【数据结构与算法】2.八大经典排序
文章目录
- 简介
- 1.分析排序算法
- 2.插入排序
- 2.1.直接插入排序
- 2.2.希尔排序
- 3.选择排序
- 3.1.直接选择排序
- 3.2.堆排序
- 3.2.1.堆的数据结构
- 3.2.2.算法实现
- 4.交换排序
- 4.1.冒泡排序
- 4.2.快速排序
- 5.归并排序
- 6.基数排序
- 7.八大排序算法总结
简介
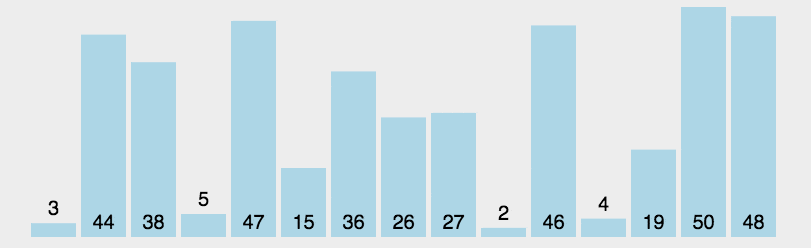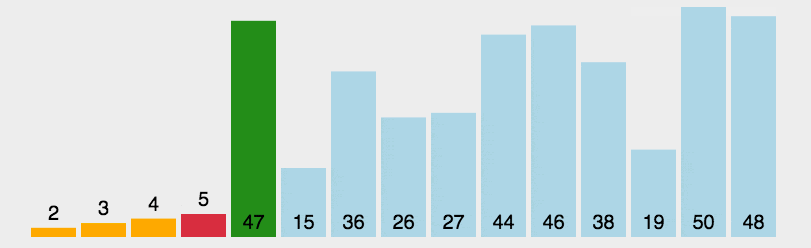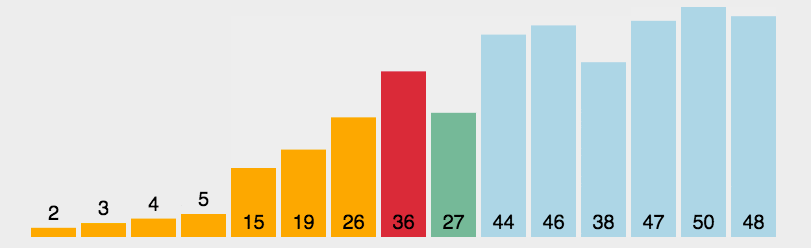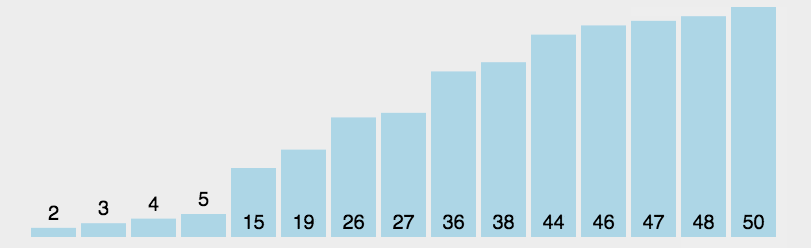
排序对于任何一个程序员来说,可能都不会陌生。我学的第一个算法就是冒泡排序。大部分编程语言中,也都提供了排序函数,如Java语言在Jdk1.8版本里Arrays.sort里使用排序算法根据不同数据量使用不同的算法,在数组元素小于47的时候用插入排序,大于47小于286用双轴快排,大于286用timsort归并排序;
比较经典和常用的就是以下八大排序。
推荐一个数据结构可视化的页面: https://visualgo.net/en
1.分析排序算法
排序算法的执行效率
对于排序算法执行效率的分析,我们一般会从这几个方面来衡量:
- 1.最好情况、最坏情况、平均情况时间复杂度:
分析排序算法的时间复杂度时,要分别给出最好情况、最坏情况、平均情况下的时间复杂度。 - 2.时间复杂度的系数、常数 、低阶
时间复杂度反应的是数据规模n很大的时候的一个增长趋势,所以它表示的时候会忽略系数、常数、低阶。但是实际的软件开发中,我们排序的可能是10个、100个这种规模很小的数据,所以,在对同一阶时间复杂度的排序算法性能对比的时候,我们就要把系数、常数、低阶也考虑进来。 - 3.比较次数和交换次数
基于比较的排序算法的执行过程,会涉及两种操作,一种是元素比较大小,另一种是元素交换。所以,如果我们在分析排序算法的执行效率(时间复杂度)的时候,应该把比较次数和交换(或移动)次数也考虑进去。
排序算法的内存消耗
算法的内存消耗可以通过空间复杂度来衡量,排序算法也不例外。不过,针对排序算法的空间复杂度,有一个新的概念原地排序(Sorted in place)。原地排序算法,就是特指空间复杂度是O(1)的排序算法,原地排序就是指不申请多余的空间来进行的排序,就是在原来的排序数据中比较和交换的排序,像归并排序和
属于原地排序算法:希尔排序、冒泡排序、直接插入排序、直接选择排序、堆排序、快速排序
排序算法的稳定性
仅仅用执行效率和内存消耗来衡量排序算法的好坏是不够的。针对排序算法,我们还有一个重要的度量指标,稳定性。这个概念是说,如果待排序的序列中存在值相等的元素,经过排序之后,相等元素之间原有的先后顺序不变。
例如我们有一组数据1,5,6,7,8,6,按照大小排序之后就是1,5,6,6,7,8。
这组数据里有两个6。经过某种排序算法排序之后,如果两个6的前后顺序没有改变,那我们就把这种排序算法叫作稳定的排序算法;如果前后顺序发生变化,那对应的排序算法就叫作不稳定的排序算法。
- 稳定排序算法: 冒泡排序、直接插入排序、归并排序、基数排序
- 不稳定排序算法: 希尔排序、堆排序、直接选择排序,快速排序
2.插入排序
2.1.直接插入排序
基本思想
直接插入排序(Insertion Sort) 对于少量元素的排序,它是一种最简单的排序方法,它的基本思想是将一个记录插入到已经排好序的有序表中,从而一个新的、记录数增1的有序表。在其实现过程使用双层循环,外层循环对除了第一个元素之外的所有元素,内层循环对当前元素前面有序表进行待插入位置查找,并进行移动。
例如我们在打牌玩斗地主的时候摸完牌然后整理顺序是一张一张的来,将每一张牌插入到其他已经有序的牌中的适当位置。在计算机的实现中,为了要给插入的元素腾出空间,我们需要将其余所有元素在插入之前都向右移动一位。
算法描述
一般来说,插入排序都采用in-place在数组上实现。具体算法描述如下:
- 1.从第一个元素开始,该元素可以认为已经被排序
- 2.取出下一个元素,在已经排序的元素序列中从后向前扫描
- 3.如果该元素(已排序)大于新元素,将该元素移到下一位置
- 4.重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 5.将新元素插入到该位置后
- 6.重复步骤2~5
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(n²) | O(n²) | O(n²) | O(1) |
基于Java语言实现代码如下
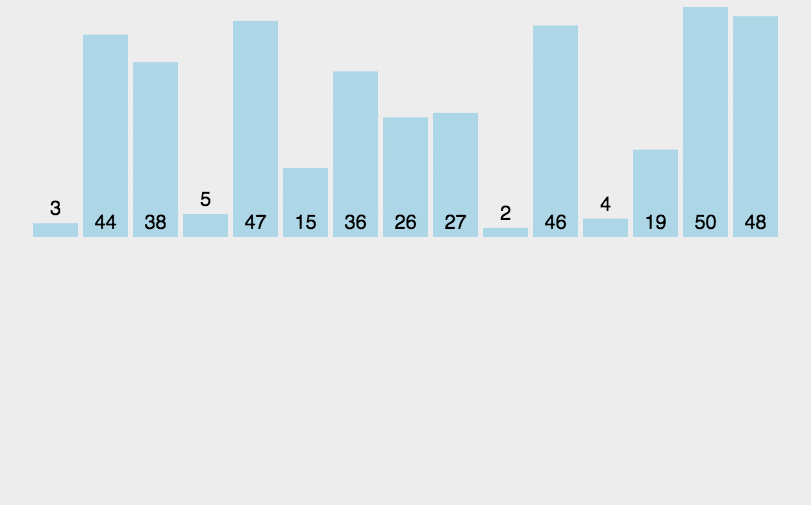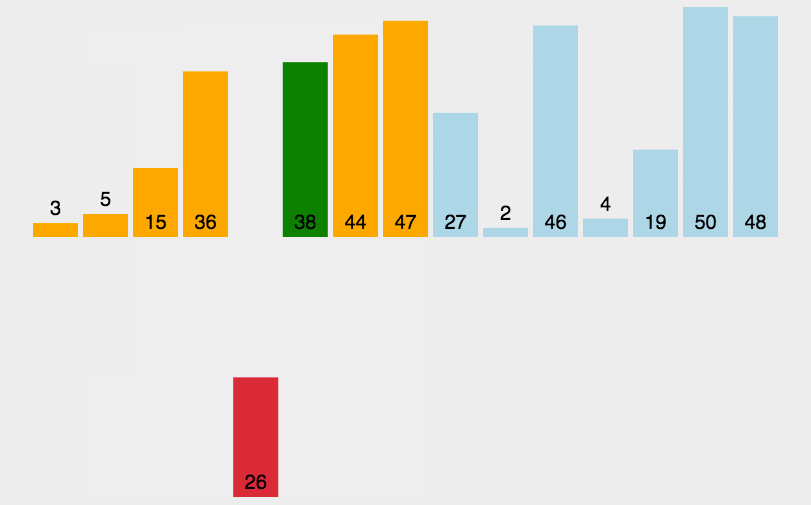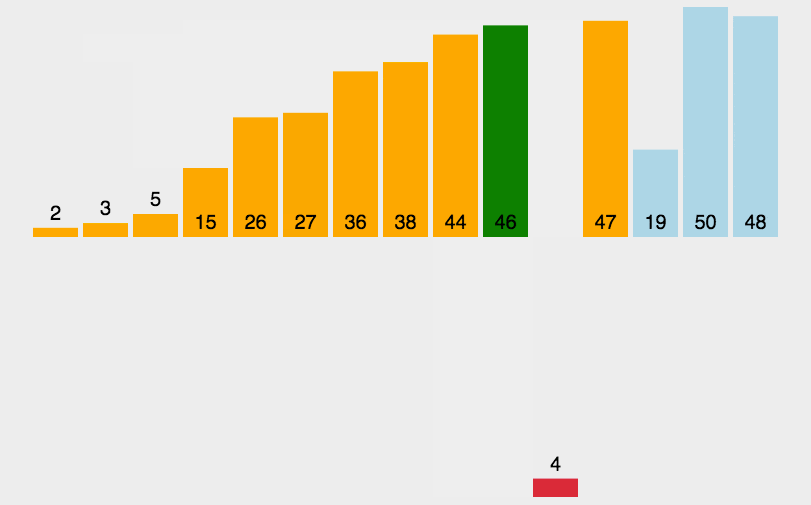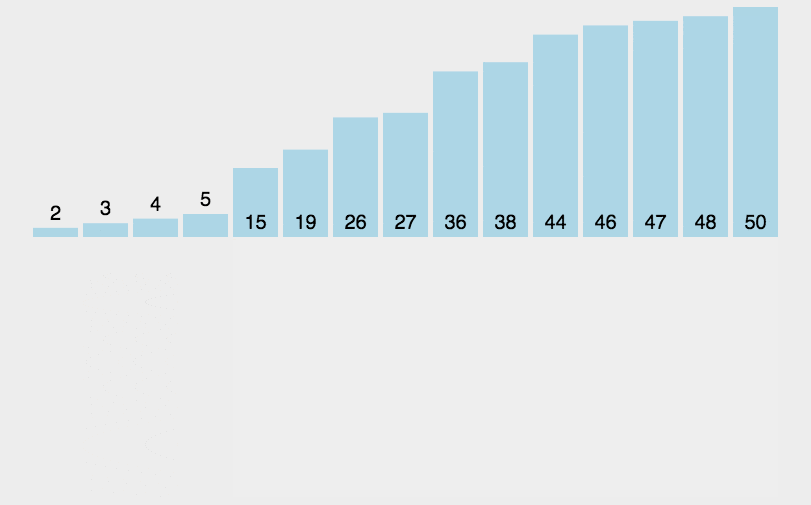
public static void sort(int nums[]) {for (int i = 1; i < nums.length; i++) {//若第 i 个元素大于 i-1 元素则直接插入;反之,需要找到适当的插入位置后在插入。if (nums[i] < nums[i - 1]) {int j = i - 1;int x = nums[i];//采用顺序查找方式找到插入的位置,在查找的同时,将数组中的元素进行后移操作,给插入元素腾出空间while (j > -1 && x < nums[j]) {nums[j + 1] = nums[j];j--;}//插入到正确位置nums[j + 1] = x;}}}//测试public static void main(String[] args) {int nums[] = new int[]{3, 44, 38, 5, 47, 15, 36, 26, 27,2,46,4,19,50,48};sort(nums);System.out.println(Arrays.toString(nums));}

