AI夏令营第三期用户新增挑战赛学习笔记
1、数据可视化
1.数据探索和理解:数据可视化可以帮助我们更好地理解数据集的特征、分布和关系。通过可视化数据,我们可以发现数据中的模式、异常值、缺失值等信息,从而更好地了解数据的特点和结构。2.特征工程:数据可视化可以帮助我们选择和创建合适的特征。通过可视化特征与目标变量之间的关系,我们可以发现特征与目标之间的相关性、线性/非线性关系、重要性等信息,从而指导特征选择、变换和创建。3.模型评估和调优:数据可视化可以帮助我们评估和比较不同模型的性能。通过可视化模型的预测结果、误差分布、学习曲线等信息,我们可以了解模型的准确性、稳定性、过拟合/欠拟合等情况,并根据可视化结果进行模型调优和改进。4.结果解释和沟通:数据可视化可以帮助我们解释和传达机器学习模型的结果。通过可视化模型的预测、特征重要性、决策边界等信息,我们可以更直观地解释模型的工作原理和结果,使非技术人员也能理解和接受模型的输出。5.发现洞察和故事讲述:数据可视化可以帮助我们发现数据中的洞察和故事,并将其传达给观众。通过可视化数据的趋势、关联、分布等信息,我们可以发现数据中的有趣模式、趋势和关系,并通过可视化故事的方式将这些发现传达给观众。
# 导入库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns# 读取训练集和测试集文件
train_data = pd.read_csv('D:/D/Download/360安全浏览器下载/用户新增预测挑战赛公开数据/train.csv')
test_data = pd.read_csv('D:/D/Download/360安全浏览器下载/用户新增预测挑战赛公开数据/test.csv')print(train_data.info())
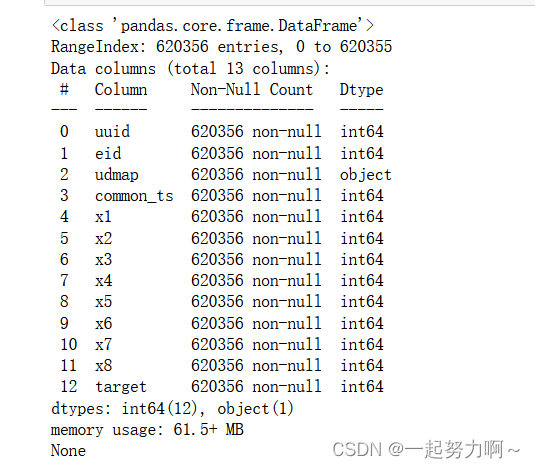
通过pd库的df.info()方法查看数据框属性,发现只有udmap字段为类别类型,其余皆为数值类型。
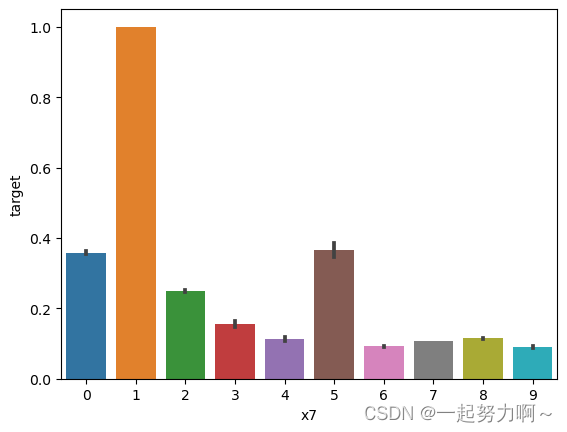
# x7分组下标签均值
sns.barplot(x='x7', y='target', data=train_data)
# 相关性热力图
sns.heatmap(train_data.corr().abs(), cmap='YlOrRd')
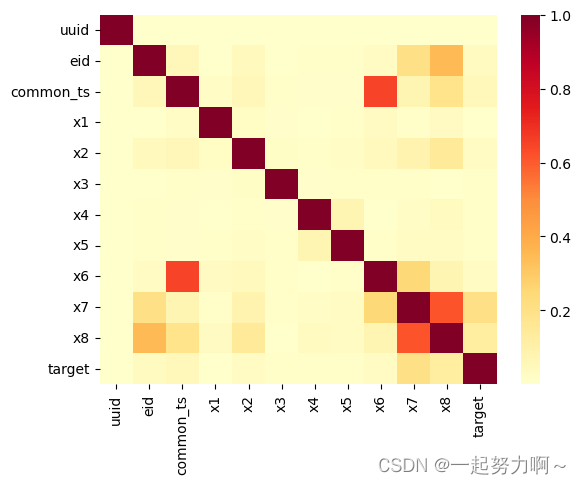
相关性热力图颜色越深代表相关性越强,所以x7和x8变量之间的关系更加密切,还有common_ts与x6也是。即存在很强的多重共线性,进行特征工程时可以考虑剔除二者中的一个变量,以免导致因多重共线性造成的过拟合。
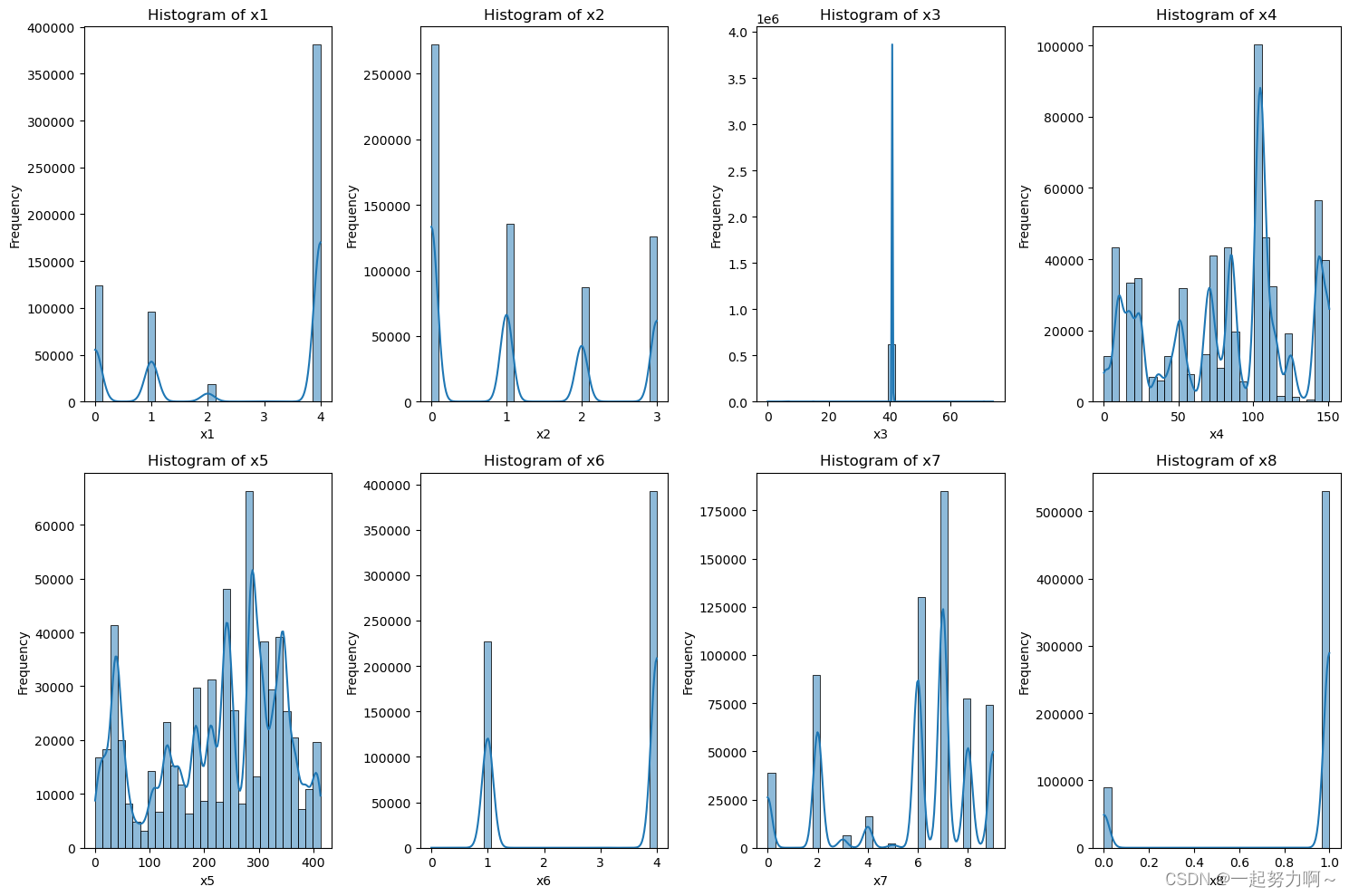
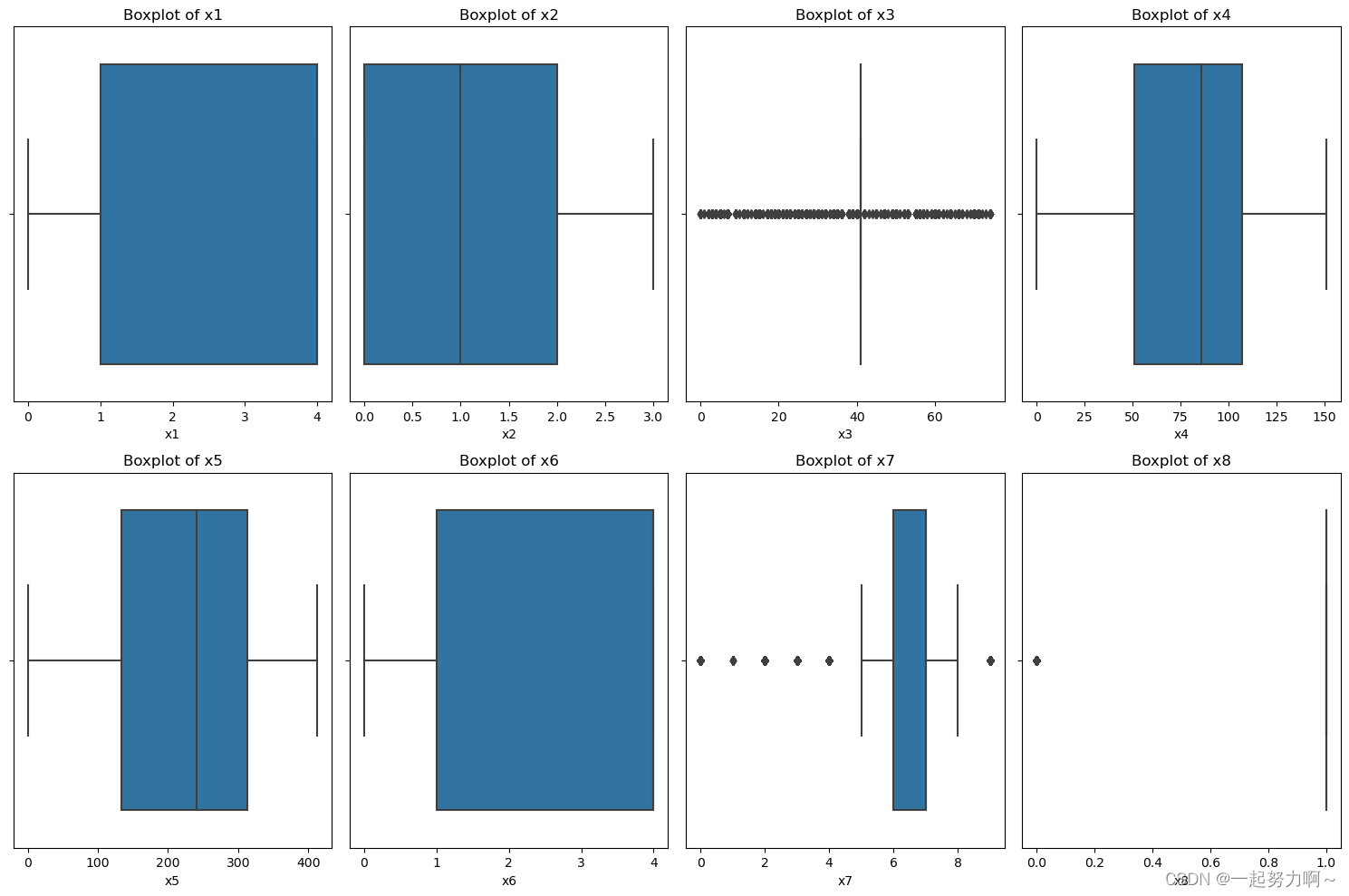
接下来对于每一个字段,绘制直方图和箱线图
# 列表,包含要分析的列名
cols = ['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8']
# 对于每一个字段,绘制直方图
plt.figure(figsize=(15, 10))
for i, col in enumerate(cols):plt.subplot(2, 4, i+1)sns.histplot(train_data[col], bins=30, kde=True)plt.title(f'Histogram of {col}')plt.xlabel(col)plt.ylabel('Frequency')
plt.tight_layout()
plt.show()# 对于每一个字段,绘制箱线图
plt.figure(figsize=(15, 10))
for i, col in enumerate(cols):plt.subplot(2, 4, i+1)sns.boxplot(train_data[col])plt.title(f'Boxplot of {col}')plt.xlabel(col)
plt.tight_layout()
plt.show()
结果如图所示:
# 获取指定时间和日期
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
# 从common_ts中提取小时
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
# 绘制每小时下标签分布变化
sns.barplot(x='common_ts_hour', y='target', data=train_data)
plt.show()
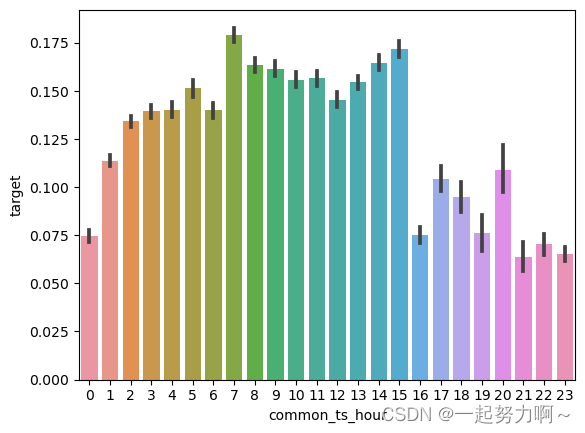 可以发现在1-15小时之间新增用户的概率相对较大,尤其在8-15小时之间。后续可以针对这部分进行特征提取尝试。
