kafka原理之springboot 集成批量消费
前言
由于 Kafka 的写性能非常高,因此项目经常会碰到 Kafka 消息队列拥堵的情况。遇到这种情况,我们可以通过并发消费、批量消费的方法进行解决。
一、新建一个maven工程,添加kafka依赖
<dependency><groupId>org.springframework.kafka</groupId><artifactId>spring-kafka</artifactId>
</dependency>二、yaml配置文件
spring:kafka:bootstrap-servers: 127.0.0.1:9002producer:key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerconsumer:group-id: test-consumer-group# 当 Broker 端没有 offset(如第一次消费或 offset 超过7天过期)时如何初始化 offset,当收到 OFFSET_OUT_OF_RANGE 错误时,如何重置 Offset# earliest:表示自动重置到 partition 的最小 offset# latest:默认为 latest,表示自动重置到 partition 的最大 offset# none:不自动进行 offset 重置,抛auto-offset-reset: latest# 是否在消费消息后将 offset 同步到 Broker,当 Consumer 失败后就能从 Broker 获取最新的 offsetenable-auto-commit: false## 当 auto.commit.enable=true 时,自动提交 Offset 的时间间隔,建议设置至少1000auto-commit-interval: 2000max-poll-records: 30heartbeat-interval: 3000key-deserializer: org.apache.kafka.common.serialization.StringDeserializervalue-deserializer: org.apache.kafka.common.serialization.StringDeserializerproperties:# 使用 Kafka 消费分组机制时,消费者超时时间。当 Broker 在该时间内没有收到消费者的心跳时,认为该消费者故障失败,Broker 发起重新 Rebalance 过程。目前该值的配置必须在 Broker 配置group.min.session.timeout.ms=6000和group.max.session.timeout.ms=300000 之间session.timeout.ms: 60000# 使用 Kafka 消费分组机制时,消费者发送心跳的间隔。这个值必须小于 session.timeout.ms,一般小于它的三分之一heartbeat.interval.ms: 3000# 使用 Kafka 消费分组机制时,再次调用 poll 允许的最大间隔。如果在该时间内没有再次调用 poll,则认为该消费者已经失败,Broker 会重新发起 Rebalance 把分配给它的 partition 分配给其他消费者max.poll.interval.ms: 300000request.timeout.ms: 600000listener:# 在侦听器容器中运行的线程数。concurrency: 2type: batchmax-poll-records: 50#当 auto.commit.enable 设置为false时,表示kafak的offset由customer手动维护,#spring-kafka提供了通过ackMode的值表示不同的手动提交方式#手动调用Acknowledgment.acknowledge()后立即提交ack-mode: manual_immediate# 消费者监听的topic不存在时,项目会报错,设置为falsemissing-topics-fatal: false三、消息消费
手动提交非批量消费
-
String 类型接入
@KafkaListener(topics = {"test-topic"}, groupId = "test-consumer-group")public void onMessage(String message, Consumer consumer) {System.out.println("接收到的消息:" + message);consumer.commitSync();} -
使用注解方式获取消息头、消息体
/*** 处理消息*/@KafkaListener(topics = "test-topic", groupId = "test-consumer-group")public void onMessage(@Payload String message,@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,@Header(name = KafkaHeaders.RECEIVED_MESSAGE_KEY, required = false) String key,@Header(KafkaHeaders.RECEIVED_TIMESTAMP) long ts,Acknowledgment ack) {try {ack.acknowledge();log.info("Consumer>>>>>>>>>>>>>end");} catch (Exception e) {log.error("Consumer.onMessage#error . message={}", message, e);throw new BizException("事件消息消费失败", e);}}
手动提交批量消费
想要批量消费,首先要开启批量消费,通过listener.type属性设置为batch即可开启,看下代码吧:
spring:kafka:consumer:group-id: test-consumer-groupbootstrap-servers: 127.0.0.1:9092max-poll-records: 50 # 一次 poll 最多返回的记录数listener:type: batch # 开启批量消费
如上设置了启用批量消费和批量消费每次最多消费记录数。这里设置 max-poll-records是50,并不是说如果没有达到50条消息,我们就一直等待。而是说一次poll最多返回的记录数为50
-
ConsumerRecord类接收
/*** kafka的批量消费监听器*/@KafkaListener(topics = "test-topic", groupId = "test-consumer-group")public void onMessage(List<ConsumerRecord<String, String>> records, Consumer consumer) {try {log.info("Consumer.batch#size={}", records == null ? 0 : records.size());if (CollectionUtil.isEmpty(records)) {//分别是commitSync(同步提交)和commitAsync(异步提交)consumer.commitSync();return;}for (ConsumerRecord<String, String> record : records) {String message = record.value();if (StringUtils.isBlank(message)) {continue;}//处理业务数据//doBuiness();}consumer.commitSync();log.info("Consumer>>>>>>>>>>>>>end");} catch (Exception e) {log.error("Consumer.onMessage#error .", e);throw new BizException("事件消息消费失败", e);}} -
String类接收
@KafkaListener(topics = {"test-topic"}, groupId = "test-consumer-group")public void onMessage(List<String> message, Consumer consumer) {System.out.println("接收到的消息:" + message);consumer.commitSync();} -
使用注解方式获取消息头、消息体,则也是使用 List 来接收:
@Component public class KafkaConsumer {// 消费监听@KafkaListener(topics = {"test-topic"})public void listen2(@Payload List<String> data,@Header(KafkaHeaders.RECEIVED_TOPIC) List<String> topics,@Header(KafkaHeaders.RECEIVED_PARTITION_ID) List<Integer> partitions,@Header(KafkaHeaders.RECEIVED_MESSAGE_KEY) List<String> keys,@Header(KafkaHeaders.RECEIVED_TIMESTAMP) List<Long> tss) {System.out.println("收到"+ data.size() + "条消息:");System.out.println(data);System.out.println(topics);System.out.println(partitions);System.out.println(keys);System.out.println(tss);} } -
并发消费
再来看下并发消费,为了加快消费,我们可以提高并发数,比如下面配置我们将并发设置为 3。注意:并发量根据实际分区数决定,必须小于等于分区数,否则会有线程一直处于空闲状态
spring:kafka:consumer:group-id: test-consumer-groupbootstrap-servers: 127.0.0.1:9092max-poll-records: 50 # 一次 poll 最多返回的记录数listener:type: batch # 开启批量监听concurrency: 3 # 设置并发数
我们设置concurrency为3,也就是将会启动3条线程进行监听,而要监听的topic有5个partition,意味着将有2条线程都是分配到2个partition,还有1条线程分配到1个partition
配置类方式
通过自定义配置类的方式也是可以的,但是相对yml配置来说还是有点麻烦的(不提倡)
/*** 消费者配置*/
@Configuration
public class KafkaConsumerConfig {/*** 消费者配置* @return*/public Map<String,Object> consumerConfigs(){Map<String,Object> props = new HashMap<>();props.put(ConsumerConfig.GROUP_ID_CONFIG, "test-consumer-group");props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "127.0.0.1:9002");props.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG, 50);props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);return props;}@Beanpublic KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, Object>> batchFactory() {ConcurrentKafkaListenerContainerFactory<String, Object> factory = new ConcurrentKafkaListenerContainerFactory<>();factory.setConsumerFactory(new DefaultKafkaConsumerFactory<>(consumerConfigs()));//并发数量factory.setConcurrency(3);//开启批量监听factory.setBatchListener(true);return factory;}
}同时监听器通过@KafkaListener注解的containerFactory 配置指定批量消费的工厂即可,如下:
同时监听器通过@KafkaListener注解的containerFactory 配置指定批量消费的工厂即可,如下:四、Kafka参数调优
一、Consumer参数说明
1、enable.auto.commit
该属性指定了消费者是否自动提交偏移量,默认值是true。
为了尽量避免出现重复数据(假如,某个消费者poll消息后,应用正在处理消息,在3秒后kafka进行了重平衡,那么由于没有更新位移导致重平衡后这部分消息重复消费)和数据丢失,可以把它设为 false,由自己控制何时提交偏移量。
如果把它设为true,还可以通过配置 auto.commit.interval.ms 属性来控制提交的频率。
2、auto.commit.interval.ms
自动提交间隔。范围:[0,Integer.MAX],默认值是 5000 (5 s)
3、手动提交:commitSync/commitAsync
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。
相同点:都会将本次poll的一批数据最大的偏移量提交。
不同点:commitSync会阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而commitAsync则没有失败重试机制,故有可能提交失败,导致重复消费。
4、max.poll.records
Consumer每次调用poll()时取到的records的最大数。
二、Kafka消息积压、消费能力不足怎么解决?
如果是Kafka消费能力不足,则可以考虑增加Topic的分区数,同时相应的增加消费者实例,消费者数=分区数(二者缺一不可)。
如果是下游的数据处理不及时,则可以提高每批次拉取的数量,通过max.poll.records这个参数可以调整。
单个消费者实例的消费能力提升,可以用多线程/线程池的方式并发消费提高单机的消费能力。
三、Kafka消费者如何进行流控?
将自动提交改成手动提交(enable.auto.commit=false),每次消费完再手动异步提交offset,之后消费者再去Broker拉取新消息,这样可以做到按照消费能力拉取消息,减轻消费者的压力。
相关文章:

kafka原理之springboot 集成批量消费
前言 由于 Kafka 的写性能非常高,因此项目经常会碰到 Kafka 消息队列拥堵的情况。遇到这种情况,我们可以通过并发消费、批量消费的方法进行解决。 一、新建一个maven工程,添加kafka依赖 <dependency><groupId>org.springframe…...
莫兰指数Moran‘s I,LISA聚类地图,显著性地图)
【GeoDa实用技巧100例】024:geoda计算全局(局部)莫兰指数Moran‘s I,LISA聚类地图,显著性地图
严重声明:本文及专栏《GeoDa空间计量案例教程100例》为CSDN博客专家刘一哥GIS原创,原文及专栏地址为:https://blog.csdn.net/lucky51222/category_12373659.html,谢绝转载或爬取!!! 文章目录 一、计算全局(或局部)单变量莫兰指数I1. 加载实验数据2. 加载权重矩阵3. 创建…...
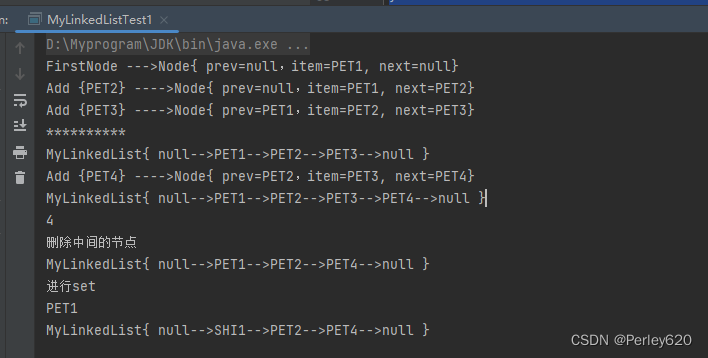
Java进阶(7)——手动实现LinkedList 内部node类的实现 增删改查的实现 toString方法 源码的初步理解
目录 引出从ArrayList到Linkedlist手动实现ArrayList从ArrayList到LinkedList 总体设计Node类Node的方法:根据index找node 增删改查的实现增加元素删除元素修改元素查询元素 toString方法完整代码List接口类LinkedList的实现测试类 总结 引出 1.linkedList的节点&am…...

