YOLOv8教程系列:三、K折交叉验证——让你的每一份标注数据都物尽其用(yolov8目标检测+k折交叉验证法)
YOLOv8教程系列:三、K折交叉验证——让你的每一份标注数据都物尽其用(yolov8目标检测+k折交叉验证法)
0.引言
k折交叉验证(K-Fold
Cross-Validation)是一种在机器学习中常用的模型评估技术,用于估计模型的性能和泛化能力。它的主要作用是在有限的数据集上对模型进行评估,以便更准确地了解模型在新数据上的表现。K折交叉验证的基本思想是将原始数据集分成K个子集(折),然后依次将每个子集作为验证集,其他K-1个子集作为训练集,进行K次训练和验证。每次验证后,计算模型在验证集上的性能指标,如准确率、精确率、召回率等。最后,将K次验证的性能指标平均,作为模型在整个数据集上的性能估计。
K折交叉验证的作用包括:
- 模型性能评估: K折交叉验证可以更准确地评估模型在数据集上的性能,避免因数据分布不均匀而导致评估结果不准确的问题。
- 泛化能力估计: 通过在不同的训练集和验证集上进行多次评估,可以更好地估计模型的泛化能力,即模型在新数据上的表现。
- 减少过拟合: K折交叉验证可以帮助检测模型是否出现过拟合问题。如果模型在训练集上表现很好,但在验证集上表现较差,可能存在过拟合。
- 参数调优: 在每一轮交叉验证中,可以使用不同的参数设置来训练模型,以找到在验证集上表现最好的参数组合。
- 数据利用率: K折交叉验证充分利用了数据集中的所有样本,因为每个样本都会在不同的折中被用作训练和验证。
总之,K折交叉验证是一种有助于评估和改进模型性能的重要技术,尤其在数据有限的情况下,它能更准确地估计模型在新数据上的表现。

