手写数字识别之优化算法:观察Loss下降的情况判断合理的学习率
目录
手写数字识别之优化算法:观察Loss下降的情况判断合理的学习率
前提条件
设置学习率
学习率的主流优化算法
手写数字识别之优化算法:观察Loss下降的情况判断合理的学习率
我们明确了分类任务的损失函数(优化目标)的相关概念和实现方法,本节我们依旧横向展开"横纵式"教学法,如 图1 所示,本节主要探讨在手写数字识别任务中,使得损失达到最小的参数取值的实现方法。

图1:“横纵式”教学法 — 优化算法
前提条件
在优化算法之前,需要进行数据处理、设计神经网络结构,代码与上一节保持一致,如下所示。
# 加载相关库
import os
import random
import paddle
from paddle.nn import Conv2D, MaxPool2D, Linear
import numpy as np
from PIL import Image
import gzip
import json# 定义数据集读取器
def load_data(mode='train'):# 读取数据文件datafile = './work/mnist.json.gz'print('loading mnist dataset from {} ......'.format(datafile))data = json.load(gzip.open(datafile))# 读取数据集中的训练集,验证集和测试集train_set, val_set, eval_set = data# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLSIMG_ROWS = 28IMG_COLS = 28# 根据输入mode参数决定使用训练集,验证集还是测试if mode == 'train':imgs = train_set[0]labels = train_set[1]elif mode == 'valid':imgs = val_set[0]labels = val_set[1]elif mode == 'eval':imgs = eval_set[0]labels = eval_set[1]# 获得所有图像的数量imgs_length = len(imgs)# 验证图像数量和标签数量是否一致assert len(imgs) == len(labels), \"length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len(labels))index_list = list(range(imgs_length))# 读入数据时用到的batchsizeBATCHSIZE = 100# 定义数据生成器def data_generator():# 训练模式下,打乱训练数据if mode == 'train':random.shuffle(index_list)imgs_list = []labels_list = []# 按照索引读取数据for i in index_list:# 读取图像和标签,转换其尺寸和类型img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')label = np.reshape(labels[i], [1]).astype('int64')imgs_list.append(img) labels_list.append(label)# 如果当前数据缓存达到了batch size,就返回一个批次数据if len(imgs_list) == BATCHSIZE:yield np.array(imgs_list), np.array(labels_list)# 清空数据缓存列表imgs_list = []labels_list = []# 如果剩余数据的数目小于BATCHSIZE,# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batchif len(imgs_list) > 0:yield np.array(imgs_list), np.array(labels_list)return data_generator# 定义模型结构
import paddle.nn.functional as F
