从聚类(Clustering)到异常检测(Anomaly Detection):常用无监督学习方法的优缺点
一、引言
无监督学习是机器学习的一种重要方法,与有监督学习不同,它使用未标记的数据进行训练和模式发现。无监督学习在数据分析中扮演着重要的角色,能够从数据中发现隐藏的模式、结构和关联关系,为问题解决和决策提供有益的信息。相比于有监督学习需要标记样本的限制,无监督学习更加灵活和适用于更广泛的场景。
无监督学习在数据分析中起到了重要的作用,其中聚类和异常检测是两个关键任务。聚类可以揭示数据中的模式和结构,应用于市场细分、社交网络分析等领域。而异常检测能够帮助发现与正常模式不同的数据样本,应用于金融、网络安全等领域。本文将探讨聚类、降维、关联规则挖掘、受限玻尔兹曼机和异常检测这些无监督学习方法的优缺点及其应用。
二、聚类方法的优缺点
2.1 聚类定义和聚类算法的基本原理
聚类是一种无监督学习方法,旨在将数据分为具有相似特征的组或簇。聚类算法的基本原理是通过计算样本之间的相似性或距离来确定它们之间的关系,并将相似的样本归为同一簇。
「下面是一些常见的聚类算法及其基本原理」:
-
「K均值聚类算法」:K均值聚类是最常用的聚类算法之一。其基本原理是通过计算数据样本与聚类中心之间的距离来确定样本的归属,并将样本分配到最近的聚类中心所代表的簇。然后,根据已分配的样本重新计算聚类中心的位置,迭代更新样本的归属和聚类中心的位置,直到达到停止条件。 -
「层次聚类算法」:层次聚类是一种自下而上或自上而下的聚类方法。其基本原理是通过计算样本之间的相似性或距离,将相似度高的样本逐步合并为越来越大的簇或者将所有样本初始为一个簇,然后逐步分割为越来越小的簇。这种逐步合并或分割的过程称为聚类树、树状图或者树状结构。 -
「密度聚类算法」(如DBSCAN):密度聚类是一种基于样本密度的聚类方法。其基本原理是通过确定样本周围邻域内的密度来判断样本是否属于一个簇。密度聚类可以自动发现任意形状和大小的簇,并且对噪声和离群值具有较好的鲁棒性。
这些是常见的聚类算法之一,每个算法都有其独特的优势和适用场景。在选择聚类算法时,应根据数据的特点、聚类目标以及算法的复杂性和效率等因素进行综合考虑。同时,在使用聚类算法时,还需注意数据预处理、选择合适的距离或相似性度量方法以及合理设置聚类数目等因素,以获得准确且有意义的聚类结果。
2.2 优点
-
揭示隐藏模式和结构:聚类能够从数据中发现隐藏的模式和结构,帮助我们更好地理解数据并找到潜在规律。 -
数据探索和可视化的有用工具:聚类可以用于数据的探索性分析和可视化,帮助我们观察和理解数据的特征和分布。 -
适用于无标签数据集:与有监督学习不同,聚类算法不需要事先标记的数据,适用于无标签的数据集。
2.3 缺点
-
计算复杂度高:某些聚类算法的计算复杂度较高,特别是在处理大规模数据集时,需要较长的运行时间和更多的计算资源。 -
高维数据集可能准确性降低:在高维数据集中,由于维度的增加,样本之间的相似性或距离度量变得困难,聚类结果的准确性可能会下降。 -
对噪声和异常值敏感:聚类算法对噪声和异常值比较敏感,这些异常数据可能会对聚类结果产生负面影响,导致错误的簇分配。
三、降维方法的优缺点
3.1 降维和常见的降维方法原理
降维(Dimensionality reduction)是在机器学习和数据分析中的一项关键任务,目的是通过减少特征空间的维度,同时保留数据的重要信息,以便更高效地分析和处理数据。降维可以有效解决高维数据面临的困难和挑战。
「下面是常见的降维方法及其原理」:
-
「主成分分析」(Principal Component Analysis,PCA):PCA是一种无监督的线性降维方法。它通过寻找数据方差最大的主成分来实现降维。主成分是原始特征的线性组合,具有数据中最大的方差。PCA将数据投影到主成分上,去除了相关性较低的维度,保留了数据中最重要的信息。 -
「线性判别分析」(Linear Discriminant Analysis,LDA):LDA是一种有监督的线性降维方法。它将数据投影到低维空间中,同时最大化类别间的间隔和最小化类别内的方差。LDA通过选择最能区分不同类别的投影方向,实现了有效的降维,并保留了分类任务所需的信息。 -
「t分布邻域嵌入」(t-Distributed Stochastic Neighbor Embedding,t-SNE):t-SNE是一种非线性降维方法,主要用于数据可视化。它通过将高维数据映射到低维空间,使得相似样本在低维空间中保持更近的距离,不相似样本保持较远的距离。t-SNE通过优化概率分布来实现降维,能够有效地可视化高维数据的聚类结构和相似性。 -