1.数据准备
使用交叉验证前,需要把数据准备为yolo格式,不知道如何数据准备的朋友可以看下这篇文章:YOLOv8教程系列:一、使用自定义数据集训练YOLOv8模型(详细版教程,你只看一篇->调参攻略),包含环境搭建/数据准备/模型训练/预测/验证/导出等
.
├── ./data
│ ├── ./data/Annotations
│ │ ├── ./data/Annotations/fall_0.xml
│ │ ├── ./data/Annotations/fall_1000.xml
│ │ ├── ./data/Annotations/fall_1001.xml
│ │ ├── ./data/Annotations/fall_1002.xml
│ │ ├── ./data/Annotations/fall_1003.xml
│ │ ├── ./data/Annotations/fall_1004.xml
│ │ ├── …
│ ├── ./data/images
│ │ ├── ./data/images/fall_0.jpg
│ │ ├── ./data/images/fall_1000.jpg
│ │ ├── ./data/images/fall_1001.jpg
│ │ ├── ./data/images/fall_1002.jpg
│ │ ├── ./data/images/fall_1003.jpg
│ │ ├── ./data/images/fall_1004.jpg
│ │ ├── …
│ ├── ./data/ImageSets
│ └── ./data/labels
│ │ ├── ./data/images/fall_0.txt
│ │ ├── ./data/images/fall_1000.txt
│ │ ├── ./data/images/fall_1001.txt
│ │ ├── ./data/images/fall_1002.txt
│ │ ├── ./data/images/fall_1003.txt
│ │ ├── ./data/images/fall_1004.txt
│ ├── ./data/classes.yaml
其中,特别要注意的一点是,需要新建个classes.yaml的文件,然后将自己的标签按序填写,如下所示:
names:0: your_label_11: your_label_2
2.代码准备
下面代码可以什么都不用改直接运行,前提是按我的数据格式,这个代码放在data的上层目录中
import datetime
import shutil
from pathlib import Path
from collections import Counter
import osimport yaml
import numpy as np
import pandas as pd
from ultralytics import YOLO
from sklearn.model_selection import KFold# 定义数据集路径
dataset_path = Path('./data') # 替换成你的数据集路径# 获取所有标签文件的列表
labels = sorted(dataset_path.rglob("*labels/*.txt")) # 所有标签文件在'labels'目录中# 获取当前文件的绝对路径
current_file_path = os.path.abspath(__file__)# 获取当前文件所在的文件夹路径(即当前文件的根目录)
root_directory = os.path.dirname(current_file_path)print("当前文件运行根目录:", root_directory)# 从YAML文件加载类名
yaml_file = 'data/classes.yaml'
with open(yaml_file, 'r', encoding="utf8") as y:classes = yaml.safe_load(y)['names']
cls_idx = sorted(classes.keys())# 创建DataFrame来存储每张图像的标签计数
indx = [l.stem for l in labels] # 使用基本文件名作为ID(无扩展名)
labels_df = pd.DataFrame([], columns=cls_idx, index=indx)# 计算每张图像的标签计数
for label in labels:lbl_counter = Counter()with open(label, 'r') as lf:lines = lf.readlines()for l in lines:# YOLO标签使用每行的第一个位置的整数作为类别lbl_counter[int(l.split(' ')[0])] += 1labels_df.loc[label.stem] = lbl_counter# 用0.0替换NaN值
labels_df = labels_df.fillna(0.0)# 使用K-Fold交叉验证拆分数据集
ksplit = 5
kf = KFold(n_splits=ksplit, shuffle=True, random_state=20) # 设置random_state以获得可重复的结果
kfolds = list(kf.split(labels_df))
folds = [f'split_{n}' for n in range(1, ksplit + 1)]
folds_df = pd.DataFrame(index=indx, columns=folds)# 为每个折叠分配图像到训练集或验证集
for idx, (train, val) in enumerate(kfolds, start=1):folds_df[f'split_{idx}'].loc[labels_df.iloc[train].index] = 'train'folds_df[f'split_{idx}'].loc[labels_df.iloc[val].index] = 'val'# 计算每个折叠的标签分布比例
fold_lbl_distrb = pd.DataFrame(index=folds, columns=cls_idx)
for n, (train_indices, val_indices) in enumerate(kfolds, start=1):train_totals = labels_df.iloc[train_indices].sum()val_totals = labels_df.iloc[val_indices].sum()# 为避免分母为零,向分母添加一个小值(1E-7)ratio = val_totals / (train_totals + 1E-7)fold_lbl_distrb.loc[f'split_{n}'] = ratio# 创建目录以保存分割后的数据集
save_path = Path(dataset_path / f'{datetime.date.today().isoformat()}_{ksplit}-Fold_Cross-val')
save_path.mkdir(parents=True, exist_ok=True)# 获取图像文件列表
images = sorted((dataset_path / 'images').rglob("*.jpg")) # 更改文件扩展名以匹配你的数据
ds_yamls = []# 循环遍历每个折叠并复制图像和标签
for split in folds_df.columns:# 为每个折叠创建目录split_dir = save_path / splitsplit_dir.mkdir(parents=True, exist_ok=True)(split_dir / 'train' / 'images').mkdir(parents=True, exist_ok=True)(split_dir / 'train' / 'labels').mkdir(parents=True, exist_ok=True)(split_dir / 'val' / 'images').mkdir(parents=True, exist_ok=True)(split_dir / 'val' / 'labels').mkdir(parents=True, exist_ok=True)# 创建数据集的YAML文件dataset_yaml = split_dir / f'{split}_dataset.yaml'ds_yamls.append(dataset_yaml.as_posix())split_dir = os.path.join(root_directory, split_dir.as_posix())with open(dataset_yaml, 'w') as ds_y:yaml.safe_dump({'path': split_dir,'train': 'train','val': 'val','names': classes}, ds_y)
print(ds_yamls)# 将文件路径保存到一个txt文件中
with open('data/file_paths.txt', 'w') as f:for path in ds_yamls:f.write(path + '\n')# 为每个折叠复制图像和标签到相应的目录
for image, label in zip(images, labels):for split, k_split in folds_df.loc[image.stem].items():# 目标目录img_to_path = save_path / split / k_split / 'images'lbl_to_path = save_path / split / k_split / 'labels'# 将图像和标签文件复制到新目录中# 如果文件已存在,可能会抛出SamefileErrorshutil.copy(image, img_to_path / image.name)shutil.copy(label, lbl_to_path / label.name)
运行代码后,会在data目录下生成一个文件夹,里面有5种不同划分的数据集
3.开始训练
下面的代码放在和上面代码的同级目录中,训练参数可以根据自己情况进行调整
from ultralytics import YOLOweights_path = 'checkpoints/yolov8s.pt'
model = YOLO(weights_path, task='train')
ksplit = 5
# 从文本文件中加载内容并存储到一个列表中
ds_yamls = []
with open('data/file_paths.txt', 'r') as f:for line in f:# 去除每行末尾的换行符line = line.strip()ds_yamls.append(line)# 打印加载的文件路径列表
print(ds_yamls)results = {}
for k in range(ksplit):dataset_yaml = ds_yamls[k]model.train(data=dataset_yaml, batch=6, epochs=2, imgsz=1280, device=0, workers=8, single_cls=False, )
相关文章:
YOLOv8教程系列:三、K折交叉验证——让你的每一份标注数据都物尽其用(yolov8目标检测+k折交叉验证法)
YOLOv8教程系列:三、K折交叉验证——让你的每一份标注数据都物尽其用(yolov8目标检测k折交叉验证法) 0.引言 k折交叉验证(K-Fold Cross-Validation)是一种在机器学习中常用的模型评估技术,用于估计模型的性…...