# 多层卷积神经网络实现
class MNIST(paddle.nn.Layer):def __init__(self):super(MNIST, self).__init__()# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2self.conv1 = Conv2D(in_channels=1, out_channels=20, kernel_size=5, stride=1, padding=2)# 定义池化层,池化核的大小kernel_size为2,池化步长为2self.max_pool1 = MaxPool2D(kernel_size=2, stride=2)# 定义卷积层,输出特征通道out_channels设置为20,卷积核的大小kernel_size为5,卷积步长stride=1,padding=2self.conv2 = Conv2D(in_channels=20, out_channels=20, kernel_size=5, stride=1, padding=2)# 定义池化层,池化核的大小kernel_size为2,池化步长为2self.max_pool2 = MaxPool2D(kernel_size=2, stride=2)# 定义一层全连接层,输出维度是10self.fc = Linear(in_features=980, out_features=10)# 定义网络前向计算过程,卷积后紧接着使用池化层,最后使用全连接层计算最终输出# 卷积层激活函数使用Relu,全连接层激活函数使用softmaxdef forward(self, inputs):x = self.conv1(inputs)x = F.relu(x)x = self.max_pool1(x)x = self.conv2(x)x = F.relu(x)x = self.max_pool2(x)x = paddle.reshape(x, [x.shape[0], -1])x = self.fc(x)return x设置学习率
在深度学习神经网络模型中,通常使用标准的随机梯度下降算法更新参数,学习率代表参数更新幅度的大小,即步长。当学习率最优时,模型的有效容量最大,最终能达到的效果最好。学习率和深度学习任务类型有关,合适的学习率往往需要大量的实验和调参经验。探索学习率最优值时需要注意如下两点:
- 学习率不是越小越好。学习率越小,损失函数的变化速度越慢,意味着我们需要花费更长的时间进行收敛,如 图2 左图所示。
- 学习率不是越大越好。只根据总样本集中的一个批次计算梯度,抽样误差会导致计算出的梯度不是全局最优的方向,且存在波动。在接近最优解时,过大的学习率会导致参数在最优解附近震荡,损失难以收敛,如 图2 右图所示。
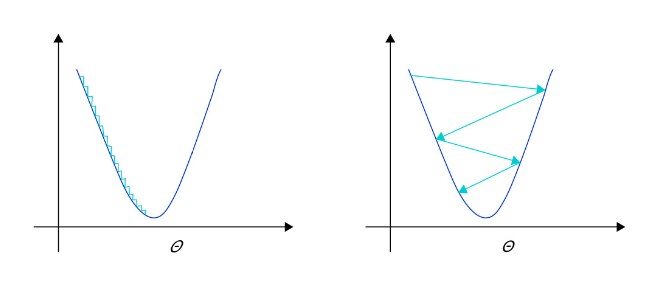
图2: 不同学习率(步长过大/过小)的示意图
在训练前,我们往往不清楚一个特定问题设置成怎样的学习率是合理的,因此在训练时可以尝试调小或调大,通过观察Loss下降的情况判断合理的学习率,设置学习率的代码如下所示。
#仅优化算法的设置有所差别
def train(model):model.train()#调用加载数据的函数train_loader = load_data('train')#设置不同初始学习率opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())# opt = paddle.optimizer.SGD(learning_rate=0.0001, parameters=model.parameters())# opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())EPOCH_NUM = 10for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据images, labels = dataimages = paddle.to_tensor(images)labels = paddle.to_tensor(labels)#前向计算的过程predicts = model(images)#计算损失,取一个批次样本损失的平均值loss = F.cross_entropy(predicts, labels)avg_loss = paddle.mean(loss)#每训练了100批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))#后向传播,更新参数的过程avg_loss.backward()# 最小化loss,更新参数opt.step()# 清除梯度opt.clear_grad()#保存模型参数paddle.save(model.state_dict(), 'mnist.pdparams')#创建模型
model = MNIST()
#启动训练过程
train(model)学习率的主流优化算法
学习率是优化器的一个参数,调整学习率看似是一件非常麻烦的事情,需要不断的调整步长,观察训练时间和Loss的变化。经过研究员的不断的实验,当前已经形成了四种比较成熟的优化算法:SGD、Momentum、AdaGrad和Adam,效果如 图3 所示。
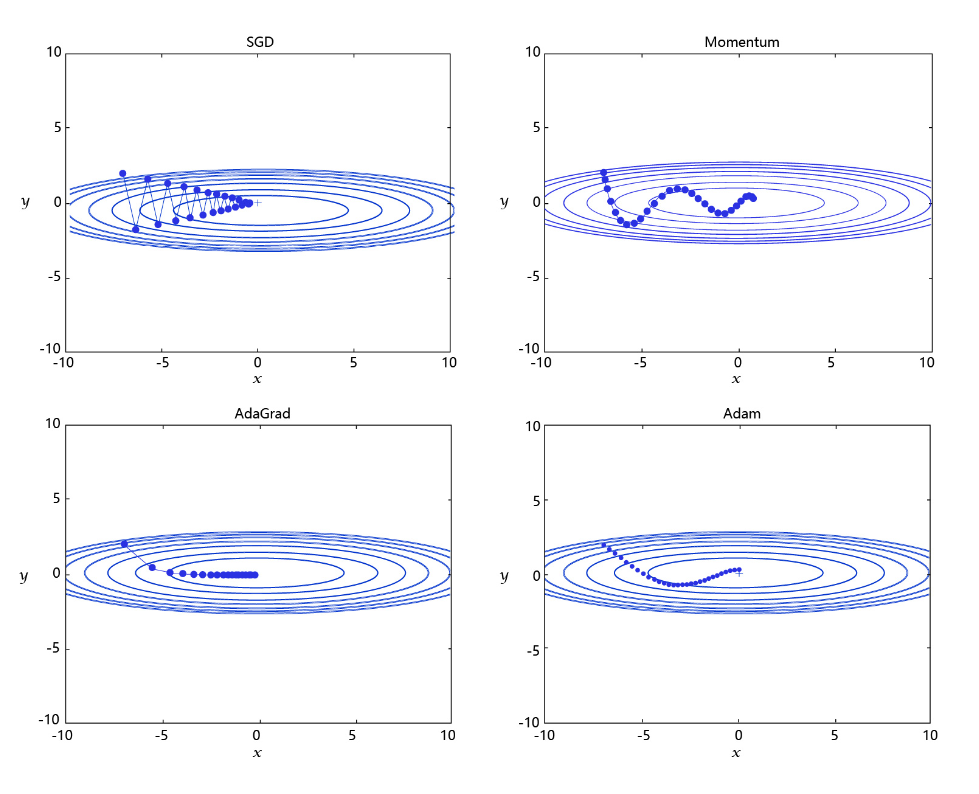
图3: 不同学习率算法效果示意图
-
SGD: 随机梯度下降算法,每次训练少量数据,抽样偏差导致的参数收敛过程中震荡。
-
Momentum: 引入物理“动量”的概念,累积速度,减少震荡,使参数更新的方向更稳定。
