianjin');
- 运行结果:在IDEA的控制台可以看到新增数据
3.4、基于快照实时增量读取数据
- 说明:基于某个snapshot-id来继续实时获取数据
(1)代码逻辑

(2)代码实现
- FlinkSQL插入数据
insert into flink_iceberg_tbl2 values (7,'s11',30,'beijing'),(8,'s22',31,'beijing');
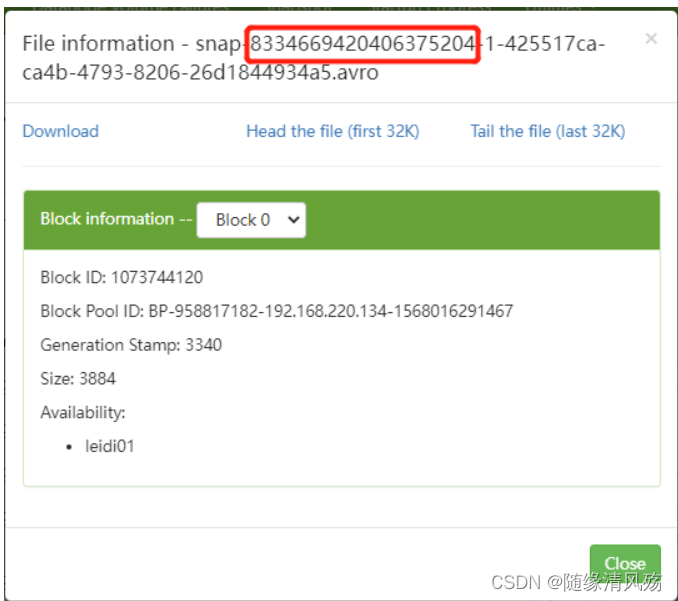
- snapshot-id如下:
- 代码实现
public class SQLSnapshotReadIceberg {public static void main(String[] args) {StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();StreamTableEnvironment tblEnv = StreamTableEnvironment.create(env);env.enableCheckpointing(1000);Configuration configuration = tblEnv.getConfig().getConfiguration();// 支持SQL语法中的 OPTIONS 选项configuration.setBoolean("table.dynamic-table-options.enabled", true);//1.创建CatalogtblEnv.executeSql("CREATE CATALOG hadoop_iceberg WITH (" +"'type'='iceberg'," +"'catalog-type'='hadoop'," +"'warehouse'='hdfs://leidi01:8020/flinkiceberg')");//2.从Iceberg 指定的快照继续实时读取数据,快照ID从对应的元数据中获取//start-snapshot-id :快照IDTableResult tableResult2 = tblEnv.executeSql("SELECT * FROM hadoop_iceberg.iceberg_db.flink_iceberg_tbl2 /*+ OPTIONS('streaming'='true', 'monitor-interval'='1s', 'start-snapshot-id'='8334669420406375204')*/");tableResult2.print();}
}(3)运行结果