leetcode算法题--表示数值的字符串
原题链接:https://leetcode.cn/problems/biao-shi-shu-zhi-de-zi-fu-chuan-lcof/description/?envTypestudy-plan-v2&envIdcoding-interviews 题目类型有点新颖,有限状态机 // CharType表示当前字符的类型 // State表示当前所处的状态 type State…...
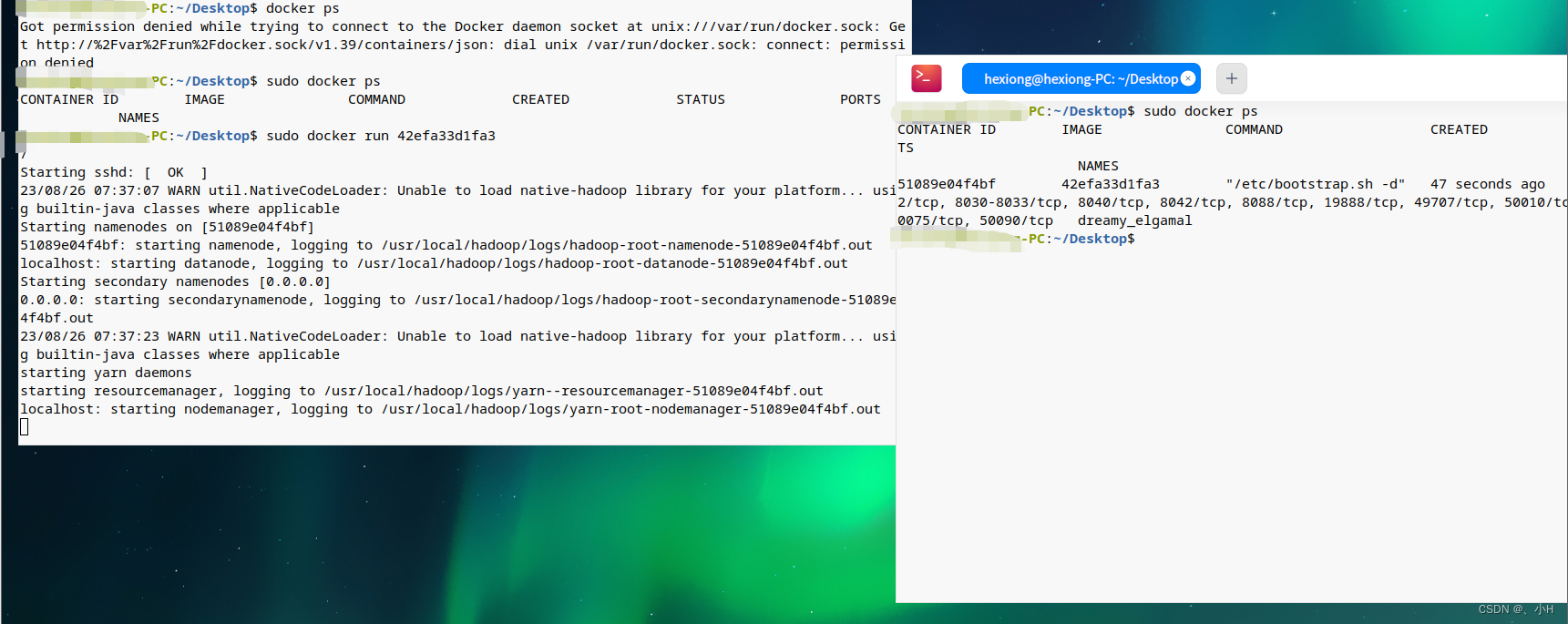
Docker安装及Docker构建简易版Hadoop生态
一、首先在VM创建一个新的虚拟机将Docker安装好 更新系统:首先打开终端,更新系统包列表。 sudo apt-get update sudo apt-get upgrade下图是更新系统包截图 安装Docker:使用以下命令在Linux上安装Docker。 sudo apt-get install -y docker.i…...

使用Burp Suite进行Web应用渗透测试
使用Burp Suite进行Web应用渗透测试是一种常见的方法,可以帮助发现Web应用程序中的安全漏洞和弱点。 步骤: 准备工作: 首先,确保已经安装了Burp Suite,并配置浏览器以使用Burp Suite作为代理。 配置代理:…...

