Python爬虫库之urllib使用详解
一、Python urllib库
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。
Python3 的 urllib。
urllib 包 包含以下几个模块:
-
urllib.request - 打开和读取 URL。
-
urllib.error - 包含 urllib.request 抛出的异常。
-
urllib.parse - 解析 URL。
-
urllib.robotparser - 解析 robots.txt 文件。
二、urllib.request模块
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
urllib.request 可以模拟浏览器的一个请求发起过程。
这里主要介绍两个常用方法,urlopen和Request。
1.urlopen函数
语法格式如下:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
-
url:url 地址。
-
data:发送到服务器的其他数据对象,默认为 None。
-
timeout:设置访问超时时间。
-
cafile 和 capath:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。
-
cadefault:已经被弃用。
-
context:ssl.SSLContext类型,用来指定 SSL 设置。
示例:
import urllib.request
#导入urllib.request模块
url=urllib.request.urlopen("https://www.baidu.com")
#打开读取baidu信息
print(url.read().decode('utf-8'))
#read获取所有信息,并decode()命令将网页的信息进行解码
运行结果:
<!DOCTYPE html><!--STATUS OK--><html><head><meta http-equiv="Content-Type" content="text/html;charset=utf-8"><meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1"><meta content="always" name="
html{color:#000;overflow-y:scroll;overflow:-moz-scrollbars}
body,button,input,select,textarea{font-size:12px;font-family:Arial,sans-serif}
h1,h2,h3,h4,h5,h6{font-size:100%}
em{font-style:normal}
small{font-size:12px}
ol,ul{list-style:none}
a{text-decoration:none}
a:hover{text-decoration:underline}
legend{color:#000}
fieldset,img{border:0}
button,input,select,textarea{font-size:100%}
...
response对象是http.client. HTTPResponse类型,主要包含 read、readinto、getheader、getheaders、fileno 等方法,以及 msg、version、status、reason、debuglevel、closed 等属性。
常用方法:
-
read():是读取整个网页内容,也可以指定读取的长度,如read(300)。获取到的是二进制的乱码,所以需要用到decode()命令将网页的信息进行解码。
-
readline() - 读取文件的一行内容。
-
readlines() - 读取文件的全部内容,它会把读取的内容赋值给一个列表变量。
-
info():返回HTTPMessage对象,表示远程服务器返回的头信息。
-
getcode():返回Http状态码。如果是http请求,200请求成功完成;404网址未找到。
-
geturl():返回请求的url。
2、Request类
我们抓取网页一般需要对 headers(网页头信息)进行模拟,否则网页很容易判定程序为爬虫,从而禁止访问。这时候需要使用到 urllib.request.Request 类:
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)
-
url:url 地址。
-
data:发送到服务器的其他数据对象,默认为 None。
-
headers:HTTP 请求的头部信息,字典格式。
-
origin_req_host:请求的主机地址,IP 或域名。
-
unverifiable:很少用整个参数,用于设置网页是否需要验证,默认是False。。
-
method:请求方法, 如 GET、POST、DELETE、PUT等。
示例:
import urllib.request
#导入模块
url = "https://www.baidu.com"
#网页连接
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36"
}
#定义headers,模拟浏览器访问
req = urllib.request.Request(url=url,headers=headers)
#模拟浏览器发送,访问网页
response = urllib.request.urlopen(req)
#获取页面信息
print(response.read().decode("utf-8"))
三、urllib.error模块
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
urllib.error 包含了两个方法,URLError 和 HTTPError。
URLError 是 OSError 的一个子类,用于处理程序在遇到问题时会引发此异常(或其派生的异常),包含的属性 reason 为引发异常的原因。
HTTPError 是 URLError 的一个子类,用于处理特殊 HTTP 错误例如作为认证请求的时候,包含的属性 code 为 HTTP 的状态码, reason 为引发异常的原因,headers 为导致 HTTPError 的特定 HTTP 请求的 HTTP 响应头。
区别:
URLError封装的错误信息一般是由网络引起的,包括url错误。
-
HTTPError封装的错误信息一般是服务器返回了错误状态码。
关系:
-
URLError是OSERROR的子类,HTTPError是URLError的子类。