CPU总线的理解
目录 CPU总线CPU总线是什么?CPU总线可以分为前端部分和后端部分吗? CPU总线 CPU总线是什么? CPU总线(Central Processing Unit Bus)是计算机硬件中的一个重要组成部分,它是连接CPU和其他硬件组件的通道。…...
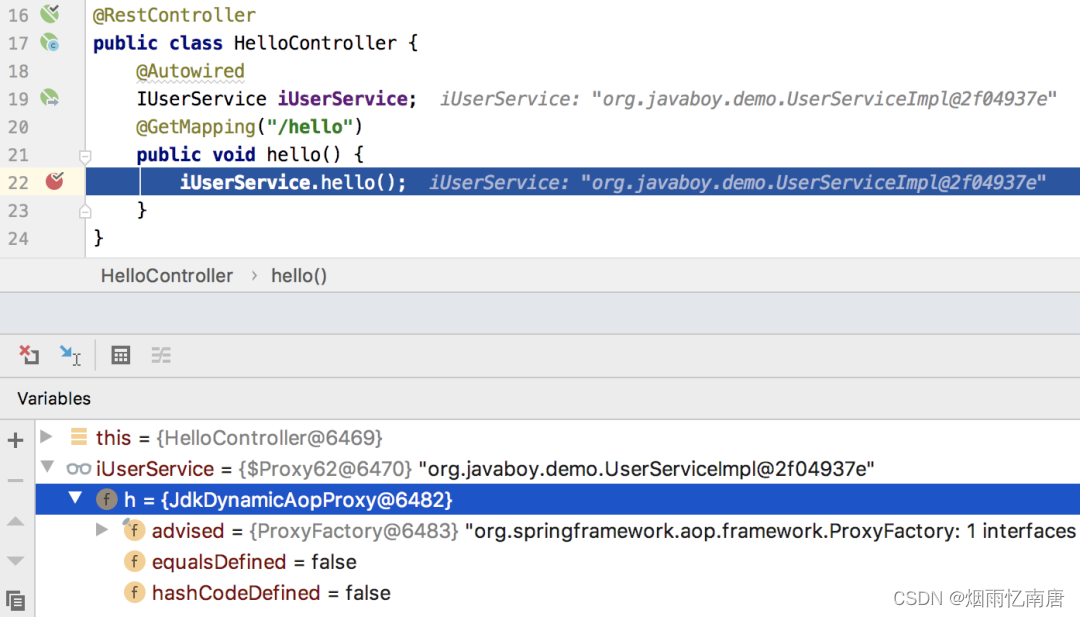
Spring Boot 中的 AOP,到底是 JDK 动态代理还是 Cglib 动态代理
大家都知道,AOP 底层是动态代理,而 Java 中的动态代理有两种实现方式: 基于 JDK 的动态代理 基于 Cglib 的动态代理 这两者最大的区别在于基于 JDK 的动态代理需要被代理的对象有接口,而基于 Cglib 的动态代理并不需要被代理对…...