可以发现在1-15小时之间新增用户的概率相对较大,尤其在8-15小时之间。后续可以针对这部分进行特征提取尝试。
# 定义函数,统计每个key对应的标签均值,绘制直方图。
def plot_keytarget_mean(df):target_mean = np.zeros(9)for i in range(1, 10):df_temp = df.copy()number = 'key' + str(i)if number in df_temp.columns:data = {f"{number}": df_temp[number],'target': df_temp['target']}df1 = pd.DataFrame(data)# 过滤出 "key" 列中非零值对应的行df_nonzero_key = df1[df1[number] != 0]# 计算非零值 "key" 对应的 "target" 均值mean_target_nonzero_key = df_nonzero_key['target'].mean()target_mean[i - 1] = mean_target_nonzero_key # 索引从 0 开始return target_meantarget_mean = plot_keytarget_mean(train_data)
print(target_mean)
keys = ['key1', 'key2', 'key3', 'key4', 'key5', 'key6', 'key7', 'key8', 'key9']
plt.bar(keys, target_mean)
plt.ylabel('Mean Target Value')
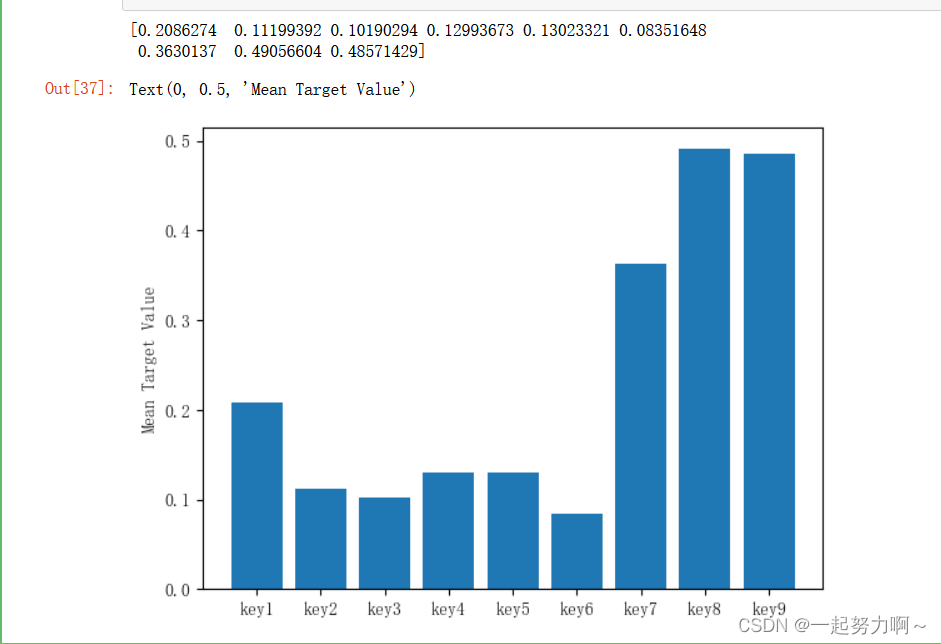 从上图看,特征key7,key8,key9对应的新增用户概率较大,后续可以做些相关的特征组合,尝试是否能够提高模型预测准确度。
从上图看,特征key7,key8,key9对应的新增用户概率较大,后续可以做些相关的特征组合,尝试是否能够提高模型预测准确度。
总结
通过数据可视化,我们可以更详细地观察不同特征与目标之间的关系,从而帮助我们筛选出有用的特征,并进行特征组合,以进一步提高模型的预测准确性。并且可以更好地理解数据,发现数据中的模式和趋势,并根据这些发现来优化我们的建模过程。
2、特征工程
特征工程指的是把原始数据转变为模型训练数据的过程,目的是获取更好的训练数据特征。特征工程能使得模型的性能得到提升,有时甚至在简单的模型上也能取得不错的效果。
由数据可视化以及观察数据可知,时间是一个比较重要的特征。
因此添加分钟,星期,年等时间特征
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hourtrain_data['common_ts_minute'] = train_data['common_ts'].dt.minute + train_data['common_ts_hour'] * 60
test_data['common_ts_minute'] = test_data['common_ts'].dt.minute + test_data['common_ts_hour'] * 60
train_data['dayofweek'] = train_data['common_ts'].dt.dayofweek
test_data['dayofweek'] = test_data['common_ts'].dt.dayofweektrain_data["weekofyear"] = train_data["common_ts"].dt.isocalendar().week.astype(int)
test_data["weekofyear"] = test_data["common_ts"].dt.isocalendar().week.astype(int)train_data["dayofyear"] = train_data["common_ts"].dt.dayofyear
test_data["dayofyear"] = test_data["common_ts"].dt.dayofyeartrain_data["day"] = train_data["common_ts"].dt.day
test_data["day"] = test_data["common_ts"].dt.daytrain_data['is_weekend'] = train_data['dayofweek'] // 6
test_data['is_weekend'] = test_data['dayofweek'] // 6
发现week的值和用户增长有很大的关系,提交后发现分数提升至0.73+