总结: 插入排序所需的时间取决于输入元素的初始顺序。例如对一个很大且其中的元素已经有序(或接近有序)的数组进行排序将会比随机顺序的数组或是逆序数组进行排序要快得多。
2.2.希尔排序
基本思想
希尔排序(SheII Sort),也称 递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是 非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一
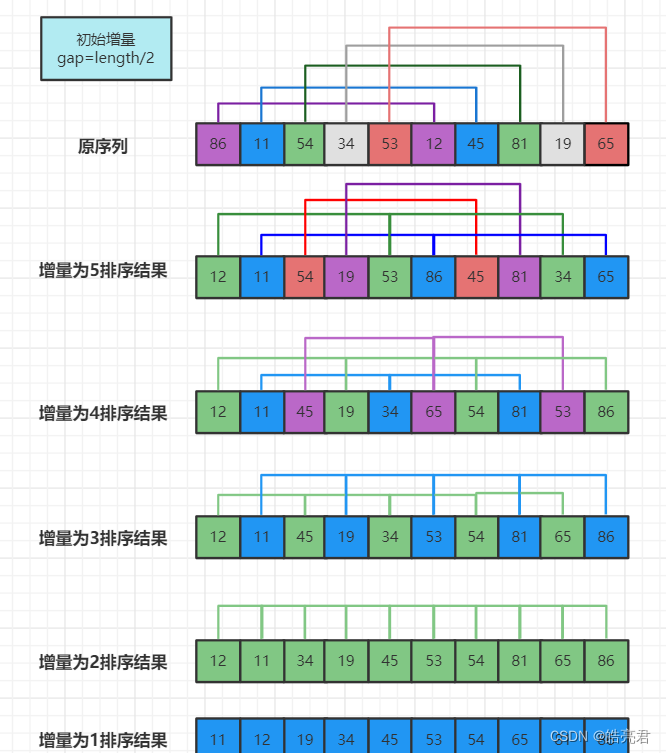
希尔排序是先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录“基本有序”时,再对全体记录进行依次直接插入排序。
将待排序数组按照步长gap进行分组,然后将每组的元素利用直接插入排序的方法进行排序;每次再将gap折半减小,循环上述操作;当gap=1时,利用直接插入,完成排序。
可以看到步长的选择是希尔排序的重要部分。只要最终步长为1任何步长序列都可以工作。一般来说最简单的步长取值是初次取数组长度的一半为增量,之后每次再减半,直到增量为1。更好的步长序列取值可以参考维基百科。
算法描述
- 1.选择一个增量序列 q1,q2,……,qk,其中 qi > qj, qk = 1;
- 2.按增量序列个数 k,对序列进行 k 趟排序;
- 3.每次排序,根据对应的增量 qi,将待排序列分割成若干长度为 m 的子序列,分别对各子表进行直接插入排序。仅增量因子为 1 时,整个序列作为一个表来处理,表长度即为整个序列的长度。
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(nlog2 n) | O(nlog2 n) | O(nlog2 n) | O(1) |
基于Java语言实现代码如下
public static void sort(int nums[]) {int gap = nums.length;while (true) {//增量每次减半gap /= 2; for (int i = 0; i < gap; i++) {//下面循环是一个插入排序for (int j = i + gap; j < nums.length; j += gap) {int k = j - gap;while (k >= 0 && nums[k] > nums[k + gap]) {int temp = nums[k];nums[k] = nums[k + gap];nums[k + gap] = temp;k -= gap;}}}if (gap == 1) {break;}}}public static void main(String[] args) {int nums[] = {86, 11, 54, 34, 53,12,45,81,19,65};sort(nums);System.out.println(Arrays.toString(nums));}
总结: 希尔排序更高效的原因是它权衡了子数组的规模和有序性。排序之初,各个子数组都很短,排序之后子数组都是部分有序的,这两种情况都很适合插入排序。