4、常见报错
4.1、window远程连接hadoop环境变量找不到
- 报错日志
HADOOP_HOME and hadoop.home.dir are unset.
- 报错原因:本地远程连接Hadoop系统时需要在本地配置相关的Hadoop变量,主要包括hadoop.dll 与 winutils.exe 等。
winutils:由于hadoop主要基于linux编写,**winutil.exe主要用于模拟linux下的目录环境**。当Hadoop在windows下运行或调用远程Hadoop集群的时候,需要该辅助程序才能运行。winutils是Windows中的二进制文件,适用于不同版本的Hadoop系统并构建在Windows VM上,该VM用以在Windows系统中测试Hadoop相关的应用程序。
- 解决方案:
(1)下载hadoop集群对应winutils版本
- 注意事项:如果你安装的hadoop版本是:3.1.2或者3.2.0 就用winutils-master里面的hadoop-3.0.0配置环境变量吧!
https://github.com/steveloughran/winutils
(2)将环境变量%HADOOP_HOME%设置为指向包含WINUTILS.EXE的BIN目录上方的目录
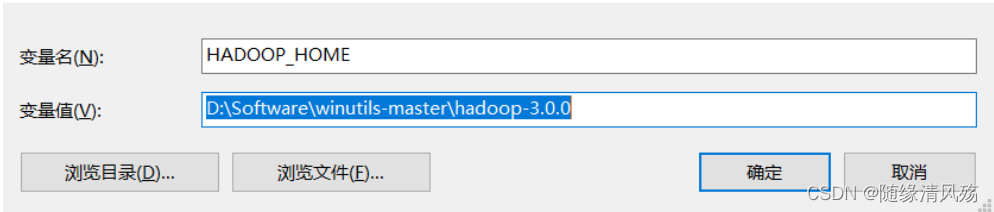
4.2、guava包版本冲突
- 报错日志
com.google.common.base.Preconditions.checkArgument(ZLjava/lang/String;Ljava/lang/Object;)V
- 报错原因:
guava包版本冲突 - 解决方案:使用Maven Helper插件解决冲突
①第一步:在pom界面点击Dependency Analyzer
②第二步:查看Dependency Analyzer功能界面
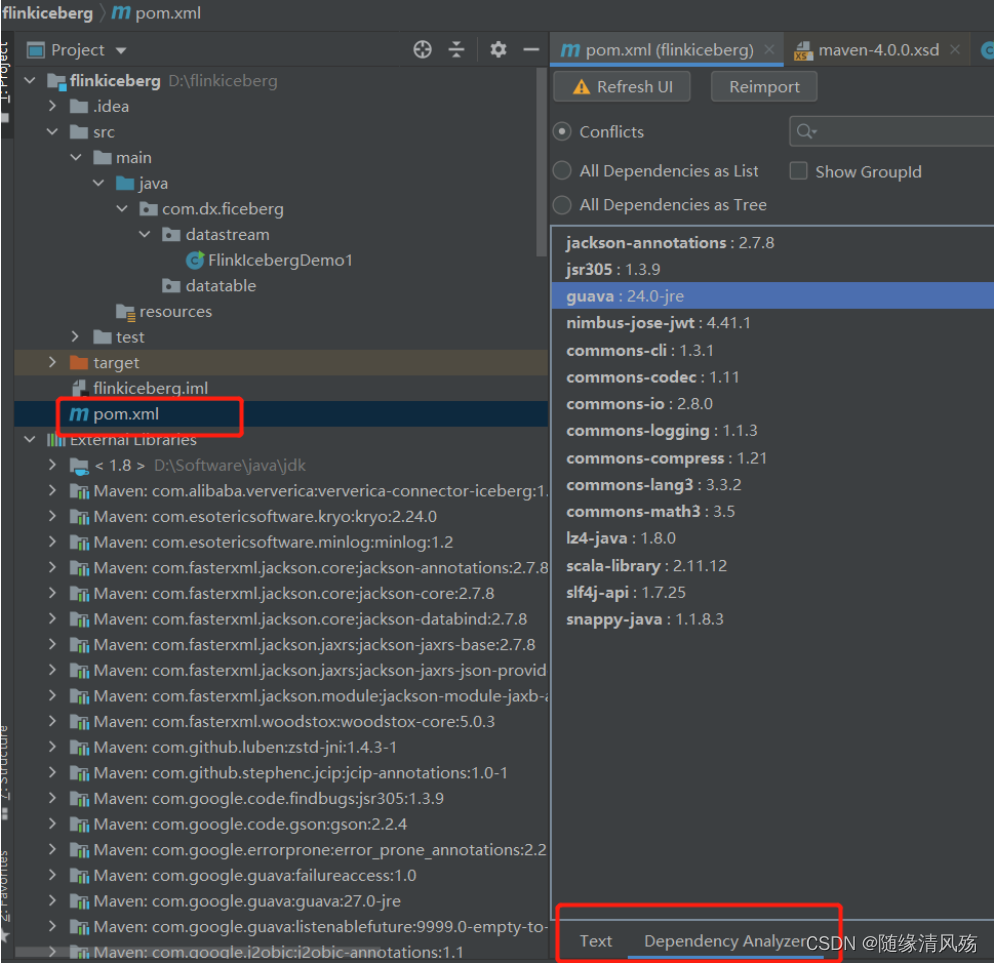
Ⅰ、显示冲突的jar包
Ⅱ、以列表形式显示所有依赖
Ⅲ、以数的形式显示所有依赖
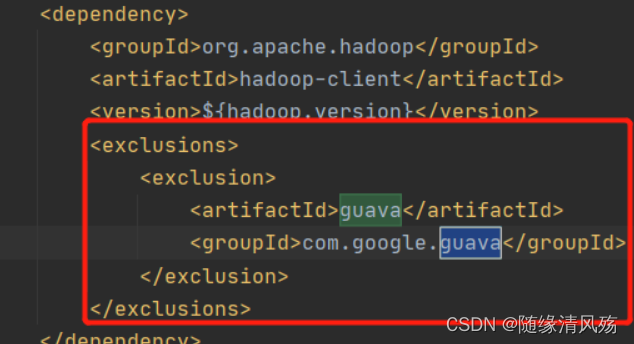
③第三步:逐个解决conflicts列表中的jar包冲突问题,以guava为例:
点击guava,找到右侧部分红色字体,即依赖冲突的地方,下图显示当前guava版本是24.0,但是有两个依赖的guava版本分别是27.0.0.1和16.0.1。
④将低版本依赖都排除掉
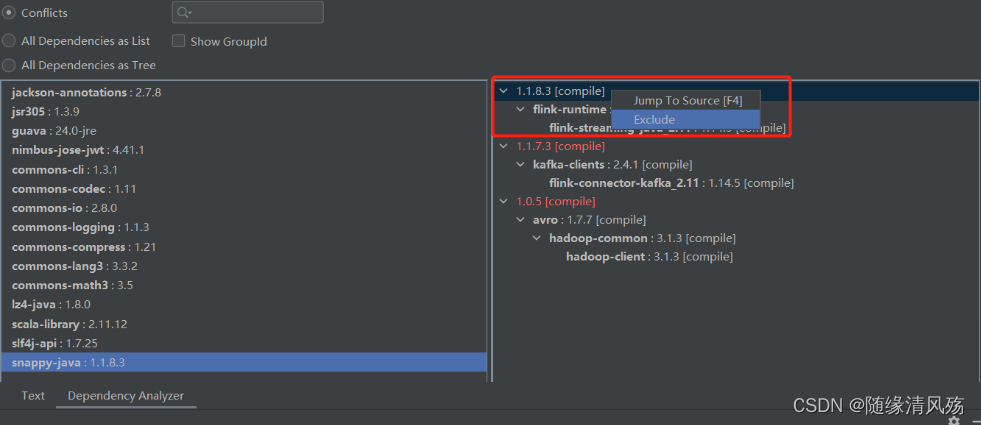
选中红色字体显示的内容->右键->Exclude,完成上述步骤结果如下:
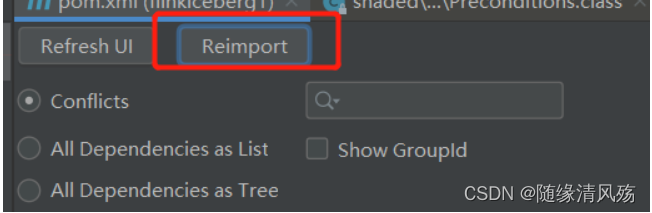
⑤重新加载依赖配置
-------------------------------------------------------------------分割线-------------------------------------------------------------------------------
以上guava包冲突解决后依旧报错,将Hadoop版本从3.2.2降低到3.1.1不报错。
注意hive-3.1.2依赖的Hadoop版本是3.1.0 [3],一般不建议runtime的Hadoop版本高于hive依赖的版本。
Ⅰ、解决方法一是在hive-exec里对guava做迁移,这个需要自己手动给hive-exec重新打包。
Ⅱ、解决方法二是降低Hadoop版本,这里不一定要降低集群的Hadoop版本,而只是降低flink和hive这边用到的Hadoop版本,相对于用老的Hadoop客户端去访问新的Hadoop服务器,这个小版本的包容性一般来说是没有问题的。
<hadoop.version>3.2.2</hadoop.version>
<!-->将hadoop版本由3.2.2版本降低为3.1.1<-->
<hadoop.version>3.1.1</hadoop.version>
4.4、log4j2配置文件报错
- 报错日志
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console. Set system property 'org.apache.logging.log4j.simplelog.StatusLogger.level' to TRACE to show Log4j2 internal initialization logging.
- 报错原因:没有发现log4j2配置文件
- 解决方案:添加配置log4j2.xml文件,对应org.apache.logging.log4j.Logger