「自编码器」(Autoencoder):自编码器是一种神经网络模型,可以用于无监督的降维。它由编码器和解码器组成,通过将原始数据压缩到低维表示,并尝试重建输入数据来学习特征表达。自编码器通过在压缩和解压缩过程中捕捉数据最重要的特征,实现降维并保留数据的关键信息。
3.2 优点
-
提高计算效率和降低存储需求:降维可以去除冗余和不相关的特征,减少数据集的维度,从而提高计算效率和降低存储需求。 -
更易于可视化、理解和解释:降维可以将高维数据转换为二维或三维空间,使得数据可视化更容易,能够更好地理解和解释数据。 -
过滤冗余特征,提取最相关的特征信息:降维方法能够过滤掉冗余特征,并且通常会选择最相关的特征进行保留,提取数据中最重要的信息。
3.3 缺点
-
可能丢失重要信息:降维过程中,由于减少了特征数量,有可能丢失一些重要的信息,影响后续任务的性能。 -
不同方法适用于不同类型的数据和任务:不同的降维方法适用于不同类型的数据和任务,没有一种方法适用于所有情况。合适的降维方法需要根据具体问题和数据特点进行选择。 -
降维过程可能引入误差:降维过程中,由于信息的丢失或映射的非完美性,可能会引入一定的误差,影响结果的准确性。
四、关联规则挖掘方法的优缺点
4.1 定义关联规则挖掘及其算法原理
关联规则挖掘是一种数据挖掘技术,用于发现数据集中的关联性和频繁项集。通过挖掘数据集中不同项之间的关联规则,可以揭示这些项之间的关系,从而帮助我们理解和预测数据的特征。
「关联规则挖掘的算法主要包括以下两种」:
-
「Apriori算法」:Apriori算法是一种基于频繁项集的关联规则挖掘算法。它通过迭代的方式逐步生成候选项集,并使用支持度来评估每个候选项集的重要性。首先,算法会扫描数据集,计算所有单个项的支持度,并找出满足最小支持度阈值的频繁项集。然后,根据频繁项集生成下一层的候选项集,并再次计算支持度。这个过程会不断迭代,直到无法生成更多的频繁项集为止。 -
FP- 「Growth算法」:FP-Growth算法是一种基于前缀树(FP-Tree)的关联规则挖掘算法。它通过构建FP-Tree来压缩数据集并表示频繁项集。首先,算法会扫描数据集,计算每个项的支持度,并构建FP-Tree。然后,从FP-Tree的根节点开始,根据支持度从大到小的顺序构建条件模式基,并递归地挖掘频繁项集。最后,根据频繁项集构建关联规则。
这些算法在挖掘关联规则时,会使用一些重要的参数和指标,包括最小支持度(minimum support)、最小置信度(minimum confidence)等。最小支持度用于筛选频繁项集,最小置信度用于评估产生的关联规则的可靠性。
4.2 优点
-
揭示数据中的关联性和频繁项集:关联规则挖掘可以帮助我们发现数据中的隐藏关联性,即通过观察一组项集中的某些项出现,预测其它项的出现概率。 -
在市场篮子分析、推荐系统等领域有应用:关联规则挖掘在市场篮子分析中可以揭示商品的关联购买模式,而在推荐系统中可以用于发现用户喜好的相关项目,从而提供个性化推荐。 -
结果易于理解和解释,可以制定业务决策:关联规则挖掘得到的结果通常以"如果...那么..."的形式呈现,易于理解和解释。这使得企业能够根据挖掘得到的关联规则制定相应的业务决策,例如促销策略、市场定位等。
4.3 缺点
-
计算复杂度高:随着数据规模的增大,关联规则挖掘的计算复杂度会显著增加,尤其是对于包含大量项和事务的数据集。这可能导致挖掘过程变得耗时。 -
只描述变量之间相关性,不能提供因果关系:关联规则挖掘只能描述变量之间的相关性,并不能提供因果关系。这意味着挖掘出的关联规则只能告诉我们两个项集之间是否有某种关联,而不能确定其中一项是另一项的原因或结果。 -
结果可能存在无意义关联或冗余规则:关联规则挖掘可能会挖掘出某些无意义的关联规则,例如"吃饭去餐厅→呼吸",这种关联规则在语义上没有实际意义。此外,挖掘得到的关联规则可能存在冗余,即多个规则描述了相同的关联性。
五、V. 受限玻尔兹曼机方法的优缺点
5.1 定义受限玻尔兹曼机及其应用
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是一种概率图模型,由可见层和隐藏层组成。它是一种无监督学习算法,用于学习输入数据的潜在分布并提取特征。
在RBM中,可见层和隐藏层之间存在连接权重,并且可见层与可见层、隐藏层与隐藏层之间没有连接。RBM的训练过程通过最大化训练样本的似然函数来更新连接权重。学习完成后,RBM可以用于生成新的样本,也可以作为特征提取器用于其他任务。
「受限玻尔兹曼机的应用包括」:
-
特征提取:RBM可以通过学习输入数据的潜在分布来自动提取有用的特征表示。这些特征可以用于后续的分类、聚类或其他机器学习任务。 -
协同过滤:RBM可以应用于协同过滤任务,通过学习用户对项目的偏好来进行推荐。RBM可以根据用户的历史行为和偏好,预测用户可能感兴趣的项目。 -