3.选择排序
3.1.直接选择排序
基本思想
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理如下。首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。以此类推,直到所有元素均排序完毕。
选择排序的主要优点与数据移动有关。如果某个元素位于正确的最终位置上,则它不会被移动。选择排序每次交换一对元素,它们当中至少有一个将被移到其最终位置上,因此对 n个元素的表进行排序总共进行至多 n-1 次交换。在所有的完全依靠交换去移动元素的排序方法中,选择排序属于非常好的一种。
算法描述
- 1.从未排序序列中,找到关键字最小的元素
- 2.如果最小元素不是未排序序列的第一个元素,将其和未排序序列第一个元素互换
- 3.重复1、2步,直到排序结束。
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(n²) | O(n²) | O(n²) | O(1) |
基于Java语言实现代码如下
public static void sort(int[] nums) {for (int i = 0; i < nums.length; i++) {int min = i;//选出之后待排序中值最小的位置for (int j = i + 1; j < nums.length; j++) {if (nums[j] < nums[min]) {min = j;}}//最小值不等于当前值时进行交换if (min != i) {int temp = nums[i];nums[i] = nums[min];nums[min] = temp;}}}public static void main(String[] args) {int nums[] = new int[]{3, 44, 38, 5, 47, 15, 36, 26, 27,2,46,4,19,50,48};sort(nums);System.out.println(Arrays.toString(nums));}

总结:选择排序的简单和直观名副其实,这也造就了它”出了名的慢性子”,无论是哪种情况,哪怕原数组已排序完成,它也将花费将近n²/2次遍历来确认一遍。即便是这样,它的排序结果也还是不稳定的。 唯一值得高兴的是,它并不耗费额外的内存空间。
3.2.堆排序
3.2.1.堆的数据结构
堆(HeapHeapHeap)一种特殊的树,堆这种数据结构的应用场景非常多,最经典的莫过于堆排序了。堆排序是一种原地的排序算法。
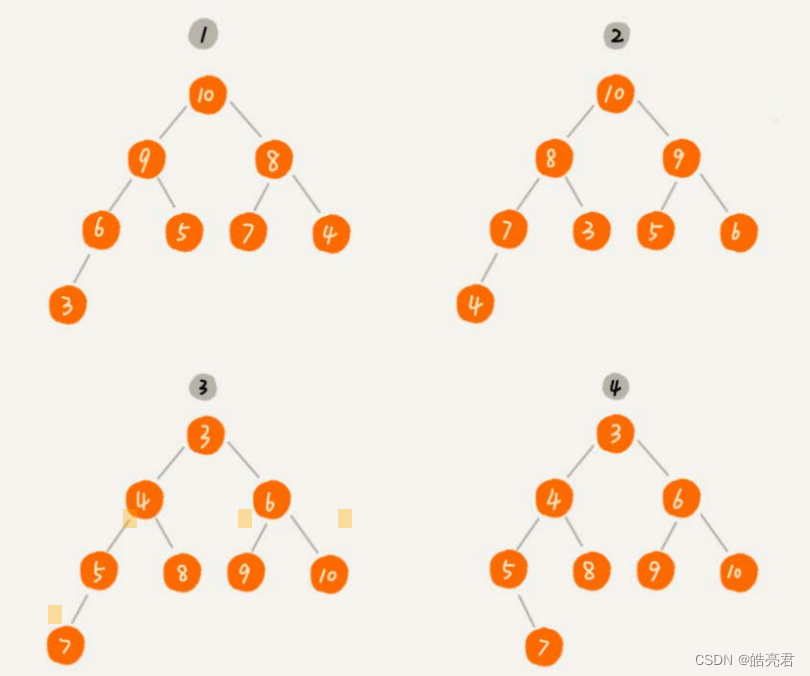
符合以下两点的树就是堆(二叉堆):
- 1.堆是一个完全二叉树;
- 2.堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。
第一点: 堆必须是一个完全二叉树,完全二叉树要求除了最后一层,其他层的节点个数都是满的,最后一层的节点都靠左排列。
第二点: 堆中的每个节点的值必须大于等于(或者小于等于)其子树中每个节点的值。实际上,我们还可以换一种说法,堆中每个节点的值都大于等于(或者小
于等于)其左右子节点的值。这两种表述是等价的。
下图中其中第1个和第2是大顶堆,第3个是小顶堆,第4个不是堆,一般在应用中大顶堆用的比较多,可用参考这个数据结构可视化网站二叉堆: https://visualgo.net/zh/heap
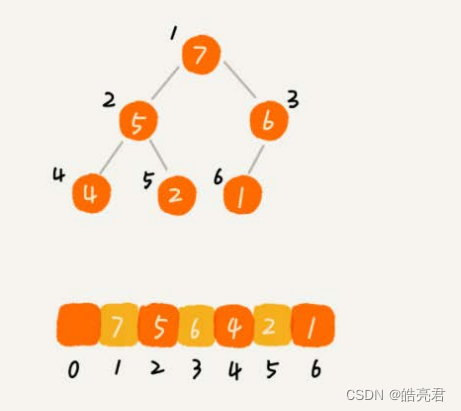
完全二叉树比较适合用数组来存储。用数组来存储完全二叉树是非常节省存储空间的。因为我们不需要存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点。
以下用数组存储堆的例子
3.2.2.算法实现
基本思想
此处以大顶堆为例,堆排序的过程就是将待排序的序列构造成一个堆,选出堆中最大的移走,再把剩余的元素调整成堆,找出最大的再移走,重复直至有序。
算法描述
- 1.先将初始序列K[1…n]建成一个大顶堆, 那么此时第一个元素K1最大, 此堆为初始的无序区.
- 2.再将关键字最大的记录K1 (即堆顶, 第一个元素)和无序区的最后一个记录 Kn 交换, 由此得到新的无序区K[1…n−1]和有序区K[n], 且满足K[1…n−1].keys⩽K[n].key
- 3.交换K1 和 Kn 后, 堆顶可能违反堆性质, 因此需将K[1…n−1]调整为堆. 然后重复步骤2, 直到无序区只有一个元素时停止。

| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(nlog2n) | O(nlog2n) | O(nlog2n) | O(1) |
代码实现
从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆函数,二是反复调用建堆函数以选择出剩余未排元素中最大的数来实现排序的函数。
创建堆和排序:
- 最大堆调整(Max_Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
- 创建最大堆(Build_Max_Heap):将堆所有数据重新排序
- 堆排序(HeapSort):移除位在第一个数据的根节点,并做最大堆调整运算
对于堆节点的访问:
- 父节点i的左子节点在位置:(2*i+1);
- 父节点i的右子节点在位置:(2*i+2);
- 子节点i的父节点在位置:floor((i-1)/2);
public static void sort(int[] nums) {for (int i = nums.length - 1; i > 0; i--) {max_heapify(nums, i);//堆顶元素(第一个元素)与Kn交换int temp = nums[0];nums[0] = nums[i];nums[i] = temp;}}/***** 将数组堆化* i = 第一个非叶子节点。* 从第一个非叶子节点开始即可。无需从最后一个叶子节点开始。* 叶子节点可以看作已符合堆要求的节点,根节点就是它自己且自己以下值为最大。*/public static void max_heapify(int[] nums, int n) {int child;for (int i = (n - 1) / 2; i >= 0; i--) {//左子节点位置child = 2 * i + 1;//右子节点存在且大于左子节点,child变成右子节点if (child != n && nums[child] < nums[child + 1]) {child++;}//交换父节点与左右子节点中的最大值if (nums[i] < nums[child]) {int temp = nums[i];nums[i] = nums[child];nums[child] = temp;}}}public static void main(String[] args) {int[] nums = new int[]{91, 60, 96, 13, 35, 65, 46, 65, 10, 30, 20, 31, 77, 81, 22};sort(nums);System.out.println(Arrays.toString(nums));}