然后继续添加学习文档中所给特征。发现存在缺失值需要填充,通过fillna用0填充缺失值。
# 提取x1~x8的频次特征和标签特征
for i in range(1, 9):train_data['x' + str(i) + '_freq'] = train_data['x' + str(i)].map(train_data['x' + str(i)].value_counts())test_data['x' + str(i) + '_freq'] = test_data['x' + str(i)].map(train_data['x' + str(i)].value_counts())test_data['x' + str(i) + '_freq'].fillna(test_data['x' + str(i) + '_freq'].mode()[0], inplace=True)train_data['x' + str(i) + '_mean'] = train_data['x' + str(i)].map(train_data.groupby('x' + str(i))['target'].mean())test_data['x' + str(i) + '_mean'] = test_data['x' + str(i)].map(train_data.groupby('x' + str(i))['target'].mean())test_data['x' + str(i) + '_mean'].fillna(test_data['x' + str(i) + '_mean'].mode()[0], inplace=True)
# 提取key1~key9的频次特征和标签特征
for i in range(1, 10):train_data['key'+str(i)+'_freq'] = train_data['key'+str(i)].map(train_data['key'+str(i)].value_counts())test_data['key'+str(i)+'_freq'] = test_data['key'+str(i)].map(train_data['key'+str(i)].value_counts())train_data['key'+str(i)+'_mean'] = train_data['key'+str(i)].map(train_data.groupby('key'+str(i))['target'].mean())test_data['key'+str(i)+'_mean'] = test_data['key'+str(i)].map(train_data.groupby('key'+str(i))['target'].mean())train_data = train_data.fillna(0)
test_data = test_data.fillna(0)
然后通过其他助教的优秀笔记中说众数比0填充效果好尝试了一下他的特征,果然效果很好增加到0.75+。