每个批次的数据含有抽样误差,导致梯度更新的方向波动较大。如果我们引入物理动量的概念,给梯度下降的过程加入一定的“惯性”累积,就可以减少更新路径上的震荡,即每次更新的梯度由“历史多次梯度的累积方向”和“当次梯度”加权相加得到。历史多次梯度的累积方向往往是从全局视角更正确的方向,这与“惯性”的物理概念很像,也是为何其起名为“Momentum”的原因。类似不同品牌和材质的篮球有一定的重量差别,街头篮球队中的投手(擅长中远距离投篮)喜欢稍重篮球的比例较高。一个很重要的原因是,重的篮球惯性大,更不容易受到手势的小幅变形或风吹的影响。
- AdaGrad: 根据不同参数距离最优解的远近,动态调整学习率。学习率逐渐下降,依据各参数变化大小调整学习率。
通过调整学习率的实验可以发现:当某个参数的现值距离最优解较远时(表现为梯度的绝对值较大),我们期望参数更新的步长大一些,以便更快收敛到最优解。当某个参数的现值距离最优解较近时(表现为梯度的绝对值较小),我们期望参数的更新步长小一些,以便更精细的逼近最优解。类似于打高尔夫球,专业运动员第一杆开球时,通常会大力打一个远球,让球尽量落在洞口附近。当第二杆面对离洞口较近的球时,他会更轻柔而细致的推杆,避免将球打飞。与此类似,参数更新的步长应该随着优化过程逐渐减少,减少的程度与当前梯度的大小有关。根据这个思想编写的优化算法称为“AdaGrad”,Ada是Adaptive的缩写,表示“适应环境而变化”的意思。RMSProp是在AdaGrad基础上的改进,学习率随着梯度变化而适应,解决AdaGrad学习率急剧下降的问题。
- Adam: 由于动量和自适应学习率两个优化思路是正交的,因此可以将两个思路结合起来,这就是当前广泛应用的算法。
说明:
每种优化算法均有更多的参数设置。理论最合理的未必在具体案例中最有效,所以模型调参是很有必要的,最优的模型配置往往是在一定“理论”和“经验”的指导下实验出来的。
我们可以尝试选择不同的优化算法训练模型,观察训练时间和损失变化的情况,代码实现如下。
#仅优化算法的设置有所差别
def train(model):model.train()#调用加载数据的函数train_loader = load_data('train')#四种优化算法的设置方案,可以逐一尝试效果opt = paddle.optimizer.SGD(learning_rate=0.01, parameters=model.parameters())# opt = paddle.optimizer.Momentum(learning_rate=0.01, momentum=0.9, parameters=model.parameters())# opt = paddle.optimizer.Adagrad(learning_rate=0.01, parameters=model.parameters())# opt = paddle.optimizer.Adam(learning_rate=0.01, parameters=model.parameters())EPOCH_NUM = 3for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据images, labels = dataimages = paddle.to_tensor(images)labels = paddle.to_tensor(labels)#前向计算的过程predicts = model(images)#计算损失,取一个批次样本损失的平均值loss = F.cross_entropy(predicts, labels)avg_loss = paddle.mean(loss)#每训练了100批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))#后向传播,更新参数的过程avg_loss.backward()# 最小化loss,更新参数opt.step()# 清除梯度opt.clear_grad()#保存模型参数paddle.save(model.state_dict(), 'mnist.pdparams')#创建模型
model = MNIST()
#启动训练过程
train(model)相关文章:
手写数字识别之优化算法:观察Loss下降的情况判断合理的学习率
目录 手写数字识别之优化算法:观察Loss下降的情况判断合理的学习率 前提条件 设置学习率 学习率的主流优化算法 手写数字识别之优化算法:观察Loss下降的情况判断合理的学习率 我们明确了分类任务的损失函数(优化目标)的相关概念和实现方法ÿ…...
软件工程(二十) 系统运行与软件维护
1、系统转换计划 1.1、遗留系统的演化策略 时至今日,你想去开发一个系统,想完全不涉及到已有的系统,基本是不可能的事情。但是对于已有系统我们有一个策略。 比如我们是淘汰掉已有系统,还是继承已有系统,或者集成已有系统,或者改造遗留的系统呢,都是不同的策略。 技术…...