总结:由于堆排序中初始化堆的过程比较次数较多, 因此它不太适用于小序列。 同时由于多次任意下标相互交换位置, 相同元素之间原本相对的顺序被破坏了, 因此, 它是不稳定的排序。
4.交换排序
4.1.冒泡排序
基本思想
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
算法描述
比较相邻的元素。如果第一个比第二个大,就交换他们两个。对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。针对所有的元素重复以上的步骤,除了最后一个。持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
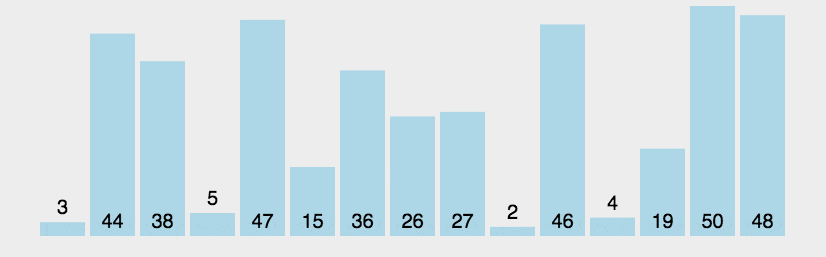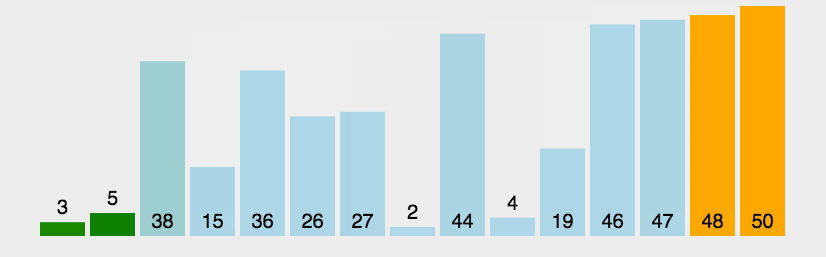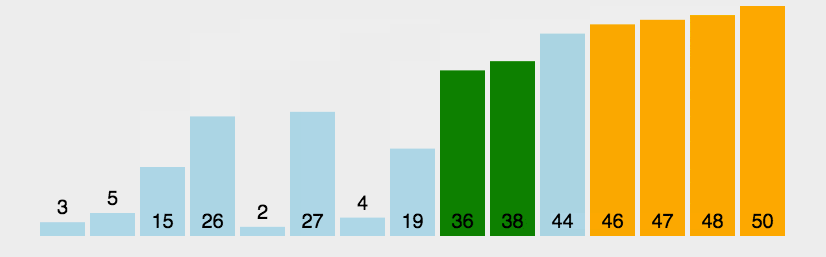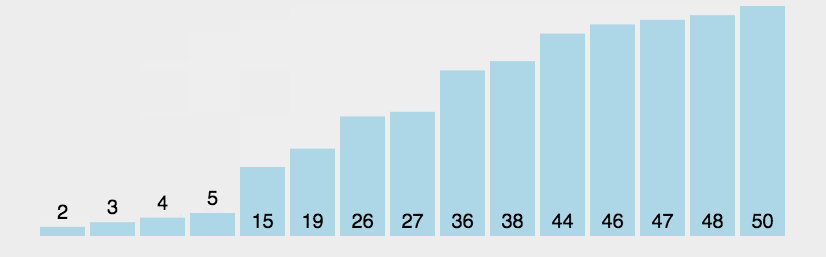
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(n²) | O(n) | O(n²) | O(1) |
基于Java语言实现代码如下
public static void sort(int nums[]) {int temp;for (int i = 0; i < nums.length; i++) {for (int j = i + 1; j < nums.length; j++) {if (nums[i] > nums[j]) {temp = nums[i];nums[i] = nums[j];nums[j] = temp;}}}}public static void main(String[] args) {int[] nums = new int[]{3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48};sort(nums);System.out.println(Arrays.toString(nums));}
总结:由于冒泡排序只在相邻元素大小不符合要求时才调换他们的位置, 它并不改变相同元素之间的相对顺序, 因此它是稳定的排序算法。
4.2.快速排序
基本思想
快速排序(Quick Sort)的基本思想:挖坑填数+分治法。快速排序使用分治法(Divide and conquer)策略来把一个串行(list)分为两个子串行(sub-lists)。快速排序又是一种分而治之思想在排序算法上的典型应用。本质上来看,快速排序应该算是在冒泡排序基础上的递归分治法。
快速排序的名字起的是简单粗暴,因为一听到这个名字你就知道它存在的意义,就是快,而且效率高!它是处理大数据最快的排序算法之一了。虽然 Worst Case 的时间复杂度达到了 O(n²),但是人家就是优秀,在大多数情况下都比平均时间复杂度为 O(n logn) 的排序算法表现要更好。
算法描述
快速排序使用分治策略来把一个序列(list)分为两个子序列(sub-lists)。步骤为:
- 1.从数列中挑出一个元素,称为"基准"(pivot)。
- 2.重新排序数列,所有比基准值小的元素摆放在基准前面,所有比基准值大的元素摆在基准后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 3.递归地(recursively)把小于基准值元素的子数列和大于基准值元素的子数列排序。
递归到最底部时,数列的大小是零或一,也就是已经排序好了。这个算法一定会结束,因为在每次的迭代(iteration)中,它至少会把一个元素摆到它最后的位置去。
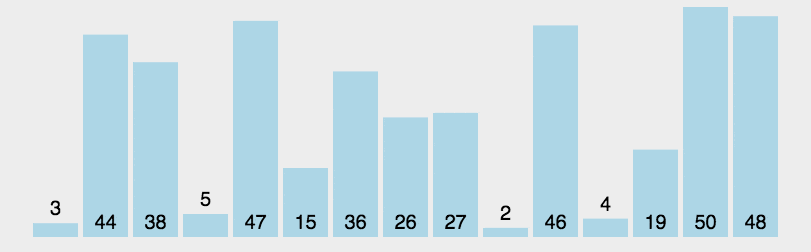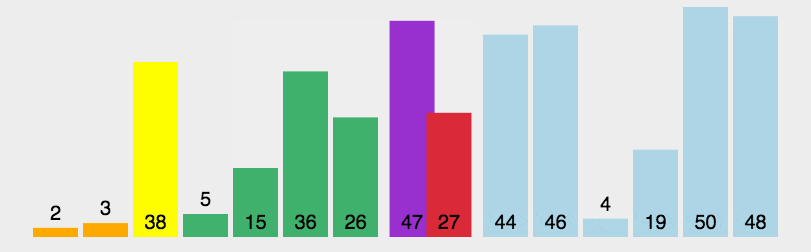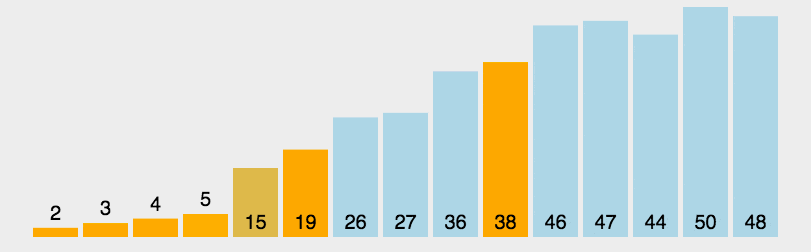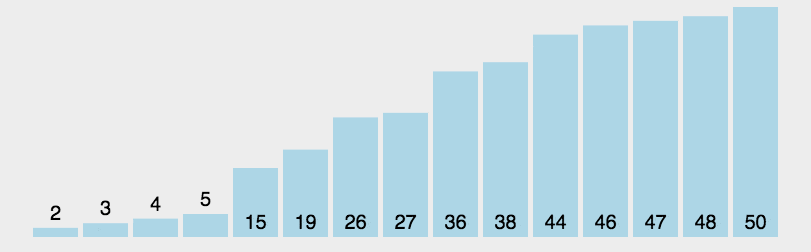
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(nlog₂n) | O(nlog₂n) | O(n²) | O(1)(原地分区递归版) |
基于Java语言实现代码如下
/*** @param nums * @param low 起始* @param high 结束*/public static void sort(int[] nums, int low, int high) {//已经排完if (low >= high) {return;}int left = low;int right = high;//保存基准值int pivot = nums[left];while (left < right) {//从后向前找到比基准小的元素while (left < right && nums[right] >= pivot) {right--;}nums[left] = nums[right];//从前往后找到比基准大的元素while (left < right && nums[left] <= pivot) {left++;}nums[right] = nums[left];}// 放置基准值,准备分治递归快排nums[left] = pivot;sort(nums, low, left - 1);sort(nums, left + 1, high);}public static void main(String[] args) {int[] nums = new int[]{2, 5, 4, 3, 7, 1, 6, 2, 10};sort(nums,0,nums.length-1);System.out.println(Arrays.toString(nums));}

