测试框架pytest教程(2)-用例依赖库-pytest-dependency
对于 pytest 的用例依赖管理,可以使用 pytest-dependency 插件。该插件提供了更多的依赖管理功能,使你能够更灵活地定义和控制测试用例之间的依赖关系。
Using pytest-dependency — pytest-dependency 0.5.1 documentation
安装 pytest-dependency 插件:
pip install pytest-dependency基本使用
依赖方法和被依赖方法都需要使用装饰器 @pytest.mark.dependency
在依赖方法装饰器参数列表里填写依赖的用例名称列表
import pytest@pytest.mark.dependency()
@pytest.mark.xfail(reason="deliberate fail")
def test_a():assert False@pytest.mark.dependency()
def test_b():pass@pytest.mark.dependency(depends=["test_a"])
def test_c():pass@pytest.mark.dependency(depends=["test_b"])
def test_d():pass@pytest.mark.dependency(depends=["test_b", "test_c"])
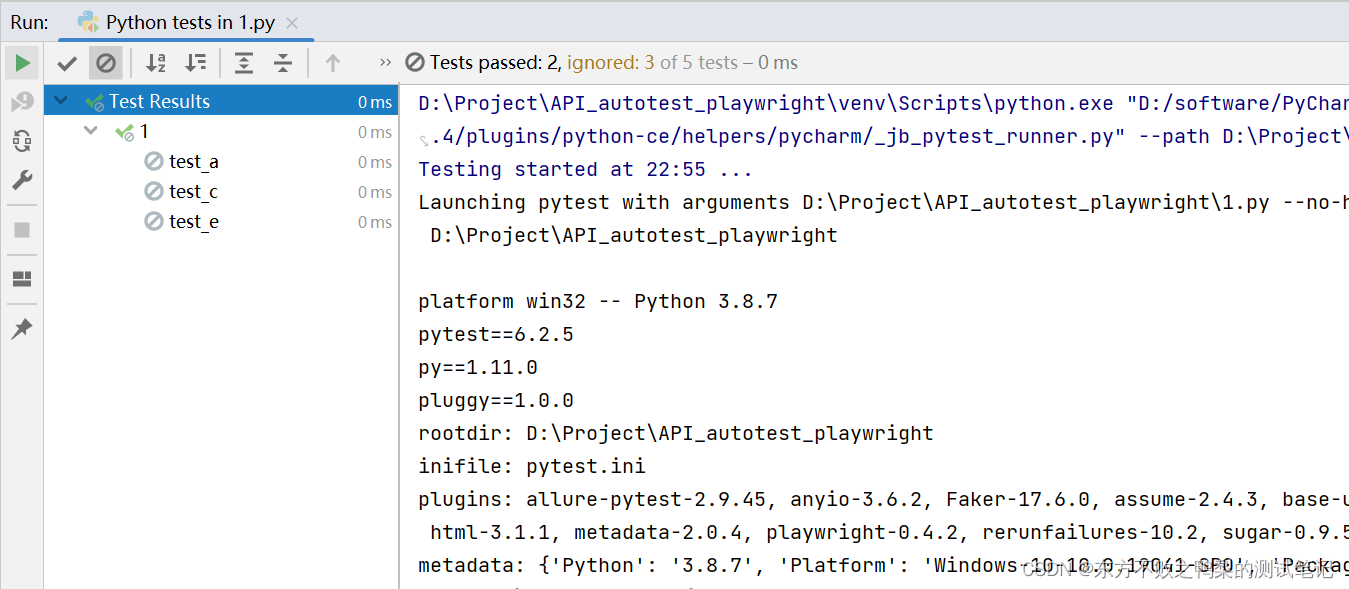
def test_e():pass执行结果:2个通过 3个忽略
被依赖的用例执行失败后,依赖的用例不执行,
a执行失败,所以c和e都被忽略了,a也被忽略了。
为测试用例命名
使用name为测试用例命名,在依赖调用列表可以使用name调用。
import pytest@pytest.mark.dependency(name="a")
@pytest.mark.xfail(reason="deliberate fail")
def test_a():assert False@pytest.mark.dependency(name="b")
def test_b():pass@pytest.mark.dependency(name="c", depends=["a"])
def test_c():pass@pytest.mark.dependency(name="d", depends=["b"])
def test_d():pass@pytest.mark.dependency(name="e", depends=["b", "c"])
def test_e():pass测试类中的测试方法
在 pytest 中,可以将测试用例分组到类中。对于测试类中的方法标记依赖关系的方式与简单的测试函数相同。在下面的示例中,我们定义了两个测试类。每个测试类的工作方式与之前的示例相同:
```python
import pytest@pytest.mark.dependency
class TestClassA:def test_a(self):assert False@pytest.mark.dependency(depends=["TestClassA::test_a"])def test_b(self):assert True@pytest.mark.dependency
class TestClassB:def test_c(self):assert False@pytest.mark.dependency(depends=["TestClassB::test_c"])def test_d(self):assert True
```在这个示例中,我们定义了两个测试类 `TestClassA` 和 `TestClassB`。每个测试类中的方法都用 `@pytest.mark.dependency` 进行了标记,以指定它们的依赖关系。依赖关系通过传递类名和方法名来指定,格式为 `"TestClass::test_method"`。
这样,你就可以使用测试类来组织和管理测试用例,并使用 `@pytest.mark.dependency` 来标记它们之间的依赖关系。在运行测试时,pytest 将按照定义的依赖关系顺序执行测试方法。
参数化测试用例
import pytest@pytest.mark.parametrize("x,y", [pytest.param(0, 0, marks=pytest.mark.dependency(name="a1")),pytest.param(0, 1, marks=[pytest.mark.dependency(name="a2"),pytest.mark.xfail]),pytest.param(1, 0, marks=pytest.mark.dependency(name="a3")),pytest.param(1, 1, marks=pytest.mark.dependency(name="a4"))
])