具体代码如下:
train_data['x1_freq'] = train_data['x1'].map(train_data['x1'].value_counts())
test_data['x1_freq'] = test_data['x1'].map(train_data['x1'].value_counts())
test_data['x1_freq'].fillna(test_data['x1_freq'].mode()[0], inplace=True)
train_data['x1_mean'] = train_data['x1'].map(train_data.groupby('x1')['target'].mean())
test_data['x1_mean'] = test_data['x1'].map(train_data.groupby('x1')['target'].mean())
test_data['x1_mean'].fillna(test_data['x1_mean'].mode()[0], inplace=True)train_data['x2_freq'] = train_data['x2'].map(train_data['x2'].value_counts())
test_data['x2_freq'] = test_data['x2'].map(train_data['x2'].value_counts())
test_data['x2_freq'].fillna(test_data['x2_freq'].mode()[0], inplace=True)
train_data['x2_mean'] = train_data['x2'].map(train_data.groupby('x2')['target'].mean())
test_data['x2_mean'] = test_data['x2'].map(train_data.groupby('x2')['target'].mean())
test_data['x2_mean'].fillna(test_data['x2_mean'].mode()[0], inplace=True)train_data['x3_freq'] = train_data['x3'].map(train_data['x3'].value_counts())
test_data['x3_freq'] = test_data['x3'].map(train_data['x3'].value_counts())
test_data['x3_freq'].fillna(test_data['x3_freq'].mode()[0], inplace=True)train_data['x4_freq'] = train_data['x4'].map(train_data['x4'].value_counts())
test_data['x4_freq'] = test_data['x4'].map(train_data['x4'].value_counts())
test_data['x4_freq'].fillna(test_data['x4_freq'].mode()[0], inplace=True)train_data['x6_freq'] = train_data['x6'].map(train_data['x6'].value_counts())
test_data['x6_freq'] = test_data['x6'].map(train_data['x6'].value_counts())
test_data['x6_freq'].fillna(test_data['x6_freq'].mode()[0], inplace=True)
train_data['x6_mean'] = train_data['x6'].map(train_data.groupby('x6')['target'].mean())
test_data['x6_mean'] = test_data['x6'].map(train_data.groupby('x6')['target'].mean())
test_data['x6_mean'].fillna(test_data['x6_mean'].mode()[0], inplace=True)train_data['x7_freq'] = train_data['x7'].map(train_data['x7'].value_counts())
test_data['x7_freq'] = test_data['x7'].map(train_data['x7'].value_counts())
test_data['x7_freq'].fillna(test_data['x7_freq'].mode()[0], inplace=True)
train_data['x7_mean'] = train_data['x7'].map(train_data.groupby('x7')['target'].mean())
test_data['x7_mean'] = test_data['x7'].map(train_data.groupby('x7')['target'].mean())
test_data['x7_mean'].fillna(test_data['x7_mean'].mode()[0], inplace=True)train_data['x8_freq'] = train_data['x8'].map(train_data['x8'].value_counts())
test_data['x8_freq'] = test_data['x8'].map(train_data['x8'].value_counts())
test_data['x8_freq'].fillna(test_data['x8_freq'].mode()[0], inplace=True)
train_data['x8_mean'] = train_data['x8'].map(train_data.groupby('x8')['target'].mean())
test_data['x8_mean'] = test_data['x8'].map(train_data.groupby('x8')['target'].mean())
test_data['x8_mean'].fillna(test_data['x8_mean'].mode()[0], inplace=True)
3、模型交叉验证
交叉验证(Cross-Validation)是机器学习中常用的一种模型评估方法,用于评估模型的性能和泛化能力。
它的主要目的是在有限的数据集上,尽可能充分地利用数据来评估模型,避免过拟合或欠拟合,并提供对模型性能的更稳健的估计。
交叉验证的基本思想是将原始的训练数据划分为多个子集(也称为折叠),然后将模型训练和验证进行多次循环。
在每一次循环中,使用其中一个子集作为验证集,其他子集作为训练集。这样可以多次计算模型的性能指标,并取这些指标的平均值作为最终的模型性能评估结果。
1、为何使用交叉验证?
- 交叉验证用于评估模型的预测性能,尤其是训练好的模型在新数据上的表现,可以在一定程度上减小过拟合。
- 可以从有限的数据中获取尽可能多的有效信息。
- 可以帮助我们选择最佳的模型参数。通过在不同的训练集和测试集上进行多次评估,可以比较不同参数设置下模型的性能,并选择最佳的参数组合。这有助于我们优化模型的性能,并提高预测准确性。
2、 常见的交叉验证方法:
- 简单交叉验证
将数据集分为两部分(或者是三部分),70%作为训练集,30%作为验证集。使用70%的数据,选择不同的模型参数,进行训练。结束后使用30%的数据(未经过训练)进行验证。选择最优的模型。 - S折交叉验证
将数据集分为规模大小相近的S个互不相交的数据集,利用S-1部分数据去训练模型,剩下的1部分数据进行验证 。经过多次训练选出最优的模型。
【注意】每次的验证集都有可能不同。 - 留一交叉验证
其实就是S折交叉验证的特殊形式,即在数据集规模及其小的时候(小于100条,甚至更夸张)。将S折的S=N,其中N为数据规模。留下1条数据做验证。
# 导入模型
from sklearn.linear_model import SGDClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier# 导入交叉验证和评价指标
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import classification_report
# 训练并验证SGDClassifier(基于随机梯度下降(Stochastic Gradient Descent)优化算法的分类器)
pred = cross_val_predict(SGDClassifier(max_iter=10),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
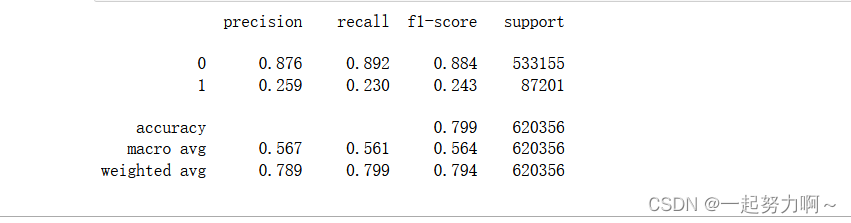