Github的使用指南
首次创建仓库 1.官网创建仓库 打开giuhub官网,右上角点击你的头像,随后点击your repositories 点击New开始创建仓库 如下图为创建仓库的选项解释 出现如下界面就可以进行后续的git指令操作了 2.git上传项目 进入需上传项目的所在目录,打开…...
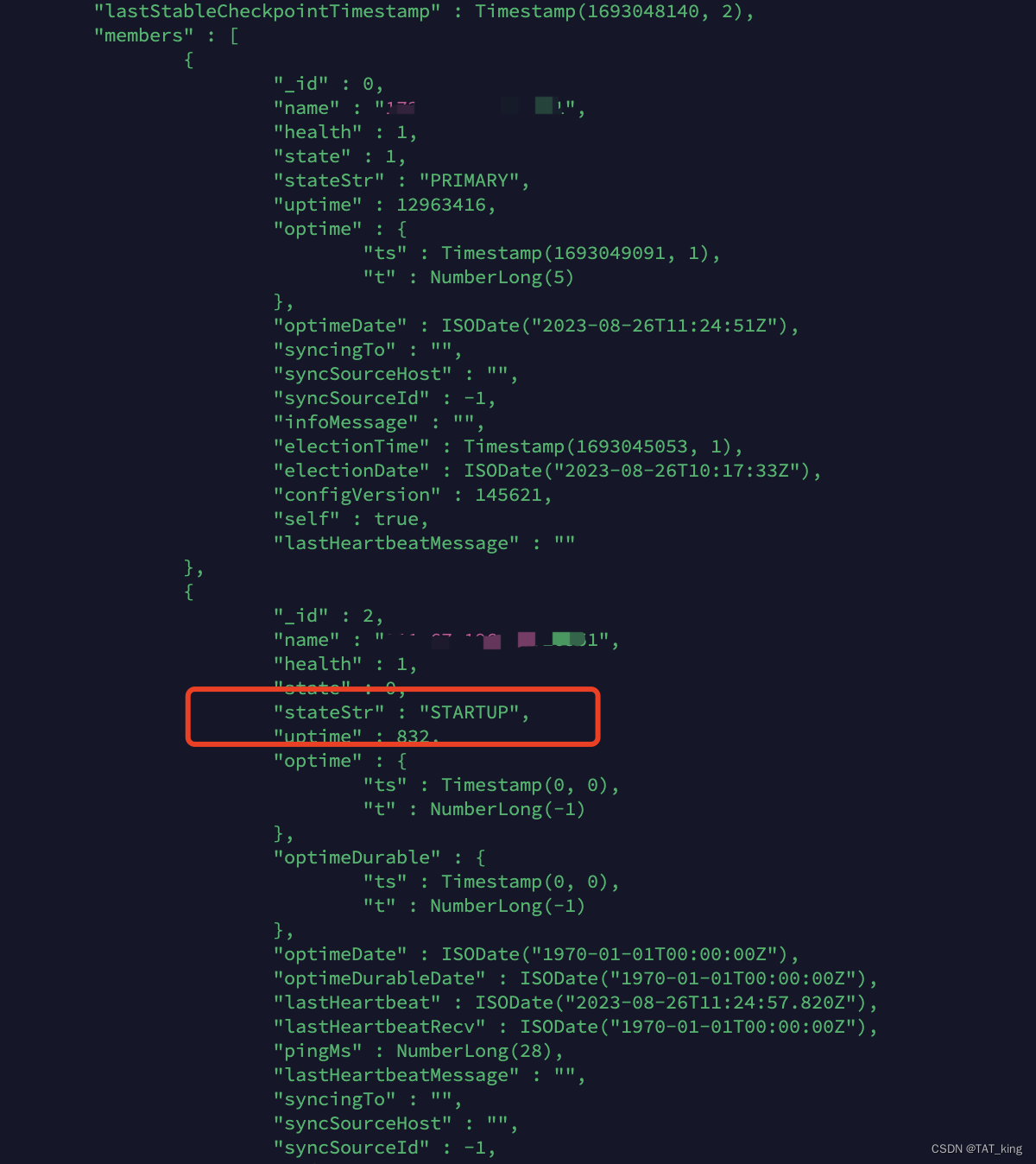
mongodb 添加加点 stateStr 停在 STARTUP
解决办法 PRIMARY 节点是的host 是否是内网IP,如果是内网IP 需要切换成外网IP 即可;...
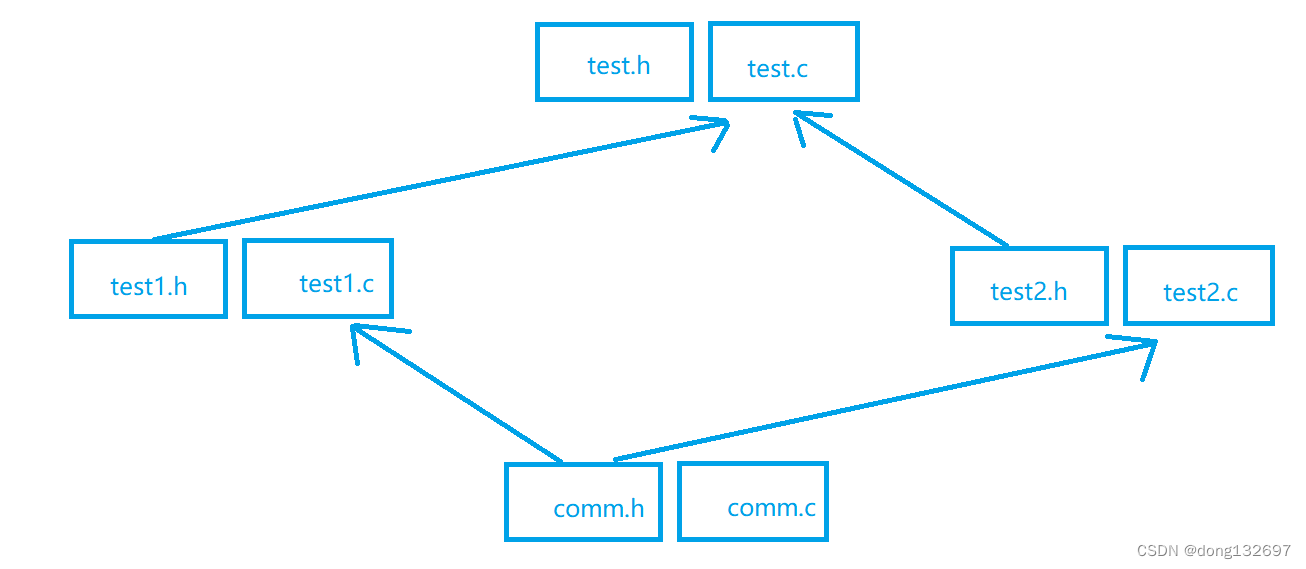
c语言中编译过程与预处理