def test_a(x,y):assert y <= x@pytest.mark.parametrize("u,v", [pytest.param(1, 2, marks=pytest.mark.dependency(name="b1", depends=["a1", "a2"])),pytest.param(1, 3, marks=pytest.mark.dependency(name="b2", depends=["a1", "a3"])),pytest.param(1, 4, marks=pytest.mark.dependency(name="b3", depends=["a1", "a4"])),pytest.param(2, 3, marks=pytest.mark.dependency(name="b4", depends=["a2", "a3"])),pytest.param(2, 4, marks=pytest.mark.dependency(name="b5", depends=["a2", "a4"])),pytest.param(3, 4, marks=pytest.mark.dependency(name="b6", depends=["a3", "a4"]))
])
def test_b(u,v):pass@pytest.mark.parametrize("w", [pytest.param(1, marks=pytest.mark.dependency(name="c1", depends=["b1", "b2", "b6"])),pytest.param(2, marks=pytest.mark.dependency(name="c2", depends=["b2", "b3", "b6"])),pytest.param(3, marks=pytest.mark.dependency(name="c3", depends=["b2", "b4", "b6"]))
])
def test_c(w):pass运行时依赖
有时,测试实例的依赖关系太复杂,无法使用 pytest.mark.dependency() 标记在运行之前明确地进行公式化。在运行时编译测试的依赖关系列表可能更容易。在这种情况下,pytest_dependency.depends() 函数非常有用。考虑以下示例:
```python
import pytest
from pytest_dependency import depends@pytest.mark.dependency
def test_a():assert False@pytest.mark.dependency
def test_b():depends(test_a())assert True
```在这个示例中,我们使用 pytest_dependency.depends() 函数定义了 test_b() 依赖于 test_a() 的关系。这样,我们可以在运行时根据 test_b() 的需要动态地编译依赖关系列表。
使用 pytest_dependency.depends() 函数时,只需将需要依赖的测试方法作为函数参数传递给它即可。
指明作用范围
scope的默认范围是module,所以基本使用的例子也可以写为如下,
实现效果没有区别,只是指明了范围
import pytest@pytest.mark.dependency()
@pytest.mark.xfail(reason="deliberate fail")
def test_a():assert False@pytest.mark.dependency()
def test_b():pass@pytest.mark.dependency(depends=["test_a"], scope='module')
def test_c():pass@pytest.mark.dependency(depends=["test_b"], scope='module')
def test_d():pass@pytest.mark.dependency(depends=["test_b", "test_c"], scope='module')
def test_e():pass跨模块需要指明范围为session
如果一个用例依赖的另一个用例在不同的模块,依赖的用例的scope必须是session或者是package。
# test_mod_01.pyimport pytest@pytest.mark.dependency()
def test_a():pass@pytest.mark.dependency()
@pytest.mark.xfail(reason="deliberate fail")
def test_b():assert False@pytest.mark.dependency(depends=["test_a"])
def test_c():passclass TestClass(object):@pytest.mark.dependency()def test_b(self):pass# test_mod_02.pyimport pytest@pytest.mark.dependency()
@pytest.mark.xfail(reason="deliberate fail")
def test_a():assert False@pytest.mark.dependency(depends=["tests/test_mod_01.py::test_a", "tests/test_mod_01.py::test_c"],scope='session'