生成模型:RBM可以用作生成模型,通过学习输入样本的分布来生成与训练数据相似的新样本。这在图像生成、自然语言处理等领域具有广泛的应用。 -
单层神经网络:RBM可以作为单独的一层神经网络,进行无监督预训练。在深度学习中,RBM可以用于构建深度信念网络(Deep Belief Networks)等更复杂的模型。
5.2 优点
-
学习输入数据的潜在分布,提取有用特征:RBM可以通过学习输入数据的潜在分布来提取特征,从而发现数据中的相关模式和结构。这些特征可以用于后续的分类、聚类或生成模型等任务。 -
用于特征提取、协同过滤和生成模型:RBM可以作为特征提取器,从原始数据中自动学习有用的特征表示。此外,RBM还可以用于协同过滤任务,通过学习用户对项目的偏好来进行推荐。此外,RBM也可以用于生成模型,生成与训练数据相似的新样本。 -
深度学习模型的基础:受限玻尔兹曼机是深度学习模型中的重要组成部分,可以作为深度信念网络(Deep Belief Networks)以及其他更复杂的深度学习模型的构建模块
5.3 缺点
-
训练复杂度高,对数据量和网络结构敏感:RBM的训练过程通常需要大量的计算资源和时间,并且对于数据量和网络结构非常敏感。较大规模的数据集和复杂的网络结构可能导致训练困难和效率低下。 -
易受到局部最优解和梯度消失等问题影响:RBM的学习过程可能会陷入局部最优解,导致无法达到全局最优。此外,当RBM的层数增加时,可能会出现梯度消失的问题,使得网络训练变得困难。 -
需要大量的训练数据和计算资源:RBM通常需要大量的训练数据才能获得良好的性能,特别是在复杂的任务和高维数据集中。此外,RBM的训练过程也需要大量的计算资源,包括内存和计算能力。
六、异常检测方法的优缺点
6.1 定义异常检测及其应用
异常检测(Anomaly detection)是一种通过识别与正常模式不同或罕见的数据样本来检测异常或异常行为的方法。它的目标是识别那些与已知正常行为或模式显著不同的数据点、实例或事件。
「异常检测广泛应用于各个领域,其中一些主要应用领域包括」:
-
欺诈检测:在金融领域,异常检测用于检测信用卡欺诈、保险欺诈以及其他非法活动。通过检测与用户行为模式不符的异常交易或行为,可以及时发现欺诈活动。 -
网络入侵检测:在网络安全领域,异常检测用于发现恶意软件、黑客攻击和其他网络入侵行为。通过监测网络流量、用户行为和系统日志等信息,可以识别与正常网络行为不符的异常活动。 -
健康监测:在医疗领域,异常检测应用于监测病人的生理指标或医学图像,以及检测可能存在的疾病、异常情况或异常变化。它可以帮助医生及早发现并处理可能的健康问题。 -
设备故障检测:在工业领域,异常检测用于监测和识别设备、机器或系统的异常行为,以及预测潜在的故障或失效。这有助于减少停机时间、提高生产效率和延长设备寿命。 -
环境监测:在环境科学领域,异常检测可以用来检测大气污染、水质异常、地震活动等异常现象,以及预测或预警自然灾害。
6.2 优点
-
识别与正常模式不同或罕见的数据样本:异常检测可以帮助识别那些与正常模式显著不同的数据样本,从而发现潜在的异常或异常行为。 -
应用于欺诈检测、网络入侵检测和健康监测等领域:异常检测广泛应用于多个领域,如金融领域的欺诈检测、网络安全领域的入侵检测以及医疗领域的健康监测等,以识别异常情况并采取相应措施。 -
无需标记异常样本,对新颖异常有较好鲁棒性:与监督学习方法不同,异常检测方法通常无需事先标记异常样本,因此可以适应未知的新颖异常情况,并具备一定的鲁棒性。
6.3 缺点
-
高维数据面临"维度灾难"问题:在处理高维数据时,由于数据稀疏性增加,异常检测算法可能面临"维度灾难"的问题,即算法的性能受到维度增加的限制。 -
处理复杂异常模式时性能可能下降:当异常模式比较复杂或异常样本与正常样本之间存在重叠时,部分异常检测方法的性能可能下降,因为它们难以准确地区分异常和正常模式。 -
可能产生误报或漏报,需要调优和评估:异常检测方法可能存在误报(将正常样本错误地标记为异常)或漏报(未能识别真实异常),因此需要进行调优和评估以提高准确性和可靠性。
*「未经许可,不得以任何方式复制或抄袭本篇文章之部分或全部内容。版权所有,侵权必究。」
相关文章:
到异常检测(Anomaly Detection):常用无监督学习方法的优缺点)
从聚类(Clustering)到异常检测(Anomaly Detection):常用无监督学习方法的优缺点
一、引言 无监督学习是机器学习的一种重要方法,与有监督学习不同,它使用未标记的数据进行训练和模式发现。无监督学习在数据分析中扮演着重要的角色,能够从数据中发现隐藏的模式、结构和关联关系,为问题解决和决策提供有益的信息。…...

