「Java」《深度解析Java Stream流的优雅数据处理》
《深度解析Java Stream流的优雅数据处理》
- 一、引言
- 1.1 背景
- 1.2 Stream流的意义
- 二、Stream流的基本概念
- 2.1 什么是Stream流
- 2.2 Stream与传统集合的对比
- 三、创建Stream流
- 3.1 通过集合创建Stream
- 3.2 使用Arrays和Stream.of创建Stream
- 3.3 从文件和网络流创建Stream
- 四、 中间操作
- 4.1 filter操作:过滤元素
- 4.2 map操作:转换元素
- 4.3 sorted操作:排序元素
- 4.4 其他常见的中间操作
- 五、终端操作
- 5.1 forEach操作:遍历元素
- 5.2 collect操作:收集元素
- 5.3 reduce操作:归约元素
- 5.4 其他常见的终端操作
- 六、并行处理与性能优化
- 6.1 并行流的概念与使用
- 6.2 Stream流的性能考虑点
- 6.3 如何优化Stream流的性能
- 七、实例演示
- 7. 使用Stream流实现常见数据处理场景
- 八、注意事项和最佳实践
- 8.1 惰性求值与及早求值
- 8.2 对于大数据量的处理,注意内存消耗和性能问题
- 九、总结
- 9.1 Stream流的优势和适用场景
- 9.2 针对不同需求选择合适的操作方法
一、引言
1.1 背景
在Java 8之前,我们通常使用循环迭代的方式对集合元素进行处理。这种方式虽然灵活,但代码比较冗长,容易引入错误。而且,我们还需要手动处理一些细节,如迭代器、条件判断等。这种繁琐的处理方式不仅增加了开发的难度,也不利于代码的维护和阅读。
1.2 Stream流的意义
Stream流的出现正是为了解决传统集合操作的痛点,并提供更好的方式来处理集合数据。它的出现具有以下几个重要意义:
简洁优雅:Stream流通过提供一套函数式的操作方法,将数据处理过程转化为一系列的链式调用操作。这种方式简洁、优雅,代码更易读、理解和维护。
函数式编程:Stream流借鉴了函数式编程的思想,强调对数据进行转换和处理,而不是通过迭代来操作。这种方式使得代码更加清晰,减少了副作用和状态的变化。
高效性能:Stream流在设计上注重并行处理的能力,可以利用多核处理器的优势,提高数据处理的效率。通过并行流的方式,我们可以更好地应对大数据量的处理需求。
支持延迟计算:Stream流具备惰性求值的特性,也即只有真正需要处理结果时才会执行操作。这样可以避免无谓的计算,提高程序的性能。
总结:
Stream流的背景和出现的意义主要是为了解决传统集合操作的繁琐性和复杂性,并提供一种更简洁、优雅、高效的数据处理方式。它的引入使得我们能够更专注于数据的转换和处理逻辑,提高代码质量和开发效率。通过学习和使用Stream流,我们能够更好地编写现代化的Java程序。
二、Stream流的基本概念
2.1 什么是Stream流
Stream流是Java 8引入的一种用于处理集合数据的抽象概念。它提供了一种更简洁、优雅的方式来对集合进行操作和转换,避免了繁琐的迭代和临时变量的使用。通过使用Stream,我们可以以声明式的方式来处理数据,将关注点从如何操作转变为要做什么操作。
在Stream的概念中,数据被视为一系列的项(elements),可以是数组、集合、I/O通道等。Stream流的设计思想源自函数式编程的概念,并提供了丰富的函数式操作方法,如过滤、映射、排序等。这些操作方法可以通过链式调用的方式组合使用,形成一个数据处理管道。
Stream流分为两种类型:中间流(Intermediate Stream)和终端流(Terminal Stream)。中间流表示一系列的操作过程,每个操作都会返回一个新的Stream作为结果,这样可以形成一条连续的操作链。终端流表示最终的操作,当调用终端操作后,Stream流的处理会触发执行,并生成最终的结果。
一个典型的Stream流操作流程可以类比于工厂生产线。我们从数据源(如集合)开始,通过一系列中间操作对数据进行转换和处理,最后通过一个终端操作得到最终的结果。
Stream流的使用具有以下几个特点:
不会修改原始数据源:Stream流的操作不会修改原始的数据源,而是通过生成一个新的Stream来保持数据的不变性。
惰性求值:Stream流使用惰性求值的策略,只有在终端操作被调用时才会执行中间操作,并生成结果。
并行处理:Stream流可以利用并行处理的优势,通过parallel()方法将流转换为并行流,提高处理大数据量时的性能。
总结而言,Stream流是Java 8引入的一种函数式编程风格的集合数据处理方式。它通过提供丰富的操作方法和链式调用的方式,使得对集合数据的操作变得更加简洁、优雅和高效。通过使用Stream流,我们可以以声明式的方式来处理数据,减少繁琐的迭代过程,提高代码的可读性和可维护性。
2.2 Stream与传统集合的对比
Stream与传统集合在数据处理方式上有着明显的不同,下面是Stream与传统集合的对比:
-
数据处理方式:
-
传统集合:传统集合需要通过迭代器或循环来遍历集合中的元素,并且在每个操作步骤中需要手动编写逻辑进行操作。
-
Stream流:使用Stream流时,我们可以以声明式的方式对集合进行操作,不需要显式地编写迭代逻辑。Stream提供了一系列的函数式操作方法,如过滤、映射、排序等,可以通过链式调用组合操作。
-
-
数据状态与副作用:
-
传统集合:传统集合在对原始集合进行操作时,会修改原始集合的状态,可能引入副作用,并且需要手动进行状态管理。
-
Stream流:Stream流的操作是无状态的,操作过程不会修改原始集合的状态,而是返回一个新的Stream作为结果。这种方式使得代码更加健壮,减少了副作用和状态管理的复杂性。
-
-
惰性求值与及早求值:
-
传统集合:传统集合的操作是即时求值的,每次使用迭代器或循环都会立即执行操作。
-
Stream流:Stream流具备惰性求值的特性,中间操作只会在终端操作被调用时才会执行。这样可以避免无用的计算,提高程序的性能。
-
-
并行处理:
-
传统集合:在传统集合中,要实现并行处理需要手动编写多线程相关的代码,并进行适当的同步和线程管理。
-
Stream流:Stream流天生支持并行处理,通过parallel()方法将流转换为并行流即可。Stream会自动将任务拆分成若干个子任务,利用多核处理器的优势提高处理效率。
-
总结而言,Stream与传统集合相比,更加强调函数式编程的思想,使得数据处理代码更加简洁、易读且易于维护。使用Stream流,我们可以以声明式的方式对集合进行操作,避免繁琐的迭代过程和手动状态管理。此外,Stream流还具备惰性求值和并行处理的特性,能够提高数据处理的性能和效率。
三、创建Stream流
3.1 通过集合创建Stream
通过集合创建Stream是使用Stream流的常见方式之一,可以通过以下两种方式来实现:
-
使用
stream()方法:
通过调用集合对象的stream()方法,可以将集合转换为一个Stream流。示例代码如下:List<String> list = Arrays.asList("apple", "banana", "orange"); Stream<String> stream = list.stream();在上述示例中,我们将一个包含三个元素的List集合通过
stream()方法转换为一个Stream流。 -
使用
parallelStream()方法:
如果需要进行并行处理,可以使用parallelStream()方法将集合转换为并行流。示例如下:List<String> list = Arrays.asList("apple", "banana", "orange"); Stream<String> parallelStream = list.parallelStream();在上述示例中,我们将List集合通过
parallelStream()方法转换为一个并行流,以便在处理大数据量时提高处理效率。
无论是使用stream()方法还是parallelStream()方法,转换后得到的Stream流都可以使用Stream所提供的丰富操作方法进行数据处理,如过滤、映射、排序等。通过链式调用这些操作方法,我们可以构建出一个数据处理的管道,最终得到我们想要的结果。
需要注意的是,通过集合创建的Stream流是有限的(Finite Stream),即其元素数量是有限的。因此,在处理大数据集合或无限流的情况下,可能需要考虑其他方式来创建Stream流,如使用数组的stream()方法、Stream类的静态方法等。
总结而言,通过集合的stream()方法或parallelStream()方法可以将集合转换为Stream流,从而以流的方式对集合进行操作和处理。这种方式使得数据处理更加简洁、易读,提高了代码的可维护性和可扩展性。
3.2 使用Arrays和Stream.of创建Stream
除了使用集合创建Stream流,还可以使用数组和Stream.of方法来创建Stream流。下面是两种方式的示例代码:
-
使用Arrays创建Stream流:
String[] array = {"apple", "banana", "orange"}; Stream<String> stream = Arrays.stream(array);在上述示例中,我们通过
Arrays.stream()方法将String类型的数组转换为一个Stream流。 -
使用Stream.of创建Stream流:
Stream<String> stream = Stream.of("apple", "banana", "orange");上述示例中,我们直接使用Stream.of方法将多个元素转换为一个Stream流。
无论是使用Arrays工具类的stream()方法还是Stream的of()方法,都能够快速创建Stream流。通过这些方法,我们可以处理任意类型的数组,包括基本类型数组和引用类型数组。
需要注意的是,通过数组创建的Stream流是有限的(Finite Stream),即其元素数量是有限的。因此,在处理大数据量或者需要生成无限流的情况下,可能需要考虑其他方式来创建Stream流。
总结而言,通过Arrays工具类的stream()方法或Stream的of()方法,可以快速创建Stream流。这种方式适用于处理各种类型的数组,并且能够以流的方式对数组进行操作和处理。这种便捷的创建方式使得代码更加简洁易读,提高了开发效率。
3.3 从文件和网络流创建Stream
创建Stream流的另一种常见方式是从文件和网络流中获取数据。Java提供了相应的API来支持从文件和网络流创建Stream流。下面是两种方式的示例代码:
-
从文件创建Stream流:
import java.io.IOException; import java.nio.file.Files; import java.nio.file.Paths; import java.util.stream.Stream;public class FileToStreamExample {public static void main(String[] args) {String fileName = "path/to/file.txt";try (Stream<String> stream = Files.lines(Paths.get(fileName))) {stream.forEach(System.out::println);} catch (IOException e) {e.printStackTrace();}} }在上述示例中,我们使用Files类的
lines()方法从指定文件中读取每一行内容,并将其转换为一个Stream流。通过使用try-with-resources语句,确保在处理完毕后自动关闭流。 -
从网络流创建Stream流:
import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.net.URL; import java.util.stream.Stream;public class NetworkStreamExample {public static void main(String[] args) {try {URL url = new URL("http://example.com/data.txt");BufferedReader reader = new BufferedReader(new InputStreamReader(url.openStream()));Stream<String> stream = reader.lines();stream.forEach(System.out::println);reader.close();} catch (IOException e) {e.printStackTrace();}} }在上述示例中,我们使用URL类打开一个网络流,并通过BufferedReader逐行读取数据。然后,使用
lines()方法将每一行数据转换为Stream流进行处理。
通过从文件和网络流创建Stream流,我们能够方便地读取文件和获取网络数据,并以流式的方式对数据进行处理。这种方式使得数据的处理更加灵活、高效,并通过Stream提供的各种操作方法实现丰富的数据转换和处理逻辑。在使用完毕后,务必关闭相关的文件和网络流以释放资源。
四、 中间操作
4.1 filter操作:过滤元素
在Stream流中,filter操作是一种常用的中间操作,它用于根据指定条件筛选出满足条件的元素,并将它们组成一个新的Stream流。filter操作接收一个Predicate(断言)作为参数,用于确定元素是否满足条件。
下面是filter操作的示例代码:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9, 10);Stream<Integer> evenNumbers = numbers.stream().filter(n -> n % 2 == 0);
evenNumbers.forEach(System.out::println);
在上述示例中,我们有一个包含整数的集合numbers,我们通过stream()方法将其转换为一个Stream流。然后,使用filter()方法传入一个Lambda表达式n -> n % 2 == 0作为条件,该条件判断数字是否为偶数。最后,通过forEach()方法打印筛选得到的偶数。
运行上述代码,将会输出所有的偶数:2, 4, 6, 8, 10。
需要注意的是,filter操作仅保留满足条件的元素,不会修改原始数据源。它返回一个新的Stream流,只包含满足条件的元素。因此,我们可以通过多次使用filter操作来筛选出满足多个条件的元素。