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN"><Properties><property name="log_level" value="info" /><Property name="log_dir" value="log" /><property name="log_pattern"value="[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%p] - [%t] %logger - %m%n" /><property name="file_name" value="test" /><property name="every_file_size" value="100 MB" /></Properties><Appenders><Console name="Console" target="SYSTEM_OUT"><PatternLayout pattern="${log_pattern}" /></Console><RollingFile name="RollingFile"filename="${log_dir}/${file_name}.log"filepattern="${log_dir}/$${date:yyyy-MM}/${file_name}-%d{yyyy-MM-dd}-%i.log"><ThresholdFilter level="DEBUG" onMatch="ACCEPT"onMismatch="DENY" /><PatternLayout pattern="${log_pattern}" /><Policies><SizeBasedTriggeringPolicysize="${every_file_size}" /><TimeBasedTriggeringPolicy modulate="true"interval="1" /></Policies><DefaultRolloverStrategy max="20" /></RollingFile><RollingFile name="RollingFileErr"fileName="${log_dir}/${file_name}-warnerr.log"filePattern="${log_dir}/$${date:yyyy-MM}/${file_name}-%d{yyyy-MM-dd}-warnerr-%i.log"><ThresholdFilter level="WARN" onMatch="ACCEPT"onMismatch="DENY" /><PatternLayout pattern="${log_pattern}" /><Policies><SizeBasedTriggeringPolicysize="${every_file_size}" /><TimeBasedTriggeringPolicy modulate="true"interval="1" /></Policies></RollingFile></Appenders><Loggers><Root level="${log_level}"><AppenderRef ref="Console" /><AppenderRef ref="RollingFile" /><appender-ref ref="RollingFileErr" /></Root></Loggers>
</Configuration>
4.5、Flink Hive Catalog报错
- 报错日志
Exception in thread "main" java.lang.NoSuchMethodError: org.apache.calcite.sql.parser.SqlParser.config()Lorg/apache/calcite/sql/parser/SqlParser$Config;
-
报错原因:依赖报错
-
解决方案:将所有依赖切换到2.12,切换
flink-table-api-java-bridge到flink-table-api-scala-bridge_2.12。
相关文章:
第八章 Flink集成Iceberg的DataStreamAPI、TableSQLAPI详解
1、概述 目前Flink支持使用DataStream API 和SQL API方式实时读取和写入Iceberg表,建议使用SQL API方式实时读取和写入Iceberg表。 Iceberg支持的Flink版本为1.11.x版本以上,以下为版本匹配关系: Flink版本Iceberg版本备注Flink1.11.XI…...