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、c语言的编译与链接1、编译与链接概述2、编译与链接详解 二、c语言预处理1.c语言中内置的预定义符号2、#define定义标识符3、#define定义宏4、#define 替换规…...
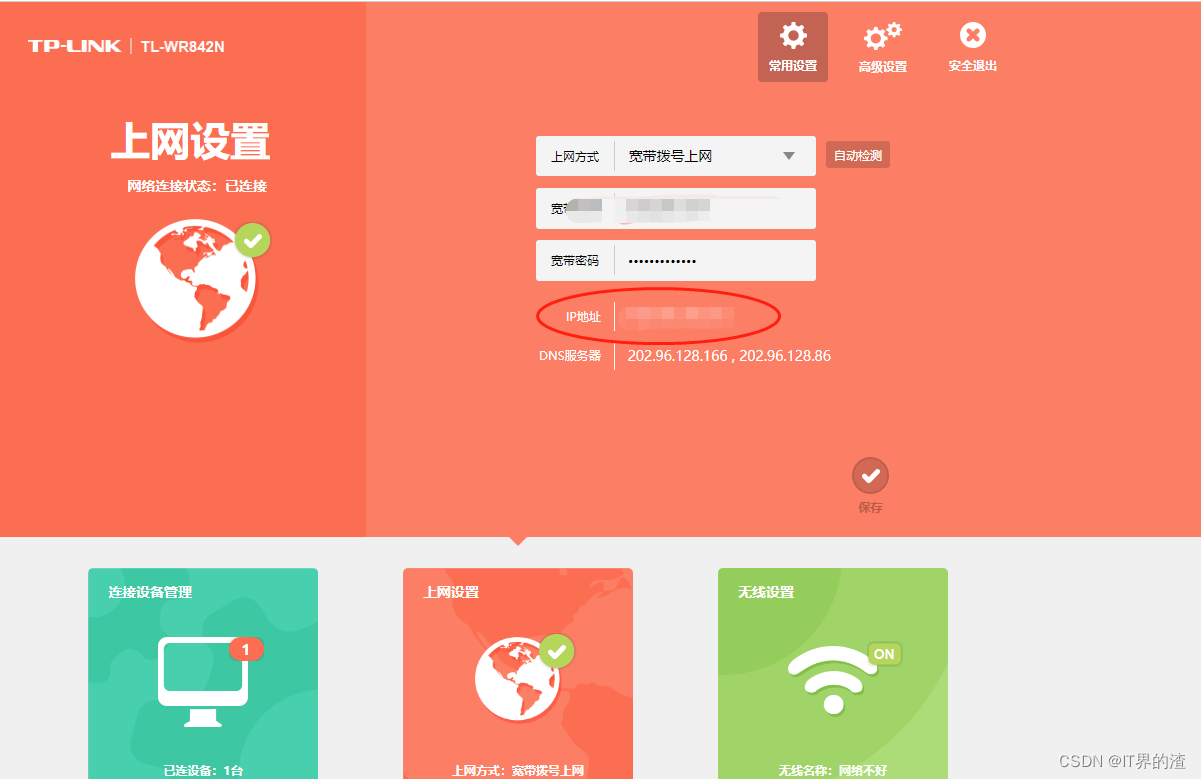
TP-LINK 路由器设置内网穿透
TP-LINK 路由器设置内网穿透 开发中经常遇到调用第三方软件回调调试的情况,例如微信开发,支付回调等测试,用内网穿透是一种简单的方式也是偷懒的方式。 以TP-LINK路由器为例实现内网穿透 登录路由器 2.找到路由器虚拟服务器,添加…...