总结而言,filter操作是一种用于过滤元素的中间操作,通过提供一个Predicate来判断元素是否满足条件,并将满足条件的元素组成一个新的Stream流。该操作使得我们能够灵活地筛选出需要的元素,从而简化了数据处理的过程。
4.2 map操作:转换元素
在Stream流中,map操作是一种常用的中间操作,它用于将一个元素转换为另一个元素,从而生成一个新的Stream流。我们可以通过传入一个Function(函数)来定义元素的转换规则。
下面是map操作的示例代码:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie", "David", "Eva");Stream<Integer> nameLengths = names.stream().map(String::length);
nameLengths.forEach(System.out::println);
在上述示例中,我们有一个包含字符串的集合names。我们通过stream()方法将其转换为一个Stream流。然后,使用map()方法传入一个方法引用String::length,该方法引用表示将每个字符串转换为其长度。最后,通过forEach()方法打印转换后的结果。
运行上述代码,将会输出所有字符串的长度:5, 3, 7, 5, 3。
需要注意的是,map操作仅对每个元素进行转换,并不会修改原始数据源。它返回一个新的Stream流,其中包含了转换后的元素。我们可以通过多次使用map操作来对元素进行连续的转换。
除了方法引用,我们还可以使用Lambda表达式来定义转换规则。例如:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);Stream<Integer> squaredNumbers = numbers.stream().map(n -> n * n);
squaredNumbers.forEach(System.out::println);
在上述示例中,我们将每个数字转换为其平方,并打印转换后的结果。
总结而言,map操作是一种用于转换元素的中间操作,它通过提供一个转换规则(方法引用或Lambda表达式)将一个元素转换为另一个元素,并生成一个新的Stream流。map操作使得我们能够对元素进行自定义的转换操作,从而简化了数据处理的过程。
4.3 sorted操作:排序元素
在Stream流中,sorted操作是一种常用的中间操作,它用于对流中的元素按照指定的排序规则进行排序。sorted操作可以通过自然排序或自定义排序器来实现。
下面是sorted操作的示例代码:
List<Integer> numbers = Arrays.asList(5, 2, 8, 1, 3);Stream<Integer> sortedNumbers = numbers.stream().sorted();
sortedNumbers.forEach(System.out::println);
在上述示例中,我们有一个包含整数的集合numbers。通过stream()方法将其转换为一个Stream流。然后,使用sorted()方法对流中的元素进行自然排序,默认是升序。最后,通过forEach()方法打印排序后的结果。
运行上述代码,将会输出排序后的结果:1, 2, 3, 5, 8。
如果要将元素按照自定义的排序规则进行排序,可以使用带有Comparator参数的sorted操作。例如:
List<String> names = Arrays.asList("David", "Alice", "Eva", "Charlie", "Bob");Stream<String> sortedNames = names.stream().sorted(Comparator.comparing(String::length));
sortedNames.forEach(System.out::println);
在上述示例中,我们通过比较字符串长度来对字符串进行排序。通过sorted()方法传入一个Comparator,该Comparator使用comparing()方法和方法引用String::length来指定按照字符串长度进行排序。最后,通过forEach()方法打印排序后的结果。
运行上述代码,将会输出按照字符串长度排序后的结果:Eva, Bob, Alice, David, Charlie。
需要注意的是,sorted操作仅对流中的元素进行排序,并不会修改原始数据源。它返回一个新的Stream流,其中包含了排序后的元素。
总结而言,sorted操作是一种用于排序元素的中间操作,通过自然排序或自定义排序器对元素进行排序,并生成一个新的Stream流。sorted操作使得我们能够对元素按照指定的排序规则进行处理,从而简化了数据处理的过程。
4.4 其他常见的中间操作
除了filter、map和sorted操作之外,还有许多其他常见的中间操作可用于对Stream流进行转换和处理。以下是一些常见的中间操作:
- distinct:去除流中的重复元素。
- limit:限制流中元素的数量。
- skip:跳过流中的前n个元素。
- peek:对流中的每个元素执行操作,不会影响流的内容。
- flatMap:将流中的每个元素转换为一个流,并将所有流的元素合并为一个流。
- sorted:对流中的元素进行排序,可以自然排序或使用自定义排序器。
- parallel / sequential:切换流的并行处理和顺序处理模式。
- takeWhile:从流中按照指定条件依次取元素,遇到第一个不满足条件的元素时停止。
- dropWhile:从流中按照指定条件依次丢弃元素,遇到第一个不满足条件的元素时开始保留。
以上仅是一些常见的中间操作,实际上Stream API提供了更多的中间操作,使得我们能够进行灵活的数据处理和转换。使用这些中间操作,我们可以根据具体需求对流进行筛选、转换、排序、去重等处理操作,以生成我们想要的结果。
需要根据具体的业务需求选择适当的中间操作,并结合使用,以构建出一个完整的数据处理管道。同时,合理使用中间操作可以提高代码的可读性和维护性,使得数据处理的逻辑更加清晰和可扩展。
五、终端操作
5.1 forEach操作:遍历元素
在Stream流中,forEach操作是一种终端操作,它用于对流中的每个元素执行指定的操作,常用于遍历和处理流中的元素。
下面是forEach操作的示例代码:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");names.stream().forEach(System.out::println);
在上述示例中,我们有一个包含字符串的集合names。通过stream()方法将其转换为一个Stream流。然后,使用forEach()方法传入一个Lambda表达式或方法引用(这里使用了方法引用System.out::println),对每个元素执行打印操作。
运行上述代码,将会遍历并打印集合中的每个元素。
需要注意的是,forEach操作是一个终端操作,一旦调用了该操作,流就会被消耗掉,无法再进行其他操作。因此,在调用forEach之前,通常应该先完成需要的中间操作和转换。
除了打印操作,我们可以根据具体需求在forEach中执行各种不同的操作,例如对每个元素进行计算、存储到数据库或其他外部资源等。
总结而言,forEach操作是一种用于遍历元素并执行指定操作的终端操作。通过forEach,我们可以方便地对流中的每个元素进行自定义的处理逻辑。使用这种操作,能够简化数据处理的过程,并灵活应用于各种业务需求中。
5.2 collect操作:收集元素
在Stream流中,collect操作是一种常见的终端操作,用于将流中的元素收集到集合或其他数据结构中。collect操作接收一个Collector参数,定义了如何将元素累积到结果容器中。
下面是collect操作的示例代码:
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");List<String> collectedNames = names.stream().filter(name -> name.length() > 4).collect(Collectors.toList());
在上述示例中,我们有一个包含字符串的集合names。通过stream()方法将其转换为一个Stream流。然后,使用filter()方法过滤出长度大于4的元素。最后,通过collect()方法传入Collectors.toList(),将过滤后的元素收集到一个新的List集合中。
运行上述代码,将会得到一个包含符合条件的元素的新列表。
除了Collectors.toList(),Java还提供了许多其他的Collector供我们选择,例如Collectors.toSet()用于转换为集合类型Set,Collectors.toMap()用于转换为Map,以及Collectors.joining()用于将元素连接成一个字符串等。
我们也可以使用自定义的Collector来实现特定的收集逻辑。自定义Collector需要实现Collector接口,并重写相应的方法来定义收集过程。
总结而言,collect操作是一种用于收集Stream流中元素的终端操作,可以将元素收集到不同类型的集合或其他数据结构中。通过使用不同的Collector或自定义Collector,我们能够自由地定义元素的收集逻辑,满足特定的需求,并得到想要的结果。
5.3 reduce操作:归约元素
在Stream流中,reduce操作是一种常见的终端操作,它将流中的元素通过指定的归约(reduce)操作进行合并,返回一个包含最终结果的Optional对象或具体的归约结果。
下面是reduce操作的示例代码:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);Optional<Integer> sumOptional = numbers.stream().reduce((a, b) -> a + b);
在上述示例中,我们有一个包含整数的集合numbers。通过stream()方法将其转换为一个Stream流。然后,使用reduce()方法传入一个Lambda表达式 (a, b) -> a + b,表示对流中的两个元素进行求和操作。最后,得到一个Optional对象,其中包含了归约的结果。
需要注意的是,由于归约操作可能为空,因此返回的是一个Optional对象,可以使用isPresent()方法检查结果是否存在,并使用get()方法获取具体的归约结果。
除了求和操作,我们还可以在reduce中执行其他的归约操作,例如求最大值、最小值、字符串连接等。
Optional<Integer> maxOptional = numbers.stream().reduce(Integer::max);Optional<Integer> minOptional = numbers.stream().reduce(Integer::min);Optional<String> concatOptional = names.stream().reduce((a, b) -> a + ", " + b);
在上述示例中,我们分别使用reduce()方法实现了求最大值、最小值和字符串连接的归约操作。
总结而言,reduce操作是一种用于通过指定的归约操作将流中的元素合并的终端操作。它能够灵活地进行各种归约操作,使得数据处理更加方便和简洁。使用reduce,我们可以根据具体需求自定义归约逻辑,并获取到最终的结果。
5.4 其他常见的终端操作
除了forEach、collect和reduce之外,还有一些常见的终端操作可用于对Stream流进行最终的处理和计算。以下是一些常见的终端操作:
- count:获取流中元素的数量。
- anyMatch:判断流中是否存在满足指定条件的元素。
- allMatch:判断流中所有元素是否都满足指定条件。
- noneMatch:判断流中是否不存在满足指定条件的元素。
- findFirst:获取流中的第一个元素(如果存在)。
- findAny:获取流中的任意一个元素(如果存在)。
- max和min:获取流中的最大或最小元素。
- toArray:将流中的元素转换为数组。
- forEachOrdered:按照流的遍历顺序执行操作。
这些终端操作用于对Stream流进行一些简单的聚合、搜索或元素访问操作。它们可以根据具体需求来选择使用,并结合其他中间操作和终端操作来完成数据处理的任务。
需要注意的是,终端操作会触发实际的流处理,因此在调用终端操作之前,应先完成想要的中间操作和过滤条件。
通过合理使用这些终端操作,我们可以实现对Stream流中的元素进行统计、搜索、排序、转换等各种操作,并得到最终的结果。这些操作使得流式数据处理变得更加便捷和灵活。
六、并行处理与性能优化
6.1 并行流的概念与使用
并行流是Java 8引入的一种特殊的Stream流,它能够以多线程的方式并发处理数据,从而提升处理速度。与顺序流不同,顺序流是以单线程的方式按顺序处理数据。
使用并行流可以提高处理大规模数据集或复杂计算的效率,特别是在多核处理器上。它充分利用了现代计算机的多核能力,将数据划分成小块,并在多个线程上并发处理这些小块,然后合并结果。
要创建并行流,只需调用parallel()方法即可。例如:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);numbers.parallelStream().forEach(System.out::println);
在上述示例中,我们使用parallelStream()方法将列表转换为一个并行流。在调用终端操作forEach()时,Stream流会以并行的方式进行处理,由多个线程同时处理不同的元素。
需要注意的是,并行流并不适用于所有情况。并行流的性能提升取决于具体的应用场景和数据量。对于小规模数据或简单的计算,顺序流可能更快且更有效。因此,在使用并行流时,应根据具体情况进行评估和测试,以确定它是否能够获得更好的性能。
此外,还应注意并行流可能引入的线程安全问题。在使用并行流时,应确保对共享数据的访问是线程安全的,避免出现竞态条件和不一致的结果。
总结而言,并行流是一种能够以多线程方式并发处理数据的Stream流。通过使用并行流,我们可以提高处理大规模数据集或复杂计算的效率,充分利用多核处理器的性能。但应谨慎使用并根据实际情况评估性能收益,并确保对共享数据的访问是线程安全的。
6.2 Stream流的性能考虑点
在使用Stream流进行数据处理时,有几个性能考虑点需要注意:
-
数据量:Stream流适用于大规模数据集或需要复杂计算的场景。对于小规模数据,顺序流可能更快且更有效。
-
中间操作的顺序:中间操作的顺序会影响性能。某些中间操作(例如filter和map)可以缩小数据集,从而提高后续操作的性能。因此,应根据需求和数据特点选择合适的中间操作顺序。
-
短路操作的使用:短路操作(如findFirst、anyMatch、allMatch)在满足条件时可以提前结束流的处理。这对于大数据集或耗时的计算可以节省时间和资源。
-
并行流的使用:并行流通过多线程并发处理数据,可以提高处理速度。但并行流不适用于所有情况,应根据具体情况评估和测试性能收益,并确保共享数据的访问是线程安全的。
-
避免不必要的装箱操作:自动装箱和拆箱会带来性能开销。如果不需要对象语义,尽量避免使用包装类型和AutoBoxing。
-
及早终止:在可能的情况下,尽早使用终端操作来结束流,以避免不必要的处理开销。
-
避免频繁创建流:频繁创建Stream流会带来一定的开销。如果有可能,尽量重用现有的流或使用基于集合的流操作。
-
数据结构选择:对于频繁进行插入、删除等操作的场景,选择适当的数据结构可以提高性能。
需要注意的是,性能优化是一个复杂的问题,具体的优化策略取决于应用的需求和具体情况。在实际使用中,应根据具体的数据规模、计算复杂度和硬件环境等因素综合考虑,并进行性能测试和评估,以找到最佳的性能优化方案。
6.3 如何优化Stream流的性能
优化Stream流的性能可以从多个方面考虑和实施。以下是一些常见的优化策略:
-
减少数据量:在数据输入阶段,尽量减少需要处理的数据量。可以通过合适的过滤条件、限制操作、或者使用更精确的数据源来达到减少数据量的目的。
-
选择合适的中间操作顺序:中间操作的顺序会影响性能。某些中间操作(例如filter和map)可以缩小数据集,从而提高后续操作的性能。根据具体需求和数据特点选择合适的中间操作顺序。
-
使用短路操作:短路操作(如findFirst、anyMatch、allMatch)可以在满足条件时提前结束流的处理,节省时间和资源。在数据集较大或计算耗时的情况下,合理使用短路操作可以提高性能。
-
并行流的使用:对于大规模数据集或复杂计算,使用并行流可以利用多核处理器的性能提升处理速度。但并行流不适用于所有情况,应进行评估和测试以确定性能收益,并确保共享数据的访问是线程安全的。
-
避免不必要的装箱操作:自动装箱和拆箱会带来性能开销。如果不需要对象语义,在可能的情况下避免使用包装类型和AutoBoxing。
-
使用基于原始类型的特化流:Java 8提供了基于原始数据类型的特化流(如IntStream、LongStream、DoubleStream),它们避免了自动装箱和拆箱的开销,可以提高性能。
-
及早终止流的处理:根据需求,在可能的情况下尽早使用终端操作来结束流的处理。这样可以避免不必要的中间操作和元素遍历。
-
避免频繁创建流:频繁创建新的Stream流会带来一定的开销。如果有可能,尽量重用现有的流或者使用基于集合的流操作。
-
使用基于索引的操作:对于需要根据索引进行访问或操作的需求,考虑使用IntStream的range和iterate等方法,以获得更高的性能。
-
优化数据结构选择:根据具体的操作需求,选择适当的数据结构可以提高性能。例如,如果频繁进行插入和删除操作,使用LinkedList可能比ArrayList更高效。
以上策略仅是一些常见的优化方法,具体的优化策略需要根据具体的应用需求和场景进行评估和实施。在实际使用中,可以通过性能测试和性能分析工具来验证和优化Stream流的性能。
七、实例演示
7. 使用Stream流实现常见数据处理场景
使用Stream流可以方便地实现常见的数据处理场景。下面是一些常见场景及其对应的Stream流处理示例:
-
过滤:根据条件过滤出符合要求的元素。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);List<Integer> filteredNumbers = numbers.stream().filter(number -> number % 2 == 0).collect(Collectors.toList()); -
映射:对每个元素进行操作,生成一个新的元素。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");List<Integer> nameLengths = names.stream().map(String::length).collect(Collectors.toList()); -
排序:按照指定的规则对元素进行排序。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");List<String> sortedNames = names.stream().sorted().collect(Collectors.toList()); -
分组:根据指定条件将元素分组。
List<Person> persons = Arrays.asList(new Person("Alice", 25),new Person("Bob", 30),new Person("Charlie", 25) );Map<Integer, List<Person>> ageGroupMap = persons.stream().collect(Collectors.groupingBy(Person::getAge)); -
统计:对元素执行统计操作,如计数、求和、最大值、最小值、平均值等。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);long count = numbers.stream().count();int sum = numbers.stream().mapToInt(Integer::intValue).sum();Optional<Integer> max = numbers.stream().max(Comparator.naturalOrder()); -
匹配:判断是否存在满足指定条件的元素。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);boolean anyMatch = numbers.stream().anyMatch(number -> number > 3);boolean allMatch = numbers.stream().allMatch(number -> number > 0);boolean noneMatch = numbers.stream().noneMatch(number -> number < 0);
这些示例只是展示了一小部分使用Stream流进行常见数据处理场景的示例。实际上,Stream流提供了丰富的中间操作和终端操作,可以根据具体需求灵活地组合和应用这些操作来完成更多类型的数据处理任务。
八、注意事项和最佳实践
8.1 惰性求值与及早求值
惰性求值(Lazy Evaluation)和及早求值(Eager Evaluation)是计算机程序中的两种不同的求值策略。
-
惰性求值:惰性求值是一种延迟计算的策略,它只在必要时才进行计算。在惰性求值中,表达式的值不会立即计算,而是在实际需要使用到结果时才进行计算。这样可以避免不必要的计算和内存占用,提高程序的效率和性能。
在Stream流中,中间操作(如filter、map、sorted等)通常采用惰性求值的策略。它们只定义了计算逻辑,并不会立即执行。只有在调用终端操作(如forEach、collect、count等)时,才会触发流的处理,并根据需要对元素进行计算和处理。
-
及早求值:及早求值是一种立即计算的策略,它在表达式被求值之前就进行计算,并生成结果。在及早求值中,表达式的值会立即计算,并在需要时将结果存储起来以供后续使用。
在传统的集合操作中,很多方法(如foreach、map、filter等)采用的是及早求值的策略。当调用这些方法时,它们会立即对所有元素进行遍历和计算,并返回结果。
惰性求值和及早求值在不同的上下文中使用,具有不同的优势和适用场景。在Stream流中,采用惰性求值的策略可以灵活地组合多个操作,并在需要的时候才进行计算,降低计算复杂度和内存占用。而及早求值的策略则更加适用于需要立即获取结果的情况。
通过区分惰性求值和及早求值,我们可以更好地控制程序的计算行为,提高程序的效率和性能。在使用Stream流时,注意选择合适的中间操作和终端操作,确保在需要时及早触发求值,以获得期望的结果。
8.2 对于大数据量的处理,注意内存消耗和性能问题
对于大数据量的处理,内存消耗和性能问题是需要特别关注的方面。以下是一些注意事项和最佳实践,可用于优化内存消耗和提升性能:
-
使用惰性求值:Stream流的惰性求值特性可以帮助减少内存占用。通过合理使用中间操作,在处理大数据集之前进行筛选、映射和过滤,可以减少要处理的数据量,从而降低内存消耗。
-
分批处理数据:对于大数据集,可以考虑将数据分割成较小的批次进行处理,而不是一次性加载所有数据。这样可以避免一次性占用过多的内存空间,减少内存压力。
-
使用基于原始类型的特化流:如果数据集的元素是基本数据类型(如int、long、double等),可以考虑使用基于原始类型的特化流(如IntStream、LongStream、DoubleStream)。这样可以避免自动装箱和拆箱操作,减少内存开销。
-
及早终止流的处理:在处理大数据集时,使用诸如findAny、findFirst、limit等短路操作可以及早终止流的处理,避免对整个数据集的处理,从而提升性能。
-
避免频繁创建流:频繁创建新的Stream流会带来一定的开销和内存消耗。如果可能,尽量重用现有的流或使用基于集合的流操作。
-
并行流处理:对于能够并行处理的任务,可以考虑使用并行流。并行流利用多线程并发处理数据,可以提高处理大数据集的效率。但要注意,并行流需要额外的线程开销和线程同步开销,因此在某些情况下,并行流可能不一定比顺序流更快。
-
使用适当的数据结构:对于频繁进行插入、删除操作的场景,选择适当的数据结构可以提高性能。例如,LinkedList适合频繁的插入和删除,而ArrayList适合随机访问。
-
及时释放资源:处理大数据量时,涉及到I/O操作(如文件读写、数据库查询等),需要及时关闭资源,避免资源泄漏和内存溢出。
以上是优化大数据量处理的一些常见注意事项和最佳实践。在实际应用中,根据具体情况结合性能测试和性能分析工具,进行调优和评估,以获得最佳的内存消耗和性能表现。
九、总结
9.1 Stream流的优势和适用场景
Stream流提供了一种函数式编程的数据处理方式,具有以下优势和适用场景:
-
声明式编程:Stream流以声明式的方式描述数据处理逻辑,使代码更加简洁、可读性更高。通过链式调用的方式组合多个操作,可以降低代码的复杂度和维护成本。
-
惰性求值:Stream流采用惰性求值的策略,只在需要结果时才进行计算,避免了不必要的计算开销和内存占用。这对于大数据集或复杂计算的场景下特别有优势。
-
并行处理:Stream流支持并行处理,可以利用多核处理器的性能优势,提高大数据集的处理效率。并行化处理可以自动将流进行并行拆分和操作,减少开发人员的负担。
-
可拓展性:Stream流提供了丰富的中间操作和终端操作,可以根据应用的需求灵活组合和处理数据。它可以与其他Java的API(如Lambda表达式、Optional、Collectors等)无缝集成,提供更强大的数据处理能力。
-
函数式思维:Stream流鼓励使用函数式编程思维,通过将数据处理过程抽象为一系列操作,使代码更加模块化、可测试和可维护。函数式编程的特性(如不可变性、纯函数等)有助于减少副作用,提高代码质量。
Stream流适用于各种数据处理场景,尤其适用于以下情况:
- 需要对集合或数组进行复杂的筛选、映射、过滤和归约操作。
- 大数据集或复杂计算的场景下,使用惰性求值和并行处理来优化性能。
- 需要通过链式调用描述数据处理逻辑,使代码更加简洁和易读。
- 需要与其他Java API(如Lambda表达式、Optional、Collectors等)结合使用,提供更强大的功能。
- 想要采用函数式编程思维,避免副作用和提高代码质量。
总之,Stream流是Java中强大的数据处理工具,适用于各种场景,可以提高代码的可读性、可维护性和性能,是现代Java编程中的重要组成部分。
9.2 针对不同需求选择合适的操作方法
针对不同的需求,选择合适的Stream流操作方法是很重要的。以下是一些常见的需求场景和对应的操作方法建议:
-
筛选:需要根据条件过滤出符合要求的元素。
- 使用
filter方法:根据指定的条件保留满足条件的元素。 - 使用
distinct方法:去除重复的元素。
- 使用
-
映射:需要对每个元素进行操作,生成一个新的元素。
- 使用
map方法:将每个元素映射为另一个对象或者根据原对象生成新的值。 - 使用
flatMap方法:将每个元素映射为一个流,然后将所有流合并为一个新的流。
- 使用
-
排序:需要按照指定的规则对元素进行排序。
- 使用
sorted方法:根据自然顺序或者指定的Comparator进行排序。
- 使用
-
分组和分区:需要根据指定的条件将元素分组或分区。
- 使用
groupingBy方法:根据指定的条件将元素分组为Map。 - 使用
partitioningBy方法:根据指定的条件将元素分为两个部分,以布尔值划分。
- 使用
-
聚合操作:需要对元素进行聚合操作,如求和、计数、最大值、最小值、平均值等。
- 使用
collect方法和Collectors工具类:使用预定义的收集器进行数据的归约操作。
- 使用
-
匹配和查找:需要判断是否存在满足指定条件的元素,或者根据条件查找元素。
- 使用
anyMatch、allMatch、noneMatch方法:判断是否存在、全部符合或者都不符合指定条件的元素。 - 使用
findFirst、findAny方法:返回第一个或任意一个满足条件的元素。
- 使用
-
处理结果收集:需要将处理结果收集到集合或数组中。
- 使用
collect方法和Collectors工具类:提供了丰富的收集器来将流的元素收集到List、Set、Map或数组中。
- 使用
-
限制和跳过:需要限制处理的数量或者跳过一部分元素。
- 使用
limit方法:限制处理的数量。 - 使用
skip方法:跳过指定数量的元素。
- 使用
以上只是一些常见需求场景和对应的操作方法,实际应用中可能会结合多个操作来完成复杂的数据处理任务。在选择操作方法时,要根据具体需求和数据特点合理选择,以达到简洁、高效和可读性的代码。
相关文章:

「Java」《深度解析Java Stream流的优雅数据处理》
《深度解析Java Stream流的优雅数据处理》 一、引言1.1 背景1.2 Stream流的意义 二、Stream流的基本概念2.1 什么是Stream流2.2 Stream与传统集合的对比 三、创建Stream流3.1 通过集合创建Stream3.2 使用Arrays和Stream.of创建Stream3.3 从文件和网络流创建Stream 四、 中间操作…...
【云驻共创】华为云之手把手教你搭建IoT物联网应用充电桩实时监控大屏
文章目录 前言1.什么是充电桩2.什么是IOT3.什么是端、边、云、应用协同4.什么是Astro轻应用 一、玩转lOT动态实时大屏(线下实际操作)1.Astro轻应用说明1.1 场景说明1.2 资费说明1.3 整体流程 2.操作步骤2.1 开通设备接入服务2.2 创建产品2.3 注册设备2.4…...

Hadoop分布式计算与资源调度:打开专业江湖的魔幻之门
文章目录 版权声明一 分布式计算概述1.1 分布式计算1.2 分布式(数据)计算模式1.3 小结 二 MapReduce概述2.1 分布式计算框架 - MapReduce2.2 MapReduce执行原理2.3 小结 三 YARN概述3.1 YARN & MapReduce3.2 资源调度3.3 程序的资源调度3.4 YARN的资…...
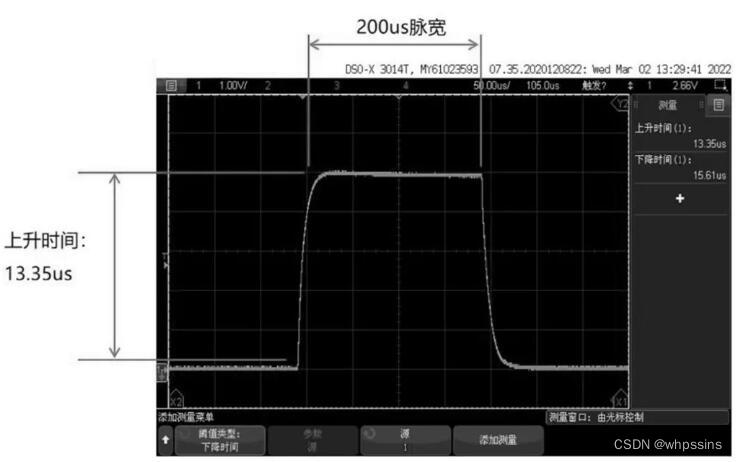
为什么叫源表?源表是如何四象限工作的?
为何称呼为源表? “源”为电压源和电流源,“表”为测量表; “源表”即指一种可作为四象限的电压源或电流源提供精确的电压或电流,同时可同步测量电流值或电压值的测量仪表。(恒流源时测电压,恒压源时测电…...