PyTorch学习笔记:nn.Sigmoid——Sigmoid激活函数
PyTorch学习笔记:nn.Sigmoid——Sigmoid激活函数 torch.nn.Sigmoid()功能:逐元素应用Sigmoid函数对数据进行激活,将元素归一化到区间(0,1)内 函数方程: Sigmoid(x)σ(x)11e−xSigmoid(x)\sigma(x)\frac1{1e^{-x}} Sigmoid(x)σ(…...
个人学习系列 - 解决拦截器操作请求参数后台无法获取
由于项目需要使用拦截器对请求参数进行操作,可是请求流只能操作一次,导致后面方法不能再获取流了。 新建SpringBoot项目 1. 新建拦截器WebConfig.java /*** date: 2023/2/6 11:21* author: zhouzhaodong* description:*/ Configuration public class W…...
【编程基础之Python】2、安装Python环境
【编程基础之Python】2、安装Python环境安装Python环境在Windows上安装Python验证Python运行环境在Linux上安装Python验证Python运行环境总结安装Python环境 所谓“工欲善其事,必先利其器”。在学习Python之前需要先搭建Python的运行环境。由于Python是跨平台的&am…...
Java开发 - 问君能有几多愁,Spring Boot瞅一瞅。
前言 首先在这里恭祝大家新年快乐,兔年大吉。本来是想在年前发布这篇博文的,奈何过年期间走街串巷,实在无心学术,所以不得不放在近日写下这篇Spring Boot的博文。在还没开始写之前,我已经预见到,这恐怕将是…...
Office Server Document Converter Lib SDK Crack
关于 Office Server 文档转换器 (OSDC) 无需 Microsoft Office 或 Adobe 软件即可快速准确地转换文档。antennahouse.com Office Server 文档转换器 (OSDC) 会将您在 Microsoft Office(Word、Excel、PowerPoint)中创建的重要文档转换为高质量的 PDF …...