)
def test_e():pass@pytest.mark.dependency(depends=["tests/test_mod_01.py::test_b", "tests/test_mod_02.py::test_e"],scope='session'
)
def test_f():pass@pytest.mark.dependency(depends=["tests/test_mod_01.py::TestClass::test_b"],scope='session'
)
def test_g():pass范围为class
测试依赖关系也可以在类范围的级别上定义。这仅适用于测试类中的方法,并将依赖限制为同一类中的其他测试方法。
import pytest@pytest.mark.dependency()
@pytest.mark.xfail(reason="deliberate fail")
def test_a():assert Falseclass TestClass1(object):@pytest.mark.dependency()def test_b(self):passclass TestClass2(object):@pytest.mark.dependency()def test_a(self):pass@pytest.mark.dependency(depends=["test_a"])def test_c(self):pass@pytest.mark.dependency(depends=["test_a"], scope='class')def test_d(self):pass@pytest.mark.dependency(depends=["test_b"], scope='class')def test_e(self):pass一组测试使用fixture
pytest 在测试用例中对 fixture 实例进行自动分组。如果有一组测试用例,并且需要针对每个测试用例运行一系列的测试,这将非常有用。
例如:
```python
import pytest# 定义一个测试用例
@pytest.fixture(params=[1, 2, 3])
def test_case(request):return request.param# 运行多次测验
def test_my_tests(test_case):assert test_case > 0def test_other_tests(test_case):assert test_case < 10
```在这个示例中,我们定义了一个名为 `test_case` 的 fixture,它使用 `@pytest.fixture` 装饰器和 `params` 参数来定义一个包含多个测试用例的列表。然后,我们使用 `test_case` fixture 来运行多个测试方法 `test_my_tests` 和 `test_other_tests`。pytest 会自动将这些测试方法与每个测试用例进行匹配,并为每个测试用例运行对应的测试方法。
通过这种方式,我们可以轻松地为每个测试用例执行一系列的测试,而不需要手动为每个测试用例编写独立的测试方法。
使用夹具为用例分组
pytest具有按夹具实例自动分组测试的功能。如果存在一组测试用例,并且对于每个测试用例都需要运行一系列的测试,这一特性尤其有用。
import pytest
from pytest_dependency import depends@pytest.fixture(scope="module", params=range(1,10))
def testcase(request):param = request.paramreturn param@pytest.mark.dependency()
def test_a(testcase):if testcase % 7 == 0:pytest.xfail("deliberate fail")assert False@pytest.mark.dependency()
def test_b(request, testcase):depends(request, ["test_a[%d]" % testcase])passif __name__ == '__main__':pytest.main(["-sv"]) 因为test_a[7]执行失败,所以test_b[7]被跳过。
因为test_a[7]执行失败,所以test_b[7]被跳过。
如果多个测试方法依赖于一个测试方法,则可以把pytest_dependency.depends()调用单独写一个fixture
import pytest
from pytest_dependency import depends@pytest.fixture(scope="module", params=range(1,10))
def testcase(request):param = request.paramreturn param@pytest.fixture(scope="module")
def dep_testcase(request, testcase):depends(request, ["test_a[%d]" % testcase])return testcase@pytest.mark.dependency()