蓝蓝设计ui设计公司作品--泛亚高科-光伏电站控制系统界面设计
泛亚高科(北京)科技有限公司(以下简称“泛亚高科”),一个以实时监控、高精度数值计算为基础的科技公司, 自成立以来,组成了以博士、硕士为核心的技术团队,整合了华北电力大学等高校资源,凭借在电…...

软考高级系统架构设计师系列论文七十:论信息系统的安全体系
软考高级系统架构设计师系列论文七十:论信息系统的安全体系 一、信息系统相关知识点二、摘要三、正文四、总结一、信息系统相关知识点 软考高级信息系统项目管理师系列之四十三:信息系统安全管理...

Softing dataFEED OPC Suite——助力数字孪生技术发展
一 行业概览 数字孪生技术是充分利用物理模型、传感器更新、运行历史等数据,集成多学科、多物理量、多尺度、多概率的仿真过程,在虚拟空间中完成映射,从而反映相对应的实体装备的全生命周期过程。数字孪生技术已经应用在众多领域:…...
LLaMA中ROPE位置编码实现源码解析
1、Attention中q,经下式,生成新的q。m为句长length,d为embedding_dim/head θ i 1 1000 0 2 i d \theta_i\frac{1}{10000^\frac{2i}{d}} θi10000d2i1 2、LLaMA中RoPE源码 import torchdef precompute_freqs_cis(dim: int, end: i…...