Cubox是什么应用?如何将Cubox同步至Notion、语雀、在线文档中
Cubox是什么应用? Cubox 是一款跨平台的网络收藏工具,通过浏览器扩展、客户端、手机应用、微信转发等方式,将网页、文字、图片、语音、视频、文件等内容保存起来,再经过自动整理、标签、分类之后,就可以随时阅读、搜索…...
计算机网络-传输层
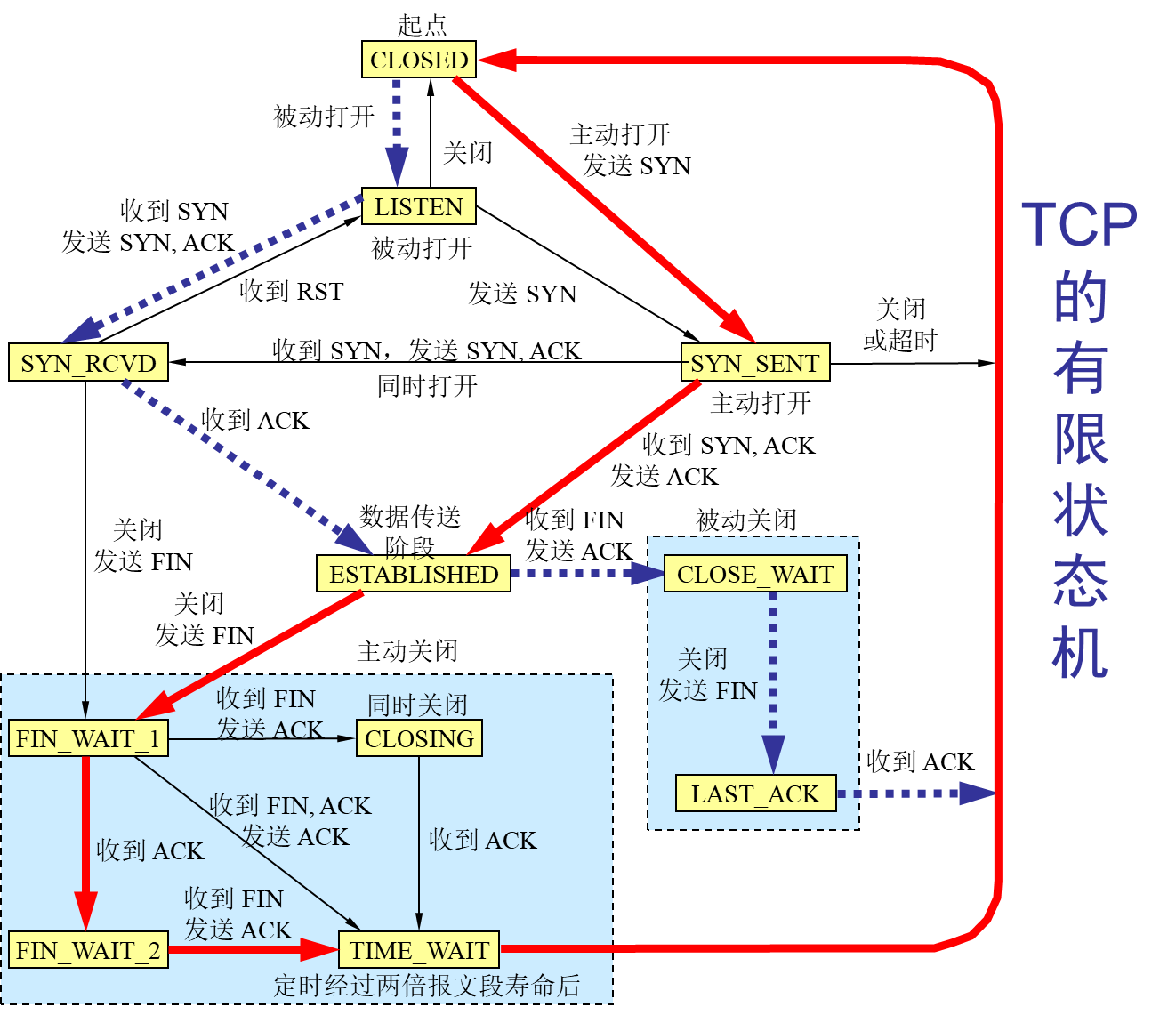
文章目录前言概述用户数据报协议 UDP(User Datagram Protocol)传输控制协议 TCP(Transmission Control Protocol)TCP 的流量控制拥塞控制方法TCP 的运输连接管理TCP 的有限状态机总结前言 本博客仅做学习笔记,如有侵权,联系后即刻更改 科普:…...