总结:快速排序和归并排序是两种稍微复杂的排序算法,它们用的都是分治的思想,代码都通过递归来实现,过程非常相似。归并排序算法是一种在任何情况下时间复杂度都比较稳定的排序算法,这也使它存在致命的缺点,即归并排序不是原地排序算法,空间复杂度比较高,是O(n)。正因为此,它也没有快排应用广泛。
5.归并排序
基本思想
归并排序(Merge Sort)是建立在归并操作上的一种有效的排序算法,1945年由约翰·冯·诺伊曼首次提出。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用,且各层分治递归可以同时进行。
归并排序算法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的。然后再把有序子序列合并为整体有序序列
算法描述
归并排序可通过两种方式实现:
- 自上而下的递归 (本文讲递归法)
- 自下而上的迭代(请自行补充)
递归法(假设序列共有n个元素):
- 1.将序列每相邻两个数字进行归并操作,形成 floor(n/2)个序列,排序后每个序列包含两个元素;
- 2.将上述序列再次归并,形成 floor(n/4)个序列,每个序列包含四个元素;
- 3.重复步骤2,直到所有元素排序完毕。
| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(nlog₂n) | O(nlog₂n) | O(nlog₂n) | O(n) |
基于Java语言实现代码如下
public static void sort(int [] nums,int lo,int hi){//判断是否是最后一个元素if(lo>=hi){return;}//重中间将数组分为两个部分int mid=lo+(hi-lo)/2;//分别递归将左右两半排好序sort(nums,lo,mid);sort(nums,mid+1,hi);//将排好序的左右两半合并merge(nums,lo,mid,hi);}/**** @param nums* @param low 右偏移的数* @param mid 中位数 * @param high 查找的范围*/private static void merge(int[] nums,int low,int mid,int high){//复制原来的数组int [] copy=nums.clone();//定义一个k指定表示重什么位置开始修改原来的数组,i指针左半边的位置,j表示右半边的位置int k=low,i=low,j=mid+1;while (k<=high){if(i>mid){// 左半边的数据处理完成,将右半边的数copy就行nums[k++]=copy[j++];}else if(j>high){// 右半边的数据处理完成,将左半边的数copy就行nums[k++]=copy[i++];}else if(copy[j]<copy[i]){//右边的数小于左边的数,将右边的数拷贝到合适的位置,j指针往前移动一位nums[k++]=copy[j++];}else{//左边的数小于右边的数,将左边的数拷贝到合适的位置,i指针往前移动一位nums[k++]=copy[i++];}}}public static void main(String[] args) {int[] nums=new int[]{1,3,4,5,11,6,7,5,28};sort(nums,0,nums.length-1);System.out.println(Arrays.toString(nums));}

总结: 从效率上看,归并排序可算是排序算法中的”佼佼者”. 假设数组长度为n,那么拆分数组共需logn,, 又每步都是一个普通的合并子数组的过程, 时间复杂度为O(n), 故其综合时间复杂度为O(nlogn)。另一方面, 归并排序多次递归过程中拆分的子数组需要保存在内存空间, 其空间复杂度为O(n)。
6.基数排序
基本思想
基数排序(Radix sort)是一种非比较型整数排序算法,其原理是将整数按位数切割成不同的数字,然后按每个位数分别比较。由于整数也可以表达字符串(比如名字或日期)和特定格式的浮点数,所以基数排序也不是只能使用于整数。
基数排序将所有待比较数值(正整数)统一为同样的数位长度,数位较短的数前面补零。然后,从最低位开始,依次进行一次排序。这样从最低位排序一直到最高位排序完成以后,数列就变成一个有序序列。
基数排序按照优先从高位或低位来排序有两种实现方案:
-
MSD(Most significant digital) 从最左侧高位开始进行排序。先按k1排序分组, 同一组中记录, 关键码k1相等, 再对各组按k2排序分成子组, 之后, 对后面的关键码继续这样的排序分组, 直到按最次位关键码kd对各子组排序后. 再将各组连接起来, 便得到一个有序序列。MSD方式适用于位数多的序列。
-
LSD (Least significant digital)从最右侧低位开始进行排序。先从kd开始排序,再对kd-1进行排序,依次重复,直到对k1排序后便得到一个有序序列。LSD方式适用于位数少的序列。
算法描述
我们以LSD为例,从最低位开始,具体算法描述如下:
-
1.取得数组中的最大数,并取得位数;
-
2.arr为原始数组,从最低位开始取每个位组成radix数组;
-
3.对radix进行计数排序(利用计数排序适用于小范围数的特点);

| 平均时间复杂度 | 最好情况 | 最坏情况 | 空间复杂度 |
|---|---|---|---|
| O(d*(n+r)) | O(d*(n+r)) | O(d*(n+r)) | O(n+r) |
基于Java语言实现代码如下
public static void sort(int[] nums) {if (nums.length <= 1) return;//取得数组中的最大数,并取得位数int max = 0;for (int i = 0; i < nums.length; i++) {if (max < nums[i]) {max = nums[i];}}int maxDigit = 1;while (max / 10 > 0) {maxDigit++;max = max / 10;}//申请一个桶空间int[][] buckets = new int[10][nums.length];int base = 10;//从低位到高位,对每一位遍历,将所有元素分配到桶中for (int i = 0; i < maxDigit; i++) {//存储各个桶中存储元素的数量int[] bktLen = new int[10];//分配:将所有元素分配到桶中for (int j = 0; j < nums.length; j++) {int whichBucket = (nums[j] % base) / (base / 10);buckets[whichBucket][bktLen[whichBucket]] = nums[j];bktLen[whichBucket]++;}//收集:将不同桶里数据挨个捞出来,为下一轮高位排序做准备,由于靠近桶底的元素排名靠前,因此从桶底先捞int k = 0;for (int b = 0; b < buckets.length; b++) {for (int p = 0; p < bktLen[b]; p++) {nums[k++] = buckets[b][p];}}base *= 10;}}public static void main(String[] args) {int[] nums = new int[]{3, 44, 38, 5, 47, 15, 36, 26, 27,2,46,4,19,50,48};sort(nums);System.out.println(Arrays.toString(nums));}

7.八大排序算法总结
各种排序性能对比如下:
| 排序类型 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 冒泡排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 |
| 插入排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 希尔排序 | O(n^1.3) | O(nlogn) | O(n²) | O(1) | 不稳定 |
| 归并排序 | O(nlog₂n) | O(nlog₂n) | O(nlog₂n) | O(n) | 稳定 |
| 快速排序 | O(nlog₂n) | O(nlog₂n) | O(n²) | O(nlog₂n) | 不稳定 |
| 堆排序 | O(nlog₂n) | O(nlog₂n) | O(nlog₂n) | O(1) | 不稳定 |
| 基数排序 | O(d(n+k)) | O(d(n+k)) | O(d(n+kd)) | O(n+kd) | 稳定 |
从时间复杂度来说:
- 平方阶O(n²)排序:各类简单排序:直接插入、直接选择和冒泡排序
- 线性对数阶O(nlog₂n)排序:快速排序、堆排序和归并排序
- O(n1+§))排序,§是介于0和1之间的常数:希尔排序
- 线性阶O(n)排序:基数排序,此外还有桶排序、计数排序
论是否有序的影响:
- 当原表有序或基本有序时,直接插入排序和冒泡排序将大大减少比较次数和移动记录的次数,时间复杂度可降至O(n);
- 而快速排序则相反,当原表基本有序时,将蜕化为冒泡排序,时间复杂度提高为O(n2);
- 原表是否有序,对简单选择排序、堆排序、归并排序和基数排序的时间复杂度影响不大。
相关文章:
【数据结构与算法】2.八大经典排序
文章目录简介1.分析排序算法2.插入排序2.1.直接插入排序2.2.希尔排序3.选择排序3.1.直接选择排序3.2.堆排序3.2.1.堆的数据结构3.2.2.算法实现4.交换排序4.1.冒泡排序4.2.快速排序5.归并排序6.基数排序7.八大排序算法总结简介 排序对于任何一个程序员来说,可能都不会…...
Windows 免安装版mysql,快速配置教程
简单步骤 下载并解压mysql压缩包,把 “<mysql根目录>/bin” 路径添加到系统环境变量path中命令行执行 mysqld --initialize --console,初始化data目录(数据库表文件默认存放在" <mysql安装根目录>/data "目录下&#…...