在c++ 20下使用微软的proxy库替代传统的virtual动态多态
传统的virtual动态多态,经常会有下面这样的使用需求: #include <iostream> #include <vector>// 声明一个包含virtual虚函数的基类 struct shape {virtual ~shape() {}virtual void draw() 0; };// 派生,实现virtual虚函数 str…...

Spring MVC:@RequestMapping
Spring MVC RequestMapping属性 RequestMapping RequestMapping, 是 Spring Web 应用程序中最常用的注解之一,主要用于映射 HTTP 请求 URL 与处理请求的处理器 Controller 方法上。使用 RequestMapping 注解可以方便地定义处理器 Controller 的方法来处…...
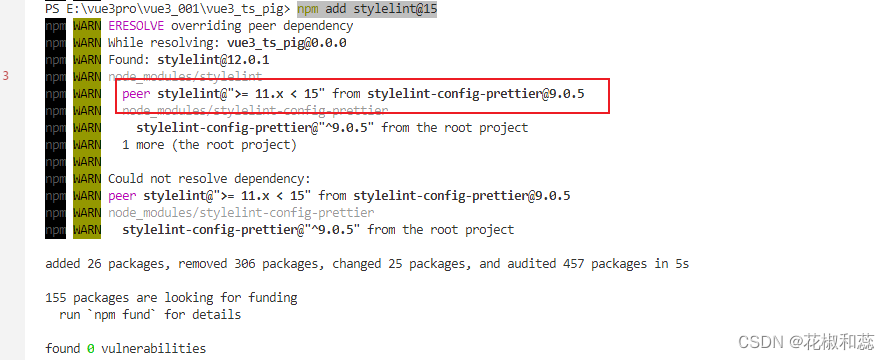
【vue3+ts项目】配置eslint校验代码工具,eslint+prettier+stylelint
1、运行好后自动打开浏览器 package.json中 vite后面加上 --open 2、安装eslint npm i eslint -D3、运行 eslint --init 之后,回答一些问题, 自动创建 .eslintrc 配置文件。 npx eslint --init回答问题如下: 使用eslint仅检查语法&…...

PHP之ZipArchive打包压缩文件
1、Linux 安装 nginx 安装zlib库 2、使用,目前我这边的需求是。 1、材料图片、单据图片,分别压缩打包到“材料.zip”和“单据.zip”。 2、“材料.zip”和“单据.zip”在压缩打包到“订单.zip” 3、支持批量导出多个订单的图片信息所有订单的压缩文件&…...

面试之快速学习C++14
文章参考:https://zhuanlan.zhihu.com/p/588826142?utm_id0 最近学了一会感慨到找工作好难,上周面试了一家医疗公司,准备攒攒经验但是不去,结果三天了没消息,感觉一面都没过… 本来自傲看不上,结果人家也…...
【算法专题突破】双指针 - 快乐数(3)
目录 1. 题目解析 2. 算法原理 3. 代码编写 写在最后: 1. 题目解析 题目链接:202. 快乐数 - 力扣(Leetcode) 这道题的题目也很容易理解, 看一下题目给的示例就能很容易明白, 但是要注意一个点&#…...
【javaweb】学习日记Day4 - Maven 依赖管理 Web入门
目录 一、Maven入门 - 管理和构建java项目的工具 1、IDEA如何构建Maven项目 2、Maven 坐标 (1)定义 (2)主要组成 3、IDEA如何导入和删除项目 二、Maven - 依赖管理 1、依赖配置 2、依赖传递 (1)查…...