HTML-CSS-js教程
HTML 双标签<html> </html> 单标签<img> html5的DOCTYPE声明 <!DOCTYPE html>html的基本骨架 <!DOCTYPE html> <html> </html>head标签 用于定义文档的头部。文档的头部包含了各种属性和信息,包括文档的标题&#…...

【Nacos】Nacos配置中心客户端启动源码分析
SpringCloud项目启动过程中会解析bootstrop.properties、bootstrap.yaml配置文件,启动父容器,在子容器启动过程中会加入PropertySourceBootstrapConfiguration来读取配置中心的配置。 PropertySourceBootstrapConfiguration#initialize PropertySource…...

中国特色地流程管理系统,天翎让流程审批更简单
编者按:本文分析了国内企业在采购流程管理系统常遇到的一些难点,并从适应中国式流程管理模式的特点出发,介绍了符合中国特色的流程审批管理系统——天翎流程管理系统。关键词:可视化开发,拖拽建模,审批控制…...
)
Python算法:DFS排列与组合算法(手写模板)
自写排列算法: 例:前三个数的全排列(从小到大) def dfs(s,t):if st: #递归结束,输出一个全排列print(b[0:n])else:for i in range(t):if vis[i]False:vis[i]Trueb[s]a[i] #存排列dfs(s1,t)vis[i]Falsea[1,2,3,4,…...
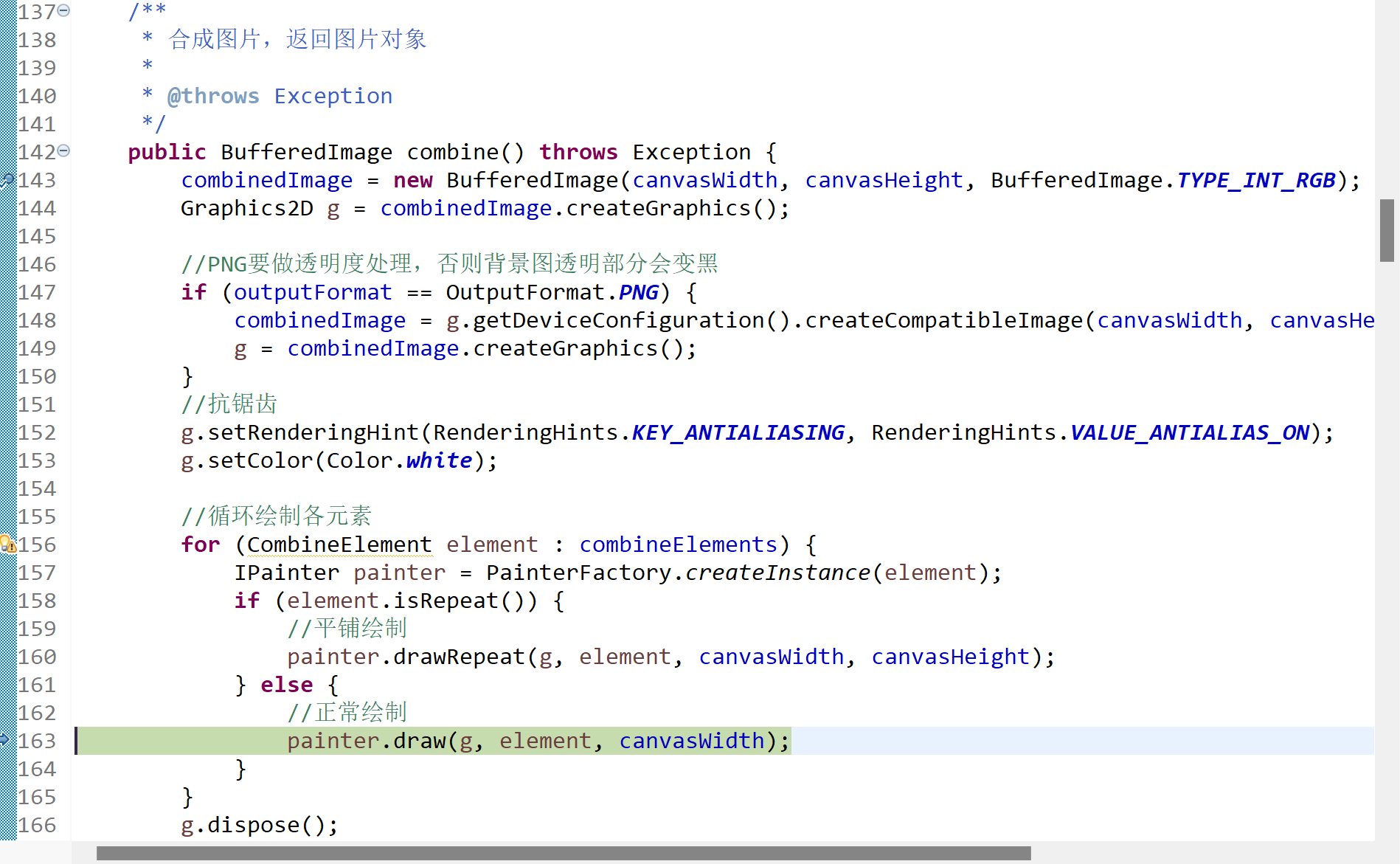
拿来就用的Java海报生成器ImageCombiner(一)
背景如果您是UI美工大师或者PS大牛,那本文一定不适合你;如果当您需要自己做一张海报时,可以立马有小伙伴帮您实现,那本文大概率也不适合你。但是,如果你跟我一样,遇上到以下场景,最近公司上了不…...