记录一下在工作中使用 LayUI bug的问题
前言: LayUI是一个很老的框架了,经常会碰到一些 bug。不过由于他的轻量级,仍然有一些项目在使用。解决这些 bug 可能会对大家产生一些意义。 layui中 slect form表单元素 不美化显现的问题 layui中美化的表单元素 在渲染完成要添加 form.re…...

手机自动无人直播,实景无人直播真的有用吗?
继数字人直播之后,手机自动直播开始火热了起来,因为其门槛低,成本低,一部手机一个账号就可以实现直播,一时深受广大商家的好评。那么,手机自动无人直播究竟是如何实现自动直播的呢? 在传统的直…...

python 面试题--2(15题)
目录 1.解释Python中的 GIL(全局解释器锁)是什么,它对多线程编程有什么影响? 2.Python中的装饰器是什么?如何使用装饰器? 3.解释Python中的迭代器和生成器的区别。 4.什么是Python中的列表解析…...

kafka复习:(11)auto.offset.reset的默认值
在ConsumerConfig这个类中定义了这个属性的默认值,如下图 也就是默认值为latest,它的含义是:如果没有客户端提交过offset的话,当新的客户端消费时,把最新的offset设置为当前消费的offset. 默认是自动提交位移的,每5秒…...
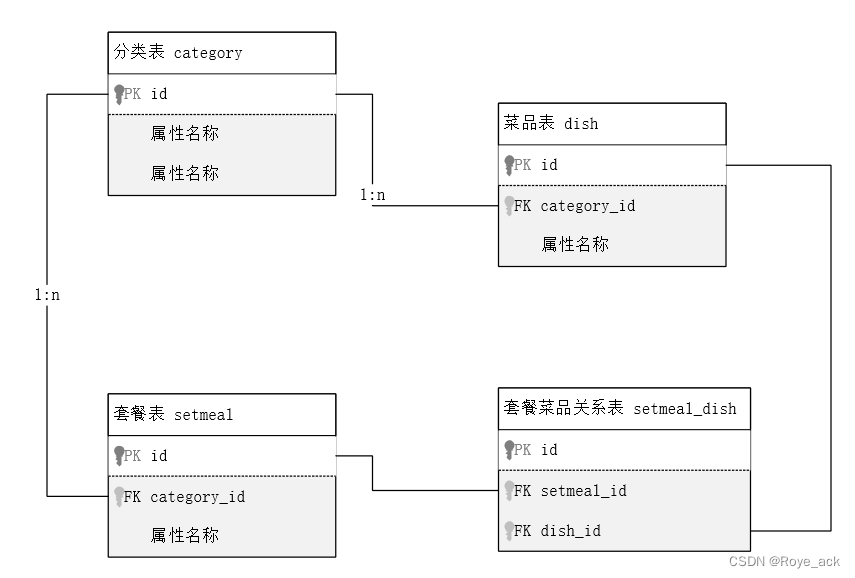
【javaweb】学习日记Day7 - Mysql 数据库 DQL 多表设计
之前学习过的SQL语句笔记总结戳这里→【数据库原理与应用 - 第六章】T-SQL 在SQL Server的使用_Roye_ack的博客-CSDN博客 目录 一、DQL 数据查询 1、基本查询 2、条件查询 3、分组查询 (1)聚合函数 ① count函数 ② max min avg sum函数 &…...