1.URLError 示例
from urllib import request
from urllib import errorif __name__ == "__main__":#一个不存在的连接url = "http://www.baiiiduuuu.com/"req = request.Request(url)try:response = request.urlopen(req)html = response.read().decode('utf-8')print(html)except error.URLError as e:print(e.reason)
返回结果:
[Errno -2] Name or service not known
reason:
此错误的原因。它可以是一个消息字符串或另一个异常实例。
2.HTTPError示例
from urllib import request
from urllib import errorif __name__ == "__main__":#网站服务器上不存在资源url = "http://www.baidu.com/no.html"req = request.Request(url)try:response = request.urlopen(req)html = response.read().decode('utf-8')print(html)except error.HTTPError as e:print(e.code)
返回结果:
404
code
一个 HTTP 状态码,具体定义见 RFC 2616。这个数字的值对应于存放在
http.server.BaseHTTPRequestHandler.responses 代码字典中的某个值。
reason
这通常是一个解释本次错误原因的字符串。
headers
导致 HTTPError 的特定 HTTP 请求的 HTTP 响应头。
3.URLError和HTTPError混合使用
注意:由于HTTPError是URLError的子类,所以捕获的时候HTTPError要放在URLError的上面。
示例:
from urllib import request
from urllib import errorif __name__ == "__main__":#网站服务器上不存在资源url = "http://www.baidu.com/no.html"req = request.Request(url)try:response = request.urlopen(req)# html = response.read().decode('utf-8')except error.HTTPError as e:print(e.code)except error.URLError as e:print(e.code)
如果不用上面的方法,可以直接用判断的形式。
from urllib import request
from urllib import errorif __name__ == "__main__":#网站服务器上不存在资源url = "http://www.baidu.com/no.html"req = request.Request(url)try:response = request.urlopen(req)# html = response.read().decode('utf-8')except error.URLError as e:if hasattr(e, 'code'):print("HTTPError")print(e.code)elif hasattr(e, 'reason'):print("URLError")print(e.reason)
执行结果:
HTTPError
404
四、urllib.parse模块
模块定义的函数可分为两个主要门类: URL 解析和 URL 转码。
4.1 URL 解析
4.1.1 urlparse()
urllib.parse 用于解析 URL,格式如下:
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)
urlstring 为 字符串的 url 地址,scheme 为协议类型。
allow_fragments 参数为 false,则无法识别片段标识符。相反,它们被解析为路径,参数或查询组件的一部分,并 fragment 在返回值中设置为空字符串。
标准链接格式为:
scheme://netloc/path;params?query#fragment
对象中包含了六个元素,分别为:协议(scheme)、域名(netloc)、路径(path)、路径参数(params)、查询参数(query)、片段(fragment)。
示例:
from urllib.parse import urlparseo = urlparse("https://docs.python.org/zh-cn/3/library/urllib.parse.html#module-urllib.parse")print('scheme :', o.scheme)
print('netloc :', o.netloc)
print('path :', o.path)
print('params :', o.params)
print('query :', o.query)
print('fragment:', o.fragment)
print('hostname:', o.hostname)
执行结果:
scheme : https
netloc : docs.python.org
path : /zh-cn/3/library/urllib.parse.html
params :
query :
fragment: module-urllib.parse
hostname: docs.python.org
以上还可以通过索引获取,如通过
print(o[0])
...
print(o[5])
4.1.2 urlunparse()
urlunparse()可以实现URL的构造。(构造URL)
urlunparse()接收一个是一个长度为6的可迭代对象,将URL的多个部分组合为一个URL。若可迭代对象长度不等于6,则抛出异常。
示例:
from urllib.parse import urlunparse
url_compos = ['http','www.baidu.com','index.html','user= test','a=6','comment']
print(urlunparse(url_compos))
结果:
http://www.baidu.com/index.html;user= test?a=6#comment