C++信息学奥赛1144:单词翻转
#include <iostream> #include <string> using namespace std; int main() {string str;// 输入一行字符串getline(cin, str);string arr;for (int i 0; i < str.length(); i){if (str[i] ! ){arr str[i]; // 将非空格字符添加到临时存储的字符串中}else{for…...

qt检查文件夹是否有写权限
Qt 使用如下函数能够判断路径或者文件是否可写: bool QFileInfo::isWritable() const 对于win10系统实测,结果不准确。继续排查,官方文档描述:a)如果未启用 NTFS 权限检查,Windows 上的结果将仅反映文件是…...
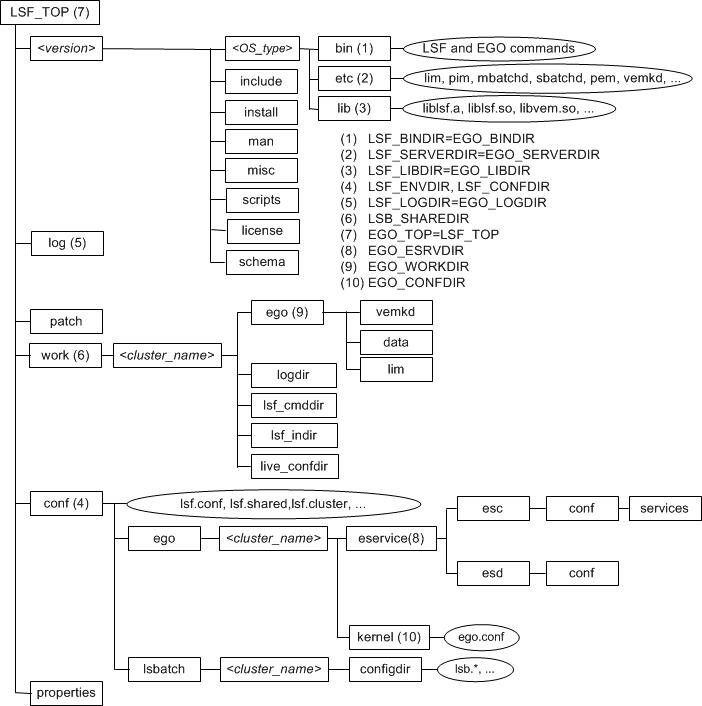
LSF 安装目录,快速参考 LSF 命令、守护程序、配置文件、日志文件和重要集群配置参数
样本 UNIX 和 Linux 安装目录 守护程序错误日志文件 守护程序错误日志文件存储在 LSF_LOGDIR 在 lsf.conf 文件中定义的目录中。 LSF 基本系统守护程序日志文件LSF 批处理系统守护程序日志文件pim.log.host_namembatchd.log.host_namembatchd.log.host_namesbatchd.log.host_…...

在Mybatis中写动态sql这些标签:if、where、set、trim、foreach、choose的作用是什么,怎么用?
在 MyBatis 中,您可以使用动态 SQL 标签来构建灵活的 SQL 查询,以根据不同的条件生成不同的查询语句。以下是这些标签的作用和用法: 1. **<if> 标签:** 用于根据某个条件动态地包含或排除 SQL 片段,test:可以写…...

7 Python的模块和包
概述 在上一节,我们介绍了Python的异常处理,包括:异常、异常处理、抛出异常、用户自定义异常等内容。在这一节中,我们将介绍Python的模块和包。Python的模块(Module)和包(Package)是…...

【JavaWeb 篇】使用Servlet、JdbcTemplate和Durid连接池实现用户登录功能与测试
在现代Web应用程序开发中,用户登录功能是基础中的基础。它为用户提供了安全访问系统的途径。本篇博客将引导您通过使用Servlet、Spring框架的JdbcTemplate以及Durid连接池,来构建一个完整的用户登录功能。我们将详细展示每个部分的代码,并解释…...

【Unity3D赛车游戏】【六】如何在Unity中为汽车添加发动机和手动挡变速?
👨💻个人主页:元宇宙-秩沅 👨💻 hallo 欢迎 点赞👍 收藏⭐ 留言📝 加关注✅! 👨💻 本文由 秩沅 原创 👨💻 收录于专栏:Uni…...