【C++】类和对象(二)
目录 一、默认成员函数 二、构造函数 1、构造函数概念 2、构造函数编写 3、默认构造函数 4、内置类型成员的补丁 三、析构函数 1、析构函数概念 2、析构函数编写 3、默认析构函数 四、拷贝构造函数 1、拷贝构造函数概念及编写 2、默认拷贝构造函数 3、拷贝构造…...
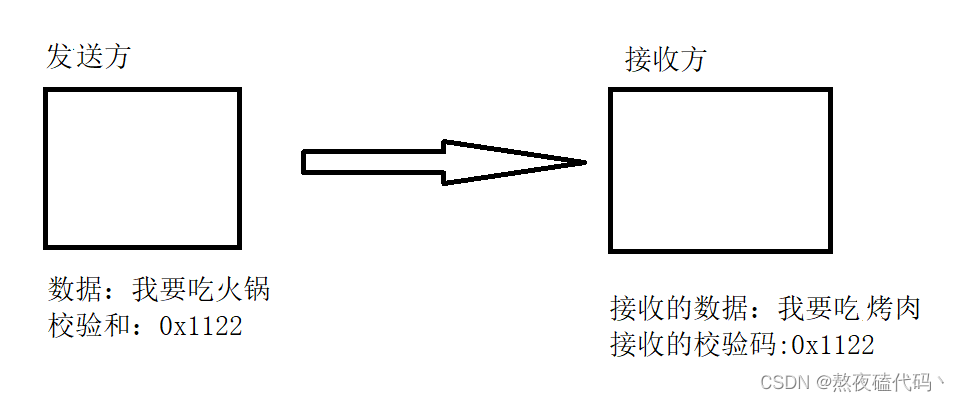
UDP协议
文章目录一、前沿知识应用层传输层二、UDP协议一、前沿知识 应用层 应用层:描述了应用程序如何理解和使用网络中的通信数据。 我们程序员在应用层的主要工作是自定义协议,因为下面四层都在系统内核/驱动程序/硬件中已经实现好了,不能去修改…...

IT人的晋升之路——关于人际交往能力的培养
对于咱们的程序员来说,工作往往不是最难的,更难的是人际交往和关系的维护处理。很多时候我们都宁愿加班,也不愿意是社交,认识新的朋友,拓展自己的圈子。对外的感觉就好像我们丧失了人际交往能力,是个呆子&a…...
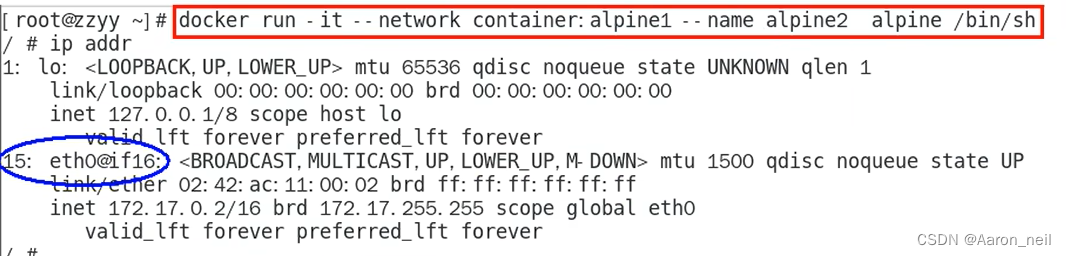
Docker进阶 - 8. docker network 网络模式之 container
目录 1. container 模式概述 2. 使用Alpine操作系统来验证 container 模式 1. container 模式概述 container网络模式新建的容器和已经存在的一个容器共享一个网络ip配置而不是和宿主机共享。新创建的容器不会创建自己的网卡,配置自己的IP,而是和一个…...

2年功能测试月薪9.5K,100多天自学自动化,跳槽涨薪4k后我的路还很长...
前言 其实最开始我并不是互联网从业者,是经历了一场六个月的培训才入的行,这个经历仿佛就是一个遮羞布,不能让任何人知道,就算有面试的时候被问到你是不是被培训的,我还是不能承认这段历史。我是为了生存,…...