4.1.3 urlsplit()
urlsplit() 函数也能对 URL 进行拆分,所不同的是, urlsplit() 并不会把 路径参数(params) 从 路径(path) 中分离出来。
当 URL 中路径部分包含多个参数时,使用 urlparse() 解析是有问题的,这时可以使用 urlsplit() 来解析.
4.1.4 urlsplit()
urlunsplit()与 urlunparse()类似,(构造URL),传入对象必须是可迭代对象,且长度必须是5。
示例:
from urllib.parse import urlunsplit
url_compos = ['http','www.baidu.com','index.html','user= test','a = 2']
print(urlunsplit(url_compos))urlunsplit()
结果:
http://www.baidu.com/index.html?user= test#a = 2
4.1.5 urljoin()
同样可以构造URL。
传递一个基础链接,根据基础链接可以将某一个不完整的链接拼接为一个完整链接.
注:连接两个参数的url, 将第二个参数中缺的部分用第一个参数的补齐,如果第二个有完整的路径,则以第二个为主。
4.2 URL 转码
python中提供urllib.parse模块用来编码和解码,分别是urlencode()与unquote()。
4.2.1 编码quote(string)
URL 转码函数的功能是接收程序数据并通过对特殊字符进行转码并正确编码非 ASCII 文本来将其转为可以安全地用作 URL 组成部分的形式。它们还支持逆转此操作以便从作为 URL 组成部分的内容中重建原始数据,如果上述的 URL 解析函数还未覆盖此功能的话
语法:
urllib.parse.quote(string, safe='/', encoding=None, errors=None)
使用 %xx 转义符替换 string 中的特殊字符。字母、数字和 '_.-~' 等字符一定不会被转码。在默认情况下,此函数只对 URL 的路径部分进行转码。可选的 safe 形参额外指定不应被转码的 ASCII 字符 --- 其默认值为 '/'。
string 可以是 str 或 bytes 对象。
示例:
from urllib import parseurl = "http://www.baidu.com/s?wd={}"
words = "爬虫"#quote()只能对字符串进行编码
query_string = parse.quote(words)
url = url.format(query_string)
print(url)
执行结果:
http://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB
4.2.2 编码urlencode()
quote()只能对字符串编码,而urlencode()可以对查询字符串进行编码。
# 导入parse模块
from urllib import parse#调用parse模块的urlencode()进行编码
query_string = {'wd':'爬虫'}
result = parse.urlencode(query_string)# format函数格式化字符串,进行url拼接
url = 'http://www.baidu.com/s?{}'.format(result)
print(url)
结果:
http://www.baidu.com/s?wd=%E7%88%AC%E8%99%AB
4.2.3 解码unquote(string)
解码就是对编码后的url进行还原。
示例:
from urllib import parse
string = '%E7%88%AC%E8%99%AB'
result = parse.unquote(string)
print(result)
执行结果:
爬虫
五、urllib.robotparser模块
(在网络爬虫中基本不会用到,使用较少,仅作了解)
urllib.robotparser 用于解析 robots.txt 文件。
robots.txt(统一小写)是一种存放于网站根目录下的 robots 协议,它通常用于告诉搜索引擎对网站的抓取规则。
Robots协议也称作爬虫协议,机器人协议,网络爬虫排除协议,用来告诉爬虫哪些页面是可以爬取的,哪些页面是不可爬取的。它通常是一个robots.txt的文本文件,一般放在网站的根目录上。
当爬虫访问一个站点的时候,会首先检查这个站点目录是否存在robots.txt文件,如果存在,搜索爬虫会根据其中定义的爬取范围进行爬取。如果没有找到这个文件,搜索爬虫会访问所有可直接访问的页面。
urllib.robotparser 提供了 RobotFileParser 类,语法如下:
class urllib.robotparser.RobotFileParser(url='')
这个类提供了一些可以读取、解析 robots.txt 文件的方法:
-
set_url(url) - 设置 robots.txt 文件的 URL。
-
read() - 读取 robots.txt URL 并将其输入解析器。
-
parse(lines) - 解析行参数。
-
can_fetch(useragent, url) - 如果允许 useragent 按照被解析 robots.txt 文件中的规则来获取 url 则返回 True。
-
mtime() -返回最近一次获取 robots.txt 文件的时间。这适用于需要定期检查 robots.txt 文件更新情况的长时间运行的网页爬虫。
-
modified() - 将最近一次获取 robots.txt 文件的时间设置为当前时间。
-
crawl_delay(useragent) -为指定的 useragent 从 robots.txt 返回 Crawl-delay 形参。如果此形参不存在或不适用于指定的 useragent 或者此形参的 robots.txt 条目存在语法错误,则返回 None。
-
request_rate(useragent) -以 named tuple RequestRate(requests, seconds) 的形式从 robots.txt 返回 Request-rate 形参的内容。如果此形参不存在或不适用于指定的 useragent 或者此形参的 robots.txt 条目存在语法错误,则返回 None。
-
site_maps() - 以 list() 的形式从 robots.txt 返回 Sitemap 形参的内容。如果此形参不存在或者此形参的 robots.txt 条目存在语法错误,则返回 None。
---END---
相关文章:

Python爬虫库之urllib使用详解
一、Python urllib库 Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。 Python3 的 urllib。 urllib 包 包含以下几个模块: urllib.request - 打开和读取 URL。 urllib.error - 包含 urllib.request 抛出的异常。 urllib.parse - 解…...
_使用Apollo做配置中心)
SpringCloud学习笔记(八)_使用Apollo做配置中心
由于Apollo支持的图形化界面相对于我们更加的友好,所以此次我们使用Apollo来做配置中心 本篇文章实现了使用Apollo配置了dev和fat两个环境下的属性配置。 Apollo官方文档https://github.com/ctripcorp/apollo/wiki 1.下载依赖 从https://github.com/ctripcorp/apo…...
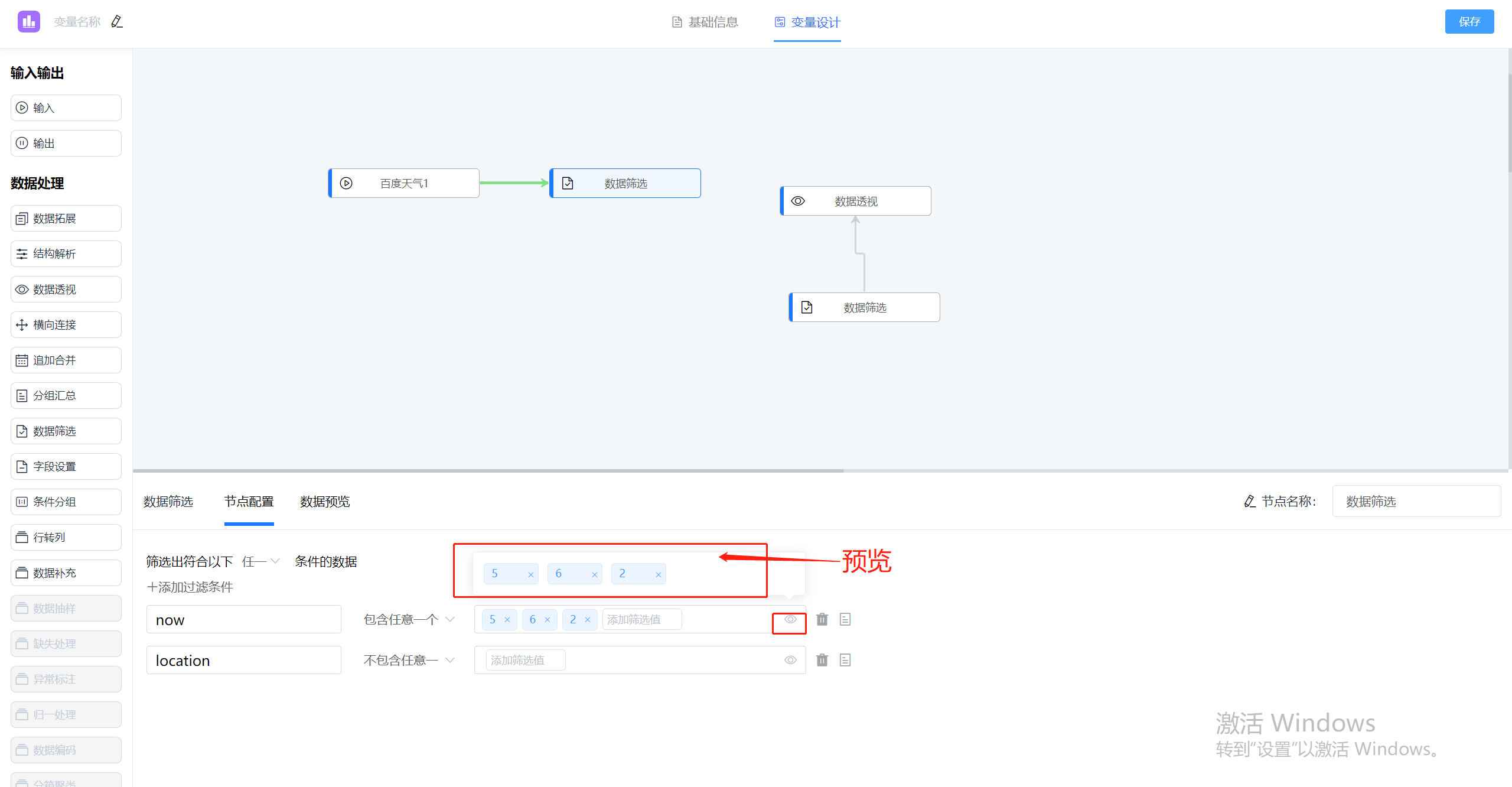
jvs-rules(规则引擎)更新:新增功能介绍
jvs-rules更新内容 1.复合变量新增数据补充节点,实现请求回来的数据再以入参方式请求其他数据进行数据补充(例如通过参数A,请求回数据B,再以数据B为入参,请求回数据C) 2.规则流结束节点支持新增、新建、引…...