accuracy:准确率。准确率(precision)可以衡量一个样本为负的标签被判成正,召回率(recall)用于衡量所有正例。
macro avg:"macro avg"是一种评估多类分类模型性能的指标之一。它是计算每个类别的指标(如准确度、精确度、召回率、F1值等),然后对所有类别的指标取平均得到的。
“micro”选项:表示在多分类中的对所有label进行micro-averaging产生一个平均precision,recall和F值
weighted avg:
“weighted”选项:表示会产生一个weighted-averaging的F值。
具体可见机器学习各种指标学习
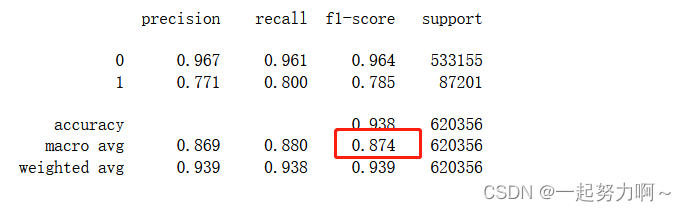
# 训练并验证决策树DecisionTreeClassifier
pred = cross_val_predict(DecisionTreeClassifier(),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
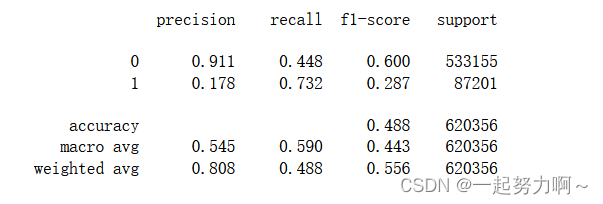
# 训练并验证MultinomialNB
pred = cross_val_predict(MultinomialNB(),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))
# 训练并验证RandomForestClassifier
pred = cross_val_predict(RandomForestClassifier(n_estimators=5),train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred, digits=3))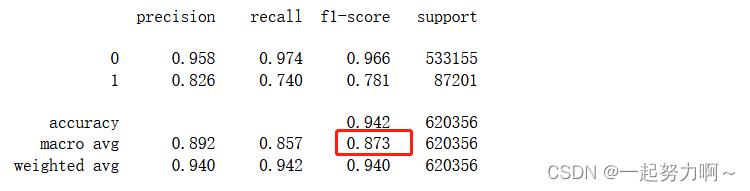
从上述四个模型来看决策树和随机森林表现较好,二者中决策树更好,我想决策树模型在本数据集上的优异表现可能是由于其对特征工程、数据分布、不平衡数据和特征交互效应的自然处理能力所致。当然,还应该进一步调整和优化所有模型的参数来进一步提高性能。
同时我又使用了XGBoost和LightgBM 两种模型进行交叉验证,效果如下:
import xgboost as xgb
import lightgbm as lgb
from sklearn.metrics import classification_report
from sklearn.model_selection import cross_val_predict
# 定义XGBoost模型
xgb_model = xgb.XGBClassifier()
# 使用交叉验证进行训练和验证
pred_xgb = cross_val_predict(xgb_model,train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
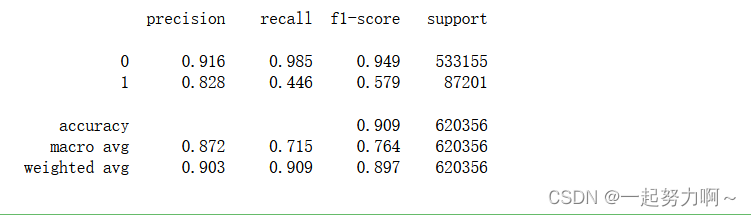
print(classification_report(train_data['target'], pred_xgb, digits=3))
# 定义LightGBM模型
lgb_model = lgb.LGBMClassifier()
# 使用交叉验证进行训练和验证
pred_lgb = cross_val_predict(lgb_model,train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),train_data['target']
)
print(classification_report(train_data['target'], pred_lgb, digits=3))
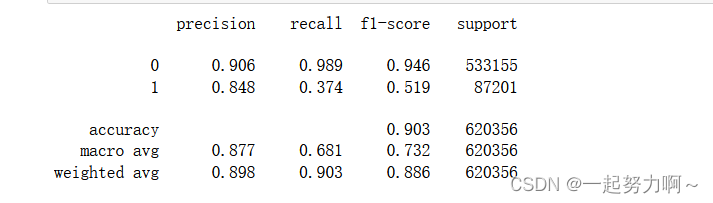
从macro avg和weightzvg的角度来看表现最好的还是决策树。
除此之外,模型本身的优化也不可忽视:
- 超参数调优机器学习中有很多人为设定的模型参数,其中不是经过模型训练得到的参数叫做超参数(hyperparameter),人工根据特定问题对训练的模型进行调参可以提高模型的准确度。常用的超参数调优算法有贝叶斯优化、网格搜索和随机搜索。
1、贝叶斯优化:贝叶斯优化是一种基于贝叶斯定理的技术,它描述了与当前知识相关的事件发生的概率。将贝叶斯优化用于超参数优化时,算法会从一组超参数中构建一个概率模型,以优化特定指标。它使用回归分析迭代地选择最佳的一组超参数。
2、网格搜索:借助网格搜索,您可以指定一组超参数和性能指标,然后算法会遍历所有可能的组合来确定最佳匹配。网格搜索很好用,但它相对乏味且计算量大,特别是使用大量超参数时。
3、随机搜索:虽然随机搜索与网格搜索基于相似的原则,但随机搜索在每次迭代时会随机选择一组超参数。当相对较少的超参数主要决定模型的结果时,该方法效果良好。
看完一位0.86+大佬的随机森林调优笔记分享我尝试使用随机森林调优模型
通过设定已知效果较好的参数组合来提高tpe参数优化的效率
#设定已知好的参数组合:就默认的参数组合就已经很好了
good_params = {'n_estimators': 100,'max_depth': None, 'min_samples_split': 2
......
}
#这里的loss就是上面五交叉认证的相反数-score,将其转化为一个结果对象,加入trials:
good_result = {'loss': 0.95, 'status': STATUS_OK}
trials.insert_trial_docs([{'tid': len(trials) + 1,'spec': good_params,'result': good_result,'misc': {}
}])
#运行tpe搜索
best = fmin(fn=objective, space=space, algo=tpe.suggest, max_evals=100, trials=trials)
本次优化的参数:
n_estimators:随机森林模型中包含决策树模型的个数
max_depth:决策树模型的最大深度
max_features:用于构建决策树时选取的最大特征数量
min_samples_leaf:叶子节点最少样本数
min_samples_split:当前节点允许分裂的最小样本数
criterion:节点分裂依据
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import StratifiedShuffleSplit
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
import matplotlib.pyplot as plt
import time
n_estimators:随机森林模型中包含决策树模型的个数
#这里的train_data就是上面读入数据后,特征处理好后的待训练的数据
data = train_data.iloc[:,:-1]
lable = train_data.iloc[:,-1]
start=time.time()
scorel = []
for i in range(0,200,10): # 迭代建立包含0-200棵决策树的RF模型进行对比rfc = RandomForestClassifier(n_estimators=i+1,n_jobs=-1,random_state=90)score = cross_val_score(rfc,data,lable,cv=10).mean()scorel.append(score)
print(max(scorel),(scorel.index(max(scorel))*10)+1)
end=time.time()
print('Running time: %s Seconds'%(end-start))
plt.figure(figsize=[20,5])
plt.plot(range(1,201,10),scorel)
plt.show()
结果:
0.9613823613698237 131 Running time: 5530.6381804943085 Seconds
…
最后优化结果
clf = RandomForestClassifier(n_estimators=131,max_depth=33,n_jobs=-1,max_features=9,min_samples_leaf=1,min_samples_split=2,criterion = 'entropy')
clf.fit(train_data.drop(['target'], axis=1),train_data['target']
)
y_pred = clf.predict(X_val)
# 计算准确率
accuracy = accuracy_score(y_val, y_pred)
print("Accuracy:", accuracy)
# 计算F1分数
f1 = f1_score(y_val, y_pred)
print("F1 score:", f1)
提交上去分数达到0.79+