A 题国际旅游网络的大数据分析-详细解析与代码答案(2023 年全国高校数据统计与调查分析挑战赛
请你们进行数据统计与调查分析,使用附件中的数据,回答下列问题: ⚫ 问题 1: 请进行分类汇总统计,计算不同国家 1995 年至 2020 年累计旅游总人数,从哪个国家旅游出发的人数最多,哪个国家旅游到达的人数最多…...

《深入理解Java虚拟机》读书笔记: 类加载器
类加载器 虚拟机设计团队把类加载阶段中的“通过一个类的全限定名来获取描述此类的二进制字节流”这个动作放到Java虚拟机外部去实现,以便让应用程序自己决定如何去获取所需要的类。实现这个动作的代码模块称为“类加载器”。 类加载器可以说是Java语言的一项创新&…...
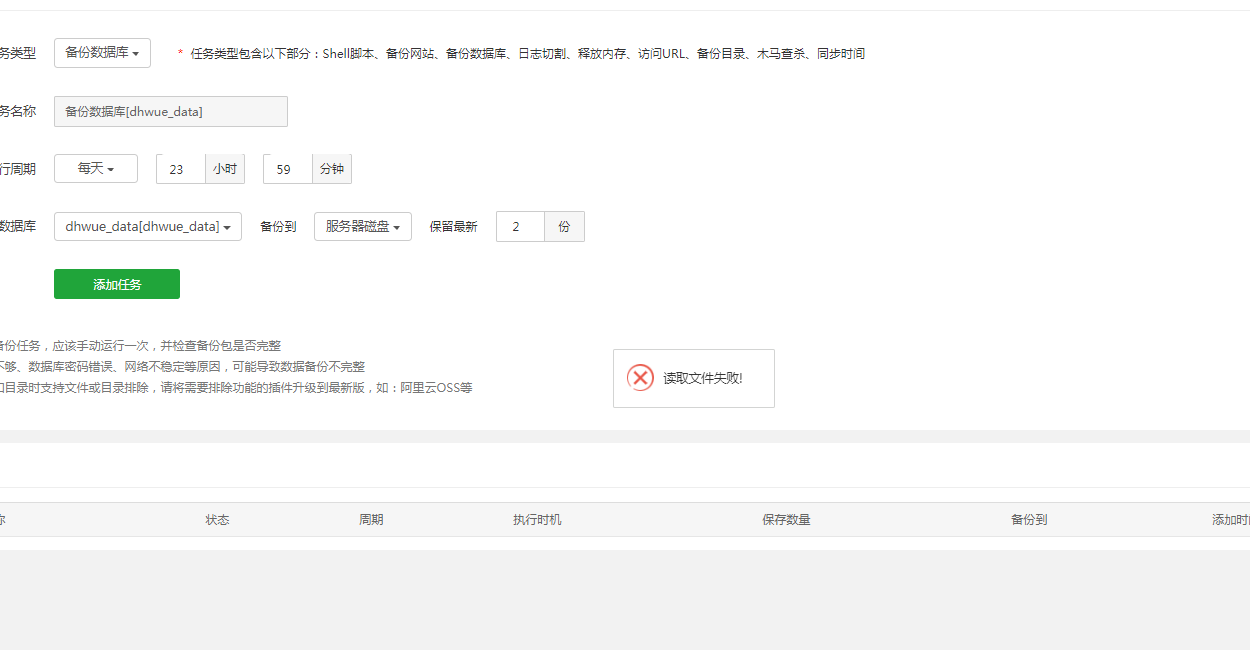
宝塔计划任务读取文件失败
想挂计划任务 相关文章【已解决】计划任务读取文件失败 - Linux面板 - 宝塔面板论坛 对方反馈的是执行下面的命令 chattr -ai /var/spool/cron 后来发现直接没有这个文件夹,然后通过mkdir命令创建文件夹,成功在宝塔创建了计划任务 后面发现任务虽然添…...

Python操作sql,备份数据库
1、批量执行sql import pymysql# 执行批量的 SQL 语句 def executeBatchSql(cursor, sqlStatements):for sql in sqlStatements:try:cursor.execute(sql)print(Executed SQL statement:, sql)except Exception as e:print(Error executing SQL statement:, e)# 创建数据库连接…...
Linux线程 --- 生产者消费者模型(C语言)
在学习完线程相关的概念之后,本节来认识一下Linux多线程相关的一个重要模型----“ 生产者消费者模型” 本文参考: Linux多线程生产者与消费者_红娃子的博客-CSDN博客 Linux多线程——生产者消费者模型_linux多线程生产者与消费者_两片空白的博客-CSDN博客…...
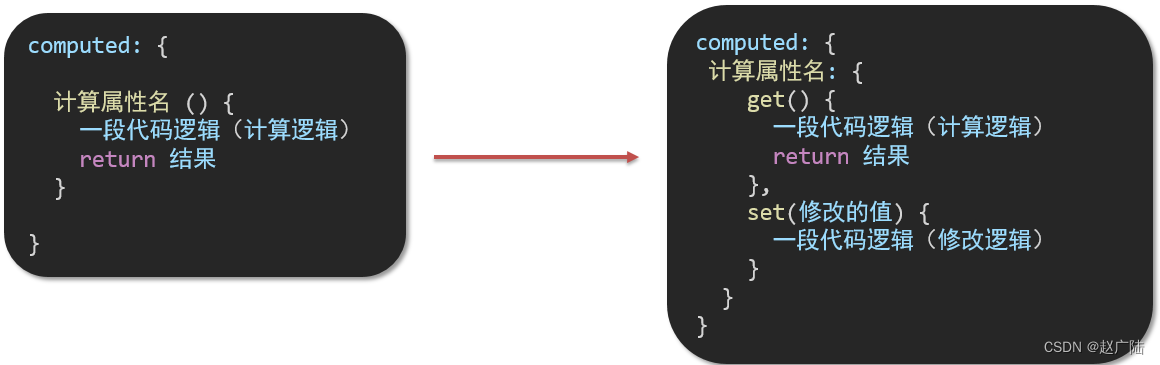
Vue2向Vue3过度核心技术computed计算属性
目录 1 computed计算属性1.1 概念1.2 语法1.3 注意1.4.案例1.5.代码准备 2 computed计算属性 VS methods方法2.1 computed计算属性2.2 methods计算属性2.3 计算属性的优势2.4 总结 3 计算属性的完整写法 1 computed计算属性 1.1 概念 基于现有的数据,计算出来的新属…...