def test_a(testcase):if testcase % 7 == 0:pytest.xfail("deliberate fail")assert False@pytest.mark.dependency()
def test_b(dep_testcase):pass@pytest.mark.dependency()
def test_c(dep_testcase):passtest_b[7]和test_c[7] 会被跳过,因为test_a[7]失败了。
依赖参数化测试方法
如果一个测试同时依赖于一个参数化测试的所有实例,逐个列出它们在 pytest.mark.dependency() 标记中可能不是最佳解决方案。但是可以根据参数值动态地编译这些列表,如以下示例所示:
import pytestdef instances(name, params):def vstr(val):if isinstance(val, (list, tuple)):return "-".join([str(v) for v in val])else:return str(val)return ["%s[%s]" % (name, vstr(v)) for v in params]params_a = range(17)@pytest.mark.parametrize("x", params_a)
@pytest.mark.dependency()
def test_a(x):if x == 13:pytest.xfail("deliberate fail")assert Falseelse:pass@pytest.mark.dependency(depends=instances("test_a", params_a))
def test_b():passparams_c = list(zip(range(0,8,2), range(2,6)))@pytest.mark.parametrize("x,y", params_c)
@pytest.mark.dependency()
def test_c(x, y):if x > y:pytest.xfail("deliberate fail")assert Falseelse:pass@pytest.mark.dependency(depends=instances("test_c", params_c))
def test_d():passparams_e = ['abc', 'def']@pytest.mark.parametrize("s", params_e)
@pytest.mark.dependency()
def test_e(s):if 'e' in s:pytest.xfail("deliberate fail")assert Falseelse:pass@pytest.mark.dependency(depends=instances("test_e", params_e))
def test_f():passtest_b, test_d, and test_f will be skipped because they depend on all instances of test_a, test_c, and test_e respectively, but test_a[13], test_c[6-5], and test_e[def] fail. The list of the test instances is compiled in the helper function instances().
缺点
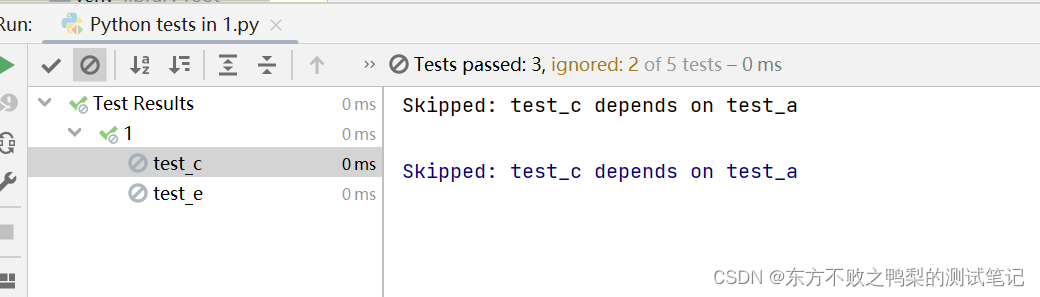
依赖用例执行顺序
这个库非常依赖用例的执行顺序,如在执行被依赖方法时,发现被依赖的方法未被执行,依赖方法会被忽略。
import pytest@pytest.mark.dependency()
def test_b():pass@pytest.mark.dependency(depends=["test_a"])
def test_c():pass@pytest.mark.dependency(depends=["test_b"])
def test_d():pass@pytest.mark.dependency(depends=["test_b", "test_c"])
def test_e():pass
@pytest.mark.dependency()
@pytest.mark.xfail(reason="deliberate fail")
def test_a():assert True
if __name__ == '__main__':pytest.main(["-sv"])这个例子最后执行a,但c,e仍被忽略了。
相关文章:
测试框架pytest教程(2)-用例依赖库-pytest-dependency
对于 pytest 的用例依赖管理,可以使用 pytest-dependency 插件。该插件提供了更多的依赖管理功能,使你能够更灵活地定义和控制测试用例之间的依赖关系。 Using pytest-dependency — pytest-dependency 0.5.1 documentation 安装 pytest-dependency 插…...