云原生周刊:Kubernetes v1.28 正式发布 | 2023.8.21
开源项目推荐 kurt 一个 Kubernetes 插件,可提供 Kubernetes 集群中重启内容的上下文信息。 Kubean Kubean 是一个基于 kubespray 的 Kubernetes 集群生命周期管理工具。 k8sgpt k8sgpt 是一款用简单的英语扫描 Kubernetes 集群、诊断和分流问题的工具。 它将…...
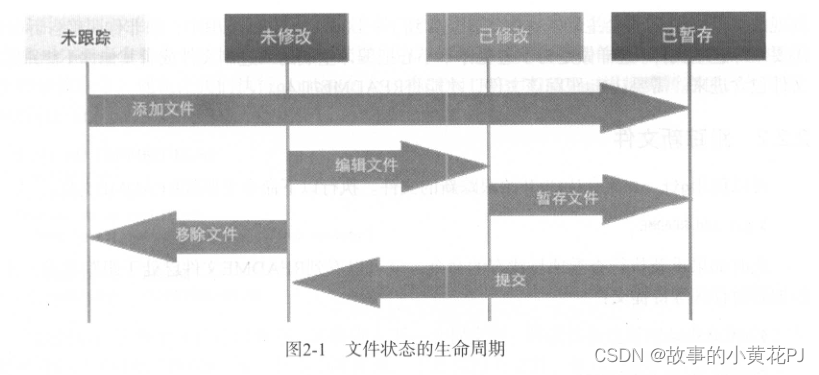
Git基础——基本的 Git本地操作
本文涵盖了你在使用Git的绝大多数时间里会用到的所有基础命令。学完之后,你应该能够配置并初始化Git仓库、开始或停止跟踪文件、暂存或者提交更改。我们也会讲授如何让Git忽略某些文件和文件模式,如何简单快速地撤销错误操作,如何浏览项目版本…...