git仓库提交流程
拉取最新代码 cd dev-ops git拉取最新master代码: git checkout master git pull git checkout wangdachu_dev git merge master :wq 1、切换到文件的本地目录 cd ~/Desktop/aldaba-ops 2、修改用户名和邮箱 git config --global user.email "xxxxxxxxxx.…...
层叠上下文、层叠顺序
原文合集地址如下,有需要的朋友可以关注 本文地址 什么是层叠上下文 层叠上下文(Stacking Context)是指在 HTML 和 CSS 中,用于控制和管理元素层叠顺序以及呈现的一种机制。在一个网页中,许多元素(例如文…...

postgres开发目录
目录 推荐 0.00001 Bruce的博客 0.00002 官方社区博客 0.00003 德哥的培训资料 0.00004 官方开发指南 0.00005 官方网站 0.00006 官方中国网站 0.00007 官方Wiki 0.00008 postgresql代码树 0.00009 gitee-学习资料1 0.00010 gitee-源码 安装与编译 1.00001git源码clone后进…...

计算机视觉入门 6) 数据集增强(Data Augmentation)
系列文章目录 计算机视觉入门 1)卷积分类器计算机视觉入门 2)卷积和ReLU计算机视觉入门 3)最大池化计算机视觉入门 4)滑动窗口计算机视觉入门 5)自定义卷积网络计算机视觉入门 6) 数据集增强(D…...