ComfyUI-WanVideoWrapper:AI视频生成性能优化的终极指南
ComfyUI-WanVideoWrapper:AI视频生成性能优化的终极指南 【免费下载链接】ComfyUI-WanVideoWrapper 项目地址: https://gitcode.com/GitHub_Trending/co/ComfyUI-WanVideoWrapper 在AI视频生成领域,显存限制和部署复杂性一直是开发者面临的核心挑…...
)
保姆级教程:用LayoutLMv3和CDLA数据集搞定文档版面分析(附完整代码)
从零构建文档智能分析系统:基于LayoutLMv3与CDLA的实战指南 当一份复杂的合同或报告需要快速解析时,传统OCR技术往往只能提供杂乱无章的文本碎片。而现代文档智能系统已经能够理解文档的逻辑结构——自动识别标题、段落、表格的位置关系,就像…...

ADRV9009+ZCU102实战:从HDL工程构建到no-OS移植的5个关键步骤
ADRV9009ZCU102全流程开发指南:从HDL工程构建到no-OS移植的深度实践 在射频系统开发领域,ADRV9009作为一款高性能射频收发器,与Xilinx ZCU102开发板的组合已成为许多硬件工程师的首选方案。本文将深入剖析五个关键环节的技术细节,…...

LeRobot终极指南:用开源框架零门槛构建智能协作机械臂
LeRobot终极指南:用开源框架零门槛构建智能协作机械臂 【免费下载链接】lerobot 🤗 LeRobot: State-of-the-art Machine Learning for Real-World Robotics in Pytorch 项目地址: https://gitcode.com/GitHub_Trending/le/lerobot 副标题…...

基于LLM的智能客服系统实战:飞书集成与高并发架构设计
最近在做一个企业级的智能客服项目,客户要求必须集成到飞书工作台,并且要能扛住业务高峰期的并发压力。传统的规则引擎客服系统,在面对五花八门的用户提问时,经常“卡壳”,尤其是那些规则库没覆盖到的“长尾问题”&…...

探索RBMO - BiLSTM - Attention分类算法:MATLAB实现与应用
【24年5月顶刊算法】RBMO-BiLSTM-Attention分类 基于红嘴蓝鹊优化器(RBMO)-双向长短期记忆网络(BiLSTM)-注意力机制(Attention)的数据分类预测(可更换为回归/单变量/多变量时序预测,前私),Matlab代码,可直接运行,适合小白新手 无需…...
)
别再用yield了!FastAPI 2.0官方弃用警告下的流式响应新范式(含ASGI StreamingResponse + async iterator最佳实践)
第一章:FastAPI 2.0流式响应弃用背景与演进动因FastAPI 2.0 将 StreamingResponse 的默认行为从“自动分块传输”转向显式、可控的流式语义,其核心动因源于对 HTTP/1.1 分块编码(Chunked Transfer Encoding)与现代客户端ÿ…...

《热江手游》千人跨服战 + 自由交易,老玩家直呼真香!
《热江手游》手游来袭,正版授权 1:1 复刻经典,剥离冗余氪金系统,回归 MMO 最本真的乐趣 —— 无 VIP 碾压、无强制付费,所有极品道具全靠打,零氪玩家也能凭实力登顶江湖! 无论是泫勃派、南林等标志性地图…...

Centos stream 9 安装后root不能远程登录问题
如果在安装Centos stream 9的时候没有"勾选允许root用户使用密码进行ssh登录",安装后使用xshell等远程工具是不能登录虚拟机或者服务器的。解决:vim /etc/ssh/sshd_config1.新增一行配置: PermitRootLogin yes2.重启ssh systemctl restart ssh…...

KKManager:Illusion游戏模组管理终极指南,一键安装更新所有插件和卡片
KKManager:Illusion游戏模组管理终极指南,一键安装更新所有插件和卡片 【免费下载链接】KKManager Mod, plugin and card manager for games by Illusion that use BepInEx 项目地址: https://gitcode.com/gh_mirrors/kk/KKManager KKManager是一…...