PythonJS逆向解密——实现翻译软件+语音播报
前言 嗨喽,大家好呀~这里是爱看美女的茜茜呐 环境使用: python 3.8 pycharm 模块使用: requests --> pip install requests execjs --> pip install PyExecJS ttkbootstrap --> pip install ttkbootstrap pyttsx3 --> pip install pyttsx3 第三…...

gPRC与SpringBoot整合教程
🌷🍁 博主猫头虎 带您 Go to New World.✨🍁 🦄 博客首页——猫头虎的博客🎐 🐳《面试题大全专栏》 文章图文并茂🦕生动形象🦖简单易学!欢迎大家来踩踩~🌺 &a…...
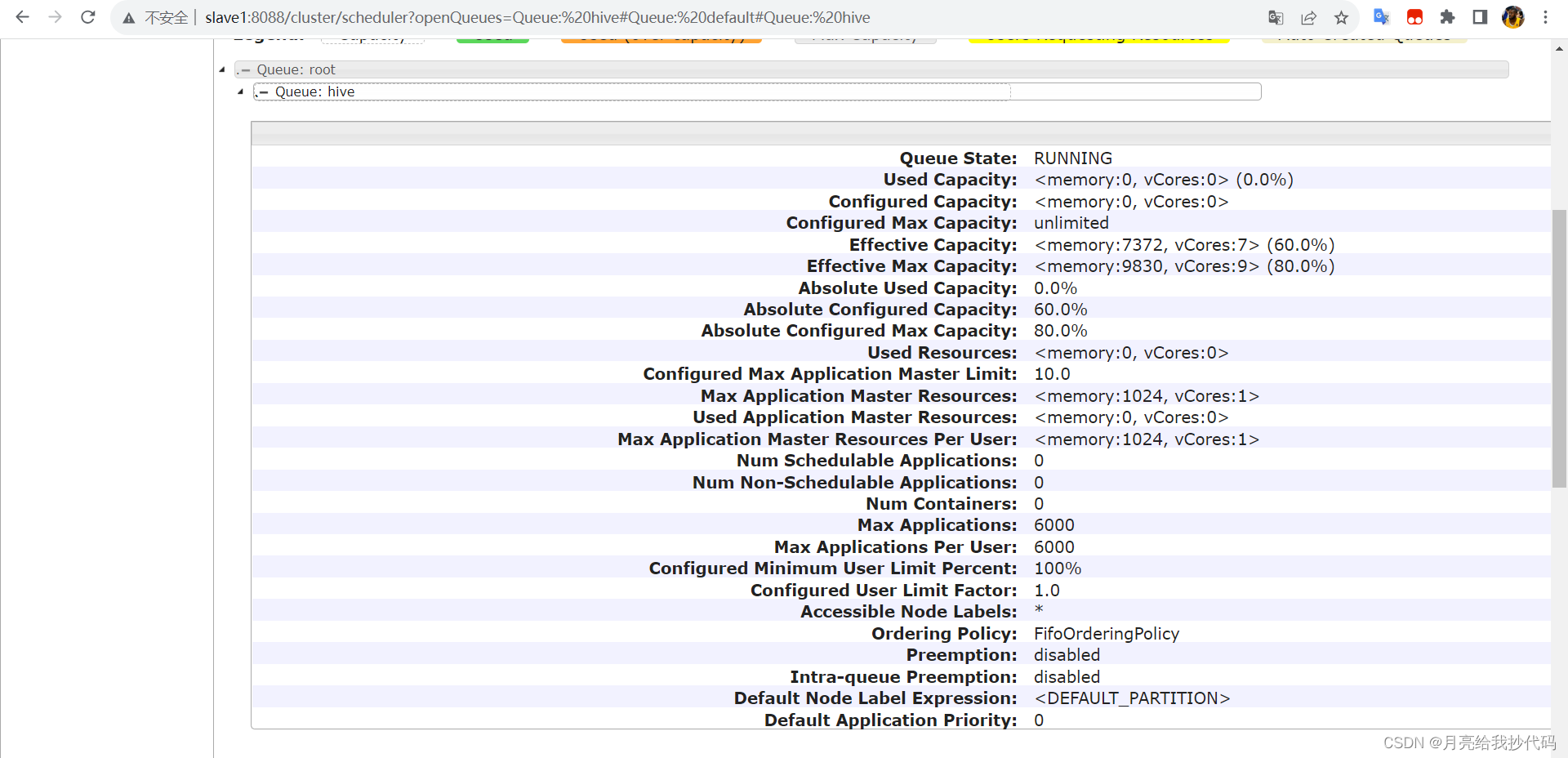
Hadoop Yarn 配置多队列的容量调度器
文章目录 配置多队列的容量调度器多队列查看 配置多队列的容量调度器 首先,我们进入 Hadoop 的配置文件目录中($HADOOP_HOME/etc/hadoop); 然后通过编辑容量调度器配置文件 capacity-scheduler.xml 来配置多队列的形式。 默认只…...