消息队列的消息异常处理
目录 1.如果消费端发生异常导致消息消费失败,补偿策略是什么 2.消息队列重试的话,如何保证消费的幂等性? 3.消息重发机制 1.如果消费端发生异常导致消息消费失败,补偿策略是什么 生产者发送消息失败: 设置mandato…...

APP上线为什么要提前部署安全产品呢?
一般平台刚上线或者日活跃量比较高的时候,很容易成为攻击者的目标,服务器如果遭遇黑客攻击,资源耗尽会导致平台无法访问,业务也无法正常开展,服务器一旦触发黑洞机制,就会被拉进黑洞很长一段时间࿰…...

SQL注入之HTTP头部注入
文章目录 cookie注入练习获取数据库名称获取版本号 base64注入练习获取数据库名称获取版本号 user-agent注入练习获取数据库名称获取版本号 cookie注入练习 向服务器传参三大基本方法:GPC GET方法,参数在URL中 POST,参数在body中 COOKIE,参数…...

软考高级系统架构设计师系列论文九十七:论软件三层结构的设计
软考高级系统架构设计师系列论文九十七:论软件三层结构的设计 一、软件结构相关知识点二、摘要三、正文四、总结一、软件结构相关知识点 软考高级系统架构设计师:软件架构设计系列二二、摘要 随着中间件与Web技术的发展,三层或多层分布式应用体系越来越流行。在这种体系结构…...

【C++心愿便利店】No.2---函数重载、引用
文章目录 前言🌟一、函数重载🌏1.1.函数重载概念🌏1.2.C支持函数重载的原理 -- 名字修饰 🌟二、引用🌏2.1.引用的概念🌏2.2.引用特性🌏2.3.常引用🌏2.4.使用场景🌏2.5.传…...