electron软件安装时,默认选择为全部用户安装
后续可能会用electron开发一些工具,包括不限于快速生成个人小程序、开发辅助学习的交互式软件、帮助运维同学一键部署的简易版CICD工具等等。 开发进度,取决于我懒惰的程度。 不过不嫌弃的同学还是可以先关注一波小程序,真的发布工具了&…...

MySQL常用表级操作
基础信息相关 1.修改表名: rename table 旧表名 to 新表名; 2、修改字段类型: alter table 表名 modify column 字段名 字段类型(长度) 3、修改字段名称和类型: alter table 表名 change 现有字段名称 修改后字段名称 数据类型 4、增加字段&a…...
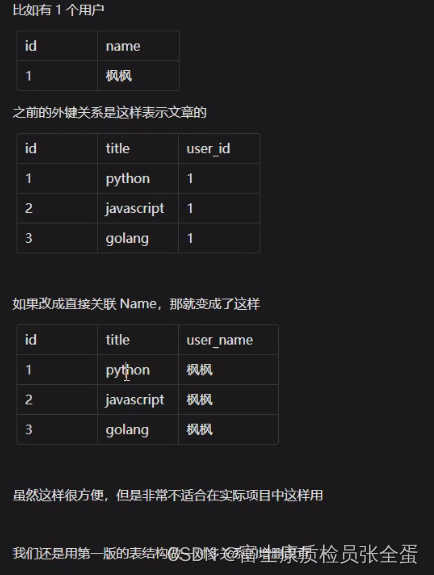
Golang Gorm 一对多关系 关系表创建
一对多关系 我们先从一对多开始多表关系的学习因为一对多的关系生活中到处都是,例如: 老板与员工女神和添狗老师和学生班级与学生用户与文章 在创建的时候先将没有依赖的创建。表名称ID就是外键。外键要和关联的外键的数据类型要保持一致。 package ma…...