Python分享之redis(2)
Hash 操作 redis中的Hash 在内存中类似于一个name对应一个dic来存储 hset(name, key, value) #name对应的hash中设置一个键值对(不存在,则创建,否则,修改) r.hset("dic_name","a1","aa&quo…...

springboot aop方式实现敏感数据自动加解密
一、前言 在实际项目开发中,可能会涉及到一些敏感信息,那么我们就需要对这些敏感信息进行加密处理, 也就是脱敏,比如像手机号、身份证号等信息。如果我们只是在接口返回后再去做替换处理,则代码会显得非常冗余…...
RabbitMQ---work消息模型
1、work消息模型 工作队列或者竞争消费者模式 在第一篇教程中,我们编写了一个程序,从一个命名队列中发送并接受消息。在这里,我们将创建一个工作队列,在多个工作者之间分配耗时任务。 工作队列,又称任务队列。主要思…...
GitRedisNginx合集
目录 文件传下载 Git常用命令 Git工作区中文件的状态 远程仓库操作 分支操作 标签操作 idea中使用git 设置git.exe路径 操作步骤 linux配置jdk 安装tomcat 查看是否启动成功 查看tomcat进程 防火墙操作 开放指定端口并立即生效 安装mysql 修改mysql密码 安装lrzsz软…...
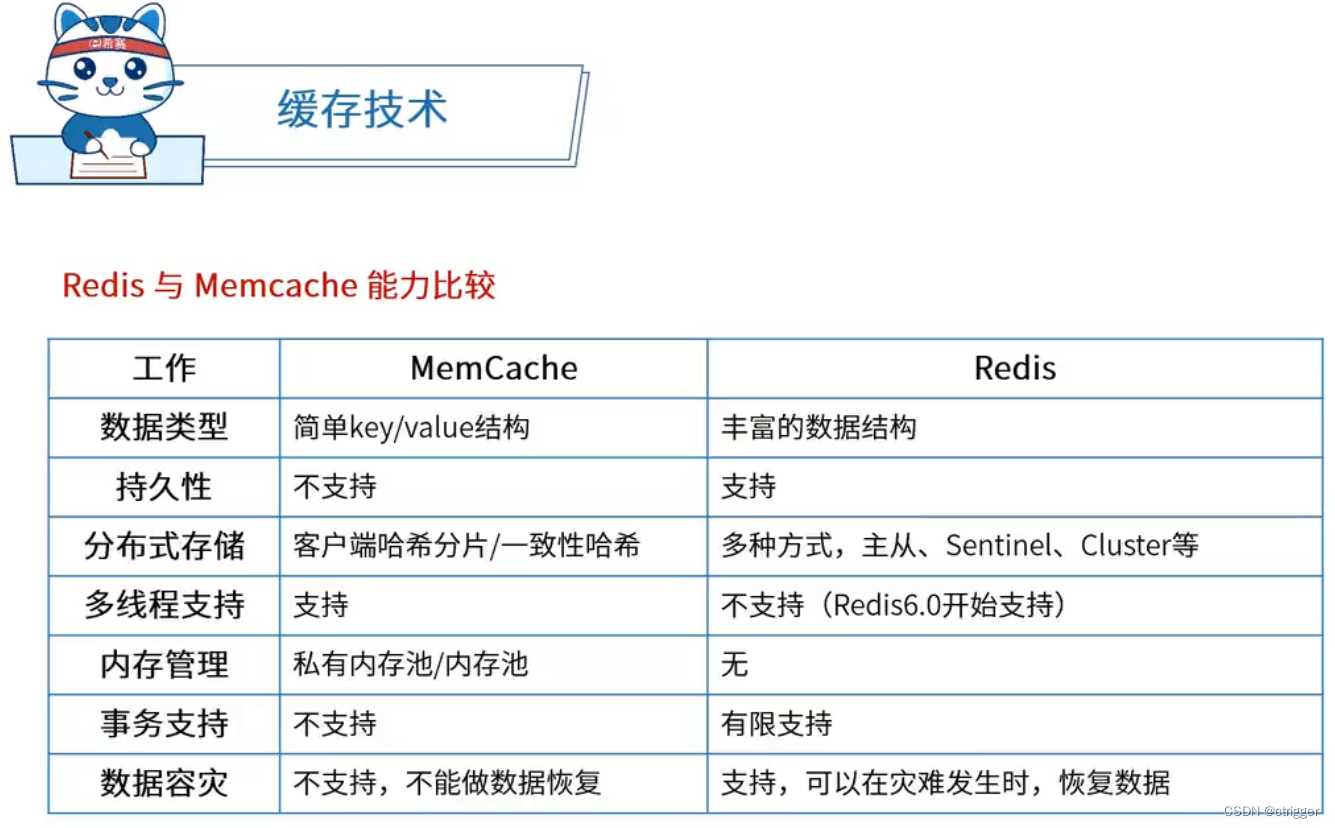
系统架构设计师之缓存技术:Redis与Memcache能力比较
系统架构设计师之缓存技术:Redis与Memcache能力比较...
02.sqlite3学习——嵌入式数据库的基本要求和SQLite3的安装
目录 嵌入式数据库的基本要求和SQLite3的安装 嵌入式数据库的基本要求 常见嵌入式数据库 sqlite3简介 SQLite3编程接口模型 ubuntu 22.04下的SQLite安装 嵌入式数据库的基本要求和SQLite3的安装 嵌入式数据库的基本要求 常见嵌入式数据库 sqlite3简介 SQLite3编程接口模…...
AIGC ChatGPT 按年份进行动态选择的动态图表
动态可视化分析的好处与优势: 1. 提高信息理解性:可视化分析使得大量复杂的数据变得易于理解,通过图表、颜色、形状、尺寸等方式,能够直观地表现不同的数据关系和模式。 2. 加快决策速度:数据可视化可以帮助用户更快…...
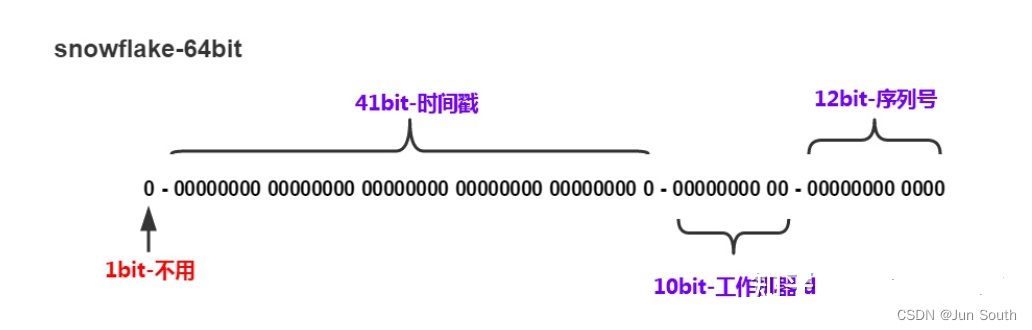
分布式—雪花算法生成ID
一、简介 1、雪花算法的组成: 由64个Bit(比特)位组成的long类型的数字 0 | 0000000000 0000000000 0000000000 000000000 | 00000 | 00000 | 000000000000 1个bit:符号位,始终为0。 41个bit:时间戳,精确到毫秒级别&a…...