掌握Six Sigma:逐步解锁业务流程优化的秘密之匙
一、Six Sigma方法简介 1. Six Sigma的起源和概念 Six Sigma起源于1980年代的摩托罗拉公司。当时的摩托罗拉在面临激烈的全球竞争和持续的质量问题时,发明了这种系统的管理方法,并通过实施,获得了显著的成绩。 所谓的“Six Sigma”&#x…...
Python中使用print()时如何实现不换行
平时刷题的时候大家可能会发现打印字符的时候需要你不换行才能得到正确答案,那么如何实现的。下面直接看例子。 使用print()函数时其实还有个默认的参数end,来看看具体怎么回事 list [a,b,c] for i in list:print(i)打印结果: 这是不加参…...

WordPress使用子主题插件 Child Theme Wizard,即使主题升级也能够保留以前主题样式
修改WordPress网站样式,主题升级会导致自己定义设置的网站样式丢失,还需要重新设置,很繁琐工作量大,发现在WordPress 中有Child Theme Wizard子主题插件,使用Child Theme Wizard子主题插件,即使主题升级&am…...
人员跌倒检测识别预警
人员跌倒检测识别预警系统通过pythonopencv深度学习网络模型架构,人员跌倒检测识别预警系统实时监测老人的活动状态,通过图像识别和行为分析算法,对老人的姿态、步态等进行检测和识别,一旦系统检测到跌倒事件,立即发出…...
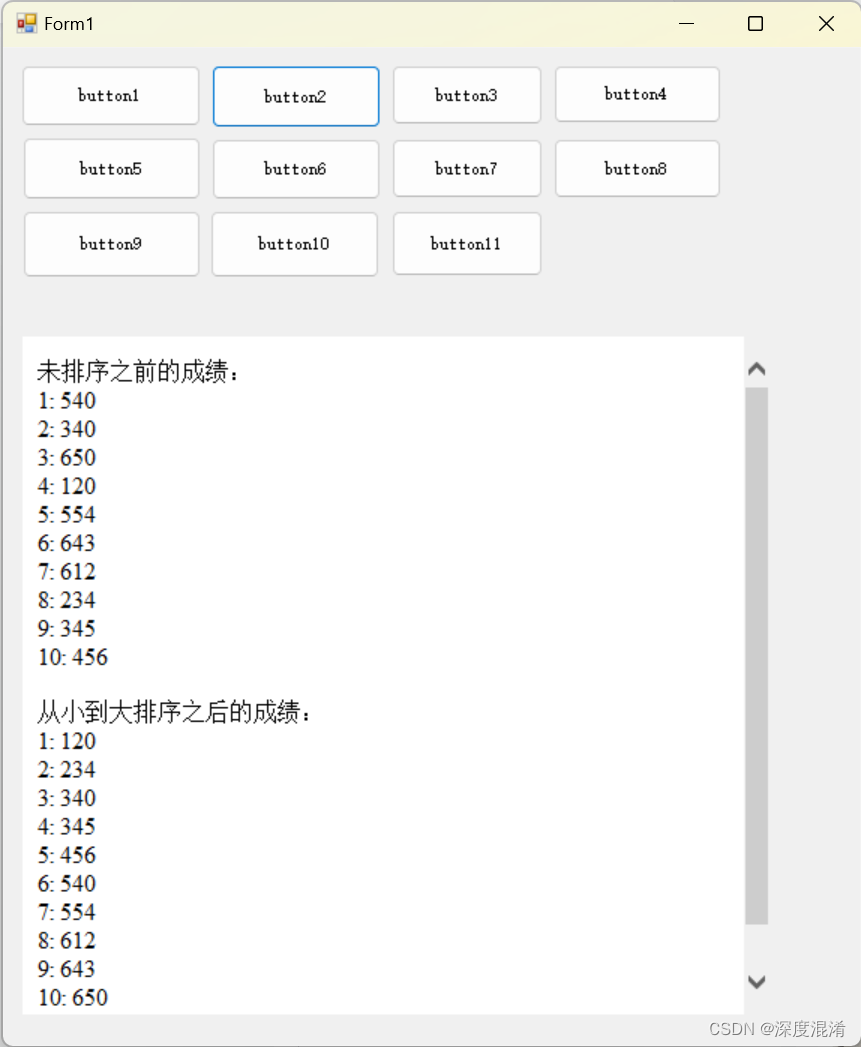
C#,《小白学程序》第二课:数组与排序