至此分数就上不去了,接下来的操作都是反向调优哈哈。
做了一下特征重要性得分,来评估各个特征对目标变量的影响程度
# 获取字段列表
l0 = ['x1_freq', 'x2_freq', 'x3_freq', 'x4_freq', 'x5_freq', 'x6_freq', 'x7_freq', 'x8_freq','x1_mean', 'x2_mean', 'x3_mean', 'x4_mean', 'x5_mean', 'x6_mean', 'x7_mean', 'x8_mean','x1_std', 'x2_std', 'x3_std', 'x4_std', 'x5_std', 'x6_std', 'x7_std', 'x8_std','key1_freq', 'key2_freq', 'key3_freq', 'key4_freq', 'key5_freq', 'key6_freq', 'key7_freq', 'key8_freq', 'key9_freq','key1_mean', 'key2_mean', 'key3_mean', 'key4_mean','key5_mean', 'key6_mean', 'key7_mean', 'key8_mean', 'key9_mean','key1_std', 'key2_std', 'key3_std', 'key4_std', 'key5_std', 'key6_std', 'key7_std', 'key8_std', 'key9_std','unmap_isunknown', 'udmap', 'common_ts', 'uuid', 'target', 'common_ts_hour', 'day', 'common_ts_minute','dayofweek','x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8','eid', 'eid_std', 'eid_mean', 'eid_freq','key1', 'key2', 'key3', 'key4', 'key5', 'key6', 'key7', 'key8', 'key9']# 训练模型:按需分组选取特征
x = train_data.drop(['x1_freq', 'x2_freq', 'x3_freq', 'x4_freq', 'x5_freq', 'x6_freq', 'x7_freq', 'x8_freq','x1_mean', 'x2_mean', 'x3_mean', 'x4_mean', 'x5_mean', 'x6_mean', 'x7_mean', 'x8_mean','x1_std', 'x2_std', 'x3_std', 'x4_std', 'x5_std', 'x6_std', 'x7_std', 'x8_std','key1_freq', 'key2_freq', 'key3_freq', 'key4_freq', 'key5_freq', 'key6_freq', 'key7_freq', 'key8_freq','key9_freq','key1_mean', 'key2_mean', 'key3_mean', 'key4_mean','key5_mean', 'key6_mean', 'key7_mean', 'key8_mean','key9_mean','key1_std', 'key2_std', 'key3_std', 'key4_std', 'key5_std', 'key6_std', 'key7_std', 'key8_std', 'key9_std','udmap', 'common_ts', 'uuid', 'target', 'common_ts_hour', 'day', 'common_ts_minute','dayofweek','x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7', 'x8','eid', 'eid_std', 'eid_mean', 'eid_freq','key1', 'key2', 'key3', 'key4', 'key5', 'key6', 'key7', 'key8', 'key9'], axis=1)
y = train_data['target']
clf = DecisionTreeClassifier()
clf.fit(x, y)# 获取特征重要性得分
feature_importances = clf.feature_importances_# 创建特征名列表
feature_names = list(x.columns)# 创建一个DataFrame,包含特征名和其重要性得分
feature_importances_df = pd.DataFrame({'feature': feature_names, 'importance': feature_importances})# 对特征重要性得分进行排序
feature_importances_df = feature_importances_df.sort_values('importance', ascending=False)# 颜色映射
colors = plt.cm.viridis(np.linspace(0, 1, len(feature_names)))# 可视化特征重要性
fig, ax = plt.subplots(figsize=(10, 6))
ax.barh(feature_importances_df['feature'], feature_importances_df['importance'], color=colors)
ax.invert_yaxis() # 翻转y轴,使得最大的特征在最上面
ax.set_xlabel('特征重要性', fontsize=12) # 图形的x标签
ax.set_title('决策树特征重要性可视化', fontsize=16)
for i, v in enumerate(feature_importances_df['importance']):ax.text(v + 0.01, i, str(round(v, 3)), va='center', fontname='Times New Roman', fontsize=10)# 保存图形
plt.savefig('./特征重要性.jpg', dpi=400, bbox_inches='tight')
plt.show()
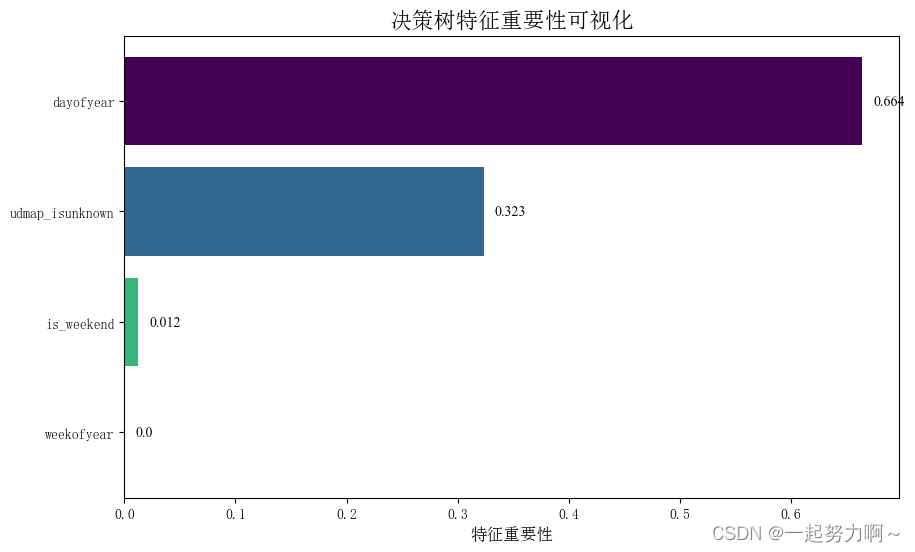
结果显示时间特征年份最重要,,
# 使用Decision Tree Classifier对模型进行训练
clf = DecisionTreeClassifier()
X = train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1)
y = train_data['target']
clf.fit(X, y)
# 绘制特征重要性柱状图
import matplotlib.pyplot as plt
# 获取特征重要性分数
feature_importances = clf.feature_importances_# 创建特征重要性 DataFrame
importance_df = pd.DataFrame({'Feature': X.columns, 'Importance': feature_importances})# 按重要性从大到小排序
importance_df = importance_df.sort_values(by='Importance', ascending=False)
plt.figure(figsize=(80, 6))
plt.bar(importance_df['Feature'], importance_df['Importance'])接着绘制了一个绘制决策树特征重要性柱状图