空间误差分析:统一的应用导向处理(Matlab代码实现)
👨🎓个人主页:研学社的博客💥💥💞💞欢迎来到本博客❤️❤️💥💥🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密…...
【C++】引用、内联函数、auto关键字、范围for、nullptr
引用什么叫引用引用的特性常引用使用场景传值、传引用效率比较引用和指针的区别内联函数auto关键字(C11)基于范围的for循环(C11)指针空值nullptr(C11)引用 什么叫引用 引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内…...

pytest数据驱动
文章目录一、数据驱动概念二、数据驱动yaml1、yaml的基本语法:2、yaml支持的数据格式:3、安装4、使用5、读取方法a、目录结构b、yaml文件c、测试方法d、测试用例e、测试结果三、数据驱动excel1、安装导入2、操作3、读取方法a、目录结构b、excel文件c、测…...
OSI七层网络模型
应用层 定义了各种应用协议规范数据格式:HTTP协议、HTTPS协议、FTP协议、DNS协议、TFTP、SMTP等等。 表示层 翻译工作。提供一种公共语言、通信。 会话层 1、可以从校验点继续恢复数据进行重传。——大文件 2、自动收发,自动寻址的功能。 传输层 1、…...

易基因|MeRIP-seq揭示m6A RNA甲基化通过调控组蛋白泛素化来促进癌症生长和进展:Cancer Res
大家好,这里是专注表观组学十余年,领跑多组学科研服务的易基因。2022年05月16日,《Cancer Res》杂志发表了题为“M6A RNA Methylation Regulates Histone Ubiquitination to Support Cancer Growth and Progression”的研究论文,该…...

Java 日期处理踩过的坑
前言 整理Java日期处理遇到过的问题,希望对大家有帮助 制作不易,一键三连,谢谢大家。 1.用 Calendar 设置时间的坑 反例: //提供者模式获取实例Calendar calendar Calendar.getInstance();//获取当前时间Date currentDate c…...

一文吃透 Spring 中的IOC和DI(二)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...
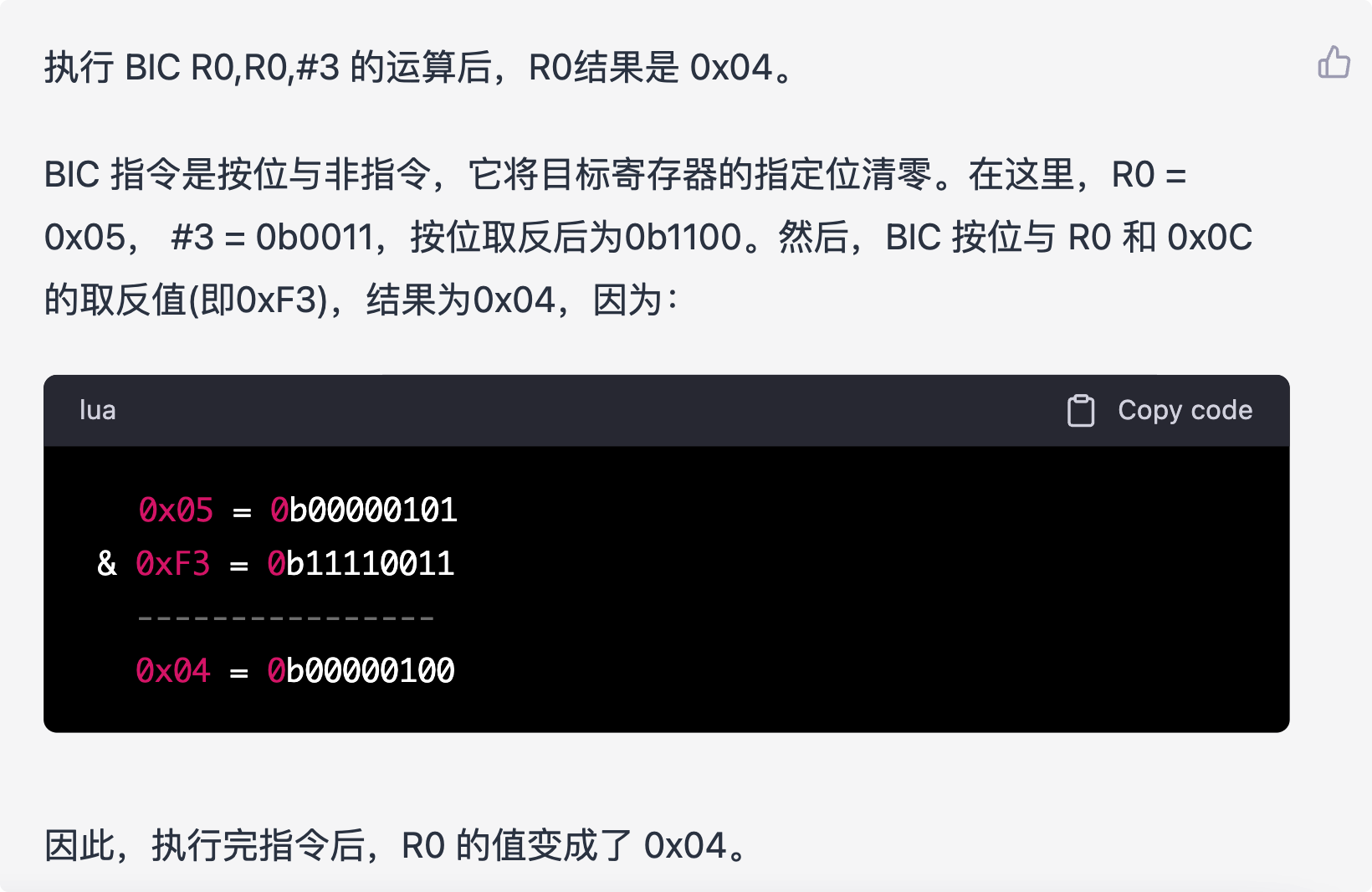
【期末指北】嵌入式系统——选择题(feat. ChatGPT)
作者|Rickyの水果摊 时间|2023年2月20日 基本信息 ☘️ 本博客摘录了一些 嵌入式系统 的 常见选择题,供有需求的同学们学习使用。 部分答案解析由 ChatGPT 生成,博主进行审核。 使用教材信息:《嵌入式系统设计与应…...
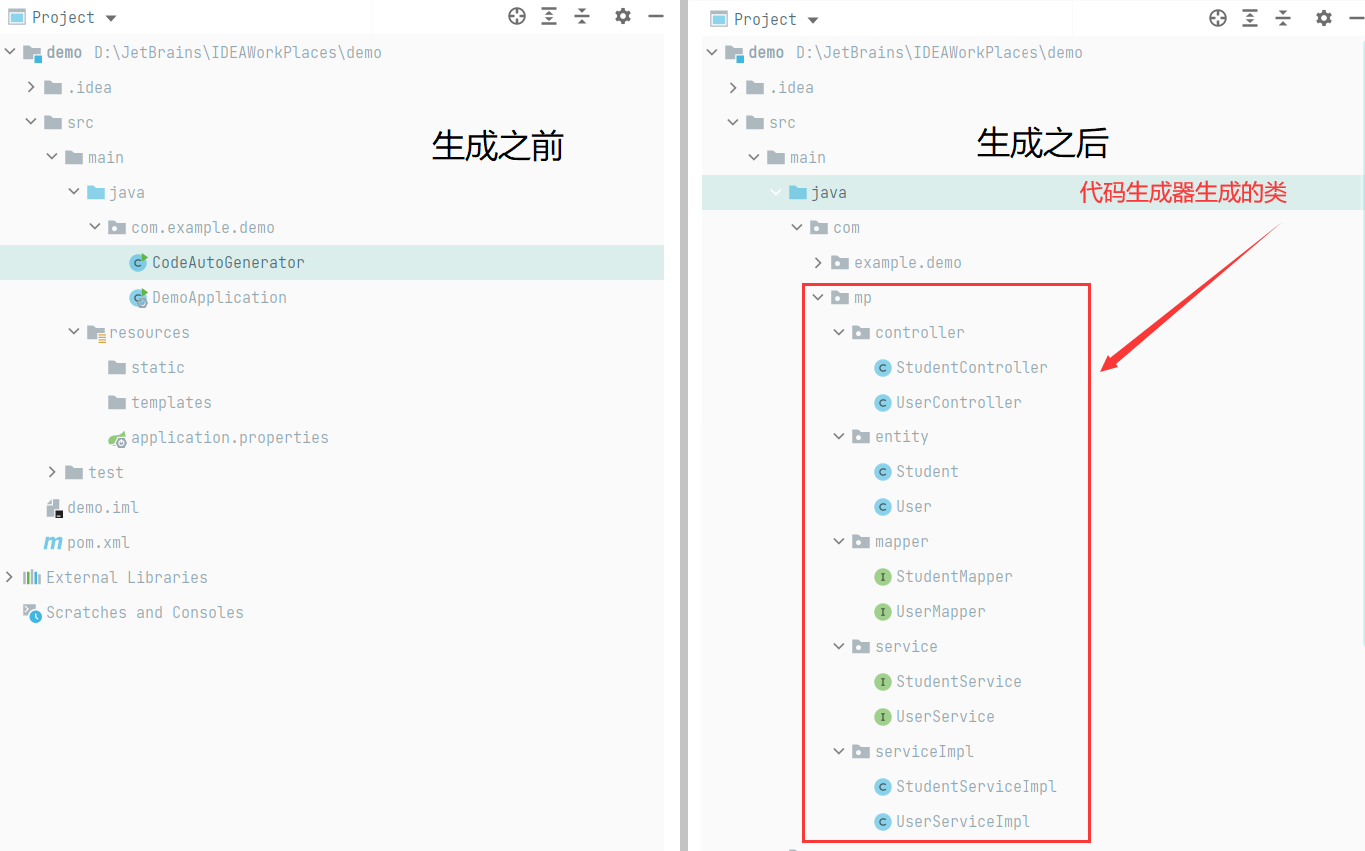
MyBatis-Plus——代码生成器(3.5.1+版本)
文章目录配置数据源配置(DataSource)全局配置(GlobalConfig)包配置(PackageConfig)策略配置(StrategyConfig)模板引擎配置(TemplateEngine)代码生成器测试样例…...