1 文本格式 /// <summary> /// 《小白学程序》第二课:数组与排序 /// </summary> /// <param name"sender"></param> /// <param name"e"></param> private void button2_Click(object sender, EventArgs …...
2023有哪些更好用的网页制作工具
过去,专业人员使用HTMLL、CSS、Javascript等代码手动编写和构建网站。现在有越来越多的智能网页制作工具来帮助任何人实现零代码基础,随意建立和设计网站。在本文中,我们将向您介绍2023年流行的网页制作工具。我相信一旦选择了正确的网页制作…...
)
Keepalived(一)
高可用集群 High Availability Cluster,简称HA Cluste。以减少服务中断时间为目的的服务器集群技术。它通过保护用户的业务程序对外不间断提供的服务,把因软件、硬件、人为造成的故障对业务的影响降低导最低 衡量可用性:在线时间/ÿ…...
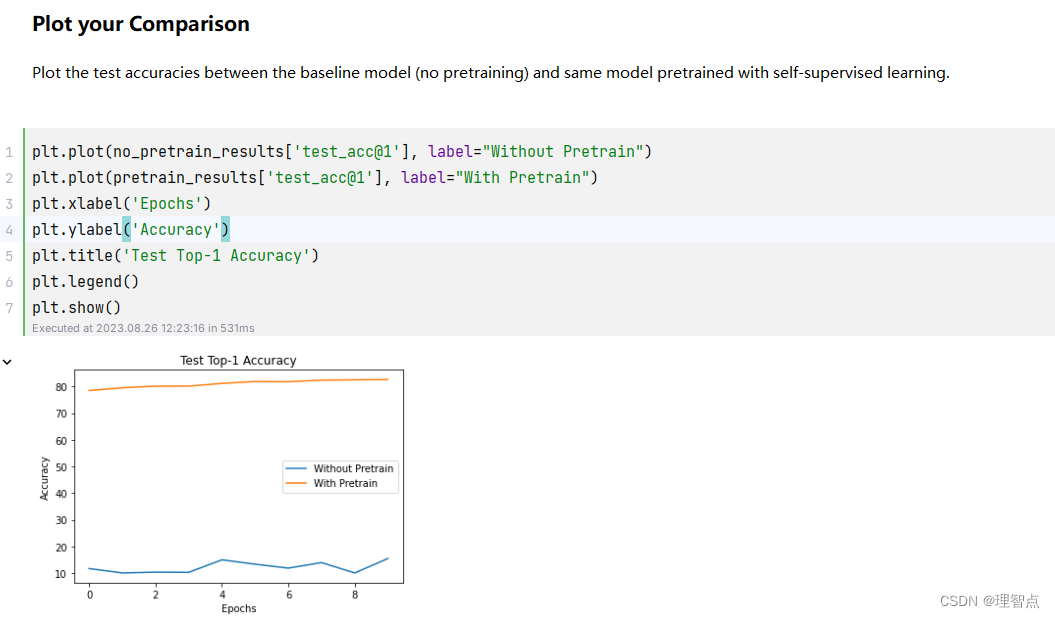
cs231n assignment3 q5 Self-Supervised Learning for Image Classification
文章目录 嫌墨迹直接看代码Q5 Self-Supervised Learning for Image Classificationcompute_train_transform CIFAR10Pair.__getitem__()题面解析代码输出 simclr_loss_naive题面解析代码输出 sim_positive_pairs题面解析代码输出 compute_sim_matrix题面解析代码输出 simclr_lo…...