利用重要的commom_ts时间特征的week, day, or minute去与target做特征组合,但是效果似乎不咋好,不如之前提取的特征分数高

最后介绍暗最高分的来源——AutoGluon
只需几行代码即可在原始数据上构建机器学习解决方案。
哈哈先上代码
pip install autogluon
import numpy as np
import pandas as pd
from autogluon.tabular import TabularDataset
from autogluon.tabular import TabularPredictor
train_data = TabularDataset('D:/D/Download/360安全浏览器下载/用户新增预测挑战赛公开数据/train.csv')
test_data = TabularDataset('D:/D/Download/360安全浏览器下载/用户新增预测挑战赛公开数据/test.csv')
submit = pd.DataFrame()
submit["uuid"] = test_data["uuid"]
label = "target"
predictor = TabularPredictor(label = label,problem_type="binary",eval_metric="f1"
).fit(train_data.drop(columns=["uuid"]),excluded_model_types=["CAT","NN_TORCH","FASTAI",],
)
submit[f"{label}"] = predictor.predict(test_data.drop(columns=["uuid"]))
submit.to_csv("D:/D/Download/360安全浏览器下载/用户新增预测挑战赛公开数据/submit.csv",index=False)
就这几行代码,我弄了几天都赶不上哈哈有点儿丢人。

关于AutoGluon
相关文章:
AI夏令营第三期用户新增挑战赛学习笔记
1、数据可视化 1.数据探索和理解:数据可视化可以帮助我们更好地理解数据集的特征、分布和关系。通过可视化数据,我们可以发现数据中的模式、异常值、缺失值等信息,从而更好地了解数据的特点和结构。2.特征工程:数据可视化可以帮助…...
pdf转ppt软件哪个好用?推荐一个好用的pdf转ppt软件
在日常工作和学习中,我们经常会遇到需要将PDF文件转换为PPT格式的情况。PDF格式的文件通常用于展示和保留文档的原始格式,而PPT格式则更适合用于演示和展示。为了满足这一需求,许多软件提供了PDF转PPT的功能,使我们能够方便地将PD…...

Linux 内核函数kallsyms_lookup_name
文章目录 一、API使用二、源码解析2.1 kallsyms_lookup_name2.2 kallsyms_expand_symbol2.3 kallsyms_sym_address2.3.1 x86_642.3.2 arm642.3.3 CONFIG_KALLSYMS_ABSOLUTE_PERCPU 参考资料 一、API使用 kallsyms_lookup_name 是一个内核函数,用于通过符号名称查找…...

强化学习在游戏AI中的应用与挑战
文章目录 1. 强化学习简介2. 强化学习在游戏AI中的应用2.1 游戏智能体训练2.2 游戏AI决策2.3 游戏测试和优化 3. 强化学习在游戏AI中的挑战3.1 探索与利用的平衡3.2 多样性的应对 4. 解决方法与展望4.1 深度强化学习4.2 奖励设计和函数逼近 5. 总结 🎉欢迎来到AIGC人…...

6 Python的异常处理
概述 在上一节,我们介绍了Python的面向对象编程,包括:类的定义、类的使用、类变量、实例变量、实例方法、类方法、静态方法、类的运算符重载、继承等内容。在这一节中,我们将介绍Python的异常处理。异常是指程序在运行过程中出现的…...

【跨语言通讯】
传统的跨语言通讯方案: 基于SOAP消息格式的WebService 基于JSON消息格式的RESTful 服务 主要弊端: XML体积太大,解析性能极差 JSON体积相对较小,解析相对较快,但表达能力较弱 如今比较流行的跨语言通讯方案&…...

Android 基础知识
一、Activity 1、onSaveInstanceState(),onRestoreInstanceState的调用时机 onSaveInstanceState 调用时机 从最近应用中选择运行其他程序时 但用户按下Home键时 屏幕方向切换时 按下电源案件时 从当前activity启动一个新的activity时 onRestorInstanceState调用时机 只…...

Linux常用命令_帮助命令、用户管理命令、压缩解压命令
文章目录 1. 帮助命令1.1 帮助命令:man1.2 帮助命令:help1.3 其他帮助命令 2. 用户管理命令2.1 用户管理命令: useradd2.2 用户管理命令: passwd2.3 用户管理命令: who2.4 用户管理命令: w 3. 压缩解压命令3.1 压缩解压命令: gzip3.2 压缩解压命令: gunzip3.3 压缩解压命令: ta…...

解决 KylinOS “Could not get lock /var/lib/dpkg/lock”错误
最近,我遇到了 “Could not get lock /var/lib/dpkg/lock”的错误,我既不能安装任何软件包,也不能更新系统。此错误也与“Could not get lock /var/lib/apt/lists/lock”错误密切相关。以下是 Ubuntu 20.04 上的一些样本输出。 Reading package lists… Done E: Could not…...

PHP pdf 自动填写表单
一、下载github上的项目,地址 二、下载pdftk 地址 // 转化PDF模板 pdftk modele.pdf output modele2.pdf# 填充pdf文件中的表单 require(fpdm.php); $fields array(name > My name,address > My address,city > My city,phone > My phone nu…...