宁盾上榜第五版《CCSIP 2022 中国网络安全行业全景册》
2月1日,国内网络安全行业媒体Freebuf咨询正式发布《CCSIP(China Cyber Security Panorama)2022 中国网络安全行业全景册》第五版。宁盾作为国产身份安全厂商入驻身份识别和访问管理(SSO、OTP、IDaaS)及边界访问控制&am…...
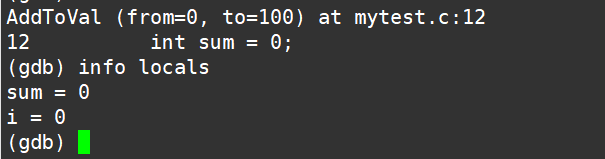
【Linux系统】第七篇:Linux调试器gdb的使用
文章目录一、gdb简介二、gdb的安装三、gdb使用3.1、release和debug版本3.2、gdb基本使用命令1、启动gdb2、调试命令3、显示代码(list)4、断点命令(breakpoint)5 、变量命令(variable)6、特殊调试命令7、调用…...

Shell 特殊变量及其含义
shell是我们在linux下编写自动执行程序的常见脚本工具,通常会涉及到以下几个特殊变量,它们分别是:$#、$*、$、$?、$$。 变量含义$0当前脚本的文件名。$n(n≥1)传递给脚本或函数的参数。n 是一个数字,表示…...

LeetCode 2396. 严格回文的数字
如果一个整数 n 在 b 进制下(b 为 2 到 n - 2 之间的所有整数)对应的字符串 全部 都是 回文的 ,那么我们称这个数 n 是 严格回文 的。 给你一个整数 n ,如果 n 是 严格回文 的,请返回 true ,否则返回 fals…...

【RocketMQ】源码详解:Broker启动流程
Broker启动 入口: org.apache.rocketmq.broker.BrokerStartup#main broker的启动主要分为两部分:1.创建brokerController 2.启动brokerController。与平时进行业务开发时不同的是,这里的BrokerController相当于Broker的一个中央控制器类&…...

vue事件
1. 事件传参 <button click"clickEvt($event, 22)">点我</button>2. 事件修饰符 prevent:阻止默认事件stop:阻止事件冒泡(加到子元素)once:事件只触发一次capture:使用事件的捕获模…...

研报精选230220
目录 【行业230220国信证券】银行业行业专题:经济复苏中的优质中小银行【行业230220国信证券】汽车行业周报(2023年第7周):吉利将发布新品牌“银河” ,2022年宇通纯电动客车获欧洲销量冠军【行业230220开源证券】商贸零…...

kubernetes sd configs配置详解
1.基于Kubernetes的服务发现 kubernetes_sd_config 这个是以角色(role)来定义收集的,Kubernetes SD配置允许从Kubernetes的RESTAPI中检索scrape目标,并始终与群集状态保持同步。 凡<role>必须是endpoints,service,pod&…...

Linux查看文件的命令
目录 1、tail 2、head 3、cat 4、more 5、sed 6、less Linux查看日志的命令有多种: tail、cat、tac、head、echo等,本文只介绍几种常用的方法。 1、tail 命令格式: tail[必要参数][选择参数][文件] -f 循环读取 -q 不显示处理信息 -v 显示详细的处理信…...

java_网络服务相关_gateway_nacos_feign区别联系
1. spring-cloud-starter-gateway 作用:作为微服务架构的网关,统一入口,处理所有外部请求。 核心能力: 路由转发(基于路径、服务名等)过滤器(鉴权、限流、日志、Header 处理)支持负…...
指令的指南)
在Ubuntu中设置开机自动运行(sudo)指令的指南
在Ubuntu系统中,有时需要在系统启动时自动执行某些命令,特别是需要 sudo权限的指令。为了实现这一功能,可以使用多种方法,包括编写Systemd服务、配置 rc.local文件或使用 cron任务计划。本文将详细介绍这些方法,并提供…...

rnn判断string中第一次出现a的下标
# coding:utf8 import torch import torch.nn as nn import numpy as np import random import json""" 基于pytorch的网络编写 实现一个RNN网络完成多分类任务 判断字符 a 第一次出现在字符串中的位置 """class TorchModel(nn.Module):def __in…...

网站指纹识别
网站指纹识别 网站的最基本组成:服务器(操作系统)、中间件(web容器)、脚本语言、数据厍 为什么要了解这些?举个例子:发现了一个文件读取漏洞,我们需要读/etc/passwd,如…...