线程的生命周期
线程的生命周期 与人有生老病死一样,线程也同样要经历开始(等待)、运行、挂起和停止四种不同的状态。这四种状态都可以通过Thread类中的方法进行控制。下面给出了Thread类中和这四种状态相关的方法。 // 开始线程 public void start( ); …...
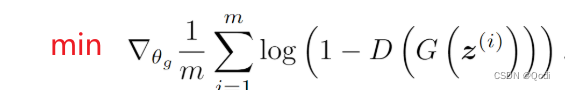
GAN | 论文精读 Generative Adversarial Nets
提出一个GAN (Generative Adversarial Nets) 1 方法 (1)生成模型G(Generative),是用来得到分布的,在统计学眼里,整个世界是通过采样不同的分布得到的,生成…...
Yolo系列-yolov2
YOLO-V2 更快!更强! YOLO-V2-BatchNormalization BatchNormalization(批归一化)是一个常用的深度神经网络优化技术,它可以将输入数据进行归一化处理,使得神经网络更容易进行学习。在YOLOv2中,B…...
Linux下的系统编程——vim/gcc编辑(二)
前言: 在Linux操作系统之中有很多使用的工具,我们可以用vim来进行程序的编写,然后用gcc来生成可执行文件,最终运行程序。下面就让我们一起了解一下vim和gcc吧 目录 一、vim编辑 1.vim的三种工作模式 2.基本操作之跳转字符 &a…...

2023年国赛 高教社杯数学建模思路 - 案例:最短时间生产计划安排
文章目录 0 赛题思路1 模型描述2 实例2.1 问题描述2.2 数学模型2.2.1 模型流程2.2.2 符号约定2.2.3 求解模型 2.3 相关代码2.4 模型求解结果 建模资料 0 赛题思路 (赛题出来以后第一时间在CSDN分享) https://blog.csdn.net/dc_sinor?typeblog 最短时…...

芯科科技推出专为Amazon Sidewalk优化的全新片上系统和开发工具,加速Sidewalk网络采用
芯科科技为Sidewalk开发提供专家级支持 中国,北京 - 2023年8月22日 – 致力于以安全、智能无线连接技术,建立更互联世界的全球领导厂商Silicon Labs(亦称“芯科科技”,NASDAQ:SLAB)今日在其一年一度的第四…...

Kotlin 丰富的函数特性
Kotlin 是一门基于 JVM 的现代编程语言,它提供了丰富的函数特性,使得编写简洁、灵活且可读性强的代码成为可能。以下是 Kotlin 函数的一些主要特性: 一、函数声明与调用 在 Kotlin 中,使用 fun 关键字来声明函数。函数声明的基本…...