java八股文面试[数据结构]——ConcurrentHashMap原理
HashMap不是线程安全: 在并发环境下,可能会形成环状链表(扩容时可能造成,具体原因自行百度google或查看源码分析),导致get操作时,cpu空转,所以,在并发环境中使用HashMap是…...

学习记录——FeatEnHancer
FeatEnHancer: Enhancing Hierarchical Features for Object Detection and Beyond Under Low-Light Vision 一种适用于任意低光照任务增强方法 ICCV 2023 提出了FeatEnHancer,一种用于低光照视觉任务的增强型多尺度层次特征的新方法。提议的解决方案重点增强相关特…...

OpenCV中常用的函数
OpenCV是一个功能强大的计算机视觉库,提供了众多用于图像处理、计算机视觉和机器学习的函数和模块。以下是一些OpenCV中常用的函数和模块的子集: 图像读取和显示: cv::imread:用于读取图像文件。cv::imshow:用于显示图…...
【福利】Google Cloud Next ’23 精彩待发,Cloud Ace 作为联合赞助商提前发福利~
【Cloud Ace 是 Google Cloud 全球战略合作伙伴,在亚太地区、欧洲、南北美洲和非洲拥有二十多个办公室。Cloud Ace 在谷歌专业领域认证及专业知识目前排名全球第一位,并连续多次获得 Google Cloud 各类奖项。作为谷歌云托管服务商,我们提供谷…...
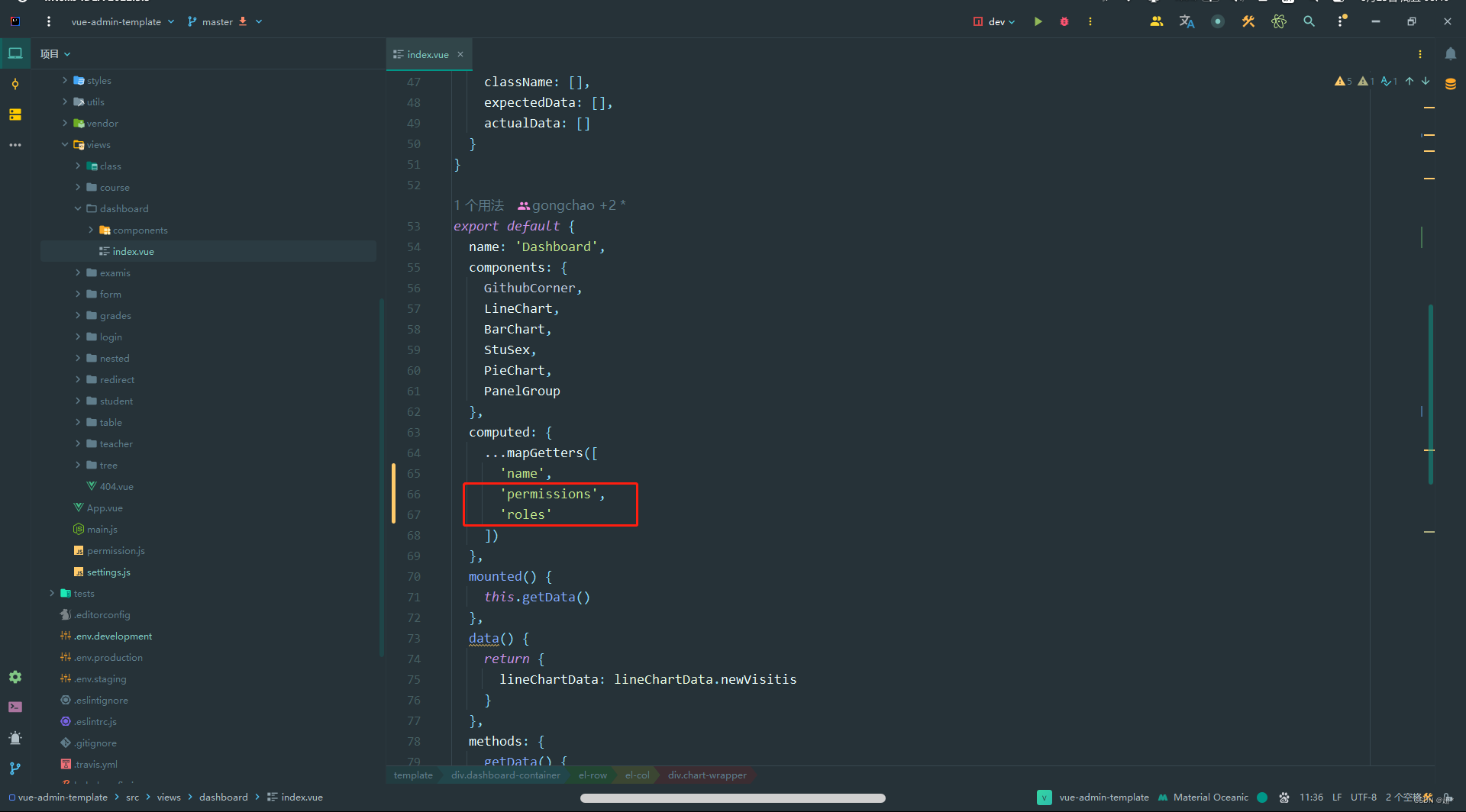
vue-admin-template实现按钮级控制
这里记录一下使用大佬的模板vue-admin-template,实现按钮级别控制 实现的思路:用户登录之后,返回用户详细信息(将用户的所有权限码发送给前端),然后将权限码保存在全局状态管理对象中,然后在组件中进行判断是否显示 最…...