Python语言实现React框架
迷途小书童的 Note 读完需要 6分钟 速读仅需 2 分钟 1 reactpy 介绍 reactpy 是一个用 Python 语言实现的 ReactJS 框架。它可以让我们使用 Python 的方式来编写 React 的组件,构建用户界面。 reactpy 的目标是想要将 React 的优秀特性带入 Python 领域,…...
Netty入门学习和技术实践
Netty入门学习和技术实践 Netty1.Netty简介2.IO模型3.Netty框架介绍4. Netty实战项目学习5. Netty实际应用场景6.扩展 Netty 1.Netty简介 Netty是由JBOSS提供的一个java开源框架,现为 Github上的独立项目。Netty提供异步的、事件驱动的网络应用程序框架和工具&…...
MySQL详细安装与配置
免安装版的Mysql MySQL关是一种关系数据库管理系统,所使用的 SQL 语言是用于访问数据库的最常用的 标准化语言,其特点为体积小、速度快、总体拥有成本低,尤其是开放源码这一特点,在 Web 应用方面 MySQL 是最好的 RDBMS(Relation…...

裸露土堆识别算法
裸露土堆识别算法首先利用图像处理技术,提取出图像中的土堆区域。裸露土堆识别算法首通过计算土堆中被绿色防尘网覆盖的比例,判断土堆是否裸露。若超过40%的土堆没有被绿色防尘网覆盖,则视为裸露土堆。当我们谈起计算机视觉时,首先…...