Win2016Server绑定多网卡实现负载均衡
一、服务器端: 1、输入ncpa.cpl打开网络连接,对要绑定的网卡勾掉IPV4,IPV4地址选择自动 2、输入servermanager.exe,打开服务器管理器 3、在 [本地服务器] 中,点后边的 “已禁用” ,在 [适配器和接口] 小窗口…...
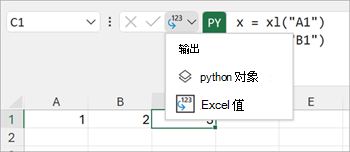
微软宣布在 Excel 中使用 Python:结合了 Python 的强大功能和 Excel 的灵活性。
文章目录 Excel 中的 Python 有何独特之处?1. Excel 中的 Python 是为分析师构建的。高级可视化机器学习、预测分析和预测数据清理 2. Excel 中的 Python 通过 Anaconda 展示了最好的 Python 分析功能。3. Excel 中的 Python 在 Microsoft 云上安全运行,…...

学习心得03:OpenCV
数学真是不可思议,不管什么东西,都能用数学来处理。OpenCV以前也接触过,这次是系统学习一下。 颜色模型 RGB,YUV,HSV,Lab,GRAY 颜色转换cvtColor()/convertTo(),通道分离split()&…...

ubuntu学习(五)----读取文件以及光标的移动
1、读取文件函数原型介绍 ssize_t read(int fd,void*buf,size_t count) 参数说明: fd: 是文件描述符 buf:为读出数据的缓冲区; count: 为每次读取的字节数(是请求读取的字节数,读上来的数据保存在缓冲区buf中,同时文…...

Python 数据分析——matplotlib 快速绘图
matplotlib采用面向对象的技术来实现,因此组成图表的各个元素都是对象,在编写较大的应用程序时通过面向对象的方式使用matplotlib将更加有效。但是使用这种面向对象的调用接口进行绘图比较烦琐,因此matplotlib还提供了快速绘图的pyplot模块。…...
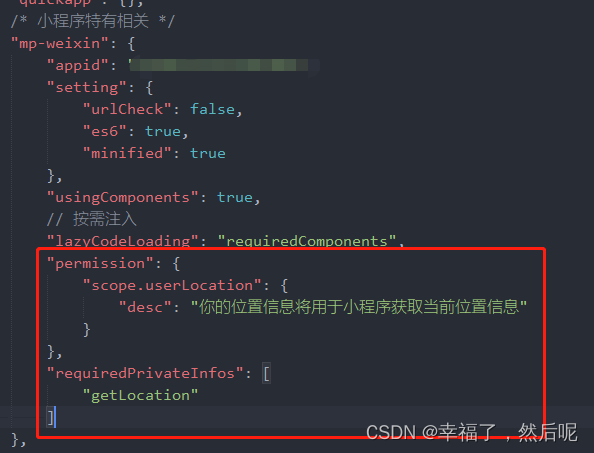
uniapp小程序位置信息配置
uniapp 小程序获取当前位置信息报错 报错信息: getLocation:fail the api need to be declared in the requiredPrivateInfos field in app.json/ext.json 需要在manifest.json配置文件中进行配置:...

《基于 Vue 组件库 的 Webpack5 配置》1.模式 Mode 和 vue-loader
一定要配置 模式 Mode,这里有个小知识点,环境变量 process.env.NODE_ENV module.exports {mode: production,// process.env.NODE_ENV 或 development, }一定要配置 vue-loader Vue Loader v15 现在需要配合一个 webpack 插件才能正确使用; …...
01.sqlite3学习——数据库概述
目录 重点概述总结 数据库标准介绍 什么是数据库? 数据库是如何存储数据的? 数据库是如何管理数据的? 数据库系统结构 常见关系型数据库管理系统 关系型数据库相关知识点 数据库与文件存储数据对比 重点概述总结 数据库可以理解为操…...

视频集中存储/云存储平台EasyCVR国标GB28181协议接入的报文交互数据包分析
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。视频汇聚融合管理…...

容器技术,1. Docker,2. Kubernetes(K8s):
目录 容器技术 1. Docker: 2. Kubernetes(K8s): Docker和Kubernetes 容器的主要应用场景有哪些? 容器技术 有效的将单个操作系统的资源划分到孤立的组中,以便更好的在孤立的组之间平衡有冲突的资源使…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...

python打卡day49
知识点回顾: 通道注意力模块复习空间注意力模块CBAM的定义 作业:尝试对今天的模型检查参数数目,并用tensorboard查看训练过程 import torch import torch.nn as nn# 定义通道注意力 class ChannelAttention(nn.Module):def __init__(self,…...

黑马Mybatis
Mybatis 表现层:页面展示 业务层:逻辑处理 持久层:持久数据化保存 在这里插入图片描述 Mybatis快速入门 
DAY 47
三、通道注意力 3.1 通道注意力的定义 # 新增:通道注意力模块(SE模块) class ChannelAttention(nn.Module):"""通道注意力模块(Squeeze-and-Excitation)"""def __init__(self, in_channels, reduction_rat…...

渗透实战PortSwigger靶场-XSS Lab 14:大多数标签和属性被阻止
<script>标签被拦截 我们需要把全部可用的 tag 和 event 进行暴力破解 XSS cheat sheet: https://portswigger.net/web-security/cross-site-scripting/cheat-sheet 通过爆破发现body可以用 再把全部 events 放进去爆破 这些 event 全部可用 <body onres…...

电脑插入多块移动硬盘后经常出现卡顿和蓝屏
当电脑在插入多块移动硬盘后频繁出现卡顿和蓝屏问题时,可能涉及硬件资源冲突、驱动兼容性、供电不足或系统设置等多方面原因。以下是逐步排查和解决方案: 1. 检查电源供电问题 问题原因:多块移动硬盘同时运行可能导致USB接口供电不足&#x…...

Linux云原生安全:零信任架构与机密计算
Linux云原生安全:零信任架构与机密计算 构建坚不可摧的云原生防御体系 引言:云原生安全的范式革命 随着云原生技术的普及,安全边界正在从传统的网络边界向工作负载内部转移。Gartner预测,到2025年,零信任架构将成为超…...

ios苹果系统,js 滑动屏幕、锚定无效
现象:window.addEventListener监听touch无效,划不动屏幕,但是代码逻辑都有执行到。 scrollIntoView也无效。 原因:这是因为 iOS 的触摸事件处理机制和 touch-action: none 的设置有关。ios有太多得交互动作,从而会影响…...
的原因分类及对应排查方案)
JVM暂停(Stop-The-World,STW)的原因分类及对应排查方案
JVM暂停(Stop-The-World,STW)的完整原因分类及对应排查方案,结合JVM运行机制和常见故障场景整理而成: 一、GC相关暂停 1. 安全点(Safepoint)阻塞 现象:JVM暂停但无GC日志,日志显示No GCs detected。原因:JVM等待所有线程进入安全点(如…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...