Node.js怎么搭建HTTP服务器
在 Node.js 中搭建一个简单的 HTTP 服务器非常容易。以下是一个基本的示例,演示如何使用 Node.js 创建一个简单的 HTTP 服务器: // 导入 http 模块 const http require(http); // 创建一个 HTTP 服务器 const server http.createServer((req, res) …...
)
基于Redisson的联锁(MultiLock)
基于Redis的分布式MultiLock对象允许对Lock对象进行分组并将它们作为单个锁进行处理。每个RLock对象可能属于不同的Redisson实例。 如果获取的Redisson实例MultiLock崩溃,那么它可能永远挂在获取状态。为了避免这种情况,Redisson维护了一个锁看门狗&…...
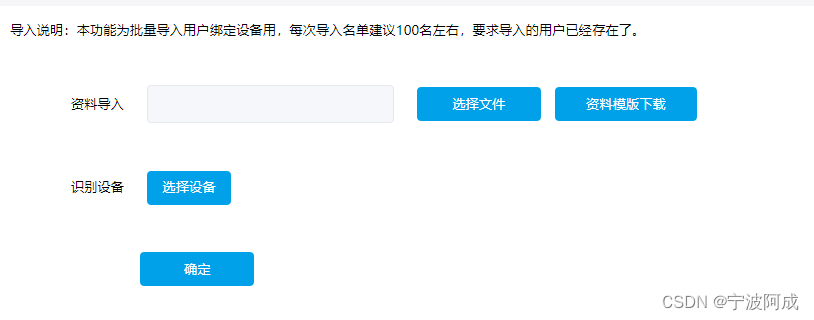
人脸识别平台批量导入绑定设备的一种方法
因为原先平台绑定设备是通过一个界面进行人工选择绑定或一个人一个人绑定设备。如下: 但有时候需要在几千个里选择出几百个,那这种方式就不大现实了,需要另外一种方法。 目前相到可以通过导入批量数据进行绑定的方式。 一、前端 主要是显示…...

网络编程(Modbus进阶)
思维导图 Modbus RTU(先学一点理论) 概念 Modbus RTU 是工业自动化领域 最广泛应用的串行通信协议,由 Modicon 公司(现施耐德电气)于 1979 年推出。它以 高效率、强健性、易实现的特点成为工业控制系统的通信标准。 包…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

Cloudflare 从 Nginx 到 Pingora:性能、效率与安全的全面升级
在互联网的快速发展中,高性能、高效率和高安全性的网络服务成为了各大互联网基础设施提供商的核心追求。Cloudflare 作为全球领先的互联网安全和基础设施公司,近期做出了一个重大技术决策:弃用长期使用的 Nginx,转而采用其内部开发…...

2025盘古石杯决赛【手机取证】
前言 第三届盘古石杯国际电子数据取证大赛决赛 最后一题没有解出来,实在找不到,希望有大佬教一下我。 还有就会议时间,我感觉不是图片时间,因为在电脑看到是其他时间用老会议系统开的会。 手机取证 1、分析鸿蒙手机检材&#x…...

AI编程--插件对比分析:CodeRider、GitHub Copilot及其他
AI编程插件对比分析:CodeRider、GitHub Copilot及其他 随着人工智能技术的快速发展,AI编程插件已成为提升开发者生产力的重要工具。CodeRider和GitHub Copilot作为市场上的领先者,分别以其独特的特性和生态系统吸引了大量开发者。本文将从功…...

大学生职业发展与就业创业指导教学评价
这里是引用 作为软工2203/2204班的学生,我们非常感谢您在《大学生职业发展与就业创业指导》课程中的悉心教导。这门课程对我们即将面临实习和就业的工科学生来说至关重要,而您认真负责的教学态度,让课程的每一部分都充满了实用价值。 尤其让我…...

C# 求圆面积的程序(Program to find area of a circle)
给定半径r,求圆的面积。圆的面积应精确到小数点后5位。 例子: 输入:r 5 输出:78.53982 解释:由于面积 PI * r * r 3.14159265358979323846 * 5 * 5 78.53982,因为我们只保留小数点后 5 位数字。 输…...
)
Android第十三次面试总结(四大 组件基础)
Activity生命周期和四大启动模式详解 一、Activity 生命周期 Activity 的生命周期由一系列回调方法组成,用于管理其创建、可见性、焦点和销毁过程。以下是核心方法及其调用时机: onCreate() 调用时机:Activity 首次创建时调用。…...