c语言练习题28:杨氏矩阵
杨氏矩阵 从左到右增加 从上到下增加 思路: 代码: #include<stdio.h> int findNum(int(*arr)[3], int x, int y, int k) {int i 0;int j y - 1;while (i<x&&j>0) {if (arr[i][j] > k) {j--;}else if (arr[i][j] < k) {i;…...

梳理系统学习R语言1-R语言实战-使用ggplot进行高阶绘图
以下为书中代码,会添加一些理解 library("ggplot2") ggplot(datamtcars,aes(xwt,ympg))geom_point()geom_point(pch17,color"blue",size2)geom_smooth(method"lm",color"red",linetype2)labs(title"Automobile Data&…...
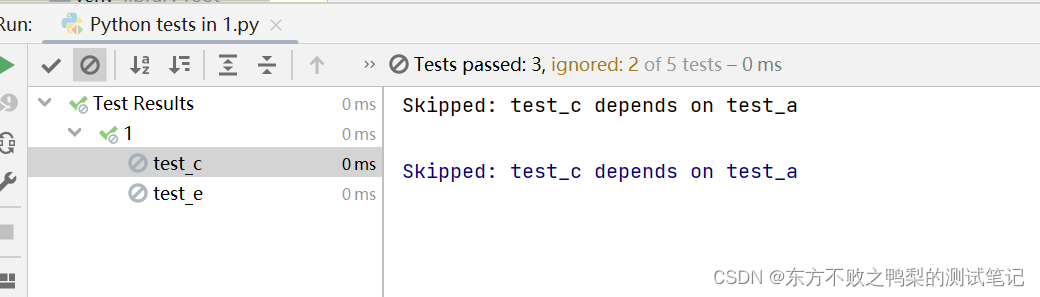
测试框架pytest教程(2)-用例依赖库-pytest-dependency
对于 pytest 的用例依赖管理,可以使用 pytest-dependency 插件。该插件提供了更多的依赖管理功能,使你能够更灵活地定义和控制测试用例之间的依赖关系。 Using pytest-dependency — pytest-dependency 0.5.1 documentation 安装 pytest-dependency 插…...

electron软件安装时,默认选择为全部用户安装
后续可能会用electron开发一些工具,包括不限于快速生成个人小程序、开发辅助学习的交互式软件、帮助运维同学一键部署的简易版CICD工具等等。 开发进度,取决于我懒惰的程度。 不过不嫌弃的同学还是可以先关注一波小程序,真的发布工具了&…...

MySQL常用表级操作
基础信息相关 1.修改表名: rename table 旧表名 to 新表名; 2、修改字段类型: alter table 表名 modify column 字段名 字段类型(长度) 3、修改字段名称和类型: alter table 表名 change 现有字段名称 修改后字段名称 数据类型 4、增加字段&a…...
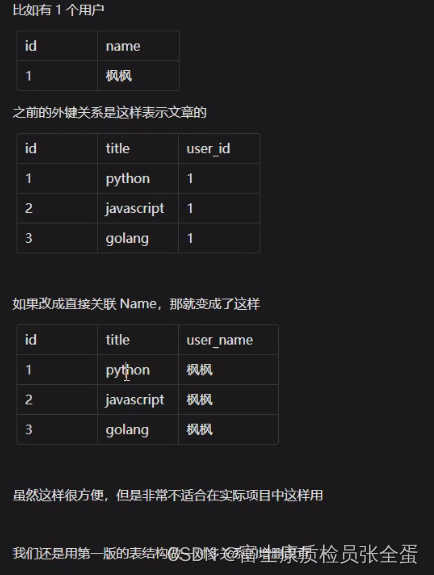
Golang Gorm 一对多关系 关系表创建
一对多关系 我们先从一对多开始多表关系的学习因为一对多的关系生活中到处都是,例如: 老板与员工女神和添狗老师和学生班级与学生用户与文章 在创建的时候先将没有依赖的创建。表名称ID就是外键。外键要和关联的外键的数据类型要保持一致。 package ma…...

java八股文面试[数据结构]——ConcurrentHashMap原理
HashMap不是线程安全: 在并发环境下,可能会形成环状链表(扩容时可能造成,具体原因自行百度google或查看源码分析),导致get操作时,cpu空转,所以,在并发环境中使用HashMap是…...

学习记录——FeatEnHancer
FeatEnHancer: Enhancing Hierarchical Features for Object Detection and Beyond Under Low-Light Vision 一种适用于任意低光照任务增强方法 ICCV 2023 提出了FeatEnHancer,一种用于低光照视觉任务的增强型多尺度层次特征的新方法。提议的解决方案重点增强相关特…...