“数字孪生”:为什么要仿真嵌入式系统?
01.仿真是什么? 仿真的概念非常广泛,但归根结底都是使用可控的手段来模仿真实的情况,通常应用于现实世界中实施难度大甚至是无法实践的事物。 众所周知,嵌入式系统通常是形式多样的、面向特定应用的软硬件综合体,无…...
)
Java基础知识总结(上)
Java基础知识总结 1. Java语言的特点 简单易学,相较于python等语言具有较好的严谨性以及报错机制; 面向对象(封装,继承,多态),Java中所有内容都是基于类进行扩展的,由类创建的实体…...

解决Beyond Compare 5授权问题的完整方案:BCompare_Keygen工具使用指南
解决Beyond Compare 5授权问题的完整方案:BCompare_Keygen工具使用指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 当你在使用Beyond Compare 5进行文件比较或同步操作时&#x…...

FreeRTOS+LwIP 2.2.0实战:手把手教你理解tcpip_thread的消息处理机制
FreeRTOSLwIP 2.2.0实战:深入解析tcpip_thread的消息驱动架构 在嵌入式网络开发中,理解协议栈的线程模型是构建稳定系统的关键。当FreeRTOS遇上LwIP,tcpip_thread就像一位不知疲倦的邮差,日夜处理着来自各方的网络报文。本文将带您…...

6种专业计时模式:让OBS直播时间管理变得如此简单
6种专业计时模式:让OBS直播时间管理变得如此简单 【免费下载链接】obs-advanced-timer 项目地址: https://gitcode.com/gh_mirrors/ob/obs-advanced-timer 想让你的直播画面看起来更加专业吗?OBS高级计时器正是你需要的秘密武器!这款…...
)
用格子玻尔兹曼方法 - 浸没边界法模拟圆柱绕流(LBM - IBM in C++)
格子玻尔兹曼方法-浸没边界法模拟圆柱绕流 LBM- IBM (C)在计算流体力学(CFD)的领域里,格子玻尔兹曼方法(Lattice Boltzmann Method, LBM)和浸没边界法(Immersed Boundary Method, IB…...

智能客服架构图实战:从高并发设计到生产环境部署
今天想和大家聊聊智能客服系统的架构实战。我们团队最近刚把一个老的单体客服系统重构为微服务架构,主要就是为了应对大促期间的高并发访问。整个过程踩了不少坑,也积累了一些经验,在这里做个梳理和分享。 先说说我们遇到的痛点。原来的系统&…...

从零开始:使用Python Add-in快速构建ArcGIS自定义工具条
1. Python Add-in入门:ArcGIS插件开发新选择 第一次接触ArcGIS插件开发时,我被各种复杂的开发方式搞得晕头转向。直到发现了Python Add-in这个神器,才发现原来开发自定义工具条可以这么简单!Python Add-in是Esri在ArcGIS 10.1引入…...

神经网络实战之dsp实现神经网络vad-1
vad神经网络有很多不同的实现,这里的神经网络是基于pytorch实现的,网络结构如下: class MiniVAD(nn.Module):def __init__(self, n_fft512):super().__init__()self.input48 #输入B T 48# 融合层self.fusion nn.Sequential(nn.Linear(self.i…...

HashCheck:Windows系统下终极文件完整性验证解决方案
HashCheck:Windows系统下终极文件完整性验证解决方案 【免费下载链接】HashCheck HashCheck Shell Extension for Windows with added SHA2, SHA3, and multithreading; originally from code.kliu.org 项目地址: https://gitcode.com/gh_mirrors/ha/HashCheck …...

Grok-1大模型实战指南:如何用5大核心模块构建企业级AI应用
Grok-1大模型实战指南:如何用5大核心模块构建企业级AI应用 【免费下载链接】grok-1 马斯克旗下xAI组织开源的Grok AI项目的代码仓库镜像,此次开源的Grok-1是一个3140亿参数的混合专家模型 项目地址: https://gitcode.com/GitHub_Trending/gr/grok-1 …...

国金证券QMT实盘连接指南:手把手教你配置交易环境与策略回测
国金证券QMT实盘连接实战:从环境搭建到策略部署全解析 引言 在量化交易的世界里,工具的选择往往决定了策略执行的效率与稳定性。国金证券QMT作为国内主流的量化交易平台之一,以其稳定的实盘连接能力和丰富的API接口受到众多量化交易者的青睐。…...