芯片行业震荡期,数字后端还可以入吗?
自去年开始,芯片行业仿佛进入了动荡期,经历了去年秋招和今年春招的小伙伴都知道,如今找工作有多难。 半导体行业人才缩减、各大厂裁员,在加上高校毕业生人数破千万,对于即将踏入IC这个行业的应届生来说,今…...

“精准时空”赋能制造业智能化发展
作者:邓中亮 高达动态厘米级的高精度定位服务,不仅是北斗卫星导航系统的一大独门绝技,其在产业化应用层面也已逐步向普适化、标配化演进,并延展出时空智能新兴产业。 5月17日,当长征三号乙运载火箭成功发射北斗系统的…...
Kotlin协程flow发送时间间隔debounce
Kotlin协程flow发送时间间隔debounce debounce的作用是让连续发射的数据之间间隔起来。典型的应用场景是搜索引擎里面的关键词输入,当用户输入字符时候,有时候,并不希望用户每输入任何一个单字就触发一次后台真正的查询,而是希望…...
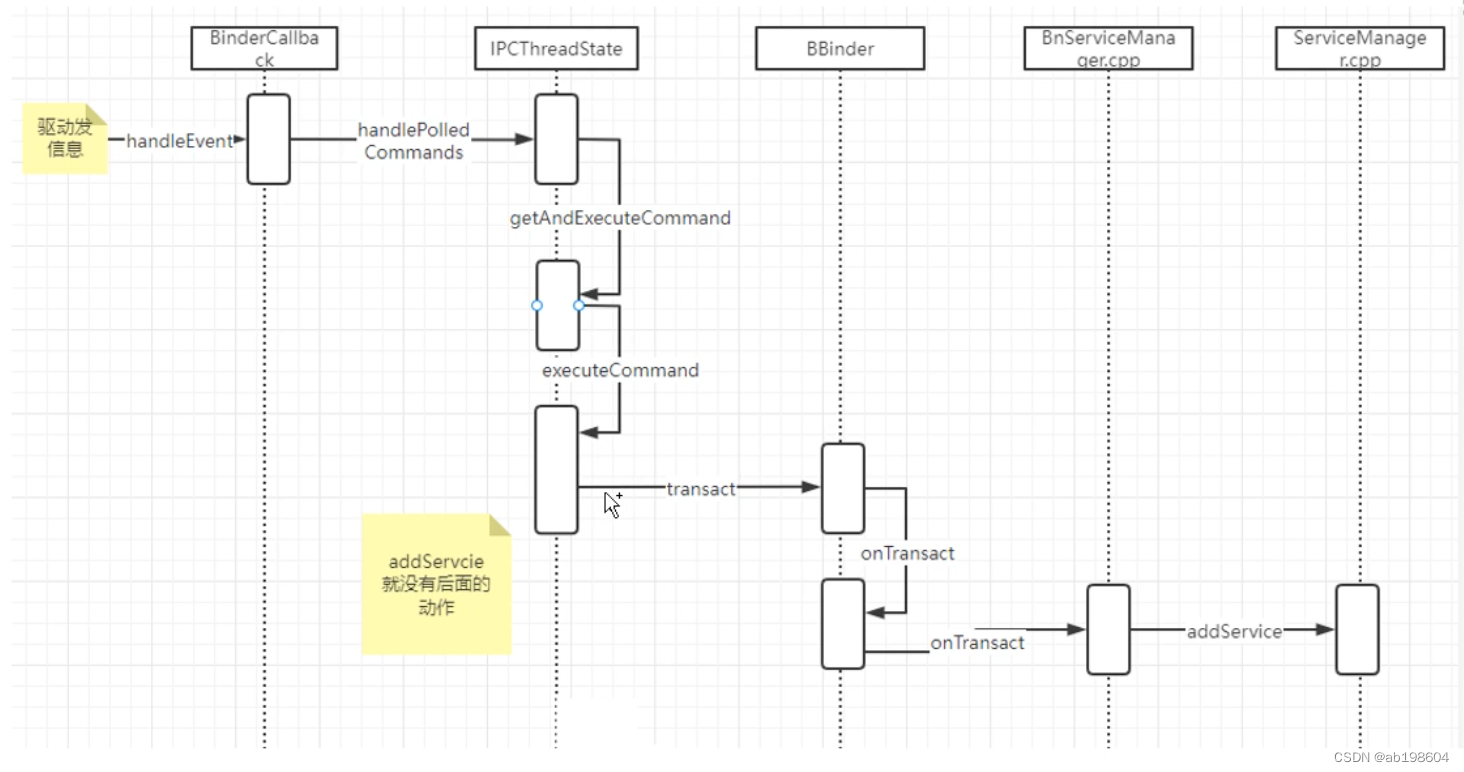
ServiceManager接收APP的跨进程Binder通信流程分析
现在一起来分析Server端接收(来自APP端)Binder数据的整个过程,还是以ServiceManager这个Server为例进行分析,这是一个至下而上的分析过程。 在分析之前先思考ServiceManager是什么?它其实是一个独立的进程,由init解析i…...
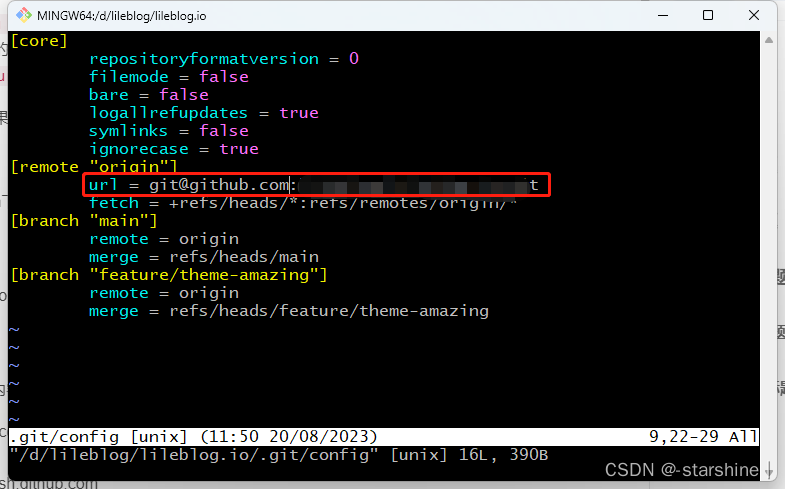
Git问题:解决“ssh:connect to host github.com port 22: Connection timed out”
操作系统 Windows11 使用Git IDEA 连接方式:SSH 今天上传代码出现如下报错:ssh:connect to host github.com port 22: Connection timed out 再多尝试几次,依然是这样。 解决 最终发现两个解决方案:(二选一…...
在Eclipse中创建javaweb工程
新建动态web工程 点击project或other之后,如何快速找到Dynamic Web Project 填写工程名等详细信息 也许会出现下面的对话框 项目结构图...