说说你对Redux的理解?其工作原理?
文章目录 redux?工作原理如何使用后言 redux? React是用于构建用户界面的,帮助我们解决渲染DOM的过程 而在整个应用中会存在很多个组件,每个组件的state是由自身进行管理,包括组件定义自身的state、组件之间的通信通…...

《基于 Vue 组件库 的 Webpack5 配置》7.路径别名 resolve.alias 和 性能 performance
路径别名 resolve.alias const path require(path);module.exports {resolve: {alias: {"": path.resolve(__dirname, "./src/"),"assets": path.resolve(__dirname, "./src/assets/"),"mixins": path.resolve(__dirname,…...
基于PaddleOCR2.7.0发布WebRest服务测试案例
基于PaddleOCR2.7.0发布WebRest服务测试案例 #WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. #警告:这是一个开发服务器。不要在生产部署中使用它。请改用生产WSGI服务器。 输出结果…...

idea大量爆红问题解决
问题描述 在学习和工作中,idea是程序员不可缺少的一个工具,但是突然在有些时候就会出现大量爆红的问题,发现无法跳转,无论是关机重启或者是替换root都无法解决 就是如上所展示的问题,但是程序依然可以启动。 问题解决…...

Ubuntu系统下交叉编译openssl
一、参考资料 OpenSSL&&libcurl库的交叉编译 - hesetone - 博客园 二、准备工作 1. 编译环境 宿主机:Ubuntu 20.04.6 LTSHost:ARM32位交叉编译器:arm-linux-gnueabihf-gcc-11.1.0 2. 设置交叉编译工具链 在交叉编译之前&#x…...

条件运算符
C中的三目运算符(也称条件运算符,英文:ternary operator)是一种简洁的条件选择语句,语法如下: 条件表达式 ? 表达式1 : 表达式2• 如果“条件表达式”为true,则整个表达式的结果为“表达式1”…...

MySQL 8.0 OCP 英文题库解析(十三)
Oracle 为庆祝 MySQL 30 周年,截止到 2025.07.31 之前。所有人均可以免费考取原价245美元的MySQL OCP 认证。 从今天开始,将英文题库免费公布出来,并进行解析,帮助大家在一个月之内轻松通过OCP认证。 本期公布试题111~120 试题1…...

Mysql中select查询语句的执行过程
目录 1、介绍 1.1、组件介绍 1.2、Sql执行顺序 2、执行流程 2.1. 连接与认证 2.2. 查询缓存 2.3. 语法解析(Parser) 2.4、执行sql 1. 预处理(Preprocessor) 2. 查询优化器(Optimizer) 3. 执行器…...

QT3D学习笔记——圆台、圆锥
类名作用Qt3DWindow3D渲染窗口容器QEntity场景中的实体(对象或容器)QCamera控制观察视角QPointLight点光源QConeMesh圆锥几何网格QTransform控制实体的位置/旋转/缩放QPhongMaterialPhong光照材质(定义颜色、反光等)QFirstPersonC…...

08. C#入门系列【类的基本概念】:开启编程世界的奇妙冒险
C#入门系列【类的基本概念】:开启编程世界的奇妙冒险 嘿,各位编程小白探险家!欢迎来到 C# 的奇幻大陆!今天咱们要深入探索这片大陆上至关重要的 “建筑”—— 类!别害怕,跟着我,保准让你轻松搞…...

从 GreenPlum 到镜舟数据库:杭银消费金融湖仓一体转型实践
作者:吴岐诗,杭银消费金融大数据应用开发工程师 本文整理自杭银消费金融大数据应用开发工程师在StarRocks Summit Asia 2024的分享 引言:融合数据湖与数仓的创新之路 在数字金融时代,数据已成为金融机构的核心竞争力。杭银消费金…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...

面试高频问题
文章目录 🚀 消息队列核心技术揭秘:从入门到秒杀面试官1️⃣ Kafka为何能"吞云吐雾"?性能背后的秘密1.1 顺序写入与零拷贝:性能的双引擎1.2 分区并行:数据的"八车道高速公路"1.3 页缓存与批量处理…...