破解路内监管盲区:免布线低位视频桩重塑停车管理新标准
城市路内停车管理常因行道树遮挡、高位设备盲区等问题,导致车牌识别率低、逃费率高,传统模式在复杂路段束手无策。免布线低位视频桩凭借超低视角部署与智能算法,正成为破局关键。该设备安装于车位侧方0.5-0.7米高度,直接规避树枝遮…...
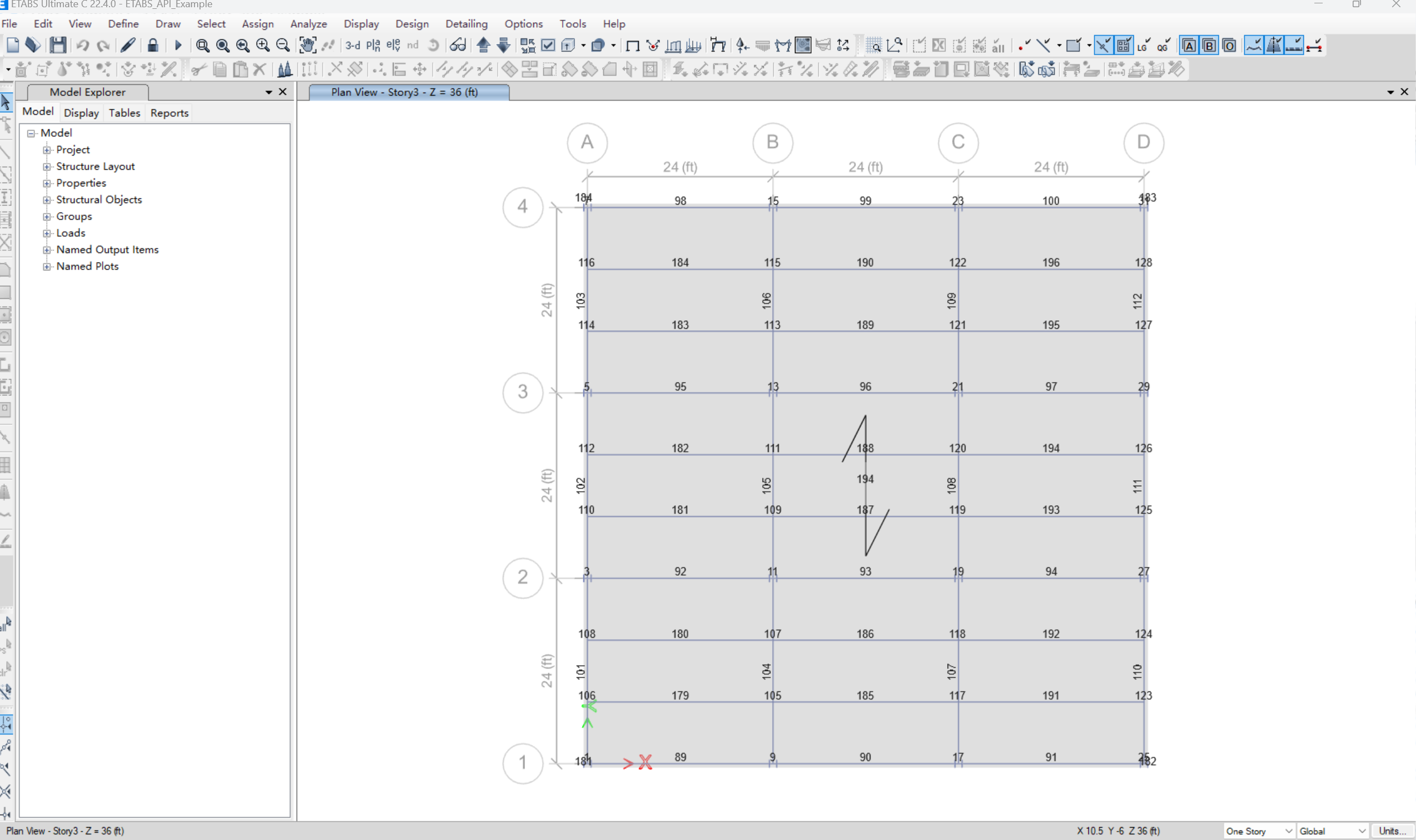
【Post-process】【VBA】ETABS VBA FrameObj.GetNameList and write to EXCEL
ETABS API实战:导出框架元素数据到Excel 在结构工程师的日常工作中,经常需要从ETABS模型中提取框架元素信息进行后续分析。手动复制粘贴不仅耗时,还容易出错。今天我们来用简单的VBA代码实现自动化导出。 🎯 我们要实现什么? 一键点击,就能将ETABS中所有框架元素的基…...
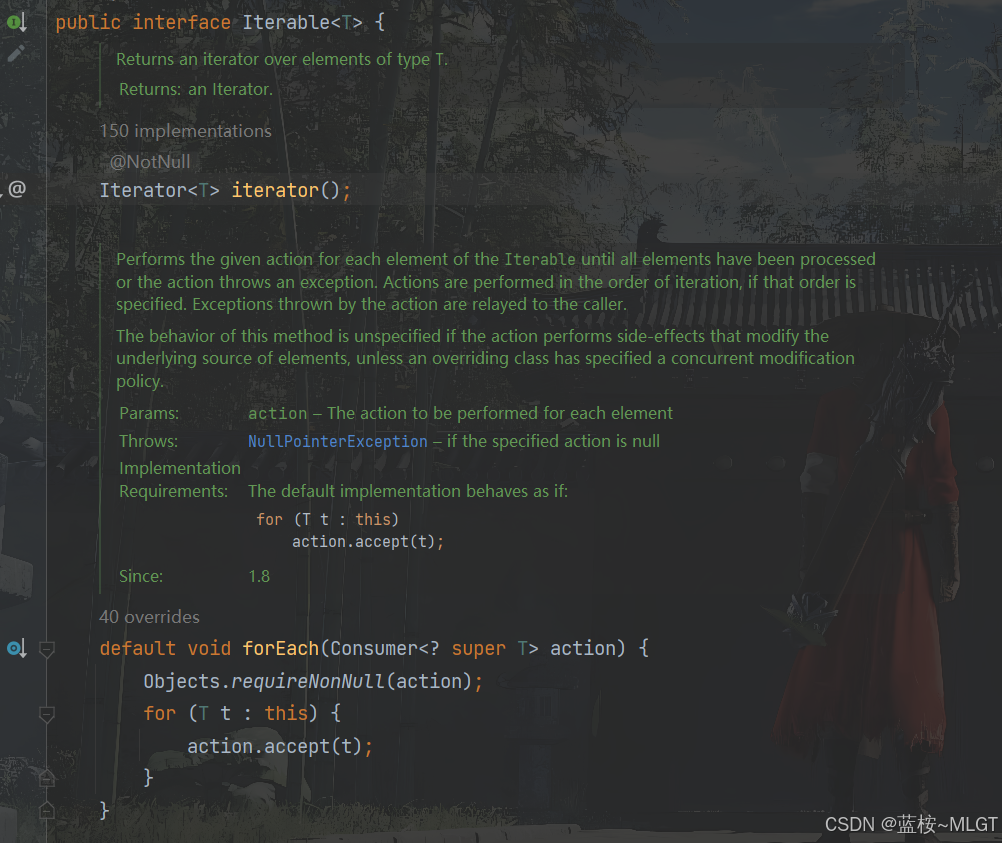
java高级——高阶函数、如何定义一个函数式接口类似stream流的filter
java高级——高阶函数、stream流 前情提要文章介绍一、函数伊始1.1 合格的函数1.2 有形的函数2. 函数对象2.1 函数对象——行为参数化2.2 函数对象——延迟执行 二、 函数编程语法1. 函数对象表现形式1.1 Lambda表达式1.2 方法引用(Math::max) 2 函数接口…...

Java 与 MySQL 性能优化:MySQL 慢 SQL 诊断与分析方法详解
文章目录 一、开启慢查询日志,定位耗时SQL1.1 查看慢查询日志是否开启1.2 临时开启慢查询日志1.3 永久开启慢查询日志1.4 分析慢查询日志 二、使用EXPLAIN分析SQL执行计划2.1 EXPLAIN的基本使用2.2 EXPLAIN分析案例2.3 根据EXPLAIN结果优化SQL 三、使用SHOW PROFILE…...

基于江科大stm32屏幕驱动,实现OLED多级菜单(动画效果),结构体链表实现(独创源码)
引言 在嵌入式系统中,用户界面的设计往往直接影响到用户体验。本文将以STM32微控制器和OLED显示屏为例,介绍如何实现一个多级菜单系统。该系统支持用户通过按键导航菜单,执行相应操作,并提供平滑的滚动动画效果。 本文设计了一个…...

boost::filesystem::path文件路径使用详解和示例
boost::filesystem::path 是 Boost 库中用于跨平台操作文件路径的类,封装了路径的拼接、分割、提取、判断等常用功能。下面是对它的使用详解,包括常用接口与完整示例。 1. 引入头文件与命名空间 #include <boost/filesystem.hpp> namespace fs b…...