RestClient
什么是RestClient RestClient 是 Elasticsearch 官方提供的 Java 低级 REST 客户端,它允许HTTP与Elasticsearch 集群通信,而无需处理 JSON 序列化/反序列化等底层细节。它是 Elasticsearch Java API 客户端的基础。 RestClient 主要特点 轻量级ÿ…...

浅谈 React Hooks
React Hooks 是 React 16.8 引入的一组 API,用于在函数组件中使用 state 和其他 React 特性(例如生命周期方法、context 等)。Hooks 通过简洁的函数接口,解决了状态与 UI 的高度解耦,通过函数式编程范式实现更灵活 Rea…...

前端倒计时误差!
提示:记录工作中遇到的需求及解决办法 文章目录 前言一、误差从何而来?二、五大解决方案1. 动态校准法(基础版)2. Web Worker 计时3. 服务器时间同步4. Performance API 高精度计时5. 页面可见性API优化三、生产环境最佳实践四、终极解决方案架构前言 前几天听说公司某个项…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...

第25节 Node.js 断言测试
Node.js的assert模块主要用于编写程序的单元测试时使用,通过断言可以提早发现和排查出错误。 稳定性: 5 - 锁定 这个模块可用于应用的单元测试,通过 require(assert) 可以使用这个模块。 assert.fail(actual, expected, message, operator) 使用参数…...
)
论文解读:交大港大上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一)
宇树机器人多姿态起立控制强化学习框架论文解析 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化学习框架(一) 论文解读:交大&港大&上海AI Lab开源论文 | 宇树机器人多姿态起立控制强化…...
)
Java入门学习详细版(一)
大家好,Java 学习是一个系统学习的过程,核心原则就是“理论 实践 坚持”,并且需循序渐进,不可过于着急,本篇文章推出的这份详细入门学习资料将带大家从零基础开始,逐步掌握 Java 的核心概念和编程技能。 …...

pikachu靶场通关笔记22-1 SQL注入05-1-insert注入(报错法)
目录 一、SQL注入 二、insert注入 三、报错型注入 四、updatexml函数 五、源码审计 六、insert渗透实战 1、渗透准备 2、获取数据库名database 3、获取表名table 4、获取列名column 5、获取字段 本系列为通过《pikachu靶场通关笔记》的SQL注入关卡(共10关࿰…...

零基础在实践中学习网络安全-皮卡丘靶场(第九期-Unsafe Fileupload模块)(yakit方式)
本期内容并不是很难,相信大家会学的很愉快,当然对于有后端基础的朋友来说,本期内容更加容易了解,当然没有基础的也别担心,本期内容会详细解释有关内容 本期用到的软件:yakit(因为经过之前好多期…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...