Linux 中如何提取压缩文件 ?
Linux 是一种流行的开源操作系统,它提供了许多工具来管理、压缩和解压缩文件。压缩文件有助于节省存储空间,使数据传输更快。本指南将向您展示如何在 Linux 中提取不同类型的压缩文件。 1. Unpacking ZIP Files ZIP 文件是非常常见的,要在 …...
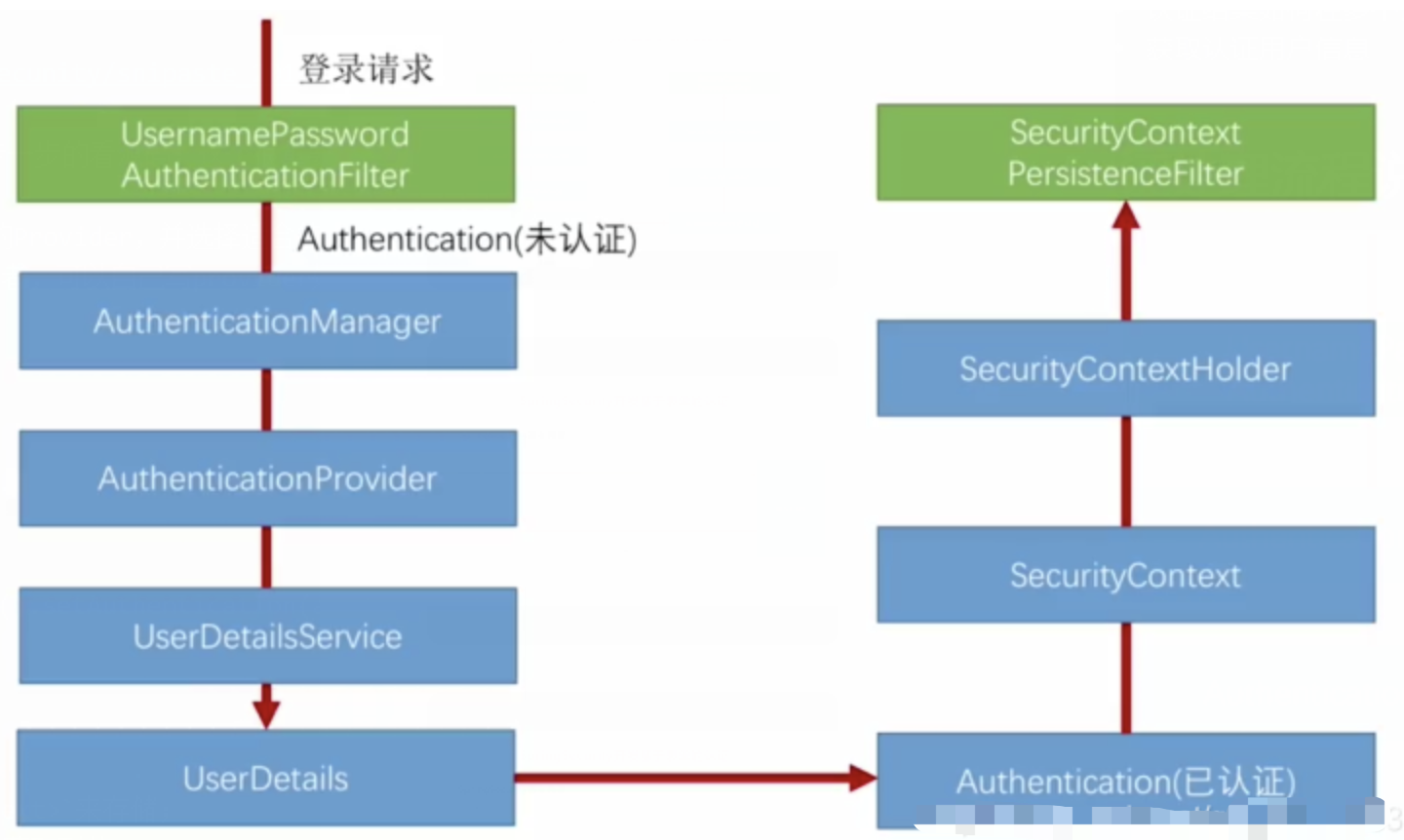
spring Security对RBAC及其ABAC的支持使用
RBAC (基于角色的访问控制) RBAC (Role-Based Access Control) 是 Spring Security 中最常用的权限模型,它将权限分配给角色,再将角色分配给用户。 RBAC 核心实现 1. 数据库设计 users roles permissions ------- ------…...