数据驱动工作效率提升的5个层次—以PreMaint设备数字化平台为例
在现代工业领域,数据分析已成为提升工作效率和优化生产的不可或缺的工具。从描述性分析到规范性分析,数据分析逐步揭示了设备运行和维护的深层信息,帮助企业更明智地做出决策。本文将以PreMaint设备数字化平台为例,探讨工业数据驱…...
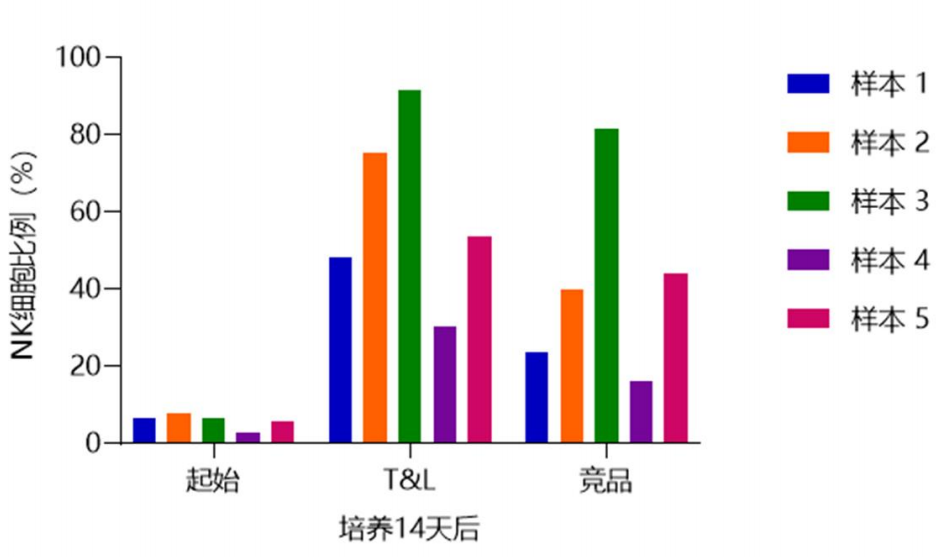
白介素对NK细胞功能的影响(IL-1β、IL-12、IL-15、IL-18、IL-21)
1、促进NK细胞扩增和活化:IL-2/21 Soiffer RJ等自1996年起即报道IL-2低剂量持续输注和间歇给药对转移癌患者的CD56NK细胞有明显扩增效果。大部分NK细胞表面具有IL-2中亲和性受体,IL-2诱导NK的杀伤活性约需18~24小时。此外,IL-2还…...

C++笔记之虚函数重写规则、返回类型协变、函数的隐藏
C笔记之虚函数重写规则、返回类型协变、函数的隐藏 code review! 文章目录 C笔记之虚函数重写规则、返回类型协变、函数的隐藏1.返回类型协变2.C中函数的隐藏 —— C Primer Plus (第6版) —— cppreference 1.返回类型协变 2.C中函数的隐藏 在C中&a…...

抢鲜体验!vLive虚拟直播5大实用新功能上线!
vLive虚拟直播系统2.6.2版本全新上线!新版本一共更新了5项实用功能,能让你的直播操作更加方便。现在就跟随小编一起来看看吧! 1.本地下载场景支持一键迁移 用户下载后的场景可以直接迁移至另一个磁盘,无需重复下载。 2.信号源添加…...
网约车平台如何开发?需要多少钱?
随着共享经济的兴起,网约车行业迅速发展,并成为人们生活中不可或缺的一部分。为了满足市场需求和提供更好的服务,开发一款高质量的网约车源码平台至关重要。本文将深入探讨网约车源码平台的开发方案,从技术架构、安全性和用户体验…...
——刷点链表的题(涉及智能指针Box,持续更新))
Rust踩雷笔记(5)——刷点链表的题(涉及智能指针Box,持续更新)
目录 leetcode 2 两数相加——模式匹配单链表Box 只能说Rust链表题的画风和C完全不一样,作为新手一时间还不太适应,于是单独为链表、智能指针开一篇,主要记录leetcode相关题型的答案以及注意事项。 leetcode 2 两数相加——模式匹配单链表Bo…...
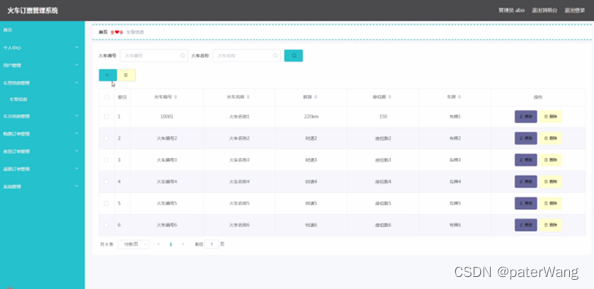
[附源码]计算机毕业设计-JAVA火车票订票管理系统-springboot-论-文-ppt
PPT论文 文章目录 前言一、主要技术javaMysql数据库JSP技术 二、系统设计三、功能截图总结 前言 本论文主要论述了如何使用JAVA语言开发一个火车订票管理系统 ,本系统将严格按照软件开发流程进行各个阶段的工作,采用B/S架构,面向对象编程思想…...
)
CARLA spawn Actor (Vehicle and Pedestrian)
1. Spawn Vehicles 2. Spawn Pedestrian References [1] Carla简单入门-1 基本的API使用 - 知乎 [2] https://carla.org/2019/07/12/release-0.9.6/...