电商首屏设计
1、主图最后成图效果 1.1 最后效果 1.2 主图尺寸,建多大的空白画布 1.3 如何让猜你喜欢展示跟搜索系统不一样的界面 2、实际操作方案 2.1 矩形屏信息 宽度为765 px 高度为770px; 2.2 第一步 矩形屏 2.3 第二步 填充颜色到空白 2.4 Crty j 复制图层 …...

SpringBoot集成Redis
Redis 的介绍 Redis(Remote Dictionary Server)是一个开源的内存数据结构存储系统,它被广泛地应用于缓存、计数器、限速器、消息队列、分布式锁等多种场景中。Redis 支持多种数据结构,包括字符串、散列、列表、集合和有序集合等&…...

qt 的基础学习计划列表
1 第一天 (qt 的基础) 什么是qt hello程序,空窗口 添加按钮(对象树、父子关系) 按钮的功能(信号和槽) 信号和槽的拓展2 第二天 各个控件 最简单的记事本界面(菜单栏、状态栏、工具…...

CSS中如何改变鼠标指针样式(cursor)?
聚沙成塔每天进步一点点 ⭐ 专栏简介⭐ CSS中改变鼠标指针样式(cursor)⭐ 示例:⭐ 写在最后 ⭐ 专栏简介 前端入门之旅:探索Web开发的奇妙世界 记得点击上方或者右侧链接订阅本专栏哦 几何带你启航前端之旅 欢迎来到前端入门之旅…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

使用Matplotlib创建炫酷的3D散点图:数据可视化的新维度
文章目录 基础实现代码代码解析进阶技巧1. 自定义点的大小和颜色2. 添加图例和样式美化3. 真实数据应用示例实用技巧与注意事项完整示例(带样式)应用场景在数据科学和可视化领域,三维图形能为我们提供更丰富的数据洞察。本文将手把手教你如何使用Python的Matplotlib库创建引…...

智能AI电话机器人系统的识别能力现状与发展水平
一、引言 随着人工智能技术的飞速发展,AI电话机器人系统已经从简单的自动应答工具演变为具备复杂交互能力的智能助手。这类系统结合了语音识别、自然语言处理、情感计算和机器学习等多项前沿技术,在客户服务、营销推广、信息查询等领域发挥着越来越重要…...

SQL慢可能是触发了ring buffer
简介 最近在进行 postgresql 性能排查的时候,发现 PG 在某一个时间并行执行的 SQL 变得特别慢。最后通过监控监观察到并行发起得时间 buffers_alloc 就急速上升,且低水位伴随在整个慢 SQL,一直是 buferIO 的等待事件,此时也没有其他会话的争抢。SQL 虽然不是高效 SQL ,但…...

【Linux】Linux 系统默认的目录及作用说明
博主介绍:✌全网粉丝23W,CSDN博客专家、Java领域优质创作者,掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域✌ 技术范围:SpringBoot、SpringCloud、Vue、SSM、HTML、Nodejs、Python、MySQL、PostgreSQL、大数据、物…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...

土建施工员考试:建筑施工技术重点知识有哪些?
《管理实务》是土建施工员考试中侧重实操应用与管理能力的科目,核心考查施工组织、质量安全、进度成本等现场管理要点。以下是结合考试大纲与高频考点整理的重点内容,附学习方向和应试技巧: 一、施工组织与进度管理 核心目标: 规…...

文件上传漏洞防御全攻略
要全面防范文件上传漏洞,需构建多层防御体系,结合技术验证、存储隔离与权限控制: 🔒 一、基础防护层 前端校验(仅辅助) 通过JavaScript限制文件后缀名(白名单)和大小,提…...

前端工具库lodash与lodash-es区别详解
lodash 和 lodash-es 是同一工具库的两个不同版本,核心功能完全一致,主要区别在于模块化格式和优化方式,适合不同的开发环境。以下是详细对比: 1. 模块化格式 lodash 使用 CommonJS 模块格式(require/module.exports&a…...