OpenCV中常用的函数
OpenCV是一个功能强大的计算机视觉库,提供了众多用于图像处理、计算机视觉和机器学习的函数和模块。以下是一些OpenCV中常用的函数和模块的子集: 图像读取和显示: cv::imread:用于读取图像文件。cv::imshow:用于显示图…...
【福利】Google Cloud Next ’23 精彩待发,Cloud Ace 作为联合赞助商提前发福利~
【Cloud Ace 是 Google Cloud 全球战略合作伙伴,在亚太地区、欧洲、南北美洲和非洲拥有二十多个办公室。Cloud Ace 在谷歌专业领域认证及专业知识目前排名全球第一位,并连续多次获得 Google Cloud 各类奖项。作为谷歌云托管服务商,我们提供谷…...
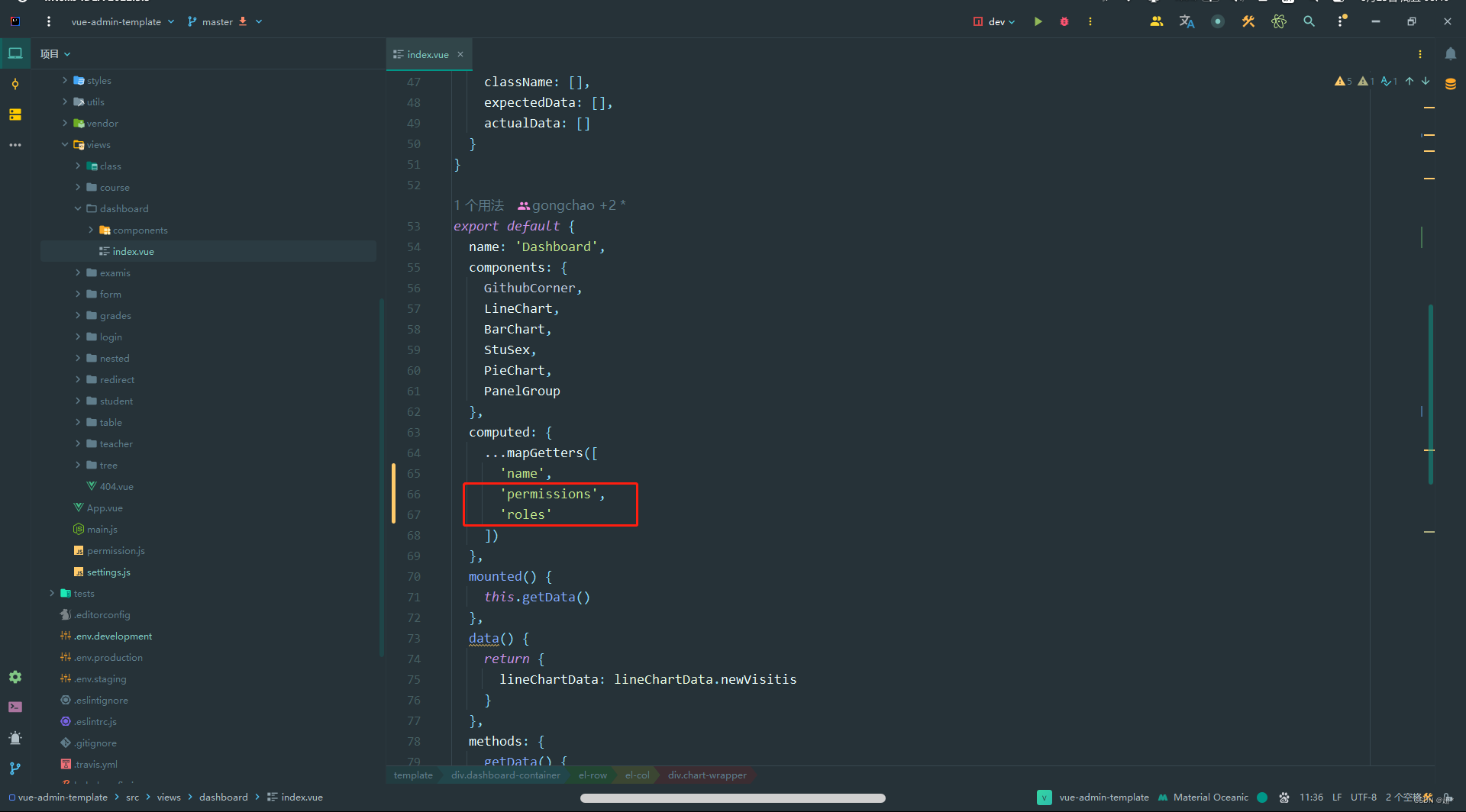
vue-admin-template实现按钮级控制
这里记录一下使用大佬的模板vue-admin-template,实现按钮级别控制 实现的思路:用户登录之后,返回用户详细信息(将用户的所有权限码发送给前端),然后将权限码保存在全局状态管理对象中,然后在组件中进行判断是否显示 最…...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

智能在线客服平台:数字化时代企业连接用户的 AI 中枢
随着互联网技术的飞速发展,消费者期望能够随时随地与企业进行交流。在线客服平台作为连接企业与客户的重要桥梁,不仅优化了客户体验,还提升了企业的服务效率和市场竞争力。本文将探讨在线客服平台的重要性、技术进展、实际应用,并…...

【论文笔记】若干矿井粉尘检测算法概述
总的来说,传统机器学习、传统机器学习与深度学习的结合、LSTM等算法所需要的数据集来源于矿井传感器测量的粉尘浓度,通过建立回归模型来预测未来矿井的粉尘浓度。传统机器学习算法性能易受数据中极端值的影响。YOLO等计算机视觉算法所需要的数据集来源于…...

tree 树组件大数据卡顿问题优化
问题背景 项目中有用到树组件用来做文件目录,但是由于这个树组件的节点越来越多,导致页面在滚动这个树组件的时候浏览器就很容易卡死。这种问题基本上都是因为dom节点太多,导致的浏览器卡顿,这里很明显就需要用到虚拟列表的技术&…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

【Go语言基础【12】】指针:声明、取地址、解引用
文章目录 零、概述:指针 vs. 引用(类比其他语言)一、指针基础概念二、指针声明与初始化三、指针操作符1. &:取地址(拿到内存地址)2. *:解引用(拿到值) 四、空指针&am…...

免费PDF转图片工具
免费PDF转图片工具 一款简单易用的PDF转图片工具,可以将PDF文件快速转换为高质量PNG图片。无需安装复杂的软件,也不需要在线上传文件,保护您的隐私。 工具截图 主要特点 🚀 快速转换:本地转换,无需等待上…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

LLMs 系列实操科普(1)
写在前面: 本期内容我们继续 Andrej Karpathy 的《How I use LLMs》讲座内容,原视频时长 ~130 分钟,以实操演示主流的一些 LLMs 的使用,由于涉及到实操,实际上并不适合以文字整理,但还是决定尽量整理一份笔…...

论文阅读:LLM4Drive: A Survey of Large Language Models for Autonomous Driving
地址:LLM4Drive: A Survey of Large Language Models for Autonomous Driving 摘要翻译 自动驾驶技术作为推动交通和城市出行变革的催化剂,正从基于规则的系统向数据驱动策略转变。传统的模块化系统受限于级联模块间的累积误差和缺乏灵活性的预设规则。…...