【官方中文文档】Mybatis-Spring #SqlSessionFactoryBean
SqlSessionFactoryBean 在基础的 MyBatis 用法中,是通过 SqlSessionFactoryBuilder 来创建 SqlSessionFactory 的。而在 MyBatis-Spring 中,则使用 SqlSessionFactoryBean 来创建。 设置 要创建工厂 bean,将下面的代码放到 Spring 的 XML …...

el-tree树回显删除某项,再次点开树形组件无变化,实际数据已改变
el-tree树回显删除某项,再次点开树形组件无变化,实际数据已改变 页面有添加和删除已选选项的按钮,点击删除一个选项,再点添加,打开树形弹窗,发现弹窗被删除的选项还在 原因: 发现是添加的时候&…...
生产作业标准化是什么?生产车间作业流程标准化的步骤
生产作业标准化是以精益化为目标,对现行作业方法进行量化细化的分析改善,最终形成优化后的更好的作业程序。标准化的作用主要是以文件的方式保存企业成员积累的技术和经验,而不是因为人员的流动而失去整个技术和经验。 生产作业标准化的实施非…...

设计模式和设计原则回顾
设计模式和设计原则回顾 23种设计模式是设计原则的完美体现,设计原则设计原则是设计模式的理论基石, 设计模式 在经典的设计模式分类中(如《设计模式:可复用面向对象软件的基础》一书中),总共有23种设计模式,分为三大类: 一、创建型模式(5种) 1. 单例模式(Sing…...
)
rknn优化教程(二)
文章目录 1. 前述2. 三方库的封装2.1 xrepo中的库2.2 xrepo之外的库2.2.1 opencv2.2.2 rknnrt2.2.3 spdlog 3. rknn_engine库 1. 前述 OK,开始写第二篇的内容了。这篇博客主要能写一下: 如何给一些三方库按照xmake方式进行封装,供调用如何按…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

k8s业务程序联调工具-KtConnect
概述 原理 工具作用是建立了一个从本地到集群的单向VPN,根据VPN原理,打通两个内网必然需要借助一个公共中继节点,ktconnect工具巧妙的利用k8s原生的portforward能力,简化了建立连接的过程,apiserver间接起到了中继节…...

实现弹窗随键盘上移居中
实现弹窗随键盘上移的核心思路 在Android中,可以通过监听键盘的显示和隐藏事件,动态调整弹窗的位置。关键点在于获取键盘高度,并计算剩余屏幕空间以重新定位弹窗。 // 在Activity或Fragment中设置键盘监听 val rootView findViewById<V…...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...

力扣-35.搜索插入位置
题目描述 给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 请必须使用时间复杂度为 O(log n) 的算法。 class Solution {public int searchInsert(int[] nums, …...

听写流程自动化实践,轻量级教育辅助
随着智能教育工具的发展,越来越多的传统学习方式正在被数字化、自动化所优化。听写作为语文、英语等学科中重要的基础训练形式,也迎来了更高效的解决方案。 这是一款轻量但功能强大的听写辅助工具。它是基于本地词库与可选在线语音引擎构建,…...